Visual Translation Embedding Network for Visual Relation Detection Slides by Fran Roldán ReadAI Reading Group, UPC 20th March, 2017 Hanwang Zhang, Zawlin Kyaw, Shih-Fu Chang, Tat-Seng Chua, [arxiv ] (27 Feb 2017) [demo ]

Visual Translation Embedding Network for Visual Relation Detection (UPC Reading Group)
Apr 11, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Visual Translation Embedding Network for Visual Relation Detection
Slides by Fran RoldánReadAI Reading Group, UPC
20th March, 2017
Hanwang Zhang, Zawlin Kyaw, Shih-Fu Chang, Tat-Seng Chua, [arxiv] (27 Feb 2017) [demo]

Index1. Visual Relation Detection2. Visual Translation Embedding (VTransE)3. VTransE Feature Extraction4. VTransE Network5. Evaluation6. Conclusion
2

Visual Relation Detection● Modeling and understanding the
relationships between objects in a scene (i.e. “person ride bike”).
● Better generalization for other tasks such as image captioning or VQA.
● Visual relations are subject-predicate-object triplets, which we can model jointly or separately.
3

VTransETranslation Embedding
● For N objects and R predicates we have to learn:○ Joint model: N2 R○ Separate model: N+R.
● However, large appearance changes of predicate (i.e . predicate ride is different when object is bike than when the object is elephant).
4

VTransETranslation Embedding
● For N objects and R predicates we have to learn:○ Joint model: N2 R○ Separate model: N+R.
● However, large appearance changes of predicate (i.e . predicate ride is different when object is bike than when the object is elephant).
...is there any solution?
5

VTransETranslation Embedding
● Based on Translation Embeddings for representing large scale knowledge bases.
● Map the features of objects and predicates in a low-dimensional space, where relation triplet can be interpreted as a vector translation.
We only need to learn the “ride” translation vector in the relation space.
6

VTransE Visual Translation Embedding
Suppose are M-dim features of subject and object. We must learn a relation translation vector and the projection matrices .
7

VTransEVisual Translation Embedding
Loss function to reward only deterministically accurate predicates:
8

VTransE Feature ExtractionKnowledge Transfer in Relation
● Region proposal network (RPN) and a classification layer.● Incorporation of knowledge transfer between objects and predicates,
which can be transferred in a single forward/backward pass.● Novel feature extraction layer:
○ Classeme (i.e. class probabilities).○ Location (i.e. bounding boxes coordinates and scales).○ RoI visual features (use of bilinear feature interpolation instead of RoI pooling).
9

VTransE Feature ExtractionIn order to extract we analyze three type of features:
● Classeme: N+1-dim vector of class probabilities (N classes and 1 background) obtained from object classification.
● Location: 4-dim vector such that:
where are bounding boxes coordinates of subject and object respectively.
● Visual Features: D-dim vector transformed from a convolutional feature of the shape . 10

VTransE Feature ExtractionBilinear Interpolation
Smooth function of two inputs: feature map F and an object bounding box.
: X x Y grid split in box
Since G is a linear function, V can be back-propagated to the bounding box coordinates
11

VTransEOptimization
● Multi-task loss function: ○ Object detection loss: ○ Relation detection loss:
● Loss trade-off:
12

VTransE Network
Built upon an object detection module and incorporates the proposed feature extraction layer.
13

Evaluation
Q1: Is the idea of embedding relations effective in the visual domain?
Q2: What are the effects of the features in relation detection and knowledge transfer?
Q3: How does the overall VTransE network perform compared to the other state-of-the-art visual relation models?
14

Evaluation● Datasets:
○ Visual Relationship Dataset (VRD): 5,000 images with 100 object categories and 70 predicates. In total, VRD contains 37,993 relation annotations with 6,672 unique relations and 24.25 predicates per object category.
○ Visual Genome Version 1.2 (VG): 99,658 images with 200 object categories and 100 predicates, resulting in 1,174,692 relation annotations with 19,237 unique relations and 57 predicates per object category.
15

Evaluation (Q1)
Q1: Is the idea of embedding relations effective in the visual domain?
Isolate VTransE from object detection and perform the task of Predicate Prediction
16
R@K computes the fraction of times a true relation is predicted in the top K confident relation predictions in an image
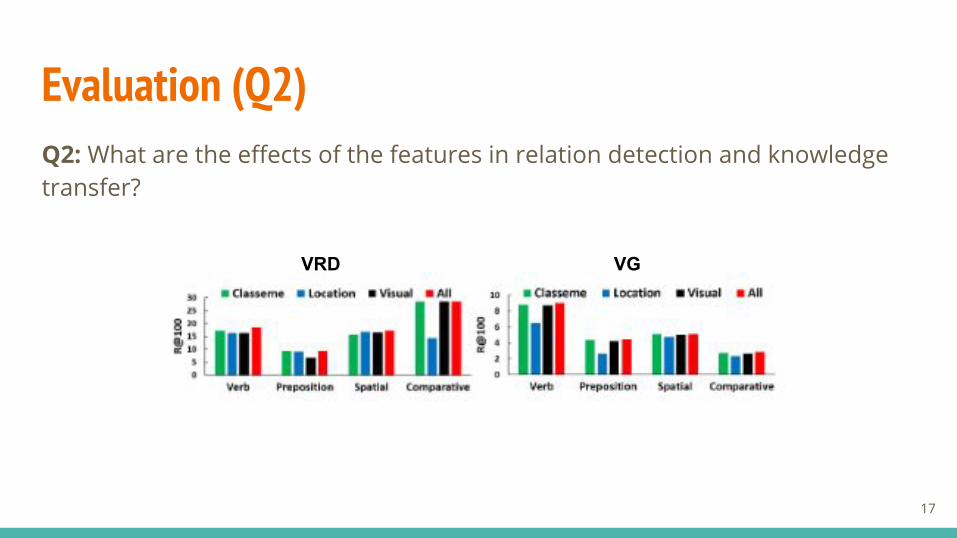
Evaluation (Q2)Q2: What are the effects of the features in relation detection and knowledge transfer?
17
VRD VG

Evaluation (Q2)Q2: What are the effects of the features in relation detection and knowledge transfer?
18

Evaluation (Q3)Q3: How does the overall VTransE network perform compared to the other state-of-the-art visual relation models?
19

Evaluation (Q3)
20

Conclusions● Visual Relation task gives us a comprehensive scene understanding for
connecting computer vision and natural language. ● VTransE designed to provide object detection and relation prediction
simultaneously ● Novel feature extraction layer that enables object-relation knowledge
transfer.
21
Related Documents











