CUDA and Caffe for deep learning Amgad Muhammad Mohamed Ghoneim

CUDA and Caffe for deep learning
Jul 15, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CUDA and Caffe for deep learningAmgad MuhammadMohamed Ghoneim

Outline
• GPU Computing• What is CUDA?• Why use CUDA?• When use CUDA?• CUDA - Machine Specs .• CUDA - Matrix Multiplication• CUDA - Closest Pair in 2D• Convolution Neural Networks• Auto Encoder

GPU Computing
• Moore’s law slowed down.• Computation is directed towards parallelism instead of
better processing unit performance.• CPU has a small number of processing units with very
high processing power.• GPU has a large number of processing units with
moderate processing power.

What is CUDA?
• Compute Unified Device Architecture• Introduced by nVidia in 2006.• Refers to 2 different concepts:1. CUDA Architecture: Massively parallel architecture of
modern GPUs with hundreds of cores.2. CUDA Programming Model: the model used to program
these GPUs
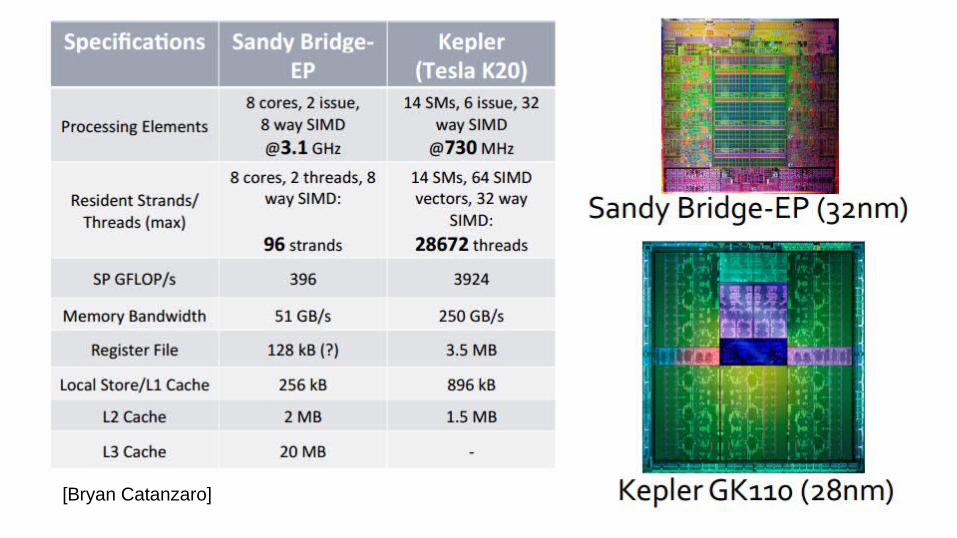
[Bryan Catanzaro]

Why use CUDA?
• Efficiently processing thousands of small/repeated tasks in parallel.
• It provides a methodology for these tasks to communicate and cooperate efficiently.
• Scalable and intuitive mechanism to express parallelism.

When use CUDA?
• Lots of computations and lots of data.• Parallel algorithms.• Neural Networks.• Physical Simulations• Distributed Computing• Accelerated Encryption, Decryption and Compression

CUDA – Machine Specs .Machine specs for this experiment:- Processor: Dual-core AMD Opteron(™) processor 2216 2.4 GHz (2
processors).- RAM: 32.0 GB- OS: 64-bit Windows 7- Graphics Card: Quadro FX 4600
- CUDA Driver: 5.5- CUDA Compatibility: 1.0- # of Cores: 96- Core Clock: 500MHz- Memory: 768MB- Memory Clock: 1400MHz
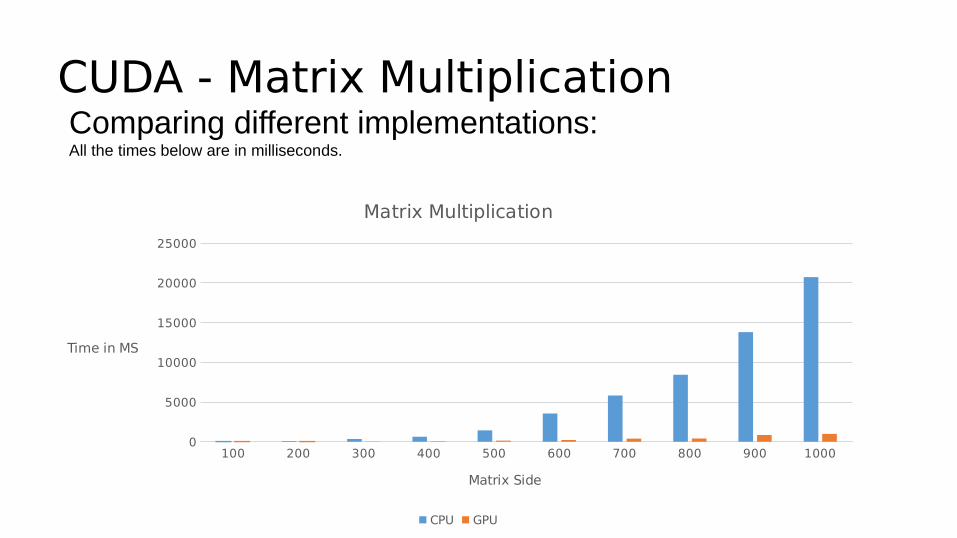
CUDA - Matrix MultiplicationComparing different implementations:All the times below are in milliseconds.
100 200 300 400 500 600 700 800 900 10000
5000
10000
15000
20000
25000
Matrix Multiplication
CPU GPU
Matrix Side
Time in MS

CUDA - Closest Pair in 2D
This is a well known problem where the algorithm tries to find the 2 points that closest to each other. There are many solutions to address this problem:
1. Brute Force complexity O( n^2 )2. Divide and Conquer O( n log(n) )
For completeness there is another implementation using KD-trees with complexity similar to D&C.
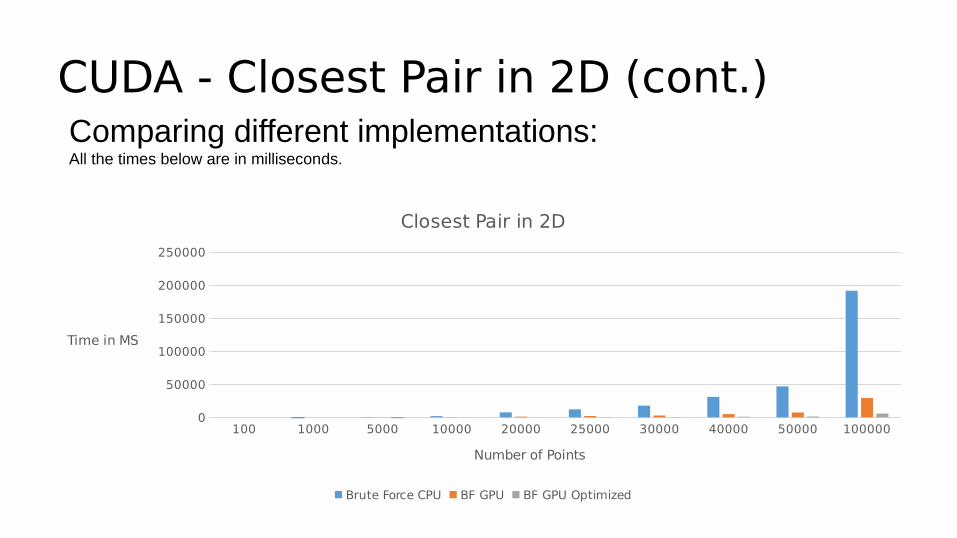
CUDA - Closest Pair in 2D (cont.)Comparing different implementations:All the times below are in milliseconds.
100 1000 5000 10000 20000 25000 30000 40000 50000 1000000
50000
100000
150000
200000
250000
Closest Pair in 2D
Brute Force CPU BF GPU BF GPU Optimized
Number of Points
Time in MS
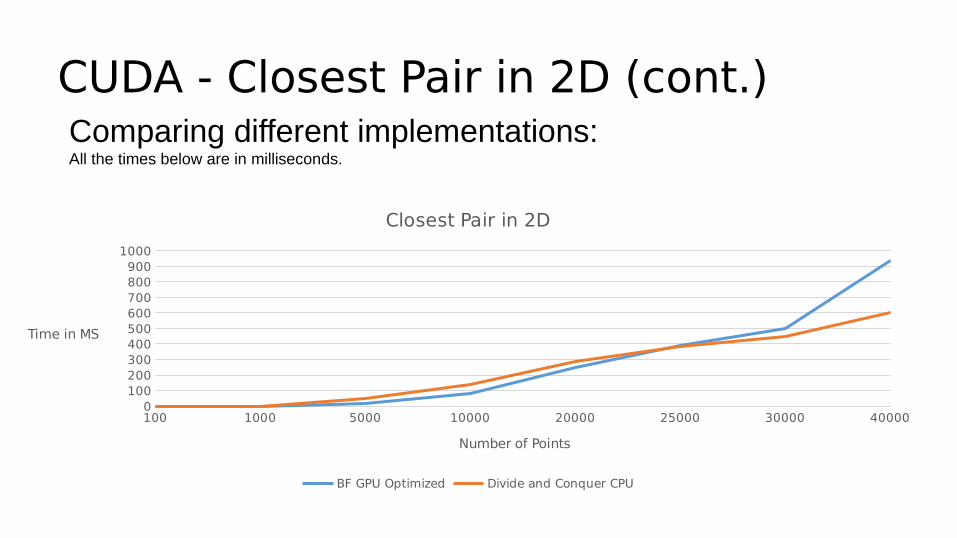
CUDA - Closest Pair in 2D (cont.)Comparing different implementations:All the times below are in milliseconds.
100 1000 5000 10000 20000 25000 30000 400000
100200300400500600700800900
1000
Closest Pair in 2D
BF GPU Optimized Divide and Conquer CPU
Number of Points
Time in MS
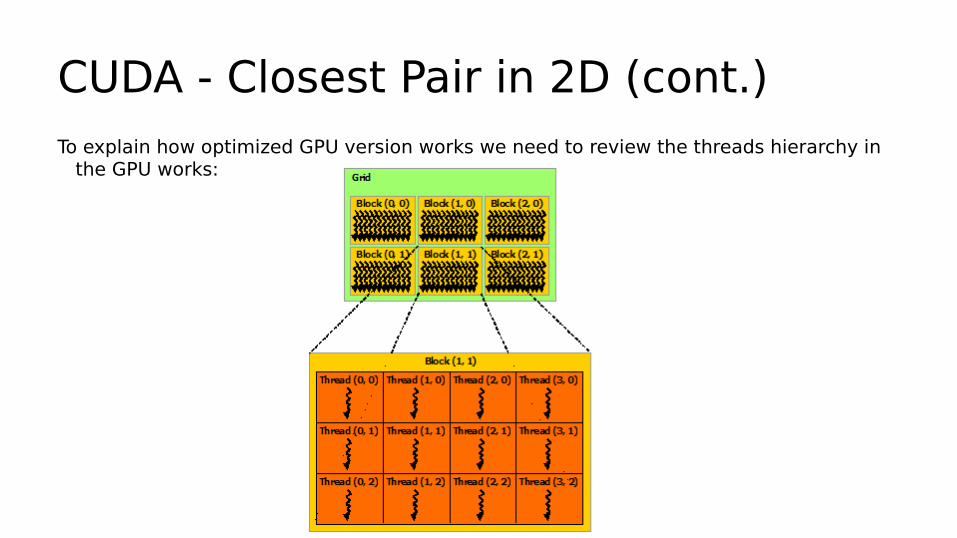
CUDA - Closest Pair in 2D (cont.)To explain how optimized GPU version works we need to review the threads hierarchy in
the GPU works:
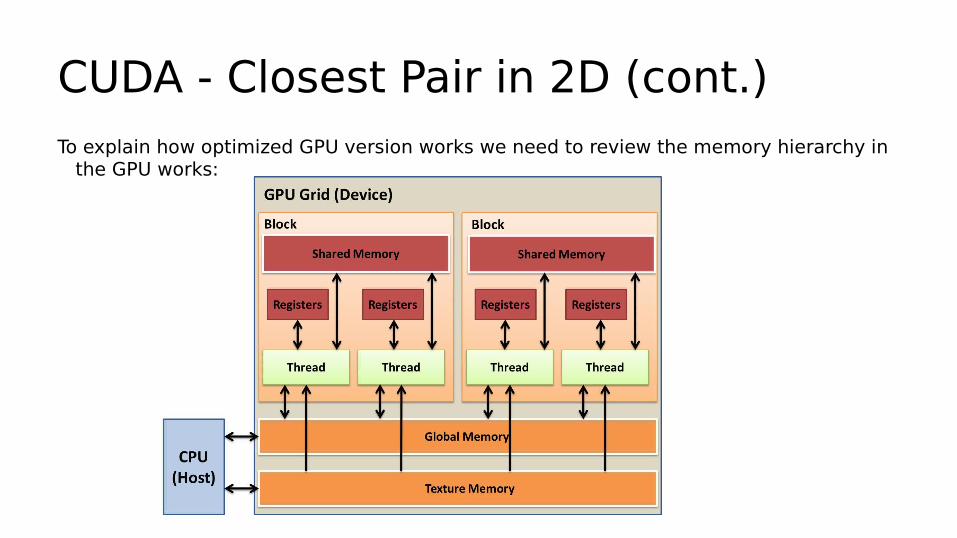
CUDA - Closest Pair in 2D (cont.)To explain how optimized GPU version works we need to review the memory hierarchy in
the GPU works:
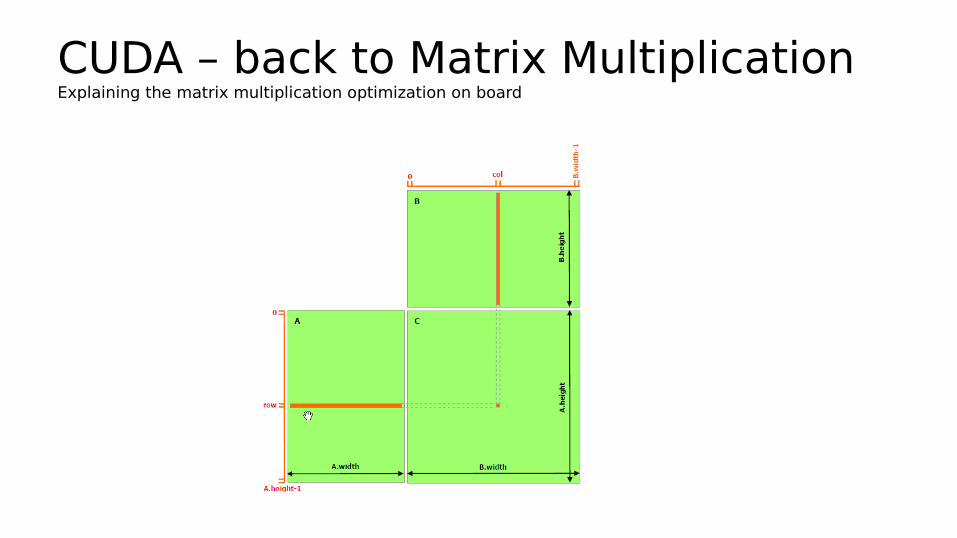
CUDA – back to Matrix MultiplicationExplaining the matrix multiplication optimization on board

CUDA - Closest Pair in 2D (cont.)Explaining the optimized code on board
__global__ void FindClosestGPU2(float2* points, float* vals, int count){
__shared__ float2 sharedPoints[blockSize];if(count <= 1) return;int idx = threadIdx.x + blockIdx.x * blockDim.x;float2 thisPoint;float distanceToClosest = FLT_MAX;if(idx < count) thisPoint = points[idx];for(int currentBlockOfPoints = 0; currentBlockOfPoints < gridDim.x; currentBlockOfPoints++) {
if(threadIdx.x + currentBlockOfPoints * blockSize < count)sharedPoints[threadIdx.x] = points[threadIdx.x + currentBlockOfPoints * blockSize];
elsesharedPoints[threadIdx.x].x = reasonableINF, sharedPoints[threadIdx.x].y = reasonableINF;
__syncthreads();if(idx < count) {
float *ptr = &sharedPoints[0].x;for(int i = 0; i < blockSize; i++) {
float dist = (thisPoint.x - ptr[0]) * (thisPoint.x - ptr[0]) +(thisPoint.y - ptr[1]) * (thisPoint.y - ptr[1]);
ptr += 2;if(dist < distanceToClosest && (i + currentBlockOfPoints * blockSize < count)
&& (i + currentBlockOfPoints * blockSize != idx))distanceToClosest = dist;
}}__syncthreads();
}if(idx < count)
vals[idx] = distanceToClosest;}
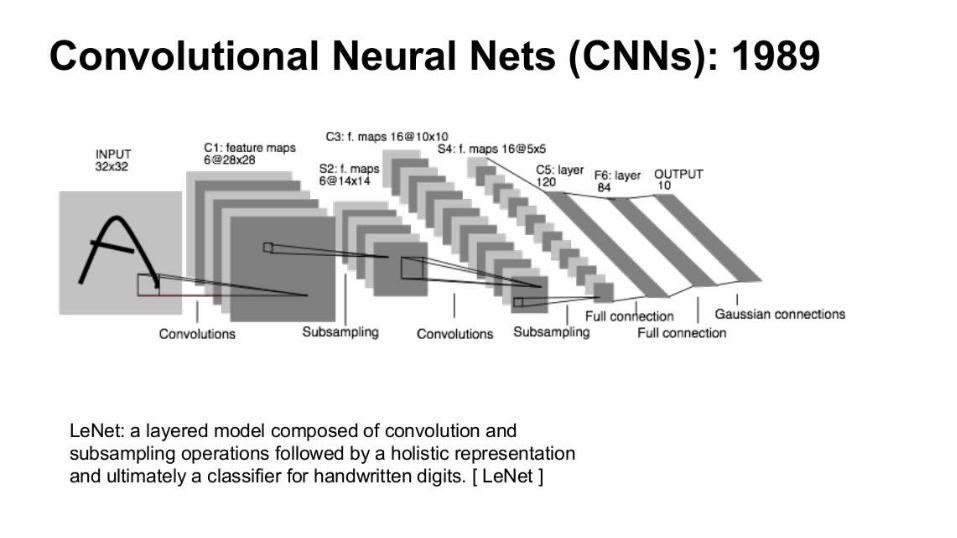
CNN
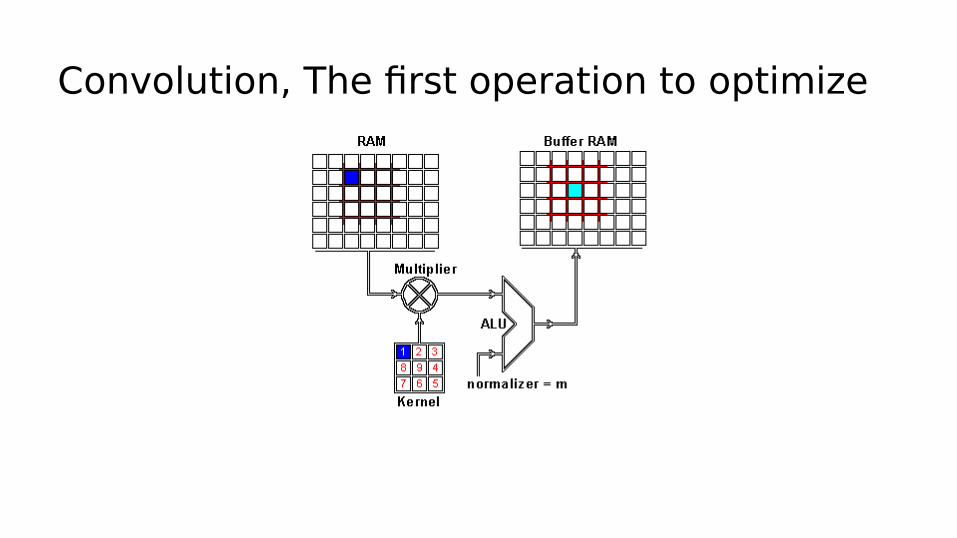
Convolution, The first operation to optimize

Pooling, the second operation to optimize

Results
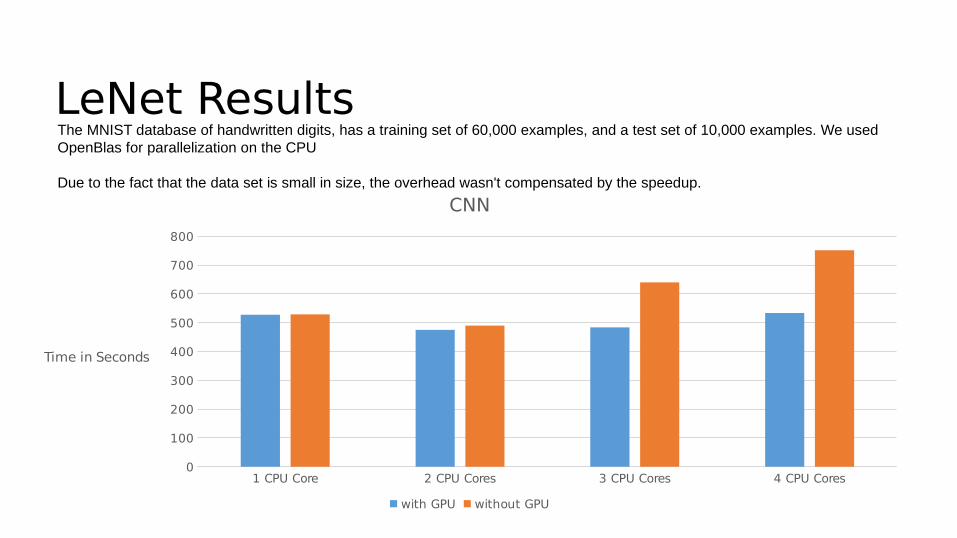
LeNet ResultsThe MNIST database of handwritten digits, has a training set of 60,000 examples, and a test set of 10,000 examples. We used OpenBlas for parallelization on the CPU
Due to the fact that the data set is small in size, the overhead wasn't compensated by the speedup.
1 CPU Core 2 CPU Cores 3 CPU Cores 4 CPU Cores0
100
200
300
400
500
600
700
800
CNN
with GPU without GPU
Time in Seconds

AutoEncoder

AutoEncoders ResultsThe MNIST database of handwritten digits, has a training set of 60,000 examples, and a test set of 10,000 examples. And the main operation here is inner product
1 CPU Core 2 CPU Cores 3 CPU Cores0
100
200
300
400
500
600
700
800
Auto Encoder
with GPU without GPU
Time in Seconds

Thank You!
Questions?
Related Documents











