© Wen-mei Hwu and S. J. Patel, 2005 ECE 511, University of Illinois Lecture 2: Basic Notions and Fundamentals

© Wen-mei Hwu and S. J. Patel, 2005 ECE 511, University of Illinois Lecture 2: Basic Notions and Fundamentals.
Dec 25, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Lecture 2: Basic Notions and
Fundamentals

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Outline
• Basic computer organization– von Neumann model and execution cycle– Pipelines and caches
• Architectural drivers– Technology– Applications and compatibility– Compilers
• Measures– Methodology– Key measures

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
von Neumann’s Contribution
• Fetch• Decode• Evaluate
addresses• Fetch operands• Execute• Store results
…
Control
Datapath
Memory
program
Input/Output
Instruction Cycle

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Pipelining
• Instruction latency does not decrease• Throughput increases• Dependencies degrade performance• General trends: deeper/wider until
2004
Fetch Execute MemDecode Write

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Fetch
adder
ALU
ALU
BR
MemDeco
de/S
wap
Stalllogic
write
write
write
Multiple Issue

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Pipeline of the Pentium IV[Courtesy of Intel Corp]
• Enables very high clock rate• Enables scalability from one
technology to the next• But does it always lead to highest
performance?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
TC nxt IP TC Fetch Drv Alloc Rename Que Sch Sch Sch Disp Disp RF RF Ex FlgsBrCk Drv

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Speeding up memory
• Fundamental: Principles of locality of memory references– Reference to X another reference to X later– Reference to X reference to Y, where X, Y are
close
• Fundamental: Memory tends to be small/fast/expensive or large/slow/cheap
• Result: Memory hierarchies with caching

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Basic Cache Organization
…
tag index offset
Data
Address
hit/miss
cache linetag valid
Direct Mapped Cache

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
CMOS Inverter
Vdd
Vss
Input Output
Schematic Notation
p+ p+ n+ n+
Cross-section of inverter in n-well process
n well p substrate
metalfield oxide
polysilicongate oxide
p-MOS trans n-MOS trans
VssVdd
gate
p-MOS trans
n-MOS trans
gate
gate

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
CMOS Trends[Collated from the 2000 update of the International Technology Roadmap for
Semiconductors]
Year 1995 1998 2001 2004 2007 2010 2013
Feature Size
(nanometers)
350nm
180nm
130nm
90nm 65nm 45nm 33nm
TransistorCount
10M 50M 110M 350M 1300M 3500M
11000M
n+ n+
For high-performance CPUs, the feature sizeis (typically) the minimum width of a gate

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
• Delay is proportional to the number of gates– typical measure FO4
• Power dissipation– dynamic (switching)– Static (leakage)
An Microarchitect’s Model of CMOS Power and Delay
Vdd
Vss
Input Output
p-MOS trans
n-MOS trans

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
CMOS Trends[Collated/extrapolated from the 2000 update of
the International Technology Roadmap for
Semiconductors]Year 1995 1998 2001 2004 2007 2010 2013
Feature Size
(nanometers)
350nm
180nm
130nm
90nm 65nm 45nm 33nm
TransistorCount
10M 50M 110M 350M 1300M 3500M
11000M
Projected FO4
delaysIn each
pipe satge
27 13 11 8 7 6 6
This will likely be revised due to the transistor variability problem from 65nm generation on.

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
• Transistors become more plentiful but variable
• Gates become faster• Wires become relatively slower
• Memory becomes relatively slower• Power becomes a critical issue• Noise, error rates, design complexity
CMOS Trends
© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
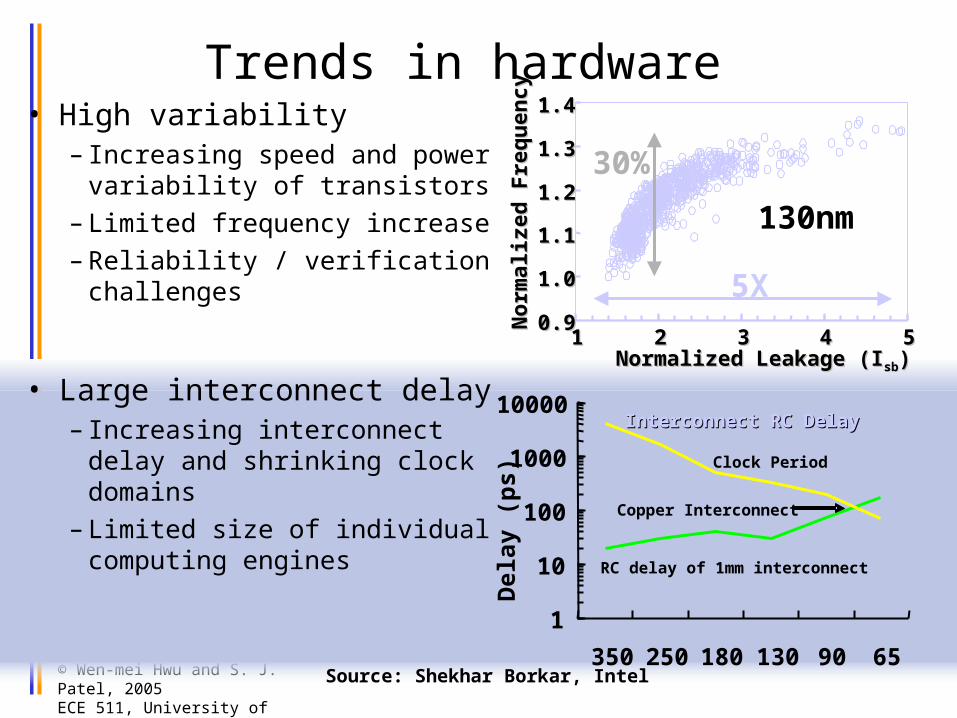
Trends in hardware• High variability
– Increasing speed and power variability of transistors
– Limited frequency increase– Reliability / verification
challenges
• Large interconnect delay– Increasing interconnect
delay and shrinking clock domains
– Limited size of individual computing engines
Interconnect RC DelayInterconnect RC Delay
1
10
100
1000
10000
350 250 180 130 90 65
Del
ay (
ps)
Clock Period
RC delay of 1mm interconnect
Copper Interconnect
130nm
30%
5X0.90.9
1.01.0
1.11.1
1.21.2
1.31.3
1.41.4
11 22 33 44 55Normalized Leakage (INormalized Leakage (Isbsb))
No
rmal
ized
Fre
qu
ency
No
rmal
ized
Fre
qu
ency
Source: Shekhar Borkar, Intel

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Dynamic-Static Interface
• Moving functionality into compilers– Most architectures today, including X86 rely on
compilers to achieve performance goals– A major issue is the number of bits required to
deliver information from the compiler to the runtime hardware
– Highly optimizing compiler also reduced the incentive for machine language programming, which makes portable programs a reality.
– The more implementation details one exposes in the instruction set architecture, the more difficult it is to adopt new implementation techniques.

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Applications
• Applications drive architecture from ‘above”
• Designing next-generation computers involves understanding the behavior of applications of importance and exploiting their characteristics
• What are applications of importance?
• For us, we will often use benchmarks to characterize different architectural options

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
In the image of the simple hardware,
humans created complex software• Software creation based on a
simple execution model– Instructions are considered to
execute sequentially– Data objects are mapped into a
flat, monolithic store reachable by all
– Reality when laid out by von Neumann in the 40’s; abstraction now
• This execution abstraction has been used in development of large, complex software– “Traditional software model”

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Future apps reflect a concurrent world
• Exciting applications in future mass computing market have been traditionally considered “supercomputing applications”– Physiological simulation – cellular pathways (GE Research)– Molecular dynamics simulation (NAMD at UIUC)– Video and audio coding and manipulation – MPEG-4
(NCTU)– Medical imaging – CT (UIUC)– Consumer game and virtual reality products
• These “Super-applications” represent and model physical world
• Various granularities of parallelism exist, but…– programming model must support required dimensions– data delivery needs careful management

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Direction of computer architecture
• Current general purpose architectures cover traditional applications• New parallel-privatized architectures cover some super-applications• Attempts to grow current architectures “out” or domain-specific
architectures “in” lack success• By properly exploiting parallelism of super-applications, the
coverage of domain-specific architectures can be extended
Traditional applications
Current architecture coverage
New applications
Domain-specificarchitecture coverage
Obstacles

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Compatibility
• The case of workstations and servers– Relatively open to new architectures.– Performance is a major concern.– Linux/UNIX is a portable operating system.– Current economics model works against new
architectures
• The case of personal computers– Very tough on new architectures.– Windows and Apple OS are not portable– Most applications are distributed in binary
code– Price is of more concern than performance.

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Experimental Methodology
• Selected real programs by characterizing workload– PERFECT Club, SPEC, MediaBench– What do these programs do?– What input was given to these programs?– How are they related to your own workload?– What do experimental results mean?
• Require high quality software support.– Tremendous variation in capability
• Trace driven simulation vs. re-compilation
• Nothing can replace real-machine measurements

© Wen-mei Hwu and S. J. Patel, 2005ECE 511, University of Illinois
Measures
Iron Law: performance = 1 / execution time= 1/ (CPI * insts * 1/freq)(Basis of SPEC Marks)or (IPC * freq)/insts
CPI : Cycles per instruction (how is this calculated)?
IPC : Instructions per cycle
other useful measures : average memory access time
Related Documents











