Fall 2006 Lillevik 333f06- l20 1 University of Portland School of Engineering EE 333 Computer Organization Lecture 20 Pipelining: “bucket brigade” MIPS pipeline & control Pentium 4 architecture

Fall 2006 1 EE 333 Lillevik 333f06-l20 University of Portland School of Engineering Computer Organization Lecture 20 Pipelining: “bucket brigade” MIPS.
Dec 15, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Fall 2006
Lillevik 333f06-l20 1University of Portland School of Engineering
EE 333
Computer OrganizationLecture 20
Pipelining: “bucket brigade”MIPS pipeline & controlPentium 4 architecture

Fall 2006
Lillevik 333f06-l20 2University of Portland School of Engineering
EE 333
Pipelining overview
• Pipelining– Increased performance through parallel
operations– Goal: complete several operations at the same
time
• Hazards– Conditions which inhibit parallel operations– Techniques exist to minimize the problem
Fall 2006
Lillevik 333f06-l20 3University of Portland School of Engineering
EE 333
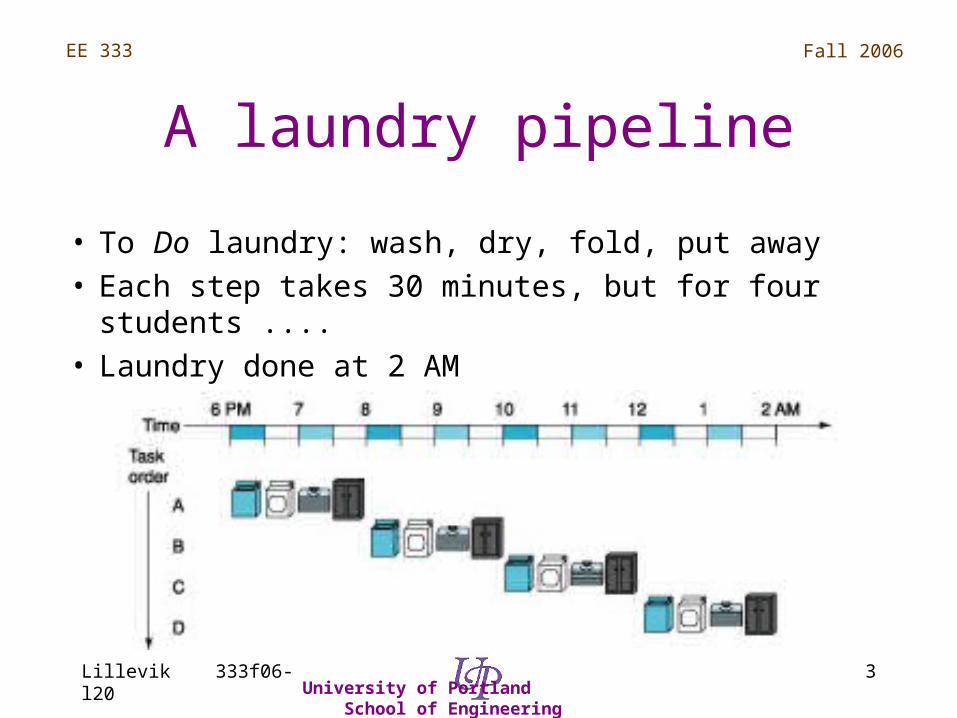
A laundry pipeline
• To Do laundry: wash, dry, fold, put away• Each step takes 30 minutes, but for four students ....• Laundry done at 2 AM

Fall 2006
Lillevik 333f06-l20 4University of Portland School of Engineering
EE 333
Let’s speed it up (pipeline)
• Move one load from one step to the next• But start the next load before first is complete• Takes only until 9:30 PM – party time !!
Bucket Brigade

Fall 2006
Lillevik 333f06-l20 5University of Portland School of Engineering
EE 333
Speedup
• Speedup– Ratio of serial time to parallel
– Metric to compare advantages of parallel operations
parallel
series
TT
S

Fall 2006
Lillevik 333f06-l20 6University of Portland School of Engineering
EE 333
Find the laundry speedup?

Fall 2006
Lillevik 333f06-l20 7University of Portland School of Engineering
EE 333
A computer pipeline
• Assume– Instructions require multiple clocks to complete– Each instruction follows approximately the
same steps (stage)
• Method– Start initial instruction on first clock– On following clocks start subsequent
instructions

Fall 2006
Lillevik 333f06-l20 8University of Portland School of Engineering
EE 333
MIPS instruction steps/stages
1. IF: Fetch instruction from memory
2. ID: Read registers while decoding instruction
3. EX: Execute the operation or calculate an address
4. MEM: Access an operand in data memory
5. WB: Write the result into a register
Fall 2006
Lillevik 333f06-l20 9University of Portland School of Engineering
EE 333
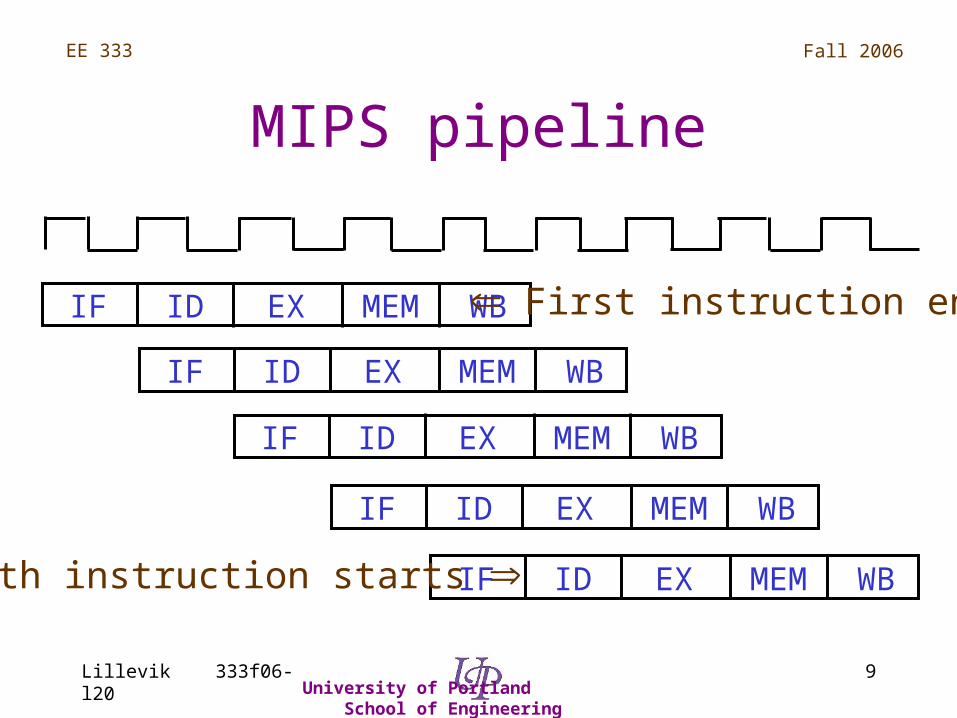
MIPS pipeline
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
First instruction ends
Fifth instruction starts

Fall 2006
Lillevik 333f06-l20 10University of Portland School of Engineering
EE 333
Find the MIPS pipeline speedup?Assume five instructions

Fall 2006
Lillevik 333f06-l20 11University of Portland School of Engineering
EE 333
What about a large program?
parallel
series
TT
S NN nseries
TTTT ...1
N5
NN nparallelTTTT ...
1
1...15
)1(5 N
NNNN
11
55
)1(55
5010
5lim
S
N
Series
Pipelined
Speedup

Fall 2006
Lillevik 333f06-l20 12University of Portland School of Engineering
EE 333
Speedup of pipeline with p stages?
Fall 2006
Lillevik 333f06-l20 13University of Portland School of Engineering
EE 333
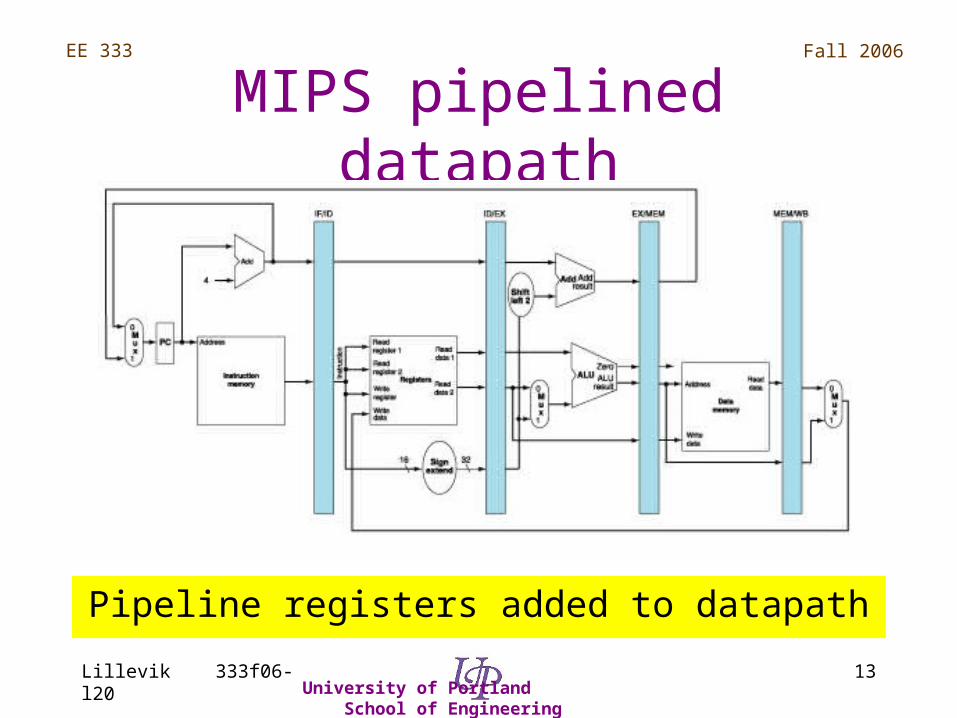
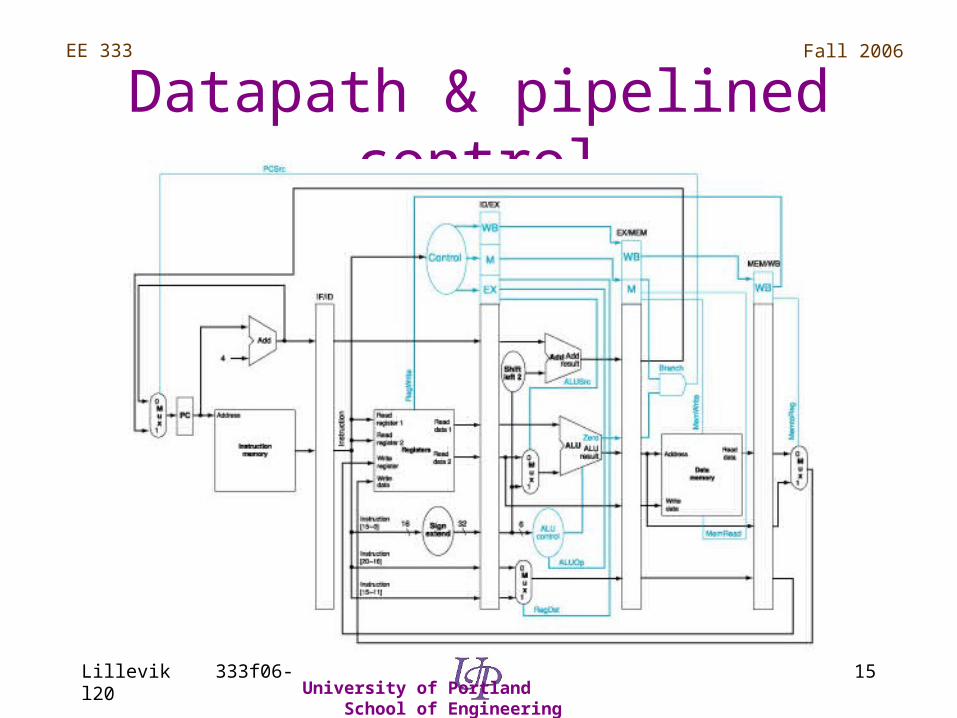
MIPS pipelined datapath
Pipeline registers added to datapath
Fall 2006
Lillevik 333f06-l20 14University of Portland School of Engineering
EE 333
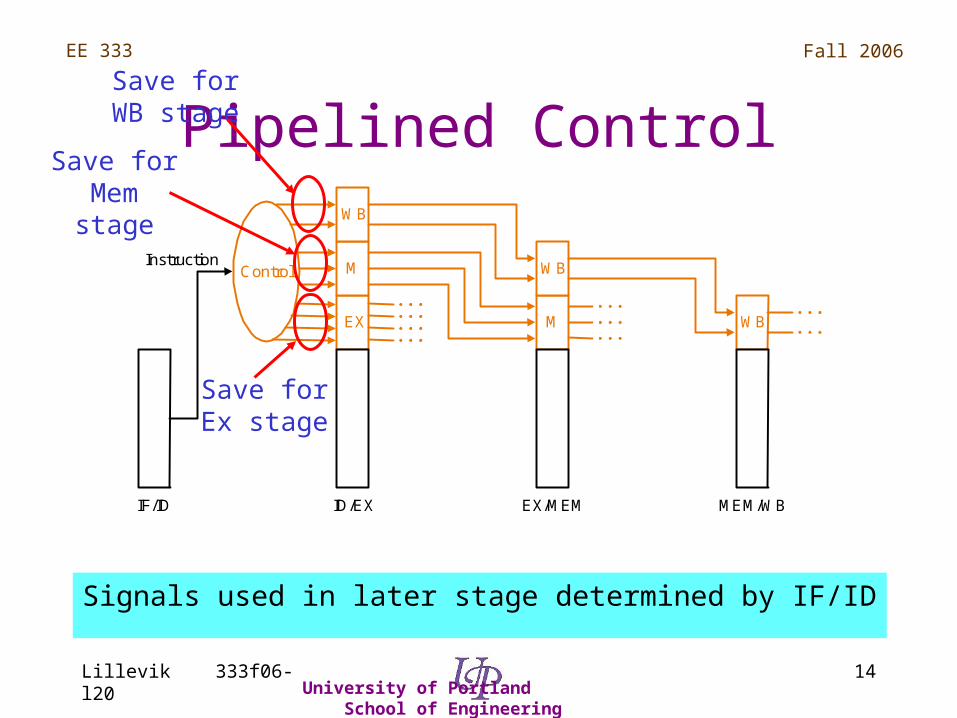
Pipelined Control
Signals used in later stage determined by IF/ID
Control
EX
M
WB
M
WB
WB
IF/ID ID/EX EX/MEM MEM/WB
Instruction
Save for Ex stage
Save for Mem stage
Save for WB stage
Fall 2006
Lillevik 333f06-l20 15University of Portland School of Engineering
EE 333
Datapath & pipelined control

Fall 2006
Lillevik 333f06-l20 16University of Portland School of Engineering
EE 333
Pentium 4 pipeline
• Twenty stages long
• Theoretical speedup of 20
• Hazards (forced sequential operations) reduce speedup– Some instructions executed “out of order” to
avoid hazard– Multiple (optimistic) pipelines created, one
selected to create result, other data discarded
Fall 2006
Lillevik 333f06-l20 17University of Portland School of Engineering
EE 333
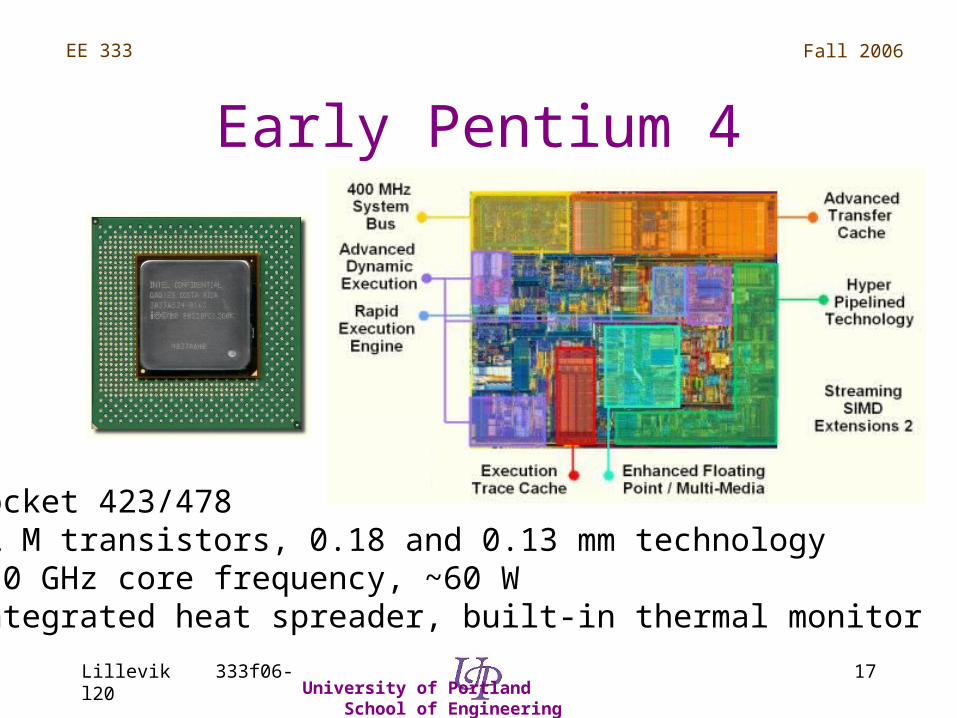
Early Pentium 4
• Socket 423/478• 42 M transistors, 0.18 and 0.13 mm technology• 2.0 GHz core frequency, ~60 W• Integrated heat spreader, built-in thermal monitor

Fall 2006
Lillevik 333f06-l20 18University of Portland School of Engineering
EE 333
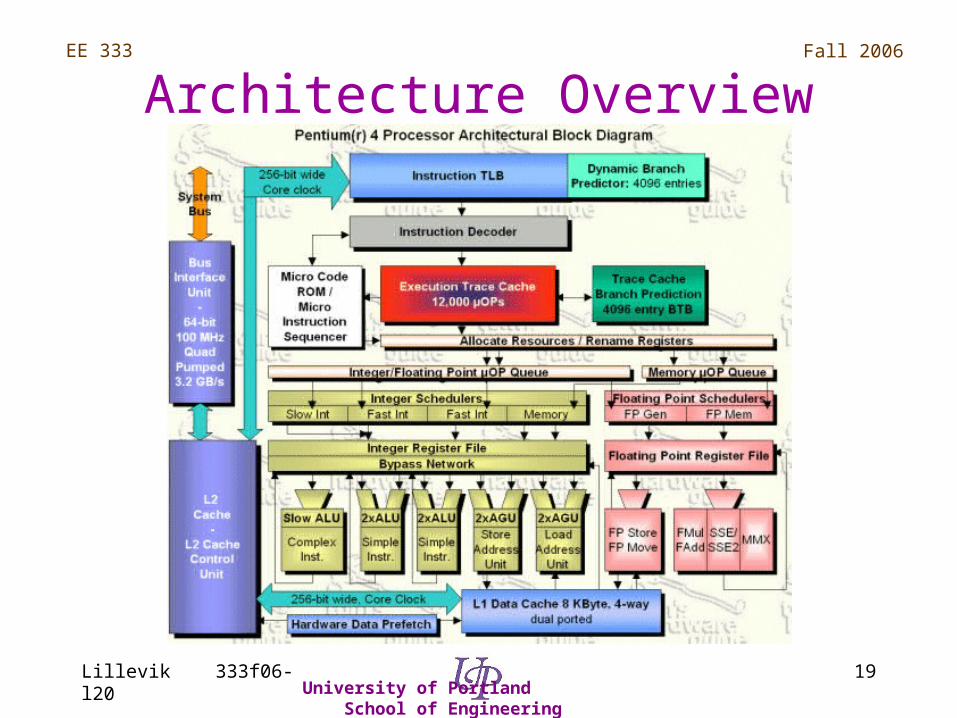
NetBurst Architecture
• Faster system bus• Advanced transfer cache • Advanced dynamic execution (execution
trace cache, enhanced branch prediction) • Hyper pipelined technology • Rapid execution engine • Enhanced floating point and multi-media
(SSE2)
Fall 2006
Lillevik 333f06-l20 19University of Portland School of Engineering
EE 333
Architecture Overview
Fall 2006
Lillevik 333f06-l20 20University of Portland School of Engineering
EE 333
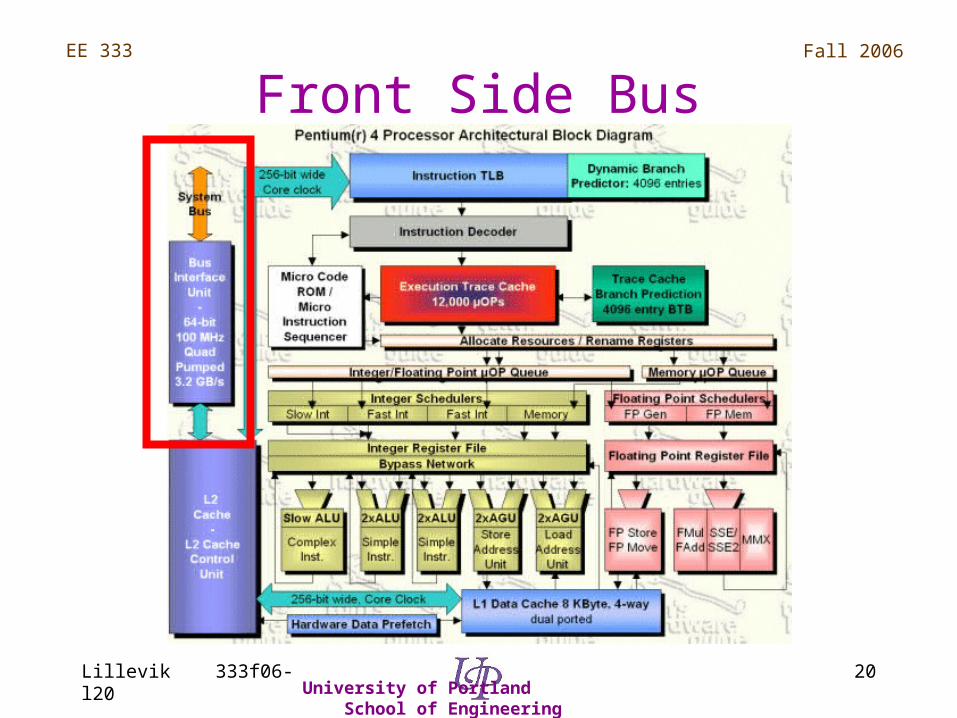
Front Side Bus

Fall 2006
Lillevik 333f06-l20 21University of Portland School of Engineering
EE 333
FSB Bandwidth
• Clocked at 100 MHz, quad “pumped”
• 128 B cache lines, 64-bit (8 B) accesses• Split transactions, pipelined• External bandwidth: 100M x 8 x 4 = 3.2 GB/s• Makes better use of bus bandwidth
Clock A
Clock B

Fall 2006
Lillevik 333f06-l20 22University of Portland School of Engineering
EE 333
L2 Advanced Transfer Cache

Fall 2006
Lillevik 333f06-l20 23University of Portland School of Engineering
EE 333
Full-Speed L2 Cache
• Depth of 256 KB• Eight-way set associative, 128 B line• Wide instruction & data interface of 256 bits (32
B)• Read latency of 7 clocks, but …• Clocked at core frequency (2.0 GHz)• Internal bandwidth, 32 x 2.0 G = 64 GB/s• Optimizes data transfers to/from memory
Fall 2006
Lillevik 333f06-l20 24University of Portland School of Engineering
EE 333
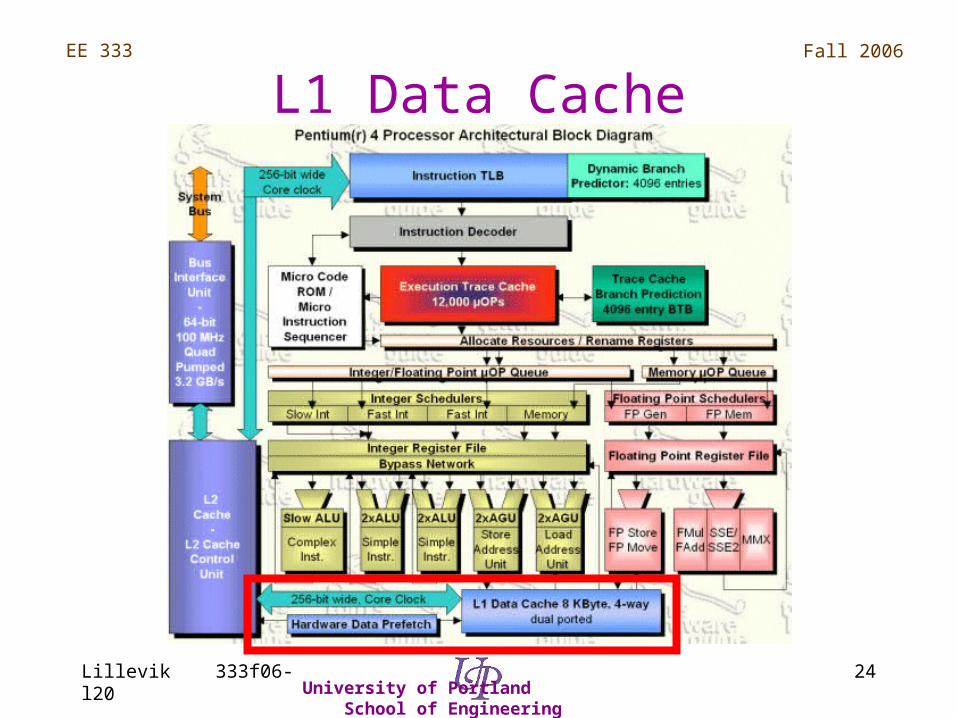
L1 Data Cache

Fall 2006
Lillevik 333f06-l20 25University of Portland School of Engineering
EE 333
L1 Data Cache
• Depth of 8 KB
• Four-way, set associative, 64 B line
• Read latency of 2 clocks, but ….
• Dual port for one load & one store-per-clock
• Supports advanced pre-fetch algorithm
Fall 2006
Lillevik 333f06-l20 26University of Portland School of Engineering
EE 333
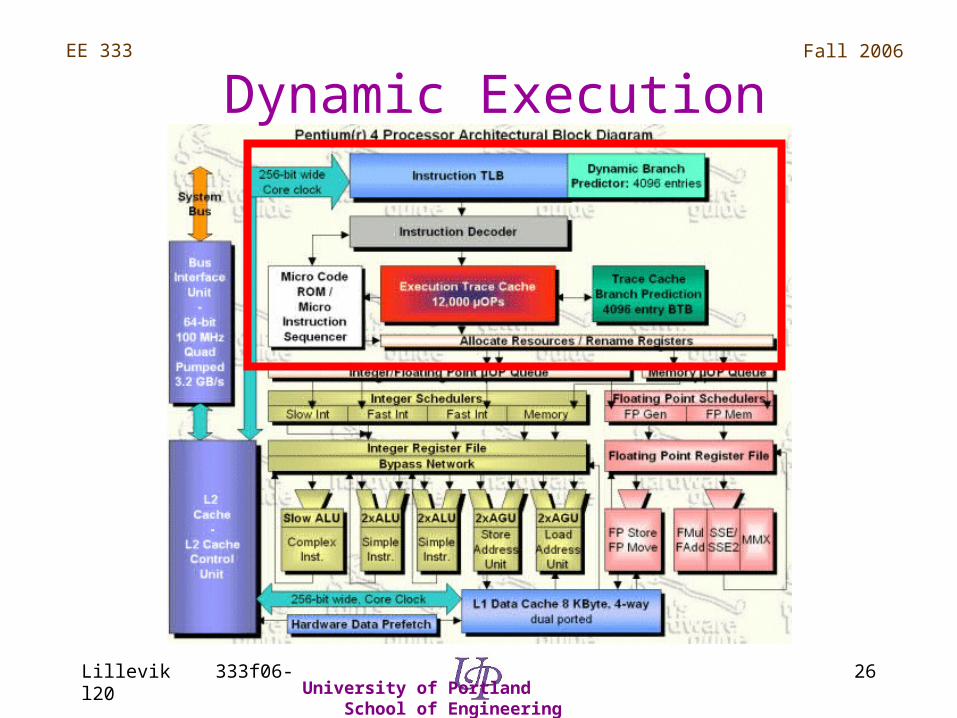
Dynamic Execution

Fall 2006
Lillevik 333f06-l20 27University of Portland School of Engineering
EE 333
Trace Cache & Branch Prediction
• Replaces traditional L1 instruction cache• Trace cache contains ~12K decoded
instructions (micro-operations), removes decode latency
• Improved branch prediction algorithm, eliminates 33% of P3 mis-predictions (pipeline stalls)
• Keeps correct instructions executing
Fall 2006
Lillevik 333f06-l20 28University of Portland School of Engineering
EE 333
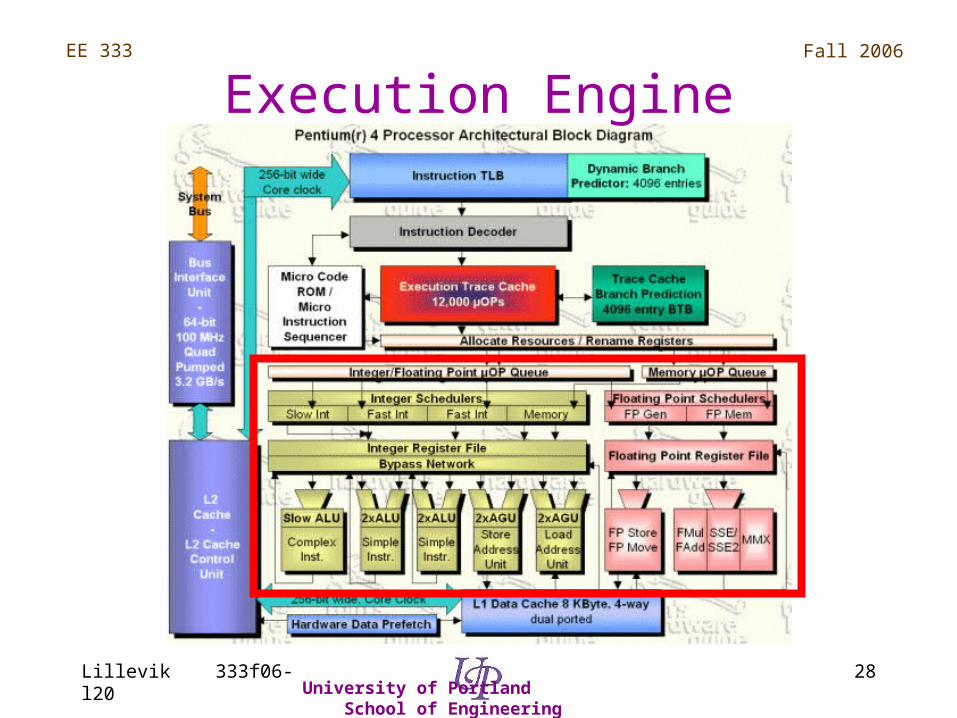
Execution Engine

Fall 2006
Lillevik 333f06-l20 29University of Portland School of Engineering
EE 333
Hyper Pipelined Technology
• Execution pipeline contains 20 stages– Out-of-order, speculative execution unit
– 126 instructions “in flight”
– Includes 48 load, 24 stores
• Rapid execution engine– 2 ALUs, 2X clocked (one instruction in ½ clock)
– 2 AGUs, 2X clocked
• Results in higher throughput and reduced latency

Fall 2006
Lillevik 333f06-l20 30University of Portland School of Engineering
EE 333
Streaming SIMD Extensions
• FPU and MMX– 128-bit format– AGU data movement register
• SSE2 (extends MMX and SSE)– 144 new instructions– DP floating-point– Integer– Cache and memory management
• Performance increases across broad range of applications

Fall 2006
Lillevik 333f06-l20 31University of Portland School of Engineering
EE 333

Fall 2006
Lillevik 333f06-l20 32University of Portland School of Engineering
EE 333
Find the laundry speedup?
parallel
series
TT
S
29.25.3
8 hrs
hrs

Fall 2006
Lillevik 333f06-l20 33University of Portland School of Engineering
EE 333
Find the MIPS pipeline speedup?
8.2925
parallel
series
TT
S
5N nseriesIT
54321IIIII
55555
25
5N npipeIT
11115
9
Assume five instructions

Fall 2006
Lillevik 333f06-l20 34University of Portland School of Engineering
EE 333
Speedup of pipeline with p stages?
parallel
series
TT
S NN nseries
TTTT ...1
pN
NN nparallelTTTT ...
1
1...1 p
)1( Np
NNp
pNp
pN1
1)1(
pp
SN
010
lim
Series
Parallel
Related Documents











