Company Confidential © ClearSpeed 2006 1 www.clearspeed.co m Programming a Heterogeneous Data Parallel Coprocessor using Cn Ray McConnell, CTO

Www.clearspeed.com Company Confidential © ClearSpeed 2006 1 Programming a Heterogeneous Data Parallel Coprocessor using Cn Ray McConnell, CTO.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Company Confidential © ClearSpeed 2006 1www.clearspeed.com
Programming a HeterogeneousData Parallel Coprocessor using Cn
Ray McConnell, CTO

2© ClearSpeed 2006 | Company Confidential
Extremely Cool - Extremely Fast
For the world's most compute-intensive applications, ClearSpeed provides low power, high performance parallel processing solutions.

Company Confidential © ClearSpeed 2006 3www.clearspeed.com
CSX Technology

4© ClearSpeed 2006 | Company Confidential
What are ClearSpeed’s products?
• New, acceleration coprocessor, the CSX600– Assists serial CPU running compute-intensive math libraries– Can be integrated next to the main CPU on the motherboard– …or installed on add-in cards, e.g. PCI-X, PCI Express– …or embedded, e.g. aerospace, auto, medical, defence
• Significantly accelerate libraries and applications– Libraries: Level 3 BLAS, LAPACK, FFTW– ISV apps: MATLAB, LS-DYNA, ABAQUS, AMBER, etc.– In-house codes: Using the SDK to port kernels
• ClearSpeed’s Advance™ board: aimed at the server market– Dual CSX600 coprocessors– R∞ ≈ 50 GFLOPS for 64-bit matrix multiply (DGEMM) calls– 133 MHz PCI-X– Low power; less than 25 Watts

5© ClearSpeed 2006 | Company Confidential
CSX600 coprocessor layout
• Array of 96 Processor Elements• 250 MHz• IBM 0.13µm FSG process, 8-layer
metal (copper)• 47% logic, 53% memory
– More logic than most processors!
– About 50% of the logic is FPUs
– Hence around one quarter of the chip is floating point hardware
• 15 mm x 15 mm die size• 128 million transistors• Approx. 10 Watts
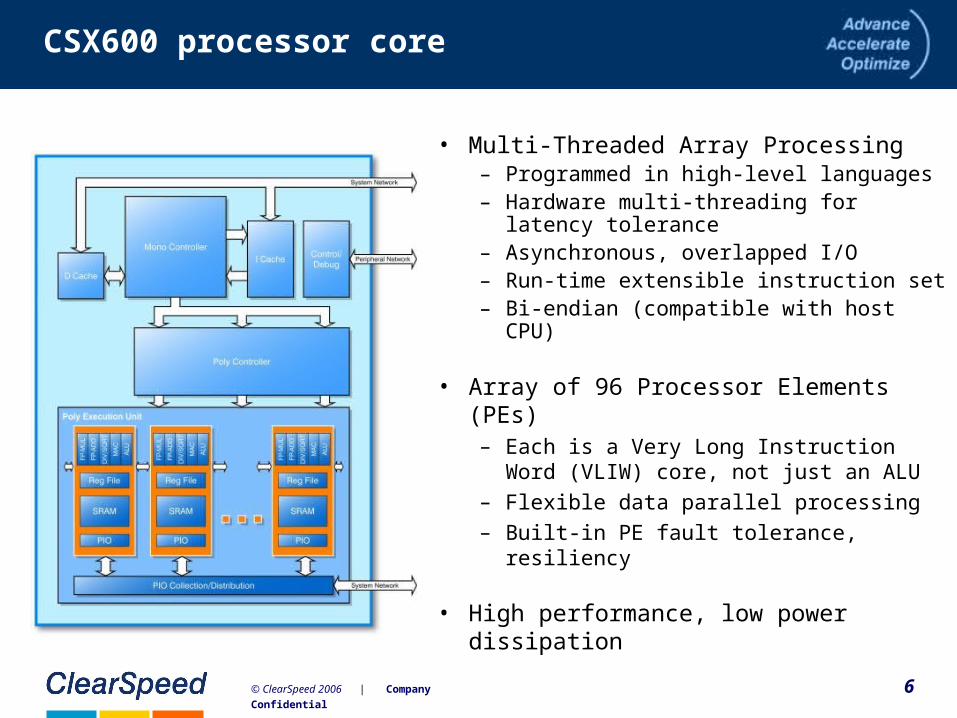
6© ClearSpeed 2006 | Company Confidential
• Multi-Threaded Array Processing– Programmed in high-level languages– Hardware multi-threading for latency
tolerance– Asynchronous, overlapped I/O– Run-time extensible instruction set– Bi-endian (compatible with host CPU)
• Array of 96 Processor Elements (PEs)– Each is a Very Long Instruction Word
(VLIW) core, not just an ALU
– Flexible data parallel processing
– Built-in PE fault tolerance, resiliency
• High performance, low power dissipation
CSX600 processor core

7© ClearSpeed 2006 | Company Confidential
CSX600 Processing Elements
Each PE is a VLIW core:
• Multiple execution units• 4-stage floating point adder
• 4-stage floating point multiplier
• Divide/square root unit
• Fixed-point MAC 16x16 32+64
• Integer ALU with shifter
• Load/store
• High-bandwidth, 5-port register file (3r, 2w)
• Closely coupled 6 KB SRAM for data
• High bandwidth per PE DMA (PIO)
• Per PE address generators
• Complete pointer model, including parallel pointer chasing and vectors of addresses
} 32/64-bit
IEEE 754

8© ClearSpeed 2006 | Company Confidential
Advance™ Dual CSX600 PCI-X accelerator board
– 50 DGEMM GFLOPS sustained– 0.4 M 1K complex single precision FFTs/s (20 GFLOPS)– ~200 Gbytes/s aggregate B/W to on-chip memories– 6.4 Gbytes/s aggregate B/W to local ECC DDR2-DRAM– 1 Gbyte of local DRAM (512 Mbytes per CSX600)– ~1 Gbyte/s to/from board via PCI-X @133 MHz– < 25 watts for entire card (8” single-slot PCI-X)
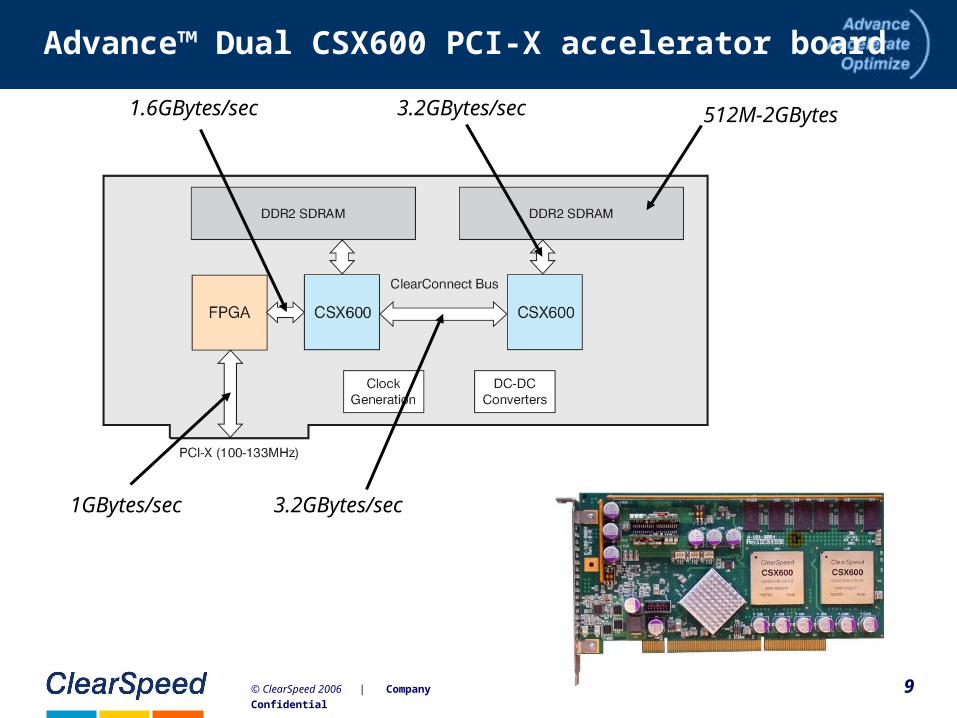
9© ClearSpeed 2006 | Company Confidential
Advance™ Dual CSX600 PCI-X accelerator board
3.2GBytes/sec
3.2GBytes/sec1GBytes/sec
1.6GBytes/sec 512M-2GBytes

10© ClearSpeed 2006 | Company Confidential
Which applications can be accelerated?
Any applications with significant data parallelism:• Fine-grained – vector operations• Medium-grained – unrolled independent loops • Coarse-grained – multiple simultaneous data channels/sets
Example applications and libraries include:• Linear algebra – BLAS, LAPACK• Bio-informatics – AMBER, GROMACS, GAUSSIAN, CPMD• Computational finance – Monte Carlo, genetic algorithms• Signal processing – FFT (1D, 2D, 3D), FIR, Wavelet• Simulation – FEA, N-body, CFD• Image processing – filtering, image recognition, DCTs• Oil & Gas – Kirchhoff Time/Wave Migration• Intelligent systems – artificial neural networks

11© ClearSpeed 2006 | Company Confidential
ClearSpeed applications strategy
Standard MathLibraries
BLASMatrix arithmetic
LAPACKLinear algebra
FFTFast FourierTransforms
LINPACK
Top500
OpenMDMolecular Dynamics
AMBER
CPMD
Density FunctionTheory (DFT)
GAMESSGaussian
ComputationalChemistry
SeismicProcessing
Oil & Gas
MATLAB
Mathematica
CAE
= strong dependence
= weak dependence

12© ClearSpeed 2006 | Company Confidential
ClearSpeed applications strategy
• Provide transparent acceleration of widely used standard libraries– Initially target BLAS, LAPACK, FFTW
• Compatible with Intel MKL, AMD ACML, …– Works just like OpenGL via shared libraries and
dynamically-linked libraries (DLLs)– Plug-and-play acceleration under Linux and Windows
• Port key widely-used applications– Choose open source where possible – dissemination– Have ported GROMACS, now porting AMBER
• Create “template” example applications• Encourage the creation and adoption of standard
libraries– OpenMD, OpenFFT
• Work with customers to port proprietary codes

13© ClearSpeed 2006 | Company Confidential
Application acceleration structure

14© ClearSpeed 2006 | Company Confidential
BLAS/LAPACK/FFTW uses
• Software known to use BLAS, LAPACK, FFTW…– MATLAB, Mathematica, Maple, Octave, …– LINPACK, HPCC– IMSL, BCSLIB-EXT, SuperLU, NAG
• FEA, CFD, Finance codes– ABAQUS, ANSYS, MSC (Nastran, Marc, ADAMS), …– LS-DYNA parallel implicit (uses BCSLIB-EXT)– CPMD, Molpro, NWChem, GAMESS, Gaussian, …– Some silicon design (EDA) tools– Numerous Oil & Gas in-house codes– Many, many more!
• ClearSpeed has a profiler for analysing an application’s use of standard libraries (ClearTrace)

15© ClearSpeed 2006 | Company Confidential
High Performance LINPACK (HPL)
High Performance Linpack
Consider a LINPACK run of 10,000 unknowns, which makes many matrix multiply (DGEMM) calls, starting at size ≈ 25x109 FMACs, and reducing in size each time.
DGEMM call
First DGEMM takes e.g.10s at 5
GFLOPS, the next DGEMM
takes 9.5s etc.
BLAS system library
DGEMM return
Main CPU(s)
System memory
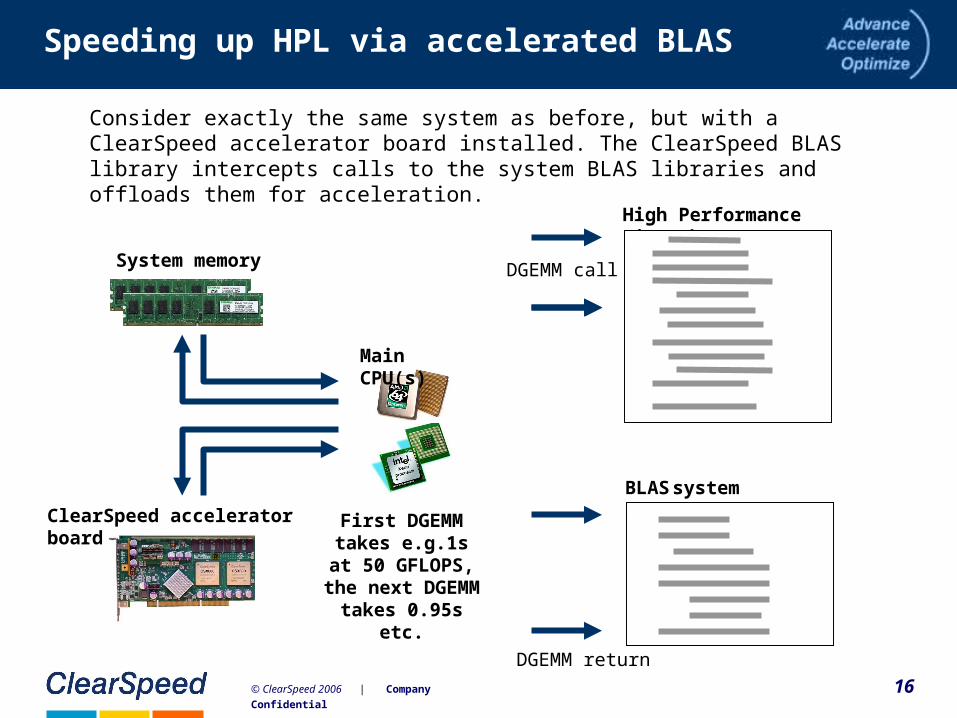
16© ClearSpeed 2006 | Company Confidential
Speeding up HPL via accelerated BLAS
High Performance Linpack
Consider exactly the same system as before, but with a ClearSpeed accelerator board installed. The ClearSpeed BLAS library intercepts calls to the system BLAS libraries and offloads them for acceleration.
DGEMM call
First DGEMM takes e.g.1s at 50
GFLOPS, the next DGEMM
takes 0.95s etc.
BLAS system library
DGEMM return
Main CPU(s)
System memory
ClearSpeed accelerator board

17© ClearSpeed 2006 | Company Confidential
CSX600 Level 3 BLAS performance
Source: vendor websites
Matrix Multiply (DGEMM)
5.2 6.5
14.49.4
12.25.9
14.0
50.0
0
10
20
30
40
50
60
IBM
BG/L
(700
MHz)
IBM
Pow
erPC 9
70 (2
.2GHz)
IBM
POW
ER5 (1
.9GHz)
AMD O
pter
on 2
85 (2
.6GHz)
Inte
l Pen
tium
D 9
50 (3
.4GHz)
Inte
l Itan
ium 2
(1.6
GHz)
NEC SX-8
(2GHz)
ClearS
peed
Adv
ance
boa
rd
GF
LO
PS
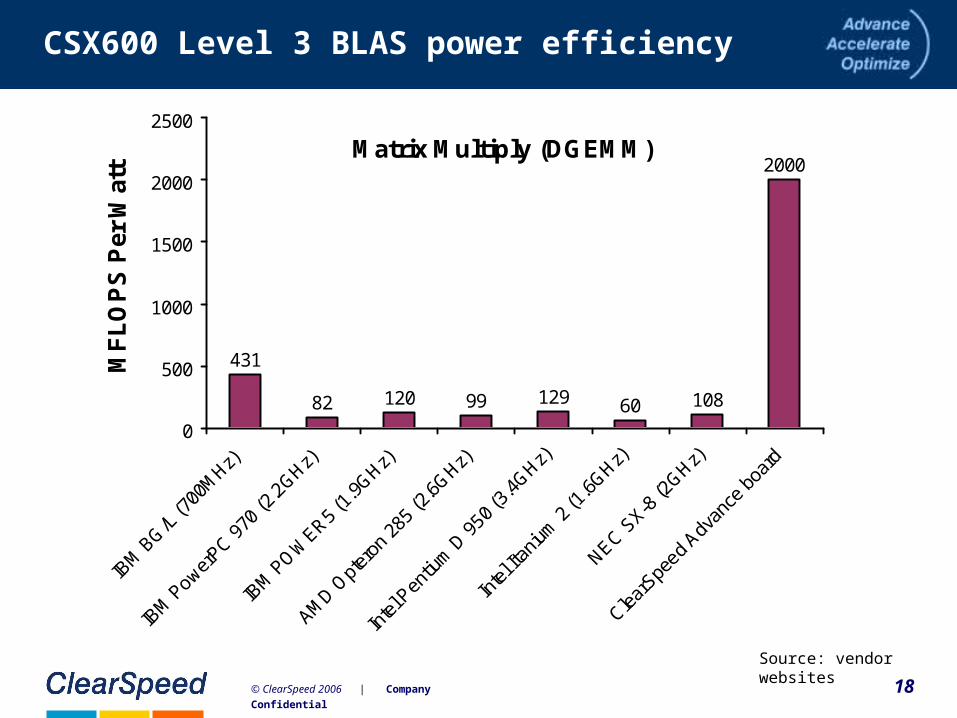
18© ClearSpeed 2006 | Company Confidential
CSX600 Level 3 BLAS power efficiency
Source: vendor websites
Matrix Multiply (DGEMM)
431
82 120 99 129 60 108
2000
0
500
1000
1500
2000
2500
IBM
BG
/L (7
00M
Hz)
IBM
Power
PC 970
(2.2
GHz)
IBM
PO
WER5
(1.9
GHz)
AMD O
pter
on 2
85 (2
.6G
Hz)
Inte
l Pen
tium
D 9
50 (3
.4GHz)
Inte
l Ita
nium
2 (1
.6GHz)
NEC SX-8
(2GHz)
Clear
Speed
Advan
ce b
oard
MF
LO
PS
Per
Wat
t

19© ClearSpeed 2006 | Company Confidential
DGEMM performance from hardware
0
5
10
15
20
25
30
35
40
45
50
0 384 768 1152 1536 1920 2304 2688 3072 3456 3840 4224 4608 4992 5376 5760 6144
Matrix Size
GF
LO
PS

20© ClearSpeed 2006 | Company Confidential
CSX600 LINPACK performance on 4-core machine

21© ClearSpeed 2006 | Company Confidential
Bandwidth Limited
CoreLimited
~1 Byte per Flop
SparseMV SPECfp2000 LinpackDGEMM
NWChemFluid DynamicsOcean Models
Petro ReservoirAuto NVH
Auto CrashWeather
SeismicGAMESS
StreamDAXPYDDOT
ClearSpeed Plays Here.
ClearSpeed applications strategy
ClearSpeed Plays Here TodayPCI-e, Next Generations

22© ClearSpeed 2006 | Company Confidential
MATLAB acceleration
Plug-and-play MATLAB acceleration
• Original time on 3.2 GHz x86:– 8.1 seconds
• Time with ClearSpeed FFT acceleration:– 1.6 seconds
• Time with ClearSpeed convolution acceleration:– 1.2 seconds
• 6X acceleration!

Company Confidential © ClearSpeed 2006 23www.clearspeed.com
Software

24© ClearSpeed 2006 | Company Confidential
Software development environment
Software Development Kit (SDK)• Cn compiler (ANSI-C based commercial compiler),
assembler, libraries, ddd/gdb-based debugger, newlib-based C-rtl etc.
• Extensive documentation and training• CSX600 dual-processor development boards• Microcode Development Kit (MDK)• Microcode compiler, debugger, and standard ISET.• Available for Linux, Windows

25© ClearSpeed 2006 | Company Confidential
Gdb/ddd debugger
Port of standard gdb enables most GUIs to “just work” with the CSX600:
• Hardware supports single step, breakpoint etc
• gdb port is multi-everything (thread, processor and board)
• Visualize all the state in the PEs
• Hardware performance counters also exposed via gdb

26© ClearSpeed 2006 | Company Confidential
Thread profiler
• The CSX600 is 8-way threaded:– Typically 1 compute thread and 1 or more I/O threads
• The hardware supports tracing in real-time:– Thread switches– I/O operation start/finish

27© ClearSpeed 2006 | Company Confidential
• Mono execution unit and poly execution unit– Instructions can be executed in either
domain
– mono variables are scalar (single value)
– poly variables are vector (multiple values)
• 2 domains, 2 types of memory:– mono memory (e.g. card memory)
– poly memory (embedded in poly execution unit)
CSX600 from a programmer’s perspective

28© ClearSpeed 2006 | Company Confidential
Cn: Extending C for SIMD Array Programming
• New Keywords– mono and poly storage qualifiers
• mono is a serial (single) variable• poly is a parallel (vector) variable
• Contrast the two types:– mono:
• One copy exists on mono execution unit• Visible to all processing elements in poly execution unit• mono assumed unless poly specified
– poly:• One per processing element in the poly execution unit• Visible to a single processing element• Data can be shared via “swazzle”• Not visible to mono execution unit

29© ClearSpeed 2006 | Company Confidential
Cn - Variables
• poly variables akin to an array of mono variables:
• Consider:int ma, mb, mc; poly int pa, pb, pc;
mc = ma + mb; pc = pa + pb;
• Variables pa,pb,pc exist on all PEs– Default configuration: 96 PEs

30© ClearSpeed 2006 | Company Confidential
Cn - Broadcast
int ma;
poly int pb, pc;
pc = ma + pb;
• mono variable ma is broadcast to all poly execution units

31© ClearSpeed 2006 | Company Confidential
Cn - Pointers
• mono and poly can be used with pointers
mono int * mono mPmi mono ptr to mono int
poly int * mono mPpi mono ptr to poly int
mono int * poly pPmi poly ptr to mono int
poly int * poly pPpi poly ptr to poly int
• Most commonly used type:– mono ptr to poly type
poly <type> * mono <varname>
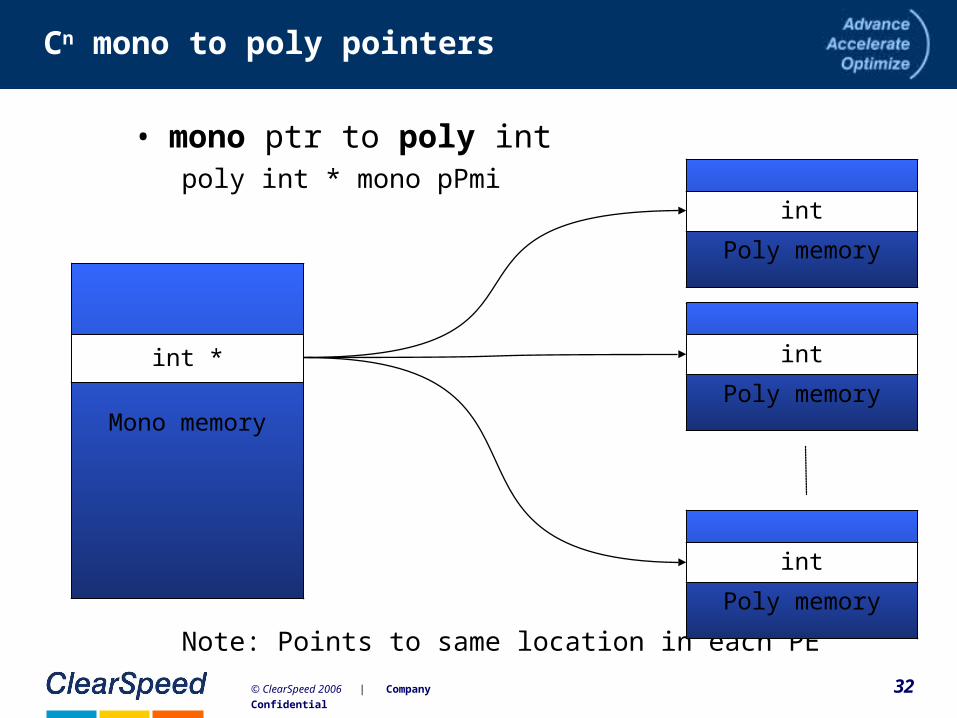
32© ClearSpeed 2006 | Company Confidential
Cn mono to poly pointers
• mono ptr to poly intpoly int * mono pPmi
Note: Points to same location in each PE
int *
Mono memory
int
Poly memory
int
Poly memory
int
Poly memory

33© ClearSpeed 2006 | Company Confidential
Cn – Poly to mono pointers
• De-reference of poly pointer to mono not permitted
mono int * poly pPmi;
poly int Pi;
Pi = *pPmi; // Not permitted
• Instead, available through a Cn library function call
mono int * poly pPmi;
poly int Pi;
memcpym2p(&Pi, pPmi, sizeof(int)); // OK

34© ClearSpeed 2006 | Company Confidential
Cn - Conditionals
• if statements in Cn depend on multiplicity of the condition• A poly execution unit (SIMD) can NOT skip poly
conditional code– Single Instruction stream for all PEs– All PEs execute instructions in lockstep– All code must be issued, but not necessarily executed
• Example:if (a == b) /* true on some PEs, false on some */
/* Always issued, may be ignored */else
/* Always issued, may be ignored */

35© ClearSpeed 2006 | Company Confidential
Porting code
void daxpy(double *c, double *a, double alpha, uint N) {
uint i;
for (i=0; i<N; i++)
c[i] = c[i] + a[i]*alpha;
}
void daxpy(double *c, double *a, double alpha, uint N) {
uint i;
poly double cp, ap;
for (i=0; i<N; i+=num_pes) {
memcpym2p(&cp, &c[i+pe_num], sizeof(double));
memcpym2p(&ap, &a[i+pe_num], sizeof(double));
cp = cp + ap*alpha;
memcpyp2m(&c[i+pe_num], &cp, sizeof(double))
}

36© ClearSpeed 2006 | Company Confidential
Example: Cn radix-2 FFT
void cn_fft(poly float *xy,poly float *w, short n) { poly short n1,n2,ie,ia,i,j,k,l; poly float xt,yt,c,s;
n2 = n; ie = 1; for (k=n; k > 1; k = (k >> 1) ) { n1 = n2; n2 = n2>>1; ia = 0; for (j=0; j < n2; j++) { c = w[2*ia]; s = w[2*ia+1]; ia = ia + ie; for (i=j; i < n; i += n1) { l = i + n2; xt = xy[2*l] - xy[2*i]; xy[2*i] = xy[2*i] + xy[2*l]; yt = xy[2*l+1] - xy[2*i+1]; xy[2*i+1] = xy[2*i+1] + xy[2*l+1]; xy[2*l] = (c*xt + s*yt); xy[2*l+1] = (c*yt - s*xt); } } ie = ie<<1; }}

37© ClearSpeed 2006 | Company Confidential
• For acceleration of standard libraries and applications, such as Level 3 BLAS, LAPACK, FFTW, MATLAB, Mathematica, ANSYS, ABAQUS, GAMESS, Gaussian, AMBER …
• 50 GFLOPS sustained from a ClearSpeed Advance™ board
• Callable from C/C++, Fortran, etc.• ~25 watts per single-slot board• Multiple Advance™ boards for even higher
performance
ClearSpeed Advance™ and CSX600 summary
ClearSpeed’s Advance™ board delivers new levels of floating-point and integer performance, performance per watt, and ease of use:
Related Documents











