Distributed Systems Programming Project Assignment 2 Using MapReduce on your Hadoop Cluster Paul Krzyzanowski TA: Yuanzhen Gu Rutgers University Fall 2015 1 11/10/15 © 2014-2015 Paul Krzyzanowski

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Distributed SystemsProgramming Project Assignment 2
Using MapReduce on your Hadoop Cluster
Paul Krzyzanowski
TA: Yuanzhen Gu
Rutgers University
Fall 2015
111/10/15 © 2014-2015 Paul Krzyzanowski

The Assignment
• You are provided with United States Census data– Download Zip Code Tabulation Areas Gazetteer File (1.1MB)
which contains:• Zip code identifying an area• Population count• Housing unit count• Land area (m2), water area (m2),• Latitude, longitude
• Find out the potential trend of rise of housing prices in northeast, northwest, southeast, and southwest.– The potential trend of the rise of housing price simply based on the ratio of supply and
demand, which is housing unit count / population density. The smaller the result the higher the trend. This ignores other factors like public infrastructures, community, environment, etc.
– Population density is simply based on population count / land area.
11/10/15 © 2014-2015 Paul Krzyzanowski 2

Assignment Goals
• Solve the problem using map-reduce
• Briefly explain how the input is mapped into (key, value) pairs in the map phase
• Briefly explain how the (key, value) pairs produced by the map stage are processed by the reduce phase
• If the job cannot be done in a single map-reduce pass, describe how it would be structured into two or more map-reduce jobs with the output of the first job becoming input to the next one(s)
• Languages:Java, Python, Go, C++
11/10/15 © 2014-2015 Paul Krzyzanowski 3

Recap – What is Hadoop?
• An open source framework for “reliable, scalable, distributed computing”
• It gives you the ability to process and work with large datasets that are distributed across clusters of commodity hardware
• It allows you to parallelize computation and ‘move processing to the data’ using the MapReduce framework
11/10/15 © 2014-2015 Paul Krzyzanowski 4

Recap – Hadoop Architecture
11/10/15 © 2014-2015 Paul Krzyzanowski 5

Recap – Hadoop Job Configuration Parameters
11/10/15 © 2014-2015 Paul Krzyzanowski 6

How to do this assignment: Step 1
Configuring Your First Hadoop Cluster
11/10/15 © 2014-2015 Paul Krzyzanowski 7

Prerequisites
• Ubuntu Linux 12.04 LTS
• Install Java v1.7+
• Add a dedicated Hadoop system user
• Configure SSH access• Disable IPv6
• Or configure your Hadoop environment on LCSR:– http://www.cs.rutgers.edu/~watrous/hadoop.html– We will give instructions on setting your own cluster in this recitation
11/10/15 © 2014-2015 Paul Krzyzanowski 8

Install Java & Hadoop• We need to install java on the cluster machines in order to run Hadoop
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java7-installer
• Configure JAVA_HOME in both ~/etc/.bashrc & hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/java-7-oracle
11/10/15 © 2014-2015 Paul Krzyzanowski 9

Hadoop Configuration
11/10/15 © 2014-2015 Paul Krzyzanowski 10

Environment variables Setup
• Modify environment variables
Go back to the root and edit the .bashrc file
11/10/15 © 2014-2015 Paul Krzyzanowski 11

Configure HDFS• HDFS is the distributed file system (similar to Google’s GFS) that sits
behind Hadoop instances, syncing data so that it’s close to the processing and providing redundancy– We need to set this up first
• We need to specify some mandatory parameters to get HDFS up and running in various XML configuration files
/usr/local/hadoop/etc/hadoop/yarn-site.xml
11/10/15 © 2014-2015 Paul Krzyzanowski 12

Step 1a: Start HDFS• Begin by starting the HDFS file system from the master server
• There is a script which will run the name node on the master and the data nodes on the slaves:$ cd /usr/local/hadoop/bin/./start-dfs.sh
• Monitor the log files on the master and slaves:$ tail –f /usr/local/hadoop/logs/
11/10/15 © 2014-2015 Paul Krzyzanowski 13
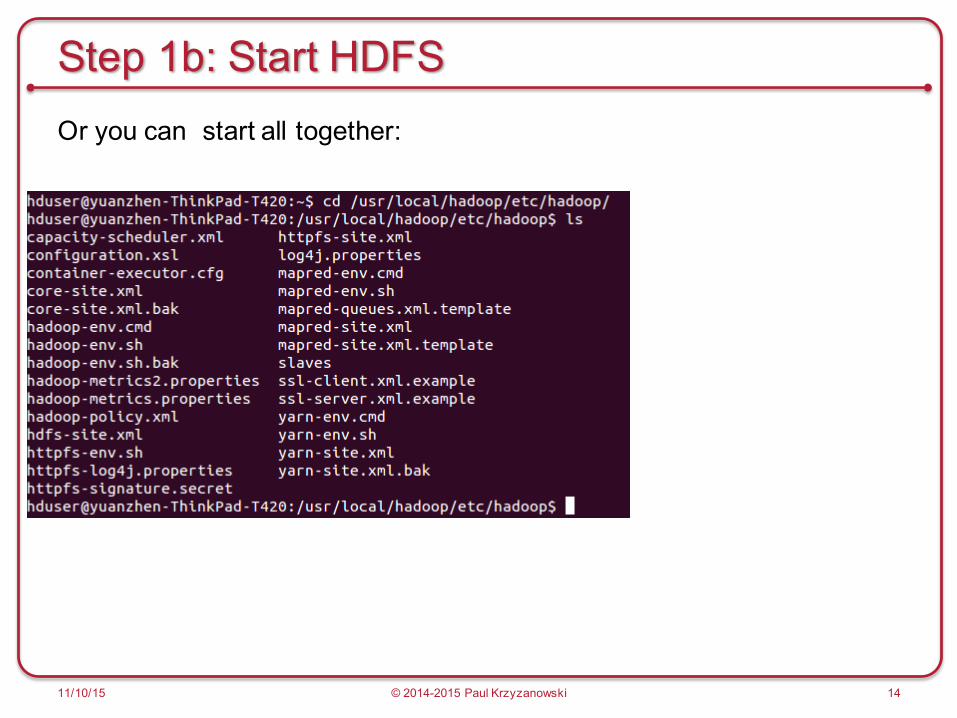
Step 1b: Start HDFSOr you can start all together:
11/10/15 © 2014-2015 Paul Krzyzanowski 14

Explore Hadoop
11/10/15 © 2014-2015 Paul Krzyzanowski 15

Web Interfaces
• HDFS Namenode and check health using http://localhost:50070
• HDFS Secondary Namenode status using http://localhost:50090
• Job Tracker Web UIhttp://192.168.65.134:50030
• TaskTracker Web UI: http://192.168.65.134:50060/
11/10/15 © 2014-2015 Paul Krzyzanowski 16

Hadoop Web Interfaces daemon
11/10/15 © 2014-2015 Paul Krzyzanowski 17

Step 2: Write your MapReduce Code
• The Mapper:
• The Reducer:
• Make sure the above “Word Count” example works properly in your Hadoop environment
11/10/15 © 2014-2015 Paul Krzyzanowski 18
public void map(Object key, Text value, Context context) { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } }
public void reduce(Text key, Iterable<IntWritable> values,Context context){ int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); }

Step 3: Copy data to HDFS & Run jar file
• Before run the actual MapReduce job, you must first copy the file from your local file system to Hadoop’s HDFS
• Download input data and copy data it to HDFS
• Run the MapReduce job$ bin/hadoop jar hadoop*your_program*.jar \
CensusTrend /user/read_file_directory \/user/result_output_directory
11/10/15 © 2014-2015 Paul Krzyzanowski 19

Step 4: Retrieve MapReduce job result
• Check the result is successfully stored in HDFS output directory
• Create a file in locally$ mkdir /local_directory/output_result
• Copy the result file directory from HDFS to local file system$ bin/hadooop dfs –getmerge \
/user/result_output_directory \/local_directory/output_result
• You should also be able to check the result from your Hadoop Web Interface.
11/10/15 © 2014-2015 Paul Krzyzanowski 20

Documentation
• Document your work NEATLY
• For your submission, explain:– The files you’re submitting and what they do– how input is mapped into (key, value) pairs– how (key, value) pairs are processed by reduce phase– If job cannot be done in a single map-reduce pass, describe how it
would be structured into two or more map-reduce jobs– How to compile & run – Any bugs or peculiarities
11/10/15 © 2014-2015 Paul Krzyzanowski 21

The End
11/10/15 22© 2014-2015 Paul Krzyzanowski
Related Documents











