©2013 DataStax Confidential. Do not distribute without consent. @rustyrazorblade Jon Haddad Technical Evangelist, DataStax Enter the Snake Pit 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

©2013 DataStax Confidential. Do not distribute without consent.
@rustyrazorblade
Jon HaddadTechnical Evangelist, DataStax
Enter the Snake Pit
1

Why is Cassandra Awesome?• Fast ingestion of data • Even on spinning disks
• Storage optimized for reading sorted rows • Linear scalability •Multi-DC: Active / Active

What’s Hard with Cassandra?• Ac hoc querying • Batch Processing • Schema migrations • Analytics • Machine Learning
• Visualizing data

Enter Apache Spark

Distributed computation,kind of like MapReduce,but not completely horrible

Apache Spark• Batch processing • Functional constructs •map / reduce / filter
• Fully distributed SQL • RDD is a collection of data • Scala, Python, Java • Streaming •Machine learning • Graph analytics (GraphX)

Batch Processing• Data Migrations • Aggregations • Read data from one source • Perform computations •Write to somewhere else
user movie rating
1 1 10
2 1 9
3 2 8
4 2 10
id name rating
1 rambo 9.5
2 rocky 9

Stream Processing• Read data from a streaming source • ZeroMQ, Kafka, Raw Socket
• Data is read in batches • Streaming is at best an approximation • ssc = StreamingContext(sc, 1) # 1 second
Time 1.1 1.5 1.7 2.1 2.4 2.8 3.4
Data (1,2) (4,2) (6,2) (9,1) (3,5) (7,1) (3,10)

Machine Learning• Supervised Learning • Predictive questions • Unsupervised learning • Classification • Batch or streaming • reevaluate clusters as new data arrives

Collaborative Filtering• Recommendation engine • Algo: Alternating least squares •Movies, music, etc • Perfect match for Cassandra • Source of truth •Hot, live data • Spark generates recommendations
(store in cassandra) • Feedback loops generates better
recommendations over time

Setup• Setup a second DC for analytics • Run spark on each Cassandra node •More RAM is good • Connector is smart about locality

In the beginning… there was RDDsc = SparkContext(appName="PythonPi") partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2 n = 100000 * partitions
def f(_): x = random() * 2 - 1 y = random() * 2 - 1 return 1 if x ** 2 + y ** 2 < 1 else 0
count = sc.parallelize(range(1, n + 1), partitions).\ map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
sc.stop()

Why Not Python + RDDs?
RDDJavaGatewayServer
Py4JRDD

Why Python?• Spark is written in Scala • Python is slow :( • Python is popular • Pandas, matplotlib, numpy •We already know it • It's so beautiful…

DataFrames• Abstraction over RDDs •Modeled after Pandas & R • Structured data • Python passes commands only • Commands are pushed down • Goal: Data Never Leaves the JVM • You can still use the RDD if you
want • Sometimes you still need to pull
data into python (UUIDs)
RDD
DataFrame

Let's play with code

Sample Dataset - Movielens• Subset of movies (1-100) • ~800k ratings
CREATE TABLE movielens.movie ( movie_id int PRIMARY KEY, genres set<text>, title text )
CREATE TABLE movielens.rating ( movie_id int, user_id int, rating decimal, ts int, PRIMARY KEY (movie_id, user_id) )

Reading Cassandra Tables• DataFrames has a standard
interface for reading • Cache if you want to keep dataset
in memory
cl = "org.apache.spark.sql.cassandra"
movies = sql.read.format(cl).\ load(keyspace="movielens", table="movie").cache()
ratings = sql.read.format(cl).\ load(keyspace="movielens", table="rating").cache()

Filtering• Select specific rows matching
various patterns • Fields do not require indexes • Filtering occurs in memory • You can use DSE Solr Search
Queries • Filtering returns a DataFrame
movies.filter(movies.movie_id == 1) movies[movies.movie_id == 1] movies.filter("movie_id=1")
movie_id title genres
44 Mortal Kombat (1995)['Action', 'Adventure', 'Fantasy']
movies.filter("title like '%Kombat%'")

Filtering•Helper function: explode() • select() to keep
specific columns • alias() to rename
title
Broken Arrow (1996)GoldenEye (1995)
Mortal Kombat (1995)
White Squall (1996)
Nick of Time (1995)
from pyspark.sql import functions as F movies.select("title", F.explode("genres").\ alias("genre")).\ filter("genre = 'Action'").select("title")
title genre
Broken Arrow (1996) Action
Broken Arrow (1996) Adventure
Broken Arrow (1996) Thriller

Aggregation• Count, sum, avg • in SQL: GROUP BY • Useful with spark streaming • Aggregate raw data • Send to dashboards
ratings.groupBy("movie_id").\ agg(F.avg("rating").alias('avg'))
ratings.groupBy("movie_id").avg("rating")
movie_id avg
31 3.24
32 3.8823
33 3.021

Joins• Inner join by default • Can do various outer joins
as well • Returns a new DF with all
the columns
ratings.join(movies, "movie_id")
DataFrame[movie_id: int, user_id: int,
rating: decimal(10,0), ts: int, genres: array<string>, title: string]

Chaining Operations
• Similar to SQL, we can build up in complexity • Combine joins with aggregations,
limits & sorting
ratings.groupBy("movie_id").\ agg(F.avg("rating").\ alias('avg')).\ sort("avg", ascending=False).\ limit(3).\ join(movies, "movie_id").\ select("title", "avg")
title avg
Usual Suspects, The (1995) 4.32
Seven (a.k.a. Se7en) (1995) 4.054
Persuasion (1995) 4.053

SparkSQL• Register DataFrame as Table • Query using HiveSQL syntax
movies.registerTempTable("movie") ratings.registerTempTable("rating") sql.sql("""select title, avg(rating) as avg_rating from movie join rating on movie.movie_id = rating.movie_id group by title order by avg_rating DESC limit 3""")

Database Migrations• DataFrame reader supports JDBC • JOIN operations can be cross DB • Read dataframe from JDBC, write
to Cassandra

Inter-DB Migration
from pyspark.sql import SQLContext sql = SQLContext(sc)
m_con = "jdbc:mysql://127.0.0.1:3307/movielens?user=root"
movies = sql.read.jdbc(m_con, "movielens.movies")
movies.write.format("org.apache.spark.sql.cassandra").\ options(table="movie", keyspace="lens").\ save(mode="append")
http://rustyrazorblade.com/2015/08/migrating-from-mysql-to-cassandra-using-spark/
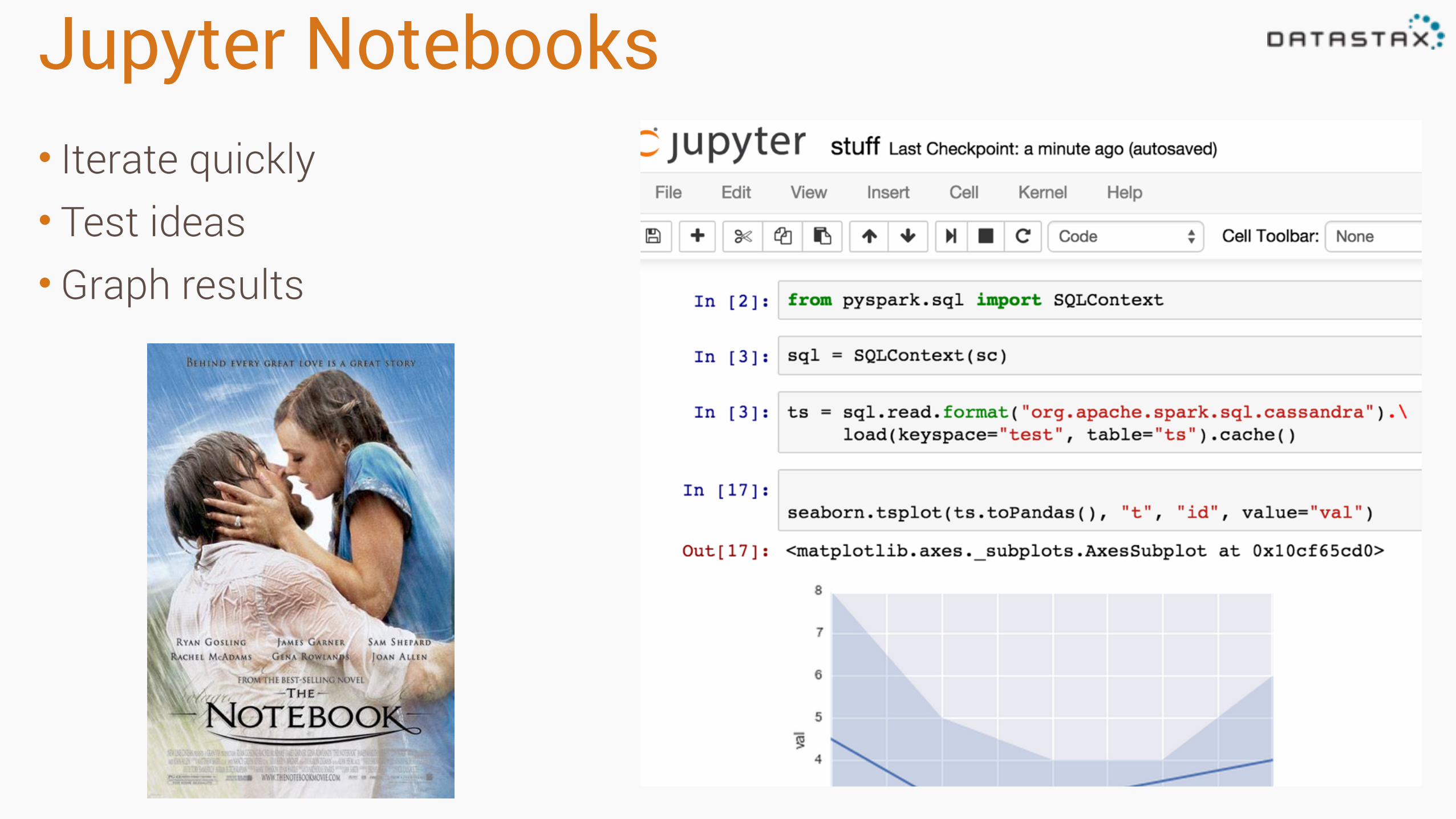
Jupyter Notebooks• Iterate quickly • Test ideas • Graph results

Visualization
• dataframe.toPandas()•Matplotlib • Seaborn (looks nicer) • Crunch big data in spark

©2013 DataStax Confidential. Do not distribute without consent. 29
Related Documents











