A Phrase-Based Model of Alignment A Phrase-Based Model of Alignment for Natural Language Inference for Natural Language Inference Bill MacCartney, Michel Galley, and Christopher D. Manning Stanford University 26 October 2008

A Phrase-Based Model of Alignment for Natural Language Inference Bill MacCartney, Michel Galley, and Christopher D. Manning Stanford University 26 October.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Phrase-Based Model of AlignmentA Phrase-Based Model of Alignmentfor Natural Language Inferencefor Natural Language Inference
Bill MacCartney, Michel Galley,and Christopher D. Manning
Stanford University26 October 2008

2
P Gazprom today confirmed a two-fold increase in its gas price for Georgia, beginning next Monday.
H Gazprom will double Georgia’s gas bill. yes
Natural language inference (NLI)Natural language inference (NLI) (aka RTE)(aka RTE)
• Does premise P justify an inference to hypothesis H?• An informal notion of inference; variability of linguistic expression
• Like MT, NLI depends on a facility for alignment• I.e., linking corresponding words/phrases in two related
sentences
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

3
Alignment exampleAlignment example
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
unaligned content:“deletions” from P
approximate match:price ~ bill
phrase alignment:two-fold increase ~ double
H (hypothesis)
P (
pre
mis
e)

4
Approaches to NLI alignmentApproaches to NLI alignment
• Alignment addressed variously by current NLI systems
• In some approaches to NLI, alignments are implicit:• NLI via lexical overlap [Glickman et al. 05, Jijkoun & de Rijke 05]
• NLI as proof search [Tatu & Moldovan 07, Bar-Haim et al. 07]
• Other NLI systems make alignment step explicit:• Align first, then determine inferential validity [Marsi & Kramer 05,
MacCartney et al. 06]
• What about using an MT aligner?• Alignment is familiar in MT, with extensive literature
[Brown et al. 93, Vogel et al. 96, Och & Ney 03, Marcu & Wong 02, DeNero et al. 06, Birch et al. 06, DeNero & Klein 08] • Can tools & techniques of MT alignment transfer to NLI?
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

5
NLI alignment vs. MT alignmentNLI alignment vs. MT alignment
Doubtful — NLI alignment differs in several respects:
1. Monolingual: can exploit resources like WordNet
2. Asymmetric: P often longer & has content unrelated to H
3. Cannot assume semantic equivalence• NLI aligner must accommodate frequent unaligned
content
4. Little training data available• MT aligners use unsupervised training on huge amounts
of bitext• NLI aligners must rely on supervised training & much less
data
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

6
Contributions of this paperContributions of this paper
In this paper, we:
1. Undertake the first systematic study of alignment for NLI• Existing NLI aligners use idiosyncratic methods, are poorly
documented, use proprietary data
2. Examine the relation between alignment in NLI and MT• How do existing MT aligners perform on NLI alignment task?
3. Propose a new model of alignment for NLI: MANLI• Outperforms existing MT & NLI aligners on NLI alignment task
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

7
The MANLI alignerThe MANLI aligner
A model of alignment for NLI consisting of four components:
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
1. Phrase-based representation
2. Feature-based scoring function
3. Decoding using simulated annealing
4. Perceptron learning

8
Phrase-based alignment Phrase-based alignment representationrepresentation
EQ(Gazprom1, Gazprom1)
INS(will2)
DEL(today2)
DEL(confirmed3)
DEL(a4)
SUB(two-fold5 increase6, double3)
DEL(in7)
DEL(its8)
…
Represent alignments by sequence of phrase edits: EQ, SUB, DEL, INS
• One-to-one at phrase level (but many-to-many at token level)
• Avoids arbitrary alignment choices; can use phrase-based resources
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

9
• Score edits as linear combination of features, then sum:
A feature-based scoring functionA feature-based scoring function
• Edit type features: EQ, SUB, DEL, INS
• Phrase features: phrase sizes, non-constituents
• Lexical similarity feature: max over similarity scores• WordNet: synonymy, hyponymy, antonymy, Jiang-Conrath• Distributional similarity à la Dekang Lin• Various measures of string/lemma similarity
• Contextual features: distortion, matching neighbors
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
10
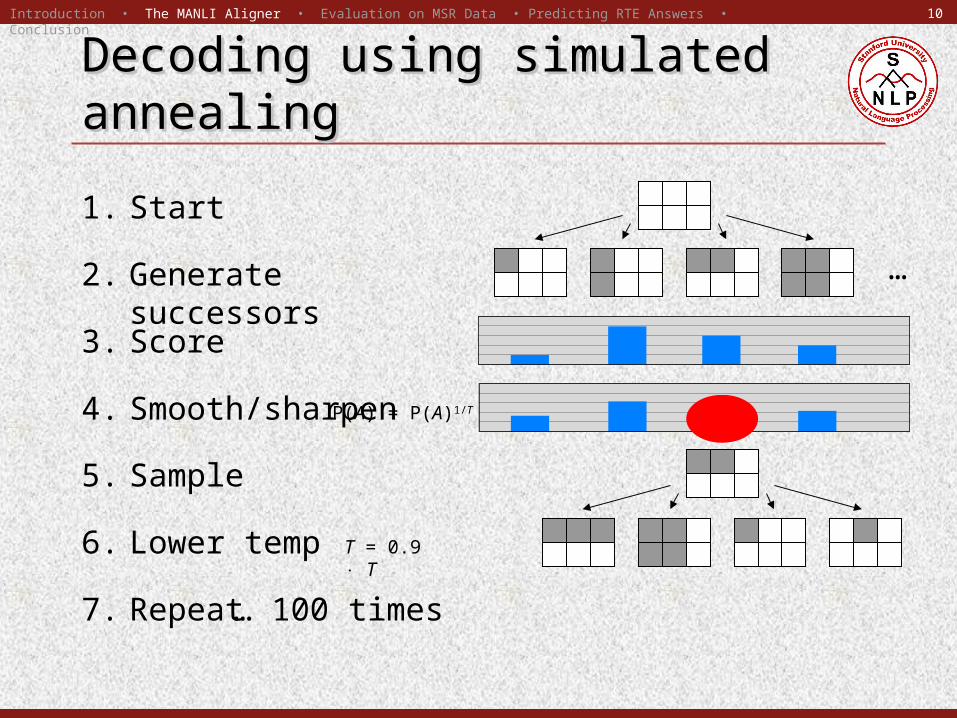
Decoding using simulated Decoding using simulated annealingannealing
1. Start
3. Score
4. Smooth/sharpenP(A) = P(A)1/T
5. Sample
6. Lower temp T = 0.9 T
…2. Generate successors
7. Repeat… 100 times
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

11
Perceptron learning of feature Perceptron learning of feature weightsweights
We use a variant of averaged perceptron [Collins 2002]
Initialize weight vector w = 0, learning rate R0 = 1
For training epoch i = 1 to 50:For each problem Pj, Hj with gold alignment Ej:
Set Êj = ALIGN(Pj, Hj, w)
Set w = w + Ri ((Ej) – (Êj))
Set w = w / ‖w‖2 (L2 normalization)
Set w[i] = w (store weight vector for this epoch)
Set Ri = 0.8 Ri–1 (reduce learning rate)
Throw away weight vectors from first 20% of epochsReturn average weight vector
Training runs require about 20 hours (on 800 RTE problems)
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

12
The MSR RTE2 alignment dataThe MSR RTE2 alignment data
• Previously, little supervised data
• Now, MSR gold alignments for RTE2• [Brockett 2007]• dev & test sets, 800 problems each
• Token-based, but many-to-many• allows implicit alignment of phrases
• 3 independent annotators• 3 of 3 agreed on 70% of proposed links• 2 of 3 agreed on 99.7% of proposed
links• merged using majority rule
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

13
Evaluation on MSR dataEvaluation on MSR data
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
• We evaluate several systems on MSR data• A simple baseline aligner• MT aligners: GIZA++ & Cross-EM• NLI aligners: Stanford RTE, MANLI
• How well do they recover gold-standard alignments?• We report per-link precision, recall, and F1• We also report exact match rate for complete
alignments

14
Baseline: bag-of-words alignerBaseline: bag-of-words alignerRTE2 dev RTE2 test
System P % R % F1 % E % P % R % F1 % E %
Bag-of-words 57.8 81.2 67.5 3.5 62.1 82.6 70.9 5.3
• Surprisingly good recall, despite extreme simplicity
• But very mediocre precision, F1, & exact match rate
• Main problem: aligns every token in H
Match each H token to most similar P token: [cf. Glickman et al. 2005]
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

15
MT aligners: GIZA++ & Cross-EM MT aligners: GIZA++ & Cross-EM
• Can we show that MT aligners aren’t suitable for NLI?
• Run GIZA++ via Moses, with default parameters• Train on dev set, evaluate on dev & test sets• Asymmetric alignments in both directions• Then symmetrize using INTERSECTION heuristic
• Initial results are very poor: 56% F1• Doesn’t even align equal words
• Remedy: add lexicon of equal words as extra training data
• Do similar experiments with Berkeley Cross-EM aligner
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

16
Results: MT alignersResults: MT alignersRTE2 dev RTE2 test
System P % R % F1 % E % P % R % F1 % E %
Bag-of-words 57.8 81.2 67.5 3.5 62.1 82.6 70.9 5.3GIZA++ 83.0 66.4 72.1 9.4 85.1 69.1 74.8 11.3Cross-EM 67.6 80.1 72.1 1.3 70.3 81.0 74.1 0.8
Similar F1, but GIZA++ wins on precision, Cross-EM on recall
• Both do best with lexicon & INTERSECTION heuristic• Also tried UNION, GROW, GROW-DIAG, GROW-DIAG-FINAL,
GROW-DIAG-FINAL-AND, and asymmetric alignments
• All achieve better recall, but much worse precision & F1
• Problem: too little data for unsupervised learning• Need to compensate by exploiting external lexical resources
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

17
The Stanford RTE alignerThe Stanford RTE aligner
• Token-based alignments: map from H tokens to P tokens• Phrase alignments not directly representable• (But, named entities & collocations collapsed in pre-
processing)
• Exploits external lexical resources• WordNet, LSA, distributional similarity, string sim, …
• Syntax-based features to promote aligning corresponding predicate-argument structures
• Decoding & learning similar to MANLI
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

18
Results: Stanford RTE alignerResults: Stanford RTE alignerRTE2 dev RTE2 test
System P % R % F1 % E % P % R % F1 % E %
Bag-of-words 57.8 81.2 67.5 3.5 62.1 82.6 70.9 5.3GIZA++ 83.0 66.4 72.1 9.4 85.1 69.1 74.8 11.3Cross-EM 67.6 80.1 72.1 1.3 70.3 81.0 74.1 0.8Stanford RTE 81.1 75.8 78.4 0.5 82.7 75.8 79.1 0.3
• Better F1 than MT aligners — but recall lags precision
• Stanford does poor job aligning function words• 13% of links in gold are prepositions & articles• Stanford misses 67% of these (MANLI only 10%)
• Also, Stanford fails to align multi-word phrasespeace activists ~ protestors, hackers ~ non-authorized personnel
* * * *
* includes (generous) correction for missed punctuation
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
19
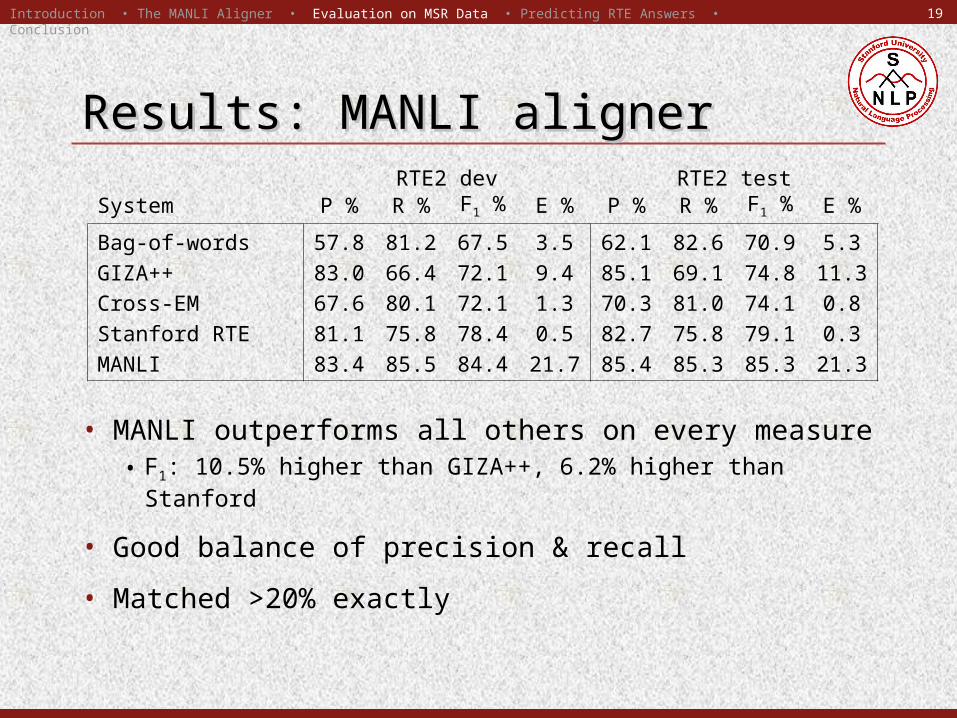
Results: MANLI alignerResults: MANLI alignerRTE2 dev RTE2 test
System P % R % F1 % E % P % R % F1 % E %
Bag-of-words 57.8 81.2 67.5 3.5 62.1 82.6 70.9 5.3GIZA++ 83.0 66.4 72.1 9.4 85.1 69.1 74.8 11.3Cross-EM 67.6 80.1 72.1 1.3 70.3 81.0 74.1 0.8Stanford RTE 81.1 75.8 78.4 0.5 82.7 75.8 79.1 0.3MANLI 83.4 85.5 84.4 21.7 85.4 85.3 85.3 21.3
• MANLI outperforms all others on every measure• F1: 10.5% higher than GIZA++, 6.2% higher than
Stanford
• Good balance of precision & recall
• Matched >20% exactly
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

20
MANLI results: discussionMANLI results: discussion
• Three factors contribute to success:1. Lexical resources: jail ~ prison, prevent ~ stop , injured ~ wounded
2. Contextual features enable matching function words3. Phrases: death penalty ~ capital punishment, abdicate ~ give up
1. But phrases help less than expected!1. If we set max phrase size = 1, we lose just 0.2% in F1
2. Recall errors: room to improve1. 40%: need better lexical resources: conservation ~ protecting,
organization ~ agencies, bone fragility ~ osteoporosis
3. Precision errors harder to reduce1. equal function words (49%), forms of be (21%),
punctuation (7%)
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

21
Can aligners predict RTE Can aligners predict RTE answers?answers?
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
• We’ve been evaluating against gold-standard alignments
• But alignment is just one component of an NLI system
• Does a good alignment indicate a valid inference?• Not necessarily: negations, modals, non-factives &
implicatives, …• But alignment score can be strongly predictive• And many NLI systems rely solely on alignment
• Using alignment score to predict RTE answers:• Predict YES if score > threshold• Tune threshold on development data• Evaluate on test data
22
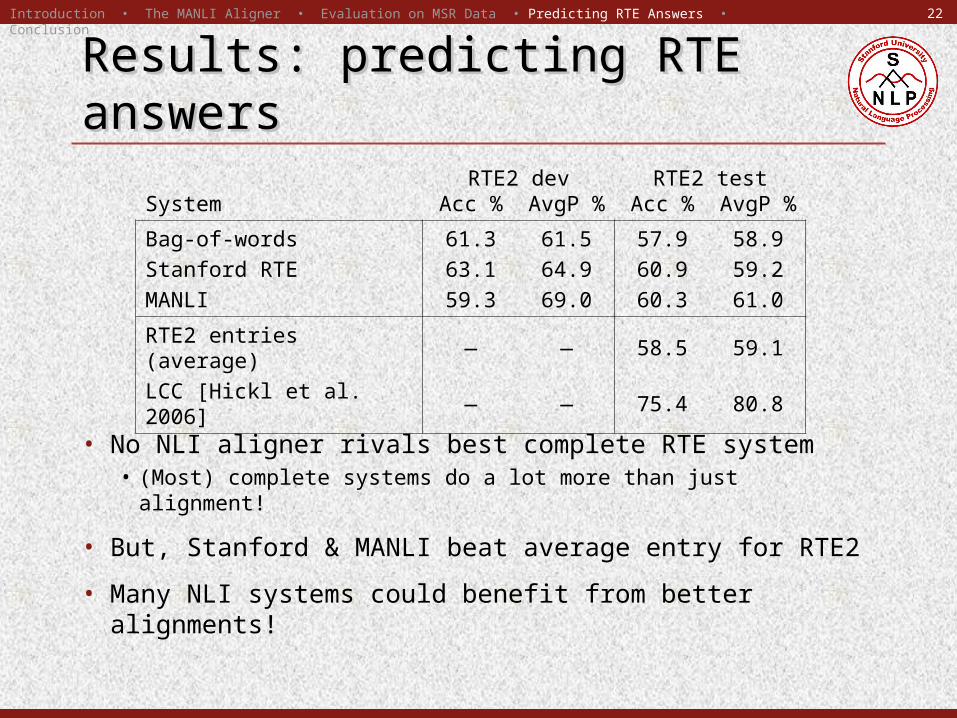
Results: predicting RTE answersResults: predicting RTE answersRTE2 dev RTE2 test
System Acc %AvgP
%Acc %
AvgP %
Bag-of-words 61.3 61.5 57.9 58.9Stanford RTE 63.1 64.9 60.9 59.2MANLI 59.3 69.0 60.3 61.0
RTE2 entries (average) — — 58.5 59.1LCC [Hickl et al. 2006] — — 75.4 80.8
• No NLI aligner rivals best complete RTE system• (Most) complete systems do a lot more than just alignment!
• But, Stanford & MANLI beat average entry for RTE2
• Many NLI systems could benefit from better alignments!
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion

23
ConclusionConclusion
:-) Thanks! Questions?
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
• MT aligners not directly applicable to NLI• They rely on unsupervised learning from massive amounts of
bitext• They assume semantic equivalence of P & H
• MANLI succeeds by:• Exploiting (manually & automatically constructed) lexical
resources• Accommodating frequent unaligned phrases
• Phrase-based representation shows potential• But not yet proven: need better phrase-based lexical resources

24
Backup slides followBackup slides follow
END

25
Related workRelated work
Introduction • The MANLI Aligner • Evaluation on MSR Data • Predicting RTE Answers • Conclusion
• Lots of past work on phrase-based MT
• But most systems extract phrases from word-aligned data• Despite assumption that many translations are non-
compositional
• Recent work jointly aligns & weights phrases[Marcu & Wong 02, DeNero et al. 06, Birch et al. 06, DeNero & Klein 08]
• However, this is of limited applicability to the NLI task• MANLI uses phrases only when words aren’t appropriate• MT uses longer phrases to realize more dependencies
(e.g. word order, agreement, subcategorization)
• MT systems don’t model word insertions & deletions
Related Documents











