A Cache-Like Memory Organization for 3D memory systems CAMEO 12/15/2014 MICRO Cambridge, UK Chiachen Chou, Georgia Tech Aamer Jaleel, Intel Moinuddin K. Qureshi, Georgia Tech

A Cache-Like Memory Organization for 3D memory systems CAMEO 12/15/2014 MICRO Cambridge, UK Chiachen Chou, Georgia Tech Aamer Jaleel, Intel Moinuddin K.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

A Cache-Like Memory Organizationfor 3D memory systems
CAMEO
12/15/2014 MICRO
Cambridge, UK
Chiachen Chou, Georgia Tech
Aamer Jaleel, Intel
Moinuddin K. Qureshi, Georgia Tech

EXECUTIVE SUMMARY
• How to use Stacked DRAM: Cache or Memory?
• Cache: software-transparent, fine-grained data transfer, but sacrifices memory capacity
• Memory: larger memory capacity, but software-support, coarse-grained data transfer
• CAMEO: software-transparent, fine-grained data transfer and almost full memory capacity
• Results: CAMEO outperforms both Cache (50%) and Two-Level Memory (50%) by providing 78% speedup
2

MEMORY BANDWIDTH WALL
3Courtesy: JEDEC, Intel, Micron
Stacked DRAM helps overcome bandwidth wall
Stacked DRAM
Bandwidth 2-8X
Latency 0.5-1X
Computer systems face memory bandwidth wall.
High Bandwidth Memory
Hybrid Memory Cube

HYBRID MEMORY SYSTEM
4Courtesy: JEDEC, Intel, Micron
How to use Stacked DRAM: Cache or Main Memory?
1-4 GB
Commodity DRAM
8-16 GBStacked DRAM
Commodity DRAM
Hybrid Memory System
Stacked DRAM

AGENDA
• Introduction
• Background– Cache– Two-Level Memory
• CAMEO– Concept– Implementation
• Methodology
• Results
• Summary5

Off-chip DRAM
HARDWARE-MANAGED CACHE
6
DRAMCache
Stacked DRAM is architected as DRAM Cache
StackedDRAM
Mem
ory
Hie
rarc
hy
fast
slow
CPU
L1$
L2$
L3$
CPU
L2$
L1$

L4 Cache
OS
HARDWARE-MANAGED CACHE
7
Off-chipmemory
L3 Miss
L4 Miss
Cache: software-transparency, fine-grained data transfer, but no capacity benefits
64B64B
Shared L3 Cache

Cache TLM CAMEO
Need OS Support No Yes No
Data Transfer @ 64B 4KB 64B
Memory Capacity No 3D Plus 3D += 3D
3D DRAM AS A CACHE
8
CPUs
DRAM $
Off-chip memory
CPU
Stacked DRAM
Commodity DRAM
?4GB
12GB
16GB12GB
(Cache)

AGENDA
• Introduction
• Background– Cache– Two-Level Memory
• CAMEO– Concept– Implementation
• Methodology
• Results
• Summary9

TWO-LEVEL MEMORY (TLM)
10
Stacked DRAM is architected as part of OS-visible memory space (Two-Level Memory)
Off-chip DRAM
StackedDRAM
OS4GB12GB
16GB
CPU
L1$
L2$
L3$
CPU
L2$
L1$

TWO-LEVEL MEMORY (NO MIGRATION)
11
Static page mapping does not exploit locality
OS
Page
Shared L3 Cache
Page
4GB12GB
25% Pages 75% Pages

TWO-LEVEL MEMORY (WITH MIGRATION)
12
TLM: OS support and inefficient use of bandwidth
Page
Shared L3 Cache
Page Migration
L3 Miss
64B
OSsupport
Page
(4KB Transfer)

MOTIVATION
13(<12GB)
Baseline: 12GB off-chip DRAMw/ 4GB stacked DRAM
(>12GB)
4+12 4+12 4+16
Small WS: Small Working Set (<12GB)

MOTIVATION
14
Baseline: 12GB off-chip DRAMw/ 4GB stacked DRAM
4+12 4+12 4+16
(>12GB) (<12GB) Cache performs poorly in Large WS
workloads, as TLM in Small WS workloads
31%

OVERVIEW
CPUs
DRAM $
Off-chipDRAMOS-visible
Memory Space
CPUs
Stacked DRAM
Off-chipDRAM
Goal
1515
Cache TLM Ideal
Need OS Support No Yes No
Data Transfer @ 64B 4KB 64B
Memory Capacity No 3D Plus 3D Plus 3D

AGENDA
• Introduction
• Background– Cache– Two-Level Memory
• CAMEO– Concept– Implementation
• Methodology
• Results
• Summary16

CAMEO
17
A CAche-Like MEmory Organization
Shared L3 Cache
Commodity DRAM
StackedDRAM
OS
PagePage
SW get full capacity; HW does data migration
4GB12GB
16GB
Hardware performs data migration

Stackedmemory
Off-chipmemory
CAMEO
18
A CAche-Like MEmory Organization
Shared L3 Cache
CAMEO transfers only 64B cache lines
L3 Miss
64B64B
64B
HW swaps lines(fine-grained transfer)

CAMEO – CONGRUENCE GROUP
19
Off-chipmemory
Stackedmemory
4GB 12GB
0
N-1
N
2N-1
2N
3N-1
3N
4N-1
A B C D
Congruence group

MIGRATION IN CONGRUENCE GROUP
20
A B C D
Request to B, B, and C:
• Request to B: Swap line A and B
B A C D
• Request to B: Hit in Stacked DRAM
B A C D
• Request to C: Swap line C and B
C A B D
Swapping changes line’s location, and requires indexing structure to keep track of the location.

11
LINE LOCATION TABLE (LLT)
Location Table for Congruence Group
21
C A B D
4 Location00 01 10 11
Request Line A B C DPhysical Location 01 10 00 11
C A B D
00 01 10

LINE LOCATION TABLE (LLT)
Size of Location Table Per Congruence Group
22
C A B D
Log2(4)=2 bits 4 lines = 8 bits (1 byte)
Storing LLT in SRAM is impractical
64M groups(64MB)
00 01 10 11

2KB
LLT IN DRAM
• LLT in DRAM incurs serialization Latency– Optimizing for common case: Hit in stacked DRAM– Co-locate Line Location Table of each congruence
group with data in stacked DRAM
LLT
L3 Miss
Stacked DRAM
1 byte LLT 64 byte Data
LEAD
31 LEAD
23
1.5% capacity loss
Location Entry And Data
Hits

AVOID LLT LOOKUP LATENCY FOR HIT
• Avoiding LLT Lookup Latency on Stacked DRAM Hit (lines in stacked memory)– Co-locate Line Location Table of each
congruence group with data in stacked DRAM
Addr
Hit: one accessStacked DRAM
24Co-Locate LLT to avoid latency on hits
Data
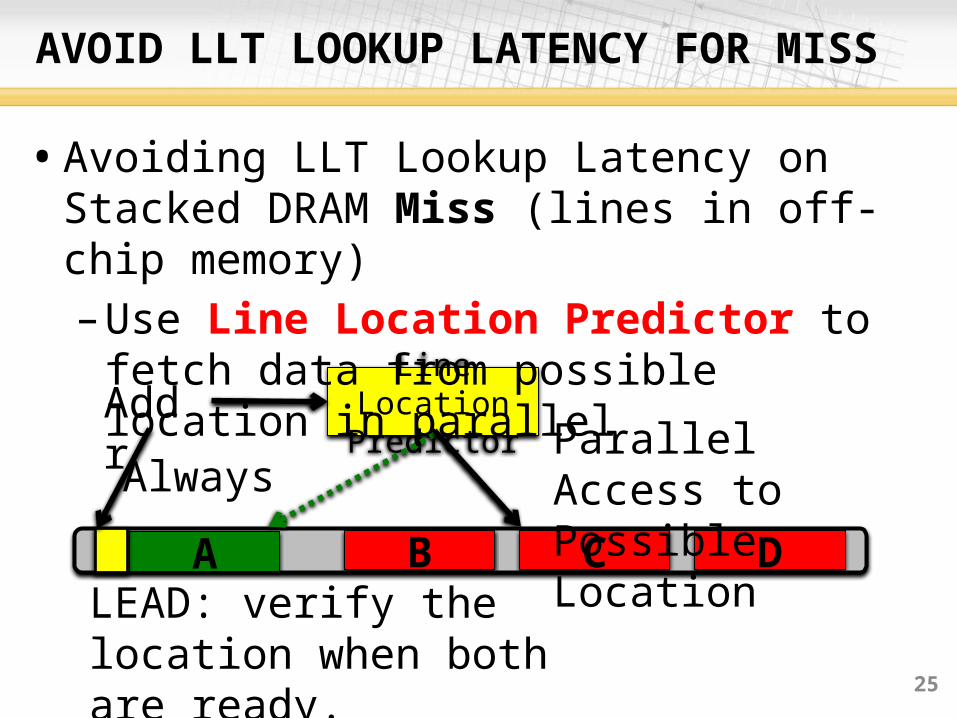
AVOID LLT LOOKUP LATENCY FOR MISS
25
A B C D
Addr
LEAD: verify the location when both are ready.
Line Location Predictor Parallel Access to
Possible Location
• Avoiding LLT Lookup Latency on Stacked DRAM Miss (lines in off-chip memory)– Use Line Location Predictor to fetch data
from possible location in parallel
Always

AVOID LLT LOOKUP LATENCY FOR MISS
26
Line Location Predictor
Addr
Stacked
Off-chip #1
Off-chip #2
Off-chip #3
Predictor Accuracy
AlwaysStacked 70%
LLP 92%
• Avoiding LLT Lookup Latency on Stacked DRAM Miss (lines in off-chip memory)– LLP makes M-ary prediction – LLP uses instruction address and last
location to make prediction
64 byte per core

AVOIDING LLT LATENCY OVERHEAD
• Co-locate LLT of each congruence group with data in stacked DRAM
27
We co-locate Line Location Table and use Line Location Predictor to mitigate latency overhead
On Hit in Stacked DRAM On Miss in Stacked DRAM
• Use Line Location Predictor to fetch data from possible location in parallel
A B C D
Stacked Off-chip
Line Location Table
Line Location Predictor
Addr
Stacked
Off-chip #1
Off-chip #2
Off-chip #3

AGENDA
• Introduction
• Background– Cache– Two-Level Memory
• CAMEO– Concept– Implementation
• Methodology
• Results
• Summary28

• Core Chip 3.2GHz 2-wide out-of-order core 32 cores, 32MB 32-way L3 shared cache
METHODOLOGY
29
Stacked DRAM
Commodity DRAM
SSDCPU

METHODOLOGY
30
Stacked DRAM
Commodity DRAM
SSDCPU
Stacked DRAM Commodity DRAM
Capacity 4GB 12GB
Bus DDR3.2GHz, 128-bit DDR1.6GHz, 64-bit
Latency 22ns 44ns
Channels 16 channels,16 banks/channel
8 channels 8 banks/channels

METHODOLOGY
Stacked DRAM
Commodity DRAM
SSDCPU
• Baseline: 12GB off-chip DRAM
• Cache: Alloy Cache [MICRO’12]
• Two-Level Memory: Page Migration enabled
• SSD Latency: 32 micro seconds
• SPEC2006: rate mode; Small Working Set (<12GB) and Large Working Set(> 12GB)

PERFORMANCE IMPROVEMENT
32Small WSet
CAMEO as good as Cache in Small WS apps

PERFORMANCE IMPROVEMENT
33Large WSetCAMEO outperforms both Cache and
TLM, and very close to DoubleUse
CAMEO outperforms TLM in Large WS apps
28%

EXECUTIVE SUMMARY
• How to use Stacked DRAM: Cache or Memory?
• Cache: software-transparent, fine-grained data transfer, but sacrifices memory capacity
• Memory: larger memory capacity, but software-support, coarse-grained data transfer
• CAMEO: software-transparent, fine-grained data transfer and almost full memory capacity
• Results: CAMEO outperforms both Cache (50%) and Two-Level Memory (50%) by providing 78% speedup
34

Thank You!
35

A Cache-Like Memory Organizationfor 3D memory system
CAMEO
12/15/2014 MICRO
Cambridge, UK
Chiachen Chou, Georgia Tech
Aamer Jaleel, Intel
Moinuddin K. Qureshi, Georgia Tech

Backup slides
37

LINE LOCATION TABLE
Size of Location Table Per Congruence Group
38
A B C D
4 Location Log2(4)=2 bits
4 lines
8 bits (1 byte)
# Locations Size
4 1 byte6 2.5 byte8 3 byte

POWER AND ENERGY
39
14% 34%
Related Documents




![[XLS] · Web viewNAJI ABDUL JALEEL KOLAKKADEN 1311296 MANUSANKAR. C.K 1320385 SHAFEENA. O 1327845 RAM REVANTH 1330346 MOHAMMED UVAIS. K ...](https://static.cupdf.com/doc/110x72/5ae8ab2b7f8b9acc26907630/xls-viewnaji-abdul-jaleel-kolakkaden-1311296-manusankar-ck-1320385-shafeena.jpg)






