Hadoop 第2章 MapReduce Shinichiro Hasegawa

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Hadoop第2章MapReduce
Shinichiro Hasegawa

2章のもくじ2章 MapReduce 2.1 気象情報データセット 2.1.1 データフォーマット 2.2 Unixのツールによるデータ分析 2.3 Hadoopによるデータの分析 2.3.1 mapとreduce 2.3.2 Java MapReduce 2.4 スケールアウト 2.4.1 データフロー 2.4.2 集約関数 2.4.3 分散MapReduceジョブの実行 2.5 Hadoopストリーミング 2.5.1 Ruby 2.5.2 Python 2.6 Hadoop Pipes 2.6.1 コンパイルと実行

おいらのもくじ
• 本書で扱っているシンプルなMapReduceモデル• スケールアウト• Hadoop用語• データフロー• 集約関数• Hadoopストリーミング

本書で扱っているアメリカの気象データ

各年の最高気温を求めたいシェルだとこんな感じ
シーケンシャルでループさせている⇛とても時間がかかる
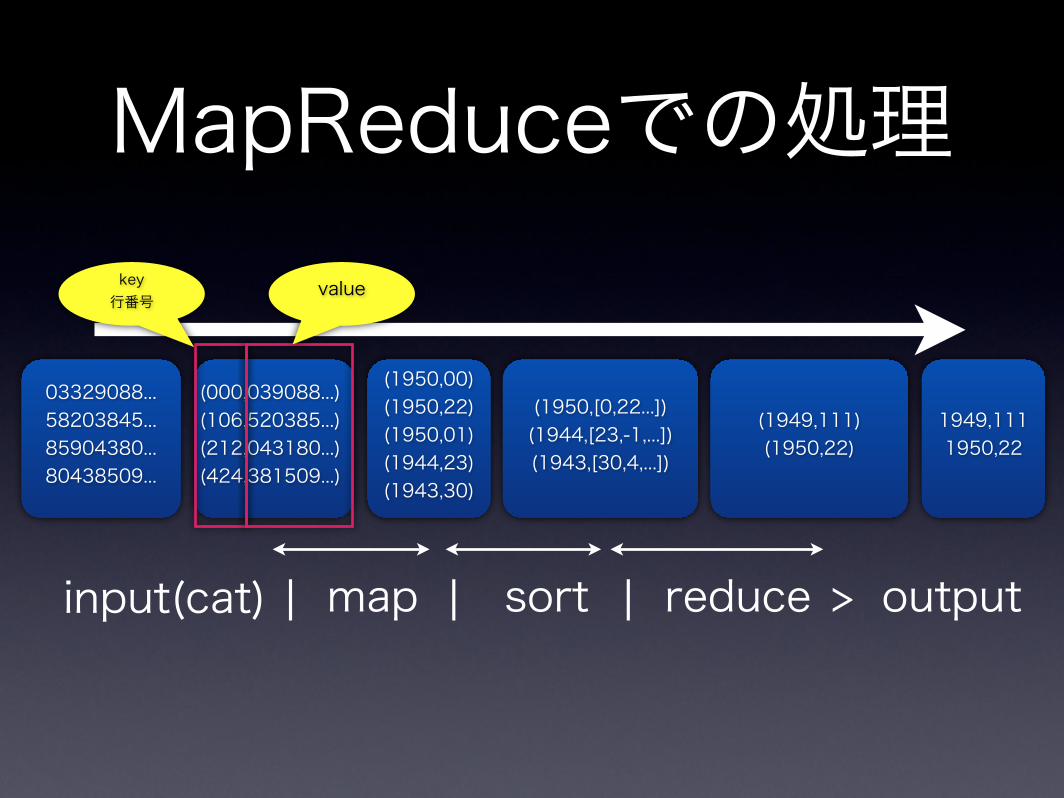
MapReduceでの処理
03329088...58203845...85904380...80438509...
(000,039088...)(106,520385...)(212,043180...)(424,381509...)
(1950,00)(1950,22)(1950,01)(1944,23)(1943,30)
(1950,[0,22...])(1944,[23,-1,...])(1943,[30,4,...])
(1949,111)(1950,22)
1949,1111950,22
key行番号
value
| map | sort | reduceinput(cat) > output

スケールアウト
•いままでは、単一のノードで実行させた話
•ローカル以外でも実行させる為には、分散ファイルシステム(ex.HDFS等)が必要

keyword #1
• job• クライアントが実行する作業単位• task• jobを分割したもの• mapタスクとreduceタスクがある

keyword #2
• jobtracker• tasktracker群によって実行されるタスクをスケジューリングし、全体を管理
• クラスタに1つだけ• tasktrackerのタスクの処理に問題があれば、違うノードに割り振る
• tasktracker• タスクを実行し、進行状況のレポートをjobtrackerに送信する

• 入力スプリット(単にスプリットとも)
• MapReduceジョブへの入力される、固定長の断片
• 各スプリットに対し、1つのmapタスクを生成。ユーザが定義したmap関数を、スプリット中の各レコードに対して実行
• データローカリティ最適化処理
• 「なるたけローカルのデータを処理するぜ」の意
• スプリットがHDFSに「実際に」格納されているノード上でmapタスクを実行しようとする。
• スプリットサイズは、HDFSのブロックサイズがベター
keyword #3

単一のreduceタスクにおけるMapReduceデータフロー
ごめん><図が描けなかったので30pを参考にして!

複数のreduceタスクを持つMapReduceデータフロー
またまた、ごめん><図が描けなかったので31pを参考にして!

Hadoopストリーミング

Hadoopストリーミングとは?
•標準入出力をインタフェースとする、map/reduce処理を書けるHadoopのAPI
•(書き方によっては)awkの7倍早い

本書サンプルそのままでは面白く無いので

?!

電力使用料推移(累計)のデータを処理してみることに
こちらで公開されているものですhttp://denki.cuppat.net/

やること
•日にちごとの電力使用量ピークをリストアップ
•本文はjavaとpythonとrubyのサンプルがあったので、あえてperlで書いてみる

元データ

map.pl 1 use strict; 2 use warnings; 3 4 while (chomp(my $line = <STDIN>) ) { 5 my ($date,@s) = split(/,/,$line); 6 foreach my $s (@s) { 7 print "$date,$s\n"; 8 } 9 }

reduce.pl 1 use strict; 2 use warnings; 3 4 my $flag = 0; 5 my $date2 = ""; 6 my $value2 = ""; 7 while (my $line = <STDIN> ) { 8 my (my $date,my $value) = split(/,/,$line); 9 10 if($flag == 0){ 11 $date2 = $date; 12 $value2 = $value; 13 } 14 15 if($date2 == $date){ 16 if($value2 < $value){ 17 $value2 = $value; 18 } 19 } else { 20 print "$date2,$value2"; 21 $date2 = $date; 22 $value2 = 0; 23 } 24 $flag = 1; 25 } 26 print "$date2,$value2";

テスト実行$ cat all.csv |perl map.pl |sort |perl reduce.pl20110323,375020110324,385020110325,375020110326,370020110327,3700...

Hadoopにて実行• 解析対象ファイルを配置
• # hadoop dfs -put /tmp/all2.csv /usr
• 解析の実行
• # hadoop jar /usr/lib/hadoop/contrib/streaming/hadoop-streaming-0.20.2-CDH3B4.jar -input /usr/all2.csv -output /usr/result4.txt -mapper /usr/bin/perl /tmp/map.pl -reducer /usr/bin/perl /tmp/reduce.pl -inputformat TextInputFormat -file /tmp/map.pl -file /tmp/reduce.pl
• ↑しかし、これはなぜかこける・・・

まとめ•MapReduce(自体)は、難しいことをしなければ簡単です
•テストコードの対象をaccess_log解析にすればよかったと、書いてから後悔したので、そのうちやります
•ちゃんと動かない件も調べます。。。

おしまい
Related Documents











