Weekly Report- Matrix multiplications Ph.D. Student: Leo Lee date: Oct. 16, 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Weekly Report-Matrix multiplications
Ph.D. Student: Leo Leedate: Oct. 16, 2009

Outline
• Matrix multiplication
• Implementation
• Experiments
• Work plan

© David Kirk/NVIDIA and Wen-mei W. HwuTaiwan, June 30-July 2, 2008
Matrix Multiplication
• A: M*N
• B: N*P
• C=A*B:M*P
A
B
C
NM
N P

Matrix Multiplication• // Matrix multiplication on the (CPU) host • void MatrixMulOnHost (float* A, float* B, float* C, int hA, int wA, int wB)• { • for (int i = 0; i < hA; ++i)• {• for (int j = 0; j < wB; ++j)• {• double sum = 0;• for (int k = 0; k < wA; ++k) • {• double a = A[i * wA + k];• double b = B[k * wB + j];• sum += a * b;• }• P[i * wB + j] = sum;• }• }• }

Implementation_1
• One thread calculates one element of C– dim3 grid(1, 1);– dim3 thread(WC, HC);– __global__ void matrixMul_low( float* C, float* A, float* B, int wA,
int wB)– {– int tx = threadIdx.x;– int ty = threadIdx.y;– float Csub = 0;– for(int k=0; k<wA; ++k)– {– Csub += A[ty*wA+k] * B[k*wB+tx]; – }– C[ty*wB+tx] = Csub;– }

Experiments_1
10000 times
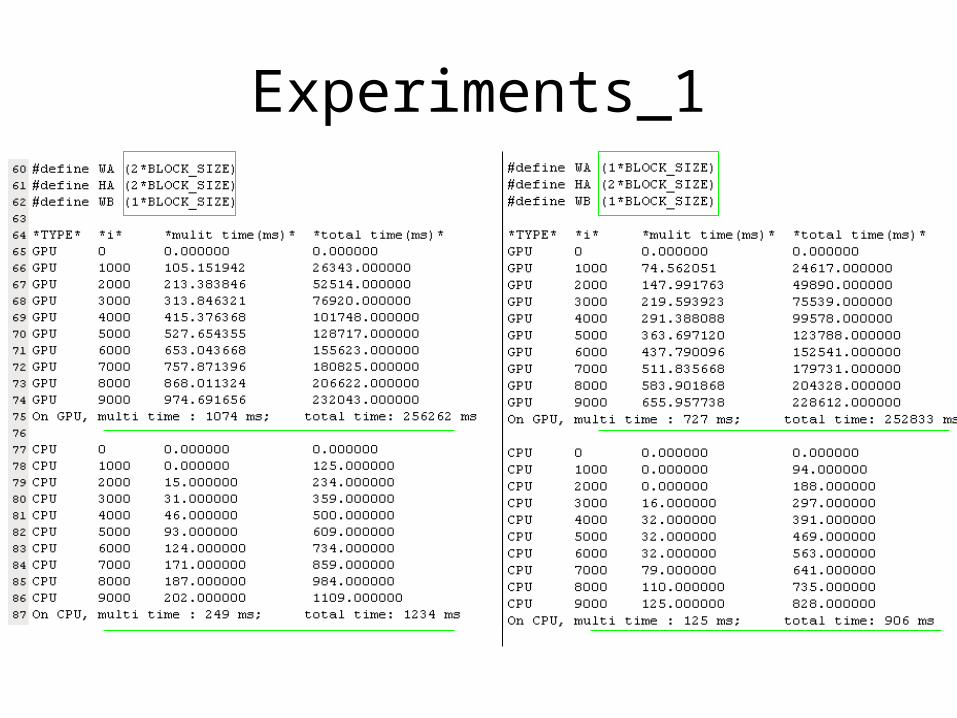
Experiments_1

Brief analysis• Less efficient than CPU;
• Data transfer occupies most of the time, each thread– Loads a row of matrix A– Loads a column of matrix B– Perform one multiply and addition for each pair of A and B elements– Compute to off-chip memory access ratio close to 1:1 (not very high)
• Size of matrix limited by the number of threads allowed in a thread block– 1*2*2 is not ok?
• Try to increase the Compute to off-chip memory access ratio !

Ad
Bd
Cd
Pdsub
TILE_WIDTH
WIDTHWIDTH
TILE_WIDTHTILE_WIDTH
bx
tx01 TILE_WIDTH-12
0 1 2
by ty 210
TILE_WIDTH-1
2
1
0
TILE_WIDTH
TILE_WIDTH
TILE_WIDTHE
WIDTH
WIDTH
Implementation_2
• Tiled Multiply– Each block computes one square sub-matrix
Pdsub of size TILE_BLOCK_SIZE
– Each thread computes one element of Csub
– Assume that the dimensions of A and B are multiples of TILE_BLOCK_SIZE

Implementation_2• dim3 thread(BLOCK_SIZE, BLOCK_SIZE);• dim3 grid(WC/thread.x, HC/thread.y);• In kernel function
– __shared__ float As[BLOCK_SIZE][BLOCK_SIZE];– __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];– //Load the matrices from device memory to shared memory– AS(ty, tx) = A[a + ty*wA + tx];– BS(ty, tx) = B[b + ty*wB + tx];– //Synchronize to make sure the matrices are loaded– __syncthreads();– for(int k=0; k<BLOCK_SIZE; ++k)– {– Csub += AS(ty,k)*BS(k,tx);– }– __syncthreads();
– int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx;– C[c + wB *ty +tx] = Csub;

Experiments_2
• Improvement by tile

Experiments_2
10000 times

Experiments_2
• Thanks for your listening

Experiments_2

Experiments_2
• Improvement by GPU compared with CPU
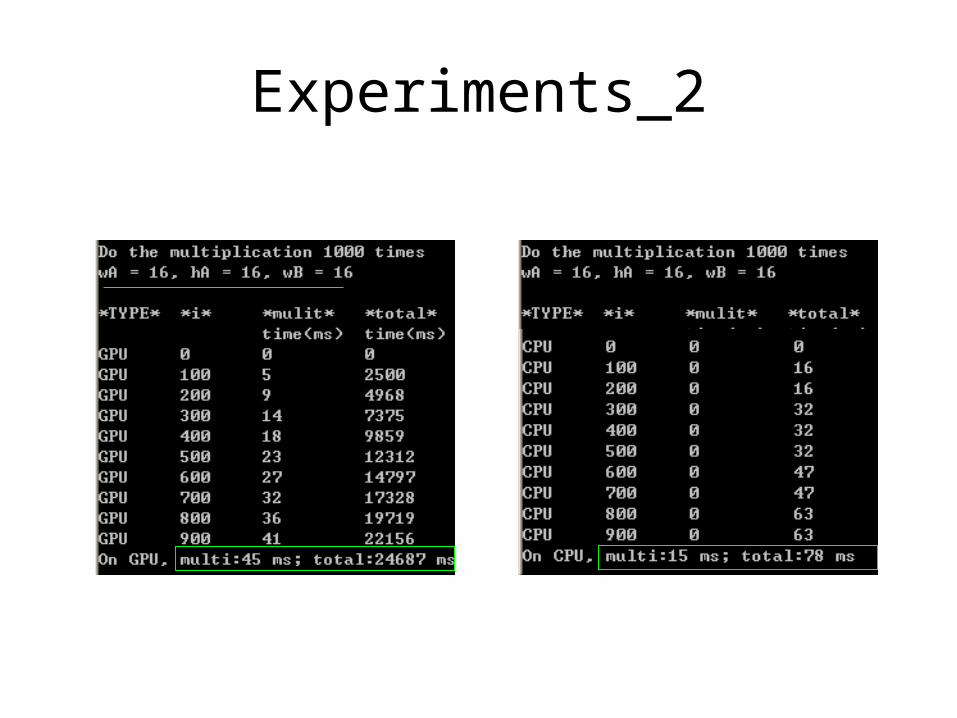
Experiments_2
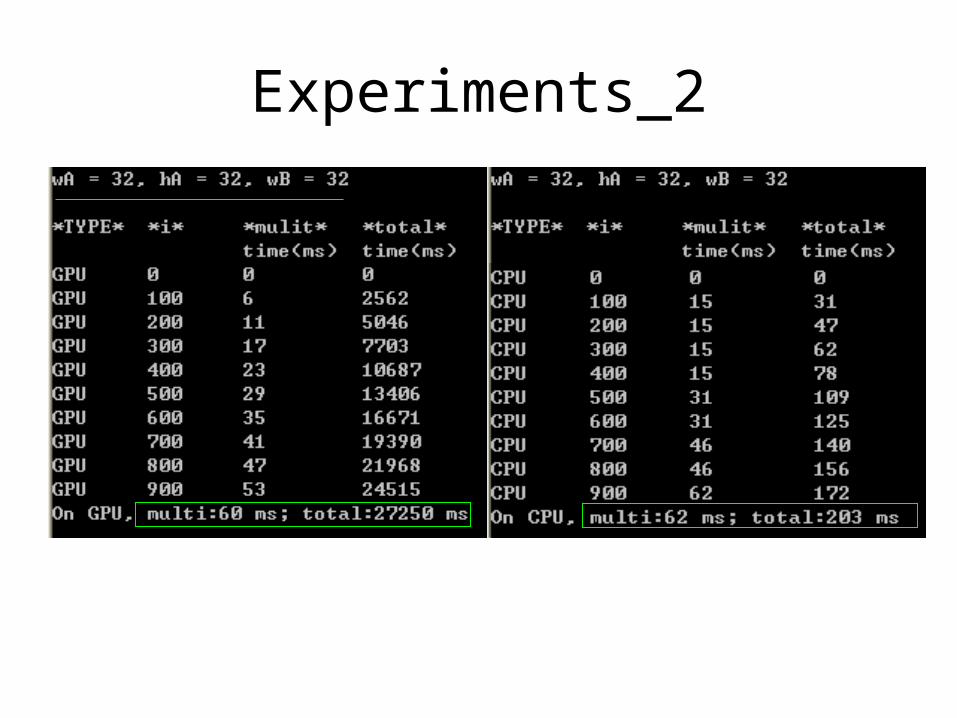
Experiments_2

Experiments_2
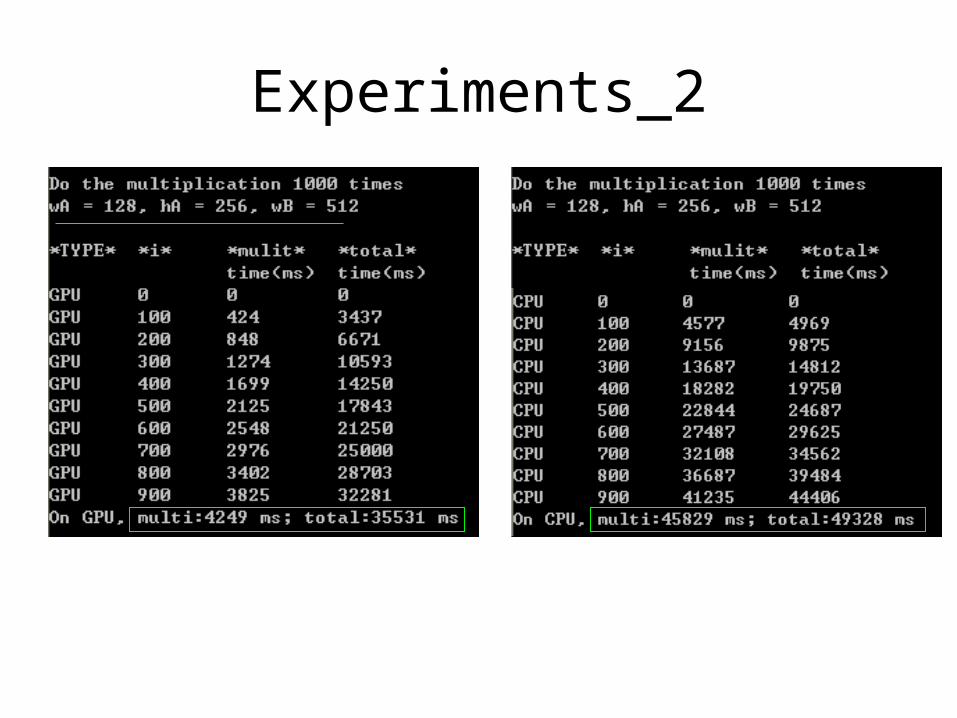
Experiments_2

Experiments_2

Experiments_2WA, HA, WB
GPU
CPU
Comput time (ms) total time (ms)
16,16,16
GPU
CPU
45
15
24678
78
32,32,32
GPU
CPU
60
62
27250
203
48,80,128
GPU
CPU
225
861
26625
1203
128,256,512
GPU
CPU
4249
45829
35531
49328
512,512,512
GPU
CPU
27441
364232
70359
382062

Brief analysis
• Using shared memory to increase Compute to off-chip memory access ratio– 256 access, (16+16)*16*16 computations.
• Data transfer still occupies much time– Coalesced accesses

Implementation_3
• Transpose matrix B– Then read B is the same as read A;– C[i, j] = ∑ A[i, k]*B[j, k];

Experiments_3
Coalesced accesses Implementation_2

Brief analysis
• No big change– Review the code– Try a new method~

Work plan
• Further experiments on Matrix Multiplication
• Learn Reduction
Related Documents

![Pointer Graph Networks - NeurIPS · Classical algorithms [5] span computations that can be substantially more expressive than typical machine learning subroutines (e.g. matrix multiplications),](https://static.cupdf.com/doc/110x72/610c311e8fb6d83d3240e468/pointer-graph-networks-neurips-classical-algorithms-5-span-computations-that.jpg)
![Secure Outsourced Matrix Computation and Application to ... · matrix multiplication as a series of matrix-vector multiplications. Halevi and Shoup [25] introduced a matrix encoding](https://static.cupdf.com/doc/110x72/6054150e95b6b014fe087785/secure-outsourced-matrix-computation-and-application-to-matrix-multiplication.jpg)


![Recurrent Neural Networks - static.packt-cdn.com · Recurrent Neural Networks Chapter 1 [ 4 ] A non-linear transformation of the sum of the two matrix multiplications—for example,](https://static.cupdf.com/doc/110x72/5ed3f6088d46b66d22632b19/recurrent-neural-networks-recurrent-neural-networks-chapter-1-4-a-non-linear.jpg)



![IEEE TRANSACTIONS ON INFORMATION FORENSICS AND … · 2017-11-01 · Atallah et al. [3] presented a framework for secure outsourcing of scientific computations such as matrix multiplications](https://static.cupdf.com/doc/110x72/5f11a796d252982ca22a4cd7/ieee-transactions-on-information-forensics-and-2017-11-01-atallah-et-al-3-presented.jpg)

