Chapter 2: Elements of Information Systems 1 of 33 ACCOUNTING INFORMATION SYSTEMS: A DATABASE APPROACH by: Uday S. Murthy, Ph.D., ACA and S. Michael Groomer, Ph.D., CPA, CISA Elements of Information Systems Learning Objectives After studying this chapter you should be able to: • distinguish between data and information • explain the hierarchy of data • describe alternative field formats , record keys , and coding systems • explain various types of files • discuss the steps in the data processing cycle • discuss data input options • explain the various file organization, file access , and file update options • discuss the relative merits and drawbacks of batch versus online processing • describe and discuss the systems approach In the previous chapter, we presented the database approach to accounting and contrasted it with conventional information systems representing the first wave of computerization of accounting information systems. However, regardless of their design and architectural differences, all computer-based information systems share some common elements. In this chapter, we will discuss the basic elements of computerized information systems. First, we will distinguish between data and information. We will then discuss how data are organized in computer systems at the most basic level. You will become familiar with alternative field formats and record keys. Thereafter, the hierarchy of data from bytes to a database will be presented. Files and the various types of files will also be discussed. We will conclude the chapter with a discussion of the "systems approach" and an explanation of what that entails. Data versus information As we saw in the previous chapter, the purpose of an information system is to convert data into information. Accounting information systems convert input transactions into financial reports and other types of informational outputs. Data represents raw, unprocessed facts that are useless without further processing. Information is data made meaningful. The information system processes data to render useless facts into useful information. For example, if you walk from door to door to every residence in your city and record the names and phone numbers of all residents in the order of your visit, you would have an extensive collection of data. However, these data are essentially useless

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chapter 2: Elements of Information Systems
1 of 33
ACCOUNTING INFORMATION SYSTEMS: A DATABASE APPROACH by: Uday S. Murthy, Ph.D., ACA and S. Michael Groomer, Ph.D., CPA, CISA
Elements of Information Systems
Learning Objectives
After studying this chapter you should be able to:
• distinguish between data and information • explain the hierarchy of data • describe alternative field formats, record keys, and coding systems • explain various types of files • discuss the steps in the data processing cycle • discuss data input options • explain the various file organization, file access, and file update options • discuss the relative merits and drawbacks of batch versus online processing • describe and discuss the systems approach
In the previous chapter, we presented the database approach to accounting and contrasted it with conventional information systems representing the first wave of computerization of accounting information systems. However, regardless of their design and architectural differences, all computer-based information systems share some common elements. In this chapter, we will discuss the basic elements of computerized information systems. First, we will distinguish between data and information. We will then discuss how data are organized in computer systems at the most basic level. You will become familiar with alternative field formats and record keys. Thereafter, the hierarchy of data from bytes to a database will be presented. Files and the various types of files will also be discussed. We will conclude the chapter with a discussion of the "systems approach" and an explanation of what that entails.
Data versus information
As we saw in the previous chapter, the purpose of an information system is to convert data into information. Accounting information systems convert input transactions into financial reports and other types of informational outputs. Data represents raw, unprocessed facts that are useless without further processing. Information is data made meaningful. The information system processes data to render useless facts into useful information. For example, if you walk from door to door to every residence in your city and record the names and phone numbers of all residents in the order of your visit, you would have an extensive collection of data. However, these data are essentially useless

Chapter 2: Elements of Information Systems
2 of 33
since it would be very difficult to locate the phone number based on a resident's last name. What converts these data into useful information, namely a phone directory, is the process of alphabetizing the data. That is, if names and phone numbers are sorted in order of the last name of residents, then the data become useful. The sorted list is useful since it is now possible to locate the phone number of any resident so long as you know the last name of the resident. Information alone is only a means to an end. The right information delivered at the right time and interpreted in the right manner can lead to knowledge. Knowledge in turn can lead to wisdom and/or power. An excellent example of information versus knowledge, wisdom, and power is the Internet. There are trillions of megabytes of information on countless home pages on the Web, but only few of us obtain knowledge about a particular topic from the Internet. Fewer still can convert that knowledge into wisdom or power. The data-to-power value chain, also referred to simply as the information value chain, is shown in the following figure.
For information to be truly useful and meaningful to a user, it must meet certain qualities. It must be relevant and reliable. The relevance of information pertains to its ability to assist a user in making a decision. For information to be relevant, it must be received in a timely manner and must have the capacity to change the user's decision. It must be made available soon enough to make a difference and must make the user better off relative to his or her situation prior to receipt of that information. Reliability of information has to do with its accuracy and freedom from errors. Information replete with errors is unreliable and can potentially lead the user to an incorrect decision. Control mechanisms must be placed within the information system to prevent intentional and unintentional errors in data input, processing, and information output. A concept closely related to reliability is reproducibility. Using the same data as input, and applying the same processing methods, another information system should generate identical information. In summary, data represents raw facts, whereas information is data made meaningful. Information must be both relevant and reliable to really be useful to a decision maker. Having discussed the difference between data and information, let us now explore how data are stored in computer-based information systems.
Hierarchy of data
At the lowest level, all computer systems store data in the form of bits. A bit is a binary digit and can take a value of either 0 (turned off) or 1 (turned on). In essence, a bit is turned on by a tiny electrical impulse and is turned off when the impulse is discharged. A group of bits forms a byte. In most computer systems, eight bits form a byte. A byte is

Chapter 2: Elements of Information Systems
3 of 33
roughly equivalent to a character, such as the letter “a” or the number “3,” which is the lowest element understandable by humans. A group of related bytes forms a field. Thus, the group of bytes that forms the word 'Jones' makes up a 'name' field. A group of related fields makes up a record. Tom Jones, Marketing, Sales Associate, 8/1/2008, $2,500 are a group of fields which make up an employee record showing the employee's name, department, grade, date hired, and monthly salary. A group of logical records constitutes a file. All employee records taken together would make up the employee file. A collection of sales invoices for July 2008 would form the sales file for July. Finally, a collection of logically related files is a database. All files relating to Division A's operations would constitute the 'Division A database.' As shown in the figure below, the hierarchy of data starts with bits at the lowest level and ends with a database at the highest level.
In creating an information system, a number of design decisions must be made relating to fields, records, and files. Let us now explore the various options relative to field, record, and file design.
Field formats
The format designated for a field is one design decision that you might be involved in. Although the field format decision is usually not irreversible, giving some forethought to the kind of data that might be stored in each field is time well spent. Back in the late 1990s, a lot was made of the “Year 2000 problem,” referred to in computer speak as the

Chapter 2: Elements of Information Systems
4 of 33
"Y2K" problem. When establishing the field format and length of fields in many of the older computer programs developed in the 1960s and 70s, no thought was given to the implications of the year 2000. These programs were written primarily in COBOL (Common Business Oriented Language), which did not have a "date" format at that time. Dates were simply stored as a string of six alphanumeric characters (e.g., XX-XX-XX for MM-DD-YY). Thus, these programs stored only the last two digits of the year (e.g., 85 instead of 1985). This was done to save storage space, which was at a premium in those days. As a result, these computer programs would have interpreted the year 2000 as 1900, thereby performing erroneous calculations in a host of applications such as those computing interest on loans, premium due on insurance policies, aging accounts receivable, etc. The "Millennium Bug," as it was referred to, was hidden within trillions of lines of COBOL code in the computer systems of most large organizations. It is estimated that the industry-wide fix for this problem cost over $100 billion! Perhaps this was money well spent, since there were almost no Y2K related problems as organizations moved from 1999 into the year 2000.
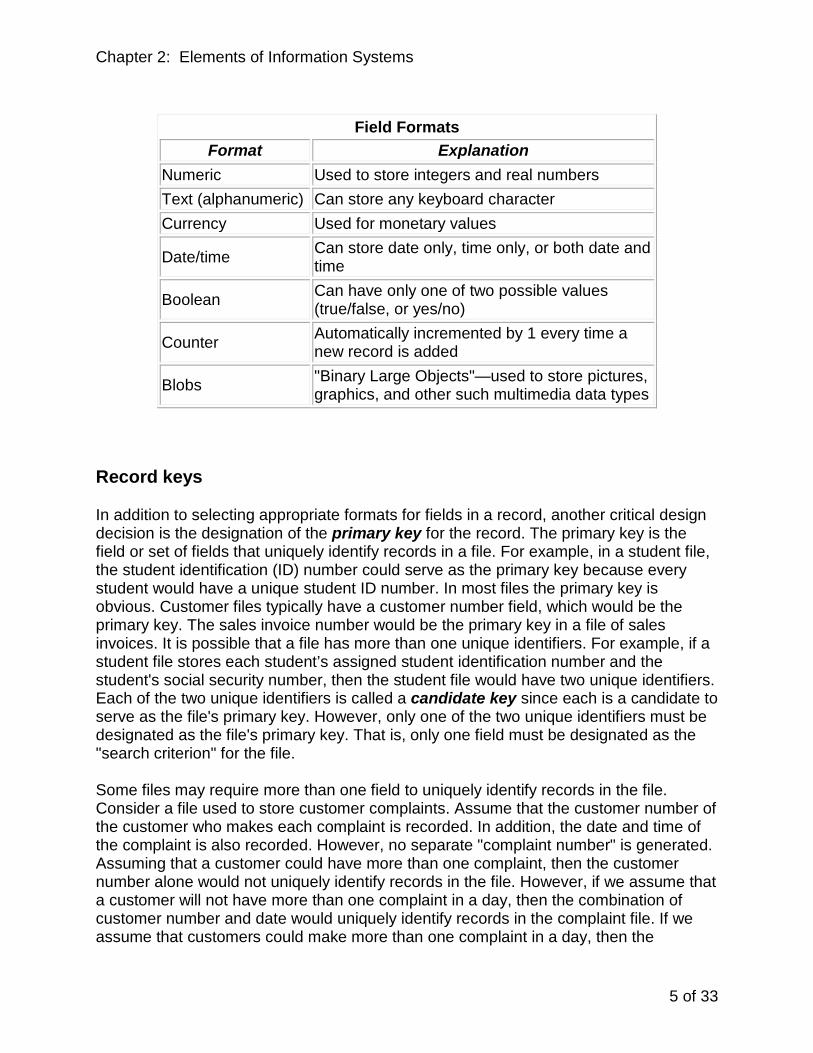
Most computer systems support the following field formats: numeric, text, currency, date/time, and Boolean. Some systems also support counter fields and fields capable of storing binary objects such as a graphical image, a video clip or a sound recording. Let us now understand each of these field formats.
As the name suggests, numeric fields can only store numbers. In contrast, text fields can store any keyboard character. Moreover, these text fields can store any character in the complete character set used for a particular computer. All the characters (numeric and non-numeric) in the character set for a computer are called alphanumeric characters. Currency fields are for storing dollars and cents appropriately formatted. Date/time fields can store dates or times in a variety of user-specified formats (e.g., MM/DD/YYYY or DD/MM/YYYY). Boolean fields can hold only one of two possible values—either true or false, or in some computer systems, yes or no. Counter fields are automatically incremented by one whenever a new record in the file is created. The user cannot update the value in the counter field. Fields capable of storing binary large objects, or BLOBS, are very useful for present day information systems that are increasingly becoming multimedia. No longer are information systems limited to storing text and numbers. Other forms of data, such as a photograph of an employee or a video image of a product, can also be stored in files. The various field formats are summarized in the following table on the next page.
Chapter 2: Elements of Information Systems
5 of 33
Field Formats
Format Explanation Numeric Used to store integers and real numbers Text (alphanumeric) Can store any keyboard character Currency Used for monetary values
Date/time Can store date only, time only, or both date and time
Boolean Can have only one of two possible values (true/false, or yes/no)
Counter Automatically incremented by 1 every time a new record is added
Blobs "Binary Large Objects"—used to store pictures, graphics, and other such multimedia data types
Record keys
In addition to selecting appropriate formats for fields in a record, another critical design decision is the designation of the primary key for the record. The primary key is the field or set of fields that uniquely identify records in a file. For example, in a student file, the student identification (ID) number could serve as the primary key because every student would have a unique student ID number. In most files the primary key is obvious. Customer files typically have a customer number field, which would be the primary key. The sales invoice number would be the primary key in a file of sales invoices. It is possible that a file has more than one unique identifiers. For example, if a student file stores each student’s assigned student identification number and the student's social security number, then the student file would have two unique identifiers. Each of the two unique identifiers is called a candidate key since each is a candidate to serve as the file's primary key. However, only one of the two unique identifiers must be designated as the file's primary key. That is, only one field must be designated as the "search criterion" for the file. Some files may require more than one field to uniquely identify records in the file. Consider a file used to store customer complaints. Assume that the customer number of the customer who makes each complaint is recorded. In addition, the date and time of the complaint is also recorded. However, no separate "complaint number" is generated. Assuming that a customer could have more than one complaint, then the customer number alone would not uniquely identify records in the file. However, if we assume that a customer will not have more than one complaint in a day, then the combination of customer number and date would uniquely identify records in the complaint file. If we assume that customers could make more than one complaint in a day, then the

Chapter 2: Elements of Information Systems
6 of 33
combination of customer number, date, and time, would uniquely identify records in the file. When a combination of fields is needed to uniquely identify records in a file, the primary key is called a composite key or a concatenated key.
Some computing environments feature system-generated identifiers for files. Recall the "counter" field format, which is automatically incremented by one when a new record is added to the file. In effect, the counter becomes the system-generated primary key for the file. The counter, however, is simply a number beginning with 1 and ending with the number of records in the file. Depending on the coding scheme chosen, the primary key can be used to reveal many different aspects of records in the file. Coding schemes are discussed later in this chapter. Thus, it is often advantageous to create a new field, such as customer number in a customer file, and designate that field as the primary key for that file rather than simply relying on the system-generated counter.
Fields, or attributes, in a file that are not part of the primary key are referred to as non-key attributes. One or more of the non-key attributes in a file can be designated as secondary keys. While primary keys uniquely identify records in a file, secondary keys are used to sort the file in some sequence for reporting purposes or to answer user queries. Consider a file of sales invoices with the following fields: invoice number, date, customer number, salesperson number, sales region, sales amount. The primary key of this file is the invoice number. Each of the remaining fields is a potential candidate for being a secondary key. Secondary keys are used to sort the file to respond to a user request for information. Thus, the sales manager might want a listing of sales invoices by date, by salesperson number, or by sales region. These requests could be handled by sorting the file by each of the relevant fields.
Indexing the file on the field can make sort operations on a field, and the selection of specific records based on the field, considerably faster. Indexing will be discussed a little later in this chapter. Although any non-key attribute could be designated as a secondary key, it is important to note that this designation comes at a cost. As discussed above, an index must be built on each secondary key field to speed queries. However, indexes comprise overhead for the computer system. An excessive number of indexes could actually slow performance in operations such as adding or deleting records, since all indexes must be rebuilt after each addition or deletion. Thus, it is necessary to be judicious in the designation of secondary key fields.
The above discussion on record keys is summarized in the following table.

Chapter 2: Elements of Information Systems
7 of 33
Record Keys
Key Explanation
Primary key The field that is used to uniquely identify records in a file; the field designated as the search criterion.
Candidate key Any unique identifier of records in a file. Composite (concatenated) key
Two or more fields that together uniquely identify records in a file.
Non-key attribute Any field that is not a primary key field.
Secondary key A non-key field (attribute) used to sort the file to answer user queries.
Coding systems
In discussing primary keys, we alluded to the process of establishing a coding system for key values. There are three types of coding systems: sequence codes, block codes, and group codes. In a sequence coding system, the records are simply numbered in sequence. This system is essentially the same as the "counter" primary key discussed earlier. Sequence codes are typically used to identify transactions or events. Sales invoices, purchase orders, and checks are examples of business documents where sequence codes are employed. An advantage of sequence codes is that missing documents can be quickly identified, either manually or by the computer system. However, in a sequence coding system it is not possible to indicate categories of the item being coded. Thus, a sequence code for sales invoices will not be able to distinguish between say East region invoices and West region invoices.
In a block coding system, ranges of numbers are reserved for each category of the item being coded. A classic example of the block coding system is the chart of accounts. A chart of accounts coding system might look like this: numbers 100 through 199 for assets, 200 through 299 for liabilities, 300 through 399 for income accounts, and 400 through 499 for expense accounts. If there are only 30 asset accounts, then the numbers 131 through 199 are simply unused and available for additional asset accounts to be set up in the future. The advantage of the block coding system is that the type of account can be discerned simply by knowing the account number. For example, the user would know that account numbers beginning with 4 are expense accounts. The drawback of block codes is that they can reveal only very limited aspects of the item being coded. In the chart of accounts example described above, the code could be further refined such that accounts numbered 100 through 149 are current assets, and accounts numbered 150 through 199 are long term assets. Each account number would then reveal not just the broad account type (i.e., asset, liability, income, expense) but also the specific type of account in each broad category (i.e., current asset, long term

Chapter 2: Elements of Information Systems
8 of 33
asset). However, it is difficult to conceive of a block code being used to represent three or more aspects of the item being coded.
In a group coding system, each digit or group of digits in the code for an item signifies a different aspect of that item. Consider the following coding system for parts: digits 1-2 indicate the division number (assuming that there are no more than 99 divisions), digit 3 indicates the warehouse number in the division (assuming a maximum of 10 warehouses in each division), digits 4 and 5 indicate the part type (assuming that there are no more than 99 part types), and digits 6 through 8 indicate the specific part number (assuming no more than 999 parts within each part type). So a part number of 16359217 indicates that it belongs to division number 16, is stored in warehouse number 3 in that division, is of part type 59, and that it is part number 217 in that warehouse. Group codes can be very flexible since there is no theoretical limit on the length of the code and the number of dimensions that it can be used to capture. However, practically speaking the group code should be of reasonable length so that it is not burdensome for users. Note that both letters and numbers can be used in group codes. The advantage of using letters is that each position has 26 options rather than just 10.
If letters are used, a coding system can be made mnemonic either in its entirety or in part. A mnemonic code is one that is suggestive of the item being coded. The two letter state codes used by the US Postal Service are an example of a mnemonic code: IN suggests Indiana, TX suggests Texas, and CA suggests California. In the part number group code described above, rather than using numbers, two meaningful letters could be used to indicate the division. For example, the letters NW could be used to suggest that the part belongs to the Northwest division. In summary, the choices for coding systems are sequence codes, block codes, and group codes. Group codes can be made mnemonic either in whole or in part such that the code itself is suggestive of what is being coded.
Some guidelines for designing coding schemes are as follows:
• Use numbers rather than letters whenever possible (numeric codes are easier to enter into a computer system)
• Allow for future expansion • Make the code as simple as possible
Let us now discuss the process of designing a coding scheme. Assume that your institution would like to devise a coding scheme for identifying students. Students can be in-state, out of state, or international students. Further, students can be either undergraduate or graduate students. The institution has about 10,000 students. There can be over a thousand students but less than 4000 students within each sub-category (e.g., in-state undergraduate, or international graduate).

Chapter 2: Elements of Information Systems
9 of 33
A block coding scheme could be devised for identifying students, as follows:
00001 - 04999 = in-state, undergraduate 05000 - 09999 = in-state, graduate 10000 - 14999 = out of state, undergraduate 15000 - 19999 = out of state, graduate 20000 - 24999 = out of state, international
Presumably, there cannot be an "in-state, international" category of students. Note that up to 5000 students can be accommodated within each category, thereby allowing room for expansion.
Group coding schemes can be either entirely numeric or alphanumeric. An alphanumeric group code would use letters. If the letters used are suggestive of the aspect of the item being coded, then the code would be referred to as a mnemonic group code. A numeric group coding scheme for identifying students follows:
Digit position Representation Values
1 In-state or out of state
1 = in-state
2 = out of state
2 Undergraduate, graduate, or international
1 = undergraduate
2 = graduate 3 = international
3 - 6 Specific student number 0001 to 9999
So student number 120875 would be an in-state graduate student, student number 231278 would be an out of state international student, and so on. In contrast to the numeric group coding scheme above, a mnemonic group coding scheme would use meaningful letters for each sub-category, as shown in the table on the next page:
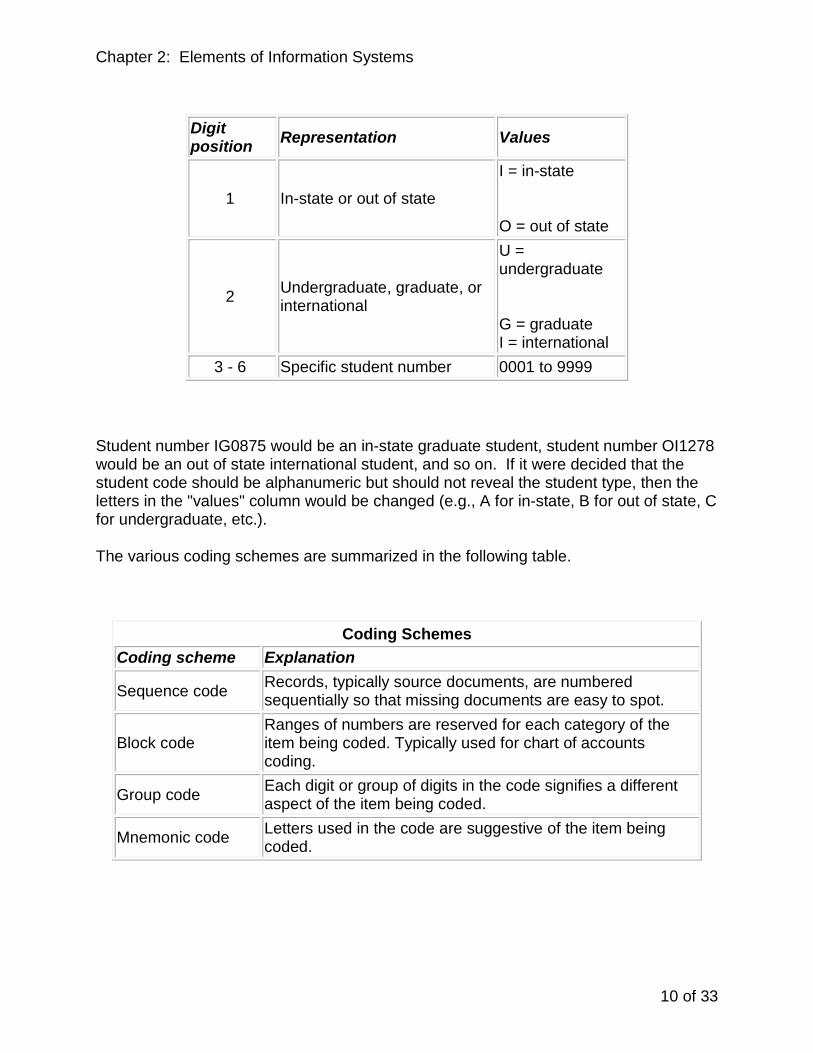
Chapter 2: Elements of Information Systems
10 of 33
Digit position Representation Values
1 In-state or out of state
I = in-state
O = out of state
2 Undergraduate, graduate, or international
U = undergraduate
G = graduate I = international
3 - 6 Specific student number 0001 to 9999
Student number IG0875 would be an in-state graduate student, student number OI1278 would be an out of state international student, and so on. If it were decided that the student code should be alphanumeric but should not reveal the student type, then the letters in the "values" column would be changed (e.g., A for in-state, B for out of state, C for undergraduate, etc.).
The various coding schemes are summarized in the following table.
Coding Schemes Coding scheme Explanation
Sequence code Records, typically source documents, are numbered sequentially so that missing documents are easy to spot.
Block code Ranges of numbers are reserved for each category of the item being coded. Typically used for chart of accounts coding.
Group code Each digit or group of digits in the code signifies a different aspect of the item being coded.
Mnemonic code Letters used in the code are suggestive of the item being coded.

Chapter 2: Elements of Information Systems
11 of 33
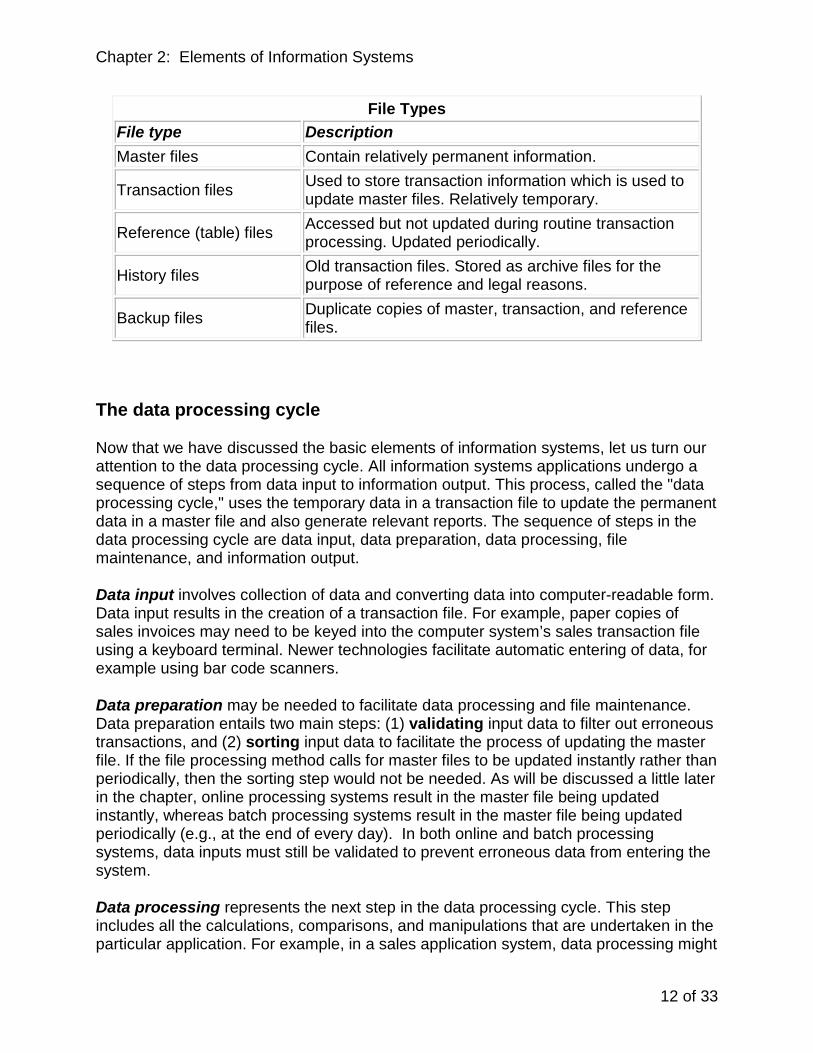
File types
Depending on the contents of a file, it can be classified under one of the following categories: master, transaction, reference or table, history, and backup. Master files contain relatively permanent information and are analogous to ledgers in a manual accounting system. Customer, employee, vendor, and inventory files are examples of master files.
Transaction files contain relatively temporary information and are analogous to journals in a manual accounting system. Sales, purchases, payroll vouchers, and cash receipts are examples of transaction files. Just as journals are used to temporarily hold transaction information until they are eventually posted into ledgers, transaction files are also used to temporarily hold transaction-related information until the information can be used to update master files. Of course, transaction files are also valuable as stores of transaction information. Transaction files are frequently accessed to provide answers to a variety of questions posed by users at all levels in the organization. This process of using transaction file information to update the appropriate master files is called the file maintenance run and will be discussed later in the chapter.
Reference files, which are also called table files, are used to store relatively permanent information that is needed only for reference purposes during a file maintenance run. Tax tables and price list files are examples of reference files. These files can of course be updated periodically, but they are accessed only for reference purposes during the process of updating a master file. For example, in the file maintenance run to update the customer master file, in which the sales invoices transaction file would be used, a price list file might be accessed to verify the unit prices of items sold. However, during this process of updating the customer master file, the price list file would typically not be updated. Rather, the price list file would be updated in a separate procedure.
History files are old transaction and master files that are maintained only for reference purposes and for legal reasons. An example of a history file would be the file containing July 2003 sales invoices. These files are usually maintained off line as archive files. That is, they are stored using inexpensive storage media such as tapes and cannot be instantaneously accessed. Presumably, there is little need to access the July 2003 sales file in the year 2008.
The last file type is backup files. As the name suggests, backup files are duplicate copies of transaction, master, and reference files. Since history files are typically maintained only for legal reasons, and since there is little danger of accidentally destroying history files, most organizations would typically not maintain backup copies of history files. It is a good practice to make frequent backups of all transaction and master files. Backup copies should be maintained on site as well as off site at a secure location.
The following table shows the various file types along with a brief description.
Chapter 2: Elements of Information Systems
12 of 33
File Types File type Description Master files Contain relatively permanent information.
Transaction files Used to store transaction information which is used to update master files. Relatively temporary.
Reference (table) files Accessed but not updated during routine transaction processing. Updated periodically.
History files Old transaction files. Stored as archive files for the purpose of reference and legal reasons.
Backup files Duplicate copies of master, transaction, and reference files.
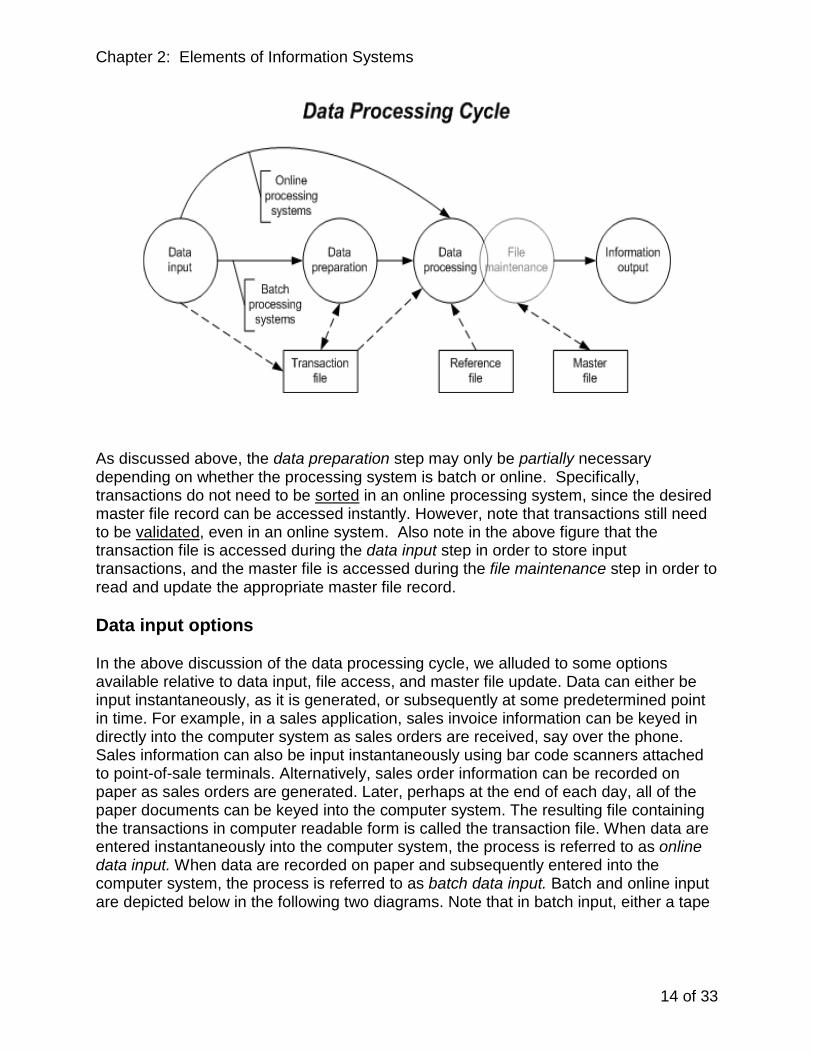
The data processing cycle
Now that we have discussed the basic elements of information systems, let us turn our attention to the data processing cycle. All information systems applications undergo a sequence of steps from data input to information output. This process, called the "data processing cycle," uses the temporary data in a transaction file to update the permanent data in a master file and also generate relevant reports. The sequence of steps in the data processing cycle are data input, data preparation, data processing, file maintenance, and information output.
Data input involves collection of data and converting data into computer-readable form. Data input results in the creation of a transaction file. For example, paper copies of sales invoices may need to be keyed into the computer system’s sales transaction file using a keyboard terminal. Newer technologies facilitate automatic entering of data, for example using bar code scanners.
Data preparation may be needed to facilitate data processing and file maintenance. Data preparation entails two main steps: (1) validating input data to filter out erroneous transactions, and (2) sorting input data to facilitate the process of updating the master file. If the file processing method calls for master files to be updated instantly rather than periodically, then the sorting step would not be needed. As will be discussed a little later in the chapter, online processing systems result in the master file being updated instantly, whereas batch processing systems result in the master file being updated periodically (e.g., at the end of every day). In both online and batch processing systems, data inputs must still be validated to prevent erroneous data from entering the system.
Data processing represents the next step in the data processing cycle. This step includes all the calculations, comparisons, and manipulations that are undertaken in the particular application. For example, in a sales application system, data processing might

Chapter 2: Elements of Information Systems
13 of 33
involve calculating the sales tax payable on each invoice. The data processing step takes a transaction file as input and may access a reference file.
File maintenance is the next step in the data processing cycle. This is the step where the master file is actually updated using transaction file data. There are three types of file maintenance activities: add, update, and delete. The add activity involves adding new master file records, for example adding a new customer to a customer master file. The update activity involves modifying an existing master file record. For example, a customer's address could be changed or the customer's balance may be updated to reflect new credit sales transactions. Specifically, customer balances will be increased for all customers who had credit sales transactions in a particular period. The delete activity involves deleting an existing master file record. Note that although the data preparation step filters the transaction file to detect erroneous transactions, some types of errors can be detected only at the file maintenance step. For example, if the customer's balance would exceed the credit limit if a credit sales transaction amount is added to the previous balance, then that transaction would have to be rejected. Such rejected transactions are stored in a "suspense file" to be dealt with subsequent to the file maintenance run. Although data processing and file maintenance are distinct steps in the data processing cycle, it should be noted that they are frequently combined into one data processing run.
Information output is the last step in the data processing cycle. This step is where reports are generated and output either on paper or on the user's computer screen. For example, in a sales application system, the information output step could result in the following reports: sales analysis report, salesperson performance report, product turnover analysis, and customer statements of account. Reports can either be routine scheduled reports that are always generated, demand reports that are generated only if specifically requested, or ad hoc custom reports that are designed to answer specific user questions. Depending on the type of data processing method employed, any of these types of reports can be instantly generated by the end user with little or no involvement of data processing personnel.
The steps in the data processing cycle, along with the types of files accessed at different stages, are shown in the following figure on the next page.
Chapter 2: Elements of Information Systems
14 of 33
As discussed above, the data preparation step may only be partially necessary depending on whether the processing system is batch or online. Specifically, transactions do not need to be sorted in an online processing system, since the desired master file record can be accessed instantly. However, note that transactions still need to be validated, even in an online system. Also note in the above figure that the transaction file is accessed during the data input step in order to store input transactions, and the master file is accessed during the file maintenance step in order to read and update the appropriate master file record.
Data input options
In the above discussion of the data processing cycle, we alluded to some options available relative to data input, file access, and master file update. Data can either be input instantaneously, as it is generated, or subsequently at some predetermined point in time. For example, in a sales application, sales invoice information can be keyed in directly into the computer system as sales orders are received, say over the phone. Sales information can also be input instantaneously using bar code scanners attached to point-of-sale terminals. Alternatively, sales order information can be recorded on paper as sales orders are generated. Later, perhaps at the end of each day, all of the paper documents can be keyed into the computer system. The resulting file containing the transactions in computer readable form is called the transaction file. When data are entered instantaneously into the computer system, the process is referred to as online data input. When data are recorded on paper and subsequently entered into the computer system, the process is referred to as batch data input. Batch and online input are depicted below in the following two diagrams. Note that in batch input, either a tape

Chapter 2: Elements of Information Systems
15 of 33
or a magnetic disk (“hard drive”) is used to store transaction records. In the case of online input, however, a magnetic disk device is invariably used.
File organization and access options
There are two primary methods of file organization and access: sequential and random. Sequential file organization means that the records in a file are stored in sequential order of the primary key. The records can be stored either in ascending or descending order. For example, an employee master file could be stored in ascending sequential order of the employee number primary key. The records must be accessed sequentially. That is, n-1 records must be traversed to access the nth record. When new records are to be added to a sequential file it is important to maintain the sequential order of all records (old and new combined). In effect, an entirely new file must be created, merging the new records with the old ones so that the correct sequential order is maintained.
Random files, or random access files, are also referred to as direct access files. Records in random files are scattered throughout the storage medium (usually a magnetic disk). Records are not stored in any particular physical order. A hashing routine is used to determine the storage location of records. The hashing routine takes the primary key of a record and applies some mathematical algorithm (formula) to generate a disk address for the record. To access a particular record, the hashing algorithm is applied to its primary key to determine its storage location. Thus, in a

Chapter 2: Elements of Information Systems
16 of 33
random access file, the nth record can be directly accessed without having to traverse n-1 records. Hashing algorithms are not perfect. It is possible that when the algorithm is applied for two records with different primary keys, the same disk address could be generated. Such duplicate disk addresses are referred to as clashes. That is, a "clash" occurs when a record is attempted to be written to a location that is already occupied. Such clashes are stored in an overflow area on the magnetic disk. When a clash occurs it is resolved by placing a pointer alongside the disk address that is already occupied. This pointer points to the overflow area location where the second record that generated the same disk address is stored.
A third option in file organization is the indexed file. File indexing involves the creation of an index that contains key values and associated storage locations (disk addresses) of records in a file. File indexing facilitates both sequential access and random access. For this reason, this method is often referred to as the indexed sequential access method (ISAM). To locate a particular record, the file index is first searched to obtain the storage location of the record and then the record itself is located on the disk. Note that the file index itself can be accessed and searched very quickly. However, locating a single record is slower in an indexed file relative to a purely random file because two accesses are required--one to the file index and a second to the actual disk location (in a purely random file only one access is needed--directly to the disk location using the hashing algorithm). To access all records in the file, for example to generate a sequential listing of the records, the file index is first accessed to obtain the first record's disk address and that record is accessed. Thereafter, each subsequent record is accessed in sequence by first looking up the index and then retrieving the record from the disk. However, this process is slower than in a purely sequential file organization since the index must be accessed after each record to determine the location of the next sequential record (in a purely sequential file the records are physically in sequence). Note also that indexed files are faster than random files when all records must be accessed because in a random file each record's location must be individually generated using the hashing algorithm. In sum, indexed files (1) permit both sequential and random access to a file, and (2) are faster than purely random files but slower than purely sequential files when all records must be accessed.
File update options
There are two options available regarding the periodicity of master file update. If batch data input is employed, then the master file can only be updated in batch mode. That is, the file maintenance run takes place at predetermined intervals such as at the end of every day. As indicated above, when data are input in batch mode, the transaction file is created. Thereafter, in the file maintenance step in the data processing cycle, all master file records are read and those records with corresponding records in the transaction file are updated to reflect transaction activity. Both the transaction file and the master file are organized sequentially. Batch processing to update the master file is depicted in the following diagram. Note that all files are on magnetic tape. The transaction file must undergo the data preparation step of sorting and editing. The transaction file must be sorted in order of the primary key of the master file. For example, in a batch processing
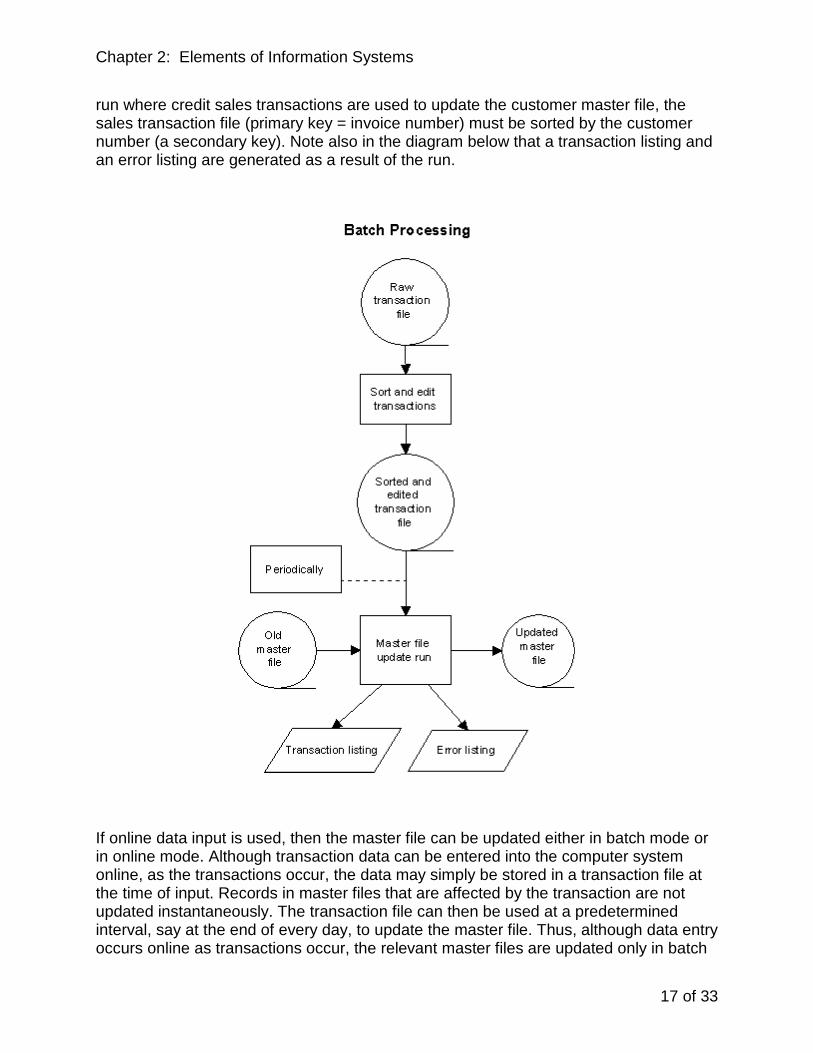
Chapter 2: Elements of Information Systems
17 of 33
run where credit sales transactions are used to update the customer master file, the sales transaction file (primary key = invoice number) must be sorted by the customer number (a secondary key). Note also in the diagram below that a transaction listing and an error listing are generated as a result of the run.
If online data input is used, then the master file can be updated either in batch mode or in online mode. Although transaction data can be entered into the computer system online, as the transactions occur, the data may simply be stored in a transaction file at the time of input. Records in master files that are affected by the transaction are not updated instantaneously. The transaction file can then be used at a predetermined interval, say at the end of every day, to update the master file. Thus, although data entry occurs online as transactions occur, the relevant master files are updated only in batch
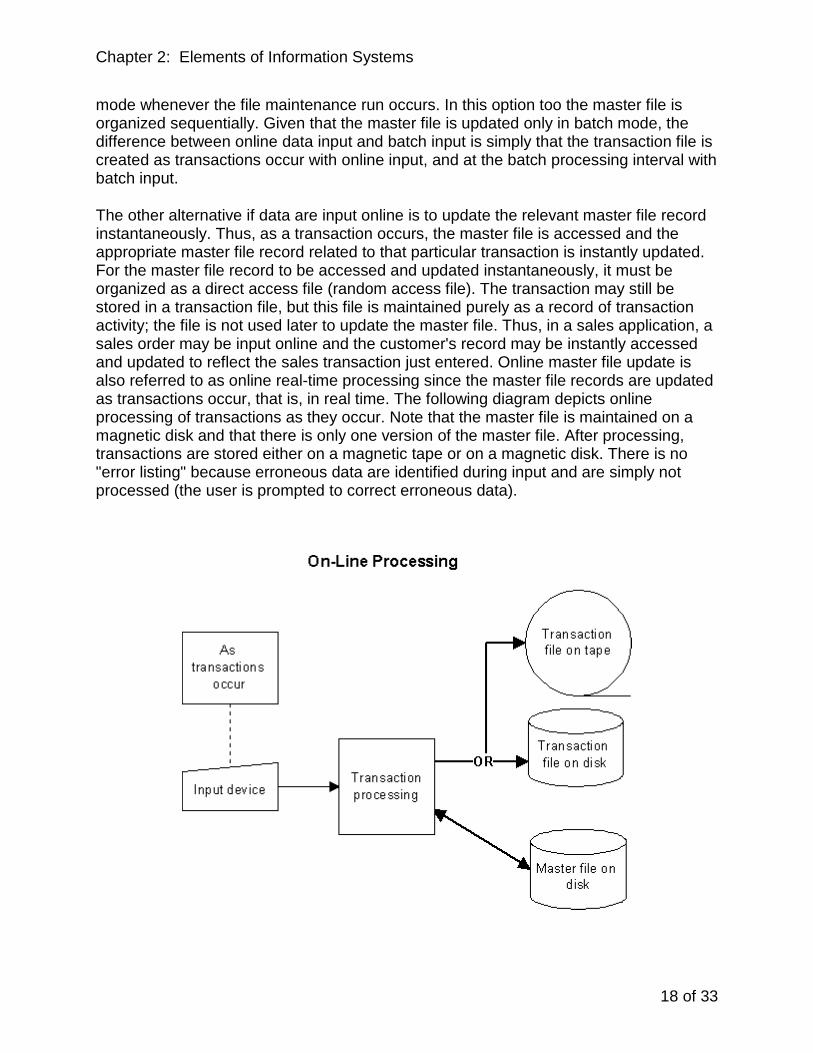
Chapter 2: Elements of Information Systems
18 of 33
mode whenever the file maintenance run occurs. In this option too the master file is organized sequentially. Given that the master file is updated only in batch mode, the difference between online data input and batch input is simply that the transaction file is created as transactions occur with online input, and at the batch processing interval with batch input.
The other alternative if data are input online is to update the relevant master file record instantaneously. Thus, as a transaction occurs, the master file is accessed and the appropriate master file record related to that particular transaction is instantly updated. For the master file record to be accessed and updated instantaneously, it must be organized as a direct access file (random access file). The transaction may still be stored in a transaction file, but this file is maintained purely as a record of transaction activity; the file is not used later to update the master file. Thus, in a sales application, a sales order may be input online and the customer's record may be instantly accessed and updated to reflect the sales transaction just entered. Online master file update is also referred to as online real-time processing since the master file records are updated as transactions occur, that is, in real time. The following diagram depicts online processing of transactions as they occur. Note that the master file is maintained on a magnetic disk and that there is only one version of the master file. After processing, transactions are stored either on a magnetic tape or on a magnetic disk. There is no "error listing" because erroneous data are identified during input and are simply not processed (the user is prompted to correct erroneous data).

Chapter 2: Elements of Information Systems
19 of 33
The following table presents the possible combinations of data input and master-file update for the batch and online options. Note that the only combination that is not possible is batch data input with online master file update. It is possible to have online data input combined with batch master file update. The more common combinations, of course, would be batch data input combined with batch master file update and online data input combined with online master file update.
Batch versus online: A comparison
In deciding between batch and online data input and master file update, the tradeoff to consider is between efficiency and timeliness. If transactions occur sporadically, as is likely for many organizations, then batch input is more efficient because data are converted into computer readable form all at once in one operation. Online input is less efficient if transactions occur sporadically since the data entry operators will remain idle during times when transactions are not occurring. Note also that batch input and update typically requires a separate data preparation step to sort and edit the data (recall the data processing cycle discussed earlier). In contrast, online input and update does not require a separate data preparation step; transactions are simply processed as they are entered. Note that transaction inputs will still need to be edited (or validated) in an online system; it is only the sorting step that is eliminated.
Let us now turn to timeliness. Online data input facilitates instantaneous updating of the master file. With batch input, the master file can only be updated periodically. In some instances, the periodic nature of the update process is preferable because of the greater control over the file update process. Care can be taken to ensure that transactions being used to update the master file during the periodic batch processing run are in fact all valid transactions. As already noted, a separate "edit run" detects errors in the transaction data file, and these erroneous transactions are excluded from the file maintenance run. However, when the master file is updated only periodically, its records are not always up to date. Consider a sales and accounts receivable application in which the customer master file is updated in batch mode at the end of every day.

Chapter 2: Elements of Information Systems
20 of 33
During the day the customer file will not reflect the correct customer balances to the extent that sales and collections transactions would have occurred but would not be used to update the appropriate master file records until the end of the day. In contrast, if sales transactions are entered online and the master file is updated as transactions occur, then the customer file would always reflect the current balance of each customer. Given that timeliness of information is becoming increasingly critical, online data entry and instantaneous master file update is the preferred option for most organizations. Moreover, decreasing hardware costs in recent years have made it cost effective for all but the smallest of organizations to use online data input combined with real time master file update. The following table compares and contrasts the relative advantages of batch and online file update options.
Comparison of batch versus online update Advantages of batch update Advantages of online update
More efficient use of computer system and personnel when transactions occur sporadically.
Master file always up to date.
More control over input and processing of transactions.
No separate data preparation step required; no need to sort transactions.
Faster access to master file data because of the use of magnetic disks for storage.
The Systems Approach
Now that we have defined and discussed a number of elements of information systems, let us explore how these various elements or components all fit together. Every system, including an information system, has an objective, one or more components, constraints within which it must operate, and a boundary separating it from its environment. The systems approach is a way of thinking about an information system and how its components interact with one another. The approach involves taking a holistic view such that the system is seen as more than just the sum of its parts. Problems, constraints, and potential solutions are examined from the entire system's point of view and not just at the subsystem or component level. One way to embrace the systems approach is through the "General Systems Model." This model defines a system as a set of elements that operate together to achieve some objective. For example, a system might be an amoeba, your family cat, an automobile, or the planet earth. For our purposes we like to think about systems from an

Chapter 2: Elements of Information Systems
21 of 33
information perspective. That is, let's focus on those systems inside organizations that take data and generate information useful for decision-making.
From the General Systems Model perspective, a system has inputs, process(es), outputs, a boundary, and operates in an environment.
Based upon an example involving sales on account, an accounting system has inputs (sales on account), processes these inputs in some way (journalize and post to the ledger accounts), and generates outputs (a trial balance and/or a set of financial statements). In addition, each system has a boundary, and the boundary defines what is contained inside the system (i.e., the processing of sales). Each system operates in an environment. The environment is what is outside the system (i.e., the remaining parts of the accounting system or generally other systems in the business organization).

Chapter 2: Elements of Information Systems
22 of 33
If the process inside a system is not understood, the system is termed a "black box." For a system at this level, the inputs and outputs are known, but exactly what occurs inside the system is unknown to the interested party. You may have heard one of your friends describe something as a "black box." What your friend is really saying is that they don't really understand what is going on about a particular issue.
Developing an understanding of what a system actually does is a critical endeavor. Let's assume that you were visiting a local business and you were attempting to understand how accounting transactions were recorded. How would you begin to develop such an understanding? The most logical way in which this could be accomplished is to divide a larger system into smaller parts. This process is known as factoring. The factored parts are known as subsystems and generally form hierarchical structures. The difficulty with factoring is that the number of interconnections between these subsystems, known as interfaces, increases rapidly. Each interconnection or interface is essentially a communication channel between each sub-system. In order to fully understand each sub-system, you must know what data (inputs or outputs) is being passed across the interconnection or channel. In the diagram on the next page, notice that the accounting system can be factored into a number of sub-systems (cycles) and each sub-system (cycle) can be further factored. In addition, each line connecting a sub-system is an interface. However, note that due to the hierarchical nature of accounting sub-systems, not all sub-systems will have interfaces between them.

Chapter 2: Elements of Information Systems
23 of 33
The general rule for specifying the number of interconnections (I) is the following relationship.
I = [(ns)*(ns-1)] / 2
Where ns = the number of subsystems.
Thus if we had four subsystems, there would be six possible interconnections. This would be calculated as follows:
I = [(4)*(4-1)] / 2
I = 6
We can also see the interconnection among four sub-systems graphically. Count them.

Chapter 2: Elements of Information Systems
24 of 33
With even ten subsystems, the number of interconnections becomes
I = [(10)*(10-1)] / 2
I = 45
Thus, the number of interconnections can escalate very rapidly.
Fortunately, as indicated earlier, not all the subsystems that make up a whole are necessarily connected, given the hierarchical nature of sub-systems discussed above. On the other hand, if we seek an understanding of a collection of available subsystems, there are two ways in which this can be accomplished. First, sub-systems can be clustered. In this way, we can group closely related subsystems and assume that there is a single interface. Second, we can ignore any weak interconnections. Some of these interconnections may not be important in our understanding of how a collection of sub-systems operates.
Another issue relating to systems is the notion of independence between related sub-systems. You may have read about a strike at a GM brake plant in Ohio a while ago. Because of the tightly connected operating plants (systems) at GM, this strike caused many GM assembly plants to shut down in a matter of days. Because GM and many other business organizations have embraced "just in time" inventories, the impact of a problem in one sub-system is quickly felt in the rest of the system. Manufacturers have for a long time used inventories to decouple sub-systems allowing these subsystems to operate independently of one another. Random access memory (RAM) is used as a buffer to allow the decoupling of computers from peripheral devices like laser printers, which operate much slower than computers. The loosening of connections between systems is called decoupling. Another way that business organizations decouple systems is to build extra (slack) capacity into their production facilities. However,
Chapter 2: Elements of Information Systems
25 of 33
decoupling systems comes at a price. Holding inventories, providing extra RAM in your personal computer, or providing extra capacity in a production facility has an associated cost. Therefore, the potential gains from decoupling (increased flexibility) must be weighed against the cost of the decoupling mechanism.
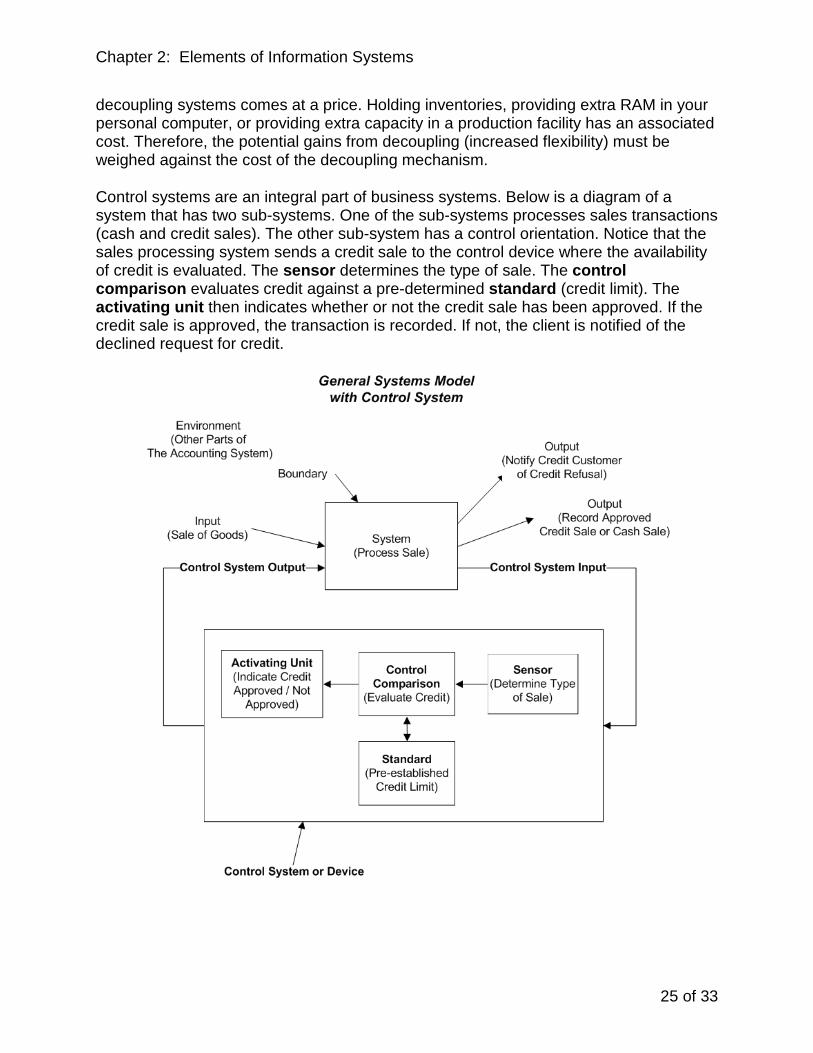
Control systems are an integral part of business systems. Below is a diagram of a system that has two sub-systems. One of the sub-systems processes sales transactions (cash and credit sales). The other sub-system has a control orientation. Notice that the sales processing system sends a credit sale to the control device where the availability of credit is evaluated. The sensor determines the type of sale. The control comparison evaluates credit against a pre-determined standard (credit limit). The activating unit then indicates whether or not the credit sale has been approved. If the credit sale is approved, the transaction is recorded. If not, the client is notified of the declined request for credit.

Chapter 2: Elements of Information Systems
26 of 33
Business control systems typically involve both man and machines under man's control. These man/machine systems typically tend to be subject to random disturbances, which are usually associated with humans. Ideally, for each way in which a system can get out of control, the control system provides for a corresponding control state. This is called the "Law of Requisite Variety." Realistically, the ability to adhere strictly to this law is nearly impossible. What is desired is a balance between controlling everything and controlling nothing. As you might suspect, what we are seeking is a balance between the horrendous cost of controlling everything and the reasonable cost of controlling high risk, high exposure events with which we are most concerned.
In summary, the systems approach involves taking a broad viewpoint and avoiding the pitfall of attempting to optimize each subsystem individually. Frequently, when a designer changes the features of a single subsystem in isolation, the result may have undesirable consequences on other subsystems through the interaction of the changed subsystem with other subsystems. The advantage of taking a macro view of the system as a whole is that inputs, processing procedures, controls, and information reports are located in the most appropriate subsystem. The resulting information system is a tightly coupled set of subsystems that are all logically interrelated.

Chapter 2: Elements of Information Systems
27 of 33
Summary
This chapter began by drawing a distinction between data and information. Data are unprocessed facts, whereas information represents data made meaningful through processing. The hierarchy of data from bits and bytes to files and databases was then presented. Alternative field formats such as text, numeric, and currency were discussed. Various record keys such as primary and secondary keys were then described. Coding systems including sequence, block, and group codes were explained. Mnemonic codes, which make codes suggestive of the item being coded, were also discussed. The various file types such as transaction, master, reference, history, and backup files were then described. The data processing cycle was then presented. The five steps in the data processing cycle are data input, data preparation, data processing, file maintenance, and information output.
Alternative data input options such as batch and online were described. File organization and access methods were then discussed. The two primary file update options—batch versus online—were then compared and contrasted in terms of their relative advantages and disadvantages. The chapter concluded with a discussion of the systems approach which involves taking a holistic view of information systems such that it is seen as much more than just the sum of its parts.

Chapter 2: Elements of Information Systems
28 of 33
Key Terms • activating units • batch input • bits • black box • boundary • buffer • byte • character • composite (concatenated) key • control comparison • database • decoupling • environment • factoring • field • file • hashing routine • independence • indexed file • inputs • interfaces • non-key attribute • online input • outputs • overflow area • processes • random access files • record • sensor • sequential file organization • standard • subsystems

Chapter 2: Elements of Information Systems
29 of 33
Discussion Questions 1. Distinguish between data and information. 2. Explain the concept of the "information value chain." 3. What are the attributes of "good" information? 4. Briefly explain the hierarchy of data from the lowest to the highest level. 5. Briefly describe any three field formats. 6. Distinguish between primary and candidate keys. 7. Giving examples, explain the concept of a "composite" or "concatenated" key. 8. Distinguish between block, sequence, and group coding systems. 9. Why is a "mnemonic" coding system more user-friendly? Explain with examples. 10. Giving examples, distinguish between master and transaction files. 11. What is a reference file? Are reference files updated during routine transaction
processing? 12. Indicate the steps in the data processing cycle. 13. Compare and contrast batch input versus online input of transactions. 14. Distinguish between sequential, random, and indexed files. 15. Briefly explain the sequence of steps in batch processing of transactions. What
storage media are typically used in batch processing? 16. Briefly explain the sequence of steps in online processing of transactions. What
storage media are typically used in online processing? 17. Compare and contrast batch and online processing in terms of their relative
advantages and disadvantages. 18. Describe the components of the general systems model. 19. Describe the nature of a "Black Box." Provide an example of a "black box." 20. How do systems achieve independence? 21. Distinguish between buffers and inventories. How are these two concepts
similar? 22. Define and describe the components of a control system.

Chapter 2: Elements of Information Systems
30 of 33
Problems and Exercises 1. Listed below are a number of files. In parentheses following the file name is a listing of fields in the file. Also indicated is the purpose of each file
• (a) INVOICES (INVOICE-NUMBER, DATE, CUSTOMER-NUMBER, SALE-AMOUNT)
Used to record credit sales to customers.
• (b) STUDENTS (STUDENT-NUMBER, NAME, ADDRESS, MAJOR, SSN, STATE-OF-RESIDENCE)
Used to store information about students at a university.
• (c) CONTACTS (CUSTOMER-NUMBER, SALESPERSON-NUMBER, CONTACT-DATE, HOURS)
Used to record information about contacts between salespersons and customers. Each customer can be contacted by many salespersons, and each salesperson can contact many customers. There can be only one contact between a given customer and a given salesperson on a particular date.
• (d) VENDORS (VENDOR-NUMBER, NAME, ADDRESS, BALANCE, TAX-ID)
Used to store information about vendors.
Required: Identify primary, candidate, and composite keys in each file.
2. Brazos Valley Supplies would like you to develop a coding scheme for their chart of accounts. The coding scheme must distinguish between assets, liabilities, income, and expense accounts. Within each of these categories, the coding scheme must further distinguish between current and long term assets and liabilities, income from sales and other income, and operating expenses versus other expenses. There are currently about 400 accounts—approximately 100 each of asset, liability, income and expense accounts.
Required: Devise a group coding scheme for Brazos Valley Supplies' chart of accounts. The code should be mnemonic with respect to the account type (assets, liabilities, income, or expense) and also with respect to the category within each account type (e.g., current and long term assets). Show example codes for each account type and category.
3. The Howdy-Ags Corp. would like you to develop a coding scheme for their customers based on the following information. The company has a branch office to serve customers in each of the following regions: East, Northeast, Mid-Atlantic, West, South,

Chapter 2: Elements of Information Systems
31 of 33
Southeast, Midwest, Canada, and Mexico. In addition to the region, it is necessary to identify whether the customer is an in-state or an out-of state customer, since each branch office serves many states. It is also necessary to identify whether the customer is a government customer or a non-government customer. There are currently about 4000 customers.
Required: Devise (1) a numeric group coding scheme and (2) a block coding scheme for Howdy-Ags' customers. For each coding scheme, show an example code for a hypothetical customer.
4. From the description of each of the following files, indicate whether the file is a master file, transaction file, reference file, or history file.
• (a) Purchase orders for July 2006. • (b) Current sales invoice file. • (c) Employee file. • (d) File containing city and states for each U.S. zip code (used during processing
of sales orders). • (e) Current vendor file. • (f) Current payroll time tickets file. • (g) March 2007 payroll file. • (h) Finished goods inventory file.
5. For each of the following activities, indicate the stage in the data processing cycle in which the activity would be undertaken.
• (a) updating the customer's balance to reflect a new credit sales transaction • (b) generating a sales analysis report • (c) sorting purchase order transactions by vendor number • (d) calculating sales tax for a sales transaction • (e) entering cash collection data into the system • (f) checking a batch of sales transactions to ensure that all fields have been
entered • (g) changing a vendor's address • (h) calculating the F.I.C.A. amount on a payroll voucher • (i) deleting a finished goods inventory item from the file • (j) scanning grocery items at the check out counter
6. PartsWorld is a specialty auto parts store. Orders for auto supplies are received over the phone from service stations in the city and surrounding communities. A sales order slip is prepared when the order is received. At the end of the day, the sales orders are batched and processed. For each step in the data processing cycle, indicate the task(s) involved in processing PartsWorld's sales orders. Indicate all documents, files, and reports that would be generated as appropriate.
• Data input

Chapter 2: Elements of Information Systems
32 of 33
• Data preparation • Data processing • File maintenance • Information output
7. Indicate the type of file organization and access method that would be most appropriate for each of the following files, given the description of its usage pattern.
• (a) a customer file which needs to be accessed at the end of each day to process the day's batch of sales transactions.
• (b) an employee file which is accessed throughout the day to obtain employees' office and phone number, but which is also used every Friday for the payroll batch processing run.
• (c) a finished goods inventory file accessed during processing of sales orders that are entered as customers call in their orders over the phone.
• (d) a vendor file used to process batches of purchase orders twice a day. • (e) a student file accessed sporadically during the day to answer student related
queries from departmental advisors and which is also used to process fee statements and other routine mailings on a weekly basis.
8. Draw a diagram of the general systems model. Make sure each component of the model is labeled clearly.
9. The number of interconnections between subsystems can escalate rapidly. Calculate the number of interconnections assuming you have
• five subsystems • ten subsystems • fifteen subsystems • twenty-five subsystems
10. Bloomington Convalescent Center is a non-profit organization that cares for individuals that are in need of non-critical extended care. The stay in the convalescent center can be either long term or short term. An individual admitted to the Center has to have an attending physician. The attending physician consults with the Center's medical staff in specifying what type of medical treatments are to be administered.
The Center is headed by an administrator. This individual is responsible to the board of directors for the day to day running of the Center. The Center has the following functions:
• An accounting function headed by a controller. The accounting function tends to the financial reporting needs of the Center, reimbursements from Medicare and Medicaid intermediaries, and payroll preparation and reporting.
• Purchasing function • Physical Plant

Chapter 2: Elements of Information Systems
33 of 33
• Food Preparation • Physical Therapy
The medical staff of the Center consists of Registered Nurses, Licensed Practical Nurses, and Staff Assistants. The staff assistants are the primary care givers in the center. An individual can be either classified as a Medicare, Medicaid, or private pay patient. Individuals are billed on a monthly basis by the accounting function. In addition to earning revenues from basic patient care, the center also earns a significant amount of revenue from physical therapy. The Center has also contracted to provide hot meals seven days a week to the local "Meals on Wheels" organization.
Required: Identify all the major systems that are a part of the Bloomington Convalescent Center. To the extent possible identify the inputs, processing, outputs, and linkages between systems.
11. Len Graham is considering purchasing a brand new Corvette Hardtop at Dan Young Chevrolet. He wants to purchase the car loaded with all the options. He currently owns a loaded 2004 Toyota Camry V-6 with 45,000 miles. Len lives in Indiana, and the used car manager at Dan Young has evaluated his Camry as “above average”. While Corvettes typically are sold at the factory sticker price, Dan Young has offered the Corvette at $500 over dealer invoice, but won't indicate to Len the exact invoice amount.
Required: Using information services found on the Web, what amount should Len offer Dan Young assuming that he plans to trade his Camry on the Corvette? Please prepare a detailed schedule in Excel that displays the amount Len should pay for the Corvette.
12. The Rudy Rose Corp. would like you to develop a coding scheme for sales order documents. Currently, Rudy Rose sells a variety of products to customers located in the following regions: East, South, Southeast, Midwest, West, and Canada. At present, 30 different products are sold. The number of products sold is likely to expand to some 200 in the next year. Fifty salespersons sell products for Rudy Rose, and there is a need to include a salesperson identifier in the sales order number.
Required: Devise a group coding scheme for the sales order at Rudy Rose. Use mnemonics where possible. Show an example code for a hypothetical customer.
Last updated: August 19, 2009
Copyright © 1996-2009 CyberText Publishing, Inc. All Rights Reserved
Related Documents











