A Random Graph Walk based Approach to Computing Semantic Relatedness Using Knowledge from Wikipedia Presenter: Ziqi Zhang OAK Research Group, Department of Computer Science, University of Sheffield Authors: Ziqi Zhang, Anna Lisa Gentile, Lei Xia, José Iria, Sam Chapman

A Random Graph Walk based Approach to Computing Semantic Relatedness Using Knowledge from Wikipedia Presenter: Ziqi Zhang OAK Research Group, Department.
Dec 25, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Random Graph Walk based Approach to Computing Semantic
Relatedness Using Knowledge from Wikipedia
Presenter: Ziqi ZhangOAK Research Group, Department of Computer Science,
University of SheffieldAuthors: Ziqi Zhang, Anna Lisa Gentile, Lei Xia, José Iria,
Sam Chapman

• Introduction to semantic relatedness
• Motivation to this research
• Methodology: random walk, Wikipedia, semantic relatedness
• Experiment and Evaluation: computing semantic relatedness, semantic relatedness for named entity disambiguation
In this presentation…In this presentation…

• Semantic relatedness (SR) measures how much words or concepts are related by encompassing all kinds of relations between them
Semantic RelatednessSemantic Relatedness > Introduction
LREC
computer science
Malta
ACL
COLING
computational linguistics
Volcano ashes
Airline
??
• It captures broader sense than semantic similarity• It enables many complex NLP tasks, e.g., sense
disambiguation, lexicon construction

• Typically, lexical resources (e.g., WordNet, Wikipedia) are needed to provide structural and content information about concepts
Method and LiteratureMethod and Literature > Introduction
• Relatedness is computed by aggregating and balancing these “semantic” elements using mathematical formula
• Some best known works: Resnik (1995), Leacock & Chodorow (1998), Strube & Ponzetto (2006), Zesch et al. (2008), Gabrilovich & Markovitch (2007)
• Recent trend: towards using collaborative lexical resources, such as Wikipedia, Wiktionary

• Wikipedia contains rich and diverse structural and content information about concepts and entities
Another SR measure, why?Another SR measure, why? > Motivation
TitleTitle
RedirectRedirect
Content words
Content words
LinksLinks
ListsLists
InfoboxInfobox
CategoryCategory
On a Wiki page:
• Which are useful for SR? Which are more useful than others?
• Can we combine them?• How to combine them?• Can we gain more if we combine them?

This paper aims to answer these questionsby
The ResearchThe Research > Motivation
Proposing a method that naturally integrates diverse features in a balanced way, and
studying the importance of different features

Overview of the methodOverview of the method> Methodology
“NLP”
“ComputationalLinguistics”
WikiPage
Retrieval
WikiPage
Retrieval
FeatureExtraction
FeatureExtraction
“NLP” F. 1F. 1
F. 2F. 2F. 3F. 3
weight=x
weight=y
weight=z
Random Walk
Random Walk
“NLP”
F. 1F. 1
F. 3F. 3
F. 2F. 2
“ComputationalLinguistics”
F’. 1
F’. 1
F’. 3
F’. 3
F’. 2
F’. 2
Rel?
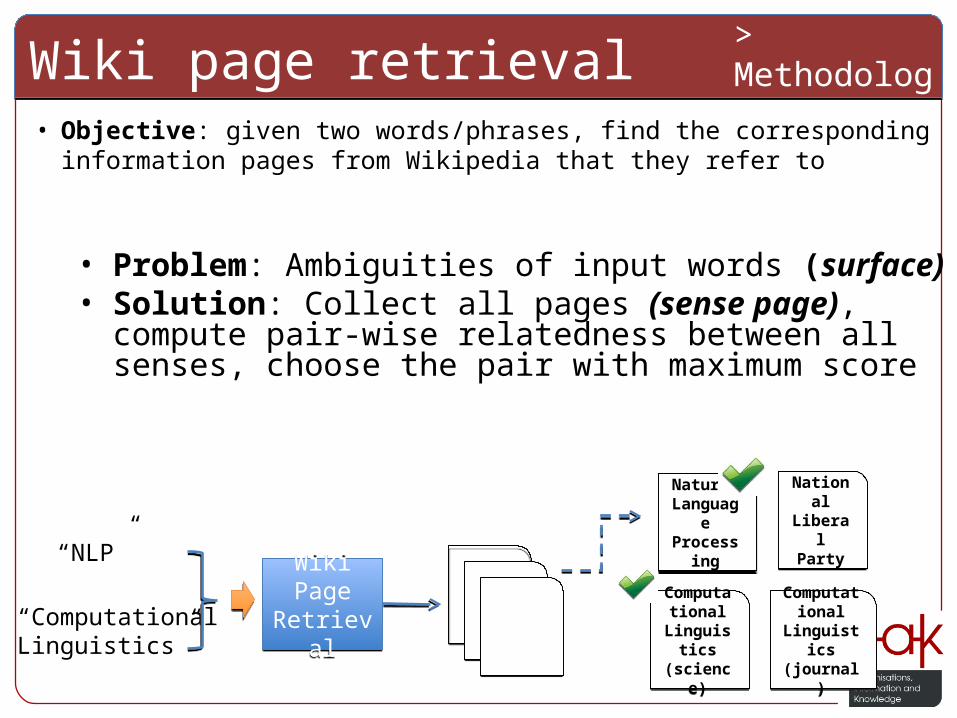
Wiki page retrievalWiki page retrieval> Methodology
• Objective: given two words/phrases, find the corresponding information pages from Wikipedia that they refer to
“ComputationalLinguistics”
WikiPage
Retrieval
WikiPage
Retrieval
“NLP”
• Problem: Ambiguities of input words (surface)• Solution: Collect all pages (sense page), compute pair-wise
relatedness between all senses, choose the pair with maximum score
Natural Language
Processing
Natural Language
Processing
National Liberal Party
National Liberal Party
Computational
Linguistics (science)
Computational
Linguistics (science)
Computational
Linguistics (journal)
Computational
Linguistics (journal)

Feature ExtractionFeature Extraction> Methodology
• Objective: identify useful features to represent each sense of a surface for algorithmic consumption
• Page title and redirect target• Content words from the first section; or top n frequent
words from the entire page
• Page categories (search depth = 2)
• Outgoing link target in list structure
• Other outgoing link targets
• Descriptive/Definitive noun (first noun phrase after be in the first sentence)
• All features formulated at word-level
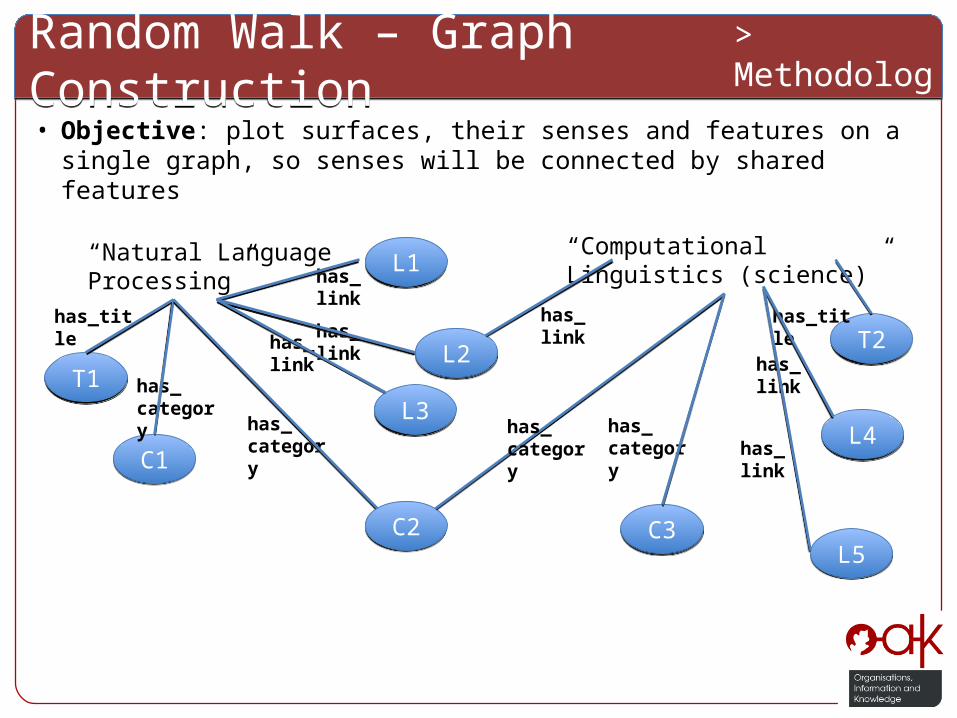
Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
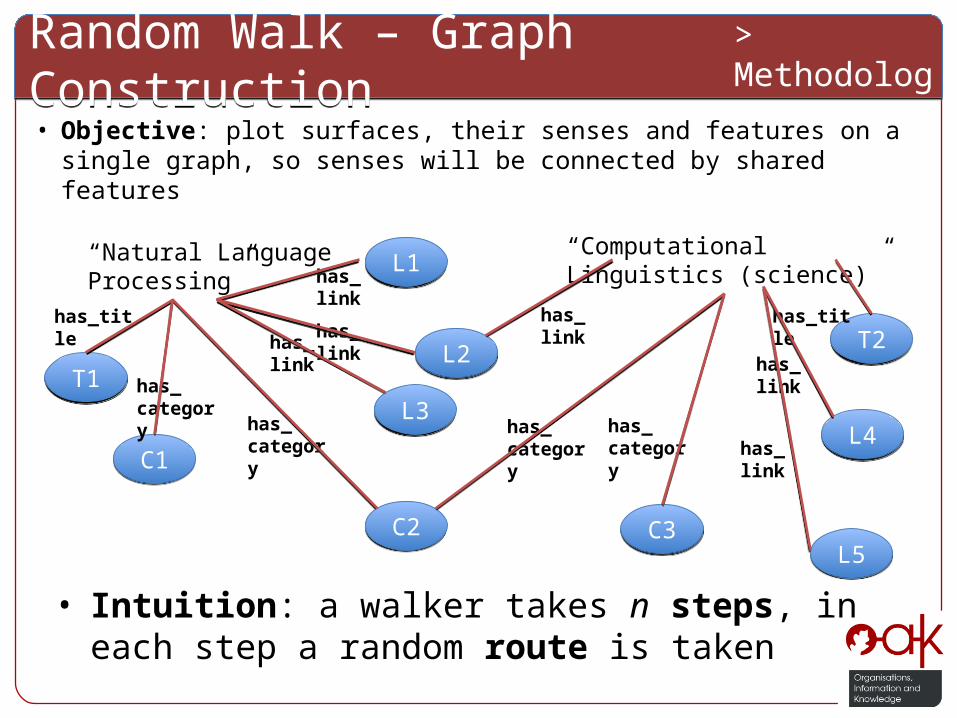
Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
• Intuition: a walker takes n steps, in each step a random route is taken
has_category

Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
• Intuition: a walker takes n steps, in each step a random route is taken

Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
• Intuition: starting from a node, in n step, one can reach a limited set of other nodes.

Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
• Intuition: the more routes connecting the desired end nodes, and the more likely the routes are taken, the more relevant two senses are

Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
• Intuition: the more routes connecting the desired end nodes, and the more likely the routes are taken, the more relevant two senses are
Routes are established by
feature extraction and graph
construction
Routes are established by
feature extraction and graph
construction

Random Walk – Graph ConstructionRandom Walk – Graph Construction> Methodology
• Objective: plot surfaces, their senses and features on a single graph, so senses will be connected by shared features
“Natural Language Processing”
T1T1L3L3
C1C1
“Computational Linguistics (science)”
has_title
has_category
has_category
has_link
has_link
has_link
C2C2
L2L2
L1L1
T2T2
C3C3
has_title
has_category L4L4
has_link
L5L5
has_link
has_link
has_category
• Intuition: the more routes connecting the desired end nodes, and the more likely the routes are taken, the more relevant two senses are
“Likelihood” is modelled by
importance of each type of feature, and
to be studied by experiments
“Likelihood” is modelled by
importance of each type of feature, and
to be studied by experiments

Random Walk – The MathRandom Walk – The Math> Methodology
• Random walk is simulated via matrix calculation and transformation
• Adjacency matrix modelling distribution of weights for different features
• T-step random walk is achieved by matrix calculation
• Translating probability to relatedness

Experiment & EvaluationExperiment & Evaluation> Experiment
• The experiments are designed to achieve three objectives– Analyse the importance of each proposed feature – Evaluate effectiveness of the random walk method for
computing semantic relatedness– Evaluate the usefulness of the method for solving other NLP
problems – Named Entity Disambiguation (NED)

Feature AnalysisFeature Analysis> Experiment
• Simulated Annealing optimisation (Nie et al., 2005) method is used to perform the analysis, in which– 200 pair of words from WordSim353 is used– To begin with, we treat each feature equally by assigning same
weights (weight model)– Compute SR using the weight model, and evaluate against the
gold standard– Hundreds of iterations are run, in each turn, different weight
model is generated randomly– Manually analysing the weight model that contribute to the
highest performance achieved on this dataset, eliminating least important features or combining them into other features that are semantically similar

Feature Analysis - findingsFeature Analysis - findings> Experiment
Weight Feature
0.166 Title (incl. redirect target)
0.166 First section words
0.166 Categories
0.166 Descriptive nouns
0.166 Out links in lists
0.166 Other out links
Achieved best accuracy of 0.45 on the data, compared to best in the literature of 0.5 by Zesch et al. (2008)

Feature Analysis - findingsFeature Analysis - findings> Experiment
Weight Feature
0.166 Title (incl. redirect target)
0.166 First section words
0.166 Categories
0.166 Descriptive nouns
0.166 Out links in lists
0.166 Other out links
This setting is then used for further evaluation

Evaluating Computation of SREvaluating Computation of SR> Experiment
• Three datasets are chosen: different set of 153 pairs of words from WordSim353; 65 pairs from Rubenstein &Goodenough (1965), RG65; 30 pairs from Miller & Charles (1991), MC30
• Compared against: a collection of WordNet-based algorithms and other state-of-the-art methods for SR
WordSim353-153
RG65 MC30 WordSim353 -200 feature analysis
Ours 0.71 0.76 0.71 0.46
Strube & Ponzetto (2006) 0.55 0.69 0.67 /
Zesch et al. ESA (2008) 0.62 / / 0.31
Zesch et al. Wiki (2008) 0.7 0.76 0.68 0.5
Zesch et al. Wiktionary (2008) 0.7 0.84 0.84 0.6
Best of WordNet 0.39 0.79 0.81 0.23

Evaluating Usefulness of SR for NEDEvaluating Usefulness of SR for NED> Experiment
• The NED method in a nutshell (Details: Gentile et al., 2009)• Identify surfaces of NEs that occur in a text passage and
that are defined by Wikipedia, retrieve corresponding sense pages
• Computing SR of each pair of their underlying senses • The sense of a surface is determined collectively by the
senses of other surfaces found in the text (contexts)• Three functions are defined to capture this collective
context

Evaluating Usefulness of SR for NEDEvaluating Usefulness of SR for NED> Experiment
• Dataset: 20 news stories by Cucerzan (2007), each story contains 10 – 50 NEs
Accuracy
Our best 91.5
Our baseline 68.7
Cucerzan baseline 51.7
Curcerzan best 91.4

ConclusionConclusion• Computing SR isn’t an easy task
• Different structural and content information in Wikipedia all contribute to the task, but in different weights
• Combining these different features in a uniform measure can improve performance
• Can we use simpler similarity functions to obtain same results?
• Can we integrate different lexical resources?• How to compute relatedness/similarity of longer text
passages?
In future

Thank you!Thank you!
• Cucerzan, S. (2007). Large-Scale Named Entity Disambiguation Based on Wikipedia Data. In EMNLP’07• Finkelstein, L., Gabrilovich, E., Matias, Y., Rivlin, E., Solan, Z., Wolfman, G., and Ruppin, E. (2002). Placing search
in context: the concept revisited. In ACM Transactions on Information Systems, 20 (1), pp. 116 – 131 • Gabrilovich, E., Markovitch, S. (2007). Computing semantic relatedness using Wikipedia-based explicit
semantic analysis. In Proceedings of IJCAI’07, pp. 1606-1611 • Gentile, A., Zhang, Z., Xia, L., Iria, J. (2009). Graph-based semantic relatedness for named entity
disambiguation. In S3T• Leacock, C., Chodorow, M. (1998). Combining local context and WordNet similarity for word sense
identification. In C. Fellbaum (Ed.), WordNet. An Electronic Lexical Database, Chp. 11, pp. 265-283.• Miller, G., Charles, W. (1991). Contextual correlates of semantic similarity. In Language and Cognitive
Processes, 6(1): 1-28• Nie, Z., Zhang, Y., Wen, J., Ma, W. (2005). Object-level ranking: bringing order to web objects. In Proceedings of
WWW’05• Resnik, P. (1995). Using information content to evaluate semantic similarity in a taxonomy. In Proceedings of
IJCAI-95, pp. 448-453 • Rubenstein, H., Goodenough, J. (1965). Contextual correlates of synonymy. In Communications of the ACM,
8(10):627-633 • Strube, M., Ponzetto, S. (2006). WikiRelate! Computing semantic relatedness using Wikipedia. In AAAI’06• Zesch, T., Müller, C., Gurevych, I. (2008). Using Wiktionary for computing semantic relatedness. In Proceedings
of AAAI’08
References (complete list can be found in paper)
Related Documents











