Jan Rusinek 50 zadań ze statystyki matematycznej dla studentów ZARZĄDZANIA z rozwiązaniami UWAGA! Ten tekst jest w trakcie przygotowania i sprawdzania. Może zawierać blędy. Jest sukcesywnie poprawiany i umiesz- czany pod aktualną datą! Autor będzie wdzięczny za uwagi: [email protected] Obecna data 1.12.2018

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Jan Rusinek
50zadań ze statystyki matematycznej dla
studentów
ZARZĄDZANIAz rozwiązaniami
UWAGA!
Ten tekst jest w trakcie przygotowania i sprawdzania.Może zawierać błędy. Jest sukcesywnie poprawiany i umiesz-czany pod aktualną datą! Autor będzie wdzięczny za uwagi:
Obecna data 1.12.2018

2

3
Wstęp
Zbiorek ten zawiera zadania ze statystyki matematycznej wybra-ne z zadań przerabianych na zajęciach, zadań domowych i egzamina-cyjnych na studiach drugiego stopnia kierunku zarządzanie w Wyż-szej Szkole Menedżerskiej w Warszawie. Część rachunków jest wyko-nana przy pomocy darmowego programu calc z pakietu OpenOffice.W zadaniach, w których trzeba samodzielnie obliczać wartości śred-nie i wariancje, próbki są bardzo niewielkiej liczności. Oczywiście wpraktyce używa się znacznie większych próbek. Chodzi jednak o to,aby poznać metody, nie tracąc czasu na żmudne (nawet jeśli używamykomputera, to samo wpisanie danych z dużej próbki zajmuje sporoczasu) obliczenia.
Mam nadzieję, że zbiorek ten pomoże studentom w opanowaniutego przedmiotu i w przygotowaniu się do egzaminu.

4
WZORY I OZNACZENIAµ – wartość średniaσ – odchylenie standardowen – liczba próbk – liczba sukcesów w n próbachx = 1
n
∑n
i=1 xi – średnia z próby
s2 = 1n−1
∑n
i=1(xi − x)2 – wariancja z próby
s =√s2 – odchylenie standardowe z próby
s√n– błąd standardowy
u(p) – p-ty kwantyl rozkładu normalnego N(0, 1)t(p, j) – p-ty kwantyl rozkładu Studenta o j stopniach swobodyχ2(p, j) – p-ty kwantyl rozkładu χ2 o j stopniach swobodyF(p, i, j) – p-ty kwantyl rozkładu Snedecora o i, j stopniach swobodyDnobl – statystyka testowa dla rozkładu Kołmogorowadn(p) – p-ty kwantyl statystyki Dn Kołmogorowak(p, i, j) – wartość krytyczna rozkładu liczby seriiWzór na dystrybuantę rozkładu jednostajnego na przedziale [a; b].
F (x) =
{0 dla x < a,x−ab−a dla a ¬ x ¬ b,1 dla x > b.

5
A) PRZEDZIAŁY UFNOŚCI DLA ŚREDNIEJ
Model A1. Rozkład normalny, znane σ.
P = [x− l;x+ l], l = u(1− α2 )σ√n.
Model A2. Rozkład normalny, nieznane σ.
P = [x− l;x+ l], l = t(1− α2 , n− 1)s√n.
Model A3. Rozkład dowolny, nieznane σ, n 30.
P = [x− l;x+ l], l = u(1− α2 )s√n.

6
B) PRZEDZIAŁY UFNOŚCI DLA FRAKCJI ELEMENTÓWWYRÓŻNIONYCH
Model B1. Raczej duża próba (n 30).
P =[k
n− l;k
n+ l], l = u
(1− α2
)√ kn
(1− k
n
)n
.
UWAGA. Można też stosować nieco dokładniejszy, ale bardziej skomplikowanywzór
P =
[u(1− α2 )
2 + 2k
2(n+ u(1− α2 )2)− l;
u(1− α2 )2 + 2k
2(n+ u(1− α2 )2)+ l
], l =
u
√u(1−α2 )
2
4 + k(n−k)n
n+ u(1− α2 )2.

7
C) PRZEDZIAŁY UFNOŚCI DLA ODCHYLENIASTANDARDOWEGO
Model C1. Rozkład normalny.
P =
[s
√n− 1
χ2(1− α2 , n− 1); s
√n− 1
χ2(α2 , n− 1)
].
Model C2. Rozkład normalny, duża próba (n 30).
P =
[s√2(n− 1)
√2n− 3 + u(1− α2 )
;s√2(n− 1)
√2n− 3− u(1− α2 )
].

8
PRZEDZIAŁY UFNOŚCI DLA KWANTYLIPróba powinna być duża (n 30 Ustawiamy próbę w kolejności rosnącej: x1 ¬x2 ¬ · · · ¬ xn. Wtedy przedziąl ufności dla kwantyla rzędu p (0 < p < 1) napoziomie ufności 1− α wynosi
[xkl ;xkr
],
gdziekl = całkowite zaokrąglenie liczby np− u(1− α2 )
√np(1− p),
kr = całkowite zaokrąglenie liczby np+ u(1− α2 )√np(1− p).
W szczególności przedział ufności dla mediany wynosi[xkl ;xkr
],
gdzie
kl = całkowite zaokrąglenie liczby n2 −u(1−α2 )2
√n,
kr = całkowite zaokrąglenie liczby n2 +u(1−α2 )2
√n.

9
MINIMALNA LICZNOŚĆ PRÓBY
Model M1. Przy wyznaczaniu przedziału ufności [x− l;x+ l] dla wartościśredniej, rozkład normalny, znane σ.
n
(u(1− α2
)σ
l
)2.
Model M2. (Procedura Steina) Przy wyznaczaniu przedziału ufności[x− l;x+ l] dla wartości średniej, rozkład normalny nieznane σ.
n (t(1− α2 , n0 − 1
) s0l
)2 n0 − 1n0
+ 1,
gdzie n0 liczność wstępnej próby,
x0 =1n0
n0∑i=1
xi, s20 =
1n0 − 1
n0∑i=1
(xi − x0)2.
Po dodaniu n−n0 prób przedział ufności liczymy z wzoru: P = [x− l;x+ l],gdzie l = t
(1− α2 , n0 − 1
)s0√n.
Model M3. Przy wyznaczaniu przedziału ufności[kn− l; k
n+ l]dla frakcji
elementów wyróżnionych.
n u(1− α2 )
2
4l2.

10
TESTY ZGODNOŚCI
Test χ2
χ2obl =∑ (wartość zaobserwowana− wartość spodziewana)2
wartość spodziewana.
Hipotezę odrzucamy, jeśli
χ2obl > χ2(1− α, k − 1),
k – liczba składników w sumie.
Test Kołmogorowa
Sprawdzamy, czy próbki pochodzą z rozkładu o dystrybuancie F (x). Usta-wiamy próbki w ciąg niemalejący: x1, . . . xn. Statystyka testowa
Dnobl = supx∈IR
|Sn(x)− F (x)|,
gdzie
Sn(x) =
{0 dla x < x1,indla xi ¬ x < xi+1,
1 dla x xn.Hipotezę odrzucamy, jeśli
Dnobl > dn(1− α).
Test serii
Sprawdzamy, czy dwie próbki pochodzą z takego samego rozkładu. α - po-ziom istotności, i liczebność pierwszej, a j liczebność drugiej próbki. Dwie próbkiustawiamy we wspólny ciąg rosnący. Serią nazywamy podciąg kolejnych elemen-tów z tej samej próbki. K oznacza liczbę serii. Hipotezę odrzucamy, jeśli
K ¬ k(α, i, j).

11
PARAMETRYCZNE TESTY ISTOTNOŚCI DLA ŚREDNIEJ
Hipoteza µ = µ0, W zbiór krytyczny. Hipotezę odrzucamy, gdy g ∈W
Model D1. Rozkład normalny o znanym σ.
g = uobl =x− µ0σ
√n.
W = (−∞;−u(1− α)] dla hipotezy przeciwnej µ < µ0;W = [u(1− α);∞) dla hipotezy przeciwnej µ > µ0;W = (−∞;−u(1− α2 )] ∪ [u(1−
α2 );∞) dla hipotezy przeciwnej µ 6= µ0.
Model D2. Rozkład normalny o nieznanym σ, mała próba.
g = tobl =x− µ0s
√n.
W = (−∞;−t(1− α, n− 1)] dla hipotezy przeciwnej µ < µ0;W = [t(1− α, n− 1);∞) dla hipotezy przeciwnej µ > µ0;W = (−∞;−t(1− α2 , n−1)]∪ [t(1−
α2 , n−1);∞) dla hipotezy przeciwnej µ 6= µ0.
Model D3. Rozkład dowolny o nieznanym σ. Duża próba.
g = uobl =x− µ0s
√n.
W jak w modelu D1.

12
PARAMETRYCZNE TESTY ISTOTNOŚCI DLA WARIANCJI
Hipoteza σ = σ0, W zbiór krytyczny. Hipotezę odrzucamy, gdy g ∈W .
Model E1. Rozkład normalny o nieznanych µ i σ, n ¬ 50. Mając do dys-pozycji komputer można ten model stosować i do dużych n.
g = χ2obl =(n− 1)s2
σ20.
W = (0;χ2(α, n− 1)] dla hipotezy przeciwnej σ < σ0;W = [χ2(1− α, n− 1);∞) dla hipotezy przeciwnej σ > σ0;W = (0;χ2(α2 , n− 1)] ∪ [χ
2(1− α2 , n− 1);∞) dla hipotezy przeciwnej σ 6= σ0;
Model E2. - Rozkład normalny o nieznanych µ i σ (n 50).
g = uobl =
√2(n− 1)s2
σ20−√2n− 3.
W = (−∞;−u(1− α)] dla hipotezy przeciwnej µ < µ0;W = [u(1− α);∞) dla hipotezy przeciwnej µ > µ0;W = (−∞;−u(1− α2 )] ∪ [u(1−
α2 );∞) dla hipotezy przeciwnej µ 6= µ0.

13
HIPOTEZY O RÓWNOŚCI FRAKCJI ELEMENTÓWWYRÓŻNIONYCH
Hipoteza p = p0. Hipotezę odrzucamy, gdy g ∈W .
Model F1. Próba powinna być raczej duża.
g = uobl =k − np0√np0(1− p0)
.
W = (−∞;−u(1− α)] dla hipotezy przeciwnej p < p0;W = [u(1− α);∞) dla hipotezy przeciwnej p > p0;W = (−∞;−u(1− α2 )] ∪ [u(1−
α2 );∞) dla hipotezy przeciwnej p 6= p0.

14
HIPOTEZY O RÓWNOŚCI WARIANCJI W DWÓCHPOPULACJACH
Model G1.
Hipoteza σ1 = σ2. Hipotezę odrzucamy, gdy g ∈W .
Gdy hipotezą przeciwną jest σ1 > σ2, to
g = Fobl =s21s22.
W = [F (1− α, n1 − 1, n2 − 1);∞).
Gdy hipotezą przeciwną jest σ1 < σ2, to zamieniamy kolejność próbek.
Gdy hipotezą przeciwną jest σ1 6= σ2, to
g = Fobl =max(s21, s
22)
min(s21, s22).
W = [F(1− α2 , nl − 1, nm − 1);∞), gdzie nl liczność probki o większej wariancji,a nm o mniejszej.

15
HIPOTEZY O RÓWNOŚCI WARTOŚCI ŚREDNIEJ W DWÓCHPOPULACJACH
Hipoteza µ1 = µ2, W zbiór krytyczny. Hipotezę odrzucamy, gdy g ∈W
Model H1 – rozkłady normalne znane σ1 i σ2.
g = uobl =x1 − x2√σ21n1+σ22n2
.
W = (−∞;−u(1− α)] dla hipotezy przeciwnej µ1 < µ2;W = [u(1− α);∞) dla hipotezy przeciwnej µ1 > µ2;W = (−∞;−u(1− α2 )] ∪ [u(1−
α2 );∞) dla hipotezy przeciwnej µ1 6= µ2.
Model H2. – rozkłady normalne, nieznane, ale równe σ1 i σ2.
g = tobl =x1 − x2√
(n1−1)s21+(n2−1)s22
n1+n2−2· n1+n2n1n2
.
W = (−∞;−t(1− α, n− 1)] dla hipotezy przeciwnej µ1 < µ2;W = [t(1− α, n− 1);∞) dla hipotezy przeciwnej µ1 > µ2;W = (−∞;−t(1− α2 , n−1)]∪[t(1−
α2 , n−1);∞) dla hipotezy przeciwnej µ1 6= µ2.
Model H3. rozkłady normalne, nieznane σ1 i σ2, nieduża próbka.
Stosujemy statystykę (tzw. statystyka Cochrana i Coxa)
g = Cobl =x1 − x2√s21n1+s22n2
.
Przybliżoną wartość kwantyla c(p, n1, n2) znajdujemy z wzoru
c(p, n1, n2) ≈s21n1t(p, n1 − 1) +
s22n2t(p, n2 − 1)
s21n1+s22n2
.
Zbiór krytyczny:W = (−∞;−c(1− α, n1, n2)] dla hipotezy przeciwnej µ1 < µ2;W = [c(1− α, n1, n2);∞) dla hipotezy przeciwnej µ1 > µ2;W = (−∞;−c(1 − α2 , n1, n2)] ∪ [c(1 −
α2 , n1, n2);∞) dla hipotezy przeciwnej
µ1 6= µ2;
Model H4 – rozkłady dowolne, nieznane σ1 i σ2 – duża próba, n1, n2 50.

16
g = uobl =x1 − x2√s21n1+s22n2
.
W = (−∞;−u(1− α)] dla hipotezy przeciwnej µ1 < µ2;W = [u(1− α);∞) dla hipotezy przeciwnej µ1 > µ2;W = (−∞;−u(1− α2 )] ∪ [u(1−
α2 );∞) dla hipotezy przeciwnej µ1 6= µ2.

17
HIPOTEZY O RÓWNOŚCI FRAKCJI ELEMENTÓWWYRÓŻNIONYCH W DWÓCH POPULACJACH
Model I1 – raczej duża próbka (n1, n2 50)
Stawiamy hipotezę p1 = p2.
Stosujemy statystykę
g = uobl =k1n1− k2n2√
k1+k2n1n2
(1− k1+k2
n1+n2
) .Gdy liczność próby nie jest dostatecznie duża stosujemy statystykę:
uobl =
(2 arc sin
√k1
n1− 2 arc sin
√k2
n2
)√n1n2
n1 + n2.
Zbiór krytyczny:W = (−∞;−u(1− α)] dla hipotezy przeciwnej p1 < p2;W = [u(1− α);∞) dla hipotezy przeciwnej p1 > p2;W = (−∞;−u(1 − α2 )] ∪ [u(1 −
α2 );∞) dla hipotezy przeciwnej p1 6= p2; gdzie
n1 i n2 liczności pierwszej i drugiej próbki, k1 i k2 liczby sukcesów w pierwszeji drugiej próbce.

18
TEST χ2 NIEZALEŻNOŚCI
χ2obl =∑ (wartość zaobserwowana− wartość spodziewana)2
wartość spodziewana.
Test odrzucamy, jeśli
χ2obl > χ2(1− α, (r − 1)(s− 1)),
gdzie r liczba wartości pierwszej cechy, a s liczba wartości drugiej cechy.
Współczynnik Cramera
V =
√χ2obl
n(m− 1),
gdzie m = min(r, s)
Współczynnik C Pearsona
C =
√χ2oblχ2obl + n
.
n liczba wszystkich danych w macierzy r × s.

19
Jak używać programu calc?
Będziemy posługiwać się tym programem do obliczanie wartościśredniej, wariancji, odchylenia standardowego oraz wynikających ztego dalszych rezultatów. Pokażemy to na przykładzie.
Zakładamy, że mamy dane empiryczne x1 = 7, x2 = 1, x3 = 5,x4 = 3, x5 = 5 oraz liczbę µ0 = 3. Mamy policzyć kolejno
x =1n
n∑k=1
xk,
s2 =1n− 1
n∑k=1
(xi − x)2,
s =√s2,
a następnie wstawić to do wzoru:
x− µ0s
√n.
Uruchamiamy program calc i wpisujemy dane np. w komórkachA1−A5.Daną µ0 możemy wpisać np w kolejnej komórce B1, a liczbę prób
(5) np. w komórce B2.
Warto wpisywać te dane w komórkach, a nie w ostatecznym wzo-rze, bo wtedy przy rozwiązywaniu następnego zadania opartego natym samym modelu, wystarczy zmienić dane bez konieczności zmianywzoru.
Wybieramy jakąć inną komórkę np. C1 i wpisujemy w niej wzór:
=ŚREDNIA(A1:A5)
Po zaakceptowaniu ukazuje się w tej komórce wynik 4.2.
Wybieramy następną komórkę powiedzmy C2 i wpisujemy w niejwzór

20
=WARIANCJA(A1:A5)
Po zatwierdzeniu ukazuje się w tej komórce wynik 5.2.
Wybieramy kolejną komórkę np. C3 i wpisujemy w niej wzór
=pierwiastek(c2)
Po zatwierdzeniu ukazuje się w tej komórce wynik 2.28 (w zależ-ności od tego jaką dokładność wybierzemy).
Wybieramy następną komórkę (np. C4) i wstawiamy w niej wzór(patrz rysunek)
=(C1-B1)*pierwiastek(B2)/C3
Zauważmy, że możemy wpisywać wzory zarówno małymi jak idużymi literami.
Po zaakceptowaniu otrzymamy już ostateczny wynik 1.1767.
Program calc zamiast tablic statystycznych
Większość danych potrzebnych do rozwiązywania zamieszczo-nych tu zadań zamiast z tablic, możemy wygenerować przy pomocy

21
programu calc. Niektóre są nieco inaczej zdefiniowane niż w tabli-cach statystycznych, dlatego podajemy dokładnie co trzeba zrobić,aby otrzymać dane zgodne z tablicami.
Ia) Dystrybuanta rozkładu normalnego
Aby wyznaczyć P (X < x), gdzie X jest zmienną o rozkładzieN(0, 1), a dana x jest umieszczona np. w komórce A1 wpisujemy wkomórce wyniku
=rozkład.normalny.s(a1)
Ib) Kwantyle rozkładu normalnego
Aby wyznaczyć kwantyl u(p) rozkładu normalnego N(0, 1) np.dla danej p umieszczonej w komórce B1 wpisujemy w komórce wyniku
=rozkład.normalny.s.odw(b1)
IIa) Dystrybuanta rozkładu t Studenta
Aby wyznaczyć P (X < x), gdzie X jest zmienną o rozkładzie tStudenta z n stopniami swobody, a dana x jest umieszczona np. wkomórce A1, a dana n w komórce B1 wpisujemy w komórce wyniku
=1-rozkład.t(a1;b1;1)
Program akceptuje tylko x-y dodatnie. Aby wyznaczyć P (X < x) dlax ujemnych wystarczy skorzystać z wzoru
P (X < x) = P (X > −x) = 1− P (X < −x).
IIb) Kwantyle rozkładu t Studenta
Aby wyznaczyć kwantyl t(p, n) rozkładu t Studenta dla danejp umieszczonej w komórce A1, danej n w komórce B1 wpisujemy wkomórce wyniku
=rozkład.t.odw(2*(1-a1);b1)
IIIa) Dystrybuanta rozkładu χ2

22
Aby wyznaczyć P (X < x), gdzie X jest zmienną o rozkładzieχ2 z n stopniami swobody, a dana x jest umieszczona np. w komórceA1, a dana n w komórce B1 wpisujemy w komórce wyniku
=1-rozkład.chi(a1;b1)
Gęstość rozkładu χ2(t) jest różna od zera tylko dla t dodatnich dla-tego wzór działa tylko dla x 0.IIIb) Kwantyle rozkładu χ2
Aby wyznaczyć kwantyl χ2(p, n) rozkładu χ2 dla danej p umiesz-czonej w komórce A1, danej n w komórce A2 wpisujemy w komórcewyniku
=rozkład.chi.odw(1-a1;a2)
IVa) Dystrybuanta rozkładu F Snedecora
Aby wyznaczyć P (X < x), gdzie X jest zmienną o rozkładzie FSnedecora z n, k stopniami swobody, dana x jest umieszczona np. wkomórce A1, a dana n w komórce B1, dana k w komórce C1 wpisujemyw komórce wyniku
=1-rozkład.f(a1;b1;c1)
IVb) Kwantyle rozkładu F Snedecora
Aby wyznaczyć kwantyl F(p, n, k) rozkładu F dla danej p umiesz-czonej w komórce B1, danej n w komórce B2 i danej k w komórce B3wpisujemy w komórce wyniku
=rozkład.f.odw(1-b1;b2;b3)
Korzystanie programu zamiast z tablic ma dodatkową zaletę, żemożemy znajdować wartości kwantyli dla nietypowych α, których niema w tablicach np. 0.03, 0.17 itp. W tablicach zwykle nie ma teżdystrybuant innych rozkładów niż normalny.
Możemy też włączyć te wzory do danego modelu otrzymującrozwiązanie w całości przy pomocy komputera. Odpowiedni przykładopiszemy przy rozwiązywaniu konkretnego zadania.

23
Zadania

24
ZADANIE 1. Dla zmiennej losowej X o rozkładzie jednostajnymna przedziale [−1; 3] znajdź a) P (X < 0), b) P (X > 2), c) takie c, żeP (X < c) = 0.95 = p, czyli p-ty kwantyl rozkładu jednostajnego naprzedziale [−1; 3].Rozwiązanie.
Dystrybuanta rozkładu jednostajnego na przedziale [−1; 3] jestrówna
F (x) =
0 dla x < −1,x+14 dla −1 ¬ x ¬ 3,1 dla x > 3.
Zatem a) P (X < 0) = F (0) = 14 ., b) P (X > 2) = 1 − P (X <2) = 1 − F (2) = 1 − 34 =
14 . c) Trzeba rozwiązać równanie P (X <
c) = 0.95, czyli c+14 = 0.95. Stąd c = 2.8.

25
ZADANIE 2. Przy pomocy tablic lub komputera znajdź dla zmien-nej X o rozkładzie normalnym standardowym N(0, 1) i α = 0.02: a)P (X > 2.3), b) P (X < −1.2), c) u(α), d) u(1− α), e) u(1− α2 ).Rozwiązanie.
a) i b) znajdujemy w tablicy 1 otrzymując: a) 1−0.9893 = 0.0107;b) 0.115 c), d) i e) można rozwiązać zarówno komputerem jak i przypomocy tablic. Otrzymamy c) u(0.02) = −2.05, d) u(0.98) = 2.05, e)u(0.99) = 2.33.

26
ZADANIE 3. Przy pomocy tablic lub komputera znajdź dla zmien-nej X rozkładzie t Studenta z n = 9 oraz α = 0.05: a) P (X > 1.3),b) P (X < −1.4), c) t(1− α, n), d) t(1− α2 , n),Rozwiązanie.
a) i b) najlepiej rozwiązać programem calc otrzymując: a) 1 −0.8870 = 0.1129; b) Musimy skorzystać z faktu, że t(−p, n) = 1 −t(p, n). Otrzymamy wynik 0.0.0975. c) t(0.95, 9) = 1.83,d) t(0.975, 9) = 2.26.

27
ZADANIE 4. Przy pomocy tablic lub komputera znajdź dla zmien-nej X o rozkładzie χ2 z n = 20 i α = 0.05: a) P (X < 20), b)P (X > 10), c) χ2(α, n), d) χ2(1− α, n) e) χ2(1− α2 , n).Rozwiązanie.
Dla a) i b) skorzystamy z programu calc. Otrzymamy dla a)wartość 0.542, a dla b) 1 − 0.0318 = 0.9682. Dla c) - e) można teżskorzystać z tablic mamy: c) χ2(0.05, 20) = 10.851, d) χ2(0.95, 20) =31.41, e) χ2(0.975, 20) = 34.17.

28
ZADANIE 5. Przy pomocy tablic lub komputera znajdź dla zmien-nej X o rozkładzie F z n = 8, k = 4, oraz dla α = 0.05: a) P (X > 3),b) P (X < 4), c) F(1− α, n, k), d) F(1− α2 , n, k).Rozwiązanie.
Dla a) i b) skorzystamy z programu calc otrzymując dla a) war-tość 0.8489, a dla b) wartość 1 − 0.9025 = 0.0975. c) F(0.95, 9, 4) =6.04, d) F(0.975, 9, 4) = 8.98.

29
ZADANIE 6. Przy pomocy programu calc znajdź dla próbkix1 = 1.31, x2 = 2.45, x3 = 3.45, x4 = −2.71: a) x, b) s2, c) s, d) błądstandardowy.
Rozwiązanie.
a) x = 1.125, b) s2 = 7.3009, c) s = 2.702, d) s√n= 1.351.

30
ZADANIE 7. Zaobserwowano, że waga noworodków w pewnymszpitalu ma rozkład normalny z wartością średnią 3.6 kg i odchy-leniem standardowym 0.26 kg. Jakie jest prawdopodobieństwo, żedziecko urodzone w tym szpitalu waży: a) więcej niż 4 kg?; b) mniejniż 3 kg?
Rozwiązanie.
a) a = 4, b =∞. Stąd c = 4−3.60.26 , d =∞. Zatem
P (4 < X) = 1− Φ(c) = 0.40.
b) a = −∞, b = 3, Stąd c = −∞, d = 3−3.60.26 = −2.31. Zatem
P (X > 3) = Φ(−2.31) = 1− Φ(2.31) = 1− 0.989 = 0.0.11.

31
ZADANIE 8. Czas pracy żarówek produkowanych w pewnym za-kładzie ma rozkład normalny z wartością średnią 700 godzin i odchy-leniem standardowym 220 godzin. Jakie jest prawdopodobieństwo, żeżarówka zepsuje się przed upływem 500 godzin pracy?
Rozwiązanie.
Mamy µ = 700, σ = 220, a = −∞, b = 500. Stąd c = −∞,d = 500−700220 = −0.91. Zatem
P (X < 500) = Φ(−0.91) = 1− Φ(0.91) = 1− 0.82 = 0.18.

32
ZADANIE 9. Plony zboża w gospodarstwach rolnych mają roz-kład normalny z wartością średnią 45 kwintali/ha i odchyleniem stan-dardowym 14 kwintali/ha. Jaki procent gospodarstw ma wydajnośćwiększą niż 50 kwintali z hektara?
Rozwiązanie.
Dane: µ = 45, σ = 14, a = 50, b = ∞. Stąd c = 50−4514 = 0.36,d =∞. Zatem
P (50 < X) = 1− Φ(.36) = 1− 0.64 = 0.36.
Odp. 36%.

33
ZADANIE 10. Wzrost żołnierzy ma rozkład normalny ze średnią177 cm i odchyleniem standardowym 13 cm. W jednostce wojskowejsłuży 1050 żołnierzy. Do kompanii honorowej zostanie wybranych 90najwyższych. Ile trzeba mieć wzrostu, aby zostać wybranym?
Rozwiązanie.
W tym zadaniu mamy dane prawdopodobieństwo P (X > a) =901050 = 0.086, a musimy wyznaczyć a. Mamy
0.086 = P (X > a) = 1− Φ(c),
gdzie c = a−17713 . Stąd Φ(c) = 0.914.W tablicach rozkładu normalne-go znajdujemy, że c = 1.35. Stąd mamy równanie
1.35 =a− 17713,
skąd a = 194.5.
Odp. Trzeba mieć co najmniej 194 cm wzrostu.

34
ZADANIE 11. Wiadomo, że maszyna do paczkowania cukru pa-kuje wg rozkładu normalnego z odchyleniem standardowym σ =2dkg. Nastawiono ją na 1 kg i przebadano losowo 10 torebek otrzymu-jąc rezultaty w dkg: 103, 96, 99, 97, 99, 100, 101, 95, 97, 99. Oszacujpunktowo i przedziałowo średnią wagę torebki na poziomie ufności1− α = 0.95.Rozwiązanie.
a) Oszacowanie punktowe:
Mamy x = 98.60, s = 2.41. Zatem błąd standardowy jest równys√n= 0.76.
Ponieważ odchylenie standardowe jest znane stosujemy modelA1, gdzie
l = u(1− α2 )σ√n.
W naszym przypadku l = 1.24 i
P = [97.36; 99.84].

35
ZADANIE 12. Rozwiąż poprzednie zadanie przy założeniu, żeodchylenie standardowe nie jest znane.
Rozwiązanie.
Tym razem stosujemy model A2, w którym
P = [x− l;x+ l],
l = t(1− α2 , n− 1)s√n.
W naszym przypadku n = 10, 1 − α2 = 0.975, t(0.975) = 2.26.Stąd l = 1.72, skąd
P = [96.88; 100.32].

36
ZADANIE 13. Pewien algorytm sortowania przetestowano na 9bazach danych losowo wymieszanych i uzyskano czasy sortowaniaw sekundach: 9, 13, 21, 7, 21, 14, 12, 21, 11. Oszacuj wartość średniąpunktowo i przedziałowo przyjmując, że rozkład jest normalny orazwspółczynnik ufności 1− α = 0.95.Rozwiązanie.
a) Oszacowanie punktowe:
Obliczamy wartość średnią i wariancję. Otrzymujemy
x = 14.33, s = 5.41.
Błąd standardowy jest równy s√9= 1.8.
b) Oszacowanie przedziałowe:
Ponieważ próba jest mała i odchylenie standardowe nie jest znanei rozkład jest normalny, stosujemy model A2.
l = t(1− α2 , n− 1)s√n.
W naszym przypadku znajdujemy t(0.975, 8) = 2.306. Stąd
l = 2.306 · 5.413= 4.16.
Zatem przedział ufności jest równy [10.18; 18.49].

37
ZADANIE 14. Pewna duża firma komputerowa chce ustalić śred-nią wielkość sprzedaży w ciągu dnia. Na podstawie danych z 3 mie-sięcy (78 dni) obliczono wartość x równą 2953 tys. zł. i odchyleniestandardowe empiryczne s = 1034 tys. zł. Oszacuj średnią wielkośćdziennej sprzedaży przy współczynniku ufności 1− α = 0.95.Rozwiązanie.
Ponieważ próbka jest duża, skorzystamy z modelu A3. Mamyα = 0.05, skąd 1−α2 = 0.975. Znajdujemy w tablicach u(1−
α2 ) = 1.96.
Stąd l = 1.96 · 1034√78= 229.5
OstatecznieP = [2723.5; 3182.5].

38
ZADANIE 15. Pan X kupił na loterii sto losów każdy po 2 złote.Za 7 z nich wygrał 10 zł., za 3 wygrał po 20 zł., a za jeden 50 zł.Zbuduj na poziomie 1 − α = 0.90 odpowiedni przedział ufności ispróbuj zinterpretować wynik.
Rozwiązanie.Oszacujemy średni wynik finansowy pana X. Pró-ba jest duża (n = 100), zastosujemy zatem model A3. W 89 =100 − 7 − 3 − 1 losach wynik był −2, w 7 losach 10 − 2 = 8, wtrzech 20− 2 = 18 oraz w jednym 50− 2 = 48. Stąd
x =1100[89 · (−2) + 7 · 8 + 3 · 18 + 1 · 48] = −0.2.
s2 =199
[89 · (−2− (−0.2))2 + 7 · (8− (−0.2))2
+3 · (18− (−0.2))2 + 1 · (48− (−0.2))2]= 4117.
Stąds =√41.17 = 6.42
Daleju(1− α2 ) = 0.95,
orazu(0.95) = 1.64.
Stąd
l = 1.64 · 6, 42√100= 1, 05.
Ostateczne
P = [−0.2− 1.05;−0.2 + 1.05] = [−1.25; 0.85].
Wynik można zinterpretować np. tak: Mimo, że śrdni wynik jestujemny są spore szanse wygranej.

39
ZADANIE 16. Trzysta wylosowanych rodzin z danej miejscowo-ści zapytano, czy posiadają w domu komputer. 121 rodzin odpowie-działo, że tak, w tym 91 rodzin ma komputer stacjonarny, a 42 ro-dziny laptop. Wyznacz przedziały ufności z 95%-ową wiarygodnościądla procentu rodzin: a) posiadających komputer; b) posiadającychkomputer stacjonarny; c) posiadających laptop; d) posiadających ikomputer stacjonarny i laptop.
Rozwiązanie.
Stosujemy model B1, czyli wzór
P =[k
n− l; kn+ l],
gdzie l = u(1− α2 )√
kn (1− kn )n .
Mamy n = 300. Znajdujemy w tablicach u(1− α2 ) = 1.96.W punkcie a) mamy k = 121, skąd k/n = 0.403 oraz l = 0.056.
ZatemP = [0.348; 0.459] = [34.8%; 45.9%].
W punkcie b) mamy k = 91, skąd k/n = 0.303 oraz l = 0.052.Zatem
P = [0.251; 0.355] = [25.1%; 35.5%].
W punkcie c) mamy k = 42, k/n = 0.14, l = 0.039. Stąd
P = [0.101; 0.179] = [10.1%; 17.9%].
W punkcie d) mamy k = 12 (dlaczego?), skąd k/n = 0.04 orazl = 0.022. Zatem
P = [0.018; 0.062] = [1.8%; 6.2%].

40
ZADANIE 17. Pewna firma cukiernicza zakupiła automat doprodukcji i porcjowania lodów. Nastawiono automat na 5 dkg i spraw-dzono na bardzo dokładnej wadze 9 losowo wybranych porcji otrzy-mując wyniki w dkg: 5.07, 5.08, 4.91, 4.95, 5.00, 5.09. 4.98, 4.95, 4.96.Zakładając, że rozkład jest normalny wyznacz przedziały ufności dlaodchylenia standardowego na poziomie ufności 1− α = 0.99.Rozwiązanie.
Stosujemy model C1. W tablicach rozkładu χ2 znajdujemy χ2(1−α2 , n− 1) = χ
2(0.995, 8) = 21.96, χ2(α2 , n− 1) = χ2(0.005, 8) = 1.34.
Natępnie mamy s = 0.065659. Stąd
P =
[s
√n− 1
χ2(1− α2 , n− 1); s
√n− 1
χ2(α2 , n− 1)
]= [0.0396; 0.1602].
Opiszemy krok po kroku jak można rozwiązać to zadanie całko-wicie przy użyciu pakietu calc
Wpisujemy w komórkach A1-A9 dane. Wpisujemy w komórce B2liczbę 0.99. Wpisujemy w komórce B3 liczbę 9. Wpisujemy w komórceC1
=średnia(a1:a9)
Wpisujemy w komórce C2
=pierwiastek(wariancja(a1:a9))
Wpisujemy w komórce C3
=rozkład.chi.odw(b1/2;8)
Wpisujemy w komórce C4
=rozkład.chi.odw(1-b1/2;8)
Wpisujemy w komórce C5
=c2*pierwiastek((b3-1)/c3)

41
To będzie lewy koniec przedziału.Wpisujemy w komórce D5
=c2*pierwiastek((b3-1)/c4)
To będzie prawy koniec przedziału.

42
ZADANIE 18. W celu sprawdzenia, czy automat do pakowaniamąki porcjuje precyzyjnie firma młynarska przed ewentualnym za-kupem zważyła 200 kilogramowych torebek mąki i otrzymała wy-niki w kg: x = 0.99 i odchylenie standardowe z próbki s = 0.077dkg. Wyznacz przedział ufności dla odchylenia standardowego przywspółczynniku ufności 1− α = 0.95.Rozwiązanie.
Dla dużej próby stosujemy nodel C2. Mamy u(1 − α2 ) = 1.96.Stąd
P =
[0.077
√398√
397 + 1.96;0.077
√398√
397− 1.96
]= [0.072; 0.083].

43
ZADANIE 19. Zważono na pewnej plantacji losowo 40 dyń otrzy-mując wyniki w kg: 12,6; 11.3; 18.4; 13.7; 11.2; 11.4; 18.5; 18.2; 21.5;11.7; 13.6; 14.8; 15.4; 14.2; 13.8; 12.6; 11.4; 17.8; 17.7; 19.5; 20.6; 21.5;22.5; 11.8; 15.5; 17.7; 16.1; 17.1; 13.2; 14.3; 17.8; 19.9; 13.3; 12.5; 16.6;16.2; 16.1; 17.8; 12.3; 14.4. Na poziomie ufności 1−α = 0.90 wyznaczprzedziały ufności: a) dla sredniej; b) dla mediany oraz pierwszego itrzeciego kwartyla.
Rozwiązanie. a) Stosujemy model A3. Wspomagając się ar-kuszem kalkulacyjnym i tablicami obliczamy x = 15.66. s = 3.18,1− α2 = 0.95, u(0.95) = 1.64. Stąd
l = 1.64 · 3.18√40= 0.83.
ZatemP = [14.83; 16.49].
b) Najpierw musimy ustawić dane w kolejnoci rozącej. Wspoma-gamy się arkuszem kalkulacyjnym. Otrzymujemy: 1. 11.2; 2. 11.3; 3.11.4; 4. 11.4; 5. 11.7; 6. 11.8; 7. 12.3; 8. 12.5; 9. 12.6; 10. 12.6; 11.13.2; 12. 13.3; 13. 13.6; 14. 13.7; 15. 13.8; 16. 14.2; 17. 14.3; 18. 14.4;19. 14.8; 20. 15.4; 21. 15.5; 22. 16.1; 23. 16.1; 24. 16.2; 25. 16.6; 26.17.1; 27. 17.7; 28. 17.7; 29. 17.8; 30. 17.8; 31. 17.8; 32. 18.2; 33. 18.4;34. 18.5; 35. 19.5; 36. 19.9; 37. 20.6; 38. 21.5; 39. 21.5; 40. 22.5.
Następnie liczymy:
Dla mediany k1 jako całkowite zaokrąglenie liczby n2−u(1− α2 )2
√n.
402− 1.64·√40 = 14.79,
zatem k1 = 15.402+1.64·√40 = 25.20,
zatem k2 = 25. Stąd
P = [x15;x25] = [13.8; 16.6].
Dla pierwszego kwartyla k1 jest zaokrągleniem całkowitym liczby40 · 0.25 − 1.64·
√40 · 0.25 · 0.75, k2 cakowitym zaokrągleniem liczby

44
40 · 0.25 + 1.64·√40 · 0.25 · 0.75. Po obliczeniu otrzymamy k1 = 5,
k2 = 15. ZatemP = [x5;x15] = [11.7; 13.8].
Dla trzeciego kwartyla k1 jest zaokrągleniem całkowitym liczby40 · 0.75 − 1.64·
√40 · 0.75 · 0.25, k2 cakowitym zaokrągleniem liczby
40 · 0.25 + 1.64·√40 · 0.75 · 0.25. Po obliczeniu otrzymamy k1 = 25,
k2 = 35. ZatemP = [x25;x35] = [16.6; 19.5].

45
ZADANIE 20. Mamy zważyć sztabkę złota. Chcemy. na pozio-mie ufności 0.95 otrzymać przedział ufności [x − l;x + l] z l = 0.01mg. Elektroniczna waga ma rozkład błędów normalny z odchyleniemstandardowym 0.02 mg. Ile niezależnych pomiarów trzeba wykonać?
Rozwiązanie.
Ponieważ odchylenie standardowe jest znane, stosujemy wzórM1. Z tablic kwantyli rozkładu normalnego znajdujemy u(1 − α2 ) =1.96. A więc
n >
(1.96 · 0.020.01
)2= 15.37.
Trzeba wykonać 16 pomiarów.

46
ZADANIE 21. Pewien program sortujący dane został przete-stowany na 7 losowo wybranych różnego rodzaju plikach długości1000000 rekordów, i otrzymano czas sortowania w sek. 111, 22, 33,42, 199, 77, 138. Ile jeszcze należy dodatkowo dokonać testów, abyotrzymać na poziomie ufności 1−α = 0.95 przedział ufności nie dłuż-szy niż 80 sek?. Zakładamy, że cecha ma rozkład normalny.
Rozwiązanie.
Zastosujemy procedurę Steina (model M2). Mamy x0 = 88.86,s0 = 64.5, l = 802 = 40, n0 = 7, t(0.975, 6) = 2.447. Wstawiając towszystko do wzoru M2 otrzymujemy
n >
(2.447 · 64.5
40
)2· 67+ 1 = 14.35.
Trzeba jeszcze dodać 15− 7 = 8 dodatkowych pomiarów.

47
ZADANIE 22. Pewien informatyk skonstruował program rozpo-znający linie papilarne. Ile prób należy przeprowadzić, aby na pozio-mie ufności 1− α = 0.95 otrzymać przedział ufności długości 10%?Rozwiązanie.
Zastosujemy wzór M3. Mamy u(1 − α2 ) = 1.96, l =0.102 = 0.05.
Zatem
n 1.962
4 · 0.052= 384.2.
Trzeba wykonać 385 prób.

48
ZADANIE 23. Pewien sklep chce przeprowadzić badanie, jakiprocent klientów po raz drugi dokonuje zakupów w tym sklepie. Iluklientów powinien uwzględnić w badaniu aby na poziomie ufności1− α = 0.9 otrzymać przedział ufności długości 6%?Rozwiązanie.
Ponownie skorzystamy z wzoru M3. Mamy u(1 − α2 ) = 1.64.l = 0.03.
n 1.642
4 · 0.032= 747.11.
Powinien w badaniu uwzględnić 748 klientów.1
1Liczba 1.64 jako wartość kwantyla u(0.95) jest w tablicach podana w przy-bliżeniu. Dlatego, jeśli użyjemy do obliczeń programu calc to użyta zostanie jakou(0.95) dokładniejsza liczba 1.64485 i otrzymamy w tym zadaniu wynik 751.

49
ZADANIE 24. Rzucamy 20 razy kostką. Otrzymaliśmy wynikiotrzymane w tabelce:
liczba oczek 1 2 3 4 5 6liczba rzutów 0 2 7 5 3 3
Zweryfikuj hipotezę, że kość jest „uczciwa”, przyjmując α = 0.05.
Rozwiązanie.
Zastosujemy test χ2. Wartość spodziewana dla każdej liczby oczekto 206 = 3.33. W takim razie wartość statystyki testowej wynosi
χ2obl =(0− 3.33)2
3.33+(2− 3.33)2
3.33+(7− 3.33)2
3.33+
(5− 3.33)2
3.33+(3− 3.33)2
3.33+(3− 3.33)2
3.33= 8.8.
W tablicach kwantyli rozkładu χ2 lub przy pomocy komputeraznajdujemy χ2(0.95, 5) = 11.071.
Nie ma powodu odrzucania hipotezy, bo 8.8 < 11.071.

50
ZADANIE 25. Ruletka ma 4 równe pola: dwa czerwone, jednobiałe i jedno czarne. Uruchomiono ją 100 razy; 60 razy wypadło po-le czerwone, 29 razy białe i 11 razy czarne. Zweryfikuj hipotezę, żeruletka jest „uczciwa” przyjmując: a) α = 0.05 i b) α = 0.005.
Rozwiązanie.
Ponownie zastosujemy test χ2. Przy 100 losowaniach wartościspodziewane to: 50 razy pole czerwone i po 25 razy pole białe i poleczarne. Zatem statystyka testowa wynosi
χ2obl =(60− 50)2
50+(29− 25)2
25+(11− 25)2
25= 10.48.
W tablicach rozkładu χ2 lub przy pomocy komputera znajduje-my χ2(0.95, 2) = 5.991 oraz χ2(0.995, 2) = 10.597 Hipotezę odrzuca-my w punkcie a), a punkcie b) nie.

51
ZADANIE 26. Łucznik strzelał z łuku do tarczy o promieniu 10cm. W 10 próbach otrzymał następujące odległości od środka tarczy(z dokładnością 1cm): 4, 7, 8, 8, 0, 3, 2, 5, 7, 6. Zweryfikuj na poziomieistotności α = 0.05 hipotezę, że rozkład odległości trafień od środkatarczy jest jednostajny na przedziale [0; 10].
Rozwiązanie.
Stosujemy test Kołmogorowa. Rozkład jednostajny na przedziale[0; 10] ma dystrybuantę
F (x) =
0 dla x < 0,x10 dla 0 ¬ x ¬ 10,1 dla x > 10.
Tworzymy tabelę
xi F (xi) i−19
i9
∣∣ i−19 − F (xi)
∣∣ ∣∣ i9 − F (xi)
∣∣0 0 0 0,1 0 0,12 0,2 0,1 0,2 0,1 0,03 0,3 0,2 0,3 0,1 0,04 0,4 0,3 0,4 0,1 0,05 0,5 0,4 0,5 0,1 0,06 0,6 0,5 0,6 0,1 0,07 0,7 0,6 0,7 0,1 0,07 0,7 0,7 0,8 0,0 0,18 0,8 0,8 0,9 0,0 0,18 0,8 0,9 1,0 0,1 0,2max 0,1 0,2
Stąd maksimum=0.2. W tablicach rozkładu Kołmogorowa znaj-dujemy d10(0.95) = 0.409. Wartość statystyki testowej jest mniejsza.Hipotezy nie odrzucamy.

52
ZADANIE 27. Zważono losowo 9 paczek wysyłanych w pewnymurzędzie pocztowym i uzyskano wyniki w kg. 6.0, 1.5, 0.7, 2.5, 6.3,1.1, 2.2, 2.8, 1.1. Postaw hipotezę, że rozkład jest typu N(x, s) 2
i zweryfikuj ją na poziomie istotności α = 0.05.
Rozwiązanie.
Obliczając przy pomocy komputera mamy x = 1.52, s = 0, 70.stawiamy hipotezę, że próbka pochodzi z rozkładu N(1.52, 0.70). Sto-sujemy test Kołmogorowa. Tworzymy tabelkę:
xi F (xi) i−19
i9
∣∣ i−19 − F (xi)
∣∣ ∣∣ i9 − F (xi)
∣∣0.7 0,17 0 0,11 0,17 0,061.1 0,22 0,11 0,22 0,11 0,001.1 0,22 0,22 0,33 0,00 0,111.5 0,28 0,33 0,44 0,05 0,162.2 0,41 0,44 0,56 0,04 0,152.5 0,46 0,56 0,67 0,09 0,202.8 0,52 0,67 0,78 0,14 0,266.0 0,94 0,78 0,89 0,16 0,066.3 0,96 0,89 1,00 0,07 0,06max 0,17 0,26
Dnobl = 0.26. Znajdujemy w tablicach d9(0.95) = 0.43. Hipotezynie odrzucamy.
2W zasadzie test Kołmogorowa powinno stosować się wtedy, gdy parametryrozkładu, z którym porównujemy próbkę są z góry dane.

53
ZADANIE 28. Próbka dała następujące wyniki 0, 0, 0, 0, 0, 6.Pokaż przy pomocy testu Kołmogorowa, że na poziomie istotnościα = 0.10 należy odrzucić hipotezę, że rozkład jest typu N(x, s).
Rozwiązanie.
Mamy x = 1, s = 2.45. Tworzymy tabelkę dla testu Kołmogoro-wa. Stawiamy hipotezę, że próbka pochodzi od rozkładu N(1, 0.245).
xi F (xi) i−16
i6
∣∣ i−16 − F (xi)
∣∣ ∣∣ i6 − F (xi)
∣∣0 0.33 0 0.17 0.34 0.170 0.33 0.17 0.33 0.17 0.010 0.33 0.33 0.50 0.01 0.160 0.33 0.50 0.67 0.16 0.320 0.33 0.67 0.83 0.33 0.496 0.96 0.83 1 0.15 0.02max 0.34 0.49
Dnobl jest równe 0.49. Natomiast d6(0.90) = 0.468. Zatem hipo-tezę odrzucamy.

54
ZADANIE 29. Rozważ próbę z poprzedniego zadania. Pokaż, żeprzy innym wyborze µ na tym samym poziomie istotności nie odrzu-cimy hipotezy, że rozkład jest typu N(µ, s).
Rozwiązanie.
Jeśli ustalimy średnią na przykład na 0.5, to test Kołmogorowada rezultat
xi F (xi) i−16
i6
∣∣ i−16 − F (xi)
∣∣ ∣∣ i6 − F (xi)
∣∣0 0.42 0 0.17 0.42 0.250 0.42 0.17 0.33 0.25 0.090 0.42 0.33 0.50 0.09 0.080 0.42 0.50 0.67 0.08 0.250 0.42 0.67 0.83 0.24 0.416 0.99 0.83 1 0.15 0.01max 0.42 0.41
Dnobl = 0.42. Natomiast d6(0.90) = 0.468. Zatem hipotezy nieodrzucamy.

55
ZADANIE 30. Jeszcze raz rozważ próbkę z poprzedniego zada-nia. Pokaż, że nie odrzucimy hipotezy na tym samym poziomie istot-ności, że rozkład jest jednostajny na przedziale [a; b] przy pewnymwyborze a i b.
Rozwiązanie.
Wybierzmy np. a = −6, b = 8. Wtedy
F (x) =
0 dla x < −6x+614 dla x ∈ [−6; 8]1 dla x > 8.
Zatem tabela do testu Kołmogorowa wygląda następująco:
xi F (xi) i−16
i6
∣∣ i−16 − F (xi)
∣∣ ∣∣ i6 − F (xi)
∣∣0 0.43 0 0.17 0.43 0.260 0.43 0.17 0.33 0.26 0.100 0.43 0.33 0.50 0.10 0.070 0.43 0.50 0.67 0.07 0.240 0.43 0.67 0.83 0.24 0.406 0.86 0.83 1 0.02 0.14max 0.43 0.40
Maksimum jest równe 0.43. Natomiast d6(0.90) = 0.468. Zatemhipotezy nie odrzucamy.

56
ZADANIE 31. Pewien sklep sprowadził jabłka tej samej odmianyod dwóch dostawców. Wybrał losowo po 7 jabłek z każdej dostawy izważył je. Otrzymał rezultaty w gramach: u pierwszego dostawcy 123,111, 134, 144, 122, 133, 145. U drugiego dostawcy 122, 133, 117, 129,137, 159, 161. Czy na poziomie istotności α = 0.05 można stwierdzić,że obaj dostawcy dają analogiczną ofertę?
Rozwiązanie.
Zastosujemy test serii. Ustawimy wszystkie wartości w ciąg ro-snący. Oznaczmy pierwszego dostawcę przez x, drugiego przez y.Otrzymamy tabelkę:
111 117 122 122 123 129 133 133 134 137 144 145 159 161x y x(y) y(x) x y x(y) y(x) x y x x y y
W dwóch przypadkach mamy te same wartości w obu próbkach,zatem serii może być najmniej 8, a najwięcej 10, w zależności od tegojak ustawimy próbki o tej samej wartości.
Znajdujemy w tablicy 8 k(0.05, 7, 7) = 4. Widzimy, że niezależ-nie od ustawienia kolejności takich samych wartości, mamy K > 4.Uznajemy, że obaj dostawcy mają podobną ofertę.

57
ZADANIE 32. Producent wag twierdzi, że jego wagi działająz odchyleniem standardowym 0.1 dkg. Aby sprawdzić, czy dostar-czone nam z hurtowni torebki cukru są kilogramowe, zważyliśmy 100losowo wybranych torebek i otrzymaliśmy wartość średnią 0.995 kg.Czy na poziomie istotności α = 0.05 możemy mieć do hurtownikazastrzeżenia?
Rozwiązanie.
Należy zastosować model D1. Stawiamy hipotezę µ = 100 prze-ciwko hipotezie µ < 100. Wartość statystyki testowej jest równa (poprzeliczeniu wszystkich danych na dekagramy)
uobl =99.5− 1000.1
· 10 = −5.
Zbiorem krytycznym jest przedział
(−∞;−u(0.95)] = (−∞;−1.64].
Wartość statystyki testowej należy do zbioru krytycznego (i to wy-raźnie!). Powinniśmy mieć poważne zastrzeżenia.

58
ZADANIE 33. Twórca programu obliczeniowego twierdzi, że je-go program rozwiązuje pewne równania różniczkowe na danym pro-cesorze w czasie około 2 sek. z odchyleniem standardowym 1 sek.Przetestowano go na 10 zadaniach z różnymi danymi początkowymii uzyskano czasy w sekundach: 0.8, 1.9, 2.3, 2.4, 2.4, 0.9, 3.5, 4.2, 2.4,2.9. Sprawdź na poziomie istotności α = 0.1 czy autor programu się„nie przechwala”.
Rozwiązanie.
Sposób I.
Zastosujemy test Kołmogorowa, aby się przekonać, że możemyrozkład uważać za normalny z parametrami zadeklarowanymi przeztwórcę programu, czyli typu N(2, 1).
Tworzymy tabelę. Przypominamy, że F (x) = Φ(x−µσ
)= Φ
(x−
).
xi F (xi) i−110
i10
∣∣ i−110 − F (xi)
∣∣ ∣∣ i10 − F (xi)
∣∣0.8 0.12 0 0.0 0.12 0.020.9 0.14 0.1 0.2 0.04 0.061.9 0.46 0.2 0.3 0.26 0.162.3 0.62 0.3 0.4 0.32 0.222.4 0.66 0.4 0.5 0.26 0.162.4 0.66 0.5 0.6 0.16 0.062.4 0.66 0.6 0.7 0.06 0.042.9 0.82 0.7 0.8 0.12 0.023.5 0.93 0.8 0.9 0.13 0.034.2 0.99 0.9 1.0 0.09 0.01max 0.32 0.22
Zatem Dnobl = 0.32, a d10(0.1) = 0.381. Ponieważ 0.32 < 0.381,hipotezy nie odrzucamy.
Sposób II.
Przyjmujemy, że rozkład jest normalny i stawiamy hipotezę µ =2 wobec hipotezy przeciwnej µ > 2. Stoujemy model D2. Wyliczamyx = 2.37, s = 1.04.
Statystyka testowa wynosi
tobl =2.37− 21.041
·√10 = 1.12.

59
Zbiór krytyczny jest równy
W = [t(0.9, 9);∞) = [1.38;∞).
Ponieważ tobl 6∈W hipotezy nie odrzucamy.

60
ZADANIE 34. Producent baterii twierdzi, że czas pracy bate-rii wynosi co najmniej 30 godzin. Przebadano 100 baterii i uzyskanośredni czas pracy 28 godzin i 20 minut i odchylenie standardowe 7godzin 25 minut. Na poziomie istotności α = 0.05 sprawdź czy pro-ducent ma rację.
Rozwiązanie.
Ponieważ próba jest duża stosujemy model D3. Po przeliczaniudanych na minuty mamy x = 1700, s = 445, µ0 = 1800. Stawiamyhipotezę µ = 1800 wobec hipotezy przeciwnej µ < 1800.
Wartość statystyki testowej wynosi
uobl =1700− 1800445
·√100 = −2.25.
Zbiór krytyczny jest równy
W = (−∞;−u(0.95)] = (−∞;−1.64].
Ponieważ uobl ∈W hipotezę odrzucamy. Producent nie ma racji.

61
ZADANIE 35. Jaki jest graniczny poziom istotności, przy któ-rym odrzucimy hipotezę w poprzednim zadaniu?
Rozwiązanie.
Wartość statystyki testowej wynosi −2.25. Trzeba znaleźć takie1 − α, że −u(1 − α) = −2.25, czyli obliczyć wartość dystrybuantystandardowego rozkładu normalnego w punkcie 2.25. Korzystając ztablic lub komputera otrzymujemy.
1− α = Φ(.) = ..
Zatem granicznym poziomem istotności jest α = 0.01222.

62
ZADANIE 36. Aby oszacować dokładność pomiarów wykony-wanych elektroniczną wagą sześciokrotnie zważono ten sam obiekti otrzymano wyniki (w gramach): 11.11, 11, 20, 11.10, 11.13, 11.12,11.21. Zakładając, że próbka pochodzi z rozkładu normalnego, napoziomie istotności 0.05 zweryfikuj hipotezę σ = 0.04 g. przeciwkohipotezie σ > 0.04 g.
Rozwiązanie.
Obliczamy x = 11, 145, s = 0, 04764.
Ponieważ rozkład cechy jest normalny, stosujemy model E1.
Statystka testowa wynosi
χ2obl =(n− 1)s2
σ20= 7.09,
a zbiór krytycznyW = [11.07;∞).
Wartość statystyki testowej nie należy do W . Hipotezy nie od-rzucamy.

63
ZADANIE 37. Dla danych z poprzedniego zadania wyznacz gra-niczny poziom istotności α, przy którym odrzucimy hipotezę.
Rozwiązanie.
Wartość statystyki testowej jest równa 7.09. Trzeba wyznaczyćtakie α, że χ2(1− α, 5) = 7.09, czyli wyznaczyć wartość dystrybuan-ty F rozkładu χ2 z 5 stopniami swobody w punkcie 7.09. Użyjemyprogramu calc i otrzymamy 1− α = 0.79, skąd α = 0.21.

64
ZADANIE 38. Aby zbadać dokładność pracy mikrometra zmie-rzono 60 razy grubość drutu i uzyskano empiryczne odchylenie stan-dardowe 0.05 mm. Przy założeniu, że rozkład błędów pomiaru jestnormalny zbadać na poziomie istotności α = 0.05 hipotezę, że mikro-metr mierzy z dokładnością 0.04 mm. Rozwiąż zadanie przy pomocymodeli E1 i E2.
Rozwiązanie.
Stawiamy hipotezę σ = 0.04 przeciwko hipotezie σ > 0.04.
Stosujemy model E1. Statystka testowa wynosi
χ2obl =(n− 1)s2
σ20= 92.19,
a zbiór krytycznyW = [χ2(0.95, 59);∞).
Wartość χ2(0.95, 59) obliczamy przy pomocy programu calc otrzy-mując wartość 77.93. Zatem
W = [77.93;∞).
Jak widać wartość statystyki testowej należy do zbioru krytycznego,a zatem hipotezę odrzucamy.
Stosujemy model E2. Statystyka testowa wynosi
uobl =
√118 · 0.0520.042
−√117 = 2.76,
a zbiór krytycznyW = [1.64;∞).
I przy tej metodzie hipotezę odrzucamy.
Przy obu metodach wyraźnie!

65
ZADANIE 39. Rzucamy 300 razy monetą. Orzeł wypadł 165 ra-zy. Na poziomie istotności α = 0.05 sprawdź hipotezę, że moneta jestsymetryczna.
Rozwiązanie.
Stosujemy model F1. Mamy p0 = 0.5, n = 300, k = 165. Stawia-my hipotezę p = 0.5 wobec hipotezy przeciwnej p 6= 0.5.Wartość statystyki testowej jest równa
uobl =k − np0√np0(1− p0)
= 1.73.
Natomiast zbiór krytyczny jest równy
(−∞;−1.96] ∪ [1.96;∞).
uobl 6∈W , zatem hipotezy nie odrzucamy.

66
ZADANIE 40. Wyznacz graniczny poziom istotności α, przy któ-rym odrzucimy hipotezę z poprzedniego zadania.
Rozwiązanie.
Trzeba znaleźć takie α, że u(1− α2 ) = 1.73, czyli obliczyć wartośćdystrybuanty Φ w punkcie 1.73. Otrzymujemy
1− α2 = 0.9582,
skąd α = 0.0836.

67
ZADANIE 41. Rozwiąż poprzednie dwa zadania przy pomocytestu zgodności χ2.
Rozwiązanie.
Orłów wypadło 165, a reszek 135, w obu wypadkach wartośćspodziewana to 150. Zatem wartość statystyki testowej jest równa
χ2obl =(165− 150)2
150+(135− 150)2
150= 3.
Liczba wyników n jest równa 2, zatem liczymy
χ2(0.95, 2− 1) = 3.841.
Ponieważ 3 < 3.841, hipotezy nie odrzucamy.
Aby wyznaczyć graniczny poziom istotności musimy policzyćwartość dystrybuanty rozkładu χ2 o jednym stopniu swobody w punk-cie 3. Najlepiej posłużyć się komputerem (np. programem calc, bow tablicach tego nie mamy). Otrzymujemy wartość 0.9167. Stąd α =0.0833.
Zauważmy, jak bardzo bliskie są wyniki przy obu metodach!

68
ZADANIE 42. Policzono pewnego dnia klientów internetowegosklepu i okazało się, że na 155 klientów, którzy wzięli udział w ankieciepodając płeć, 31 było kobietami. Na poziomie istotności α = 0.05zweryfikuj hipotezę, że procent klientów kobiet w tym sklepie wynosi25%.
Rozwiązanie.
Stosujemy model F1. Mamy p0 = 0.25, n = 155, k = 31. Stawia-my hipotezę p = 0.25 wobec hipotezy przeciwnej p 6= 0.25.Wartość statystyki testowej wynosi
uobl =k − np0√np0(1− p0)
= −1.44.
Zbiór krytyczny:
W = (−∞;−1.96] ∪ [1.96;∞).
Wartość −1.44 nie należy do zbioru krytycznego. Nie odrzucamy hi-potezy.

69
ZADANIE 43. Pewien sklep z odzieżą chce sprawdzić, czy rów-nież na terenie jego działalności potwierdzą się dane, że co najmniej90% klientów stanowią panie. Przez tydzień skrupulatnie liczono klien-tów i okazało się, że na 527 osób, pań było 450. Czy dane te przecząogólnej statystyce na poziomie istotności α = 0.05?
Rozwiązanie.
Ponownie trzeba zastosować model F1. Mamy p0 = 0.9, n = 527,k = 450. Stawiamy hipotezę p = 0.9 wobec hipotezy przeciwnej p <0.9 (dlaczego?).
Wartość statystyki testowej wynosi
uobl =k − np0√np0(1− p0)
= −3.53.
Zbiór krytyczny:W = (−∞;−1.64].
Wartość −3.53 należy do zbioru krytycznego. Odrzucamy hipotezę.

70
ZADANIE 44. Dwa narzędzia pomiarowe przebadano mierząc ni-mi po 20 razy pewien obiekt. Uzyskano następujące rezultaty: s1 =0.13, s2 = 0.20. Czy na poziomie istotności α = 0.05 można zakładać,że oba urządzenia mierzą jednakowo dokładnie?
Rozwiązanie.
Przyjmujemy hipotezę σ1 = σ2 wobec hipotezy przeciwnej σ1 6=σ2.
Stosujemy model G1. Ponieważ większa jest wariancja w drugiejpróbce, przyjmujemy statystykę
Fobl =s22s21= 2.37.
Zbiór krytyczny
W = F(1− α2 , 19, 19);∞) = [2.53;∞).
2.37 6∈W , hipotezy nie odrzucamy.

71
ZADANIE 45. Właściciel sklepu zauważył, że jego waga nie wa-ży dokładnie. Zważył 50 razy tę samą paczkę kilogramową cukru iotrzymał odchylenie standardowe 2 dkg. Oddał wagę do remontu,i po naprawie zważył ponownie 50 razy kilogram cukru otrzymującodchylenie standardowe 0.5 dkg. Czy może na poziomie istotnościα = 0.05 uznać naprawę za dobrą?
Rozwiązanie.
Zastosujemy model G1. Stawiamy hipotezę σ1 = σ2 wobec hipo-tezy przeciwnej σ1 > σ2. Statystyka testowa jest równa
Fobl =s21s22= 16.
Natomiast zbiór krytyczny jest równy
W = F(1− α, 49, 49);∞) = [1.61;∞).
Wartość statystyki testowej wyraźnie należy do zbioru krytycznego.Hipotezę o równości wariancji odrzucamy. Możemy stąd wywniosko-wać, że waga została porządnie naprawiona!

72
ZADANIE 46. W pewnej fabryce zmierzono średnice śrub nadwóch przyrządach pomiarowych od dwóch różnych dostawców uzy-skując wyniki w cm: 0.99, 0.97, 0.97, 1.00, 0.98, 0.99, oraz odpo-wiednio 1.06, 1.07, 1.03, 1.01, 1.08. Wiadomo, że pierwszy przyrządpomiarowy działa z dokładnością σ1 = 0.01 cm, a drugi przyrządz dokładnością σ2 = 0.02 cm. Zakładamy, że rozpatrywana cechadługości śrub ma rozkład normalny. Zweryfikuj na poziomie istotno-ści α = 0.05 hipotezę, że długości śrub u obu dostawców są takiesame.
Rozwiązanie.
Nasze dane n1 = 6, n2 = 5. Ponieważ znane są odchylenia stan-dardowe możemy zastosować model H1. Stawiamy hipotezę µ1 = µ2wobec hipotezy przeciwnej µ1 6= µ2. Obliczamy x1 = 0.9833, x2 =1.050. (odchyleń standardowych w tym modelu nie trzeba obliczać).Statystyka testowa jest równa
uobl =x1 − x2√σ21n21+ σ
22n22
= −6.78.
Zbiór krytyczny
W = (−∞;−1.96] ∪ [1.96;∞).
Hipotezę wyraźnie odrzucamy.

73
ZADANIE 47. Jaki jest graniczny poziom istotności, przy któ-rym odrzucimy hipotezę w poprzednim zadaniu?
Rozwiązanie.
Wartość statystyki testowej jest równa 6.78. Musimy zatem zna-leźć takie α, aby −u(1 − α2 ) = −6.78. Trzeba policzyć dystrybuantęΦ(.). Jest ona praktyczne równa 1 (największy argument w ta-blicach jest zwykle 3.5). Wartość ta policzona programem calc jestrówna 0.999999996. Stąd α = 0.000000007. Możemy zatem uznać, żehipotezę odrzucimy na każdym sensownym poziomie istotności.

74
ZADANIE 48. Rozwiąż zadanie 40 bez informacji o odchyleniachstandardowych.
Rozwiązanie.
Zadanie rozwiążemy w dwóch etapach. W pierwszym etapie spraw-dzimy, czy możemy przyjąć, że obie próby mają podobne odchyleniestandardowe. Dodatkowo obliczamy s1 = 0.01211, s2 = 0.02915.
Stosujemy model G1. Statystyka testowa jest równa
Fobl =s22s21= 5.8.
Zbiór krytyczny
W = [F(0.975, 5− 1, 6− 1);∞) = [7.39;∞).
Możemy uznać, że odchylenia standardowe są równe. Zatem wdrugim, głównym etapie stosujemy model H2.
tobl =x1 − x2√
(n1−1)s21+(n2−1)s22
n1+n2−2 · n1+n2n1n2
.
Wstawiając nasze dane otrzymujemy wartość −5.14. Zbiór krytycznyjest postaci
W = (−∞;−t(0.975, 9)] ∪ [t(0.975, 9);∞),
czyliW = (−∞;−2.26] ∪ [2.26;∞).
I w tym wypadku hipotezę wyraźnie odrzucamy.

75
ZADANIE 49. Zbadano płace 5 kobiet i 5 mężczyzn pracującychw pewnej firmie. Otrzymano dla kobiet dane (w złotych) 1700, 1300,1900, 1900, 3500, a dla mężczyzn 1600, 1700, 1800, 2700, 4500. Spraw-dzić na poziomie istotności α = 0.05, czy można stwierdzić, że płacekobiet są niższe w tej firmie niż mężczyzn. Zakładamy, że płace mająrozkłady normalne.
Rozwiązanie.
Najpierw obliczamy x1 = 2060, s1 = 841.43, x2 = 2460, s2 =1221.88.
Test przeprowadzimy w dwóch etapach.
W etapie pierwszym sprawdzimy, czy oba odchylenia standardo-we możemy uznać za jednakowe. W zależności od tego do właściwegotestu wybierzemy model H2 lub H3.
ETAP 1.
Stawiamy hipotezę σ1 = σ2 wobec hipotezy przeciwnej σ1 6= σ2.Stosujemy model G1. Druga próbka ma większą wariancję, zatemnasza statystyka testowa jest równa
Fobl =s22s21= 2.11.
Natomiast zbiór krytyczny jest równy
W = [F(1− α2 , 5− 1, 5− 1);∞) = [9.6;∞).Nie odrzucamy hipotezy o równość odchyleń standardowych. Zatemw trzecim etapie zastosujemy model H2.
ETAP 2.
Stawiamy hipotezę µ1 = µ2 wobec hipotezy przeciwnej µ1 < µ2.Statystyka testowa jest równa
tobl =x1 − x2√
(n1−1)s21+(n2−1)s22
n1+n2−2 · n1+n2n1n2
.
Dla naszych danych otrzymujemy wynik −0.6. Zbiór krytycznyW = (−∞;−2.31] ∪ [2.31;∞).
Hipotezy nie odrzucamy. Przyjmujemy, że płace są podobne.

76
ZADANIE 50. W zakładzie z poprzedniego zadania odeszła zpracy kobieta zarabiająca 3500 złotych i do próby losowej wybranotylko poprzednie 4 kobiety. Rozwiąż poprzednie zadanie przy nowychdanych.
Rozwiązanie.
Teraz mamy n1 = 4, x1 = 1700, s1 = 282.84. Pozostałe dane bezzmian.
Test równości wariancji wypada teraz negatywnie, bo wartośćstatystyki testowej jest równa 18.66, natomiast zbiór krytyczny jestrówny W = [15.1;∞).Zatem w drugim etapie stosujemy model H3. Wartość statystyki
Cobl = −1.35, natomiast zbiór krytyczny W = (−∞;−2.8]∪ [2.8;∞).Widzimy, że Cobl 6∈W , zatem hipotezy nie odrzucamy.

77
ZADANIE 51. Policja przeprowadziła badania prędkości samo-chodów w pewnym niebezpiecznym miejscu na próbach liczności 200dla samochodów osobowych i ciężarowych i uzyskała wyniki: dla oso-bowych 101 km/h przy odchyleniu standardowym 7.8 km/h, a dla cię-żarowych 88 km/h przy odchyleniu standardowym 10.9 km/h. Zwery-fikuj na poziomie istotności α = 0.05 hipotezę, że samochody osobowew tym miejscu jeżdżą nie prędzej niż samochody ciężarowe.
Rozwiązanie.
Próbki są duże, stosujemy więc model H4. Mamy x1 = 101,s1 = 7.8, x2 = 88, s2 = 10.9, n1 = n2 = 200. Stawiamy hipotezęµ1 = µ2 wobec hipotezy µ1 > µ2.
Statystyka testowa dana jest wzorem
uobl =x1 − x2√s21n1+ s
22n2
.
W naszym wypadkuuobl = 13.72,
a zbiór krytyczny ma postać
W = [1.64;∞).
Hipotezę bardzo zdecydowanie odrzucamy.

78
ZADANIE 52. Do sklepu pewnego dnia przyszło: 180 kobiet, spo-śród których 88 dokonało zakupu, oraz 122 mężczyzn, spośród nich101 dokonało zakupu. Czy słuszna jest hipoteza, że procent osób do-konujących zakupu po wejściu do sklepu nie zależy od płci? Przyjmijα = 0.05.
Rozwiązanie. Trzeba zastosować model I1.
Mamy n1 = 180, k1 = 88, n2 = 122, k2 = 101. Stawiamy hipote-zę p1 = p2 wobec hipotezy przeciwnej p1 6= p2. Stosujemy statystykę
uobl =k1n1− k2n2√
k1+k2n1n2
(1− k1+k2n1+n2
) .Podstawiając nasze dane otrzymujemy
uobl = −5.97,
natomiast zbiór krytyczny
W = (−∞;−1.96] ∪ [1.96;∞).
uobl należy do zbioru krytycznego, hipotezę odrzucamy.

79
ZADANIE 53. Pewna firma niezadowolona z wielkości sprzedażypostanowiła zatrudnić agencję reklamową. Tabelka pokazuje średniątygodniową sprzedaż wybranych asortymentów (w tys. zł.) po zatrud-nieniu tej agencji. Czy słuszna jest hipoteza, że zatrudnienie agencjinie zmieniło wielkości sprzedaży. Zakładamy, że wszystkie próbki po-chodzą z rozkładu normalnego i przyjmujemy α = 0.05
wielkość sprzedaży przed 9 11 17 4 7 9wielkość sprzedaży po 21 21 18 5 9 19
Rozwiązanie.
Tworzymy nową zmienną Y = X2−X1. Mamy y1 = 12, y2 = 10,y3 = 1, y4 = 1, y5 = 2, y6 = 10. Mamy y = 6.00, s = 5.18. Testujemyhipotezę µ = 0 wobec hipotezy µ > 0.
Ponieważ próbka jest nieliczna, stosujemy model E2. Wartośćstatystyki wynosi 1.89, a zbiór krytycznyW = [2.02;∞). Hipotezy nieodrzucamy. Wynika z tego, że zatrudnienie agencji tylko nieznaczniepoprawiło sprzedaż.

80
ZADANIE 54. W pewnym niebezpiecznymmiejscu doszło w pew-nym miesiącu do 32 kolizji drogowych. Policja ustawiła tam ostrze-gawczy oświetlony znak. Po ustawieniu tego znaku w najbliższymmiesiącu doszło do 19 kolizji. Czy można uznać, że sytuacja się po-prawiła? Przyjmij α = 0.05.
Rozwiązanie.
Problem ten można próbować rozwiązać kilkoma sposobami. Popierwsze możemy zastosować model I1, ale nie będzie on w stu pro-centach dobry, bo próby nie są niezależne.
Można liczbę wypadków potraktować jako liczbę „sukcesów” wrozkładzie dwupunktowym np. obliczając liczbę godzin w miesią-cu (744) i przyjąć, że każdy wypadek zdarzył się w innej godzinie.Następnie rozważać zmienną k = k1 − k2 = 13 przyjąć hipotezęp = p0 = 0, wobec hipotezy p > 0 i zastosować model F1. Ale wewzorze na statystykę testową p0 musi być większe od zera.
Możemy rozumowanie poprawić tak. Możemy przyjąć, że mini-malna liczba kolizji zawsze będzie: np. 1 na 1000 godzin. I jako hipo-tezę zerową przyjąć p = 0.001 wobec hipotezy przeciwnej p > 0.001.Jeśli te dane: n = 744, k = 13, p0 = 0.0001 wstawimy do modeluF1, to wartość statystyki testowej wyjdzie 14.22, a zbiór krytycznybędzie równy W = [1.64;∞). Hipotezę zdecydowanie odrzucamy. Tooznacza, że sytuacja się wyraźnie poprawiła.

81
ZADANIE 55. Wyniki egzaminu ze statystyki studentów cho-dzących na wykłady (C) i niechodzących (N) w pewnej grupie wgrezultatów (zaliczony - ZAL i niezaliczony - NZAL) podane są w ta-belce
ZAL NZALN 2 102C 28 36
Zbadaj, czy hipoteza zaliczenie egzaminu jest niezależne od tegoczy student chodzi na zajęcia jest słuszna. Przyjmij α = 0.05.
Rozwiązanie.
Dodając dane w kolumnach i wierszach zapiszmy naszą tabelkęnastępująco
ZAL NZAL razemN 2 102 104C 28 36 64razem 30 138 168
Zastosujemy test χ2. Obliczamy
χ2obl =
(2− 30 · 104168
)230 · 104168
+
(102− 138 · 104168
)2138 · 104168
+
(28− 30 · 64168
)230 · 64168
+
(36− 138 · 64168
)2138 · 64168
≈ 47.
Natomiast χ2(0.95, (2−1)·(2−1)) = 3.84. Hipotezę zdecydowanieodrzucamy.

82
ZADANIE 56. Wyznacz współczynniki Cramera i C Pearsonadla poprzedniego zadania.
Rozwiązanie. Mamy n = 168, m = 2.
V =
√χ2obln(m− 1)
≈ 0.53.
C =
√χ2oblχ2obl + n
≈ 0.47.
Tablice 83
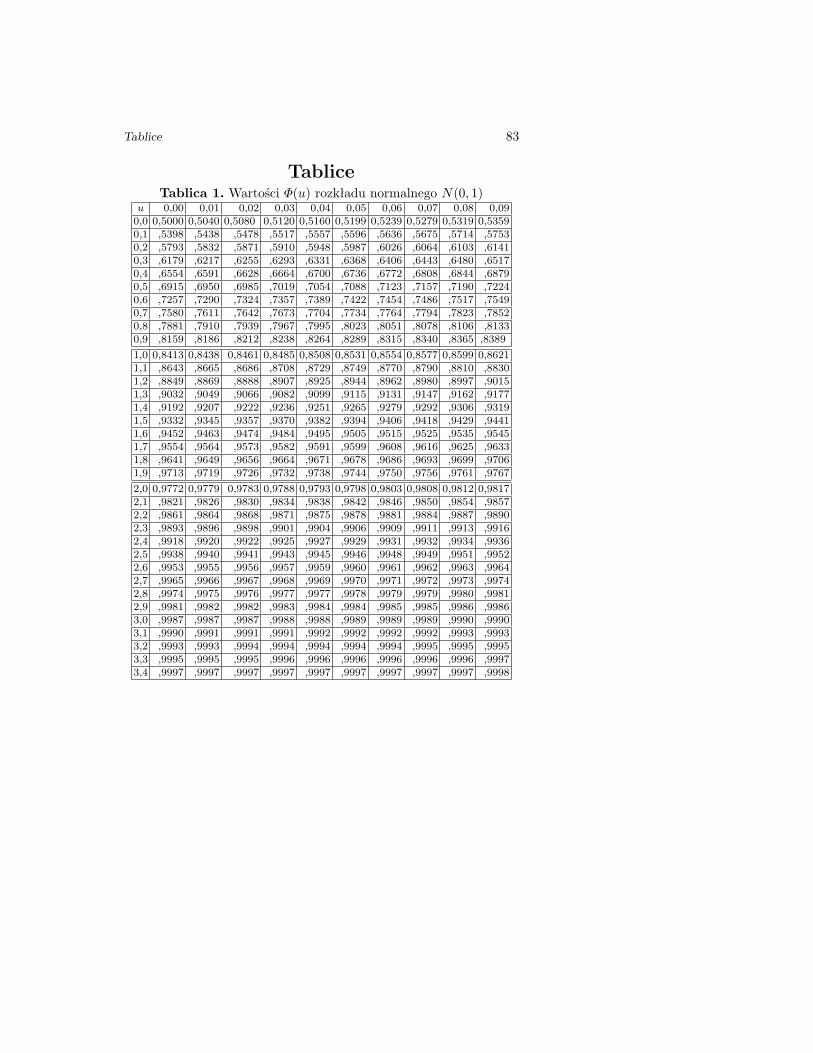
TabliceTablica 1. Wartości Φ(u) rozkładu normalnego N(0, 1)
u 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,090,0 0,5000 0,5040 0,5080 0,5120 0,5160 0,5199 0,5239 0,5279 0,5319 0,53590,1 ,5398 ,5438 ,5478 ,5517 ,5557 ,5596 ,5636 ,5675 ,5714 ,57530,2 ,5793 ,5832 ,5871 ,5910 ,5948 ,5987 ,6026 ,6064 ,6103 ,61410,3 ,6179 ,6217 ,6255 ,6293 ,6331 ,6368 ,6406 ,6443 ,6480 ,65170,4 ,6554 ,6591 ,6628 ,6664 ,6700 ,6736 ,6772 ,6808 ,6844 ,68790,5 ,6915 ,6950 ,6985 ,7019 ,7054 ,7088 ,7123 ,7157 ,7190 ,72240,6 ,7257 ,7290 ,7324 ,7357 ,7389 ,7422 ,7454 ,7486 ,7517 ,75490,7 ,7580 ,7611 ,7642 ,7673 ,7704 ,7734 ,7764 ,7794 ,7823 ,78520,8 ,7881 ,7910 ,7939 ,7967 ,7995 ,8023 ,8051 ,8078 ,8106 ,81330,9 ,8159 ,8186 ,8212 ,8238 ,8264 ,8289 ,8315 ,8340 ,8365 ,8389
1,0 0,8413 0,8438 0,8461 0,8485 0,8508 0,8531 0,8554 0,8577 0,8599 0,86211,1 ,8643 ,8665 ,8686 ,8708 ,8729 ,8749 ,8770 ,8790 ,8810 ,88301,2 ,8849 ,8869 ,8888 ,8907 ,8925 ,8944 ,8962 ,8980 ,8997 ,90151,3 ,9032 ,9049 ,9066 ,9082 ,9099 ,9115 ,9131 ,9147 ,9162 ,91771,4 ,9192 ,9207 ,9222 ,9236 ,9251 ,9265 ,9279 ,9292 ,9306 ,93191,5 ,9332 ,9345 ,9357 ,9370 ,9382 ,9394 ,9406 ,9418 ,9429 ,94411,6 ,9452 ,9463 ,9474 ,9484 ,9495 ,9505 ,9515 ,9525 ,9535 ,95451,7 ,9554 ,9564 ,9573 ,9582 ,9591 ,9599 ,9608 ,9616 ,9625 ,96331,8 ,9641 ,9649 ,9656 ,9664 ,9671 ,9678 ,9686 ,9693 ,9699 ,97061,9 ,9713 ,9719 ,9726 ,9732 ,9738 ,9744 ,9750 ,9756 ,9761 ,9767
2,0 0,9772 0,9779 0,9783 0,9788 0,9793 0,9798 0,9803 0,9808 0,9812 0,98172,1 ,9821 ,9826 ,9830 ,9834 ,9838 ,9842 ,9846 ,9850 ,9854 ,98572,2 ,9861 ,9864 ,9868 ,9871 ,9875 ,9878 ,9881 ,9884 ,9887 ,98902,3 ,9893 ,9896 ,9898 ,9901 ,9904 ,9906 ,9909 ,9911 ,9913 ,99162,4 ,9918 ,9920 ,9922 ,9925 ,9927 ,9929 ,9931 ,9932 ,9934 ,99362,5 ,9938 ,9940 ,9941 ,9943 ,9945 ,9946 ,9948 ,9949 ,9951 ,99522,6 ,9953 ,9955 ,9956 ,9957 ,9959 ,9960 ,9961 ,9962 ,9963 ,99642,7 ,9965 ,9966 ,9967 ,9968 ,9969 ,9970 ,9971 ,9972 ,9973 ,99742,8 ,9974 ,9975 ,9976 ,9977 ,9977 ,9978 ,9979 ,9979 ,9980 ,99812,9 ,9981 ,9982 ,9982 ,9983 ,9984 ,9984 ,9985 ,9985 ,9986 ,99863,0 ,9987 ,9987 ,9987 ,9988 ,9988 ,9989 ,9989 ,9989 ,9990 ,99903,1 ,9990 ,9991 ,9991 ,9991 ,9992 ,9992 ,9992 ,9992 ,9993 ,99933,2 ,9993 ,9993 ,9994 ,9994 ,9994 ,9994 ,9994 ,9995 ,9995 ,99953,3 ,9995 ,9995 ,9995 ,9996 ,9996 ,9996 ,9996 ,9996 ,9996 ,99973,4 ,9997 ,9997 ,9997 ,9997 ,9997 ,9997 ,9997 ,9997 ,9997 ,9998

84
Tablica 2. Kwantyle rozkładu normalnego N(0, 1), u(p) = Φ−(p)
p Φ−(p)0.50 0.00000.51 0.02510.52 0.05020.53 0.07530.54 0.10050.55 0.12570.56 0.15100.57 0.17640.58 0.20190.59 0.22760.60 0.25340.61 0.27940.62 0.30550.63 0.33190.64 0.35850.65 0.38540.66 0.41250.67 0.44000.68 0.46770.69 0.49590.70 0.52440.71 0.55340.72 0.58290.73 0.61290.74 0.6434
p Φ−(p)0.75 0.67450.76 0.70630.77 0.73890.78 0.77220.79 0.80650.80 0.84170.81 0.87790.82 0.91540.83 0.95420.84 0.99450.85 1.03650.86 1.08040.87 1.12640.88 1.17500.89 1.22660.90 1.28160.91 1.34080.92 1.40510.93 1.47580.94 1.55480.95 1.64490.96 1.75070.97 1.88080.98 2.05370.99 2.3263
Tablica 2.5 Uproszczone kwantyle u(p) rozkładu normalnegoN(0, 1)
p 0,90 0,95 0,975 0,99 0,995u(p) 1,28 1,64 1,96 2,33 2,58
Tablice 85
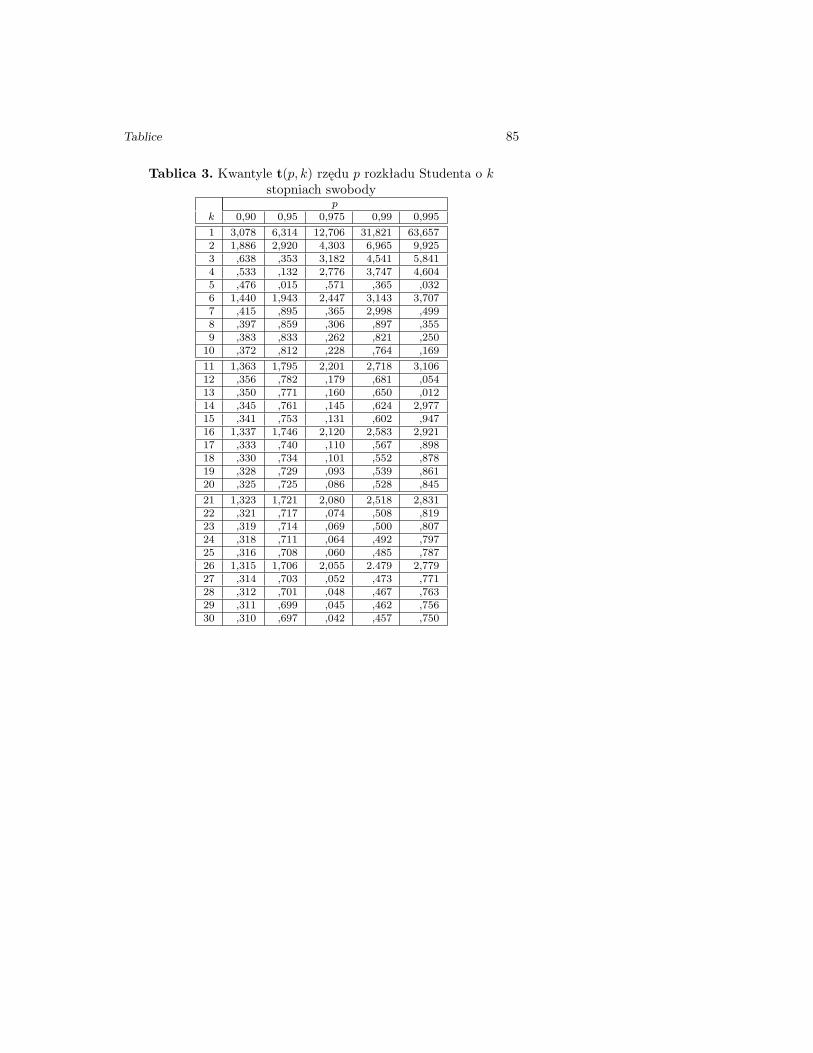
Tablica 3. Kwantyle t(p, k) rzędu p rozkładu Studenta o kstopniach swobody
pk 0,90 0,95 0,975 0,99 0,995
1 3,078 6,314 12,706 31,821 63,6572 1,886 2,920 4,303 6,965 9,9253 ,638 ,353 3,182 4,541 5,8414 ,533 ,132 2,776 3,747 4,6045 ,476 ,015 ,571 ,365 ,0326 1,440 1,943 2,447 3,143 3,7077 ,415 ,895 ,365 2,998 ,4998 ,397 ,859 ,306 ,897 ,3559 ,383 ,833 ,262 ,821 ,25010 ,372 ,812 ,228 ,764 ,169
11 1,363 1,795 2,201 2,718 3,10612 ,356 ,782 ,179 ,681 ,05413 ,350 ,771 ,160 ,650 ,01214 ,345 ,761 ,145 ,624 2,97715 ,341 ,753 ,131 ,602 ,94716 1,337 1,746 2,120 2,583 2,92117 ,333 ,740 ,110 ,567 ,89818 ,330 ,734 ,101 ,552 ,87819 ,328 ,729 ,093 ,539 ,86120 ,325 ,725 ,086 ,528 ,845
21 1,323 1,721 2,080 2,518 2,83122 ,321 ,717 ,074 ,508 ,81923 ,319 ,714 ,069 ,500 ,80724 ,318 ,711 ,064 ,492 ,79725 ,316 ,708 ,060 ,485 ,78726 1,315 1,706 2,055 2.479 2,77927 ,314 ,703 ,052 ,473 ,77128 ,312 ,701 ,048 ,467 ,76329 ,311 ,699 ,045 ,462 ,75630 ,310 ,697 ,042 ,457 ,750

86
Tablica 3. Kwantyle t(p, k) rzędu p rozkładu Studenta o kstopniach swobody c.d.
pk 0,90 0,95 0,975 0,99 0,995
31 1,309 1,695 2,039 2,453 2,74432 ,309 ,694 ,037 ,449 ,73833 ,308 ,692 ,034 ,445 ,73334 ,307 ,691 ,032 ,441 ,72835 ,306 ,690 ,030 ,438 ,72436 1,305 1,688 2,028 2,434 2,72037 ,305 ,687 ,025 ,431 ,71538 ,304 ,686 ,024 ,429 ,71239 ,304 ,685 ,023 ,425 ,70840 ,303 ,684 ,021 ,423 ,704
41 1,303 1,683 2,019 2,421 2,70142 ,302 ,682 ,018 ,418 ,69843 ,302 ,681 ,017 ,416 ,69544 ,301 ,680 ,015 ,414 ,69245 ,301 ,679 ,014 ,412 ,69046 1.300 1,679 2,013 2,410 2,68747 ,300 ,678 ,012 ,408 ,68548 ,299 ,677 ,011 ,407 ,68249 ,299 ,677 ,010 ,405 ,68050 ,299 ,676 ,009 ,403 ,678
55 1,297 1,673 2,004 2,396 2,66860 ,295 ,671 ,000 ,390 ,66065 ,295 ,669 1,997 ,385 ,65470 ,294 ,667 ,994 ,381 64875 ,293 ,665 ,992 ,377 ,64380 1,292 1,664 1,990 2,374 2,63990 ,291 ,662 ,987 ,369 632100 ,290 ,660 ,984 ,364 ,626
120 ,289 ,658 ,980 ,358 ,617150 ,287 ,655 ,976 ,351 ,609200 1,286 1,653 1,972 2,345 2,601300 ,284 ,650 ,968 ,339 ,592500 ,283 ,648 ,965 ,334 ,5861000 ,282 ,646 ,962 ,330 ,581∞ ,282 ,645 ,960 ,326 ,576
Tablice 87
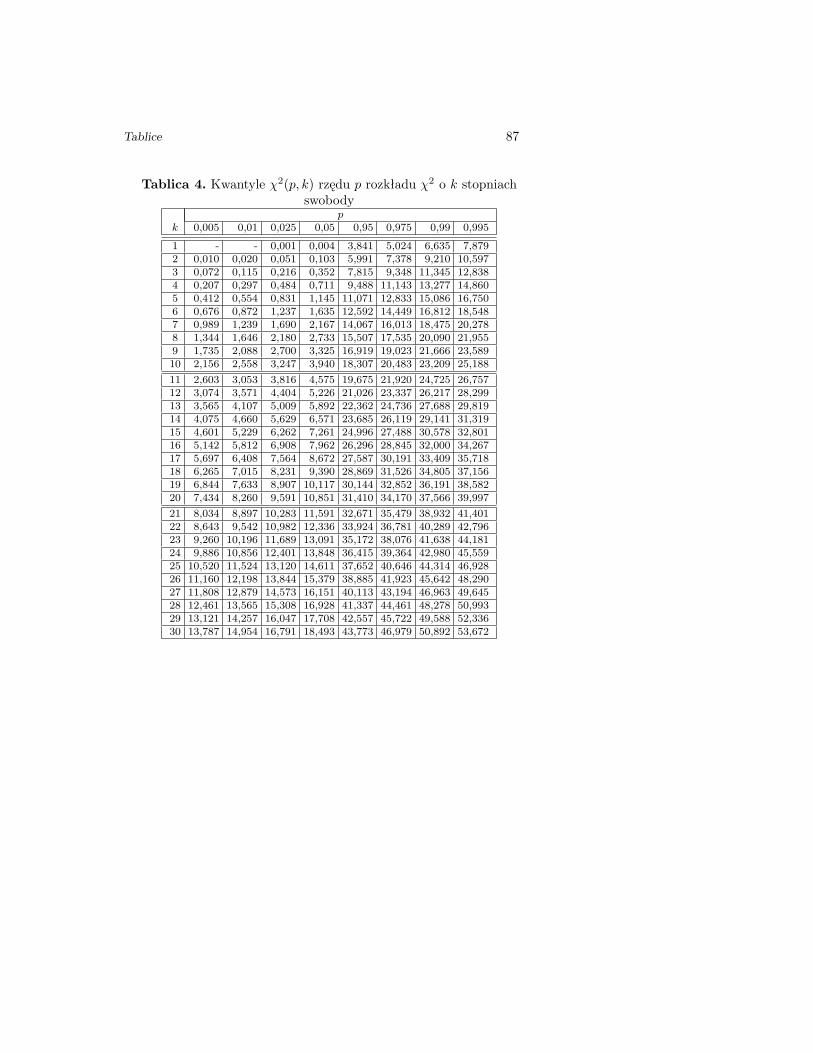
Tablica 4. Kwantyle χ2(p, k) rzędu p rozkładu χ2 o k stopniachswobody
pk 0,005 0,01 0,025 0,05 0,95 0,975 0,99 0,995
1 - - 0,001 0,004 3,841 5,024 6,635 7,8792 0,010 0,020 0,051 0,103 5,991 7,378 9,210 10,5973 0,072 0,115 0,216 0,352 7,815 9,348 11,345 12,8384 0,207 0,297 0,484 0,711 9,488 11,143 13,277 14,8605 0,412 0,554 0,831 1,145 11,071 12,833 15,086 16,7506 0,676 0,872 1,237 1,635 12,592 14,449 16,812 18,5487 0,989 1,239 1,690 2,167 14,067 16,013 18,475 20,2788 1,344 1,646 2,180 2,733 15,507 17,535 20,090 21,9559 1,735 2,088 2,700 3,325 16,919 19,023 21,666 23,58910 2,156 2,558 3,247 3,940 18,307 20,483 23,209 25,188
11 2,603 3,053 3,816 4,575 19,675 21,920 24,725 26,75712 3,074 3,571 4,404 5,226 21,026 23,337 26,217 28,29913 3,565 4,107 5,009 5,892 22,362 24,736 27,688 29,81914 4,075 4,660 5,629 6,571 23,685 26,119 29,141 31,31915 4,601 5,229 6,262 7,261 24,996 27,488 30,578 32,80116 5,142 5,812 6,908 7,962 26,296 28,845 32,000 34,26717 5,697 6,408 7,564 8,672 27,587 30,191 33,409 35,71818 6,265 7,015 8,231 9,390 28,869 31,526 34,805 37,15619 6,844 7,633 8,907 10,117 30,144 32,852 36,191 38,58220 7,434 8,260 9,591 10,851 31,410 34,170 37,566 39,997
21 8,034 8,897 10,283 11,591 32,671 35,479 38,932 41,40122 8,643 9,542 10,982 12,336 33,924 36,781 40,289 42,79623 9,260 10,196 11,689 13,091 35,172 38,076 41,638 44,18124 9,886 10,856 12,401 13,848 36,415 39,364 42,980 45,55925 10,520 11,524 13,120 14,611 37,652 40,646 44,314 46,92826 11,160 12,198 13,844 15,379 38,885 41,923 45,642 48,29027 11,808 12,879 14,573 16,151 40,113 43,194 46,963 49,64528 12,461 13,565 15,308 16,928 41,337 44,461 48,278 50,99329 13,121 14,257 16,047 17,708 42,557 45,722 49,588 52,33630 13,787 14,954 16,791 18,493 43,773 46,979 50,892 53,672

88
Tablica 4. Kwantyle χ2(p, k) rzędu p rozkładu χ2 o k stopniachswobody c.d
pk 0,005 0,01 0,025 0,05 0,95 0,975 0,99 0,99531 14,458 15,655 17,539 19,281 44,985 48,232 52,191 55,00332 15,134 16,362 18,291 20,072 46,194 49,480 43,486 56,32833 15,815 17,074 19,047 20,867 47,400 50,725 54,776 57,64834 16,501 17,789 19,806 21,664 48,602 51,966 56,061 58,96435 17,192 18,509 20,569 22,465 49,802 53,203 57,342 60,27536 17,887 19,233 21,336 23,269 50,998 54,437 58,619 61,58137 18,586 19,960 22,106 24,075 52,192 55,668 59,892 62,88338 19,289 20,691 22,878 24,884 53,384 56,896 61,162 64,18139 19,996 21,426 23,654 25,695 54,572 58,120 62,428 65,47640 20,707 22,164 24,433 26,509 55,758 59,342 63,691 66,766
41 21,421 22,906 25,215 27,326 56,942 60,561 64,950 68,05342 22,138 23,650 25,999 28,144 58,124 61,777 66,206 69,33643 22,859 24,398 26,785 28,965 59,304 62,990 67,459 70,61644 23,584 25,148 27,575 29,787 60,481 64,201 68,710 71,89345 24,311 25,901 28,366 30,612 61,656 65,410 69,957 73,16646 25,041 26,657 29,160 31,439 62,830 66,617 71,201 74,43747 25,775 27,416 29,956 32,268 64,001 67,821 72,443 75,70448 26,511 28,177 30,755 33,098 65,171 69,023 73,683 76,96949 27,249 28,941 31,555 33,930 66,339 70,222 74,919 78,23150 27,991 29,707 32,357 34,764 67,505 71,420 76,154 79,490
Tablice 89
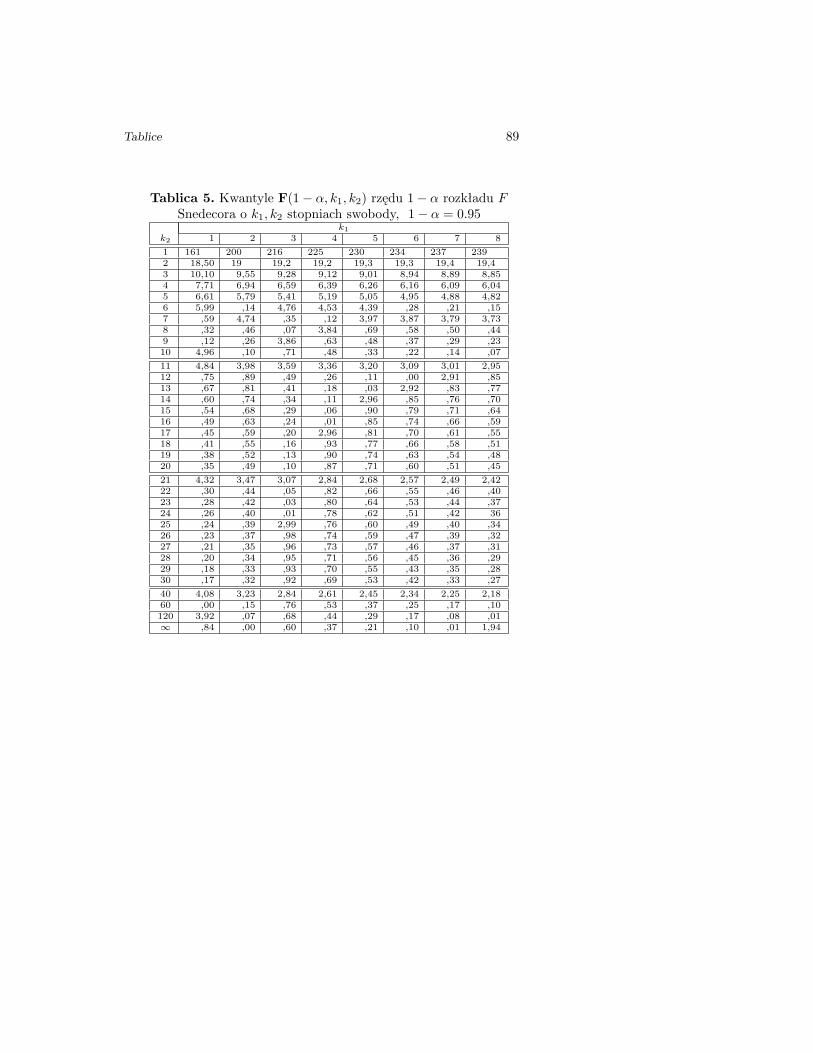
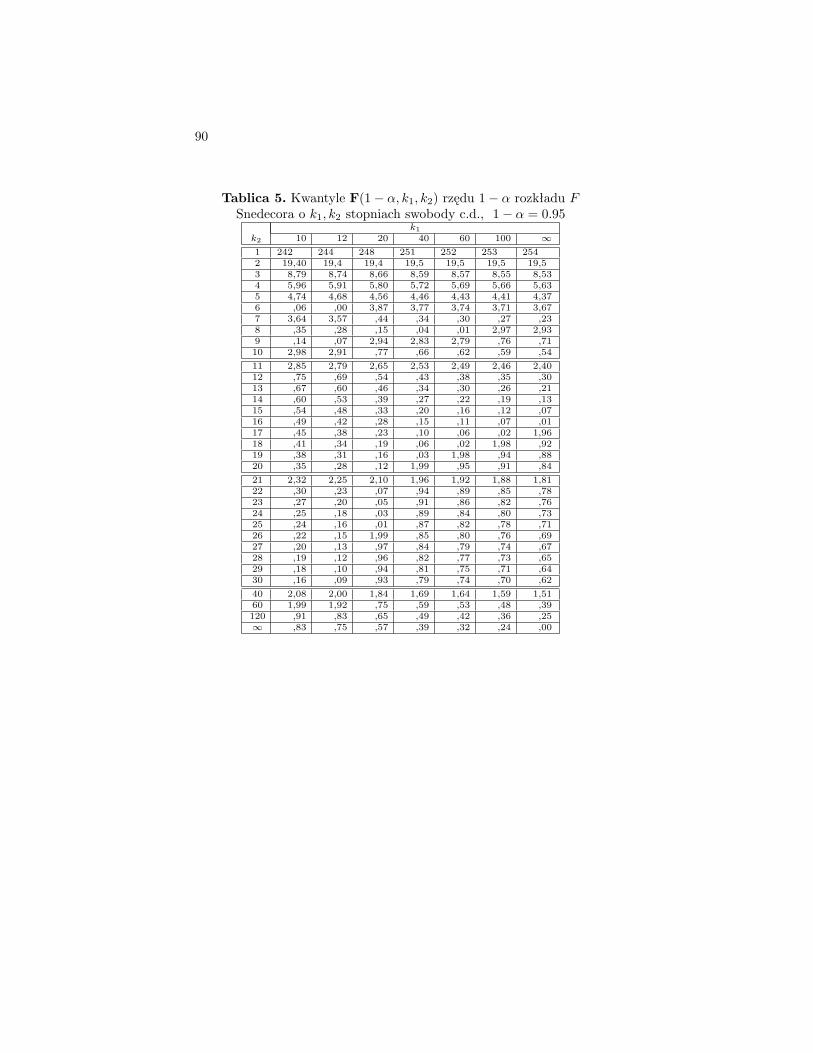
Tablica 5. Kwantyle F(1− α, k1, k2) rzędu 1− α rozkładu FSnedecora o k1, k2 stopniach swobody, 1− α = 0.95
k1k2 1 2 3 4 5 6 7 8
1 161 200 216 225 230 234 237 2392 18,50 19 19,2 19,2 19,3 19,3 19,4 19,43 10,10 9,55 9,28 9,12 9,01 8,94 8,89 8,854 7,71 6,94 6,59 6,39 6,26 6,16 6,09 6,045 6,61 5,79 5,41 5,19 5,05 4,95 4,88 4,826 5,99 ,14 4,76 4,53 4,39 ,28 ,21 ,157 ,59 4,74 ,35 ,12 3,97 3,87 3,79 3,738 ,32 ,46 ,07 3,84 ,69 ,58 ,50 ,449 ,12 ,26 3,86 ,63 ,48 ,37 ,29 ,2310 4,96 ,10 ,71 ,48 ,33 ,22 ,14 ,07
11 4,84 3,98 3,59 3,36 3,20 3,09 3,01 2,9512 ,75 ,89 ,49 ,26 ,11 ,00 2,91 ,8513 ,67 ,81 ,41 ,18 ,03 2,92 ,83 ,7714 ,60 ,74 ,34 ,11 2,96 ,85 ,76 ,7015 ,54 ,68 ,29 ,06 ,90 ,79 ,71 ,6416 ,49 ,63 ,24 ,01 ,85 ,74 ,66 ,5917 ,45 ,59 ,20 2,96 ,81 ,70 ,61 ,5518 ,41 ,55 ,16 ,93 ,77 ,66 ,58 ,5119 ,38 ,52 ,13 ,90 ,74 ,63 ,54 ,4820 ,35 ,49 ,10 ,87 ,71 ,60 ,51 ,45
21 4,32 3,47 3,07 2,84 2,68 2,57 2,49 2,4222 ,30 ,44 ,05 ,82 ,66 ,55 ,46 ,4023 ,28 ,42 ,03 ,80 ,64 ,53 ,44 ,3724 ,26 ,40 ,01 ,78 ,62 ,51 ,42 3625 ,24 ,39 2,99 ,76 ,60 ,49 ,40 ,3426 ,23 ,37 ,98 ,74 ,59 ,47 ,39 ,3227 ,21 ,35 ,96 ,73 ,57 ,46 ,37 ,3128 ,20 ,34 ,95 ,71 ,56 ,45 ,36 ,2929 ,18 ,33 ,93 ,70 ,55 ,43 ,35 ,2830 ,17 ,32 ,92 ,69 ,53 ,42 ,33 ,27
40 4,08 3,23 2,84 2,61 2,45 2,34 2,25 2,1860 ,00 ,15 ,76 ,53 ,37 ,25 ,17 ,10120 3,92 ,07 ,68 ,44 ,29 ,17 ,08 ,01∞ ,84 ,00 ,60 ,37 ,21 ,10 ,01 1,94
90
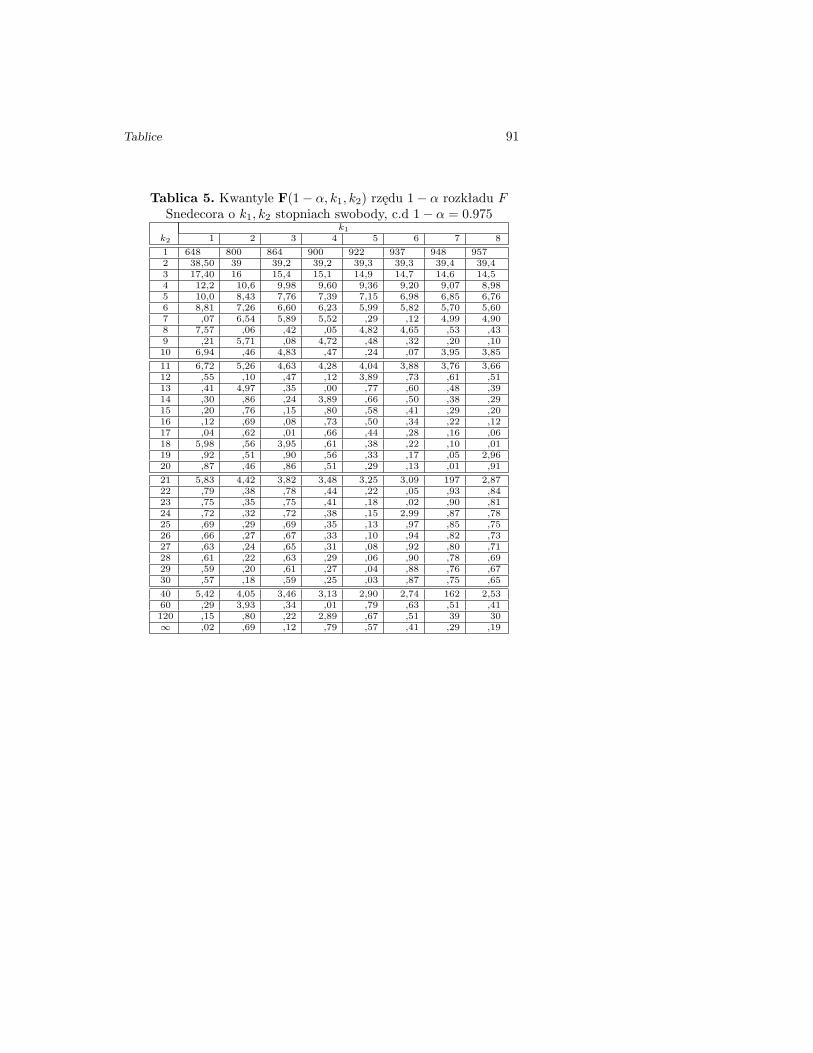
Tablica 5. Kwantyle F(1− α, k1, k2) rzędu 1− α rozkładu FSnedecora o k1, k2 stopniach swobody c.d., 1− α = 0.95
k1k2 10 12 20 40 60 100 ∞1 242 244 248 251 252 253 2542 19,40 19,4 19,4 19,5 19,5 19,5 19,53 8,79 8,74 8,66 8,59 8,57 8,55 8,534 5,96 5,91 5,80 5,72 5,69 5,66 5,635 4,74 4,68 4,56 4,46 4,43 4,41 4,376 ,06 ,00 3,87 3,77 3,74 3,71 3,677 3,64 3,57 ,44 ,34 ,30 ,27 ,238 ,35 ,28 ,15 ,04 ,01 2,97 2,939 ,14 ,07 2,94 2,83 2,79 ,76 ,7110 2,98 2,91 ,77 ,66 ,62 ,59 ,54
11 2,85 2,79 2,65 2,53 2,49 2,46 2,4012 ,75 ,69 ,54 ,43 ,38 ,35 ,3013 ,67 ,60 ,46 ,34 ,30 ,26 ,2114 ,60 ,53 ,39 ,27 ,22 ,19 ,1315 ,54 ,48 ,33 ,20 ,16 ,12 ,0716 ,49 ,42 ,28 ,15 ,11 ,07 ,0117 ,45 ,38 ,23 ,10 ,06 ,02 1,9618 ,41 ,34 ,19 ,06 ,02 1,98 ,9219 ,38 ,31 ,16 ,03 1,98 ,94 ,8820 ,35 ,28 ,12 1,99 ,95 ,91 ,84
21 2,32 2,25 2,10 1,96 1,92 1,88 1,8122 ,30 ,23 ,07 ,94 ,89 ,85 ,7823 ,27 ,20 ,05 ,91 ,86 ,82 ,7624 ,25 ,18 ,03 ,89 ,84 ,80 ,7325 ,24 ,16 ,01 ,87 ,82 ,78 ,7126 ,22 ,15 1,99 ,85 ,80 ,76 ,6927 ,20 ,13 ,97 ,84 ,79 ,74 ,6728 ,19 ,12 ,96 ,82 ,77 ,73 ,6529 ,18 ,10 ,94 ,81 ,75 ,71 ,6430 ,16 ,09 ,93 ,79 ,74 ,70 ,62
40 2,08 2,00 1,84 1,69 1,64 1,59 1,5160 1,99 1,92 ,75 ,59 ,53 ,48 ,39120 ,91 ,83 ,65 ,49 ,42 ,36 ,25∞ ,83 ,75 ,57 ,39 ,32 ,24 ,00
Tablice 91
Tablica 5. Kwantyle F(1− α, k1, k2) rzędu 1− α rozkładu FSnedecora o k1, k2 stopniach swobody, c.d 1− α = 0.975
k1k2 1 2 3 4 5 6 7 8
1 648 800 864 900 922 937 948 9572 38,50 39 39,2 39,2 39,3 39,3 39,4 39,43 17,40 16 15,4 15,1 14,9 14,7 14,6 14,54 12,2 10,6 9,98 9,60 9,36 9,20 9,07 8,985 10,0 8,43 7,76 7,39 7,15 6,98 6,85 6,766 8,81 7,26 6,60 6,23 5,99 5,82 5,70 5,607 ,07 6,54 5,89 5,52 ,29 ,12 4,99 4,908 7,57 ,06 ,42 ,05 4,82 4,65 ,53 ,439 ,21 5,71 ,08 4,72 ,48 ,32 ,20 ,1010 6,94 ,46 4,83 ,47 ,24 ,07 3,95 3,85
11 6,72 5,26 4,63 4,28 4,04 3,88 3,76 3,6612 ,55 ,10 ,47 ,12 3,89 ,73 ,61 ,5113 ,41 4,97 ,35 ,00 ,77 ,60 ,48 ,3914 ,30 ,86 ,24 3,89 ,66 ,50 ,38 ,2915 ,20 ,76 ,15 ,80 ,58 ,41 ,29 ,2016 ,12 ,69 ,08 ,73 ,50 ,34 ,22 ,1217 ,04 ,62 ,01 ,66 ,44 ,28 ,16 ,0618 5,98 ,56 3,95 ,61 ,38 ,22 ,10 ,0119 ,92 ,51 ,90 ,56 ,33 ,17 ,05 2,9620 ,87 ,46 ,86 ,51 ,29 ,13 ,01 ,91
21 5,83 4,42 3,82 3,48 3,25 3,09 197 2,8722 ,79 ,38 ,78 ,44 ,22 ,05 ,93 ,8423 ,75 ,35 ,75 ,41 ,18 ,02 ,90 ,8124 ,72 ,32 ,72 ,38 ,15 2,99 ,87 ,7825 ,69 ,29 ,69 ,35 ,13 ,97 ,85 ,7526 ,66 ,27 ,67 ,33 ,10 ,94 ,82 ,7327 ,63 ,24 ,65 ,31 ,08 ,92 ,80 ,7128 ,61 ,22 ,63 ,29 ,06 ,90 ,78 ,6929 ,59 ,20 ,61 ,27 ,04 ,88 ,76 ,6730 ,57 ,18 ,59 ,25 ,03 ,87 ,75 ,65
40 5,42 4,05 3,46 3,13 2,90 2,74 162 2,5360 ,29 3,93 ,34 ,01 ,79 ,63 ,51 ,41120 ,15 ,80 ,22 2,89 ,67 ,51 39 30∞ ,02 ,69 ,12 ,79 ,57 ,41 ,29 ,19

92
Tablica 5. Kwantyle F(1− α, k1, k2) rzędu 1− α rozkładu FSnedecora o k1, k2 stopniach swobody c.d., 1− α = 0.975
k1k2 10 12 20 40 60 100 ∞1 969 977 993 1006 1010 1013 10182 39,4 39,4 39,4 39,5 39,5 39,5 39,53 14,4 14,3 14,2 14,0 14,0 14,0 13,94 8,84 8,75 8,56 8,41 8,36 8,32 8,265 6,62 6,52 6,33 6,18 6,12 6,08 6,026 5,46 5,37 5,17 5,01 4,92 4,92 4,857 4,76 4,67 4,47 4,31 ,25 ,21 ,148 ,30 ,20 ,00 3,84 3,78 3,74 3,679 3,96 3,87 3,67 ,51 ,45 ,40 ,3310 ,72 ,62 ,42 ,26 ,20 ,15 ,08
11 3,53 3,43 3,23 3,06 3,00 2,96 2,8812 ,37 ,28 ,07 2,91 2,85 ,80 ,7213 ,25 ,15 2,95 ,78 ,72 ,67 ,6014 ,15 ,05 ,84 ,67 ,61 ,56 ,4915 ,06 2,96 ,76 ,58 ,52 ,47 ,4016 2,99 ,89 ,68 ,51 ,45 ,40 ,3217 ,92 ,82 ,62 ,44 ,38 ,33 ,2518 ,87 ,77 ,56 ,38 ,32 ,27 ,1919 ,82 ,72 ,51 ,33 ,27 22 ,1320 ,77 ,68 ,46 ,29 ,22 ,17 ,09
21 2,73 2,64 2,42 2,25 2,18 2,13 2,0422 ,70 ,60 ,39 ,21 ,14 ,09 ,0023 ,67 ,57 ,36 ,18 ,11 ,06 1,9724 ,64 ,54 ,33 ,15 ,08 ,02 ,9425 ,61 ,51 ,30 ,12 ,05 ,00 ,9126 ,59 ,49 ,28 ,09 ,03 1,97 ,8827 ,57 ,47 ,25 ,07 ,00 ,94 ,8528 ,55 ,45 ,23 ,05 1,98 ,92 ,8329 ,53 ,43 ,21 ,03 ,96 ,90 ,8130 ,51 ,41 ,20 ,01 ,94 ,88 ,79
40 2,39 2,29 2,07 1,88 1,80 1,74 1,6460 ,27 ,17 1,94 ,74 ,67 ,60 ,48120 ,15 ,05 ,82 ,61 ,52 ,45 ,31∞ ,05 1,94 ,71 ,48 ,39 ,30 ,00
Tablice 93
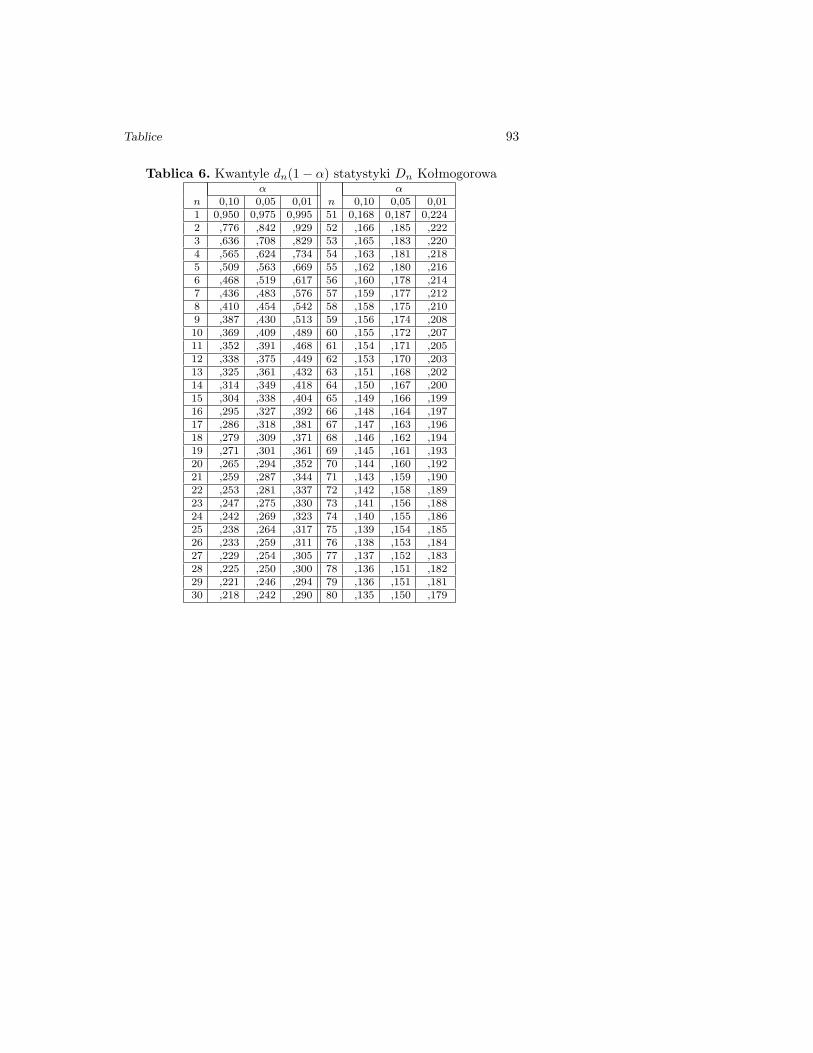
Tablica 6. Kwantyle dn(1− α) statystyki Dn Kołmogorowaα α
n 0,10 0,05 0,01 n 0,10 0,05 0,011 0,950 0,975 0,995 51 0,168 0,187 0,2242 ,776 ,842 ,929 52 ,166 ,185 ,2223 ,636 ,708 ,829 53 ,165 ,183 ,2204 ,565 ,624 ,734 54 ,163 ,181 ,2185 ,509 ,563 ,669 55 ,162 ,180 ,2166 ,468 ,519 ,617 56 ,160 ,178 ,2147 ,436 ,483 ,576 57 ,159 ,177 ,2128 ,410 ,454 ,542 58 ,158 ,175 ,2109 ,387 ,430 ,513 59 ,156 ,174 ,20810 ,369 ,409 ,489 60 ,155 ,172 ,20711 ,352 ,391 ,468 61 ,154 ,171 ,20512 ,338 ,375 ,449 62 ,153 ,170 ,20313 ,325 ,361 ,432 63 ,151 ,168 ,20214 ,314 ,349 ,418 64 ,150 ,167 ,20015 ,304 ,338 ,404 65 ,149 ,166 ,19916 ,295 ,327 ,392 66 ,148 ,164 ,19717 ,286 ,318 ,381 67 ,147 ,163 ,19618 ,279 ,309 ,371 68 ,146 ,162 ,19419 ,271 ,301 ,361 69 ,145 ,161 ,19320 ,265 ,294 ,352 70 ,144 ,160 ,19221 ,259 ,287 ,344 71 ,143 ,159 ,19022 ,253 ,281 ,337 72 ,142 ,158 ,18923 ,247 ,275 ,330 73 ,141 ,156 ,18824 ,242 ,269 ,323 74 ,140 ,155 ,18625 ,238 ,264 ,317 75 ,139 ,154 ,18526 ,233 ,259 ,311 76 ,138 ,153 ,18427 ,229 ,254 ,305 77 ,137 ,152 ,18328 ,225 ,250 ,300 78 ,136 ,151 ,18229 ,221 ,246 ,294 79 ,136 ,151 ,18130 ,218 ,242 ,290 80 ,135 ,150 ,179

94
Tablica 6. Kwantyle dn(1− α) statystyki Dn Kołmogorowa c.d.α α
n 0,10 0,05 0,01 n 0,10 0,05 0,0131 ,214 ,238 ,285 81 ,134 ,149 ,17832 ,211 ,234 ,281 82 ,133 ,148 ,17733 ,208 ,231 ,277 83 ,132 ,147 ,17634 ,205 ,227 ,273 84 ,131 ,146 ,17535 ,202 ,224 ,269 85 ,131 ,145 ,17436 ,199 ,221 ,265 86 ,130 ,144 ,17337 ,196 ,218 ,262 87 ,129 ,144 ,17238 ,194 ,215 ,258 88 ,128 ,143 ,17139 ,191 ,213 ,255 89 ,128 ,142 ,17040 ,189 ,210 ,252 90 ,127 ,141 ,16941 ,187 ,208 ,249 91 ,126 ,140 ,16842 ,185 ,205 ,246 92 ,126 ,140 ,16843 ,183 ,203 ,243 93 ,125 ,139 ,16744 ,181 ,201 ,241 94 ,124 ,138 ,16645 ,179 ,198 ,238 95 ,124 ,137 ,16546 ,177 ,196 ,235 96 ,123 ,137 ,16447 ,175 ,194 ,233 97 ,122 ,136 ,16348 ,173 ,192 ,231 98 ,122 ,135 ,16249 ,171 ,190 ,228 99 ,121 ,135 ,16250 ,170 ,188 ,226 100 ,121 ,134 ,161

Tablice 95
Tablica 8. Wartości krytyczne k(α, n1n2) rozkładu liczby serii;k(α, n1, n2) = k(α, n1, n2)
α = 0, 05→n15 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 n2 ↓3 3 3 3 4 4 4 4 4 5 5 5 5 5 5 5 5
↓ n2 3 4 4 4 5 5 5 5 5 6 6 6 6 6 6 65 2 4 4 5 5 5 6 6 6 6 6 7 7 7 7 76 2 2 5 5 6 6 6 6 7 7 7 7 8 8 8 87 2 3 3 6 6 6 7 7 7 8 8 8 8 8 9 98 2 3 3 4 6 7 7 8 8 8 8 9 9 9 9 109 3 3 4 4 4 7 8 8 8 9 9 9 10 10 10 1110 3 3 4 4 5 5 8 9 9 9 10 10 10 10 10 1211 3 4 4 5 5 5 6 9 9 10 10 10 11 11 11 1312 3 4 4 5 5 6 6 7 10 10 11 11 11 12 12 1413 3 4 5 5 6 6 6 7 7 11 11 11 12 12 12 1514 3 4 5 5 6 6 7 7 8 8 11 12 12 13 13 1615 4 4 5 5 6 7 7 8 8 8 9 12 13 13 13 1716 4 4 5 6 6 7 7 8 8 9 9 10 13 14 14 1817 4 5 5 6 7 7 8 8 9 9 10 10 10 14 14 1918 4 5 5 6 7 7 8 8 9 9 10 11 11 11 15 2019 4 5 6 6 7 8 8 9 9 10 10 11 11 12 1220 4 5 6 6 7 8 8 9 10 10 11 11 11 12 12 13→n15 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
α = 0.01
Related Documents











