GP-Fileprints Ahmed Kattan, Edgar Galva ́n-Lo ́pez, Riccardo Poli and Michael O’Neill File Types Detection Using Genetic Programming A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010

GP-Fileprints Ahmed Kattan, Edgar Galva n-Lo pez, Riccardo Poli and Michael O’Neill File Types Detection Using Genetic Programming A.I. Esparcia-Alcazar.
Jan 03, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

GP-Fileprints
Ahmed Kattan, Edgar Galva n-Lo pez, Riccardo Poli and Michael O’Neill ́� ́�
File Types Detection Using Genetic Programming
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010.
©Springer-Verlag Berlin Heidelberg 2010
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
2
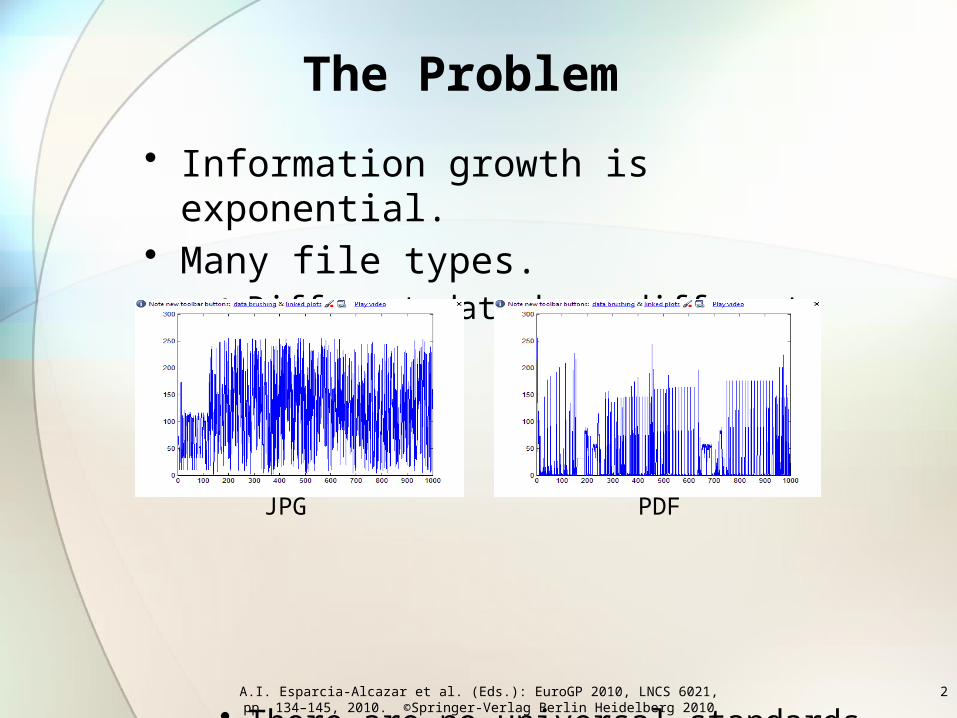
The Problem
• Information growth is exponential. • Many file types.
• Different data have different structures.
• There are no universal standards for file types and there are thousands of file types. Increase security risk.
JPG PDF

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
3
The solution
Identify the file contents by analysing the raw binary streams and without the need of any other meta data!

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
4
Why this is useful ?
• Email spam filter.• Virus detection.• Forensic analysis.• Network security.• Quick hard disk scan.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
5
Some of the previous works• McDaniel, M., Heydari, M.H.: Content based file type detection algorithms.
In: HICSS 2003: Proceedings of the 36th Annual Hawaii International Conference on System Sciences (HICSS 2003) - Track 9, Washington, DC, USA, p. 332.1. IEEE Computer Society, Los Alamitos (2003)
• Proposed an approach for automatically generating “fingerprints” for files.
• Three algorithms to build fingerprints: 1. Byte Frequency Analysis (BFA).2. Byte Frequency Cross-Correlation (BFC).3. File Header/Trailer (FHT) algorithm.
• Experiments: (30 file-type fingerprints using four test files for each file)• Results: They reported that BFA and BFC showed poor
performance (i.e., an accuracy in the range of 27.5% and 45.83%) compared to FHT algorithm (which had an accuracy of 95.83%).

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
6
Some of the previous works• Li, W.-J., Stolfo, S.J., Herzog, B.: Fileprints: Identifying file types by n-gram
analysis. In: Proceedings of the 2005 IEEEWorkshop on Information Assurance, pp. 64–71 (2005).
• Proposed to analyse the data using n-grams to identify multiple centroids – fingerprints – for each file type.
• Three different techniques: 1. Truncation. 2. Multi-centroids. 3. Exemplar files.
• The authors reported some problems when classifying similar data types such as GIF and JPG. Also, some difficulties appeared when classifying PDF and MS office file types, as some embedded images and figures mislead the algorithms.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
7
Some of the previous works• Karresand, M., Shahmehri, N.: Oscar – file type identification of binary data
in disk clusters and ram pages. In: Security and Privacy in Dynamic Environments, pp. 413–424. Springer, Boston (2006)
• Proposed file type identification method called Oscar. • For each data fragment they calculated:
1- Byte Frequency Distribution (BFD).2- Mean 3- Standard deviation.
When these measures are put together, they form a model which is used to identify unknown data fragments.
• Results: The authors reported that their approach, tested using only JPEG files, gave a 99.2% detection rate. The slowest implementation of the algorithm scans a 72.2MB in approximately 2.5 seconds and this scales linearly.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
8
None of the previous methods used evolutionary algorithms, including GP, to solve the problem of identifying file types
from their raw binary streams.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
9
In this Research
The question that we investigate is whether it is possible for GP to extract certain regularities from the raw byte-series of files and correlate them with particular data types without the need of any other meta data.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
10
The Approach
• Each individual has a multi-tree representation

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
11
Function set
Function InputMedian, Mean,
Average deviation, Standard deviation,
Vaiance, Skew, Kurtosis Entropy
Vector of Integers (0-255)
+, -, /, *, Sin, Cos, Sqrt, log
Real number

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
12
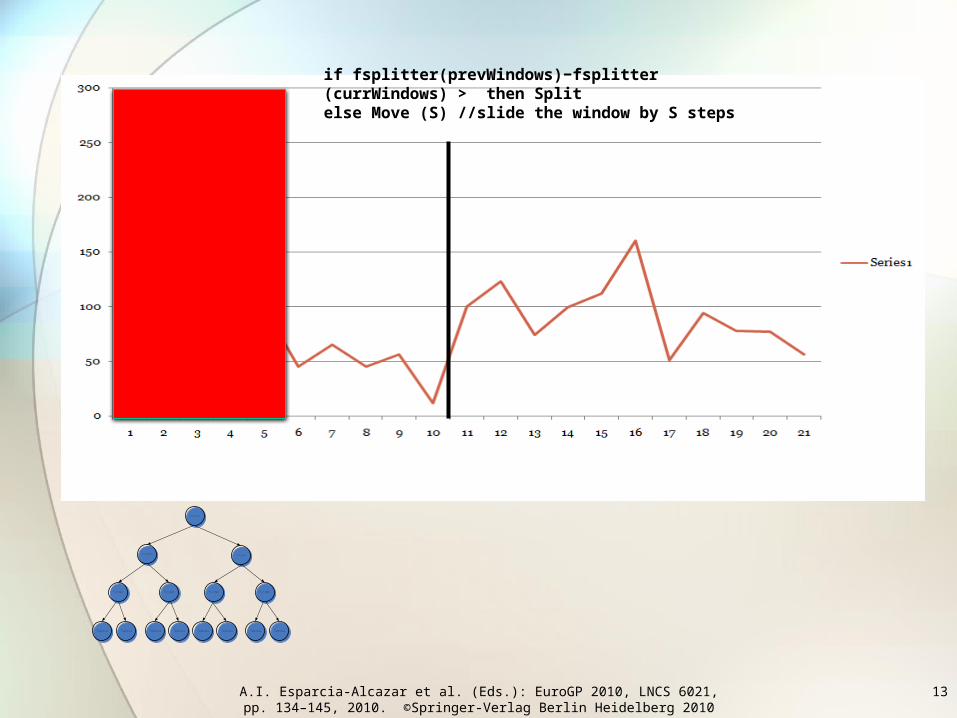
Splitter tree
• The main job of the splitter trees is to split the given raw byte-series into smaller segments based on their statistical features in such a way that each segment is composed of statistically uniform data.
• Why ? • Files with complex structures that store data of different types
simultaneously.• A single game file might contain executable code, text, pictures
and background music. • OpenOffice’s ODT, Microsoft’s DOCX or a ZIP file, are in fact
archives containing inhomogeneous data.
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
13
Function
Function Function
Function FunctionFunctionFunction
Terminal Terminal Terminal Terminal Terminal Terminal Terminal Terminal
if fsplitter(prevWindows)−fsplitter (currWindows) > then Splitelse Move (S) //slide the window by S steps

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
14
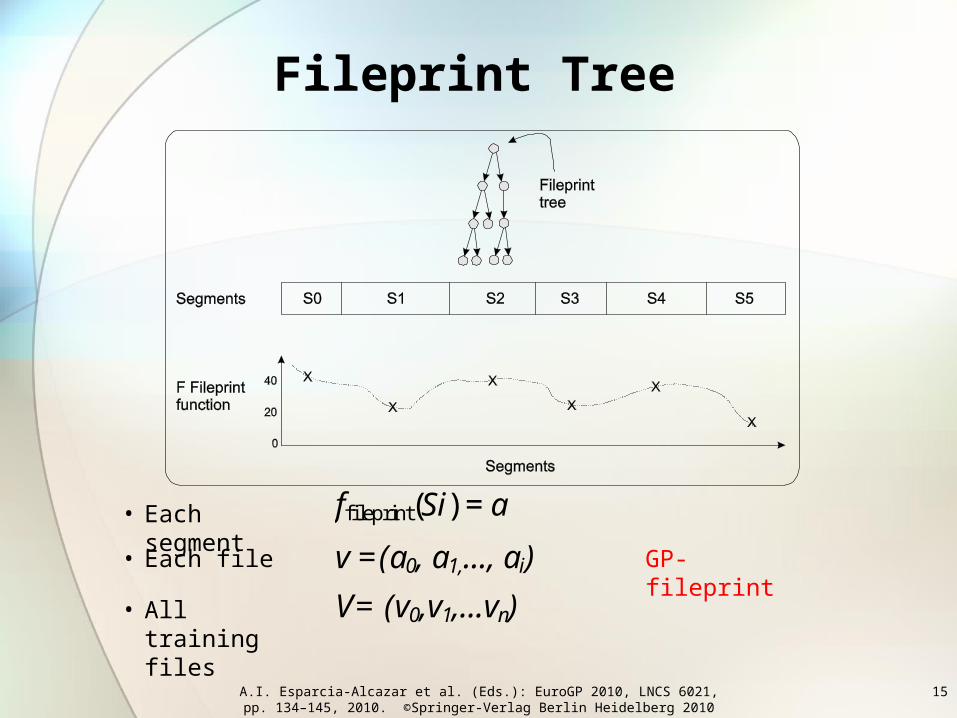
Fileprint Tree
• The main job of the fileprint tree is to identify a unique signature for each file.
• These signatures are meant to be similar for files of the same type and different for files of different types.
• The outputs of the fileprint tree are easier to classify into different classes.
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
15
Fileprint Tree
ffileprint(Si) = a
v =(a0, a1,..., ai)
V= (v0,v1,...vn)
• Each segment
• Each file
• All training files
GP-fileprint

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
16
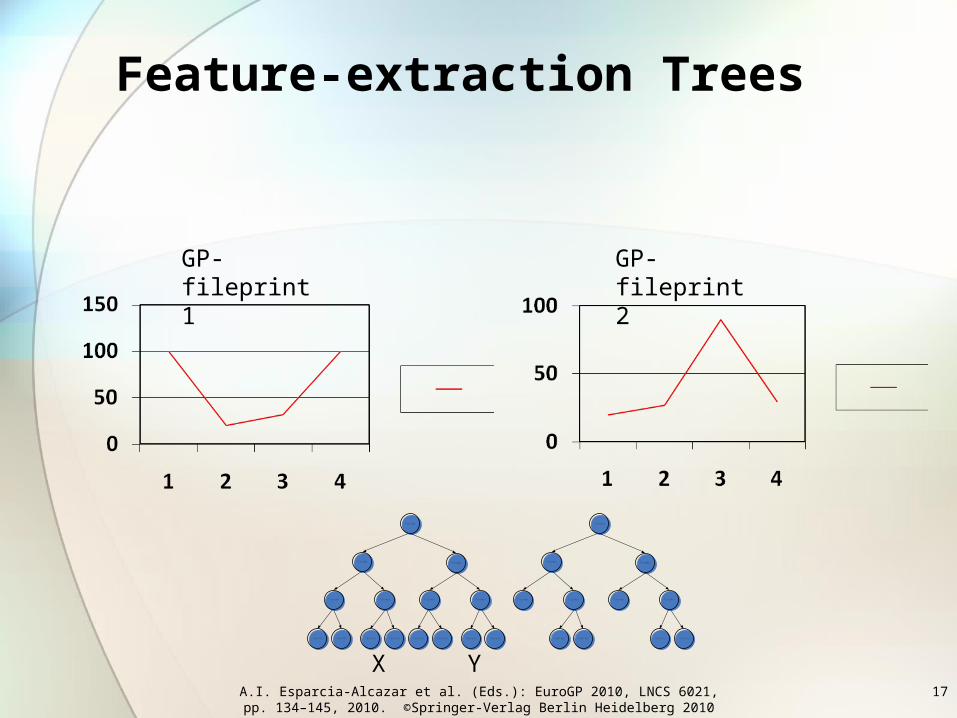
Feature-extraction Trees
• The main job of the feature-extraction trees in our GP representation is to extract features from the GP-fingerprints identified by the fileprint tree and to project them onto a two-dimensional Euclidian space.
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
17
Feature-extraction Trees
Function
Function Function
Function FunctionFunctionFunction
Terminal Terminal Terminal Terminal Terminal Terminal Terminal Terminal
Function
Function Function
Function FunctionFunctionFunction
Terminal Terminal Terminal Terminal
X Y
GP-fileprint 1 GP-fileprint 2

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
18
Feature-extraction Trees

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
19
Feature-extraction Trees
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6 7 8
y
xCluster 1 Cluster 2
EXE PDF

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
20
Fitness Evaluation
• Measure the classification accuracy of the training examples.
• Quality of the clusters:1. Homogeneity.2. Clusters separation.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
21
Homogeneity
• Label the clusters according to the dominant data type.
𝑓homogeneity = σ 𝐻ሺ𝑐𝑖ሻ− 𝜖𝑘𝑖=1 𝑘
Function rates Homogeneity i th Cluster Penalty value
Total number of clusters

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
22
Cluster separation
• Modified Davis Bouldin Index (DBI)
𝐷𝐵𝐼= σ 𝑠𝑡𝑑ሾ𝑑𝑖𝑠ሺ𝑐𝑖,𝑑0ሻ,…,𝑑𝑖𝑠ሺ𝑐𝑖,𝑑𝑛ሻሿ𝑘𝑖=1 𝑑𝑖𝑠(𝑐0,𝑐1,…𝑐𝑘)
Standard deviation Distance between cluster’s centiod and data members
Distance between all cluster’s centiods

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
23
Classifying Unseen Data
• The final output is: • Splitter tree. • Fileprint tree.• Two feature-extraction trees. • Clusters’ members.
• Unseen data goes through the same process.• New GP-fileprints are classified based on the majority
class labels of their K-nearest neighbors.
𝑤= 1𝑑𝑖𝑠𝑡𝑎𝑛𝑐𝑒(𝑥𝑖,𝑧𝑖)

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
24
Search Operators
• For each tree in each individual • Select an operator with predefined probability
• In the crossover, a restriction is applied so that splitter and fileprint trees can only be crossed over with their equivalent tree type. However, the system is able to freely crossover feature-extractions trees at any position.
𝑇𝑐𝑖
A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
25
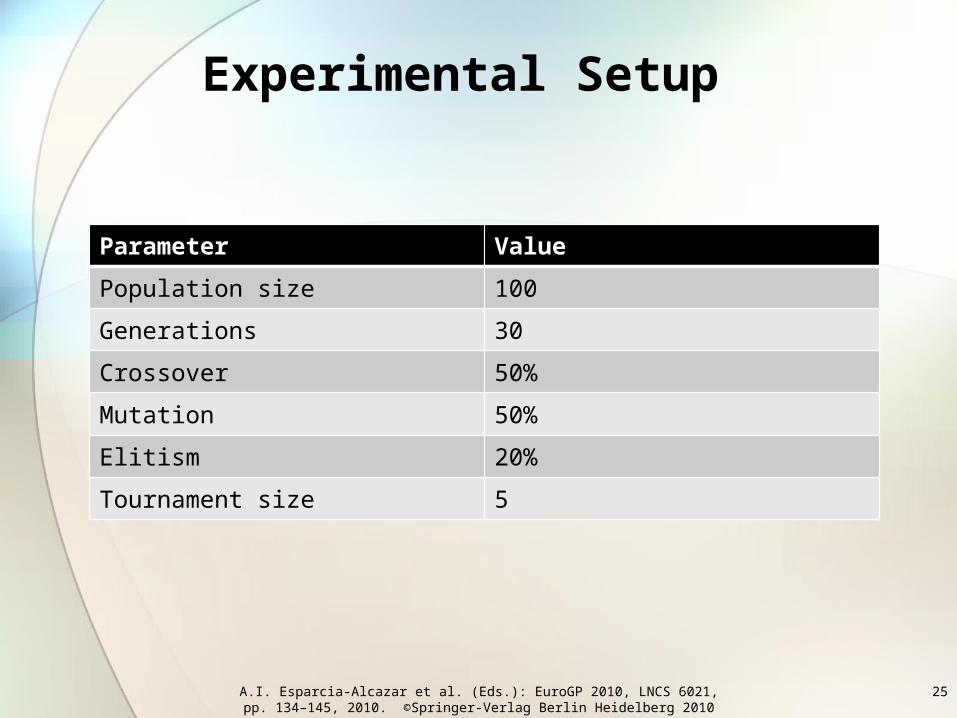
Experimental Setup
Parameter Value
Population size 100
Generations 30
Crossover 50%
Mutation 50%
Elitism 20%
Tournament size 5

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
26
Experimental Setup
• Four parts• 10 GP runs for each part.• 10 different training files from each type. • 30 different testing files from each type.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
27
Results
• Same training sets.• Same primitive sets as our GP system.• For Neural Networks and Bayes Network systems we
performed 10 different runs for each data set, as we did for our GP system.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
28
Results Summary

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
29
Conclusions
• A system based on genetic programming to evolve programs that can identify file contents without making use of any meta data has been proposed.
• The proposed system used multi-tree representation, each tree performed sub-task of the main job.
• The system used special technique to apply the search operators.
• Results outperformed other state of the art classification techniques.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
30
Conclusions
• The major disadvantage of the system is the slow training process (measured by hours).
• Resulting programs are entirely practical, being able to process tens of megabytes of data in seconds.
• The proposed algorithm can be trained according to the user needs. • Identify files with special contents
• Pictures with illegal contents.• EXE that perform illegal task on a network.• Capture particular data on high traffic network.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
31
Future works
• Extend the work to larger and more varied data sets.• Integrate solutions in spam filters and anti-virus
software.• Investigate different dimensions of feature-extraction
trees.• Try more sophisticated clustering techniques.

A.I. Esparcia-Alcazar et al. (Eds.): EuroGP 2010, LNCS 6021, pp. 134–145, 2010. ©Springer-Verlag Berlin Heidelberg 2010
32
Thank ́you ́for ́paying ́attention!
Related Documents











