USATLAS dCache System and Service Challenge at BNL Zhenping (Jane) Liu RHIC/ATLAS Computing Facility, Physics Department Brookhaven National Lab 10/13/2005 HEPIX Fall 2005 at SLAC

USATLAS dCache System and Service Challenge at BNL Zhenping (Jane) Liu RHIC/ATLAS Computing Facility, Physics Department Brookhaven National Lab 10/13/2005.
Dec 13, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

USATLAS dCache System and Service Challenge at BNL
Zhenping (Jane) LiuRHIC/ATLAS Computing Facility, Physics Department
Brookhaven National Lab
10/13/2005 HEPIX Fall 2005 at SLAC

Outline USATLAS dCache system at BNL
Overview of the System Usage of the system Experiences Long-term plan
Service Challenge

USATLAS dCache system at BNL A distributed disk caching system as a
front-end for Mass Storage System (BNL HPSS).
In production service for ATLAS users since November 2004.

Benefits of using dCache Allows transparent access to large amount
of data files distributed on disk pools or stored on HSM (HPSS). Provides the users with one unique name-
space for all the data files. File system names space view available
through an nfs2/3 interface Data is distributed among a large amount of
cheap disk servers.

Benefits of using dCache (Cont.) Significantly improves the efficiency of
connected tape storage systems, through caching, i.e. gather & flush, and scheduled staging techniques.

Benefits of using dCache (Cont.) Clever selection mechanism and flexible
system tuning The system determines whether the file is already
stored on one or more disks or in HPSS. The system determines the source or destination
dCache pool based on storage group and network mask of clients, I/O direction, also “CPU” load and disk space, configuration of the dCache pools.

Benefits of using dCache (Cont.) Load balanced and fault tolerant
Automatic load balancing using cost metric and inter pool transfers.
Dynamically replicate files upon detection of hot spot.
Allow multiple distributed administrative servers for each type, e.g., read pools, write pools, DCAP doors, SRM doors, GridFTP doors.

Benefits of using dCache (Cont.) Scalability
Distributed Movers and Access Points (Doors) Highly distributed Storage Pools Direct client – disk(pool) and disk (pool) – hsm
(HPSS) connection.

Benefits of using dCache (Cont.) Support of various access protocols
Local access protocol: DCAP (posix like) GsiFTP data transfer protocol
Secure Wide Area data transfer protocol Storage Resource Manager Protocol (SRM) -
Provide SRM based storage element Space allocation Transfer Protocol Negotiation Dataset pinning Checksum management

USATLAS dCache system at BNL
Hybrid model for read pool servers Read pool servers (majority of dCache servers) share
resources with worker nodes. Each worker node in Linux farm acts as both storage
and compute node. Cheap Linux farm solution to achieve high
performance data I/O throughput.
Dedicated critical servers Dedicated PNFS node, various door nodes, write
pool nodes.

USATLAS dCache system at BNL (Cont.)
Optimized backend tape prestage batch system. Oak Ridge Batch System
Current version: v1.6.5.2. System architecture (see the next slide)

Read poolsDCap doors
SRM door
GridFTP doors
Control Channel
Write pools
Data Channel
DCap Clients
Pnfs Manager
Pool Manager
HPSS
GridFTP Clients
SRM Clients
Oak Ridge Batch system
DCache System

USATLAS dCache system at BNL (Cont.)
Note: “shared” means that servers share resource with worker nodes

Usage of the system Total amount of datasets (only production data counted)
100.9 TB as of 10/04/2005 (123 TB in HPSS for atlas archive) Grid production jobs have used dCache as data source.
Positive Feedback; Globus-url-copy as client in the past. Future production system.
Will use dCache as both data source and destination, also repository of intermediate data.
Will use SRMCP as client. DCAP protocol will be selected instead of GridFTP for higher performance throughput when jobs and data are both on BNL site
SC3 (testing phase) used production dCache.


Users and use pattern Clients from BNL on-site
Local analysis application from Linux farm (dccp client tool or dCap library) Users write RAW data to the dCache (HPSS), analyze/reanalyze
it on farms, then write results into the dCache (HPSS). Grid production jobs submitted to BNL Linux farm
(globus-url-copy) Currently only use dCache as data sources. Will use it as for
source, intermediate repository and destination. Other on-site users from interactive nodes (dccp)
Off-site grid users GridFTP clients
Grid production jobs submitted to remote sites Other grid users
SRM clients

Experiences and issues Read pool servers sharing resource with worker
nodes. Utilize idle disk on compute nodes. Hybrid model works fine.
Write pool servers Should run on dedicated servers.
Crashed frequently when sharing node with computing. Dedicated servers solved the problem.
XFS shows better performance then EXT3. Need reliable disks.

Experiences and issues (Cont.) Potential PNFS bottleneck problem.
Should use multiple metadata (PNFS) databases for better performance.
Postrgres PNFS database shows better performance and stability than GDBM database.
Issue: no quota control on prestage requests that one user can submit at one time.

Experiences and issues (Cont.) No support for globus-url-copy client to do
3rd party transfer SRMCP support 3rd part transfer, however not
easy to push SRMCP client tool to every site. Anyway, next version of USATLAS
production system will use SRMCP Client.

Experiences and issues (Cont.) Current system is stable.
Continuously running since last restart on July 21st even with intensive SC3 phase in the middle.
One problem: on average, one read server has bad disk per week. Still reasonable.
System administration Not easy in early phase. Much better later
Great help from DESY and FNAL dCache project team. More documents Software is better and better. Developed automatic monitoring scripts to avoid, detect or solve
problems.

Long-term plan To build petabyte-scale grid-enabled
storage element Use petabyte-scale disk space on thousands
of farm nodes to hold most recently used data in disk. Altas experiment run will generate data volumes
each year on the petabyte scale.
HPSS as tape backup for all data.

Long-term plan (Cont.) DCache as grid-enabled distributed storage element
solution. Issues need to be investigated
Is dCache scalable to very large clusters (thousands of nodes)? Expect higher metadata access rate. Potential bottleneck in dCache
Centralized metadata database management currently. Many (i.e. 20) large dCache systems or several very large dCache
system(s)? Will network I/O be a bottleneck for a very large cluster?
How to decrease internal data I/O and network I/O on Linux farm? File affinity Job Scheduler (???)
Monitoring and administration of petabyte scale disk storage system.

Service challenge Service Challenge
To test the readiness of the overall computing system to provide the necessary computational and storage resources to exploit the scientific potential of the LHC machine.
SC2 Disk-to-disk transfer from CERN to BNL
SC3 testing phase Disk-to-disk transfer from CERN to BNL Disk-to-tape transfer from CERN to BNL Disk-to-disk transfer from BNL to Tier-2 centers

SC2 at BNL Testbed dCache
Four dCache pool servers with 1 Gigabit WAN network connection.
SRMCP was used for transfer control. Only two sites used SRM in SC2
Meet the performance/throughput challenges (disk-to-disk transfer rate at 70~80MB/sec from CERN to BNL).

One day data transfer of SC2

SC3 testing phase Steering: FTS Control: SRM Transfer protocol:GridFTP Production dCache system was used with network upgrade to 10
Gbps between USATLAS storage system and BNL BGP router Disk-to-disk transfer from CERN to BNL
Achieved rate at 100~120MB/sec with peak rate at 150MB/sec (sustained for one week)
Disk-to-tape transfer from CERN to BNL HPSS Achieved Rate: 60MB/sec (sustained for one week)
Disk-to-disk transfer testing from BNL to tier-2 centers tier-2 centers: BU, UC, IU, UTA Aggregated transfer rate at 30MB~40MB/sec
Issues: dCache SRM problem; tier-2 network bandwidth; tier-2 storage systems.
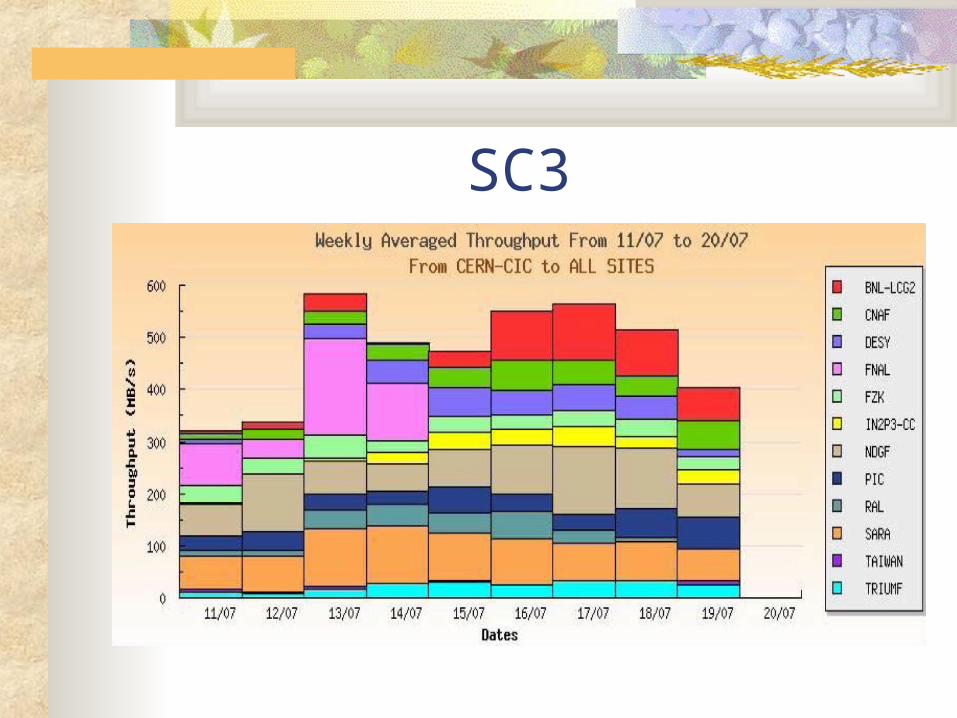
SC3

Top daily averages for dCache sites

Benefits of SC activities Help us identify problems and potential issues in
dCache storage system upon intensive client usage. Report issues to dCache developers.
Srm pinManager crashed with high frequency
Better understanding of potential system bottleneck. PNFS
More monitoring and maintenance tools developed.
System is more stable with fixes.

USATLAS tier-2 dCache deployment USATLAS Tier 1/2 dCache Workshop,
BNL, September 12-13, 2005 http://agenda.cern.ch/fullAgenda.php?ida=a0
55146 UC, UTA, OU have deployed testbed
dCache systems. Ready for SC3 service phase.

dCache development BNL plans to contribute to dCache
development. Very early phase. Still looking for possible
topics One interesting topic: File affinity job scheduler
(Integration of dCache and job scheduler)
Manpower increased in September. Now 2 FTE.

Links BNL dCache user guide website
http://www.atlasgrid.bnl.gov/dcache/manuals/
USATLAS tier-1 & tier-2 dCache systems. http://www.atlasgrid.bnl.gov/dcache_admin/
USATLAS dCache workshop http://agenda.cern.ch/fullAgenda.php?ida
=a055146
Related Documents











