Enhancing Storage System Availability on Multi-Core Architectures with Recovery-Conscious Scheduling Sangeetha Seshadri ∗ Lawrence Chiu † Cornel Constantinescu † Subashini Balachandran † Clem Dickey † Ling Liu ∗ Paul Muench † ∗ Georgia Institute of Technology † IBM Almaden Research Center 801 Atlantic Drive GA-30332 650 Harry Road CA-95120 {sangeeta,lingliu}@cc.gatech.edu {lchiu, cornel, sbalach, pmuench}@us.ibm.com Abstract In this paper we develop a recovery conscious frame- work for multi-core architectures and a suite of tech- niques for improving the resiliency and recovery ef- ficiency of highly concurrent embedded storage soft- ware systems. Our techniques aim at providing con- tinuous availability and performance during recov- ery while minimizing the time to recovery and the need for rearchitecting the system (legacy code). The main contributions of our recovery conscious frame- work include (1) a task-level recovery model, which consists of mechanisms for classifying storage tasks into recovery groups and dividing the overall system resources into recovery-oriented resource pools, and (2) the development of recovery-conscious schedul- ing, which enforces some serializability of failure- dependent tasks in order to reduce the ripple effect of software failure and improve the availability of the system. We present three alternative recovery- conscious scheduling algorithms; each represents one way to trade-off between recovery time and system performance. We have implemented and evaluated these recovery-conscious scheduling algorithms on a real industry-standard storage system. Our exper- imental evaluation results show that the proposed recovery conscious scheduling algorithms are non- intrusive and can significantly improve (throughput by 16.3% and response time by 22.9%) the perfor- mance of the system during failure recovery. 1 Introduction Enterprise storage systems are the foundations of most data centers today and extremely high avail- ability is expected as a basic requirement from these systems. With rapid and exponential growth of digital information and the increasing popularity of multi-core architectures, the demand for large scale storage systems of extremely high availability (moving close to 7 nines) continues to grow. On the other hand, embedded storage software systems (controllers) are becoming much more complex and difficult to test especially given concurrent develop- ment and quality assurance processes. With software failures and bugs becoming an ac- cepted fact, focusing on recovery and reducing time to recovery has become essential in many modern storage systems today. In current system architec- tures, even with redundant controllers, most mi- crocode failures trigger system-wide recovery [9, 10] causing the system to lose availability for at least a few seconds, and then wait for higher layers to redrive the operation. This unavailability is visible to customers as service outage and will only increase as the platform continues to grow using the legacy architecture. In order to reduce the recovery time and more importantly scale the recovery process with sys- tem growth, it is essential to perform recovery at a fine-grained level: recovering only failed compo- nents and allowing the rest of the system to func- tion uninterrupted. However, due to fuzzy compo- nent interfaces, complex dependencies and involved operational semantics of the system, implementing such fine-grained recovery is challenging. Therefore, firstly we must develop a mechanism to perform fine- grained recovery taking into consideration interac- tions between components and recovery semantics. Secondly, since localized recovery spans multiple de- pendent threads in reality, we must bound this local- ized recovery process in time and resource consump- tion in order to ensure that resources are available for other normally operating tasks even during re- covery. Finally, since we are dealing with a large legacy architecture (> 2M loc), to ensure feasibility in terms of development time and cost we should minimize changes to the architecture. In this paper we develop a recovery conscious framework for multi-core architectures and a suite of techniques for improving the resiliency and recov- ery efficiency of highly concurrent embedded storage software systems. Our techniques aim at providing FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association 143

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Enhancing Storage System Availability on Multi-Core
Architectures with Recovery-Conscious Scheduling
Sangeetha Seshadri∗ Lawrence Chiu† Cornel Constantinescu†
Subashini Balachandran† Clem Dickey† Ling Liu∗ Paul Muench†
∗Georgia Institute of Technology †IBM Almaden Research Center801 Atlantic Drive GA-30332 650 Harry Road CA-95120
{sangeeta,lingliu}@cc.gatech.edu {lchiu, cornel, sbalach, pmuench}@us.ibm.com
Abstract
In this paper we develop a recovery conscious frame-work for multi-core architectures and a suite of tech-niques for improving the resiliency and recovery ef-ficiency of highly concurrent embedded storage soft-ware systems. Our techniques aim at providing con-tinuous availability and performance during recov-ery while minimizing the time to recovery and theneed for rearchitecting the system (legacy code). Themain contributions of our recovery conscious frame-work include (1) a task-level recovery model, whichconsists of mechanisms for classifying storage tasksinto recovery groups and dividing the overall systemresources into recovery-oriented resource pools, and(2) the development of recovery-conscious schedul-ing, which enforces some serializability of failure-dependent tasks in order to reduce the ripple effectof software failure and improve the availability ofthe system. We present three alternative recovery-conscious scheduling algorithms; each represents oneway to trade-off between recovery time and systemperformance. We have implemented and evaluatedthese recovery-conscious scheduling algorithms on areal industry-standard storage system. Our exper-imental evaluation results show that the proposedrecovery conscious scheduling algorithms are non-intrusive and can significantly improve (throughputby 16.3% and response time by 22.9%) the perfor-mance of the system during failure recovery.
1 Introduction
Enterprise storage systems are the foundations ofmost data centers today and extremely high avail-ability is expected as a basic requirement from thesesystems. With rapid and exponential growth ofdigital information and the increasing popularityof multi-core architectures, the demand for largescale storage systems of extremely high availability(moving close to 7 nines) continues to grow. Onthe other hand, embedded storage software systems
(controllers) are becoming much more complex anddifficult to test especially given concurrent develop-ment and quality assurance processes.
With software failures and bugs becoming an ac-cepted fact, focusing on recovery and reducing timeto recovery has become essential in many modernstorage systems today. In current system architec-tures, even with redundant controllers, most mi-crocode failures trigger system-wide recovery [9, 10]causing the system to lose availability for at leasta few seconds, and then wait for higher layers toredrive the operation. This unavailability is visibleto customers as service outage and will only increaseas the platform continues to grow using the legacyarchitecture.
In order to reduce the recovery time and moreimportantly scale the recovery process with sys-tem growth, it is essential to perform recovery ata fine-grained level: recovering only failed compo-nents and allowing the rest of the system to func-tion uninterrupted. However, due to fuzzy compo-nent interfaces, complex dependencies and involvedoperational semantics of the system, implementingsuch fine-grained recovery is challenging. Therefore,firstly we must develop a mechanism to perform fine-grained recovery taking into consideration interac-tions between components and recovery semantics.Secondly, since localized recovery spans multiple de-pendent threads in reality, we must bound this local-ized recovery process in time and resource consump-tion in order to ensure that resources are availablefor other normally operating tasks even during re-covery. Finally, since we are dealing with a largelegacy architecture (> 2M loc), to ensure feasibilityin terms of development time and cost we shouldminimize changes to the architecture.
In this paper we develop a recovery consciousframework for multi-core architectures and a suiteof techniques for improving the resiliency and recov-ery efficiency of highly concurrent embedded storagesoftware systems. Our techniques aim at providing
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 143

continuous availability and good performance evenduring a recovery process by bounding the time torecovery while minimizing the need for rearchitect-ing the system.
The main contributions of our recovery consciousframework include (1) a task-level recovery model,which consists of mechanisms for classifying storagetasks into recovery groups and dividing the over-all system resources into recovery-oriented resourcepools; and (2) the development of recovery-consciousscheduling, which enforces some serializability offailure-dependent tasks in order to reduce the rip-ple effect of software failures and improve the avail-ability of the system. We present three alternativerecovery-conscious scheduling algorithms, each rep-resenting one way to trade-off between recovery timeand system performance.
We have implemented and evaluated theserecovery-conscious scheduling algorithms on a realindustry-standard storage system. Our experimen-tal evaluation results show that the proposed re-covery conscious scheduling algorithms are non-intrusive, involve minimal new code and can signifi-cantly improve performance during failure recoverythereby enhancing availability.
2 Problem Definition
In this section we motivate this research and illus-trate the problem we address by considering the stor-age controllers of some representative storage systemarchitecture. We focus on system recoverability fromsoftware failures. Storage controllers are embeddedsystems that add intelligence to storage and providefunctionalities such as RAID, I/O routing, error de-tection and recovery. Failures in storage controllersare typically more complex and more expensive torecover if not handled appropriately. Although thissection discusses specifically about embedded soft-ware failures in a storage controller, we believe thatmost of the concepts may be applicable to otherhighly concurrent system software too.
2.1 Motivation and Technical Challenges
Figure 1 gives a conceptual representation of a stor-age subsystem. This is a single storage subsystemnode consisting of hosts, devices, a processor com-plex and the interconnects. In practice, storage sys-tems may be composed of one or more such nodes inorder to avoid single-points-of-failure. The proces-sor complex provides the management functionali-ties for the storage subsystem. The system memoryavailable within the processor complex serves as pro-gram memory and may also serve as the data cache.The memory is accessible to all the processors withinthe complex and holds the job queues through which
N−way SMP
Device
. . . .
Persistent Memory
Host
Host Complex
ProcessorComplex
DeviceComplex
JobQ
Data Cache/
Figure 1: Storage Subsystem Architecture
functional components dispatch work. As shown inFigure 1, this processor complex has a single jobqueue and is an N-way SMP node. Any of the N pro-cessors may execute the jobs available in the queue.Some storage systems may have more than one jobqueue (e.g. multiple priority queues).
The storage controller software typically consistsof a number of interacting components each of whichperforms work through a large number of asyn-chronous, short-running threads (∼ μsecs). We re-fer to each of these threads as a ‘task’. Examples ofcomponents include SCSI command processor, cachemanager and device manager. Tasks (e.g., process-ing a SCSI command, reading data into cache mem-ory, discarding data from cache etc.) are enqueuedonto the job queues by the components and thendispatched to run on one of the many available pro-cessors each of which runs an independent scheduler.Tasks interact both through shared data-structuresin memory as well as through message passing.
With this architecture, when one thread encoun-ters an exception that causes the system to enter anunknown or incorrect state, the common way to re-turn the system to an acceptable, functional stateis by restarting and reinitializing the entire system.Since the system state may either be lost, or can-not be trusted to be consistent, some higher layermust now redrive operations after the system hasperformed basic consistency checks of non-volatilemetadata and data. While the system reinitializesand waits for the operations to be redriven by a host,access to the system is lost contributing to the down-time. This recovery process is widely recognized as abarrier to achieving high(er) availability. Moreover,as the system scales to larger number of cores and asthe size of the in-memory structures increase, suchsystem-wide recovery will no longer scale.
The necessity to embark on system-wide recoveryto deal with software failures is mainly due to thecomplex interactions between the tasks which may
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association144

belong to different components. Due to the high vol-ume of tasks (more than 20 million/minute in a typi-cal workload), their short-running nature and the in-volved semantics of each task, it becomes infeasibleto maintain logs or perform database-style recoveryactions in the presence of software failures. Oftensuch software failures need to be explicitly handledby the developer. However, the number of scenariosare so large, especially in embedded systems, thatthe programmer cannot realistically anticipate ev-ery possible failure. Also, an individual developermay only be aware of the clean-up routines for thelimited scope being handled by them. This knowl-edge is insufficient to recover the entire system fromfailures, given that often interactions among tasksand execution paths are determined dynamically.
Many software systems, especially legacy systems,do not satisfy the conditions outlined as essentialfor micro-rebootable software [3]. For instance, eventhough the storage software may be reasonably mod-ular, component boundaries, if they exist, are veryloosely defined. In addition, the scenario where com-ponents are stateful and interact with other com-ponents through globally shared structures (data-structures, metadata), often leads to componentsmodifying each other’s state irreversibly. Moreover,resources such as hardware and software locks, de-vices and metadata are shared across components.Under these circumstances, the scope of a recoveryaction is not limited to a single component.
The discussion above highlights some key prob-lems that need to be addressed in order to im-prove system availability and provide scalable re-covery from software failures. Concretely, we mustanswer the following questions:
• How do we implement fine-grained recovery ina highly concurrent storage system?
• Can we identify recovery dependencies acrosstasks and construct efficient recovery scopes?
• How do we ensure availability of the system dur-ing a recovery process? What are importantfactors that will impact the recovery efficiency?
In addition to maintaining system performancewhile reducing the time to recovery, another keychallenge in developing a scalable solution is to en-sure that the recovery-conscious framework is non-intrusive and thus minimize re-architecting of thelegacy application code. We will describe our solu-tion to the first two problems − how to implement lo-calized recovery and how to discover efficient recov-ery scopes in Section 3. We will dedicate Section 4to address the third problem: how do we bound therecovery process and ensure system availability evenduring localized recovery?
2.2 Taxonomy of Failures
Studies classify software faults as both permanentand transient. Gray [6] classifies software faults intoBohrbugs and Heisenbugs. Bohrbugs are essentiallydeterministic bugs that may be caused due to per-manent design failures. Such bugs are usually easilyidentified during the testing phases and are weededout early in the software life cycle. On the otherhand, ‘heisenbugs’ which are transient or intermit-tent faults that occur only under certain conditionsare not easily identifiable and may not even be re-producible. Such faults are often due to reasons suchas the system entering an unexpected state, insuffi-cient exception handling, boundary conditions, tim-ing/concurrency issues or due to other external fac-tors. Many studies have shown that most softwarefailures occurring in production systems are due totransient faults that disappear when the system isrestarted [6, 3, 15].
Our work is targeted at dealing with such tran-sient failures in a storage software system and in par-ticular the embedded storage controller’s microcode.Below, we provide a classification of transient fail-ures which we intend to deal with through localizedrecovery.
In complex systems, often code paths are dynamicand input parameters are determined at runtime. Asa result many faults are not caught at compile time.On pure functions, faults may be classified as:
• Domain errors: are caused by bad input ar-guments, such as a divide by zero error or wheneach individual input is correct, but the combi-nation is wrong (e.g. negative number raised to anon-integral power in a real arithmetic system).
• Range errors: are caused when input argu-ments are correct, but the result cannot be com-puted (such as a result which would cause anoverflow).
With actions based on system state there are ad-ditional complexities. For example, a configurationissue that appeared early in the installation processmay have been fixed by trying various combinationsof actions that were not correctly undone. As aresult the system finds itself in an unknown statewhich manifests as a failure after some period of nor-mal operation. Such errors are very difficult to trace,and although transient may continue to appear ev-ery so often. We classify such system state basederrors as:
• State error: where the input arguments arewrong for the current state of the object.
• Internal logic error: where the system hasunexpectedly entered an incorrect or unknownstate. Such an error often triggers further state
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 145

errors.
Each of the above error types can lead to tran-sient failures. Some of the transient failures canbe fixed through appropriate recovery actions whichmay range from dropping the current request toretrying the operation or performing a set of actionsthat take the system to a known consistent state.For example, some of such transient faults that oc-cur in storage controller code are:
• Unsolicited response from adapter: An adapter(a hardware component not controlled by our mi-crocode) sends a response to a message which wedid not send - or do not remember sending. Thisis an example of a state error.
• Incorrect Linear Redundancy Code (LRC): Acontrol block has the wrong LRC check bytes,for instance, due to an undetected memory er-ror; an example of an internal logic error.
• Queue full: An adapter refuses to accept morework due to a queue full condition; an exampleof both an internal logic error and state error.
In addition, there are other error scenarios such asviolation of a storage system or application servicelevel agreements. The ‘time-out’ conditions are alsovery common in large scale embedded storage sys-tems. While the legacy system grows along multipledimensions, the growth is not proportional along alldimensions. As a result hard-coded constant time-out values distributed in the code base often createunexpected artificial violations.
2.3 Recovery Models
Intuitively we can see that localized recovery maybe possible for many of the failure scenarios outlinedabove, and thus system-wide software reboots can beavoided. Sometimes even for situations of resolvingdeadlock or livelock, it may be sufficient if a minimalsubset of tasks or components of the system undergorestarts (e.g., deadlock resolution in transactionaldatabases [7]). Of course there are scenarios, suchas severe memory corruption, where the only high-confidence way of repairing the fault is to performsystem-wide clean-up.
In production environments, techniques for fault-tolerance, i.e., coping with the existence and mani-festation of software faults can be classified into twoprimary categories with respect to the fault repair-ing methods: (1) those that provide fault treatment,such as restarts of the software, rebooting of thesystem and utilizing process pair redundancy; and(2) those that provide error recovery, such as check-pointing and log-based recovery. Alternatively, onecan categorize the recovery models based on thegranularity of the recovery scopes. All the above-
mentioned techniques could be applied to any recov-ery scope. In our context, we consider the followingthree types of recovery scopes:
• System level: Performing fault treatment atthis level has proven to be an effective high-confidence way of recovering the system fromtransient faults [2], but has a high cost in termsof recovery time and the resulting system down-time. On the other hand performing error re-covery at the system level through checkpointingand recovery can be prohibitively expensive forsystems with very high volumes of workload andcomplex semantics.
• Component level: Both fault treatment anderror recovery are more scalable and cost effectiveat this granularity. For fault treatment, the mainchallenge is identifying these ‘component bound-aries’ especially in systems that do not have welldefined interfaces. Again, the difficult hurdle toperforming checkpoint/log-based error recoveryat this level is understanding the semantics ofoperations.
• Task level: At this very fine-grained level,the issue of operational semantics still remains.However, performing fault treatment at this levelis efficient both in terms of cost and system avail-ability.
The main advantage of performing error recoveryor fault-treatment at the task-level as compared tothe component-level, is that it allows us to accommo-date cross-component interactions and define ‘recov-ery boundaries’ in place of ‘component boundaries’.Our goal is to handle most of the failures and ex-ceptions through task-level (localized) recovery, andavoid resorting to system-wide recovery unless it isabsolutely necessary.
3 Task-level Recovery Framework
Transactional recovery in relational DBMSs is a suc-cess story of fine-grained error recovery, where theset of operations, their corresponding recovery ac-tions and their recovery scopes are well-defined inthe context of database transactions. However, thisis not the case in many legacy storage systems.For example, consider the embedded storage con-troller in which tasks executed by the system are in-volved in more complex operational semantics, suchas dynamic execution paths and complex interac-tions with other tasks. Under these circumstances,in order to implement task-level recovery, we haveto deal with both the semantics of recovery and theidentification of recovery scopes.
Recovery from a software failure involves choos-ing an appropriate strategy to treat/recover fromthe failure. The choice of recovery strategy depends
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association146

�WriteToCache
•� startSCSICmd()
•� processRead()
• getTrack()
• getTempResource()
….
PANIC(error_code)
….
CB-0sets
sets CB-1 Clean -up func�
User-�specified �context�
sets� CB-2RB�
(error_code)�
CB Clean-�Up Block
RB Resource Block
RB� RB
Figure 2: Framework for Task Level Recovery
on the nature of the task, the context of the failure,and the type of failure. For example, within a singlesystem, the recovery strategy could range from con-tinuing the operations (ignoring the error), retryingthe operation (fault treatment using environmentaldiversity) or propagating the fault to a higher layer.In general, with every failure context and type, wecould associate a recovery action. In addition, to en-sure that the system will return to a consistent state,we must also avoid deadlock or resource hold-up sit-uations by relinquishing resources such as hardwareor software locks, devices or data sets that are in thepossession of the task.
Bearing these design principles in mind, we de-velop a two-tier framework for performing task-levelrecovery through a set of non-intrusive recoverystrategies. The top tier provides the capabilities ofdefining the recovery scope at task level through acareful combination of both the programmer’s speci-fication at much coarser granularity and the system-determined recovery scope at finer-granularity. Thebottom tier provides the recovery-conscious schedul-ing algorithms that balance the performance and therecovery efficiency.
In this framework, we refer to the context of a fail-ure as a recovery point and provide mechanismsfor developers to define clean-up blocks which arerecovery procedures and re-drive strategies. A clean-up block is associated with a recovery point and en-capsulates failure codes, the associated recovery ac-tions, and resource information. The specification ofthe actual recovery actions in each of the clean-upblocks is left to the developers due to their task-specific semantics.
In our implementation, the recovery-consciousscheduler alone was implemented in approximately1000 lines of code. A naive coding and the designeffort for task level recovery would be directly pro-
portional to the number of “panics” or failures inthe code that are intended to be handled using ourframework. In general, the coding effort for a sin-gle recovery action is small and is estimated to bearound a few tens of lines of code (using semicolonsas the definition of lines of code) per recovery actionon average. Note that, the clean-up block does notinvolve any logging or complex book-keeping and isintended to be light-weight. A more efficient han-dling of clean-up blocks would involve classifyingcommon error/failure situations and then addressingthe handling of the errors in a hierarchical fashion.For example, recoveries may be nested and we couldre-throw an error and recover with the next higherclean-up block defined in the stack. This would in-volve design effort towards the classification of errorcodes into classes and sub-classes and identificationof common error handling situations. Finally, if weare unable to address an error using our framework,existing error handling mechanisms would be used asdefault. The point of recovery in the stack may bedetermined by factors such as access to data struc-tures and possibilities of recovery strategies such asretrying, termination or ignoring the error.
Figure 2 shows a schematic diagram of the re-covery framework using the call stack of a singletask. As the task moves through its execution path,it passes through multiple recovery points and ac-cumulates clean-up blocks. When the task leavesa context, the clean-up actions associated with thecontext go out of scope. On the other hand, nestingof contexts results in the nesting of the correspond-ing clean-up blocks and the framework keeps trackof necessary clean-up blocks.
The clean-up blocks are gathered and carriedalong during task execution but are not invoked un-less a failure occurs. Resource information can alsobe gathered passively. Such a framework allows achoice of recovery strategy based on task require-ments and requires minimal rearchitecting of the sys-tem.
Example : We describe the selection of recoverystrategy and design of clean-up blocks using an ex-ample from our storage controller implementation.Consider the error described in Figure 2 which de-picts relevant portions of the call stack. The fail-ure situation described in this example is similar tothe commonly used ‘assert’ programming construct.The error is encountered when a task has run out ofa temporary cache data structure known as a ‘con-trol block’ which is not expected to occur normallyand hence results in a ‘panic’.
In this particular situation, ignoring the error isnot a possible recovery strategy since the task wouldbe unable to complete until a control block is avail-able. One possible strategy is to search the list of
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 147

��������
��� � �� �������� �
����������������
�� ��� ��� ��������������
��������
������������
��������
Figure 3: Implicit recovery scopes
control blocks to identify any instances that are notcurrently in use, but have not been freed correctly(for example, due to incorrect flags). If any suchinstances exist, they could be made available to thestalled task. An alternative strategy would be toretry the operation beginning at the ‘WriteToCache’routine at a later time in order to work around con-currency issues. Retrying the operation may involverolling back the resource and state setup along thiscall path to their original state. Resource blocks areused to carry the information required to success-fully execute this strategy. Finally, in the case ofless critical tasks, aborting the task may also be anoption. Alternatively, consider a situation where anerror is encountered due to a component releasingaccess to a track to which it did not have access inthe first place. The error was caused due to a mis-match in the number of active users as perceivedby the component. In this case, a possible recoverystrategy would be to correctly set the count for thenumber of active users and proceed with the execu-tion, effectively ignoring the error.
Note that, it is important we ensure that theinterfaces with the recovery code and the recoverycode itself are reliable. The most important issuein the tier one design is how to adequately identifythe recovery scopes or boundaries, and how to con-cretely determine what are the set of tasks that needto undergo recovery upon a failure?
3.1 Identifying fine-grained recovery scopes
Tasks interact with each other in complex ways.When a single task encounters an exception, morethan one task may need to initiate recovery proce-dures in order to avoid deadlocks and return the sys-tem to a consistent state. In order to identify thenecessary and yet sufficient scope of a recovery ac-tion, we need to characterize dependencies betweentasks.
Dependencies between tasks may be explicit asin the case of functional dependencies or implicitsuch as those arising from shared access to state-ful structures (e.g., data structures, metadata) or
devices. For example, tasks belonging to the sameuser request may be identified as having the same re-covery scope. Likewise, identical tasks belonging tothe same functional component may also be markedwith the same recovery scope. Explicit dependenciescan be specified by the programmer.
However, explicit dependencies specified by theprogrammer may be very coarse. For example, an‘adapter queue full’ error should only affect tasks at-tempting to write to that adapter and should not ini-tiate recovery across the component. Likewise, somedependencies may have been overlooked due to theirdynamic nature and the immense complexity of thesystem. Therefore one way to refine explicit depen-dencies is to identify implicit dependencies continu-ously and utilize them to refine the developer-definedrecovery scopes over time. For example, one ap-proach to identifying implicit dependencies at run-time is by observing patterns of hardware and soft-ware lock acquisitions. We can group the tasks thatshare locks into the same recovery scope, since shar-ing locks typically implies that they have shared ac-cess to a stateful global object. Figure 3 illustratesthis approach through an example. It shows fivetasks and their respective lock acquisition patterns.Tasks T1, T2 and T4 are accessing overlapping setsof locks during their execution and thus are groupedinto one recovery scope. Similarly, tasks T3 and T5are grouped into another recovery scope. Clearly,this approach further refines the developer-specifiedrecovery scope at task level into smaller recoveryscopes based on runtime characterization of the de-pendencies with respect to lock acquisition.
Due to the space limit of this paper, we will omitthe detailed development of recovery scope refine-ment mechanisms. In the remaining part of this pa-per, we assume that tasks are organized into disjointrecovery scopes refined based on implicit dependen-cies identified dynamically at runtime. In additionto recovery scopes, we argue that recovery-consciousresource management can be critical for improvingsystem availability during localized recovery.
3.2 Ensuring resource availability
Multi-core processors are delivering huge system-level benefits to embedded applications. Both SMP-based and multi-core systems are very popular inthis segment. With the number of processing coresincreasing continuously, we argue that the storagesoftware needs to scale both in terms of performanceand recoverability to take advantage of the systemresources.
An important goal for providing fine-grained re-covery (task or component level) is to improve re-coverability and make efficient use of resources onthe multi-core architectures. This ensures that re-
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association148

Job Queue
R1
R1 R2 R2 R3 R3 R3R2 R2R2
R1R1 R1
CPU1� CPU2 CPU3 CPU4�
� ������� � ��� ���
Figure 4: Current Scheduler
sources are available for normal system operation inspite of some localized recovery being underway andthat the recovery process is bounded both in timeand in resource consumption. Without careful de-sign, it is possible that more dependent tasks aredispatched before a recovery process can complete,resulting in an expansion of the recovery scope oran inconsistent system state. This problem is aggra-vated by the fact that recovery takes orders of mag-nitude longer (ranging from milliseconds to seconds)compared to normal operation (∼ μ secs). Also adangerous situation may arise where it is possiblethat many or all of the threads that are concurrentlyexecuting are dependent, especially since tasks oftenarrive in batches. Then the recovery process couldconsume all system resources essentially stalling theentire system.
Ideally we would like to “fence” the failed andrecovering tasks until the recovery is complete. Inorder to do so we must control the number of de-pendent tasks that are scheduled concurrently, bothduring normal operation and during recovery. Inthe next section we discuss how to design a recoveryconscious scheduler that can control how many de-pendent tasks are dispatched concurrently and whatmeasures should be taken in the event of a failure.
4 Recovery-Conscious Scheduling
The goal of recovery-conscious scheduling (RCS) isto ensure system availability even during localizedrecovery. By recovery-consciousness, we mean thatthe scheduler must assure availability of resourcesfor normal operation even during a localized recov-ery process. One way to achieve this objective is tointelligently isolate the recovery process by bound-ing the amount of resources that will be consumedby the recovering tasks.
Figure 4 shows a performance-oriented schedulingalgorithm that does not take recovery dependenciesinto consideration while scheduling tasks. The dia-gram shows a 4-way SMP system where each pro-cessor independently schedules tasks from the same
job queue. This scheduling algorithm aims at maxi-mizing the throughput and minimizing the responsetime of user requests, which are internally trans-lated by the system into numerous tasks of threetypes R1, R2, R3. The ovals represent tasks andthe same shading scheme is used to denote tasksthat are dependent in terms of recoverability. Asshown in Figure 4, when all CPU resources are uti-lized for concurrently executing the tasks that havefailure/recovery dependencies, then failure and sub-sequent recovery can consume all the resources ofthe system, stalling other tasks that could have pro-ceeded with normal operation. Moreover, contin-uing to dispatch additional dependent tasks beforethe localized recovery process can be completed onlyfurther aggravates the problem of unavailability.
4.1 Recovery Groups and Resource Pools
In order to deal with the problem illustrated in Fig-ure 4, we infuse “recovery consciousness” into thescheduler. Our recovery-conscious scheduler will en-force some serialization of dependent tasks therebycontrolling the extent of a localized recovery oper-ation that may occur at any time. To formally de-scribe recovery conscious scheduling, we first definetwo important concepts: recovery groups and re-source pools.
Recovery Groups: A recovery group is definedas the unit of a localized recovery operation i.e., theset of tasks that will undergo recovery concurrently.When clean-up procedures are initiated for any taskwithin a recovery group, all other tasks belonging tothe same recovery group that are executing concur-rently will also initiate appropriate clean-up proce-dures in order to maintain the system in a consistentstate. Note that recovery groups are determinedbased on explicitly specified dependencies that arefurther refined by the system based on observationsof implicit dependencies. By definition, every taskbelongs to a single recovery group. Thus tasks inthe system can be partitioned into multiple disjointrecovery groups.
Resource Pools: The concept of resource poolsis used as a method to partition the overall pro-cessing resources into smaller independent resourceunits, called resource pools. Although we restrictresource pools in this paper to processors, the con-cept can be extended to any pool of identical re-sources such as replicas of metadata or data. Re-covery conscious scheduling maps resource pools torecovery groups, thereby confining a recovery oper-ation to the resources available within the resourcepool assigned to it.
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 149

Job Queue
R1
R2 R2
R3 R3
R3R2
R2R2
R1 R1
R1 R1
CPU1 CPU2 CPU3� CPU4�
� ������� � ��� ���
Figure 5: Recovery Oriented Scheduling
4.2 Mapping of Resource Pools toRecovery-Groups
The recovery-conscious scheduling (RCS) algorithmsimplement the mapping between recovery groupsand resource pools. There are different ways thatone can map recovery groups to resource pools. Thechoice of decision depends on the type of trade-offsone would like to make between recovery time andsystem availability and performance. Static schedul-ing of resource pools to recovery groups is one endof the spectrum and is only effective in situationswhere task level dependencies with respect to recov-erability are well understood and the workloads ofthe system is stable. Dynamic scheduling of recov-ery groups to resource pools represents another endof the spectrum and may better adapt to the chang-ing workload and more effectively utilize resources,but it is more costly in terms of scheduling manage-ment. Between the two ends of the spectrum are thepartially dynamic scheduling algorithms.
Figure 5 depicts a recovery-conscious schedulerfor the same set up as the one used for theperformance-oriented scheduler, where tasks are or-ganized into recovery groups − R1 (shaded as fill),R2 (horizontal lines) and R3 (downward diagonal).The processing resources (four CPUs in this exam-ple) are organized into three resource pools such thatrecovery group R1 is mapped to a pool consisting oftwo processors and recovery groups R2 and R3 areeach mapped to a pool consisting of one processor.In case of a failure within group R1, the recover-ing tasks are now restricted to two of the availablefour processors so that the other two processors re-main available for normal operation. Additionally,the scheduler suspends further dispatching of tasksbelonging to group R1 until the localized recoveryprocess completes. This example highlights two as-pects of a recovery-conscious scheduler: proactiveand reactive.
Proactive RCS comes into play during normal op-eration and enhances availability by enforcing some
while true dorepeat
repeatScanDispatch(HighPriorityQueue)
until HighPriorityLoopCountScanDispatch(MediumPriorityQueue)
until MediumPriorityLoopCountScanDispatch(LowPriorityQueue)
end while
Figure 6: Qos-based scheduling
while true dorepeat
repeatScanDispatch(HighPriorityQueue for ρ1)
until HighPriorityLoopCountScanDispatch(MediumPriorityQueue for ρ1)
until MediumPriorityLoopCountScanDispatch(LowPriorityQueue for ρ1)
end while
Figure 7: Recovery conscious scheduling
degree of serialization of dependent tasks. The goalof proactive scheduling is to reduce the impact of afailure by trying to bound the number of outstand-ing tasks per recovery group. Then in the event ofa failure within any recovery group, the number oftasks belonging to that recovery group that are cur-rently executing and need to undergo recovery arealso controlled. By limiting the extent of a recoveryprocess, proactive scheduling can help the system re-cover sooner, and at the same time, it controls theamount of resources dedicated to the recovery pro-cess. Proactive RCS thereby ensures resource avail-ability to normal operation even during a localizedrecovery process.
The reactive aspect of recovery conscious schedul-ing takes over after a failure has occurred. Whenlocalized recovery is in progress, reactive RCS sus-pends the dispatch of tasks belonging to the groupundergoing recovery until the recovery completes.This ensures quick completion of recovery by pre-venting transitive expansion of the recovery scopeand avoiding deadlocks.
4.3 System Considerations
The deployment of recovery conscious scheduling inpractice requires the design and implementation ofthe scheduler to meet the stringent performance re-quirements of the storage system, sustaining the de-sired high throughput and low response time. Putdifferently, recovery-conscious scheduling should of-fer comparable efficiency in throughput and latencyas those provided by performance oriented schedul-ing.
We outline below some factors that must betaken into consideration while comparing recov-ery conscious scheduling with performance oriented
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association150

scheduling in a multi-core/SMP environment.Note that our scheduling algorithms are con-
cerned with partitioning resources between tasks be-longing to different “components” of the same sys-tem which adds a second orthogonal level to thescheduling problem. We continue to respect the QoSor priority considerations specified by the designerat the level of user requests. For example, Figure 6shows an existing QoS based scheduler using high,medium and low priority queues. Figure 7 showshow recovery-conscious scheduling used by a pool ρ1
dispatches jobs based on both priority and recovery-consciousness (by picking jobs only from the recov-ery groups assigned to it).
We use good-path and bad-path performanceas the two main metrics for comparison of therecovery-conscious schedulers with performance ori-ented schedulers. By ‘good-path’ performance wemean the performance of the system during normaloperation. We use the term ‘bad-path’ performanceto refer to the performance of the system under lo-calized failure/recovery.
Both good path and bad path performance canbe measured using end-to-end performance metricssuch as throughput and response time. In addition,we can also measure the performance of a sched-uler from system-level factors, including cpu utiliza-tion, number of tasks dispatched over time, queuelengths, the overall utilization of other resourcessuch as memory, and the ability to meet service levelagreements and QoS specifications.
5 Classification of RCS Algorithms
We classify recovery conscious scheduling (RCS) al-gorithms based on the method in which resourcepools are distributed across recovery groups. Asdiscussed in the previous section, we categorizerecovery-conscious scheduling algorithms into threeclasses: static, partially dynamic, and fully dy-namic. This classification represents varying de-grees of trade-offs between fault isolation and per-formance, ranging from static mappings which em-phasize recoverability over performance, to differentways of balancing between recoverability and per-formance, to a completely dynamic mapping of re-sources to recovery groups, which maximizes the uti-lization of resources while trying to meet recoveryconstraints.
In order to provide a better understanding of thedesign philosophy of our recovery-conscious schedul-ing, we devise a running example scenario that isused to illustrate the design of all three classes ofRCS algorithms. This running example has five re-source pools: ρ1, ρ2, ρ3, ρ4 and ρ5 and four recov-ery groups: γ1, γ2, γ3 and γ4. We use σi to denotethe recoverability constraint for the recovery group
Recovery Groups γ1 γ2 γ3 γ4
% of Workload 40% 20% 20% 20%Recoverability 2 1 1 1constraints (σi)
Table 1: Recovery constraints
Recovery Groups γ1 γ2 γ3 γ4
Resource Pools ρ1, ρ2 ρ3 ρ4 ρ5
Table 2: Static mapping
γi. Constraint σi specifies the upper limit on theamount of resources (processors in this case) thatcan be dedicated to the recovery group γi (1 ≤ i ≤ 4in our running example). Since we are concernedwith processing resources in this paper, it also in-dicates the number of tasks belonging to a recov-ery group that can be dispatched concurrently. Therecoverability constraint σi is determined based onboth the recovery group workload i.e., the numberof tasks dispatched, and the observed task-level re-covery time. Although recoverability constraints arespecified from the availability standpoint, they musttake performance requirements into consideration inorder to be acceptable. Recoverability constraintsare primarily used for proactive RCS.
For ease of exposition we assume that all re-source pools are of equal size (1 processor each). Ta-ble 1 shows the workload distribution between therecovery groups and the recoverability constraint pergroup, where two processors are assigned to the re-covery group γ1 and one processor is assigned to eachof the remaining three groups.
In contrast to the scenario in Table 1 where noresource pools are shared by two or more recov-ery groups, when more than one recovery group ismapped to a resource pool the scheduler must en-sure that the dispatching scheme does not result instarvation. By avoiding starvation, it ensures thatthe functional interactions between the componentsare not disrupted. For example in our implementa-tion we used a simple round-robin scheme for eachscheduler to choose the next task from different re-covery groups sharing the same resource pool. Otherschemes such as those based on queue lengths ortask arrival time are also appropriate as long as theyavoid starvation.
5.1 Static RCS
Static recovery conscious scheduling algorithms con-struct static mappings between recovery groups andresource pools. The initial mapping is provided tothe system based on the observations of the work-load and known recoverability constraints, such aspreviously observed localized recovery times. The
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 151

mappings are static in the sense that they do notcontinuously adapt to changes in resource demandsand workload distribution. Table 2 shows a mappingbetween the pools ρ1 . . . ρ5 and the recovery groupsγ1 . . . γ4. This mapping assigns resource pools torecovery groups based on the workload distributionand the recoverability constraints given in Table 1.Concretely, in this mapping recovery group γ1 ismapped to two pools ρ1 and ρ2. Similarly groupsγ2, γ3 and γ4 are each assigned a single resourcepool. Each processor dispatches work only from itsassigned recovery group.
This approach aims at achieving strict recoveryisolation. As a result, it loses out on utilization of re-sources, which in turn impacts both throughput andresponse time. Although this is a naive approach toperforming recovery-conscious scheduling it helps usin understanding issues related to the performanceand recoverability trade-off. Note that all our RCSalgorithms avoid starvation by using a round-robinscheme to cycle between recovery groups sharing thesame resource pool. In systems where the workloadis well understood and sparse in terms of resourceutilization, static mappings offer a simple means ofachieving serialization of recovery dependent tasks.
Implementation Considerations: There aretwo main data structures that are common to allRCS algorithms: (1) the mapping tables and (2) thejob queues. Mapping table implementations keeptrack of the list of recovery groups assigned to eachresource pool. They also keep track of groups thatare currently undergoing recovery for the purpose ofreactive scheduling. In our system we used a simplearray-based implementation for mapping tables.
There are a couple of options for implementingjob queues. Recall that recovery-consciousness isbuilt on top of the QoS or priority based scheduling.We could use multiple QoS based job queues (forexample, high, medium and low priority queues) foreach pool or for each group. In our first prototype,we chose the latter option and implemented multi-ple QoS based job queues for each recovery groupfor a number of reasons. Firstly, this choice easilyfits into the scenario where a single recovery groupis assigned to multiple resource pools. Secondly, itoffers greater flexibility to modify mappings at run-time. Finally, reactive scheduling (i.e., suspendingdispatch of tasks belonging to a group undergoinglocalized recovery) can be implemented more ele-gantly as the resource scheduler can simply skip thejob queues for the recovering group. Enqueue anddequeue operations on each queue are protected by alock. An additional advantage of a mapping imple-mented using multiple independent queues is that itreduces the degree of contention for queue locks.
Recovery Groups γ1 γ2 γ3 γ4
Resource Pools All All ρ4 ρ5
Table 3: Partial Dynamic RCS: Alternative mapping
. . .
repeatworkFound := falsefor γi in current mapping do
workFound := ScanDispatch(HighQueue for γi)if workFound then
breakend if
end forif !workFound then
AcquireLease()for γj in alternative mapping do
workFound := ScanDispatch(HighQueue for γj)if leaseExpired() OR workFound then
breakend if
end forend if
until HighPriorityLoopCount//Similarly for Medium and Low Priority tasks
Figure 8: Partial Dynamic RCS
5.2 Partial dynamic RCS
The second class of algorithms are partially dynamicand allow the recovery-conscious scheduler to react(in a constrained fashion though) to sudden spikesor bursty workload of a recovery group.
The main drawback of static RCS is that it resultsin poor utilization of resources due to the strictlyfixed mapping. Partial dynamic RCS attempts toalleviate this problem by using a relatively moreflexible mapping of resources to recovery groups, al-lowing groups to utilize spare resources. Partiallydynamic RCS algorithms begin with a static map-ping. However, when the utilization is low, the sys-tem switches to an alternative mapping that redis-tributes resources across recovery groups.
For example, with the static mapping of Table 2with changing distribution of workloads, resourcesallocated to recovery groups γ3 and γ4 may be un-der utilized while groups γ1 and γ2 may be swampedwith work. Under these circumstances, the systemswitches to an alternative mapping shown in Table 3.Now groups γ1 and γ2 can utilize spare resourcesacross the system even if this may mean potentiallyviolating their recoverability constraints specified inTable 1. Note that γ3 and γ4 still obey their re-coverability constraints. In summary, partially dy-namic mappings allows the flexibility of selectivelyviolating the recoverability constraints when thereare spare resources to be utilized, whereas staticmappings strictly obey recoverability constraints.
The aim of the partial dynamic mapping is toimprove utilization over static schemes by openingup spare resources to recovery groups with heavyworkloads. With the above example although there
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association152

is a danger of a single recovery group (for e.g., γ1)running concurrently across all resource pools, notethat this is highly unlikely if other groups have anytasks enqueued for dispatching. There are multi-ple combinatorial possibilities in designing alterna-tive mappings for partially-dynamic schemes. Thechoice of which components should continue to staywithin their recoverability bounds is to be made bythe system designer using prior information aboutindividual component vulnerabilities to failures.
Implementation Considerations: There aretwo implementation considerations that are specificto the partially dynamic scheduling schemes: (1) themechanism to switch between initial schedule and analternative schedule, and (2) the mapping of recov-ery group tasks to the shared resource pools.
We use a lease expiry methodology to flexiblyswitch between alternative mappings. Note that thepool schedulers switch to the alternative mappingbased on the resource utilization of the current pool.With the partially dynamic scheme, the alternativemappings are acquired under a lease, which uponexpiry causes the scheduler to switch back to theoriginal schedule. The lease-timer is set based onobserved component workload trends (such as du-ration of a burst or spike) and the cost of switch-ing. For example, since our implementation had avery low cost of switching between mappings, weset the lease-timer to a single dispatch cycle. Fig-ure 8 shows the pseudo-code for a partial dynamicscheduling scheme using a lease expiry methodology.For the sake of simplicity we do not show the track-ing method (round-robin) used to avoid starvationin the scheduler.
Recall from the implementation considerationsfor the static mapping case that we chose to imple-ment job queues on a per recovery group basis. Thisallowed for easy switching between the current andalternative mapping which only involves consultinga different mapping table. Task enqueue operationsare unaffected by the switching between mappings.
5.3 Dynamic RCS
Dynamic recovery-conscious scheduling algorithmsassign recovery groups to resource pools at runtime.In dynamic RCS, tasks are still organized into recov-ery groups with recoverability bounds specified foreach group. However, all resource pools are mappedto all recovery groups. The schedulers cycle throughall groups giving preference to groups that are stillwithin their recoverability bounds, i.e., occupyingfewer resources than specified by the bound. If nosuch group is found, then tasks are dispatched whiletrying to minimize the resource consumption by anyindividual recovery group.
This class of algorithms aim at maximizing uti-lization of resources at the cost of selectively vio-lating the recoverability constraints. Note that allrecovery-conscious algorithms are still designed toperform reactive scheduling, i.e., suspend the dis-patching of tasks whose group is currently undergo-ing localized recovery. The aspect that differentiatesthe various mapping schemes is the proactive han-dling of tasks to improve system availability. Thedynamic scheme can be thought of as trying to useload balancing among recovery groups in order toachieve both recovery isolation and good resourceutilization.
Implementation Considerations: A key im-plementation consideration specific to dynamic RCSis the problem of keeping track of the number ofoutstanding tasks belonging to each recovery group.We maintain this information in a per-processor datastructure that keeps track of the current job.
Recall that implementing job queues on the perrecovery-group basis helps us implement dynamicmappings efficiently and flexibly. One of the criticaloptimizations for dynamic RCS algorithms involvesunderstanding and mitigating the scheduling over-head imposed by the dynamic dequeuing process. Inon going work we are conducting experiments withdifferent setups to characterize this overhead. How-ever our results in this paper show that even withthe additional scheduling cost dynamic RCS schemesperform very well both under good-path and bad-path conditions.
6 Experiments
We have implemented our recovery-consciousscheduling algorithms on a real industry-standardstorage system. Our implementation involved nochanges to the functional architecture. Our resultsshow that dynamic RCS can match performance ori-ented scheduling under good path conditions whilesignificantly improving performance under failure re-covery.
6.1 Experimental Setup
Our algorithms were implemented on a high-capacity, high-performance and highly reliable enter-prise storage system built on proprietary server tech-nology due to which some of the setup and architec-ture details presented in this paper have been desen-sitized. The system is a storage facility that consistsof a storage unit with two redundant 8-way serverprocessor complexes (controllers), memory for I/Ocaching, persistent memory (Non-Volatile Storage)for write caching, multiple FCP, FICON or ESCONadapters connected by a redundant high bandwidth(2 GB) interconnect, fiber channel disk drives, and
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 153

�������
�� �������������
�������� ����
���
� � � �� �� �� � �� �� ��
�� ���� �� ���� �� ���� �� ������ ���� �� ���� �� ��� �� �����
�!
"�
#�!��"�� !�������
Figure 9: Cache-Standard
�
�
��
��
��
��
��
��
� � � �� �� � � �� �� ��
�� ���� �� ����� �� �����
�����������������
���
�����
�������
� !�
�����
�"�##����
�
Figure 10: Efficiency vs Recoverygroups
�
��
��
��
��
���
���
��� �����
������� ��� ��� ���� !
������� ��� �� ���� !
�����""� �������
���
������ ���
#$�
�%$�
��
���& '�
� !
Figure 11: Good path throughput
management consoles. The system is designed tooptimize both response time and throughput. Thebasic strategy employed to support continuous avail-ability is the use of redundancy and highly reliablecomponents.
The embedded storage controller software is simi-lar to the model presented in Section 2. The softwareis also highly-reliable with provisions for quick recov-ery(under ∼6 seconds) at the system-level. The sys-tem has a number of interacting components whichdispatch a large number of short running tasks. Forthe experiments in this paper based on programmerexplicit recovery dependency specifications, we iden-tified 16 recovery groups which roughly correspondto functional components such as cache manager, de-vice manager, SCSI command processor etc. How-ever, some recovery groups may perform no workin certain workloads possibly due to features beingturned off. We chose a pool size of 1 CPU whichresulted in 8 pools of equal size. The system al-ready implements high, medium and low priority jobqueues. Our recovery-conscious scheduling imple-mentation therefore uses three priority based queuesper recovery group. For the partially dynamic case,based on the workload we have identified two can-didates for strict isolation - groups 4 and 5. For thestatic mapping case each recovery group is mappedto resource pools proportional to its ratio of the totaltask workload.
6.2 Workload
We use the z/OS Cache-Standard workload [1, 14] toevaluate our algorithms. The z/OS Cache-standardworkload is considered comparable to typical onlinetransaction processing in a z/OS environment. Theworkload has a read/write ratio of 3, read hit ra-tio of 0.735, destage rate of 11.6% and a 4K averagetransfer size. The setup for the cache-standard work-load was CPU-bound. Figure 9 shows the number oftasks dispatched per-recovery group under the work-
load over 30 minutes. Group 4 has the highest taskworkload (∼6.5M tasks/min) followed by group 5(∼ 5M/min). Eight of the groups which have nearlynegligible workload are not visible in the graph. Weuse this workload to measure throughput and re-sponse times. While measuring cpu utilization weonly count time actually spent in task execution anddo not include time spent acquiring queue locks, de-queuing jobs or polling for work.
6.3 Experimental Results
We compare RCS and performance oriented schedul-ing algorithms using good-path (i.e. normal condi-tion) and bad-path (under failure recovery) perfor-mance.
6.3.1 Effect of additional job queues
We first performed some benchmarking experimentsto understand the effect of additional job queueson the efficiency of the scheduler. Using the cache-standard workload, we measured the aggregate num-ber of dispatches per minute with varying number ofrecovery groups - 16, 4 and 1 (which is identical toperformance-oriented scheduling) to measure sched-uler efficiency with dynamic RCS. The four and onerecovery group cases were implemented by collaps-ing multiple groups into a single larger group. Recallthat each recovery group results in three job queuesfor high, medium and low priority jobs. Figure 10shows the aggregate number of tasks dispatched perminute with 1, 4 and 16 recovery groups. As the fig-ure shows the number of dispatches are almost iden-tical in the three cases (+/- 2%). Although more jobqueues imply having to cycle through more queuelocks while dispatching work, increasing the numberof job queues reduces contention for queue locks bothwhen enqueuing and dequeuing tasks. For most ofthe experiments in this paper we choose a configu-ration with 16 recovery groups.
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association154
��
��
��
��
��
��
��� ����
��������
���
�
�
��
��
����� �������
������ �� !�" #�$���
������ �� !� #�$���
��������� ������
��
����� ��
����
!� �
Figure 12: Good path latency
���
����
����
����
��������� �
��
���� ���������� ������
������������� � ���!��"#�$�%�&� ���'� ���!��"#�$(�&� ���' ����� �� ���!��"##���!��"#
Figure 13: CPU utilization
��
��
���
���
��
��
����
���
�
��
��
����������� ��
������ �!"#�
������ �!"#�$��%������ �&��
��� ��%%�������� �
!"#
# � � �!"#
'��
$��
Figure 14: Bad path throughput
6.3.2 Good-path Performance
Recovery-conscious scheduling can be an acceptablesolution only if it is able to meet the stringent perfor-mance requirements of a high-end system. In this ex-periment we compare the good-path (i.e. under nor-mal operation) performance of our RCS algorithmswith the existing performance-oriented scheduler.
Figure 11 shows the good-path throughput forthe performance-oriented and recovery-consciousscheduling algorithms. The average throughput forthe dynamic RCS case with 16 groups (105 KIOps)and 4 groups (106 KIOps) was close to that for theperformance-oriented scheduler (107 KIOps). Onthe other hand, with partially dynamic RCS, thesystem throughput drops by nearly 34% (∼ 69.9KIOps), and with static RCS by nearly 58% (∼ 44.6KIOps) compared to performance oriented schedul-ing.
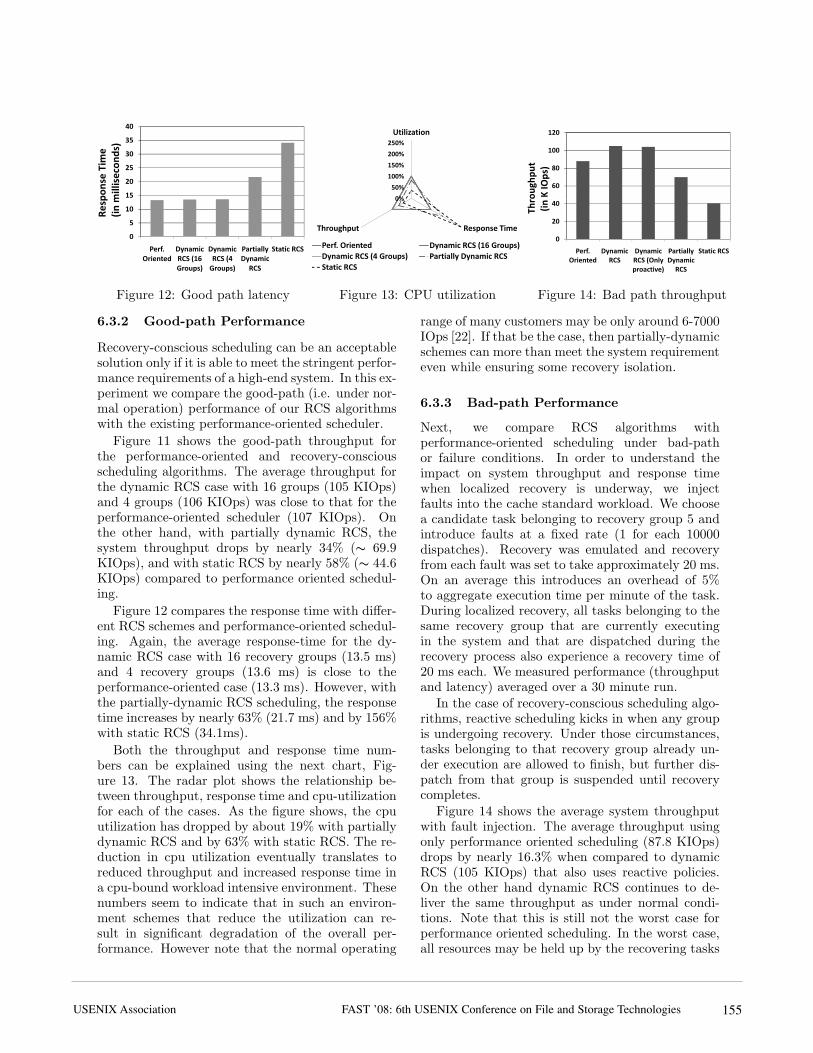
Figure 12 compares the response time with differ-ent RCS schemes and performance-oriented schedul-ing. Again, the average response-time for the dy-namic RCS case with 16 recovery groups (13.5 ms)and 4 recovery groups (13.6 ms) is close to theperformance-oriented case (13.3 ms). However, withthe partially-dynamic RCS scheduling, the responsetime increases by nearly 63% (21.7 ms) and by 156%with static RCS (34.1ms).
Both the throughput and response time num-bers can be explained using the next chart, Fig-ure 13. The radar plot shows the relationship be-tween throughput, response time and cpu-utilizationfor each of the cases. As the figure shows, the cpuutilization has dropped by about 19% with partiallydynamic RCS and by 63% with static RCS. The re-duction in cpu utilization eventually translates toreduced throughput and increased response time ina cpu-bound workload intensive environment. Thesenumbers seem to indicate that in such an environ-ment schemes that reduce the utilization can re-sult in significant degradation of the overall per-formance. However note that the normal operating
range of many customers may be only around 6-7000IOps [22]. If that be the case, then partially-dynamicschemes can more than meet the system requirementeven while ensuring some recovery isolation.
6.3.3 Bad-path Performance
Next, we compare RCS algorithms withperformance-oriented scheduling under bad-pathor failure conditions. In order to understand theimpact on system throughput and response timewhen localized recovery is underway, we injectfaults into the cache standard workload. We choosea candidate task belonging to recovery group 5 andintroduce faults at a fixed rate (1 for each 10000dispatches). Recovery was emulated and recoveryfrom each fault was set to take approximately 20 ms.On an average this introduces an overhead of 5%to aggregate execution time per minute of the task.During localized recovery, all tasks belonging to thesame recovery group that are currently executingin the system and that are dispatched during therecovery process also experience a recovery time of20 ms each. We measured performance (throughputand latency) averaged over a 30 minute run.
In the case of recovery-conscious scheduling algo-rithms, reactive scheduling kicks in when any groupis undergoing recovery. Under those circumstances,tasks belonging to that recovery group already un-der execution are allowed to finish, but further dis-patch from that group is suspended until recoverycompletes.
Figure 14 shows the average system throughputwith fault injection. The average throughput usingonly performance oriented scheduling (87.8 KIOps)drops by nearly 16.3% when compared to dynamicRCS (105 KIOps) that also uses reactive policies.On the other hand dynamic RCS continues to de-liver the same throughput as under normal condi-tions. Note that this is still not the worst case forperformance oriented scheduling. In the worst case,all resources may be held up by the recovering tasks
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 155

�
�
��
��
��
��
��
��
��
��� �����
������� ���
������� ��� ����� �������
�������� �������
���
������ ���
�!�
��!
"��
���
����
�!�
���!
Figure 15: Bad path latency
resulting in actual service outage and the problemwould only worsen with increasing localized recov-ery time and system size.
The figure also compares proactive and reactivepolicies in dynamic RCS. The results show that withonly proactive scheduling we are able to sustain athroughput (104 KIOps) which is just ∼ 1% less thanthat using both proactive and reactive policies (105KIOps).
The graph also compares partially dynamic RCS(69.9 KIOps) and static RCS (40.4 KIOps). Whilethese schemes are able to sustain almost the samethroughput as they do under good path, overall, theperformance of these schemes results in 20% and54% drop in throughput respectively compared toperformance oriented scheduling.
Figure 15 compares the latency under bad-pathcode with different scheduling schemes. Comparedto dynamic RCS (13.5 ms), performance orientedscheduling (16.6 ms) results in a 22.9% increase inresponse time. At the same time, even without re-active scheduling, dynamic RCS (13.6 ms with onlyproactive) increases response time by only 0.7%.Again, partially dynamic RCS (21.7ms) and staticRCS (37.1 ms) result in latency close to their goodpath performance but which is still too high whencompared to dynamic RCS.
We performed experiments with other configu-rations of dynamic, partially dynamic and staticschemes and using other workloads too. Howeverdue to space constraints we only present key find-ings from those experiments. In particular we useda disk-bound internal workload (and hence low cpuutilization of about ∼25%) to study the effect ofour scheduling algorithms under a sparse workload.We used the number of task dispatches as a metricof scheduler efficiency. The fault injection mecha-nism was similar to the cache-standard workload,however due to the workload being sparse, we in-troduced an overhead of only 0.3% to the aggregateexecution time of the faulty recovery group. Our re-sults showed that dynamic RCS was able to achieve
as many dispatches as performance oriented schedul-ing under good path operation and increase the num-ber of dispatches by 0.7% under bad-path execution.With partial dynamic RCS dispatches dropped by20% during good path operation and by only 3.9%during bad path operation compared to performanceoriented scheduling. The same static mapping usedin the cache standard workload when run in thisnew environment resulted in the system not comingup. While this may be due to setup issues, it is alsolikely that insufficient resources were available to theplatform tasks during start-up. We are investigat-ing further on a more appropriate static mapping forthis environment.
6.4 Discussion
The fact that recovery-conscious scheduling requiresminimal change to the software allows for it to beeasily incorporated even in legacy systems.
Dynamic RCS can match good path performanceof performance oriented scheduling and at the sametime significantly improve performance under local-ized recovery. Even for the small 5% recovery over-head introduced by us, we could witness a 16.3% im-provement in throughput and a 22.9% improvementin response time with dynamic RCS. Moreover, thequalitative benefits of RCS in enhancing availabil-ity and ensuring that localized recovery is scalablewith system size makes it an interesting possibilityas systems are moving towards more parallel archi-tectures. Our experiments with various schedulingschemes (some not reported in this paper) have givenus some insights into the overhead costs such as lockspin times imposed by RCS algorithms. In ongoingwork we are continuing to characterize and investi-gate further optimizations to RCS schemes.
Our results also seem to indicate that for smalllocalized recovery time and system sizes, proac-tive policies i.e. mapping resource pools to recov-ery groups, can deliver the advantage of recovery-consciousness. However as system size increases orlocalized recovery time increases, we believe that theactual benefits of reactive policies such as suspend-ing dispatch from groups undergoing recovery maybecome more pronounced. In ongoing research weare experimenting with larger setups and longer lo-calized recovery times.
Static and partial dynamic RCS schemes are lim-ited by their poor resource utilization in workloadintensive environments. Hence we do not recom-mend these schemes in an environment where thesystem is expected to run at maximum through-put. However, the tighter qualitative control thatthese schemes offer may make them, especially par-tially dynamic RCS, more desirable in less intensiveenvironments where there is a possibility to over-
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association156

provision resources, or when the workload is verywell understood. Besides in environments where it‘pays’ to isolate some components of the system fromthe rest such mappings may be useful. We are con-tinuing research on optimizing these algorithms andunderstanding properties that would prescribe theuse of such static or partially dynamic schemes.
7 Related Work
Our work is largely inspired by previous work in thearea of software fault tolerance and storage systemavailability. Techniques for software fault tolerancecan be classified into fault treatment and error pro-cessing. Fault treatment aims at avoiding the ac-tivation of faults through environmental diversity,for example by rebooting the entire system [6, 24],micro-rebooting sub-components of the system [2],through periodic rejuvenation [13, 5] of the soft-ware, or by retrying the operation in a differentenvironment [17]. Error processing techniques areprimarily checkpointing and recovery techniques [7],application-specific techniques like exception han-dling [21] and recovery blocks [19] or more recenttechniques like failure-oblivious computing [20].
In general our recovery conscious approaches arecomplementary to the above techniques. Howeverwe are faced with several unique challenges in thecontext of embedded storage software. First, thesoftware being legacy code rules out re-architectingthe system. Second, the tight coupling between com-ponents makes both micro-reboots and periodic re-juvenation tricky. Rx [17] demonstrates an interest-ing approach to recovery by retrying operations ina modified environment but it requires checkpoint-ing of the system state in order to allow ‘rollbacks’.However given the high volume of requests (tasks)experienced by the embedded storage controller andtheir complex operational semantics, such a solutionmay not be feasible in this setup.
Failure-oblivious computing [20] introduces anovel method to handle failures - by ignoring themand returning possibly arbitrary values. This tech-nique may be applicable to systems like search en-gines where a few missing results may go unnoticed,but is not an option in storage controllers.
The idea of localized recovery has been exercisedby many. Transactional recovery using checkpoint-ing/logging methods is a classic topic in DBMSs [16]and is a successful implementation of fine-grainedrecovery. In fact application-specific recovery mech-anisms such as recovery blocks [19], and exceptionhandling [21] are used in almost every software sys-tem. However, very few have made an effort onunderstanding the implications of localized recoveryon system availability and performance in a multi-core environment where interacting tasks are exe-
cuting concurrently. Likewise, the idea of recovery-conscious scheduling is to raise the awareness aboutlocalized recovery in the resource scheduling algo-rithms to ensure that the benefits of localized recov-ery actually percolate to the level of system avail-ability and performance visible to the user. Al-though vast amounts of prior work have been ded-icated to resource scheduling, to the best of ourknowledge, such work has mainly focused on per-formance [25, 11, 12, 8, 4]. Also much work in thevirtualization context has been focused on improvingsystem reliability [18] by isolating VMs from failuresat other VMs. In contrast, our development focusesmore on improving system availability by distribut-ing resources within an embedded storage softwaresystem by identifying fine-grained recovery scopes.Compared to earlier work on improving storage sys-tem availability at the RAID level [23], we are con-cerned with the embedded storage software reliabil-ity. These techniques are at different levels of thestorage system and are complementary.
8 Conclusion and Future Work
In this paper we presented a recovery consciousframework for multi-core architectures and tech-niques for improving the resiliency and recovery ef-ficiency of highly concurrent embedded storage soft-ware. Our main contributions include a task-levelrecovery model and the development of recovery-conscious scheduling, a non-intrusive technique toreduce the ripple effect of software failure and im-prove the availability of the system. We presenteda suite of RCS algorithms and quantitatively evalu-ated them against performance oriented scheduling.Our evaluation showed that dynamic RCS can sig-nificantly improve performance under failure recov-ery while matching performance oriented schedulingduring normal operation.
In order to adopt RCS for large software systems,a significant challenge is to identify efficient recoveryscopes. In ongoing work we are working on devel-oping more generic guidelines that would assist inidentifying fine-grained recovery scopes. Even withpluggable mechanisms like RCS it is necessary toemphasize that high-availability should still be a de-sign concern and not an after-thought. We hope ourframework would encourage developers to incorpo-rate additional error handling and anticipate moreerror scenarios and that our scheduling schemeswould aid in scaling efficient error handling with sys-tem size.
9 Acknowledgments
The authors would like to express their gratitudeto David Whitworth, Andrew Lin, Juan Ruiz (JJ),
FAST ’08: 6th USENIX Conference on File and Storage TechnologiesUSENIX Association 157

Brian Hatfield, Chiahong Chen and Joseph Hydefor helping us perform experimental evaluations andinterpret the data. We would also like to thankK.K.Rao, David Chambliss, Brian Henderson andmany others in the Storage Systems group at IBMAlmaden Research Center who provided us with theresources to perform our experiments and providedvaluable feedback. We thank our anonymous review-ers, our shepherd Dr. Mary Baker and Prof. KarstenSchwan for the useful comments and feedback thathave helped us improve the paper.
This work is partially supported by an IBM PhDscholarship and an IBM Storage Systems internshipfor the first author, and the NSF CISE IIS and CSRgrants, an IBM SUR grant, as well as an IBM facultyaward for the authors from Georgia Tech.
References
[1] Ibm z/architecture principles of operation. SA22-7832, IBM Corporation, 2001.
[2] G. Candea, J. Cutler, and A. Fox. Improving avail-ability with recursive microreboots: a soft-state sys-tem case study. Perform. Eval., 56(1-4):213–248,2004.
[3] G. Candea, S. Kawamoto, Y. Fujiki, G. Friedman,and A. Fox. Microreboot–a technique for cheap re-covery. OSDI, 2004.
[4] S. Chen, P. B. Gibbons, M. Kozuch, V. Liaskovi-tis, A. Ailamaki, G. E. Blelloch, B. Falsafi, L. Fix,N. Hardavellas, T. C. Mowry, and C. Wilkerson.Scheduling threads for constructive cache sharingon cmps. In SPAA, pages 105–115, New York, NY,USA, 2007. ACM Press.
[5] S. Garg, A. Puliafito, M. Telek, and K. Trivedi. Onthe analysis of software rejuvenation policies. InProceedings of the 12th Annual Conference on Com-puter Assurance (COMPASS’97), 1997.
[6] J. Gray. Why do computers stop and what canbe done about it? In Symposium on Reliability inDistributed Software and Database Systems, pages3–12, 1986.
[7] J. Gray and A. Reuter. Transaction Processing :Concepts and Techniques (Morgan Kaufmann Se-ries in Data Management Systems). Morgan Kauf-mann, October 1992.
[8] A. Gulati, A. Merchant, and P. J. Varman. pclock:an arrival curve based approach for qos guaranteesin shared storage systems. In SIGMETRICS, pages13–24, New York, NY, USA, 2007. ACM Press.
[9] M. Hartung. IBM totalstorage enterprise storageserver: A designer’s view. IBM Syst. J., 42(2):383–396, 2003.
[10] HP. HSG80 array controller software.
[11] S. Iyer and P. Druschel. Anticipatory scheduling:A disk scheduling framework to overcome deceptiveidleness in synchronous i/o. In Symposium on Op-erating Systems Principles, pages 117–130, 2001.
[12] M. Karlsson, C. Karamanolis, and X. Zhu. Triage:Performance differentiation for storage systems us-ing adaptive control. Trans. Storage, 1(4):457–480,2005.
[13] N. Kolettis and N. D. Fulton. Software rejuvena-tion: Analysis, module and applications. In FTCS,page 381, Washington, DC, USA, 1995. IEEE Com-puter Society.
[14] L. LaFrese. Ibm totalstorage enterprise storageserver model 800 new features in lic level 2.3.0 (performance white paper ). ESS Performance Eval-uation, IBM Corporation, 2003.
[15] I. Lee and R. K. Iyer. Software dependability in thetandem guardian system. IEEE Trans. Softw. Eng.,21(5):455–467, 1995.
[16] C. Mohan, D. Haderle, B. Lindsay, H. Pirahesh,and P. Schwarz. ARIES: a transaction recov-ery method supporting fine-granularity locking andpartial rollbacks using write-ahead logging. ACMTrans. Database Syst., 17(1):94–162, 1992.
[17] F. Qin, J. Tucek, J. Sundaresan, and Y. Zhou. Rx:Treating bugs as allergies — a safe method to sur-vive software failure. In SOSP, Oct 2005.
[18] H. Ramasamy and M. Schunter. Architecting de-pendable systems using virtualization. In Workshopon Architecting Dependable Systems in conjunctionwith 2007 International Conference on DependableSystems and Networks (DSN-2007), 2007.
[19] B. Randell. System structure for software fault tol-erance. In Proceedings of the international con-ference on Reliable software, pages 437–449, NewYork, NY, USA, 1975. ACM Press.
[20] M. Rinard, C. Cadar, D. Dumitran, D. M. Roy,T. Leu, and J. William S. Beebee. Enhancing serveravailability and security through failure-obliviouscomputing. In OSDI, Berkeley, CA, USA, 2004.USENIX Association.
[21] S. Sidiroglou, O. Laadan, A. D. Keromytis, andJ. Nieh. Using rescue points to navigate softwarerecovery. In SP, pages 273–280, Washington, DC,USA, 2007. IEEE Computer Society.
[22] Sirius. Sirius enterprise systems group disk drivestorage hardware. Solicitation EPS050059-A4.
[23] M. Sivathanu, V. Prabhakaran, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. ImprovingStorage System Availability with D-GRAID. ACMTransactions on Storage (TOS), 1(2):133–170, May2005.
[24] M. Sullivan and R. Chillarege. Software defects andtheir impact on system availability - a study of fieldfailures in operating systems. FTCS, pages 2–9,1991.
[25] J. Zhang, A. Sivasubramaniam, Q. Wang, A. Riska,and E. Riedel. Storage performance virtualizationvia throughput and latency control. Trans. Storage,2(3):283–308, 2006.
FAST ’08: 6th USENIX Conference on File and Storage Technologies USENIX Association158
Related Documents











