Mark Silberstein - UT Austin 1 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) ASPLOS 2013

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Mark Silberstein - UT Austin 1
GPUfs:Integrating a file system with
GPUs
Mark Silberstein(UT Austin/Technion)
Bryan Ford (Yale), Idit Keidar (Technion)Emmett Witchel (UT Austin)
ASPLOS 2013

Mark Silberstein - UT Austin 2
Traditional System Architecture
Applications
OS
CPU

Mark Silberstein - UT Austin 3
Modern System Architecture
Manycoreprocessors
FPGAHybrid
CPU-GPUGPUsCPU
Accelerated applications
OS

Mark Silberstein - UT Austin 4
Software-hardware gap is widening
Manycoreprocessors
FPGAHybrid
CPU-GPUGPUsCPU
Accelerated applications
OS

Mark Silberstein - UT Austin 5
Software-hardware gap is widening
Manycoreprocessors
FPGAHybrid
CPU-GPUGPUsCPU
Accelerated applications
OSAd-hoc abstractions and management mechanisms

Mark Silberstein - UT Austin 6
On-accelerator OS support closes the programmability gap
Manycoreprocessors
FPGAHybrid
CPU-GPUGPUsCPU
Accelerated applications
OS On-accelerator OS support
Native accelerator applications
Coordination

Mark Silberstein - UT Austin 7
● GPUfs: File I/O support for GPUs● Motivation● Goals● Understanding the hardware● Design● Implementation● Evaluation

Mark Silberstein - UT Austin 8
Building systems with GPUs is hard.Why?

Mark Silberstein - UT Austin 9
Data transfersGPU invocation
Memory management
Goal of GPU programming frameworks
GPU
Parallel Algorithm
CPU

Mark Silberstein - UT Austin 10
Headache for GPU programmers
Parallel Algorithm
GPU
Data transfersInvocation
Memory management
CPU
Half of the CUDA SDK 4.1 samples:at least 9 CPU LOC per 1 GPU LOC

Mark Silberstein - UT Austin 11
GPU kernels are isolated
Parallel Algorithm
GPU
Data transfersInvocation
Memory management
CPU

Mark Silberstein - UT Austin 12
Example: accelerating photo collage
http://www.codeproject.com/Articles/36347/Face-Collage
While(Unhappy()){ Read_next_image_file() Decide_placement() Remove_outliers()}

Mark Silberstein - UT Austin 13
CPU Implementation
CPUCPUCPU Application
While(Unhappy()){ Read_next_image_file() Decide_placement() Remove_outliers()}

Mark Silberstein - UT Austin 14
Offloading computations to GPU
CPUCPUCPU Application
While(Unhappy()){ Read_next_image_file() Decide_placement() Remove_outliers()}
Move to GPU

Mark Silberstein - UT Austin 15
Offloading computations to GPU
GPU
CPU
Kernel start
Datatransfer
Kernel termination
Co-processor programming model

Mark Silberstein - UT Austin 16
Kernel start/stop overheads
CPU
GPU
copy to
GP
Uco
py to
CP
U
invoke
Invocationlatency
Synchronization
Cache flush

Mark Silberstein - UT Austin 17
Hiding the overheads
CPU
GPU
copy to
GP
Uco
py to
CP
U
invoke
Manual data reuse managementAsynchronous invocation
Double buffering
copy to
GP
U
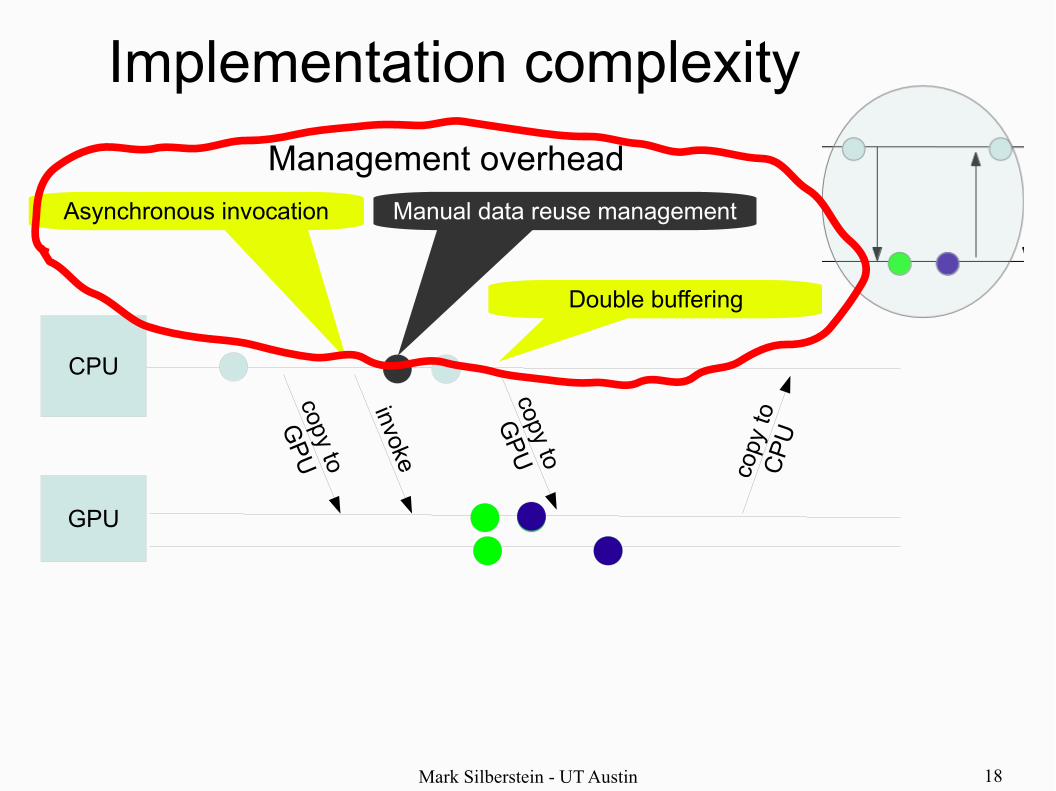
Mark Silberstein - UT Austin 18
Implementation complexity
CPU
GPU
copy to
GP
Uco
py to
CP
U
invoke
Manual data reuse managementAsynchronous invocation
Double buffering
copy to
GP
U
Management overhead

Mark Silberstein - UT Austin 19
Implementation complexity
CPU
GPU
copy to
GP
Uco
py to
CP
U
invoke
Manual data reuse managementAsynchronous invocation
Double buffering
copy to
GP
U
Why do we need to deal withlow-level system details?
Management overhead

Mark Silberstein - UT Austin 20
The reason is....
GPUs are peer-processors
They need I/O OS services

Mark Silberstein - UT Austin 21
GPUfs: application viewCPUs GPU1 GPU2 GPU3
open(“shared_file”)
mm
ap()
open(“shared_file”)w
rite(
)
Host File System
GPUfs

Mark Silberstein - UT Austin 22
GPUfs: application viewCPUs GPU1 GPU2 GPU3
open(“shared_file”)
mm
ap()
open(“shared_file”)w
rite(
)
Host File System
GPUfs
System-wideshared
namespace
Persistentstorage
POSIX (CPU)-like API

Mark Silberstein - UT Austin 23
Accelerating collage app with GPUfs
CPUCPUCPU
GPUfsGPUfs
open/read from GPU
GPU
No CPUmanagement code

Mark Silberstein - UT Austin 24
CPUCPUCPU
GPUfs buffer cacheGPUfs
GPU
GPUfs
OverlappingOverlapping computations and transfers
Read-ahead
Accelerating collage app with GPUfs

Mark Silberstein - UT Austin 25
CPUCPUCPU
GPUfs
GPU
Data reuse
Accelerating collage app with GPUfs
Random data access

Mark Silberstein - UT Austin 26
Challenge
GPU ≠ CPU

Mark Silberstein - UT Austin 27
Massive parallelism
NVIDIA Fermi* AMD HD5870*
From M. Houston/A. Lefohn/K. Fatahalian – A trip through the architecture of modern GPUs*
23,000 active threads
31,000 active threads
Parallelism is essential for performance in deeply multi-threaded wide-vector hardware

Mark Silberstein - UT Austin 28
Heterogeneous memory
CPU GPU
Memory Memory
10-32GB/s
6-16 GB/s
288-360GB/s
~x20
GPUs inherently impose high bandwidth demands on memory

Mark Silberstein - UT Austin 29
How to build an FS layer on this hardware?

Mark Silberstein - UT Austin 30
GPUfs: principled redesign of the whole file system stack
● Relaxed FS API semantics for parallelism
● Relaxed FS consistency for heterogeneous memory
● GPU-specific implementation of synchronization primitives, lock-free data structures, memory allocation, ….

Mark Silberstein - UT Austin 31
GPU applicationusing GPUfs File API
OS File System Interface
GPUfs high-level design
GPU Memory(Page cache)CPU Memory
GPUfs Distributed Buffer Cache
Unchanged applicationsusing OS File API
GPUfs hooks GPUfs GPU File I/O library
OS
CPU GPU
Disk
Host File System
Massiveparallelism
Heterogeneousmemory

Mark Silberstein - UT Austin 32
GPU applicationusing GPUfs File API
OS File System Interface
GPUfs high-level design
GPU Memory(Page cache)CPU Memory
GPUfs Distributed Buffer Cache
Unchanged applicationsusing OS File API
GPUfs hooks GPUfs GPU File I/O library
OS
CPU GPU
Disk
Host File System

Mark Silberstein - UT Austin 33
Buffer cache semantics
Local or Distributed file systemdata consistency?

Mark Silberstein - UT Austin 34
GPUfs buffer cacheWeak data consistency model
● close(sync)-to-open semantics (AFS)
write(1)
open() read(1)
GPU1
GPU2
fsync() write(2)
Not visible to CPU
Remote-to-Local memory performanceratio is similar to
a distributed system
>>

Mark Silberstein - UT Austin 35
On-GPU File I/O API
open/close
read/write
mmap/munmap
fsync/msync
ftrunc
gopen/gclose
gread/gwrite
gmmap/gmunmap
gfsync/gmsync
gftrunc
In th
e p
aper
Changes in the semantics are crucial

Mark Silberstein - UT Austin 36
Implementation bits
● Paging support ● Dynamic data structures and memory
allocators● Lock-free radix tree● Inter-processor communications (IPC)● Hybrid H/W-S/W barriers● Consistency module in the OS kernel
In t h
e p a
per
~1,5K GPU LOC, ~600 CPU LOC

Mark Silberstein - UT Austin 37
Evaluation
All benchmarks are written as a GPU
kernel: no CPU-side development

Mark Silberstein - UT Austin 38
Matrix-vector product(Inputs/Outputs in files)Vector 1x128K elements, Page size = 2MB, GPU=TESLA C2075
280 560 2800 5600 112000
500
1000
1500
2000
2500
3000
3500CUDA piplined CUDA optimized GPU file I/O
Input matrix size (MB)
Th
rou
gh
pu
t (M
B/s
)

Mark Silberstein - UT Austin 39
Word frequency count in text
● Count frequency of modern English words in the works of Shakespeare, and in the Linux kernel source tree
ChallengesDynamic working setSmall filesLots of file I/O (33,000 files,1-5KB each)Unpredictable output size
English dictionary: 58,000 words

Mark Silberstein - UT Austin 40
Results
8CPUs GPU-vanilla GPU-GPUfs
Linux source33,000 files, 524MB
6h 50m (7.2X) 53m (6.8X)
Shakespeare1 file, 6MB 292s 40s (7.3X) 40s (7.3X)

Mark Silberstein - UT Austin 41
Results
8CPUs GPU-vanilla GPU-GPUfs
Linux source33,000 files, 524MB
6h 50m (7.2X) 53m (6.8X)
Shakespeare1 file, 6MB 292s 40s (7.3X) 40s (7.3X)
Unboundedinput/outputsize support
8% overhead

Mark Silberstein - UT Austin 42
GPUfsCPU
GPU
CPU GPU
Code is available for download at:https://sites.google.com/site/silbersteinmark/Home/gpufs
http://goo.gl/ofJ6J
GPUfs is the first system to provide native accessto host OS services from GPU programs
Related Documents











