Practical File on Compiler Design BACHELOR OF TECHNOLOGY IN COMPUTER SCIENCE & ENGINEERING Submitted By: Submitted To: Shahrukhane Alam Mr. Pankaj Sejwal B.Tech 6 th Sem. Faculty of Computer Science Roll No.13017001009 DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING P.M. COLLEGE OF ENGINEERING , KAMI , SONEPAT

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Practical File on Compiler Design
BACHELOR OF TECHNOLOGY
IN
COMPUTER SCIENCE & ENGINEERING
Submitted By: Submitted To:
Shahrukhane Alam Mr. Pankaj Sejwal
B.Tech 6th Sem. Faculty of Computer Science
Roll No.13017001009
DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING
P.M. COLLEGE OF ENGINEERING , KAMI , SONEPAT
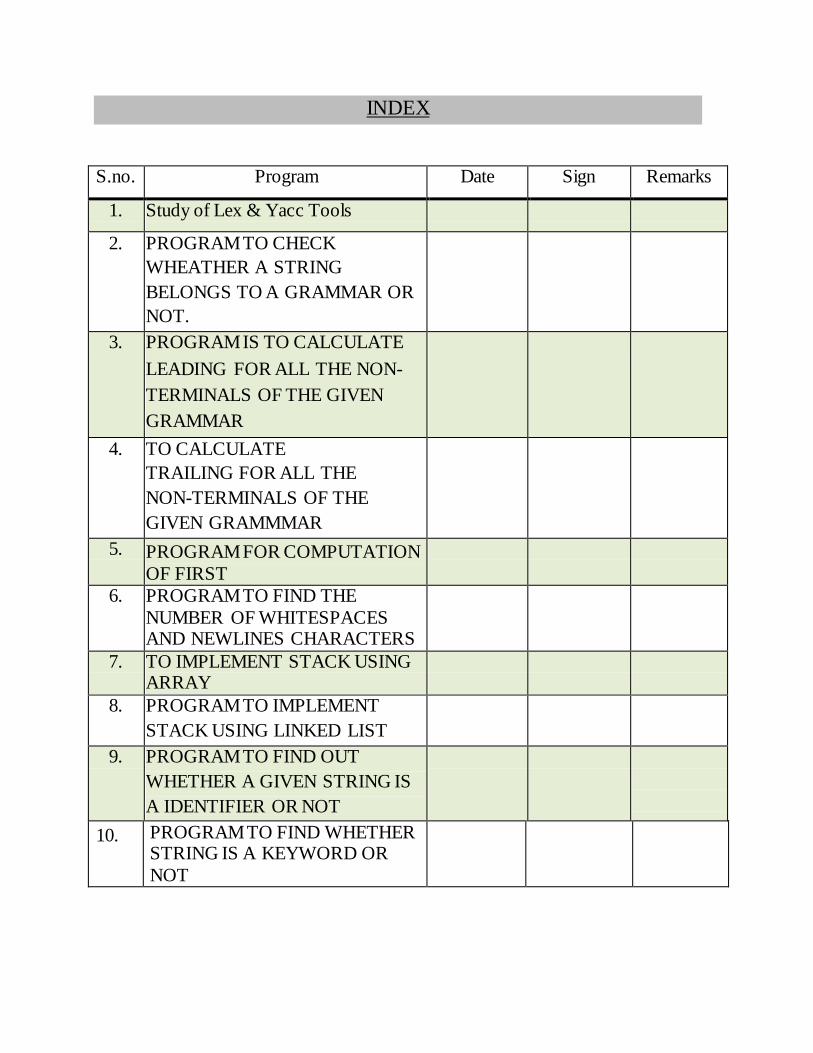
INDEX
S.no. Program Date Sign Remarks
1. Study of Lex & Yacc Tools
2. PROGRAM TO CHECK
WHEATHER A STRING
BELONGS TO A GRAMMAR OR
NOT.
3. PROGRAM IS TO CALCULATE
LEADING FOR ALL THE NON-
TERMINALS OF THE GIVEN
GRAMMAR
4. TO CALCULATE
TRAILING FOR ALL THE
NON-TERMINALS OF THE
GIVEN GRAMMMAR
5. PROGRAM FOR COMPUTATION
OF FIRST
6. PROGRAM TO FIND THE
NUMBER OF WHITESPACES AND NEWLINES CHARACTERS
7. TO IMPLEMENT STACK USING ARRAY
8. PROGRAM TO IMPLEMENT
STACK USING LINKED LIST
9. PROGRAM TO FIND OUT
WHETHER A GIVEN STRING IS
A IDENTIFIER OR NOT
10. PROGRAM TO FIND WHETHER STRING IS A KEYWORD OR
NOT

Practical =1. Study of Lex & Yacc Tools Lex - A Lexical Analyzer Generator ABSTRACT Lex helps write programs whose control flow is directed by instances of regular
expressions in the input stream. It is well suited for editor-script type
transformations and for segmenting input in preparation for a parsing routine. Lex source is a table of regular expressions and corresponding program
fragments. The table is translated to a program which reads an input stream,
copying it to an output stream and partitioning the input into strings which
match the given expressions. As each such string is recognized the
corresponding program fragment is executed. The recognition of the expressions
is performed by a deterministic finite automaton generated by Lex. The program
fragments written by the user are executed in the order in which the
corresponding regular expressions occur in the input stream. The lexical analysis programs written with Lex accept ambiguous
specifications and choose the longest match possible at each input point. If
necessary, substantial lookahead is performed on the input, but the input stream
will be backed up to the end of the current partition, so that the user has general
freedom to manipulate it. Lex can generate analyzers in either C or Ratfor, a language which can be
translated automatically to portable Fortran. It is available on the PDP-11
UNIX, Honeywell GCOS, and IBM OS systems. 1. Introduction.
Lex is a program generator designed for lexical processing of character input streams. It accepts a high-level, problem oriented specification for character
string matching, and produces a program in a general purpose language which
recognizes regular expressions. The regular expressions are specified by the user
in the source specifications given to Lex. The Lex written code recognizes these expressions in an input stream and partitions the input stream into strings
matching the expressions. At the boundaries between strings program sections
provided by the user are executed. The Lex source file associates the regular

expressions and the program fragments. As each expression appears in the input
to the program written by Lex, the corresponding fragment is executed. The user supplies the additional code beyond expression matching needed to
complete his tasks, possibly including code written by other generators. The
program that recognizes the expressions is generated in the general purpose
programming language employed for the user's program fragments. Thus, a
high level expression language is provided to write the string expressions to be
matched while the user's freedom to write actions is unimpaired. This avoids forcing the user who wishes to use a string manipulation language for input
analysis to write processing programs in the same and often inappropriate string
handling language. Lex is not a complete language, but rather a generator representing a new
language feature which can be added to different programming languages, called ``host languages.'' Just as general purpose languages can produce code to run on
different computer hardware, Lex can write code in different host languages.
The host language is used for the output code generated by Lex and also for the program fragments added by the user. Compatible run-time libraries for the
different host languages are also provided. This makes Lex adaptable to
different environments and different users. Each application may be directed to the combination of hardware and host language appropriate to the task, the user's
background, and the properties of local implementations. At present, the only supported host language is C, although Fortran (in the form of Ratfor [2] has
been available in the past. Lex itself exists on UNIX, GCOS, and OS/370; but
the code generated by Lex may be taken anywhere where appropriate compilers exist. Lex turns the user's expressions and actions (called source in this pic) into the
host general-purpose language; the generated program is named yylex. The
yylex program will recognize expressions in a stream (called input in this pic)
and perform the specified actions for each expression as it is detected.
+-------+ Source -> | Lex | -> yylex
+-------+
+-------+ Input -> | yylex | -> Output
+-------+
An overview of Lex

For a trivial example, consider a program to delete from the input all blanks or
tabs at the ends of lines. %% [ \t]+$ ;
is all that is required. The program contains a %% delimiter to mark the beginning of the rules, and one rule. This rule contains a regular expression
which matches one or more instances of the characters blank or tab (written \t for visibility, in accordance with the C language convention) just prior to the
end of a line. The brackets indicate the character class made of blank and tab;
the + indicates ``one or more ...''; and the $ indicates ``end of line,'' as in QED. No action is specified, so the program generated by Lex (yylex) will ignore
these characters. Everything else will be copied. To change any remaining string of blanks or tabs to a single blank, add another rule:
%% ;
[ \t]+$
[ \t]+ printf(" "); The finite automaton generated for this source will scan for both rules at once,
observing at the termination of the string of blanks or tabs whether or not there is a newline character, and executing the desired rule action. The first rule
matches all strings of blanks or tabs at the end of lines, and the second rule all
remaining strings of blanks or tabs. Lex can be used alone for simple transformations, or for analysis and statistics
gathering on a lexical level. Lex can also be used with a parser generator to perform the lexical analysis phase; it is particularly easy to interface Lex and
Yacc [3]. Lex programs recognize only regular expressions; Yacc writes parsers
that accept a large class of context free grammars, but require a lower level analyzer to recognize input tokens. Thus, a combination of Lex and Yacc is
often appropriate. When used as a preprocessor for a later parser generator, Lex
is used to partition the input stream, and the parser generator assigns structure to
the resulting pieces. The flow of control in such a case (which might be the first half of a compiler, for example) is shown in Figure 2. Additional programs,
written by other generators or by hand, can be added easily to programs written
by Lex.

lexical grammar rules rules
| |
+
v
+
v
+
Lex +---------
| | | Yacc |
+----
-----
| + +--------- +
|
+
v
+
v
+
yylex +---------
Input -> | | -> | yyparse | -> Parsed input +-
------
-- + +--------- +
Lex with Yacc
Yacc users will realize that the name yylex is what Yacc expects its lexical
analyzer to be named, so that the use of this name by Lex simplifies interfacing. Lex generates a deterministic finite automaton from the regular expressions in
the source. The automaton is interpreted, rather than compiled, in order to save
space. The result is still a fast analyzer. In particular, the time taken by a Lex program to recognize and partition an input stream is proportional to the length
of the input. The number of Lex rules or the complexity of the rules is not
important in determining speed, unless rules which include forward context
require a significant amount of rescanning. What does increase with the number
and complexity of rules is the size of the finite automaton, and therefore the size of the program generated by Lex. In the program written by Lex, the user's fragments (representing the actions
to be performed as each regular expression is found) are gathered as cases
of a switch. The automaton interpreter directs the control flow. Opportunity

is provided for the user to insert either declarations or additional statements
in the routine containing the actions, or to add subroutines outside this
action routine. Lex is not limited to source which can be interpreted on the basis of one
character lookahead. For example, if there are two rules, one looking for ab and
another for abcdefg, and the input stream is abcdefh, Lex will recognize ab and
leave the input pointer just before cd. . . Such backup is more costly than the
processing of simpler languages. 2. Lex Source. The general format of Lex source is:
{definitions} %%
{rules} %% {user subroutines}
where the definitions and the user subroutines are often omitted. The
second %% is optional, but the first is required to mark the beginning of the rules. The absolute minimum Lex program is thus
%% (no definitions, no rules) which translates into a program which copies the
input to the output unchanged. In the outline of Lex programs shown above, the rules represent the user's
control decisions; they are a table, in which the left column contains regular
expressions and the right column contains actions, program fragments to be
executed when the expressions are recognized. Thus an individual rule might
appear
integer printf("found keyword INT"); to look for the string integer in the input stream and print the message ``found keyword INT'' whenever it appears. In this example the host procedural language is C and the C library function printf is used to print the string. The
end of the expression is indicated by the first blank or tab character. If the action is merely a single C expression, it can just be given on the right side of the line;
if it is compound, or takes more than a line, it should be enclosed in braces. As a slightly more useful example, suppose it is desired to change a number of words from British to American spelling. Lex rules such as colour

printf("color") mechaniseprintf("mechanize");
petrolprintf("gas"); would be a start. These rules are not quite enough, since the word
petroleum would become gaseum; a way of dealing with this will be a bit
more compl

Practical=2
PROGRAM TO CHECK WHEATHER A STRING BELONGS TO A
GRAMMAR OR NOT. #include<stdio.h>
#include<conio.h> #include<ctype.h>
#include<string.h> void main() {
int a=0,b=0,c,d; char str[20],tok[11]; clrscr();
printf("Input the expression = "); gets(str); while(str[a]!='\0')
{ if((str[a]=='(')||(str[a]=='{'))
{ tok[b]='4';
b++; }
if((str[a]==')')||(str[a]=='}')) { tok[b]='5';
b++; }
if(isdigit(str[a])) {
while(isdigit(str[a])) {
a++; }
a--; tok[b]='6'; b++; }
if(str[a]=='+') {
tok[b]='2'; b++; }

if(str[a]=='*')
{ tok[b]='3';
b++; }
a++;
} tok[b]='\0';
puts(tok); b=0;
while(tok[b]!='\0') {
if(((tok[b]=='6')&&(tok[b+1]=='2')&&(tok[b+2]=='6'))||((tok[b]=='6')&&(tok[b+1
]=='3')&&(tok[b+2]=='6'))||((tok[b]=='4')&&(tok[b+1]=='6')&&(tok[b+2]=='5'))/*||((tok[b
]!=6)&&(tok[b+1]!='\0'))*/) {
tok[b]='6'; c=b+1;
while(tok[c]!='\0') {
tok[c]=tok[c+2]; c++;
} tok[c]='\0'; puts(tok);
b=0; }
else {
b++;
puts(tok); }
} d=strcmp(tok,"6"); if(d==0)

{ printf("It is in the grammar.");
} else
{ printf("It is not in the grammar.");
} getch();
}

OUTPUT Input the expression = (23+) 4625 4625 4625 4625 4625
It is not in the grammar. Input the expression = (2+(3+4)+5) 46246265265 46246265265 46246265265
46246265265 46246265265 462465265 462465265 462465265 462465265 4626265 4626265 46265 46265 465 6 6
It is in the grammar.

Practical=3 TO CALCULATE LEADING OF NON-TERMINALS
#include<conio.h>
#include<stdio.h>
char arr[18][3] =
{
{'E','+','F'},{'E','*','F'},{'E','(','F'},{'E',')','F'},{'E','i','F'},{'E','$','F'}, {'F','+','F'},{'F','*','F'},{'F','(','F'},{'F',')','F'},{'F','i','F'},{'F','$','F'},
{'T','+','F'},{'T','*','F'},{'T','(','F'},{'T',')','F'},{'T','i','F'},{'T','$','F'},
}; char prod[6] = "EETTFF"; char res[6][3]=
{
{'E','+','T'},{'T','\0'}, {'T','*','F'},{'F','\0'},
{'(','E',')'},{'i','\0'}, };
char stack [5][2]; int top = -1; void install(char pro,char re)
{ int i; for(i=0;i<18;++i)
{ if(arr[i][0]==pro && arr[i][1]==re) {
arr[i][2] = 'T'; break; }
} ++top;
stack[top][0]=pro; stack[top][1]=re;
} void main()
{

int i=0,j; char pro,re,pri=' '; clrscr();
for(i=0;i<6;++i)
{
for(j=0;j<3 && res[i][j]!='\0';++j) {
if(res[i][j] =='+'||res[i][j]=='*'||res[i][j]=='('||res[i][j]==')'||res[i][j]=='i'||res[i][j]=='$')
{ install(prod[i],res[i][j]);
break; }
} } while(top>=0)
{ pro = stack[top][0]; re = stack[top][1]; --top; for(i=0;i<6;++i)
{
if(res[i][0]==pro && res[i][0]!=prod[i]) {
install(prod[i],re); }
} }
for(i=0;i<18;++i) {
printf("\n\t"); for(j=0;j<3;++j)
printf("%c\t",arr[i][j]); }
getch(); clrscr();
printf("\n\n"); for(i=0;i<18;++i)
{ if(pri!=arr[i][0])

{ pri=arr[i][0]; printf("\n\t%c -> ",pri);
} if(arr[i][2] =='T')
printf("%c ",arr[i][1]); }
getch();}

OUTPUT
E + T E * T
E ( T E ) F
E I T E $ F
F + F F * F F ( T
F ) F F I T
F $ F T + F
T * T T ( T
T ) F T I T
T $ F

PRACTICAL =4
TO CALCULATE TRAILING FOR ALL THE NON-TERMINALS
OF THE GIVEN GRAMMMAR #include<conio.h>
#include<stdio.h>
char arr[18][3] =
{ {'E','+','F'},{'E','*','F'},{'E','(','F'},{'E',')','F'},{'E','i','F'},{'E','$','F'},
{'F','+','F'},{'F','*','F'},{'F','(','F'},{'F',')','F'},{'F','i','F'},{'F','$','F'}, {'T','+','F'},{'T','*','F'},{'T','(','F'},{'T',')','F'},{'T','i','F'},{'T','$','F'},
}; char prod[6] = "EETTFF"; char res[6][3]=
{ {'E','+','T'},{'T','\0','\0'},
{'T','*','F'},{'F','\0','\0'}, {'(','E',')'},{'i','\0','\0'},
}; char stack [5][2]; int top = -1;
void install(char pro,char re)
{
int i; for(i=0;i<18;++i) {
if(arr[i][0]==pro && arr[i][1]==re) { arr[i][2] = 'T'; break;
} }
++top; stack[top][0]=pro;
stack[top][1]=re;

}
void main()
{ int i=0,j;
char pro,re,pri=' ';
clrscr();
for(i=0;i<6;++i)
{ for(j=2;j>=0;--j)
{ if(res[i][j]=='+'||res[i][j]=='*'||res[i][j]=='('||res[i][j]==')'||res[i][j]=='i'||res[i][j]=='
$')
{ install(prod[i],res[i][j]);
break; }
else if(res[i][j]=='E' || res[i][j]=='F' || res[i][j]=='T') {
if(res[i][j-1]=='+'||res[i][j-1]=='*'||res[i][j-1]=='('||res[i][j-1]==')'||res[i][j-1]=='i'||res[i][j-1]=='$')
{ install(prod[i],res[i][j-1]); break; }
} }
}
while(top>=0)
{ pro = stack[top][0]; re = stack[top][1]; --top; for(i=0;i<6;++i)
{

for(j=2;j>=0;--j) {
if(res[i][0]==pro && res[i][0]!=prod[i]) {
install(prod[i],re); break;
} else if(res[i][0]!='\0') break;
} }}
for(i=0;i<18;++i) {
printf("\n\t");
for(j=0;j<3;++j) printf("%c\t",arr[i][j]); }
getch(); clrscr();
printf("\n\n"); for(i=0;i<18;++i)
{ if(pri!=arr[i][0])
{ pri=arr[i][0]; printf("\n\t%c -> ",pri);
} if(arr[i][2] =='T')
printf("%c ",arr[i][1]); } getch();
}

OUTPUT
E + T
E * T E ( F
E ) T E i T E $ F F + F
F * F F ( F F ) T
F i T F $ F
T + F T * T
T ( F T ) T
T i T T $ F
E -> + * ) i F -> ) i
T -> * )

PRACTICAL= 5
PROGRAM FOR COMPUTATION OF FIRST
#include<stdio.h>
#include<conio.h> #include<string.h>
void main() {
char t[5],nt[10],p[5][5],first[5][5],temp; int i,j,not,nont,k=0,f=0; clrscr();
printf("\nEnter the no. of Non-terminals in the grammer:"); scanf("%d",&nont); printf("\nEnter the Non-terminals in the grammer:\n"); for(i=0;i<nont;i++)
{ scanf("\n%c",&nt[i]);
} printf("\nEnter the no. of Terminals in the grammer: ( Enter e for absiline ) "); scanf("%d",¬);
printf("\nEnter the Terminals in the grammer:\n"); for(i=0;i<not||t[i]=='$';i++) {
scanf("\n%c",&t[i]); }
for(i=0;i<nont;i++) {
p[i][0]=nt[i]; first[i][0]=nt[i];
} printf("\nEnter the productions :\n"); for(i=0;i<nont;i++)
{ scanf("%c",&temp);
printf("\nEnter the production for %c ( End the production with '$' sign ) :",p[i][0]);
for(j=0;p[i][j]!='$';) {
j+=1; scanf("%c",&p[i][j]);
}

} for(i=0;i<nont;i++)
{
printf("\nThe production for %c -> ",p[i][0]); for(j=1;p[i][j]!='$';j++) {
printf("%c",p[i][j]);
} }
for(i=0;i<nont;i++) {
f=0; for(j=1;p[i][j]!='$';j++) {
for(k=0;k<not;k++) { if(f==1)
break;
if(p[i][j]==t[k])
{ first[i][j]=t[k]; first[i][j+1]='$'; f=1;
break;
} else if(p[i][j]==nt[k])
{ first[i][j]=first[k][j]; if(first[i][j]=='e')
continue; first[i][j+1]='$'; f=1;
break; }
} }
} for(i=0;i<nont;i++)
{ printf("\n\nThe first of %c -> ",first[i][0]); for(j=1;first[i][j]!='$';j++)

{ printf("%c\t",first[i][j]);
} }
getch(); }

OUTPUT Enter the no. of Non-terminals in the grammer:3 Enter the Non-terminals in the grammer: ERT Enter the no. of Terminals in the grammer: ( Enter e for absiline ) 5 Enter the Terminals in the grammer: ase*+ Enter the productions : Enter the production for E ( End the production with '$' sign ) :a+s$ Enter the
production for R ( End the production with '$' sign ) :e$ Enter the production for
T ( End the production with '$' sign ) :Rs$
The production for E -> a+s The production
for R -> e The production for T -> Rs The first of E -> a The first of R -> e The
first of T -> e s

PRACTICAL-6
PROGRAM TO FIND THE NUMBER OF WHITESPACES AND
NEWLINES CHARACTERS
#include<stdio.h> #include<conio.h> #include<string.h>
void main() {
char str[200],ch;
int a=0,space=0,newline=0; clrscr();
printf("\n enter a string(press escape to quit entering):"); ch=getche();
while((ch!=27) && (a<199)) {
str[a]=ch; if(str[a]==' ')
{ space++;
} if(str[a]==13) {
newline++; printf("\n");
} a++;
ch=getche(); }
printf("\n the number of lines used : %d",newline+1); printf("\n the number of spaces
used is : %d",space); getch(); }

OUTPUT enter a string(press escape to quit entering):hello! how r u? Do you like prog. in compiler? the number of lines used : 4 the number of spaces used is : 7

PRACTICAL-7 TO IMPLEMENT STACK USING ARRAY #include<stdio.h>
#include<conio.h> #include<string.h>
void main() {
char a[20]={NULL},inp; int ans=0,pos,i;
clrscr(); while(ans<4)
{ pos=0;
while(a[pos]!=NULL && pos<=20) pos++;
printf("\n\n####\tstack=%s, pos=%d",a,pos); printf("\n\n\t\t-- Main Menu --\n\n1. Push\n2. Pop\n3. View Stack\n4.Exit\nYour Choice: ");
scanf("%d",&ans); switch(ans)
{ case 1:
{ if(pos==20)
printf("\nStack is already Full."); else
{ printf("\nEnter input character: ");
scanf("%s",&a[pos]); printf("\nPush Operation Successful."); }
break; }
case 2: {
if(pos==0) printf("\nStack already empty.");
else

{ a[pos-1]=NULL;
printf("\nPop operation Successful."); }
break; }
case 3: {
if(pos==0) printf("\nEmpty Stack.");
else {
printf("\nStack Content:--\n"); for(i=pos-1;i>=0;i--)
{ printf("\n %c",a[i]); if(i==pos-1)
printf(" (Top of the Stack.)"); }
} break;
} case 4:
{ exit();
break; }
default: { printf("\nInvalid Input.");
getch(); exit();
} }
getch(); }
}

OUTPUT
#### stack=, pos=0
-- Main Menu --
1. Push 2. Pop
3. View Stack 4.Exit
Your Choice: 1 Enter input character: karan
Push Operation Successful.

Practical- 8
PROGRAM TO IMPLEMENT STACK USING LINKED LIST
#include<stdio.h> #include<conio.h> struct stack
{
int no; struct stack *next;
} *start=NULL;
typedef struct stack st; void push(); int pop(); void display(); void main()
{
char ch; int choice,item; do
{ clrscr();
printf("\n 1: push"); printf("\n 2: pop"); printf("\n 3: display"); printf("\n Enter your choice"); scanf("%d",&choice);
switch (choice)
{ case 1: push(); break;
case 2: item=pop(); printf("The delete element in %d",item); break;
case 3: display(); break;
default : printf("\n Wrong choice"); }; printf("\n do you want to continue(Y/N)"); fflush(stdin);
scanf("%c",&ch); }
while (ch=='Y'||ch=='y'); }
void push()

{ st *node;
node=(st *)malloc(sizeof(st)); printf("\n Enter the number to be insert"); scanf("%d",&node->no);
node->next=start; start=node;
}
int pop()
{
st *temp; temp=start; if(start==NULL)
{ printf("stack is already empty"); getch();
exit(); }
else {
start=start->next; free(temp); }
return(temp->no); }
void display() {
st *temp; temp=start; while(temp->next!=NULL)
{ printf("\nno=%d",temp->no); temp=temp->next;
} printf("\nno=%d",temp->no);
}

OUTPUT
1: push
2: pop 3: display
Enter your choice3
no=234 do you want to continue(Y/N)

Practical -9
THIS PROGRAM IS TO FIND OUT WHETHER A GIVEN STRING IS A
IDENTIFIER OR NOT
#include<stdio.h> #include<conio.h> int isiden(char*);
int second(char*);
int third(); void main() { char *str; int
i = -1; clrscr(); printf("\n\n\t\tEnter the desired String: "); do
{
++i; str[i] = getch();
if(str[i]!=10 && str[i]!=13)
printf("%c",str[i]); if(str[i] == '\b')
{
--i; printf(" \b"); }
}while(str[i] != 10 && str[i] != 13); if(isident(str))
printf("\n\n\t\tThe given strig is an identifier"); else
printf("\n\n\t\tThe given string is not an identifier");
getch(); } //To Check whether the given string is

identifier or not //This function acts like first
stage of dfa int isident(char *str) { if((str[0]>='a' && str[0]<='z') || (str[0]>='A' && str[0]<='Z'))
{
return(second(str+1)); }
else return 0;
} second(char *str)
{ if((str[0]>='0' && str[0]<='9') || (str[0]>='a' && str[0]<='z') || (str[0]>='A' && str[0]<='Z'))
{
return(second(str+1));
} else
{ if(str[0] == 10 || str[0] == 13)
{ return(third(str));
} else
{ return 0; }
}
} int third() {
return 1; }

OUTPUT:
Enter the desired String: a123
The given strig is an identifier ________________________________________________________________
______________
Enter the desired String: shailesh
The given strig is an identifier ________________________________________________________________
_______________
Enter the desired String: 1asd
The given string is not an identifier ________________________________________________________________
________________
Enter the desired String: as-*l
The given string is not an identifier ________________________________________________________________
_____

Practical -10
PROGRAM TO FIND WHETHER STRING IS A KEYWORD OR
NOT
#include<stdio.h> #include<conio.h> #include<string.h>
void main() {
int i,flag=0,m; char s[5][10]={"if","else","goto","continue","return"},st[10];
clrscr(); printf("\n enter the string :");
gets(st); for(i=0;i<5;i++)
{ m=strcmp(st,s[i]);
if(m==0) flag=1;
} if(flag==0)
printf("\n it is not a keyword"); else
printf("\n it is a keyword");
getch(); }

OUTPUT enter the string :return it is a keyword
enter the string :hello it is not a keyword
Related Documents











