Application performance and communication profiles of M3DC1_3D on NERSC babbage KNC with 16 MPI Ranks Thanh Phung, Intel TCAR Woo-Sun Yang, NERSC

Application performance and communication profiles of M3DC1_3D on NERSC babbage KNC with 16 MPI Ranks Thanh Phung, Intel TCAR Woo-Sun Yang, NERSC.
Jan 01, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Application performance and communication profiles of M3DC1_3D on NERSC babbage KNC with 16 MPI Ranks
Thanh Phung, Intel TCARWoo-Sun Yang, NERSC

M3DC1 performance and MPI communication profiling method
• Serial performance – Using Intel VTune – Hot functions– Vectorization and compilation options– Bandwidth– HW performance details: L1, L2, TLB misses, memory latency, …
• Parallel performance with MPI – MPI trace using Intel ITAC– Breakdown of performance Vs communication– Performance of all MPI calls – Messaging profile and statistics– Identify areas for improving communication performance
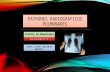
Overall performance summary with general-exploration metric: high CPI, low L1 cache hit ratio and average memory latency impact per cache misses, good VPU, not small L1 TLB miss ratio
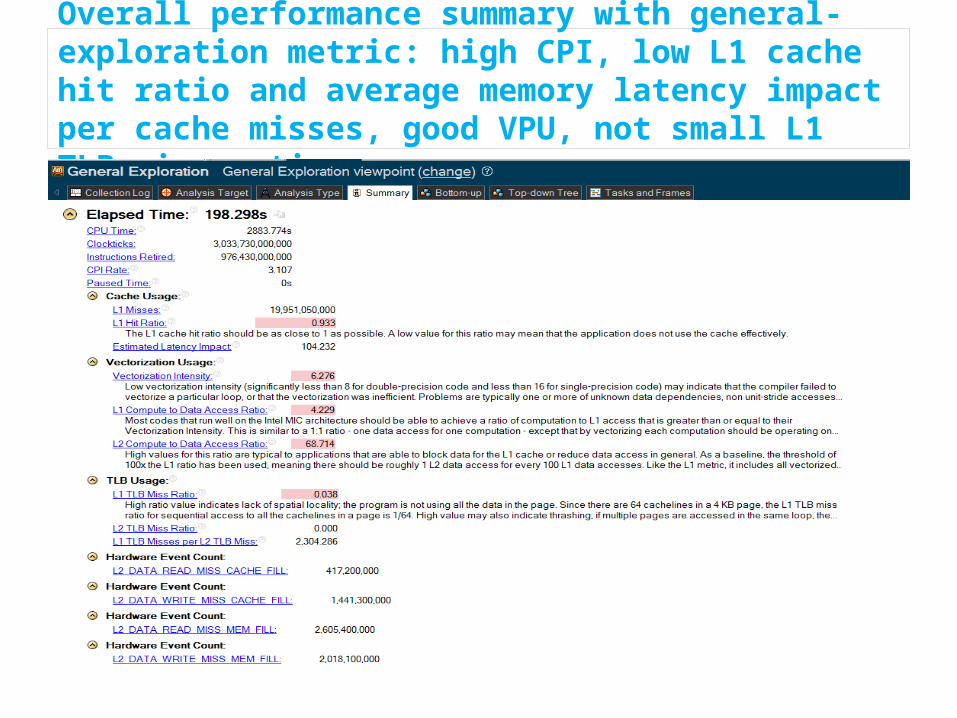
Load imbalance of 16 MPI ranks – could use binding all MPI ranks to physical cores to prevent process migration from core to core
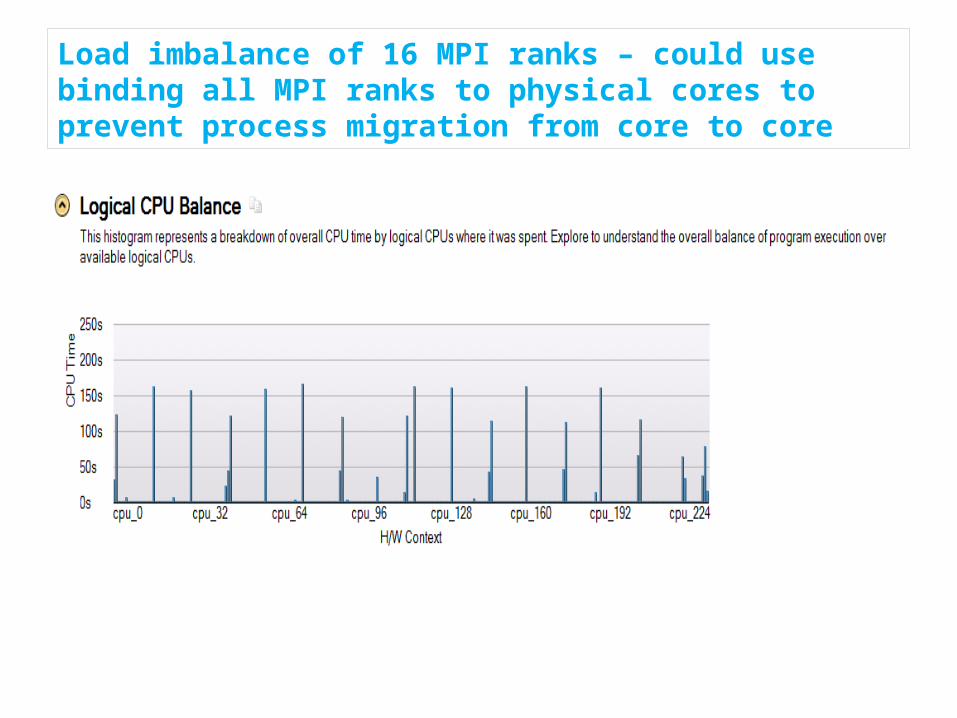
Core performance profile with general-exploration metric and VPU element active high lighted – small L1 and L2 data cache reuse
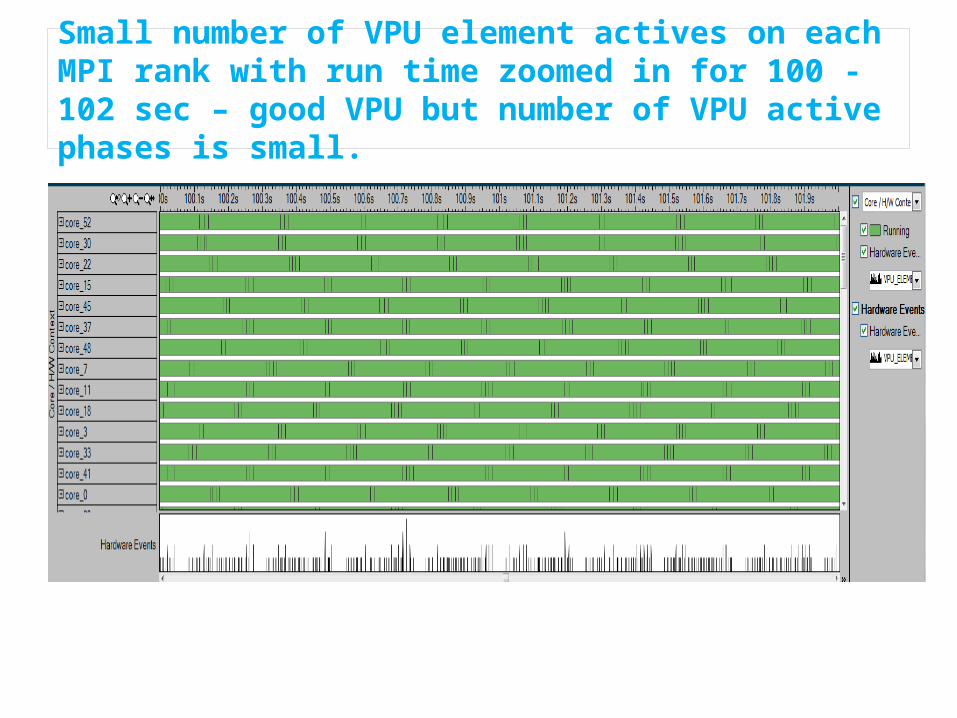
Small number of VPU element actives on each MPI rank with run time zoomed in for 100 -102 sec – good VPU but number of VPU active phases is small.
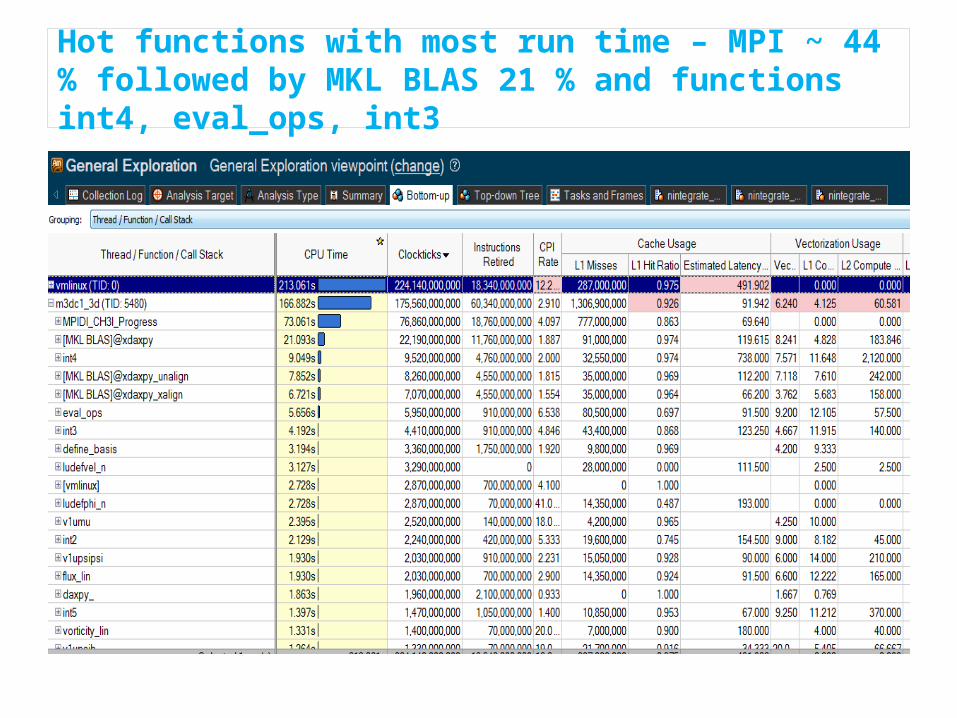
Hot functions with most run time – MPI ~ 44 % followed by MKL BLAS 21 % and functions int4, eval_ops, int3
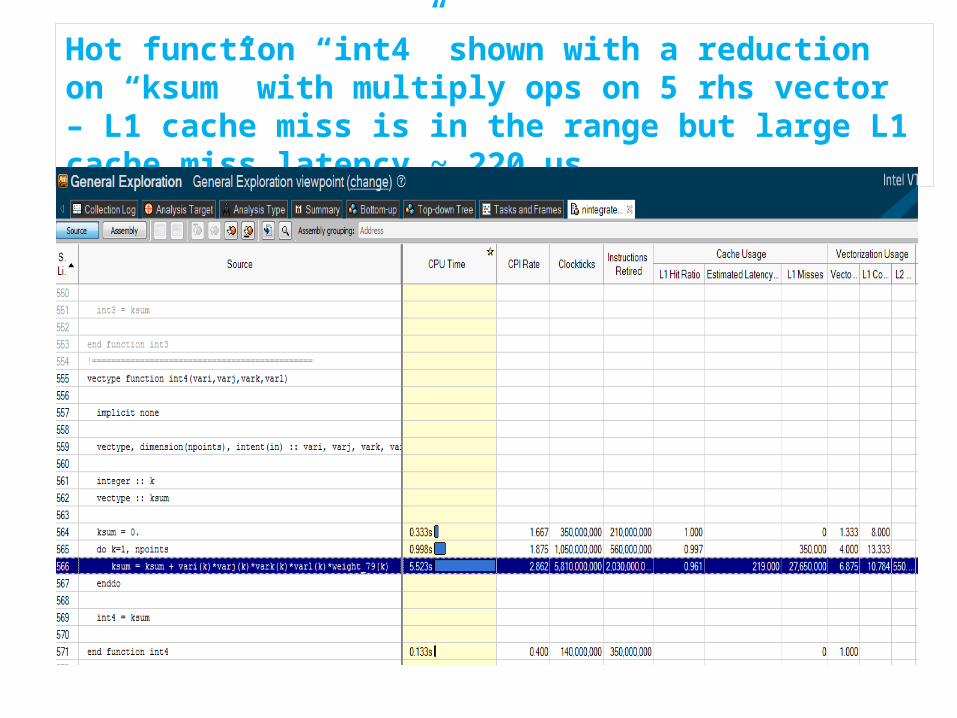
Hot function “int4” shown with a reduction on “ksum” with multiply ops on 5 rhs vector – L1 cache miss is in the range but large L1 cache miss latency ~ 220 us
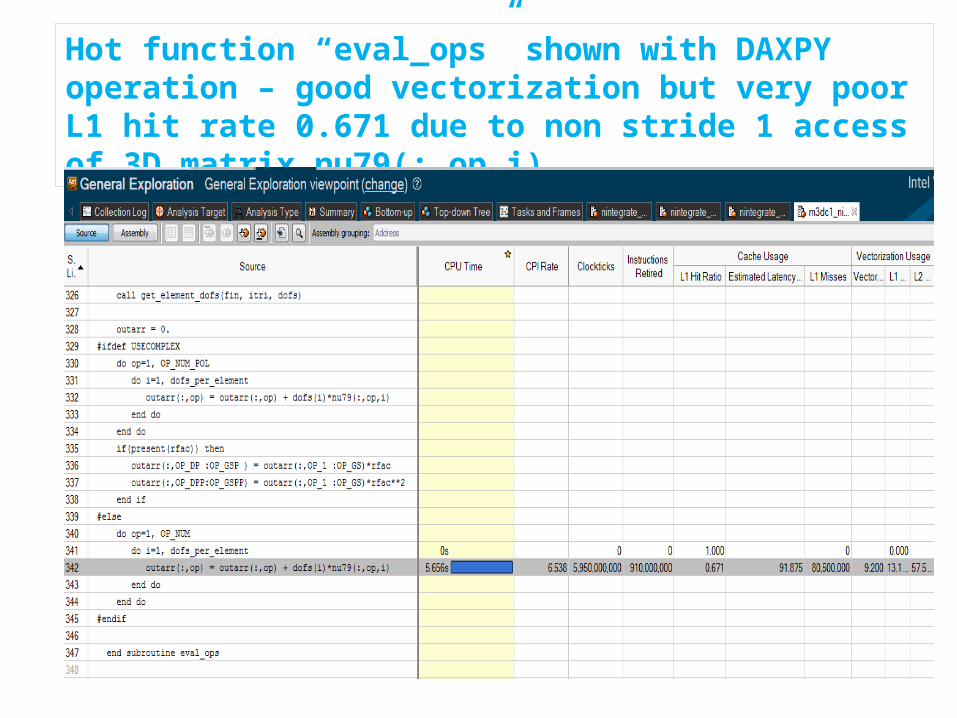
Hot function “eval_ops” shown with DAXPY operation – good vectorization but very poor L1 hit rate 0.671 due to non stride 1 access of 3D matrix nu79(:,op,i)
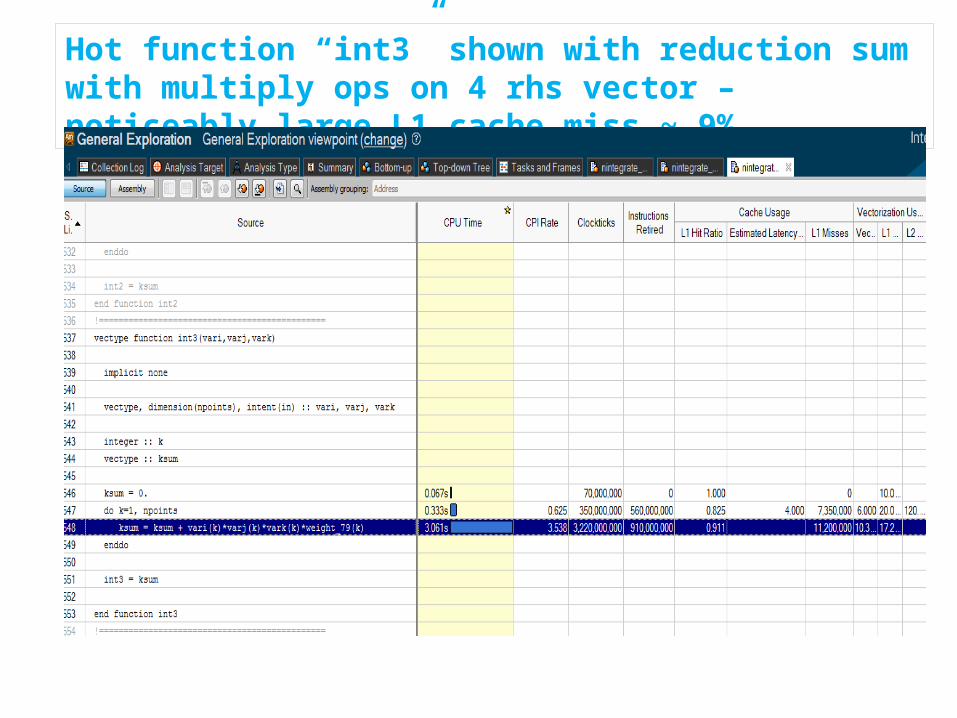
Hot function “int3” shown with reduction sum with multiply ops on 4 rhs vector – noticeably large L1 cache miss ~ 9%

Timing statistics, CPU loads of all 16 MPI ranks and time distribution of hot functions using “advanced-hotspots” metric (thread profiling) - overall CPU loads are very imbalance
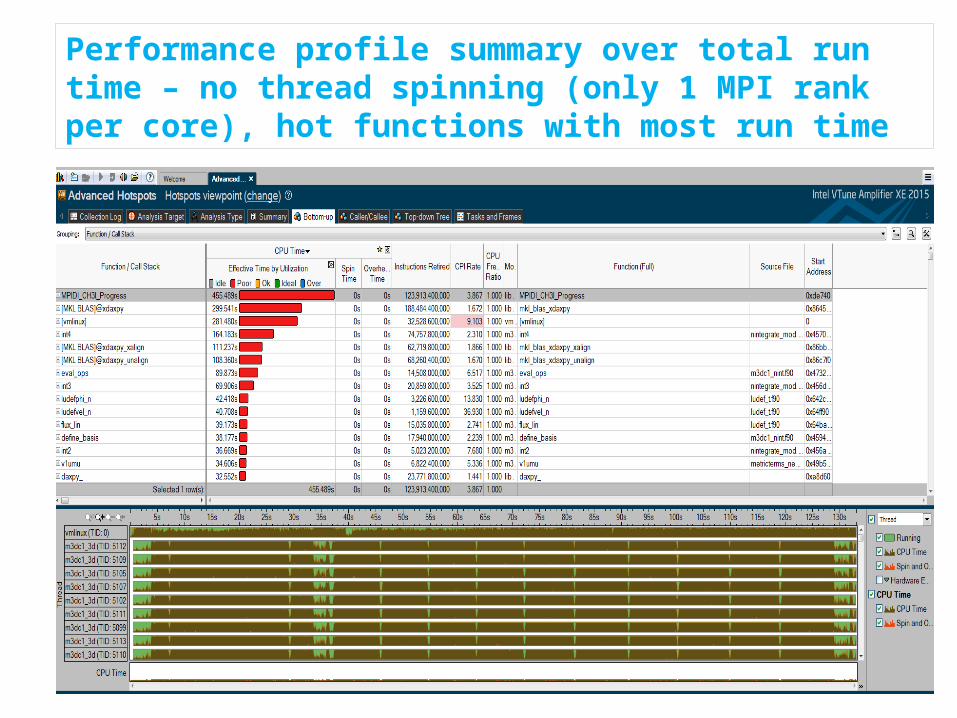
Performance profile summary over total run time – no thread spinning (only 1 MPI rank per core), hot functions with most run time
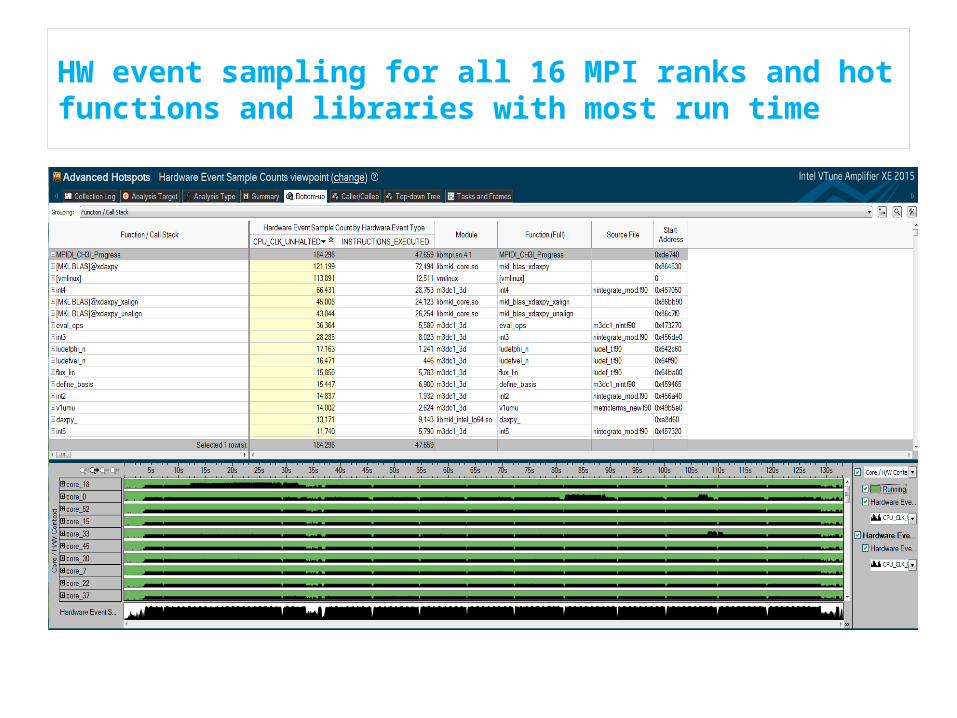
HW event sampling for all 16 MPI ranks and hot functions and libraries with most run time
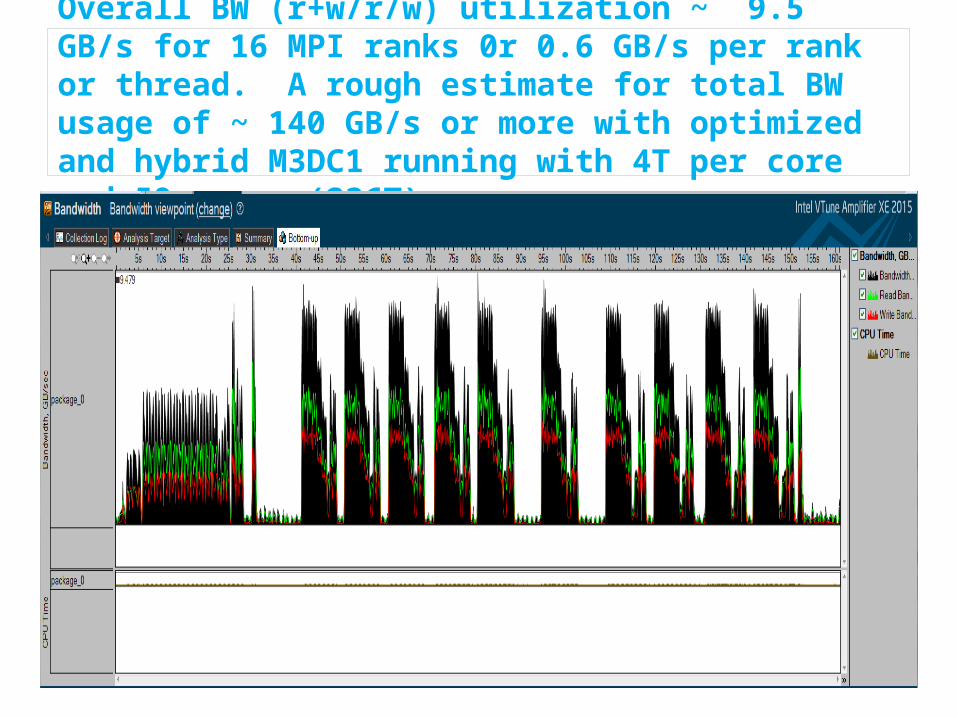
Overall BW (r+w/r/w) utilization ~ 9.5 GB/s for 16 MPI ranks 0r 0.6 GB/s per rank or thread. A rough estimate for total BW usage of ~ 140 GB/s or more with optimized and hybrid M3DC1 running with 4T per core and 59 cores (236T)

Communication profile and statistics: MPI tracing using Intel
ITAC tool
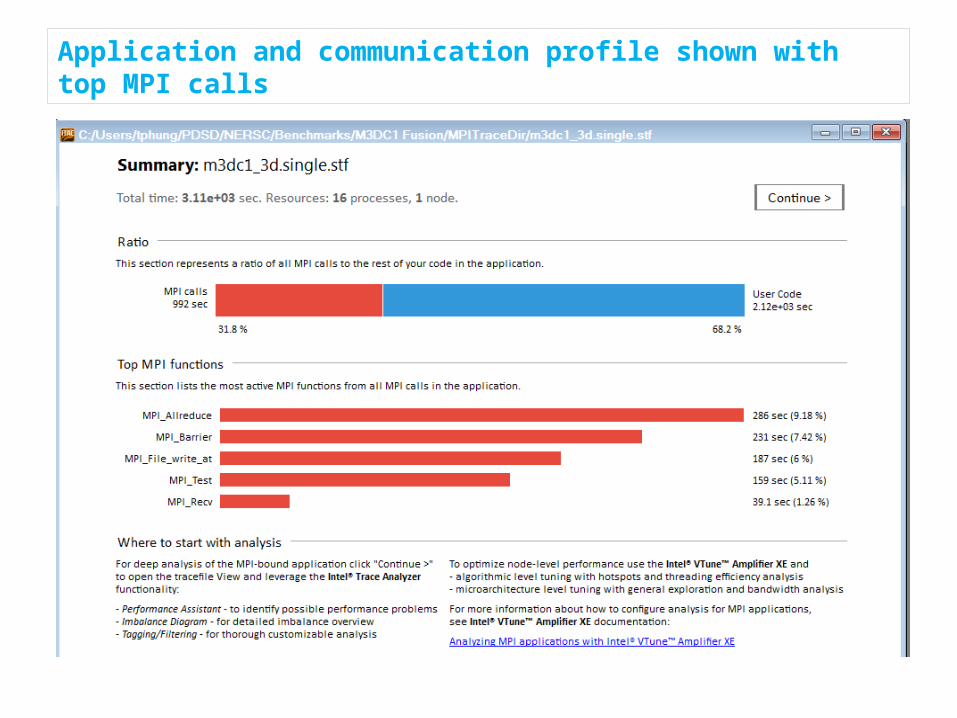
Application and communication profile shown with top MPI calls
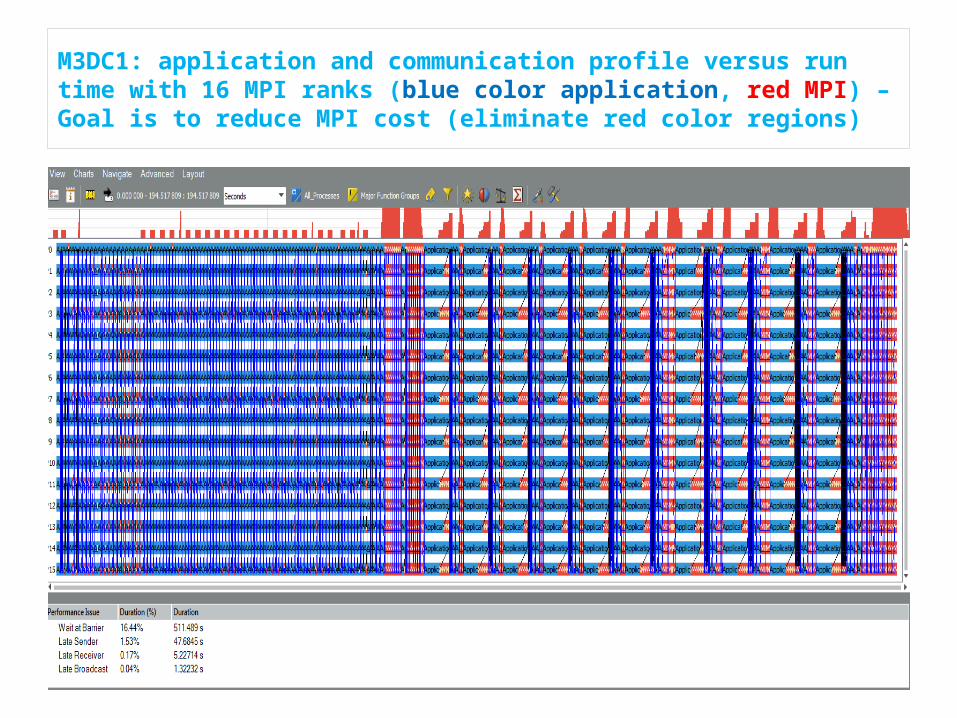
M3DC1: application and communication profile versus run time with 16 MPI ranks (blue color application, red MPI) – Goal is to reduce MPI cost (eliminate red color regions)
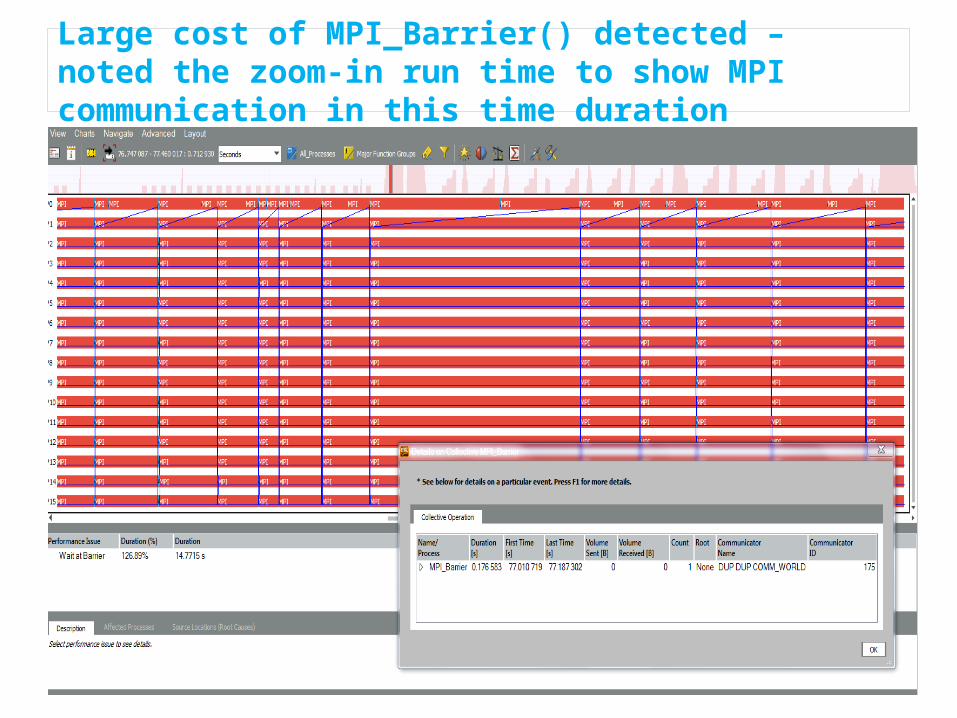
Large cost of MPI_Barrier() detected – noted the zoom-in run time to show MPI communication in this time duration
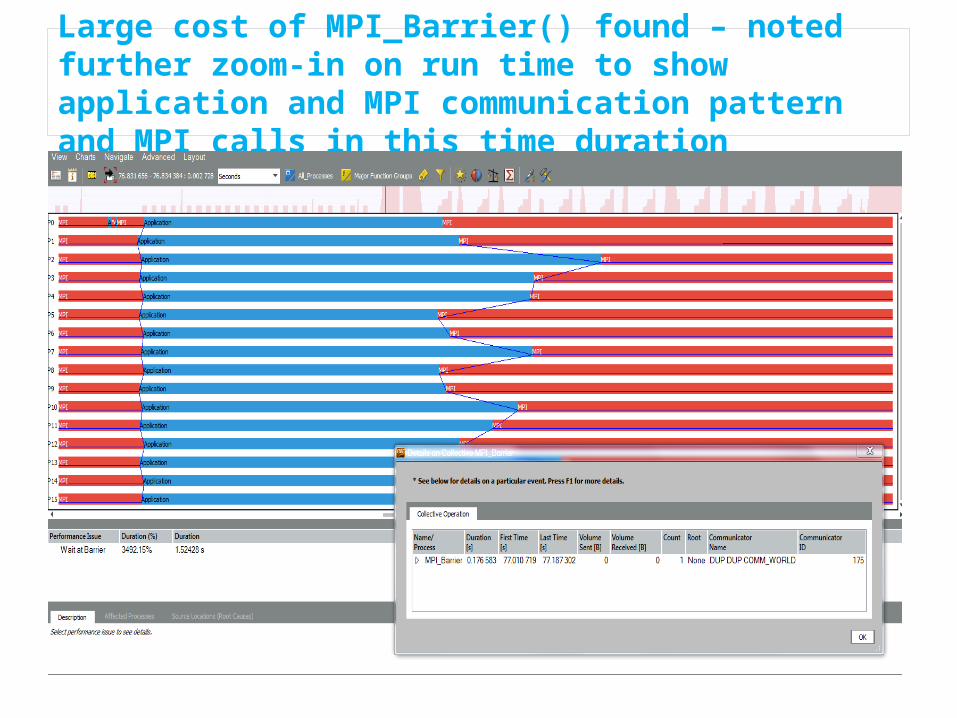
Large cost of MPI_Barrier() found – noted further zoom-in on run time to show application and MPI communication pattern and MPI calls in this time duration
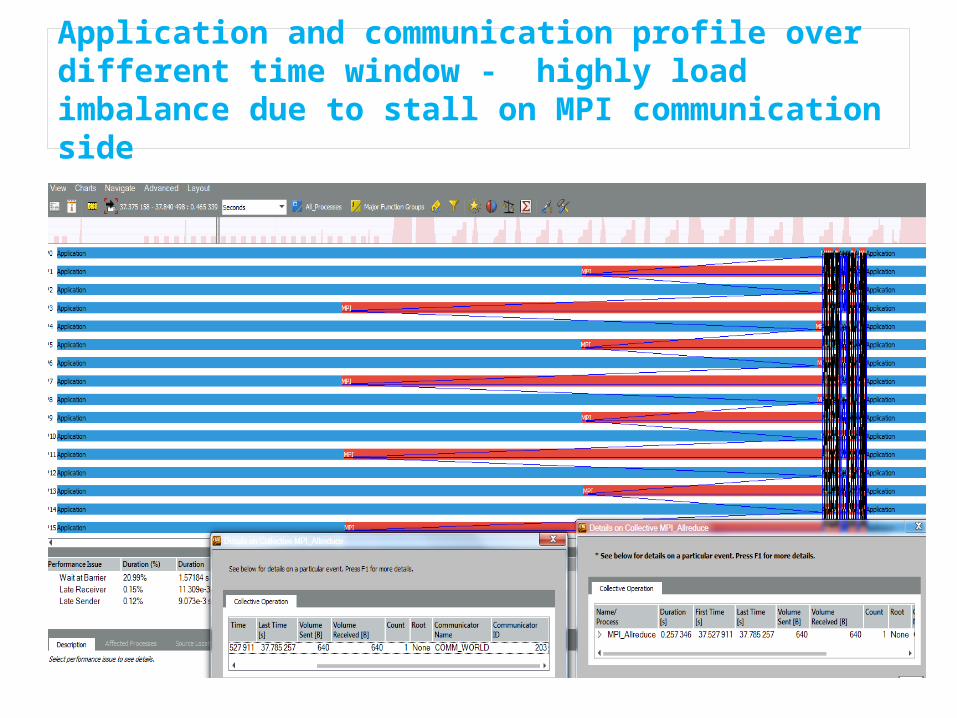
Application and communication profile over different time window - highly load imbalance due to stall on MPI communication side

Details of all MPI calls with MPI_Iprobe(), MPI_Test() before MPI_Recv() and MPI_Issend(), --- large communication cost
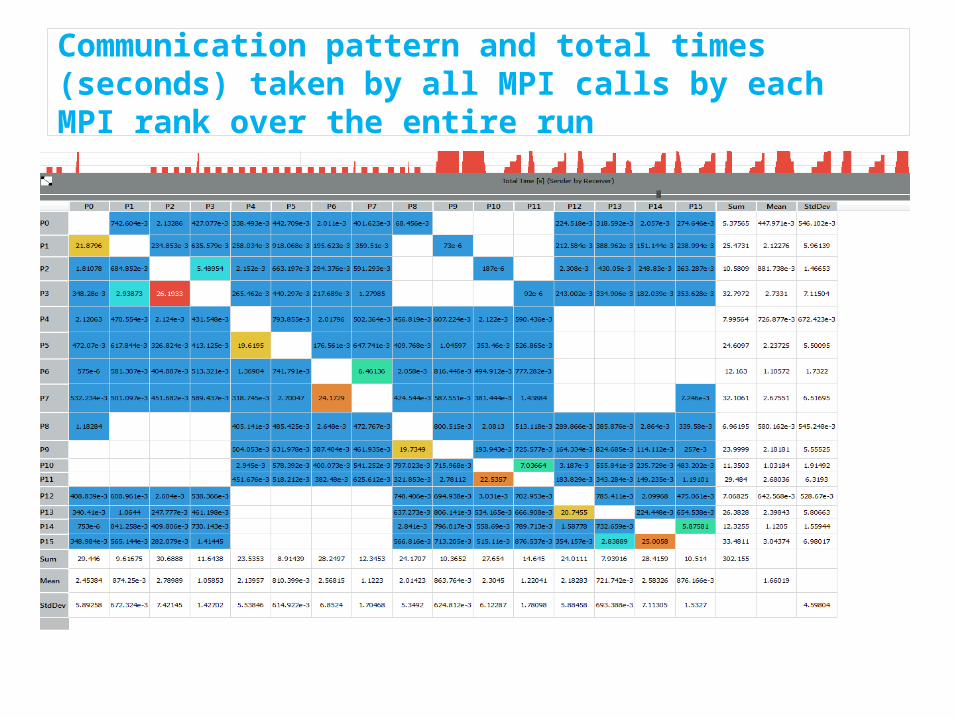
Communication pattern and total times (seconds) taken by all MPI calls by each MPI rank over the entire run

Communication pattern and volume of all messages (bytes) taken by all MPI calls by each MPI rank over the entire run
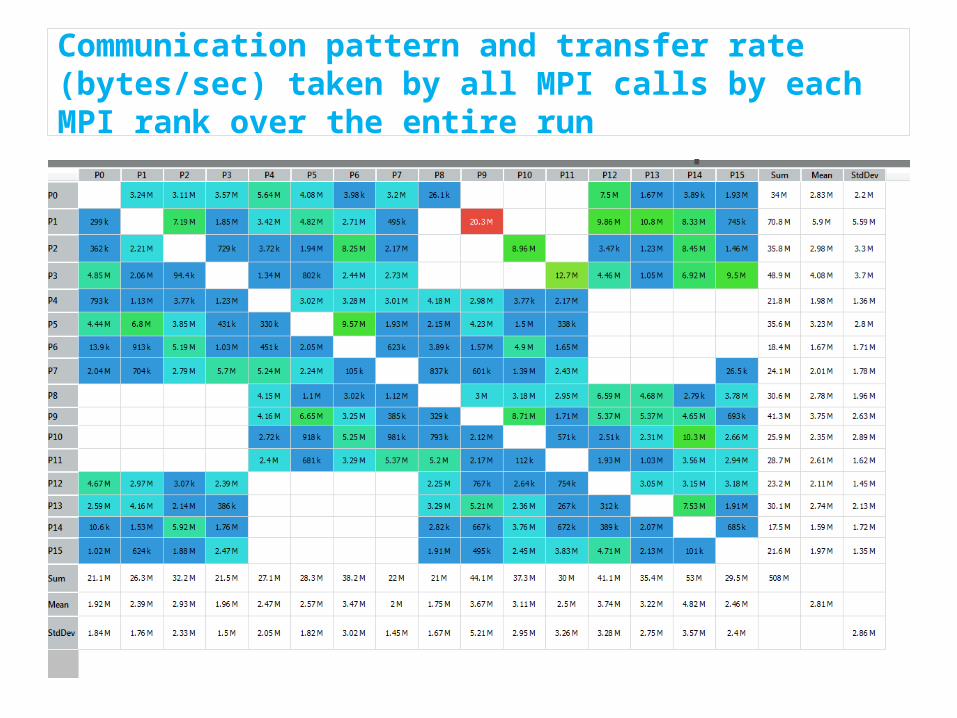
Communication pattern and transfer rate (bytes/sec) taken by all MPI calls by each MPI rank over the entire run
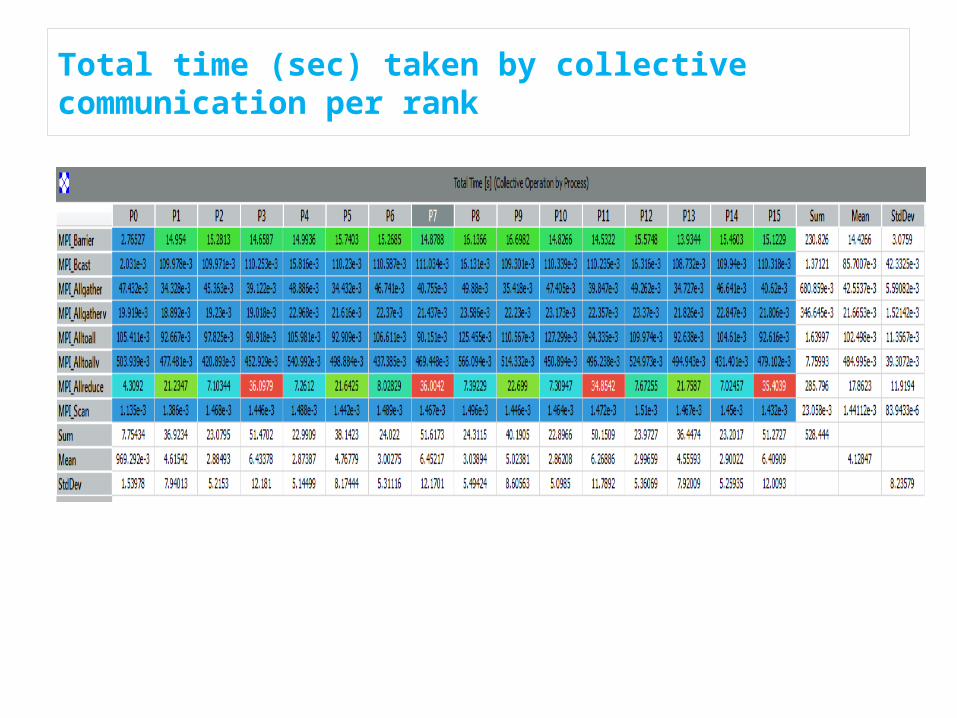
Total time (sec) taken by collective communication per rank

MPI calls, number of calls, time (sec) required for MPI calls

Performance summary and code tuning suggestions
• Overall serial performance on KNC:– Vectorizing is good (6 out of 8 as maximum VPU lanes)– Improve L1 cache hit ratio is a must
• Suggestions: interchange op and i index loop to improve access of 3D matrix nu79(:,op,i) at the smaller cost of vector dofs(i)
– The reduction sum found in the hot functions int4 and int3 using multiply ops on either 4 or 5 rhs vector can be further vectorized using ksumm(i) instead of just ksum and add extra reduction ksum loop over all ksumm(i)
– An estimate of overall BW usage shows M3DC1 will require more than 140 GB/s if we tune up the code, add hybrid MPI+OMP and running with 3 or 4T per core and all 59 cores
• Overall parallel performance with MPI:– Large MPI communication cost (32% of overall timing) due to probe, wait and collective calls that
blocking and/or synchronizing all MPI ranks– Need to schedule and post non-blocking (asynchronous) receiving/sending ahead and overlap with
computing avoiding blocking on the wait – Reduce number of collective calls if possible– On Xeon Phi like KNC/KNL, use hybrid programming with small number of MPI ranks (1 to 4) but
large number of OMP threads will make use of all HW threads per core and certainly improve parallel performance
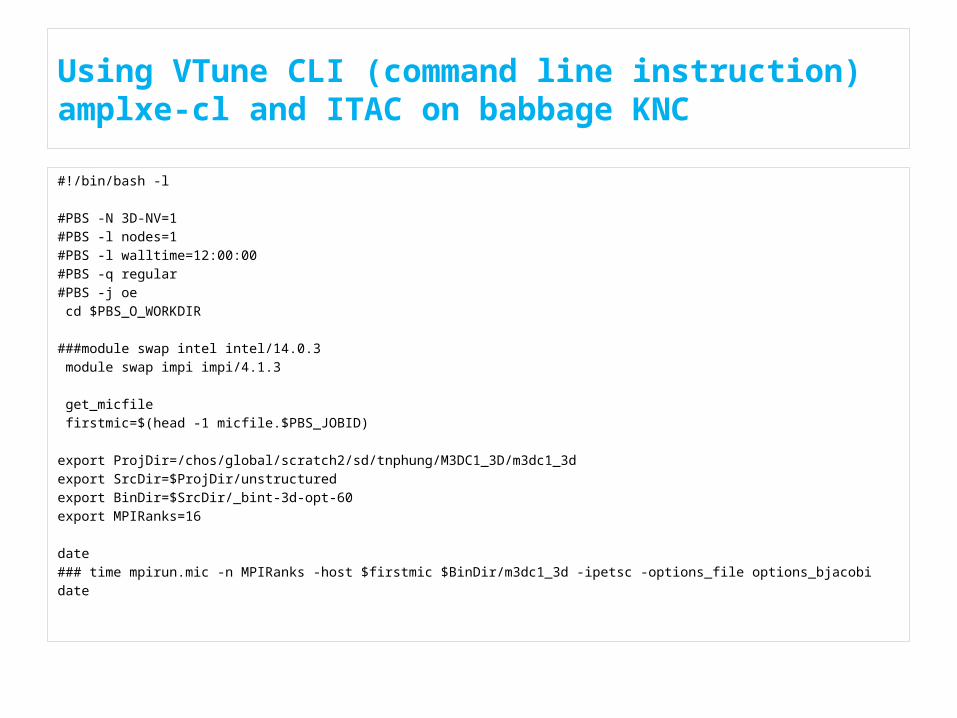
Using VTune CLI (command line instruction) amplxe-cl and ITAC on babbage KNC
#!/bin/bash -l
#PBS -N 3D-NV=1#PBS -l nodes=1#PBS -l walltime=12:00:00#PBS -q regular#PBS -j oe cd $PBS_O_WORKDIR
###module swap intel intel/14.0.3 module swap impi impi/4.1.3
get_micfile firstmic=$(head -1 micfile.$PBS_JOBID)
export ProjDir=/chos/global/scratch2/sd/tnphung/M3DC1_3D/m3dc1_3dexport SrcDir=$ProjDir/unstructuredexport BinDir=$SrcDir/_bint-3d-opt-60export MPIRanks=16
date### time mpirun.mic -n MPIRanks -host $firstmic $BinDir/m3dc1_3d -ipetsc -options_file options_bjacobidate

Using VTune CLI (command line instruction) amplxe-cl and ITAC on babbage KNC (continued)
module load vtune/2015.update2
export MPSSDir=/opt/mpss/3.4.1/sysroots/k1om-mpss-linux/lib64
### three choices for VTune preset metrics: general-exploration, bandwidth and advanced-hotspotsexport VTuneMetric=general-exploration
###three choices for VTune preset metrics: GeneralExploration, AdvancedHotSpots and BandWidthexport VTuneResultDir=$ProjDir/3D-NV=1/VTuneResultDir/GeneralExploration
date
### same CLI for both bandwidth and advanced-hotspots without any knobs option###echo 'Running amplxe-cl with ' $VTuneMetric
###amplxe-cl -collect $VTuneMetric -r $VTuneResultDir -target-system=mic-host-launch \### -source-search-dir $SrcDir \### -- mpirun.mic -n $MPIRanks -host $firstmic $BinDir/m3dc1_3d -ipetsc -options_file options_bjacobi
date

Using VTune CLI (command line instruction) amplxe-cl and ITAC on babbage KNC (continued)
date
###knobs are only for knc-general-exploration metric.###amplxe-cl -collect $VTuneMetric -r $VTuneResultDir \### -knob enable-vpu-metrics=true -knob enable-tlb-metrics=true \### -knob enable-l2-events=true -knob enable-cache-metrics=true \### -target-system=mic-host-launch -source-search-dir $SrcDir \### -- mpirun.mic -n $MPIRanks -host $firstmic $BinDir/m3dc1_3d -ipetsc -options_file options_bjacobi
date

Using VTune CLI (command line instruction) amplxe-cl and ITAC on babbage KNC (continued)
############################################################################################################################################################################################### ITAC FOR MPI TRACE SETTING ###############################################################################################################################################################################################
module load itac/8.1.update4
export VT_LOGFILE_FORMAT=stfsingleexport VT_LOGFILE_PREFIX=$ProjDir/3D-NV=1/MPITraceDir
echo 'Running ITAC and Save single file to the path: ' $VT_LOGFILE_PREFIX
export I_MPI_MIC=1echo 'MIC_LD_LIBRARY_PATH ' $MIC_LD_LIBRARY_PATH
datetime mpirun.mic -trace -n $MPIRanks -host $firstmic $BinDir/m3dc1_3d -ipetsc -options_file options_bjacobidate
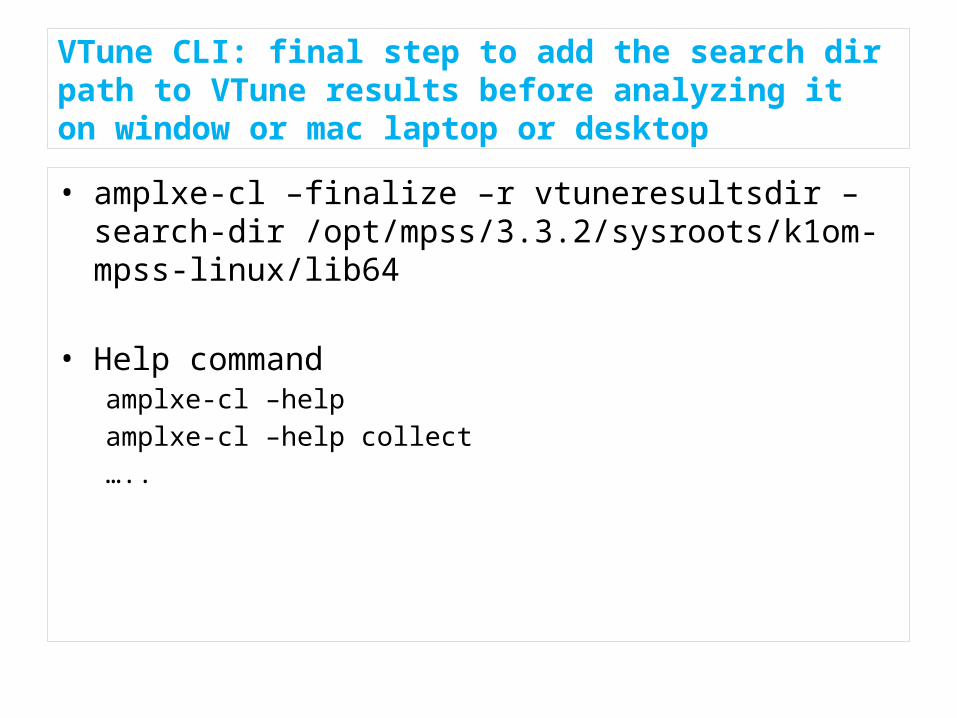
VTune CLI: final step to add the search dir path to VTune results before analyzing it on window or mac laptop or desktop
• amplxe-cl –finalize –r vtuneresultsdir –search-dir /opt/mpss/3.3.2/sysroots/k1om-mpss-linux/lib64
• Help commandamplxe-cl –helpamplxe-cl –help collect…..
Related Documents