YARN by default (Spark on YARN) Ferran Galí i Reniu @ferrangali

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

YARN by default(Spark on YARN)
Ferran Galí i Reniu@ferrangali

About me
@ferrangali

100 MB/s
2 TB = 3.5 hours
The Big Data problem
100 MB/s
2 TB = 30 min
The Big Data problem

Source: Google data centers



HDFS
Node Node Node Node Node Node Node NodeHardware

HDFS
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage

HDFS
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage

$> hadoop fs -ls
HDFS
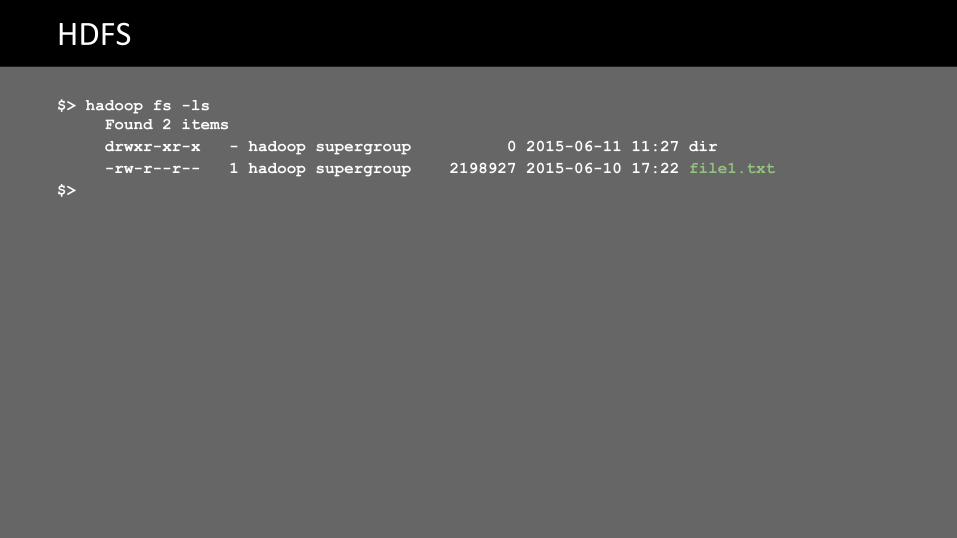
$> hadoop fs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-06-11 11:27 dir-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 file1.txt
$>
HDFS
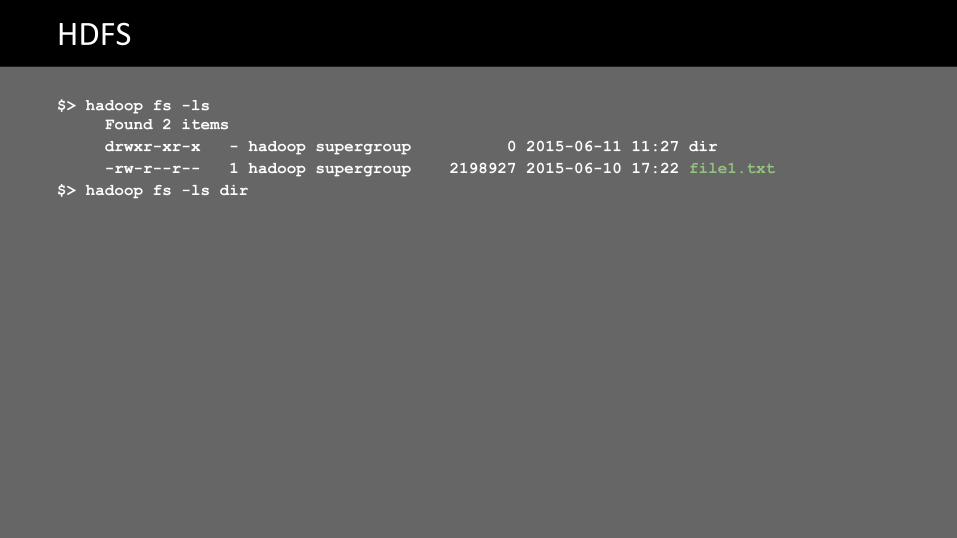
$> hadoop fs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-06-11 11:27 dir-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 file1.txt
$> hadoop fs -ls dir
HDFS
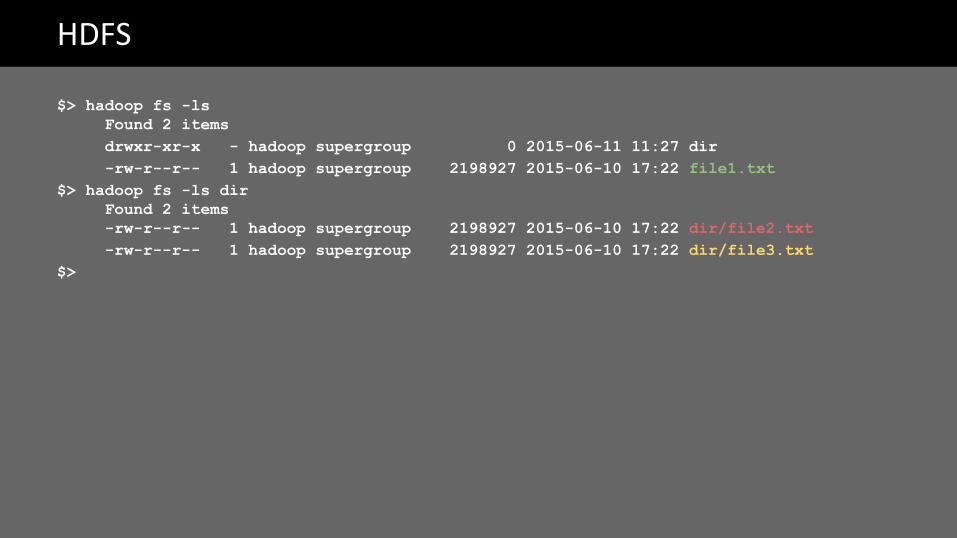
$> hadoop fs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-06-11 11:27 dir-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 file1.txt
$> hadoop fs -ls dirFound 2 items-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file2.txt-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file3.txt
$>
HDFS
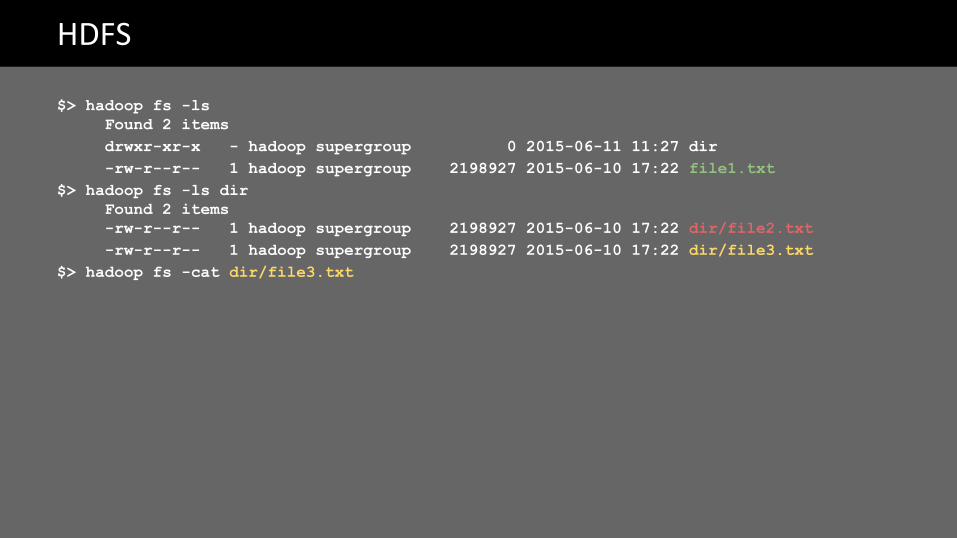
$> hadoop fs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-06-11 11:27 dir-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 file1.txt
$> hadoop fs -ls dirFound 2 items-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file2.txt-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file3.txt
$> hadoop fs -cat dir/file3.txt
HDFS
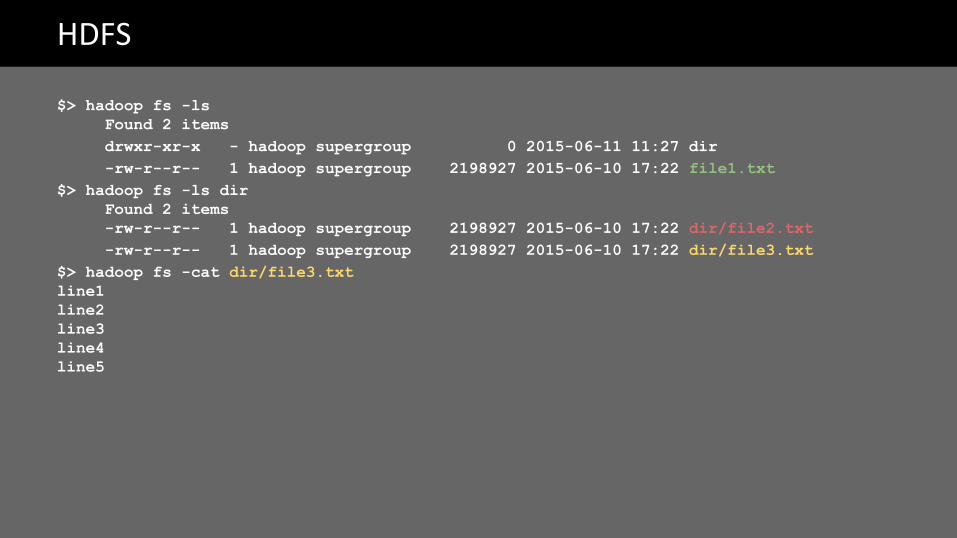
$> hadoop fs -lsFound 2 itemsdrwxr-xr-x - hadoop supergroup 0 2015-06-11 11:27 dir-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 file1.txt
$> hadoop fs -ls dirFound 2 items-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file2.txt-rw-r--r-- 1 hadoop supergroup 2198927 2015-06-10 17:22 dir/file3.txt
$> hadoop fs -cat dir/file3.txtline1line2line3line4line5
HDFS

MapReduce
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage

MapReduce
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing Job
The Big Data problemData Pipeline
Application
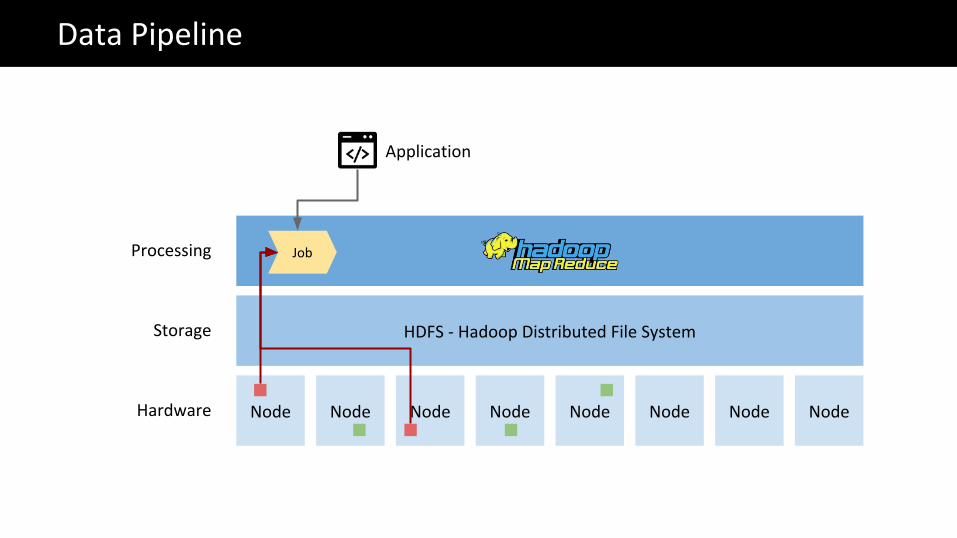
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing Job
The Big Data problemData Pipeline
Application
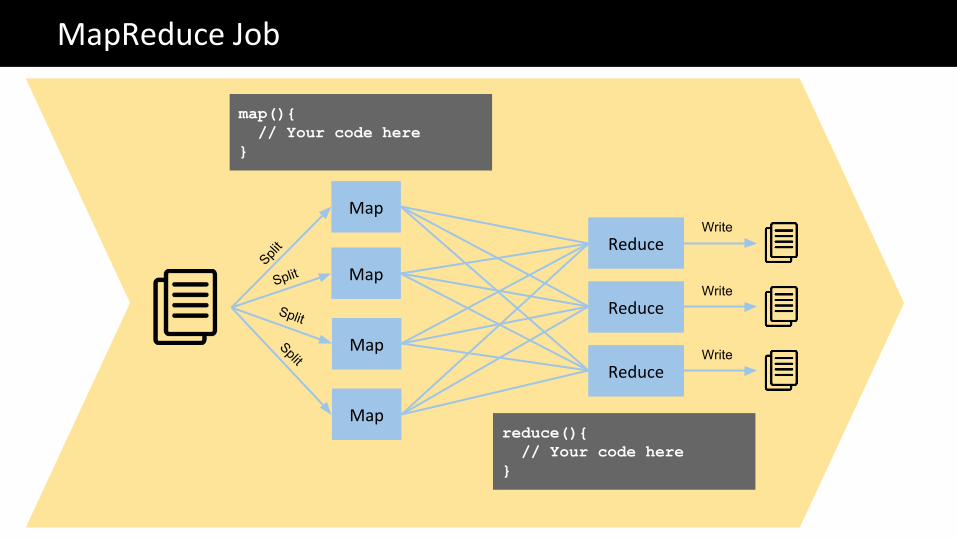
Map
Map
Map
Map
Reduce
Reduce
Reduce
MapReduce Job
Split
Write
Write
Write
Split
Split
Split
map(){ // Your code here}
reduce(){ // Your code here}

Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing Job
The Big Data problemData Pipeline
Application
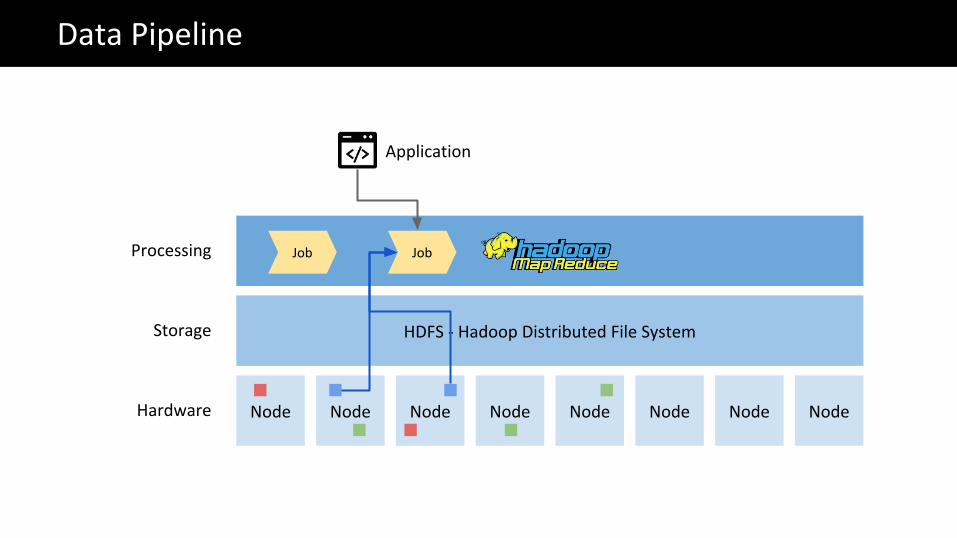
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing Job Job
The Big Data problemData Pipeline
Application
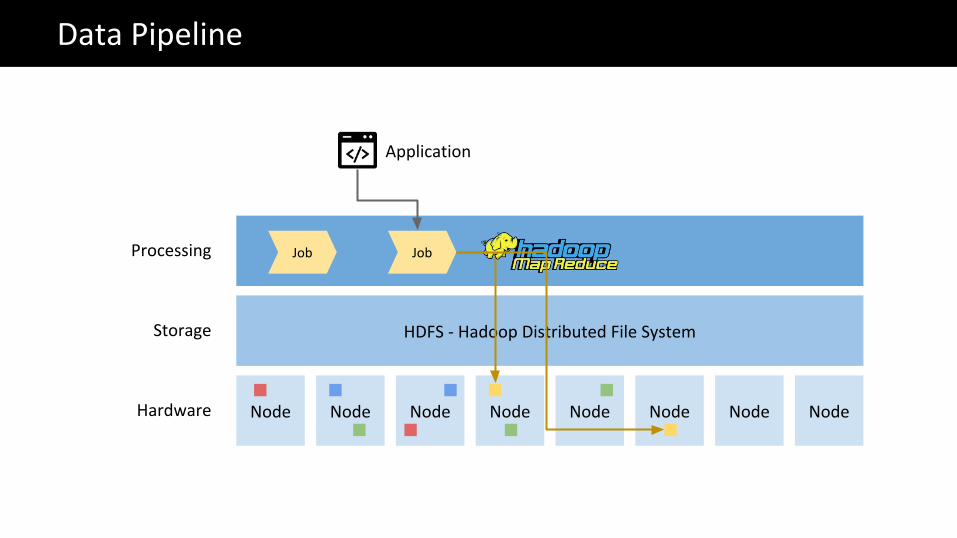
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
Hardware
Storage
Processing Job Job
The Big Data problemData Pipeline
Application
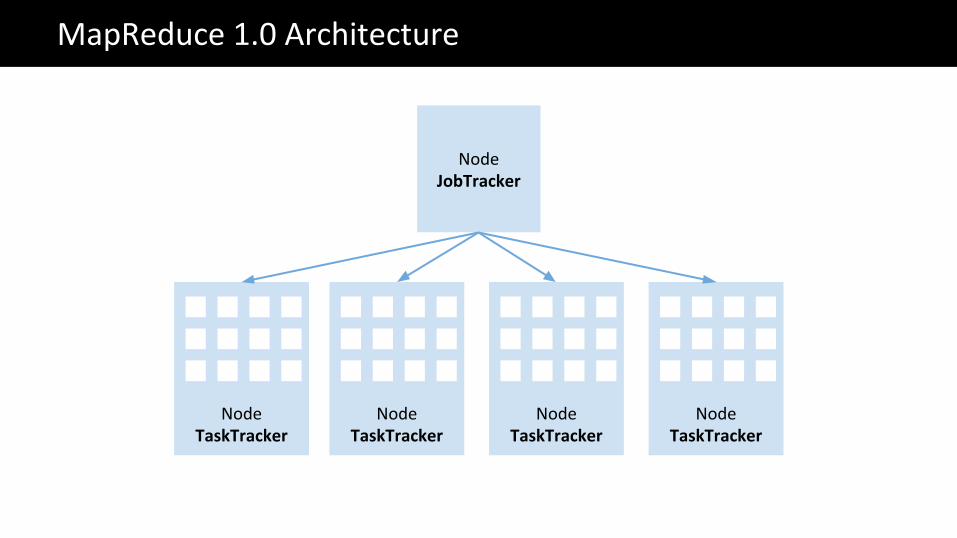
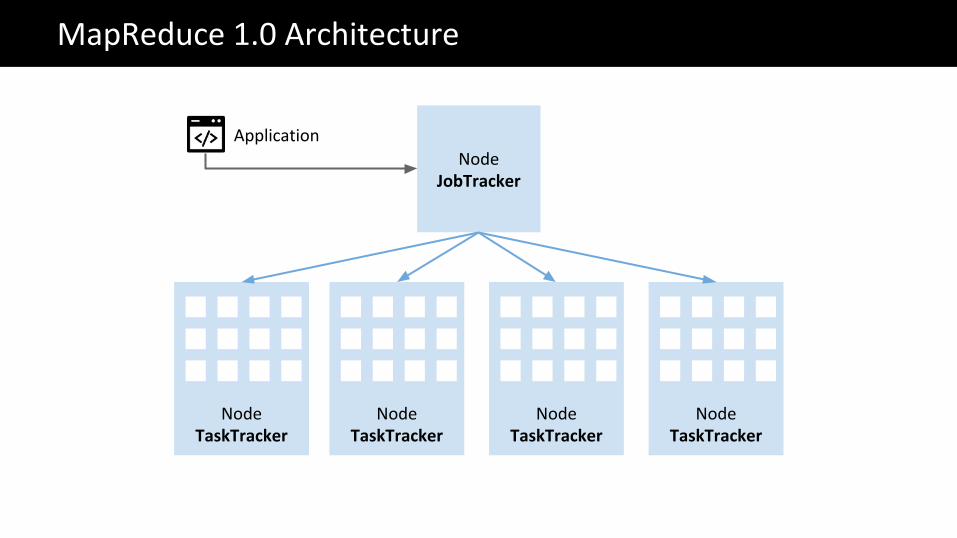
NodeJobTracker
NodeTaskTracker
MapReduce 1.0 Architecture
NodeTaskTracker
NodeTaskTracker
NodeTaskTracker

MapReduce 1.0 Architecture
NodeTaskTracker
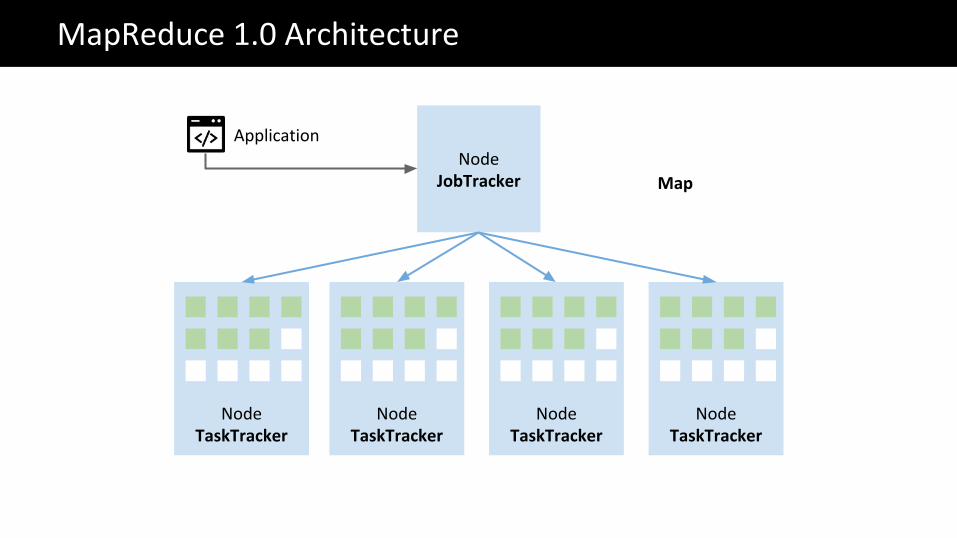
Map Map Map Map
Map Map Map Reduce
Reduce Reduce Reduce Reduce
NodeJobTracker
NodeTaskTracker
MapReduce 1.0 Architecture
NodeTaskTracker
NodeTaskTracker
NodeTaskTracker
Application
NodeJobTracker
NodeTaskTracker
MapReduce 1.0 Architecture
NodeTaskTracker
NodeTaskTracker
NodeTaskTracker
Application
Map
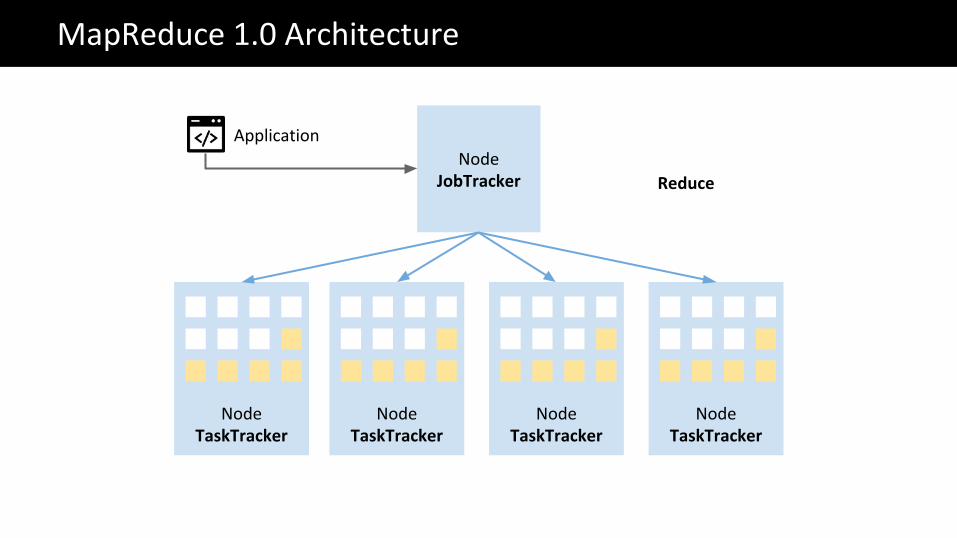
NodeJobTracker
NodeTaskTracker
MapReduce 1.0 Architecture
NodeTaskTracker
NodeTaskTracker
NodeTaskTracker
Application
Reduce

Limitations
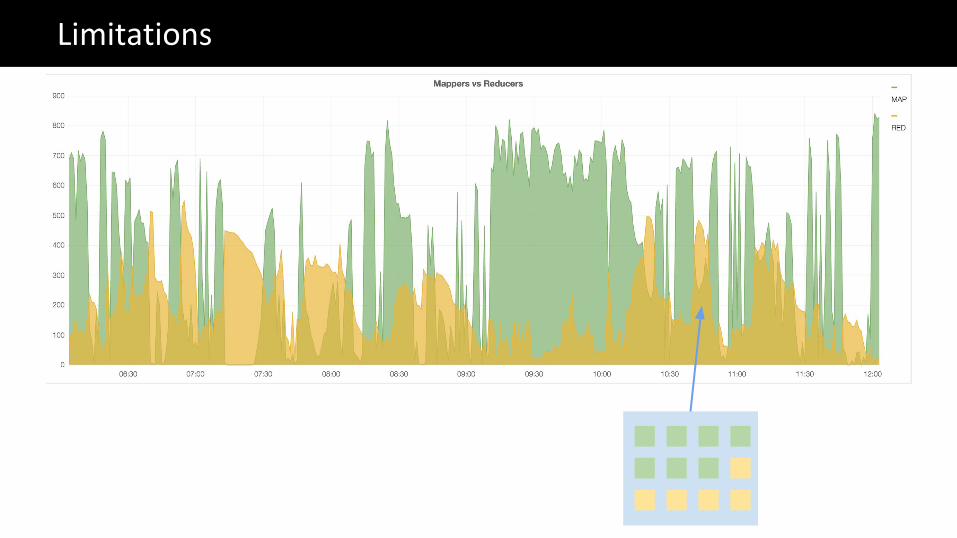
Limitations
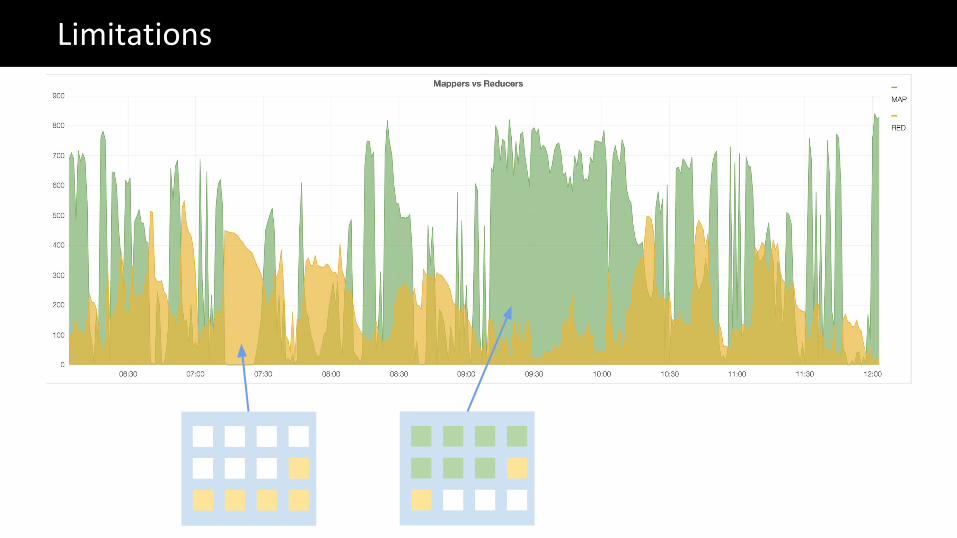
Limitations

YARN

Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemYARN - Yet Another Resource Negotiator
Processing

Cores

Memory
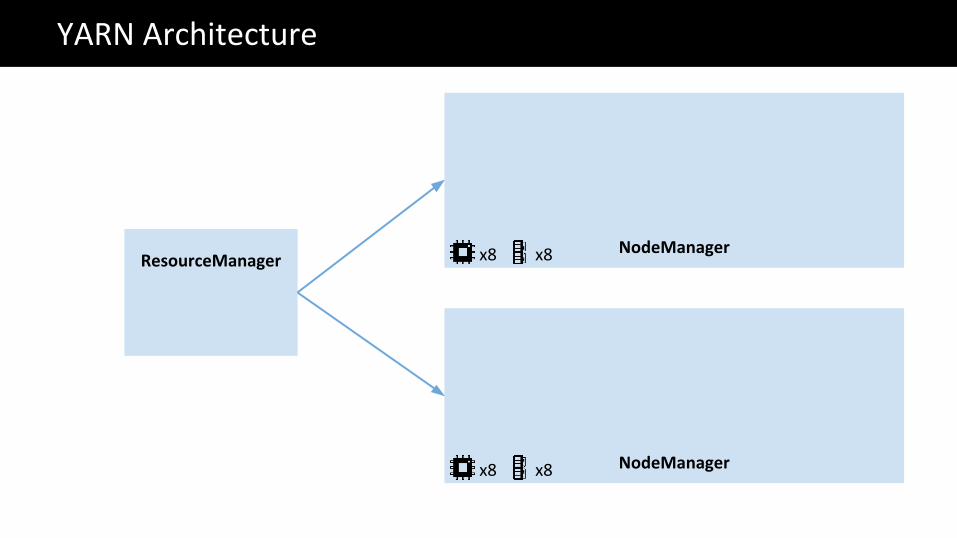
NodeManagerResourceManager
YARN Architecture
NodeManager
x8 x8
x8 x8

NodeManagerResourceManager
YARN Architecture
NodeManager
Applicationx61 core1024MB
x8 x8
x8 x8
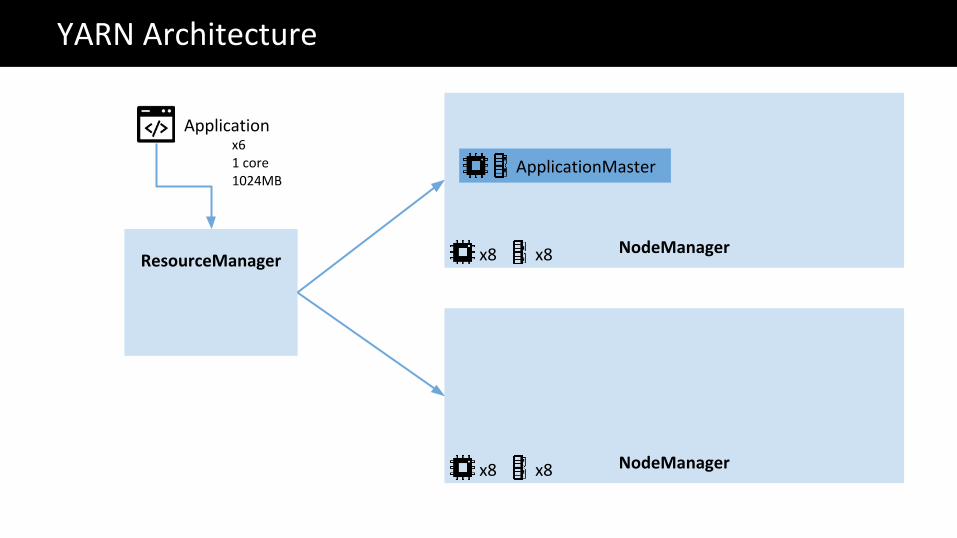
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
NodeManager
Applicationx61 core1024MB
x8 x8
x8 x8
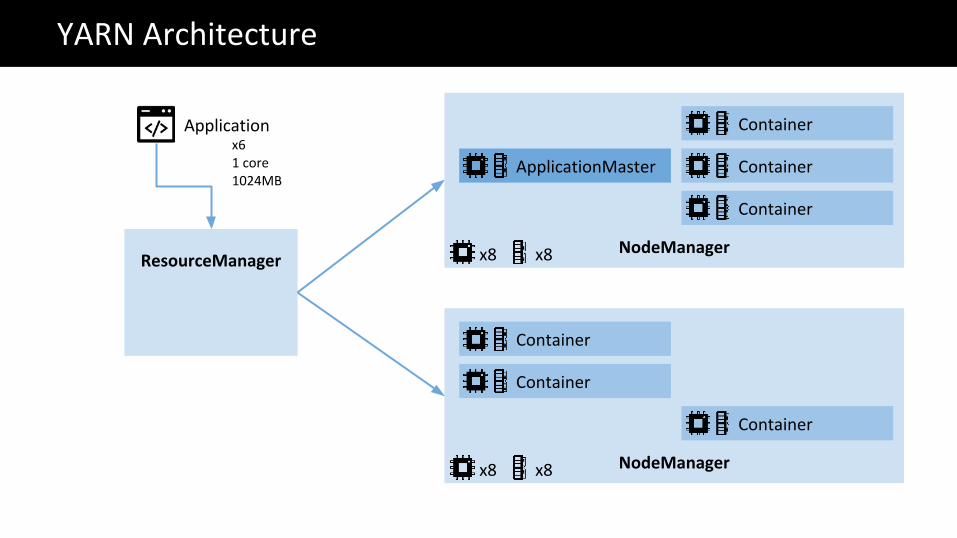
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
Container
Container
Container
NodeManager
Container
Container
Applicationx61 core1024MB
Container
x8 x8
x8 x8
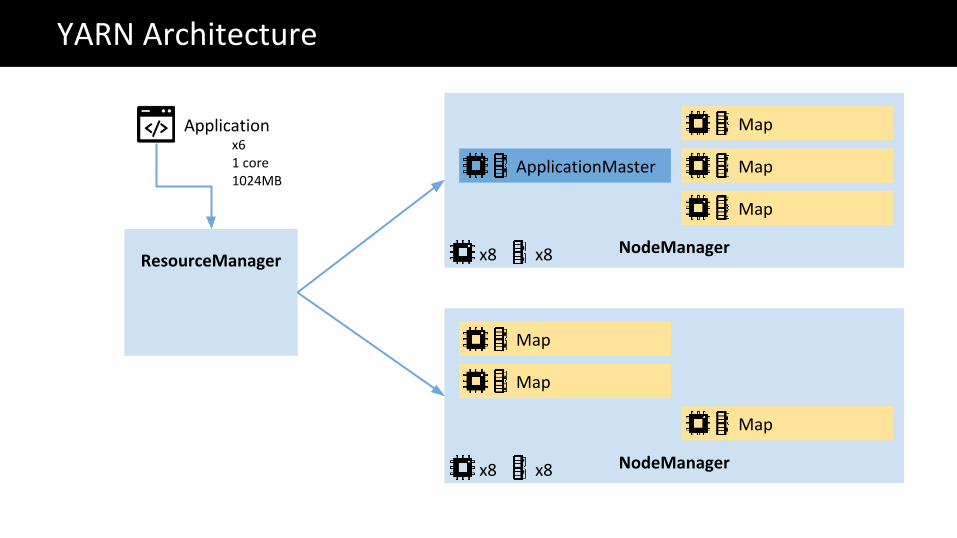
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
Map
Map
Map
NodeManager
Map
Map
Applicationx61 core1024MB
Map
x8 x8
x8 x8
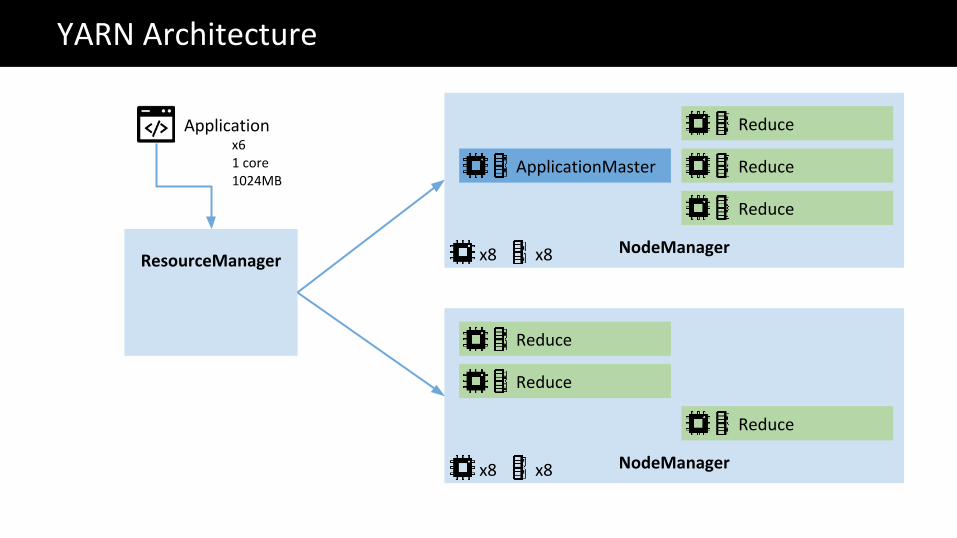
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
Reduce
Reduce
Reduce
NodeManager
Reduce
Reduce
Applicationx61 core1024MB
Reduce
x8 x8
x8 x8
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
Container
Container
Container
NodeManager
Container
Container
Container
Applicationx61 core1024MB
Application 2x42 cores2048MB
x8 x8
x8 x8
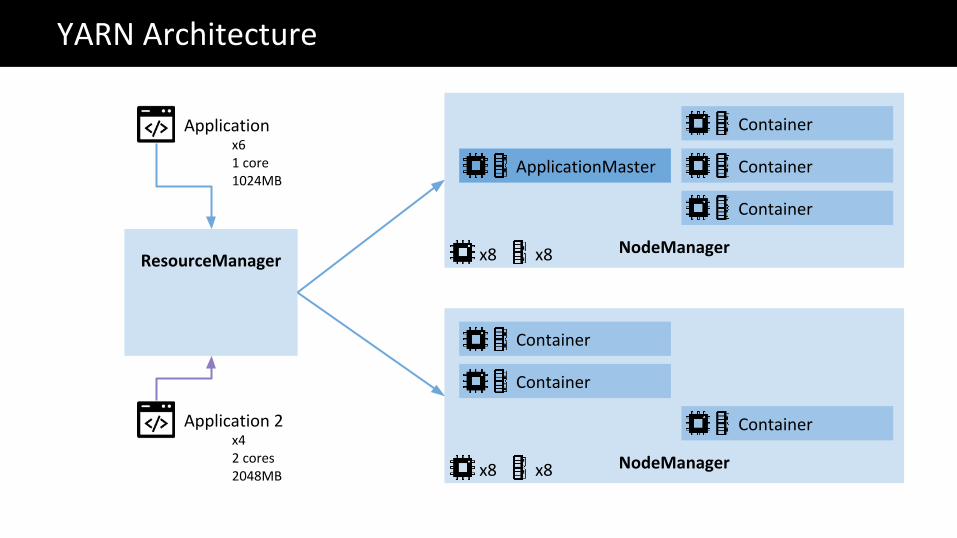
NodeManagerResourceManager
YARN Architecture
ApplicationMaster
Container
Container
Container
NodeManager
Container
Container
ApplicationMaster
Container
Applicationx61 core1024MB
Application 2x42 cores2048MB
x8 x8
x8 x8

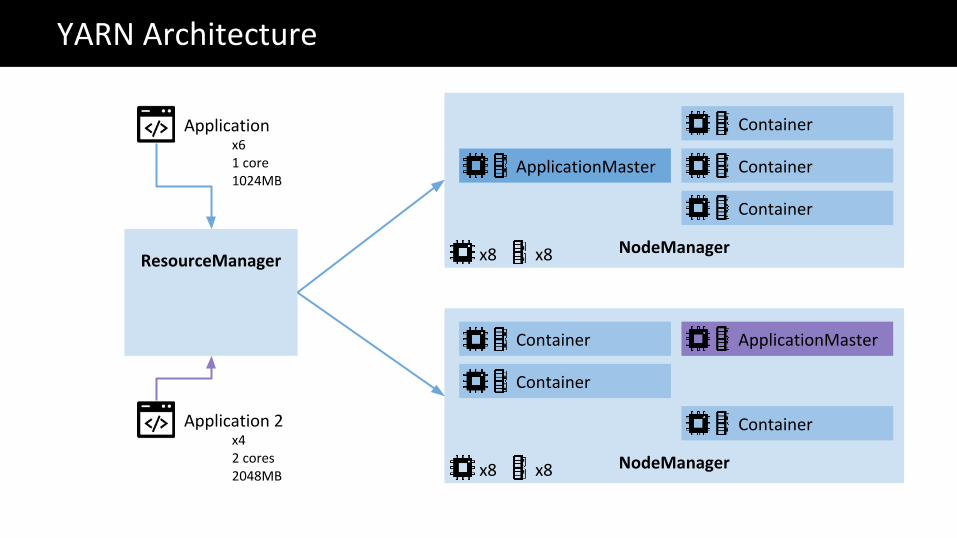
NodeManager
Container
ResourceManager
YARN Architecture
Container
ApplicationMaster
Container
Container
Container
NodeManager
Container
Container
Container
ApplicationMaster
Container
Container
Applicationx61 core1024MB
Application 2x42 cores2048MB
x8 x8
x8 x8
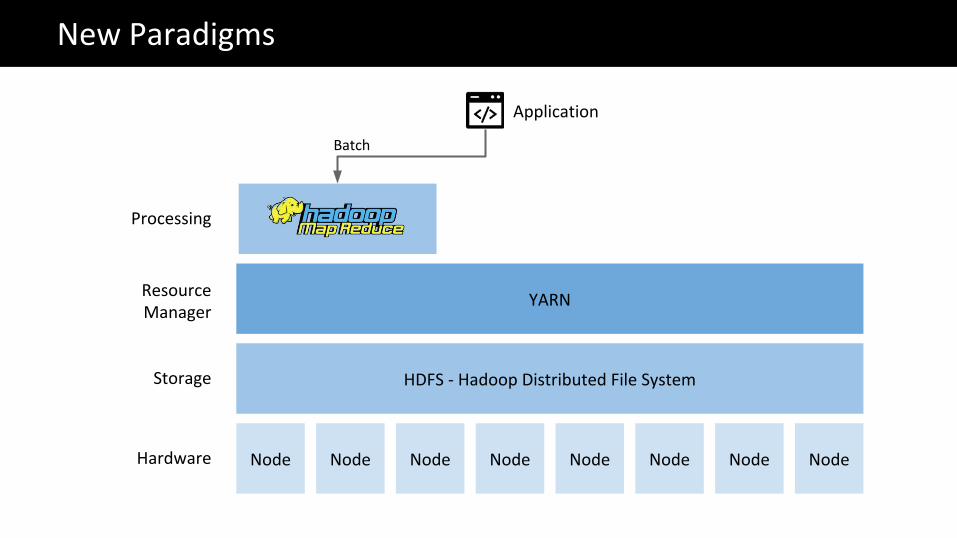
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemNew Paradigms
Processing
Application
Batch
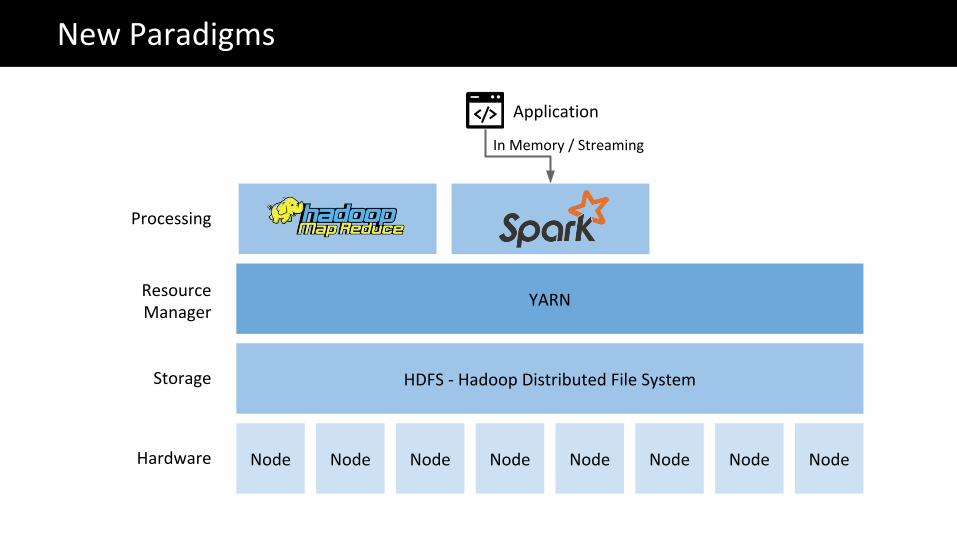
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemNew Paradigms
Processing
Application
In Memory / Streaming
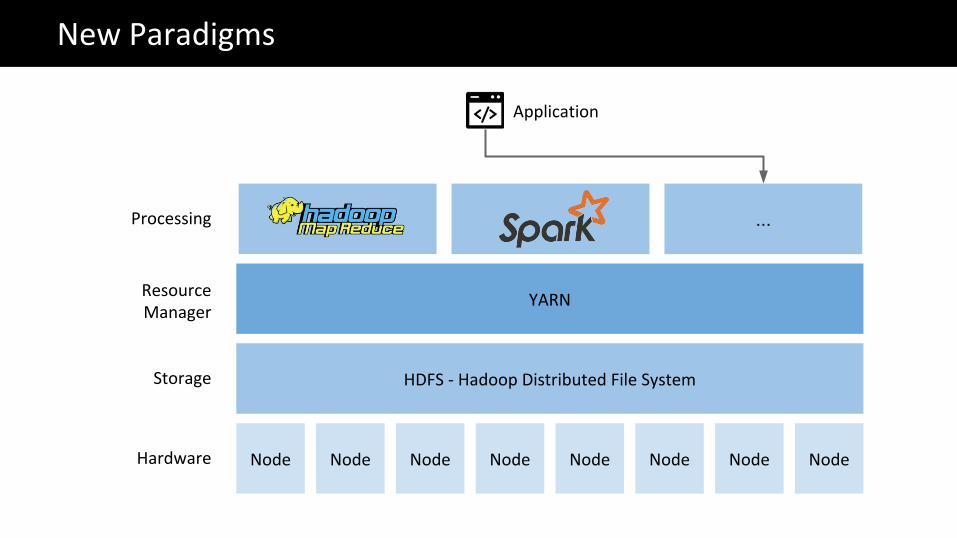
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemNew Paradigms
Processing ...
Application

Improved Data Pipelines
Map
Reduce
Map
Map
Reduce
Map
Map
Reduce
Map
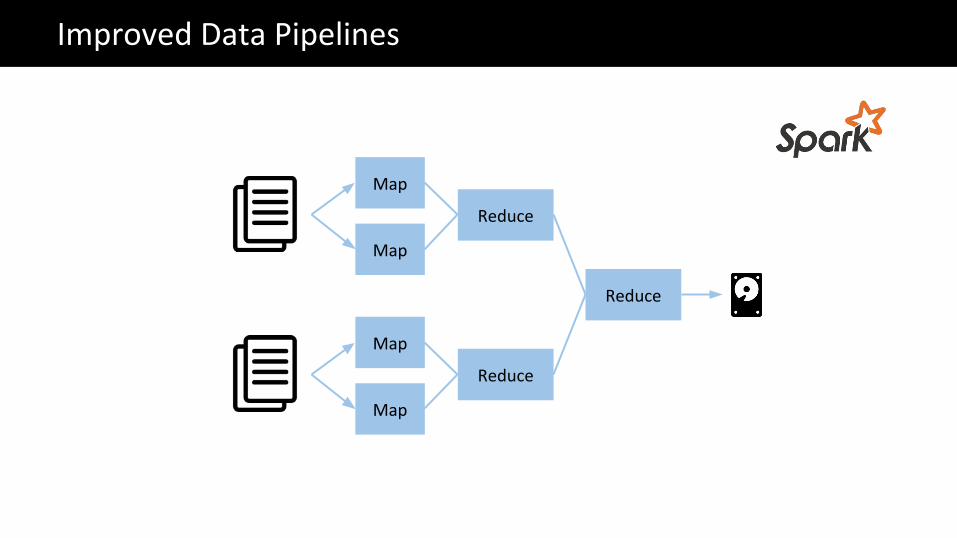
Improved Data Pipelines
Map
Reduce
Map
Map
Reduce
Map
Reduce

Demo


The Big Data problemSpark Job
def main(args: Array[ String]): Unit = { val sparkConf = new SparkConf() val sc = new SparkContext(sparkConf)
sc.rdd(...).action() sc.stop()}

RDDs
The Big Data problemSpark Job
Main
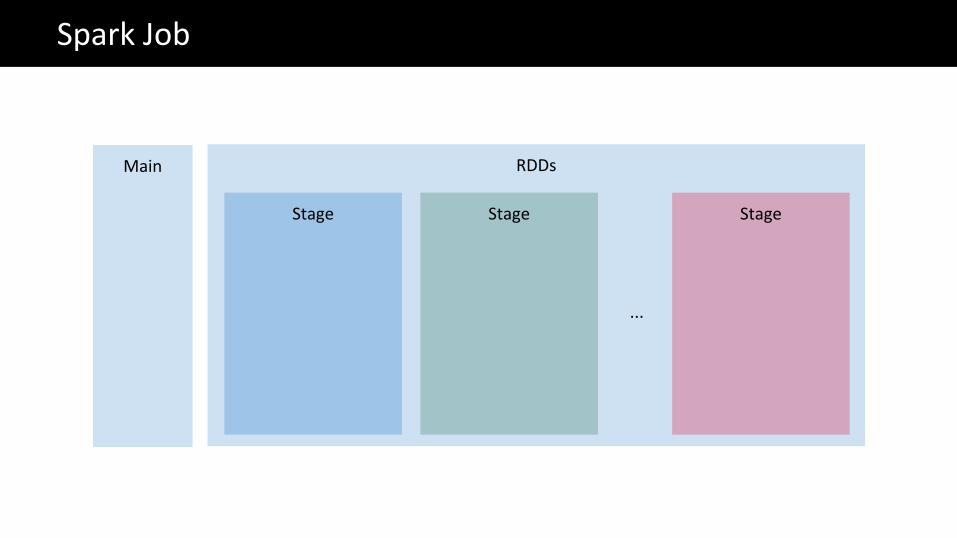
RDDs
Stage Stage Stage
...
The Big Data problemSpark Job
Main
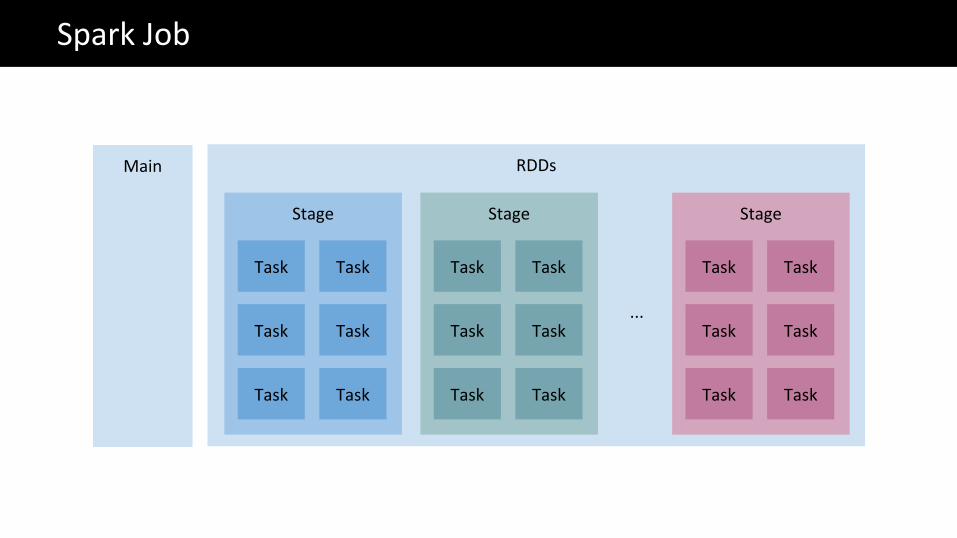
RDDs
Stage
Task Task
Task Task
Stage Stage
Task
Task
...
The Big Data problemSpark Job
Task
Main
Task Task Task
Task
Task
Task Task
Task Task
Task Task
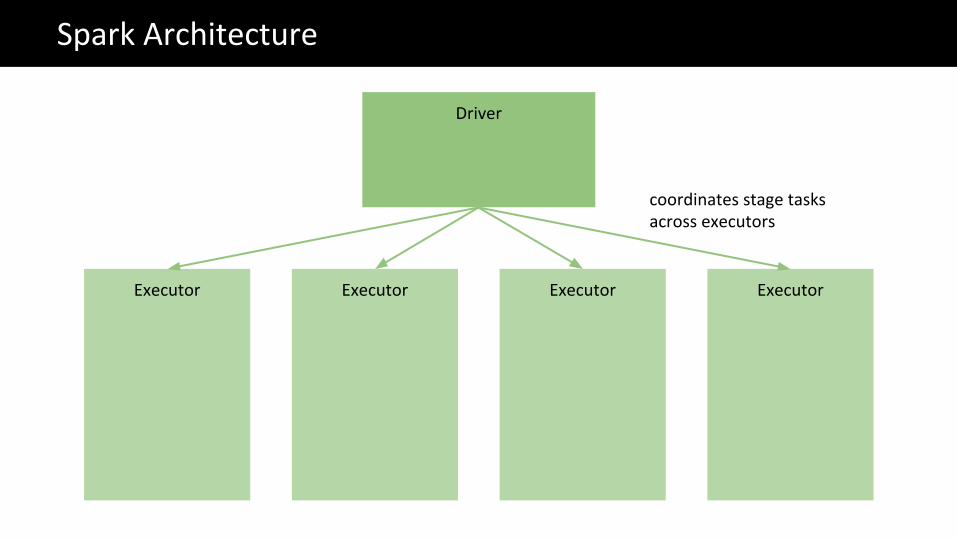
The Big Data problemSpark Architecture
Executor
Driver
Executor Executor Executor
coordinates stage tasks across executors
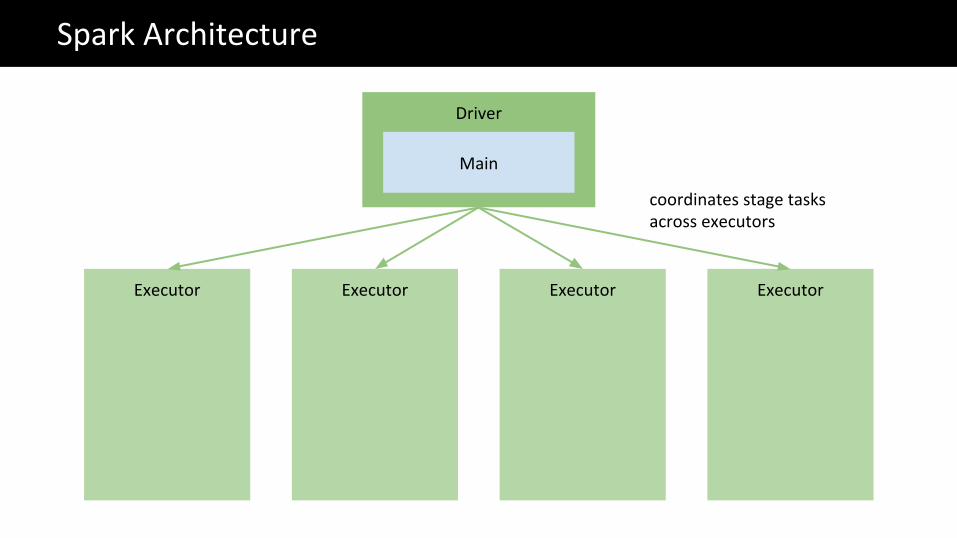
The Big Data problemSpark Architecture
Executor
Driver
Executor Executor Executor
Main
coordinates stage tasks across executors
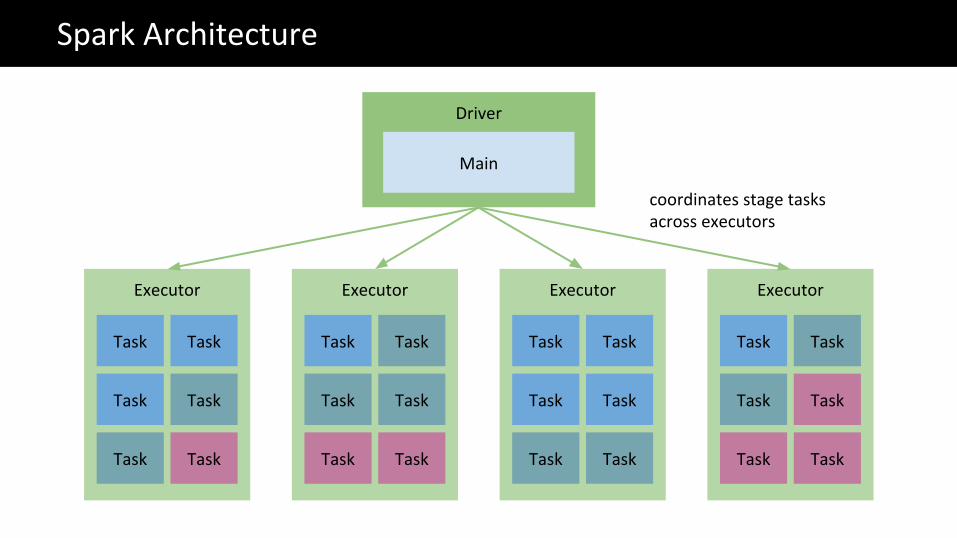
The Big Data problemSpark Architecture
Executor
Driver
Executor Executor Executor
Main
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
Task Task
coordinates stage tasks across executors

Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemSpark on YARN
Processing

The Big Data problemConfiguration
export HADOOP_CONF_DIR="/opt/hadoop/hadoop_install/conf"core-site.xmlhdfs-site.xmlyarn-site.xml

The Big Data problemConfiguration
spark.yarn.jar hdfs:///user/hadoop/libs/spark-assembly.jar# need to upload the file to HDFS
spark.eventLog.enabled truespark.eventLog.dir hdfs:///app-logs/spark/logsspark.yarn.historyServer.address historyserver_host:18080
# needed if you want to analyse finished jobs
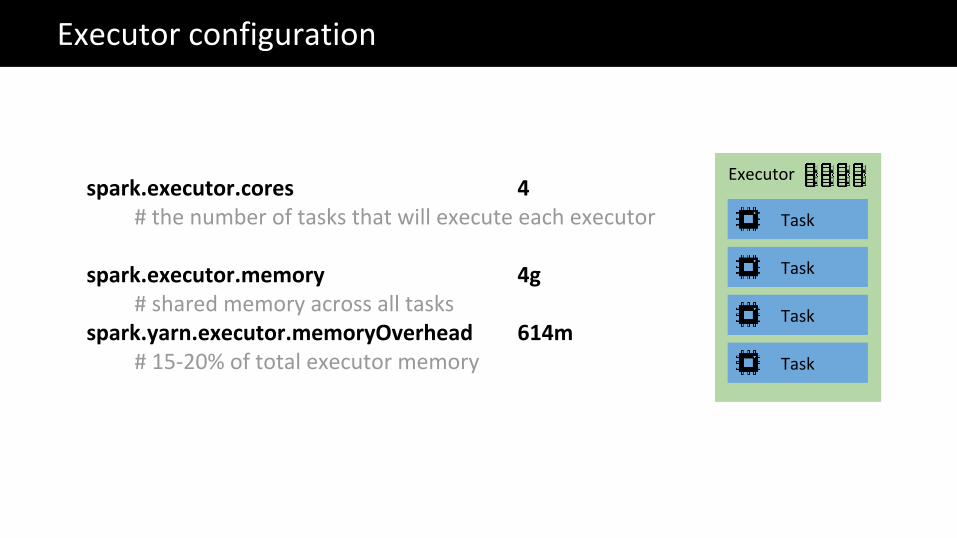
The Big Data problemExecutor configuration
spark.executor.cores 4# the number of tasks that will execute each executor
spark.executor.memory 4g# shared memory across all tasks
spark.yarn.executor.memoryOverhead 614m# 15-20% of total executor memory
Executor
Task
Task
Task
Task

The Big Data problemDeployment
$ ./spark-submit--class my.main.class--master {deploy-mode}my-jar.jararg1 arg2 arg3 ...
yarn-client
yarn-cluster
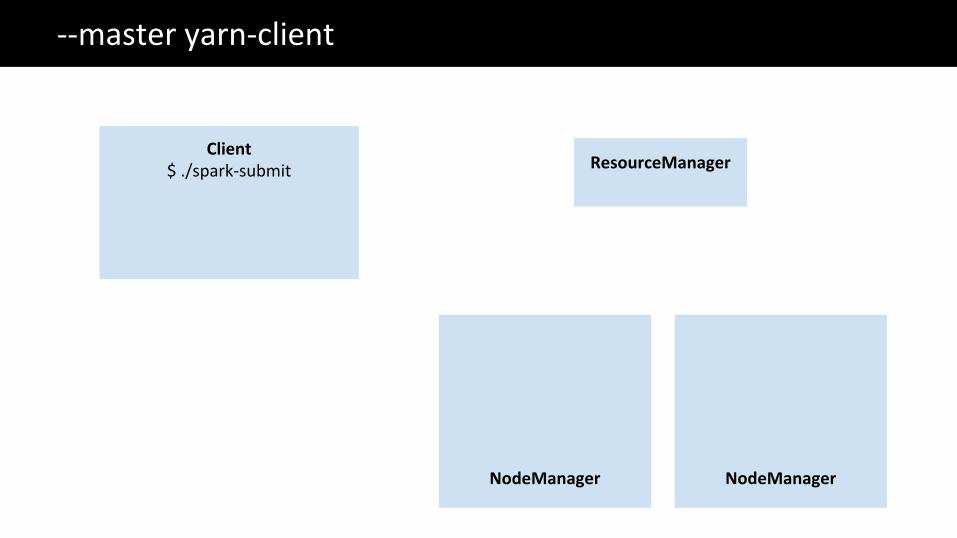
The Big Data problem--master yarn-client
ResourceManager
NodeManager
Client$ ./spark-submit
NodeManager

The Big Data problem--master yarn-client
ResourceManager
NodeManager
Client$ ./spark-submit
Driver
NodeManager
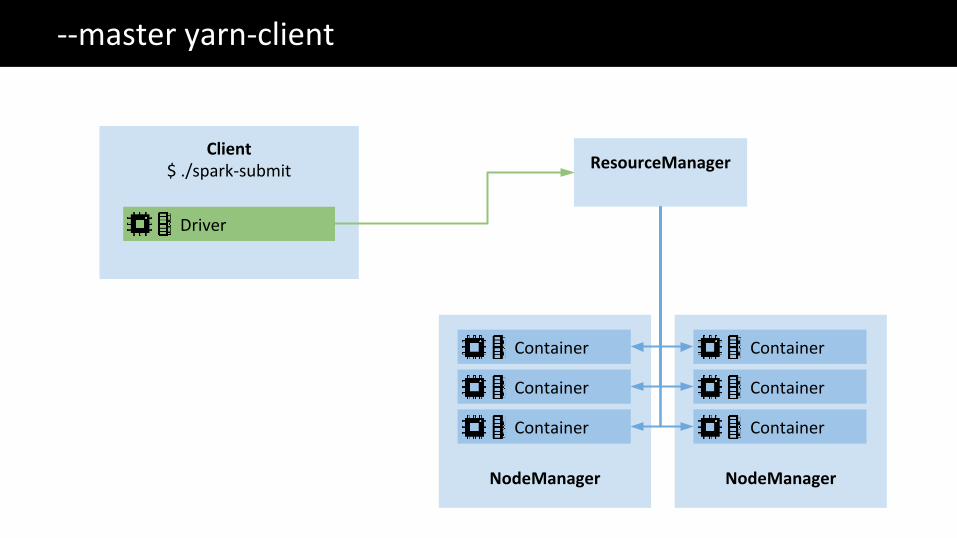
The Big Data problem--master yarn-client
ResourceManager
NodeManager
Client$ ./spark-submit
Container
Container
Container
Driver
NodeManager
Container
Container
Container
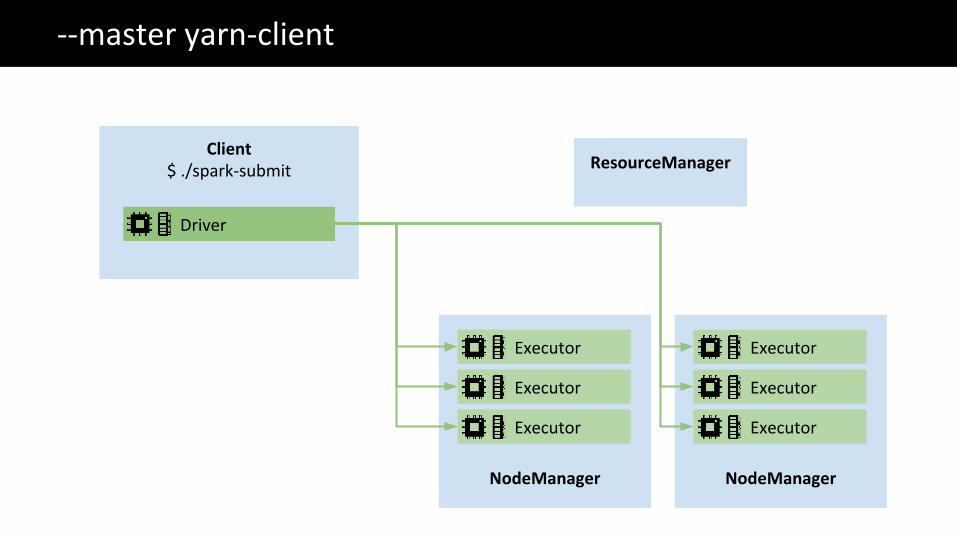
The Big Data problem--master yarn-client
ResourceManager
NodeManager
Client$ ./spark-submit
Executor
Executor
Executor
Driver
NodeManager
Executor
Executor
Executor

Demo

The Big Data problem--master yarn-cluster
ResourceManager
NodeManager
Client$ ./spark-submit
NodeManager
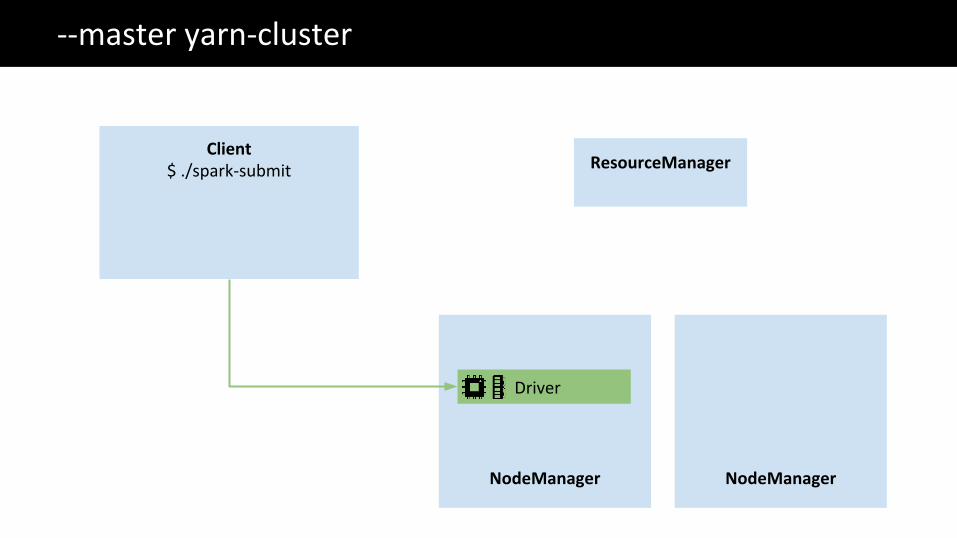
The Big Data problem--master yarn-cluster
ResourceManager
NodeManager
Client$ ./spark-submit
Driver
NodeManager
NodeManager
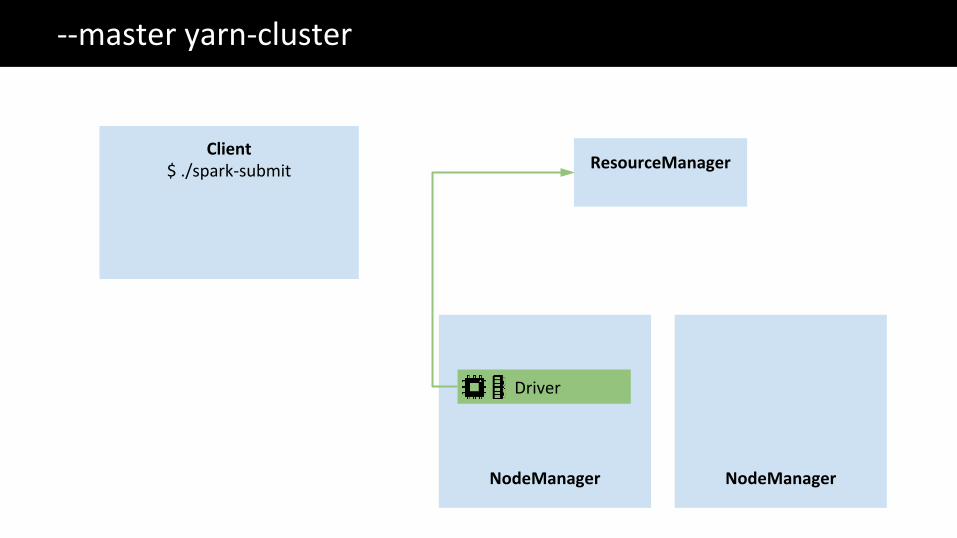
The Big Data problem--master yarn-cluster
ResourceManagerClient
$ ./spark-submit
Driver
NodeManager
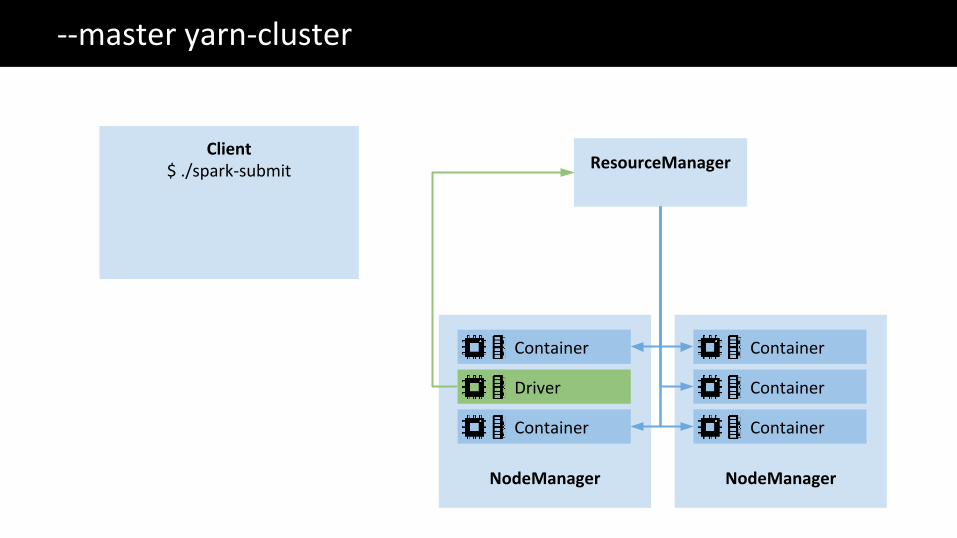
The Big Data problem--master yarn-cluster
ResourceManager
NodeManager
Client$ ./spark-submit
Container
Driver
Container
NodeManager
Container
Container
Container
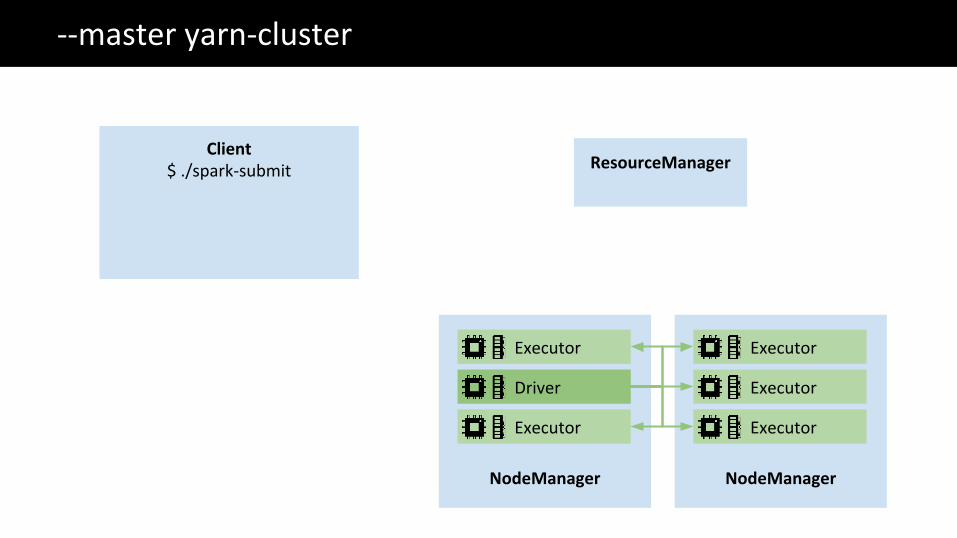
The Big Data problem--master yarn-cluster
ResourceManager
NodeManager
Client$ ./spark-submit
Executor
Driver
Executor
NodeManager
Executor
Executor
Executor

Demo

The Big Data problemStatic allocation
spark.executor.instances 10# it will allocate this fixed number of executors

The Big Data problemStatic allocation

The Big Data problemDynamic allocation
spark.shuffle.service.enabled true# also need to install an auxiliary services to the nodemanagers
spark.dynamicAllocation.enabled truespark.dynamicAllocation.initialExecutors 0spark.dynamicAllocation.minExecutors 1spark.dynamicAllocation.maxExecutors 10
# will allocate and release executors as needed
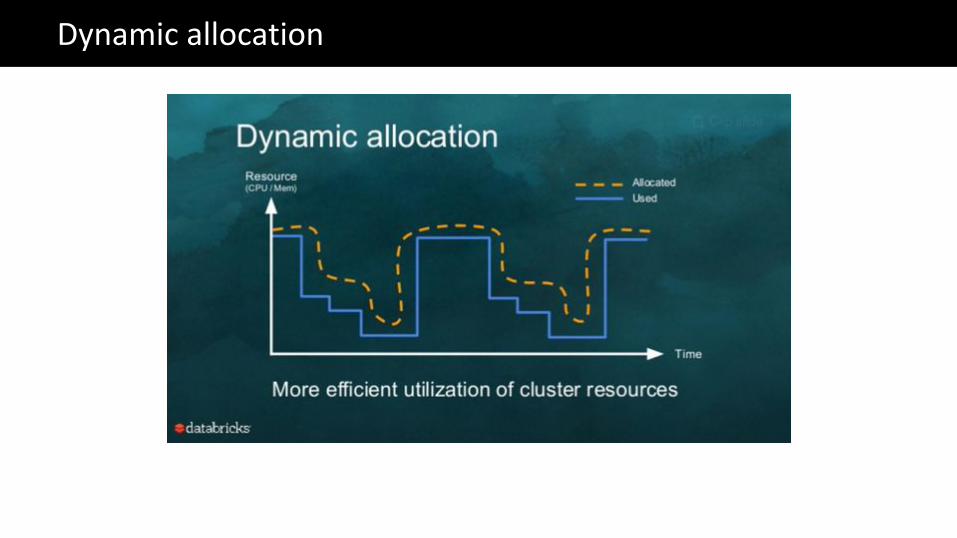
The Big Data problemDynamic allocation

Demo

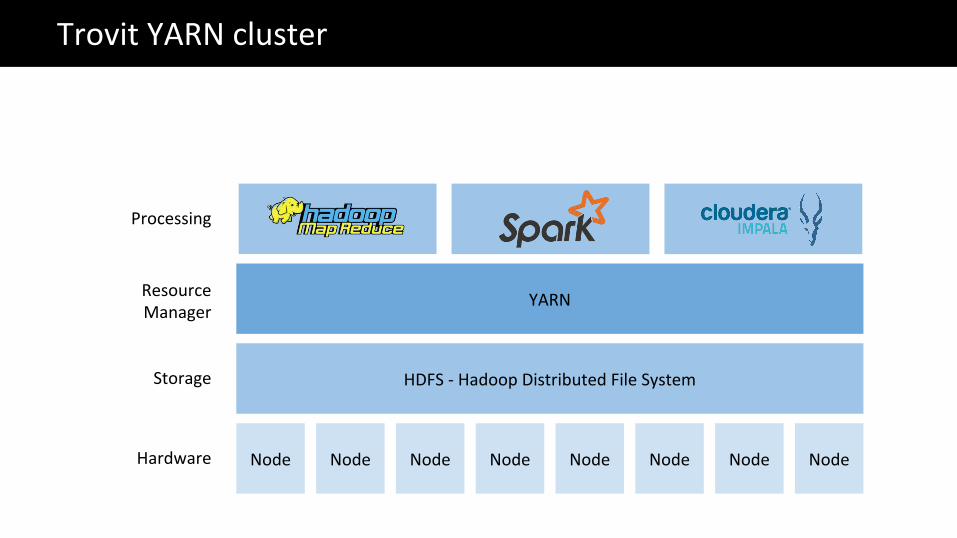
Node Node Node Node Node Node Node Node
HDFS - Hadoop Distributed File System
YARN
Hardware
Storage
Resource Manager
The Big Data problemTrovit YARN cluster
Processing

Trovit
Business Intelligence
Search engine
Mailing Push Notifications
Online Media Buying

Questions?

Thank YouFerran Galí i Reniu
@ferrangali
Icons made by Freepik from Flaticon is licensed by CC BY 3.0
Related Documents









![Installation Guide Version 1.7 - KNIME · • master = yarn-client for running Spark in YARN-client mode • master = spark://localhost:7077 for stand-alone mode • master = local[4]](https://static.cupdf.com/doc/110x72/5ed2394f5189212a3731b801/installation-guide-version-17-knime-a-master-yarn-client-for-running-spark.jpg)

