FACULDADE DE E NGENHARIA DA UNIVERSIDADE DO P ORTO Implementação em FPGA de Algoritmo de Navegação Autónoma com Adaptação Dinâmica da Qualidade de Serviço José Carlos Pereira de Sá Mestrado Integrado em Engenharia Eletrotécnica e de Computadores Orientador: Prof. João Paulo de Castro Canas Ferreira Coorientador: Prof. José Carlos dos Santos Alves 26 de Outubro de 2012

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO
Implementação em FPGA de Algoritmode Navegação Autónoma com
Adaptação Dinâmica da Qualidade deServiço
José Carlos Pereira de Sá
Mestrado Integrado em Engenharia Eletrotécnica e de Computadores
Orientador: Prof. João Paulo de Castro Canas Ferreira
Coorientador: Prof. José Carlos dos Santos Alves
26 de Outubro de 2012

c© José Sá, 2012

Resumo
Esta dissertação teve como objetivo principal a implementação em FPGA de um algoritmo denavegação autónoma baseado em imagens estéreo obtidas em tempo real. Este tema é um doscasos de estudo proposto pelo projeto do consórcio Europeu REFLECT.
O algoritmo de navegação estéreo utilizado é composto por várias tarefas, onde algumas re-querem grande poder de processamento.
O sistema embarcado reconfigurável foi construído numa plataforma de desenvolvimentoconstituída por um processador IBM PowerPC 440 auxiliado por uma FPGA da família XilinxVirtex-5, de forma a proporcionar a melhor integração software/hardware possível, para que astarefas críticas do algoritmo de navegação pudessem ser aceleradas em hardware.
O ajuste dinâmico da qualidade de serviço prestada pelo sistema foi alcançado através da uti-lização das capacidades reconfiguráveis da FPGA, possíveis de obter através do uso de diferentesestratégias de reconfiguração, tendo em vista aspetos como o número de reconfigurações, ou deáreas reconfiguráveis para a execução de determinada tarefa.
Para a execução deste sistema, optou-se por seguir um fluxo de projeto que teve como princi-pais fases a síntese de alto nível das tarefas críticas, da qual resultaram módulos de aceleração emhardware, a criação de um modelo de unidade reconfigurável, cuja funcionalidade interna derivada versão da tarefa a executar pelo módulo reconfigurável neste contido, e a adaptação da apli-cação original ao sistema embarcado reconfigurável, onde algumas estratégias de reconfiguraçãoforam implementadas e analisadas.
A aplicação foi executada de forma dedicada no processador PowerPC 440 auxiliado por cachee as unidades de hardware foram executadas na FPGA XC5VFX70T, a um frequência de 100 Mhz.
Como resultado, a utilização do sistema reconfigurável projetado permitiu a aceleração de2 vezes o tempo de execução da tarefa crítica do algoritmo de navegação estéreo em comparaçãocom a execução desta mesma tarefa unicamente em software. A aceleração desta tarefa aumentoua cadência total de processamento das imagens estéreo em 20%.
Foi ainda concluído que a aceleração total obtida pela utilização do sistema reconfigurávelconstruído é proporcional à resolução das imagens estéreo utilizadas. Em imagens com o dobroda resolução das originais, foi estimado que o tempo de execução da tarefa crítica é acelerado em2.5 vezes comparativamente à execução em software.
i

ii

Abstract
The main goal of this dissertation was to build a FPGA implementation of an autonomousnavigation algorithm based on real-time stereo images. This subject is one of the case studiesproposed by the European consortium REFLECT project.
The navigation stereo algorithm used consists of several tasks, some of which require highprocessing power.
The system was built on an reconfigurable embedded development platform consisting ofIBM PowerPC 440 processor aided by a FPGA family Xilinx Virtex-5 to provide a better softwa-re/hardware integration as possible so that the most critical navigation algorithm tasks could beaccelerated on hardware.
The dynamic adjustment of system’s quality of service was achieved by using the capabilitiesof reconfigurable FPGA obtainable by using different reconfiguration strategies in some aspectslike the number of reconfigurations involved, or the size of reconfigurable areas to perform acertain task.
To implement this system, we chose to follow a design flow that had as main phases to high-level synthesis of critical tasks, which resulted in hardware accelerated modules, the creation ofa reconfigurable unit model, whose internal functionality derives from the version of the task toexecute by reconfigurable module, and adaptation of the original application to reconfigurableembedded system, where some reconfiguration strategies were implemented and analysed.
The application was run on a dedicated PowerPC 440 processor aided by caching and imple-mented hardware units were ran in the XC5VFX70T FPGA at 100 Mhz.
As a result, the use of the reconfigurable designed system has permitted the acceleration by2 times the critical task execution time of the stereo navigation algorithm, compared to the execu-tion of that task solely in software.
It was also concluded that the total acceleration obtained by using reconfigurable system builtis proportional to the stereo images resolution. In images with twice the resolution of the original,it was estimated that the execution time of critical task is accelerated by 2.5 times compared torunning on software.
iii

iv

Agradecimentos
No momento em que me encontro a finalizar este projeto, e com este encerro mais uma impor-tante fase do meu percurso académico e pessoal, não poderia deixar de agradecer a todos aquelesque me ajudaram estando sempre presentes.
Começo, sem dúvida, por agradecer ao meu Orientador, o professor João Paulo de CastroCanas Ferreira e Coorientador, o professor José Carlos dos Santos Alves, por todos os conselhose todo o auxílio que me prestaram e sem os quais esta tarefa seria dificultada.
Em seguida, aos meus colegas da sala I224, principalmente ao João Teixeira, por todos osconselhos transmitidos, bem como aos restantes, André Lima, Carla Brito, Helder Campos, HugoMarques e Nuno Paulino por todo o apoio e amizade.
Gostaria de agradecer à minha família. Aos meus pais, Carlos e Celeste, por todo o esforço eapoio incondicional que me deram, mesmo nos momentos mais complicados. À minha irmã, Vera,por estar sempre presente nas horas mais difíceis. À minha avó Rosa, pelo carinho e sorriso quesempre me demonstrou. À minha namorada, Liliana, pessoa bastante importante na minha vida, eque sempre me apoiou na decisão de entrar neste mundo académico.
Por último, gostaria de agradecer aos meus antigos professores, A. Silva Pereira, Mário Águas,Montana e Rogério Baldaia por todo o conhecimento que me transmitiram.
A todos, muito obrigado.
José Sá
v

vi

“Man is still the most extraordinary computer of all.”
John F. Kennedy
vii

viii

Conteúdo
1 Introdução 11.1 Contexto e Motivação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.3 Estrutura da Dissertação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Revisão Bibliográfica 52.1 Ambientes de Sistemas Embarcados Complexos . . . . . . . . . . . . . . . . . . 52.2 Aceleração em FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 A Importância dos Sistemas Reconfiguráveis . . . . . . . . . . . . . . . . . . . 6
2.3.1 Sistemas Parciais Dinâmicos Reconfiguráveis . . . . . . . . . . . . . . . 72.3.2 Desafios dos Sistemas Computacionais . . . . . . . . . . . . . . . . . . 82.3.3 Exemplos de Aplicações que usam Sistemas Reconfiguráveis . . . . . . . 9
2.4 O Projeto REFLECT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.4.1 Objetivos da REFLECT Como Linha Orientadora da Dissertação . . . . 9
2.5 Plataforma de desenvolvimento utilizada . . . . . . . . . . . . . . . . . . . . . . 102.5.1 Placa de desenvolvimento Xilinx ML507 . . . . . . . . . . . . . . . . . 102.5.2 Ferramentas de Desenvolvimento Utilizadas . . . . . . . . . . . . . . . . 122.5.3 Outras Ferramentas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Análise da Aplicação Navegação Estéreo 173.1 Visão Global da Aplicação . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.2 Montagem de Sistema Básico de Execução . . . . . . . . . . . . . . . . . . . . 193.3 Análise Temporal Prévia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
3.3.1 Informação Proveniente de Implementação Prévia do Projeto . . . . . . . 203.3.2 Informação Fornecida pela REFLECT . . . . . . . . . . . . . . . . . . . 213.3.3 Análise Temporal no Sistema Atual . . . . . . . . . . . . . . . . . . . . 213.3.4 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4 Análise das Tarefas Críticas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.4.1 Função Extração de Caraterísticas . . . . . . . . . . . . . . . . . . . . . 223.4.2 Função Estimação Robusta de Pose . . . . . . . . . . . . . . . . . . . . 26
4 Tarefas Críticas - Implementação em Hardware 294.1 Implementação da Função Extração de Caraterísticas . . . . . . . . . . . . . . . 30
4.1.1 Definições Utilizadas na Ferramenta de Síntese de Alto Nível . . . . . . 304.1.2 Problema do Uso de Variáveis do Tipo float e Soluções Consideradas . . 354.1.3 Simulação dos módulos gerados: ModelSim . . . . . . . . . . . . . . . . 464.1.4 Adaptação Verilog e Análise de Relatórios Gerados: Precision RTL . . . 49
4.2 Implementação da Função Estimação Robusta de Pose . . . . . . . . . . . . . . 50
ix

x CONTEÚDO
5 Sistema Reconfigurável - Implementação 555.1 Criação das Unidades Reconfiguráveis: Xilinx ISE . . . . . . . . . . . . . . . . 555.2 Montagem de um Sistema Base Reconfigurável . . . . . . . . . . . . . . . . . . 635.3 Implementação Física do Sistema Reconfigurável . . . . . . . . . . . . . . . . . 655.4 Software de Adaptação Dinâmica da Qualidade de Serviço . . . . . . . . . . . . 72
5.4.1 Estratégias de Reconfiguração Consideradas . . . . . . . . . . . . . . . . 725.4.2 Implementação das Estratégias Abordadas em Software . . . . . . . . . . 765.4.3 Melhoria de solução: Utilização Fixa Sequencial paralela . . . . . . . . . 78
6 Resultados Obtidos 816.1 Discussão Sobre os Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . 836.2 Extrapolação de Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 856.3 Validação de Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
7 Conclusões e Trabalho Futuro 937.1 Satisfação dos Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 937.2 Trabalho Futuro . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 94
A Anexos 95A.1 Ficheiro Verilog de Descrição da Unidade Reconfigurável . . . . . . . . . . . . . 95A.2 Ficheiro Verilog de Descrição do Módulo Reconfigurável . . . . . . . . . . . . . 99A.3 Profiling Gráfico da Função Estimação Robusta de Pose . . . . . . . . . . . . . . 100A.4 Profiling Gráfico da Função Estimação Robusta de Pose . . . . . . . . . . . . . . 101
Referências 103

Lista de Figuras
2.1 Exemplo de Sistema Parcial Dinâmico Reconfigurável. . . . . . . . . . . . . . . 72.2 Placa de desenvolvimento Xilinx ML507. . . . . . . . . . . . . . . . . . . . . . 112.3 Fluxo de projeto Catapult C. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.4 Fluxo de projeto ISE. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.5 Fluxo de projeto PlanAhead. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1 Algoritmo de Navegação Estéreo. . . . . . . . . . . . . . . . . . . . . . . . . . 173.2 Ilustração da distorção com efeito de barril. . . . . . . . . . . . . . . . . . . . . 183.3 Verificação circular para correspondência de caraterísticas. . . . . . . . . . . . . 193.4 a) Secção original da imagem captada; b) Resultado do operador de deteção de
cantos Harris. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.5 Fluxo de operações com numeração das tarefas críticas de convolução. . . . . . . 233.6 Diagrama de operações do bloco RANSAC da função Estimação Robusta de Pose. 28
4.1 Sinais de sincronização (handshake). . . . . . . . . . . . . . . . . . . . . . . . . 314.2 Exemplo: Fronteira de implementação efetuado pelo Catapult C com uma variável
de entrada e uma variável de saída. . . . . . . . . . . . . . . . . . . . . . . . . . 314.3 Exemplo da necessidade de re-acesso a elementos. . . . . . . . . . . . . . . . . 334.4 Interfaces: array H por registos, arrays U e Y por RAM, restantes por registos. . 344.5 Versão do módulo reconfigurável com interface final simplificada. . . . . . . . . 354.6 Utilização do bloco Xilinx FPO (Floating-Point Operator) para execução de ope-
rações usando vírgula flutuante. . . . . . . . . . . . . . . . . . . . . . . . . . . 364.7 Formato de vírgula flutuante de 32 bits (single float). . . . . . . . . . . . . . . . 374.8 Variável real do array H, representada em formato inteiro de 32 bits. . . . . . . . 424.9 À esquerda: Excerto da matriz de entrada U; À direita: Filtro horizontal H. . . . 434.10 Ajustamento da vírgula, executado pela função ConvRepl1. . . . . . . . . . . . . 444.11 Ajustamento da vírgula, executado pela função ConvRepl2. . . . . . . . . . . . . 454.12 Processo de simulação utilizada pela ferramenta Catapult C. . . . . . . . . . . . 484.13 Simulação da versão hardware da função ConvRepl1. . . . . . . . . . . . . . . . 484.14 Possível implementação do algoritmo RANSAC em hardware. . . . . . . . . . . 514.15 Formato de variável em vírgula fixa necessário para representação dos valores
manipulados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.1 Soluções de arquitetura para periféricos reconfiguráveis: (a) - Contendo apenasum módulo reconfigurável; (b) - Contendo vários módulos reconfiguráveis. . . . 58
5.2 Solução para arquitetura de periférico reconfigurável. . . . . . . . . . . . . . . . 595.3 Constituição original do modelo de unidade reconfigurável. . . . . . . . . . . . . 605.4 Constituição completa da unidade reconfigurável. . . . . . . . . . . . . . . . . . 615.5 Adição de sinal auxiliar no módulo reconfigurável. . . . . . . . . . . . . . . . . 62
xi

xii LISTA DE FIGURAS
5.6 Arquitetura da Solução Proposta. . . . . . . . . . . . . . . . . . . . . . . . . . . 645.7 Endereçamento do sistema. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 655.8 Representação de um trama reconfigurável. . . . . . . . . . . . . . . . . . . . . 675.9 Visão global da FGPA, onde as três partições reconfiguráveis estão realçadas. . . 685.10 Estimativa de recursos ocupados pelas funções: ConvConst (a), ConvRepl1 (b),
ConvRepl2 (c); Estimativa do tamanho de bitstream resultante (d). . . . . . . . . 695.11 Representação da nova partição reconfigurável. . . . . . . . . . . . . . . . . . . 705.12 Estimativa do tamanho de bitstream resultante. . . . . . . . . . . . . . . . . . . 705.13 Visão global da implementação física da FGPA, onde as três partições reconfigu-
ráveis estão realçadas nas cores verde, amarela e vermelha. . . . . . . . . . . . . 715.14 Estratégia de reconfiguração utilizando apenas uma unidade reconfigurável. . . . 735.15 Estratégia de reconfiguração utilizando duas unidades reconfiguráveis. . . . . . . 735.16 Estratégia de reconfiguração paralela utilizando três unidades reconfiguráveis. . . 745.17 Estratégia de reconfiguração singular e execução sequencial, utilizando três uni-
dades reconfiguráveis. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 755.18 Operações executadas na situação de requisito temporal BAIXO. . . . . . . . . . 775.19 Operações executadas na situação de requisito temporal MÉDIO. . . . . . . . . . 785.20 Operações executadas na situação de requisito temporal ALTO. . . . . . . . . . . 795.21 Pipelining das operações existentes na função Extração de Caraterísticas - requi-
sito temporal SUPER. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
A.1 Gráfico da avaliação das dependências e percentagens de tempo de execução dafunção Estimação Robusta de Pose e sub-funções (Primeira Parte). . . . . . . . . 100
A.2 Gráfico da avaliação das dependências e percentagens de tempo de execução dafunção Estimação Robusta de Pose e sub-funções (Segunda Parte). . . . . . . . . 101

Lista de Tabelas
3.1 Resultado da análise temporal obtido em trabalho prévio[1]. . . . . . . . . . . . 213.2 Resultado da análise temporal obtido no sistema base atual. . . . . . . . . . . . . 21
4.1 Tabela de resultados da síntese Catapult C na versão SoftFloat. . . . . . . . . . . 394.2 Comparação: Funções originais versus funções SoftFloat. . . . . . . . . . . . . . 404.3 Resultado da síntese Catapult C da função ConvRepl1, após correção de folga
temporal. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 404.4 Comparação: Função ConvRepl1 original versus versão SoftFloat. . . . . . . . . 404.5 Representação de valores do tipo real em formato inteiro. . . . . . . . . . . . . . 424.6 Resultados de execução da função ConvRepl1, na situação de pior caso. . . . . . 434.7 Resultados de execução da função ConvRepl2, na situação de pior caso. . . . . . 444.8 Resultados de execução da função ConvRepl2, na situação de pior caso, após
ajuste de vírgula da função convRepl1. . . . . . . . . . . . . . . . . . . . . . . . 464.9 Tabela de resultados da síntese Catapult C das funções em vírgula fixa. . . . . . . 474.10 Comparação: Funções originais versus funções em vírgula fixa. . . . . . . . . . . 474.11 Dados resultantes dos relatórios temporal e área, gerados pelo Precision RTL. . . 494.12 Comparação do número de bits necessários mais díspar para representação dos
valores internos ao algoritmo RANSAC para as sequências de imagem 59→ 60 e328→ 329. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.13 Dados resultantes dos relatórios temporal e área, gerados pelo Precision RTL. . . 54
5.1 Dados resultantes da síntese da unidade reconfigurável. . . . . . . . . . . . . . . 615.2 Dados resultantes da re-síntese do módulo reconfigurável, com a instanciação de
cada função. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 625.3 Tamanho do mapeamento necessário para as memórias da unidade reconfigurável. 645.4 Resultados da implementação física. . . . . . . . . . . . . . . . . . . . . . . . . 71
6.1 Comparação de resultados entre o software original e as estratégias de reconfigu-ração. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
6.2 Resultado da medição do tempo de configuração parcial e transferência de dados. 826.3 Resultado de análise temporal efetuada no PC, utilizando imagens 640x480. . . . 866.4 Resultado de análise temporal efetuada no PC, utilizando imagens 320x240. . . . 866.5 Resultados obtidos e extrapolados para ambas as resoluções de imagem capturadas. 896.6 Validação das soluções SoftFloat e vírgula fixa da função Feature Extraction. . . 91
xiii

xiv LISTA DE TABELAS

Abreviaturas e Símbolos
AC Algorthmic CAPU Accelerated Processing UnitASIC Application-Specific Integrated CircuitBRAM Block RAMCCD Charged-Coupled DevicesEDK Embedded Development KitFIFO First In, First OutFPGA Field-Programmable Gate ArrayGPP General Propose ProcessorGPRS General Packet Radio ServiceGSM Global System for Mobile CommunicationsIC Integrated CircuitLCD Liquid Crystal DisplayMIPS Milhões de Instruções Por SegundoPAR Place and RouteRANSAC RANdom SAmple ConsensusRTL Register Transfer LevelSDR Software-Defined RadioSoC System-on-ChipSFPS Stereo Frames Per SecondSVD Singular Value DecompositionVHDL VHSIC Hardware Description LanguageXST Xilinx Synthesis Technology2D, 3D Duas e Três Dimensões
xv


Capítulo 1
Introdução
O contínuo avanço na tecnologia de circuitos integrados (IC) leva a que a cada ano, um número
maior de transístores caibam em áreas cada vez mais pequenas. Esses avanços estimulam a neces-
sidade, por parte do mercado eletrónico de consumo, de sistemas computacionais mais potentes
mas ao mesmo tempo mais eficientes.
O aparecimento de sistemas eletrónicos inteligentes com um grande número de funcionali-
dades é impulsionado por avanços na tecnologia System-on-Chip (SoC). Esta é caraterizada pela
integração de múltiplos elementos computacionais num único dispositivo, onde cada um executa
a sua tarefa individual. Exemplos de dispositivos usando tecnologia SoC, são o caso dos telemó-
veis, câmaras digitais ou leitores MP3. Estes dispositivos incorporam não apenas os componentes
vitais com microprocessadores, memórias e controladores LCD, mas também tecnologias orienta-
das a aplicações específicas como GSM, GPRS, CCD, Wi-Fi e unidades de compressão MPEG4
e MP3, entre outros. Devido ao facto de todos estes elementos computacionais estarem presentes
e prontos a trabalhar, esta contínua integração de funcionalidades pode causar um alto consumo
energético. Para além de que quanto maior for o nível de integração de novas funcionalidades nes-
ses dispositivos, maiores serão os custos de projeto e mais baixos serão os níveis de fiabilidade.
Alguns destes problemas podem ser resolvidos com a ajuda de lógica reconfigurável, a qual
oferece aos sistemas a capacidade de alterar a sua estrutura interna, tornado-os mais adequados às
adaptações provenientes da necessidade da aplicação executada.
Particularmente, no que diz respeito ao estado de arte da tecnologia de reconfiguração, a re-
configuração parcial dinâmica permite que porções dos circuitos eletrónicos possam ser alteradas
durante a execução, sem a necessidade de reinicialização de todo o sistema, abrindo portas para
novos aspetos e tipos de abordagem como a definição de áreas reconfiguráveis, escalonamento de
paralelismo de tarefas, ou o particionamento de tarefas grandes em várias tarefas mais pequenas
com a intenção de reduzir o desenho da área de hardware.
Razões como o aumento da capacidade de processamento dos novos sistemas computacionais,
a utilização de lógica reconfigurável e a necessidade alcançar um menor tempo de introdução no
mercado fizeram com que as Field-Programmable Gate Array (FPGA) se tornassem comummente
utilizadas tanto para prototipagem como para implementação do produto final.
1

2 Introdução
Com a utilização de FPGA, é atingido um compromisso entre alta performance, consumo
de baixa potência e capacidade de paralelismo existentes em circuitos integrados para aplicações
específicas (ASIC), e a flexibilidade dos processadores de uso geral (GPP).
Adicionalmente, a sua boa capacidade de reconfiguração dinâmica torna-os numa excecional
ferramenta para a pesquisa de novas metodologias para a implementação de sistemas reconfigurá-
veis onde a aceleração de aplicações híbridas soft-hardware é exigida.
1.1 Contexto e Motivação
Este projeto está inserido no contexto da utilização de sistemas embarcado de alto desempenho
em tempo real, aplicados na área da robótica e ao mundo da visão por computador, com o intuito
de projetar um sistema de navegação autónomo capaz de auxiliar a determinação da localização de
veículos em caso de falha temporária dos serviços de localização por satélite. Este tema enquadra-
se num dos casos de estudo proposto pelo projeto do consórcio Europeu REFLECT (Rendering
FPGAs to Multi-Core Embedded Computing) [2].
1.2 Objetivos
Este trabalho teve como objetivo a implementação em FPGA de um algoritmo de navegação
autónoma baseado em imagens estéreo obtidas em tempo real, capaz de variar dinamicamente a
qualidade de serviço oferecida. Para o atingir foi necessário efetuar a determinação das tarefas
críticas existentes no algoritmo de navegação autónoma escrito em linguagem C, a criação de
módulos de hardware equivalentes capazes de acelerar as tarefas determinadas, a construção de
uma plataforma base para um sistema dinâmico reconfigurável, a análise das estratégias de imple-
mentação dos módulos gerados com ênfase nos aspetos reconfiguração dinâmica e a adaptação do
algoritmo de navegação original de forma a poder variar de forma dinâmica, através da utilização
das estratégias de reconfiguração estudadas, a qualidade de serviço do sistema, como por exem-
plo, o número de imagens estéreo processadas por instante de tempo. O trabalho resultou numa
implementação efetiva.
1.3 Estrutura da Dissertação
Para além da introdução, esta dissertação contém mais cinco capítulos. No capítulo 2, é efetu-
ado o estudo e pesquisa bibliográfica das tecnologias utilizadas nos sistemas embarcados atuais, a
vantagem da utilização de aceleração em FPGA por parte destes sistemas e a explicação do estado
da arte da tecnologia de reconfiguração por estes oferecida, a tecnologia de reconfiguração parcial
dinâmica. No final é feita a apresentação da plataforma de desenvolvimento utilizada, onde os
dispositivos e ferramentas de desenvolvimento serão enumerados e analisados.
O capítulo 3 apresenta a aplicação usada pelo sistema embarcado de navegação autónoma. Este
é composto pela explicação dos seus blocos principais, montagem de sistema básico de execução

1.3 Estrutura da Dissertação 3
na placa de desenvolvimento Xilinx ML507, recolha de informação e determinação das tarefas
críticas executadas, finalizando com a análise detalhada dessas mesmas tarefas.
No capítulo 4 é feita a explicação de como os módulos hardware utilizados para aceleração
das tarefas críticas foram idealizados e implementados, seguindo o fluxo de projeto de síntese de
alto nível.
No capítulo 5 são discutidas várias formas de conjugação entre os módulos anteriormente
gerados e a implementação de um sistema embarcado dinâmico reconfigurável, onde temas como
a forma de interação entre software-hardware e as estratégias de reconfiguração dinâmicas são
discutidas e implementadas.
No capítulo 6 são apresentados e discutidos os ganhos temporais resultantes da implementa-
ção destas estratégias de reconfiguração, bem como a estimação de resultados para execução da
aplicação em condições alternativas.
Por fim, o capítulo 7 apresenta a conclusão deste trabalho, bem como algumas propostas para
trabalho futuro.

4 Introdução

Capítulo 2
Revisão Bibliográfica
Neste capítulo é apresentada a bibliografia consultada e considerada relevante para a explica-
ção das principais tecnologias e processos abordados neste trabalho.
Este será iniciado pela explicação do conceito de sistema embarcado, vantagens da aceleração
em FPGA e a sua evolução da sua utilização culminando na tecnologia reconfiguração parcial
dinâmica por esta oferecida.
2.1 Ambientes de Sistemas Embarcados Complexos
Nos últimos anos a complexidade dos sistemas embarcados tem crescido dramaticamente.
Enquanto que no século XX, um sistema embarcado era pensado como uma simples unidade
de processamento apenas controlada por um simples bloco de software com funções específicas,
nos dias de hoje, devido ao constante aumento da capacidade de processamento destas unidades
computacionais, um novo nível de exigência a estes requerida tornou-os cada vez mais complexos.
A unidade de processamento comummente utilizada por sistemas embarcados, GPP1, ou mi-
croprocessador, é um dispositivo com a capacidade de ser programado para executar qualquer tipo
de tarefa, através de instruções genéricas, oferecendo desta forma uma alta flexibilidade para inter-
pretação de novos blocos de instruções. Por outro lado, estes aspetos tornam-no num dispositivo
relativamente lento e ineficiente dada a sua arquitetura interna.
Para superar esta lacuna, as unidades de processamento, GPP, são normalmente integradas
juntamente com circuitos de aplicações específicas, ASIC2. Estes circuitos são dispositivos espe-
cializados, desenhados para cumprir funções específicas, altamente orientados para as aplicações,
projetados para satisfazer necessidades de baixo consumo energético e alta performance em acele-
ração, o que é principalmente garantido pelas suas capacidades de paralelismo. Nos seus aspetos
negativos, salientam-se os elevados custos de produção e a sua pouca flexibilidade.
Enquanto muitas das aplicações destes sistemas estão direcionadas para a indústria, onde são
utilizados como núcleos de monitorização e controlo recorrendo para isso a sensores e atuadores,
1GPP - General Purpose Processor2ASIC - Application-Specific Integrated Circuit
5

6 Revisão Bibliográfica
outras aplicações porém, pela sua natureza, exigem um nível de fiabilidade e confiabilidade crí-
tico como é o caso da utilização em áreas como a medicina[3][4], o controlo de dispositivos de
comunicação móvel[5][6][7] ou controlo de orientação em dispositivos militares e civis[8].
2.2 Aceleração em FPGA
As FPGAs, tal como os circuitos ASIC, para além de permitirem elevados níveis de aceleração
em hardware, podem ser utilizados como elementos de aceleração em sistemas embarcados.
Os circuitos ASIC são projetados especialmente para satisfazer as particulares necessidades
das aplicações. Sendo especializados e limitados apenas à execução de funções predefinidas, estes
circuitos são altamente eficientes. A sua utilização, contudo, implica altos custos de prototipagem,
apesar da sua produção em massa ser economicamente reduzida. Como desvantagem, este tipo
de circuitos, não permite alteração à sua estrutura interna. Uma vez fabricados, a mais pequena
necessidade de alteração à sua estrutura envolve obrigatoriamente a redefinição do projeto ini-
cial, implicando atrasos adicionais e custos extremamente elevados. Estes fatores impedem a sua
utilização para efeitos de prototipagem, ou produção em pequena escala.
Pelo contrário, as FPGAs eliminam estes obstáculos. Em primeiro lugar, a sua utilização
possibilita prototipagem rápida e de baixo custo, uma vez que estas são constituídas por blocos
reprogramáveis, os quais podem ser combinados e programados de forma a cumprir as mesmas
funcionalidades desempenhadas pelos ASIC.
Embora não tão energeticamente eficientes quanto os circuitos ASIC, a crescente evolução
tecnológica derivada do aumento do número de transístores disponíveis elevou as FPGAs à con-
dição de ferramenta preferencial no desenho de sistemas reconfiguráveis, graças à sua elevada
capacidade de reutilização e infinita reprogramabilidade.
Um exemplo de sistema embarcado acelerado por FPGA, é demonstrado no trabalho “FPGA-
Based Acceleration of Block Matching Motion Estimation Techniques”, em [9]. Neste trabalho,
é utilizada a plataforma embutida Altera DE2, constituída por um soft-processor NIOS II, traba-
lhando em conjunto com uma FPGA Cyclone II EP2C35F672C6. A aplicação discutida aborda
algoritmos de estimação de movimento, para além de compressão de vídeo H.264/AVC MPEG-
4.10. Uma aceleração de pelo menos duas ordens de grandeza é alcançada em comparação com a
execução em Pentium III 800 Mhz.
2.3 A Importância dos Sistemas Reconfiguráveis
O desenho de sistemas digitais reconfiguráveis conjuga dois conceitos chave principais, no
que diz respeito à tecnologia reconfigurável: O paralelismo, que representa a maior vantagem das
implementações de hardware, oferecida pelos circuitos ASIC e a flexibilidade, o principal motivo
de sucesso de aplicações em software executados por GPPs.

2.3 A Importância dos Sistemas Reconfiguráveis 7
O conceito de sistema reconfigurável vem quebrar a barreira entre estes dois tipos de dispo-
sitivos. Este permitiu a junção das particularidades de ambos e de elevar o conceito de sistema
embarcado a um novo patamar, criando novos tipos de compromisso entre o software e a região
reconfigurável da FPGA.
Um sistema embarcado reconfigurável, permite que porções da região hardware do sistema
sejam alteradas, consoante a necessidade da aplicação executada pelo GPP, alterando as funci-
onalidades implementadas, oferecendo dessa forma novo grau de flexibilidade ao sistema. Por
outro lado, a execução de mais tarefas em hardware, por densidade de recursos, oferece um ní-
vel múltiplo de aceleração ímpar, jamais obtido por apenas um circuito ASIC. Para além destas
caraterísticas, este conceito permite a desativação completa dos blocos hardware não necessários,
alcançando dessa forma um excelente nível de consumo energético.
A próxima figura 2.1, mostra um exemplo de um sistema embarcado reconfigurável. Como
pode ser verificado a título de exemplo, os blocos de hardware que executam as funções A e
B, apoiam de forma fixa o processador nas tarefas críticas, necessárias à correta execução da
aplicação. Por outro lado, as funções C, D e E, F, são apenas executadas de maneira alternada
entre si, podendo estas ocupar apenas um bloco reconfigurável.
GPP
Função
Fixa B
Função
Fixa A
Região Hardware
Função
Reconfigurável
C
Função
Reconfigurável
E
Função
Reconfigurável
D
Função
Reconfigurável
F
Figura 2.1: Exemplo de Sistema Parcial Dinâmico Reconfigurável.
2.3.1 Sistemas Parciais Dinâmicos Reconfiguráveis
A capacidade de reconfiguração de regiões da FPGA, só por si, apenas oferece uma parte
das reais funcionalidades existentes nos microprocessadores. Esta limitação deve-se ao facto de
não ser possível aquando da reconfiguração de uma porção da região de hardware, a execução
dos restantes módulos reconfiguráveis, havendo a necessidade de interrupção da execução destes.
Porém esta limitação é ultrapassada utilizando o estado de arte da tecnologia de reconfiguração, a
reconfiguração parcial dinâmica, permitindo desta forma que as áreas já configuradas permaneçam
em completo funcionamento durante a configuração de uma nova área. Esta caraterística oferece
ao sistema a capacidade de monitorização e constante adaptação às condições envolventes ao
sistema, sem a perca do contexto da aplicação.

8 Revisão Bibliográfica
2.3.2 Desafios dos Sistemas Computacionais
Os sistemas reconfiguráveis encontram-se intimamente ligados às exigências dos sistemas
computacionais modernos.
De acordo com o estudo efetuado [10], os futuros desafios dos sistemas computacionais estão
relacionados com fatores de eficiência, complexidade e fiabilidade. Sendo que alguns dos desafios
considerados são apresentados de seguida:
• Os computadores pessoais entrarão lentamente em declínio enquanto principal motor de
desenvolvimento de hardware e software, em detrimento de dispositivos móveis orientados
para o utilizador.
• Apesar da sua atualidade em termos de densidade de transístores, a “Lei de Moore” prevê
atualmente apenas pequenos aumentos e diminuições de frequência, relativamente à dissi-
pação de energia por transístor. Para manter o aumento de performance, a abordagem atual
consiste em adicionar mais unidades de processamento (processamento multi-core).
• Nos sistemas computacionais móveis, ao funcionarem no seu limite de capacidade e con-
sumo energético, o uso simultâneo de todos as funcionalidades integradas num dispositivo
poderá não ser possível, criando a necessidade da adaptação da disponibilidade das funcio-
nalidades existentes devido a restrições energéticas.
• A eficiência é um conceito chave na sustentação da contínua evolução das capacidades com-
putacionais, tendo como objetivo maximizar a quantidade de computação obtida por unidade
de energia e por um custo mínimo, no desenvolvimento e na produção.
• A conjugação, cada vez mais elaborada, entre software e hardware, necessária para a exe-
cução de aplicações com maior grau de complexidade, exige uma contínua adaptação e
fornecimento de novas ferramentas e técnicas de desenvolvimento para sistemas embarca-
dos.
• A fiabilidade engloba a previsibilidade necessária a sistemas de segurança críticas, assim
como a segurança e privacidade exigidas à computação.
Estes desafios indicam que será cada vez mais imperativo pesquisar novas direções, rompendo
com os clássicos sistemas Von Neuman e com a tradicional ligação entre hardware e software.
As novas direções apontam para a possibilidade de executar tarefas particulares a altos níveis de
eficiência, reduzindo o impacto das restrições das novas barreiras tecnológicas.

2.4 O Projeto REFLECT 9
2.3.3 Exemplos de Aplicações que usam Sistemas Reconfiguráveis
Uma vez que não existem regras definidas em relação à forma de como é efetuada a integração
e a gestão dos processos de reconfiguração entre o software e o hardware, grande parte da discus-
são efetuada sobre este tema, recai naturalmente sobre o estudo de estratégias de reconfiguração.
Os projetos abordados remetem para a discussão deste assunto em diferentes aplicações. O
primeiro exemplo apresentado [11] é o trabalho “Managing Dynamic Partial Reconfiguration on
Heterogeneous SDR Platforms”, onde é feita uma análise aos casos de uso resultantes da monta-
gem de um sistema reconfigurável aplicado à implementação de um sistema de comunicação de
rádio SDR, tendo sido utilizadas várias estratégias de reconfiguração. O estudo realizado neste
mostra que a total flexibilidade de reconfiguração é atingida com uma razoável complexidade de
implementação.
No segundo exemplo [12], o trabalho “Dynamic Reconfiguration for Robot Software”, recon-
figuração dinâmica é aplicada a dois diferentes tipos de sistemas de navegação, onde é feita uma
análise aos casos de uso. São apresentadas técnicas de abordagem de reconfiguração dinâmica de
software para robôs. Os resultados mostram que a eficiência obtida está bastante interligada com
as técnicas de interação entre os objetos de processamento.
2.4 O Projeto REFLECT
O projeto Europeu REFLECT (Rendering FPGAs to Multi-Core Embedded Computing) pro-
movido pelo consórcio constituído pelos parceiros Honeywell, INESC-ID, FEUP, TU Delft, KIT,
Imperial College e ACE foi fundada em 2010 com o propósito de investigar, desenvolver, imple-
mentar e avaliar novas técnicas e abordagens de síntese relacionadas com plataformas baseadas
em FPGA. Estas abordagens baseiam-se em especificações orientadas aos aspetos de aplicações
envolvendo domínios de processamento crítico, transmitindo essa informação a todas as etapas de
desenvolvimento.
Este está a avaliar a eficácia da abordagem utilizada em aplicações desde o domínio do proces-
samento de áudio/vídeo a aviónica em tempo real. Quatro aplicações formam o conjunto de apli-
cações selecionadas, nomeadamente: a codificação de áudio MPEG, o algoritmo de compressão
de voz G.279, planeamento de caminhos em três dimensões utilizados em veículos não tripulados
e o algoritmo de navegação estéreo, utilizado para a localização autónoma de veículos em caso de
indisponibilidade temporária de sistemas de navegação por satélite.
2.4.1 Objetivos da REFLECT Como Linha Orientadora da Dissertação
Os objetivos do projeto REFLECT abrangem três áreas fundamentais:
• Tornar a tecnologia reconfigurável acessível – Através da aposta em tecnologias recon-
figuráveis, baixando a barreira da adoção desta tecnologia e facilitando a portabilidade dos
programas para novas arquiteturas;

10 Revisão Bibliográfica
• Melhorar a produtividade – Acelerando o tempo de design em mais de duas ordens de
magnitude, para além de oferecer ao designer o controlo total das etapas de desenvolvimento
de uma maneira consistente e sistemática;
• Integrar novos aspetos no fluxo de projeto – Através do conhecimento das particularida-
des do algoritmo, os seus requisitos não funcionais, a flexibilidade da definição da organi-
zação da memória dependendo das propriedades da FPGA e o melhoramento das práticas
de design de sistemas através da utilização de modelos de conjugação entre hardware e
software;
2.5 Plataforma de desenvolvimento utilizada
Neste capítulo é apresentada a plataforma de desenvolvimento utilizada, sendo descrita infor-
mação sobre a placa e software de desenvolvimento utilizados.
2.5.1 Placa de desenvolvimento Xilinx ML507
A placa de desenvolvimento Xilinx ML507, apresentada na Figura 2.2, foi a plataforma em-
barcada utilizada para realização do projeto. Esta combina as caraterísticas necessárias à imple-
mentação de um sistema reconfigurável graças à tecnologia presente na família de FPGA Virtex
e à flexibilidade do uso de um processador de utilização geral, GPP, neste caso processador IBM
PowerPc 440, descrito com maior detalhe na Secção 2.5.1.2.
Entre as caraterísticas mais importantes desta placa destacam-se os periféricos utilizados[13]:
• FPGA Xilinx Virtex-5 XC5VFX70T-1FFG1136 com o processador embarcado PowerPC
440;
• Controlador CompactFlash Xilinx System ACETM, utilizado para carregamento dos fichei-
ros de configuração da FPGA;
• Controlador de porta série;
2.5.1.1 Virtex-5 XC5VFX70T FPGA
A família Virtex-5 oferece algumas das caraterísticas tecnologicamente mais avançadas e de
mais alto desempenho existentes no mercado de FPGA.
Alguns dos elementos configuráveis de maior destaque existentes na FPGA Virtex-5 FXT
utilizada no desenvolvimento deste trabalho são:
• CLB – Os blocos lógicos configuráveis (CLB) são os elementos lógicos básicos existentes
nas FPGA da Xilinx. Baseadas numa tecnologia de look-up table (LUT3) de seis entradas,
este blocos permitem configurações lógicas combinacionais e síncronas, bem como memó-
rias distribuídas ou de deslocação de registos;3LUT - Unidade de memória de N entradas e M saídas capaz que armazenar funções, baseadas nas funções lógicas
básicas AND, OR, XOR e NOT entre os elementos de entrada.

2.5 Plataforma de desenvolvimento utilizada 11
Figura 2.2: Placa de desenvolvimento Xilinx ML507.
• DSP48E – Blocos de cálculo rápido dedicado, capazes de efetuar multiplicações entre va-
lores de 18 e 25 bit em complemento para dois, com capacidade adição integrada, per-
mitem efetuar operações de multiplicação complexa e multiplicação e acumulação rápida,
orientados para aceleração de algoritmos com alto nível de integração e requisitos de baixa
potência;
• BlockRam – Blocos de memória dedicada, capazes de armazenar um máximo de 36 Kib
de dados, oferecem a possibilidade de ligação em cascata para a obtenção de memórias de
maior dimensão;
• CMT – Módulos de gestão de sinais de relógio (CMT4) até 500 Mhz, aplicado a regiões da
FPGA;
2.5.1.2 Processador embarcado PowerPC 440
O processador embarcado IBM PowerPC 440 faz parte da família de processadores IBM 32 bit
PowerPC 400 RISC, especialmente desenhados para implementações SoC, no qual o critério de
máxima performance e alta integração de periféricos é exigido. Para comunicação com a FPGA,
este utiliza um barramento de 128 bit, PLB5, parte integrante da arquitetura IBM CoreConnectTM,
totalmente compatível com a tecnologia crossbar da Virtex-5. Entre as caraterísticas disponibili-
zadas por este processador encontram-se:
• Capacidade de processamento de mais de 1000 MIPS a 500 Mhz;
• Controladores DMA scatter/gather integrados;
• Interface dedicada para conexão com controlador de memória DDR2;
• Arquitetura Enhanced PowerPC ArchitectureTM;
4CMT - Clock Management Tiles.5PLB - Processor Local Bus

12 Revisão Bibliográfica
• Separação lógica de processador e barramento PLB;
• Interface de unidade de processamento auxiliar (APU) com suporte aceleração de hardware
e integração com crossbar;
• Pipeline superescalar para operações de 7 estágios com previsão dinâmica de ramificação
de software;
• Cache de instruções e dados até 32 KiB;
• Interface de depuração via JTAG;
2.5.2 Ferramentas de Desenvolvimento Utilizadas
De seguida serão apresentadas as principais ferramentas de software utilizadas no desenvolvi-
mento deste trabalho.
2.5.2.1 Catapult C
A ferramenta Catapult C da Calypto Design Systems, é a ferramenta de síntese de alto ní-
vel utilizada neste projeto. Esta é capaz de gerar a partir de linguagem de código de alto nível
como ANSI C, C++ ou SystemC, linguagens de descrição de hardware (HDL6) como Verilog ou
VHDL, para além de criar scripts de simulação, esquemáticos, relatório temporais e de ocupação
de recursos entre outros. A figura 2.3 demonstra o fluxo de desenvolvimento oferecido por esta
ferramenta, sendo este caraterizado pelas seguintes fases do processo:
• Preparação dos ficheiros fonte para a síntese – Uma vez que os ficheiros escritos em lin-
guagem de alto nível descrevem apenas a funcionalidade da função a sintetizar, a primeira
fase envolvida no fluxo de projeto da ferramenta é caraterizada pela seleção e adaptação
da função considerada tendo em vista a sua realização em contexto de execução em hard-
ware. As regras envolvidas no processo de adaptação do código fonte são fornecidas pelo
manual[14];
• Configuração do projeto – Neste fase é possível selecionar a FPGA e frequência alvo,
restrições da tecnologia envolvida, as tecnologias de interface entre software e hardware e
os núcleos IP7 disponíveis para utilização.
• Especificação das restrições arquitetónicas da síntese – Uma vez que a funcionalidade
define o que o sistema deve produzir, a arquitetura define a forma de como o sistema o deve
executar. Para tal, nesta fase são definidas as caraterísticas internas da síntese associadas
à natureza da execução e à otimização do código a executar, tais como o desenrolamento
e paralelismo de ciclos de execução ou a partilha de operadores de computação, para além
da definição das interfaces de comunicação entre as barreiras software e hardware. Esta
definição permite encontrar um compromisso ótimo entre a performance e a área desejada à
implementação da função6HDL - Hardware Description Language.7IP Core - Intellectual Property Core: Bloco, célula ou unidade lógica especializada para execução de determinada
funcionalidade, pronta para incorporação em projetos.

2.5 Plataforma de desenvolvimento utilizada 13
• Análise do escalonamento (Diagrama de Gantt) – Uma vez definidos os restrições de
síntese, para a análise da arquitetura definida é disponibilizado o escalonamento prévio das
operações a realizar pelo módulo de hardware, o qual será posteriormente sintetizado. Nesta
fase, é apresentada sob a forma de um diagrama de Gantt, informação relativa à hierarquia
e escalonamento de operações, número de ciclos de relógio e correspondente tempo de
execução relativo a cada ciclo de execução While ou For, bem como caminhos de dados e
dependências entre operações.
• Criação RTL8 e relatórios da síntese – Fase de execução da síntese de alto nível e criação
de netlist9 RTL. Após conclusão da síntese, um conjunto de resultados são apresentados
tais como, o ficheiro de descrição de hardware HDL e respetivos esquemáticos bem como
relatórios de performance temporal e utilização de recursos;
• Verificação da síntese SCVerify – Esta última fase permite a criação automática de test-
bench10 e da integração do módulo produzido em ferramentas de simulação e validação tais
como ModelSim R©/QuestaSim R©, OSCI, NCSim,VistaTM ou VCS;
A utilização desta ferramenta no trabalho permitiu a estimativa temporal e a criação de módu-
los Verilog, representativos de operações a efetuar em software.
2.5.2.2 Xilinx ISE
A ferramenta Xilinx ISE R© (Integrated Software Environment), faz parta do pacote de ferra-
mentas de desenvolvimento de sistemas embarcados (EDK11) fornecidas pela Xilinx e possibilita
ao utilizador a execução dos passos necessários à concretização de um projeto de construção de
circuitos digitais em FPGA, desde a conceção dos ficheiros de descrição HDL, a implementação
da netlist RTL resultante e a criação e programação dos bitstreams gerados. Após seleção da tec-
nologia, o fluxo de projeto da ferramenta, apresentado na figura 2.4, é caraterizado pelos seguintes
passos:
• Criação/Edição de módulos HDL e integração de IP cores – Tal como o nome indica,
esta fase permite a criação, modificação de módulos HDL, bem como a integração destes
com blocos funcionais já criados;
• Especificação de restrições de projeto – Fase de estabelecimento dos objetivos e estraté-
gias da síntese RTL. De entre alguns objetivos encontram-se ’Performance temporal’, ’Re-
dução de área’ ou ’Balanceado’. Para cada objetivo escolhido, uma lista de estratégias é
oferecida, algumas destas tendo em vista questões de otimização do processo de implemen-
tação física, ocorrida a diante;
8RTL - Register Transfer Level: Nível de abstração utilizado na descrição de circuitos digitais.9Netlist - Lista de ligações lógicas existente no módulo considerado.
10Testbench - Conjunto de testes de validação criados, representados por estímulos de sinais à entrada do módulo, osquais produzem correspondentes efeitos na sua saída.
11EDK - Embedded Development Kit.

14 Revisão Bibliográfica
• Síntese RTL – Nesta fase é executada a síntese RTL do conjunto dos módulos HDL que
constituem o sistema a implementar. Como resultado, para cada módulo é gerado um fi-
cheiro em formato NGC que engloba a netlist gerada, do tipo XST12, juntamente com as
restrições inerentes;
• Implementação do projeto ’Translate’, MAP e PAR – A fase de implementação é cons-
tituída por três processos fundamentais, o primeiro, ’Translate’ junta todas as netlists exis-
tentes no ficheiro NGC (Xilinx Native Generic Circuit) e traduz o esquema lógico existente
em primitivas básicas da Xilinx. No processo seguinte, MAP, é efetuado o mapeamento da
lógica resultante do processo anterior nas componentes existentes na FPGA a utilizar, como
o caso dos blocos CLB, DSP48E e BlockRam. Por fim o último processo realizado, PAR,
efetua o posicionamento das componentes, bem como o roteamento da ligações efetuadas;
• Geração do bitstream – Uma vez concluído o projeto de implementação, a informação
sobre a configuração de todas as componentes da FPGA a utilizar, bem como as suas li-
gações é compilada no ficheiro ‘bitstream’, sendo este por fim descarregado para a FPGA,
efetuando dessa forma à sua configuração.
Durante o fluxo de projeto são efetuados pelo menos dois tipos verificação, uma simulação fun-
cional, proveniente apenas da descrição comportamental do circuito, proveniente da fonte HDL, e
uma pós-síntese, destinada à validação temporal do circuito.
2.5.2.3 Xilinx XPS
A ferramenta Xilinx XPS (Xilinx Platform Studio), parte da suite EDK, permite uma fácil
construção, conexão e configuração das componentes pertences ao sistema embarcado. Caraterís-
ticas como o tipo de processador utilizado, a incorporação dos núcleos IP fornecidos pela Xilinx ou
modelos HDL gerados, bem como a interligação das componentes e mapeamento dos endereços
de sistema podem ser facilmente definidas e implementadas.
2.5.2.4 Xilinx PlanAhead
A ferramenta Xilinx PlanAhead R©, também esta parte da suite EDK, insere-se no fluxo de
projeto da ferramenta Xilinx ISE, oferecendo um novo grau de liberdade ao disponibilizar dois
tipos caraterísticas fundamentais à elaboração deste trabalho, sendo estes, a possibilidade de criar
projetos envolvendo reconfiguração parcial dinâmica, para além de proporcionar um integrado e
intuitivo ambiente de controlo sobre todo o processo de implementação.
Nesta ferramenta, a implementação de um projeto de reconfiguração parcial dinâmica em
FPGA é semelhante à implementação de múltiplos projetos estáticos os quais partilham lógica
comum entre si. Estas múltiplas entidades são denominadas partições, podendo estas representar
lógica estática, invariável às mudanças de lógica nas partições reconfiguráveis. A figura 2.5 ilustra
12XST - Xilinx R© Synthesis Technology

2.5 Plataforma de desenvolvimento utilizada 15
An
ális
e e
re
fin
am
en
to
do
alg
ori
tmo
Inic
iaç
ão
do
pro
jeto
Preparação dos ficheiros
fonte para a síntese
Configuração do projeto
Especificação das
restrições arquitetónicas
da síntese
Análise do
escalonamento
(Diagrama de Gantt)
Criação RTL e
relatórios da síntese
Verificação da síntese
SCVerify
Objetivos
temporais
atingidos ?
Objetivos
de concepção
atingidos ?
Sim
Sim
Não
Verilog / VHDL
Não
Ge
raç
ão
de
Te
stb
en
ch
Ge
raç
ão
e
ve
rifi
ca
çã
o R
TL
Figura 2.3: Fluxo de projeto Catapult C.
Verificação do projeto
Seleção da tecnologia
Criação/Edição de
módulos HDL e
integração de IP cores
Especificação de
restrições de projeto
Implementação
do projeto
(Translate, MAP e PAR)
Síntese RTL
Geração de bitstream
Download do bitstream
para a FPGA
Avaliação da área
e performence
obtidas
Análise e
simulação temporal
NGC
Simulação
funcional
Figura 2.4: Fluxo de projeto ISE.
este conceito. Como requisito à iniciação do projeto de reconfiguração parcial, devem ser conside-
rados os ficheiros de netlist NGC resultante da síntese RTL dos módulos estáticos, pertencentes à
partição estática, para além da netlist de cada módulo reconfigurável, pertencente a uma determi-
nada partição reconfigurável. De salientar que a região estática apenas contém uma versão vazia
dos módulos reconfiguráveis, garantindo dessa forma a correta interligação entre a região estática
e cada módulo reconfigurável implementado na partição reconfigurável.
Uma vez associados o módulo estático com um dos módulos reconfiguráveis, são definidas
as restrições relativos a este conjunto e é efetuada a implementação desta solução. Uma vez va-
lidada, os módulos pertencentes à partição estática são promovidos a um nível definitivo. Desta
forma esta partição estática é reutilizada aquando da implementação dos restantes módulos recon-
figuráveis. No final, para cada conjunto partição estática/reconfigurável são gerados dois ficheiros
bitstream (‘*.bit’), os quais configuram a totalidade da FPGA, ou apenas a área pertencente à
partição reconfigurável.

16 Revisão Bibliográfica
Módulo
Estático
‘vazia’Módulo
Reconfig. A
Módulo
Reconfig. B
Partição
Estática
Partição
Reconfig.
Estático
MR A MR B
restrições do
design A
restrições do
design B
Síntese RTL
Ficheiros HDL
Netlist NGC
ImplementaçãoEstático
MR A
ImplementaçãoEstático
MR B
Cópia Partição
Estática
An
ális
e d
e r
esu
lta
do
s
Fluxo ISE
Fluxo PlanAhead
Total_A.bit
MR_A.bit
Total_B.bit
MR_B.bit
Legenda:
Figura 2.5: Fluxo de projeto PlanAhead.
2.5.2.5 Xilinx SDK
A ferramenta Xilinx SDK (Software Development Kit), também esta parte da suite EDK,
oferece um ambiente gráfico de desenvolvimento de software para sistemas embarcados baseados
nas arquiteturas FPGA da Xilinx.
2.5.3 Outras Ferramentas
2.5.3.1 Precision RTL
A ferramenta Precision RTL da Mentor Graphics, à semelhança da ferramenta Xilinx ISE,
também é uma ferramenta de síntese e implementação em FPGA. Neste trabalho, a ferramenta foi
utilizada para a conversão de ficheiros de descrição de hardware (HDL) gerados pelo Catapult C,
de modo a serem utilizados pelas ferramentas da Xilinx.
2.5.3.2 ModelSim
A ferramenta ModelSim da Mentor Graphics é a ferramenta de simulação e análise temporal
utilizada para a validação dos circuitos gerados ao longo de todo o projeto de implementação
envolvido neste trabalho.

Capítulo 3
Análise da Aplicação Navegação Estéreo
Esta secção do documento tem como objetivo descrever com maior pormenor os principais
blocos da aplicação adotada, a Navegação Estéreo, e tem como finalidade recolher informação so-
bre qual ou quais as funções suscetíveis de serem substituídas por blocos dedicados em hardware,
a fim de ser obtida uma aceleração do tempo total de execução da aplicação.
3.1 Visão Global da Aplicação
O mundo dos sistemas de navegação de veículos, sejam estes aéreos ou terrestres, é domi-
nado pelos sistemas globais de navegação por satélite. Para algumas aplicações, como no caso da
aviação, a disponibilidade do serviço de localização é um fator de grande importância.
A aplicação Navegação Estéreo tem como objetivo apoiar os mecanismos de localização em
veículos onde este serviço está temporariamente indisponível recorrendo a dispositivos de captura
de imagem existentes a bordo, os quais, aliados ao processamento de informação relativa ao mundo
envolvente, possibilitam a sua navegação de forma autónoma durante um certo período de tempo.
O conceito da aplicação passa por adquirir imagens vindas de duas câmaras orientadas sen-
sivelmente para a mesma direção no mesmo instante de tempo. O processamento destes pares
de imagens possibilita a deteção de caraterísticas bem definidas no seu espaço tridimensional. A
sequência de aquisição de imagens estéreo em instantes t(n) e t(n−1) juntamente com a determina-
ção das suas caraterísticas permite inferir a matriz de rotação e o vetor de translação, e consequente
variação absoluta da rotação e translação do veículo em cada instante de tempo.
O algoritmo da aplicação de Navegação Estéreo apresentado na Figura 3.1 está presente no
código fonte fornecido em linguagem C e tem como sequência de funções:
Right Image
Left Image
ΔR
ΔT
Image
Rectification
Right Feature
Extraction
Left Feature
Extraction
Left / Right
Feature
Matching
t(n) / t(n-1)
Feature
Matching
3D
Reprojection
Robust Pose
Estimate
Figura 3.1: Algoritmo de Navegação Estéreo.
17

18 Análise da Aplicação Navegação Estéreo
• Retificação da Imagem — Função responsável por eliminar distorções nas imagens, sobre-
tudo a distorção com efeito de barril causado pela superfície convexa das lentes, apresentado
na Figura 3.2, e o erro de orientação entre câmaras;
Figura 3.2: Ilustração da distorção com efeito de barril.
• Extração de Caraterísticas — Função responsável por detetar caraterísticas de uma dada
imagem, utilizando o algoritmo de deteção de cantos ’Harris Corner Detector’, e de as
descrever em vetores de dados;
• Correspondência de Caraterísticas — Função que executa um algoritmo de verificação
circular entre as caraterísticas encontradas no presente instante e as caraterísticas já vali-
dadas do instante de tempo anterior. Este método procura correspondências entre as cara-
terísticas da imagem estéreo do presente instante tR(n) e tL(n), repetindo o processo para as
imagens do lado direito pertencentes aos instantes presente e anterior, tR(n) e tR(n−1) e, por
fim, as do lado esquerdo tL(n) e tL(n−1).
A Figura 3.3 demonstra as quatro imagens captadas envolvidas neste processamento, sendo
as duas de topo referentes à imagem estéreo captada no instante t(n−1). Neste exemplo, os
vértices das linhas apresentadas a vermelho representam uma caraterística presente em todas
as imagens, tendo esta correspondência sido validada.
O método de correspondência utilizado é o produto interno entre caraterísticas de imagens
diferentes, onde o nível de decisão equivale a um valor de treshold entre uma correspondên-
cia total (valor resultante igual a 1.0) e o total desacordo (valor resultante 0.0).
Todo este processo é executado com vista a aumentar a probabilidade do correto funciona-
mento da função Reprojeção 3D, uma vez que embora, na teoria, as correspondências de
caraterísticas entre imagens adquiridas num certo instante bastariam para determinar a sua
projeção no mundo tridimensional, na realidade, como no exemplo urbano demonstrado na
Figura 3.3, essa probabilidade pode ser bastante baixa, como verificado em [15];
• Reprojeção 3D — Esta função calcula analiticamente as coordenadas tridimensionais de
um ponto a partir da projeções da imagem nesse mesmo ponto. O resultado desta função

3.2 Montagem de Sistema Básico de Execução 19
Figura 3.3: Verificação circular para correspondência de caraterísticas.
carateriza-se pela criação de duas listas de pontos tridimensionais geradas respetivamente a
partir das imagens estéreo obtidas nos instantes tL(n) e tL(n−1);
• Estimação Robusta de Pose — Por fim esta função utiliza a sub-função de RANSAC
(RANdom SAmple Consensus) que retira do algoritmo os elementos que poderiam influ-
enciar negativamente o resultado final, concluindo todo o algoritmo com a extrapolação da
matriz de rotação e do vetor de translação;
3.2 Montagem de Sistema Básico de Execução
Com a finalidade de iniciar o processo de adaptação e desenvolvimento da aplicação na placa
Xilinx ML507, houve a necessidade de montar um sistema embarcado base. Para tal, foi utilizada a
ferramenta Xilinx Platform Studio (XPS). O assistente de configuração presente nesta ferramenta
permite ao utilizador construir, conectar e configurar todo os periféricos necessários ao sistema
embarcado.
Um sistema embarcado base foi então construído, contendo os elementos básicos necessá-
rios como processador e memória, para além de uma interface de comunicação com o exterior,
sendo esta um controlador de comunicação por porta série RS-232, utilizado para comunicação
via terminal.
Embora o intuito do projeto seja a utilização de câmaras como fonte de entrada de dados no
sistema de Navegação Estéreo, o código fonte em linguagem C fornecido não utiliza câmaras
‘reais’ como fonte de entrada de dados. Este porém, permite dois tipos de entrada de dados

20 Análise da Aplicação Navegação Estéreo
consoante certos parâmetros de configuração inicial, sendo estes, a utilização de ficheiros em
escala de cinzento de formato *.PGM, ou a incorporação do conteúdo destes ficheiros, referentes
a imagens estéreo consecutivas, no código fonte em forma de matriz de dados.
A última opção foi a utilizada, sendo esta a configuração já presente por omissão, na aplicação.
Criado o sistema base, restava definir o tipo de sistema operativo utilizado para execução da
aplicação. A ferramenta de desenvolvimento da Xilinx (XSDK), oferece bibliotecas de suporte a
software, para os seguintes tipo de sistema operativo:
• Standalone - O ambiente de execução mais simples oferecido, fornecendo apenas uma
única thread de execução, permitindo acesso completo às funcionalidades do processador,
para além de recursos de entrada/saída;
• Xilkernel - Ambiente de execução baseado num pequeno e básico kernel que oferece servi-
ços POSIX como escalonamento de tarefas, multithreading e sincronização;
• Kernel Unix - Ambiente de execução com suporte para as distribuições Unix LinuxTM e
VxWorksTM;
Uma vez que a aplicação fornecida não necessita da utilização de mais do que uma tarefa em
simultâneo, um sistema operativo do tipo Standalone foi à partida o escolhido. Esta escolha é
ainda mais sustentada, pelo facto de a Xilinx não oferecer device driver de suporte ao periférico
HWICAP, responsável pela comunicação com a porta de configuração ICAP.
Como medida de validação desta escolha, procedeu-se à comparação do tempo total de execu-
ção da aplicação obtido pela presente configuração, com os resultados obtidos numa implementa-
ção prévia do projeto de Navegação Estéreo[1], onde a mesma placa de desenvolvimento, ML507,
sustentava um sistema embarcado semelhante, embora executado em Linux, baseado no processa-
dor PowerPC440 a 400 Mhz e onde o nível de otimização utilizado na compilação foi o mesmo,
-O2.
O tempo total de execução obtido utilizando sistema operativo Standalone foi cerca de 6.27 se-
gundos, contrastando com os 13.54 segundos obtidos usando Linux. Estes resultados evidenciam
que o sistema operativo escolhido, baseado em Standalone, foi a opção correta.
3.3 Análise Temporal Prévia
3.3.1 Informação Proveniente de Implementação Prévia do Projeto
Uma vez que o projeto de aceleração em hardware da aplicação de Navegação Estéreo, sem
a componente de reconfiguração dinâmica e qualidade de serviço, fora anteriormente implemen-
tado [1], com utilização da mesma plataforma de desenvolvimento que o projeto atual, decidiu-se
aproveitar os resultados da extensa análise temporal previamente efetuada.

3.3 Análise Temporal Prévia 21
Neste trabalho, para além da determinação da flag da otimização que oferecia a maior perfor-
mance, a -O2, o autor concluiu, através da utilização da ferramenta de profiling Gprof, que as ta-
refas críticas, responsáveis por um total de cerca de 60% do tempo total de execução da aplicação,
são causadas pelas sub-funções ConvVBConst_uS_hS_yS, ConvVBRepl1_uS_hS_yS e ConvV-
BRepl2_uS_hS_yS, as quais são chamadas a partir da função harrisTile_model_step, sendo que
todos estes processos pertencem à função Extração de Caraterísticas. A Tabela 3.1 apresenta os
resultados obtidos.
Tabela 3.1: Resultado da análise temporal obtido em trabalho prévio[1].
% Tempo deExecução
Função
23.98 ConvVBRepl1_uS_hS_yS23.97 ConvVBRepl2_uS_hS_yS13.97 ConvVBConst_uS_hS_yS11.07 harrisTile_model_step8.32 RobustPoseEst_RANSAC_diag6.58 sift_match_one
3.3.2 Informação Fornecida pela REFLECT
A REFLECT, entidade que desenvolveu a aplicação de Navegação Estéreo, aponta ela própria
para os tempos estimados de execução máxima dos processos envolvidos na aplicação[15]. Entre
estes tempos, destacam-se como tarefas críticas a função Extração de caraterísticas com 15% do
tempo máximo de execução, a função Correspondência de Caraterísticas com 20% e a função de
Estimação Robusta de Pose que, no pior caso, pode consumir até 40% do tempo de execução.
3.3.3 Análise Temporal no Sistema Atual
Como medida de comprovação destes resultados, procedeu-se à verificação temporal da apli-
cação no sistema base montado. Para tal, utilizou-se a ferramenta de profiling existente no XSDK.
A informação resultante da análise, é apresentada na Tabela 3.2.
Tabela 3.2: Resultado da análise temporal obtido no sistema base atual.
% Tempo deExecução
Número deChamadas
Função
19.53 144 ConvVBRepl1_uS_hS_yS19.47 144 ConvVBRepl2_uS_hS_yS19.3 48 harrisTile_model_step15.77 1 RobustPoseEst_RANSAC_diag12.86 96 ConvVBConst_uS_hS_yS6.53 270 sift_match_one

22 Análise da Aplicação Navegação Estéreo
3.3.4 Conclusão
Com base na informação apresentada[1][15], juntamente com a análise feita no sistema atual,
pode-se afirmar que as subfunções ConvVBConst_uS_hS_yS, ConvVBRepl1_uS_hS_yS e ConvV-
BRepl2_uS_hS_yS, pertencentes à função Extração de Caraterísticas e a sub-função RobustPose-
Est_RANSAC_diag pertencente à função Estimação Robusta de Pose, são funções críticas da
aplicação e as candidatas a implementação em hardware.
3.4 Análise das Tarefas Críticas
Esta secção do documento tem como objetivo a análise das funções envolvidas nas tarefas
críticas, nomeadamente as tarefas Extração de Caraterísticas e Estimação Robusta de Pose.
3.4.1 Função Extração de Caraterísticas
Como explicado anteriormente, esta função é utilizada para deteção de caraterísticas existentes
nas imagens capturadas, sendo baseado no algoritmo de deteção de cantos de Harris[16].
No caso da versão da aplicação fornecida, existe a possibilidade de execução de dois tipos
diferentes de tamanhos de imagens capturadas, 640×480 e 320×240 pixeis, sendo estas compostas
por uma profundidade de cor de 8 bit na escala de cinzentos. Com base nesta possibilidade, o
método de processamento efetuado pela função Extração de Caraterísticas passa pela subdivisão
da imagem captada em secções de menor dimensão, possibilitando dessa forma a existência de um
núcleo de processamento capaz de ser utilizado em cada uma das dimensões de captura possível.
Cada secção, é resultado da subdivisão inteira da imagem total, em secções de 80×80 pixeis,
ao qual uma borda de sobreposição de 8 pixeis é adicionada, desta feita, cada secção resultante é
portanto constituída por 96×96 pixeis.
A Figura 3.4, demonstra a finalidade da utilização do método de deteção de Harris. O resultado
deste processo é constituído por uma imagem com a mesma dimensão e profundidade de cores da
secção analisada e representa a tons mais claros os cantos detetados.
Filtro
Harris
(a) (b)
80
80
Figura 3.4: a) Secção original da imagem captada; b) Resultado do operador de deteção de cantosHarris.

3.4 Análise das Tarefas Críticas 23
Para cada secção de 96×96 pixeis, o processo responsável pela execução do algoritmo de Har-
ris, a função harrisTile_model_step, é constituída por uma sequência de operações, entre as quais
se encontram as tarefas críticas detetadas aquando da análise temporal da aplicação, sendo estas, as
sub-funções ConvVBConst_uS_hS_yS, ConvVBRepl1_uS_hS_yS e ConvVBRepl2_uS_hS_yS.
Cada uma destas sub-funções, doravante designadas respetivamente por ConvConst, Con-
vRepl1 e ConvRepl2, executa um conjunto de etapas de convolução bidimensionais, necessárias
ao algoritmo de Harris. Na Figura 3.5, encontra-se numerada a sequência de operações de convo-
lução executada neste processo. Cada operação de convolução tem como informação de entrada
um array de 9216 elementos, representado pela variável u, para além de um array representante
do filtro a aplicar, a variável h.
1x11
1x11
Filtro
Horizontal
Filtro
Vertical
Filtro
Horizontal
Filtro
Vertical
ConvConst
1
( )²
ConvRepl1
2
ConvRepl2
3
ConvRepl2
8
ConvRepl1
7
x
ConvRepl2
6
ConvRepl1
5
( )²
ConvConst
4
3x3 3x3
Secção
de imagem
96x96
Figura 3.5: Fluxo de operações com numeração das tarefas críticas de convolução.
As operações de convolução existentes são baseadas na mesma expressão matemática, apre-
sentada pela equação 3.1. Para cada elemento de entrada do array u, esta expressão permite cal-
cular o valor de convolução, representado pelo valor accn, o qual é armazenado no correspondente
elemento pertencente ao array de saída y.
accn = u[i]×h[ j]+accn−1; (3.1)

24 Análise da Aplicação Navegação Estéreo
3.4.1.1 ConvConst
A função ConvConst executada nas etapas de convolução 1 e 4, calcula o resultado das ope-
rações da convolução entre a secção de imagem 96×96 pixeis, oriunda da imagem captada, e os
correspondentes filtros Horizontal e Vertical, os quais representam operadores de Prewitt[17], es-
tando estes demonstrados nas Equações 3.2 e 3.3. Estes permitem detetar as bordas horizontal
e vertical existentes na secção, possibilitando às secções posteriores a união desta informação e
correspondente deteção de cantos.
Filtro Horizontal =
1 1 1
0 0 0
−1 −1 −1
(3.2)
Filtro Horizontal =
1 0 −1
1 0 −1
1 0 −1
(3.3)
A partir desta informação, o valor de cada elemento de saída resultante da operação de convo-
lução, y[m,n], entre o array de 9216 elementos e o filtro horizontal pode ser calculado a partir da
Equação 3.4.
y[m,n] = u[m−1,n−1]×h[0]+u[m−1,n]×h[1]+u[m−1,n+1]×h[2]+
u[m,n−1]×h[3]+u[m,n]×h[4]+u[m,n+1]×h[5]+
u[m+1,n−1]×h[6]+u[m+1,n]×h[7]+u[m+1,n+1]×h[8]; (3.4)
Verificando o construtor da função ConvConst, apresentado na Listagem 3.1, é possível veri-
ficar que para além dos arrays de entrada u, h e saída y, esta função conta também com os arrays
de entrada bSStart, bSEnd, bSNumPreEdges, bSPreEdges, bSNumPostEdges e bSPostEdges, os
quais são utilizados como parâmetros para controlo dos elementos pertencentes à borda exterior
da matriz u.
Listagem 3.1: Cabeçalho da função ConvConst.
void ConvVBConst_uS_hS_yS ( c o n s t r e a l 3 2 _ T h [ ] ,c o n s t r e a l 3 2 _ T u [ ] ,r e a l 3 2 _ T y [ ] ,i n t 3 2 _ T b S S t a r t [ ] , i n t 3 2 _ T bSEnd [ ] ,i n t 3 2 _ T bSNumPreEdges [ ] , i n t 3 2 _ T bSPreEdges [ ] ,i n t 3 2 _ T bSNumPostEdges [ ] , i n t 3 2 _ T bSPos tEdges [ ]) ;

3.4 Análise das Tarefas Críticas 25
3.4.1.2 ConvRepl1
A função ConvRepl1 executada nas etapas de convolução 2, 5 e 7, calcula o resultado das ope-
rações da convolução entre os arrays de 9216 elementos, resultantes de operações de multiplicação
entre os arrays originados a partir das convoluções horizontal e vertical, pela função ConvConst,
e um array de 11 elementos, cujo conteúdo é apresentado na Equação 3.5, o qual representa um
filtro gaussiano horizontal. Este filtro é utilizado para realçar as bordas detetadas pelo processo
anterior, facilitando desta forma as operações posteriores à função Extração de Caraterísticas.
Filtro Horizontal =
−0,0354829430580139
−0,0585014708340168
−0,0863095894455910
−0,1139453053474430
−0,1346104741096500
−0,1423004716634750
−0,1346104741096500
−0,1139453053474430
−0,0863095894455910
−0,0585014708340168
−0,0354829356074333
(3.5)
À semelhança da função ConvConst, o valor de cada elemento de saída resultante da operação
de convolução, y[m,n], pode ser calculado a partir da Equação 3.6.
y[m,n] = u[m,n−5]×h[0]+u[m,n−4]×h[1]+u[m,n−3]×h[2]+
u[m,n−2]×h[3]+u[m,n−1]×h[4]+u[m,n]×h[5]+
u[m,n+1]×h[6]+u[m,n+2]×h[7]+u[m,n+3]×h[8]+
u[m,n+4]×h[9]+u[m,n+5]×h[10]; (3.6)
3.4.1.3 ConvRepl2
À semelhança das funções anteriores, a função ConvRepl2, executada nas etapas de convolu-
ção 3, 6 e 8, calcula o resultado das operações da convolução entre os arrays de 9216 elementos,
resultantes da função ConvRepl1, e um array de 11 elementos, cujo conteúdo é apresentado na
Equação 3.7, o qual representa um filtro gaussiano vertical.

26 Análise da Aplicação Navegação Estéreo
Filtro Vertical =
−0,0354829356074333
−0,0585014633834362
−0,0863095894455910
−0,1139453053474430
−0,1346104741096500
−0,1423004418611530
−0,1346104741096500
−0,1139453053474430
−0,0863095894455910
−0,0585014745593071
−0,0354829318821430
(3.7)
Mais uma vez, à semelhança das funções ConvConst e ConvRepl2, o valor de cada elemento
de saída resultante da operação de convolução, y[m,n], pode ser calculado a partir da Equação 3.8.
y[m,n] = u[m−5,n]×h[0]+u[m−4,n]×h[1]+u[m−3,n]×h[2]+
u[m−2,n]×h[3]+u[m−1,n]×h[4]+u[m,n]×h[5]+
u[m+1,n]×h[6]+u[m+2,n]×h[7]+u[m+3,n]×h[8]+
u[m+4,n]×h[9]+u[m+5,n]×h[10]; (3.8)
3.4.2 Função Estimação Robusta de Pose
Como explicado anteriormente, o resultado produzido pela função Reprojeção 3D carateriza-
se por dois conjuntos de pontos com coordenadas tridimensionais pertencentes respetivamente às
caraterísticas existentes, correlacionadas entre as imagens estéreo obtidas nos instantes de tempo
t(n) e t(n−1).
O propósito da função Estimação Robusta de Pose é o de remover com segurança os pontos
erradamente correlacionados e produzir uma estimativa robusta e fidedigna das variações de rota-
ção e translação do veículo, entre imagens estéreo consecutivas. O método utilizado para cumprir
tal objetivo, recorre ao algoritmo de RANSAC (RANdom SAmple Consensus).
3.4.2.1 Algoritmo RANSAC
O algoritmo RANSAC, primeiramente introduzido em [18], é um método iterativo de estima-
ção de parâmetros de modelos matemáticos, a parir de um conjunto de dados observados. Este é
capaz de analisar cada elemento da observação e de os separar entre elementos contribuintes para
um modelo, os inliers, e aqueles que não contribuem ao modelo ou que correspondem a ruído na

3.4 Análise das Tarefas Críticas 27
observação, os outliers.
Este algoritmo, aplicado ao problema específico da função Estimação Robusta de Pose, de-
monstrada na figura 3.6, funciona sobre os seguintes princípios:
• O algoritmo funciona sobre o processamento sequencial de pequenos sub-conjuntos de pon-
tos escolhidos. Dependendo do número total de pontos existente, esta escolha é efetuada de
forma aleatória quando este número é elevado, maior que 32 pontos, ou maneira combina-
cional em caso contrário;
• A seguinte rotina é executada L vezes:
– Um sub-conjunto de três pontos tridimensionais são escolhidos a partir de imagens
estéreo subsequentes referentes a t(n) e t(n−1);
– É avaliada a matriz de transformação estimada entre os pontos considerados, através
da sub-função de cálculo da orientação absoluta, formando esta uma hipótese de re-
sultado, constituída pela matriz de rotação absoluta R e o vetor de translação T;
– Cada ponto do sub-conjunto pertencente ao instante t(n−1) é transformado segundo a
hipótese resultante e comparado com o ponto recolhido no instante t(n);
– Segundo certo limite de erro considerado, os pontos são classificados em grupos de
inliers e outliers;
– Se o erro resultante for menor que um limiar mínimo anterior, então este é considerado
de melhor hipótese e um novo ciclo é executado;
– A rotina é terminada uma vez satisfeito o nível de qualidade mínima da hipótese re-
sultante, rondando valores entre 95% e 98%, ou atingido o limite máximo de iterações
da rotina, 5000 iterações;
3.4.2.2 Cálculo da Orientação Absoluta
A sub-função de cálculo da matrizes de transformação da rotação R e translação T executada
em cada iteração do algoritmo de RANSAC, constitui o ponto crítico de processamento da função
Estimação Robusta de Pose. Segundo [15], as operações efetuadas nesta sub-função envolvem:
• A computação de centróides de cada sub-conjunto considerado. Utilizando operações de
multiplicação e divisão;
• A manipulação de matrizes, também envolvendo operações de multiplicação e divisão;
• O método utilizado para o cálculo dos vetores próprios, necessários para determinação das
matrizes de transformação, executa operações entre vetores de quaterniões, sendo estes per-
tencente à decomposição dos valores próprios (SVD1). Esta operação envolve multiplica-
ções entre valores reais em vírgula flutuante;
Segundo os mesmos autores, o algoritmo de operação sobre os vetores de quateniões, SVD, é
extremamente sensível à precisão dos dados processados, sendo que este pode facilmente produzir1SVD - Singular Vector Decomposition.

28 Análise da Aplicação Navegação Estéreo
Dados
O conjunto
contém poucos
pontos?
Gerar vetor de
combinações
Utilizar modo de
recolha aleatória
Sim Não
i < L
Escolher subconjunto
de três pontos 3D
Sim
FimNão
[R,T] = AbsoluteOrientation
Testar R e T nos
pontos considerados
Erro
resultante é o
melhor?
Guardar R, T e o
novo erro
Sim
R, T e
erro bons o
suficiente?
Não
NãoFim
Sim
Figura 3.6: Diagrama de operações do bloco RANSAC da função Estimação Robusta de Pose.
resultados errados se a precisão for diminuída. Para além desta informação, estes adicionam que o
tipo de dados single floating-point é até ao momento o único tipo funcional de representação dos
dados envolvidos nesta operação.
O facto do número de ciclos de execução do algoritmo RANSAC se basear num processo
estocástico, aliado à complexidade da sub-função cálculo da orientação absoluta, produzida pelo
algoritmo SVD, torna a função Estimação Robusta de Pose numa tarefa crítica caracterizada por
um alto grau de variação temporal de execução.

Capítulo 4
Tarefas CríticasImplementação em Hardware
Depois de determinadas as funções que mais atraso causam ao funcionamento do algoritmo
da Navegação Estéreo, passa-se agora à secção de criação dos módulos.
Para os construir, utilizou-se a ferramenta de síntese de alto nível Catapult C da Calypto Design
Systems. Como explicado anteriormente 2.5.2.1, esta ferramenta é capaz de converter linguagens
de código de alto-nível, como é caso do código de linguagem C fornecido, em módulos Veri-
log. Contudo, esta conversão não é automática. Vários fatores como o tipo de dados envolvidos,
estrutura de dados de entrada/saída e tipo de protocolo (handshake) entre software e hardware, ne-
cessitam de uma correta ponderação, pois variam consoante o tipo de função a executar. O fluxo
de projeto seguido está representado na Figura 2.3.
Após a criação dos módulos Verilog, será feita a simulação destes, usando a ferramenta de
simulação ModelSim da Mentor Graphics, a fim destes serem validados comportamentalmente e
a nível de registos, RTL1.
Uma vez que posteriormente se utilizou a ferramenta ISE da Xilinx, como plataforma de in-
tegração, os módulos gerados teriam de ser incorporados no sistema como IP Cores, seguindo
parte do fluxo de projeto da ferramenta ISE disponível na Figura 2.4, e sintetizados pelas ferra-
mentas da própria Xilinx, usando a Xilinx Synthesis Technology (XST) como comando de síntese.
Contudo , sabendo que, o XST não é suportado pelo Catapult C, houve a necessidade de utilizar
uma ferramenta de síntese intermédia, o Precision RTL da Mentor Graphics, esta sim, suportada
pelo Catapult C, possibilitando desta forma a criação de ficheiros Verilog passíveis de serem uti-
lizados pelas ferramentas da Xilinx. Para além disso, o Precision RTL é capaz de criar relatórios
de síntese com resultados mais próximos dos valores realmente resultantes da fase de Place and
Route (PAR).
1RTL - Register Transfer Level.
29

30 Tarefas Críticas - Implementação em Hardware
4.1 Implementação da Função Extração de Caraterísticas
Como visto na secção da análise da aplicação, Secção 3.4.1, esta função é composta por cha-
madas sequenciais a um conjunto de três funções básicas, sendo estas as funções ConvConst,
ConvRepl1 e ConvRepl2.
Na próxima secção, serão descritas algumas configurações de projeto, referentes à ferramenta
Catapult C.
4.1.1 Definições Utilizadas na Ferramenta de Síntese de Alto Nível
4.1.1.1 Catapult C: Configurações de Projeto
Para criar módulos de hardware a partir de cada uma das três funções críticas atrás detetadas,
utilizou-se novamente a ferramenta Catapult C, demonstrando e justificando todas as decisões
acerca das configurações utilizadas do projeto.
O fluxo de desenvolvimento necessário para a criação das versões em hardware das funções
críticas foi iniciado com o recurso à ferramenta de síntese de alto nível Catapult C. A primeira
etapa de configuração da ferramenta passou pela escolha das definições a utilizar, tendo-se op-
tado pela mais recente das ferramentas de síntese disponíveis entre as fornecidas, a Precision
2010a_up2. Foi escolhida como plataforma de desenvolvimento a FPGA disponível na placa
ML507 e também as bibliotecas de suporte necessárias. Estas bibliotecas não só contemplam os
interfaces de hardware, descritos mais à frente, como todos os blocos internos capazes oferecer
a máxima performance possível, como por exemplo, os blocos DSP48E que aceleram operações
básicas com hardware dedicado.
Como frequência alvo para a implementação, reutilizou-se informação da implementação pré-
via do projeto de navegação estéreo [1], onde, à semelhança deste projeto, a função Extração de
Caraterísticas foi implementada. Nesta Dissertação de Mestrado, onde tanto o código fonte origi-
nal como a placa de desenvolvimento eram os mesmos, o autor utilizou como sistema operativo
uma versão Linux, enquanto que neste projeto é usada uma versão de mais baixo nível, Xilinx
Standalone OS. Como verificado na Secção 3.4.1, os seus resultados da análise temporal estão
em concordância com os obtidos neste projeto, portanto optou-se por reaproveitar o resultado de
frequência de implementação ótima, o valor de 100 Mhz. Para além disto, esta é a frequência
base de todo o sistema, pelo que está disponível como predefinição em qualquer módulo criado,
distribuída através do barramento central. Com base nestes factos, e com o objetivo de acelerar o
tempo de implementação do projeto, optou-se por utilizar os 100 Mhz como frequência de projeto
para os módulos gerados pelo Catapult C.
Configuradas as definições referentes à tecnologia utilizada, foi altura de definir de que forma,
no projecto Catapult C, os módulos de hardware saberão quando irão começar a executar e como o
software saberá qual é a altura de utilizar os valores de retorno. Para isso, na secção de handshake
do Catapult C, ativaram-se os sinais de sincronismo start, done e ready. Esta é a maneira de como
o software e o módulo de hardware podem comunicar. Como verificado na Figura 4.1, após o reset

4.1 Implementação da Função Extração de Caraterísticas 31
inicial do módulo, este fica pronto a operar assim que necessário, indicando ao exterior, através do
sinal ready. Assim que seja necessário executar função em software, o sistema indicará a intenção
de o executar no módulo em hardware ativando o sinal de start, invertendo automaticamente o
estado para not ready. Finalizada a execução do módulo, este indicará levantando o sinal de done
durante 1 ciclo de relógio. Após esse ciclo, o módulo levantará de novo o sinal ready, indicando
ao sistema que este está pronto para a próxima execução. Assim que tenha detetado o sinal de
done, o sistema poderá devolver os valores de retorno ao software.
Reset
Ready
Start
Done
Clock
Figura 4.1: Sinais de sincronização (handshake).
4.1.1.2 Catapult C: Interfaces de Comunicação
O Catapult C necessita obrigatoriamente da preparação prévia das funções a converter, espe-
cialmente no que à arquitetura de memória utilizada diz respeito. Uma vez que este tenta criar
módulos de hardware a partir de código de alto nível, informações como o sentido do fluxo de
informação nas variáveis utilizadas, sendo estas de entrada ou saída, ou o tamanho dos arrays uti-
lizados necessitam de estar obrigatoriamente bem definidos. Uma vez que o Catapult C tem como
linha de fronteira de implementação as interfaces com as unidades externas de armazenamento,
como demonstrado na Figura 4.2, este tentará corresponder os módulos de interface, existentes
nas suas bibliotecas da tecnologia, a cada uma das variáveis utilizadas em software dependendo
tanto do tipo como dos tamanhos dos arrays dessas variáveis.
Hardware Module Function
Function
Core
Input
Interface
Output
Interface
Input
Variable
Storage
Output
Variable
Storage
Figura 4.2: Exemplo: Fronteira de implementação efetuado pelo Catapult C com uma variável deentrada e uma variável de saída.

32 Tarefas Críticas - Implementação em Hardware
Como exemplo desta adaptação, os cabeçalhos originais da funções ConvConst, ConvRepl1
e ConvRepl2, listados na Secção 3.4.1, necessitaram de ser alterados, resultando nos cabeçalhos
verificados na próxima listagem. Nesta, podemos constatar, por exemplo, que o Catapult C terá em
conta a existência de um array de 96×96 (9216) elementos, correspondente à matriz de entrada
U, criando o bloco de interface necessário para o núcleo do módulo em hardware poder aceder a
todos os seus elementos.
Listagem 4.1: Cabeçalho alterado da função ConvConst.
void ConvVBConst_uS_hS_yS ( c o n s t r e a l 3 2 _ T h [ 9 ] ,c o n s t r e a l 3 2 _ T u [ 9216 ] ,r e a l 3 2 _ T y [ 9216 ] ,i n t 3 2 _ T b S S t a r t [ 16 ] , i n t 3 2 _ T bSEnd [ 16 ] ,i n t 3 2 _ T bSNumPreEdges [ 8 ] , i n t 3 2 _ T bSPreEdges [ 16 ] ,i n t 3 2 _ T bSNumPostEdges [ 8 ] , i n t 3 2 _ T bSPos tEdges [ 16 ] ) ;
void ConvVBRepl1_uS_hS_yS ( c o n s t r e a l 3 2 _ T h [ 11 ] ,c o n s t r e a l 3 2 _ T u [ 9216 ] ,r e a l 3 2 _ T y [ 9216 ] ) ;
void ConvVBRepl2_uS_hS_yS ( c o n s t r e a l 3 2 _ T h [ 11 ] ,c o n s t r e a l 3 2 _ T u [ 9216 ] ,r e a l 3 2 _ T y [ 9216 ] ) ;
Como interfaces de comunicação com cada variável, foram consideradas três soluções possí-
veis, disponibilizadas pelas bibliotecas do Catapult C, sendo estas:
• A ligação de cada elemento da variável ao módulo por meio de fios, estando cada variável
armazenada num registo, sendo que cada bit desse elemento necessita de um fio;
• A ligação do módulo a uma memória RAM, desta feita, cada elemento da variável está
armazenado numa posição de memória, sendo apenas necessário ao módulo fazer um pedido
de leitura/escrita de certa posição de memória para aceder a esse elemento;
• A ligação do módulo a uma fila de elementos do tipo FIFO (First In, First Out), desta
maneira, o módulo apenas pode aceder aos elementos de uma maneira sequencial;
Devido à natureza comum das três funções, cada elemento obtido na matriz de saída Y, resulta
de operações envolvendo elementos ao redor dessa mesma posição, oriundos da matriz de entrada
U. Este facto inviabiliza a utilização de FIFOs como elemento de entrada, uma vez que o acesso
a cada elemento é efetuado apenas uma vez, deixando de estar presente na FIFO. A Figura 4.3
demonstra a necessidade de reutilização de elementos (a sublinhado) a cada iteração de execu-
ção. Este facto é válido também no acesso às variáveis de filtragem H e aos arrays referentes ao
processamento dos bordos, existentes na função ConvConst.
Descartando a última opção, sobram apenas duas alternativas possíveis: a utilização de regis-
tos, ou a utilização de memoria RAM.

4.1 Implementação da Função Extração de Caraterísticas 33
... ... ... ... ...
... 234 230 218 ...
... 215 156 ...
... 185 153 97 ...
... ... ... ... ...
...
206
146
86
...
195
Figura 4.3: Exemplo da necessidade de re-acesso a elementos.
Começando por analisar as variáveis U e Y, ambas contêm o maior número de elementos,
9216. A utilização de registos implica uma ligação direta e permanente com o módulo, sendo
que cada registo depende do número de bits utilizados com cada tipo de variável, portanto para
as variáveis U e Y, comuns entre as três funções e considerando tipos de variáveis de 32 bits,
obtém-se 2x9216x32 fios, cada um conectado a um registo. Este tipo de complexidade implica
um grau de dificuldade bastante elevado à ferramenta de síntese, o qual se irá repercutir também à
fase de Place&Route, podendo degradar tempos de propagação, os quais influenciam diretamente
a frequência máxima obtida. A utilização de memórias RAM implica outro tipo de considerações.
Primeiramente, ao contrário do uso de registos, o acesso aos dados da variável é feito elemento
a elemento, para além da existência de um atraso de um clock no pedido de leitura a cada um
desses elementos. Esta informação está contida em[19]. Por outro lado, a interface necessária
para comunicar com cada memória é muito menos complexa, necessitando apenas de um registo
de endereçamento, para escolha do elemento a aceder, registo este com o número de bits neces-
sário para endereçar qualquer um dos 9216 elementos, um registo de saída com o número de bits
utilizados pelo tipo de variável e fios de indicação de pedido de escrita ou leitura.
Embora o acesso aos dados seja mais lento, a opção pelo uso de memórias RAM nesta fase do
projeto foi a escolhida, uma vez que se pretendia evitar possíveis problemas nas últimas fases da
implicação causados pela complexidade da escolha de interfaces com registos.
Contrariamente às variáveis U e Y, a variável H é de muito menor dimensão, havendo 9 ele-
mentos na função ConvConst e 11 elementos nas funções ConvRepl1 e ConvRepl2. Nesta situa-
ção, a utilização de interface por registos entendia-se ser justificável, mas a existência de outras
variáveis na função ConvConst teve de ser levada em conta, como será compreendido de seguida.
Como visto anteriormente, a tecnologia de reconfiguração parcial dinâmica, existente na placa
de desenvolvimento ML507, dá ao sistema a possibilidade de projetar módulos em que todo o
seu conteúdo, por exemplo registos, blocos internos e interligações físicas, pode ser alterado,
sem que o resto do sistema seja interrompido. Esse tipo de módulos, doravante denominados
como módulos reconfiguráveis, irão coincidir com a fronteira de módulo gerado pelo Catapult C,
demonstrado anteriormente na Figura 4.2.

34 Tarefas Críticas - Implementação em Hardware
Desta forma, o sistema será capaz de alternar entre módulos que executam cada uma das três
funções em apenas um módulo reconfigurável. Este facto vem aumentar o grau de requisitos de
interoperabilidade exigido a esse módulo reconfigurável, novamente, tal como no Catapult C, no
que à arquitetura de memória utilizada diz respeito. Como tal, a existência de funções que ne-
cessitem de um diferente número de interfaces de acesso, como o caso da função ConvConst, em
relação às restantes, não vem trazer qualquer inconveniente ao processo de implementação, ha-
vendo apenas a necessidade de um correto controlo dos sinais não utilizados pelos módulos que
destes não necessitem, como demonstrado na Figura 4.4. Porém, se o número de módulos recon-
figuráveis for maior, e se o sistema puder alocar os módulos de uma maneira dinâmica, consoante
a disponibilidade (como será o caso deste projeto), então todos os módulos reconfiguráveis terão
obrigatoriamente de suportar o mesmo número de interfaces que o módulo mais requerente nesse
aspeto. Embora esta seja a solução natural, este facto levaria à exagerada multiplicação de recur-
sos utilizados, aumentando a complexidade e grau de dificuldade do processo de implementação
física, pelo que neste projeto optou-se por agrupar o mais possível as interfaces de entrada e saída
de dados, deixando apenas as interfaces comuns às três funções, os arrays H, U e Y.
addr
data_out
en
addr
data_in
we
Reconfigurable
Module ConvConst
Module
addr
data_in
re
addr
data_out
we
(to logic)
(to logic)
(to logic)
Modules:
ConvRepl 1
ConvRepl 2
addr
data_in
re
addr
data_out
we
.
.
.
.
.
.
reg H[0]
reg H[1]
reg H[10]
....
.
.
reg opt.[0]
reg opt.[1]
reg opt.[70]
....
.
.
.
.
.
(to logic)
(to logic)
(to logic)
(to logic)
(to logic)
.
.
.
Only 9
elements
needed
Not needed
elements
RAM U
RAM Y
.
.
.
Figura 4.4: Interfaces: array H por registos, arrays U e Y por RAM, restantes por registos.
Desta feita, para esta função, na tarefa Architecture do Catapult C, procedeu-se ao agrupa-
mento dos arrays bSStart, bSEnd, bSNumPreEdges, bSPreEdges, bSNumPostEdges e bSPostEd-
ges, de preferência no array de entrada de menor dimensão, array H, tendo este sido aumentado de
9 para 89 elementos. Julgando já ser um número significativo de elementos, optou-se por escolher
o armazenamento e interface por meio de memória RAM. Desta forma, obtemos uma versão de
módulo reconfigurável com uma interface bastante simplificada, como demonstrado na Figura 4.5.
Do ponto de vista de software, esta opção não implica qualquer alteração referente à chamada à

4.1 Implementação da Função Extração de Caraterísticas 35
addr
data_out
en
addr
data_in
weReconfigurable
Module
ConvConst
addr
data_in
re
addr
data_out
weRAM U
RAM Yaddr
data_out
en
RAM H
addr
data_in
re
ConvRepl1
addr
data_in
re
addr
data_out
we
addr
data_in
re
ConvRepl2
addr
data_in
re
addr
data_out
we
addr
data_in
re
Figura 4.5: Versão do módulo reconfigurável com interface final simplificada.
função, tendo esta apenas que transferir os dados do novo array h de 89 elementos para a memória
RAM correta.
4.1.2 Problema do Uso de Variáveis do Tipo float e Soluções Consideradas
Um fator da máxima importância, ainda não abordado na secção de implementação da função
Extração de Caraterísticas, é a maneira como o Catapult C interpreta o tipo das variáveis utilizadas
pelas funções internas.
Os tipos de variáveis usualmente utilizadas em programação de software dependem direta-
mente da arquitetura do CPU e compilador utilizados, mas normalmente estão definidos entre
tipos inteiro de 1, 8, 16, 32 e 64 bits e os tipo de vírgula flutuante (float) de 32 e 64 bits.
No caso das funções aqui tratadas, os arrays H,U e Y estão descritos no tipo real32_T, sendo
este uma definição utilizada para representar variáveis do tipo float de 32 bits.
Este facto, criou mais um entrave no fluxo do projecto, pois o Catapult C não é capaz de
criar blocos de hardware equivalentes, em funções que utilizem este tipo de dados, uma vez que
segundo [20], a precisão dos resultados não poder ser determinada pelo compilador de C.
Novamente, esta nova informação resultou em diferentes tipos de considerações para cada uma
das funções a implementar. No caso da função ConvConst, analisada na Secção 3.4.1, esta tem a
particularidade de operar sobre valores de fonte inteira. Relembro que, nesta função, a informação
contida no array U tem como origem a imagem captada, sendo esta constituída por pixeis com
uma profundidade de 8 bits em escala de cinza. Já o array H contém os valores do operador de
Prewitt, necessário no algoritmo Harris Corner detector, estando compreendidos entre {-1; 0; 1}.
Já o processamento efetuado tem como base operações de soma e multiplicação, pelo que não é
possível a produção de um resultado em que seja necessário representação em vírgula flutuante,
validando desta feita a alteração para a utilização de tipos de dados de natureza inteira. Desta
feita, procedeu-se novamente à alteração do cabeçalho da função ConvConst, estando o resultado
representado na Listagem 4.2.

36 Tarefas Críticas - Implementação em Hardware
Listagem 4.2: Nova alteração do cabeçalho da função ConvConst.
void ConvVBConst_uS_hS_yS ( c o n s t int32_T h [ 9 ] ,c o n s t int32_T u [ 9 2 1 6 ] ,int32_T y [ 9 2 1 6 ] ,i n t 3 2 _ T b S S t a r t [ 1 6 ] , i n t 3 2 _ T bSEnd [ 1 6 ] ,i n t 3 2 _ T bSNumPreEdges [ 8 ] , i n t 3 2 _ T bSPreEdges [ 1 6 ] ,i n t 3 2 _ T bSNumPostEdges [ 8 ] , i n t 3 2 _ T bSPos tEdges [ 1 6 ] ) ;
O mesmo não acontece com as restantes funções, ConvRepl1 e ConvRepl2. Estas têm como
fator comum o facto do array de filtragem, H, conter valores onde a representação em vírgula flu-
tuante não pode ser descartada, produzindo desta forma resultados utilizando também essa mesma
representação.
Uma das soluções para a implementação de blocos capazes de operar com variáveis desta natu-
reza seria a da inclusão de blocos de hardware dedicados, disponibilizados pela Xilinx, desenvol-
vidos para a execução dessa tarefa. Porém, infelizmente, esse bloco não faz parte das bibliotecas
de hardware existentes no Catapult C, pelo que ele não seria capaz de o inferir.
Outra solução, seria a do Catapult C responsabilizar-se apenas pelo controlo algorítmico da
função e das interfaces, enquanto que um bloco dedicado, conectado a este, neste caso o Xilinx
FPO (Floating-Point Operator) [21], executaria as operações de vírgula flutuante, como demons-
trado na Figura 4.6. Infelizmente, a versão do Catapult C utilizada não permite essa funcionali-
dade.
addr
data_out
en
addr
data_in
weReconfigurable
ModuleRAM U
RAM Yaddr
data_out
en
RAM H
FPO
R = A op B
A
B
Op
R
A
B
Op
R
Figura 4.6: Utilização do bloco Xilinx FPO (Floating-Point Operator) para execução de operaçõesusando vírgula flutuante.
Estes factos conduziram à necessidade de alterar o código fonte original destas funções para
versões equivalentes que utilizassem algum tipo de dados alternativo.
Nesta altura do projeto foram consideradas dois tipos de estratégias diferentes, ambas com o
objetivo de substituir a utilização de variáveis de vírgula flutuante, cada uma destas envolvendo o
mínimo de alterações possíveis ao código fonte original. Foram então considerados duas soluções
possíveis: uma versão já abordada em [1], a versão SoftFloat de 32 bits e uma solução desenvol-
vida de raiz para a função Extração de Caraterísticas, que utiliza variáveis de vírgula fixa, também
esta de 32 bits, adaptadas às funções ConvRepl1 e ConvRepl2.

4.1 Implementação da Função Extração de Caraterísticas 37
4.1.2.1 Versão SoftFloat 32 bits
A opção de tentar solucionar o problema através desta abordagem não foi em vão. Tal como
comentado atrás, em [1], o autor deparou-se com a mesma situação atualmente presente neste
projeto, e entre outras duas soluções envolvendo operações com inteiros de 32 e 64 bits, esta
abordagem foi a eleita.
Antes de explicar o conceito de SoftFloat, existe a necessidade de dar a conhecer a estrutura
interna de variável do tipo vírgula flutuante de 32 bits, denominado de single float, ou variável real
de precisão simples.
A sua estrutura, descrita pela norma IEEE-754 [22], representada pela Figura 4.7 e definida
pela equação 4.1, é constituída por três elementos, sendo estes o bit de sinal, estando este situado
na posição mais significativa, seguida de uma gama de 8 bits que representa o valor de expoente
e, por fim, os últimos 23 bits representam a mantissa, valor que tem como significado a parte
fracionária do logaritmo da expoente.
f loat value = (−1)S×2(exponent−127)×1,mantissa (4.1)
Como informação complementar, este tipo de variável é capaz de representar valores duma
gama compreendida entre 3.4028235E38 e −3.4028235E38.
s exponent mantissa
31 8-bit 23-bit
Figura 4.7: Formato de vírgula flutuante de 32 bits (single float).
Segundo [23], o tipo de dados SoftFloat é uma fiel implementação em software do tipo de va-
riável em vírgula flutuante, definido pela norma IEEE-754. Esta solução foi criada com o objetivo
de permitir o uso destes tipos de dados e operações, em sistemas sem acesso a unidades de hard-
ware dedicado para o efeito, denominadas de FPU (Floating-Point Unit). Esta implementação é
composta por uma biblioteca que contém as funções que convertem e operam sobre um novo tipo
de dados, o float32. Como exemplo, aquando da necessidade de uma operação de multiplicação
de duas variáveis reais, utilizando a biblioteca SoftFloat, o processo será o de conversão de ambas
as variáveis para tipos float32, a execução da função de operação equivalente à multiplicação e a
conversão do resultado do tipo float32 para o tipo real (float).
Os fatores negativos, resultantes da utilização desde tipo de solução, dependem do facto desta
solução introduzir operações aritméticas inerentes às funções SoftFloat, as quais causarão o au-
mento do número de ciclos de relógio por cada operação e maior número de recursos utilizados.
Uma vez que esta implementação representa a norma IEEE-754, isto significa também que
toda a análise dos casos excecionais, como resultados de operações sem significado numérico
(NaN[not a number]), ou operações envolvendo valores infinitos, também estarão presentes na

38 Tarefas Críticas - Implementação em Hardware
implementação. Com a finalidade de obter o menor tempo de execução possível, procedeu-se a
uma cuidadosa simplificação dessas verificações.
Desta feita, procedeu-se à alteração das funções ConvRepl1 e ConvRepl2, para utilização das
funções de SoftFloat. Poucas alterações foram necessárias em cada uma das funções, sendo estas,
a alteração dos tipos de variáveis de entrada e saída e as chamadas às funções de multiplicação e
adição. As alterações referentes à função ConvRepl1 podem ser verificadas na Listagem 4.3.
Listagem 4.3: Alteração da função ConvRepl1.
void ConvVBRepl1_uS_hS_yS ( c o n s t float32 h [ 9 ] ,c o n s t float32 u [ 9 2 1 6 ] ,float32 y [ 9 2 1 6 ] ){
. . .temp = float32_mul ( u [ i ] , h [ j ] ) ;acc = float32_add ( temp , acc ) ;. . .
}
Uma vez encontrada uma solução, chegava o momento de prosseguir com a síntese do Catapult
C.
Definidos que estão todos os tipos de dados utilizados pelos módulos, pode-se então concluir a
configuração das interfaces utilizadas. O Catapult C, como seria de esperar, detetou corretamente
todos os tipos de dados e comprimento dos arrays das variáveis de entrada. Relembro que a função
ConvConst utiliza variáveis do tipo inteiro de 32 bits, enquanto que as restantes utilizam variáveis
do tipo float32, também estas de 32 bits.
Tal como concluído atrás, quanto às interfaces de comunicação com cada um dos arrays, U,
Y e H (agregando as restantes variáveis para o caso da função ConvConst), estas foram definidas
como sendo memórias RAM.
Com o objetivo de minimizar os tempos de execução, foram escolhidos os seguintes parâme-
tros de projeto:
• Nível de Esforço – Alto;
• Objetivo de Projeto – Latência;
Após a conclusão da síntese, o Catapult C disponibiliza informação referente ao número de ci-
clos de execução para cada uma das três funções. Essa informação, disponibilizada na Tabela 4.1,
refere-se especificamente aos seguintes campos:
• Ciclos de atraso — Número de ciclos de relógio entre dois resultados consecutivos;
• Tempo de atraso — Tempo decorrido entre dois resultados consecutivos;
• Ciclos da entrada à saída — Número de ciclos de relógio entre o primeiro valor de entrada
e o primeiro valor de saída;

4.1 Implementação da Função Extração de Caraterísticas 39
• Tempo da entrada à saída — Tempo decorrido entre o primeiro valor de entrada e o pri-
meiro valor de saída;
• Folga — Folga, denominado em Inglês por slack, é o valor que representa a diferença tem-
poral entre o atraso pertencente ao caminho crítico, explicado adiante, e o período de relógio,
tal como demonstrado pela Equação 4.2, em nanosegundos. Um resultado positivo significa
que o módulo resultante da síntese é capaz de atingir os requisitos temporais projetados;
slack = TCriticalPath−TClk (4.2)
Tabela 4.1: Tabela de resultados da síntese Catapult C na versão SoftFloat.
FunçãoCiclos de Tempo de Ciclos da entrada Tempo da entrada
Folgaatraso atraso (ns) à saída à saída (ns)
ConvConst 89487 894870 89585 895850 2.03ConvRepl1 415100 4151000 415299 4152990 -1.18ConvRepl2 413938 4139380 413955 4139550 -1.18
O caminho crítico está intrinsecamente relacionado com a natureza de circuitos digitais sín-
cronos. Este tipo de circuitos, como é o caso dos circuitos resultantes de síntese no Catapult C,
utilizam com elementos básicos de armazenamento, flip-flops, sendo que todas as transições de
dados são despoletadas por sinais de relógio. Conectados a estes flip-flops existe normalmente
um conjunto de elementos que executam certo tipo de resultado lógico, denominados de circuitos
combinacionais, e associado a esta produção de resultado, um certo tempo de execução é reque-
rido, denominado de atraso combinacional. O tempo de propagação de sinais entre flip-flops está
relacionada com a acumulação destes atrasos combinacionais com os atrasos das suas interliga-
ções, dependentes dos comprimentos dos fios.
O caminho crítico carateriza-se por ser o valor da acumulação de tempos de propagação mais
longo de todo o circuito, estando este diretamente relacionado com a frequência máxima atingida
do circuito sintetizado.
Com o objetivo de aprovação para adoção da versão SoftFloat, dois fatores, frutos deste resul-
tado de síntese, necessitavam de ser verificados: os ganhos relativos à versão original em software
e a indicação da folga temporal. Quanto ao primeiro ponto, procedeu-se à comparação de re-
sultados e medição de ganhos relativos, em relação à versão original, obtidos na fase de análise
da aplicação. Desta feita, usou-se como atributo de comparação o valor de número de ciclos de
atraso, os quais representam o número de ciclos de clock da execução em hardware, desde o le-
vantamento da flag de start, até à indicação, por parte do módulo, do término da execução, através
da flag done.
Os valores de comparação, demonstrados na Tabela 4.2, indicam que a execução destas fun-
ções é acelerada se executada em hardware, embora a utilização da implementação das funções

40 Tarefas Críticas - Implementação em Hardware
Tabela 4.2: Comparação: Funções originais versus funções SoftFloat.
FunçãoCiclos de Atraso Ciclos de Atraso Ganho RelativoVersão Software Versão SoftFloat Aproximado
(a 100Mhz) (a 100Mhz) (%)ConvConst 468970 89487 81ConvRepl1 474555 415100 13ConvRepl2 474093 413938 13
ConvRepl1 e ConvRepl2, em SoftFloat, implique uma perda bastante considerável em comparação
com a solução puramente ’inteira’ da função ConvConst.
Quanto à folga temporal resultante da síntese, embora estes valores possam sofrer alterações
até ao momento final de implementação física Place&Route, eles indicam que existe a grande
possibilidade do projeto não atingir os requisitos temporais exigidos para a frequência de operação
pretendida.
Com o objetivo de corrigir esta falha, o manual de referência que acompanha o Catapult C [24],
indica que os projetos que não atinjam os requisitos temporais devem ser alvo de retificação quanto
ao parâmetro de alocação de percentagem de partilha. Este parâmetro determina a percentagem
de tempo da frequência de relógio utilizada para estimação das componentes lógica físicas, ne-
cessárias para a partilha de recursos, nomeadamente dos multiplexadores, registos e interligações
necessárias. O processo de síntese RTL do Catapult C utiliza esta percentagem com um valor por
omissão de 20%, valor esse que foi alterado para 30% com a finalidade de estimar estes com-
ponentes de maneira mais conservadora. O resultado desta alteração para a função ConvRepl1
demonstrado pelas Tabelas 4.3 e 4.4, conclui que o número de ciclos de execução é aumentado,
piorando dessa forma o ganho em comparação com a função original em software.
Tabela 4.3: Resultado da síntese Catapult C da função ConvRepl1, após correção de folga tempo-ral.
FunçãoCiclos de Tempo de Ciclos da Entrada Tempo da Entrada
FolgaAtraso Atraso (ns) à Saída à Saída (ns)
ConvRepl1 470396 4703960 470595 4705950 0.32Tabela 4.4: Comparação: Função ConvRepl1 original versus versão SoftFloat.
FunçãoCiclos de Atraso Ciclos de Atraso Ganho RelativoVersão Software Versão SoftFloat Aproximado
(a 100Mhz) (a 100Mhz) (%)ConvRepl1 474555 470595 8
Uma vez que se prevê um ganho não muito significativo por parte dos dois módulos mais
complexos, iniciou-se a procura de uma solução alternativa capaz de substituir a utilização da
biblioteca SoftFloat. Essa solução está descrita na seguinte secção.

4.1 Implementação da Função Extração de Caraterísticas 41
4.1.2.2 Versão Emulada em Vírgula Fixa de 32 bits
Esta solução tem como objetivo a utilização de um método de computação que utilize apenas
variáveis que representam números inteiros de 32 bits, à semelhança do módulo que implementa a
função ConvConst. Esta solução tem em vista usufruir da particularidade das funções ConvRepl1
e ConvRepl2, derivada da natureza do algoritmo implementado estudado na Secção 3.4.1, exe-
cutarem sempre de maneira sequencial, isto é, o resultado produzido pela função ConvRepl1 é
sempre utilizado como entrada pela função ConvRepl2. Este facto permite que a passagem dessa
informação seja efetuada usando qualquer tipo de representação, desde que o erro induzido pela
utilização deste método seja pequeno o suficiente para não influenciar os resultados finais.
O método de funcionamento deste módulo passa por manipular variáveis reais num tipo de
dados representado usando vírgula fixa. Como visto anteriormente, as funções ConvRepl1 e Con-
vRepl2 produzem resultados do tipo real uma vez que uma das suas variáveis entradas, o array
H, é desse tipo. Caso fosse possível representar os elementos dessa variável, duma maneira uni-
camente inteira, sem perdas de informação, multiplicando por uma potência de base-2 suficiente
para representar essa variável em formato inteiro, então estaríamos no fundo a utilizar um formato
de vírgula fixa, onde esta se encontraria na posição do logaritmo dessa mesma potência. A utili-
zação da base-2 como fator de multiplicação, tem como objetivo a simplificação do processo de
deslocação da vírgula em notação binária.
Analisando o array H, verificamos que os valores de cada elemento são de facto passíveis de
serem representados usando uma notação em vírgula fixa, sendo ao todo necessário multiplicar
cada valor por 228, ficando essa vírgula na vigésimo-oitavo bit a contar do bit menos significativo.
Querendo isto significar que é possível utilizar o valor de cada elemento real numa notação em
vírgula fixa sem qualquer perda de precisão. A Tabela 4.5, demonstra o array de onze elementos
da variável H utilizada pela função ConvRepl1 na nova notação inteira, para além do número de
bits necessários para os representar, calculado pela Equação 4.3.
Número de bits necessários = log2(|valor|)+1 (4.3)
De notar o facto de todos os valores originais serem menores que 2−2(0,25), pelo que o bit
mais significativo do valor convertido vai de facto situar-se no vigésimo-sexto bit a contar do bit
menos significativo, como demonstrado na Figura 4.8.
Para além do mais, sendo possível representar estes valores com um número de bits menor que
32, possibilita-se também a utilização de variáveis do tipo int32_T como interface de entrada, o
mesmo tamanho utilizado pelo módulo que implementa a função ConvConst.
Desta maneira, poderemos então tratar de ambos os módulos de uma maneira ’inteira’, pelo
que será necessário estimar o número de bits capaz para conter o maior resultado possível, o pior
caso. Para analisarmos a situação, teremos obrigatoriamente que voltar ao início da execução
da função Extração de Caraterísticas, a função ConvConst. Como é sabido, esta função utiliza a

42 Tarefas Críticas - Implementação em Hardware
,26-bit
1 1 1 1 1 1 0 1 1 0 1 1 1 0 0 1 0 0 1 0 0 0 1 1 0 0 1 0 0 0 1 1
31 0
-0,1423004716634750 2 = -38198492,028
( int32_T )( -38198492,0 ) = -38198492
coma
position28-bit
MSB
Figura 4.8: Variável real do array H, representada em formato inteiro de 32 bits.
matriz 3×3, H, para a filtragem horizontal ou vertical da matriz de entrada U obtida pelas câmaras,
através do algoritmo de soma de produtos, anteriormente visto em 3.1.
A situação de pior caso produzida pela primeira execução da função ConvConst pode ocorrer,
por exemplo, na situação demonstrada na Figura 4.9. Neste caso, o resultado da filtragem para a
posição da matriz U identificada a cinza-claro tem como resultado:
YConvConst [poscinza] = 1×255+1×255+1×255 = 765
Este resultado é elevado ao quadrado antes de entrar na primeira execução da função Con-
vRepl1, sendo o valor de entrada para a mesma posição, o resultado:
UConvRepl1[poscinza] = 7652 = 585225
À semelhança da anterior, procede-se à estimação de pior caso da função ConvRepl1, desta
vez, utilizando os valores inteiros do array de filtragem H, adaptados anteriormente, e o valor de
Tabela 4.5: Representação de valores do tipo real em formato inteiro.
Valor original (formato real)Fator de Valor representado Núm. bits necessários
multiplicação em inteiro para representação binária-0,0354829430580139
228
-9524880 25-0,0585014708340168 -15703869 25-0,0863095894455910 -23168554 26-0,1139453053474430 -30586960 26-0,1346104741096500 -36134224 27-0,1423004716634750 -38198492 27-0,1346104741096500 -36134224 27-0,1139453053474430 -30586960 26-0,0863095894455910 -23168554 26-0,0585014708340168 -15703869 25-0,0354829356074333 -9524878 25

4.1 Implementação da Função Extração de Caraterísticas 43
... ... ... ... ...
... 255 255 255 ...
... 0 0 ...
... 0 0 0 ...
... ... ... ... ...
0
1 1 1
0 0
-1 -1 -1
0
Figura 4.9: À esquerda: Excerto da matriz de entrada U; À direita: Filtro horizontal H.
pior caso precedente. A próxima tabela, Tabela 4.6, apresenta a evolução do resultados da rotina
de soma de produtos, onde o resultado final e correspondente número de bits de representação se
encontram a vermelho.
Tabela 4.6: Resultados de execução da função ConvRepl1, na situação de pior caso.
Execução da rotina: Número de bitsacci =U [u]×H[h]+acci−1 do resultado
−5,5742E+12 = 585225 × -9524880 + 0 44−1,47645E+13 = 585225 × -15703869 + −5,5742E+12 45−2,83233E+13 = 585225 × -23168554 + −1,47645E+13 46−4,62236E+13 = 585225 × -30586960 + −2,83233E+13 47−6,73702E+13 = 585225 × -36134224 + −4,62236E+13 47−8,97249E+13 = 585225 × -38198492 + −6,73702E+13 48−1,10872E+14 = 585225 × -36134224 + −8,97249E+13 48−1,28772E+14 = 585225 × -30586960 + −1,10872E+14 48−1,42331E+14 = 585225 × -23168554 + −1,28772E+14 49−1,51521E+14 = 585225 × -15703869 + −1,42331E+14 49−1,57095E+14 = 585225 × -9524878 + −1,51521E+14 49
Por fim, estimou-se o valor resultante da situação de pior caso para a função ConvRepl2,
repetindo o mesmo processo, onde a evolução do resultados e número de bits de representação,
apresentados na Tabela 4.7, se encontram a vermelho.
O resultado destas medições não foi o mais promissor, isto porque, como é possível verificar,
tem como aspetos negativos a necessidade de 77 bits para representar o pior resultado gerado pela
função ConvRepl2, para além do que segundo [19], os blocos de memoria RAM, disponibilizados
pela Xilinx, aos quais estariam conectados os interfaces dos módulos, apenas permitem leituras
em blocos fixos de 1, 2, 4, 8, 16, 32, 64 e 128 bits, o que obrigaria a uma mal aproveitada e
desvantajosa utilização da interface. Para piorar ainda mais a situação, tal como discutido na
Secção 4.1.1.2, o facto de se usar interfaces de diferentes dimensões em cada uma das funções,

44 Tarefas Críticas - Implementação em Hardware
Tabela 4.7: Resultados de execução da função ConvRepl2, na situação de pior caso.
Execução da rotina: Número de bitsacci =U [u]×H[h]+acci−1 do resultado
1,49631E+21 = −1,57095E+14 × -9524878 + 0 723,96331E+21 = −1,57095E+14 × -15703867 + 1,49631E+21 737,60298E+21 = −1,57095E+14 × -23168554 + 3,96331E+21 741,2408E+22 = −1,57095E+14 × -30586960 + 7,60298E+21 75
1,80846E+22 = −1,57095E+14 × -36134224 + 1,2408E+22 752,40854E+22 = −1,57095E+14 × -38198484 + 1,80846E+22 762,97619E+22 = −1,57095E+14 × -36134224 + 2,40854E+22 763,45669E+22 = −1,57095E+14 × -30586960 + 2,97619E+22 763,82066E+22 = −1,57095E+14 × -23168554 + 3,45669E+22 774,06736E+22 = −1,57095E+14 × -15703870 + 3,82066E+22 774,21699E+22 = −1,57095E+14 × -9524877 + 4,06736E+22 77
obrigaria a que o sistema estivesse preparado para a pior situação possível. Pelo que este tipo de
utilização de recursos seria totalmente inadequado.
Para tentar minimizar este problema foi considerada uma solução alternativa, a qual está re-
lacionada uma certa quantidade de perda de precisão, mas que permite o melhor aproveitamento
possível das interfaces, na situação de pior caso. Resultando na adoção da seguinte rotina de ajuste
da posição da vírgula:
1. Em software, representar a variável H em vírgula fixa, como visto anteriormente, ficando
esta à partida, situada na posição 28;
2. Uma vez que seriam necessários 49 bits para representar o pior caso, a função ConvRepl1
deve efetuar um deslize de 18 bits para a direita, dividindo os resultados por 218, movendo
desta forma o bit mais significativo para dentro da gama de 32 bits e ocupando completa-
mente desta forma uma variável do tipo int32_T. Como resultado, a posição da vírgula será
desta forma ajustada para a posição 102, como demonstrado na Figura 4.10;
positivenegative Frac
228
IntegerFrac
231
210
negative positive
0
Integer
249
Frac
Frac
Integer
Integer
210
(-1) 231
(-1) 210
Figura 4.10: Ajustamento da vírgula, executado pela função ConvRepl1.
228 bits - 18 bits = 10 bits

4.1 Implementação da Função Extração de Caraterísticas 45
3. Novamente em software, representar variável H da função ConvRepl2, em vírgula fixa,
deslizando de novo a vírgula 28 bits para a esquerda, ficando esta agora posicionada no bit
38;
4. Antes do retorno da função ConvRepl2, efetuar o deslize da vírgula 28 posições novamente
para a direita, efetuando a divisão dos resultados por 228. A posição da vírgula foi de novo
ajustada para a posição número 10, como demonstrado na Figura 4.11;
259
positivenegative Frac
228
IntegerFrac
231
210
negative positive
0
Integer
FracInteger
238
FracInteger
(-1) 231
(-1) 210
Figura 4.11: Ajustamento da vírgula, executado pela função ConvRepl2.
5. Efetuar o processo inverso ao da representação em vírgula fixa em software, ou seja, guardar
os resultados da função ConvRepl2 em variáveis de formato real e dividi-las pelo valor da
posição da vírgula, ou seja, por 210
O resultado de todo este processo pode ser verificado através dos valores obtidos na Tabela 4.8,
onde o valor de pior caso resultante da função ConvRepl1 sofre a seguinte alteração:
−1,57095E+14 >> 18 =−599270418
log2(|−599270418|)+1 = 31bits
Este valor, representável em variável inteira, é então utilizado como valor de entrada da função
ConvRepl2, onde o resultado também sofre alteração semelhante:
1,60865E+17 >> 28 = 599270409
log2(599270409)+1 = 31bits
Ao ser utilizado este método, certifica-se que as variáveis de entrada e saída conseguem ser
representadas unicamente através de variáveis inteiras de 32 bits, o que simplifica a escolha das
interfaces.
O erro induzido pela utilização deste método está diretamente relacionado com a utilização
do ajustamento da vírgula. Este induz uma perda de precisão, pelo que valores menores que 2−10
serão considerados zero absoluto. A fórmula caraterística deste método pode ser verificada pela
próxima Equação 4.4.

46 Tarefas Críticas - Implementação em Hardware
Tabela 4.8: Resultados de execução da função ConvRepl2, na situação de pior caso, após ajustede vírgula da função convRepl1.
Execução da rotina: Número de bitsacci =U [u]×H[h]+acci−1 do resultado
5,70798E+15 = −599270418 × -9524878 + 0 541,51188E+16 = −599270418 × -15703867 + 5,70798E+15 552,90031E+16 = −599270418 × -23168554 + 1,51188E+16 564,73329E+16 = −599270418 × -30586960 + 2,90031E+16 576,89871E+16 = −599270418 × -36134224 + 4,73329E+16 589,18783E+16 = −599270418 × -38198484 + 6,89871E+16 581,13532E+17 = −599270418 × -36134224 + 9,18783E+16 581,31862E+17 = −599270418 × -30586960 + 1,13532E+17 581,45747E+17 = −599270418 × -23168554 + 1,31862E+17 591,55157E+17 = −599270418 × -15703870 + 1,45747E+17 591,60865E+17 = −599270418 × -9524877 + 1,55157E+17 59
Y [n] =
Y [n], se Y [n]>= 2−10
0, se Y [n]< 2−10(4.4)
Tal como na solução anterior, SoftFloat, procedeu-se à verificação dos resultados intermédios
e finais deste novo método alternativo. Estes resultados, presentes na tabela de validação 6.6, pro-
vam que não são induzidos resultados incorretos, pelo que este método ficou desta forma validado.
Mais uma vez, após validação deste método, procedeu-se à síntese Catapult C e comparação
de resultados e medição de ganhos relativos, em relação à versão original. Os resultados desta
medição, visualizados nas Tabelas 4.9 e 4.10, indicam que a utilização da versão com vírgula
fixa, nas funções ConvRepl1 e ConvRepl2, oferece, como esperado, resultados comparáveis ao
número de ciclos de execução da função ConvConst, cerca de 80% de ganho no número de ciclos
de execução, face à execução original em software.
Concluindo o estudo de soluções que substituam a utilização de variáveis do tipo float, a
solução de implementação das funções ConvRepl1 e ConvRepl2 através da utilização de variáveis
de vírgula fixa provou ser de ambas a melhor solução possível, pelo que esta foi a escolhida.
4.1.3 Simulação dos módulos gerados: ModelSim
Na sequência da utilização da ferramenta de síntese de alto nível Catapult C, é chegada altura
da verificação dos módulos de hardware gerados a partir de código C. Genericamente, o pro-
cesso de verificação de cada módulo baseia-se na simulação de um modelo representativo, uma
“caixa negra”, onde são estimulados certos sinais na entrada desse modelo, a que o modelo res-
ponderá com certos sinais de saída, diretamente relacionados com os anteriormente inseridos. Este

4.1 Implementação da Função Extração de Caraterísticas 47
Tabela 4.9: Tabela de resultados da síntese Catapult C das funções em vírgula fixa.
FunçãoCiclos de Tempo de Ciclos da Entrada Tempo da Entrada
FolgaAtraso Atraso (ns) à Saída à Saída (ns)
ConvConst 89487 894870 89585 895850 2.03ConvRepl1 101385 1013850 101391 1013910 1.49ConvRepl2 101385 1013850 101391 1013910 1.19
Tabela 4.10: Comparação: Funções originais versus funções em vírgula fixa.
FunçãoCiclos de Atraso Ciclos de Atraso Ganho RelativoVersão Software Versão Virg. Fixa Aproximado
(a 100Mhz) (a 100Mhz) (%)ConvConst 468970 89487 81ConvRepl1 474555 101391 79ConvRepl2 474093 101391 79
processo de verificação de entradas/saídas, normalmente denominado de testbench, é automatica-
mente gerado pelo Catapult C, após prévia preparação do código C para cada uma das funções
implementadas em hardware, sendo para isso necessário indicar através do uso de pragmas3, as
barreiras de separação entre software e hardware. Desta forma o Catapult C pode então gerar a
lista de estímulos de entrada necessários e correspondentes sinais de saída, proveniente da apli-
cação original e comparar a execução das versões software e hardware para cada função, como
demonstrado pela Figura 4.12. Para além disso, ao testbench são adicionados os sinais de interco-
nexão e sincronismo necessários para o correto controlo do módulo.
Como modelo representativo do módulo a simular, existem dois tipos de abstração possíveis,
o modelo comportamental, onde o comportamento da lógica envolvida é modelado utilizando um
alto nível de abstração, e o modelo RTL, onde toda a lógica envolvida é modelada ao nível das
unidades de registo e suas interligações, sendo este o modelo com o nível de abstração mais baixo.
Desta maneira, o Catapult C permite a criação de ambas as simulações.
Uma vez criados os testbenchs, estes terão de ser executados utilizando a ferramenta de simu-
lação ModelSim da Mentor Graphics.
No âmbito do projeto, todas as funções foram alvo de simulação comportamental e RTL, tendo
obtido aprovação em todas elas. A título de exemplo, a Figura 4.13 representa uma simulação
comportamental que demonstra o comportamento dos sinais de handshake start e stop, e dos
sinais envolvidos no processo de leitura e escrita de blocos de memória da função ConvRepl1.
Todos estes sinais estão representados a vermelho na figura, e demonstram, por exemplo, que a
leitura das memórias H e U é desencadeada aquando do levantamento do sinal de start e que após
a escrita do último endereço da memória Y, o sinal done é elevado durante um ciclo de relógio.
De notar que o endereço 0x23FFh em notação hexadecimal, 9215 em notação decimal, representa
a última posição da memória de saída, a memória Y.
3Pragma - Diretiva de preprocessamento.

48 Tarefas Críticas - Implementação em Hardware
Estímulos
softwareFunção
C/C++
RTL
gerado
Passou /
Falhou
Testbench C/C++
Testbench dos módulos gerados
Passou /
Falhou
Co
mp
ara
çã
o
Figura 4.12: Processo de simulação utilizada pela ferramenta Catapult C.
Endereço Y
Valor Y
Endereço U
Endereço H
Valor H
Valor U
StartDone
Figura 4.13: Simulação da versão hardware da função ConvRepl1.
No caso exemplo da simulação comportamental da função ConvRepl1, a versão da aplica-
ção usada em testbench, efetua o processo de cálculo da variação de rotação e translação numa
sequência de dois instantes temporais, os instantes 59 e 60. Este determina que no total da exe-
cução da aplicação, esta função irá ser executada 1444 vezes. Após simulação de cada módulo
criado, o ModelSim apresenta uma listagem informativa sobre o resultado da simulação. No caso
em exemplo, a Listagem 4.4 demonstra que nenhuma das 144 execuções da função ConvRepl1 em
hardware falha no cálculo e apresentação de resultados, comparativamente com a versão original
4Cada imagem é constituída por 12 (3×4) fatias, sendo que cada uma executa a função ConvRepl1 3 vezes. Essevalor é multiplicado por 4 uma vez que é feito o processamento de imagens provenientes de ambos os lados em doisinstantes de tempo consecutivos. No total é executada 144 vezes (12×3×4).

4.1 Implementação da Função Extração de Caraterísticas 49
em software.
Listagem 4.4: Resultado da simulação da aplicação usando versão hardware da função Con-
vRepl1.
# I n f o : E x e c u t i o n o f use r−s u p p l i e d C++ t e s t b e n c h ’ main ( ) ’ has comple t ed wi the x i t code = 0
## I n f o : C o l l e c t i n g d a t a comple t ed# c a p t u r e d 144 v a l u e s o f h# c a p t u r e d 144 v a l u e s o f u# c a p t u r e d 144 v a l u e s o f y# I n f o : s c v e r i f y _ t o p / u s e r _ t b : S i m u l a t i o n comple t ed# I n f o : s c v e r i f y _ t o p / Moni to r : r u n s wi th c o n s t a n t c l o c k p e r i o d 10 ns# I n f o : s c v e r i f y _ t o p / Moni to r : Throughput : 1 t r a n s a c t i o n p e r 1013760 ns# I n f o : s c v e r i f y _ t o p / Moni to r : La t ency : 1013790 ns## Checking r e s u l t s# ’ y ’# c a p t u r e c o u n t = 144# compar i son c o u n t = 144# i g n o r e c o u n t = 0# error c o u n t = 0# s t u c k i n d u t f i f o = 0# s t u c k i n g o l den f i f o = 0## I n f o : S i m u l a t i o n PASSED! @ 145981606 ns# ∗∗ Note : ( vsim−6574) SystemC s i m u l a t i o n s t o p p e d by u s e r .
4.1.4 Adaptação Verilog e Análise de Relatórios Gerados: Precision RTL
Uma vez que a versão Verilog presente nos resultados de síntese de alto nível não é compatível
com as ferramentas da Xilinx adiante utilizadas, esta necessitava de ser adaptada. Para esse efeito,
utilizou-se a ferramenta recomendada pelo Catapult C, Precision RTL, da Mentor Graphics.
Esta ferramenta, para além desta conversão, é capaz de apresentar relatórios bastante mais
detalhados que o Catapult C. A exemplo desses relatórios, a Tabela 4.11, apresenta a frequência
de operação resultante do relatório temporal e uma lista de percentagem de recursos utilizados,
para a FPGA utilizada, derivados do relatório de área ocupada produzido.
Tabela 4.11: Dados resultantes dos relatórios temporal e área, gerados pelo Precision RTL.
FunçãoRelatório temporal Relatório de área
Frequência Frequência LUTs CLBs FF-D DSP48Ereq. (Mhz) obtida (Mhz) req. (%) req. (%) req. (%) req. (%)
ConvConst 100 131.631 2.77 2.77 2.58 2.34ConvRepl1 100 131.631 1.77 1.95 1.94 3.12ConvRepl2 100 131.631 2.59 2.60 2.17 3.12

50 Tarefas Críticas - Implementação em Hardware
Estes evidenciam dois aspectos fundamentais para o decorrer do projeto. Primeiro, o facto da
frequência obtida resultante da síntese RTL representar mais de 30% da frequência projetada an-
tevê uma boa probabilidade da síntese física atingir facilmente os requisitos temporais projetados
na fase de síntese física (PAR). O segundo fator prende-se com o facto da lista estimada de compo-
nentes utilizados representar uma percentagem razoavelmente pequena dos recursos disponíveis,
o que estará diretamente relacionado com a área de ocupação final de cada módulo funcional. Este
fator será determinante no âmbito do projeto reconfigurável, uma vez que os tempos de reconfi-
guração são diretamente proporcionais à área de reconfiguração. Estas questões serão abordadas
com maior detalhe mais adiante na fase de projeto de reconfiguração dinâmica.
4.2 Implementação da Função Estimação Robusta de Pose
Uma vez gerados os módulos de aceleração em hardware referente à função Função Extração
de Caraterísticas, optou-se por efetuar o mesmo processo para a função crítica restante, a função
Estimação Robusta de Pose.
Como descrito anteriormente na Secção 3.4.2, esta função recorre ao algoritmo de RANSAC,
sendo este constituído por uma rotina de execução sem número de iterações definido, dependente
do número de pontos tridimensionais obtidos a partir da correlação de caraterísticas detetadas, e
da qualidade e erro da hipótese inferida sobre a matriz de transformação da rotação e translação.
Uma vez que o número de iterações desta rotina pode ser bastante elevado (5000 iterações, no
máximo), optou-se por idealizar uma forma de implementação que não recorre-se à quebra desta
rotina, evitando dessa forma o desperdiçar de um elevado número de ciclos de execução apenas
para protocolo de comunicação entre o processador e os módulos gerados. Para além deste fator, a
integração total da rotina de RANSAC em hardware, permite uma oferecer uma execução paralela
e de processamento acelerado, libertando do processador uma grande parte da carga neste presente
durante este processo.
A Figura 4.14 demonstra o exemplo de implementação considerado. Tal como na versão origi-
nal descrita em 3.4.2, a aplicação escolhe um sub-conjunto de três pontos tridimensionais, mas ao
invés de utilizar apenas um bloco de processamento em software, esta distribui os sub-conjuntos
existentes por um ou vários módulos de processamento paralelo em hardware. Cada módulo gera
um hipótese de partida inicial e recebe diferentes sub-conjuntos de pontos tridimensionais. Uma
vez que um dos módulos encontre uma hipótese com qualidade superior à mínima desejada, a
sua informação é passada para a aplicação em software, e o processo em execução em todos os
restantes módulos é interrompido e seus dados descartados.
Desta feita foi iniciado o trabalho de adaptação da função original aos requisitos invocados
pelo Catapult C. O fator fundamental prende-se pela utilização quase exclusiva de variáveis do
tipo real32_T, sendo esta a representação de variáveis do tipo vírgula flutuante em 32 bits.
Como efetuado para a função Extração de Caraterísticas, foi necessário alterar o tipo de re-
presentação dos dados existentes no interior da rotina de RANSAC. De forma a analisar as gamas

4.2 Implementação da Função Estimação Robusta de Pose 51
Sub-conjunto #1
de pontos 3D
Sub-conjunto #2
de pontos 3D
Sub-conjunto #3
de pontos 3D
RANSAC RANSAC RANSAC
…
...
t(n)
t(n+1)
…
Retorna a melhor
hipótese R, T e
erro relativo
Instantes
de tempoConjunto de
pontos 3D
Ha
rdw
are
So
ftw
are
So
ftw
are
Figura 4.14: Possível implementação do algoritmo RANSAC em hardware.
dinâmicas das variáveis presentes no seu interior, foi adicionada à aplicação original uma secção
parametrizável de análise e registo da posição do bit mais significativo (MSB5) em variável inteira
de vírgula fixa, necessário para representar qualquer valor originalmente manipulado em variável
do tipo vírgula flutuante. A Equação 4.2.5 demonstra a forma de como a posição do bit mais
significativo foi calculada, sendo que x representa cada valor a ser manipulado.
MSB =
blog2(abs(x))+1c se abs(x)> 1
0 se x = 0
blog2(abs(x))c se 1 > abs(x)> 0
(4.2.5)
Foram registadas para cada operação aritmética de soma, subtração, multiplicação e divisão, as
gamas de valores do resultado e dos operadores envolvidos, em dois instantes temporais distintos,
de forma a analisar com alguma coerência, um certo grau de realismo dos valores presentes em
5MSB - Most Significant Bit, posição do bit mais significativo para representação do valor x em variável inteira.

52 Tarefas Críticas - Implementação em Hardware
situações diversas. Para além desta monitorização, foi também registado o número de ciclos exe-
cutados em cada rotina interna existente. Uma vez que para algumas destas rotinas, o número de
ciclos executados está dependente do grau de precisão presente por estas variáveis, considerou-se
que o registo do número de ciclos efetuados seria um bom método de análise do impacto resultante
da mudança do tipo de dados.
O bloco de código fornecido relativo ao algoritmo RANSAC, apresenta uma estrutura com-
plexa, em grande parte herdada do algoritmo SVD executado no seu interior, sendo este rico em
reutilizações das variáveis existentes, em várias rotinas internas independentes. Devido a este
facto e ao pouco tempo disponível para a tarefa de implementação, optou-se por não efetuar o
isolamento destas variáveis temporárias e de permanecer intactas as suas utilizações em todo o
algoritmo.
A Tabela 4.12, demonstra o resultado da análise efetuada para determinação da posição do
bit mais significativo, necessário para representação dos valores manipulados, se estes fossem
representados num formato de vírgula fixa generalizado, para substituição de todas as variáveis
de vírgula flutuante. Como é possível visualizar, os valores presentes no interior do algoritmo
podem variar bastante, sendo que no máximo estas variáveis podem ser representadas utilizando
um tipo de dados de vírgula fixa com 30 bits para a parte inteira e 101 bits para representar o bit
mais significativo na parte fracionária, necessitando de mais alguns bits à direita para oferecer a
precisão desejada. A Figura 4.15, apresenta o formato de variável em vírgula fixa necessário para
representação dos valores manipulados.
,n-bit para precisão
1 x x ... x x x x ... x x x 1 x x ... x x30 -101
Posição da
vírgula
MSB do maior
número inteiro
em absoluto
MSB do
número com
maior precisão
0 -1
Parte fracionáriaParte inteira
-(101+n)
Figura 4.15: Formato de variável em vírgula fixa necessário para representação dos valores mani-pulados.
Para a manipulação dos dados em vírgula fixa, utilizou-se o tipo de dados Algorithmic C (AC),
disponibilizado pela Calypto Systems, [20]. Uma solução utilizando a biblioteca SoftFloat foi à
partida excluída, uma vez que se demonstrou exigente em requisitos, para a fraca performance
temporal obtida, aquando da implementação da função Extração de Caraterísticas.
As variáveis em vírgula flutuante foram então substituídas por versões do tipo AC, com 32 bit
para parte inteira e 128 bit para a fracionária e sinal. O resultado da comparação com a versão
original pode ser verificada na Listagem 4.5.

4.2 Implementação da Função Estimação Robusta de Pose 53
Tabela 4.12: Comparação do número de bits necessários mais díspar para representação dos valo-res internos ao algoritmo RANSAC para as sequências de imagem 59→ 60 e 328→ 329.
TipoNúmero da
Número de bits na Número de bits na
operaçãosequência 59→ 60 sequência 328→ 329Máx. Min. Máx Min
Soma #49 24 -64 21 -62Soma #73 30 -76 27 -70Soma #185 0 -101 0 -33
Multiplicação #51 30 -54 26 -57Multiplicação #72 30 -101 26 -91Multiplicação #192 0 -50 0 -18
Divisão #35 30 0 26 -5Divisão #181 0 -41 0 -20
Raiz #186 0 -51 0 -17
Listagem 4.5: Comparação do número de ciclos das rotinas internas ao algoritmo RANSAC para
a versão original e a utilização do tipo Algorithmic C.
===== O r i g i n a l r e s u l t s =================================dR = [ 0 . 9 9 9 9 6 4 ; 0 . 0 0 8 4 5 9 ; −0.000438;
−0.008461; 0 . 9 9 9 9 4 3 ; −0.006538;0 . 0 0 0 3 8 2 ; 0 . 0 0 6 5 4 1 ; 0 . 9 9 9 9 7 9 ; ]
dT = [ 0 . 5 5 9 0 1 8 ; 0 . 0 1 0 7 7 1 ; 0 . 0 0 0 0 9 6 ; ]
RanSaC r o u t i n e c o u n t e r :l oop : R a n s a c _ i n n e r : 1540loop : Ransac_AbsOrQuat_ inner : 2840loop : Ransac_AbsOrQuat_SVD_inner : 13693loop : Ransac_AbsOrQuat_SVD_inner_inner : 22730loop : Ransac_AbsOrQuat_SVD_inner_inner2 : 34470loop : Ransac_AbsOrQuat_SVD_inner_inner3 : 0loop : Ransac_AbsOrQuat_ inner2 : 0
===== A l g o r i t h m i c−C D a t a t y p e r e s u l t s ===================dR = [ 0 . 9 9 9 9 6 4 ; 0 . 0 0 8 4 5 9 ; −0.000438;
−0.008461; 0 . 9 9 9 9 4 3 ; −0.006538;0 . 0 0 0 3 8 2 ; 0 . 0 0 6 5 4 1 ; 0 . 9 9 9 9 7 9 ; ]
dT = [ 0 . 5 5 9 0 1 8 ; 0 . 0 1 0 7 7 1 ; 0 . 0 0 0 0 9 6 ; ]
RanSaC r o u t i n e c o u n t e r :l oop : R a n s a c _ i n n e r : 1540loop : Ransac_AbsOrQuat_ inner : 2840loop . Ransac_AbsOrQuat_SVD_inner : 106998loop : Ransac_AbsOrQuat_SVD_inner_inner : 319248loop : Ransac_AbsOrQuat_SVD_inner_inner2 : 532756loop : Ransac_AbsOrQuat_SVD_inner_inner3 : 0loop : Ransac_AbsOrQuat_ inner2 : 0

54 Tarefas Críticas - Implementação em Hardware
Neste pode ser verificado que o resultado final, correspondente às matrizes de variação de ro-
tação e translação, é o correto. Porém o número de ciclos das rotinas internas é significativamente
maior. Cada entrada do tipo loop corresponde a uma rotina sendo que o valor à direita representa
o número total de vezes que essa rotina completou um ciclo. O encadeamento de sub-rotinas é
descrito pelo símbolo “_”, sendo que as grandes sub-rotinas como as funções de cálculo da orien-
tação absoluta e SVD, enquanto que as suas sub-rotinas internas são denominadas innerX.
Desta feita é possível verificar que o algoritmo SVD, tal como o esperado foi o bloco mais
afetado pela falta de precisão resultante da utilização do tipo de dados em vírgula fixa. Com o
objetivo de diminuir o efeito causado foi aumentado o número de bits de representação fracionária
para 256 bit, mas mesmo assim o número de ciclos resultantes foi equivalente ao obtido anterior-
mente. Estranhamente também se verificou que a diminuição do número de bits de representação
fracionária para 32 obtém um número de ciclos equivalente aos dois testes anteriores.
O facto de algumas rotinas internas ao algoritmo de SVD, serem executadas 15 vezes mais que
a rotina original, demonstrou não ser este o tipo de adaptação ideal, pelo que a implementação da
função Estimação Robusta de Pose foi colocada em questão, devido ao tempo restante.
Como medida rápida de avaliação da exequibilidade desta implementação, foi efetuada a sín-
tese de alto nível do bloco RANSAC, na ferramenta Catapult C. Foram escolhidas como parâme-
tros de configuração da ferramenta os sinais de controlo equivalentes aos utilizados nos módulos
da função Extração de Caraterísticas, memória de transferência de dados do tipo FIFO6, uma vez
que cada sub-conjunto de pontos 3D é transferido apenas uma vez, para além de serem testados
dois tipos de frequência de execução, 1 e 100 Mhz. Foi também selecionado como otimização
alvo, a diminuição da área ocupada.
A próxima tabela apresenta a informação gerada pelos relatórios de síntese da ferramenta Pre-
cision RTL, após a síntese de alto nível efetuada pelo Catapult C. Neste, é possível verificar que
para ambas as frequências implementadas, os recursos disponíveis na FGPA utilizada neste traba-
lho, não suportam os requisitos requeridos, sendo mesmo necessário quase o triplo dos recursos
disponíveis.
Por este motivo, não se procedeu à implementação da função Estimação Robusta de Pose,
prosseguindo-se para a conclusão da implementação da função Extração de Caraterísticas.
Tabela 4.13: Dados resultantes dos relatórios temporal e área, gerados pelo Precision RTL.
FunçãoRelatório temporal Relatório de área
Frequência Frequência LUTs CLBs FF-D DSP48Ereq. (Mhz) obtida (Mhz) req. (%) req. (%) req. (%) req. (%)
RANSAC 1 2.697 259.94 259.94 41.17 89.84RANSAC 100 22.190 243 243 54,72 53.12
6FIFO - First In, First Out.

Capítulo 5
Sistema ReconfigurávelImplementação
Este capítulo descreve a forma de como o sistema reconfigurável foi projetado, partindo dos
módulos gerados a partir da síntese de alto nível da tarefa crítica Extração de Caraterísticas. Este
está dividido em quatro secções fundamentais, estando estas relacionadas com a criação de unida-
des reconfiguráveis através do ISE, as quais podem alternar entre os módulos funcionais criados no
Catapult C, a montagem de uma arquitetura de sistema embarcado reconfigurável na ferramenta
XPS, a definição das áreas de reconfiguração na FPGA, a implementação do sistema de recon-
figuração parcial dinâmica através da ferramenta de projeto PlanAhead, e por fim, a adaptação
do software original com a finalidade de controlar a manipulação das reconfigurações, sendo esta
feita na ferramenta XSDK.
A conjugação deste fluxo de projeto oferece ao projetista a capacidade de projetar sistemas
onde as configurações e funcionalidades de certos módulos possam ser alteradas, em tempo real,
sem que haja suspensão do restante sistema.
5.1 Criação das Unidades Reconfiguráveis: Xilinx ISE
Definidos que estão as versões em hardware das funções envolvidas no processo de extração
de caraterísticas, chega o momento de definição da forma como os módulos gerados se integrarão
no ambiente de desenvolvimento de sistemas embarcados da Xilinx, seguindo parte do fluxo de
projeto da ferramenta ISE disponível na Figura 2.4.
Nesta secção do documento, serão discutidas algumas possíveis soluções de integração e suas
implicações, para além de algumas alternativas de melhoramentos futuros.
Como visto anteriormente, os módulos físicos que executam as funções ConvConst, Con-
vRepl1 e ConvRepl2 foram especialmente desenhados para possuir interfaces compatíveis entre
55

56 Sistema Reconfigurável - Implementação
si. Estes, serão alternadamente configurados em módulos projetados para conter regiões reconfi-
guráveis, possuindo, também estes, as mesmas interfaces que as anteriores. Estes módulos espe-
ciais, capazes de receber cada uma das três configurações possíveis, são a partir deste momento
designados de módulos reconfiguráveis.
A arquitetura utilizada em sistemas construídos sobre plataformas de desenvolvimento de
sistemas embarcados da Xilinx (Xilinx EDK), baseia-se numa arquitetura centralizada ao bar-
ramento, neste caso, o barramento PLB[25]. Conectados a este, estarão não só os elementos
primários num sistema computacional como processador, memórias e respetivo controlador, mas
também todos os periféricos necessários à execução da aplicação, como a unidade de processa-
mento em vírgula flutuante (FPU), ou o controlador de porta série. Para que os módulos recon-
figuráveis possam comunicar com o restante sistema, havia a necessidade de criar um complexo
controlador capaz de efetuar a interface com o barramento PLB. Felizmente, a Xilinx oferece a
possibilidade de criação de periféricos modelo através de assistente de configuração, os quais for-
necem toda a parametrização necessária para a correta comunicação com periféricos, bem como
a inclusão de serviços de sistema que poderão ser úteis, tais como o serviço de interrupção, ou a
possibilidade de transferências de dados em modo rajada.
Uma das configurações oferecidas pelo assistente, passa pela definição do número de regiões
de memória existentes no interior do periférico. Uma vez que a escolha desta configuração está
diretamente relacionada com a maneira como os módulos reconfiguráveis estarão presentes no seu
interior, esta decisão necessita de alguma ponderação.
Antes de mais, uma vez que os módulos reconfiguráveis utilizarão dados armazenados em
elementos de memória, é necessário analisar a forma como a informação pode ser armazenada
no interior da FPGA existente na placa ML507. Como visto anteriormente 2.5.1, uma região de
memória é constituída por um ou vários elementos de memória primitivos, os elementos Bloc-
kRAM, em pormenor definidos em [26], capítulo 4o. Estes elementos primitivos, desenhados
expressamente para introduzir o menor atraso temporal possível, são capazes de armazenar até 36
Kib de dados, que podem ser configurados inteiramente numa região, ou em duas regiões inde-
pendentes de 18 Kib cada. Cada BlockRam de 36 Kib pode ser configurado como memórias do
tipo, 32k×1bit, 16k×2bit, 8k×4bit, 4k×9bit, 2k×18bit, 1k×36bit, ou múltiplos valores usando
estas combinações, quando conectados a primitivas adjacentes em cascata. Por outro lado, cada
BlockRam de 18 Kib pode ser configurado em memórias do tipo 16k×1bit, 8k×2bit, 4k×4bit,
2k×9bit, 1k×18bit. Estes módulos permitem o acesso através duas portas distintas para escrita
e leitura dos dados em modo síncrono, e possibilitam o acesso aos dados através de portas com
larguras diferentes à largura original dos dados armazenados no seu interior. Para além disso, a
largura da porta de entrada pode diferir da de saída.
Uma vez que os módulos criados na secção 4.1.1.1 comunicam com os elementos de memória
através de portas com 32 bit, uma das portas de cada memória fica obrigatoriamente dessa forma
definida. As restantes portas de cada memória necessitarão de estar conectadas com o restante
sistema, através do barramento PLB. Embora o barramento PLB permita transferências de dados

5.1 Criação das Unidades Reconfiguráveis: Xilinx ISE 57
em larguras de 128, 64 e 32 bit, por simplificação, optou-se por utilizar a mesma largura dos
elementos a armazenar, 32 bit.
Para além disso, resta saber a quantidade de elementos primitivos BlockRam, necessários para
conter todos os 9216 elementos de memória, pertencentes aos arrays de entrada U e saída Y.
Segundo [19] e [26], a arquitetura interna do elemento primitivo, necessária para conter o maior
número de dados com uma largura de 32 bit, é a arquitetura 1k×36bit. O número de primitivas
BlockRams necessário para armazenar todos os elementos pode ser então calculado seguindo a
próxima equação.9216×32 bit1000×36 bit
= 8.192
Portanto, ao todo, serão necessárias 9 primitivas BlockRam para representar o array de valores
de cada uma das matrizes U e Y. Já o array H, no máximo ocupará 89 elementos de 32 bit, pelo
que ocupará somente uma BlockRam.
Com vista à definição da disposição dos elementos de memória existentes nos módulos recon-
figuráveis, foram consideradas três tipos soluções diferentes.
A primeira solução, apresentada na Figura 5.1 (a) é constituída apenas contendo um módulo
reconfigurável e três BlockRams necessárias para abarcar os dados oriundos do arrays de entrada
H e U, e o array de saída Y. Esta solução tem duas desvantagens, sendo estas a repetição dos
recursos necessários à interface com o barramento PLB por cada periférico com módulo reconfi-
gurável, e a necessidade da inteira ocupação das primitivas BlockRam por cada array de dados.
Como aspeto positivo, esta solução oferece a melhor liberdade no que à disposição de módulos
diz respeito.
A segunda solução, apresentada na Figura 5.1 (b), é composta por vários módulos reconfi-
guráveis e correspondentes memórias de entrada e saída de dados. Comparativamente à solução
anterior, esta tem a vantagem de utilizar apenas uma interface para o barramento PLB, eliminando
dessa forma a repetição de recursos, mas tem como ponto negativo o facto de não ser capaz de efe-
tuar comunicações simultâneas para memórias pertencentes a módulos diversos. Para além desse
aspeto, esta solução carece da mesma má gestão dos recursos de memória que a solução anterior.
A última solução, apresentada na Figura 5.2, também esta composta por vários módulos re-
configuráveis, apresenta a melhor solução a nível de recursos, uma vez que necessita apenas de
uma interface para o barramento PLB, para além de que consegue aglomerar no menor número
possível de primitivas de memória, os dados referentes às memórias de entrada e saída dos módu-
los reconfiguráveis. Porém, esta solução obriga à utilização de blocos que executem a conversão
do offset de posições de memória e de controlo da posse do canal de leitura e escrita das memó-
rias. Uma vez que existe a possibilidade de execução de módulos em simultâneo, situações de
concorrência a recursos podem acontecer, pelo que devem ser geridos de maneira automática e
sem perdas.
Dada a maior liberdade de configuração que um sistema reconfigurável modular deve oferecer,
oferecendo a possibilidade de inclusão de mais ou menos periféricos reconfiguráveis consoante a

58 Sistema Reconfigurável - Implementação
Interface
PLB
Periférico Reconfigurável (a)
Módulo
Reconfigurável
1addr
data_out
en
addr
data_out
en
RAM U
addr_H
data_in_H
re_H
addr_U
data_in_U
re_U
addr_Y
data_out_Y
we_Y
addr
data_out
we
RAM YRAM H
Periférico Reconfigurável (b)
Módulo
Reconfigurável
naddr
data_out
en
addr
data_out
en
RAM U
addr_H
data_in_H
re_H
addr_U
data_in_U
re_U
addr_Y
data_out_Y
we_Y
addr
data_out
we
RAM Y
Região
Reconfigurável
RAM HInterface
PLB
Módulo
Reconfigurável
addr
data_out
en
addr
data_out
en
RAM U
addr_H
data_in_H
re_H
addr_U
data_in_U
re_U
addr_Y
data_out_Y
we_Y
addr
data_out
we
RAM Y
Região
Reconfigurável
RAM H
Figura 5.1: Soluções de arquitetura para periféricos reconfiguráveis: (a) - Contendo apenas ummódulo reconfigurável; (b) - Contendo vários módulos reconfiguráveis.
necessidade do utilizador, escolheu-se a primeira solução de implementação. Sendo que esta con-
tém no seu interior apenas um módulo reconfigurável, este periférico é neste momento designado
de unidade reconfigurável.
Escolhida que está a arquitetura interna das regiões de memória, foi possível retomar o assis-
tente de criação de periféricos modelo, no qual foi definido que este teria acesso a três regiões
de memória. Para além desta definição, configurou-se o periférico para dispor de quatro registos
de 32 bit para uso variado, acessíveis via PLB, uma quantidade que à partida seria a suficiente
para executar tarefas de controlo dos sinais de sincronismo, identificação e testes dos módulos
reconfiguráveis, via software. Antes de terminado o assistente, neste foi ainda incluído um sinal
de controlo de reinicialização do módulo, controlado por hardware, o soft-reset, um controlador
para serviço de interrupção, e a habilitação de um modo especial de transferência de dados via
barramento, o modo de transferências por rajada.
Como resultado do assistente de configuração de periféricos, é gerado um projeto ISE refe-
rente ao modelo de unidade reconfigurável, contendo no seu interior a hierarquia apresentada na
Figura 5.3. Nesta, é possível verificar a existência de quatro sub-módulos, sendo estes referentes
respetivamente ao controlador do barramento PLB, o controlador responsável pelo soft-reset, o
controlador de interrupção e por último, a zona de região disponível para lógica configurada pelo
utilizador, realçada a amarelo na figura.
É neste último sub-módulo que serão incorporados, utilizando a linguagem de descrição em

5.1 Criação das Unidades Reconfiguráveis: Xilinx ISE 59
MR1
MRn
MR2
MR1…….
MRn…….
MR2…….
MR1…….
MRn…….
Módulo
Reconfigurável
1
Conversor de
Endereço H
addr(1)
en(1)
addr(2)
en(2)
...
addr(n)
en(n)addr
en
Conversor de
Endereço U
addr(1)
en(1)
addr(2)
en(2)
...
addr(n)
en(n)addr
en
addr
en
data_out
addr
en
data_out
RAM U
addr_H
data_in_H
re_H
addr_U
data_in_U
re_U
Módulo
Reconfigurável
2addr_H
data_in_H
re_H
addr_U
data_in_U
re_U
Módulo
Reconfigurável
naddr_H
data_in_H
re_H
addr_U
data_in_U
re_U
addr_Y
data_out_Y
we_Y
addr_Y
data_out_Y
we_Y
addr_Y
data_out_Y
we_Y
Conversor de
Endereço Y
addr(1)
data_out(1)
we(1)
addr(2)
data_out(2)
we(2)
...
addr(n)
data_out(n)
we(n)
addr
data_out
we
addr
data_out
we
RAM Y
Região
Reconfigurável
MR2…….
Periférico Reconfigurável
Interface
PLB
RAM H
Figura 5.2: Solução para arquitetura de periférico reconfigurável.
hardware Verilog, o módulo reconfigurável, bem como os três blocos de memória e toda a lógica
de controlo necessária para gestão do sincronismo e dos protocolos de comunicação.
Começando por incluir os elementos de memória necessários, utilizou-se a ferramenta de cri-
ação de blocos de memória, disponibilizada pela aplicação, acelerando dessa forma o tempo de
implementação.
Segundo o manual da ferramenta [19], esta possibilita a criação de três tipos de memória RAM
distintos, sendo estes:
• Single-port (SP) – Como o nome indica, este tipo de memória apenas contém uma porta
de escrita e leitura de dados, sendo que o controlo do endereçamento de acesso é efetuado
via porta comum. Embora o elemento de memória utilizado necessite de comunicar com
duas entidades, o módulo reconfigurável e o restante sistema, este tipo de memória poderia
ser utilizado, uma vez que não haveria momentos de escrita e leituras simultâneos, bastando
para isso gerir através de multiplexagem a porta de endereçamento, consoante a necessidade
de escrita ou leitura;
• Simple Dual-port (SDP) – Este tipo de memória, ao contrário da anterior, oferece duas
portas de acesso, uma para escrita e outra para leitura, ambas contendo controlos de endere-
çamento independentes. Esta seria a escolha ideal para utilização de memória;

60 Sistema Reconfigurável - Implementação
Figura 5.3: Constituição original do modelo de unidade reconfigurável.
• True Dual-port (TDP) – Por fim, este último tipo de memória carateriza-se por oferecer
um duplo acesso de escrita e leitura ao elemento de memória. Desta forma, é possível ao
sistema o preenchimento do seu conteúdo e consequente verificação dos dados armazena-
dos, enquanto que o módulo reconfigurável se encontra, também ele, conectado à memoria
RAM. Para além de oferecer todas as vantagens de memórias do tipo Simple Dual-port,
este tipo de memórias oferece ainda a possibilidade de verificação dos dados de entrada do
módulo reconfigurável, caraterística vantajosa em situação de debug. Estas razões levaram
que este fosse o tipo de memória escolhido;
Desta feita, foram incluídos ao sub-módulo user-logic da unidade reconfigurável, os módulos
Verilog resultantes da ferramenta de criação de blocos de memória, correspondentes a uma me-
mória do tipo TDP com 89 elemento de 32 bit e duas com 9216 elementos, também estas de 32
bit.
A este sub-módulo, foi também adicionada a lógica necessária para controlo dos sinais de sin-
cronismo, sendo que enquanto o sinal de entrada start foi conectado a um bit de registo, acessível
pelo barramento PLB, o sinal ready foi conectado a um sinal de saída, enquanto que o restante si-
nal done, para além de conectar a um sinal de saída, está também ligado ao serviço de interrupção
através de uma porta conectada ao serviço de atendimento de interrupções do processador.
Foi ainda incluída toda a lógica necessária para respeitar o protocolo de transferência de dados
em modo de rajadas. Este modo, como será verificado mais adiante, possibilitará que periféricos
de acesso direto a memória (DMA) retirem ao processador a tarefa de escrita e leitura, valor a
valor, dos elementos de memória existentes no sistema, libertando dessa forma tempo de execução
para outras tarefas e acelerando no total os tempos de transferência.
Finalmente, foi criado um módulo Verilog vazio, reconfig_module.v, o qual representa o mó-
dulo reconfigurável. Este contém os mesmos interfaces de comunicação que os módulos fun-
cionais ConvConst, ConvRepl1 e ConvRepl2, acrescentados de um sinal auxiliar, que ajudará à
identificação, em qualquer altura, da versão funcional existente no módulo reconfigurável. Este
módulo é conectado tanto aos módulos de memória como à lógica de controlo.
A constituição final da unidade reconfigurável fica então representada na Figura 5.4, sendo que
o ficheiro Verilog que descreve o conteúdo do módulo configurado pelo utilizador, user_logic.v

5.1 Criação das Unidades Reconfiguráveis: Xilinx ISE 61
está presente no Anexo A.1, e o ficheiro que descreve o módulo reconfigurável vazio está presente
no Anexo A.2.
(Apenas interfaces)
Lógica de controlo do sincronismo e
transferência de dados
reconfig_unit.vhd
Serviço
Interrupção
Soft-reset
Interface
PLB
user_logic.v
TDP_89x32.v
TDP_9216x32.v
reconfig_module.v
TDP_9216x32.v
Figura 5.4: Constituição completa da unidade reconfigurável.
Uma vez concluída a descrição interna da unidade reconfigurável, procedeu-se à síntese da
mesma. Os resultados de síntese, presentes na Tabela 5.1, indicam que a configuração atual é a su-
ficiente, uma vez que a estimativa de frequência obtida aponta para um valor mais de 100% acima
da frequência mínima pretendida, para além da percentagem de recursos necessários ser bastante
pequena. Razões suficientes para continuar o projeto, não necessitando de qualquer alteração.
Tabela 5.1: Dados resultantes da síntese da unidade reconfigurável.
MóduloEstimação temporal Estimação de recursos ocupados
Frequência Frequência Registos LUTs BlockRamsreq. (Mhz) obtida (Mhz) req. (%) req. (%) req. (%)
reconfig_unit.v 100 208.247 493 (1) 649 (1) 19 (12)
Embora a síntese efetuada pela ferramenta Precision RTL não tenha apenas produzido o fi-
cheiro de descrição de hardware em Verilog, mas também o correspondente ficheiro de netlist,
não poderíamos prosseguir com o projeto, uma vez que a inclusão do sinal auxiliar, que permite
a identificação da versão da função implementada no módulo reconfigurável utilizado durante o
processo de debug da aplicação reconfigurável, obriga a uma re-síntese dos módulos referentes às
funções a implementar. Como é possível visualizar na Figura 5.5, este sinal de identificação não
passa apenas, de facto, de um sinal estático de 3 bit, sendo que representa o valor decimal 1, 2
e 4, quando implementar correspondentemente as funções ConvConst, ConvRepl1 e ConvRepl2.
Desta forma, não apenas o processo de debug fica simplificado, como também a aplicação po-
derá gerir de maneira mais inteligente o processo de reconfiguração, ou seja, no caso da aplicação
necessitar de executar, por exemplo, a função ConvConst, o sistema poderá primeiro saber se o

62 Sistema Reconfigurável - Implementação
módulo que implementa essa função se encontra, nesse momento, implementado. Desta forma,
o sistema não necessitaria de ter de esperar pelo correspondente tempo de reconfiguração desse
módulo.
clk
rst
h_rsc_singleport_addr [6:0]
h_rsc_singleport_re
h_rsc_singleport_data_out [31:0]
u_rsc_singleport_addr [13:0]
u_rsc_singleport_re
u_rsc_singleport_data_out [31:0]
start
ready
done
rp [2:0]
reconfig_module.v
ConvConst.v
[31:0] y_rsc_singleport_data_in
[13:0] y_rsc_singleport_addr
y_rsc_singleport_we
Valor
constante ‘001 ’2
Figura 5.5: Adição de sinal auxiliar no módulo reconfigurável.
Executando a re-síntese dos módulos representantes das funções a implementar, no interior do
módulo reconfigurável, obtiveram-se os resultados apresentados na Tabela 5.2. Nesta, verifica-se
que os resultados, como se esperaria, são comparáveis ao resultado da síntese efetuada em 4.11,
embora a estimativa de frequência de operação máxima estimada tenha obtido um valor menos
pessimista.
Tabela 5.2: Dados resultantes da re-síntese do módulo reconfigurável, com a instanciação de cadafunção.
Módulo Estimação temporal Estimação de recursos ocupadosReconfigurável Frequência Frequência Registos LUTs DSP48ECorrespondente req. (Mhz) obtida (Mhz) req. (%) req. (%) req. (%)
ConvConst.v 100 144.991 1181 (2) 1483 (3) 3 (2)ConvRepl1.v 100 150.317 871 (1) 817 (1) 4 (3)ConvRepl2.v 100 150.317 970 (2) 1084 (2) 4 (3)

5.2 Montagem de um Sistema Base Reconfigurável 63
5.2 Montagem de um Sistema Base Reconfigurável
Uma vez concluído todo o processo de criação da unidade reconfigurável e de cada versão do
módulo reconfigurável, foi possível regressar á ferramenta de configuração da plataforma de de-
senvolvimento de sistemas embarcados da Xilinx EDK, o Xilinx Platform Studio. Nele, procedeu-
se à inclusão dos seguintes periféricos, necessários para a execução da aplicação reconfigurável:
• 3 Unidades Reconfiguráveis – Optou-se pela inclusão de três unidades reconfiguráveis,
uma vez que à partida, como visto anteriormente, estes forneceriam o número de módulos
reconfiguráveis suficientes para o estudo de um conjunto de estratégias de reconfiguração
distintas;
• Controlador XPS HWICAP – Segundo [27], o controlador HWICAP oferece a possibi-
lidade de processadores, como o caso dos PowerPC, poderem ler e escrever a memória de
configuração da FPGA durante a execução da mesma, através do barramento PLB. O que
permite ao utilizador desenvolver programas de software capazes de modificar a estrutura
do circuito e funcionalidades durante o tempo de operação. O controlador XPS HWICAP,
fornece a interface necessária para transferir bitstreams da e para a porta de configuração
ICAP (Internal Configuration Access Port). Estas caraterísticas fazem deste controlador a
peça fundamental em todo o funcionamento de um sistema embarcado reconfigurável;
• Controlador XPS Central DMA – Este controlador, descrito em [28], fornece ao sistema
serviços de DMA (Direct Memory Access), os quais permitem aos periféricos e dispositivos
de memória conectados ao barramento PLB a transferência de determinada quantidade de
dados entre endereços de origem e destino, sem intervenção do processador;
Uma vez incluídos estes periféricos, ficou desta forma definida a arquitetura final do sistema
embarcado reconfigurável, apresentada na Figura 5.6.
Em sistemas computacionais, todos os periféricos necessitam de conter gamas de endereço de
sistema distintos, para que estes possam ser acedidos por parte do processador. Por esse motivo,
o passo que se seguiu envolveu o mapeamento dos endereços de todos os periféricos existentes no
sistema. Com a ajuda da ferramenta geração de endereços de sistema do XPS, foi possível atribuir
automaticamente os endereços e gamas necessárias dos dispositivos pertencentes à biblioteca de
componentes da Xilinx. Quanto às unidades reconfiguráveis restantes, estas pelo contrário, neces-
sitaram da configuração das gamas de endereçamento necessárias, sendo que estas serão discutidas
de seguida.
Por definição, o tamanho das gamas de endereçamento disponibilizadas pelo sistema apenas
admite valores resultantes de potências de base dois (2N). A tabela 5.3, apresenta o cálculo do
espaço necessário para o mapeamento das memórias contidas nas unidades reconfiguráveis.
Por fim, a gama de endereçamento necessária para acesso aos registos e sinais internos da
unidade reconfigurável foi definida 1 Kib.

64 Sistema Reconfigurável - Implementação
DD
R2
(2
56
MB
)
PPC 440
FPU
INTC
Central
DMA
UART
SysACE
MPMC
PL
B v
4.6
HwICAP
ICAP
BRAM
H
BRAM
U
BRAM
Y
Unidade Reconfigurável 0
Modulo
Reconfigurável
BRAM
H
BRAM
U
BRAM
Y
Unidade Reconfigurável 1
Modulo
Reconfigurável
BRAM
H
BRAM
U
BRAM
Y
Unidade Reconfigurável 2
Modulo
Reconfigurável
Figura 5.6: Arquitetura da Solução Proposta.
Tabela 5.3: Tamanho do mapeamento necessário para as memórias da unidade reconfigurável.
Tipos de Número de bits Tamanho da Gama deMemória a Mapear Endereços Necessário
TDP_9216×329216 × 32 bit
512 Kib= 288 Kib
TDP_89×3289 × 32 bit
4 Kib= 2868 bit
A Figura 5.7, demonstra o mapeamento total do sistema, estando realçadas nas cores azul,
laranja e cinza as gamas de endereços necessárias para o acesso às componentes de cada uma das
três unidades reconfiguráveis instanciadas.
Finalizado que está todo o processo de definição da arquitetura do sistema reconfigurável,
procedeu-se finalmente à criação das netlists de todo o sistema.

5.3 Implementação Física do Sistema Reconfigurável 65
Figura 5.7: Endereçamento do sistema.
5.3 Implementação Física do Sistema Reconfigurável
Continuando no fluxo de desenvolvimento de projetos reconfiguráveis adotado, o passo que
se seguiu teve como objetivo a criação dos bitstreams, referentes à regiões estática e dinâmica,
utilizando para isso a ferramenta PlanAhead da Xilinx.
Para além da correspondente configuração de placa de desenvolvimento e FPGA a utilizar,
o processo efetuado utiliza como fonte de informação não apenas a netlist da região estática do
sistema, região esta que contém as três unidades reconfiguráveis e respetivos módulos reconfigu-
ráveis, representando apenas uma caixa negra, mas também a netlist das regiões dinâmicas, sendo
estas cada uma das três versões que representam as funções ConvConst, ConvRepl1 e ConvRepl2.
O resultado deste processo apresentará um único bitstream da componente estática do sistema
e três bitstreams parciais por cada módulo reconfigurável, ou seja, no total, serão geradas nove
bitstreams parciais, referentes às regiões dinâmicas do sistema.
Desta feita, uma vez criado e configurado o projeto de reconfiguração parcial no PlanAhead,
este informa sobre a presença de uma instância não definida existente na netlist do sistema, o
módulo reconfig_module. Esta instância, referente aos módulos reconfiguráveis existentes, fará
com que seja identificada como sendo uma caixa negra, a qual será substituída pelas netlist parciais
de cada função a executar, aquando da reconfiguração.
Em cada um desses módulos identificados, procedeu-se à inclusão de três partições recon-
figuráveis, cada uma associada respetivamente às netlists das funções ConvConst, ConvRepl1 e

66 Sistema Reconfigurável - Implementação
ConvRepl2. Para além destas, também um partição vazia, referente à caixa negra, foi adicionada.
Esta partição, uma vez que não possui qualquer lógica interna, servirá como base de comparação
de recursos, entre as várias versões de cada módulo reconfigurável.
A configuração que se seguiu envolveu a definição do posicionamento das partições reconfi-
guráveis no interior da FPGA. A decisão da distribuição física destas partições é um dos pontos
cruciais no fluxo de projeto de reconfiguração dinâmica, influenciando drástica e diretamente o
desempenho final da aplicação. Os fatores que podem influenciar esta decisão baseiam-se na as-
sociação de dois elementos: o tipo de distribuição dos recursos na FPGA, que pode influenciar
na dimensão final da partição, e o tempo de configuração, diretamente proporcional a essa mesma
dimensão. Desta forma, as decisões tomadas em relação a estes fatores requereram as devidas
justificações, apresentadas de seguida.
O posicionamento destas partições é, naturalmente, dependente da localização física dos re-
cursos necessários para o funcionamento de todos os módulos passíveis de serem configurados.
Em certas situações, a disponibilização física dos recursos pode não ser a mais homogénea possí-
vel. Um destes exemplos é a FPGA utilizada neste projeto, onde a vista global sobre os recursos
disponíveis, demonstra que componentes como as unidades DSP estão concentradas unicamente
na região lateral direita da FPGA.
Quanto ao tempo de reconfiguração, esta informação deriva diretamente da forma de como a
Virtex-5 está construída. Como anteriormente discutido em 2.5.1.1, qualquer tipo de informação
programável pelo utilizador na FPGA, está armazenada em memória volátil, que necessita de con-
figuração sempre que ligada. Essas memórias de configuração definem todos os aspetos elétricos
da região programável da FPGA, como os sinais que definem as equações existentes em LUTs, o
roteamento dos sinais ou registos.
Uma pequena porção contendo estas memórias de configuração, doravante denominada trama
de configuração, é o elemento mais pequeno, endereçável pelo espaço de memória do sistema de
configuração.
Na Virtex-5, cada trama de reconfiguração é constituída por 20 CLB de altura, por um CLB de
largura e é separado por cada região de relógio diferente, como mostrado na Figura 5.8. Mesmo
que apenas uma trama configurável seja utilizada para reconfiguração, todo este conjunto de 20×1
CLBs é utilizado e configurado.
O número total de tramas reconfiguráveis, juntamente com o tipo de porta de reconfigura-
ção utilizada, e, principalmente, com o mecanismo de colocação dessa informação nessa porta,
definem a velocidade de reconfiguração.
Segundo [29], utilizando a porta ICAP com largura de 32 bit, a uma frequência de comunica-
ção de 100 Mhz, a largura de banda atingida é de 3,2 Gbps. Desta feita, uma estimativa do tempo
de transmissão da trama reconfigurável pela porta ICAP, pode ser obtida através da expressão:
Tempo de transmissão (s) =Tamanho da trama reconfigurável (bit)
3 200 000 000
Uma vez que o tempo de reconfiguração depende diretamente do tamanho da sequência de

5.3 Implementação Física do Sistema Reconfigurável 67
Trama
reconfigurável
Fronteira da
região de relógio
Figura 5.8: Representação de um trama reconfigurável.
bits que representam as tramas de reconfiguração, optou-se por utilizar o menor número de tramas
possível.
Sendo o objetivo do projeto a possibilidade de configuração de qualquer função tratada, em
qualquer módulo reconfigurável, optou-se por criar três áreas reconfiguráveis idênticas em forma
e em recursos disponíveis, em quantidade suficiente para conter a função que mais requisitos
necessita, a função ConvConst.
Deste modo, foram definidas as áreas de reconfiguração, apresentadas em realce na Figura 5.9.
De notar, também, que foram seguidos os conselhos de projeto, disponíveis em [30], dirigidos es-
pecificamente à ferramenta PlanAhead, com o objetivo de obter resultados o mais previsíveis pos-
sível. O resultado desses conselhos foi a compactação dos maiores blocos existentes no sistema,
o caso do controlador de memória, MPMC, junto da porta de acesso ao exterior, e na unidade de
computação em vírgula flutuante, FPU.
Os valores que representam a estimativa de recursos físicos, referentes às netlist de cada fun-
ção, são apresentados respetivamente nas Figuras 5.10(a),(b), e (c). Já o número de tramas de
configuração ocupadas, e correspondente tamanho do bitstream final resultante, é apresentado na
Figura 5.10(d)
Desta feita, o tempo estimado pela transmissão de cada bitstream, através da porta ICAP, é
apresentado na seguinte expressão:
89216×83 200 000 000
= 223µs
Perante este valor, não deve ser esquecido o facto de este não contabilizar o tempo de trans-
missão perdido por processamento e passagem da informação através do barramento PLB.
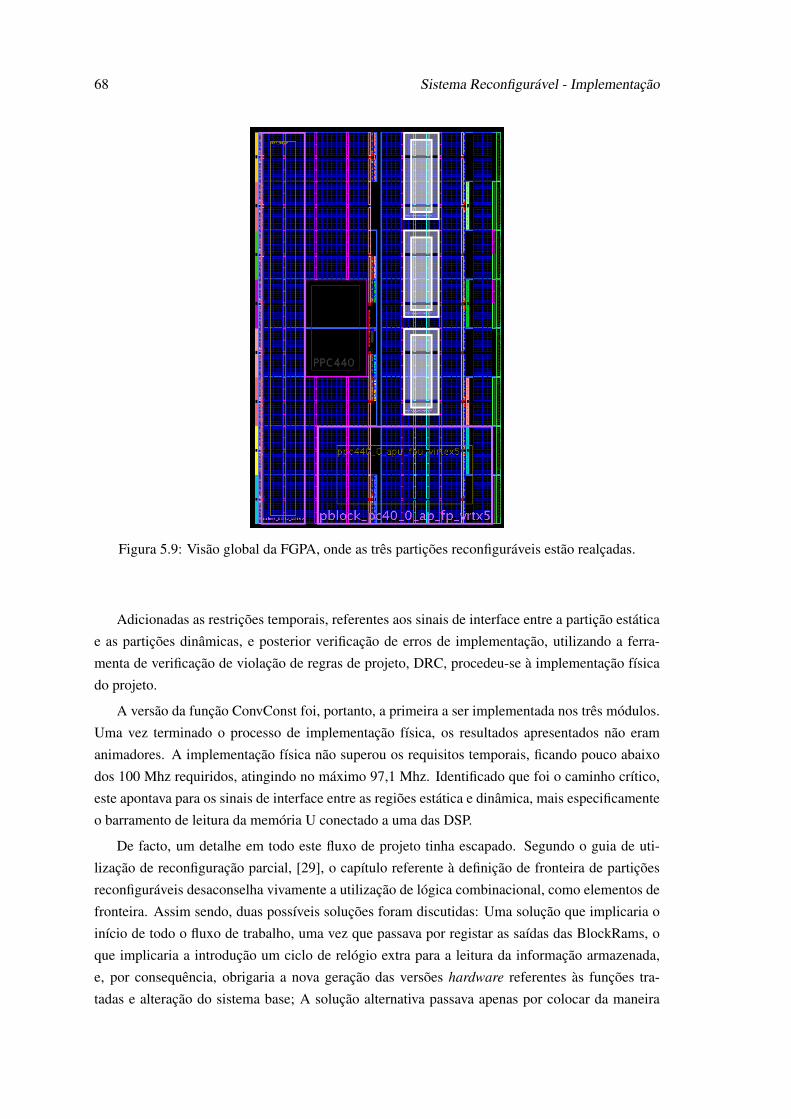
68 Sistema Reconfigurável - Implementação
Figura 5.9: Visão global da FGPA, onde as três partições reconfiguráveis estão realçadas.
Adicionadas as restrições temporais, referentes aos sinais de interface entre a partição estática
e as partições dinâmicas, e posterior verificação de erros de implementação, utilizando a ferra-
menta de verificação de violação de regras de projeto, DRC, procedeu-se à implementação física
do projeto.
A versão da função ConvConst foi, portanto, a primeira a ser implementada nos três módulos.
Uma vez terminado o processo de implementação física, os resultados apresentados não eram
animadores. A implementação física não superou os requisitos temporais, ficando pouco abaixo
dos 100 Mhz requiridos, atingindo no máximo 97,1 Mhz. Identificado que foi o caminho crítico,
este apontava para os sinais de interface entre as regiões estática e dinâmica, mais especificamente
o barramento de leitura da memória U conectado a uma das DSP.
De facto, um detalhe em todo este fluxo de projeto tinha escapado. Segundo o guia de uti-
lização de reconfiguração parcial, [29], o capítulo referente à definição de fronteira de partições
reconfiguráveis desaconselha vivamente a utilização de lógica combinacional, como elementos de
fronteira. Assim sendo, duas possíveis soluções foram discutidas: Uma solução que implicaria o
início de todo o fluxo de trabalho, uma vez que passava por registar as saídas das BlockRams, o
que implicaria a introdução um ciclo de relógio extra para a leitura da informação armazenada,
e, por consequência, obrigaria a nova geração das versões hardware referentes às funções tra-
tadas e alteração do sistema base; A solução alternativa passava apenas por colocar da maneira

5.3 Implementação Física do Sistema Reconfigurável 69
(a)
(b)
(c)
(d)
Figura 5.10: Estimativa de recursos ocupados pelas funções: ConvConst (a), ConvRepl1 (b),ConvRepl2 (c); Estimativa do tamanho de bitstream resultante (d).
mais próxima possível, toda a lógica de leitura da memória U, de modo a não violar os requisitos
temporais.
Desta feita, devido ao tempo restante para a conclusão do projeto, foi dada a hipótese de tentar
corrigir o problema utilizando a solução mais rápida e que envolvia apenas alteração de definições
na ferramenta PlanAhead.
Foi tido em conta um aspecto importante, indicado no guia de utilização de reconfiguração
parcial, [29]. Este informa que se existir lógica estática dentro de uma trama de reconfiguração,
essa lógica não é de nenhuma forma afetada pelo processo de reconfiguração. Por outro lado,
também o conteúdo de elementos dinâmicos, como o caso de BlockRams, sendo estes qualificados
como pertencentes à região estática, não sofrem qualquer alteração do seu conteúdo aquando de
uma reconfiguração.
Utilizando esta informação, procedeu-se à inclusão de lógica de controlo da memória U no
interior da unidade reconfigurável, e da compactação das memórias de entrada H e U ao seu
centro. Para esse efeito, foram adicionados ao ficheiro os requisitos posicionais referentes à fixa-
ção dos elementos abordados. A Figura 5.11, demonstra o resultado desses mesmos requisitos,

70 Sistema Reconfigurável - Implementação
encontrando-se a laranja os elementos fixos, através de restrições locais do tipo ’LOC’, as Bloc-
kRam, a lógica de interface e a DSP de receção de dados.
Elementos
fixos
Figura 5.11: Representação da nova partição reconfigurável.
De novo verificada a inexistência de erros utilizando a ferramenta DRC, procedeu-se mais uma
vez à implementação física dos módulos reconfiguráveis, estando estes novamente configurados
com a netlist da função Convconst.
Desta vez, os resultados, foram os suficientes para satisfazer os requisitos temporais existentes,
alcançando uma frequência máxima de 100,251 Mhz. Para além disso, verificando a Figura 5.12
constata-se que este método permite a utilização de uma área mais pequena, graças a uma disposi-
ção física mais regular, necessitando apenas de 13 tramas, para a sua configuração e influenciando,
desta maneira, o tempo estimado pela transmissão de cada bitstream, através da porta ICAP, per-
mitindo desta maneira tempos de transferência de:
74128×83 200 000 000
= 185,32µs
Figura 5.12: Estimativa do tamanho de bitstream resultante.
Repetindo novamente o processo de implementação, mas desta vez para as versões que execu-
tam as restantes funções, obtiveram-se as seguintes frequências de operação:
O resultado da implementação física na FPGA pode ser visualizada na Figura 5.13.

5.3 Implementação Física do Sistema Reconfigurável 71
Tabela 5.4: Resultados da implementação física.
Função a Implementar em Percentagem de Frequência MáximaCada Módulo Reconfigurável Recursos Ocupados (%) Atingida (Mhz)
Caixa Negra 26 100,513ConvConst 35 (+9%) 100,251ConvRepl1 31 (+5%) 98,319ConvRepl2 33 (+7%) 99,265
Quanto à validação da implementação, novamente, nem todas as funções atingiram os requisi-
tos mínimos temporais. Uma vez que a implementação que definiu a região estática, a implemen-
tação da função ConvConst, superou esses objetivos, e acreditando que as estimativas temporais
apresentadas pela Xilinx são pessimistas, assumiu-se que a diferença para os 100 Mhz, não justi-
ficava a repetição de todos os os processos anteriores.
Continuando o projeto, o passo final, envolveu a geração de todos os bitstreams, sendo este
uma versão da região estática, para além dos nove bitstreams parciais.
Figura 5.13: Visão global da implementação física da FGPA, onde as três partições reconfiguráveisestão realçadas nas cores verde, amarela e vermelha.

72 Sistema Reconfigurável - Implementação
5.4 Software de Adaptação Dinâmica da Qualidade de Serviço
A presente secção do documento tem como objetivo a apresentação e discussão de várias
estratégias de reconfiguração, tendo em vista a sua utilização num sistema em que a qualidade do
serviço prestado varie conforme certos parâmetros de entrada. No caso da aplicação Navegação
Estéreo, o parâmetro de entrada considerado foi a velocidade do veículo, sendo que as estratégias
de reconfiguração consideradas têm em vista a adaptação dinâmica do sistema, a determinadas
gamas de velocidade.
Após a determinação das estratégias a implementar, a explicação do processo de inicialização
dos periféricos utilizados no processo de reconfiguração dinâmica será efetuada. Por fim, as alte-
rações em software, efetuadas à aplicação original, com vista à implementação das estratégias de
reconfiguração para execução da adaptação dinâmica da qualidade de serviço, serão apresentadas
e demonstradas.
5.4.1 Estratégias de Reconfiguração Consideradas
Como visto na Secção 3.4.1, a rotina de execução da função Extração de Caraterísticas, en-
volve a execução sequencial das oito operações de convolução, constituídas pelas funções Conv-
Const, ConvRepl1, e ConvRepl2.
As estratégias de reconfiguração aqui discutidas têm como objetivo a adaptação do sistema a
diferentes situações de navegação, sendo que será a velocidade de circulação do veículo a variável
de adaptação considerada.
Uma vez que o sistema capta e processa pares de imagens oriundas do mesmo cenário, é o
tempo de processamento desse par o fator a ser adaptado à velocidade do veículo. Com vista ao
alcance destes requisitos temporais, as estratégias de reconfiguração aqui abordadas terão como
objetivo a utilização de diferentes números de unidades reconfiguráveis. Desta forma, vários graus
de aceleração podem ser oferecidos ao sistema.
As várias estratégias de reconfiguração consideradas, dependendo do número de unidades
reconfiguráveis disponíveis, foram:
• 1 Unidade Reconfigurável – Execução da sequência de funções, através da utilização de
apenas uma unidade reconfigurável. A Figura 5.14, demonstra as operações realizadas, uti-
lizando apenas uma unidade reconfigurável. Este processo envolve a sucessiva configuração
e execução das oito etapas existentes na função Extração de Caraterísticas.
Uma vez que a operação de reconfiguração requer que a execução do módulo funcional
esteja terminada, esta estratégia foi associada a um requisito temporal baixo;
• 2 Unidades Reconfiguráveis – Execução da sequência de operações envolvidas, utilizando
um estilo de reconfiguração do tipo Ping-Pong. Uma vez que este tipo de estratégia dispõe
de duas unidades reconfiguráveis, foi considerada a possibilidade de execução de uma fun-
ção, enquanto a função subsequente é configurada, tal como demonstrado na Figura 5.15. O
único fator limitativo prende-se com o facto das novas funções reconfiguradas necessitarem

5.4 Software de Adaptação Dinâmica da Qualidade de Serviço 73
ConvConst 1.
2.
3.
4.
5.
6.
7.
8.
Configuração: ConvConst
Configuração: ConvRepl1
Configuração: ConvRepl2
Configuração: ConvConst
Configuração: ConvRepl1
Configuração: ConvRepl2
Configuração: ConvRepl1
Configuração: ConvRepl2
ConvRepl1
ConvRepl2
ConvConst
ConvRepl1
ConvRepl2
ConvRepl1
ConvRepl2
Processamento
consecutivo
Figura 5.14: Estratégia de reconfiguração utilizando apenas uma unidade reconfigurável.
do término de execução das funções anteriores, uma vez que existe dependência dos seus
dados resultantes. Este fator, obriga a espera consecutiva do término das funções subse-
quentes.
Esta articulação de recursos possibilita o aproveitamento do considerável tempo de reconfi-
guração, pelo que esta estratégia foi associada a um requisito temporal médio;
ConvConst Un
ida
de
Re
co
nfig
urá
ve
l
Configuração
ConvConst
Configuração
ConvRepl2
ConvRepl1Configuração
ConvRepl1
ConvRepl2
ConvConst Configuração
ConvConst
Configuração
ConvRepl1
1
0
t
Figura 5.15: Estratégia de reconfiguração utilizando duas unidades reconfiguráveis.
• 3 Unidades Reconfiguráveis – Com a finalidade de utilização de três unidades reconfigu-
ráveis foram consideradas duas estratégias de execução distintas, seguidamente discutidas:
– Configuração e Execução Paralela - O conceito desta estratégia passa por repartir
as oito operações pertencentes à função Extração de Caraterísticas em três processos
paralelos, dedicados a cada unidade reconfigurável. Como é possível visualizar na
Figura 5.16, a sequência de operações ConvConst, ConvRepl1 e ConvRepl2 é confi-
gurada e executada paralelamente, em três unidades reconfiguráveis.

74 Sistema Reconfigurável - Implementação
Configuração: ConvRepl2
Configuração: ConvRepl1
Configuração: ConvConst
ConvConst 1.
2.
3.
ConvRepl1
ConvRepl2
ConvConst
ConvRepl1
ConvRepl2
ConvRepl1
ConvRepl2
Configuração: ConvConst
Configuração: ConvRepl1
Configuração: ConvRepl2
Configuração: ConvRepl1
Configuração: ConvRepl2
Processamento
consecutivo
Figura 5.16: Estratégia de reconfiguração paralela utilizando três unidades reconfiguráveis.
Embora esta solução represente bem toda a vantagem de execução paralela em hard-
ware, o facto do sistema oferecer apenas uma porta ICAP impede parte deste parale-
lismo, uma vez que obriga a um processo de reconfiguração sequencial, entre funções
idênticas, em cada iteração de execução. Este cenário é piorado se o tempo de reconfi-
guração for bastante significante, ou até maior, comparando com o tempo de execução
do módulo funcional mais demorado, o que será o caso, verificando os valores tempo-
rais retirados. Como resultado, esta estratégia de reconfiguração foi abandonada;
– Utilização Fixa Sequencial - O procedimento que constituí esta solução é carateri-
zado por efetuar apenas a configuração de cada uma das três funções independentes a
executar, em unidades reconfiguráveis independentes. Estas configurações são efetu-
adas apenas uma única vez, aquando da entrada na função Extração de Caraterísticas,
e permanecem dessa forma configuradas durante o processamento de todas as 12 fa-
tias de cada imagem. A Figura 5.17(a) e (b), demonstra as duas possíveis situações
encontradas. Na primeira, o tempo de execução de cada função é superior ao de re-
configuração; O caso oposto é encontrado na segunda situação. Em ambos os casos,
fica demonstrado que o tempo total de execução da função Extração de Caraterísticas
é apenas afetado em pequena parte pela dimensão da área reconfigurável, a qual induz
o tempo de reconfiguração inicial necessário.
Uma vez que o processo de reconfiguração é efetuado apenas uma vez por cada função,
a estratégia resultante tem como consequência a utilização dedicada das unidades reconfi-
guráveis disponíveis, existentes no sistema, a partir do momento do início da execução da
função Extração de Caraterísticas.
Desta forma, a estratégia abordada por esta solução foi associada a um requisito temporal
alto;

5.4 Software de Adaptação Dinâmica da Qualidade de Serviço 75
Co... ConvConst
Un
ida
de
Re
co
nfig
urá
ve
l
Configuração
ConvConst
ConvRepl1Configuração
ConvRepl1
ConvConst
2
1
0
t
ConvRepl2Configuração
ConvRepl2
ConvRepl1
ConvRepl2
ConvConst
Un
ida
de
Re
co
nfig
urá
ve
l
Configuração
ConvConst
ConvRepl1Configuração
ConvRepl1
ConvConst
2
1
0
t
ConvRepl2Configuração
ConvRepl2
(a)
(b)
Figura 5.17: Estratégia de reconfiguração singular e execução sequencial, utilizando três unidadesreconfiguráveis.
Resumindo os resultados obtidos pelas estratégias consideradas, foram determinados três ní-
veis de requisitos temporais a satisfazer pelo sistema, sendo estes:
• Nível BAIXO – Utilizando apenas uma unidade reconfigurável, num estilo de configuração
e execução sequencial;
• Nível MÉDIO – Utilizando duas unidades reconfiguráveis, num estilo de configuração do
tipo Ping-Pong;
• Nível ALTO – Utilizando três unidades reconfiguráveis, num estilo de utilização dedicada a
cada função, após a configuração independente de cada sub-função a executar;
5.4.1.1 Inicialização do Sistema Reconfigurável
Uma vez estudadas as várias estratégias de reconfiguração a implementar, a presente secção
do documento irá abordar a forma de como o sistema reconfigurável é inicializado.
Uma vez inicializado o sistema e após configuração inicial da região estática, o sistema, cons-
tituído conforme a arquitetura projetada anteriormente visualizada na Figura 5.6 da página 64,
encontra-se pronto para execução de software.
Porém, o sistema ainda não está pronto para execução da aplicação Navegação Estéreo, pois
todos os periféricos e informação de reconfiguração necessários ao processo de reconfiguração
necessitam de ser inicializados.
Uma vez iniciada a execução do software, a primeira tarefa a realizar, à semelhança do sistema
utilizado para medição temporal prévia da aplicação, tem como objetivo a ativação das caches de
instruções e dados do processador.

76 Sistema Reconfigurável - Implementação
De seguida, são inicializados e configurados os periféricos de comunicação com a porta ICAP
(HWICAP), o controlador de acesso à memória não volátil do cartão compactFlash (SysACE),
o controlador de transferência direta de memória (CentralDMA) e o periférico centralizador dos
sinais de interrupção de sistema (XPS Intc). Este último em particular, ativa todas as interrupções
relativas aos demais periféricos do sistema, para além de ativar também as interrupções relativas
às unidades reconfiguráveis.
Como passo final antes da execução da aplicação de Navegação Estéreo, e como medida de
aceleração do processamento de toda a execução, procedeu-se à alocação da informação relativa a
cada um dos nove bitstreams, que representam as versões de cada função a implementar em cada
unidade reconfigurável, em áreas de memória situada no módulo de memória externa DDR2.
Uma vez que o tempo de acesso à memória DDR2 é mais rápido que o acesso ao cartão CF, o
processo de configuração de cada bitstream acabará por ser menos demorado.
Desta feita, apenas nesta altura o sistema se encontra pronto a ser executado.
5.4.2 Implementação das Estratégias Abordadas em Software
Definido que está o processo de inicialização e as estratégias a implementar, chegava o mo-
mento de implementar de facto em software as várias estratégias de reconfiguração anteriormente
abordadas.
O fator comum entre estas estratégias está na substituição das funções originais por funções
que executam o processo de transferência de dados entre a memória de sistema e as BlockRam e
vice-versa, e a interação de sinais necessários ao sincronismo dos módulos existentes no interior
das unidades reconfiguráveis.
Começando pela estratégia referente ao requisito temporal mais baixo, este segue naturalmente
a sequência original, verificada anteriormente na Figura 3.4.1.
Como apresentado na Figura 5.18, uma vez iniciada a execução, é feita uma verificação au-
tomática por todas as unidades reconfiguráveis, com a finalidade de encontrar um módulo Conv-
Const atualmente configurado e disponível para execução. Se este não existir, a função é configu-
rada na primeira unidade reconfigurável livre no sistema. De seguida, é efetuada a transferência
dos 9216 elementos da memória U, juntamente com os 89 elementos na memória H, para as
BlockRam existentes no interior da unidade reconfigurável e é dado sinal de start ao módulo que
executa a função em hardware. O algoritmo utilizado, fica então em loop, esperando a existência
do sinal de término de execução do módulo. Este sinal é gerado aquando da captura do sinal done,
através da interrupção na unidade reconfigurável. Uma vez terminado, é efetuada a configuração
da função subsequente na mesma unidade reconfigurável, seguida da leitura dos 9216 elementos
resultantes do array Y.
Processo idêntico é efetuado a todas as subsequentes funções, até atingir o término de execu-
ção da fatia processada.

5.4 Software de Adaptação Dinâmica da Qualidade de Serviço 77
Algum
módulo ConvConst
pronto para arrancar
?
Configura módulo para ConvConst
Não
Sim
Inicia ConvConst
ConvConst
terminou ?
Não
Sim
Configura módulo para ConvRepl1
Inicia ConvRepl1
ConvRepl1
terminou ?
Não
Sim
Configura módulo para ConvRepl2
Inicia ConvRepl2
ConvRepl2
terminou ?
Não
Sim
Configura módulo para ConvConst
Inicia ConvConst
ConvConst
terminou ?
Não
Sim
Configura módulo para ConvRepl1
Inicia ConvRepl1
ConvRepl1
terminou ?
Não
Sim
Configura módulo para ConvRepl2
Inicia ConvRepl2
ConvRepl2
terminou ?
Não
Sim
Configura módulo para ConvRepl1
Inicia ConvRepl1
ConvRepl1
terminou ?
Não
Sim
Configura módulo para ConvRepl2
Inicia ConvRepl2
ConvRepl2
terminou ?
Não
Sim
Configura módulo para ConvConst
Início de processamento de
da função Extração de
Características
Fim do processamento da
funçãoExtração de
Características
Fu
nç
ão
Co
nv
Co
ns
t
Fu
nç
ão
Co
nv
Re
pl1
Fu
nç
ão
Co
nv
Re
pl2
Legenda:
Transferência dos arrays de
entrada H e U
Transferência do array de saída Y
Figura 5.18: Operações executadas na situação de requisito temporal BAIXO.

78 Sistema Reconfigurável - Implementação
Passando para a estratégia referente ao requisito temporal mais médio. Como visto anterior-
mente, esta solução possibilita a execução de uma função numa unidade reconfigurável, enquanto
que a função subsequente é configurada em simultâneo na segunda unidade.
É apresentada na Figura 5.19 a solução referente a esta estratégia. Como exemplo nesta figura,
é possível verificar que uma vez dado o sinal de início de execução da função ConvConst, é
iniciado o processo de configuração da função ConvRepl1 na unidade reconfigurável disponível,
a segunda unidade. De seguida, o algoritmo espera pelo término da tarefa de transferência de
resultados.
Por outro lado, a função de atendimento à interrupção que sinaliza o término de execução da
função ConvConst inicializa a tarefa de transferência automática dos elementos de saída, através
do módulo DMA. Este, por sua vez, causará uma nova interrupção, desta vez devido ao término
desta operação de transferência. Esta nova chamada de atendimento à interrupção, libertará o loop,
preso aquando da execução da função ConvConst.
Este estilo de configuração do tipo Ping-Pong, será desta forma igualmente executado para as
restantes funções.In
terr
up
çã
o d
o
mó
du
lo C
on
vC
on
st
Handler de interrupção
Sinaliza ‘done’
Retorno
Inicia ConvConst
Tarefa de
transferência DMA
terminada ?
Não
Fu
nç
ão
Co
nv
Co
ns
t
Sim
Configura novo módulo com ConvRepl1
Inicia tarefa transf. DMA
Figura 5.19: Operações executadas na situação de requisito temporal MÉDIO.
A estratégia escolhida para implementar o requisito temporal mais alto começa por dar o sinal
de início de execução da função ConvConst, seguindo-se a pesquisa de uma unidade reconfigurável
livre para configurar a função ComvRepl1, ao que se segue a espera do término de transferência
dos dados resultantes, à semelhança da solução anterior, apresentada na Figura 5.20.
Uma vez que estão disponíveis ao todo três unidades reconfiguráveis para esta estratégia, este
processo apenas resulta numa configuração para cada função.
5.4.3 Melhoria de solução: Utilização Fixa Sequencial paralela
Aquando da elaboração da estratégia que utiliza todas as três unidades reconfiguráveis do
sistema, existiu a possibilidade de concretizar uma melhoria da estratégia de Utilização Fixa Se-
quencial. Esta melhoria, parte da particularidade da função Extração de Caraterísticas, possibilita
um fluxo de execução em dois níveis de pipeline, como verificado na Figura 5.21. Uma vez que

5.4 Software de Adaptação Dinâmica da Qualidade de Serviço 79
Algum
módulo ConvRepl1
pronto para arrancar
?
Configura novo módulo com ConvRepl1
Não
Sim
Tarefa de
transferência DMA
terminada ?
Não
Fu
nç
ão
Co
nv
Co
ns
t
Sim
Inicia ConvConst
Inte
rru
pç
ão
do
mó
du
lo C
on
vC
on
st
Handler de interrupção
Sinaliza ‘done’
Retorno
Inicia tarefa transf. DMA
Figura 5.20: Operações executadas na situação de requisito temporal ALTO.
na sequência original de funções existem casos onde não há dependência de dados, há, portanto, a
possibilidade da execução paralela dessas funções. Como resultado desta melhoria, o número de
etapas a concretizar baixou de 8 para apenas 5.
Desta forma, esta estratégia também foi considerada na implementação, e foi associada a um
requisito temporal super;

80 Sistema Reconfigurável - Implementação
1º ConvConst
2º ConvConst 1º ConvRepl1
1º ConvRepl2 2º ConvRepl1
2º ConvRepl2 3º ConvRepl1
3º ConvRepl2
( )²
( )²
V
1ª etapa
2ª etapa
3ª etapa
4ª etapa
5ª etapa
Figura 5.21: Pipelining das operações existentes na função Extração de Caraterísticas - requisitotemporal SUPER.

Capítulo 6
Resultados Obtidos
A presente secção do documento destina-se a expor os resultados obtidos, provenientes da
implementação das estratégias delineadas na Secção 5.4.1.
A Tabela 6.1 demonstra as medições resultantes da análise temporal efetuada das secções rele-
vantes da aplicação Navegação Estéreo, comuns entre a versão totalmente executada em software
e as versões em hardware. Na Tabela 6.2 está também apresentada a medição dos tempos envolvi-
dos nos processos de configuração e transferência de dados, necessários ao processo de execução
em hardware.
Foi dada maior ênfase às secções envolvidas na função Extração de Caraterísticas, a qual foi
alvo de implementação de algumas estratégias de reconfiguração dinâmica em hardware.
O método de medição temporal teve como base a utilização de um módulo Timer/Counter em
hardware, o qual foi utilizado para incrementar um registo de 32 bit, à cadência da frequência de
relógio do processador, sendo esta os 400 Mhz inicialmente projetados. Desta forma, foi possível
contabilizar o número de ciclos de relógio ocorridos em cada secção de código avaliado, referente
a uma determinada operação ou função executada. Numa forma de diminuir o erro de medição ex-
perimental da tarefas analisadas, foi considerado efetuar uma média da sequência dos dez últimos
valores recolhidos.
Todos os valores foram medidos de forma independente e parametrizável a cada execução da
aplicação, com o objetivo do tempo necessário para impressão da informação no terminal não ser
contabilizado. Para além disso, e com o mesmo objetivo, uma vez validados os resultados finais
∆R e ∆T, todas as impressões no terminal, provenientes da aplicação original, foram também
desativadas.
Foi utilizada como unidade de processamento do sistema o número de imagens estéreo proces-
sadas por segundo (SFPS1), o qual será de em diante utilizado como base comparativas das várias
estratégias de reconfiguração.
1SFPS - Stereo Frames Per Second.
81

82 Resultados Obtidos
Tabela 6.1: Comparação de resultados entre o software original e as estratégias de reconfiguração.
Secção deCódigo
Avaliado
VersãoOriginal em
Software
RequisitoTemporal
BAIXO
RequisitoTemporalMÉDIO
RequisitoTemporal
ALTO
RequisitoTemporal
SUPER(ciclos) (ciclos) (ciclos) (ciclos) (ciclos)
Execução 1370389468 2000474424 1789782342 1179750436 1117895310Total da ∼3420 ms ∼5001 ms ∼4474 ms ∼2950 ms ∼2794 ms
Aplicação (+46%) (+30%) (-13.9%) (-18.4%)Processamento 807000657 1119233318 1012992964 702954221 672351075
de Cada Par ∼2018 ms ∼2798 ms ∼2532 ms ∼1757 ms ∼1680 msde Imagens (+38.7%) (+25.5%) (-12.9%) (-16.7%)
Função 259595004 413945170 361829483 208107591 190254329Extração de ∼650 ms ∼1035 ms ∼904 ms ∼520 ms ∼475 ms
Caraterísticas (+59%) (+39%) (-19.8%) (-26.7%)Execução 1875879 470394
ConvConst ∼4.68 ms ∼1.18 ms (-75%)Execução 1898219 406360
ConvRepl1 ∼4.75 ms ∼1.02 ms (-78%)Execução 1896371 406369
ConvRepl2 ∼4.74 ms ∼1.02 ms (-78%)Cadência de
∼0.50 SFPS∼0.36 SFPS ∼0.39 SFPS ∼0.57 SFPS ∼0.60 SFPSProcessamento
(-30%) (-22%) (+14%) (+20%)da Aplicação
Tabela 6.2: Resultado da medição do tempo de configuração parcial e transferência de dados.
Secção de CódigoAvaliado
Número deciclos deexecução
Configuração 2147597ConvConst ∼5.37 ms
Configuração 2147596ConvRepl1 ∼5.37 ms
Configuração 2147599ConvRepl2 ∼5.37 ms
Escrita MemH 2516(89×32 bit) ∼6.29 µs
Escrita MemU 207887(9216×32 bit) ∼0.52 msLeitura MemY 203677(9216×32 bit) ∼0.51 ms

6.1 Discussão Sobre os Resultados Obtidos 83
6.1 Discussão Sobre os Resultados Obtidos
As tabelas de resultados estão organizadas de modo a apresentar, para cada secção avaliada, o
número de ciclos de relógio da execução (conforme atrás explicado, o tempo referente à execução
dessa mesma secção), para além de apresentar também, caso possível, a percentagem diferencial
relativa ao tempo de execução dessa mesma secção na versão original, em software.
A primeira secção avaliada na Tabela 6.1 foi a execução completa da aplicação de Navegação
Estéreo. A conclusão retirada deste resultado é de que apenas as estratégias de reconfiguração
envolvendo três unidades reconfiguráveis conseguem, de facto, acelerar o processamento da apli-
cação, uma vez que estas possuem o número mínimo de unidades reconfiguráveis livres, sufici-
entes para dispensar o tempo gasto em sucessivas reconfigurações. Situação diferente acontece
nas restantes estratégias de reconfiguração, as quais requerem a correta gestão dos três módulos
funcionais reconfiguráveis em apenas uma ou duas unidades livres.
Lembrando que a versão da aplicação executada, envolvia o processamento de apenas dois
pares de imagens consecutivas, uma significante parte do tempo de execução, decorre na iniciali-
zação e término da aplicação.
Um resultado mais evidente dos ganhos obtidos, pode ser verificado pela segunda medição
efetuada. Esta secção, representa o tempo que de facto é consumido pelo processamento de uma
imagem estéreo, constituída por um par de imagens obtidas no mesmo instante de tempo. O re-
sultado, vem corroborar a medição temporal anterior, referente à execução completa da aplicação.
Uma perda de cerca de 40%, obtida pela utilização de apenas uma unidade reconfigurável, con-
trastando com o ganho de cerca de 17% obtido pela utilização de três unidades numa execução
em modo pipeline, indicam que o processo de reconfiguração pode contribui negativamente para o
tempo total de processamento, dependendo do número de reconfigurações envolvido na execução
de determinada tarefa.
O facto do tempo total de execução da aplicação ser menor que o hipotético dobro do tempo
de processamento de duas imagens estéreo, uma vez que na totalidade são processadas ao todo
quatro imagens, deve-se à inexistência de informação relativa às caraterísticas da imagem estéreo
anterior à primeira imagem processada, uma vez que a função Correspondência de Caraterísticas
necessita de informação pertencente à iteração anterior, o que significa que o processamento rela-
tivo à primeira imagem estéreo termina logo após a execução da função Extração de Caraterísticas,
saltando automaticamente para a imagem estéreo seguinte.
Prosseguindo a análise, a próxima secção a ser medida foi a função Extração de Caraterísticas.
Esta função inclui todo o processamento efetuado a cada imagem capturada, isto é, ao proces-
samento efetuado a cada uma das doze fatias que compõem uma imagem, onde as sub-funções
ConvConst, ConvRepl1 e ConvRepl2 são executadas. No caso das versões executas em hardware,
são ainda executados os processos de reconfiguração e transferência de dados.
Mais uma vez, é fácil constatar, que a função é acelerada quase 27% quando executada uti-
lizando três unidades reconfiguráveis, mas perde 59% e 39% quando respetivamente executadas
utilizando uma unidade em modo sequencial e duas unidades em modo Ping-Pong.

84 Resultados Obtidos
Os resultados referentes à medição dos ciclos de execução das funções ConvConst, ConvRepl1
e ConvRepl2, cumpriram com as estimativas produzidas pela ferramenta de síntese de alto nível
Catapult C, apresentadas na Tabela 4.10, atingindo uma diminuição do tempo de execução na
ordem dos 80% para cada uma das funções implementadas em hardware.
Os tempos envolvidos na reconfiguração de cada um dos três módulos reconfiguráveis, pre-
sentes na Tabela 6.2, revelaram ser bastante pesados. Cada configuração consome até 5.3 vezes
o tempo de execução de qualquer uma das funções implementadas, demonstrando-se como espe-
rado, grande desvantagem resultante do uso de reconfiguração dinâmica.
Ainda na mesma tabela, estão apresentadas as medições dos tempos envolvidos nos acessos
às unidades de memória. Embora o processo de leitura de 89 elementos de 32 bit cada, consuma
apenas cerca de 6.29 µs, os processos de leitura ou escrita de todos os elementos referentes a
uma parte imagem com 96×96 pixeis consomem cerca de metade do tempo de execução de cada
função, o que já de si, é bastante considerável.
Os últimos valores apresentados na tabela de resultados, Tabela 6.1, demonstram a cadência
de processamento de cada imagem estéreo oferecida pelo sistema e foram calculados a partir dos
resultados temporais referentes à secção de processamento de cada imagem estéreo segundo a
Equação 6.1.1. Os resultados obtidos evidenciam uma melhoria da cadência de processamento
oferecida pela aplicação de cerca de 20%, no qual o número de imagens estéreo processadas por
segundo (SFPS) é aumento de 0.5 para 0.6 SFPS, o que, tendo em conta o overhead causado
pelo processo de reconfiguração, evidencia a viabilidade da utilização de unidades reconfiguráveis
como meio para a obtenção de aceleração da aplicação.
Cadência de SFPS =1
Tempo de Processamento da Imagem Estéreo Capturada(6.1.1)
O valor máximo da aceleração obtido pela implementação em hardware das funções Conv-
Const, ConvRepl1 e ConvRepl2 pode ser estimado através do modelo matemático caraterizado
pela lei de Amdahl[31]. Esta lei afirma que o ganho obtido pela utilização de processamento
paralelo em relação à utilização de um único processador, o que acontece aquando da execução
paralela dos processos de transferência de dados, reconfiguração e pipeline de funções, pode ser
expresso através da fórmula matemática apresentada na Equação 6.1.2, onde f representa a fração
de tempo de processamento acelerado e onde S representa o fator de aceleração desse mesmo fator.
Speedup Total =1
(1− f )+ fS
(6.1.2)
Neste caso em concreto, a fração f é caraterizada pelo ’peso’ que a função Extração de Cara-
terísticas induz sobre o processamento de cada imagem estéreo, na versão original em software.

6.2 Extrapolação de Resultados 85
Verificando os valores presentes na tabela de resultados 6.1, verifica-se que este representa um to-
tal de 32.21%. Já a aceleração da cadência de processamento total da aplicação é representado pela
fração entre o número de pares de imagens processadas por segundo relativos às versões software
e hardware, sendo este valor 1.2, representando um ganho de 20%. A aceleração total obtida pela
execução das três funções implementadas em hardware em comparação com as versões originais
em software é calculado pela seguinte equação:
f =650 ms2018 ms
= 32.21% = 0.3221
Speedup Total =SFPShardware
SFPSsoftware=
0.60.5
= 1.2
1.2 =1
(1−0.3221)+0.3221
S
⇐⇒ S = 2.0722
Ou seja, a secção de processamento executado em hardware obteve um ganho em cerca de
2 vezes comparado com a versão original. Sendo de realçar que neste resultado estão incluídos
não apenas os tempos de execução dos módulos implementados, como também os tempos de
reconfiguração e de transferência de dados.
6.2 Extrapolação de Resultados
Um aspeto possível de ser analisado é o comportamento do sistema em relação a imagens de
maior dimensão, mais concretamente o estudo da aceleração do sistema causada pela utilização
de módulos reconfiguráveis quando este processa imagens capturadas de dimensão 640×480 pi-
xeis. Uma vez que como explicado anteriormente, a versão da aplicação executada na placa de
desenvolvimento apenas processa imagens capturadas de pequenas dimensões, 320×240 pixeis,
não processando imagens de maior dimensão, uma estimativa do overhead temporal necessário
ao processamento teve de ser efetuada. Para isso foi medida a relação de tempo necessário à exe-
cução das funções ConvConst, ConvRepl1 e ConvRepl2, para ambas as dimensões de imagem na
versão executada em software no computador, seguindo-se à estimação do tempo de execução da
aplicação para as imagens de maior dimensão. Uma vez obtido este valor, uma extrapolação da
aceleração temporal, obtida pela utilização de unidades reconfiguráveis executadas em hardware,
pode ser obtida. Finalizando, a aceleração global da aplicação pode por fim ser estimada utilizando
novamente a expressão de Amdahl.
O processo de obtenção da informação necessária foi iniciado com a utilização da ferramenta
de profiling Gprof, tendo este apresentado os resultados presentes nas Tabelas 6.3 e 6.4, sendo que
estes, por motivos de precisão amostral, representam as percentagens e tempos de execução de
uma dezena de execuções da aplicação Navegação Estéreo, obtendo-se dessa forma um resultado
mais preciso.

86 Resultados Obtidos
O resultado obtido vai de encontro com as medições efetuadas na secção de medição temporal
prévia, apresentada na Secção 3.3, em que as três funções implementadas em hardware pertencem
ao grupo de tarefas críticas. Os valores úteis para o prosseguimento da análise de aceleração, são
os valores provenientes da segunda coluna, os quais representam os tempos totais de execução de
cada função em toda a aplicação. Por sua vez, a Equação 6.2.1, apresenta a relação temporal exis-
tente entre a execução da aplicação para ambos os formatos de imagem capturados, concluindo-se
que a aplicação executada em computador demorou cerca de 4.54 vezes mais a executar as fun-
ções consideradas para imagens de formato 640×480, comparativamente com o formato original
de imagens 320×240. Uma vez que o número de pixeis é quatro vezes maior, considerou-se o
resultado obtido um valor dentro do esperado.
relaçãoTemporal =(Convconst +ConvRepl1+ConvRepl2)640×480
(Convconst +ConvRepl1+ConvRepl2)320×240
=0.42+0.74+0.700.10+0.13+0.18
= 4.54 (6.2.1)
Tabela 6.3: Resultado de análise temporal efetuada no PC, utilizando imagens 640x480.
% Tempo deExecução
Tempo deexecução
(segundos)
Número deChamadas
Função
31.76 0.74 5760 ConvVBRepl1_uS_hS_yS30.04 0.70 5760 ConvVBRepl2_uS_hS_yS18.03 0.42 3840 ConvVBConst_uS_hS_yS13.30 0.31 1920 harrisTile_model_step2.58 0.06 3550 sift_match_one
Tabela 6.4: Resultado de análise temporal efetuada no PC, utilizando imagens 320x240.
% Tempo deExecução
Tempo deexecução
(segundos)
Número deChamadas
Função
25.35 0.18 1440 ConvVBRepl2_uS_hS_yS19.72 0.14 480 harrisTile_model_step18.31 0.13 1440 ConvVBRepl1_uS_hS_yS14.08 0.10 960 ConvVBConst_uS_hS_yS8.45 0.06 10 R_c4_RobustPoseEstimate_library
Os últimos resultados necessários para o estudo pretendido, são os tempos de execução das
três funções consideradas, referentes ao processamento de uma imagem completa, na placa de
desenvolvimento, para as versões software e hardware. A partir de informação exposta na Sec-
ção 3.4.1, é sabido que cada imagem 320×240 pixeis executa 12 vezes a função de processamento

6.2 Extrapolação de Resultados 87
do algoritmo de Harris, e que por sua vez, este algoritmo executa duas vezes a função ConvConst
e três vezes cada função ConvRepl1 e ConvRepl2. Com esta informação o tempo de execução
da fração de execução destas três funções, referente a uma imagem completa, Te, processado em
software é composto apenas pelo tempo de computação, C.
Te(software) =C
C = 12× ((2×ConvConst)+(3×ConvRepl1)+(3×ConvRepl2))
Na versão em hardware, para proceder a uma análise justa com a versão em software, foi
considerado apenas a estratégia de reconfiguração do tipo ALTO, de execução sequencial com três
unidades reconfiguráveis, sem pipelining de operações. O tempo de execução da mesma fração,
é constituído pelas três parcelas de tempo referentes a reconfiguração, transferência de dados e
computação, respetivamente R, T e C. Nesta estratégia, o processo de reconfiguração das três
funções implementadas é efetuado apenas uma vez aquando do processamento da primeira secção
da imagem, sendo que são necessárias as tarefas de escrita e leitura de memória por cada módulo
executado.
Te(hardware) = R+T +C
R = 3×Reconfiguração
T = 12×8× (Escrita+Leitura)
C = 12× ((2×ConvConst)+(3×ConvRepl1)+(3×ConvRepl2))
Com base nos resultados temporais obtidos nas Tabelas 6.1 e 6.2, são calculados, com recurso
às seguintes equações, os tempos totais de execução em software e hardware das três funções
consideradas.
Software:
Te = 12× ((2×4.68 ms)+(3×4.75 ms)+(3×4.74 ms))
= 453.96 ms (6.2.2)

88 Resultados Obtidos
Hardware:
R = 3×5.37 ms
= 16.11 ms (6.2.3)
T = 12× (8× (0.52 ms+0.51 ms))
= 98.88 ms (6.2.4)
C = 12× ((2×1.18 ms)+(3×1.02 ms)+(3×1.02 ms))
= 101.76 ms (6.2.5)
Te = 16.11 ms+98.88 ms+101.76 ms
= 216.75 ms (6.2.6)
Calculados que estão os tempos de execução referentes às imagens mais pequenas, os respe-
tivos tempos de execução para as imagens de formato 640×480 pixeis podem ser extrapolados.
Para a versão em software, foi considerado o aumento de tempo de execução pelo fator medido
anteriormente, um fator de aumento de 4,54 vezes. Para a versão em hardware, é necessário sali-
entar, que o processo de reconfiguração dos três módulos reconfiguráveis para a estratégia ALTO, é
apenas efetuado uma vez por cada imagem, sendo que na imagem de maior dimensão, as restantes
tarefas de transferência e computação são executadas quatro vezes mais, devido ao aumento do
número de secções processadas, de 12 para 48 secções no total.
Software:
Te640×480 = C(software,320×240)×4.54
= 2060.98 ms (6.2.7)
Hardware:
R = R(320×240)
= 16.11 ms (6.2.8)
T = 48× (8× (0.52 ms+0.51 ms))
= 395.52 ms (6.2.9)
C = 48× ((2×1.18 ms)+(3×1.02 ms)+(3×1.02 ms))
= 407.04 ms (6.2.10)
Te = 16.11 ms+395.52 ms+407.04 ms
= 818.67 ms (6.2.11)
A Tabela 6.5 apresenta os tempos de execução envolvidos nas tarefas de execução das frações
executadas em software e hardware pelas funções ConvConst, ConvRepl1 e ConvRepl2, para as
resoluções de imagem consideradas.

6.3 Validação de Resultados 89
Tabela 6.5: Resultados obtidos e extrapolados para ambas as resoluções de imagem capturadas.
Resolução deImagem Capturada
Tempo de ExecuçãoSoftware (ms)
Extrapolação doTempo de Execução
Hardware (ms)
Fator deAceleração
320×240 453.96 216.75 2.09640×480 2060.98 818.67 2.51
Antes de continuar o processo de extrapolação de resultados, é de realçar o valor da aceleração
de mais de 100%, em imagens de resolução 320×240, obtido pela execução dos módulos imple-
mentados. Este resultado está de acordo com a estimativa proporcionada pela equação de Amdahl
verificada na página 84, comprovando a utilização desta expressão.
Os resultados presentes na última tabela demonstram que o fator de aceleração obtido pela
utilização de unidades reconfiguráveis implementadas em hardware é maior consoante o sistema
utilize imagens também de maior resolução. No caso das imagens de resolução 640×480, o fator
de aceleração estimado foi de 2.5 vezes, o que significa um aumento de aceleração relativo de
38.5%, em relação às imagens de resolução menor.
6.3 Validação de Resultados
Esta secção do documento tem como finalidade descrever o processo de verificação de resulta-
dos obtidos, devido principalmente à simplificação efetuada nas funções ConvRepl1 e ConvRepl2.
Como discutido anteriormente na secção de implementação, as versões originais de ambas as fun-
ções operam sobre variáveis de vírgula flutuante, tendo estas sido simplificadas, passando a operar
sobre variáveis inteiras, que representam valores em vírgula fixa, os quais foram dimensionadas de
forma a serem capazes de representar na totalidade a magnitude de valores mais pessimista possí-
vel. Como consequência dessa simplificação, a precisão apresentada pelos resultados é menor do
que na versão original. Devido a esta simplificação, houve a necessidade de efetuar uma sequência
de testes com a finalidade de verificar se os resultados intermédios e finais são ou não afetados.
A próxima Tabela 6.6, apresenta os resultados obtidos pela execução da aplicação Navegação
Estéreo, na qual são comparadas as versões original e modificada da função Extração de Carate-
rísticas. Uma vez que a versão da aplicação executada pela placa de desenvolvimento é apenas
capaz de processar uma sequência de duas imagens estéreo, este teste foi efetuado em computa-
dor, onde a versão modificada da função Extração de Caraterísticas utilizou a mesma versão das
funções ConvConst, ConvRepl1 e ConvRepl2 implementadas em hardware, mas processando as
imagens estéreo obtidas nos instantes 61 a 65, 161 a 165 e 261 a 265. Para cada imagem estéreo
processada, o número de caraterísticas encontradas em cada bloco funcional principal é apresen-
tado, para além dos resultados finais, sendo estes a matriz de rotação do veículo, ∆R e o vetor de
translação, ∆T.
As colunas de resultados intermédios da tabela representam o número de caraterísticas en-
contradas pelas funções (Fn) e sub-funções (fn) pertencentes à sequência de funções existentes na

90 Resultados Obtidos
aplicação Navegação Estéreo sendo estas:
• F1 : Extração de caraterísticas;
– L: Executada na imagem capturada pela câmara da esquerda;
– R: Executada na imagem capturada pela câmara da direita;
• F2 : Correspondências entre caraterísticas;
– f1 : Entre a imagem da esquerda e direita;
– f2 : Entre as imagens atual e anterior provenientes da esquerda;
– f3 : Entre as imagens atual e anterior provenientes da direita;
– f4 : Caraterísticas resultantes da interceção das correspondências f1,f2 e f3 ;
• F4 : Número de caraterísticas utilizadas pela rotina de Estimação Robusta de Pose;
Como pode ser observado, o número de caraterísticas detetadas e processadas por cada etapa
da aplicação para ambas as versões utilizando variáveis do tipo vírgula fixa e SoftFloat, compa-
rando com a versão original em software é idêntico.
Mais, a razão da apresentação de apenas uma matriz de rotação e translação para as versões
original e vírgula fixa, prende-se apenas com razões de simplificação da tabela a apresentar, uma
vez que os resultados obtidos são exatamente os mesmos. Desta forma a utilização deste tipo
de representação de dados foi validada, tendo este sido utilizada nas funções implementadas em
hardware.

6.3 Validação de Resultados 91
.Tabela 6.6: Validação das soluções SoftFloat e vírgula fixa da função Feature Extraction.
Par Versão deResultados intermédios Resultados finais
L,R softwareF1 F2 F3 ∆R ∆T
L R f1 f2 f3 f4
61Original 200 200 48 - - - - - -SoftFloat 200 200 48 - - - - - -Vírg.Fixa 200 200 48 - - - - - -
62Original 200 200 51 38 33 25 9
01.00 −0.01 −0.0000.01 01.00 00.0000.00 −0.00 01.00
00.38−0.1300.01
SoftFloat 200 200 51 38 33 25 9Vírg.Fixa 200 200 51 38 33 25 9
63Original 200 200 44 26 28 17 6
01.00 −0.01 00.0000.01 01.00 00.00−0.00 −0.00 01.00
00.82−0.2300.01
SoftFloat 200 200 44 26 28 17 6Vírg.Fixa 200 200 44 26 28 17 6
64Original 200 200 39 27 24 15 6
01.00 00.02 −0.00−0.02 01.00 00.0100.00 −0.01 01.00
01.60−0.00−0.02
SoftFloat 200 200 39 27 24 15 6Vírg.Fixa 200 200 39 27 24 15 6
65Original 200 200 47 32 26 18 6
01.00 00.01 −0.01−0.01 01.00 00.0100.01 −0.01 01.00
02.00−0.09−0.04
SoftFloat 200 200 47 32 26 18 6Vírg.Fixa 200 200 47 32 26 18 6
161Original 200 200 55 - - - - - -SoftFloat 200 200 55 - - - - - -Vírg.Fixa 200 200 55 - - - - - -
162Original 200 200 49 34 32 22 8
01.00 00.00 00.0000.00 01.00 00.0000.00 −0.00 01.00
00.1300.07−0.04
SoftFloat 200 200 49 34 32 22 8Vírg.Fixa 200 200 49 34 32 22 8
163Original 200 200 61 35 28 18 5
01.00 −0.00 −0.00−0.01 01.00 −0.0000.00 00.00 01.00
00.3000.07−0.02
SoftFloat 200 200 61 35 28 18 5Vírg.Fixa 200 200 61 35 28 18 5
164Original 200 200 63 39 35 27 7
01.00 −0.03 −0.0000.03 01.00 00.0100.00 00.00 01.00
01.34−0.0200.01
SoftFloat 200 200 63 39 35 27 7Vírg.Fixa 200 200 63 39 35 27 7
165Original 200 200 54 28 33 20 7
01.00 −0.06 −0.0100.06 01.00 00.0000.01 −0.00 01.00
01.6200.07−0.12
SoftFloat 200 200 54 28 33 20 7Vírg.Fixa 200 200 54 28 33 20 7
261Original 200 200 68 - - - - - -SoftFloat 200 200 68 - - - - - -Vírg.Fixa 200 200 68 - - - - - -
262Original 200 200 63 39 35 24 11
01.00 00.05 −0.01−0.05 01.00 00.0000.01 −0.00 01.00
00.4500.00−0.07
SoftFloat 200 200 63 39 35 24 11Vírg.Fixa 200 200 63 39 35 24 11
263Original 200 200 51 31 30 20 6
00.99 00.11 −0.02−0.11 00.99 00.0000.02 00.00 01.00
00.9500.13−0.28
SoftFloat 200 200 51 31 30 20 6Vírg.Fixa 200 200 51 31 30 20 6
264Original 200 200 53 34 32 22 9
00.99 00.13 −0.00−0.13 00.99 00.0000.00 −0.00 01.00
01.40−0.14−0.03
SoftFloat 200 200 53 34 32 22 9Vírg.Fixa 200 200 53 34 32 22 9
265Original 200 200 38 25 24 19 6
00.99 00.15 −0.00−0.15 00.99 00.0100.01 −0.01 01.00
01.97−0.07−0.06
SoftFloat 200 200 38 25 24 19 6Vírg.Fixa 200 200 38 25 24 19 6

92 Resultados Obtidos

Capítulo 7
Conclusões e Trabalho Futuro
O projeto e implementação de um sistema embarcado dinâmico reconfigurável foi completado
com sucesso. O objetivo proposto, sendo este a implementação em FPGA de um algoritmo de
navegação autónoma capaz de ser dinamicamente adaptado, consoante as requisitos do sistema,
foi atingido com satisfação. Todo o fluxo de desenvolvimento do projeto foi explicado e todas
as opções foram devidamente justificadas. Este fluxo teve como principais fases a síntese de alto
nível das tarefas críticas do sistema, a criação de uma estrutura de unidade reconfigurável capaz
de ser englobada numa arquitetura de um sistema embarcado e a adaptação da aplicação origi-
nal ao sistema reconfigurável, onde algumas estratégias de reconfiguração foram com sucesso
implementadas e devidamente analisadas. Todos os obstáculos e respetivas soluções alternativas
foram ultrapassadas e devidamente justificadas. Entre estes obstáculos, encontram-se o estudo de
soluções alternativas à utilização de variáveis representadas em vírgula flutuante, o tipo de agrupa-
mento das interfaces utilizadas na barreira software/hardware ou o planeamento das localizações
e dimensões físicas dos módulos reconfiguráveis na obtenção da melhor relação o entre o tama-
nho do bitstream que influencia diretamente o tempo de reconfiguração e a frequência final de
implementação obtida.
7.1 Satisfação dos Objetivos
As funções pertencentes à tarefa crítica foram identificadas e implementadas em hardware,
tendo o tempo de computação das operações internas destas funções sido acelerado em 75% para
a função ConvConst e 78% para as funções ConvRepl1 e ConvRepl2. Contudo, a utilização
dos módulos em hardware, necessitou de um overhead temporal adicional devido ao processo
de transferência dos dados e configuração das unidades reconfiguráveis, o quais constituem uma
substancial porção do tempo de execução.
Foram implementadas em software com sucesso quatro tipos de estratégias de reconfigurações
distintas, as quais podem operar utilizando até três unidades reconfiguráveis. Foram consideradas
estratégias de reconfiguração do tipo sequencial utilizando apenas uma unidade, onde a execu-
ção de cada módulo é precedida de reconfiguração, reconfiguração do tipo Ping-Pong, utilizando
93

94 Conclusões e Trabalho Futuro
duas unidades reconfiguráveis, proporcionando paralelismo entre a execução de um módulo e
reconfiguração do módulo seguinte na sequência de funções, e a utilização de três unidades re-
configuráveis as quais são configuradas aquando da entrada na tarefa de crítica se processamento.
Uma estratégia adicional baseada na última estratégia de paralelismo dos módulos, utilizando a
possibilidade de pipeline das operações foi criada e demonstrou obter os melhores resultados.
Das quatro estratégias de reconfiguração implementadas, apenas as que utilizam 3 unidades
reconfiguráveis obtiveram ganhos em relação à aplicação original. Sendo que as frações de código
substituídas por blocos em hardware contribuíram para uma aceleração de 2 vezes da tarefa crítica.
Esta fração, por sua vez contribuiu para um aumento da cadência de processamento do sistema em
20%.
Foi também estudada a estimativa da aceleração obtida caso a aplicação opere sobre imagens
de maior resolução, tendo-se concluído que para imagens com quatro vezes mais resolução, a
fração relativa ao processamento da tarefa crítica é acelerada de 2.5 vezes, demonstrando que a
aceleração em relação ao software aumenta consoante o aumento da resolução da imagem.
7.2 Trabalho Futuro
Uma vez que a tarefa crítica tratada apenas representa uma fração de todo o processamento
necessário ao algoritmo de navegação autónoma, algum trabalho futuro passaria pela aceleração
em hardware das restantes tarefas, utilizando unidades reconfiguráveis de utilização generalizada,
derivadas das utilizadas neste trabalho, capazes de serem utilizadas por diferentes tarefas de exe-
cução.
Outra possível evolução passaria pela criação de um periférico dedicado utilizado para re-
configuração a partir da porta ICAP, um periférico semelhante ao HWIcap utilizado, mas que
não necessite de utilizar o barramento PLB, descongestionando dessa forma o barramento, me-
lhorando não só os tempos totais de reconfiguração como hipoteticamente também os tempos de
transferência dos dados utilizados pelos módulos reconfiguráveis. Um exemplo de um periférico
de reconfiguração dedicado pode ser visualizado em[32].
Deverá também ser corrigida a questão da não obtenção da frequência projetada, mesmo que
por pequena diferença, fator este que não teve qualquer implicação na placa de desenvolvimento
utilizada, mas não deixa de ser um detalhe a corrigir. Uma sugestão para a sua correção foi referida
na pág. 68.
Perante todos estes fatores, é de realçar que, perante os bons resultados obtidos e a possibili-
dade de o sistema ser alvo de grandes melhorias, o sistema embarcado reconfigurável construído
utilizado para esta aplicação prova ser uma boa e viável solução.

Anexo A
Anexos
A.1 Ficheiro Verilog de Descrição da Unidade Reconfigurável
Este anexo tem como finalidade de mostrar algum do trabalho efetuado durante o processo de
criação das unidades reconfiguráveis em Verilog.
Os três listagens seguintes demonstram correspondentemente a instanciação das memórias
utilizadas, do módulo reconfigurável e o controlo dos sinais de comunicação e controlo das me-
mórias.
Listagem A.1: Bloco de instanciação das três memórias utilizadas
/ / −− Block RAM’ s I n s t a n t i a t i o n/ / −− I n p u t memories :TDP_89x32 memH(
. c l k a ( c l k ) ,
. ena ( enA [ 2 ] ) ,
. wea ( w r i t e _ e n a b l e _ H ) ,
. a d d r a ( addressA_H_U [14−7 : 14−1]) ,
. d i n a ( data_in_H_U ) ,
. d o u t a ( memH_data_out ) ,
. c l k b ( c l k ) ,
. enb ( enB_H ) ,
. web ( 1 ’ b0 ) ,
. add rb ( addressB_H ) ,
. d inb (32 ’ d0 ) ,
. dou tb ( da t a_ou t_H )) ;
TDP_9216x32 memU(. c l k a ( c l k ) ,. ena ( enA [ 1 ] ) ,. wea ( w r i t e _ e n a b l e _ U ) ,. a d d r a ( addressA_H_U ) ,. d i n a ( data_in_H_U ) ,
95

96 Anexos
. d o u t a ( memU_data_out ) ,
. c l k b ( c l k ) ,
. enb ( enB_U ) ,
. web ( 1 ’ b0 ) ,
. add rb ( addressB_U ) ,
. d inb (32 ’ d0 ) ,
. dou tb ( da t a_ou t_U )) ;
/ / −− Outpu t memoryTDP_9216x32 memY(
. c l k a ( c l k ) ,
. ena ( enA [ 0 ] ) ,
. wea (weA_Y) ,
. a d d r a ( addressA_Y ) ,
. d i n a ( da t a_ in_Y ) ,
. d o u t a ( ) ,
. c l k b ( c l k ) ,
. enb ( enB [ 0 ] ) ,
. web ( wr i t e_enab leA_Y ) ,
. addrb ( addressB_Y ) ,
. d inb ( data_in_H_U ) ,
. dou tb ( da t a_ou t_Y )) ;
Listagem A.2: Bloco de instanciação do módulo reconfigurável
r e c o n f i g _ m o d u l e r e c o n f i g _ m o d u l e 1 (/ / −− c l o c k , r e s e t and c o n t r o l s i g n a l s. c l k ( c l k ) ,. r s t ( r s t ) ,. s t a r t ( s l v _ r e g 0 [ 3 1 ] ) ,. r e a d y ( s l v _ r e g 3 [ 3 0 ] ) ,. done ( done ) ,. r p ( s l v _ r e g 3 [ 2 7 : 2 9 ] ) ,/ / −− Memory a c c e s s t o H (+ o p t i o n a l s ) m a t r i x. h _ r s c _ s i n g l e p o r t _ a d d r ( addressB_H ) ,. h _ r s c _ s i n g l e p o r t _ r e ( enB [ 2 ] ) ,. h _ r s c _ s i n g l e p o r t _ d a t a _ o u t ( da t a_ou t_H ) ,/ / −− Memory a c c e s s t o U m a t r i x. u _ r s c _ s i n g l e p o r t _ a d d r ( addressB_U ) ,. u _ r s c _ s i n g l e p o r t _ r e ( enB [ 1 ] ) ,. u _ r s c _ s i n g l e p o r t _ d a t a _ o u t ( da t a_ou t_U ) ,/ / −− Memory a c c e s s t o Y m a t r i x. y _ r s c _ s i n g l e p o r t _ d a t a _ i n ( da t a_ in_Y ) ,. y _ r s c _ s i n g l e p o r t _ a d d r ( addressA_Y ) ,. y _ r s c _ s i n g l e p o r t _ w e ( w r i t e _ e n a b l e _ Y )
) ;

A.1 Ficheiro Verilog de Descrição da Unidade Reconfigurável 97
Listagem A.3: Bloco de controlo dos sinais de comunicação e controlo das memórias
/ / −− imp lemen t s i n g l e c l o c k wide or b u r s t c l o c k wide read r e q u e s t sa s s i g n mem_read_req = ( Bus2 IP_Burs t | | b u r s t _ d e l a y ) ? ( Bus2 IP_Burs t &&
Bus2IP_RdReq && mem_read_enable ) : ( mem_read_enable && ! (mem_read_enab le_d ly1 ) ) ;
always @( posedge Bus2IP_Clk )begin : BRAM_RD_REQ_PROC
i f ( Bus2IP_Rese t == 1 )begin
mem_read_enab le_d ly1 <= 0 ;b u r s t _ d e l a y <= 1 ’ b0 ;
ende l s ebegin
i f ( Bus2 IP_Burs t == 1 ’ b1 )b u r s t _ d e l a y <= 1 ’ b1 ;
e l s eb u r s t _ d e l a y <= 1 ’ b0 ;
mem_read_enab le_d ly1 <= mem_read_enable ;end
end
/ / −− imp lemen t s i n g l e c l o c k wide or b u r s t c l o c k wide read r e q u e s t sa s s i g n mem_read_req = ( Bus2 IP_Burs t | | b u r s t _ d e l a y ) ? ( Bus2 IP_Burs t &&
Bus2IP_RdReq && mem_read_enable ) : ( mem_read_enable && ! (mem_read_enab le_d ly1 ) ) ;
always @( posedge Bus2IP_Clk )begin : BRAM_RD_REQ_PROC
i f ( Bus2IP_Rese t == 1 )begin
mem_read_enab le_d ly1 <= 0 ;b u r s t _ d e l a y <= 1 ’ b0 ;
ende l s ebegin
i f ( Bus2 IP_Burs t == 1 ’ b1 )b u r s t _ d e l a y <= 1 ’ b1 ;
e l s eb u r s t _ d e l a y <= 1 ’ b0 ;
mem_read_enab le_d ly1 <= mem_read_enable ;end
end
/ / −− t h i s p r o c e s s g e n e r a t e s t h e read acknowledge 1 c l o c k a f t e r read e n a b l e/ / −− i s p r e s e n t e d t o t h e BRAM b l o c k . The BRAM b l o c k has a 1 c l o c k d e l a y/ / −− f rom read e n a b l e t o da ta o u t .

98 Anexos
always @( posedge Bus2IP_Clk )begin : BRAM_RD_ACK_PROC
i f ( Bus2IP_Rese t == 1 )mem_read_ack_dly1 <= 0 ;
e l s emem_read_ack_dly1 <= mem_read_req ;
end
/ / −− imp lemen t B lock RAM read muxalways @( mem_data_out or memU_data_out or memH_data_out or mem_selec t )begin : MEM_IP2BUS_DATA_PROC
case ( mem_se lec t )3 ’ b100 : mem_ip2bus_data <= mem_data_out ;3 ’ b010 : mem_ip2bus_data <= memU_data_out ;3 ’ b001 : mem_ip2bus_data <= memH_data_out ;d e f a u l t : mem_ip2bus_data <= 0 ;
endcaseend
/ / −− code t o c o n n e c t Chip S e l e c t and w r i t e e n a b l e s i g n a l sa s s i g n mem_selec t = Bus2IP_CS ;a s s i g n mem_read_enable = ( Bus2IP_CS [ 0 ] | | Bus2IP_CS [ 1 ] | | Bus2IP_CS [ 2 ] ) &&
Bus2IP_RNW ;a s s i g n mem_read_ack = mem_read_ack_dly1 ;a s s i g n mem_write_ack = ( Bus2IP_CS [ 0 ] | | Bus2IP_CS [ 1 ] | | Bus2IP_CS [ 2 ] ) && ! (
Bus2IP_RNW ) && Bus2IP_WrReq && ( Bus2IP_Burs t | | b u r s t _ d e l a y ) ;a s s i g n mem_address = Bus2IP_Addr ;a s s i g n s l v _ r e g 3 [ 3 1 ] = done2IP ;a s s i g n w r i t e _ e n a b l e _ H = ! ( Bus2IP_RNW ) && Bus2IP_CS [ 2 ] ;a s s i g n w r i t e _ e n a b l e _ U = ! ( Bus2IP_RNW ) && Bus2IP_CS [ 1 ] ;a s s i g n wri t e_enab leA_Y = ! ( Bus2IP_RNW ) && Bus2IP_CS [ 0 ] ;a s s i g n data_in_H_U = Bus2IP_Data ;a s s i g n mem_data_out = da ta_ou t_Y ;
/ / −− Code t o d r i v e IP t o Bus s i g n a l sa s s i g n IP2Bus_Data = ( s l v _ r e a d _ a c k == 1) ? s l v _ i p 2 b u s _ d a t a : ( mem_read_ack ==
1) ? mem_ip2bus_data : 0 ;a s s i g n IP2Bus_WrAck = s l v _ w r i t e _ a c k | | mem_write_ack ;a s s i g n IP2Bus_RdAck = s l v _ r e a d _ a c k | | mem_read_ack ;a s s i g n I P 2 B u s _ E r r o r = 0 ;a s s i g n IP2Bus_AddrAck = mem_read_req | | mem_write_ack ;

A.2 Ficheiro Verilog de Descrição do Módulo Reconfigurável 99
A.2 Ficheiro Verilog de Descrição do Módulo Reconfigurável
Listagem A.4: Ficheiro de Verilog de descrição do módulo reconfigurável
module r e c o n f i g _ m o d u l e (/ / −− C o n t r o l s i g n a l sc lk , r s t , s t a r t , ready , done , rp ,/ / −− Memory a c c e s s t o H (+ o p t i o n a l s ) m a t r i xh _ r s c _ s i n g l e p o r t _ a d d r ,h _ r s c _ s i n g l e p o r t _ r e ,h _ r s c _ s i n g l e p o r t _ d a t a _ o u t ,/ / −− Memory a c c e s s t o U m a t r i xu _ r s c _ s i n g l e p o r t _ a d d r ,u _ r s c _ s i n g l e p o r t _ r e ,u _ r s c _ s i n g l e p o r t _ d a t a _ o u t ,/ / −− Memory a c c e s s t o Y m a t r i xy _ r s c _ s i n g l e p o r t _ d a t a _ i n ,y _ r s c _ s i n g l e p o r t _ a d d r ,y _ r s c _ s i n g l e p o r t _ w e
) ;/ / −− c l o c k , r e s e t and c o n t r o l s i g n a l sinput c lk , r s t , s t a r t ;output ready , done ;output [ 2 : 0 ] rp ;/ / −− Memory a c c e s s t o H (+ o p t i o n a l s ) m a t r i xoutput [ 6 : 0 ] h _ r s c _ s i n g l e p o r t _ a d d r ;output h _ r s c _ s i n g l e p o r t _ r e ;input [ 3 1 : 0 ] h _ r s c _ s i n g l e p o r t _ d a t a _ o u t ;/ / −− Memory a c c e s s t o U m a t r i xoutput [ 1 3 : 0 ] u _ r s c _ s i n g l e p o r t _ a d d r ;output u _ r s c _ s i n g l e p o r t _ r e ;input [ 3 1 : 0 ] u _ r s c _ s i n g l e p o r t _ d a t a _ o u t ;/ / −− Memory a c c e s s t o Y m a t r i xoutput [ 3 1 : 0 ] y _ r s c _ s i n g l e p o r t _ d a t a _ i n ;output [ 1 3 : 0 ] y _ r s c _ s i n g l e p o r t _ a d d r ;output y _ r s c _ s i n g l e p o r t _ w e ;
/ / −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−/ // / B lack Box zone t o i n c l u d e C a t a p u l t C c r e a t e d modules/ // / −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
a s s i g n rp = 3 ’dX ; / / X=1 − ConvConst ;/ / X=2 − ConvRepl1 ;/ / X=3 − ConvRepl2 ;
endmodule

100 Anexos
A.3 Profiling Gráfico da Função Estimação Robusta de PosePrimeira Parte
Figura A.1: Gráfico da avaliação das dependências e percentagens de tempo de execução da funçãoEstimação Robusta de Pose e sub-funções (Primeira Parte).

A.4 Profiling Gráfico da Função Estimação Robusta de Pose 101
A.4 Profiling Gráfico da Função Estimação Robusta de PoseSegunda Parte
Figura A.2: Gráfico da avaliação das dependências e percentagens de tempo de execução da funçãoEstimação Robusta de Pose e sub-funções (Segunda Parte).

102 Anexos

Referências
[1] João Teixeira. Acceleration of a Stereo Navigation Application for Autonomous Vehicles.Tese de mestrado, Faculdade de Engenharia da Universidade do Porto, 2011.
[2] REFLECT consortium. REFLECT (Rendering FPGAs for Multi-Core Embedded Compu-ting) Project, 2010. URL: http://www.reflect-project.eu [último acesso em 2012-09-21].
[3] G.N. Khan e M. Jin. Hardware Software Codesign of a Safety-Critical Embedded Com-puter System for an Automatic Endoscope. Em 2002 Canadian Conference on Electri-cal and Computer Engineering. IEEE CCECE 2002., volume 2, páginas 657 –662, 2002.doi:10.1109/CCECE.2002.1013019.
[4] Bing-Nan Li, Ming-Chui Dong, Vai Mang I, e Mak Peng Un. An Embedded Medi-cal Advisory System for Mobile Cardiovascular Monitoring Devices. Em 2004 IEEE In-ternational Workshop on Biomedical Circuits and Systems, páginas 1 – 1–4, dec. 2004.doi:10.1109/BIOCAS.2004.1454087.
[5] Liang Si, Zhonghui Chen, Xiaojuan Yu, Qian Zhang, e Xiangyun Liu. EmbeddedReal-Time Damage Detection and Identification Algorithms in Wireless Health Monito-ring System for Smart Structures. Em 2009 IEEE International Conference on Com-munications Technology and Applications. ICCTA ’09., páginas 676 –681, oct. 2009.doi:10.1109/ICCOMTA.2009.5349114.
[6] R. Marculescu, B. Nikolic, e A.-S. Vincentelli. Fresh Air: The Emerging Landscape ofDesign for Networked Embedded Systems. Em 2007 5th IEEE/ACM/IFIP InternationalConference on Hardware/Software Codesign and System Synthesis (CODES+ISSS), página124, 30 2007-oct. 3 2007.
[7] Hye-Jin Lee, Dong-Oh Kim, Bub-Joo Kang, e Sang-Woo Ban. Mobile Embedded Health-Care System Working on Wireless Sensor Network. Em 2011 Third International Confe-rence on Communications and Mobile Computing (CMC), páginas 161 –164, april 2011.doi:10.1109/CMC.2011.118.
[8] T. Lange, N. Harb, Haisheng Liu, S. Niar, e R. Ben Atitallah. An Improved AutomotiveMultiple Target Tracking System Design. Em 2010 13th Euromicro Conference on DigitalSystem Design: Architectures, Methods and Tools (DSD), páginas 255 –258, sept. 2010.doi:10.1109/DSD.2010.54.
[9] D. Gonzalez, G. Botella, S. Mokheerje, e U. Meyer-Base. FPGA-Based Accelerationof Block Matching Motion Estimation Techniques. Em 2011 International Conferenceon Field Programmable Logic and Applications (FPL), páginas 389 –392, sept. 2011.doi:10.1109/FPL.2011.76.
103

104 REFERÊNCIAS
[10] HiPEAC roadmap - 2011, 2011. URL: http://www.hipeac.net/system/files/hipeac-roadmap2011.pdf [último acesso em 2012-09-09].
[11] J.P. Delahaye, C. Moy, P. Leray, e J. Palicot. Managing Dynamic Partial Reconfiguration onHeterogeneous SDR Platforms. 5, 2005.
[12] Z. Yu, I. Warren, e B. MacDonald. Dynamic Reconfiguration for Robot Software. Em 2006IEEE International Conference on Automation Science and Engineering. CASE’06., páginas292–297. IEEE, 2006.
[13] Xilinx. DS100 - Virtex-5 Family Overview, 2009.
[14] Calypto Design Systems Inc. Catapult R© C High-Level Synthesis - Blue Book, 2011.
[15] REFLECT consortium. Deliverable 1.2 - Technical report of applications delivered by Ho-neywell. Relatório técnico, October 2009.
[16] C. Harris e M. Stephens. A Combined Corner and Edge detector. Em Alvey vision conference,volume 15, página 50, 1988.
[17] J.M.S. Prewitt. Object Enhancement and Extraction. Em Picture processing and Psychopic-torics, 1970.
[18] Martin A. Fischler e Robert C. Bolles. Random Sample Consensus: A Paradigm for Mo-del Fitting With Applications To Image Analysis and Automated Cartography. Commun.ACM, 24(6):381–395, Junho 1981. URL: http://doi.acm.org/10.1145/358669.358692, doi:10.1145/358669.358692.
[19] Xilinx. DS512 - LogiCORE IP Memory Generator (v4.3), 2010.
[20] Calypto Design Systems Inc. Algorithmic C Datatypes, v2.6, 2011.
[21] [DS335 - LogiCORE IP Floating-Point Operator (v5.0).
[22] IEEE Standard for Floating-Point Arithmetic. IEEE Std 754-2008, páginas 1 –58, 29 2008.doi:10.1109/IEEESTD.2008.4610935.
[23] John Hauser. SoftFloat, 2010. URL: http://www.jhauser.us/arithmetic/SoftFloat.html [último acesso em 2012-08-13].
[24] Calypto Design Systems Inc. Catapult R© C Synthesis User’s and Reference Manual, Uni-versity Version, 2011.
[25] Xilinx. DS531 - LogiCORE IP Processor Local Bus(PLB) v4.6 (v1.05a), 2010.
[26] Xilinx. UG190 - Virtex-5 FPGA User Guide, 2012.
[27] Xilinx. DS586 - LogiCORE IP XPS HWICAP (v5.00a), 2010.
[28] Xilinx. DS579 - LogiCORE IP XPS Central DMA Controller (v2.03a), 2010.
[29] Xilinx. UG702 - Partial Reconfiguration User Guide, 2010.
[30] Xilinx. UG747 - PlanAhead Software Tutorial - Leveraging Design Preservation for Predic-table Results, 2010.

REFERÊNCIAS 105
[31] Gene M. Amdahl. Validity of the single processor approach to achieving large scale compu-ting capabilities. Em Proceedings of the April 18-20, 1967, spring joint computer conference,AFIPS ’67 (Spring), página 483–485, New York, NY, USA, 1967. ACM. URL: http://doi.acm.org/10.1145/1465482.1465560, doi:10.1145/1465482.1465560.
[32] M. Liu, W. Kuehn, Z. Lu, e A. Jantsch. Run-Time Partial Reconfiguration Speed Inves-tigation and Architectural Design Space Exploration. Em 2009 International Conferenceon Field Programmable Logic and Applications. FPL 2009., página 498–502, 2009. URL:http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5272463.
Related Documents











