Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis David Patterson Stanford University U.C. Berkeley http://csl.stanford.edu/~christos

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Vector Architectures Vs. Superscalar and VLIW
for Embedded Media Benchmarks
Christos Kozyrakis David Patterson
Stanford University U.C. Berkeley
http://csl.stanford.edu/~christos

2© C. Kozyrakis,11/ 2002
Motivation
• Ideal processor for embedded media processing– High performance for media tasks
– Low cost• Small code size, low power consumption, highly integrated
– Low power consumption (for portable applications)
– Low design complexity
– Easy to program with HLLs
– Scalable
• This work– How efficient is a simple vector processor for embedded media
processing?• No cache, no wide issue, no out-of-order execution
– How does it compare to superscalar and VLIW embedded designs?

3© C. Kozyrakis,11/ 2002
Outline
• Motivation
• Overview of VIRAM architecture
– Multimedia instruction set, processor organization, vectorizing compiler
• EEMBC benchmarks & alternative architectures
• Evaluation
– Instruction set analysis & code size comparison
– Performance comparison
– VIRAM scalability study
• Conclusions

4© C. Kozyrakis,11/ 2002
VIRAM Instruction Set
• Vector load-store instruction set for media processing
– Coprocessor extension to MIPS architecture
• Architecture state
– 32 general-purpose vector registers
– 16 flag registers
– Scalar registers for control, addresses, strides, etc
• Vector instructions
– Arithmetic: integer, floating-point, logical
– Load-store: unit-stride, strided, indexed
– Misc: vector & flag processing (pop count, insert/extract)
– 90 unique instructions

5© C. Kozyrakis,11/ 2002
VIRAM ISA Enhancements
• Multimedia processing
– Support for multiple data-types (64b/32b/16b)
• Element & operation width specified with control register
– Saturated and fixed-point arithmetic
• Flexible multiply-add model without accumulators
– Simple element permutations for reductions and FFTs
– Conditional execution using the flag registers
• General-purpose systems
– TLB-based virtual memory
• Separate TLB for vector loads & stores
– Hardware support for reduced context switch overhead
• Valid/dirty bits for vector registers
• Support for “lazy” save/restore of vector state
6© C. Kozyrakis,11/ 2002
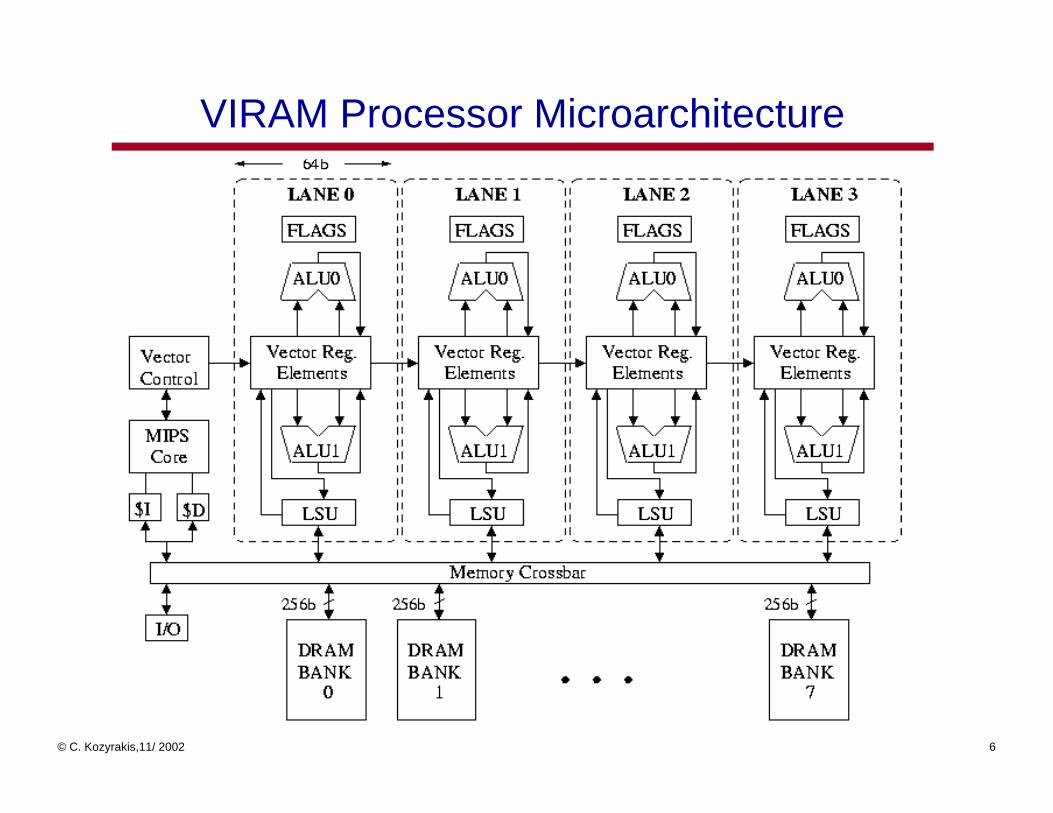
VIRAM Processor Microarchitecture
7© C. Kozyrakis,11/ 2002
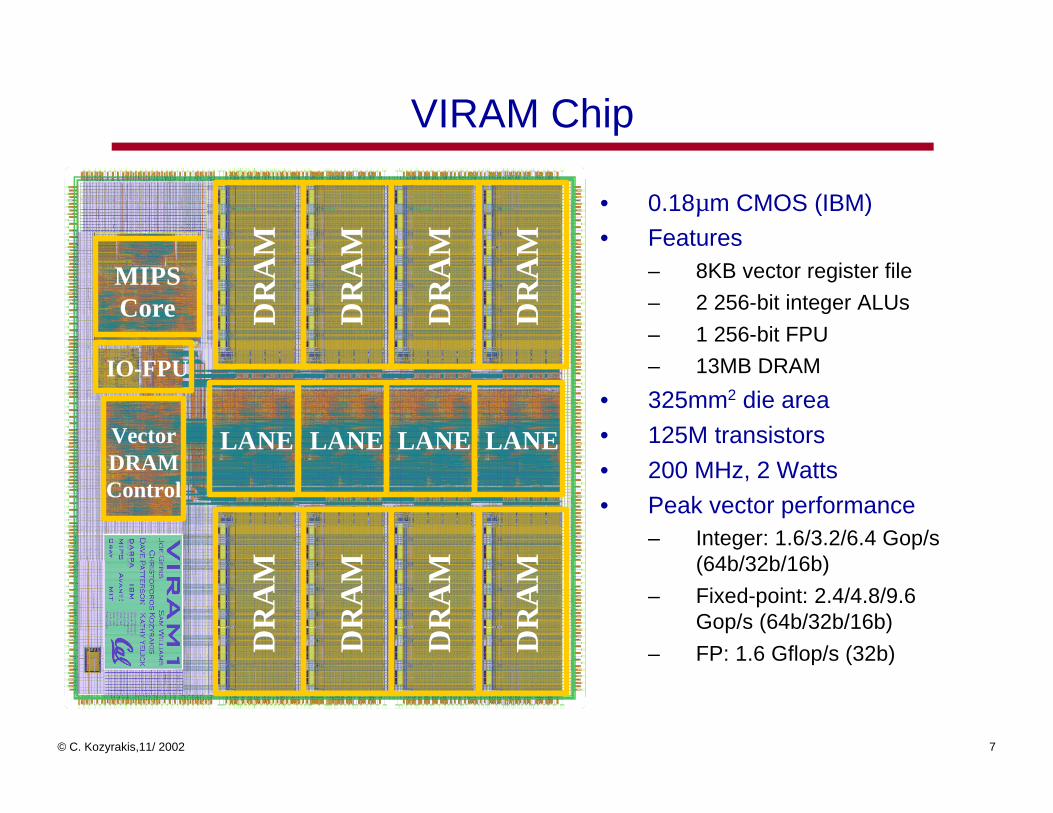
VIRAM Chip
DR
AM
DR
AM
DR
AM
DR
AM
DR
AM
DR
AM
DR
AM
DR
AM
LANE LANE LANE LANE
MIPS Core
IO-FPU
Vector DRAM Control
• 0.18µm CMOS (IBM)
• Features– 8KB vector register file
– 2 256-bit integer ALUs
– 1 256-bit FPU
– 13MB DRAM
• 325mm2 die area
• 125M transistors
• 200 MHz, 2 Watts
• Peak vector performance– Integer: 1.6/3.2/6.4 Gop/s
(64b/32b/16b)
– Fixed-point: 2.4/4.8/9.6 Gop/s (64b/32b/16b)
– FP: 1.6 Gflop/s (32b)
8© C. Kozyrakis,11/ 2002
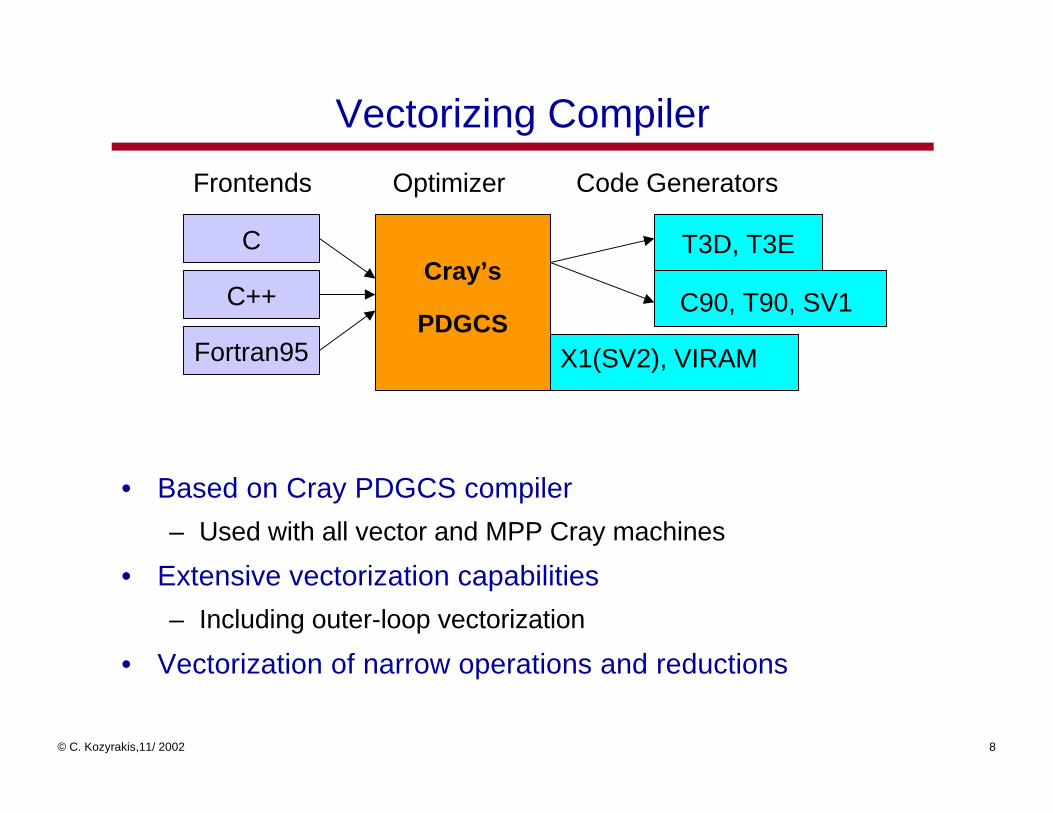
Vectorizing Compiler
• Based on Cray PDGCS compiler
– Used with all vector and MPP Cray machines
• Extensive vectorization capabilities
– Including outer-loop vectorization
• Vectorization of narrow operations and reductions
Optimizer
C
Fortran95
C++
Frontends Code Generators
Cray’s
PDGCS
T3D, T3E
X1(SV2), VIRAM
C90, T90, SV1

9© C. Kozyrakis,11/ 2002
EEMBC Benchmarks
• The de-facto industrial standard for embedded CPUs
• Used consumer & telecommunication categories– Representative of workload for multimedia devices with
wireless/broadband capabilities
– C code, EEMBC reference input data
• Consumer category– Image processing tasks for digital camera devices
– Rgb2cmyk & rgb2yiq conversions, convolutional filter, jpeg encode & decode
• Telecommunication category– Encoding/decoding tasks for DSL/wireless
– Autocorrelation compression, convolutional encoder, DSL bit allocation, FFT, Viterbi decoding

10© C. Kozyrakis,11/ 2002
EEMBC Metrics
• Performance: repeats/second (throughput)
– Use geometric means to summarize scores
• Code size and static data size in bytes
– Data sizes the same for the processors we discuss
• Pitfall with caching behavior
– Fundamentally, no temporal locality in most benchmarks
– Repeating kernel on same (small) data creates locality
– Unfair advantage for cache based architectures
• VIRAM has no data cache for vector loads/stores
11© C. Kozyrakis,11/ 2002
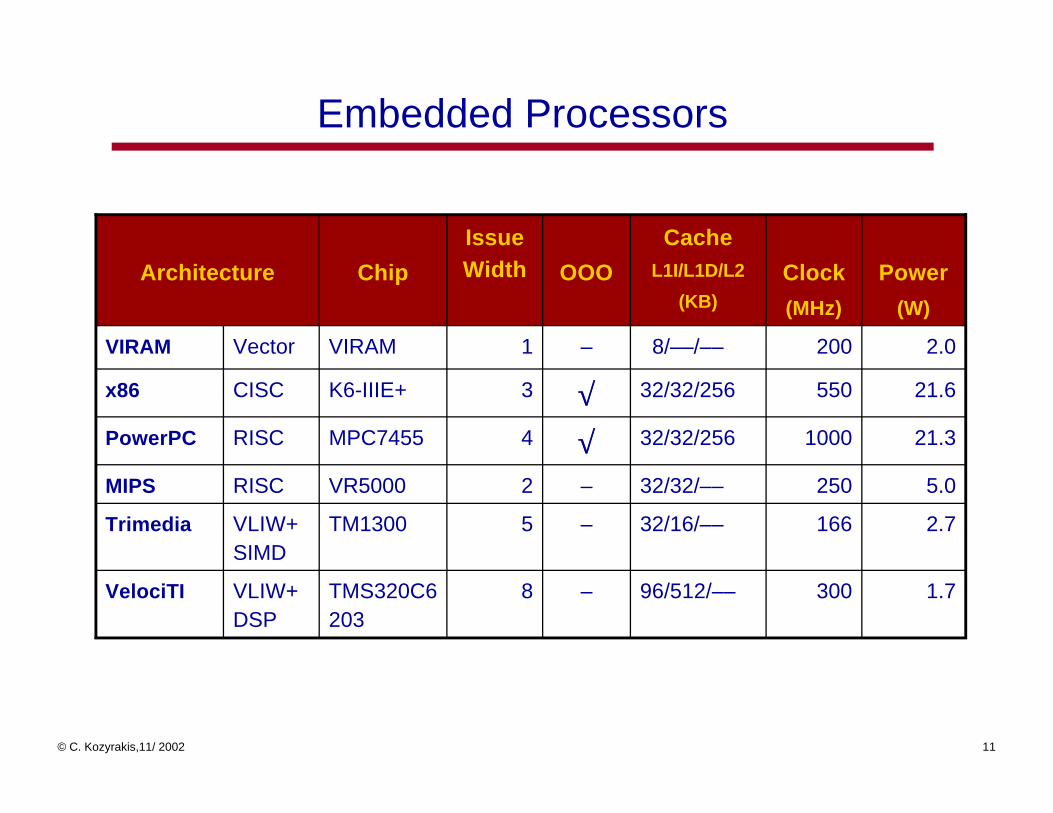
Embedded Processors
1.730096/512/–––8TMS320C6203
VLIW+DSP
VelociTI
2.716632/16/–––5TM1300VLIW+SIMD
Trimedia
5.025032/32/–––2VR5000RISCMIPS
21.3100032/32/256√√4MPC7455RISCPowerPC
21.655032/32/256√√3K6-IIIE+CISCx86
2.02008/––/–––1VIRAMVectorVIRAM
Power
(W)
Clock
(MHz)
CacheL1I/L1D/L2
(KB)
OOO
Issue WidthChipArchitecture
12© C. Kozyrakis,11/ 2002
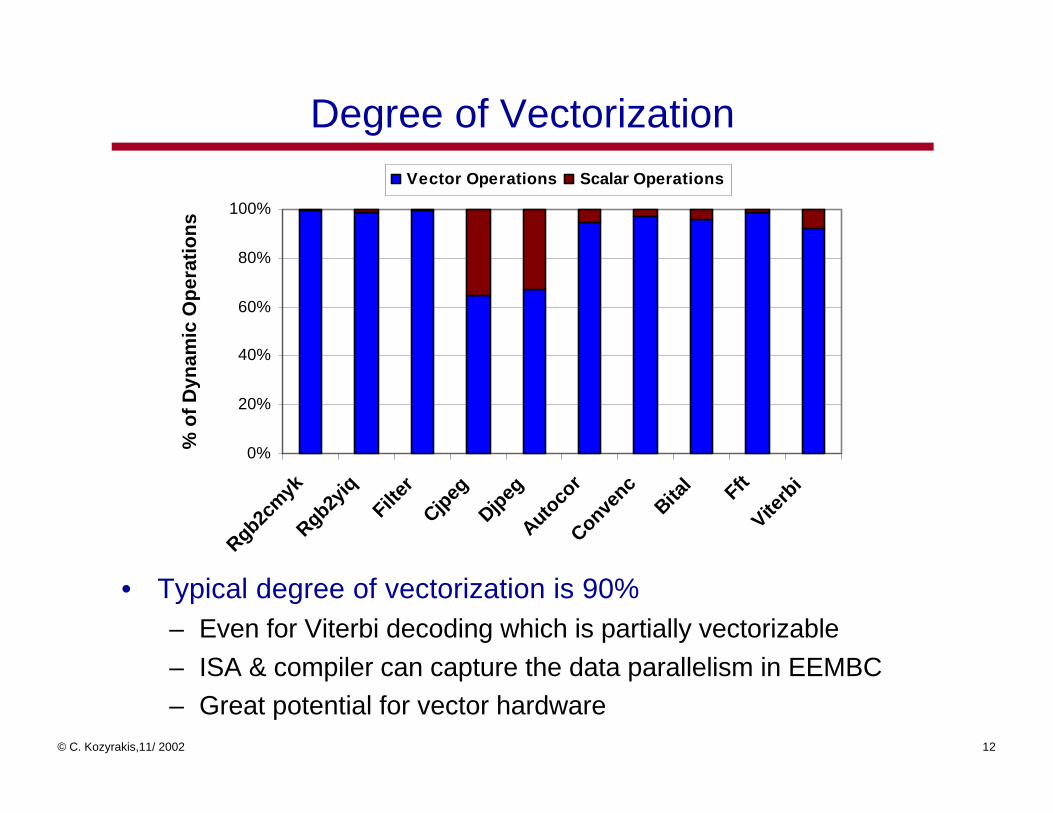
Degree of Vectorization
0%
20%
40%
60%
80%
100%
Rgb2cm
yk
Rgb2yiq
Filter
Cjpeg
Djpeg
Autoco
r
Convenc
Bital Fft
Viterb
i
% o
f D
ynam
ic O
per
atio
ns
Vector Operations Scalar Operations
• Typical degree of vectorization is 90%– Even for Viterbi decoding which is partially vectorizable
– ISA & compiler can capture the data parallelism in EEMBC
– Great potential for vector hardware
13© C. Kozyrakis,11/ 2002
0
20
40
60
80
100
120
Rgb2cm
yk Filter
CjpegDjpeg
Conven
cVite
rbi
Rgb2yiq
CjpegDjpeg
Autocor Bita
l FftVect
or L
engt
h (E
lem
ents
)Average Maximum Supported
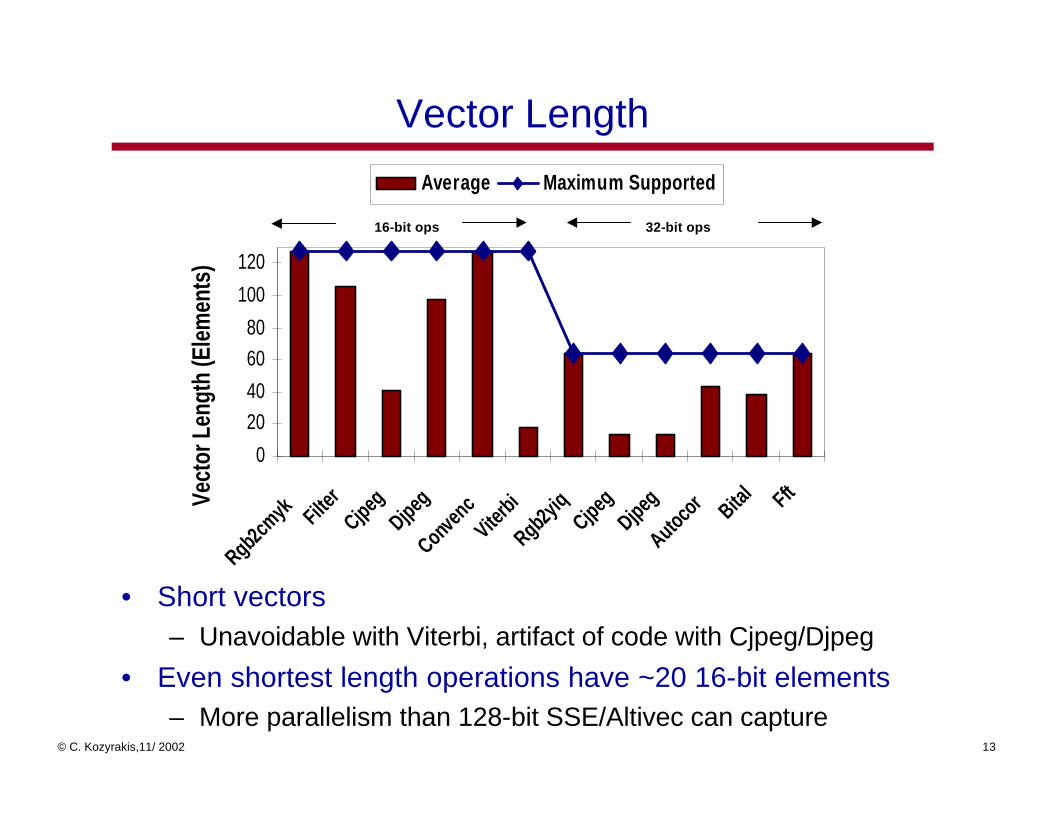
Vector Length
16-bit ops 32-bit ops
• Short vectors– Unavoidable with Viterbi, artifact of code with Cjpeg/Djpeg
• Even shortest length operations have ~20 16-bit elements– More parallelism than 128-bit SSE/Altivec can capture
14© C. Kozyrakis,11/ 2002
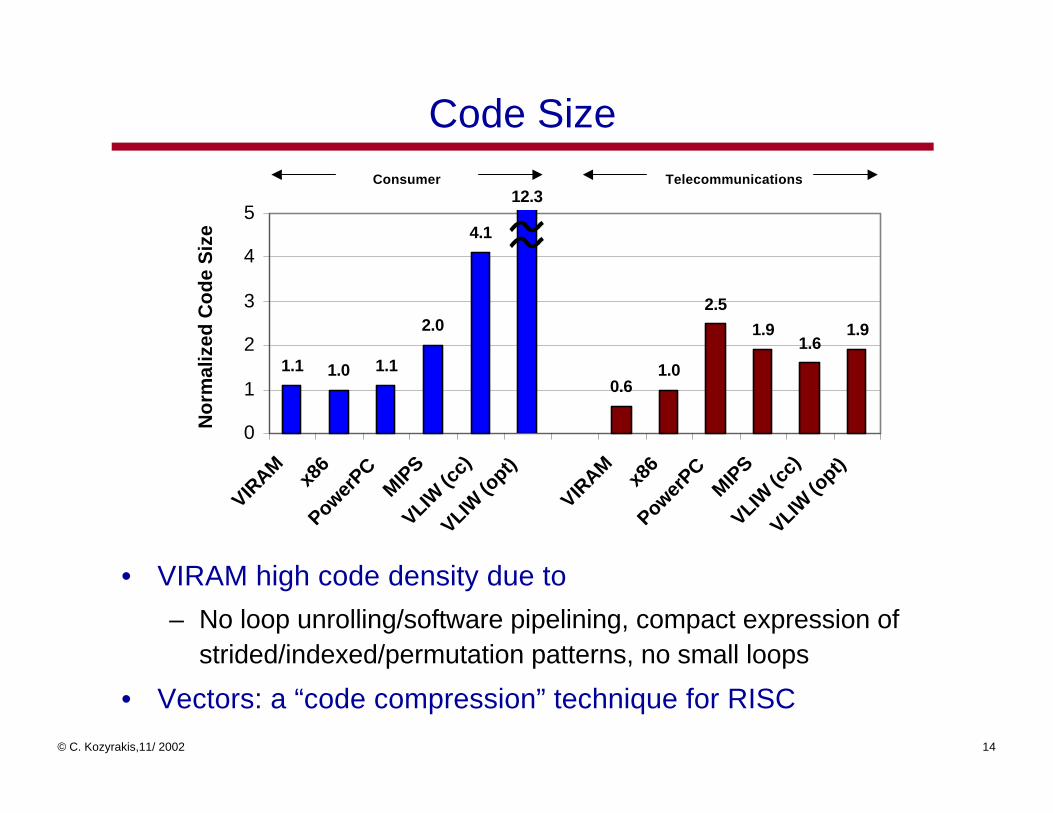
Code Size
• VIRAM high code density due to
– No loop unrolling/software pipelining, compact expression of strided/indexed/permutation patterns, no small loops
• Vectors: a “code compression” technique for RISC
1.1 1.1
2.0
4.1
12.3
0.61.0
2.5
1.91.6
1.9
1.0
0
1
2
3
4
5
VIRAM
x86
PowerPC
MIP
S
VLIW (c
c)
VLIW (o
pt)
VIRAM
x86
PowerPC
MIP
S
VLIW (c
c)
VLIW (o
pt)
No
rmal
ized
Co
de
Siz
eConsumer Telecommunications
15© C. Kozyrakis,11/ 2002
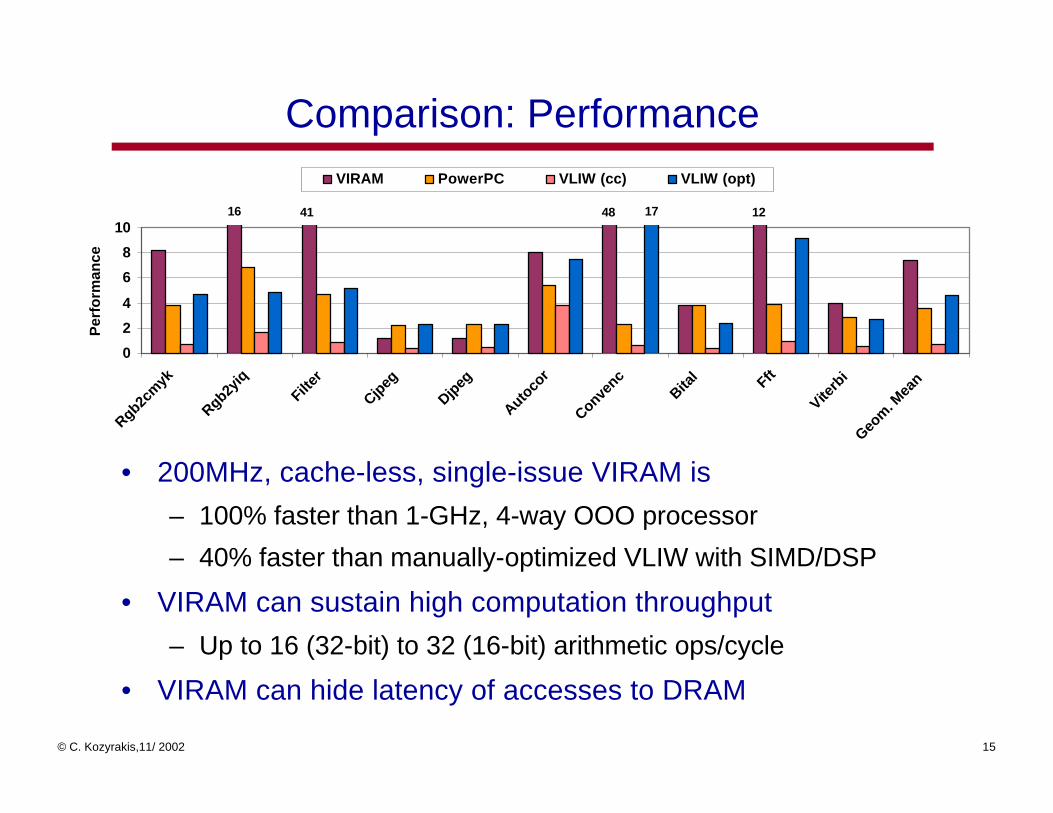
Comparison: Performance
16 41 48 1217
0
2
4
6
8
10
Rgb2cm
yk
Rgb2yiq
Filter
Cjpeg
Djpeg
Autoco
r
Convenc
Bital Fft
Viterb
i
Geom
. Mea
n
Per
form
ance
VIRAM PowerPC VLIW (cc) VLIW (opt)
• 200MHz, cache-less, single-issue VIRAM is
– 100% faster than 1-GHz, 4-way OOO processor
– 40% faster than manually-optimized VLIW with SIMD/DSP
• VIRAM can sustain high computation throughput
– Up to 16 (32-bit) to 32 (16-bit) arithmetic ops/cycle
• VIRAM can hide latency of accesses to DRAM
16© C. Kozyrakis,11/ 2002
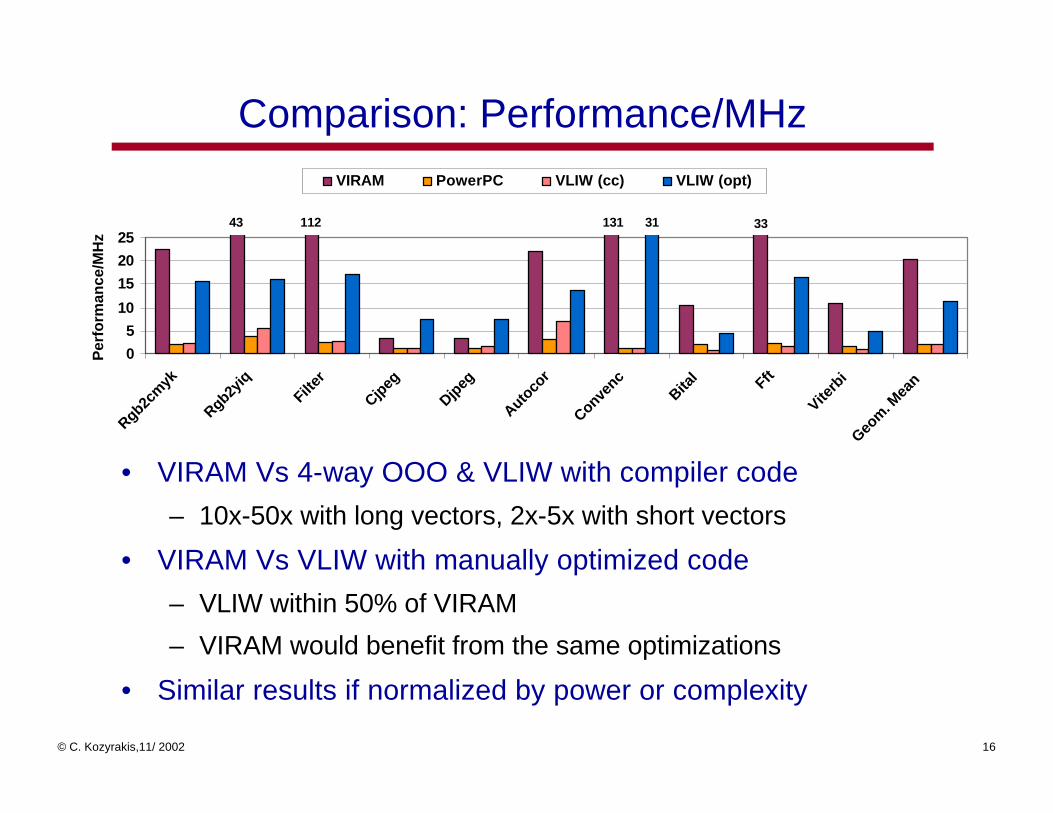
Comparison: Performance/MHz
43 112 131 3331
0
5
10
15
20
25
Rgb2cm
yk
Rgb2yiq
Filter
Cjpeg
Djpeg
Autoco
r
Convenc
Bital Fft
Viterb
i
Geom
. Mea
n
Per
form
ance
/MH
z
VIRAM PowerPC VLIW (cc) VLIW (opt)
• VIRAM Vs 4-way OOO & VLIW with compiler code
– 10x-50x with long vectors, 2x-5x with short vectors
• VIRAM Vs VLIW with manually optimized code
– VLIW within 50% of VIRAM
– VIRAM would benefit from the same optimizations
• Similar results if normalized by power or complexity
17© C. Kozyrakis,11/ 2002
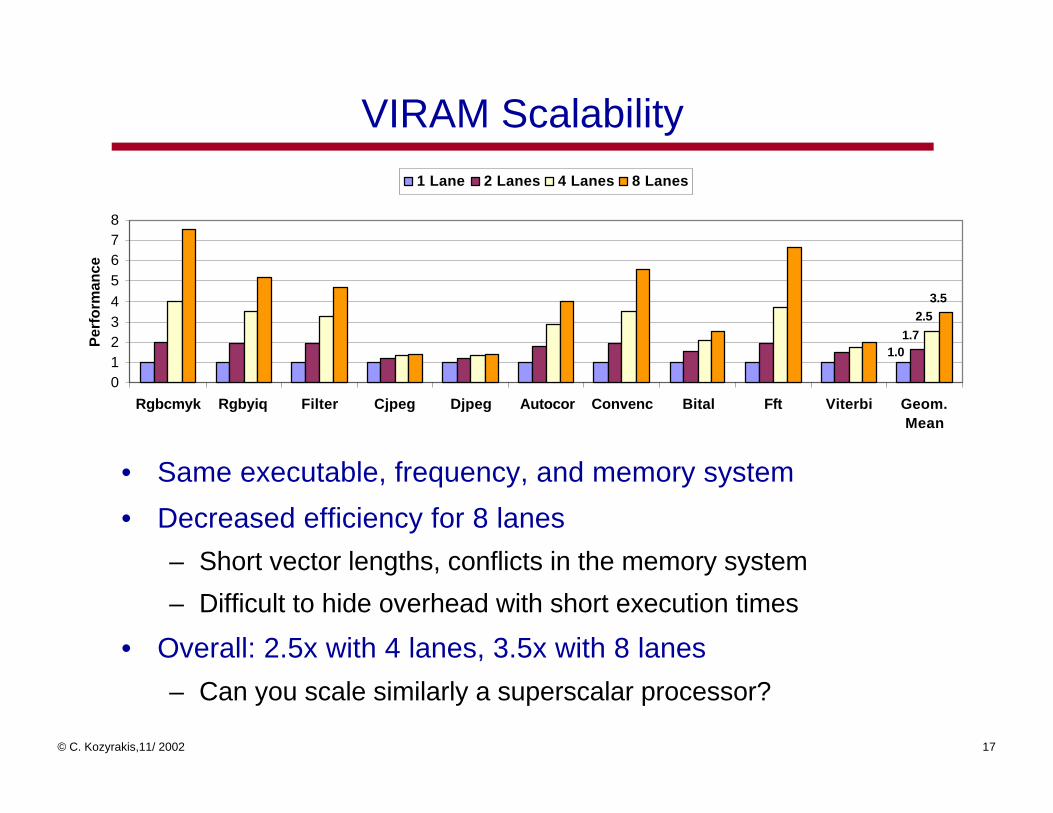
VIRAM Scalability
• Same executable, frequency, and memory system
• Decreased efficiency for 8 lanes
– Short vector lengths, conflicts in the memory system
– Difficult to hide overhead with short execution times
• Overall: 2.5x with 4 lanes, 3.5x with 8 lanes
– Can you scale similarly a superscalar processor?
1.01.7
2.53.5
012345678
Rgbcmyk Rgbyiq Filter Cjpeg Djpeg Autocor Convenc Bital Fft Viterbi Geom.Mean
Per
form
ance
1 Lane 2 Lanes 4 Lanes 8 Lanes

18© C. Kozyrakis,11/ 2002
Conclusions
• Vectors architectures are great match for embedded multimedia processing
– Combined high performance, low power, low complexity
– Add a vector unit to your media-processor!
• VIRAM code density
– Similar to x86, 5-10 times better than optimized VLIW
• VIRAM performance• With compiler vectorization and no hand-tuning
– 2x performance of 4-way OOO superscalar
• Even if OOO runs at 5x the clock frequency
– 50% faster than manually-optimized 5 to 8-way VLIW
• Even if VLIW has hand-inserted SIMD and DSP support
Related Documents











