1 Data Mining over the Deep Web Tantan Liu, Gagan Agrawal {liut,agrawal}@cse .ohio-state.edu Ohio State University April 12, 2011

1 Data Mining over the Deep Web Tantan Liu, Gagan Agrawal {liut,agrawal}@cse.ohio-state.edu Ohio State University April 12, 2011.
Dec 25, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Data Mining over the Deep Web
Tantan Liu, Gagan Agrawal {liut,agrawal}@cse.ohio-state.edu
Ohio State University
April 12, 2011

2
Outline
• Introduction– Deep Web– Data Mining on the deep web
• Frequent itemset mining over the deep web– Bayesian network– Active learning based sampling method
• Experiment Result• Conclusion

3
Deep Web
• Data sources hidden from the Internet– Online query interface vs. Database– Database accessible through online Interface– Input attribute vs. Output attribute
• An example of Deep Web

4
Data Mining over the Deep Web
• High level summary of data– Scenario 1: A student wants to find a job as a software En
gineer• Will a master degree help?
• Which language to learn: Java, C, or C#?
• Try MSN careers – to much information!
• Frequent itemset mining!

5
Challenges
• Databases cannot be accessed directly– Sampling method for Deep web mining
• Obtaining data is time consuming– Efficient sampling method
– High accuracy with low sampling cost

6
Roadmap
• Introduction– Deep Web– Data Mining
• Frequent Itemset mining over the deep web – Bayesian Network– Active learning based sampling method
• Experiment Result
• Conclusion

7
Frequent Itemset Mining
• Itemset: a set of attributes with instantiations, e.g I={Brand=benz, Age>5}• Support(Brand=Benz, Age>5)=2/8=0.25• Frequent Itemset: Support is larger than a threshold

8
Frequent Itemset Mining on Deep Web
• Challenges
– Support of itemsets is unavailable
– The size of itemsets could be huge• Considering 1-itemsets
– Simple random sample – Inefficient• Support of itemsets of input attributes is known
– # of data records satisfying the query is provided

9
Main Idea
• Task: Estimating the support of itemsets of output attributes• Questions
– Can we use information about input attributes?• Bayesian Network
– Relation between input attributes and output attributes
– Compute support for itemsets of output attributes
– How to quickly build the model• Active learning based sample method

10
Bayesian Network
• Relation between input and output attributes• Graphical model
– Random variables • Input and output attributes
– Conditional dependencies• Output attributes depend on input attributes

11
Active Learning
• In machine learning– Passive learning: data are randomly chosen – Active Learning
• Certain data are selected, to help build a better model
• Active Learning– Obtaining data is costly and/or time-consuming
• Frequent Itemset Mining on Deep Web
12
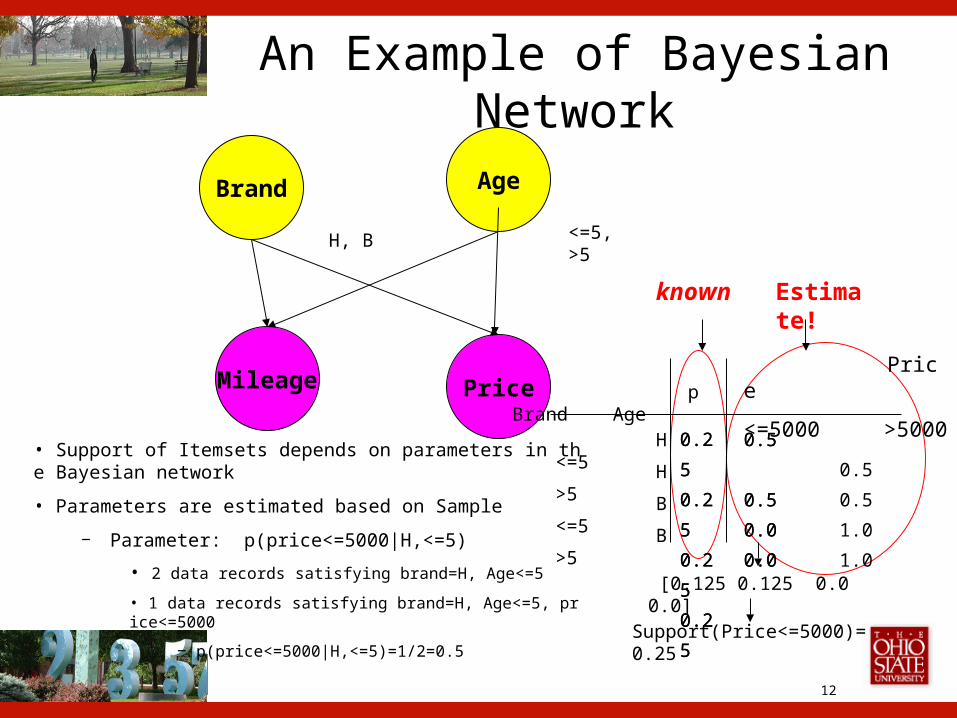
An Example of Bayesian Network
Brand Age
Mileage Price Price
<=5000 >5000 Brand Age
H <=5 0.5
0.5
0.0
0.0
H >5
B <=5
B >5
• Support of Itemsets depends on parameters in the Bayesian network
• Parameters are estimated based on Sample
‒ Parameter: p(price<=5000|H,<=5)
• 2 data records satisfying brand=H, Age<=5
• 1 data records satisfying brand=H, Age<=5, price<=5000
‒ p(price<=5000|H,<=5)=1/2=0.5
p
Support(Price<=5000)= 0.25
H, B <=5, >5
known Estimate!
[0.125 0.125 0.0 0.0]
0.25
0.25
0.25
0.25
0.5
0.5
1.0
1.0
0.25
0.25
0.25
0.25
0.5
0.5
0.0
0.0
13
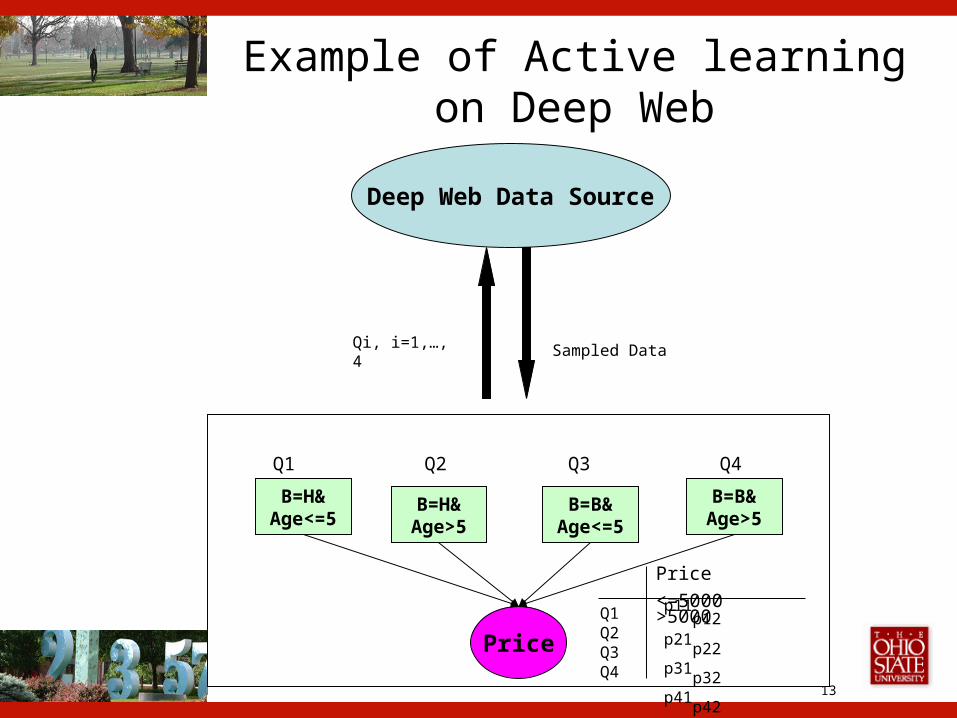
Example of Active learning on Deep Web
Deep Web Data Source
B=H&Age<=5
B=H&Age>5
B=B&Age<=5
B=B&Age>5
Price
Q1 Q2 Q3 Q4
Q1Q2Q3Q4
Price
<=5000 >5000p11 p12 p21 p22p31 p32p41 p42
Qi, i=1,…, 4 Sampled Data

14
An Example of Active Learning Based Sampling
• Hidden idea– Sampling heavily on query spaces with high impurity
Q1(B=H) Q2(B=B)
Price 0.01 0.99 0.5 0.5
Q2
Q1
Deep Web Data Source

15
Detailed Formulation
• Support for output attributes
‒ : an instantiation of input attributes, or a query– : prior probability
• Known
– , • Conditional probability• Parameters in conditional table
• Unknown, need to estimate

16
Parameters in Bayesian Network
• are estimated based on a sample
• Difference between estimated values and true values
• Consider as statistical variables
• Conjugate distribution– After observing data D, is in the same family with
• Hyper parameter – Expectation: , where
• Estimation for support of output attributes– Expectation on the distribution

17
Active Learning on Deep Web
• Risk Function– Risk with the estimation for 1-itemsets composed of output attributes– Based on the hyper parameter in the Bayesian Network,
• Data Selection– Data are obtained by queries : query selection– Data records are selected step by step– Choosing the query with most reduction on risk function
• Updating Model– For , and sample
where denotes the number of data records containing

18
Support for n-itemsets(n>1)
• Estimation based on the Bayesian network
– • Support value of in the query space

19
Roadmap
• Introduction– Deep Web– Data Mining
• Frequent Itemset mining over the deep web – Bayesian Network– Active learning based sampling method
• Experiment Result
• Conclusion

20
Experiment Result
• Data set: US census– 2008 US Census on the income of US households– 40,000 data records
• Three Methods– Dir:
• Random Sample• Direct Computation
– Bay• Random Sample• Computation Based on Bayesian Network
– Act: our proposed method• Active Learning based Sample• Computation Based on Bayesian Network

21
US census
• Square Error Rate:
• Absolute Error Rate (AER):

22
Conclusion
• Data mining on the deep web is challenging• Frequent itemset mining over the deep web• Bayesian network is used to model the deep web• A active learning based sampling method• The experiment results show the efficiency of our work

23
Questions?
Related Documents











