Evolutionary feature selection and electrode reduction for EEG classification Adham Atyabi, Martin Luerssen, Sean Fitzgibbon, David M. W. Powers School of Computer Science, Engineering, and Mathematics, Flinders University, Adelaide, Australia {Adham.Atyabi, Martin.Luerssen,Sean.Fitzgibbon, David.Powers}@flinders.edu.au Abstract—EEG signals usually have a high dimensionality which makes it difficult for classifiers to learn the difference of various classes in the underlying pattern in the signal. This paper investigates several evolutionary algorithms used to reduce the dimensionality of the data. The study presents electrode and feature reduction methods based on Genetic Algorithms (GA) and Particle Swarm Optimization (PSO). Evolution-based methods are used to generate a set of indexes presenting either electrode seats or feature points that maximizes the output of a weak classifier. The results are interpreted based on the dimensionality reduction achieved, the significance of the lost accuracy, and the possibility of improving the accuracy by passing the chosen electrode/feature sets to alternative classifiers. I. I NTRODUCTION Electroencephalography (EEG) is the human brain signal recorded from the scalp. The signal originates from the cortex and reflects surface potential variation. EEG based Brain Computer Interface (BCI) systems use EEG signals to identify patterns associated with predefined brain activity. To be able to have an EEG based BCI system capable of recognizing subject’s intention in an on-line (asynchronous) mode, it is necessary to minimize the dimension of the data so that the used classifiers can learn the underlying pattern in a shorter time. This dimension reduction should be done in a way that prevents important data points that maximize the classifier’s performance from being omitted. It is thus potentially useful to explore the information provided by different parts of an epoch 1 , and automatically select subsets of features from the epoch that best represent the performed task. This is called Feature Reduction/Selection (FR). Another method for improving the accuracy of classi- fication is to only include the signal of electrodes that best represent the subject’s intention. This process is called Elec- trode Selection/Reduction (ER). Electrode reduction mainly focuses on the use of electrodes and scalp locations that best represent the subject’s intention and have a high contribution to classification accuracy. This can be achieved through neuro- scientific and psychological knowledge, yet different subjects may have different reactions toward the tasks, and the optimal electrode set for specific tasks may also vary among sub- jects. Decomposition based methods such as Common Spatial Pattern (CSP), Principle Component Analysis (PCA), and 1 “Epoch” usually refers to a prefixed time duration within the EEG signal that represents a performed task by a subject Singular Value Decomposition (SVD) are common choices for feature and electrode reduction. However, since their usage depends on having the entire trial duration (all epochs), they are not appropriate for real time systems, and the reduction is mostly based on isolating a set of features or electrodes that improve a certain criteria while they do not take in to the account the feasibility of the selected set with the classifiers. This means that even though the decomposed set represents a data subset that typically contains the greatest proportion of variance across data points, there is no guarantee that this subset improves the classification performance, since their selection is not based on consideration of their interaction with the classifier’s learning rule. Considering the aforementioned general problems and am- biguities that exist within the extracted signal and its feature extraction and classification process, it is possible to model the EEG data as a set of data-points that follow some patterns with some degree of randomness. Given the high level of dynamism in the EEG signal, it would be an appropriate sug- gestion to address the problem of distinguishing these patterns from each other using theories that in particular address the dynamic probability optimization. This reasoning guides us toward Evolutionary Algorithms (EA) in which a performance function – the population generator function – attains one or more optima under the influence of some predefined as- sessment criteria, collectively representing the fitness function. Complexities such as search dynamism, uncertainty, and the multi-objective nature of the targeted optimization can be addressed using different types of population generators and fitness functions. Popular EA-based methods include Genetic Algorithms (GA) and Particle Swarm Optimization (PSO), which offer researchers extensive flexibility in accommodating different search optimization behaviors. This study investigates the potential of EA based approaches for feature and electrode reduction. This is done by providing comparisons between GA based, PSO based, and random search based electrode and feature reduction methods on a set of subjects performing motor imagery tasks. The designed procedure is demonstrated in Fig. 1. In the study, the Feature- Electrode Reduction step of the flowchart is implemented using a variety of methods such as Binary GA based feature / electrode reduction, PSO based feature reduction, and random based feature / electrode reduction. Section II introduces the used datasets and explains the pre- U.S. Government work not protected by U.S. copyright WCCI 2012 IEEE World Congress on Computational Intelligence June, 10-15, 2012 - Brisbane, Australia IEEE CEC

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Evolutionary feature selection and electrodereduction for EEG classification
Adham Atyabi, Martin Luerssen, Sean Fitzgibbon, David M. W. PowersSchool of Computer Science, Engineering, and Mathematics,
Flinders University, Adelaide, Australia{Adham.Atyabi, Martin.Luerssen,Sean.Fitzgibbon, David.Powers}@flinders.edu.au
Abstract—EEG signals usually have a high dimensionalitywhich makes it difficult for classifiers to learn the differenceof various classes in the underlying pattern in the signal. Thispaper investigates several evolutionary algorithms used to reducethe dimensionality of the data. The study presents electrode andfeature reduction methods based on Genetic Algorithms (GA) andParticle Swarm Optimization (PSO). Evolution-based methodsare used to generate a set of indexes presenting either electrodeseats or feature points that maximizes the output of a weakclassifier. The results are interpreted based on the dimensionalityreduction achieved, the significance of the lost accuracy, andthe possibility of improving the accuracy by passing the chosenelectrode/feature sets to alternative classifiers.
I. INTRODUCTION
Electroencephalography (EEG) is the human brain signalrecorded from the scalp. The signal originates from the cortexand reflects surface potential variation. EEG based BrainComputer Interface (BCI) systems use EEG signals to identifypatterns associated with predefined brain activity. To be ableto have an EEG based BCI system capable of recognizingsubject’s intention in an on-line (asynchronous) mode, it isnecessary to minimize the dimension of the data so that theused classifiers can learn the underlying pattern in a shortertime. This dimension reduction should be done in a way thatprevents important data points that maximize the classifier’sperformance from being omitted.
It is thus potentially useful to explore the informationprovided by different parts of an epoch1, and automaticallyselect subsets of features from the epoch that best representthe performed task. This is called Feature Reduction/Selection(FR). Another method for improving the accuracy of classi-fication is to only include the signal of electrodes that bestrepresent the subject’s intention. This process is called Elec-trode Selection/Reduction (ER). Electrode reduction mainlyfocuses on the use of electrodes and scalp locations that bestrepresent the subject’s intention and have a high contributionto classification accuracy. This can be achieved through neuro-scientific and psychological knowledge, yet different subjectsmay have different reactions toward the tasks, and the optimalelectrode set for specific tasks may also vary among sub-jects. Decomposition based methods such as Common SpatialPattern (CSP), Principle Component Analysis (PCA), and
1“Epoch” usually refers to a prefixed time duration within the EEG signalthat represents a performed task by a subject
Singular Value Decomposition (SVD) are common choices forfeature and electrode reduction. However, since their usagedepends on having the entire trial duration (all epochs), theyare not appropriate for real time systems, and the reductionis mostly based on isolating a set of features or electrodesthat improve a certain criteria while they do not take in to theaccount the feasibility of the selected set with the classifiers.This means that even though the decomposed set represents adata subset that typically contains the greatest proportion ofvariance across data points, there is no guarantee that thissubset improves the classification performance, since theirselection is not based on consideration of their interaction withthe classifier’s learning rule.
Considering the aforementioned general problems and am-biguities that exist within the extracted signal and its featureextraction and classification process, it is possible to modelthe EEG data as a set of data-points that follow some patternswith some degree of randomness. Given the high level ofdynamism in the EEG signal, it would be an appropriate sug-gestion to address the problem of distinguishing these patternsfrom each other using theories that in particular address thedynamic probability optimization. This reasoning guides ustoward Evolutionary Algorithms (EA) in which a performancefunction – the population generator function – attains oneor more optima under the influence of some predefined as-sessment criteria, collectively representing the fitness function.Complexities such as search dynamism, uncertainty, and themulti-objective nature of the targeted optimization can beaddressed using different types of population generators andfitness functions. Popular EA-based methods include GeneticAlgorithms (GA) and Particle Swarm Optimization (PSO),which offer researchers extensive flexibility in accommodatingdifferent search optimization behaviors.
This study investigates the potential of EA based approachesfor feature and electrode reduction. This is done by providingcomparisons between GA based, PSO based, and randomsearch based electrode and feature reduction methods on aset of subjects performing motor imagery tasks. The designedprocedure is demonstrated in Fig. 1. In the study, the Feature-Electrode Reduction step of the flowchart is implementedusing a variety of methods such as Binary GA based feature /electrode reduction, PSO based feature reduction, and randombased feature / electrode reduction.
Section II introduces the used datasets and explains the pre-
U.S. Government work not protected by U.S. copyright
WCCI 2012 IEEE World Congress on Computational Intelligence June, 10-15, 2012 - Brisbane, Australia IEEE CEC

EEG DataAcquisition
Pre-Processing
Apply n ×k-fold CV
Createtraining,
testing, andvalidationsets using90%, 5%,and 5%ratios
Feature /ElectrodeReduction
Classificationis
k ≤ 20?
k← k+1
isn ≥ 10?
n← n+1;k← 0;
stop
no
yes
yes
no
Fig. 1. The applied steps for EEG data processing
processing stages that are taken before applying EA basedmethods. The used EA based approaches and their pseudocoderepresentations are presented in section III. The experimentsand the results are discussed in IV and V. Section VI containsthe discussion and the conclusion.
II. DATASET AND PRE-PROCESSING
This study uses BCI competition III dataset IVa [1]. Thedataset contain 3.5s of motor imagery tasks performed by 5healthy subjects over 280 trials. Even though the visual cuewas presented to subjects for the total amount of 3.5s, thebeginning and end 0.5s can be ignored since they representthe transition time during which subject is changing its statefrom non-task to task and from task to non-task. Therefore, itis reasonable to omit the first and last 0.5s and only use themiddle 2.5s for classification. The used datasets contain EEGrecordings from 118 channels for 2.5s over 280 trials/super-epochs with 1000Hz sample rate. In order to provide consis-tency with other studies done on the same dataset [2], [3],the 2.5s superepochs are divided into five 0.5s sub-epochs.Frequency features (Abs-DFT) are extracted and an Extreme
Learning Machine (ELM) is used as a primary classifier. Thechoice of using frequency features is based on consistentperformance observed in several previous experiments doneon the same datasets. Considering the massive amount ofevaluation needed to assess the quality of the populationof possible solutions in each iteration, ELM is used as theprimary classifier due to its fast learning capability [4], [5].Additionally, a Polynomial SVM and a modified Perceptronthat takes advantage from early stopping are used for furtherevaluation of findings. All experiments are done based on10 repetitions of 20-fold Cross-Validation (CV). BookmakerInformedness [6] is used for assessment of the feasibilityof the approaches. It quantifies how informed a classifier isfor the specified condition, and specifies the probability thata classifier is informed in relation to the condition (versuschance). Lillie-test and Kruskal-Wallis and n-Way ANOVAare used to assess the significance of findings.
III. METHODS
In this study, Genetic Algorithm (GA), Particle Swarmoptimization (PSO), and Random search are use to selectthe set of electrodes/features that best represent the subject’sintention. The scope of this investigation incorporates GAand Random based Electrode reduction, and GA, PSO, andRandom based Feature reduction.
A. Genetic Algorithm (GA) based feature / electrode reduc-tion:
Genetic Algorithms were first developed by John Hollandin 1975 [7]. Holland’s evolutionary method involved naturalselection, crossover, and mutation [8]. GA has been success-fully applied to various problems where the main objectiveis to optimize or select the best solution out of a numberof possible solutions such as the classical traveling salesmanproblem, flow-shop optimization, and job shop scheduling [9].
Algorithm 1 offers pseudocode for the GA based feature /electrode reduction performed in this study. Each member ofthe population represents a mask containing indices represent-ing features or electrodes from feature or electrode space. Themask size for each member of the population is equivalentto the number of feature-time samples in each sub-epoch2 orthe number of electrode locations in the dataset3. Here, thepopulation size is equal to 100 and maximum iteration is setto 100 iterations.
To clarify a flowchart of the Binary GA feature / electrodereduction is illustrated in Fig. 2.
B. PSO based feature reduction:
Particle swarm optimization (PSO) is a population-based,self-organized, unsupervised learning algorithm inspired by
2Since we used Abs-FFT (complex frequency features) for 0.5s sub-epochswith 1000Hz sample rate, the mask would be a vector of 0 and 1 with thesize of 250. The choice of the frequency features is due to showing consistentresults with this dataset among several studies [2], [11]
3Since the dataset contains 118 electrode channels, the binary mask size forelectrode reduction is equal to 118 (0 and 1 indicating omission and selectionof the electrode respectively).

Initialization:Pop-
size=100,CurrIt=1,
MaxIt=100
Generaterandommasks
of 0 and1 by the
dimensionof feature/ electrode
vector
Evaluation:assess
the initialpopulation
by applyingthe masks
to thetrainingand the
validationset andusing
Sig ELM
select thetop 50%
of thepopulation
basedon theirachievedinformed-ness in theprevious
step
UseCrossoveroperant toregeneratethe new
population
Mutatation
Evaluation:assess thepopulation
by applyingthe masks
to thetrainingand the
validationset andusing
Sig ELM
CurrIt←CurrIt+1
is bestmask’s
informde-ness ≥ 0.9or CurrIt≥
MaxIt?
FinalEvaluation:
re-assessthe bestmask byapplyingit to thetrainingand the
testing setand usingSig ELM,PSVM anda modifiedPerceptron
stop
no
yes
Fig. 2. Binary GA Feature / Electrode Reduction flowchart. CurrIt, MaxIt,Pop-Size, Sig ELM, and PSVM represent Current Iteration, Maximum Itera-tion, Population size, Sigmoid ELM, and Polynomial SVM respectively.
Algorithm 1 Binary GA pseudocode for feature & electrodereduction
Initialization: Randomly initialize the population by creating bi-nary masks of 0 and 1 (i.e., omitting and selecting the features /electrodes, respectively).Initial Evaluation: Evaluate all members of the population byapplying their masks to the training and the validation sets andassess the performance using a Sigmoid ELM.repeat
Selection: Sort the population based on their classificationperformance and eliminate the lesser half.Crossover: Crossover the remaining masks to regenerate thepopulationMutation: Replace a mask with a random one if it did notimprove after m number of iterations (here, m = 10% ofmaximum iterations (100)).Evaluation: Evaluate all members of the population by applyingtheir masks to the training and the validation sets and asses theperformance using Sigmoid ELM.
until (Termination: the maximum iteration is achieved or the bestmember of the population is performing above 0.9 informedness)Final Evaluation: Select the best member of the population (basedon previous evaluation results) and apply its mask to the trainingand testing sets.
animal social behavior. PSO favors a global optimum dueto the use of particles that influence the social and cognitivebehaviors of the swarm.
In basic PSO, particles are defined based on their positionand their velocity in the search space denoted as Xi,j and Vi,j
where i represents the particle’s index and j is the dimension inthe search space. Particles fly through the virtual space and areattracted to positions (e.g., local and global-best positions) inthe search space that yield the best results [13]. These positionsin the search space are solutions, and the global optimum is theglobal best solution (position) achieved by the entire swarm.The following equations are defined to address Xi,j and Vi,j
in basic PSO.
Vi,j(t) = w ∗ Vi,j(t− 1) + Ci,j + Si,j
Ci,j = c1r1,j ∗ (pi,j(t− 1)− xi,j(t− 1))Si,j = c2r2,j ∗ (gi,j(t− 1)− xi,j(t− 1))
(1)
xi,j(t) = xi,j(t− 1) + Vi,j(t) (2)
In the velocity equation, r1,j and r2,j are different randomvalues in the range between 0 and 1. c1 and c2 are accelerationcoefficients that control the effectiveness of social and cogni-tive components and w is the inertia weight. In basic PSO,a particle’s memory contains local and global-best positions.The local-best position (pi,j ) is the position in which theyachieved their highest performance (personal best solution).Global-best position (gi,j ) is the best overall position of theswarms.
pi(t) =
{pi(t− 1) if f(xi(t)) >= f(pi(t− 1))xi(t) otherwise
(3)g(t) = argmin {(p1(t)), f(p2(t)), ...f(ps(t))} (4)

Various neighborhood topologies are defined to addressbasic PSO’s particles interactions and knowledge sharing.The most well-known neighborhood topologies are local4 andglobal5 neighborhood topologies. In a local neighborhood,each particle has preset connections with a group of subsetparticles (particles with closest indexes) [14]. In a globalneighborhood, all particles of the swarm are connected to eachother [16]. Local neighborhoods are said to converge morequickly towards optima (local or global optimum), whereasglobal neighborhoods promote global optimum convergence,although the convergence is slow [15].
In basic PSO, inertia weight controls the impact of previousvelocity (decision) on the solution finding task. Hence, largeand small values of inertia weight favor exploration (avoidinglocal-minima) and exploitation (converging toward the optimalsolution), respectively6.
Algorithm 2 represents a PSO based feature reduction.Similar to the GA, each member of the population (particle)represent a mask with a predefined size. Unlike the GA imple-mentation, the mask is a matrix of (number of channels*30)7.That is, each row in the mask represents indices of 30features chosen to represent a feature vector for that particularelectrode. The idea is to find a set of features (indices in time-frequency dimension) for each electrode that best representthe performed task during each sub-epoch recorded by thatelectrode.
To provide consistency between GA and PSO structuraldesign, it is possible to imagine the PSO’s structure as a twolevel structure in which each mask can be seen as a swarmof particles in a way that each particle in the swarm representa set of features for a specific electrode. In that notation, thepopulation size is set to 100 (number of masks), the swarmsize (number of particles) is set to 118 (equal to the number ofchannels/electrodes in each dataset) and the particle dimensionis set to 30 (set of indexes that are representing the chosenfeatures for a particular electrode). The particles are allowedto leave the search space by the use of large velocity valuesin equation 1 and 2 but they are mapped back to the properdimensions before evaluation. That is to guarantee that thechosen indexes in each mask in each particle is legit. Themaximum iteration is set to 100 iterations.
This PSO design provides more variance among the chosenfeatures on electrodes inside each mask. Unlike the GAimplementation in which the same feature indexes are usedfor all electrodes (in the feature reduction version), in ourPSO design different electrodes can contain different featureindices. In addition, in the PSO, the evaluation is done foreach swarm separately (that is, different features selected fordifferent electrodes are patched together and assessed as onemask based on their classification performance) while in theGA design, the evaluation is explicitly done on the selected
4Also known as local best, Lbest, and ring topology [14].5Also known as global best, Gbest, and star topology [16].6It is recommended to initialize the algorithm with a high inertia weight
and linearly decrease the value during the iterations [12]7This value is selected arbitrarily.
TABLE ITHE INITIAL SETUP OF PSO
Parameters The Value The Adjustment Methodc1 0.5 Fixed Acceleration Coefficientc2 0.5 (FAC)w1 0.2 Linearly Decreasing Inertia Weightw2 1 (LDIW)
feature indices. The used parameter adjustment is presented intable I.
Algorithm 2 PSO pseudecode for feature reductionInitialization: Randomly initialize the population by creating bi-nary mask of indexes ∈ [1, 250].Initial Evaluation: Evaluate all members of the population byapplying their masks to the training and the validation sets andassess the performance using Sigmoid ELM.repeat
Updating the population: Update the velocity in each particleusing equation 1 and update the mask by applying the newvelocity to equation 2.Evaluation: Evaluate all members of the population by applyingtheir masks to the training and the validation sets and asses theperformance using Sigmoid ELM.Update Bests: Update Personal (pi,j) and Global Best (g)particles using equation 3 and 4 and current informedness resultsof particles.
until (Termination: the maximum iteration is achieved or the bestmember of the population (Global Best) is performing above 0.9informedness)Final Evaluation: Evaluate Global Best’s mask by applying it tothe training and testing sets.
For more clarity of the used approach, a flowchart of thePSO based feature reduction is illustrated in Fig. 3. Eventhough the used values for parameter settings in both GAand PSO are selected in an arbitrary fashion, some limitedexperiments with other parameter settings are conducted toensure the properness of the chosen settings.
C. Random Search for feature / electrode reduction:
Similar to GA and PSO, Random Search creates a pop-ulation of masks containing indexes of the electrodes orfeatures. The population size is set to 100 and the maximumiteration is set to 100 iterations. In each new iteration, only themember of the population (the mask) that achieved the highestperformance is maintained and the rest of the population arerandomly generated. Unlike GA in which on average only 50%of feature or electrode dimension is reduced, in the randomsearch, the mask size is set to 30 features and 10 electrodesfor feature and electrode reduction respectively (approximately90% reduction). The choice of using only 30 features and 10electrodes for random based feature/electrode reduction wasmade arbitrarily.
IV. EXPERIMENTS
In this study, a 10*20 CV (cross validation) is used toevaluate the impact of each method on each subject.
At first, the data is divided into 3 sets of training, validationand testing containing 90%, 5% and 5% of the samples

Initialization:Pop-
Size=100,CurrIt=1,
MaxIt=100,mask-
dimension=30
Generaterandommasks
containing30 feature
indexes∈ [1, 250]
Evaluation:assess
the initialpopulation
by applyingthe masks
to thetrainingand the
validationset andusing
Sig ELM
Update thepopulationusing Eq.1 and 2
Evaluation:assess thepopulation
by applyingthe masks
to thetrainingand the
validationset andusing
Sig ELM
UpdateGlobal
Best andPersonal
best masksusing Eq.4 and 3,
CurrIt←CurrIt+1
is GlobalBest
mask’sinformde-
ness ≥ 0.9or CurrIt≥
MaxIt?
FinalEvaluation:
re-assessthe best
mask(Global
Best ) byapplyingit to thetrainingand the
testing setand usingSig ELM,PSVM anda modifiedPerceptron
stop
no
yes
Fig. 3. PSO based Feature Reduction flowchart. CurrIt, MaxIt, Pop-Size, SigELM, and PSVM represent Current Iteration, Maximum Iteration, Populationsize, Sigmoid ELM, and Polynomial SVM respectively.
respectively. The CVs are done in a way that an instancefrom the same super-epoch (0.5s sub epochs coming froma 2.5s super-epoch) only appears in one out of three sets(training, validation or testing); under no circumstance is anyset contaminated with samples of another set.
In each fold, the training set is used to generate a chosenset of indexes (called Mask) representing electrode or featurepoints that best represent the performing task. Each memberof the population constitutes a mask that is generated basedon the criteria indicated by the used method. The quality ofthese masks are assessed by applying them on the training andthe validation sets and using the informedness results of theExtreme Learning Machine (ELM) (with Sigmoid activationfunction). In all experiment, the number of hidden nodes inELM is set to 80. This decision is made based on the heuristicthat this was twice the number that was determined to be
optimum for Single layer back propagation NN (SLBPNN) in[3] with the same dataset. After determining that preliminarytests with up to 200 nodes showed no significant differencegiven the extra computation time required. The choice ofSigmoid activation function is made based on its consistentperformance in different experiments with this dataset.
This procedure is used to direct the population towardgenerating masks that improve the performance (during somenumber of iterations) on the validation sets. In the final stage,the chosen mask (the mask that achieved the best performancein the population) is applied to the training and the testing setsto evaluate the performance on samples that were not involvedin the mask generating procedure. That is to further assessgeneralizability of the chosen features/electrodes on a sub-setof the data from the same subject on the same set of tasks. Atthis final evaluation stage, two extra classifiers (PolynomialSupport Vector Machine (SVM) and a modified Perceptronwith early stopping) are introduced to investigate the possibil-ity of improving the performance by the use of different (andstronger, in the case of the SVM) learners, based on a maskthat is customized for a different learner (ELM). BookmakerInformedness is used for assessing the performance because itis indeed more informative in comparison to accuracy, recallor precision, as it takes specificity and sensitivity into account.A further discussion of Informedness can be found in [6].
The following experiments are designed:
A. Experiment 1
This experiment assesses the impact of dimension reductionthrough the use of masks generated by an evolutionary ap-proach. The comparison is made based on the relative amountof data reduction, the loss of informedness in classifiers, andthe re-usability of the masks (in terms of being used fordifferent classifiers) generated by different methods.
B. Experiment 2
This experiment is designed to investigate the generalizabil-ity of the masks evolved by different methods. To do so, foreach subject, the best overall mask (i. e., the mask that reachedto the highest performance across all folds and repetitions) andthe Common Mask (a mask that represent the most chosenelectrode or feature indexes across all masks in all folds andrepetitions) are used with a 10 fold CV on polynomial SVM,sigmoid ELM and Perceptron with early stopping.
V. RESULTS
A. Experiment 1
Table II and Fig 4 represents the impact of electrodeand feature reduction using EA based methods. Here, threemethods of random search, GA and PSO are used for featureand electrode reduction denoted as FR and ER respectively.To facilitate better understanding, a test with no dimensionreduction is added. The results presented in Table II depictthe averaged informedness achieved by methods using trainingand validation sets and Sigmoid ELM as the classifier. In allsubjects and across all methods the used reduction methods

TABLE IITHE AVERAGED INFORMEDNESS ACHIEVED ON VALIDATION SET USING
SIGMOID ELM.
Subject Full-Set GA based Random based PSOER FR ER FR based FR
AA 0.09 0.33 0.31 0.44 0.44 0.46AL 0.30 0.47 0.39 0.58 0.57 0.55AV 0.10 0.34 0.32 0.44 0.44 0.47AW 0.18 0.39 0.34 0.49 0.49 0.49AY 0.09 0.39 0.35 0.54 0.53 0.52
improve the classification informedness results. Since in eachiteration the achieved informedness result on the validationset throughout the population is used as a reference for theselection of a sub-set of population for the next generation(except in random search), it can be concluded that the learninginside the used evolutionary methods is influenced by thevalidation set. Despite the fact that such results are reportedin several studies [17],[18],[19], and [20] it is possible toconsider this as a case of contamination between the trainingand evaluation sets. To avoid such scenario, a final evaluationstep is conducted in which the training and testing sets areused to evaluate the results using Sigmoid ELM (the classifierthat the EA approaches outcomes are customized on) and twoalternative classifiers (Polynomial SVM and Perceptron). Thetesting set is a sub-set of the data that has not been used inany of the population regeneration steps. This can also providebetter insight about the generalizability of EA’s outputs. Thisstep is denoted as the Final Evaluation in EA based algorithms(Algorithm 1 and 2) and flowcharts (Fig 2, 3).
Fig 4 describes 6 sets; among which the first 5 illustrate theoutcome on individual subjects while the sixth (right bottom)represents the average results across 5 subjects.
The results with Sigmoid ELM indicate a lack of gener-alized and net loss of informedness in almost all subjectsusing Sigmoid ELM as classifier (subject ay is the apparentexception). In all subjects, electrode reduction (ER) had agreater impact on classification performance compared tofeature reduction (FR), and the combination of polynomialSVM and GA based ER performed better than all othermethods except the combination of the use of the full-setwith polynomial SVM. The results illustrate the possibilityof improving the performance through the use of alternativelearners across all subjects and all methods. Table III presentthe best average informedness result achieved on testing setwith Polynomial SVM by either of reduction methods andevolutionary approaches. The choice of Polynomial SVM isdue to its results’ superiority in most cases. PSO and GA basedFR methods achieved similar performance across all subjects.
B. Experiment 2
In this experiment, for each subject, two new masks rep-resenting the best mask and common mask are assessedusing various classifiers. In each subject, the best mask ischosen based on the achieved performance in different foldsof experiment 1 using the sigmoid ELM. In each subject, thecommon mask represents the most chosen indexes by either
Fig. 4. Comparison of EA based methods across different subjects. Thedimensions of the EEG data are first reduced by the combination of an EAmethod and a Sigmoid ELM (weak classifier), and subsequently the reduceddimension signal is passed to a different classifier (polynomial SVM andmodified Perceptron with early stopping). Feature reduction and electrodereduction are denoted as FR and ER respectively.
TABLE IIITHE BEST AVERAGED INFORMEDNESS ACHIEVED ON TESTING SET USING
POLYNOMIAL SVM.
Subject Full-Set GA based Random based PSOER FR ER FR based FR
AA 0.38 0.22 0.18 0.19 0.08 0.1AL 0.72 0.60 0.38 0.51 0.4 0.41AV 0.22 0.20 0.13 0.15 0.10 0.11AW 0.58 0.40 0.22 0.30 0.23 0.2AY 0.51 0.41 0.26 0.38 0.21 0.26
of the feature/electrode reduction methods across all foldsand repetitions. The results of a set of experiments withoutany dimension reduction is added to the figure for moreclarity. The results in figs 5 and 6 illustrate the possibility offurther improving the performance using either the best overallmask or the common mask. This suggests a certain degree ofgenerality of the created mask, i.e., it should be possible tocreate the mask for a subject once and reuse it for the futuresessions with the same subject.
The results indicate significance for p < 0.0005 among EAbased feature and electrode reduction methods and for p <0.05 between the best mask and the common mask and alsofor p < 0.05 between different subjects. The interaction ofsubjects and EA based reduction methods is not significantwith p > 0.5.
Fig 7 and 8 represent the selected electrodes by GA and
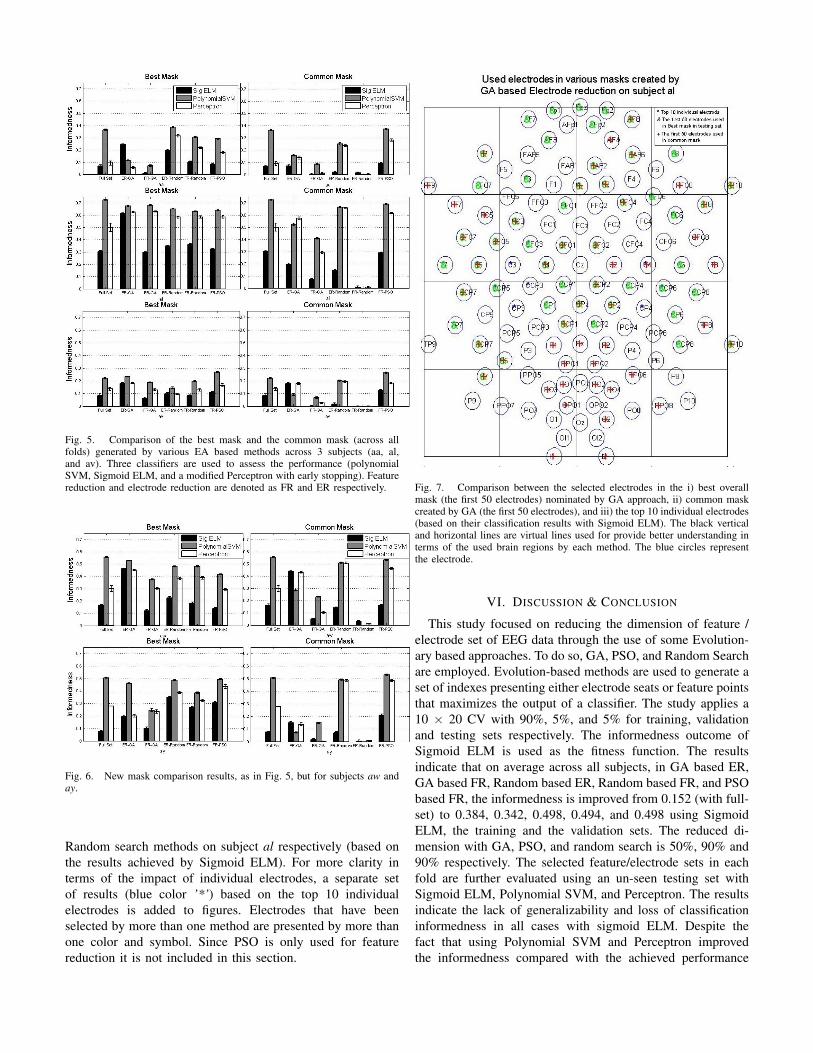
Fig. 5. Comparison of the best mask and the common mask (across allfolds) generated by various EA based methods across 3 subjects (aa, al,and av). Three classifiers are used to assess the performance (polynomialSVM, Sigmoid ELM, and a modified Perceptron with early stopping). Featurereduction and electrode reduction are denoted as FR and ER respectively.
Fig. 6. New mask comparison results, as in Fig. 5, but for subjects aw anday.
Random search methods on subject al respectively (based onthe results achieved by Sigmoid ELM). For more clarity interms of the impact of individual electrodes, a separate setof results (blue color ’*’) based on the top 10 individualelectrodes is added to figures. Electrodes that have beenselected by more than one method are presented by more thanone color and symbol. Since PSO is only used for featurereduction it is not included in this section.
Fig. 7. Comparison between the selected electrodes in the i) best overallmask (the first 50 electrodes) nominated by GA approach, ii) common maskcreated by GA (the first 50 electrodes), and iii) the top 10 individual electrodes(based on their classification results with Sigmoid ELM). The black verticaland horizontal lines are virtual lines used for provide better understanding interms of the used brain regions by each method. The blue circles representthe electrode.
VI. DISCUSSION & CONCLUSION
This study focused on reducing the dimension of feature /electrode set of EEG data through the use of some Evolution-ary based approaches. To do so, GA, PSO, and Random Searchare employed. Evolution-based methods are used to generate aset of indexes presenting either electrode seats or feature pointsthat maximizes the output of a classifier. The study applies a10 × 20 CV with 90%, 5%, and 5% for training, validationand testing sets respectively. The informedness outcome ofSigmoid ELM is used as the fitness function. The resultsindicate that on average across all subjects, in GA based ER,GA based FR, Random based ER, Random based FR, and PSObased FR, the informedness is improved from 0.152 (with full-set) to 0.384, 0.342, 0.498, 0.494, and 0.498 using SigmoidELM, the training and the validation sets. The reduced di-mension with GA, PSO, and random search is 50%, 90% and90% respectively. The selected feature/electrode sets in eachfold are further evaluated using an un-seen testing set withSigmoid ELM, Polynomial SVM, and Perceptron. The resultsindicate the lack of generalizability and loss of classificationinformedness in all cases with sigmoid ELM. Despite thefact that using Polynomial SVM and Perceptron improvedthe informedness compared with the achieved performance

Fig. 8. Comparison between the selected electrodes in the i) best overall mask(10 electrodes) randomly selected, ii) common mask created by random search(the first 10 electrodes), and iii) the top 10 individual electrodes (based on theirclassification results with Sigmoid ELM). The black vertical and horizontallines are virtual lines used for provide better understanding in terms of theused brain regions by each method. The blue circles represent the electrode.
with the Sigmoid ELM, only the combination of commonlyused features in FR-PSO and Polynomial SVM performed aswell as or marginally better than the combination of full-setand Polynomial SVM and other EA based reduction methodsshowed some degree of informedness loss across subjects inmost cases.
Given that the proposed EA-based paradigms reduces upto 90% of the data, the required time for training in the finalstage (on-line mode) is highly reduced. Such an advantage canexplain computational intensiveness of the paradigm in the off-line mode during which the extra EA-based masks (the bestmask and the most commonly used indexes) are generated.
A useful application of this paradigm can be to generatemore generalized and task-specific masks from data of groupsof subjects who performed the same task in an off-linemode and later use it for new subjects aiming to reduce therequired subject training and calibration time [21]. This canalso eliminate the possible contamination between the trainingand the testing sets that might appear as a result of re-applyingthe masks generated from one subject to himself/herself again.
REFERENCES
[1] B. Blankertz, K.-R. Muller, D. J. Krusienski, G. Schalk, J.R. Wolpaw, A.Schlogl, G. Pfurtscheller, J. del R. Millan, M. Schroder and N. Birbaumer:The BCI competition III:Validating alternative approaches to actual BCIproblems. Neural Syst. Rehabil. Eng., vol. 14, no. 2, pp. 153-159, 2006.
[2] A. Atyabi, S. P. Fitzgibbon and D. M. W. Powers: Multiplying themileage of your dataset with subwindowing, BI’11 Proceedings of the2011 international conference on Brain informatics, Lanzhou, China, pp.173–184, 2011.
[3] S. Fitzgibbon: A Machine Learning Approach to Brain-Computer In-terfacing. School of Psychology. Faculty of Social Sciences, FlindersUniversity, 2007.
[4] G.-B. Huang, H. Zhou, X. Ding, and R. Zhang, Extreme LearningMachine for Regression and Multiclass Classification, IEEE Transactionson Systems, Man, and Cybernetics - Part B: Cybernetics, pp. 1-17, 2011.
[5] G.-B. Huang, H. Zhou, X. Ding, and R. Zhang, Extreme learningmachines: a survey, Int. J. Mach. Learn. & Cyber. vol. 2, pp. 107122,2011.
[6] D. M. W. Powers: Recall and Precision versus the Bookmaker. Interna-tional Conference on Cognitive Science (ICSC-2003), pp. 529–534, 2003.
[7] J.H. Holland, Adaptation in Natural and Artificial Systems, University ofMichigan Press, Ann Arbor, 1975.
[8] K.M. Han, Collision Free Path Planning Algorithms for Robot NavigationProblem, M.Sc Thesis, Department of Electrical and Computer Engineer-ing, Missouri-Columbia University, 2007.
[9] A. Konar, Computational Intelligence principles, techniques and appli-cations, Springer Verlag, 2005.
[10] A. Elshamli, H. A. Abdullah, S. Areibi, Genetic Algorithm for DynamicPath Planning, Proceeding of IEEE CCECE 2004, pp. 677-680, 2004.
[11] A. Atyabi and D. M. W. Powers, The impact of Segmentation andReplication on Non-Overlapping windows: An EEG study, The Sec-ond International Conference on Information Science and Technology(ICIST2012), China, 2012.
[12] P. C., Chen, Y. K., Hwang SANDROS, A Dynamic Graph SearchAlgorithm for Motion Planning, IEEE Transactions on Robotics andAutomation, Vol. 14, no. 3, pp. 390-403, 1998.
[13] Y. K., Hwang and P. C., Chen, A Heuristic and Complete Planner for theClassical Movers Problem, Proceedings of the 1995 IEEE InternationalConference on Robotics and Automation, IEEE, pp. 729-736, 1995.
[14] Deneb, TELEGRIP User Manual, Deneb Robotics Inc, 1994.[15] P., Bessire, J. M., Ahuactzin, E. G., Talbi, and E. Mazer, The .Adrianes
Clew. Algorithm: Global Planning with Local Methods, Proceedings ofthe 1993 IEEE/RSJ International Conference on Intelligent Robots andSystems, IEEE, pp. 1373-1380, 1993.
[16] S., Pasupuleti, and R., Battiti, The gregarious particle swarm optimizer(G-PSO), Proceedings of the 8th annual conference on Genetic andevolutionary computation, Seattle, Washington, USA, pp. 67-74, 2006.
[17] R. Largo, C. Munteanu, and A. Rosa, CAP Event Detection by Waveletsand GA Tuning, IEEE Workshop on Intelligent Signal Processing WISP,Portugal, pp. 44-48,2005.
[18] R. Palaniappan and P. Raveendran, Genetic Algorithm to select featuresfor fuzzy ARTMAP classification of Evoked EEG, Asia-Pacific Conferenceon Circuits and Systems. APCCAS ’02, vol.2, pp. 53-56, 2002.
[19] X. Zhang and X. Wang, A Genetic Algorithm based Time-FrequencyApproach to a movement prediction task, proceedings of the 7th worldcongress on intelligent control and automation, China, pp. 1032-1036,2008.
[20] D.M. Dobrea and M.C. Dobrea, Optimisation of a BCI system usingGA technique, 2nd International Symposium on Applied Sciences inBiomedical and Communication Technologies ISABEL , pp.1 - 6 , 2009.
[21] A., Atyabi, M., Luerssen, S., Fitzgibbon and D. M. W., Powers,Adapting Subject-Independent Task-Specific EEG Feature Masks usingPSO, Congress of Evolutionary Computation CEC12, Brisbane, Australia,2012.
Related Documents











