Int. J. Inf. Secur. (2009) 8:433–445 DOI 10.1007/s10207-009-0089-y REGULAR CONTRIBUTION Secure steganography based on embedding capacity Hedieh Sajedi · Mansour Jamzad Published online: 15 August 2009 © Springer-Verlag 2009 Abstract Mostl y the embed ding capac ity of steganog raphy methods is assessed in non-zero DCT coefficients. Due to unequal distribution of non-zero DCT coefficients in images wit h dif fer ent con ten ts, ima geswith thesame number of non - zero DCT coefficients may have different actual embedding capacities. This paper introduces embedding capacity as a proper ty of ima ges in the pre sen ce of mul tiple stegan aly zer s, and discusses a method for computing embedding capacity of cover images. Using the capacity constraint, embedding can be done more secure than the state when the embed- der does not know how much data can be hidden securely in an image. In our proposed approach, an ensemble system that uses different steganalyzer units determines the security limits for embedding in cover images. In this system, each steganalyzer unit is formed by a combination of multiple steganalyzers from the same type, which are sensitive to dif- ferent payloads. The confidence of each steganalyzer on an image leads us to determine the upper bound of embedding rate for the image. Considering embedding capacity , the ste- ganographer can minimize the risk of detection by selecting a proper cover image that is secure for a certain payload. Moreover , we analyzed the relation between complexity and embed ding capa city of image s. Exper iment al resu lts sho wed the effectiveness of the proposed approach in enhancing the security of stego images. Keywords Steganalysis · Steganography · Embedding capacity · Support vector machine · Ensemble method · Image complexity H. Sajedi (B) · M. Jamzad Department of Computer Engineering, Sharif University of Technology, Tehran, Iran e-mail: [email protected] .edu M. Jamzad e-mail: [email protected] du 1 Introduction St eganography istheart andsc ie nc e of hidi ng a se cr et da ta in such a way that no one, except the intended recipient knows the existe nc e of the data [1]. Itutil iz esa typi ca l di gi tal me di a such as text, image, audio, video, and multimedia as a car- rier for a secret data. The success of steganography methods depends upon the carrier medium not to attract attention. Different image steganography methods have been pro- posed in the literature. Embedding techniques in discrete cosine transform (DCT) domain are popular because of the large usage of JPEG images. Embedding in various stega- nography methods such as F5 [ 2], model based (MB) [3], perturbed quantization (PQ) [4], and YASS [5] is done by modifying some properly selected DCT coefficients. Some other steganography methods embed secret data in other transform domains. For example, a Contourlet-based stega- nography method [6] embeds secret data in contourlet coef- ficients of an image. The goal of steganalysis methods is to detect the presence of hidden data from the observed media. Steganalyzers hav e achieve d great advances in the past few years and a number of efficient steganalysis techniques have been proposed. Sta- tistical steganalysis schemes work by evaluating a suspected stego image against an assumed or computed cover distri- bution or model. Blind statistical steganalysis methods use a supervised learning technique trained on features derived from the cover as well as the stego images. In order to have secure communication in the presence of blind steganalysis methods, the steganographer must embed secret data into a cover image in such a way that the statisti- calfeatures of thecover ima ge are not sig nif ica ntl y per tur bed during the embedding process. It is shown in [ 7] that, when the embedding data size gets larger than a threshold then it becomes easier for a 123

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 1/13

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 2/13
434 H. Sajedi, M. Jamzad
steganalysis technique to detect the presence of the hidden
data. This gives an upper bound limit for embedding capac-
ity, such that if the hidden data size is less than that upper
bound, we may claim that the stego image is safe and the
steganalysis methods cannot detect it.
Embedding capacity is the key measure to compare the
performance of differentdata embedding algorithms. In gen-
eral sense, it is the maximum data size that can be securelyembedded in an image with respect to certain constraints.
It is shown in [8] that the average embedding capacity of
existing steganography methods for grayscale JPEG images
with quality factor of 70 is approximately 0.05 bits per non-
zero AC DCT coefficient. Until now, embedding capacity
has been considered as a property of steganography meth-
ods [7–10]. However,usinga steganography technique, there
is no guaranty that if two images have equal number of
non-zero DCT coefficients, they have the same embedding
capacities. Consequently, since the distribution of non-zero
DCT coefficients may differ in different images, the embed-
ding capacity should be considered relative to the images.Therefore, the embedding capacity may not be associated
to a steganography method rather it depends on the content
of images. Furthermore, a high-performance steganography
method is the one that in average case, its produced stego
imagesmay be detected by the steganalyzers randomly (with
a probability around 0.5). However, there is no guarantee
that a specific stego image could not be detected reliably by
the steganalyzers. Furthermore, there is not any criterion to
know how much secret data one can embed in a given cover
image securely. For example, if the steganographer wants to
embed a secret data with size of 5,000 bits in a certain cover
image, he does not know if the resulted stego image will be
secureor not. Maybe hadhe selected another cover image, its
stego version would have been misclassified by steganalysis
methods.
1.1 Our contribution
In this paper, we propose a structure that guarantees the
security of stego images in embedding a certain payload
against the existing steganalyzers. First, we determine the
embedding capacity of an image regarding to the efficient
and well-known steganalysis methods and then we clarify
cover selection steganography based on embeddingcapacity.
In other viewpoint, for embedding a determined size secret
data, thesteganography methodcancheck an image database
andsuggest a setof propercover images forembedding. This
strategy canbe combined with all the existing steganography
methods as a preprocessing step. We should note that the
embedding capacity of an image depends on its content, the
steganography method used and the steganalysis algorithms.
Due to the complexity of steganography and progressive
strength of steganalysis algorithms, it becomes a challenge
to develop secure steganography techniques. We aim to pro-
vide a solution for this problem by determining the embed-
ding capacity of imagesusing an ensemble classifiermethod.
Considering the embedding capacity of an image, the stega-
nographer can securely embed a secret data, which its size is
smaller than or equal to the embedding capacity of the cover
image.
An ensemble classifier is often used for boosting weak classifiers, such as decision tree, neural networks, etc. [11].
Ensemble learning is the aggregation of multiple learned
models with the goal of improving accuracy. In our work,
each weak classifier is a steganalyzer and our intent is to dis-
tinguish between the secure and non-secure limits of embed-
ding rate in an image.
Each steganalyzer is a voter (determinant) on whether an
imageis cleanorstego.The combinationofvotebyallthe ste-
ganalyzers in the ensembledeterminesthe embeddingcapac-
ityof a cover image.If thesteganalyzersagreewitheachother
that a stego image is a cover (clean) image (e.g. false neg-
ative), the goal of the steganography is satisfied. Therefore,we can increase the size of embedded data in an image until
the distortion of image features does not overrun a safety
threshold.
We arranged an experiment to investigate the relation
between the image complexity of a cover image and the
detectability of the corresponding stego image against ste-
ganalyzers. The experimental results suggest that in order
to obtain higher embedding capacity, we shall select cover
images among middle and high-complexity images.
To evaluate the effect of proposed embedding capacity
measure on security of steganography methods, we per-
formed different experiments. The results showed the effi-
ciency of the proposed approach in enhancing the security of
stego images.
The remainder of this paper is organized as follows.
Section 2 describes previous works in defining embedding
capacity, steganalysismethods,ensemblemethods, andSVM
classifierbriefly. In Sect.3, weintroducetheembeddingsecu-
rity definition and describe how to calculate the embed-
ding capacity based on embedding security definition. Cover
selection steganography method is also discussed in Sect.3.
Experimental results are given in Sect. 4 and finally, we con-
clude our work in Sect. 5.
2 Background
2.1 Previous works
A number of ways to compute the embedding capacity have
beenproposedpreviously[7,9,10,13].In [7] thedefinition of
embeddingcapacityispresentedfroma steganalysisperspec-
tive. This work argues that as themain goal of steganography
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 3/13
Secure steganography based on embedding capacity 435
is hidden communications, embedding capacity is dependent
on the type of steganalysis detector employed to break the
embedding algorithm. It defines γ -security so that in pres-
ence of a steganalysisdetector D, a steganography algorithm
is said to be perfectly secure if γ D = 0.
The work in [9] defines a steganography method to be
ε-secure (ε ≥ 0) if the relative entropy between the cover
and the stego probability distributions ( Pc and Ps , respec-tively) is at most ε, i.e.,
D(Pc |Ps ) =
Pc log
Pc
Ps
≤ ε (1)
A stego technique is said to be perfectly secure if ε = 0.
This definition assumes that cover andstego imagesare inde-
pendent identically distributed (i.i.d.) random variables. This
assumption is not true for many real life cover signals [7].
One approach to rectify this is to put the constraint that the
relative entropy computed using the nth order joint probabil-
ity distributions must be less than εn . Then one can force a
steganography technique to preserve the n order distribution.However, it may be possible to use (n+1) order statistics for
steganalysis. Estimations for embedding capacity of images,
based on a parallel Gaussian model in the transform domain
is provided by Moulin and Mihcak [10].
Batch steganography generalizes the problems of hiding
and detecting secret data to multiple cover objects [12]. Ker
in [13] defines batch-embedding capacity and theoretically
proves that thesize of secretdata cansafely increase no faster
than the square root of the number of cover images.
2.2 Steganalysis methods
Steganalysis methods seek to analyze an image to decide
whether a secretdata hasbeen embedded in it.Consequently,
steganalysis can be considered as a two-class classification
problem [14]. At the heart of every steganalyzer there is
a classifier, which given an image feature vector, decides
whether the image contains any secret messages.
Essentially, there are two approaches to steganalysis: one
is to come up with a steganalysis method specific for a par-
ticular steganography technique. The other is developing
universal techniques that are effective for all steganography
methods [15].
Specific steganalysis methods concentrate on image fea-
tures, which are modified by the embedding algorithm.
Although a steganalysis technique specific to an embedding
method would give good results when tested only on that
embedding method, but it might fail on all other steganogra-
phy methods.
Universal steganalysis techniques work by designing a
classifier based on a training set of cover images and stego
images obtained from a variety of different embedding
algorithms. Classification is done based on some inherent
features of cover images. These features may be modified
when an image undergoes an embedding process. A number
of universal steganalysis techniques are proposed in the liter-
ature.Thesetechniquesdiffer in thefeature sets they consider
for capturing the image statistics. For example, Martin et al.
[14] calculates several binary similarity measures between
the seventh and eighth bit planes of an image. Steganalyzers
in [17,18] obtain a number of statistics from an image thatis decomposed by wavelet. On the other hand, [19] utilizes
statistics of DCT coefficients as well as spatial domainstatis-
tics. It is observed in [15,16] that the universal steganalysis
techniques do not perform equally over all embedding tech-
niques. In addition, they are not able to distinguish perfectly
between cover and stego images.
A powerfulsteganalyzer isable todetectthe presenceofan
embedded data in an image with high accuracy. This implies
that theembeddingmethodemployed to hide thedata is inse-
cure. In practice, since the steganalyst is not able to know
what steganography technique has been employed, he has
to deploy several techniques on suspected stego images. Inavailability of different steganalysis techniques that extract
non-overlapping feature sets for analysis, each one makes
mistakes independently of the rest. As a solution to this
problem, we investigate how steganalyzers can incorporate
together with the help of ensemble methods.
2.3 Ensemble methods
In the area of machine learning, the concept of combining
classifiers isproposed to improve theperformanceof individ-
ual classifiers. These classifiers could be based on a variety
of classification methodologies, and could achieve different
rates of correctly classified data instances. The goal of an
ensemble method that integrates the results of classifiers is
to generate more certain, precise and accurate results [20].
Ensemble learning refers to a collection of methods that learn
a target function by training a number of individual learners
andcombiningtheir predictions.Ensemblelearninghassome
benefits as below [21]:
– Accuracy: a more reliable classification result can be
obtained by combining the output of multiple classifiers.
Furthermore, uncorrelated errors of individual classifierscan be eliminated.
– Efficiency: a complex problem can be decomposed into
multiple sub-problems that are easier to understand and
solve (divide-and-conquer approach).
– There is not a single model of classifier that works for all
pattern recognition problems.
– To solve hard problems the desired target function may
not be implementable with individual classifiers, but may
be approximated by ensemble classifiers.
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 4/13
436 H. Sajedi, M. Jamzad
Fig. 1 A SVM trained with samples from two classes [20]. Two sup-
port vectors (data points) are shown in black circles on the border of
left and right boundary lines
2.4 Support vector machine (SVM)
A classificationtaskusually involves withtrainingandtesting
data, which consist of several data instances. Each instance
in the training set contains one “target value” (class labels)
and several “attributes” (features).
SVM is a very powerful learning tool in solving binary
classification problems [22–24]. The goal of SVM is to pro-
duce a model, which predicts target value of data instances
in the testing set given only the attributes [25]. Here training
vectors X I aremappedinto a higherdimensional space.Then
SVM finds a linear separating hyper-plane with the maximal
margin in this higher dimensional space.
The radial basis function (RBF) kernel nonlinearly maps
data instances into a higher dimensional space. Therefore,
unlike the linear kernel (a special case of RBF), it can handle
the case when the relation between class labels and attributes
is nonlinear. The RBF kernel is defined by Eq. (2).
K ( x, y) = exp(−γ x − y2), γ > 0 (2)
Figure1 shows a SVM for a two-class classification prob-
lem. Samples on the margins are called support vectors. Sup-
port vectors (a subset of training samples) are the data points
that lie closest to the decision surface and they are the most
difficult to classify. In addition, they have direct bearing on
the optimum location of the decision surface.
3 Proposed approach
3.1 Embedding security
We define embedding security as follows. A stego image
has embedding security when the embedded secret data is
undetectable by steganalyzers.Embeddingsecurity is mostly
influenced by the places within the cover image that might be
modified, the type of embedding operation, and the amount
of changes imposed to the cover image. Steganography is a
two-class classification problem. In two-class namely, stego
and cover image classification, the classifier decides about
the observed images based on Eq. (3) as the following:
decision =⎧⎪⎪⎨⎪⎪⎩
I ∈ stego, P( I ∈ stego| X I ) > 0.5
no-decision, P( I ∈ cover| X I ) = 0.5
I ∈ cover, P( I ∈ cover| X I ) > 0.5
(3)
where P( I ∈ stego| X I ) is theposterior probability of image
I represented by feature vector X I carrying a secret data.
Since there areonly twoclassesavailable (i.e. cover or stego),
we have:
P( I ∈ cover | X I ) = 1 − P( I ∈ stego| X I ) (4)
To determinethesecurity, first,we composea steganalyzer
unit that is a multiple classifier system. Combining different
classifiers to make an ensemble, we can benefit from bet-
ter classification performance than individual classifiers and
more resilience to noise. Each vote (detection result) is the
confidence of a classifier on classifying an image to clean or
stego class.
The result of a steganalyzer that uses SVM classifier is
obtained as follows:
decision =
⎧⎪⎨⎪⎩
I ∈ stego, d j ( I ) > 0
no-decision, d j ( I ) = 0
I ∈ cover, d j ( I ) < 0
(5)
where d j ( I ) is the distance of an image in feature space from
the j th decisionhyper-plane between clean andstego images.
The result of multiple steganalyzers can be combined using
schemes such as the sum, average, or maximum rule. We
consider the maximum result of all the steganalyzers as the
result of the whole steganalyzer unit as the following:
d = max(d j ( X I )) (6)
Secure upper bound for embedding in an image is deter-
mined regarding to the maximum distance of the image from
all the steganalyzer discriminant hyper-planes. This distance
shows the closeness of the image to the unsafe region in fea-
ture space (stego space). If d > 0, it demonstrates that the
security of the stego image is threatened by at least one of the
steganalyzers. Consequently, if d ≤ 0, the stego image has
embeddingsecurity andit cannotbe recognized by any of the
steganalyzers. In this definition, we treat cautiously andif the
stego image is recognized by even one of the steganalyzers,
we consider the stego image insecure.
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 5/13
Secure steganography based on embedding capacity 437
Fig. 2 The structure of
ensemble steganalyzer for
determining the security of
embedding in an image
3.2 Embedding capacity
With the definition of embedding security, we are now ready
to define embedding capacity regarding to this definition.
Embedding capacity is the upper limit of embedding rate
that if the size of hidden data goes over that limit, the stego
image can be recognized by a steganalyzer.
We combine some moderately inaccurate base classifiers
(steganalyzers) into a combined predictor to determine the
upper bound of embedding capacity of an image. Embed-
ding capacity of an image may differ using various stega-
nography methods. Therefore, to have a safe covert commu-
nication, each steganography method is allowed to continue
embedding in the image until steganalysis algorithms do not
threaten the security of the image.
The steganography security scheme, which is based on an
ensemble steganalyzer, is constructed according to the steg-
analysis methods in the literature:
1. Wavelet-based steganalysismethod(WBS) proposed by
Lyu andFarid[17] where in thefeature extraction part of
thismethod, statistics suchas mean,variance, skewness,
andkurtosis arecalculated from each waveletdecompo-
sition sub-band of an image. WBS extracts 24 features
for classification.
2. Markov-DCT-based steganalysis method (274-dim) has
a 274-dimensional feature vector that merges Markov
and DCT features of an image [26]. Another steganaly-
sis technique, which has 23-dimensional feature vector
(23-dim) [19], obtains a set of distinguishing features
from DCT and spatial domains. Since Markov-DCT-
based steganalysis method is stronger than the 23-dim
steganalyzer [27], we do not use 23-dim steganalysis
method in the structure of the ensemble steganalyzer.
3. 324-dimensional feature vector steganalysis method
(324-dim) proposed by Chen et al. [28], which is an
improvement of the 39 dimensional feature vector
method [29], based on statistical moments of wavelet
characteristic functions.
Figure2 shows thestructure of theensemble steganalyzer.
Using this structure, we expect that the embedding capac-
ity determined in this manner can be valid for upcoming
steganalysis methods and this combination fill some gaps
between feature spaces of the steganalyzers and can provide
a suitable computation for secure capacity regarding to the
advantage of steganalysis methods.
Figure3 shows thestate of a steganalyzerunit in its feature
space. In each unit, some SVM classifiers separate the fea-
ture space into two parts of clean and stego spaces. If a stego
image in feature space resides in the clean side close to the
hyper-plane discriminator line, it is a secure stego image that
is misclassified by the classifier. In the presence of multiple
classifiers, each one is a discriminator between certain pay-
load stego imagesand clean images. Gray part inFig. 3 shows
the safe region for stego images. To explain the operation
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 6/13
438 H. Sajedi, M. Jamzad
Fig. 3 Hyper-planes (discriminants) of a steganalyzer unit in its fea-
ture space
of each steganalyzer unit we show the structure with linear
SVMs but in the real application, for each steganalyzer with
certain payload, a nonlinear SVM is trained to classify clean
and stego images.
The distance of an image in feature space from decision
boundary of SVM classifier, represents the confidence of the
vote of SVM. The vote is positive if the image is recognized
as a stego image; otherwise, it is negative.
We assume that if a steganalyzer classifies clean images
and stego images with payload of 1,000 bits, this classifier
can correctly detect stego images with a higher payload, as
well. To prove the assumption we did some experiments and
verified this assumption. However, the accuracy of a stegan-
alyzer trained with a certain payload, in detection of stego
imageswithhigherpayloadsis notmuchhigh. To havehigher
detection accuracy we train one classifier for each quantized
payload and let a cascade classifier to detect stego images.
We call each cascade classifier a steganalyzer unit. The result
of a steganalyzer unit is the vote of confidence that the unit
gives to an image.
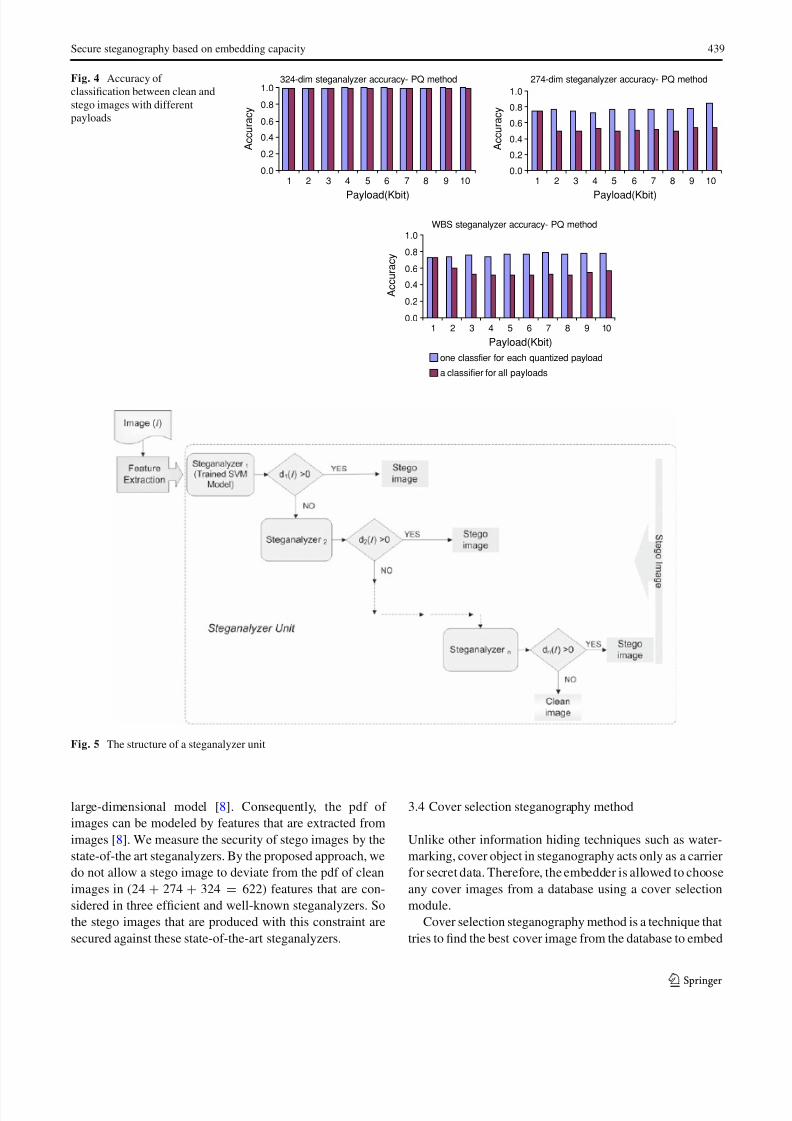
Figure 4 shows theaverage detection accuracy of stegana-
lyzers forall the images. Ourexperimental results (the exper-
iment setup will be described in Sect. 4) illustrated that a
distinct classifier for each quantized payload provides more
accuracyfor a steganalyzer. Therefore,we consider the pessi-
mistic result as the limit for secure steganography. The most
secure state for a stego image is when all the units in the
ensemble steganalyzer announce that the image is clean.
To construct each steganalyzer unit we quantized the pay-
load range between 0 and 10,000 bits to ten equal parts. For
each payload, we construct a SVM classifier trained for that
specific payload. Since when a steganalyzer detects a stego
image, the steganography purpose gets broken, therefore the
steganalyzer unit checks the classifiers in an ascending order
of payloads. If any one detects the stego image, the unit stops
and reports the result without checking other classifiers. This
structure is shown in Fig. 5.
The receiver operating characteristic (ROC) is a plot of
false alarm versus true alarm. Figure 7 shows the random
guess state of a steganalyzer in a ROC curve. The points on
the ROC curve represent the achievable performance of asteganalyzer. The steganalyzer makes purely random guess
when it operates on the 45◦ line in the ROC plane. This
means that the detector does not have sufficient information
to make a correct decision. Therefore, if the embedder forces
the detector to operate around the 45◦ ROC curve by choos-
ing proper algorithms or parameters, then we say that the
stego image is secure [7].
When the detection accuracy of a steganalyzer is 0.5, it
works randomly. However, in practice, when the detection
accuracy of a certain steganalyzer is less than 0.6, the stega-
nography scheme that produces the stego images, is consid-
ered statistically undetectable against that steganalyzer [27].We see that usually a tolerance range of 0.1 (i.e. detection
accuracy in [0.5, 0.6]) is considered for random detection of
steganalyzers. Using SVM classifier, we consider this toler-
ance around the hyper-plane discriminator, which is placed
on zero point. Figure 8 shows the zero point and the ran-
domdecisioninterval that lies on [−0.05,+0.05] in classifier
result range [−1,+1].
3.3 Determining embedding capacity of an image
To determine the embedding capacity of an image an incre-
mental embedding routine is applied. In this regard, we
increase the embedding rate until the maximum distance of
the image from discriminants in feature space reaches the
random decision threshold, as the following relation remains
true. This implies that the image is a cover.
max(d U i ) ≤ 0.05 (7)
where d Ui is the distance of i th steganalyzer unit from safe
embeddingthreshold.Equation (7) shows theupper limit that
we can decide an image is a cover.
We allow increase embedding in an image while all the
votes of the steganalyzers reside in the random guess range
[−0.05,+0.05]. This procedure is the operation of Evalua-
tion block in Fig. 2. Figure6 illustrates the block diagram of
incremental embedding procedure to determine the embed-
ding capacity of cover images.
Since the feature sets employed in classification of ste-
ganalyzers are capable of detecting a wide range of stego
systems, the features are map out the space of images. There-
fore, it makes sense to use the features extracted from a large
number of images as a practical model for images and
evaluate security of stego schemes with respect to this
123
8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 7/13
Secure steganography based on embedding capacity 439
Fig. 4 Accuracy of
classification between clean and
stego images with different
payloads
324-dim steganalyzer accuracy- PQ method
0.0
0.2
0.4
0.6
0.8
1.0
Payload(Kbit)
A c c u r a c y
274-dim steganalyzer accuracy- PQ method
0.0
0.2
0.4
0.6
0.8
1.0
1 2 3 4 5 6 7 8 9 10 1 2 3 4 5 6 7 8 9 10
Payload(Kbit)
A c c u r a c y
WBS steganalyzer accuracy- PQ method
0.0
0.2
0.4
0.6
0.8
1.0
1 2 3 4 5 6 7 8 9 10
Payload(Kbit)
A c c u r a c y
one classfier for each quantized payload
a classifier for all payloads
Fig. 5 The structure of a steganalyzer unit
large-dimensional model [8]. Consequently, the pdf of
images can be modeled by features that are extracted from
images [8]. We measure the security of stego images by the
state-of-the art steganalyzers. By the proposed approach, we
do not allow a stego image to deviate from the pdf of clean
images in (24 + 274 + 324 = 622) features that are con-
sidered in three efficient and well-known steganalyzers. So
the stego images that are produced with this constraint are
secured against these state-of-the-art steganalyzers.
3.4 Cover selection steganography method
Unlike other information hiding techniques such as water-
marking, cover object in steganography acts only as a carrier
for secret data. Therefore, the embedder is allowed to choose
any cover images from a database using a cover selection
module.
Cover selection steganography method is a technique that
tries to find the best cover image from the database to embed
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 8/13
440 H. Sajedi, M. Jamzad
Fig. 6 Detector ROC plane
Fig. 7 The random detection interval is shown by No-decision arrow
in classifier result range
a given secret data. In this respect, cover images are retrieved
based on a measure like undetectability of their stego image
versions. Efficient retrieval of a proper cover image from the
database can lead us to the secure steganography.
Cover selection module can offer some ranked images
according to their risk of detectability. In this manner, theste-
ganographer could choose a cover image so that the humans
and steganalyzerswouldmisclassify its stego version.There-
fore, the steganographer can minimize the detectability of a
given secret data by choosing an appropriate cover image.
In this section, we shortly review the existing cover selec-
tion methods and then, we propose cover selection based on
embedding capacity.
3.4.1 Previous cover selection steganography methods
A cover selection technique for hiding a secret image in a
cover image was first introduced in [30]. This method oper-
ates based on image texture similarity and replaces some
blocks of a cover image with similar secret image blocks;
then, indices of secret image blocks are stored in the cover
image. In this cover selection method, the blocks of the
secret image are compared with the blocks of a set of cover
images and the image with most similar blocks to those of
the secret image is selected as the best candidate to carry the
Fig. 8 The block diagram of incremental embedding procedure to
determine the embedding capacity of cover images
secret image. An improvement on this method is proposed
in [31] that uses statistical features of image blocks and their
neighborhoods. Using block neighborhood information pre-
vents appearance of virtual edges in the sides and corners
of the replaced blocks. In [32], the cover selection problem
was studied by investigating three scenarios in which the
embedder has either no knowledge, partial knowledge, or
complete knowledge of the steganalysis method. In addition,
some measures for cover selection were introduced in [32]
as follows:
– Cardinality of changeable DCT coefficients;
– JPEG quality factor;
– Number of modifications of a cover image;
– Mean square error (MSE) obtained from cover-stego
image pairs;
– Local prediction error, which is the difference between
the mean prediction error of the cover and stego images;
– Watson’s metric [33] used for quantifying the quality of
JPEG images;
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 9/13
Secure steganography based on embedding capacity 441
– Structural similarity measure (SSIM) [34] quantifies the
similarity between the cover and stego images.
Most of the existing work in cover selection domain like
[31,32] assumed that the secret object is an image. We con-
sider binary bit sequences with random distribution as secret
objects
3.4.2 Cover selection based on embedding capacity
In Sect. 3, we described a new measure that can be used for
cover selection. In this way, to have a secure covert commu-
nication, the steganographer can select a cover image with
high embedding capacity from a database. The embedding
procedure canbe carried on by any steganography method. It
should be noted that the result of the cover selection scheme
depends onvarietyof imagesin thedatabase.Utilizinga data-
base, which has images with very different contents, could
result in more secure stego images.
4 Experimental results
To evaluate the effect of the proposed embedding capac-
ity measure on security of steganography methods, differ-
ent experiments were done. To train the SVM classifiers
that collaborate in determining the embedding capacity of
images, wecollected1,000 JPEG imagesin train-image data-
base from Washington University image database [35] and
some others from typical images. To test the performance of
the proposed method, we downloaded 1,000 JPEG images
from Internet to make test-image database. These images
are not used in training of SVM classifiers, which are uti-
lized to determine the embedding capacity of images. All the
images were converted to grayscale and then cropped to size
512 × 512.
An image may have different embedding capacities
depending on the steganography method used. We made
different distinct stego datasets and classifiers to determine
the embedding capacity of the image using each steganog-
raphy method. For example, to construct the structure for
determining the embedding capacity of the image using PQ
steganography method, we made stego datasets as follows.
Random binary data were embedded in images using PQ ste-
ganography method. In the PQ method, the ‘desired capac-
ity’ parameter that is defined for this algorithm was set to
different amounts to achieve 10 stego image datasets with
different payloads. For example, those images that have the
payload between 1,500 and 2,500 bits reside in 2,000-bit-
payload stego dataset. Each one of ten stego datasets has
1,000 stego images. Thus, totally, we have 11,000 images in
our image database, 1,000 clean images, and 10,000 stego
images. Input cover images and output stego images are in
JPEG formatwiththe quality factorof 70.Totrainthe SVMof
each steganalyzer that collaborates in computing the embed-
ding capacity, 2,000 (1,000 clean and 1,000 stego) images
from the train-image database were used. Each classifier is
a nonlinear SVM using RBF kernel with γ = 1. In RBF
kernel, γ determines the RBF width.
4.1 Incremental embedding to determine embedding
capacity of images
In this experiment some randomimagesare selected from the
database and their embedding capacity are determined when
the steganography method is PQ. To calculate the embed-
ding capacity of an image, the embedding rate is increased
steadily until the security of the produced stego image is
threatened by the ensemble steganalyzer. Figure 9 shows the
results. Since the embedding capacities are determined by
the ensemble steganalyzer, the security of these images with
mentioned payload is satisfied.
Although the time required for incremental embedding is
more than classical embedding, but since it provides more
secure stego images, its time complexity can be acceptable.
Due to differences in contents of various images, the time for
incremental embedding may differ from t to [(CI/1,000) ×
t × ETT]. t is the time needed by classical embedding and
ETT is Ensemble TestTime,which approximately is thesum
of time that each steganalyzer unit takes in the ensemble ste-
ganalyzer. In incremental embedding, the size of payload is
increased by 1,000 bits in each iteration. Hence, the num-
ber of iterations is CI/1,000. At the end of each iteration,
the ensemble steganalyzer evaluates the security of the stego
image. For example if the embedding capacity of an image
is 10,000 bits, both usual embedding and ensemble stegan-
alyzer work 10 times. The most time consuming part in a
steganalyzer unit is feature extraction part of steganalyzers.
Therefore, ETT is computed as Eq. (8).
Ensemble test time (ETT)
≈ (274-dim FET+ 324-dim FET+WBS FET) (8)
where Feature Extraction Time (FET) is the time that fea-
ture extraction part of a steganalyzer takes.Theexperimental
results are carried out on a 2,046 MB PIV processor using
MATLAB 7.6.0 and lib-SVM software [36]. In such envi-
ronment, the average time for incremental embedding in
one image is around 2min. It should be noted that Matlab
codes are usually nine or ten times slower than their C/C++
equivalents [37]. Since the main goal of steganography is to
embed thesecretdata securely and if any of thesteganalyzers
gets suspicious, the purpose of steganography is broken, it
is worth to spend time further to make stego images more
secure.
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 10/13
442 H. Sajedi, M. Jamzad
Fig. 9 Some cover images with
embedding capacity of 3,000,
5,000, and 10,000 bits using PQ
steganography method
Embedding Capacity Cover image with a certain embedding capacity
3000 bits
4500 bits
9000 bits
4.2 Cover selection based on embedding capacity of images
For cover selection purpose, a batch process determines the
embedding capacity of every image in the database and the
results are stored in a feature database.When thesteganogra-
pher wants to select a cover image, he can refer to the feature
database and choose an image that can hold his secret data
securely. All the images that their embedding capacities are
greater than a secret data size are proper to hold the data.
In this approach, the steganographer can select one of the
proper images suggested by the proposed method to embed
the certain payload. Figure 10 shows the results of our cover
selectionmethodwhen thepayloads are2,000 and5,800 bits.Theupper fiveimageshaveembeddingcapacity of 2,000 bits
and the lower five images have embedding capacity of 5,800
bits. In addition, a secret data with a large size can be hidden
in more than one image securely if its size is larger than the
embedding capacity of one image.
4.3 Relation between complexity and embedding capacity
of images
The following experiment is arranged to investigate the rela-
tion between the complexity of an image and its correspond-
ing stego image detectability against steganalyzers. For this
purpose, first we group all the images in the test-image data-
base once based on embedding capacity, and another time
based on complexity. The correlation between these two sep-
arationsdemonstrates the relationbetween imagecomplexity
and embedding capacity. We use two complexity definitions
for categorizing of images as following:
1. Quad-Tree-based complexity measure. This complex-
ity measure proposed in [38] is calculated according to
quad-tree representation of an image by Eq. (9).
C =
ni=1
(2 xi )i (9)
where n is the number of quad-tree levels and xi refers
to the number of nodes at level i.
2. Uniformity-based complexity measure. One way of
evaluating the uniformity of an image as a complex-
ity measure is employment of its co-occurrence matrix
[39].
Due to the wide range of image complexity values, we
compute the logarithm of each image complexity value and
divide therange of results to five equal intervalsnamely, very
low, low, middle, high andvery high image complexity. Then
the embedding capacity of each image is computed and at
last, the average value and the standard deviation of embed-
ding capacities in each group are achieved. Table 1 shows
the relation between the complexity of all the images in the
database and their embedding capacities. In other represen-
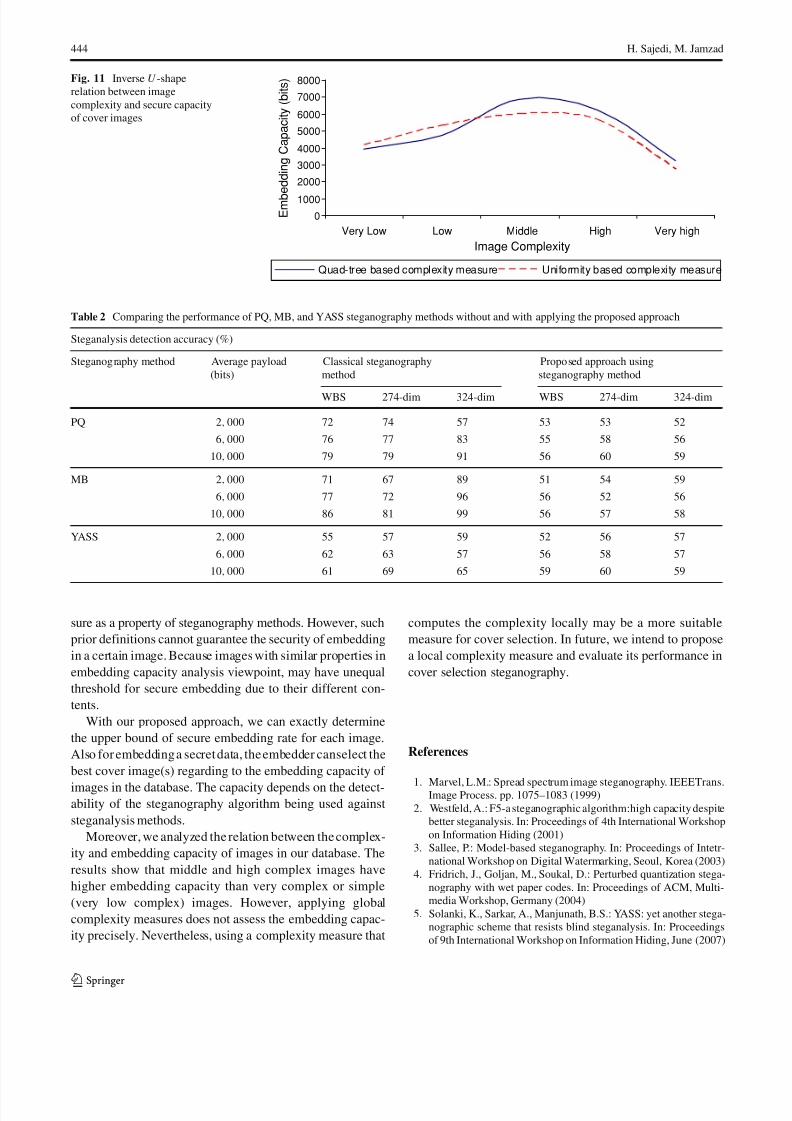
tation, the correlation analysis in Fig. 11 reveals an inverse
U -shaped relation between image complexity and embed-
ding capacity of cover images using PQ steganography
method. This relation is true in applying MB and YASS ste-
ganography methods as well.
The experimental results showed that using Quad-tree-
and Uniformity-based complexity measures, it is preferred
to select a high capacity cover image among low, middle,
and high complexity images in the database. In contrast,
very high and very low complexity images do not have a
high embedding capacity. On the other hand, steganalysis
methods extract some features from cover and stego images
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 11/13
Secure steganography based on embedding capacity 443
Fig. 10 Cover selection based
on image capacity. For each
secret data size, five most proper
cover images are shown for
applying PQ steganography
method
secret data size suitable covers
2000 bits
5800 bits
Table 1 Relation between
complexity and embedding
capacity of images
Image complexity Embedding capacity
Average (bits) Standard deviation (bits)
Quad-tree based complexity measure
Very low 3,921 1,931
Low 4,713 1,698
Middle 6,832 2,942
High 6,234 3,428
Very high 3,201 2,411
Uniformity complexity (bits)
Very low 4,132 2,507
Low 5,288 2,826
Middle 5,986 2,710
High 5,663 3,208
Very high 2,698 2,549
and use a learning method to train a classifier. The features
can be extracted in spatial domain, transform domains such
as DCT, or several domains. Mostly steganalysis methods
divide images to blocks of size 8 × 8, and extract inter and
intra features from the blocks. Therefore, if an image has
parts with different complexities (i.e. complex and noncom-
plex), extracted features will have a large variance and the
steganalyzers cannot learn and vote about the image reliably.
Therefore, we canconclude that steganalyzers mayfail on
detectionof stego images if theyhaveheterogeneouscontents
with different textures and various sizes of textones with dis-similar shapes.
4.4 Performance of the proposed approach
The proposed approach can be used by every existing stega-
nography method. In fact, the cover selection idea proposed
in this paper is a preprocessing routine that can improve the
performance of the existing steganography algorithms.
Table2 shows the detection accuracy of three stegana-
lyzers on the proposed approach using PQ, MB, and YASS
steganographymethodsandtheclassical usage of thesemeth-
ods. As we see, our approach provides higher security than
classicalsteganographymethods.The resultsobviouslyshow
that the stego images, which are produced by the proposed
approach, are less detectable than the stego images con-
structed by classical use of steganography methods.
Employing WBS, 274-dim, and 324-dim steganalysis
methods, to train the SVM of each steganalyzer, 1,200 (600
clean and 600 stego) images from the test-image databasewere used. The remaining 800 images are used for testing.
5 Conclusion
In this paper, we define embedding capacity in the presence
of multiple steganalyzers, as a property of images regarding
to the constraints of the steganography method that is used.
Previous works have considered embedding capacity mea-
123
8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 12/13
444 H. Sajedi, M. Jamzad
Fig. 11 Inverse U -shape
relation between image
complexity and secure capacity
of cover images
0
1000
2000
3000
4000
5000
6000
7000
8000
Very Low Low Middle High Very high
Image Complexity
E m b
e d d i n g C a p a c i t y ( b i t s )
Quad-tree based complexity measure Uniformity based complexity measure
Table 2 Comparing the performance of PQ, MB, and YASS steganography methods without and with applying the proposed approach
Steganalysis detection accuracy (%)
Steganography method Average payload Classical steganography Proposed approach using
(bits) method steganography method
WBS 274-dim 324-dim WBS 274-dim 324-dim
PQ 2, 000 72 74 57 53 53 52
6, 000 76 77 83 55 58 56
10, 000 79 79 91 56 60 59
MB 2, 000 71 67 89 51 54 59
6, 000 77 72 96 56 52 56
10, 000 86 81 99 56 57 58
YASS 2, 000 55 57 59 52 56 57
6, 000 62 63 57 56 58 57
10, 000 61 69 65 59 60 59
sure as a property of steganography methods. However, such
prior definitions cannot guarantee the security of embedding
in a certain image. Because imageswith similar properties in
embedding capacity analysis viewpoint, may have unequal
threshold for secure embedding due to their different con-
tents.
With our proposed approach, we can exactly determine
the upper bound of secure embedding rate for each image.
Also forembeddinga secretdata, theembedder canselect the
best cover image(s) regarding to the embedding capacity of
images in the database. The capacity depends on the detect-ability of the steganography algorithm being used against
steganalysis methods.
Moreover, we analyzed the relation between thecomplex-
ity and embedding capacity of images in our database. The
results show that middle and high complex images have
higher embedding capacity than very complex or simple
(very low complex) images. However, applying global
complexity measures does not assess the embedding capac-
ity precisely. Nevertheless, using a complexity measure that
computes the complexity locally may be a more suitable
measure for cover selection. In future, we intend to propose
a local complexity measure and evaluate its performance in
cover selection steganography.
References
1. Marvel, L.M.: Spread spectrum image steganography. IEEETrans.Image Process. pp. 1075–1083 (1999)
2. Westfeld,A.: F5-asteganographic algorithm:high capacity despite
better steganalysis. In: Proceedings of 4th International Workshop
on Information Hiding (2001)
3. Sallee, P.: Model-based steganography. In: Proceedings of Intetr-
national Workshop on Digital Watermarking, Seoul, Korea (2003)
4. Fridrich, J., Goljan, M., Soukal, D.: Perturbed quantization stega-
nography with wet paper codes. In: Proceedings of ACM, Multi-
media Workshop, Germany (2004)
5. Solanki, K., Sarkar, A., Manjunath, B.S.: YASS: yet another stega-
nographic scheme that resists blind steganalysis. In: Proceedings
of 9th International Workshop on Information Hiding, June (2007)
123

8/2/2019 Secure Steganography
http://slidepdf.com/reader/full/secure-steganography 13/13
Secure steganography based on embedding capacity 445
6. Sajedi, H., Jamzad, M.:Adaptive Steganography Method Based on
ContourletTransform. In: Proceedings of 9th International Confer-
ence on Signal Processing, pp. 745–748 (2008)
7. Chandramouli, R., Memon, N.D.: Steganography capacity: a steg-
analysis perspective. Proc. SPIE Secur. Watermarking Multimed.
Contents 5020, 173–177 (2003)
8. Fridrich, J., Pevny, T., Kodovsky, J.: Statistically Undetectable
JPEG Steganography: Dead Ends, Challenges, and Opportunities.
MM&Sec. ACM, Dallas (2007)
9. Cachin, C.: An information-theoretic model for steganography. In:
Proceedingsof 2nd InternationalWorkshop on Information Hiding.
LNCS, vol. 1525, pp. 306–318 (1998)
10. Moulin, P., Mihcak, M.K.: A framework for evaluating the
data hiding capacity of image sources. IEEE Trans. Image Pro-
cess. 11, 1029–1042 (2002)
11. Dong, Y., Han, K.:Boosting SVMclassifiers by ensemble. In:Pro-
ceedings of 14th International Conference of ACMon World Wide
Web, pp. 1072–1073 (2005)
12. Ker, A.D.: A Batch steganography and pooled steganalysis. Proc.
Inf. Hiding Workshop 4437, 265–281 (2006)
13. Ker, A.D.: A capacity result for batch steganography. IEEE Signal
Process. Let. 14(8), 525–528 (2007)
14. Martin, A., Sapiro, G., Seroussi, G.: Is Image Steganography Nat-
ural? Technical Report, Information Theory Research Group, HP
Laboratories Palo Alto (2004)
15. Kharrazi, M., Sencar, T.H., Memon, N.: Benchmarking stegano-
graphic and steganalysis, techniques. EI SPIE, San Jose (2005)
16. Avcibas, I., Kharrazi, M., Memon, N., Sankur, B.: Image steganal-
ysis with binary similarity measures. EURASIP J. Appl. Signal
Process. (2005)
17. Lyu, S., Farid, H.: Detecting hidden messages using higher-order
statisticsand support vector machines. In:Proceedingsof 5th Inter-
national Workshop on Information Hiding (2002)
18. Lyu, S., Farid, H.: Steganalysis using color wavelet statistics and
one-classsupport vector machines.SPIE Symposiumon Electronic
Imaging, San Jose, CA (2004)
19. Fridrich, J.: Feature-based steganalysis for jpeg images and its
implications for future design of steganographic schemes. In: Pro-
ceedings of 6th International Workshop on Information Hiding,Toronto (2004)
20. Dietterich, T.G.: Ensemble methods in machine learning. Multiple
Classifier Systems. LNCS, vol. 1857, pp. 1–15. Springer, Heidel-
berg (2001)
21. Freund, Y., Schapire, R.: A short introduction to boosting. J. Jpn.
Soc. Artif. Intell. 14(5), 771–780 (1999)
22. Qing, T., Jue, W.: A new fuzzy support vector machine based on
the weighted margin. Neural Process. Lett.20(3), 139–150 (2004)
23. Zhang, L., Lin, F., Zhang, B.: Support vector machine learning for
image retrieval. In: Proceedings of IEEE International Conference
on Image Processing, pp. 721–724 (2001)
24. Burges, C.J.C.: A tutorial on support vector machines for pattern
recognition. Data Min. Knowl. Discov.2, 121–167 (1998)
25. Meyer, D., Leisch, F., Hornik, K.: The support vector machine
under test. Neurocomputing 55, 169–186 (2003)
26. Pevny T., Fridrich J.: Merging Markov and DCT features for
multi-class JPEG steganalysis. In: Proceedings of SPIE, San Jose,
CA (2007)
27. Sarkar, A., Solanki, K., Manjunath, B.S.: Further study on YASS:
steganography basedon randomized embeddingto resist blindsteg-
analysis. In: Proceedings of SPIE Security, Steganography, and
Watermarking of Multimedia Contents (2008)
28. Chen, C.,Shi, Y.Q., Chen, W., Xuan, G.:Statisticalmomentsbased
universal steganalysis using JPEG-2D array and 2-D characteristic
function. In: Proceedings of ICIP, Atlanta, GA, USA, pp. 105–108
(2006)
29. Xuan, G.,Shi, Y.Q., Gao, J.,Zou, D.,Yang,C., Yang, C.,Zhang, Z.,
Chai, P., Chen, C., Chen, W.: Steganalysis based on multiple fea-
tures formed by statistical moments of wavelet characteristic func-
tions. In: Proceedings of 7th International Workshop on Informa-
tion Hiding (2005)
30. Kermani, Z.Z., Jamzad, M.: A robust steganography algorithm
based on texture similarity using gabor filter. In: Proceedings of
IEEE Intrnational Symposium on Signal processing and Informa-
tion Technology, pp. 578–582 (2005)
31. Sajedi, H., Jamzad, M.: Cover selection steganography method
based on similarity of image blocks. In: Proceedings of IEEE 8th
CIT Conference, Sydney, Australia (2008)
32. Kharrazi, M., Sencar, H., Memon, N.: Cover Selection for stega-
nograpic embedding. In: Proceedings of ICIP, pp. 117–121 (2006)
33. Watson, B.A.: DCT quantization matrices visually optimized for
individual images, humanvision. In: VisualProcessingand Digital
Display IV, Proceedings of SPIE, vol. 1913, pp. 202–216 (2005)
34. Wang, Z., Bovik, A., Sheikh, H., Simoncelli, E.: Perceptual image
quality assessment: from error visibility to structural similar-
ity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
35. http://www.cs.washington.edu/research/imagedatabase
36. Chang, C.-C., Lin, C.-J.: Libsvm: a library for support vector
machine. 2007. Software available athttp://www.csie.ntu.edu.tw/
~cjlin/libsvm37. Cho, K., Jang, J., Hong, K.:Adaptive skin-color filter. Pattern Rec-
ognit. 34(5), 1067–1073 (2001)
38. Jamzad, M., Yaghmaee, F.: Achieving higher stability in water-
marking according to image complexity. Sci. Iran. J. 13(4),
404–412 (2006)
39. Haller,R.S.:Complexity of Real Images Evaluated by Densitomet-
ric Analysis and by PsychophysicalScaling. M.Sc. Thesis, Univer-
sity of Arizona (1970)
123
Related Documents










