978-1-4244-2677-5/08/$25.00 ©2008 IEEE A SECURE COVERT COMMUNICATION MODEL BASED ON VIDEO STEGANOGRAPHY Amr A. Hanafy, Gouda I. Salama and Yahya Z. Mohasseb The Military Technical College, Cairo, Egypt 11331 ABSTRACT This paper presents a steganographic model which utilizes cover video files to conceal the presence of other sensitive data regardless of its format. The model presented is based on pixel-wise manipulation of colored raw video files to embed the secret data. The secret message is segmented into blocks prior to being embedded in the cover video. These blocks are then embedded in pseudo random locations. The locations are derived from a re-orderings of a mutually agreed upon secret key. Furthermore, the re-ordering is dynamically changed with each video frame to reduce the possibility of statistically identifying the locations of the secret message blocks, even if the original cover video is made available to the interceptor. The paper also presents a quantitative evaluation of the model using four types of secret data. The model is evaluated in terms of both the average reduction in Peak Signal to Noise Ratio (PSNR) compared to the original cover video; as well as the Mean Square Error (MSE) measured between the original and steganographic files averaged over all video frames. Results show minimal degradation of the steganographic video file for all types of data, and for various sizes of the secret messages. Finally, an estimate of the embedding capacity of a video file is presented based on file format and size. Index Terms— Video-based Steganography, Audio video interleaved, Imperceptibility, Payload capacity. I. INTRODUCTION The word Steganography is of Greek origin and means "covered or hidden writing". Data hiding can be used for clandestine transmissions, closed captioning, indexing, or watermarking. It is in contrast to cryptography, where the existence of the message itself is not disguised, but the content is obscured [1]. Steganography is implemented in different fields such as military and Industrial applications. By using lossless steganography techniques messages can be sent and received securely. Traditionally, steganography was based on hiding secret information in image files [2,3]. Lately, there has been growing interest in applying steganographic techniques to video files as well [ 4,5]. The advantage of using video files in hiding information is the added security against hacker attacks due to the relative complexity of video compared to image files [4]. Image-based and video-based steganography techniques are mainly classified into spatial domain and frequency domain based methods [5-7]. The former embeds messages directly in Least Significant Bits (LSB) of the intensity of pixels of image or video. Spatial domain techniques either operate on pixel wise or block wise bases. In frequency domain, images are first transformed to frequency domain e.g. by using FFT, DCT or DWT and then the messages are embedded in some or all of the transformed coefficients. In this paper, we focus on spatial domain techniques. In spatial domain, it is possible to hide a significant amount of information in the covert file, by using the LSB of each color channel to carry the secret information. Depending on the color depth of the original image/video and the number of LSB bits used the degradation of the original image/video can be minimal. For instance, using the two LSB bits of each color channel in a 24-bit image/video merely results in a maximum color change of 64 values out of a possible 16+ Million colors. Several techniques of LSB insertion exist [8]. Several researchers have addressed the problem of video steganography. In [4] a comparative analysis between Joint Picture Expert Group (JPEG) image stegano and Audio Video Interleaved (AVI) video stegano by quality and size was performed. The authors propose to increase the strength of the key by using UTF-32 encoding in the swapping algorithm and lossless stegano technique in the AVI file. However, payload capacity is low. In [9] an adaptive invertible information hiding method for Moving Picture Expert Group (MPEG) video is proposed. Hidden data can be recovered without requiring the destination to have a prior copy of the covert video and the original MPEG video data can be recovered if needed. This technique works in frequency domain only. It has the advantages of low complexity and low visual distortion for covert communication applications. However, it suffers from low payload capacity. The work presented in this paper is based on spatial domain processing of AVI video files as covert video. The data hiding mechanism provides significant payload increase over [4]. This paper is organized as follows: Section II introduces the proposed steganographic algorithm, and then presents the steps of embedding and extraction process. Section III presents a performance evaluation. Section IV reports the experimental results and analysis. Finally, conclusions are presented in section V.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

978-1-4244-2677-5/08/$25.00 ©2008 IEEE
A SECURE COVERT COMMUNICATION MODEL BASED ON VIDEO STEGANOGRAPHY
Amr A. Hanafy, Gouda I. Salama and Yahya Z. Mohasseb The Military Technical College,
Cairo, Egypt 11331
ABSTRACT This paper presents a steganographic model which
utilizes cover video files to conceal the presence of other sensitive data regardless of its format. The model presented is based on pixel-wise manipulation of colored raw video files to embed the secret data. The secret message is segmented into blocks prior to being embedded in the cover video. These blocks are then embedded in pseudo random locations. The locations are derived from a re-orderings of a mutually agreed upon secret key. Furthermore, the re-ordering is dynamically changed with each video frame to reduce the possibility of statistically identifying the locations of the secret message blocks, even if the original cover video is made available to the interceptor. The paper also presents a quantitative evaluation of the model using four types of secret data. The model is evaluated in terms of both the average reduction in Peak Signal to Noise Ratio (PSNR) compared to the original cover video; as well as the Mean Square Error (MSE) measured between the original and steganographic files averaged over all video frames. Results show minimal degradation of the steganographic video file for all types of data, and for various sizes of the secret messages. Finally, an estimate of the embedding capacity of a video file is presented based on file format and size.
Index Terms— Video-based Steganography, Audio video interleaved, Imperceptibility, Payload capacity.
I. INTRODUCTION The word Steganography is of Greek origin and
means "covered or hidden writing". Data hiding can be used for clandestine transmissions, closed captioning, indexing, or watermarking. It is in contrast to cryptography, where the existence of the message itself is not disguised, but the content is obscured [1].
Steganography is implemented in different fields such as military and Industrial applications. By using lossless steganography techniques messages can be sent and received securely. Traditionally, steganography was based on hiding secret information in image files [2,3]. Lately, there has been growing interest in applying steganographic techniques to video files as well [ 4,5]. The advantage of using video files in hiding information is the added security against hacker attacks due to the relative complexity of video compared to image files [4].
Image-based and video-based steganography techniques are mainly classified into spatial domain and frequency domain based methods [5-7]. The former embeds messages directly in Least Significant Bits (LSB) of the intensity of pixels of image or video.
Spatial domain techniques either operate on pixel wise or block wise bases. In frequency domain, images are first transformed to frequency domain e.g. by using FFT, DCT or DWT and then the messages are embedded in some or all of the transformed coefficients.
In this paper, we focus on spatial domain techniques. In spatial domain, it is possible to hide a significant amount of information in the covert file, by using the LSB of each color channel to carry the secret information. Depending on the color depth of the original image/video and the number of LSB bits used the degradation of the original image/video can be minimal. For instance, using the two LSB bits of each color channel in a 24-bit image/video merely results in a maximum color change of 64 values out of a possible 16+ Million colors. Several techniques of LSB insertion exist [8].
Several researchers have addressed the problem of video steganography. In [4] a comparative analysis between Joint Picture Expert Group (JPEG) image stegano and Audio Video Interleaved (AVI) video stegano by quality and size was performed. The authors propose to increase the strength of the key by using UTF-32 encoding in the swapping algorithm and lossless stegano technique in the AVI file. However, payload capacity is low.
In [9] an adaptive invertible information hiding method for Moving Picture Expert Group (MPEG) video is proposed. Hidden data can be recovered without requiring the destination to have a prior copy of the covert video and the original MPEG video data can be recovered if needed. This technique works in frequency domain only. It has the advantages of low complexity and low visual distortion for covert communication applications. However, it suffers from low payload capacity.
The work presented in this paper is based on spatial domain processing of AVI video files as covert video. The data hiding mechanism provides significant payload increase over [4].
This paper is organized as follows: Section II introduces the proposed steganographic algorithm, and then presents the steps of embedding and extraction process. Section III presents a performance evaluation. Section IV reports the experimental results and analysis. Finally, conclusions are presented in section V.

2 out of 6
II. PROPOSED STEGANOGRAPHIC ALGORITHM
A. Embedding Stage The block diagram of the embedding processes is
shown in Figure (1). Assume we have a cover video sequence consisting of S frames as illustrated in Figure (2). The video frame dimension is WH × Pixels. Each input pixel is encoded to K -byte precision. Assume that we have a secret message of size V . The first step in the embedding phase is secret message preprocessing. In this step, the secret message is partitioned into s non-overlapping blocks, each with size 2N bytes. The proposed scheme requires that Ss ≤ and
( ) 4WFHKN ∗−≤ where F represents the number of rows in each cover video frame reserved for embedding the stego key data. The user can select any value of N satisfying the above condition. Furthermore, the format of the secret message file is identified and saved. The second step is cover video frame preprocessing. In this step, the non-overlapping blocks s are assigned to the number of video frames for embedding and then, the stego key data is embedded in a row number R in cover video frame calculated as:
( ) ( )( )FYMDfFR mod,,−= (1)
where f (D,M,Y) is a function calculated from the
system date (DD/MM/YY). For example;
( ) ⎟⎠⎞
⎜⎝⎛ +=
MYDroundYMDf ,, (2)
F is given by:
⎥⎦
⎥⎢⎣
⎢⎟⎟⎠
⎞⎜⎜⎝
⎛−=
WNHF
24 (3)
Equation (3) indicates that we embed one byte of
secret data in four bytes of cover data. The third step is the generation of two permuted
vectors 1Q and 2Q , each of size N to randomize the positions (row, column) of the secret-message blocks of data and the secret message format. To do this, we generate two permuted vectors ( )NQ :11 , and ( )NQ :12 . Starting with a secret message block ( )NNP :1,:1 , we construct the randomized permuted secret message block
( )NNU :1,:1 as follows: ( ) ( ) ( )( )jQiQPjiU 21 ,, = (4)
Where i and j are image/video frame row and
column coordinates respectively. In effect, we utilize the generated random permuted values of 1Q and 2Q
vectors to change the locations of pixels in P matrix in a manner specified by the stego key which is the seed to generate the 1Q and 2Q vectors. The locations in each of the two vectors are unique, therefore the mapping P U→ is one to one.
The fourth step is the conversion of the randomized secret message blocks, secret message file format and stego key data to binary stream. This is done by replacing the two LSB of the red, green and blue values in each pixel in the desired cover video frame with the binary stream sequentially. It will be shown in Section IV that this order achieves higher PSNR ratio than the traditional approach, which embeds the data into layers of Red, Green or Blue. The previous steps are repeated for all secret message blocks.
Fig. 1 Schematic block diagram for the embedding process
Fig. 2 A sequence of S frames of size H×W with a secret-message of s blocks of size 2N byte embedded randomly.
B. Extraction Stage The block diagram of the extraction processes is
shown in Figure (3). First, the stego video file header is read to determine the date, month and year of modification which is simply a surrogate for the actual stego key. R is then calculated from Equation (1), and the stego key is extracted. The second step is the extraction of the two LSB from each pixel of the stego video frame based on the extracted stego key data. The

3 out of 6
length of secret message block 2N is determined from the length of the stego key. Third the random location block matrix of size NN × for each stego video frame is generated based on the extracted stego key data. Finally, the randomized secret block and randomized secret message format are recovered based on the extracted stego key data and the secret message block is reconstructed. The process is repeated for all s blocks.
Extraction all needed information
(Date and time for modification of stego video file, stego key, number video frames used for embedding , randomized secret message format )
Generation of two random permuted
vectors
Construction of secret message
Modify N*N block in reverse order to the randomization in the embedding process
Modify the randomized secret
message format
Extraction of N *N randomized block
Stego video frame
Number of video frames used for embedding
Stego key
Randomizedblock
Modified N*N block
Randomized secret message format
Modified secret message format
Secret message
Fig. 3 Schematic block diagram for the extraction process.
III. PERFORMANCE EVALUATION OF THE PROPOSED SCHEME
Steganography is characterized mainly by two aspects; imperceptibility and capacity. Imperceptibility means the embedded data must be imperceptible to the observer (perceptual invisibility) and computer analysis (statistical invisibility). Capacity means maximum payload is required, i.e. maximum amount of data that can be embedded into the cover image without losing the fidelity of the original image [10].
The perceptual imperceptibility of the embedded data is indicated by comparing the original image or video to its stego counterpart so that their visual differences, if any, can be determined. Additionally, as an objective measure, the Mean squared Error (MSE), Peak Signal to Noise Ratio (PSNR) and Root Mean Square error (RMS) between the cover and stego images may be calculated. These parameters are given by:
( ) ( )( )∑∑= =
−=H
i
W
j
jiUjiPHW
MSE1 1
2,,1 (5)
where P(i,j) and U(i,j) are the pixel values at row i and column j of the cover image and stego image respectively.
MSELPSNR
2
10log10= (6)
where L is the peak signal level (L = 255 for 8-bit gray scale images).
The maximum capacity of cover video file is given by:
( ) ByteFHKSWC −=41
(7)
IV.DISCUSSION AND EXPERIMENTAL RESULTS
The Proposed algorithm was implemented using MATLAB. For all the experiments presented herein, we used N = 256 and the numbers of LSB bits to be replaced was fixed at two. Several experiments were conducted to test the robustness and imperceptibility of the algorithm using audio, text, image and video files in different formats and different sizes as secret-messages.
C. Audio experiment In this experiment, nine audio files representing
various formats, MPEG version 3 (MP3), Musical Instrument Digital Interface (MIDI) and Windows Media Audio (WMA), of different sizes were considered as a secret message in the evaluation as listed in Table I.
D. Image experiment In this experiment, nine Image files representing
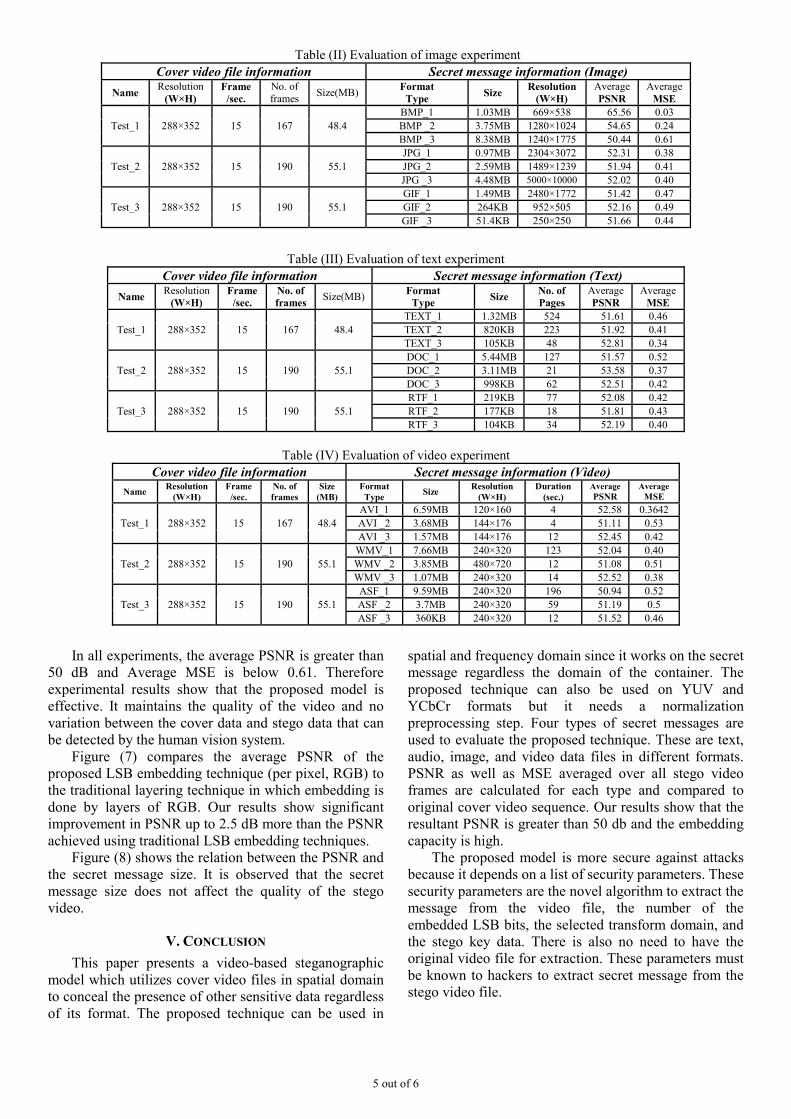
various formats, Bitmap (BMP), JPEG and Graphical Interchange Format (GIF), of different sizes were considered as a secret-message. A sample of cover video frame, stego video frame, secret message (BMP format) and the secret-message after applying proposed technique, i.e. effect of Equation (4) are shown in Figure 4. Results of the experiment are summarized in Table (II).
E. Text experiment In this experiment, nine document files representing
various formats, plain Text, Microsoft Word (DOC) and Rich Text Format (RTF), of different sizes were considered as secret messages. PSNR, and MSE results are listed in Table (III). A sample of cover video frame, stego video frame, secret message (DOC format) and the secret-message after applying proposed technique are shown in Figure (5).
F. Video experiment In this experiment, nine video files representing
various formats, AVI, Windows Media Video (WMV) and Advanced Streaming Format (ASF), of different sizes were considered as a secret-message in the evaluation as listed in Table (IV). A sample of cover video frame, stego video frame, secret message (AVI format) and the secret-message after applying proposed technique are shown in Figure (6).

4 out of 6
It should be noted that for Figures 4-8, the secret message is shown assuming that the interceptor has knowledge of the file format and type, the locations of the hidden message and the number of bits, but not the vectors Q1 and Q2.
a) b)
c) d)
Fig.4 Embedded image of size 3.75MB. a) Cover video frame; b) stego video frame; c) secret message; d)secret message
after applying proposed technique.
a) b)
c) d) Fig.5 Embedded document file of size 998KB. a) Cover video
frame; b) stego video frame; c) secret message; d)secret message after applying proposed technique.
a) b)
c) d) Fig.6 Embedded video file of size 6.59MB. a) Cover video frame; b) stego video frame; c) secret message; d)secret
message after applying proposed technique.
Table (I) Evaluation of audio experiment Secret message information (Audio) Cover video file information
Average MSE
Average PSNR
Duration (min.) Size Format
Type Size(MB) No. of frames
Frame /sec. resolution Name
0.31 53.71 1.01 843KB MP3_1 48.4 167 15 288×352 Test_1 0.32 53.11 3.48 3.04MB MP3_2
0.33 52.96 5.35 5.12MB MP3_3 0.07 59.3 1.44 18.7KB MIDI_1
55.1 190 15 288×352 Test_2 0.18 55.67 8.47 106KB MIDI_2 0.29 53.41 5.59 171KB MIDI_3 0.48 51.31 4.06 0.97MB WMA_1
55.1 190 15 288×352 Test_3 0.54 50.86 5.45 3.31MB WMA_2 0.49 51.26 4.14 4.88MB WMA_3
5 out of 6
Table (II) Evaluation of image experiment Secret message information (Image) Cover video file information
Average MSE
Average PSNR
Resolution (W×H) Size Format
Type Size(MB) No. of frames
Frame /sec.
Resolution (W×H) Name
0.03 65.56 669×538 1.03MB BMP_1 48.4 167 15 288×352 Test_1 0.24 54.65 1280×1024 3.75MB BMP _2
0.61 50.44 1240×1775 8.38MB BMP _3 0.38 52.31 2304×3072 0.97MB JPG_1
55.1 190 15 288×352 Test_2 0.41 51.94 1489×1239 2.59MB JPG_2 0.40 52.02 5000×10000 4.48MB JPG _3 0.47 51.42 2480×1772 1.49MB GIF_1
55.1 190 15 288×352 Test_3 0.49 52.16 952×505 264KB GIF_2 0.44 51.66 250×250 51.4KB GIF _3
Table (III) Evaluation of text experiment Secret message information (Text) Cover video file information
Average MSE
Average PSNR
No. of Pages Size Format
Type Size(MB) No. of frames
Frame /sec.
Resolution (W×H) Name
0.46 51.61 524 1.32MB TEXT_1 48.4 167 15 288×352 Test_1 0.41 51.92 223 820KB TEXT_2
0.34 52.81 48 105KB TEXT_3 0.52 51.57 127 5.44MB DOC_1
55.1 190 15 288×352 Test_2 0.37 53.58 21 3.11MB DOC_2 0.42 52.51 62 998KB DOC_3 0.42 52.08 77 219KB RTF_1
55.1 190 15 288×352 Test_3 0.43 51.81 18 177KB RTF_2 0.40 52.19 34 104KB RTF_3
Table (IV) Evaluation of video experiment
Secret message information (Video) Cover video file information Average
MSE Average PSNR
Duration (sec.)
Resolution (W×H) Size Format
Type Size
(MB) No. of frames
Frame /sec.
Resolution (W×H) Name
0.3642 52.58 4 120×160 6.59MB AVI_1 48.4 167 15 288×352 Test_1 0.53 51.11 4 144×176 3.68MB AVI _2
0.42 52.45 12 144×176 1.57MB AVI _3 0.40 52.04 123 240×320 7.66MB WMV_1
55.1 190 15 288×352 Test_2 0.51 51.08 12 480×720 3.85MB WMV _2 0.38 52.52 14 240×320 1.07MB WMV _3 0.52 50.94 196 240×320 9.59MB ASF_1
55.1 190 15 288×352 Test_3 0.5 51.19 59 240×320 3.7MB ASF _2 0.46 51.52 12 240×320 360KB ASF _3
In all experiments, the average PSNR is greater than
50 dB and Average MSE is below 0.61. Therefore experimental results show that the proposed model is effective. It maintains the quality of the video and no variation between the cover data and stego data that can be detected by the human vision system.
Figure (7) compares the average PSNR of the proposed LSB embedding technique (per pixel, RGB) to the traditional layering technique in which embedding is done by layers of RGB. Our results show significant improvement in PSNR up to 2.5 dB more than the PSNR achieved using traditional LSB embedding techniques.
Figure (8) shows the relation between the PSNR and the secret message size. It is observed that the secret message size does not affect the quality of the stego video.
V. CONCLUSION This paper presents a video-based steganographic
model which utilizes cover video files in spatial domain to conceal the presence of other sensitive data regardless of its format. The proposed technique can be used in
spatial and frequency domain since it works on the secret message regardless the domain of the container. The proposed technique can also be used on YUV and YCbCr formats but it needs a normalization preprocessing step. Four types of secret messages are used to evaluate the proposed technique. These are text, audio, image, and video data files in different formats. PSNR as well as MSE averaged over all stego video frames are calculated for each type and compared to original cover video sequence. Our results show that the resultant PSNR is greater than 50 db and the embedding capacity is high.
The proposed model is more secure against attacks because it depends on a list of security parameters. These security parameters are the novel algorithm to extract the message from the video file, the number of the embedded LSB bits, the selected transform domain, and the stego key data. There is also no need to have the original video file for extraction. These parameters must be known to hackers to extract secret message from the stego video file.

6 out of 6
0
10
20
30
40
50
60
70
MP3_1
MP3_2
MP3_3
MIDI_1
MIDI_2
MIDI_3
WMA_1
WMA_2
WMA_3
TEXT_1
TEXT_2
TEXT_3
DOC_1
DOC_2
DOC_3
RTF_1
RTF_2
RTF_3
BMP_1
BMP_2
BMP_3
JPG_1
JPG_2
JPG_3
GIF_1
GIF_2
GIF_3
AVI_1AVI_2
AVI_3
WMV_1
WMV_2
WMV_3
ASF_1
ASF_2
ASF_3
Secret message file format
PS
NR
(d
B)
PROPOSED TEQNIQUE EMBEDDING WITHOUT RANDOMIZATION
Fig.7 Average PSNR versus the secret message file format for the proposed and traditional LSB embedding technique.
Fig.8 Peak Signal to Noise Ratio versus secret message size
using different data types.
REFERENCES: [1] Daniela Stanescu, Mircea Stratulat, Voicu Groza, Joana
Ghergulescu and Daniel Borca, "Steganography in YUV color space", IEEE International Workshop on Robotic and Sensors Environments (ROSE 2007), Ottawa- Canada, pp.1-4, October 2007.
[2] N. Provos and P. Honeyman, "Hide and Seek: An Introduction to Steganography", IEEE Security & Privacy Magazine, Vol. 1, issue 3, pp. 32-44, June 2003.
[3] Stefan Katzenbeisser and Fabien A. P. Petitcolas, "Information Hiding Techniques for Steganography and Digital Watermarking", Artech House Books, December 1999, ISBN 1-58053-035-4.
[4] R.Kavitha and A. Murugan, "Lossless Steganography on AVI File using Swapping Algorithm", International Conference on Computational Intelligence and Multimedia Applications, pp. 83-88, Sivakasi-Tamil Nadu, Dec. 2007
[5] Yeunan-Kuen Lee and Ling-Hwei Chen, “High Capacity Image Steganohraphic Model”, IEE Proceedings in Vision, Image and Signal Processing, Vol. 147, issue 3, pp. 288-294, June 2000.
[6] Neil F. Johnson, Zoran Duric and Sushil Jajodia, "Information Hiding: Steganography and Watermarking - Attacks and Countermeasures", Kluwer Academic Publishers, 2000, ISBN: 0-79237-204-2.
[7] C. Ming, Z. Ru, N. Xinxin and Y. Yixian, "Analysis of Current Steganography Tools: Classifications & Features", Proceedings of the 2006 International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP'06), pp. 384-387, California, Dec. 2006.
[8] Hema Ajetrao, Dr.P.J.Kulkarni and Navanath Gaikwad, ” A Novel Scheme of Data Hiding in Binary Images”, International Conference on Computational Intelligence and Multimedia Applications,Vol.4, pp. 70-77, Sivakasi-Tamil Nadu, Dec. 2007.
[9] Yueyun Shang, "A New Invertible Data Hiding in Compressed Videos or Images", Third International Conference on Natural Computation (ICNC 2007), Vol. 4, pp. 576-580, Haikou, Aug. 2007.
[10] Venkatraman S., Ajith Abraham and Marcin Paprzycki,
“Significance of Steganography on Data Security”, International Conference on Information Technology: Coding and Computing (ITCC’04), Vol. 2, April 2004.
Related Documents











