Anjalai Ammal Mahalingam Engineering College Kovilvenni-614 403 Department of Information Technology IT2351 NETWORK PROGRAMMING AND MANAGEMENT UNIT IV ADVANCED SOCKETS 1. IPv4 and IPv6 Interoperability 2. Threads 3. Raw Sockets 4. PING Program 5. Trace Route Program IPv4 and IPv6 Interoperability: - During transition phase i.e., Internet from IPV4 to IPV6, it is important that existing IPV4 applications continue to work with newer IPV6 applications. - For example, a vendor cannot provide a telnet client that works only with IPV6 telnet servers but must provide one that works with IPV4 servers and one that works with IPV6 servers. - 4 combinations of clients and servers 1. IPv4 client and IPv4 server 2. IPv4 client and IPv6 server 3. IPv6 client and IPv4 server 4. IPv6 client and IPv6 server IPV4 Client, IPV6 Server 1. A general property of a dual-stack host is that IPV6 servers can handle both IPV4 and IPV6 clients. 2. This is done using IPv4-mapped IPv6 addresses. EXAMPLE :IPv6 server on dual stack host serving IPv4 and IPv6 clients 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Anjalai Ammal Mahalingam Engineering CollegeKovilvenni-614 403
Department of Information TechnologyIT2351 NETWORK PROGRAMMING AND MANAGEMENT
UNIT IV ADVANCED SOCKETS
1. IPv4 and IPv6 Interoperability
2. Threads
3. Raw Sockets
4. PING Program
5. Trace Route Program
IPv4 and IPv6 Interoperability:- During transition phase i.e., Internet from IPV4 to IPV6, it is important that
existing IPV4 applications continue to work with newer IPV6 applications.- For example, a vendor cannot provide a telnet client that works only with
IPV6 telnet servers but must provide one that works with IPV4 servers and one that works with IPV6 servers.
- 4 combinations of clients and servers1. IPv4 client and IPv4 server2. IPv4 client and IPv6 server3. IPv6 client and IPv4 server4. IPv6 client and IPv6 server
IPV4 Client, IPV6 Server1. A general property of a dual-stack host is that IPV6 servers can handle both IPV4 and
IPV6 clients. 2. This is done using IPv4-mapped IPv6 addresses.
EXAMPLE :IPv6 server on dual stack host serving IPv4 and IPv6 clients
1
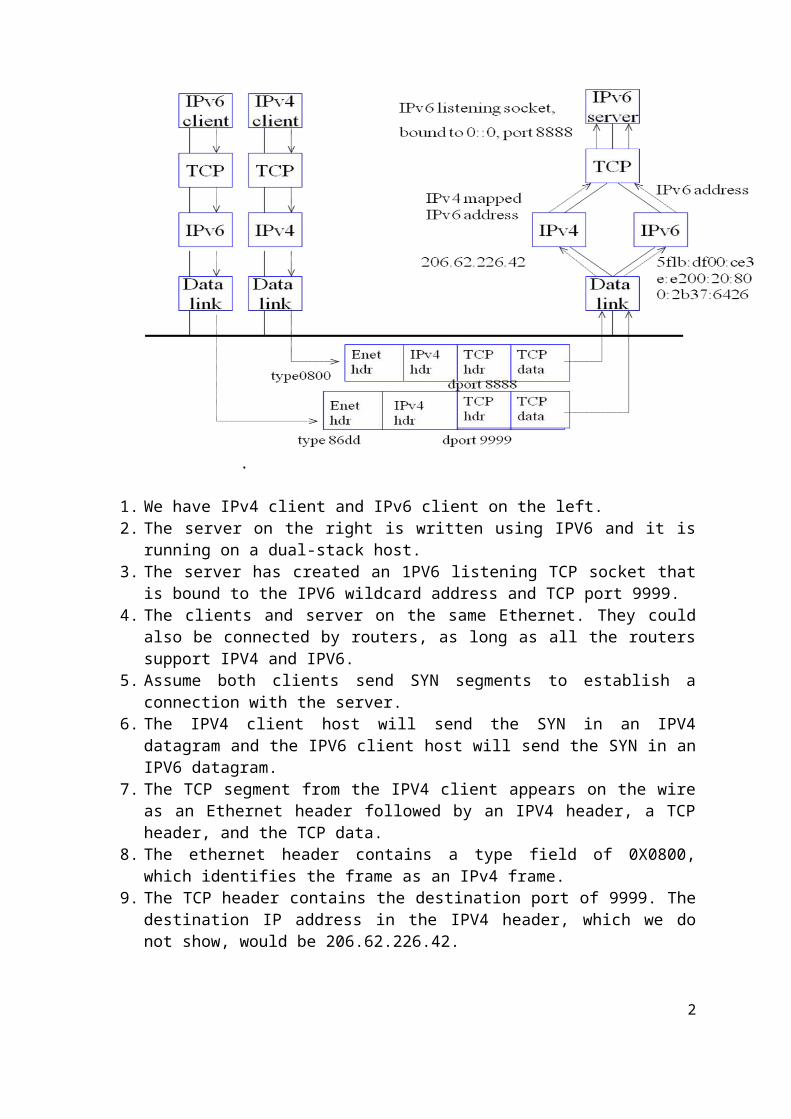
.
1. We have IPv4 client and IPv6 client on the left.2. The server on the right is written using IPV6 and it is running on a dual-stack host. 3. The server has created an 1PV6 listening TCP socket that is bound to the IPV6
wildcard address and TCP port 9999.4. The clients and server on the same Ethernet. They could also be connected by routers,
as long as all the routers support IPV4 and IPV6.5. Assume both clients send SYN segments to establish a connection with the server. 6. The IPV4 client host will send the SYN in an IPV4 datagram and the IPV6 client host
will send the SYN in an IPV6 datagram.7. The TCP segment from the IPV4 client appears on the wire as an Ethernet header
followed by an IPV4 header, a TCP header, and the TCP data.8. The ethernet header contains a type field of 0X0800, which identifies the frame as an
IPv4 frame. 9. The TCP header contains the destination port of 9999. The destination IP address in
the IPV4 header, which we do not show, would be 206.62.226.42.10. The TCP segment from the IPV6 client appears on the wire as an Ethernet header
followed by an IPV6 header, a TCP header, and the TCP data.11. The Ethernet header contains a type field of 0X86dd, which identifies the frame as an
IPv6 frame.12. The TCP header contains the destination port of 9999. The destination IP address in
the IPv6 header, which we do not show, would be 5flb:dfoo:ce3e:e200:20:800:2b37:6426.
13. The receiving datalink looks at the Ethernet type field and passes each frame to the appropriate IP module.
IPV4 TCP Client Communicate with IPV6 ServerSteps
1. The IPv6 server starts, creates an IPv6 listening socket and binds the wildcard address to the socket.
2

2. The IPV4 client calls gethostbyname() and finds an A record for the server. In the dual-stack transition strategy, DNS is populated with A and AAAA records.
3. The client calls connect() and the client’s host sends an IPv4 SYN to the server.4. The server host receives the IPV4 SYN packet. 5. The destination port in the packet indicates an IPV6 listening socket, thus a flag is set
to the server know that this connection is using an IPv4- mapped IPv6 address. 6. The server responds with an IPV4 SYN/ ACK. 7. When the connection is established, the address returned to the server by accept() is
the IPv4-mapped IPv6 address.8. When the server sends message to the IPv4-mapped IPv6 address, its IP stack
generates IPV4 datagrams to the IPV4 address. All communications between the client and server occur over IPv4.
9. Unless the server explicitly checks whether this IPv6 address is an IPv4-mapped IPv6 address, the server never knows that it is communicating with an IPv4 client.
10. The scenario is similar for an IPv6 UDP server, but the address format can change for each datagram.
11. For example ,If an IPv6 server receives a datagram from an IPv4 client, the address returned by recvfrom, will be the client‘s IPv4- mapped IPv6 address.
12. The server responds to this clients request by calling sendto with the IPv4- mapped IPv6 address as the destination. This address format tells the kernel to send IPv4 datagram to the client.
13. But the next datagram received for the server could be an IPv6 datagram, and recvfrom will return the IPv6 address. If the server responds, the kernel will generate an IPv6 datagram.
Most dual stack hosts should use the following rules in dealing with listening sockets:
- A listening IPv4 socket can accept incoming connection from only IPv4 clients.- If server has a listening IPv6 socket that has bound the wildcard address, that
socket can accept incoming connections from either IPv4 client or IPv6 client. For a connection from an IPv4 client, the server‘s local address for the connection will be the corresponding IPv4- mapped IPv6 address.
- If a server has a listening IPv6 socket that has bound an IPv6 address other than an IPv4-mapped IPv6 address, then the socket can accept incoming connections from IPv6 clients only.
IPv6 client and IPV4 Server: This scene is the swapping of the client and server protocols used in the previous case. Consider the IPv6 TCP client running on dual stack host.
1. An IPv4 server starts on an IPv4-only host and creates an IPv4 listening socket. 2. The IPv6 client starts and calls getaddrinfo( ) asking for only IPv6 addresses. (It
enables the RES_USE_INET6 option).3. Since the IPv4-only server host has only A record, an IPv4- mapped IPv6 address
is returned to the client. 4. The IPv6 client calls connect with IPv4-mapped IPv6 address in the IPv6 socket
address structure. The kernel detects the mapped address and automatically sends an IPv4 SYN to the server
5. The server responds with an IPv4 SYN/ACK, and the connection is established using IPv4 datagrams.
3

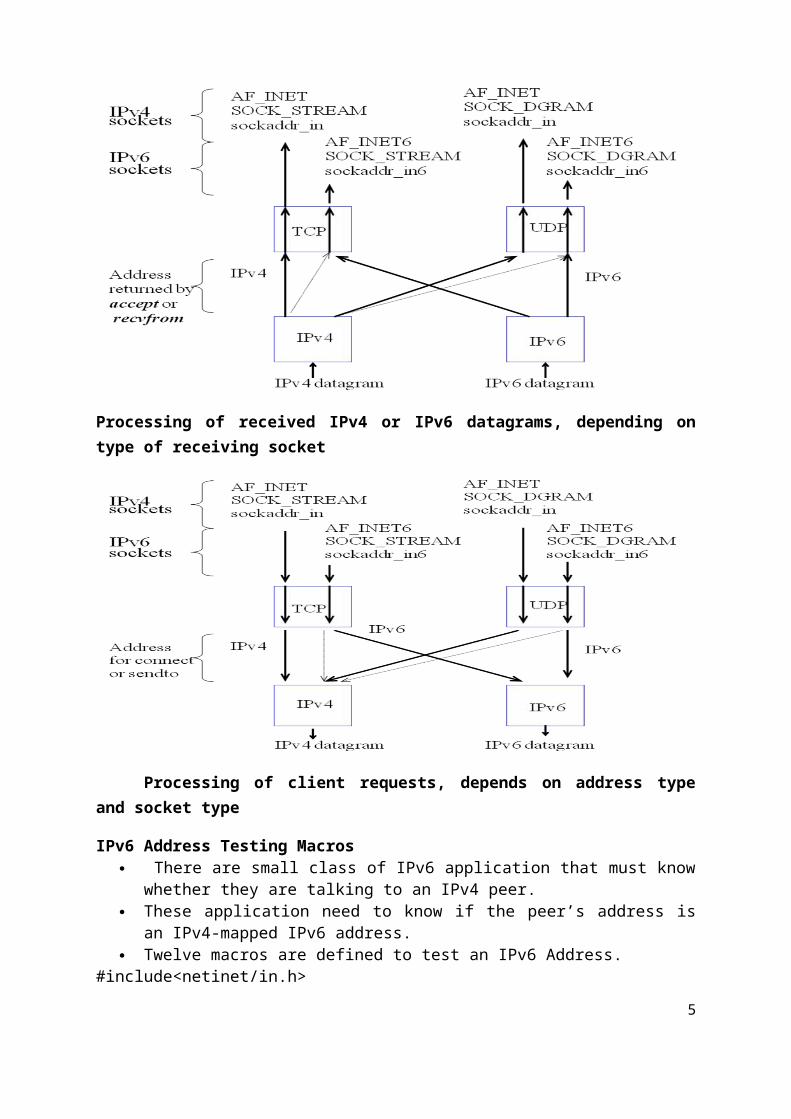
Processing of received IPv4 or IPv6 datagrams, depending on type of receiving socket
Processing of client requests, depends on address type and socket type
IPv6 Address Testing Macros There are small class of IPv6 application that must know whether they are talking to
an IPv4 peer. These application need to know if the peer’s address is an IPv4-mapped IPv6 address. Twelve macros are defined to test an IPv6 Address.
#include<netinet/in.h>
int IN6_IS_ADDR_UNSPECIFIED (const struct in6_addr *addr);
int IN6_ IS_ ADDR_ LOOPBACK (const struct in6_addr *addr);
int IN6_IS_ADDR_MULTICAST (const struct in6_addr *addr);
4
int IN6_ IS_ ADDR_ LINKLOCAL (const struct in6_addr *addr);
int IN6 _IS_ ADDR_ SITELOCAL (const struct in6 addr *addr);
int IN6_IS_ADDR_V4MAPPED (const struct in6_addr *addr);
int IN6_IS_ADDR_V4COMPAT (const struct in6_addr *addr);
int IN6_IS_ADDR_MC_NODELOCAL (const struct in6_addr *addr);
int IN6_IS_ADDR_MC_LINKLOCAL (const struct in6 addr *addr);
int IN6_IS_ADDR_MC_SITELOCAL (const struct in6_addr *addr);
int IN6_IS_ADDR_MC_ORGLOCAL (const struct in6_addr *addr);
int, IN6_IS_ADDR_MC_GLOBAL (const struct in6_addr *addr);
All return: nonzero if IPv6 address is of specified type, zero otherwise
THREAD
* When a process needs something to be performed by another entity, it forks a child process and lets the child perform processing. (Similar to concurrent server program.)For example, in UNIX the parent accepts the connection, forks a child, and the child handles the client. The problem associated with fork are:
a. fork is expensive . All descriptors are copied from parent to child thereby occupying more memory.
b. Inter process communication (IPC) requires to pass information between the parent and child after each fork. Passing information from the parent to the child before thefork is easy, since the child starts with a copy of the parent's data space and with a copy of all the parent's descriptors. But, returning information from the child to the parent takes more work.
* Threads Threads help with both problems. Threads are sometimes called lightweight processes since a thread is "lighter weight" than a process. That is, thread creation can be 10–100 times faster than process creation.
All threads within a process share the same global memory. This makes the sharing of information easy between the threads, but along with this simplicity comes the problem of synchronization.
In addition to these global variables, threads also share 1. Process instructions 2. Data 3. Open files 4. Signal handlers and signal dispositions 5. Current working directory 6. User Groups Ids.
5

But each thread has its own
1. Thread ID2. Set of registers including program counter and stack pointer)3. Stack( for local variables and return addresses)4. errno 5. Signal mask 6. Priority
Basic thread functions: Creation and TerminationThere are five basic thread functions 1.pthread_create function:
When a program is started by exec, a single thread is created, called the initial thread or main thread.
Additional threads are created by pthread_create.
#include<pthread.h>int int pthread_create (pthread_t *tid, const pthread_attr_t *attr, void * (*func) (void*), void arg );
Returns 0 if OK,positive Exxx value on error
tid: Each thread within a process is identified by a thread ID, whose datatype is pthread_t (often an unsigned int). On successful creation of a new thread, its ID is returned through the pointer tid.
- It is the thread ID whose data type is pthread_t - unsigned integer. pthread_atttr_t :
- Each thread has a number of attributes – priority, initial stack size, whether it should be a demon thread or not.
- If this variable is specified, it overrides the default. To accept the default, attr argument is set to null pointer. *func :
- When the thread is created, a function is specified for it to execute. - The thread starts by calling this function and then terminates either explicitly (by calling
pthread_exit) or implicitly by letting this function to return. - The address of the function is specified as the func argument and this function is called
with a single pointer argument, arg. - If multiple arguments are to be passed, the address of the structure can be passed. - The function takes one argument – a generic pointer (void *) and returns a generic
pointer ( void *). This lets us to pass one pointer to the thread and return one pointer. - The return is normally 0 if OK or nonzero on an error .
2.pthread_join function : #include<pthread.h>int pthread_join (pthread_t tid, void ** status ) Returns 0 if OK,positive Exxx value on error
1. We can wait for a given thread to terminate by calling pthread_join .2. Comparing threads to unix processes, pthread_create is similar to fork,and
pthread_join is similar to waitpid.3. We must specify the tid of the thread that we want to wait for. 4. If the status pointer is non -null, the return value from the thread is stored in the
location pointed to by status.
6

3.pthread_self function : 1. Each thread has an ID that identifies it within a given process. 2. The thread ID is returned by pthread_create.3. This function fetches this value for itself by using pthread_self function:
#include<pthread.h>pthread_t pthread_self(void);
Returns :thread ID of calling thread4.pthread_detach function :
1. A thread is either joinable (the default) or detached. 2. When a joinable thread terminates, its thread ID and exit status are retained until
thread calls pthread_join(). 3. But a detached thread is like a daemon process: when it terminates, all its
resources are released and we cannot wait for it to terminate. 4. If one thread needs to know when another thread terminates, it is best to leave the
thread as joinable. #include<pthread.h>
int pthread_detach (pthread_t tid); Returns 0 if OK,positive Exxx value on error
5.pthread_exit function: 1. One way for a thread to terminate is to call pthread_exit().
#include<pthread.h>void pthread_exit (void *status);
Does not return to caller
The pointer status must not point to an object that is local to the calling thread, since that object disappears when the thread terminates.
There are two ways for a thread to terminate
1. The function that started the thread can return. Since this function must be declared as returning a void pointer that return value is the exit status of the thread.
2. If the main function of the process returns or if any thread calls exit, the process terminates, including any threads.
TCP Echo Server Using Threads
Here we redo our TCP echo server using one thread per client instead of one child process per client. We also make it protocol independent, using our tcp_listen function.
1 #include “unpthread.h”
2 static void *doit (void *); /* each thread executes this function */
3 int
4 main (int argc, char ** argv)
5 {
6 int listenfd, connfd; 7

7 pthread_t tid;
8 socklen_t addrlen,len;
9 struct sockaddr * cliaddr;
10 if (argc ==2)
11 1istenfd = TCP_listen (NULL, argv[l], & addrlen);
12 else if (argc ==3)
13 listendfd = TCP_listen (argv[l], argv[2], & addrlen);
14 else
15 err_quit (“usage: tcpserv0l [<host>] <service or port>”);
16 cliaddr = Malloc(addrlen);
17 for ( ; ; ) {
18 1en=addr1en;
19 connfd = Accept (listenfd, clidaddr, &len);
20 Pthread_create (&tid, NULL, & doit, (void*) connfd):
21 }
22 }
23 static void *
24 doit (void *arg)
25 {
26 pthread_detach (pthread_self( ));
27 str_echo ((int) arg); /* same function as before */
28 close ((int)arg); / * done with connected socket */
29 return (NULL);
30 }
Line 17-21: Create a thread
When accept returns, we call pthread_create instead of fork. The single argument that we pass to the do it function is the connected socket descriptor, connfd.
8

Line 23-30: Thread function
- doit is the function executed by the thread. The thread detaches itself since there is no reason for main thread to wait for each thread that it creates.
- When str_echo function returns, we must close the connected socket.
- With fork, the child did not need to close the connected socket because when the child terminated, all open descriptors were closed on process termination.
- The main thread does not close the connected socket, which we always did with a concurrent server that calls fork.
- This is because all threads within a process share the descriptors, so if the main thread called close, it would terminate the connection.
- Creating a new thread does not affect the reference counts for open descriptors, which is different from fork.
Passing arguments to new threads
- We cast the integer variable connfd to be a void pointer, but this is not guaranteed to work on all systems.
- To handle this we need additional work. First we should not pass the address of connfd to the new thread.
- From ANSIC perspective this is acceptable: we are guaranteed that we can cast the integer pointer to be a void * and then cast this pointer back to an integer pointer.
- The problem is that what this pointer points to.
- There is one integer variable, connfd in the main thread, and each call to accept overwrites this variable with new value.
Solution to this problem
- Each time we call accept, we first call malloc and allocate space for an integer variable, the connected descriptor.
- This gives each thread its own copy of the connected descriptor.
- The thread fetches the value of the connected descriptor and then calls free to release the memory.
Thread-Safe Functions
- Posix 1 requires all functions desired by ANSIC standard be thread safe. Even though some vendors have defined thread safe versions whose names end in _r, these is no standard for these functions and they should be avoided.
9

- Two of the functions are thread safe only if the caller allocates space for the result and passes the pointer as argument to the function.
Mutexes: Mutual Exclusion
1. The main problem is multiple threads updating a shared variable.
2. The solution is to protect the shared variable with a mutex and access the variable only when we hold the mutex.
3. In terms of Pthreads, a mutex is a variable of type pthread_mulex_t.
4. We lock and unlock the mutex using the following two functions.
#include<pthread.h>
int pthread_mutex_lock (pthread_mutex_t * mptr) ;
int pthread_mutex_unlock (pthread_mutex_t *mptr):
Both return: 0 if OK, positive Exxx value on error
5. If we try to lock a mutex that is already locked by some other thread, we are blocked until the mutex is unlocked.
6. If a mutex variable is statically allocated, we must initialize it to the constant PTHREAD_MUTEX_INITIALIZER.
7. If we allocate a mutex in shared memory we must initialize it at run time by calling the pthread_mutex_init function.
Condition variables
1. A mutex is fine to prevent simultaneous access to a shared variable, but we need something else to let us go to sleep waiting for some condition to occur.
2. We cannot call the pthread function until we know that a thread has terminated.
3. We first declare a global variable that counts the number of terminated threads and protect it with a mutex.
4. We want a method for the main loop to go to sleep until one of its threads notifies it that something is ready.
5. A condition variable, in conjunction with a mutex, provides this facility.
6. The mutex provides mutual exclusion and the condition variable provides a signaling mechanism.
7. In terms of Pthreads, a condition variable is a variable of type pthread_cond_t.
8. They are used with the following two functions.
10

#include <pthread.h>
int pthread_cond_wait (pthread_cond_t *cptr, pthread_mutex_t * mptr);
int pthread_cond_signal (pthread_cond_t * cptr).;
Both return: 0 if OK, positive Exxx value on error.
9. Exampleint ndone;pthread_mutex_t ndone_mutex= PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t ndone_mutex= PTHREAD_COND_INITIALIZER;Pthread_mutex_lock(&ndone_mutex);ndone++;Pthread_cond_signal(&ndone_cond);Pthread_mutex_unlock(&ndone_mutex);
RAW SOCKET BASICS
Raw sockets provide three features not provided by normal TCP and UDP sockets:
1. Raw sockets let us read and write ICMPv4, IGMPv4, and ICMPv6 packets.
The ping program, for example, sends ICMP echo requests and receives ICMP echo replies.
The multicast routing daemon, mrouted, sends and receives IGMPv4 packets.
This capability also allows applications that are built using ICMP or IGMP to be handled entirely as user processes, instead of putting more code into the kernel.
2. With a raw socket, a process can read and write IPv4 datagrams with an IPv4 protocol field that is not processed by the kernel.
Most kernels only process datagrams containing values of 1 (ICMP), 2 (IGMP), 6 (TCP), and 17 (UDP).
But many other values are defined for the protocol field: The IANA’s “Protocol Numbers” registry lists all the values.
For example, the OSPF routing protocol does not use TCP or UDP, but it uses IP directly, setting the protocol field of the IP datagram to 89.
The gated program that implements OSPF must use a raw socket to read and write these IP datagrams since they contain a protocol field the kernel knows nothing about. This capability carries over to IPv6 also.
11

3. With a raw socket, a process can build its own IPv4 header using the IP _HDRINCL socket option. This can be used, for example, to build UDP and TCP packets.
Raw socket creation
The steps involved in creating a raw socket are as follows:
1. The socket function creates a raw socket when the second argument is SOCK_ RAW. The third argument (the protocol) is normally nonzero. For example, to create an IPv4 raw socket we would write
int sockfd;
sockfd = socket(AF_INET, SOCK RAW, protocol);
where protocol is one of the constants, IPPROTO_xxx, defined by including the <netinet/in.h> header, such as IPPROTO_ ICMP.
Only the super user can create a raw socket. This prevents normal users from writing their own IP datagrams to the network.
2. The IP_HDRJNCL socket option can be set as follows:
const int on = 1;
if (setsockopt(sockfd, IPPROTOJP, IP_HDRINCL, &on, sizeof(on)) < 0) error
3. bind can be called on the raw socket, but this is rare. This function sets only the local address: There is no concept of a port number with a raw socket.
4. With regard to output, calling bind sets the source IP address that will be used for datagrams sent on the raw socket (but only if the IP_HDRINCL socket option is not set).
5. If bind is not called, the kernel sets the source IP address to the primary IP address of the outgoing interface.
6. connect can be called on the raw socket, but this is rare.
7. This function sets only the foreign address: Again, there is no concept of a port number with a raw socket.
8. With regard to output, calling connect let us call write or send instead of sendto, since the destination IP address is already specified.
Raw socket output
Output on a raw socket is governed by the following rules:
1. Normal output is performed by calling sendto or sendmsg and specifying the destination IP address.
12

2. write, writev, or send can also be called if the socket has been connected.3. If the IP_HDRINCL option is not set, the starting address of the data for the
kernel to send specifies the first byte following the IP header because the kernel will build the IP header and prepend it to the data from the process.
4. The kernel sets the protocol field of the IPv4 header that it builds to the third argument from the call to socket.
5. If the IP_HDRINCL option is set, the starting address of the data for the kernel to send specifies the first byte of the IP header.
6. The amount of data to write must include the size of the caller’s IP header. The process builds the entire IP header, except:
(i) the IPv4 identification field can be set to 0, which tells the kernel to set this value.
(ii) the kernel always calculates and stores the IPv4 header checksum.
(iii) IP options may or may not be’included;
7. The kernel fragments raw packets that exceed the outgoing interface Maximum Transmission Unit.
Raw socket input
The first question that we must answer regarding raw socket input is: Which received IP datagrams does the kernel pass to raw sockets? The following rules apply:
1. Received UDP packets and received TCP packets are never passed to a raw socket. If a process wants to read IP datagrams containing UDP or TCP packets, the packets must be read at the datalink layer.
2. Most ICMP packets are passed to a raw socket after the kernel has finished processing the ICMP message. Berkeley-derived implementations pass all received ICMP packets to a raw socket other than echo request, timestamp request, and address mask request. These three ICMP messages are processed entirely by the kernel.
3. All IGMP packets are passed to a raw socket after the kernel has finished processing the IGMP message.
4. All IP datagram with a protocol field that the kernel does not understand are passed to a raw socket. The only kernel processing done on these packets is the minimal verification of some IP header fields: the IP version, IPv4 header checksum, header length, and destination IP address.
5. If the datagram arrives in fragments, nothing is passed to a raw socket until all fragments have arrived and have been reassembled.
- When the kernel has an IP datagram to pass to the raw sockets, all raw sockets for all processes are examined, looking for all matching sockets.
- A copy of the IP datagram is delivered to each matching socket.
13

- The following tests are performed for each raw socket and only if all three tests are true is the datagram delivered to the socket
(i) If a nonzero protocol is specified when the raw socket is created (the third argument to socket), then the received datagram’s protocol field must match this value or the datagram is not delivered to this socket.
(ii) If a local IP address is bound to the raw socket by bind, then the destination IP address of the received datagram must match this bound address or the datagram is not delivered to this socket.
(iii) If a foreign IP address was specified for the raw socket by connect, then the source IP address of the received datagram must match this connected address or the datagram is not delivered to this socket.
- Notices that if a raw socket is created with a protocol of 0, and neither bind nor connect is called, then that socket receives a copy of every raw datagram the kernel passes to raw sockets.
- Whenever a received datagram is passed to a raw IPv4 socket, the entire datagram, including the IP header, is passed to the process.
- For a raw IPv6 socket, only the payload (i.e., no IPv6 header or any extension headers) is passed to the socket.
Limitations of Raw Sockets
1. Loss of Reliability
2. No ports
3. Non Standard Communications
4. No automatic ICMP
5. No Raw TCP or UDP
6. Must have root (or administrator) privilege
PING PROGRAM
1. The ping program works with both IPv4 and IPv6.
2. We will develop our own program instead of presenting the publicly available source code for two reasons.
3. First, the publicly available ping program suffers from a common programming disease known as creeping featurism: It supports a dozen different options.
14

4. Our goal in examining a ping program is to understand the network programming concepts and techniques without being distracted by all these options.
5. Our version of ping supports only one option and is about five times smaller than the public version.
6. Second, the public version works only with IPv4 and we want to show a version that also supports IPv6.
Operation of PING Program:
1. The operation of ping is extremely simple: An ICMP echo request is sent to some IP address and that node responds with an ICMP echo reply.
2. These two ICMP messages are supported under both IPv4 and IPv6. The below Figure shows the format of the ICMP messages.
0 7 8 15 16 31
type code checksum
Identifier Sequence number
Optional Data
Format of ICMPv4 and ICMPv6 echo request and echo reply messages
3. The identifier represents the PID of the ping process; sequence number is initialized for the first packet and increment by one for each packet we send.
4. We store the 8-byte timestamp of when the packet is sent as the optional data.
5. The rules of ICMP require that the identifier, sequence number, and any optional data be returned in the echo reply.
6. Storing the timestamp in the packet lets us calculate the RTT when the reply is received.
7. Some examples are shown of our program. The first uses IPv4 and the second uses IPv6. Note that we made our ping program set-user-ID, as it takes superuser privileges to create a raw socket.
Sample output from our ping program.15

freebsd % ping www.google.com PING www.google.com (216.239.57.99): 56 data bytes 64 bytes from 216.239.57.99: seq=0, ttl=53, rtt=5.611 ms 64 bytes from 216.239.57.99: seq=l, ttl=53, rtt=5.562 ms 64 bytes from 216.239.57.99: seq=2, ttl=53, rtt=5.589 ms 64 bytes from 216.239.57.99: seq=3, ttl=53, rtt=5.910 msFreebsd % ping www.kame.net
PING orange.kame.net (2001:200:0:4819:203:47ff:fea5:3085): 56 data bytes64 bytes from 2001:200:0:4819:203:47ff:fea5:3085: seq=0, hlim-52, rtt=422.066 ms
64 bytes from 2001:200:0:4819:203:47ff:fea5:3085: seq=l, hlim=52, rtt=417.398 ms
64 bytes from 2001:200:0:4819:203:47ff:fea5:3085: seq=2, hlim=52,. rtt=416.528 ms
64 bytes from 2001:200:0:4819:203:47ff:fea5:3085: seq=3, hlim=52, rtt=429.192 ms
The program operates in two parts: One half reads everything received on a raw socket, printing the ICMP echo replies, and the other half sends an ICMP echo request once per second. The second half is driven by a SIGALRM signal once per second.
Overview of the functions in our ping program
ping.h header
1 #include “unp.h”
2 #irclude <netinet/in_systm.h>
3 #include <netinet/ip.h>
16

4 #include <netinet/ip_icmp.h>
5 #define BUFSIZE 1500
6 /* globals */
7 char sendbuf[BUFSIZE];
8 int datalen; /* # bytes of data following ICMP header */
9 char *host;
10 int nsent; /* add 1 for each sendto() */
11 pid t pid; /* our PID */
12 int sockfd;
13 int verbose;
14 /* function prototypes */
15 void init_v6(void);
16 void proc_v4(char *, ssize t, struct msghdr *, struct timeval *);
1 7 void proc_v6(char *, ssize t, struct msghdr *, struct timeval *);
18 void send_v4(void);
19 void send_v6(void);
20 void readloop(void);
21 void sig_alrm(int);
22 void tv_sub(struct timeval *, struct timeval *);
23 struct proto {
24 void (*fproc) (char *, ssize_t, struct msghdr *, struct timeval *);
25 void (*fsend) (void);
26 void (*finit) (void);
27 struct sockaddr *sasend; /* sockaddr{} for send, from getaddrinfo */
28 struct sockaddr *sarecv; /* sockaddr{} for receiving */
29 socklen t salen; /* length of sockaddr {}s */ ”
30 int icmrpproto; /* IPPROTO xxx value for ICMP */
17

31 } *pr;
32 #ifdef IPV6
33 #include <netinet/ip6.h>
34 #include <netinet/icmp6.h>
35 #endif
Include IPv4 and ICMPv4 headers
1–22 We include the basic IPv4 and ICMPv4 headers, define some global variables, and our function prototypes.
Define proto structure
23–31 We use the proto structure to handle the difference between IPv4 and IPv6. This structure contains two function pointers, two pointers to socket address structures, the size of the socket address structures, and the protocol value for ICMP. The global pointer pr will point to one of the structures that we will initialize for either IPv4 or IPv6.
Include IPv6 and ICMPv6 headers
32–35 We include two headers that define the IPv6 and ICMPv6 structures and constants
readloop Function
1 #include “ping.h”
2 void
3 readloop(void)
4 {
5 int size;
6 char recvbuflBUFSIZE];
7 char controlbuf[BUFSlZE];
8 struct msghdr msg;
9 struct iovec iov;
10 ssizet n;
11 struct timeval tval; .
12 sockfd = Socket(pr->sasend->sa_family,SOCK_RAW,pr->icmpproto);
13 setuid(getuid()); /* don’t need special permissions any more */
14 if (pr->finit)
15 (*pr->fmit) ( );18

16 size = 60 * 1024; ‘ /* OK if setsockopt fails */
19 iov.iov_base = recvbuf;
20 iov.iov_len = sizeof (recvbuf);
21 msg.msg_name = pr->sarecv;
22 msg.msg_iov = &iov;
23 msg.msg_iovlen = 1;
24 msg.msg_control = controlbuf;
25 for ( ; ; ) {
26 msg.msgnamelen = pr->salen;
27 msg.msgcontrollen = sizeof (controlbuf);
28 n = recvmsg (sockfd, &msg, 0);
29 if (n < o) {
30 if (errno == EINTR)
31 continue;
32 else
33 err_sys(“recvmsg error”);
34 }
35 Gettimeofday (&tval, NULL);
36 (*pr->fproc) (recvbuf, n, &msg, &tval);
37 }
38 }
Perform protocol-specific initialization
14–15 If the protocol specified an initialization function, we call it.
Set socket receive buffer size
16–17 We try to set the socket receive buffer size to 61,440 bytes (60 x 1024), which should be larger than the default. We do this in case the userpings either the IPv4 broadcast address or a multicast address, either of which can generate lots of replies. By making the buffer larger, there is a smaller chance that the socket receive buffer will overflow.
19

Send first packet
18 We call our signal handler, which we will see sends a packet and schedules a SIGALRM for one second in the future. It is not common to see a signal handler called directly, as we do here, but it is acceptable. A signal handler is just a C function, even though it is normally called asynchronously.
Set up msghdr for recvmsg
19–24 We set up the unchanging fields in the msghdr and iovec structs that we will pass to recvmsg.
Infinite loop reading all ICMP messages
25–37 The main loop of the program is an infinite loop that reads all packets returned on the raw ICMP socket. We call gettimeofday to record the time that the packet was received and then call the appropriate protocol function (proc_v4 or proc_v6) to process the ICMP message.
TRACE ROUTE
PURPOSE
1. Like the ping program in the previous section, we will develop and present our own version, instead of presenting the publicly available version.
2. We do this because we need a version that supports both IPv4 and IPv6.
3. Trace route lets us determine the path that IP datagrams follow from our host to some other destination.
4. Its operation is simple. Trace route uses the IPV4 TTL field or the IPV6 hop limit field and two ICMP messages. It starts by sending a UDP datagram to the destination with a TTL at 1.
5. This datagram causes the first -hop router to return an ICMP “time exceeded in transit” error.
6. The TTL is then increased by one and another UDP datagram sent, which locates the next router in the path.
7. When the UDP datagram reaches the final destination, the goal is to have that host return an ICMP “port unreachable” error.
8. This is done by sending the UDP datagram to a random port that is (hopefully) not in use on that host.
9. Early versions of traceroute were able to set the TTL field in the IPv4 header only by setting the IP HDRINCL socket option and then building their own IPv4 header.
20

10. Current systems, however, provide an IP TTL socket option that lets us specify the TTL to use for outgoing datagrams. (This socket option was introduced with the 4.3BSDRenorelease.)
11. It is easier to set this socket option than to build a complete IPv4 header.
12. The IPv6 IPV6 UNICAST HOPS socket option lets us control the hop limit field for IPv6 datagrams.
The following program shows our trace header, which all of our program files include. We include the standard IPV4 headers that define the IPV4, ICMPV4, and UDP structure and constants.
trace.h header
traceroute/trace.h 1 #include "unp.h" 2 #include <netinet/in_systm.h> 3 #include <netinet/ip.h> 4 #include <netinet/ip_icmp.h> 5 #include <netinet/udp.h> 6 #define BUFSIZE 1500 7 struct rec { /* of outgoing UDP data */ 8 u_short rec_seq; /* sequence number */ 9 u_short rec_ttl; /* TTL packet left with */ 10 struct timeval rec_tv; /* time packet left */ 11 }; 12 /* globals */ 13 char recvbuf [BUFSIZE]; 14 char sendbuf [BUFSIZE]; 15 int datalen; /* # bytes of data following ICMP header */ 16 char *host; 17 u_short sport, dport; 18 int nsent; /* add 1 for each sendto () */ 19 pid_t pid; /* our PID */ 20 int probe, nprobes; 21 int sendfd, recvfd; /* send on UDP sock, read on raw ICMP sock */ 22 int ttl, max_ttl; 23 int verbose; 24 /* function prototypes */ 25 const char *icmpcode_v4 (int); 26 const char *icmpcode_v6 (int); 27 int recv_v4 (int, struct timeval *); 28 int recv_v6 (int, struct timeval *); 29 void sig_alrm (int); 30 void traceloop (void); 31 void tv_sub (struct timeval *, struct timeval *); 32 struct proto { 33 const char *(*icmpcode) (int); 34 int (*recv) (int, struct timeval *);
21

35 struct sockaddr *sasend; /* sockaddr{} for send, from getaddrinfo */ 36 struct sockaddr *sarecv; /* sockaddr{} for receiving */ 37 struct sockaddr *salast; /* last sockaddr{} for receiving */ 38 struct sockaddr *sabind; /* sockaddr{} for binding source port */ 39 socklen_t salen; /* length of sockaddr{}s */ 40 int icmpproto; /* IPPROTO_xxx value for ICMP */41 int ttllevel; /* setsockopt () level to set TTL */ 42 int ttloptname; /* setsockopt () name to set TTL */ 43 } *pr; 44 #ifdef IPV6 45 #include <netinet/ip6.h> 46 #include <netinet/icmp6.h> 47 #endif
Define proto structures
2–9 We define the two proto structures, one for IPv4 and one for IPv6, although the pointers to the socket address structures are not allocated until the end of this function.
Set defaults
10–13 The maximum TTL or hop limit that the program uses defaults to 30, although we provide the -m command-line option to let the user change this. For each TTL, we send three probe packets, but this could be changed with another command-line option. The initial destination port is 32768+666, which will be incremented by one each time we send a UDP datagram. We hope that these ports are not in use on the destination host when the datagrams finally reach the destination, but there is no guarantee.
Process command-line arguments
19–37 The -v command-line option causes most received ICMP messages to be printed.
Process hostname or IP address argument and finish initialization
38–58 The destination hostname or IP address is processed by our host_serv function, returning a pointer to an addrinfo structure. Depending on the type of returned address, IPv4 or IPv6, we finish initializing the proto structure, store the pointer in the pr global, and allocate additional socket address structures of the correct size.
59 The function traceloop, sends the datagrams and reads the returned ICMP messages. This is the main loop of the program.
Main Function
1 #include ”trace.h”
2 struct proto proto_v4 ={icmpcode_v4, recv_v4, NULL, NULL, NULL, NULL 0,3 IPFROTO_ICMP, IPPROTO_IP, IP_TTL
22

4 };
5 #ifdef IPV6
6 struct proto proto_v6 ={icmpcode_v6, rec_v6, NULL, NULL, NULL, NULL, 0,
7 IPPROTO_ICMPV6, IPROTO_V6, IPV6_UNICAST_HOPS
8 };
9 #endif
10 int datalen = sizeof (struct rec) ; / *defaults */
11 int max_ttl =30;
12 int nprobes = 3;
13 u_short dport = 32768 + 666;
14 int
15 main (int argc, char argv)
16 {
17 int c;
18 struct addrinfo ai;
19 char *h;
20 opterr = 0; / * don’t want getopt () writing to stderr * /
21 while ( ( c = getopt (argc, argv, “m:v”) )!= -1) {
22 switch (c) {
23 case ‘m’:
24 if ( (max_ttl = atoi (optarg) ) <= 1 )
25 err_quitt (*invalid -m value”); 2 5 break;
26 break;
27 case ‘v’:
28 verbose++;
29 break;
30 case ‘?’:
23

31 err_quit (“unrecognized option: c”, c);
32 }
33 }
34 if (optind != argc – 1 )
35 err_quit (“usage: traceroute [ -m <maxttl> -v ] <hostname>”);
36 host = argv [optind] ;
37 pid = getpid ();
38 Signal (SIGALRM, sig_alrm);
39 ai = Host_serv (host, NULL, 0, 0);
40 h= sock_ntop_host (ai_>ai_addr, ai->ai_addrlen);
41 printf (“traceroute to %s (%s): %d hops max, %d data bytes \n”,
42 ai->ai_canonname? ai->ai_canoname :h,h,max_ttl,datalen);
43 / initialize according to protocol /
44 if (ai_>ai_family == AF_INET) {
45 pr = &proto_v4;
46 #ifdef IPV6
47 } else if (ai_>ai_f amily == AF_INET6) {
48 pr = &proto_V6;
49 if (IN6_IS_ADDR_V4MAPPED
50 (& ( ( (struct sockaddr_in6 *) ai_>ai_addr) ->sin6_addr)))
51 err_quit (“cannot traceroute IPv4-mapped IPv6 address”);
52 #endif
53 } else
54 err_quit (“unknown address family %dn, i ai_>ai_family); *
55 pr->sasend = ai->ai_addr; / contains destination * address /
56 pr->sarecv = Calloc (1, ai->ai_addrlen)
57 pr->salast = Calloc (1, ai->ai_addrlen)
24

58 pr->sabind = Calloc (1, ai->ai_addrlen)
59 pr->salen = ai->ai_addrlen;
60 traceloop ();
61 exit (0);
}
Create raw socket
Line9–10 We need two sockets: a raw socket on which we read all returned ICMP messages and a UDP socket on which we send the probe packets with the increasing TTLs. After creating the raw socket, we reset our effective user ID to our real user ID since we no longer require superuser privileges.
Set ICMPv6 receive filter
Line 11–20 If we are tracing the route to an IPv6 address and the -v command-line option was not specified, install a filter that blocks all ICMP message types except for the ones we expect: "time exceeded" or "destination unreachable." This reduces the number of packets received on the socket.
Create UDP socket and bind source port
Line 21–25 We bind a source port to the UDP socket that is used for sending, using the low-order 16 bits of our PID with the high-order bit set to 1. Since it is possible for multiple copies of the trace route program to be running at any given time, we need a way to determine if a received ICMP message was generated in response to one of our datagrams, or in response to a datagram sent by another copy of the program. We use the source port in the UDP header to identify the sending process because the returned ICMP message is required to include the UDP header from the datagram that caused the ICMP error.
Establish signal handler for SIGALRM
Line 26 We establish our function sig_alrm as the signal handler for SIGALRM because each time we send a UDP datagram, we wait three seconds for an ICMP message before sending the next probe.
25