©Wen-mei W. Hwu and David Kirk/NVIDIA 2010 ECE 498HK Computational Thinking for Many-core Computing Lecture 15: Dealing with Dynamic Data

©Wen-mei W. Hwu and David Kirk/NVIDIA 2010 ECE 498HK Computational Thinking for Many-core Computing Lecture 15: Dealing with Dynamic Data.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

©Wen-mei W. Hwu and David Kirk/NVIDIA 2010
ECE 498HK
Computational Thinking for Many-core Computing
Lecture 15: Dealing with Dynamic Data

Objective
• To understand the nature of dynamic input data extraction
• To learn efficient queue structures that support massively parallel extraction of input data form bulk data structures
• To learn efficient kernel structures that cope with dynamic variation of working set size
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Examples of Computation with Dynamic Input Data
• Graph search and optimization problems– Breadth-first search– Shortest path– Graph coverage– …
• Rendering and game physics– Ray tracing– Collision detection– …
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Dynamic Data Extraction
• The data to be processed in each phase of computation need to be dynamically determined and extracted from a bulk data structure– Harder when the bulk data structure is not organized
for massively parallel access, such as graphs.
• Graph algorithms are popular examples that deal with dynamic data– Widely used in EDA and large scale optimization
applications– We will use Breadth-First Search (BFS) as an
example©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Main Challenges of Dynamic Data
• Input data need to be organized for locality, coalescing, and contention avoidance as they are extracted during execution
• The amount of work and level of parallelism often grow and shrink during execution– As more or less data is extracted during each phase– Hard to efficiently fit into one CUDA/OPenCL kernel
configuration, which cannot be changed once launched– Different kernel strategies fit different data sizes
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Breadth-First Search (BFS)
sr t u
v w x y
sr t u
v w x y
sr t u
v w x y
sr t u
v w x y
s
r w
v t x
u y
Frontier vertex
Level 1
Level 2
Level 3
Level 4Visited vertex
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Sequential BFS
• Store the frontier in a queue• Complexity (O(V+E))
s
r w
v t x
u y
Level 1
Level 2
Level 3
Level 4
sr tv xywuDequeue Enqueue
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Parallelism in BFS
• Parallel Propagation in each level• One GPU kernel per level
s
r w
v t x
u y
Parallel
Parallel
v t x
u y
Level 1
Level 2
Level 3
Level 4
Kernel 3
Example kernel
Kernel 4
Parallel
global barrier
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010
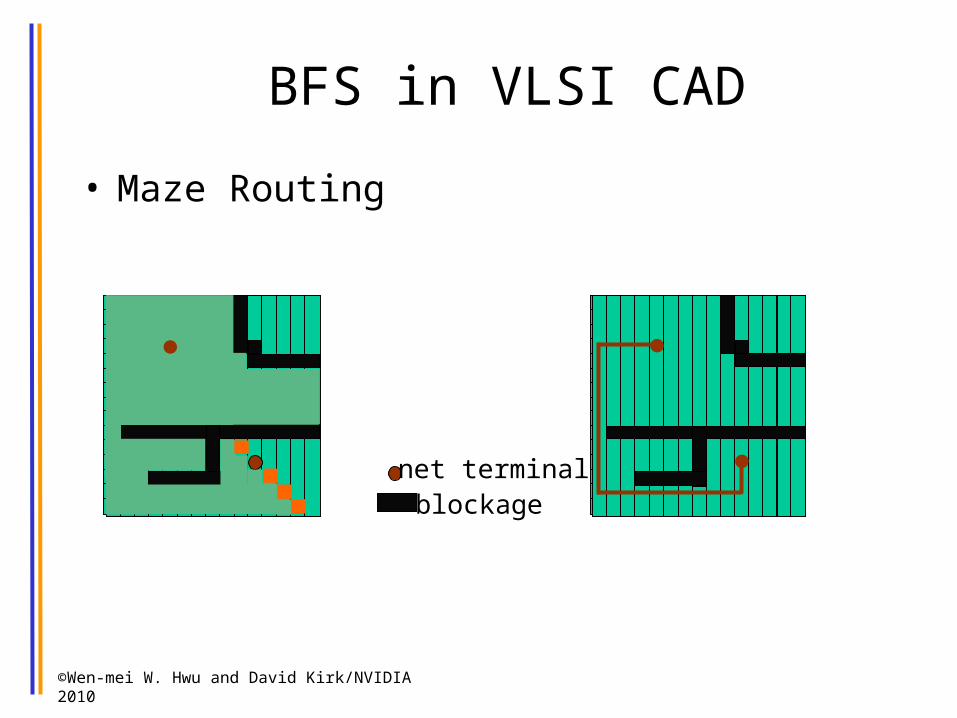
BFS in VLSI CAD
• Maze Routing
blockage net terminal
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

BFS in VLSI CAD
• Logic Simulation/Timing Analysis
00
00
00
0 1
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

BFS in VLSI CAD
• In formal verification for reachabiliy analysis.• In clustering for finding connected components.• In logic synthesis • ……..
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Potential Pitfall of Parallel Algorithms
• Greatly accelerated n2 algorithm is still slower than an nlogn algorithm.
• Always need to keep an eye on fast sequential algorithm as the baseline.
Running
Tim
e
Problem Size©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Node Oriented Parallelization
• IIIT-BFS – P. Harish et. al. “Accelerating large graph algorithms on the GPU
using CUDA”
– Each thread is dedicated to one node
– Every thread examines neighbor nodes to determine if its node will be a frontier node in the next phase
– Complexity O(VL+E) (Compared with O(V+E))
– Slower than the sequential version for large graphs• Especially for sparsely connect graphs
r s t u v w x y
r s t u v w x y
v t x
u y©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Matrix-based Parallelization• Yangdong Deng et. al. “Taming Irregular EDA
applications on GPUs”• Propagation is done through matrix-vector multiplication
– For sparsely connected graphs, the connectivity matrix will be a sparse matrix
• Complexity O(V+EL) (compared with O(V+E))– Slower than sequential for large graphs
0
1
0
0
0
1
010
101
010su
v
su
v
s
u
v
s
u
vs u v
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Need a More General Technique
• To efficiently handle most graph types• Use more specialized formulation when
appropriate as an optimization
• Efficient queue-based parallel algorithms– Hierarchical scalable queue implementation– Hierarchical kernel arrangements
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

An Initial Attempt
• Manage the queue structure– Complexity: O(V+E)
– Dequeue in parallel
– Each frontier node is a thread
– Enqueue in sequence. • Poor coalescing
• Poor scalability
– No speedup v t x
uy
u y
v t x
u y
Parallel
Sequential
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Parallel Insert-Compact Queues
• C.Lauterbach et.al.“Fast BVH Construction on GPUs”
• Parallel enqueue with compaction cost• Not suitable for light-node problems
v t
y
x
uΦ Φ Φ Φ
u yCompact
Propagate
v t x
u y
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Basic ideas
• Each thread processes one or more frontier nodes
• Find the index of each new frontier node• Build queue of next frontier hierarchically
hLocal queues
Global queue
q1 q2 q3
Index = offset of q2 (#node in q1) + index in q2
a b c g i jLocal
Global h
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Two-level Hierarchy
• Block queue (b-queue)– Inserted by all threads in a
block– Reside in Shared Memory
• Global queue (g-queue)– Inserted only when a block
completes
• Problem:– Collision on b-queues
– Threads in the same block can cause heavy contention
g-queue
b-queue
Global Mem
Shared Mem
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Warp-level Queue
Time
WiT7
WiT6
WiT0
WiT15
WiT14
WiT8
WiT23
WiT22
WiT16
WiT30
WiT29
WiT24
WjT7
WjT6
WjT0
WjT15
WjT14
WjT8
WjT23
WjT22
WjT16
WjT30
WjT29
WjT24
Warp i Warp j
• Thread Scheduling
• Divide threads into 8 groups (for GTX280)– Number of SP’s in each SM in general– One queue to be written by each SP in the SM
• Each group writes to one warp-level queue• Still should use atomic operation
– But much lower level of contention©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

Three-level hierarchy
w-queue
b-queue
g-queue
b-queue
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

©Wen-mei W. Hwu and David Kirk/NVIDIA 2010
• Shared Memory: – Interleaved queue layout, no bank conflict
• Global Memory: – Coalescing when releasing a b-queue to g-queue– Moderate contention across blocks
• Texture memory :– Store graph structure (random access, no coalescing)
– Fermi cache may help.
W-queues[][8]
Hierarchical Queue Management
W-
queue0
W-
queue1
W-
queue7

Hierarchical Queue Management
• Advantage and limitation– The technique can be applied to any inherently
sequential data structure– The w-queues and b-queues are limited by the
capacity of shared memory. If we know the upper limit of the degree, we can adjust the number of threads per block accordingly.
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010

ANY FURTHER QUESTIONS?
©Wen-mei W. Hwu and David Kirk/NVIDIA 2010
Related Documents











