A novel carbonic anhydrase from the giant clam Tridacna gigas contains two carbonic anhydrase domains William Leggat 1,2 , Ross Dixon 1 , Said Saleh 1 and David Yellowlees 1 1 Biochemistry and Molecular Biology, James Cook University, Townsville, Queensland, Australia 2 Centre for Marine Studies, University of Queensland, Queensland, Australia Carbonic anhydrase (CA; EC 4.2.1.1) catalyses the hydration of CO 2 to HCO 3 – , is ubiquitous amongst all living organisms and fulfils a variety of metabolic roles [1]. Currently there are five evolutionarily distinct CA gene families (a, b, c, d and e) [1,2] and it is generally believed that all animal CAs belong to the a-CA fam- ily. a-CAs are characterized by 36 amino acids found around the active site [3]. Of these, 15 are conserved in all active CAs, suggesting that they are required for CA activity [3]. To date 15 a-CA or a-CA-like proteins have been identified in mammals. These can be divided into five broad subgroups, the cytosolic CAs (CA I, CA II, CA III, CA VII and CA XIII), mitochondrial CAs (CA VA and CA VB), secreted CAs (CA VI), mem- brane-associated CAs (CA IV, CA IX, CA XII and CA XIV) and those without CA activity, the CA-related proteins (CA-RP VIII, X and XI). The cytosolic and mitochondrial CAs and the secreted and membrane-associated CAs are often further Keywords carbonic anhydrase; clam; symbiosis Correspondence W. Leggat, Centre for Marine Studies, University of Queensland, Queensland 4072, Australia Fax: +61 7 33654755 Tel: +61 7 33469576 E-mail: [email protected] Notes The nucleotide sequences for carbonic anhydrase from T. gigas have been deposited in the GenBank database under GenBank accession numbers AY790884 and AY799986-AY799998. The alignment for the genomic sequence of tgCA between positions 101 and 1810 of the cDNA has been submitted to EMBL-ALIGN database under the accession number ALIGN_000833. (Received 14 February 2005, revised 11 April 2005, accepted 28 April 2005) doi:10.1111/j.1742-4658.2005.04742.x This report describes the presence of a unique dual domain carbonic anhydrase (CA) in the giant clam, Tridacna gigas. CA plays an important role in the movement of inorganic carbon (C i ) from the surrounding sea- water to the symbiotic algae that are found within the clam’s tissue. One of these isoforms is a glycoprotein which is significantly larger (70 kDa) than any previously reported from animals (generally between 28 and 52 kDa). This a-family CA contains two complete carbonic anhydrase domains within the one protein, accounting for its large size; dual domain CAs have previously only been reported from two algal species. The protein contains a leader sequence, an N-terminal CA domain and a C-terminal CA domain. The two CA domains have relatively little identity at the amino acid level (29%). The genomic sequence spans in excess of 17 kb and con- tains at least 12 introns and 13 exons. A number of these introns are in positions that are only found in the membrane attached ⁄ secreted CAs. This fact, along with phylogenetic analysis, suggests that this protein represents the second example of a membrane attached invertebrate CA and it con- tains a dual domain structure unique amongst all animal CAs characterized to date. Abbreviations CA, carbonic anhydrase; C i , inorganic carbon; GPI, glycosylphosphatidylinositol. FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3297

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A novel carbonic anhydrase from the giant clam Tridacnagigas contains two carbonic anhydrase domainsWilliam Leggat1,2, Ross Dixon1, Said Saleh1 and David Yellowlees1
1 Biochemistry and Molecular Biology, James Cook University, Townsville, Queensland, Australia
2 Centre for Marine Studies, University of Queensland, Queensland, Australia
Carbonic anhydrase (CA; EC 4.2.1.1) catalyses the
hydration of CO2 to HCO3–, is ubiquitous amongst all
living organisms and fulfils a variety of metabolic roles
[1]. Currently there are five evolutionarily distinct CA
gene families (a, b, c, d and e) [1,2] and it is generally
believed that all animal CAs belong to the a-CA fam-
ily. a-CAs are characterized by 36 amino acids found
around the active site [3]. Of these, 15 are conserved in
all active CAs, suggesting that they are required for
CA activity [3].
To date 15 a-CA or a-CA-like proteins have been
identified in mammals. These can be divided into five
broad subgroups, the cytosolic CAs (CA I, CA II,
CA III, CA VII and CA XIII), mitochondrial CAs
(CA VA and CA VB), secreted CAs (CA VI), mem-
brane-associated CAs (CA IV, CA IX, CA XII and
CA XIV) and those without CA activity, the
CA-related proteins (CA-RP VIII, X and XI). The
cytosolic and mitochondrial CAs and the secreted
and membrane-associated CAs are often further
Keywords
carbonic anhydrase; clam; symbiosis
Correspondence
W. Leggat, Centre for Marine Studies,
University of Queensland, Queensland
4072, Australia
Fax: +61 7 33654755
Tel: +61 7 33469576
E-mail: [email protected]
Notes
The nucleotide sequences for carbonic
anhydrase from T. gigas have been
deposited in the GenBank database under
GenBank accession numbers AY790884 and
AY799986-AY799998.
The alignment for the genomic sequence of
tgCA between positions 101 and 1810 of
the cDNA has been submitted to
EMBL-ALIGN database under the accession
number ALIGN_000833.
(Received 14 February 2005, revised
11 April 2005, accepted 28 April 2005)
doi:10.1111/j.1742-4658.2005.04742.x
This report describes the presence of a unique dual domain carbonic
anhydrase (CA) in the giant clam, Tridacna gigas. CA plays an important
role in the movement of inorganic carbon (Ci) from the surrounding sea-
water to the symbiotic algae that are found within the clam’s tissue. One of
these isoforms is a glycoprotein which is significantly larger (70 kDa) than
any previously reported from animals (generally between 28 and 52 kDa).
This a-family CA contains two complete carbonic anhydrase domains
within the one protein, accounting for its large size; dual domain CAs have
previously only been reported from two algal species. The protein contains
a leader sequence, an N-terminal CA domain and a C-terminal CA
domain. The two CA domains have relatively little identity at the amino
acid level (29%). The genomic sequence spans in excess of 17 kb and con-
tains at least 12 introns and 13 exons. A number of these introns are in
positions that are only found in the membrane attached ⁄ secreted CAs. This
fact, along with phylogenetic analysis, suggests that this protein represents
the second example of a membrane attached invertebrate CA and it con-
tains a dual domain structure unique amongst all animal CAs characterized
to date.
Abbreviations
CA, carbonic anhydrase; Ci, inorganic carbon; GPI, glycosylphosphatidylinositol.
FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3297

consolidated into two separate groups based upon
sequence similarity [3]. Of the membrane-associated
CAs, CA IX, XII and XIV contain integral trans-
membrane domains while CA IV is membrane atta-
ched through a glycosylphosphatidylinositol (GPI)
anchor.
Mammalian CAs function in a variety of roles inclu-
ding pH balance, H+ secretion, HCO3– secretion, CO2
exchange, bone resorption and ion transport [1]. The
diversity in mammalian genes and the presence of
homologs in other animals suggests that a large num-
ber of CAs are yet to be characterized from the animal
kingdom. Complete cDNA sequences from inverte-
brate sources have only been obtained from the tube-
worm Riftia pachyptila [4], cnidarians [5] and
mosquitoes [6,7]. In addition a cDNA sequence enco-
ding a protein involved in calcification from the pearl
oyster Pinctada fucata contains an a-CA-like domain
[8].
All animal CAs purified to date have subunit
molecular weights less than 58 kDa. The only excep-
tion is a report of the purification of a protein display-
ing CA activity from the giant clam Tridacna gigas,
where the purified protein has a molecular weight
of 70 kDa [9]. This protein is glycosylated through
both N- and O-links and is thought to be involved in
the transport of inorganic carbon (Ci) from seawater
to symbiotic photosynthetic dinoflagellates that are
found intercellularly within the clam tissue [9,10]. It
has been demonstrated that these alga can supply
up to 100% of the clam’s energy requirements [11].
In addition T. gigas contains two other CA isoforms,
one of 32 kDa and one of approximately 200 kDa
[9,10].
Here we present further characterization of the
70 kDa CA isoform from T. gigas, including cDNA
sequence indicating that it codes for a unique animal
CA containing two putative CA catalytic domains
within the one protein. Each domain contains those
residues thought to be essential for CA activity.
Results
tgCA cDNA sequence, deduced amino acid
sequence and domains
Only cDNA sequence for the first 1438 bp of the
70 kDa CA could be obtained from both the gill and
mantle cDNA libraries; both sequences were identical.
In both cases the sequence terminated in an identical
position (1438 bp after the start codon), suggesting that
the mRNA secondary structure prevented complete sec-
ond strand synthesis. For this reason cDNA sequence
was also obtained using RT-PCR using a higher than
normal temperature for second strand synthesis. Using
RT-PCR the 3¢ end of the cDNA was obtained yielding
an open reading frame of 1803 bp encoding 600 amino
acids and a protein of 66.7 kDa (Fig. 1). This is flanked
by a 58 bp 5¢-UTR and an 89 bp 3¢-UTR. Although no
polyadenylation signal was found a poly A tail was
sequenced. The translated protein sequence (tgCA) was
found to contain three domains, based upon database
searches, a signal sequence (Met1–Ala17) and two
domains with homology to the a-CA family, n-tgCA
(Ala18–Thr289) and c-tgCA (Ala290–Ser600) (Fig. 2).
The predicted cleavage point of the signal sequence,
between Ala17 and Ala18 (Centre for Biological
Sequence Analysis Database), produces a mature
N-terminal amino acid sequence almost identical (21
out of 22 residues) to an N-terminal peptide sequence
previously obtained [9], suggesting that this is the cor-
rect cleavage point for the signal sequence. A potential
GPI-modification site was identified at Gly577 by the
DPGI database.
Five consensus sites for N-glycosylation (NXS or
NXT) were found in the deduced amino acid sequence
at positions Asn66, Asn97, Asn177, Asn421 and Asn452.
Phylogenetic comparison of both CA domains with
a number of characterized human CA isoforms and
representative invertebrate CAs shows the clear group-
ing of the three recognized a-CA groups, the cytosolic,
Fig. 1. Translated protein sequence of tgCA
from T. gigas. The first CA domain (n-tgCA)
begins at Ala18, the second CA domain
(c-tgCA) begins at Ala290 (bold). The signal
sequence is highlighted and the five poten-
tial glycosylation sites (three in n-tgCA and 2
in c-tgCA) are underlined. Gly577 (double
underline) is the predicted GPI-anchor site.
A dual domain carbonic anhydrase W. Leggat et al.
3298 FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS

secreted ⁄membrane-associated and the CA-related pro-
teins (Fig. 3). Both domains of the clam CA group
with the membrane-associated CAs.
Intron ⁄exon mapping
There are a number of intron ⁄ exon locations that are
specific for the various CA classes [3,12]. With this in
mind the introns for tgCA were mapped to further
characterize the two CA domains. The genomic
sequence of tgCA, between positions 101 and 1810 of
the cDNA, was amplified in a number of PCR reac-
tions spanning in excess of 17 kb. These sequences
included the complete coding sequence for the gene
between positions 101 and 1810. Twelve introns and
13 exons were found in this region, five in n-tgCA, six
Fig. 2. Alignment of n-tgCA and c-tgCA with other CAs showing intron position and conserved motifs. The 15 amino acids thought to be
required for CA activity are indicated (#), while cysteine residues involved in disulfide bonding in CA IV (two disulfide bonds) and CA VI, XII,
XIV (one disulfide bond) are indicated (�) above the alignment. Numbers below the alignment indicate the intron number while intron posi-
tions are represented by: ( ⁄ ) intron between amino acids, (\) intron located after the first codon position of the following amino acid, (+)
intron located after the second codon position of the following amino acid, and (*) represents no intron present. Residues shared by more
than 50% of the CAs examined are shaded. The alignment was performed using CLUSTALW. Note that hCA1 contains an alanine at position
122 rather then the conserved Val122, however, the consensus for the CA-1 isoform from vertebrates is valine [3]. hCA, human CA; NCBI
accession numbers in brackets, hCA1 (NM_001738), hCA2 (NM_000067), hCA3 (NM_005181), hCA4 (NM_000717), hCA5 (NM_001739),
hCA6 (NM_001215), hCA7 (NM_005182), hCA8 (NM_004056), hCA12 (NP_001209), hCA14 (NP_036245).
W. Leggat et al. A dual domain carbonic anhydrase
FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3299

in c-tgCA and one between the two domains (Fig. 2).
Unfortunately, despite repeated attempts it was not
possible to obtain genomic sequence corresponding to
the cDNA sequence prior to position 101 of the cDNA
sequence, this may have been due to the presence of
an extremely large intron. Alignment of the intron
positions with those of the human CAs shows that
both n-tgCA and c-tgCA share the majority of intron
locations with the secreted ⁄membrane-associated CAs
(Fig. 2). All introns conformed to the gt-ag rule [13]
(Table 1). In three cases (introns 2, 7 and 11) multiple
sequences were obtained for introns, suggesting that
tgCA is a multiple copy gene, this was confirmed by
the Southern analysis (data not shown). Only one base
pair of the genomic sequence differed to that previ-
ously obtained for the cDNA sequence (1586CfiT). Of
the � 15.7 kb of intron in the gene, sequence data was
obtained for � 9.8 kb. The GC content of the coding
sequence (44.5%) was significantly higher than that of
the introns (36.0%). In addition microsatellite repeat
sequences were found in exon 5 (CAAA, 21 repeats)
and exon 7 (GTTT, 13 repeats) (data not shown).
tgCA subunit size
In addition to the 70 kDa CA, another protein of
200 kDa with characteristics of CA was also identified
[9]. Although a minor component of the purified CA
fraction this protein had an identical N-terminal amino
acid sequence to the 70 kDa isoform [9]. When gel
purified and separated on an 8% SDS ⁄PAGE gel it
was found that the apparent molecular mass of this
Fig. 3. Phylogeny of the CA domains of
tgCA (n-tgCA and c-tgCA) with representa-
tives of other CA classes using maximum
likelihood. Alignments were performed using
CLUSTALW, bootstrapped 1000 times and the
trees constructed using maximum likelihood.
hCA, human CA; ce, Caenorhabditis
elegans; Dr, Drosophila melanogaster; ae,
Anthopleura elegantissma; CAH1 from the
alga Clamydomonas reinhardtii was used as
an outgroup.
Table 1. Exon ⁄ intron junctions of tgCA. No genomic sequence was obtained before the position corresponding to base pair 101 in the cDNA
sequence. Numbering of the cDNA sequence begins at the first codon position of the first in-frame methionine. The exact intron size is
given where known; estimates were made from the size of PCR products. Uppercase letters indicate coding sequence, while lowercase
indicate intron sequence.
Intron cDNA codon position preceding intron (bp) Intron size (bp) 5¢ Splice donor 3¢ Splice acceptor
1 265 � 1040 CACGG gtaaac ttccag TGGTA2 417 � 956a TTGAG gtaggt ttgtag GTACA3 510 � 1200 TTGAG gtgggt ttctag ATCGA4 583 � 1830 TAAAA gttagt ttctag ATGGA5 744 � 2280 CTCAG gtatat tttcag CTTGC6 868 � 2000 TACAG gttggg ttacag CTCAA7 910 � 1380a TCAAG gtatgt ttacag GAGTG8 1093 � 950 TACAA gtactt ctacag TCCAA9 1242 � 1100 TCGAG gtactg tttcag CTACA10 1335 � 1370 TTGAA gtaagt tttcag ATCGG11 1399 � 1300, �1200a TAAAG gtatgt tttcag ATGCC12 1581 347 GTCAG gtaagt ttccag TTGGT
a Two intron sequences were found for these introns.
A dual domain carbonic anhydrase W. Leggat et al.
3300 FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS
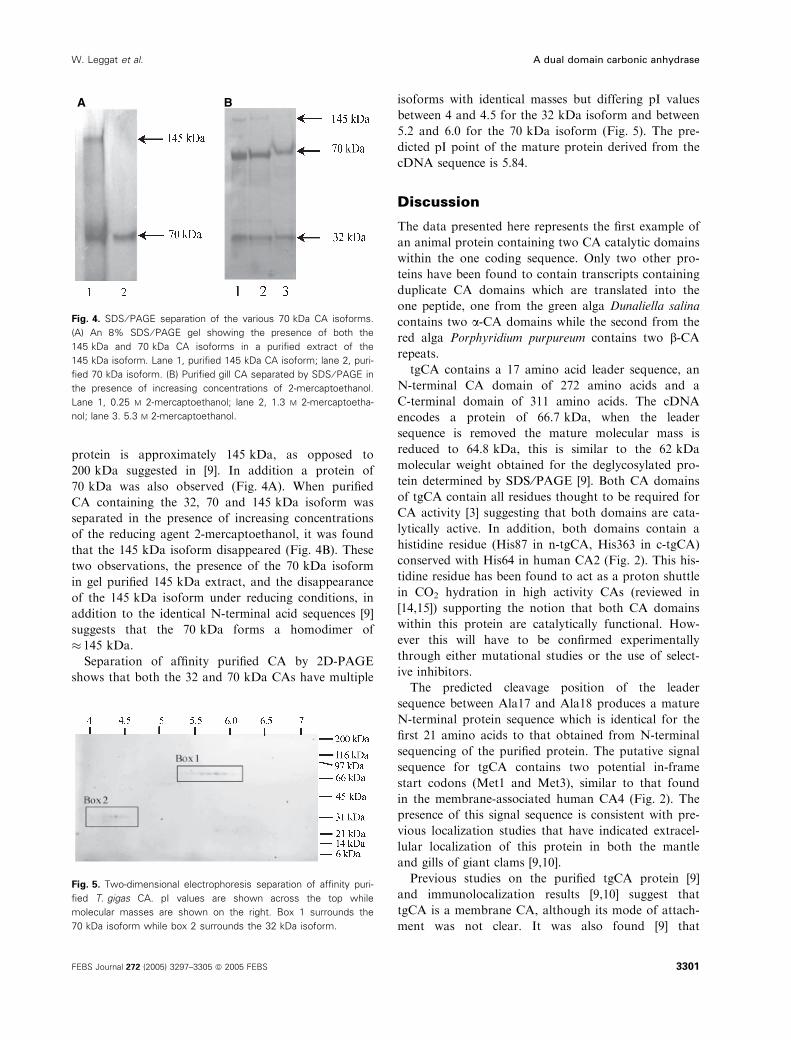
protein is approximately 145 kDa, as opposed to
200 kDa suggested in [9]. In addition a protein of
70 kDa was also observed (Fig. 4A). When purified
CA containing the 32, 70 and 145 kDa isoform was
separated in the presence of increasing concentrations
of the reducing agent 2-mercaptoethanol, it was found
that the 145 kDa isoform disappeared (Fig. 4B). These
two observations, the presence of the 70 kDa isoform
in gel purified 145 kDa extract, and the disappearance
of the 145 kDa isoform under reducing conditions, in
addition to the identical N-terminal acid sequences [9]
suggests that the 70 kDa forms a homodimer of
� 145 kDa.
Separation of affinity purified CA by 2D-PAGE
shows that both the 32 and 70 kDa CAs have multiple
isoforms with identical masses but differing pI values
between 4 and 4.5 for the 32 kDa isoform and between
5.2 and 6.0 for the 70 kDa isoform (Fig. 5). The pre-
dicted pI point of the mature protein derived from the
cDNA sequence is 5.84.
Discussion
The data presented here represents the first example of
an animal protein containing two CA catalytic domains
within the one coding sequence. Only two other pro-
teins have been found to contain transcripts containing
duplicate CA domains which are translated into the
one peptide, one from the green alga Dunaliella salina
contains two a-CA domains while the second from the
red alga Porphyridium purpureum contains two b-CArepeats.
tgCA contains a 17 amino acid leader sequence, an
N-terminal CA domain of 272 amino acids and a
C-terminal domain of 311 amino acids. The cDNA
encodes a protein of 66.7 kDa, when the leader
sequence is removed the mature molecular mass is
reduced to 64.8 kDa, this is similar to the 62 kDa
molecular weight obtained for the deglycosylated pro-
tein determined by SDS ⁄PAGE [9]. Both CA domains
of tgCA contain all residues thought to be required for
CA activity [3] suggesting that both domains are cata-
lytically active. In addition, both domains contain a
histidine residue (His87 in n-tgCA, His363 in c-tgCA)
conserved with His64 in human CA2 (Fig. 2). This his-
tidine residue has been found to act as a proton shuttle
in CO2 hydration in high activity CAs (reviewed in
[14,15]) supporting the notion that both CA domains
within this protein are catalytically functional. How-
ever this will have to be confirmed experimentally
through either mutational studies or the use of select-
ive inhibitors.
The predicted cleavage position of the leader
sequence between Ala17 and Ala18 produces a mature
N-terminal protein sequence which is identical for the
first 21 amino acids to that obtained from N-terminal
sequencing of the purified protein. The putative signal
sequence for tgCA contains two potential in-frame
start codons (Met1 and Met3), similar to that found
in the membrane-associated human CA4 (Fig. 2). The
presence of this signal sequence is consistent with pre-
vious localization studies that have indicated extracel-
lular localization of this protein in both the mantle
and gills of giant clams [9,10].
Previous studies on the purified tgCA protein [9]
and immunolocalization results [9,10] suggest that
tgCA is a membrane CA, although its mode of attach-
ment was not clear. It was also found [9] that
A B
Fig. 4. SDS ⁄ PAGE separation of the various 70 kDa CA isoforms.
(A) An 8% SDS ⁄PAGE gel showing the presence of both the
145 kDa and 70 kDa CA isoforms in a purified extract of the
145 kDa isoform. Lane 1, purified 145 kDa CA isoform; lane 2, puri-
fied 70 kDa isoform. (B) Purified gill CA separated by SDS ⁄ PAGE in
the presence of increasing concentrations of 2-mercaptoethanol.
Lane 1, 0.25 M 2-mercaptoethanol; lane 2, 1.3 M 2-mercaptoetha-
nol; lane 3. 5.3 M 2-mercaptoethanol.
Fig. 5. Two-dimensional electrophoresis separation of affinity puri-
fied T. gigas CA. pI values are shown across the top while
molecular masses are shown on the right. Box 1 surrounds the
70 kDa isoform while box 2 surrounds the 32 kDa isoform.
W. Leggat et al. A dual domain carbonic anhydrase
FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3301

phosphoinositol phospholipase C digestion did not
result in the release of tgCA from crude gill homogen-
ate, suggesting that it is not GPI-anchored and is
instead an integral membrane protein. However analy-
sis of the predicted protein sequence presented here
does not seem to support this hypothesis, as evidence
of a putative transmembrane domain region is ambigu-
ous (data not shown). In addition the DPGI database
predicts that a GPI anchor may be present at Gly577
(it must be stated that the big-PI Predictor did not
identify a GPI-anchor for this protein). How tgCA is
associated with the membrane is still unknown and
requires further research, although the lack of a hydro-
phobic domain suggests that, as with human CA4, it is
attached through a GPI-anchor.
Perhaps surprisingly there is very little identity
between the two CA domains of this protein at either
the coding (48%) or amino acid level (29%). This level
of identity is similar to that seen when comparing the
different domains of tgCA to human CAs. Of the ver-
tebrate and invertebrate CAs used for the tree con-
struction (Fig. 3), n-tgCA had the greatest identity at
the amino acid level with human CA2 and human
CA7 (32% for both) while c-tgCA was most similar to
human CA1 and human CA7 (28% identity for both).
The lowest identity was with the alga C. reinhardtii
CAH1 gene (13% n-tgCA and 16% c-tgCA).
Despite this greater identity with human cytosolic
CAs, phylogenetic analysis suggests that both the
N- and C-terminal domains belong to the secreted ⁄membrane-associated CA group (Fig. 3). Despite low
bootstrap values for the tree in general, the support
for the division between the cytosolic and secre-
ted ⁄membrane-associated CAs is high (80%). This tree
clearly groups the human cytosolic CAs, the CA-like
proteins and secreted ⁄membrane-associated CAs. Of
the invertebrate CAs, both the fly and anemone fall
within the cytosolic group while the two putative
Caenorhabditis elegans CAs (CAH1 and CAH2) group
with the CA-RP vertebrate genes. To our knowledge
there is only one published report of a cDNA coding
for an invertebrate membrane attached CA [7], indica-
ting that tgCA represents the second example of a
membrane-associated CA from the invertebrates.
The phylogenetic grouping of tgCA with the mem-
brane-associated CAs from vertebrates is supported by
a range of other properties of this protein including
the presence of a signal sequence and the presence of a
conserved disulfide bond. All CAs of this group have
been found to contain two conserved cysteine residues
involved in an intrachain disulfide bond (Fig. 2). The
tgCA sequence is no exception with each CA domain
containing two conserved cysteine residues (Cys41,
Cys229, Cys315, Cys508) that are homologous to those
found in all other CAs of this group (Fig. 2). The pres-
ence of disulfide bonds in tgCA is supported by chan-
ges in electrophoretic mobility when the purified
protein is subjected to varying levels of reducing agent.
In the presence of higher concentrations of 2-merca-
ptoethanol, the 70 kDa isoform migrates more slowly
(Fig. 4A). This is consistent with human CA4 which
shows a similar pattern in the presence of 5% 2-merca-
ptoethanol [16].
While four of the six cysteines in tgCA are implica-
ted in intrachain disulfide bonds, evidence suggests
that at least one of the remaining two cysteines forms
a disulfide bond with another tgCA subunit making a
dimer of the 70 kDa protein. Gel filtration experiments
had previously suggested that tgCA exists as a dimer,
with a native weight of approximately 141 kDa [9].
When a gel purified fraction of similar estimated mole-
cular mass (145 kDa) is separated by SDS ⁄PAGE, the
70 kDa band is found in addition to the original
145 kDa protein. Upon addition of high concentra-
tions of the reducing agent 2-mercaptoethanol this
band (� 145 kDa) disappears (Fig. 4B) supporting the
conclusion that this represents a dimer. The gel filtra-
tion results in combination with reduction of the
145 kDa protein to the 70 kDa isoform suggest that
there are interchain disulfide bonds between two
70 kDa subunits.
Analysis of the genomic sequence data, where differ-
ent intron sequences have been obtained (Table 1),
Southern blots (data not shown) and protein two-
dimensional gels all suggest that tgCA is a multicopy
gene. Despite this no sequence differences were
observed in the coding sequence or intron position
where different copies, evidenced by different intron
sequences, were obtained. Given this it seems reason-
able then to use the combined genomic data, even if it
does not represent one gene, for analysis of intron ⁄exon structure.
Intron ⁄ exon positions are considered diagnostic for
animal CAs with characteristic pattern differences
being found in cytosolic and secreted ⁄membrane-asso-
ciated CAs [3,12]. For example of the 15 possible
intron sites shown in Fig. 2, three introns are shared
between these two groups, three are found only in the
cytosolic CAs and at least two more are found only in
the secreted ⁄membrane-associated CAs. Genomic
sequence of tgCA revealed 12 introns and 13 exons
(Fig. 2), all of which conformed to the gt ⁄ ag rule for
splice junctions [13] (Table 1). The majority of these
introns (11) were found to be homologous to those in
the secreted ⁄membrane-associated CAs (intron posi-
tions 5, 9 and 13 of all possible introns, Fig. 2) or
A dual domain carbonic anhydrase W. Leggat et al.
3302 FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS

those introns common to the majority of vertebrate
CAs (introns 7, 8, 11). This distribution of intron ⁄ exonboundaries supports the phylogeny and protein prop-
erties discussed above that groups both CA domains
of tgCA with the secreted ⁄membrane attached CAs.
However, surprisingly one intron in the c-tgCA was
found to differ from this pattern. Intron 3 in c-tgCA
(Fig. 2) is diagnostic for the cytosolic CAs. The pres-
ence of a cytosolic specific intron in a CA that would
otherwise belong to the secreted ⁄membrane attached
CA grouping suggests that this intron was present
before the division of these two groups and has subse-
quently been lost from the membrane-associated CAs.
The dual domain structure of tgCA could have arisen
through one of two mechanisms, either the fusion of
two separate CA genes or a duplication of a single gene
followed by a fusion event. If this protein arose through
duplication and fusion event, and given the poor iden-
tity between the two CA domains (29%), the duplication
event must be old, thereby allowing time for the two
domains to diverge. This low identity between domains
is especially striking when compared to other duplicated
domain CA proteins, 52 and 72% identity for D. salina
and P. purpureum, respectively [17,18]. Furthermore
there are similar examples of non-CA duplicated domain
proteins from invertebrates. Phosphagen kinases from a
number of bivalves [19–21], sea anemones [22] and sea
urchins [23] have been shown to contain bi- or tripartite
repeat domains. In all of these examples, identity
between the domains is in excess of 60%. For each pro-
tein it has been concluded that the dual domain struc-
ture arose through gene duplication of one gene and
subsequent fusion. Where genomic sequence is available
[20,22] this is supported by the presence of an intron
between the two domains. Similarly in tgCA an intron is
found between the two domains. Given the low homol-
ogy between the two domains of tgCA in comparison to
other duplicated domain proteins it is not possible
to exclude the possibility that this protein has arisen
through the fusion of two different CA genes rather
than a duplication event.
Given the unique structure of this CA protein it
would be interesting to know if both domains display
CA activity. Previous studies [9] have shown that the
purified protein is active, however, from this data it is
not possible to conclude if this is due to one or both
domains. As both domains contain all the required
residues it seems likely that they are both active. A fur-
ther area of study is the interaction of the two
domains, for example are both required for activity
and ⁄or do they function cooperatively and what is
their three-dimensional arrangement? These questions
are areas of future study.
To date the dual domain structure of tgCA is unique
amongst animals, whether this gene duplication of CA
is present in other symbiotic or nonsymbiotic bivalves,
and possibly other invertebrates, remains to be seen. If
this CA arrangement is restricted to symbiotic bivalves
it may represent a mechanism by which a symbiotic
animal can increase the rate of inorganic carbon trans-
port to their photosynthetic symbionts, and thereby
maximize the benefits of symbiosis.
Experimental procedures
Purification of carbonic anhydrase from clam gills
The 70 kDa CA isoform was purified from the gills of
the giant clam T. gigas as previously described [9]. The
145 kDa CA isoform was electroeluted from affinity puri-
fied CA after separation by SDS ⁄PAGE.
Separation of CA isoforms by two-dimensional
gel electrophoresis
Affinity purified CA was analyzed by two-dimensional gel
electrophoresis (2D-PAGE). Separation in the first dimen-
sion was performed using an Immobiline DryStrip (pH 4–7,
Pharmacia, Piscataway, NJ, USA) which was then further
separated on an 8–18% SDS ⁄PAGE gradient gel using the
manufacturer’s protocol (Pharmacia, Cat # 18-1038-63).
Gels were visualized using Sypro-Ruby (Molecular Probes,
Eugene, OR, USA).
Purification of RNA and cDNA library construction
Total RNA was prepared from T. gigas mantle and gill
tissue. Fresh tissue (1.3 g) was snap frozen in liquid nitro-
gen and ground in a mortar and pestle. Total RNA was
prepared from the tissue using cesium chloride [24].
mRNA was then purified from total RNA using the
QuickPrep� mRNA Purification Kit (Pharmacia). The gill
cDNA was synthesized for rapid amplification of cDNA
ends by the polymerase chain reaction (RACE-PCR) using
the ClontechTM cDNA Amplification Kit. The mantle lib-
rary was initially synthesized as a phage library in k-ZapII(Stratagene, La Jolla, CA, USA). It was used as a
template for RACE-PCR using specific primers for the
adaptors.
Clam CA primers were designed to previously known
cDNA sequence of the 70 kDa CA isoform from T. gigas
[25] and to N-terminal amino acid sequence [9] (Fig. 1).
From the derived sequence further primers were designed
to amplify the remaining portion of the cDNA.
Products were also amplified using RT-PCR. mRNA was
purified as previously described and first strand synthesis
performed using OmniscriptTM Reverse Transcriptase
W. Leggat et al. A dual domain carbonic anhydrase
FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3303

(Qiagen, Valencia, CA, USA) using the following primer:
5¢-CCAgTgAgCAgAgTgACggAggACTCgAgCTCAAgCTT
TTTTTTTTTTTTTT-3¢. PCR products were then amplified
using a gene specific primer and Q0 (5¢-CCAgTgAgCAgAg
TgACg-3¢) whose sequence was contained in the poly(T)
primer. The second-strand synthesis was conducted at 38 �Crather than 16 �C to overcome problems associated with sec-
ondary structure inhibition of second-strand synthesis which
had previously been observed.
DNA sequencing
Gel purified PCR products (High Pure PCR Product Purifi-
cation Kit, Roche, Mannheim, Germany) or 1.5 lL of the
PCR reaction were ligated into T-Vector Easy (Promega,
USA) and transformed into XL-1 Blue cells. After plasmid
purification (High Purity Plasmid Isolation Kit, Roche)
clones were sequenced using capillary separation on a ABI
3730xl sequencer using the ABI v3.0 sequencing kit (Applied
Biosystems, Foster City, CA, USA).
Sequence analysis
Sequence alignments were performed using the program
clustal w [26], bootstrapped 1000 times and trees con-
structed using maximum likelihood [27], the C. reinhardtii
a-CA gene (CAH1) was used as an outgroup. All analyses
were performed using biomanager by ANGIS (http://
www.angis.org.au). Signal sequences were identified using
the Centre for Biological Sequence Analysis database [28].
Potential GPI-anchor sites were examined using the DPGI
database (http://129.194.185.165/dgpi/DGPI_demo_en.html)
and the big-PI Predictor (http://mendel.imp.univie.ac.at/gpi/
gpi_server.html) [29].
Isolation of genomic DNA
Genomic DNA was isolated from T. gigas sperm. Spawning
was induced by the injection of approximately 5 mL of a
2 mm serotonin solution into the gonads. The sperm was
collected from the water and centrifuged (1000 g for
5 min). Sperm (1 mL packed cell volume) was diluted with
11 mL proteinase K solution [50 mm Tris ⁄HCl pH 7.5,
20 mm EDTA, 100 mm NaCl, 1% (w ⁄ v) SDS, 100 lgÆmL)1
proteinase K] and the sample was incubated overnight at
55 �C. The solution was centrifuged (1000 g for 15 min at
4 �C), the supernatant removed, mixed with 10 mL of
ultra-pure phenol (Sigma, St Louis, MO, USA) and then
equilibrated with 4 mL of TE (10 mm Tris pH 8.0, 1 mm
EDTA) buffer. After adding an equal volume of chloro-
form, the solution was left overnight. The solution was
again centrifuged (1000 g for 15 min at 4 �C) and the aque-
ous phase removed. This was re-extracted twice with chlo-
roform and the DNA precipitated with 0.1 volume sodium
acetate (3 m, pH 5.2) and 2.5 volume 100% (v ⁄ v) ethanol.
After precipitation the DNA was spooled and resuspended
in TE buffer.
Genomic sequencing
The intron ⁄ exon structure of the 70 kDa CA was mapped
using a series of sequence specific primers obtained from the
cDNA sequence that bracketed possible intron positions [3].
Acknowledgements
This work was supported by an Australian Research
Council grant to David Yellowlees. We would like to
thank three anonymous referees for their helpful com-
ments.
References
1 Pastorekova S, Parkkila S, Pastorek J & Supuran CT
(2004) Carbonic anhydrases: current state of the art,
therapeutic applications and future prospects. J Enz
Inhib Med Chem 19, 199–229.
2 So AKC, Espie GS, Williams EB, Shively JM, Hein-
horst S & Cannon GC (2004) A novel evolutionary line-
age of carbonic anhydrase e is a component of the
carboxysome shell. J Bacteriol 186, 623–630.
3 Hewett-Emmett D & Tashian RE (1996) Functional
diversity, conservation, and convergence in the evolu-
tion of the a-, b-, and c-carbonic anhydrase gene famil-
ies. Mol Phylo Evol 5, 50–77.
4 De Cian M, Bailly X, Morales J, Strub J, van Doressel-
aer A & Lallier FH (2003) Characterization of carbonic
anhydrases from Riftia pachyptila, a symbiotic inverte-
brate from deep-sea hydrothermal vents. Proteins Struct
Func Genet 51, 327–339.
5 Weis VM & Reynolds WS (1999) Carbonic anhydrase
expression and synthesis in the sea anemone Anthopleura
elegantissima are enhanced by the presence of dinoflagel-
late symbionts. Physiol Biochem Zool 72, 307–316.
6 Pilar Corena M, Seron TJ, Lehman HK, Ochrietor JD,
Kohn A, Tu C & Linser PJ (2002) Carbonic anhydrase
in the midgut of larval Aedes aegypti: cloning, localiza-
tion and inhibition. J Exp Biol 205, 591–602.
7 Seron TJ, Hill J & Linser PJ (2004) A GPI-linked car-
bonic anhydrase expressed in the larval mosquito mid-
gut. J Exp Biol 207, 4559–4572.
8 Miyamoto H, Miyashita T, Okushima M, Nakano S,
Morita T & Matsushiro A (1996) A carbonic anhydrase
from the nacreous layer in oyster pearls. Proc Natl Acad
Sci USA 93, 9657–9660.
9 Baillie B & Yellowlees D (1998) Characterization and
function of carbonic anhydrase in the zooxanthellae-
giant clam symbiosis. Proc R Soc Lond B 265, 465–473.
A dual domain carbonic anhydrase W. Leggat et al.
3304 FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS

10 Leggat W, Marendy EM, Baillie B, Whitney SM,
Ludwig M, Badger MR & Yellowlees D (2002) Dinofla-
gellate symbioses: strategies and adaptations for the
acquisition and fixation of inorganic carbon. Funct
Plant Biol 29, 309–322.
11 Fisher CR, Fitt WK & Trench RK (1985) Photosynth-
esis and respiration in Tridacna gigas as a function of
irradiance and size. Biol Bull 169, 230–245.
12 Jiang W & Gupta D (1999) Structure of the carbonic
anhydrase VI (CA6) gene: evidence for two distinct
groups within the a-CA gene family. Biochem J 344,
385–390.
13 Mount SM (1982) A catalog of splice junction
sequences. Nucleic Acids Res 10, 459–472.
14 Lindskog S (1997) Structure and mechanism of carbonic
anhydrase. Pharmacol Ther 74, 1–20.
15 Supuran CT, Scozzafava A & Casini A (2003) Carbonic
anhydrase inhibitors. Med Res Rev 23, 146–189.
16 Zhu XL & Sly WS (1990) Carbonic anhydrase IV from
human lung: purification, characterization, and compar-
ison with membrane carbonic anhydrase from human
kidney. J Biol Chem 265, 8795–8801.
17 Fisher M, Gokhman I, Pick U & Zamir A (1996) A
salt-resistant plasma membrane carbonic anhydrase is
induced by salt in Dunaliella salina. J Biol Chem 271,
17718–17723.
18 Mitsuhashi S & Miyachi S (1996) Amino acid sequence
homology between N- and C-terminal halves of a carbo-
nic anhydrase in Porphyridium purpureum, as deduced
from a cloned cDNA. J Biol Chem 271, 28703–28709.
19 Compaan DM & Ellington WR (2003) Functional con-
sequences of a gene duplication and fusion event in an
arginine kinase. J Exp Biol 206, 1545–1556.
20 Suzuki T, Kawasaki Y, Unemi Y, Nishimura Y, Soga
T, Kamidochi M, Yazawa Y & Furukohri T (1998)
Gene duplication and fusion have occurred frequently
in the evolution of phosphagen kinases – a two-domain
arginine kinase from the clam Pseudocardium sachalinen-
sis. Biochim Biophys Acta 1388, 253–259.
21 Suzuki T, Sugimura N, Taniguchi T, Unemi Y, Murata
T, Hayashida M, Yokouchi K, Uda K & Furukohri T
(2002) Two-domain arginine kinases from the clams
Solen strictus and Corbicula japonica: exceptional amino
acid replacement of the functionally important D62 by
G. Int J Biochem Cell Biol 34, 1221–1229.
22 Suzuki T, Kawasaki Y & Furukohri T (1997) Evolution
of phosphagen kinase: Isolation, characterization and
cDNA-derived amino acid sequence of two-domain
arginine kinase from the sea anemone Anthopleura japo-
nicus. Biochem J 328, 301–306.
23 Wothe DD, Charbonneau H & Shapiro BM (1990) The
phosphocreatine shuttle of sea urchin sperm: flagellar
creatine kinase resulted from a gene triplication. Proc
Natl Acad Sci USA 87, 5203–5207.
24 Sambrook J, Fritsch EF & Manniatis T (1989) Mole-
cular Cloning, 2nd edn. Cold Spring Harbor Laboratory
Press, Cold Spring Harbour, NY.
25 Baillie BK, (1995) Inorganic carbon acquisition and utili-
sation in the giant clam symbiosis. PhD Thesis, James
Cook University of North Queensland, Australia.
26 Thompson JD, Higgins DG & Gibson TJ (1994) CLUS-
TAL W: improving the sensitivity of progressive multi-
ple sequence alignment through sequence weighting,
position-specific gap penalties and weight matrix choice.
Nucleic Acids Res 22, 4673–4680.
27 Felsenstein J (1989) PHYLIP – Phylogeny Inference Pack-
age Version 3.2. Cladistics, 5, 164–166.
28 Bendtsten JD, Nielsen H, von Heijne G & Brunak S
(2004) Improved prediction of signal peptides: SignalP
3.0. J Mol Biol 340, 783–795.
29 Eisenhaber B, Bork P & Eisenhaber F (1999) Prediction
of potential GPI-modification sites in proprotein
sequences. J Mol Biol 292, 741–758.
W. Leggat et al. A dual domain carbonic anhydrase
FEBS Journal 272 (2005) 3297–3305 ª 2005 FEBS 3305
Related Documents











