Egocentric Future Localization Hyun Soo Park, Jyh-Jing Hwang, Yedong Niu, and Jianbo Shi

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Egocentric Future Localization
Hyun Soo Park, Jyh-Jing Hwang, Yedong Niu, and Jianbo Shi

VIRAT Dataset

VIRAT Dataset
Where will he go?

VIRAT Dataset Kitani et al. ECCV12
Where will he go?

VIRAT Dataset Kitani et al. ECCV12
Where will he go?

VIRAT Dataset Kitani et al. ECCV12
Where will he go? If I were him, how would I move into the scene?

What is he experiencing visually?

First person view

RGBD First person view

First person view

Occlusion
Occlusion
First person view
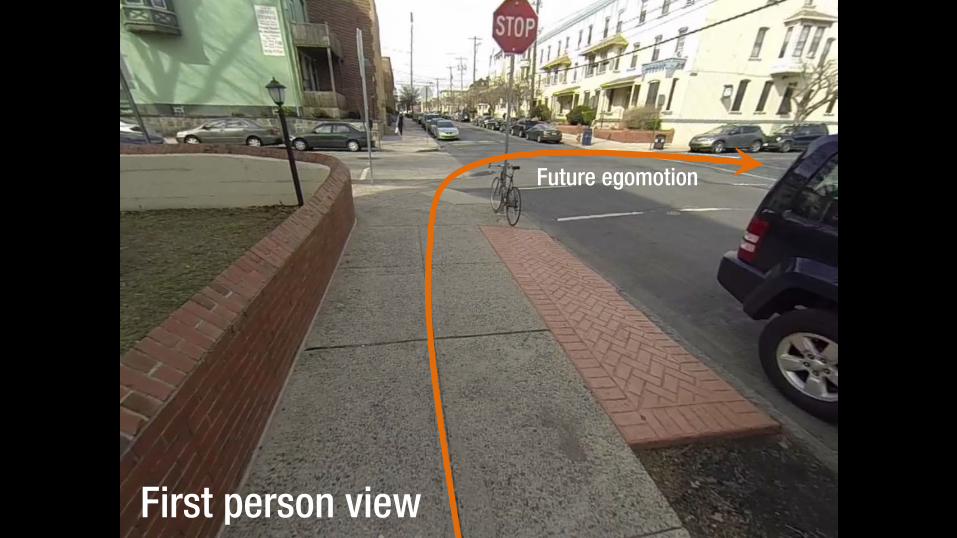
First person view
Future egomotion

Future localization

Future localization

Future localization

Why challenging?

Training
Why challenging?

Training
Why challenging? Prediction

Wall
Wall
Cars
Cars Tree Tree
Training
Road
Hand Prediction
Road
Hand Why challenging?

Wall
Wall
Cars
Cars Tree Tree
Training
Road
Hand Prediction
Road
Why challenging? Hand
1. Geometric inconsistency

Wall
Wall
Cars
Cars Tree Tree
Training
Road
Hand
Road
Why challenging? Hand
Vanishing line
Looking down Looking forward
Prediction 1. Geometric inconsistency

Wall
Wall
Cars
Cars Tree Tree
Training
Road
Hand
Road
1. Geometric inconsistency
Why challenging? Hand
Vanishing line
Prediction
2. Semantic inconsistency
Looking down Looking forward

Wall
Wall
Cars
Cars Tree Tree
Training
Road
Hand
Road
Why challenging? Hand
Vanishing line
Prediction 1. Geometric inconsistency
2. Semantic inconsistency
EgoRetinal representation
Preference learning
Looking down Looking forward
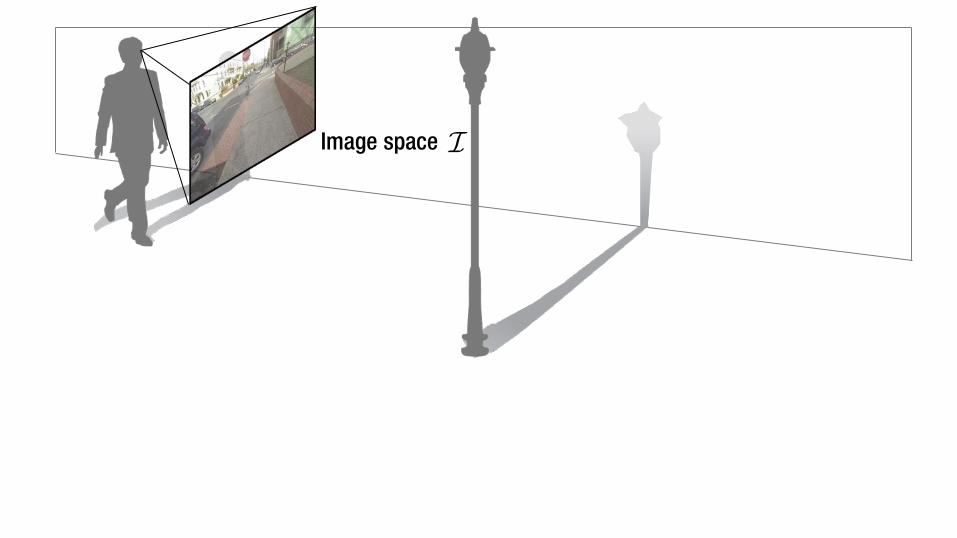
Image space

n
Ground plane
Prediction: Configuration space (ground plane)
Image space
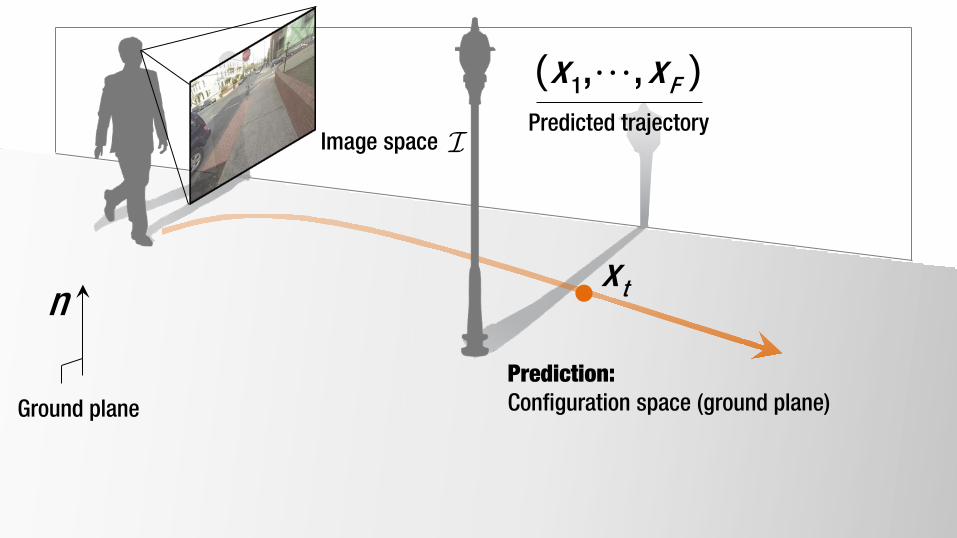
n
Ground plane
Prediction: Configuration space (ground plane)
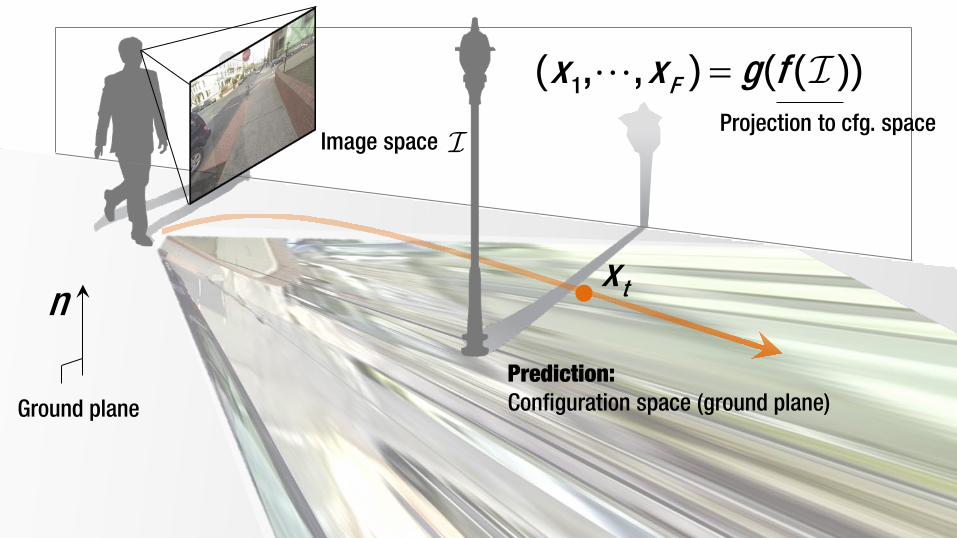
Image space
tx
=1, , Fx x g( ) ( )Predicted trajectory
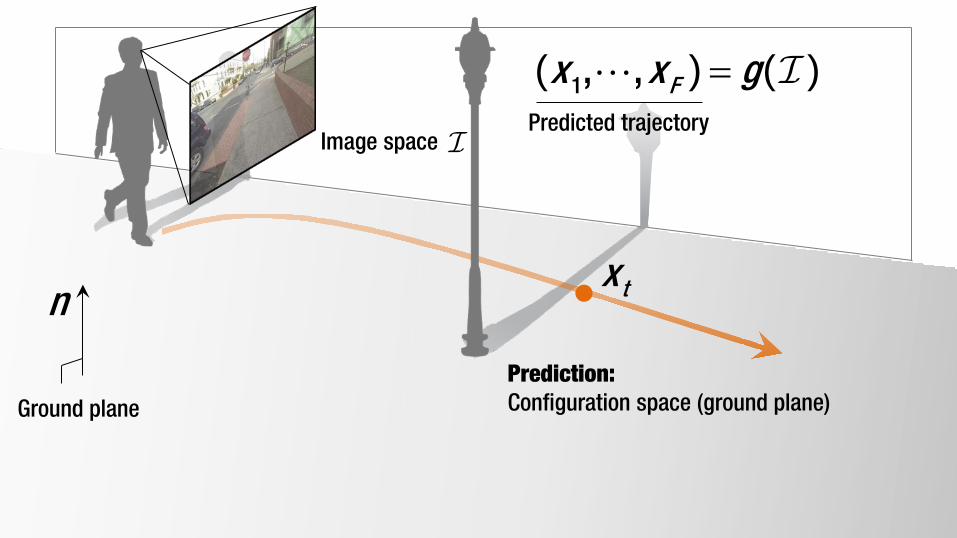
n
Ground plane
Prediction: Configuration space (ground plane)
Image space
tx
=1, , Fx x g( ) ( )Predicted trajectory
=1, , Fx x g( ) ( )
n
Ground plane
tx
g f( ( ))
Prediction: Configuration space (ground plane)
Projection to cfg. space Image space
=1, , Fx x g( ) ( )
tx
g f( ( ))
Prediction: Configuration space (ground plane)
Projection to cfg. space
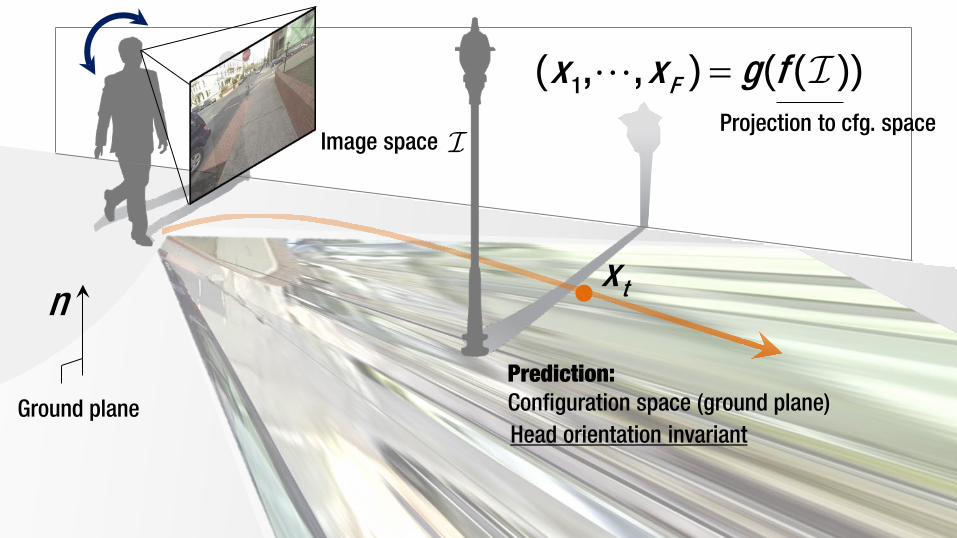
n
Ground plane
Image space
Head orientation invariant

=1, , Fx x g( ) ( )g f( ( ))
n
Ground plane
Image space
r( , )θ
rf ,( ) θ

=1, , Fx x g( ) ( )g f( ( ))
n
Ground plane
Image space
r( , )θ
Tr rf u n, proj( , )( ) = ( , ) θ θ
Image projection
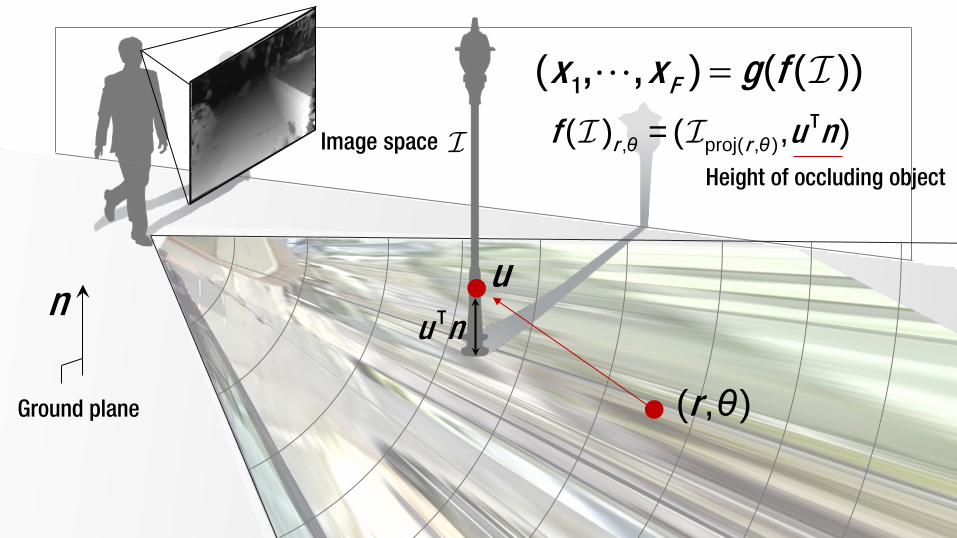
=1, , Fx x g( ) ( )g f( ( ))
n
Ground plane
Image space
r( , )θ
Tr rf u n, proj( , )( ) = ( , ) θ θ
uTu n
Height of occluding object

n
Ground plane
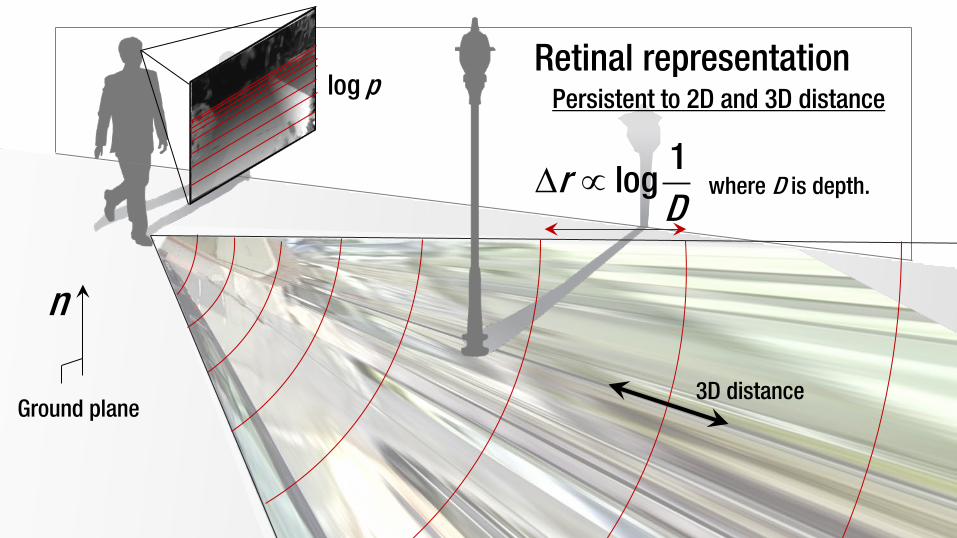
∆ ∝1
logrD
where D is depth.
Retinal representation
Cf) Proxemics
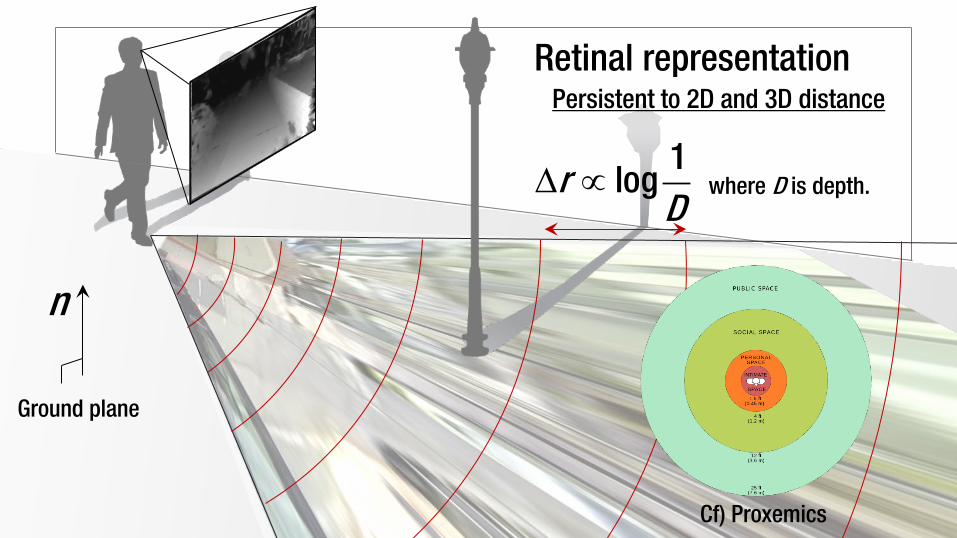
n
Ground plane
∆ ∝1
logrD
where D is depth.
Retinal representation
Cf) Proxemics
Persistent to 2D and 3D distance

n
Ground plane
∆ ∝1
logrD
where D is depth.
Retinal representation Persistent to 2D and 3D distance
3D distance
n
Ground plane
∆ ∝1
logrD
where D is depth.
Retinal representation Persistent to 2D and 3D distance
3D distance
log p

EgoRetinal image projection EgoRetinal RGB

EgoRetinal image projection EgoRetinal RGB EgoRetinal depth

EgoRetinal image projection EgoRetinal RGB EgoRetinal depth
P2: 2D and 3D persistent P3: Occlusion reasoning P1: Head orientation invariant

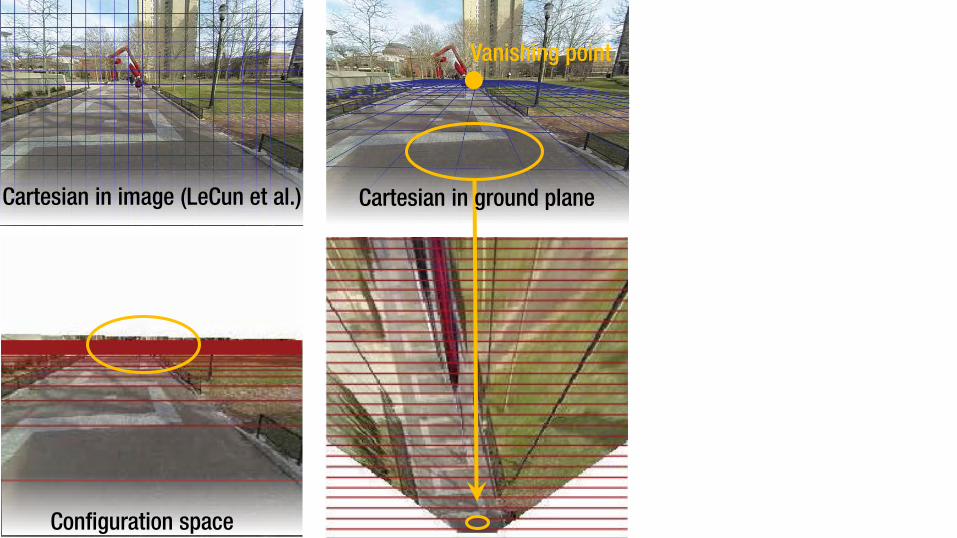
Cartesian in image (LeCun et al.)
Configuration space

Cartesian in image (LeCun et al.)
Configuration space

Cartesian in image (LeCun et al.)
Configuration space
Cartesian in ground plane

Cartesian in image (LeCun et al.)
Configuration space
Cartesian in ground plane
Cartesian in image (LeCun et al.)
Configuration space
Cartesian in ground plane
Vanishing point

Cartesian in image (LeCun et al.) Cartesian in ground plane EgoRetinal space
Configuration space
Vanishing point


• 1280x960 stereo (100mm baseline, ~15m depth resolution) • 26 scenes (13 indoor, 13 outdoor) • 65.5k frames (9.1 hours)
Dataset summary

n
Ground plane

n
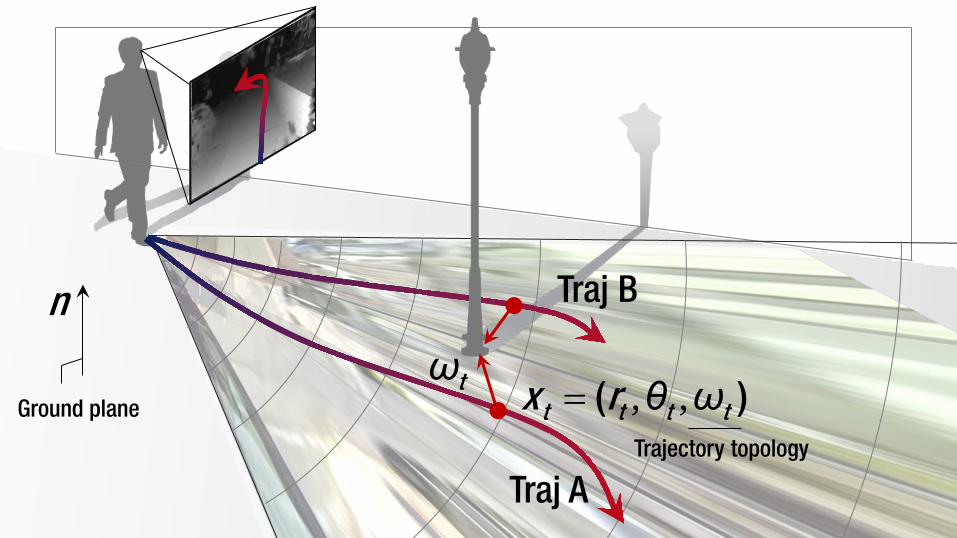
Ground plane , ,= ( )t t t tx r θ ω

n
Ground plane , ,= ( )t t t tx r θ ωtω
Trajectory topology
n
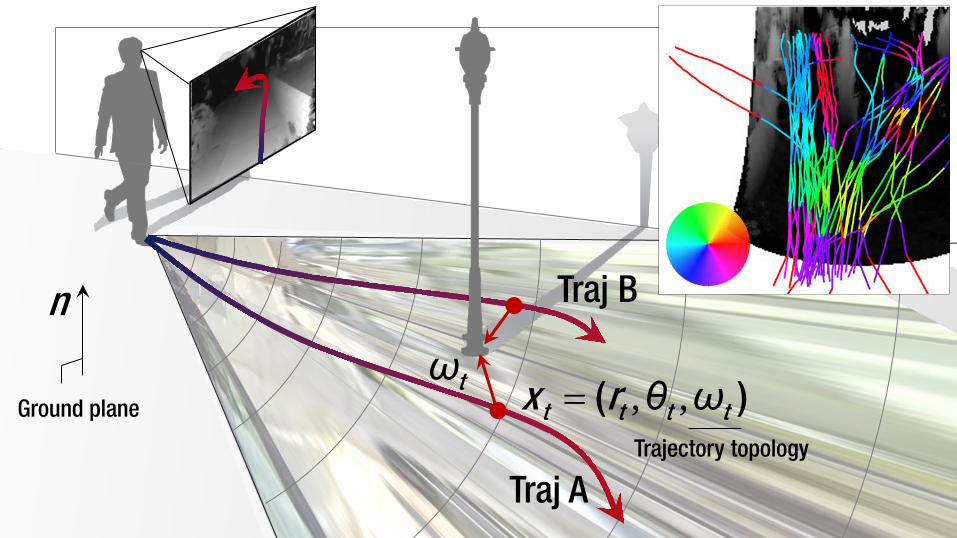
Ground plane , ,= ( )t t t tx r θ ωtω
Trajectory topology
Traj A
Traj B
n
Ground plane , ,= ( )t t t tx r θ ωtω
Trajectory topology
Traj A
Traj B
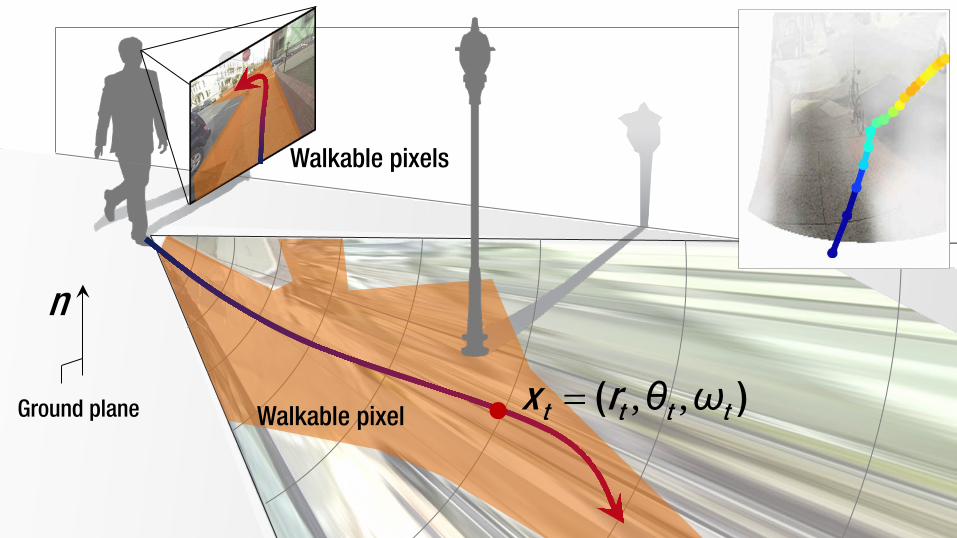
n
Ground plane Walkable pixel
Walkable pixels
, ,= ( )t t t tx r θ ω
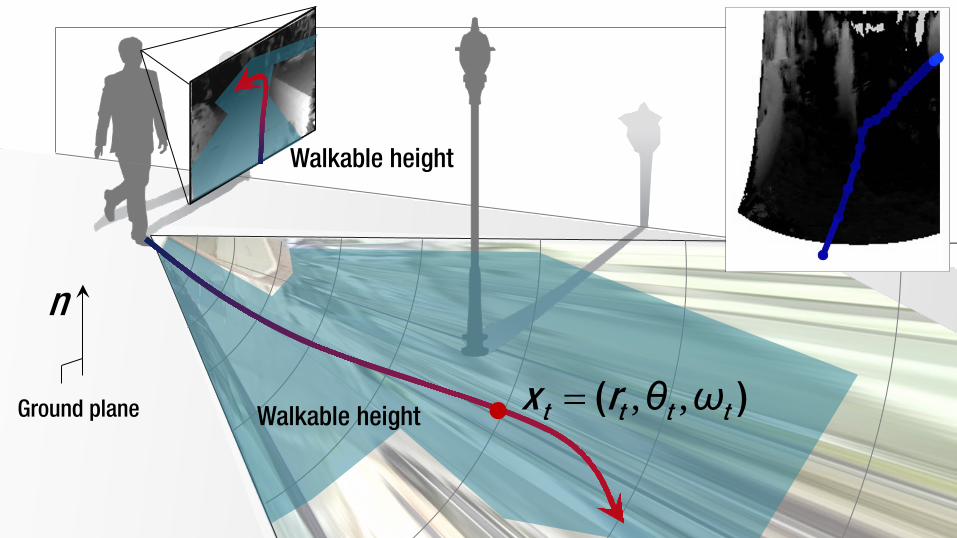
n
Ground plane
Walkable height
Walkable height , ,= ( )t t t tx r θ ω

Testing image Trajectory retrieval Depth cost Walking affordance

Testing image Trajectory retrieval Depth cost Walking affordance
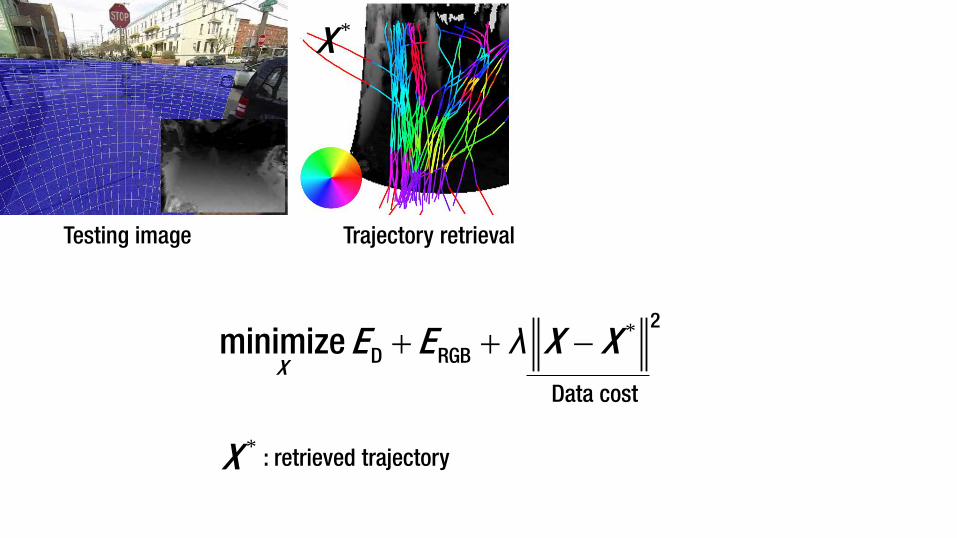
Testing image Trajectory retrieval
*+ + −2
D RGBminimize X
E E X Xλ
Depth cost Walking affordance
Data cost
*X
*X : retrieved trajectory

Testing image Trajectory retrieval
*+ + −2
D RGBminimize X
E E X Xλ
Depth cost Walking affordance
Depth walking preference
*X : retrieved trajectory
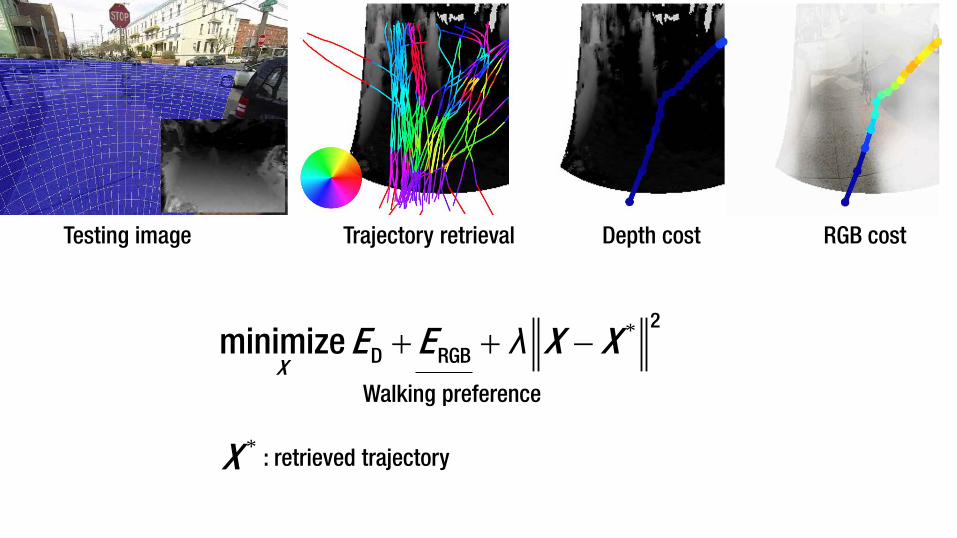
Testing image Trajectory retrieval
*+ + −2
D RGBminimize X
E E X Xλ
Depth cost RGB cost
Walking preference
*X : retrieved trajectory
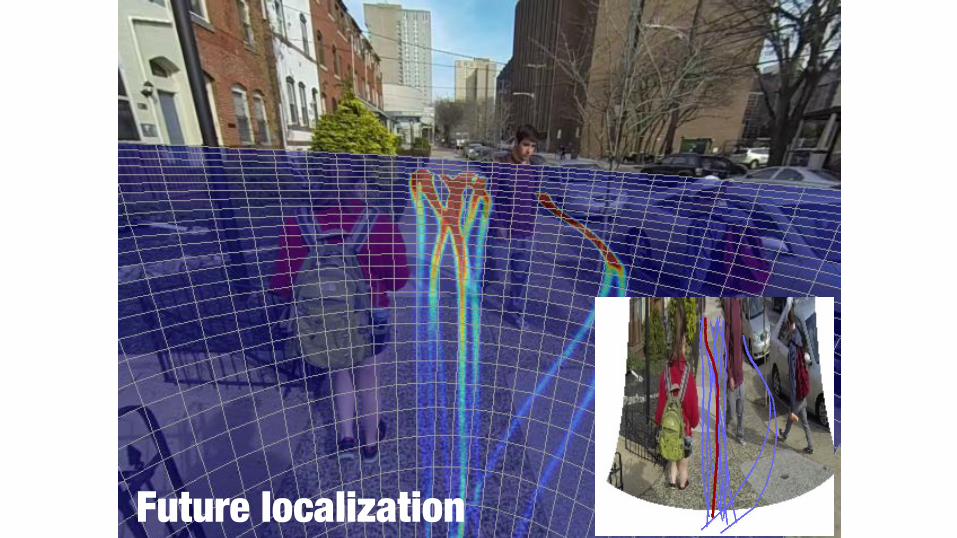
Future localization
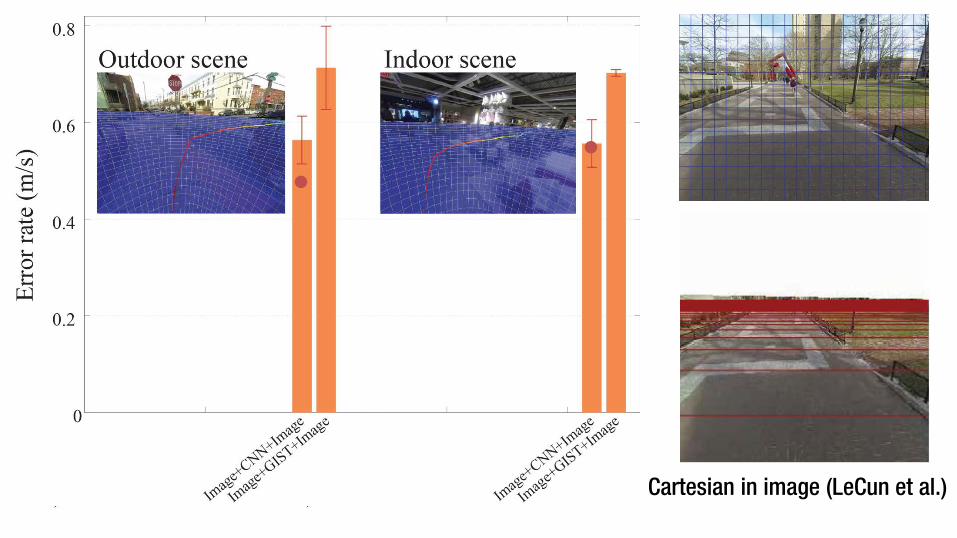
Cartesian in image (LeCun et al.)

Cartesian on ground plane

Cartesian on ground plane
Short range error
Short range
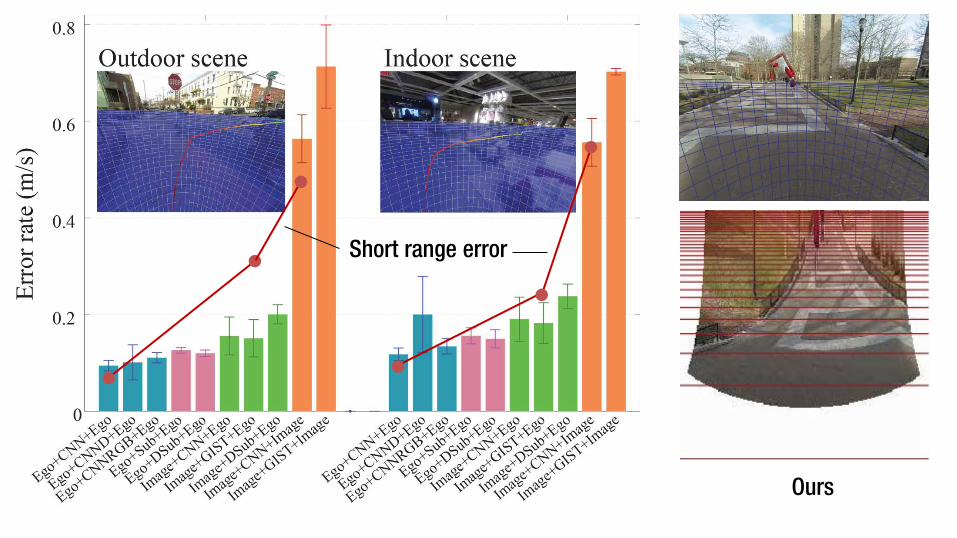
Ours
Short range error

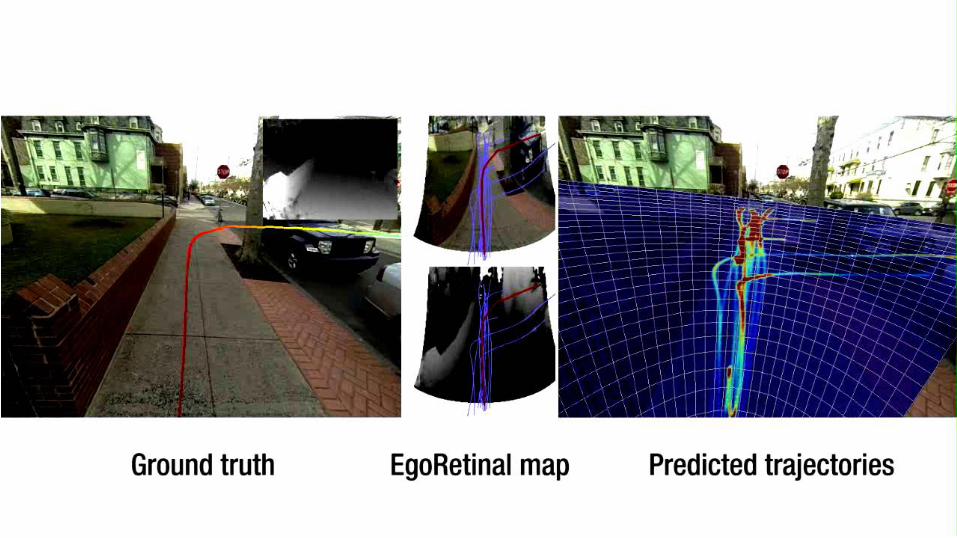
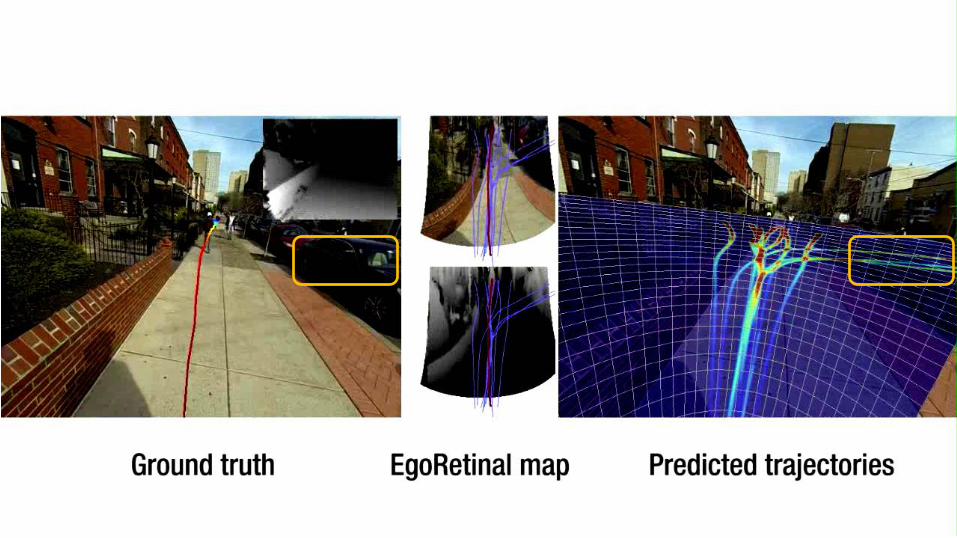




EgoRetinal map
Putting yourself in his shoes

Egocentric Future Localization
Website: http://www.seas.upenn.edu/~hypar/future_loc.html
Related Documents











