CSNB334 Advanced Operating Systems 4. Process & Resource Management

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CSNB334 Advanced Operating Systems4. Process & ResourceManagement

What is a process? A process is a program (object code) in execution. Threads of execution, or threads, are the objects of activity within the
process. Each thread includes a unique program counter, process stack,
and set of processor registers. The kernel schedules individual threads, not processes.
Processes provide two virtualizations: a virtualized processor
The virtual processor gives the process the illusion that it alone monopolizes the system, despite possibly sharing the processor among dozens of other processes.
virtual memory. Virtual memory lets the process allocate and manage memory
as if it alone owned all the memory in the system.
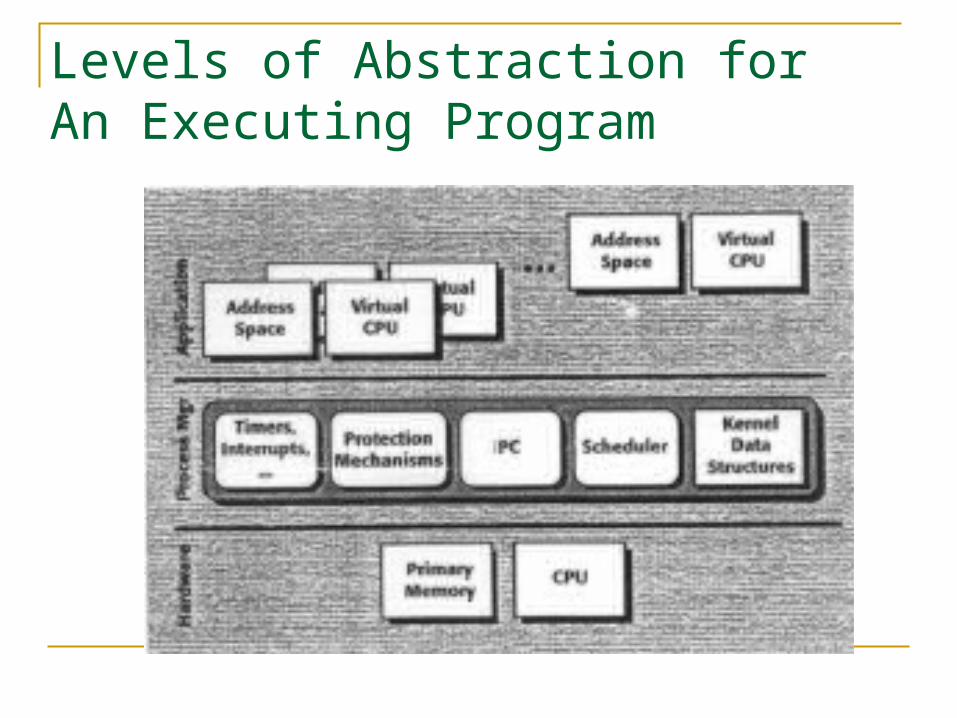
Levels of Abstraction for An Executing Program
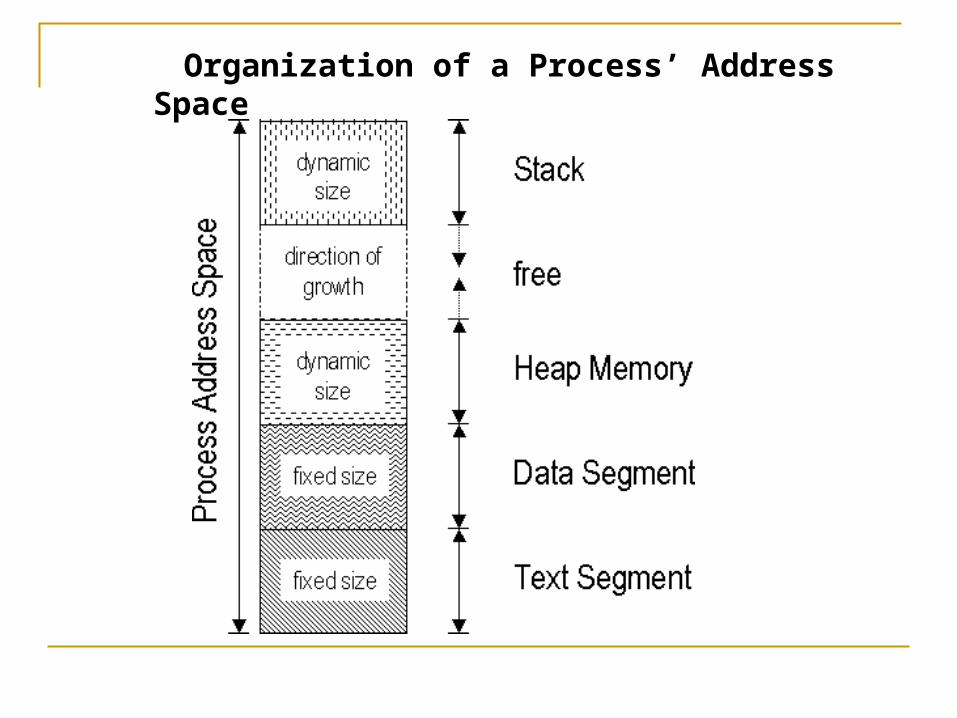
Organization of a Process’ Address Space

Processes and Threads Process abstraction combines two concepts
Concurrency Each process is a sequential execution stream of instructions
Protection Each process defines an address space Address space identifies all addresses that can be touched by the program
Threads Key idea: separate the concepts of concurrency
from protection A thread represents a sequential execution
stream of instructions A process defines the address space that may
be shared by multiple threads Threads can execute on different cores on a
multicore CPU (parallelism for performance) and can communicate with other threads by updating memory

Threads vs. ProcessesThreads A thread has no data
segment or heap A thread cannot live on its
own, it must live within a process
There can be more than one thread in a process, the first thread calls main & has the process’s stack
If a thread dies, its stack is reclaimed
Inter-thread communication via memory.
Processes
A process has code/data/ heap & other segments
There must be at least one thread in a process
Threads within a process share code/data/heap, share I/O, but each has its own stack & registers
If a process dies, its resources are reclaimed & all threads die
Inter-process communication via OS and data copying.
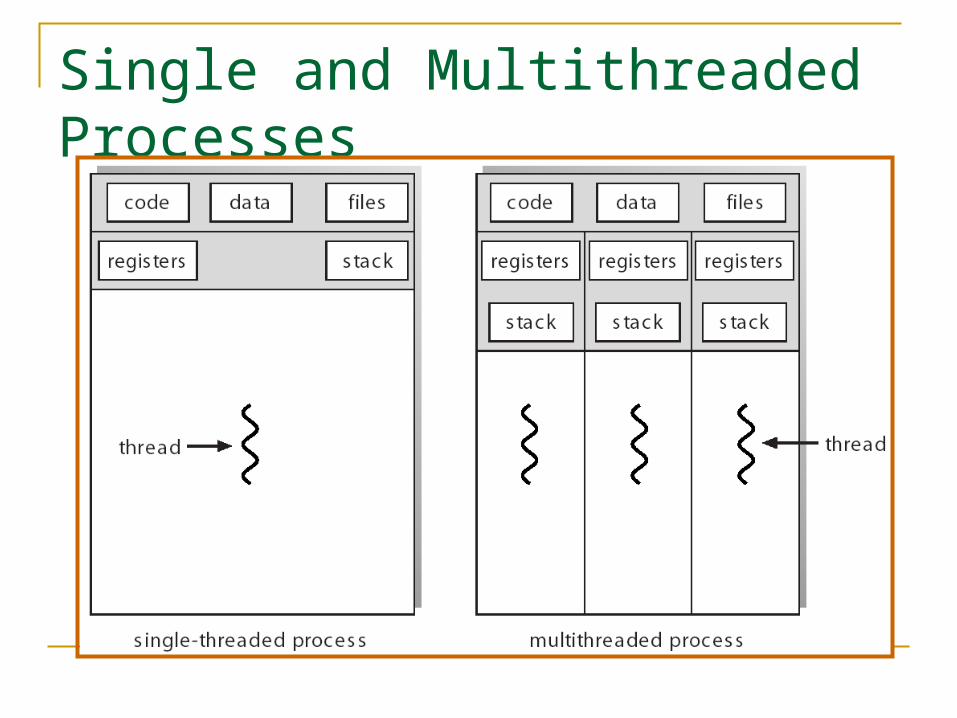
Single and Multithreaded Processes
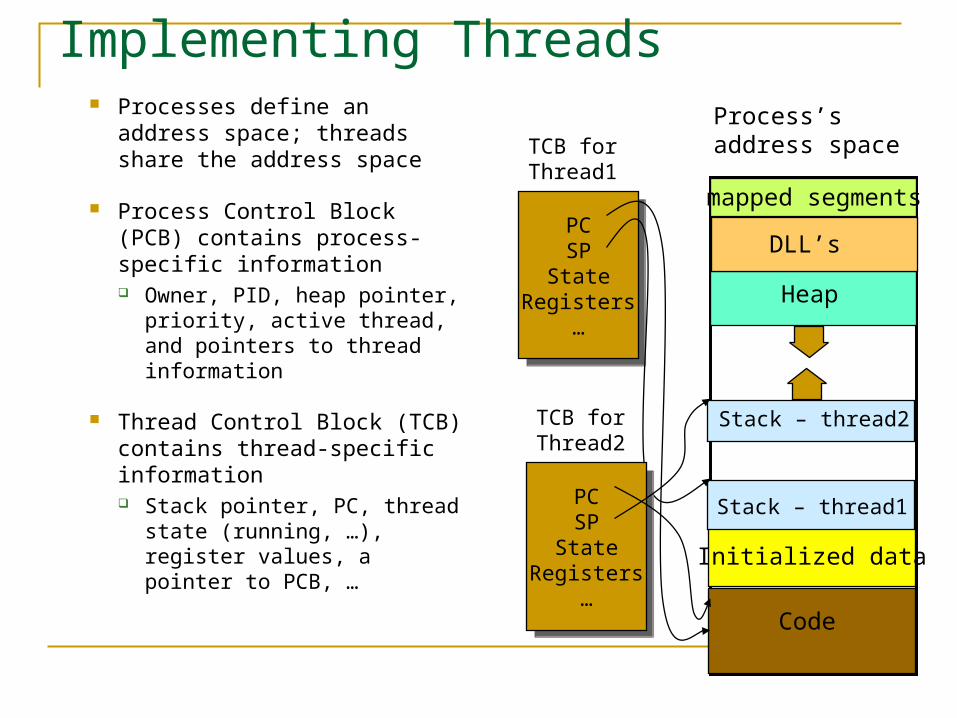
Implementing Threads Processes define an address
space; threads share the address space
Process Control Block (PCB) contains process-specific information Owner, PID, heap pointer,
priority, active thread, and pointers to thread information
Thread Control Block (TCB) contains thread-specific information Stack pointer, PC, thread
state (running, …), register values, a pointer to PCB, …
Code
Initialized data
Heap
DLL’s
mapped segments
Process’s address space
Stack – thread1
PCSP
StateRegisters
…
PCSP
StateRegisters
…
TCB for Thread1
Stack – thread2
PCSP
StateRegisters
…
PCSP
StateRegisters
…
TCB for Thread2

Examples of Threads A web browser
One thread displays images One thread retrieves data from network
A word processor One thread displays graphics One thread reads keystrokes One thread performs spell checking in the background
A web server One thread accepts requests When a request comes in, separate thread is created to
service Many threads to support thousands of client requests
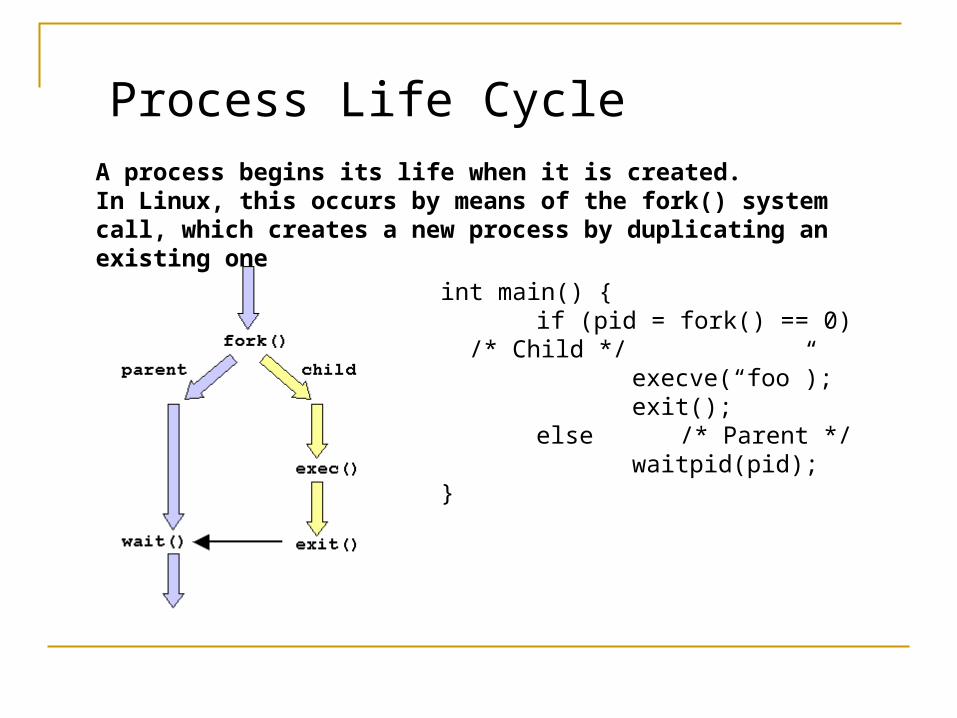
Process Life CycleA process begins its life when it is created. In Linux, this occurs by means of the fork() system call, which creates a new process by duplicating an existing one
int main() { if (pid = fork() == 0) /* Child */
execve(“foo”); exit();
else /* Parent */ waitpid(pid);
}

Process Creation : fork(), vfork() and clone() system calls All are declared in <unistd.h> fork: The fork call basically makes a duplicate of the current
process, identical in almost every way (not everything is copied over, for example, resource limits in some implementations but the idea is to create as close a copy as possible).
vfork: The basic difference between vfork and fork is that when a new process is created with vfork(), the parent process is temporarily suspended, and the child process might borrow the parent's address space.
clone : Clone, as fork, creates a new process. Unlike fork, these calls allow the child process to share parts of its execution context with the calling process, such as the memory space, the table of file descriptors, and the table of signal handlers.
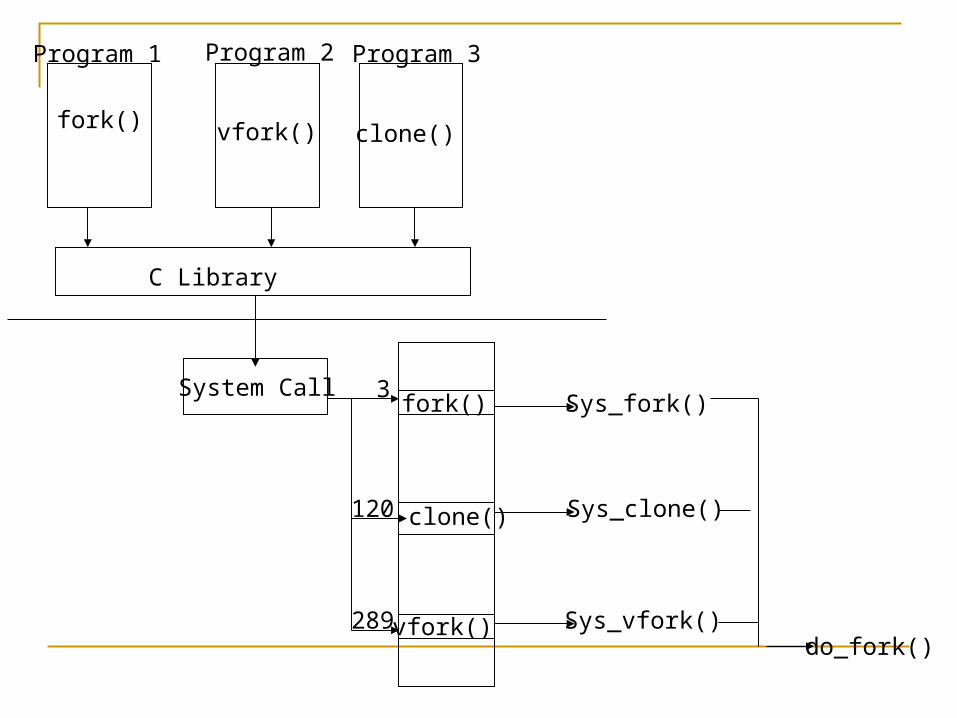
fork()clone()vfork()
System Callfork()
clone()
vfork()
C Library
Sys_fork()
Sys_clone()
Sys_vfork()do_fork()
3
120
289
Program 1 Program 2 Program 3
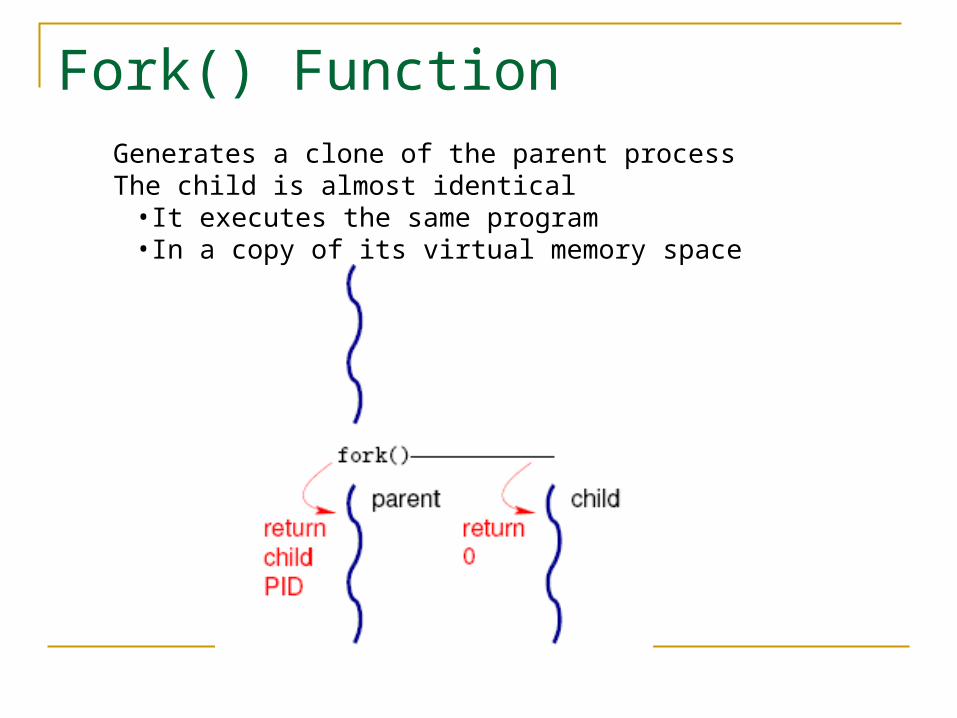
Fork() FunctionGenerates a clone of the parent processThe child is almost identical
•It executes the same program•In a copy of its virtual memory space

System Call: fork()Create a Child Process #include <sys/types.h> #include <unistd.h> pid_t fork();
Semantics The child process is identical to its parent, except:
Its PID and PPID (parent process ID) Zero resource utilization (initially, relying on copy-on-write) No pending signals, file locks, inter-process communication
objects On success, returns the child PID
Simple way to detect “from the inside” which of the child or parent runs
Also use getpid(), getppid() Returns −1 on error

Terminating a Process#include <stdlib.h>
void exit (int status)
This function instructs the kernel to terminate the process. exit() never returns – therefore, no statement should follow the exit()
call. The process status is used to denote the process’ exit status.
Can be used by other programs or at the shell. It invokes the system call _exit() to tell the kernel to terminate the
process.
#include <unistd.h>
void _exit(int status); When a process terminates, the kernel reclaims
Allocated memory Open files System V semaphores Notifies the parent of it’s child’s demise

Waiting for terminated child processes When a child dies before its parent, the kernel puts it in a special
state – zombie. A process in this state waits for its parent to inquire about its
status. Only after this inquiry does the terminated child exit and cease to
exist even as a zombie.#include <sys/types.h>#include <sys/wait.h>pid_t wait (int *status)
A call to wait() returns pid of a terminated child, or -1 on error
If no child has terminated, the call blocks until a child terminates.

A simple examplemain(){ int status; int pid,child1,child2;
if((child1=fork()==0)) printf("child 1 is running\n"); else { if ((child2=fork())==0)
printf("child 2 is running\n"); else {
pid=wait(&status);if(pid==child1)
printf("child1 has terminated first\n");else
printf("child2 has terminated first\n");printf("goodbye\n");
} }}

Execve() System call
Load and execute a different program. The execve() system call has the following form:
execve(char *path, char *argv[], char*envp[]) path : pathname of the program to be executed (Relative/Absolute) argv : list of parameter strings with the command. envp : list of environment variable strings and values.
Causes the kernel to do the following Find the new executable file in file system Check for access permissions Load the file for execution into the address space currently being
used by the calling process. Set the argv array and environment variables for the new
program. Start the process executing at the new program’s entry point.

System Call: execve() and variantsExecute a Program: Variants#include <unistd.h>
int execl(const char *path, const char *arg, ...);int execv(const char *path, char *const argv[]);int execlp(const char *file, const char *arg, ...);int execvp(const char *file, char *const argv[]);int execle(const char *path, const char *arg, ..., char *const envp[]);int execve(const char *filename, char *const argv[], char *const envp[]);
Arguments
execl() operates on NULL-terminated argument list
Warning: arg, the first argument after the pathname/filename corresponds to argv[0] (the program name)
execv() operates on argument array
execlp() and execvp() are $PATH-relative variants (if file does not
contain a ‘/’ character)
execle() also provides an environment

Some examples
int ret;ret = execl(“/bin/vi”, “vi”, “/home/STUDENT/file.txt”, NULL);if (ret == -1)
perror(“execl”);
const char *args[ ] = {“vi”, “/home/STUDENT/file.txt”, NULL};int ret;ret = execvp (“vi”, args);if (ret == -1)
perror(“execvp”);

Copy-on-Write Traditionally, upon fork() all resources owned by the
parent were duplicated and the copy was given to the child.
Copy-on-write (or COW) is a technique to delay or altogether prevent copying of the data. Rather than duplicate the process address space, the
parent and the child can share a single copy. The data, however, is marked in such a way that if it is
written to, a duplicate is made and each process receives a unique copy. Consequently, the duplication of resources occurs only when
they are written; until then, they are shared read-only. In the case that the pages are never written—for
example, if exec() is called immediately after fork()—they never need to be copied.
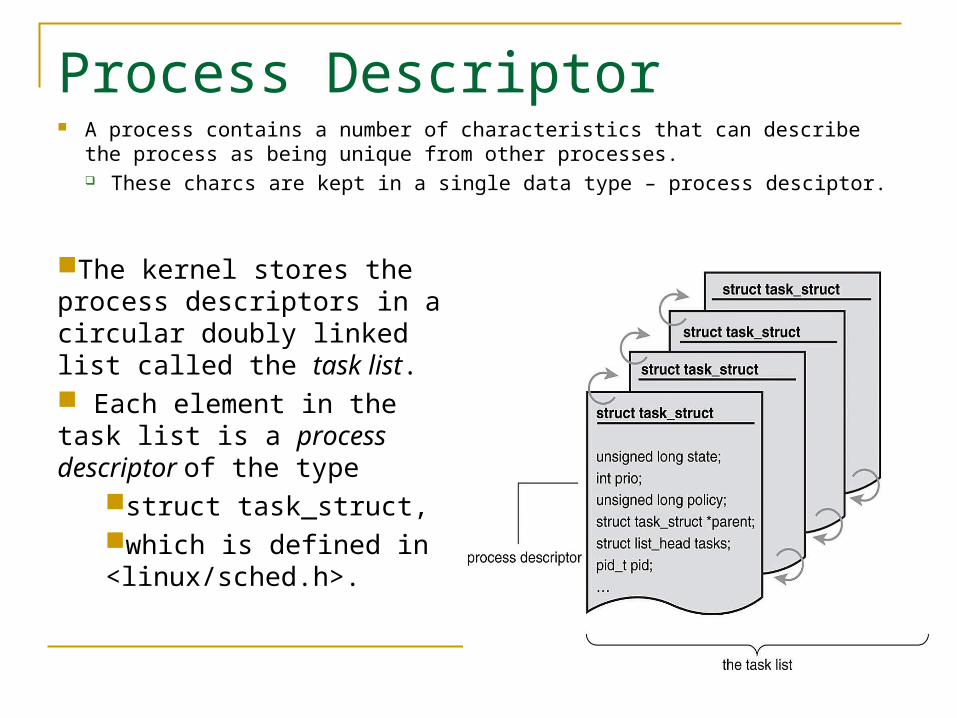
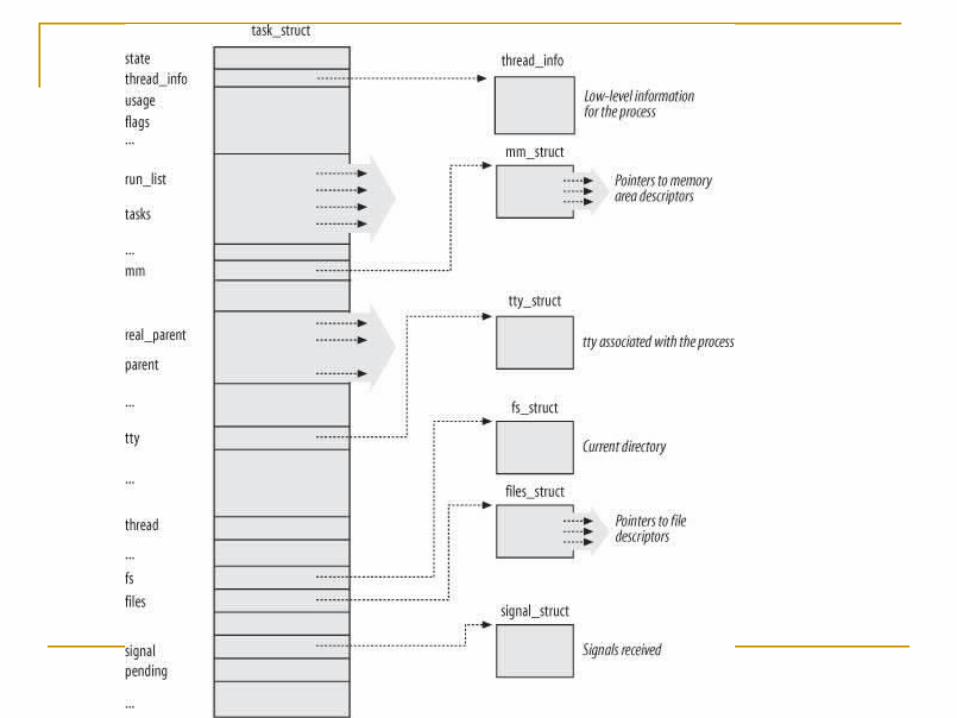
Process Descriptor A process contains a number of characteristics that can describe the
process as being unique from other processes. These charcs are kept in a single data type – process desciptor.
The kernel stores the process descriptors in a circular doubly linked list called the task list. Each element in the task list is a process descriptor of the type
struct task_struct, which is defined in <linux/sched.h>.

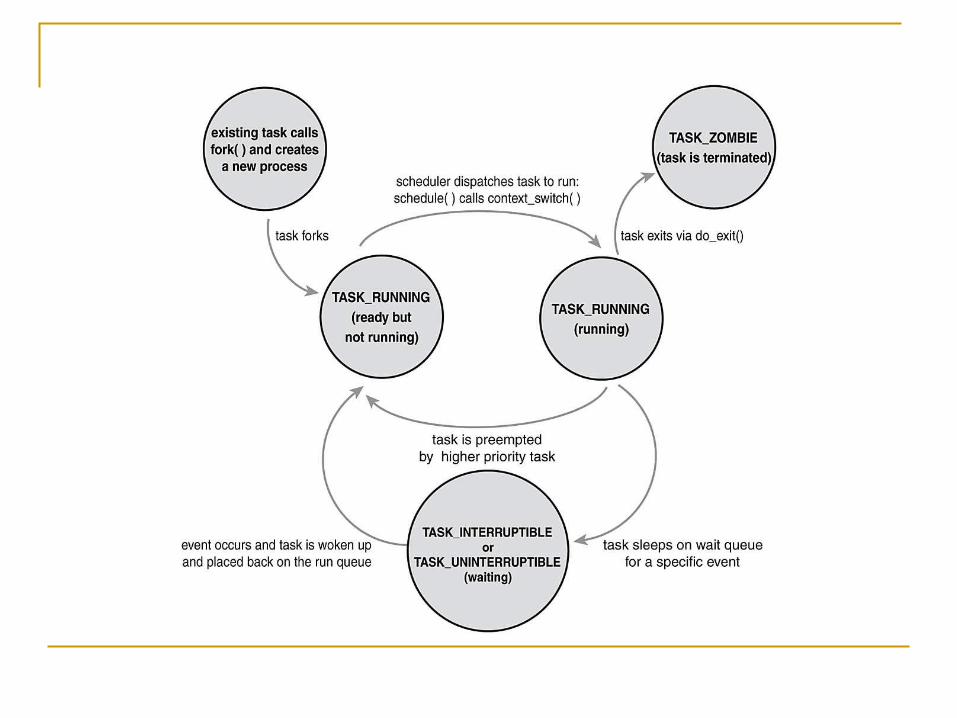
Process State TASK_RUNNING—The process is runnable; it is either currently
running or on a runqueue waiting to run. TASK_INTERRUPTIBLE—The process is sleeping (that is, it is
blocked), waiting for some condition to exist. When this condition exists, the kernel sets the process's state to TASK_RUNNING. The process also awakes prematurely and becomes runnable if it receives a signal.
TASK_UNINTERRUPTIBLE—This state is identical to TASK_INTERRUPTIBLE except that it does not wake up and become runnable if it receives a signal. This is used in situations where the process must wait without interruption or when the event is expected to occur quite quickly.
TASK_ZOMBIE—The task has terminated, but its parent has not yet issued a wait() system call. The task's process descriptor must remain in case the parent wants to access it. If the parent calls wait(), the process descriptor is deallocated.
TASK_STOPPED—Process execution has stopped; the task is not running nor is it eligible to run. This occurs if the task receives the SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal or if it receives any signal while it is being debugged.
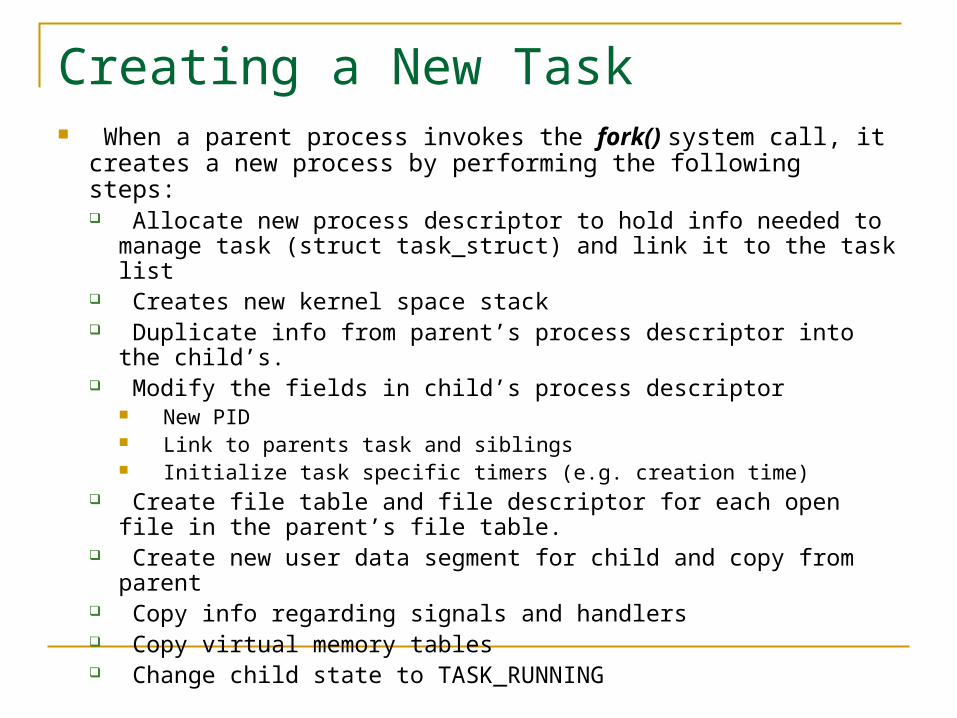
Creating a New Task When a parent process invokes the fork() system call, it creates
a new process by performing the following steps: Allocate new process descriptor to hold info needed to manage
task (struct task_struct) and link it to the task list Creates new kernel space stack Duplicate info from parent’s process descriptor into the child’s. Modify the fields in child’s process descriptor
New PID Link to parents task and siblings Initialize task specific timers (e.g. creation time)
Create file table and file descriptor for each open file in the parent’s file table.
Create new user data segment for child and copy from parent Copy info regarding signals and handlers Copy virtual memory tables Change child state to TASK_RUNNING

The Linux Implementation of Threads Linux has a unique implementation of
threads. To the Linux kernel, there is no concept of a thread.
Linux implements all threads as standard processes. The Linux kernel does not provide any special
scheduling semantics or data structures to represent threads.
Instead, a thread is merely a process that shares certain resources with other processes. The scheduler has nothing to think about separate
scheduling techniques for threads and processes Each thread has a unique task_struct and appears
to the kernel as a normal process (which just happens to share resources, such as an address space or open files, with other processes).
The Linux Scheduler

What is a scheduler? The scheduler is that part of the kernel code
that makes it possible to execute multiple programs at the same time, thus sharing the CPU among a number of processes.
Deciding which process to run, when and for how long is the scheduler’s primary responsibility.

The Linux Scheduling Policy Linux scheduling is based on the time-sharing
technique the CPU time is roughly divided into "slices," one for
each runnable process If a currently running process is not terminated
when its time slice or quantum expires, the process is preempted.
Time-sharing relies on timer interrupts and is thus transparent to processes. No additional code needs to be inserted in the
programs in order to ensure CPU time-sharing.

How Long Must a Quantum Last? The quantum duration is critical for system performances: it
should be neither too long nor too short.
If the quantum duration is too short, the system overhead caused by task switches becomes excessively high. For instance, suppose that a task switch requires 10 milliseconds;
if the quantum is also set to 10 milliseconds, then at least 50% of the CPU cycles will be dedicated to task switch.
If the quantum duration is too long, processes no longer appear to be executed concurrently. For instance, let's suppose that the quantum is set to five seconds;
each runnable process makes progress for about five seconds, but then it stops for a very long time (typically, five seconds times the number of runnable processes).

The Linux Scheduling Policy The scheduling policy is also based on ranking
processes according to their priority. Each process is associated with a value that
denotes how appropriate it is to be assigned to the CPU.
In Linux, process priority is dynamic. The scheduler keeps track of what processes are
doing and adjusts their priorities periodically; Processes that have been denied the use of the CPU
for a long time interval are boosted by dynamically increasing their priority.
Processes running for a long time are penalized by decreasing their priority.

Static task prioritization All tasks have a static priority, often called a nice value. On Linux, nice values range from -20 to 19, with higher values
being lower priority The lower a process’ nice value, the higher its priority and the larger it’s
timeslice. Tasks with high nice values are nicer to other tasks – lower priority (let
others run), smaller timeslice (give more time to others). By default, tasks start with a static priority of 0, but that priority
can be changed via the nice() system call. Apart from its initial value and modifications via the nice() system
call, the scheduler never changes a task’s static priority. Static priority is the mechanism through which users can modify
task’s priority, and the scheduler will respect the user’s input A task’s static priority is stored in its static_prio variable. Where p
is a task_struct, p->static_prio is its static priority.

Nice()
#include <unistd.h>int nice (int inc);
A successful call to nice increments a process’ nice value by inc and returns the newly updated value.
int ret;errno = 0;ret = nice(10);if (ret == -1 && errno !=0)
perror(nice);else
printf(“nice value is now %d\n”, ret);

Dynamic task prioritization The Linux 2.6 scheduler can dynamically alter a
task's priority by adding or subtracting from a its static priority
It does so by penalizing CPU-bound tasks and rewarding tasks that are I/O bound. .
The priority of I/O bound tasks is decreased (a reward) by a maximum of five priority levels. CPU-bound tasks are punished by having their priority increased by up to five levels.
Tasks are determined to be I/O-bound or CPU-bound based on an interactivity heuristic.
It's important to note that priority adjustments are performed only on user tasks, not on real-time tasks.

The Linux 2.6 Scheduler Before the 2.6 kernel, the scheduler had significant limitations
when many tasks were active. This was due to the scheduler being implemented using an
algorithm with O(n) complexity. At very high loads, the processor can be consumed with
scheduling and devote little time to the tasks themselves. The pre-2.6 scheduler also used a single runqueue for all
processors in a symmetric multiprocessing system (SMP) - good for load balancing but bad for memory caches.
The Linux 2.4.x kernel is not preemptable, and thus the support for RT applications is weak. Interrupts and exceptions result in short periods of kernel mode execution during which runnable RT tasks cannot resume execution immediately. Linux 2.6.x is a preemptable kernel, and thus RT application
support is considerably better.
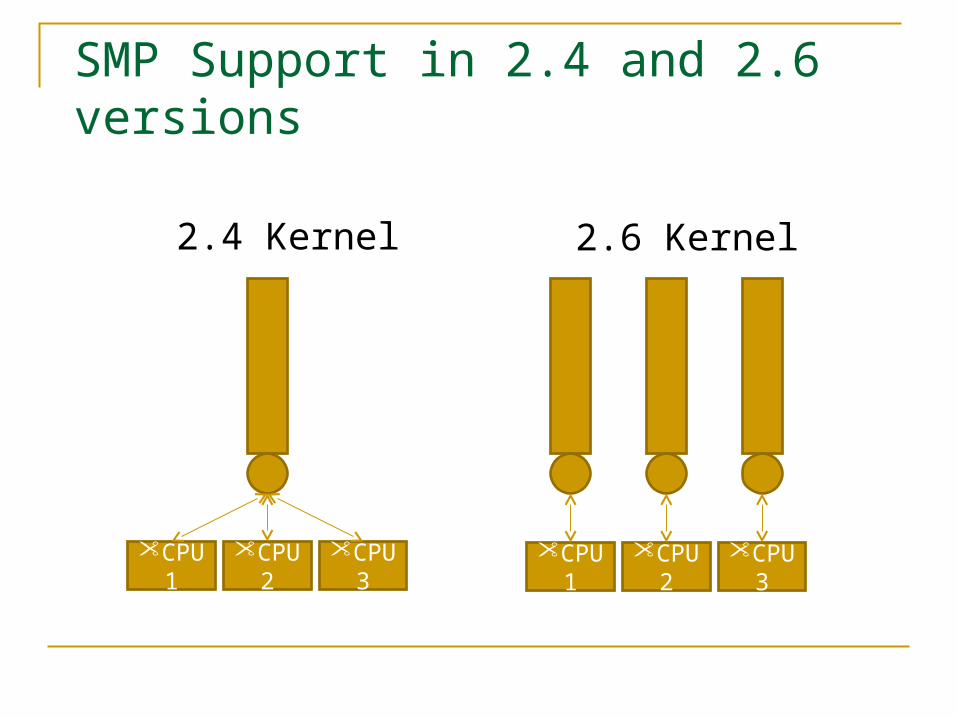
SMP Support in 2.4 and 2.6 versions
CPU1
CPU2
CPU3
CPU1
CPU2
CPU3
2.4 Kernel 2.6 Kernel

The Linux 2.6 scheduling Algorithm Major scheduling structures
Each CPU has a runqueue is serviced in FIFO order. The core data structures within a runqueue are two
priority-ordered arrays. One contains active tasks : tasks which have time slices left Other contains expired tasks : tasks which have run
Each task has a time slice that determines how much time it's permitted to execute after which it is added to the expired array to wait for more CPU time.
When the active array is empty, the scheduler swaps the two arrays by exchanging their pointers and begins executing tasks on the new active array.
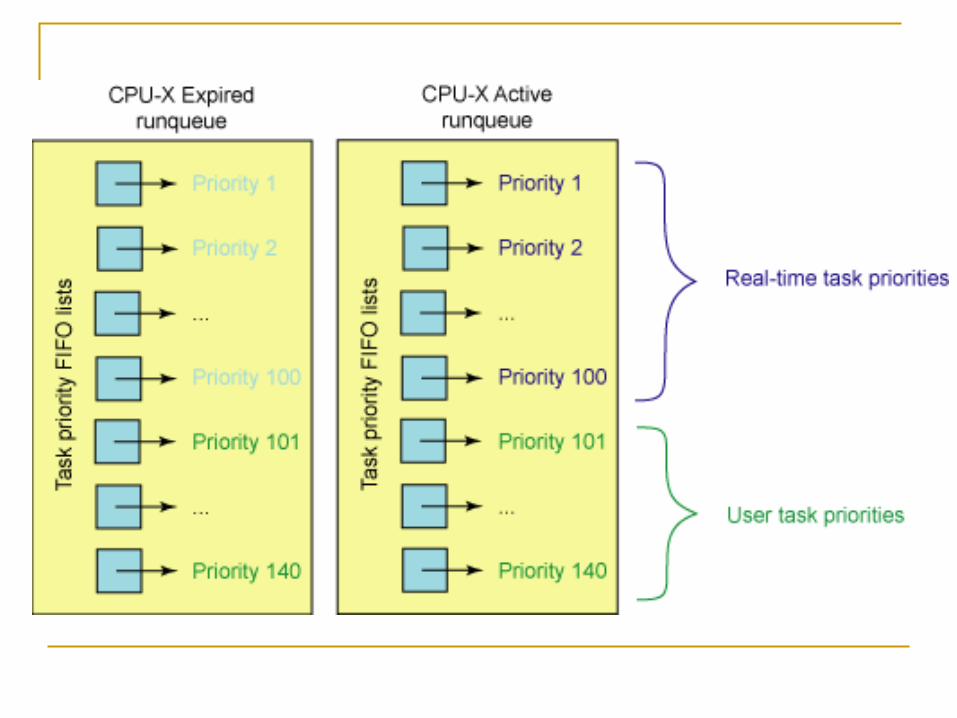

O(1) time in the Linux 2.6 scheduler Possible because of the priority array The Linux 2.6 scheduler always schedules the highest priority
task on a system, and if multiple tasks exist at the same priority level, they are scheduled roundrobin with each other. After running, tasks are put at the bottom of their priority level’s
list. The job of the scheduler is simple: choose the task on the highest
priority list to execute. To make this process more efficient, a bitmap is used to define
when tasks are on a given priority list. A find-first-bit-set instruction is used to find the highest priority bit
set in one of five 32-bit words (for the 140 priorities). The time it takes to find a task to execute depends not on the
number of active tasks but instead on the number of priorities Also, using two priority arrays in unison (the active and expired
priority arrays) makes transitions between timeslice epochs a constant-time operation. An epoch is the time between when all runnable tasks begin with
a fresh timeslice and when all runnable tasks have used up their timeslices.

Scheduling policy
140 Priority levels 1-100 : RT prio ( MAX_RT_PRIO = 100 ) 101-140 : User task Prio ( MAX_PRIO = 140 )
Normal tasks Each task assigned a “Nice” value PRIO = MAX_RT_PRIO + NICE + 20 Assigned a time slice Tasks at the same prio are round-robined.
Ensures Priority + Fairness
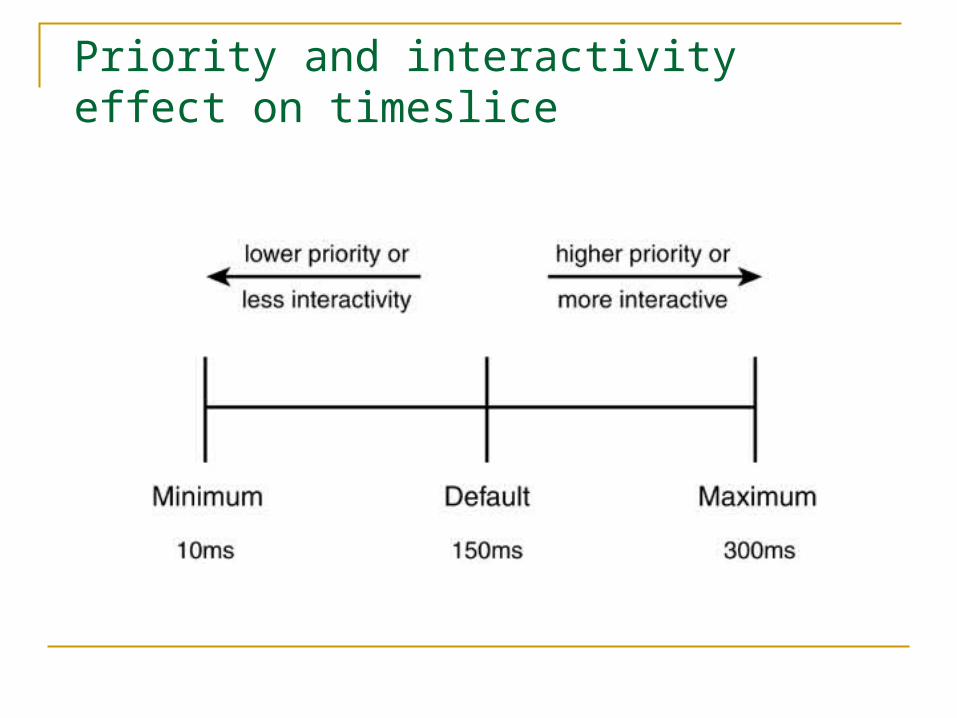
Priority and interactivity effect on timeslice
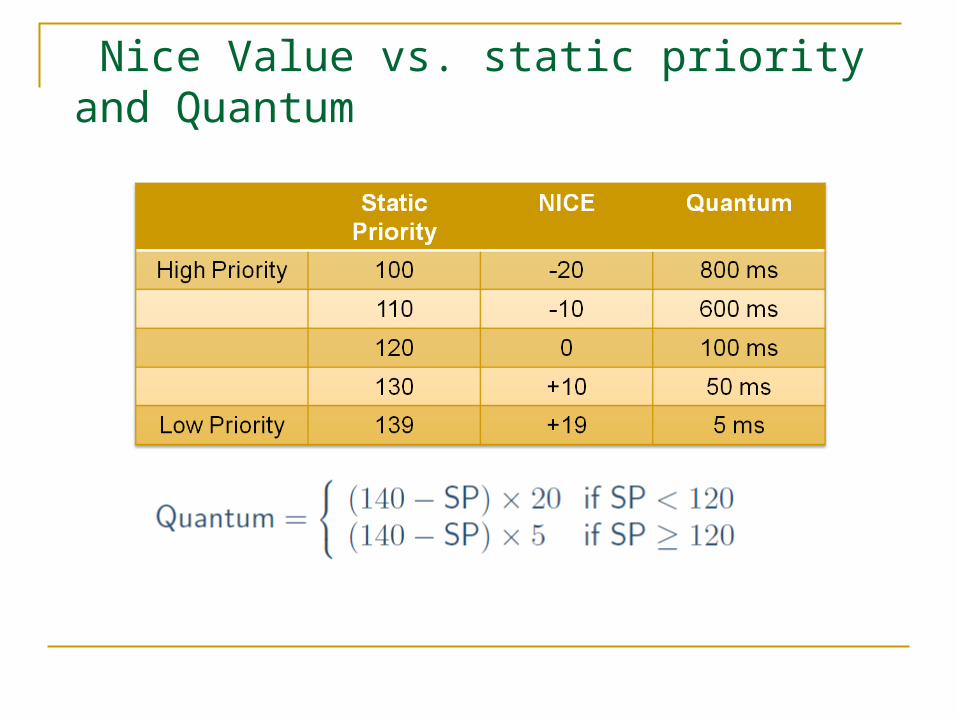
Nice Value vs. static priority and Quantum

Dynamic priority
Dynamic priority is calculated from static priority and average sleep time
Roughly speaking, the bonus is a number in [0, 10] that measures what percentage of the time the process was sleeping recently; 5 is neutral, 10 helps priority by 5, 0 hurts priority by 5
DP = max (100,min(SP − bonus + 5, 139))

Interactivity Dynamically scales a tasks priority based on it‘s
Interactivity Interactive tasks receive a prio bonus [ -5 ]
Hence a larger timeslice CPU bound tasks receive a prio penalty [ +5 ] Interactivity estimated using a running sleep
average. Interactive tasks are I/O bound. They wait for events to
occur. Sleeping tasks are I/O bound or interactive !! Actual bonus/penalty is determined by comparing the
sleep average against a constant maximum sleep average.

Recalculation of priorities
When a task finishes it's timeslice : It's interactivity is estimated Interactive tasks can be inserted into the 'Active'
array again. Else, priority is recalculated Inserted into the NEW priority level in the
'Expired' array.

Scheduling in Linux
The scheduler selects the next process to be assigned to the CPU based on process priority.
In a high-level C program the “nice” value can be modified using the following functions: int getpriority(int which, id_t who); int setpriority(int which, id_t who, int value); int nice(int incr);

Parameters
which : Specifies the type of target. Can be one of PRIO_PROCESS, PRIO_PGRP, or PRIO_USER.
who : Is the target of the setpriority() request; a process ID, process group ID, or user ID, respectively, depending on the value of which. A value of 0 indicates that the target is the current process, process group, or user.
value : Is the new nice value for the process. Values in the range [-20, 19] are valid; values outside that range are silently clipped to this range.

Nice value
Varies between[-20,19] Lower value, higher priority The current process needs super user
privilege to lower the nice value. But, it can lower the priority.

Nice value vs. Win32 Priority
nice value Win32 Priority
-20 to -16 THREAD_PRIORITY_HIGHEST
-15 to -6 THREAD_PRIORITY_ABOVE_NORMAL
-5 to +4 THREAD_PRIORITY_NORMAL
+5 to +14 THREAD_PRIORITY_BELOW_NORMAL
+15 to +19 THREAD_PRIORITY_LOWEST

Scheduler source code In the file /usr/src/linux/kernel/sched.c including the runqueue
structure The statistics are available at /proc/schedstat and present a variety of
data for each CPU in the system, including load-balancing and process-migration statistics.
schedule The main scheduler function. Schedules the highest priority
task for execution. load_balance
Checks the CPU to see whether an imbalance exists, and attempts to move tasks if not balanced.
effective_prio Returns the effective priority of a task (based on the static
priority, but includes any rewards or penalties). recalc_task_prio Determines a task's bonus or penalty based on its
idle time. source_load Calculates the load of the source CPU (from which a
task could be migrated) .target_load Calculates the load of a target CPU (where a task has
the potential to be migrated) migration_thread High-priority system thread that migrates tasks
between CPUs.
Related Documents











