
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A PROBABILISTIC ANALYSIS OF A PATTERN MATCHING PROBLEMJuly 9, 1992Mikhail J. Atallah� Philippe Jacquety Wojciech SzpankowskizDept. of Computer Science INRIA Dept. of Computer SciencePurdue University Rocquencourt Purdue UniversityW. Lafayette, IN 47907 78153 Le Chesnay Cedex W. Lafayette, IN 47907U.S.A. France U.S.A.AbstractThe study and comparison of strings of symbols from a �nite or an in�nite alphabetis relevant to various areas of science, notably molecular biology, speech recognition, andcomputer science. In particular, the problem of �nding the minimum "distance" betweentwo strings (in general, two blocks of data) is of great importance. In this paper we in-vestigate the (string) pattern matching problem in a probabilistic framework, namely, itis assumed that both strings form an independent sequences of i.i.d. symbols. Given atext string a of length n and a pattern string b of length m, let Mm;n be the maximumnumber of matches between b and all m-substrings of a. Our main probabilistic resultshows that Mm;n �mP = �(p2m log n) in probability (pr.) provided m;n!1 such thatlog n = o(m), where P is the probability of a match between any two symbols of thesestrings. If the alphabet is symmetric (i.e., all symbols occur with the same probability),a stronger result holds, namely (Mm;n � mP ) � p2m(1=V � 1=V 2) log n (pr.), where Vis the size of the alphabet. In either case, symmetric alphabet or not, we also prove thatMm;n=m! P almost surely (a.s).�This author's research was supported by the O�ce of Naval Research under Grants N0014-84-K-0502and N0014-86-K-0689, and in part by AFOSR Grant 90-0107, and the NSF under Grant DCR-8451393, andin part by Grant R01 LM05118 from the National Library of Medicine.yThis research was primary supported by NATO Collaborative Grant 0057/89.zThis author's research was supported by AFOSR Grant 90-0107 and NATO Collaborative Grant0057/89, and, in part by the NSF Grant CCR-8900305, and by Grant R01 LM05118 from the NationalLibrary of Medicine. 1

1. INTRODUCTIONPattern matching is one of the most fundamental problems in computer science. It isrelevant to various areas of science, notably molecular biology, speech recognition, theoryof languages, coding, and so forth. For example, in molecular biology often one comparestwo, say DNA, sequences to detect an unusual homology (similarity) between these strings.Comparisons of blocks of data representing, say time series of physical measurements, prices,etc., also lead to string comparisons, but with possibly in�nite alphabets. In general, theproblem of �nding the minimum "distance" between two strings is of great importance.The version of the string matching problem we investigate here is the following one.Consider two strings, a text string a = a1a2:::an and a pattern string b = b1b2:::bm oflengths n and m respectively, such that symbols ai and bj belong to a V -ary alphabet� = f1; 2; :::; V g. The alphabet may be �nite or not. Let Ci be the number of positions atwhich the substring aiai+1:::ai+m�1 agrees with the pattern b (the index j that is out ofrange is understood to stand for 1+(j mod n)). That is, Ci =Pmj=1 equal(ai+j�1; bj) whereequal(x; y) is one if x = y, and zero otherwise. In other words, the "distance" between aand b is the Hamming distance. We are interested in the quantity Mm;n = max1�i�nfCigwhich represents the best matching between b and any m-substring of a.We analyze Mm;n under the following probabilistic assumption: symbols from the al-phabet � are generated independently, and symbol i 2 � occurs with probability pi. Thisprobabilistic model is known as the Bernoulli model [26]. An estimate of Mm;n can be usedin various statistical tests, for example in the usual hypothesis-testing context in which oneneeds to detect a "signi�cant" matching. In that context, a matching is considered signi�-cant when it is much larger than the one obtained for random strings, that is, than Mm;n;indeed, if even random independent strings give rise to a match of Mm;n, it is reasonablenot to attach particular signi�cance to this amount of \similarity" between two strings.Furthermore, an estimate of Mm;n can be used to control some parameters of algorithmsdesigned for pattern matching, as we did in Atallah et al. [8].Our main probabilistic result concerning Mm;n can be summarized as follows. We provethat with high probabilityMm;n�mP = �(p2m log n) for n;m!1 such that log n = o(m)where P is the probability that two symbols match. The restriction on n andm is important.We explicitly give the constants that are implicit in the �(�) notation. Our simulation exper-iments indicate that the second term inMm;n, that is, �(p2m log n), spreads in probabilitybetween these two bounds, that is, we conjecture that the second term is rather a randomvariable than a constant. However, for the symmetric alphabet (i.e., all symbols occur with2

the same probability) stronger result holds, namely (Mm;n�mP ) � p2m(1=V � 1=V 2) log n(pr.). In either case { symmetric alphabet or not { we demonstrate that almost surely (a.s.)Mm;n=m! P as long as logn = o(m).A probabilistic analysis of any pattern matching is a "very complicated\ problem asasserted by Arratia, Gordon and Waterman [7]. In fact, the literature on probabilisticanalysis of pattern matching is very scanty. To the best of our knowledge, it is restrictedto three papers of Arratia, Gordon and Waterman [5, 6, 7], however, only [7] is relevant toour study. Papers [5, 6] investigate the Erd�os-R�enyi law for the longest contiguous run ofmatches. Only in [7] is the number of matches in a segment of length m investigated. Thislast problem resembles the one discussed in this paper, however the authors of [7] restrictthemselves to log n = �(m) while we analyze the case when log n = o(m). Finally, it shouldbe mentioned that our formulation of the problem is an attempt to study a more importantproblem of deletion, insertion and substitution developed during the evolution of nucleotidesequences (cf. Apostolico et al. [4], Louchard and Szpankowski [23]).Algorithmic issues of pattern matching (with possible mismatches) are discussed inseveral papers. The problem of pattern matching with mismatches was posed by Galil [15]for the case of more than one mismatch. Of course, it has a linear time solution for thecase of zero mismatch (i.e., k = m). For the case of a single mismatch (i.e., k = m � 1)a linear time solution is also known (attributed to Vishkin in [15]). The best known timebound for the general case of arbitrary k is O(npmpolylog(m)) and is due to Abrahamson[1]. The elegant probabilistic method of Chung and Lawler [9] led to an algorithm ofO((n=m)k logm) time complexity on the average, assuming that k < m= logm+O(1) andthat the alphabet size is O(1).The paper is organized as follows. The next section makes a more precise statement ofour results. In particular, Theorem 2 contains our main probabilistic result. All proofs aredelayed until Section 3, which is also of independent interest. It discusses a fairly generalapproach that can be used to analyze pattern matching in strings. In that section we applyextensively the saddle point method [18] to evaluate necessary asymptotic approximations.2. MAIN RESULTSThis section presents our main results derived under the Bernoulli model discussedabove. Note that, in such a model, P = PVi=1 p2i represents the probability of a matchbetween a given position of the text string a and a given one in the pattern string b.All our asymptotic results are valid in the so called right domain asymptotic, that is, for3

log n = o(m). In fact, the most interesting range of values for m and n is such thatm = �(n�) for some 0 � � � 1. However, to cover the whole right domain asymptotics,we assume that � may also slowly converge to zero, that is, 1 � ��1 � o(m= logm) (forsimplicity of notation we write � instead of �n).Finally, for simplicity of the presentation, it helps to imagine that a is written on acycle of size n � 2m. Then, we call �i(b) the version of b written on the same cycle, andcyclically shifted by i positions relative to a.Note that Ci is the number of matches between a and b when b is shifted by i positions.In our cyclic representation, Ci can alternatively be thought of as the number of places onthe cycle in which a and �i(b) agree. It is easy to see that the distribution of Ci is binomial,hence for any i PrfCi = `g = m̀!P `(1� P )m�` : (1)Naturally, the average number of matches EC1 is equal to mP . Furthermore, Ci tendsalmost surely to its mean mP (by the Strong Law of Large Numbers [12]).Now we can present our �rst result regarding Mm;n = max1�i�nfCig which can beinterpreted as the amount of similarity between a and b.Theorem 1 If m and n are in the right domain asymptotic, that is , log n = o(m), thenlimm!1 Mm;nm = P (a:s:) (2)Proof. A lower bound on Mm;n follows from the fact that, by its de�nition, Mm;n must begreater than C1 which tends { by the Strong Law of Large Numbers { almost surely to mP .So, now we concentrate on an upper bound. We �rst establish the bound in probability (pr.)sense. From Boole's inequality we havePrfMm;n > rg = PrfC1 > r or C2 > r or ::: Cn > rg � nPrfC1 > rg : (3)It su�ces to show that for r � mP the above probability becomes o(1), that is, nPrfC1 >(1 + �)mPg = o(1). For this we need an estimate of the tail for the binomial distribution(1). Such an estimate is computed in Section 2 by the saddle point method. A simpler(and more general) approach, however, is necessary for the purpose of this proof. Wenote that C1 can be represented as a sum of m independent Bernoulli distributed randomvariables Xi, where Xi is equal to one when there is a match at the ith position, and zerootherwise. From the Central Limit Theorem we know that (C1 �EC1)=(pmP (1� P )) !4

N (0; 1), whereN (0; 1) is the standard normal distribution. Let Gm(x) be the distribution of(Pmi=1Xi �mEX1)=pm � varX1, and let �(x) be the standard normal distribution. Then,from Feller [12] Gm(x) = �(x) + e�x2=2p2� o(pm) ;where �(x) � e�x2=2xp2� . In (3), set r = mP + (1 + ")pm2P (1 � P ) log n. ThenPrfMm;n > mP + (1 + ")q2mP (1� P ) log ng � 1n" : (4)The above rate of convergence does not yet warrant the application of the Borel-Cantellilemma to prove (2), but clearly (4) proves Mm;n=m! P (pr.) in the right domain asymp-totic.To establish the stronger (a.s.) convergence, we proceed as follows. De�ne a subse-quence nr = s2r for some integers r and s. Let fMn = (Mm;n �mP )=p2m. Then, by (4)fMnr=plog nr � pP � P 2 (a.s.). To �nish the proof we need to extend this to all n. Notethat for a �xed s we can always �nd an r such that s2r � n � (s+1)2r. Furthermore, sincefMn is a stochastically increasing sequence, we havelimn!1 sup fMnplog n � limr!1 sup fM(s+1)2rplog(s+ 1)2r plog(s+ 1)2rplog s2r = pP � P 2 (a:s:) :This proves (2).Theorem 1 does not provide much useful information, and an estimate of Mm;n basedon it would be a very poor one. From the proof of Theorem 1 we learn, however, thatMm;n �EC1 = O(pm log n), hence the next term in the asymptotics of Mm;n plays a verysigni�cant role, and de�nitely cannot be omitted in any reasonable computation. The nexttheorem { our main result { provides an extension of Theorem 1, and shows how much themaximumMm;n di�ers from the average EC1. The proof of the above theorem will be givenin Section 3.Theorem 2 Under the hypothesis of Theorem 1 we also have for every " > 0limn!1Prf�(1� ") � Mm;n �mPp2m log n < ��(1 + ")g = 1 ; (5)where � = maxfq(1� �)(P � T ); qminf(P � T ); (1� �)�1gg (6)�� = minfpP � P 2; VXj=1 pjq1� pjg : (7)5

In the above, �1 = (P � T )(P � 3P 2 + 2T )6(T � P 2) ;where T =PVi=1 p3i .Remark 1. The lower bound (6) and the upper bound (7) are composed of two di�erentexpressions. None of the expressions is better than the other for the entire range of theprobabilities 0 < pi < 1. With respect to the lower bound, we can show that there existvalues of the probabilities fpigVi=1 such that either �2 = (1 � �)(P � T ) or �2 = minf(P �T ); (1��)�1g. The latter case clearly can occur. Surprisingly enough, the former case mayhappen too. Indeed, let one of the probability pi dominates all the others, e.g., p1 = 1� ".Then, we have either �2 = (1 � �)" + O("2) or �2 = minf2=3 � (1 � �)"; "g + O("2). For� close to one the former bound is tighter. With respect to the upper bound, we have asimilar situation. In most cases, ��2 = P � P 2. However, sometimes �� = PVi=1 pip1� pi.Indeed, this occurs for example for a binary alphabet with p1 < 0:1. 2Note that, when all the pi ! 1=V (the symmetric case) we have �1 !1. Thus, for all� < 1 we have � = �� = p1=V � 1=V 2. Thus, we obtain the following corollary.Corollary 1 If the alphabet is symmetric and � < 1, then for every " > 0 the followingholds limn!1Prf1� " < Mm;n �mPp2m(1=V � 1=V 2) log n < 1 + "g = 1 ; (8)that is, Mm;n �mP � p2m(1=V � 1=V 2) log n (pr.).In the last subsection we will extend the condition of the corollary to the limiting case� = 1.In order to verify our bounds forMm;n we have performed some simulation experiments,which are presented in Figures 1, 2, and 3. In these �gures we plot the experimental distri-bution function Prf(Mm;n�mP )=pmP (1� P ) � xg versus x. Our simulation experimentspresented in Figure 1 con�rm our theoretical result of Corollary 1. Namely, for the sym-metric alphabet, (Mm;n�mP )=pm log n) converges to a constant. But { surprisingly { thisis not true for an asymmetric alphabet, as indicated by Figures 2 and 3. In fact, based onthese simulations we conjecture, that (Mm;n�mP )=pm log n) converges in probability to arandom variable, say Z, which is not a degenerate one, except for the symmetric alphabet.A study of the limiting distribution of Z seems to be very di�cult. Our Theorem 2 providessome information regarding the behavior of the tail of the distribution of Z. In particular,6

Prf Mm;n�mPpmP (1�P ) < xg
Lower=Upperbound x0 2 4 6 8 100.0
0.2
0.4
0.6
0.8
1.0
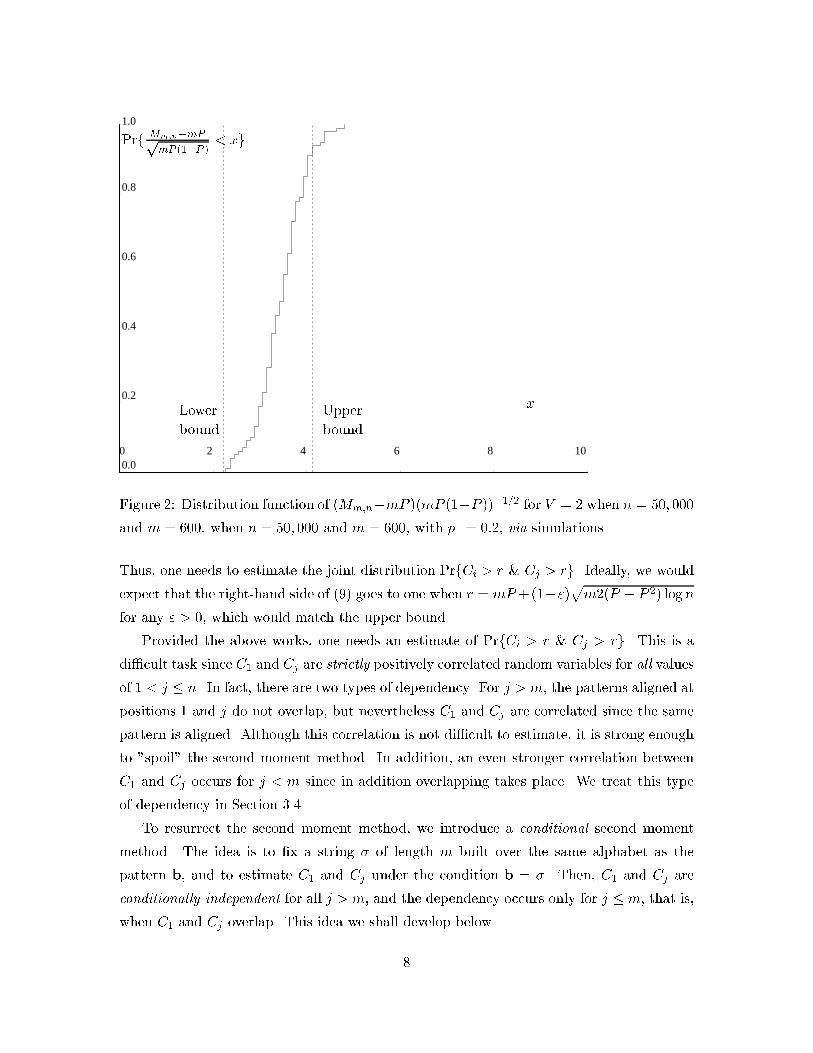
Figure 1: Distribution function of (Mm;n �mP )(mP (1 � P ))�1=2 for V = 2 with p1 = 0:5(symmetric case), via simulations.we know that Z degenerates for the symmetric alphabet, that is, possibly the variance ofZ becomes asymptotically zero in this case.3. ANALYSISIn this section, we prove our main result, namely Theorem 2. In the course of deriving it,we establish some interesting combinatorial properties of pattern matching that have somesimilarities with the work of Guibas and Odlyzko [16, 17] (see also [19]). The proof itselfconsists of two parts: the upper bound (cf. Section 3.2) and the more di�cult lower bound(cf. Section 3.3). Section 3.1 provides necessary mathematical background, and presentssome preliminary results.Before we plunge into technicalities, we present an overview of our approach. An upperbound on Mm;n is obtained from (3), or a modi�cation of it, and the real challenge is inestablishing a tight lower bound. The idea was to apply the second moment method, in theform of Chung and Erd�os [10] which states that for events fCi > rg, the following holdsPrfMm;n > rg = Prf n[i=1(Ci > r)g � (Pi PrfCi > rg)2Pi PrfCi > rg+P(i6=j) PrfCi > r & Cj > rg : (9)7
Prf Mm;n�mPpmP (1�P ) < xg
Lowerbound Upperbound x0 2 4 6 8 100.0
0.2
0.4
0.6
0.8
1.0
Figure 2: Distribution function of (Mm;n�mP )(mP (1�P ))�1=2 for V = 2 when n = 50; 000and m = 600, when n = 50; 000 and m = 600, with p1 = 0:2, via simulations.Thus, one needs to estimate the joint distribution PrfCi > r & Cj > rg. Ideally, we wouldexpect that the right-hand side of (9) goes to one when r = mP+(1�")pm2(P � P 2) log nfor any " > 0, which would match the upper bound.Provided the above works, one needs an estimate of PrfCi > r & Cj > rg. This is adi�cult task since C1 and Cj are strictly positively correlated random variables for all valuesof 1 < j � n. In fact, there are two types of dependency. For j > m, the patterns aligned atpositions 1 and j do not overlap, but nevertheless C1 and Cj are correlated since the samepattern is aligned. Although this correlation is not di�cult to estimate, it is strong enoughto "spoil" the second moment method. In addition, an even stronger correlation betweenC1 and Cj occurs for j < m since in addition overlapping takes place. We treat this typeof dependency in Section 3.4.To resurrect the second moment method, we introduce a conditional second momentmethod. The idea is to �x a string � of length m built over the same alphabet as thepattern b, and to estimate C1 and Cj under the condition b = �. Then, C1 and Cj areconditionally independent for all j > m, and the dependency occurs only for j � m, that is,when C1 and Cj overlap. This idea we shall develop below.8

Prf Mm;n�mPpmP (1�P ) < xg
Lowerbound Upperbound x0 2 4 6 8 100.0
0.2
0.4
0.6
0.8
1.0
Figure 3: Distribution function of (Mm;n � mP )(mP (1 � P ))�1=2 for V = 2 when n =100; 000 and m = 1000, with p1 = 0:1, via simulations.We introduce some notation. For a given �, we de�neG(r; �) = PrfC1 > rjb = �g ; (10)F (r; �) = mXi=2PrfC1 > r & Ci > r jb = �g (11)p(�) = Prfb = �g : (12)Considering our Bernoulli model, p(�) = Qj=Vj=1 pjj where the j denotes the number ofoccurrence of the symbol j in the string �. When � varies, we may consider the conditionalprobabilitiesG(r; �) and F (r; �) as random variables with respect to �. We adopt this pointof view.3.1 Preliminary ResultsIn this subsection, we put together several results concerning the tail of a binomiallydistributed random variable, that are used in the proof of our main results. If X is abinomially distributed random variable with parametersm and p, then we writeB(m; p; r) =PrfX > rg for the tail of X. We need the following result concerning the tail of C1.9

Lemma 1 When m and � both tend to in�nity such that � = O(logm), thenB(m;P;mP +pm�) = PrfC1 � mP +pm�g � 1p2�(P � P 2)� exp� ��2(P � P 2)� : (13)Proof: According to (1), C1 is binomially distributed, that is, PrfC1 = rg = �mr �P r(1 �P )m�r. Introducing the generating function C(u) =Pmr=1 PrfC1 = rgur for u complex, weeasily get the formula C(u) = (1 + P (u� 1))m. Then, by Cauchy's celebrated formula [18]PrfC1 � rg = 12i� I (1 + P (u� 1))m 1ur(u� 1)du ; (14)where the integration is along a path around the unit disk for u complex. The problem ishow to evaluate this integral for large m. In this case the best suited method seems to bethe saddle point method [18, 13]. This method applies to integrals of the following formI(m) = ZP �(x)e�mh(x)dx ; (15)where P is a closed curve, and �(x) and h(x) are analytical functions inside P. We evaluateI(m) for large m. The value of the integral does not depend on the shape of the curve P.The idea is to run the path of integration through the saddle point, which is de�ned tobe a place where the derivative of h(x) is zero. To apply this idea to our integral (14) werepresent it in the form of (15) and �nd the minimum of the exponent.De�ne u = 1 + h, and then the exponent in our integral can be expanded aslog((1 + P (u� 1))m=ur) = m log(1 + hP )� r log(1 + h)= (Pm� r)h� 1=2(P 2m� r)h2 +O(m+ r)h3)= �12(r �mP )2(r �mP 2)�1 + (r �mP 2) (h�h0)22 +O(m+ r)h3)with h0 = (r �mP )=(r �mP 2). Let r = mP +pmx, with x > 0. Changing the scale ofthe variable under the integrand: h = h0 + it=pm(P � P 2), we obtainPrfC1 � mP+pmxg = exp x22(P � P 2 + x=pm)! 12� Z logm� logm exp(�t2=2)xpP�P 2 + itdt �1 +O(1=pm)� :Therefore, when x!1 (e.g., as plogm) we getZ logm� logm exp(�t2=2)xpP�P 2 + itdt � pP � P 2x Z 1�1 exp(�t2=2)dt = p2�(P � P 2)xwhere the last integral can be computed from the error function [2]. This completes theproof of our lemma. 10

To estimate the conditional probability G(r; �), we need some additional asymptoticsfor the binomial distribution, which are summarized in the lemma below.Lemma 2 Let rm = mp+pm�m where �m = O(logm). Then for all � > 1 there exists asequence m ! +1 such that the following holdlim infm!1 B(m� mpm; p; rm) exp( �m�2(p� p2)) � 1 (16)and lim supm!1 B(m+ mpm; p; rm) exp( �m�2(p� p2)) � 1 : (17)Proof: These are computational consequences of Lemma 1. Details are deferred to theAppendix.Now, we use Lemma 2 to estimate a typical behavior of the probability G(r; �) (recallthat we treat G(r; �) as a random variable with respect to �). For a string � 2 �m, wede�ne j as the number of occurrences of the symbol j 2 � in �. If � varies, then j canbe treated as a random variable, too. Let also C1(j) be the number of matches that involvesymbol of j 2 � between b = � and a1a2 � � � am. Clearly, C1 = PVj=1C1(j), and C1(j) isbinomially distributed with parameters j and pj. We have the following simple estimateof G(r; �).Lemma 3 For all rj such that PVj=1 rj = r, the following holdsVYj=1B(j; pj; rj) � G(r; �) � VXj=1B(j; pj ; rj) : (18)Proof: This follows immediately from the next two trivial boundsPrfC1 > rg � Prf8j : C1(j) > rjg ;and PrfC1 > rg � Prf9j : C1(j) > rjg :This completes the proof.Our main result of this subsection is contained in the next theorem. It provides (a.s.)bounds for the probability G(r; �). 11

Theorem 3 Let rm = mP + pm�m with �m = O(logm), and P and T as de�ned inTheorem 2. For all � > 1, the following estimates hold:(i) limm!1Prf� : G(rm; �) � exp�� �m�2(P � T )�g = 1 ; (19)(ii) limm!1Prf� : G(rm; �) � exp�� �m�2S2�g = 1 ; (20)where S =PVj=1 pjp1� pj.Proof: We �rst deal with part (i). For convenience of presentation we drop the subscriptm from rm and �m. Let rj = mp2j + �jpm� with PVj=1 �j = 1. By (16) of Lemma 2, forany � > 1 there exists a sequence m !1 such that the following holds for m large enoughVYj=1B(mpj � mpm; pj ; rj) � VYj=1 exp(� �2j��2p2j (1� pj)) :Taking �j = p2j(1� pj)=(P p2i (1� pi)), after some algebra involving an optimization of theright-hand side of the above, we obtain (���=2(P � T )) in the exponent of the right-handside (RHS) of the above. But, by Lemma 3, G(r; �) � QVj=1B(mpj � mpm; pj; rj) where� is such that for all j: j � mpj � mpm. Thus,Prf� : G(r; �) � exp(� ��2(P � T ))g � Prf8j : j � mpj � mpmg :By the Central Limit Theorem, every random variable j tends to the Gaussian distributionwith mean mpj and with the standard deviation qm(pj � p2j). So, it is clear thatlimm!1Prf8j : j � mpj � mpmg = 1as m !1.The proof of part (ii) goes along the same lines. For completeness, we provide the detailsbelow. Let rj = mp2j + �jpm� with PVj=1 �j = 1. By Lemma 2, for every � > 1 we can�nd a sequence m !1 such that the following holds for m large enough:VXj=1B(mpj + mpm; pj ; rj) � V �1 VXj=1 exp(� �2j��2p2j(1� pj))Taking �j = S�1pjp1� pj, we obtain (��=2S2) in the exponent of the RHS of the above.But, by Lemma 3, G(r; �) � PVj=1B(mpj + mpm; pj ; rj) where � is such that for all j:j � mpj + mpm. Thus,Prf� : G(r; �) � exp�� ��2S2�g � Prf8j : j � mpj + mpmg :12

By the Central Limit Theorem, every j tends to the Gaussian random variable with meanmpj and with standard deviation qm(pj � p2j). Hence,limm!1Prf8j : j � mpj + mpmg = 1for m !1.Remark 2. If we denote by Gm the set of � 2 �m such that G(r; �) � exp �� ��2(P�T )�,then (19) asserts that PrfGmg ! 1. As above, if we denote by G0m a set of � 2 �m suchthat G(r; �) � exp(� ��2S2) ), then (20) implies that PrfG0mg ! 1.3.2 Upper BoundsWe establish here the two upper bounds claimed in Theorem 2. We prove the followingtheorem.Theorem 4 Let " > 0 be an arbitrary non-negative real number. Then(i) If � = 2(1 + ")(P � P 2) log n, then the following holds limn;m!1PrfMm;n < rg = 1with r = mP +pm� .(ii) If � = 2(1 + ")S2 log n, with S = PVi=1 pip1� pi, then limn;m!1PrfMm;n < rg = 1with r = mP +pm� .Proof: Part (i) was in fact already proved in Theorem 1, and it really follows directly fromPrfMm;n < rg � nB(m;P; r).We concentrate on proving part (ii). We havePrfMm;n > rg � X�2G0m np(�)G(r; �) + Prf� 62 G0mg� max�2G0mfnG(r; �)g + Prf� 62 G0mg ;where the set G0m is de�ned in Theorem 3 (ii) with � = p1 + ". Note that Prf� =2 G0mg ! 0,by Theorem 3. Then by (20) G(r; �) � exp(��=(�2S2)) for � 2 G0m, thusPrfMm;n > rg � n1�p1+" + Prf� 62 Gmg :But both terms of the above tend to zero, and this establishes the second upper bound inTheorem 2.3.3 Lower Bounds 13

The lower bounds are much more intricate to prove. We start with a simple one that doesnot take into account overlapping. Then, we extend this bound to include the overlapping.This extension is of interest to us since it leads to the exact constant in the symmetric case.In the �rst lower bound we ignore overlapping by considering M�m;n � Mm;n whereM�m;n = max1�i�bn=mcfC1+img, that is, the maximum is taken over all nonoverlappingpositions of a. Note also that C1 and C1+m are conditionally independent (i.e., underb = �). Our �rst lower bound is contained in the theorem below.Theorem 5 Let 0 < " < 1. If � = 2(1� ")(P � T )(1� �) log n and r = mP +pm� , thenlimn;m!1PrfMm;n < rg ! 0.Proof. Due to conditional independence we can writePrfM�m;n < rg = X�2�m p(�)(1�G(r; �))n=m� max�2Gmf(1 �G(r; �))n=mg+ Prf� =2 Gmg ;where Gm is de�ned in remark 2, that is, for � = (1�")�1=2 we haveG(r; �) > exp(���=(2(P�T ))) for all � 2 Gm. Note also that Prf� =2 Gmg ! 0. We concentrate now on the �rst termof the above. Using log(1� x) � �x, we obtain(1�G(r; �))n=m � e�(n=m)G(r;�) :Now, it su�ces to show that (n=m)G(r; �) ! 1 for � 2 Gm. By Theorem 3, we have for� 2 Gm nmG(r; �) � nm exp�� ��2(P � T )� � (n=m)1�p1�" !1 ;where the convergence is a consequence of our restrictions log n = o(m). This completesthe proof of the "easier" lower bound in Theorem 2.The second lower bound is more elaborate. It requires an estimate of PrfC1 > r & Ci >rg also for i < m. Let Fm;n = Pmi=2 PrfC1 > r & Ci > rg. Note that Fm;n � F �m;n =Pmi=2 PrfC1 + Ci > 2rg. In the next subsection we prove the following theorem.Theorem 6 For �m = O(logm)!1 we haveF �m;n(mP +pm�m) � m(P � 3P 2 + 2T )5=22(T � P 2)p��3m exp(� �mP � 3P 2 + 2T ) : (21)for m!1. 14

Assuming that Theorem 6 is available, we proceed as follows. Using the second momentmethod we have PrfMm;n > rg � X�2�m p(�)S(r; �) ; (22)where following (9)S(r; �) = (nG(r; �))2nG(r; �) + nF (r; �) + (n2 � n(2m+ 1))(G(r; �))2 :In the above, the probability F (r; �) is de�ned in (12) (to recall, F (r; �) = Pmi=2 PrfC1 >r & Ci > r jb = �g). We rewrite S(r; �) asS(r; �) = � 1nG(r; �) + F (r; �)n(G(r; �))2 + 1� 2m+ 1n ��1 : (23)We also have the following identityX�2�m p(�)F (r; �) = Fm;n(r) ;where the probability Fm;n(r) � F �m;n(r) is estimated in Theorem 6. The almost surebehavior of F (r; �) { as a random function of � { is discussed in the next lemma.Lemma 4 If � !1, then for any constant � we havelimm!1Prf� : F (r; �) � �m exp�� �P � 3P 2 + 2T �g = 1 : (24)Proof: It is a simple consequence of Markov's inequality: Since P�2�m p(�)F (r; �) =Fm(r), it is clear that PrfF (r; �) > mFm(r)g � 1= m.Remark 3. We denote by G00m the set of � 2 �m such that F (r; �) � �m exp(� �P�3P 2+2T )holds. The lemma shows that limm!1 Prf� 2 G00mg = 1. 2Now we are ready to prove the main result of this subsection that provides the mostelaborate lower bound. Let �1 be de�ned as in Theorem 2, that is,�1 = (P � T )(P � 3P 2 + 2T )3(T � P 2) :Let also �2 = minf(1 � �)�1; 2(P � T )g. 15

Theorem 7 Let 0 < " < 1. If � = (1 � ")�2 log n, then limm;n!1PrfMm;n > rg = 1 forr = mP +pm� .Proof: Note that it su�ces to prove the theorem for any positive and arbitrarily small ".By (22) and (23) we need to show thatnG(r; �) ! 1 (25)F (r; �)nG2(r; �) ! 0 : (26)The �rst identity is easy to prove. For � 2 Gm by Theorem 3 with � � (1� ")�1=2 we havenG(r; �) � n1�1=2p1�"�2=(P�T ) !1since �2=(2(P � T )) � 1.Now, we deal with (26). Note that �1 > 0 since P 2 < T . For � 2 Gm \ G00m where Gmand G00m are de�ned as in (respectively) Theorem 3 and Lemma 4 (with � = 1), we haveF (r; �)nG2(r; �) � mn exp( ��P � T � �P � 3P 2 + 2P )� 1n1���(1�")�2=�1 exp((�� 1) �P � T )We know that 1 � � � �2=�1(1 � ") � "�2=�1. Choosing � � 1 = O("2) in the above, we�nally obtain F (r; �)nG2(r; �) � 1n1����2=�1(1�")+O("2) ! 0 ;since " can be arbitrary small.Putting everything together, we have just proved that S(r; �)! 1 for all � 2 Gm \ G00m.But, by (22), Theorem 3 and Lemma 4PrfMm;n > rg � X�2�m p(�)S(r; �)� Prf� 2 Gm \ G00mg min�2Gm\G00mfS(r; �)g ! 1 ;which completes the proof.3.4 Proof of Theorem 6In this subsection, we prove Theorem 6 concerning the asymptotic behavior of theprobability PrfC1 > r; Ci > rg for i < m. In fact, we evaluate the generating functionHm;`(u; v) = Pr1;r2 PrfC1 = r1 & C` = r2gur1vr2 , and then compute the probabilityPrfC1 = r1 & C` = r2g through the Cauchy integral as it was done in Lemma 1.16

Let x and y be column vectors of dimension V , that is, x = fxigVi=1 and y = fyigVi=1.We de�ne the scalar product hx;yi by x1y1 + � � � + xV yV . Then, the next crucial theoremcaptures some important combinatorial properties of fC1; C`g that allow to estimate thegenerating function Hm;2(u; v) for ` = 2, and �nally Hm;`(u; v) for any ` (cf. Theorem 9).Now we are ready to establish a closed-form formula for the generating functionHm;2(u; v).We construct a recurrence relationship between the distributions of fC1(b); C2(b)g andfC2(b0); C3(b0)g where b0 is the su�x of b of length m � 1. In the above we write Ci(b)instead of Ci in order to show explicitly a dependency of Ci on the string b. With this inmind, we can proceed to the following key theorem.Theorem 8 We have the identity Hm;2(u; v) = hx(u);Am�1(u; v)y(v)i, where A(u; v) is aV � V square matrix whose generic element aij(u; v) satis�es the followingaij(u; v) = pi(1 + pi(v � 1) + pj(u� 1))when i 6= j, and aii(u; v) = pi(1 + pi(uv � 1))for i = j. The row vectors x(u) and y(v) are de�ned as x(u) = f1 + pi(u � 1)gVi=1 andy(v) = fpi(1 + pi(v � 1))gVi=1.Proof: Let us de�ne a random variable �i as the number of matches between string aand �i(b) without counting the eventual �rst matching at position i (recall that �i(b) isthe shifted version of b by i positions on the cycle). For example, �1 = C1 if there is nomatching at position 1, and �1 = C1 � 1 otherwise. De�ne next the generating functionPi;m(u; v) asPi;m(u; v) = Xr1;r2 Prf�1 = r1 & C2 = r2 & string b starts with symbol igur1vr2 ;and let Pm(u; v) denote the row vector fPi;m(u; v)gVi=1. Note that P1(u; v) = y(v) andHm;2(u; v) =Pi=Vi=1 (1 + pi(u� 1))Pi;m(u; v), thus Hm;2(u; v) = hx(u);Pm(u; v)i.The most interesting fact that we prove next is the following relationship Pm(u; v) =A(u; v)Pm�1(u; v) when m > 1. A proof of this relies on building a recurrence relationshipbetween fC1(b); C2(b)g and fC2(b0); C3(b0)g, as explained above. Let i and j be the two�rst symbols of string b and let k be the second symbol of string a. When i 6= j we have�1(b) = �2(b0) + 1 and C2(b) = C3(b0) if k = j, �1(b) = �2(b0) and C2(b) = C3(b0) + 1if k = i, and �1(b) = �2(b0) and C2(b) = C3(b0) otherwise. When i = j, we have17

0 1 0 1 1 0 0 1 0 1 0 1 1 10 1 0 1 1 0 0 1 0 1 0 1 1 1 1 1 10 1 1 1 0 0 1 0 1 1 1 0 1 0 1 1 1 1 0 1 0 0 0 1 0 1 1 11 1 10 1 1 1 0 0 1 0 1 1 1 0 1 0 1 1 1 1 0 1 0 0 0 1 0 1 1 1
a = 01100101110101011110101110010111b = 01011001010111b0 = 1011001010111b0 = 1011001010111C1(bfb) = 6, �1(b) = 5, C2(b0) = 5, �2(b0) = 4C2(bfb) = 7, �2(b) = 7, C3(b0) = 7, �3(b0) = 6Figure 4: Illustration of the relationship between fC1; C2g and f�2;�3g (boxes showmatches).�1(b) = �2(b0)+1 and C2(b) = C3(b0)+1 if k = i, and �1(b) = �2(b0) and C2(b) = C3(b0)otherwise. This is illustrated in Figure 4. Since fC2(b0); C3(b0)g has the same distributionas fC1(b0); C2(b0)g, we obtain the following identityPi;m(u; v)pi = (1 + pi(uv � 1))Pi;m�1(u; v) +Xj 6=i(1 + pi(v � 1) + pj(u� 1))Pj;m�1(u; v) ;which proves our theorem.The next theorem extends Theorem 8 and give a formula for the generating functionHm;`(u; v), which is of independent interest.Theorem 9 For all q < m the following holds: Hm;1+q(u; v) = (Hh;2(u; v))q�`(Hh+1;2(u; v))`,where h = bmq c and ` = m� hq.Proof. For i � q de�ne b(i) as a subsequence of string b obtained by selecting the ithsymbol of b, then the i + qth, then i + 2qth, and so forth. For 1 � i � `, string b(i) is oflength h + 1, whereas for `+ 1 � i � q its length is h. We can do the same with string aand obtain subsequences a(1); : : : ;a(q).Let ha; �i(b); �j(b)i be a new notation for the two dimensional row vector [Ci; Cj], thatis, it represents the number of matches between a and simultaneously �i(b) and �j(b). It iseasy to see that [C1; C1+q] = ha(1); �1(b(1)); �2(b(1))i + � � � + ha(q); �1(b(q)); �2(b(q))i. Notethat ha(i); �1(b(i)); �2(b(i))i's has the same distribution as [C1; C2] when b(i) is of length18

h+ 1 for i � `, and the same distribution as [C1; C2] when b(i) is of length h for ` < i � q.This �nally proves the theorem.Theorem 9 establishes a closed form formula for the generating function of the jointdistribution PrfC1 = r1; C` = r2g. Therefore, in principle we can recover the probabilitiesPrfC1 = r1; C` = r2g from Hm;`(u; v) by Cauchy's formula, as we did in Lemma 1. Thedi�culty is that the generating function Hm;`(u; v) is expressed in terms of matrix A(u; v),so we need some tools from linear algebra to apply the saddle point method. However,before we plunge into this, we should treat the symmetric case (i.e., pk = 1=V ) separatelysince, as the next lemma shows, it possesses a very special property.Lemma 5 In the symmetric case, for all i 6= j, the random variables Ci and Cj are pairwiseindependent.Proof: It su�ces to prove that C1 is independent of C1+q for all 1 � q � m. In thesymmetric case the aij(u; v)'s are all identical and equal to 1V (1+ 1V (u�1+v�1)) except wheni = j where aii(u; v) = 1V (1+ 1V (uv�1)). Note that y(v) coincides with an eigenvector of thematrix A and A(u; v)y(v) = (1 + 1V (u� 1))(1 + 1V (v � 1))y(v), and therefore Hm;2(u; v) =(1 + 1V (u� 1))m(1 + 1V (v� 1))m. This last formula shows that C1 and C2 are independent.Applying Theorem 9 one concludes that also Hm;1+q(u; v) = (1+ 1V (u�1))m(1+ 1V (v�1))m.Therefore C1 and C1+q are also independent.Corollary 2 In the symmetric case we have Mm;n �mP �p2m(1=V � 1=V 2) log n whenm;n!1, given logn = o(m).Proof: We already know that the above is true when � < 1 (cf. Theorem 2). Usingthe result stated in Lemma 5 about pairwise independence of the Ci's, we can rewriteinequality (9) asPrfMm;n > rg � (nPrfC1 > rg)2nPrfC1 > rg+ (n2 � n)(PrfC1 > rg)2 : (27)It is clear that the RHS of the above tends to 1 if and only if nPrfC1 > rg ! 1. Referringto Lemma 1, it is clear that this occurs for � = 2(1 � ")(P � P 2) log n and any arbitrarilychosen " > 0.Hereafter, we concentrate on the asymmetric case. Let �(u; v) be the principal eigenvalueof the matrix A(u; v). Let �(u; v) (resp. �(u; v)) be the corresponding right (resp. left)eigenvector of A(u; v) such that h�(u; v); �(u; v)i = 1, that is, A(u; v)�(u; v) = �(u; v)�(u; v)andAT (u; v)�(u; v) = �(u; v)�(u; v) (cf. [25, 24]). We distinguish the following three cases:19

1. When u = v = 1, �(1; 1) = 1, �(1; 1) = y(1) and �(1; 1) = x(1), the other eigenvaluesare null.2. When v = 1, �(u; 1) = 1 + P (u � 1), �(u; 1) = �(1; 1) = y(1) and �(u; 1) =1=�(u; 1)x(u), the other eigenvalues are null.3. When u = 1, �(1; v) = �(v; 1) = 1 + P (v � 1), �(1; v) = y(v) and �(1; v) =1=�(1; v)x(1), the other eigenvalues are null.It follows that the other eigenvalues are O((u � 1)(v � 1)), and therefore we immediatelyprove the following fact.Corollary 3 Hm;2(u; v)=�m�1(u; v) = hx(u); �(u; v)i h�(u; v);y(v)i+O((u�1)m(v�1)m).Proof: This is a classical property of the principal eigenvalue and follows from the Perron-Frobenius theorem (the interested reader is referred to [3, 24, 25] for details).As a consequence of Corollary 3 we have the following important expansion of thegenerating function Hm;`(u; v).Corollary 4 Let Fm(u; v) =Pmi=2Hm;i(u; v). We haveFm(u; v)(�(u; v))m = a(u; v)� am(u; v)1� a(u; v) +O((u� 1)(v � 1)) ; (28)with a(u; v) = hx(u); �(u; v)i h�(u; v);y(v)i=�(u; v)Proof: From Corollary 3 and Theorem 9 we have the estimateHm;1+q(u; v) = (�(u; v))m(a(u; v))q +O((u� 1)h+1(v � 1)h+1)) :Therefore Fm(u; v)(�(u; v))m = m�1Xq=1 (a(u; v))q + mXh=2O((u� 1)h+1(v � 1)h+1) :The proof is easily completed by summing the geometric series in the last expression.The following two lemmas present more detailed Taylor's expansions of the principaleigenvalue of A(u; v) de�ned in Corollary 4. These expansions are next used in the saddlepoint method to obtain a sharp estimate of Fm;n(r) around r = mP +p2mP (1 � P ) log n.Lemma 6 The Taylor expansion of �(u; v) to the second order is 1+(u�1)P +(v�1)P +(u� 1)(v � 1)(2T � P 2), with T = p31 + � � �+ p3V .20

Proof. We know that �(u; v) = 1 + (u � 1)P + (v � 1)P + O((u � 1)(v � 1)). We adoptthe following notation. If f(u; v) is a function of two variables u and v, then we denoteby fu(u; v) (resp. fv(u; v)) the partial derivative of f(u; v) with respect to u (resp. to v).We have � = h�;A�i, where the variables (u; v) have been dropped in the last expressionto simplify the presentation. Thus, �u = h�u;A�i + h�;Au�i+ h�;A�ui. Since A� = ��,AT� = ��, and since h�u; �i + h�; �ui = 0 (because we assume h�; �i = 1), we get�u = h�;Au�i. Substituting u = 1 in the last expression, we obtain the identity �(1; v) =(P +2T (v� 1) +Pi=Vi=1 p4i (v� 1)2)=(1 +P (v� 1)), and after some simple algebra the proofis completed.Lemma 7 The Taylor expansion of a(u; v) to the second order is 1�(u�1)(v�1)(T �P 2).Proof. Easy computations give a(u; 1) = a(1; v) = 1, therefore a(u; v)�1 isO((u�1)(v�1)).Di�erentiating twice a(u; v) and setting u = v = 1 leads to a formula beginning withh�uv ; �i + h�; �uvi and ending with a linear combination of scalar products involving �rstpartial derivatives of �, �, x and y. These �rst derivatives are already known since � and� are completely determined when u = 1 or v = 1. For h�uv; �i+ h�; �uvi, we di�erentiatetwice both sides of h�; �i = 1 in order to get h�uv; �i + h�; �uvi + h�u; �vi + h�v ; �ui = 0,which leads to a complete determination of auv(1; 1).Lemmas 6 and 7 are crucial to apply Cauchy's formula in order to estimate Fm;n(r) forr > mP . To do that, we can use the double Cauchy formulaFm;n(r) = 1(2i�)2 I I Fm(u; v) dudvur(u� 1)vr(v � 1) :This kind of integration is rather unusual. Since PrfCi > r;Cj > rg � PrfCi + Cj > 2rgwe can estimate F �m;n(r) =Pmi=2 PrfC1 +Ci > 2rg, which leads to a single integrationF �m;n(r) = 12i� I Fm(u; u) 1u2r(u� 1)du :Finally, we can prove the following asymptotics for the tail of Fm;n(r), which establishesTheorem 6.Proof of Theorem 6. We parallel the proof of Lemma 1. By Cauchy and (28) we haveF �m;n(r) � 12i� I �m(u; u)(a(u; u) � am(u; u))u2r(1� a(u; u)) duu� 1 ; (29)21

the integration path encircling the unit disk. Let 1 + h = u. Using Lemmas 18 and 19, weobtain the expansionlog(�m(u; u)=u2r) = m log(1 + 2hP + h2(2T � P 2) +O(h3))� 2r log(1 + h)= �2(r �mP )h+ (r + 2mT � 3mP 2)h2 +O((m+ r)h3)= �(r �mP )2(r �m(3P 2 � 2T ))�1 ++ (r � 3mP 2 + 2mT )(h� h0)2 +O((m+ r)h3) ;with h0 = (r�mP )=(r�3mP 2+2mT ). Let r = mP +pmx. Substituting h = h0+ it=pm,and using 1� a(1 + h; 1 + h) = h2(T � P 2) +O(h3) we get the �rst estimate12i� I �m(u; u)a(u; u)duu2r(u� 1)(1 � a(u; u)) == exp � x2P � 3P 2 + 2T ! m2(T � P 2)� Z exp(�(P � 3P 2 + 2T )t2)( xP�3P 2+2T + it)3 dt(1 +O(1=pm)) :Since x = O(plogn), we obtain12i� I �m(u; u)a(u; u)duu2r(u� 1)(1 � a(u; u)) � m(P � 3P 2 + 2T )5=22(T � P 2)p�x3 exp � x2P � 3P 2 + 2T ! : (30)It remains to evaluate the second term in (29), that is,12i� I �m(u; u)am(u; u)duu2r(u� 1)(1 � a(u; u)) : (31)Using the estimates from Lemmas 18 and 19 we �ndlog(�m(u; u)am(u; u)=u2r) = �(r �mP )h+ (r +mT � 2mP 2)h2 +O((m+ r)h3) :Hence (31) becomes12i� I �m(u; u)am(u; u)duu2r(u� 1)(1� a(u; u)) � m(P � 2P 2 + T )5=22p�x3 exp � x2P � 2P 2 + T ! : (32)Since P � 2P 2 + T < P � 3P 2 + 2T in the asymmetric case, the exponent in (32) is largerthan in (30), so (30) is the leading term in the asymptotic expansion of F �m;n(r). Thisconcludes the proof of Theorem 6. APPENDIXProof of Lemma 2: We �rst prove the existence of a sequence m such that (16) holds.Since for all p and r we have B(0; p; r) = 0 and limx!1B(x; p; r) = 1, we can �nd for theBernoulli distribution a sequence m such thatB(m� mpm; p; rm) > exp(� �m�2(p� p2) ) ; (33)22

and B(m� mpm� 1; p; rm) � exp(� �m�2(p� p2)) < 1 : (34)Our aim is to prove that limm!1 m =1. Let us assume contrary that lim infm!1 m <1, thus there exists and a subsequence of m bounded from the above by the constant . For simplicity of the presentation, we assume that m < for all m. Then, dueto monotonicity of B(m; p; r) with respect to m, we have B(m � mpm � 1; p; rm) >B(m � pm � 1; p; rm). Furthermore, for rm = (m � pm � 1)p +q(m� pm� 1)��mwith ��m = (p�m + p )21� =pm = �m +O(p�m) ; (35)we obtainB(m� pm� 1; p; rm) � 1p2�(p� p2)��m exp���m +O(p�m)2(p� p2) �� exp�� ��m2(p� p2)� ;(36)where the last inequality holds for large m due to � > 1 and �m ! 1. Clearly, the abovecontradicts (34), hence, m !1, as needed.The proof for the second inequality is similar and is only sketched. We set m such thatB(m+ mpm; p; rm) < exp(� �m�2(p� p2) ) (37)and B(m+ mpm+ 1; p; rm) � exp(� �m�2(p� p2)) : (38)If one assumes m < <1, thenB(m+ mpm+ 1; p; rm) < B(m+ pm+ 1; p; rm) � 1p2�(p� p2)��m exp(� ��m2(p� p2) ) ;(39)with ��m = �m+O(p�m), which contradicts B(m+ mpm+1; p; rm) � exp(��m=2�(p�p2)).ACKNOWLEDGEMENTThe authors sincerely thank a referee who pointed out an error in an earlier version ofthe paper.References[1] K. Abrahamson, Generalized String Matching, SIAM J. Comput., 16, 1039-1051, 1987.23

[2] Abramowitz, M. and Stegun, I., Handbook of Mathematical Functions, Dover, NewYork (1964).[3] Aldous, D., Probability Approximations via the Poisson Clumping Heuristic, SpringerVerlag, New York 1989.[4] Apostolico, A., Atallah, M., Larmore, L., and McFadin, S., E�cient Parallel Algo-rithms for String Editing and Related Problems, SIAM J. Computing, 19, 968-988,1990.[5] Arratia, R., Gordon, L., and Waterman, M., An Extreme Value Theory for SequenceMatching, Annals of Statistics, 14, 971-993, 1986.[6] Arratia, R., and Waterman, M., The Erd�os-R�enyi Strong Law for pattern matchingwith a Given Proportion of Mismatches, Annals of Probability, 17, 1152-1169, 1989.[7] Arratia, R., Gordon, L., and Waterman, M., The Erd�os-R�enyi Law in Distribution, forCoin Tossing and Sequence Matching, Annals of Statistics, 18, 539-570, 1990.[8] Atallah, M., Jacquet, P., and Szpankowski, W., Pattern Matching with Mismatches: ASimple Randomized Algorithm and Its Analysis, Proc. Combinatorial Pattern Match-ing, Tuscon 1992.[9] Chang, W.I., and Lawler, E.L., Approximate String Matching in Sublinear ExpectedTime, Proc. 31st Ann. IEEE Symp. on Foundations of Comp. Sci., 116-124, 1990.[10] Chung, K.L. and Erd�os, P., On the Application of the Borel-Cantelli Lemma, Trans.of the American Math. Soc., 72, 179-186, 1952.[11] DeLisi, C., The Human Genome Project, American Scientist, 76, 488-493, 1988.[12] Feller, W., An Introduction to Probability Theory and its Applications, Vol. II, JohnWiley & Sons, New York (1971).[13] Flajolet, P., Analysis of Algorithms, in Trends in Theoretical Computer Science (ed.E. B�orger), Computer Science Press, 1988.[14] Galambos, J., The Asymptotic Theory of Extreme Order Statistics, John Wiley &Sons, New York (1978).[15] Z. Galil, Open Problems in Stringology, Combinatorial Algorithms on Words (Eds. A.Apostolico and Z. Galil), 1-8 (1984).[16] L. Guibas and A. Odlyzko, Periods in Strings Journal of Combinatorial Theory, SeriesA, 30, 19-43 (1981).[17] L. Guibas and A. W. Odlyzko, String Overlaps, Pattern Matching, and NontransitiveGames, Journal of Combinatorial Theory, Series A, 30, 183-208 (1981).[18] Henrici, P., Applied and Computational Complex Analysis, vol. I., John Wiley& Sons,New York 1974. 24

[19] Jacquet, P. and Szpankowski, W., Autocorrelation on Words and Its Applications.Analysis of Su�x Trees by String-Ruler Approach, INRIA Technical report No. 1106,October 1989; submitted to a journal.[20] Karlin, S. and Ost, F., Counts of Long Aligned Matches Among Random Letter Se-quences, Adv. Appl. Probab., 19, 293-351, 1987.[21] Knuth, D.E., J. Morris and V. Pratt, Fast Pattern Matching in Strings, SIAM J.Computing, 6, 323-350, 1977.[22] Lander, E., Langridge, R., and D. Saccocio, Mapping and Interpreting Biological In-formation, Comm. of the ACM, 34, 33-39, 1991.[23] Louchard, G., and Szpankowski, W., String Matching: A Preliminary ProbabilisticResults, Universite de Bruxelles, TR-217, 1991.[24] Noble, B. and Daniel, J., Applied Linear Algebra, Prentice-Hall, New Jersey 1988[25] Seneta, E., Non-Negative Matrices and Markov Chains, Springer-Verlag, New York1981.[26] Szpankowski, W., On the Height of Digital Trees and Related Problems, Algorithmica,6, 256-277 (1992).[27] M. Zuker, Computer Prediction of RNA Structure, Methods in Enzymology, 180, 262-288, 1989.
25
Related Documents











