P. Bozanis and E.N. Houstis (Eds.): PCI 2005, LNCS 3746, pp. 25 – 35, 2005. © Springer-Verlag Berlin Heidelberg 2005 Visual Techniques for the Interpretation of Data Mining Outcomes Ioannis Kopanakis 1 , Nikos Pelekis 2 , Haralampos Karanikas 3 , and Thomas Mavroudkis 4 1 Technological Educational Institute of Crete, Heraklion Crete, Greece [email protected] 2 Univ. of Piraeus, Piraeus, Greece [email protected] 3 UMIST, Manchester, UK [email protected] 4 National & Kapodistrian Univ. of Athens, Knowledge Management Lab., Athens, Hellas Abstract. The visual senses for humans have a unique status, offering a very broadband channel for information flow. Visual approaches to analysis and mining attempt to take advantage of our abilities to perceive pattern and struc- ture in visual form and to make sense of, or interpret, what we see. Visual Data Mining techniques have proven to be of high value in exploratory data analysis and they also have a high potential for mining large databases. In this work, we try to investigate and expand the area of visual data mining by proposing a new 3-Dimensional visual data mining technique for the representation and mining of classification outcomes and association rules. Keywords: Visual Data Mining, Association Rules, Classification, Visual Data Mining Models. Categories: I.2.4, I.2.6 Research Paper: Data Bases, Work Flow and Data mining 1 Introduction and Motivation Classification is a primary method for machine learning and data mining [Frawley, 92]. It is either used as a stand-alone tool to get insight into the distribution of a data set, e.g. to focus further analysis and data processing, or as a pre-processing step for other algorithms operating on the detected clusters. The main enquiries that the knowledge engineer usually has on his/her attempt to understand the classification outcomes are: How well separated are the different classes? What classes are similar or dissimilar to each other? What kind of surface separates various classes, (i.e. are the classes linearly separable?) How coherent or well formed is a given class? Those questions are difficult to be answered by applying the conventional statisti- cal methods over the raw data produced by the classification algorithm. Unless the user is supported by a visual representation that will actually be his/her navigational

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

P. Bozanis and E.N. Houstis (Eds.): PCI 2005, LNCS 3746, pp. 25 – 35, 2005. © Springer-Verlag Berlin Heidelberg 2005
Visual Techniques for the Interpretation of Data Mining Outcomes
Ioannis Kopanakis1, Nikos Pelekis2, Haralampos Karanikas3, and Thomas Mavroudkis4
1 Technological Educational Institute of Crete, Heraklion Crete, Greece [email protected]
2 Univ. of Piraeus, Piraeus, Greece [email protected] 3 UMIST, Manchester, UK
[email protected] 4 National & Kapodistrian Univ. of Athens,
Knowledge Management Lab., Athens, Hellas
Abstract. The visual senses for humans have a unique status, offering a very broadband channel for information flow. Visual approaches to analysis and mining attempt to take advantage of our abilities to perceive pattern and struc-ture in visual form and to make sense of, or interpret, what we see. Visual Data Mining techniques have proven to be of high value in exploratory data analysis and they also have a high potential for mining large databases. In this work, we try to investigate and expand the area of visual data mining by proposing a new 3-Dimensional visual data mining technique for the representation and mining of classification outcomes and association rules.
Keywords: Visual Data Mining, Association Rules, Classification, Visual Data Mining Models.
Categories: I.2.4, I.2.6
Research Paper: Data Bases, Work Flow and Data mining
1 Introduction and Motivation
Classification is a primary method for machine learning and data mining [Frawley, 92]. It is either used as a stand-alone tool to get insight into the distribution of a data set, e.g. to focus further analysis and data processing, or as a pre-processing step for other algorithms operating on the detected clusters. The main enquiries that the knowledge engineer usually has on his/her attempt to understand the classification outcomes are: How well separated are the different classes? What classes are similar or dissimilar to each other? What kind of surface separates various classes, (i.e. are the classes linearly separable?) How coherent or well formed is a given class?
Those questions are difficult to be answered by applying the conventional statisti-cal methods over the raw data produced by the classification algorithm. Unless the user is supported by a visual representation that will actually be his/her navigational

26 I. Kopanakis et al.
tool in the N-dimensional classified world, concluding inferences will be a tedious task [Keim, 95]. Our main aim therefore should be to visually represent and under-stand the spatial relationships between various classes in order to answer questions such as the above mentioned.
Further more, mining for association rules, as a central task of data mining, has been studied extensively by many researchers. Much of the existing research, how-ever, is focused on how to generate rules efficiently. Limited work has been done on how to help the user understand and use the discovered rules. In real-life applications though, the knowledge engineer wants first to have a good understanding over a set of rules before trusting them and use the mining outcomes [David, 01]. Investigation and comprehension of rules is a critical pre-requirement for their application. Those issues become even more tightening if we consider the “large resulting rule set”, the “hard to understand” and the “rule behaviour” problem [Zhao, 01].
In this paper, the proposed visual data mining model constructs 3D graphical rep-resentations of the classification outcomes produced by common data mining proc-esses. Furthermore, association rules are also visualized in that representation, reveal-ing each association rule’s “state” in their original N-dimensional world. Our attempt is to equip the knowledge engineer with a tool that would be utilized on his/her at-tempt to gain insight over the mined knowledge, presenting as much information extracted in a human perceivable way. The model proposed have distinctive advanta-geous characteristics, addressing the commonly tedious issues that the knowledge engineer handles during the exploitation of the classification outcomes. Furthermore, it brings us one step closer to make human part of the data mining process, in order to exploit human’s unmatched abilities of perception.
In section 2 we introduce our application domain, along with the presentation of our 3D Class-Preserving Projection Technique. In section 4 we investigate the appli-cation of this model for the visualization of association rules, which is followed by two case studies in sections 5 and 6. Finally, the related work is presented in section 7 and we summarize our work in section8.
2 Visualizing Data Mining Classification Outcomes
On our attempt to graphically reveal the knowledge extracted by a classifier we have mainly based our research effort on the underlying ideas of the geometric projection techniques [Dhillon, 98]. Among the several geometric projection techniques that we have studied, the most interesting methodology was the Class-Preserving Projection Algorithm [Dhillon, 99], due to the robust behaviour that it has and its middle level of computational complexity.
The main characteristic of classified data embedded in high-dimensional Euclidean space is that proximity in Rn implies similarity. During the mapping procedures, class-preserving projection techniques preserve the properties of the classified data in the Rn space also to the projection plane in order to construct corresponding represen-tations from which accurate inferences could be extracted. Our research study on those techniques formed a new geometric projection technique that expands the exist-ing methods in the area of visualizing classified data. That new technique named 3D

Visual Techniques for the Interpretation of Data Mining Outcomes 27
Class-Preserving Projection technique projects from the Rn to the R3 space along with being capable of preserving the class distances (discriminating) among a larger num-ber of classes.
3 3D Class-Preserving Projection Technique
In this section we introduce 3D class-preserving projections of multidimensional data. The main advantage of those projections is that they maintain the high-dimensional class structure by the utilization of linear projections, which can be displayed on a computer screen. The challenge is in the choice of those planes and the associated projections. Considering the problem of visualizing high-dimensional data that have been categorized into various classes, our goal is to choose those projections that best preserve inter-class and intra-class distances in order to extract inferences regarding their relationships.
On our attempt to expand the existing projection techniques we worked on the definition of a projection scheme that would result on the construction of a 3D world. Compared to the existing 2D class-preserving projection techniques, the proposed 3D technique results on the construction of an information rich representation due to the freedom provided by the additional dimension in the projection world would. In order to project onto the 3D space we should define our orthonormal projection vectors based on four points. If we chose those four points to be the class-means of the classes of our interest, we have managed to maximize the inter-class distances among those four classes on our projection. Such an approach provides the flexibility of distin-guishing among four classes instead of three, as long as being promoted into the 3D projection space.
We consider the case where the data is divided into four classes. Let x1, x2, …, xn be all the N-dimensional data points, and m1, m2, m3, m4, denote the corresponding class-centroids. Let w1, w2 and w3 be an orthonormal basis of the candidate 3D world of projection. The point xi gets projected to (w1
Txi, w2Txi, w3
Txi) and consequently, the means mj get mapped to (w1
Tmj, w2Tmj, w3
Tmj) j=1,2,3,4. One way to obtain good separation of the projected classes is to maximize the dif-
ference between the projected means. This may be achieved by choosing vectors w1, w2, w3 ∈ R
n such that the objective function
{∑=
+−+−+−=3
1
2
14
2
13
2
12321 )()()( ),,(i
Ti
Ti
Ti mmwmmwmmwwwwC
2
34
2
24
2
23 )()()( mmwmmwmmw Ti
Ti
Ti −+−+−
is maximized. The above may be rewritten as
( ) { }{ }∑=
−−++−−=3
134341212321 ))((...))(( ,,
ii
TTTi wmmmmmmmmwwwwC
332211 wSwwSwwSw B
TB
TB
T ++= WSW BT=
Where 3,2,1, , ,0 ,1 ],,,[ 321 =≠=== jijiwwwwwwwW jTii
Ti
and TT
B mmmmmmmmS ))((...))(( 34341212 −−++−−=

28 I. Kopanakis et al.
The positive semi-definite matrix SB can be interpreted as the inter-class or between-class scatter matrix. Note that SB has rank≤3, since ( ) ( ) ( ){ }131223 , mmmmspanmm −−∈− ,
( ) ( ) ( ){ }121424 , mmmmspanmm −−∈− , ( ) ( ) ( ){ }131434 , mmmmspanmm −−∈− .
It is clear that the search for the maximizing w1, w2 and w3 can be restricted to the column (or row) space of SB. But as we noted above, this space is at most of dimen-sion 3. Thus, in general, the optimal w1, w2 and w3 must form an orthonormal basis spanning the space determined by the vectors (m2 – m1), (m3 – m1) and (m4 – m1). This technique can be applied in any number of classes. In the constructed visual representation though it will best discriminate the four selected classes.
4 Class-Preserving Projection Techniques and Association Rules
Class-preserving projection techniques could be also applied in the area of visual mining of association rules. Even in the case of association rules, inventing new vis-ual data mining models is actually conceiving new mapping techniques from the mul-tidimensional space to a lower dimensional space. As each attribute participating in a rule is actually adding an additional dimension to our data space, we try to map each association rule existing in Rn to a lower dimensional space. Those notions conform to the fundamental theory of the class-preserving projection techniques.
Theoretically, each rule could be perceived as an n-dimensional surface which en-closes a sub-space in the high dimensional data space. The boundaries of that area are defined by the conditions of rule’s sub-expressions, which pose the limits in each dimension (i.e. the sub-expressions of the association rule IF ((L1<x1<U1) and (L2<x2<U2) and … (Ln<xn<Un)) THEN (…) set the upper and lower limits for each dimension of the n-dimensional space). The set of tuples in the data set, correspond-ing to points in the high-dimensional space, that have been included into the sub-space are those which satisfy rule’s conditions. This is actually a different perspective that we could perceive the definition of association rules.
Following the mapping procedures of the class-preserving projection techniques, we are able to construct 2D or 3D representations of the classified high-dimensional data space, which has also been partitioned by the examined rule’s sub-space. That attempt will equip us with a model capable to represent the “state” of an association rule in the high-dimensional world that it belongs. As in the case of visual mining the classified data space, the enquiries posed in this case will also be regarding coherence, discrimination, relationships etc. among the classes and the rule’s sub-space. It will be like representing an association rule under the prism of the projection of the high-dimensional world.
In sections 5 and 6 we are evaluating the behavior of this model, which suggests the application of the class-preserving projection techniques for the visual mining of association rules. We are presenting two case studies, in order to examine the poten-tial of constructing 2D and 3D representations of the classified high-dimensional world when partitioned to the sub-space defined by the association rule examined.

Visual Techniques for the Interpretation of Data Mining Outcomes 29
5 Wine Case Study
To begin with, we selected for our case study the wine data set [Blake, 98]. These data are the results of a chemical analysis of 178 wines grown in the same region in Italy but derived from three different cultivars. The analysis determined the quantities of 13 constituents found in each wine of the three cultivars. We selected to visualize the following rules:
Rule Sup.% Conf.% IF ((3.82 < ColorIntensity <= 4.85)) THEN (Class=Class3) 15.73 21.43 IF ((3.82 < ColorIntensity <= 4.85)) THEN (Class=Class2) 15.73 28.57 IF ((3.82 < ColorIntensity <= 4.85)) THEN (Class=Class1) 15.73 50
This set of rules is actually providing the information regarding the categorization of the wines with color intensity in the range of (3.82 , 4.85] among the three cultivars. It would be interesting to visually examine this information and derive inferences if possible.
Fig. 1. 2D Class-Preserving Projection (Wine Case Study)
In Fig. 1 the sub-set of wines that has color intensity in the range of (3.82 , 4.85] has been yellow marked. As expected, the distribution of those points is among all three classes. In Fig. 2 we have visualized the first rule which provides the information regard-ing the third cultivar (class 3). In Fig. 3 all three rules have been visualized. The green
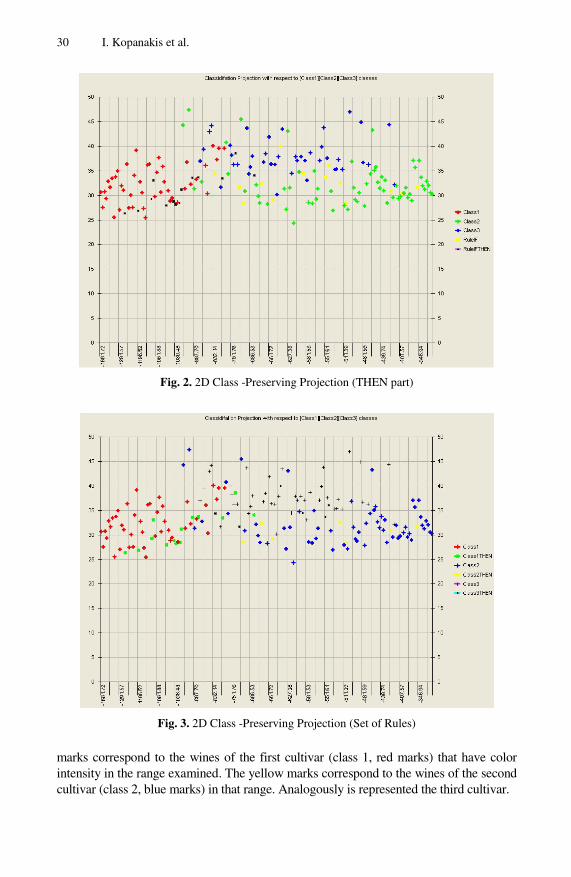
30 I. Kopanakis et al.
Fig. 2. 2D Class -Preserving Projection (THEN part)
Fig. 3. 2D Class -Preserving Projection (Set of Rules)
marks correspond to the wines of the first cultivar (class 1, red marks) that have color intensity in the range examined. The yellow marks correspond to the wines of the second cultivar (class 2, blue marks) in that range. Analogously is represented the third cultivar.

Visual Techniques for the Interpretation of Data Mining Outcomes 31
Several inferences are concluded by the investigation of the alternative perspec-tives of the segmented high dimensional space provided by those representations. The distribution of the points in each class is quite high. In our application domain that is translated to the conclusion that each cultivar has made sure that it has a variety of types of “rose” wines. That range of middle color intensity is expected to correspond to the category of “rose” wines. Therefore, the distribution of this category to the whole class indicates the different properties of the chemical analysis that those wines have. In other words, there is a significant chemical variance among the wines of this sub-category, indicating the desirable variety of rose wines in each cultivar.
Following a reverse way of thinking, evaluating the three cultivars on respect to the variety of the wines of this type would be like comparing the distribution and the number of wines in each cultivar with color intensity in the range of (3.82 , 4.85]. Examining the corresponding representation of Fig. 3 we could urge that the first and second cultivars have a satisfactory variety and number of “rose” wines, in contradic-tion to the third cultivar which has a small production of wines of this type. The small variance of the third cultivar’s “rose” wines in the representation indicates also the similarity among their chemical analysis factors and as a consequence the small vari-ety among the types of wines of this category.
6 Letter Image Recognition Case Study
Having examined the application of class-preserving projection technique for the visual mining of association rules in 2D we are expecting that the advanced properties of the presented model will be enhanced even more by the additional dimension pro-vided in the 3D space. That flexibility of our projection world is expected to represent more accurately larger volumes of information regarding the classified data and the rules’ sub-spaces.
For our case study we have selected the letter image recognition data set [Blake, 98]. Character images of the 26 capital letters of the English alphabet based on 20 different fonts were converted into 16 primitive numerical attributes (statistical mo-ments and edge counts) that formed our data set. We have chosen to visualize the instances of A, B, C and D letters for the following set of association rules.
Rule Sup.% Conf.% IF ((5.50 < x2ybr <= 6.50)) THEN (lettr=C) 25 32 IF ((5.50 < x2ybr <= 6.50)) THEN (lettr=B) 25 32 IF ((5.50 < x2ybr <= 6.50)) THEN (lettr=D) 25 28
In the context of the classified world constructed, according to our projection tech-nique, the set of tuples that satisfy rules left-hand clause has been represented in Fig. 4 by the white spheres. The instances of letters A, B, C and D have been represented by the red, green, blue and mauve spheres correspondingly. The x2ybar attribute cor-responds to the x2y statistical factor, where x and y are the mean values of the position of the “on” pixels in each character in the horizontal and vertical direction. As expected from the set of rules examined, the tuples with x2ybar within the range of (5.5 , 6.5] are among the classes B, C and D.
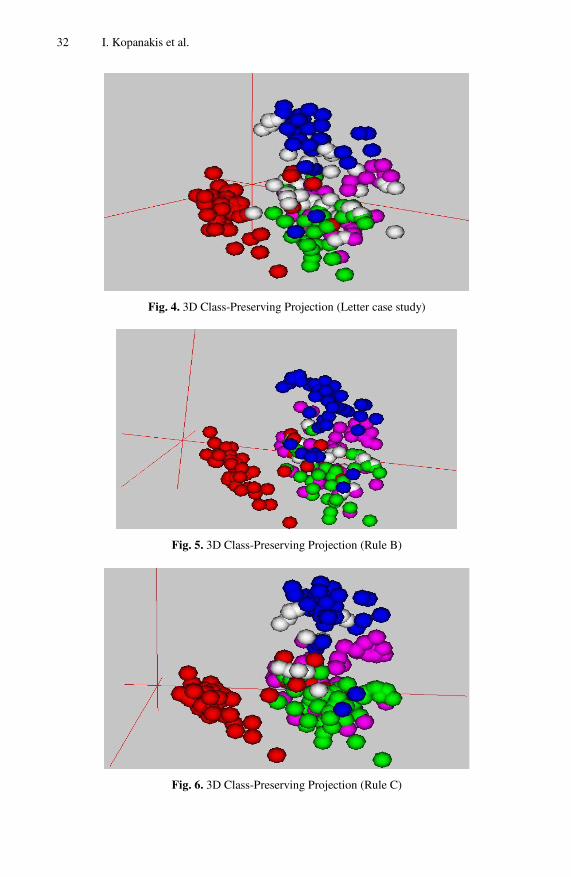
32 I. Kopanakis et al.
Fig. 4. 3D Class-Preserving Projection (Letter case study)
Fig. 5. 3D Class-Preserving Projection (Rule B)
Fig. 6. 3D Class-Preserving Projection (Rule C)

Visual Techniques for the Interpretation of Data Mining Outcomes 33
In Fig. 6 and Fig. 5 we are analogously presenting each one of the rules selected to be mined, following the same coloring scheme. For their printed presentation we tried to select the best viewing angle that would give us an adequate perspective of the 3D world. The resulting image though can not be compared with the actual model devel-oped. The ability to interact and navigate in the constructed 3D world finding visual patters, making assumptions and trying to verify them could not be presented in a single figure.
Our attempt to derive inferences regarding the properties of the statistical factor examined is quite difficult, as it is not easy to assign qualitative properties to the fac-tor x2ybar. A combined observation which is derived when we examine each rule’s representation is that they all tend to occupy space in the area among the classes B, C and D. That directed us to make the assumption that the space among the three classes is the projection space of the examined range (5.5 < x2ybar <= 6.5) in the 3D world. In other words, that hypothesis indicates that most spheres that enter in that region of the 3D world tend to be within the range of (5.5 , 6.5]. Our mapping procedure there-fore, preserved the properties of the classified data, along with the sub-space of the rules examined and projected the x2ybar statistical factor with quite good properties.
7 Related Work
In the context of visualizing classified data, geometric projection techniques try to find “interesting” projections of multidimensional data sets in such a way that the structure, properties and patterns of the data set in the n-dimensional space will be revealed [Spears, 99] [Dhillon, 98] [Dhillon, 99]. Scatter Plots generate N(N-1)/2 pair-wise parallel projections with each one providing a general impression of the relationships among the data visualized, within the context of the pair of dimensions selected (i.e. Scatter-Plot Matrix, HyperSlice [Van, 93]). Advantages of scatter plots include ease of interpretation and robustness to the size of the data set. Major limita-tion though is that the high dimensionality results in decreasing the screen space pro-vided for each projection.
The Prosection Views model indicates the application of the various projection techniques to sections of the data, in the hope that various multidimensional structures will reveal themselves in lower dimensions [Furnas, 94]. Grand Tour Technique & Projection Pursuit model [Spears, 99] smoothly rotate the 2D plane revealing unusual structures within the multidimensional data [Asimov, 85]. The quest for “interesting” projections of the data is referred to as “projection pursuit” [Friedman, 87]. Parallel Coordinates [Inselberg, 85], Radial Coordinate (RadViz) [Hoffman, 00] and GridViz [Hoffman, 99] are also well known techniques of this category.
In the commercial field, several innovative techniques have been proposed. Cluster Visualizer of SGI’s MineSet tool [SGI, M] for the visualization of clustering results uses box plots arranged in rows and columns. For the visualization of association rules, IBM Intelligent Miner - Rules Graph has been based on the graph-based tech-niques [IBM, IMD]. The rules graph uses nodes to represent item sets and lines with arrows to represent rules. The 3D Scatter-Plots of IBM’s Data Explorer [IBM, DE] have been proposed for the exploration of raw data. The SAS Enterprise Miner Scat-ter-Plots [SAS, EM] has utilized the scatter-plot matrix technique linked with simple

34 I. Kopanakis et al.
bar and plot charts. According to SGI’s MineSet Scatter and Splat Visualizers, [SGI, M] data points are represented in one, two, or three dimensional scatter-plots. For the visualization of classified data and association rules several techniques have been proposed. None of them though combines them both.
8 Conclusions
Conclusively, the utilization of the class-preserving projection techniques for the visual mining of association rules is expected to enhance our attempt on gaining in-sight into the properties of the sub-spaces defined by the examined association rules in the context of the classified high dimensional data space. As in the case studies presented, we expect that in general the deductive abilities of the human analytical mind will be capable to combine the perspectives of the high dimensional space pro-vided by those views and analogously derive combined inferences. Interesting infer-ences are possible to be derived and the interaction among the visualization technique and the human is enhanced by the flexibility of the model.
That flexibility and adaptive characteristics of this visual data mining model makes us confident that further study in this research area will derive fruitful outcomes. The research focus should be mainly targeted to the visualization capabilities regarding lager volumes of data and association rules as long as its behavior and capability to reveal visual patterns in a variety of case studies and application domains.
References
[Asimov, 85] D. Asimov: “The Grand Tour: A Tool for Viewing Multidimensional Data”, SIAM Journal on Scientific Computing, 6, 1985, pp.128-143.
[Blake, 98] C. L. Blake & C. J. Merz: “UCI Repository of machine learning databases” [http://www.ics.uci.edu/~mlearn/MLRepository.html]. Irvine, CA: University of California, Department of Information and Computer Science, (1998).
[David, 01] David Law & Yuh Foong: “A Visualization-Driven Approach for Strategic Knowledge Discovery”, In: Information Visualization in Data Mining and Knowledge Discovery, Morgan Kaufmann 2001, pp. 182-190, (2001).
[Dhillon, 98] I. S. Dhillon, D. S. Modha & W. S. Spangler: “Visualizing Class Structure of Multidimensional Data”, Proceedings of the 30th Symposium on the Inter-face: Computing Science and Statistics, Interface Foundation of North Amer-ica, vol. 30, pages 488-493, Minneapolis, May, (1998).
[Dhillon, 99] I. S. Dhillon, D. S. Modha & W. S. Spangler: “Class Visualization of High-Dimensional Data with Application”, IBM Almaden Research Center, San Jose, (1999).
[Frawley, 92] W. Frawley, G. Piatetsky-Shapiro & C. Matheus: “Knowledge Discovery in Databases: An Overview”, AI Magazine, pp. 213-228, (1992).
[Friedman, 87] J. H. Friedman: “Exploratory Projection Pursuit”, Journal of the American Statistical Association, Vol. 82, 1987, pp.249-266.
[Furnas ,94] G. Furnas and A. Buja: “Prosection Views: Dimensional Inference through Sections and Projections”, In: Journal of Computational and Graphical Statis-tics, Vol. 3, No. 4, pp. 323-353, 1994.

Visual Techniques for the Interpretation of Data Mining Outcomes 35
[Hoffman, 00] P. E. Hoffman and G. Grinstein: “Dimensional Anchors: A Graphic Primitive for Multidimensional Multivariate Information”, Workshop of New Para-digms in Information Visualization and Manipulation, in conjunction with the ACM conference on Information and knowledge Management CIKM ’99, to be published in 2000.
[Hoffman, 99] P. E. Hoffman: “Table Visualizations: A Formal Model and its Applications”, Doctoral Dissertation, Computer Science Department, University of Massa-chusetts Lowell, MA, 1999.
[IBM, DE] IBM Open Visualization Data Explorer Project: “What is IBM Open Visuali-zation Data Explorer?”, “Documentation”, “Proceedings of 1996 Data Ex-plorer Symposium”, http://www.research.ibm.com/dx/
[IBM, IMD] IBM DB2 Intelligent Miner for Data: “Using the Intelligent Miner for Data”, http://www-3.ibm.com/software/data/iminer/fordata/
[Inselberg, 85] A. Inselberg: “The plane with Parallel Coordinates”, Special Issue on Compu-tational Geometry, The Visual Computer, Vol. 1, 1985, pp. 69-91.
[Keim, 95] D. A. Keim & H.-P. Kriegel: “Possibilities and Limits in Visualizing Large Amounts of Multidimensional Data”, In: Perceptual Issues in Visualization, Springer 1995, pp. 203-214, (1995).
[SAS, EM] SAS Enterprise Miner: “Data Mining and Enterprise Miner Stand-alone Tuto-rial”, http://www.sas.com/products/miner/
[SGI, M] SGI MineSet ™ Enterprise Edition: “User’s Guide for the Windows”, “Tuto-rial for Windows”, “Reference Guide”, “Interface Guide”, http://www.sgi.com/software/mineset.html
[SGI, M] SGI MineSet ™ Enterprise Edition: “User’s Guide for the Windows”, “Tuto-rial for Windows”, “Reference Guide”, “Interface Guide”, http://www.sgi.com/software/mineset.html
[Spears, 99] W. Spears: “An Overview of Multidimensional Visualization Techniques”, Visualization Workshop of GECCO’99, Genetic and Evolutionary Computa-tion Conference, Orlando, Florida, USA, July 1999.
[Van, 93] J. J. Van Wijk and R. Van Liere: “HyperSlice”, IEEE Visualization ’93, G. M. Nielson and R. D. Bergeron editors, Los Alamitos, CA, IEEE Computer Society Press, 1993, pp.119-125.
[Zhao, 01] K. Zhao & B. Liu: “Visual Analysis of the Behavior of Discovered Rules”, ACM SIGKDD Int. Conf. on Knowledge Discovery & Data Mining (KDD 2001), Proc. Workshop on Visual Data Mining, San Francisco, USA. pp. 59-64, (2001).
Related Documents











