Wprowadzenie do technologii Big Data Radosław Stankiewicz

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Wprowadzenie do technologii Big Data
Radosław Stankiewicz


HackerBig Data NerdEnterpreneur Trainer
3
Src: computing.co.uk , https://www.flickr.com/photos/barron/15483113 , tech.co

Agenda
Wstęp -> Map Reduce -> Pig -> Hive -> Ambari
4

Wprowadzenie
5

V O LUME6

Variety
7
A|123|10$ B|555|20$ Y|333|15$
{ 'typ'='A', 'id'=123, 'kwota'='10$'
}

Velocity
OLAP
Real Time
Batch
Streaming Interactive analytics
8


Value
10

Klasyfikacja problemu• Baza danych ulic Warszawy, Dane w formacie JSON,
optymalizacja odbioru śmieci jednego z usługodawców.
• Zdarzenia z bazy transakcyjnej i kart kredytowych w celu lepszego wykrywania fraudów
• System wyszukujący dobre oferty samochodów z wielu serwisów - web crawling, parsowanie danych, analiza trendów cen samochodów
• Centralne repozytorium skanów umów, TB danych, codziennie przybywa kilkaset nowych dokumentów
11

Geneza
• za dużo danych
• pady serwerów
• wolne relacyjne bazy danych
12

13

14

Architektura
15 źródło: Hortonworks

Ekosystem Hadoop
16 źródło: Hortonworks

17
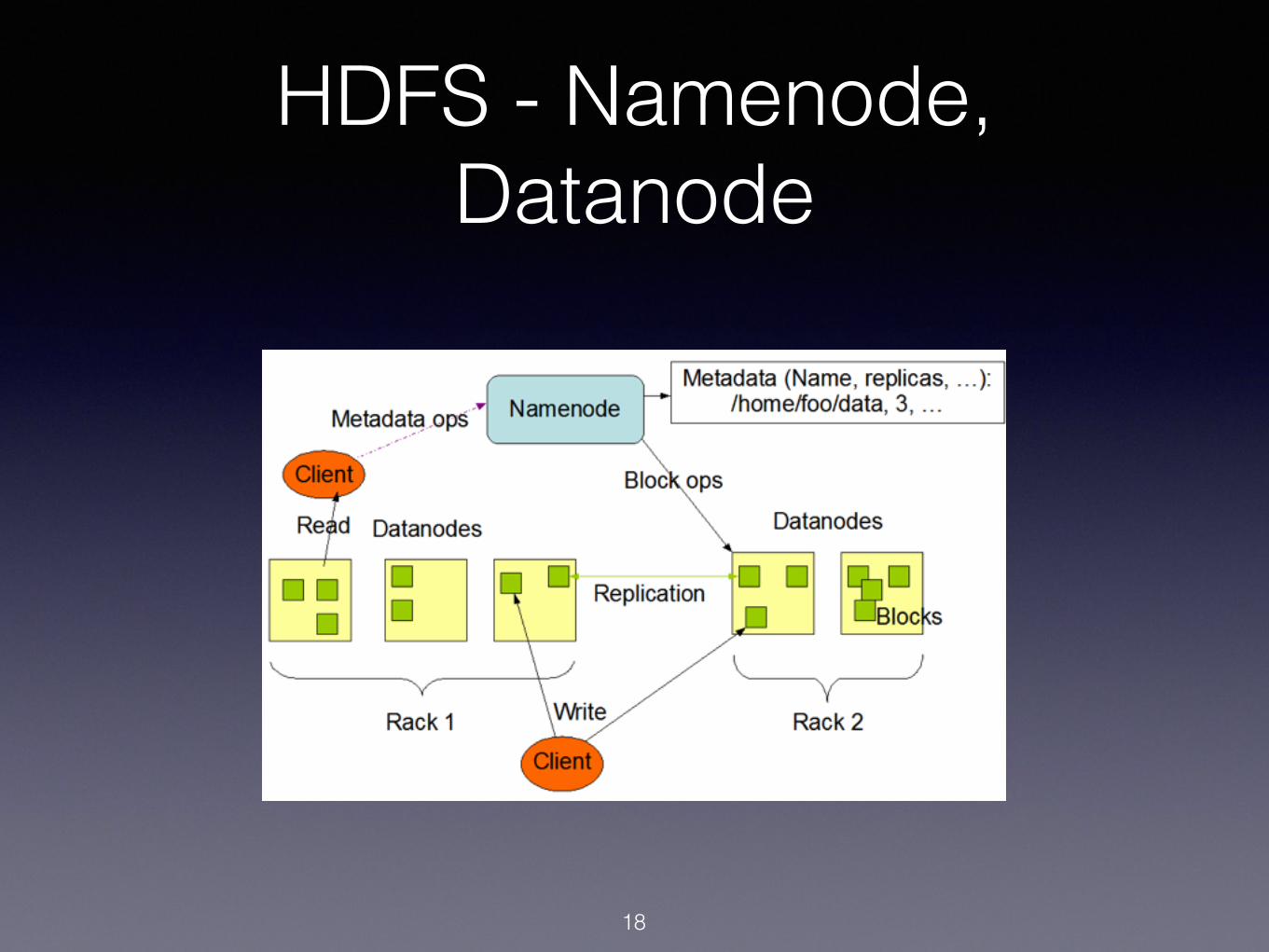
HDFS - Namenode, Datanode
18

● User Commands o dfs o fsck
● Administration Commands o datanode o dfsadmin o namenode
dfs: appendToFile cat chgrp chmod chown copyFromLocal copyToLocal count cp du dus expunge get getfacl getfattr getmerge ls lsr mkdir moveFromLocal moveToLocal mv put rm rmr setfacl setfattr setrep stat tail test text touchz
hdfs dfs -put localfile1 localfile2 /user/tmp/hadoopdir hdfs dfs -getmerge /user/hadoop/output/ localfile
komendy
19

HDFS - uprawnienia• prawie POSIX
• Users, Groups • chmod, chgrp, chown • ACL • getfacl, setfacl • można wyłączyć kontrolę uprawnień
• dodatkowo: • Apache Knox • Apache Ranger
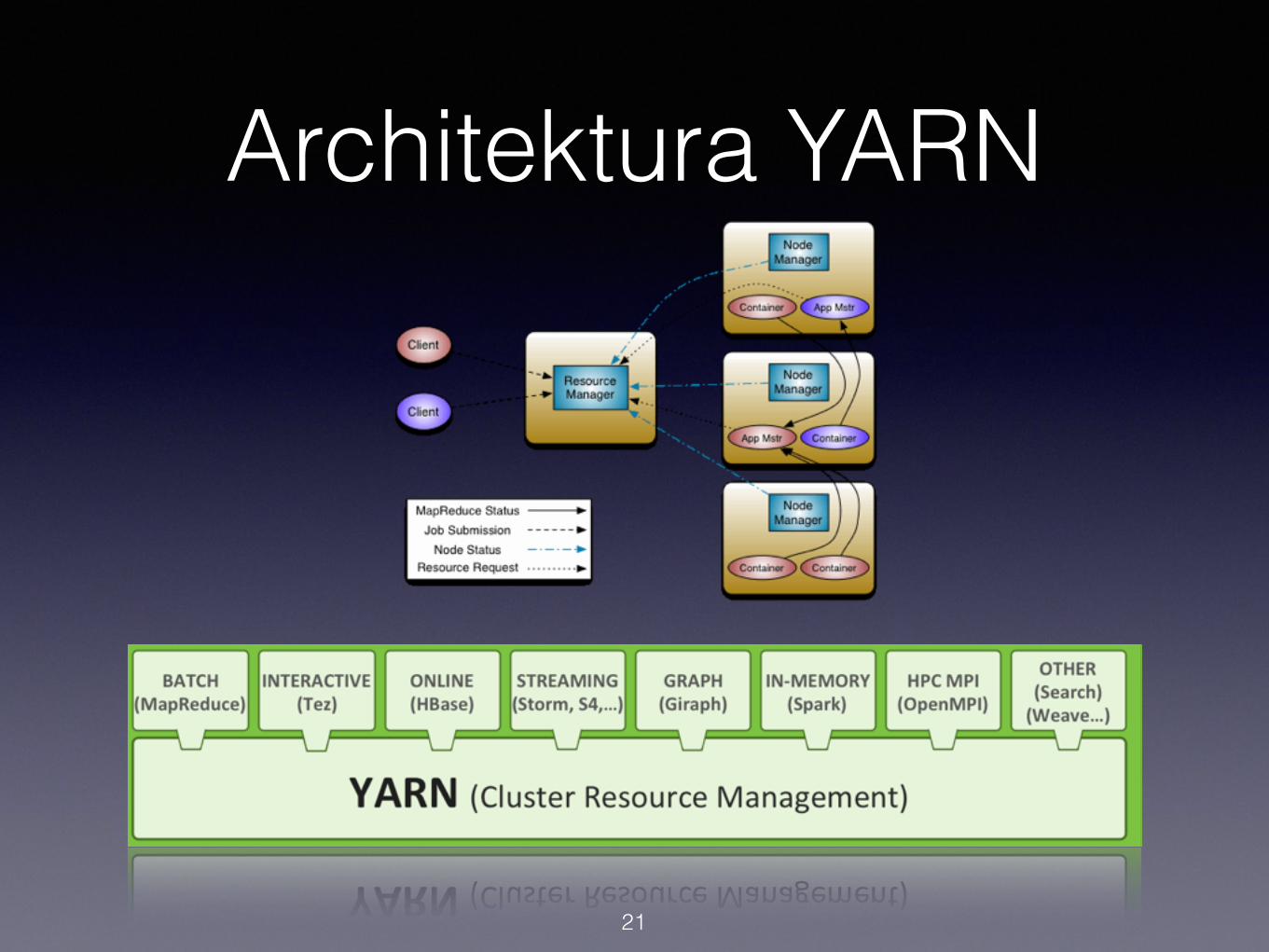
Architektura YARN
21

Map Reduce Framework
22

Map Reduce Framework
23
M
M
M
M
R
R
R
R
R

Mapper
#!/usr/bin/env python import sys for line in sys.stdin: words = line.strip().split() for word in words: print '%s\t%s' % (word, 1)
line = “Ala ma kota”
Ala 1 ma 1 kota 1
24

Reducer#!/usr/bin/env python import sys current_word = None current_count = 0 word = None for line in sys.stdin: line = line.strip() word, count = line.split('\t', 1) count = int(count) if current_word == word: current_count += count else: if current_word: print '%s,%s' % (current_word, current_count) current_count = count current_word = word if current_word == word: print '%s,%s' % (current_word, current_count)
ala 1 ala 1 bela 1 dela 1
ala,2 bela,1 dela,1
25

Uruchomienie streaming
cat input.txt | ./mapper.py | sort | ./reducer.py
bin/yarn jar [..]/hadoop-*streaming*.jar \ -file mapper.py -mapper ./mapper.py -file reducer.py -reducer ./reducer.py \-input /tmp/wordcount/input -output /tmp/wordcount/output
26

Map Reduce w Java(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output) 1) Mapper 2) Reducer 3) run public class WordCount extends Configured implements Tool { public static class TokenizerMapper{...} public static class IntSumReducer{...} public int run(...){...}
}
27

Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } public void setup(...) {...} public void cleanup(...) {...} public void run(...) {...} }
value = “Ala ma kota”
Ala,1 ma,1 kota,1

Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } public void setup(...) {...} public void cleanup(...) {...} public void run(...) {...} }
kota,(1,1,1,1)
kota,4

Mainpublic int run(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new Configuration(), new WordCount(),args); System.exit(res); }
yarn jar wc.jar WordCount /tmp/wordcount/input /tmp/wordcount/output

Co dalej?• Map Reduce w Javie
• Testowanie MRUnit
• Joins
• Avro
• Custom Key, Value
• Złączanie wielu zadań
• Custom Input, Output
31

Warsztat
https://notehub.org/jkrqs

Wprowadzenie do przetwarzania danych na
przykładzie Pig
33

Architektura Pig
34

Czy warto?
Top 5 stron odwiedzanych przez użytkowników mających 18 lat

import java.io.IOException; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapred.FileInputFormat; import org.apache.hadoop.mapred.FileOutputFormat; import org.apache.hadoop.mapred.JobConf; import org.apache.hadoop.mapred.KeyValueTextInputFormat; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.RecordReader; import org.apache.hadoop.mapred.Reducer; import org.apache.hadoop.mapred.Reporter; import org.apache.hadoop.mapred.SequenceFileInputFormat; import org.apache.hadoop.mapred.SequenceFileOutputFormat; import org.apache.hadoop.mapred.TextInputFormat; import org.apache.hadoop.mapred.jobcontrol.Job; import org.apache.hadoop.mapred.jobcontrol.JobControl; import org.apache.hadoop.mapred.lib.IdentityMapper; public class MRExample { public static class LoadPages extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String key = line.substring(0, firstComma); String value = line.substring(firstComma + 1); Text outKey = new Text(key); // Prepend an index to the value so we know which file // it came from. Text outVal = new Text("1" + value); oc.collect(outKey, outVal); } }
public static class LoadAndFilterUsers extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable k, Text val, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // Pull the key out String line = val.toString(); int firstComma = line.indexOf(','); String value = line.substring(firstComma + 1); int age = Integer.parseInt(value); if (age < 18 || age > 25) return; String key = line.substring(0, firstComma); Text outKey = new Text(key); // Prepend an index to the value so we know which file // it came from. Text outVal = new Text("2" + value); oc.collect(outKey, outVal); } } public static class Join extends MapReduceBase implements Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterator<Text> iter, OutputCollector<Text, Text> oc, Reporter reporter) throws IOException { // For each value, figure out which file it's from and store it // accordingly. List<String> first = new ArrayList<String>(); List<String> second = new ArrayList<String>(); while (iter.hasNext()) { Text t = iter.next(); String value = t.toString(); if (value.charAt(0) == '1') first.add(value.substring(1)); else second.add(value.substring(1)); reporter.setStatus("OK"); } // Do the cross product and collect the values for (String s1 : first) { for (String s2 : second) { String outval = key + "," + s1 + "," + s2; oc.collect(null, new Text(outval)); reporter.setStatus("OK"); } } } }

public static class LoadJoined extends MapReduceBase implements Mapper<Text, Text, Text, LongWritable> { public void map( Text k, Text val, OutputCollector<Text, LongWritable> oc, Reporter reporter) throws IOException { // Find the url String line = val.toString(); int firstComma = line.indexOf(','); int secondComma = line.indexOf(',', firstComma); String key = line.substring(firstComma, secondComma); // drop the rest of the record, I don't need it anymore, // just pass a 1 for the combiner/reducer to sum instead. Text outKey = new Text(key); oc.collect(outKey, new LongWritable(1L)); } } public static class ReduceUrls extends MapReduceBase implements Reducer<Text, LongWritable, WritableComparable, Writable> { public void reduce( Text key, Iterator<LongWritable> iter, OutputCollector<WritableComparable, Writable> oc, Reporter reporter) throws IOException { // Add up all the values we see long sum = 0; while (iter.hasNext()) { sum += iter.next().get(); reporter.setStatus("OK"); } oc.collect(key, new LongWritable(sum)); } }
public static class LoadClicks extends MapReduceBase implements Mapper<WritableComparable, Writable, LongWritable, Text> { public void map( WritableComparable key, Writable val, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { oc.collect((LongWritable)val, (Text)key); } } public static class LimitClicks extends MapReduceBase implements Reducer<LongWritable, Text, LongWritable, Text> { int count = 0; public void reduce( LongWritable key, Iterator<Text> iter, OutputCollector<LongWritable, Text> oc, Reporter reporter) throws IOException { // Only output the first 100 records while (count < 100 && iter.hasNext()) { oc.collect(key, iter.next()); count++; } } }

public static void main(String[] args) throws IOException { JobConf lp = new JobConf(MRExample.class); lp.setJobName("Load Pages"); lp.setInputFormat(TextInputFormat.class); lp.setOutputKeyClass(Text.class); lp.setOutputValueClass(Text.class); lp.setMapperClass(LoadPages.class); FileInputFormat.addInputPath(lp, new Path("/user/gates/pages")); FileOutputFormat.setOutputPath(lp, new Path("/user/gates/tmp/indexed_pages")); lp.setNumReduceTasks(0); Job loadPages = new Job(lp); JobConf lfu = new JobConf(MRExample.class); lfu.setJobName("Load and Filter Users"); lfu.setInputFormat(TextInputFormat.class); lfu.setOutputKeyClass(Text.class); lfu.setOutputValueClass(Text.class); lfu.setMapperClass(LoadAndFilterUsers.class); FileInputFormat.addInputPath(lfu, new Path("/user/gates/users")); FileOutputFormat.setOutputPath(lfu, new Path("/user/gates/tmp/filtered_users")); lfu.setNumReduceTasks(0); Job loadUsers = new Job(lfu); JobConf join = new JobConf(MRExample.class); join.setJobName("Join Users and Pages"); join.setInputFormat(KeyValueTextInputFormat.class); join.setOutputKeyClass(Text.class); join.setOutputValueClass(Text.class); join.setMapperClass(IdentityMapper.class); join.setReducerClass(Join.class); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/indexed_pages")); FileInputFormat.addInputPath(join, new Path("/user/gates/tmp/filtered_users")); FileOutputFormat.setOutputPath(join, new Path("/user/gates/tmp/joined")); join.setNumReduceTasks(50); Job joinJob = new Job(join); joinJob.addDependingJob(loadPages); joinJob.addDependingJob(loadUsers); JobConf group = new JobConf(MRExample.class); group.setJobName("Group URLs"); group.setInputFormat(KeyValueTextInputFormat.class); group.setOutputKeyClass(Text.class); group.setOutputValueClass(LongWritable.class); group.setOutputFormat(SequenceFileOutputFormat.class); group.setMapperClass(LoadJoined.class); group.setCombinerClass(ReduceUrls.class); group.setReducerClass(ReduceUrls.class); FileInputFormat.addInputPath(group, new Path("/user/gates/tmp/joined")); FileOutputFormat.setOutputPath(group, new Path("/user/gates/tmp/grouped")); group.setNumReduceTasks(50); Job groupJob = new Job(group);
groupJob.addDependingJob(joinJob); JobConf top100 = new JobConf(MRExample.class); top100.setJobName("Top 100 sites"); top100.setInputFormat(SequenceFileInputFormat.class); top100.setOutputKeyClass(LongWritable.class); top100.setOutputValueClass(Text.class); top100.setOutputFormat(SequenceFileOutputFormat.class); top100.setMapperClass(LoadClicks.class); top100.setCombinerClass(LimitClicks.class); top100.setReducerClass(LimitClicks.class); FileInputFormat.addInputPath(top100, new Path("/user/gates/tmp/grouped")); FileOutputFormat.setOutputPath(top100, new Path("/user/gates/top100sitesforusers18to25")); top100.setNumReduceTasks(1); Job limit = new Job(top100); limit.addDependingJob(groupJob); JobControl jc = new JobControl("Find top 100 sites for users 18 to 25"); jc.addJob(loadPages); jc.addJob(loadUsers); jc.addJob(joinJob); jc.addJob(groupJob); jc.addJob(limit); jc.run(); } }

Users = load ‘users’ as (name, age); Fltrd = filter Users by age >= 18 and age <= 25; Pages = load ‘pages’ as (user, url); Jnd = join Fltrd by name, Pages by user; Grpd = group Jnd by url; Smmd = foreach Grpd generate group, COUNT(Jnd) as clicks; Srtd = order Smmd by clicks desc; Top5 = limit Srtd 5; store Top5 into ‘top5sites’;

Architektura Pig
40

Tryb Pracy
Interaktywny lub Wsadowy
41

Tryb Pracy
Lokalny lub Rozproszony
42

Tryb Pracy
Map Reduce lub Tez
43

Typy danych
44
int long float double
chararray datetime boolean
bytearray biginteger bigdecimal

Złożone typy
45
tuple bag map

Podstawy Pig Latin - wielkość liter
• A = LOAD 'data' USING PigStorage() AS (f1:int, f2:int, f3:int);B = GROUP A BY f1;C = FOREACH B GENERATE COUNT ($0);DUMP C;
• Nazwy zmiennych A, B, and C (tzw. aliasy) są case sensitive.• Wielkość liter jest też istotna dla:
• nazwy pól f1, f2, i f3• nazwy zmiennych A, B, C• nazwy funkcji PigStorage, COUNT
• Z wyjątkiem: LOAD, USING, AS, GROUP, BY, FOREACH, GENERATE, oraz DUMP
46

assert, and, any, all, arrange, as, asc, AVG, bag, BinStorage, by, bytearray, BIGINTEGER, BIGDECIMAL, cache, CASE, cat, cd, chararray, cogroup, CONCAT, copyFromLocal, copyToLocal, COUNT, cp, cross, datetime, %declare, %default, define, dense, desc, describe, DIFF, distinct, double, du, dump, e, E, eval, exec, explain, f, F, filter, flatten, float, foreach, full, generate, group, help, if, illustrate, import, inner, input, int, into, is, join, kill, l, L, left, limit, load, long, ls, map, matches, MAX, MIN, mkdir, mv, not, null, onschema, or, order, outer, output, parallel, pig, PigDump, PigStorage, pwd, quit, register, returns, right, rm, rmf, rollup, run, sample, set, ship, SIZE, split, stderr, stdin, stdout, store, stream, SUM, TextLoader, TOKENIZE, through, tuple, union, using, void
47
Słowa kluczowe

Pierwsze kroki
data = LOAD 'input' AS (query:CHARARRAY);
A = LOAD 'data' USING PigStorage('\t') AS (f1:int, f2:int, f3:int);
STORE A INTO '/tmp/result' USING PigStorage(';')
48

Pierwsze kroki
SAMPLEDESCRIBE
DUMPEXPLAIN
ILLUSTRATE
49

Kolejne kroki - operacje na danych
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, semestre:int, scholarship:float);
B = FILTER A BY age > 20;
50

Kolejne kroki - operacje na danych
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, semestre:int, scholarship:float);
B = FILTER A BY age > 20; C = LIMIT B 5;
51

Kolejne kroki - operacje na danych
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, semestre:int, scholarship:float);
B = FILTER A BY age > 20; C = LIMIT B 5;
D = FOREACH C GENERATE name, scholarship*semestre as funds
52

Kolejne kroki - operacje na danych
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, semestre:int, scholarship:float);
E = GROUP A by age
53

Kolejne kroki - operacje na danych
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, semestre:int, scholarship:float);
E = GROUP A by age F = FOREACH E GENERATE group as age, AVG(A.scholarship)
54

Wydajność
Tez, Projekcje, Filtrowanie, Join
55

Co dalej?• Pig ma całą masę funkcji
• UDF
• Facebook DataFu, PiggyBank
• napisać samemu (java, jvm, python, ruby etc.)
• testy jednostkowe PigUnit
56

Warsztat
57
https://notehub.org/k2glz

Wprowadzenie do analizy danych na przykładzie
Hive
58

Architektura
59

Unikalne cechy Hive
Zapytania SQL na plikach płaskich, np. CSV
60

Unikalne cechy Hive
Znaczne przyspieszenie analizy - nie potrzeba pisać Map Reduce Optymalizacja, wykonywanie części operacji w pamięci zamiast MR
61

Unikalne cechy Hive
Nieograniczone formy integracji - MongoDB, Elastic Search, HBase
62

Unikalne cechy Hive
Integracja narzędzi BI oraz DWH z Hive poprzez JDBC
63

Hive CLITryb Interaktywny
hive Tryb Wsadowy:
hive -e ‘select foo from bar’ hive -f ‘/path/to/my/script.q’ hive -f ‘hdfs://namenode:port/path/to/my/script.q’
więcej opcji: hive --help
64

Typy danychINT, TINYINT, SMALLINT, BIGINTBOOLEANDECIMALFLOAT, DOUBLESTRINGBINARYTIMESTAMPARRAY, MAP, STRUCT, UNIONDATECHARVARCHAR
65

Składnia zapytańSELECT, INSERT, UPDATE
GROUP BY
UNION
LEFT, RIGHT, FULL INNER, FULL OUTER JOIN
OVER, RANK
(NOT) IN, HAVING
(NOT) EXISTS
66

Data Definition Language
• CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX • DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX • TRUNCATE TABLE • ALTER DATABASE/SCHEMA, TABLE, VIEW • MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS) • SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE
• DESCRIBE DATABASE/SCHEMA, table_name, view_name
67

Tabele
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User') COMMENT 'This is the page view table' PARTITIONED BY(dt STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' STORED AS TEXTFILE;
68

Pierwsze kroki w Hive
CREATE TABLE tablename1 (foo INT, bar STRING) PARTITIONED BY (ds STRING); LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename1;
INSERT INTO TABLE tablename1 PARTITION (ds='2014') select_statement1 FROM from_statement;
69

Inne formaty plików? SerDe
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326 "http://www.example.com/
start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
CREATE TABLE apachelog (
host STRING, identity STRING, user STRING, time STRING, request STRING, status STRING,
size STRING, referer STRING, agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^]*) ([^]*) ([^]*) (-|\\[^\\]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?:
([^ \"]*|\".*\") ([^ \"]*|\".*\"))?"
)
STORED AS TEXTFILE;
70

Inne formaty plików? SerDe
CREATE TABLE table (
foo STRING, bar STRING)
STORED AS TEXTFILE; ← lub SEQUENCEFILE, ORC, AVRO lub PARQUET
71

Zalety, wady, porównanieHive Pig
deklaratywny proceduralny
tabele tymczasowe pipeline
polegamy na optymalizatorze bardziej ingerujemy w implementacje
UDF, Transform UDF, streaming
sterowniki sql data pipeline splits
72

Stinger
http://hortonworks.com/labs/stinger/73

Tips & Trickshive.vectorized.execution.enabled=true
ORC
hive.execution.engine=tez
John Lund Stone Getty Images74

Co dalej?
• Integracje z Solr, Elastic, MongoDB, HBase
• UDF
• multi table inserts
• JDBC
75

Warsztat
źródło:HikingArtist76
https://notehub.org/hz5od


Now what?78
Spark

Chcesz wiedzieć więcej?Szkolenia pozwalają na indywidualną pracę z każdym uczestnikiem
• pracujemy w grupach 4-8 osobowych • program może być dostosowany do oczekiwań
grupy • rozwiązujemy i odpowiadamy na indywidualne
pytania uczestników • mamy dużo więcej czasu :)

Szkolenie dedykowane dla CiebieInteresuje Cię tematyka warsztatu? Zapoznaj się z programami szkoleń:
Projektowanie rozwiązań Big Data z wykorzystaniem Apache Hadoop & Family
Analiza danych tekstowych i języka naturalnego
Przetwarzanie Big Data z użyciem Apache Spark
Podstawy uczenia maszynowego w języku Python

Wspierają nas


źródła
• HikingArtist.com - rysunki
• hortonworks.com - architektura HDP
• apache.org - grafiki Pig, Hive, Hadoop
Related Documents











