Twitter Author Prediction from Tweets using Bayesian Network Hendy Irawan 23214344 TMDG 9 – Electrical Engineering - STEI ITB

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Twitter Author Prediction
from Tweets using
Bayesian NetworkHendy Irawan
23214344
TMDG 9 – Electrical Engineering - STEI ITB

Can We Predict the Author from a
Tweet?
Most authors have a distinct writing style
... And unique topics to talk about
... And signature distribution of words used to tweet
Can we train Bayesian Network so that occurrence of words in a tweet can be
used to infer the author of that tweet?
In summary: YES!
Disclaimer: Accuracy varies
In a test suite with @dakwatuna vs @farhatabbaslaw (very different tweet topics)
– 100% prediction accuracy is achieved

Analysis & Implementation Plan
Visualize Word Distribution in Tweets with Word Clouds
Using R Statistical Language in RStudio
Implement in Java
Natural Language Preprocessing
Train Bayesian Network
Predict Tweet Author

Visualize Word Distribution in Tweets
with Word Clouds
Using R Statistical Language in RStudio
All documentation and sources (open
source) available at:
http://ceefour.github.io/r-tutorials/
Install R Packages
libcurl4-openssl-dev, TwitteR,
httpuv, tm, wordcloud,
RColorBrewer
Setup Twitter Oauth
Grab Data
Prepare Stop Words
Make A Corpus
Word Cloud

1. Install R Packages
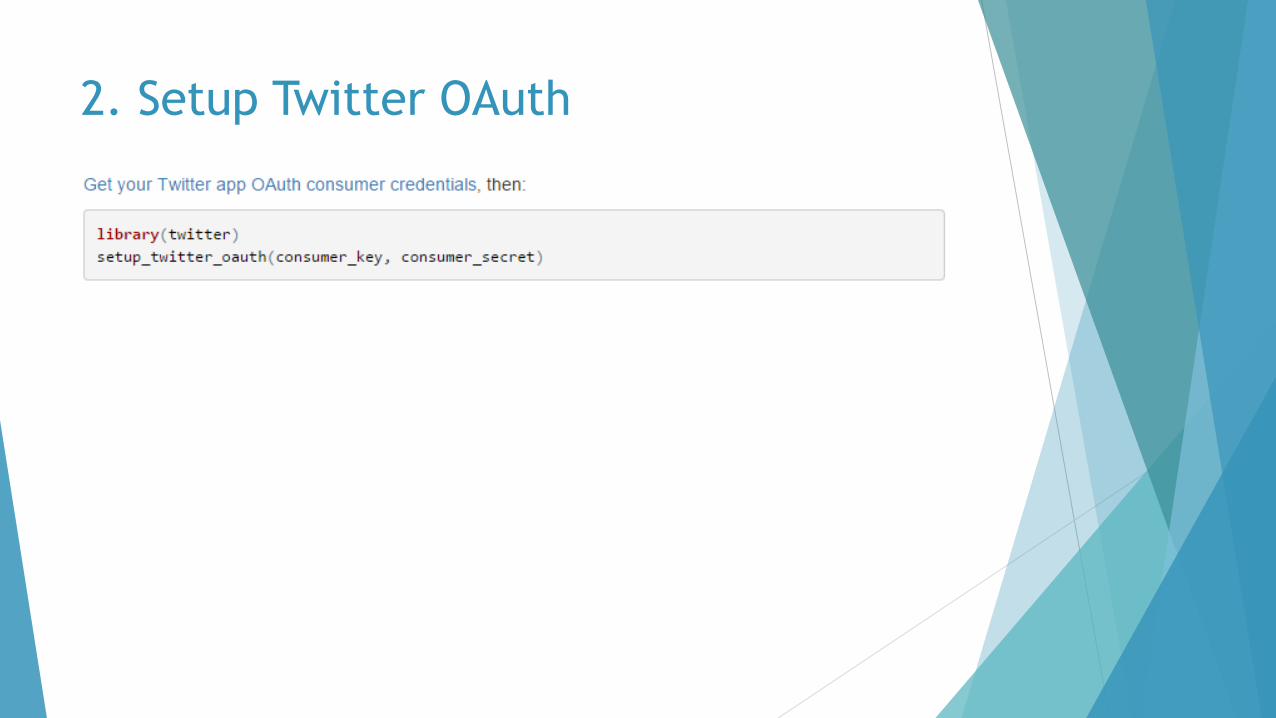
2. Setup Twitter OAuth

3. Grab Data

4. Prepare Stop Words

5. Make A Corpus

6. Visualize Word Cloud: @dakwatuna

Word Clouds (2)
@suaradotcom @kompascom

Word Clouds (3)
@VIVAnews @liputan6dotcom

Word Clouds (3)
@pkspiyungan @MTlovenhoney

Word Clouds (4)
@hidcom @farhatabbaslaw

Java Implementation
Natural Language Preprocessing
Read tweets from CSV
Lower case
Remove http(s) links
Remove punctuation symbols
Remove numbers
Canonicalize different word forms
Remove stop words
Train Bayesian Network
Predict Tweet Author
Initial experiments and dataset
validation available at:
http://ceefour.github.io/r-
tutorials/
Java application source code (open
source) available on GitHub at:
https://github.com/lumenitb/nlu-
sentiment

1. Read Tweets from CSV
/*** Read CSV file {@code f} and put its contents into {@link #rows},* {@link #texts}, and {@link #origTexts}.* @param f*/public void readCsv(File f) {
try (final CSVReader csv = new CSVReader(new FileReader(f))) {headerNames = csv.readNext(); // headerrows = csv.readAll();texts = rows.stream().map(it -> Maps.immutableEntry(it[0], it[1]))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));origTexts = ImmutableMap.copyOf(texts);
} catch (Exception e) {throw new RuntimeException("Cannot read " + f, e);
}}

2. Lower Case
/*** Lower case all texts.*/public void lowerCaseAll() {
texts = Maps.transformValues(texts, String::toLowerCase);}

3. Remove Links
/*** Remove http(s) links from texts.*/public void removeLinks() {
texts = Maps.transformValues(texts, it -> it.replaceAll("http(s?):\\/\\/(\\S+)", " "));}

4. Remove Punctuation Symbols
/*** Remove punctuation symbols from texts.*/public void removePunctuation() {
texts = Maps.transformValues(texts, it -> it.replaceAll("[^a-zA-Z0-9]+", " "));}

5. Remove Numbers
/*** Remove numbers from texts.*/public void removeNumbers() {
texts = Maps.transformValues(texts, it -> it.replaceAll("[0-9]+", ""));}

6. Canonicalize Words
/*** Canonicalize different word forms using {@link #CANONICAL_WORDS}.*/public void canonicalizeWords() {
log.info("Canonicalize {} words for {} texts: {}",CANONICAL_WORDS.size(), texts.size(), CANONICAL_WORDS);CANONICAL_WORDS.entries().forEach(entry ->
texts = Maps.transformValues(texts,it -> it.replaceAll("(\\W|^)" + Pattern.quote(entry.getValue()) +
"(\\W|$)", "\\1" + entry.getKey() + "\\2")));
}
// Define contents of CANONICAL_WORDSfinal ImmutableMultimap.Builder<String, String> mmb = ImmutableMultimap.builder();mmb.putAll("yang", "yg", "yng");mmb.putAll("dengan", "dg", "dgn");mmb.putAll("saya", "sy");mmb.putAll("punya", "pny");mmb.putAll("ya", "iya");mmb.putAll("tidak", "tak", "tdk");mmb.putAll("jangan", "jgn", "jngn");mmb.putAll("jika", "jika", "bila");mmb.putAll("sudah", "udah", "sdh", "dah", "telah", "tlh");mmb.putAll("hanya", "hny");mmb.putAll("banyak", "byk", "bnyk");mmb.putAll("juga", "jg");mmb.putAll("mereka", "mrk", "mereka");mmb.putAll("gue", "gw", "gwe", "gua", "gwa");mmb.putAll("sebagai", "sbg", "sbgai");mmb.putAll("silaturahim", "silaturrahim", "silaturahmi", "silaturrahmi");mmb.putAll("shalat", "sholat", "salat", "solat");mmb.putAll("harus", "hrs");mmb.putAll("oleh", "olh");mmb.putAll("tentang", "ttg", "tntg");mmb.putAll("dalam", "dlm");mmb.putAll("banget", "bngt", "bgt", "bingit", "bingits");CANONICAL_WORDS = mmb.build();

7. Remove Stop Words
/*** Remove stop words using {@link #STOP_WORDS_ID} and {@code additions}.* @param additions*/public void removeStopWords(String... additions) {
final Sets.SetView<String> stopWords = Sets.union(STOP_WORDS_ID, ImmutableSet.copyOf(additions));
log.info("Removing {} stop words for {} texts: {}",stopWords.size(), texts.size(), stopWords);
stopWords.forEach(stopWord ->texts = Maps.transformValues(texts, it ->it.replaceAll("(\\W|^)" + Pattern.quote(stopWord) +"(\\W|$)", "\\1\\2"))
);}
/*** Indonesian stop words.*/public static final Set<String> STOP_WORDS_ID = ImmutableSet.of(
"di", "ke", "ini", "dengan", "untuk", "yang", "tak", "tidak", "gak",
"dari", "dan", "atau", "bisa", "kita", "ada", "itu","akan", "jadi", "menjadi", "tetap", "per", "bagi", "saat","tapi", "bukan", "adalah", "pula", "aja", "saja","kalo", "kalau", "karena", "pada", "kepada", "terhadap","amp", // &"rt" // RT:
);

8. Split Text into Words
/*** Split texts into {@link #words}.*/public void splitWords() {
Splitter whitespace = Splitter.on(Pattern.compile("\\s+")).omitEmptyStrings().trimResults();
words = Maps.transformValues(texts,it -> whitespace.splitToList(it));
}
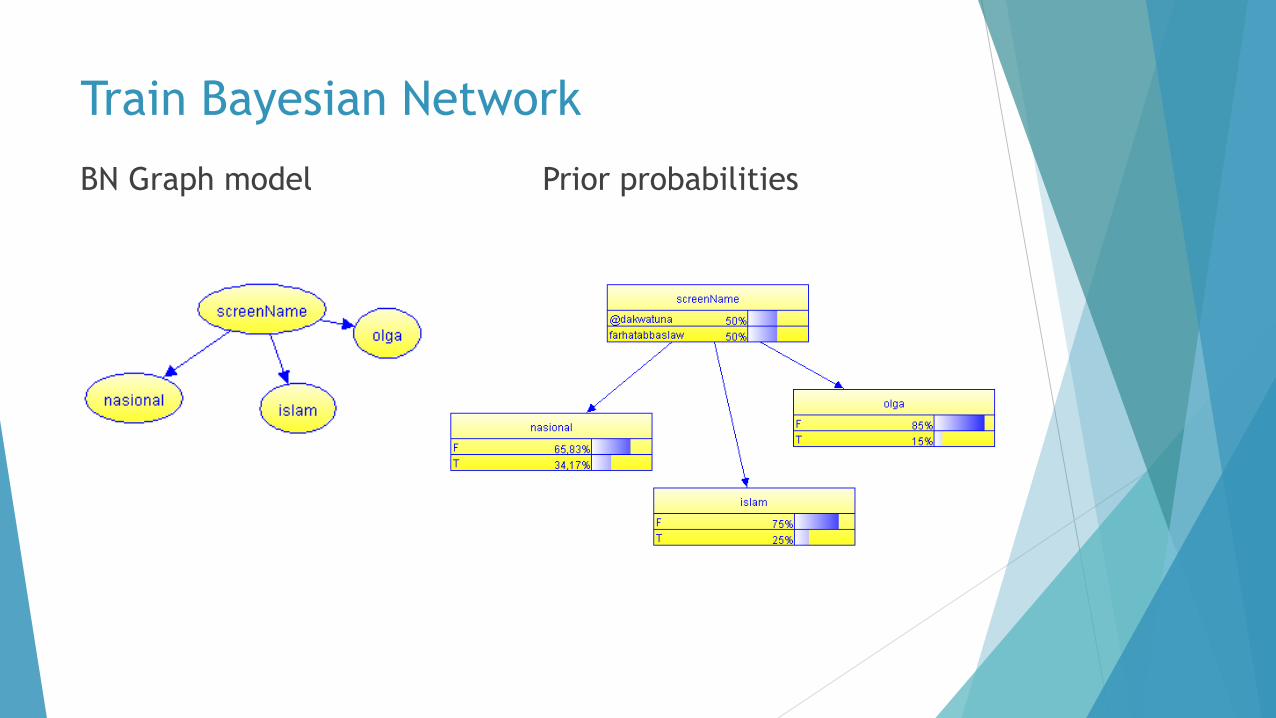
Train Bayesian Network
BN Graph model Prior probabilities

Train Bayesian Network: Java (1)
/*** Creates a {@link SentimentAnalyzer} then analyzes the file {@code f},* with limiting words to {@code wordLimit} (based on top word frequency),* and additional stop words of {@code moreStopWords} (base stop words* are {@link SentimentAnalyzer#STOP_WORDS_ID}.* @param f* @param wordLimit* @param moreStopWords* @return*/protected SentimentAnalyzer analyze(File f, int wordLimit, Set<String> moreStopWords) {
final SentimentAnalyzer sentimentAnalyzer = new SentimentAnalyzer();
sentimentAnalyzer.readCsv(f);sentimentAnalyzer.lowerCaseAll();sentimentAnalyzer.removeLinks();sentimentAnalyzer.removePunctuation();sentimentAnalyzer.removeNumbers();sentimentAnalyzer.canonicalizeWords();
sentimentAnalyzer.removeStopWords(moreStopWords.toArray(new String[] {}));
log.info("Preprocessed text: {}", sentimentAnalyzer.texts.entrySet().stream().limit(10)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)));
sentimentAnalyzer.splitWords();log.info("Words: {}",
sentimentAnalyzer.words.entrySet().stream().limit(10).collect(Collectors.toMap(Map.Entry::getKey,
Map.Entry::getValue)));
final ImmutableMultiset<String> wordMultiset = Multisets.copyHighestCountFirst(HashMultiset.create(
sentimentAnalyzer.words.values().stream().flatMap(it -> it.stream()).collect(Collectors.toList())) );
final Map<String, Integer> wordCounts = new LinkedHashMap<>();
// only the N most used words
wordMultiset.elementSet().stream().limit(wordLimit).forEach( it -> wordCounts.put(it, wordMultiset.count(it)) );
log.info("Word counts (orig): {}", wordCounts);
// Normalize the twitterUser "vector" to length 1.0
// Note that this "vector" is actually user-specific, i.e. it's not a user-independent vector
long origSumSqrs = 0;for (final Integer it : wordCounts.values()) {
origSumSqrs += it * it;}double origLength = Math.sqrt(origSumSqrs);final Map<String, Double> normWordCounts =
Maps.transformValues(wordCounts, it -> it / origLength);
log.info("Word counts (normalized): {}", normWordCounts);
sentimentAnalyzer.normWordCounts = normWordCounts;
return sentimentAnalyzer;}

Train Bayesian Network: Java (2)
/*** Train Bayesian network {@code bn}, with help of {@link #analyze(File, int, Set)}.* @param bn* @param f* @param screenName* @return*/protected SentimentAnalyzer train(BayesianNetwork bn, File f, String screenName) {
final SentimentAnalyzer analyzer = analyze(f, 100, ImmutableSet.of(screenName));
allWords.addAll(analyzer.normWordCounts.keySet());
for (final Map.Entry<String, Double> entry : analyzer.normWordCounts.entrySet()) {wordNormLengthByScreenName.put(screenName + "/" + entry.getKey(), entry.getValue());
}
return analyzer;}

Predict Twitter Author:
“nasional” found
“nasional” found ->
85.37% probability of @dakwatuna
“nasional” found, “olga” missing ->
89.29% probability of @dakwatuna
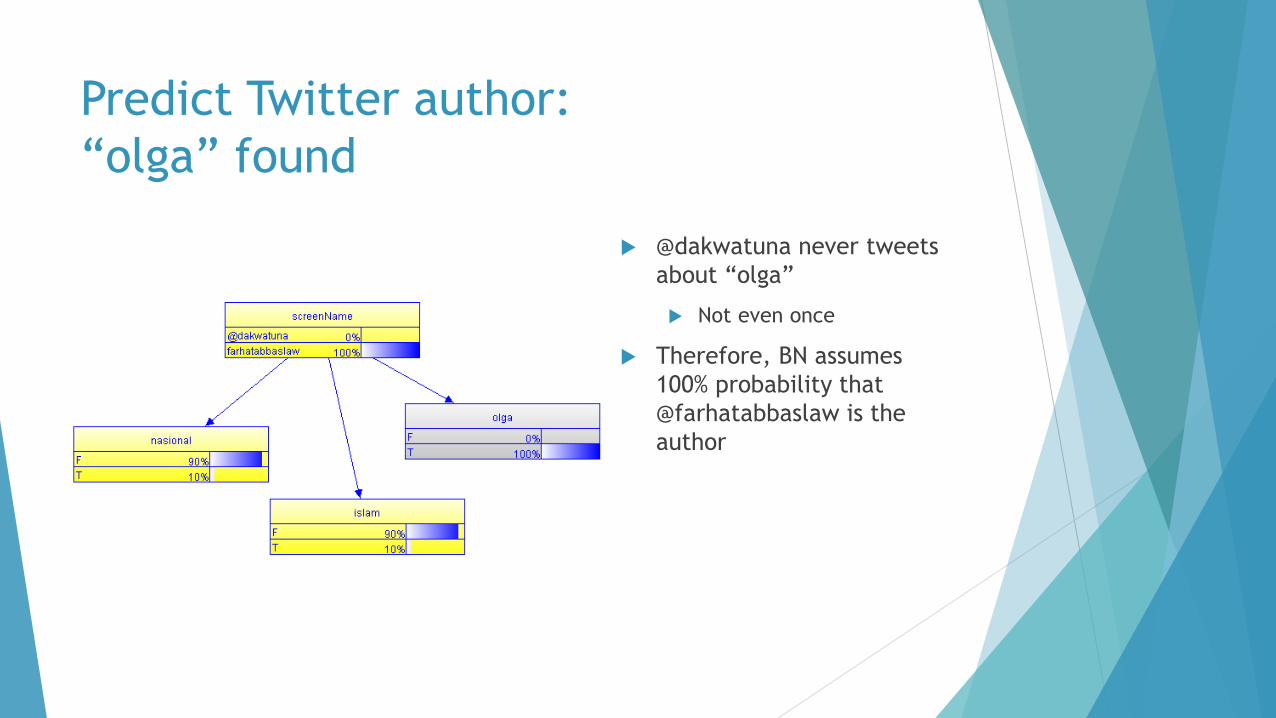
Predict Twitter author:
“olga” found
@dakwatuna never tweets
about “olga”
Not even once
Therefore, BN assumes
100% probability that
@farhatabbaslaw is the
author

Predict Twitter Author
Initial corpus:
@dakwatuna: 3200 tweets
@farhatabbaslaw: 3172 tweets
Split into:
@dakwatuna
1000 training tweets
2200 test tweets
@farhatabbaslaw:
1000 training tweets
2172 test tweets

Twitter Author Prediction Test:
@dakwatuna
Classification of 2200 tweets took 7855 ms
~ 3.57 ms per tweet classification
100% accuracy of prediction

Twitter Author Prediction Test:
@farhatabbaslaw
Classification of 2172 tweets took 7353 ms
~ 3.38 ms per tweet classification
100% accuracy of prediction

Conclusion
Initial results is promising
Bayesian Networks is able to predict tweet author with “very good” accuracy
Note that accuracy depends largely of:
Twitter author’s writing style
Twitter author’s topics of interest
Twitter author’s distribution of words
In other words, two different authors with similar writing style or topics will
have greater chance of “false positive” prediction
Related Documents
![New DO TWEETS AFFECT STUDENTS PERFORMANCE Revision … · 2020. 1. 19. · PAPER REVISION THROUGH TWITTER: DO TWEETS AFFECT STUDENTS’ PERFORMANCE? [5] argued that Twitter helps](https://static.cupdf.com/doc/110x72/6057739fad408258b52d306b/new-do-tweets-affect-students-performance-revision-2020-1-19-paper-revision.jpg)










