Universidad Politécnica de Madrid Escuela Técnica Superior de Ingenieros Informáticos Máster Universitario en Inteligencia Artificial Trabajo Fin de Máster SISTEMA de PREGUNTA-RESPUESTA Autor(a): David Pérez Alberto Tutor(a): Jesús Cardeñosa Lera Madrid, Julio 2021

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Universidad Politécnicade Madrid
Escuela Técnica Superior deIngenieros Informáticos
Máster Universitario en Inteligencia Artificial
Trabajo Fin de Máster
SISTEMA de PREGUNTA-RESPUESTA
Autor(a): David Pérez AlbertoTutor(a): Jesús Cardeñosa Lera
Madrid, Julio 2021

Este Trabajo Fin de Máster se ha depositado en la ETSI Informáticos de laUniversidad Politécnica de Madrid para su defensa.
Trabajo Fin de MásterMáster Universitario en Inteligencia Artificial
Título: SISTEMA de PREGUNTA-RESPUESTA
Julio 2021
Autor(a): David Pérez AlbertoTutor(a): Jesús Cardeñosa Lera
Departamento de Inteligencia ArtificialETSI InformáticosUniversidad Politécnica de Madrid

Resumen
El procesamiento de lenguaje natural (PLN) es un campo de vital importancia den-tro de la inteligencia artificial, ya que es uno de los elementos clave para conseguiruna interacción entre personas y máquinas. Sin embargo, todavía estamos muy lejosde conseguir una verdadera interacción fluida, ya que se ha de conseguir una com-prensión del lenguaje que se está tratando y generar respuestas de acuerdo con elmensaje comprendido, tareas que no están del todo garantizadas hoy en día, debidoa la dificultad que presentan las distintas lenguas, y las reglas por las que se rigen.
Esta tesis tratará sobre los sistemas de pregunta-respuesta, analizando como estándiseñados dichos sistemas y las técnicas que se utilizan. Para trabajar con estossistemas se experimentará sobre la temática concreta de las averías de los trenes,buscando comprender lo que una persona plantea y se obtendrá respuesta más idó-nea que resuelva dicha pregunta.
i


Abstract
Natural language processing (NLP) is a very important field in artificial intelligence,due to it is one of the key elements for achieving human-machine interaction. Howe-ver, we are still so far from achieving a true smooth interaction, since it is necessaryto achieve an understanding of the language being processed and to generate res-ponses in accordance with the message understood, tasks that are not so guaranteedtoday, due to the difficulty of the different languages and the rules by which they aremade up.
This thesis will deal with question-answer systems, analysing how these systems aredesigned and the techniques that they used. In order to deal with these systems,we will experiment with the specific subject of train failures, in which we will try tounderstand what a person is asking, and we will provide him with an answer thatresolves the question.
iii


Tabla de contenidos
1. Introducción 1
2. Desarrollo 32.1. Procesamiento de Lenguaje Natural (PLN) . . . . . . . . . . . . . . . . . . 3
2.1.1. Breve historia del PLN . . . . . . . . . . . . . . . . . . . . . . . . . . 32.1.2. Estudio del PLN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92.1.3. Campos del PLN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
a. Comprensión del lenguaje natural (NLU) . . . . . . . . . . 14b. Generación del lenguaje natural (NLG) . . . . . . . . . . . 18
2.1.4. Áreas de aplicación de las técnicas de PLN . . . . . . . . . . . . . . 222.2. Sistemas de pregunta-respuesta (QA) . . . . . . . . . . . . . . . . . . . . . 25
2.2.1. Estructura de los sistemas QA . . . . . . . . . . . . . . . . . . . . . 27a. Estructura de sistema QA usando el habla . . . . . . . . . 35
2.2.2. Clasificación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 362.2.3. Aplicaciones de los sistemas de pregunta-respuesta . . . . . . . . 39
2.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
3. Planteamiento del Problema 513.1. Hipótesis de trabajo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4. Modelo Propuesto 53
5. Experimentación 575.1. Librerías utilizadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 575.2. Almacenamiento de la información del pdf . . . . . . . . . . . . . . . . . . 585.3. Pedir al usuario la pregunta . . . . . . . . . . . . . . . . . . . . . . . . . . 595.4. Preprocesamiento de la pregunta . . . . . . . . . . . . . . . . . . . . . . . 615.5. Aplicar la similitud del coseno a los capítulos . . . . . . . . . . . . . . . . 625.6. Obtener las mejores opiniones almacenadas en la memoria de aprendizaje 635.7. Mostrar al usuario la mejor respuesta obtenida . . . . . . . . . . . . . . . 63
5.7.1. Mostrar al usuario las 5 mejores respuestas . . . . . . . . . . . . . 645.8. Almacenar la información en la memoria de aprendizaje y reiniciar el
bucle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 665.9. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6. Conclusiones 79
Bibliografía 85
v


Índice de figuras
2.1. Ejemplo de las reglas de producción. . . . . . . . . . . . . . . . . . . . . . 42.2. Ejemplo de los frames. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3. Ejemplo de la lógica de primer orden. . . . . . . . . . . . . . . . . . . . . . 62.4. Ejemplo de red semántica. . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.5. Ejemplo de red bayesiana. . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.6. Tipos de conocimientos basándose en los niveles [7]. . . . . . . . . . . . . 102.7. Arquitectura de un sistema de PLN [7]. . . . . . . . . . . . . . . . . . . . . 112.8. Análisis morfológico y sintáctico. . . . . . . . . . . . . . . . . . . . . . . . 112.9. Análisis semántico y pragmático. . . . . . . . . . . . . . . . . . . . . . . . 122.10.Gramática y ejemplo de aplicación [7]. . . . . . . . . . . . . . . . . . . . . 132.11.Parsing sintáctico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.12.Reglas reescribiendo la CFG. . . . . . . . . . . . . . . . . . . . . . . . . . . 152.13.Redes de transición. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.14.Ejemplo del proceso del NLU (Parsing sintáctico). . . . . . . . . . . . . . . 172.15.Ejemplo del proceso del NLU (Parsing semántico). . . . . . . . . . . . . . 182.16.Base de conocimiento sobre el partido. . . . . . . . . . . . . . . . . . . . . 192.17.Fase de Document planning. . . . . . . . . . . . . . . . . . . . . . . . . . . 202.18.Fase de Microplanning. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 202.19.Fase de Surface realisation mediante plantillas. . . . . . . . . . . . . . . . 212.20.Fase de Surface realisation mediante gramáticas. . . . . . . . . . . . . . . 222.21.Esquema típico de un sistema IR [10]. . . . . . . . . . . . . . . . . . . . . 232.22.Esquema de un sistema QA [21]. . . . . . . . . . . . . . . . . . . . . . . . 272.23.Clasificación de preguntas según Moldovan [5]. . . . . . . . . . . . . . . . 282.24.Clasificación de preguntas según Graesser et al [5]. . . . . . . . . . . . . 292.25.Esquema de cómo puede quedar representada la pregunta al final [5]. . 302.26.Esquema de un diálogo en el que el sistema dirige las interacciones. . . 312.27.Esquema de un diálogo en el que el usuario dirige las interacciones. . . 312.28.Esquema de diálogo en el que se dirige de forma mixta las interacciones. 322.29.Esquema de un diálogo mediante Theorem Proving. . . . . . . . . . . . . . 332.30.Esquema de un diálogo mediante máquina de estados finita. . . . . . . . 342.31.Esquema de un diálogo mediante el modelo de form filling. . . . . . . . . 342.32.Esquema de un agente conversacional usando el habla [24] . . . . . . . 352.33.Tipos de chatbots según [27]. . . . . . . . . . . . . . . . . . . . . . . . . . 382.34.Representación de un AoG [39]. . . . . . . . . . . . . . . . . . . . . . . . . 412.35.Generación de respuesta a partir del AoG [39]. . . . . . . . . . . . . . . . 422.36.Esquema general de SuperAgent [44]. . . . . . . . . . . . . . . . . . . . . . 432.37.Esquema conceptual del sistema propuesto por [46]. . . . . . . . . . . . . 442.38.Esquema conceptual del sistema Isa [53]. . . . . . . . . . . . . . . . . . . 48
vii

ÍNDICE DE FIGURAS
4.1. Esquema general del modelo propuesto. . . . . . . . . . . . . . . . . . . . 534.2. Esquema del módulo de NLU en el modelo propuesto. . . . . . . . . . . . 544.3. Esquema del módulo de Gestor de Diálogo. . . . . . . . . . . . . . . . . . 554.4. Esquema del módulo de NLG en el modelo propuesto. . . . . . . . . . . . 56
5.1. Texto almacenado en la lista ”apartadosAverias2”. . . . . . . . . . . . . . . 595.2. Texto almacenado en la lista ”subApartadosAverias”. . . . . . . . . . . . . 595.3. Variabilidad de los saludos iniciales en función del momento del día. . . 605.4. Tipos de pregunta que pueden ser detectados y la forma de expresarlos. 605.5. Ejemplo de aplicación de reglas y lógica para obtener el tipo de pregunta. 615.6. Preprocesamiento de la pregunta y obtención de las raíces significativas. 625.7. Puntuaciones de los 12 apartados, según la similitud del coseno. . . . . 625.8. Mejores opiniones extraídas de la memoria de aprendizaje. . . . . . . . . 635.9. Mejor resultado y ránking de los subapartados detectados por el sistema. 645.10.Variabilidad de las 2 posibles respuestas (lugar o explicación). . . . . . . 655.11.Formato del fichero Excel de la memoria de aprendizaje. . . . . . . . . . 675.12.Palabras vacías de significado que el sistema no contempla. . . . . . . . 675.13.Preguntas de tipo lugar escritas incorrectamente. . . . . . . . . . . . . . 685.14.Preguntas de una temática distinta. . . . . . . . . . . . . . . . . . . . . . 685.15.Preguntas invariantes a las mayúsculas y tildes. . . . . . . . . . . . . . . 695.16.Preguntas que el sistema no detecta correctamente. . . . . . . . . . . . . 695.17.Inicio del sistema y pregunta inicial (1º Iteración). . . . . . . . . . . . . . 705.18.Disconformidad de la mejor respuesta y valoración (1º Iteración). . . . . 715.19.Lista de las 5 mejores soluciones (1º Iteración). . . . . . . . . . . . . . . . 715.20.Almacenamiento de la pregunta y de las opiniones (1º Iteración). . . . . 725.21.Información relevante al procesar la pregunta para obtener la respuesta. 725.22.Inicio del sistema y pregunta inicial (2º Iteración). . . . . . . . . . . . . . 735.23.Disconformidad de la mejor respuesta y valoración (2º Iteración). . . . . 735.24.Lista de las 5 mejores soluciones (2º Iteración). . . . . . . . . . . . . . . . 745.25.Almacenamiento de la pregunta y de las opiniones (2º Iteración). . . . . 745.26.Última iteración. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75
viii

Capítulo 1
Introducción
Hoy en día el uso de técnicas y procesos relacionados con la Inteligencia Artificial(IA) se ha visto aumentado exponencialmente, ya que se ha conseguido automatizar yobtener resultados muy prometedores, al menos, en algunos aspectos, aunque es unatecnología que debe evolucionar y mejorar. Uno de los dominios en el que se aplica laIA es en el Procesamiento de Lenguaje Natural (PLN), campo de vital importancia alser un elemento clave para conseguir la interacción entre personas y máquinas. Sinembargo, a pesar de los grandes avances realizados en las últimas décadas, todavíaestamos muy lejos de conseguir una verdadera interacción fluida.
El funcionamiento de las técnicas de PLN puede ser dividido en 2 partes, la com-prensión del lenguaje natural (NLU) y la generación de lenguaje natural (NLG), queconsiguen abordar el reto de la comunicación humano-máquina en los ámbitos enlos que se utilice. En este trabajo, la aplicación de este tipo de sistemas va a estarfocalizado en los sistemas de pregunta-respuesta, centrados en comprender lo queuna persona formula (ya sea de manera escrita u oral), con el fin de que el sistemaproporcione una respuesta que resuelva la necesidad formulada. Para acotar el pro-blema, la temática elegida sobre la que actuará el sistema será resolver cuestionessobre averías de trenes, tema sobre el que se realizarán el modelo y la experimen-tación necesarios, aunque podría extrapolarse el trabajo realizado a cualquier otratemática.
La siguiente tesis estará fragmentada en capítulos, que estarán organizados de lasiguiente manera:
Desarrollo: En este capítulo se realizará un estudio sobre el estado del arte,detallando conceptos sobre el procesamiento de lenguaje natural y sus partes.Después, se focalizará el estudio en los sistemas de pregunta-respuesta y losdominios en los que se aplica.
Planteamiento del problema: Aquí se detallará el problema concreto sobre el quese va a aplicar el sistema de pregunta-respuesta diseñado.
Modelo propuesto: Modelo sobre el que se diseñará el sistema, con las partes quetiene y como se desarrollarán los distintos módulos que componen al sistema.
Experimentación: Aquí se detallará el proceso de implementación del sistema yalgunos de los resultados conseguidos.
1

Conclusiones: Capítulo final en el que se formularán las conclusiones y se des-cribirán posibles mejoras para líneas de trabajo futuras.
2

Capítulo 2
Desarrollo
El sistema a implementar es un agente conversacional del ámbito de preguntas-respuesta. Vamos a empezar explicando qué es el PLN, en qué consiste, un desarrollobreve sobre su historia a lo largo de los años y los dominios en los que se divide. Des-pués trataremos los sistemas pregunta-respuesta en particular, tratando el conjuntode sistemas que se han desarrollado estos años, las partes de las que se compone ylas aplicaciones en las que pueden ser usados.
2.1. Procesamiento de Lenguaje Natural (PLN)
El Procesamiento de Lenguaje Natural (PLN), en inglés Natural Language Processing(NLP), es una disciplina formada por un conjunto de otras disciplinas como la lin-güística, la computación, las matemáticas, la inteligencia artificial o la lógica, entreotras, que se encarga de la comprensión del lenguaje (tanto en forma escrita comohablada) por parte de los ordenadores para poder usarlo posteriormente.
Las técnicas de PLN tienen una elevada complejidad, ya que hay que realizar tareastales como la comprensión de palabras, su relación dentro de una oración y las re-laciones de estas en relación con el documento. Además, hay que tener en cuentaaspectos como la ambigüedad, el contexto o la elipsis.
2.1.1. Breve historia del PLN
Aunque parece una tecnología reciente, el PLN surgió hace varias décadas, en concre-to sobre los años 50, sin embargo, el crecimiento exponencial de la tecnología (mayorpoder computacional y la generación masiva de datos) ha permitido que los estudios ymétodos desarrollados hace años se pudiesen implementar (conllevando, sobre todo,a una generación de aplicaciones comerciales cada vez con mayor éxito) [1].
La historia de la tecnología del Procesamiento del Lenguaje Natural puede dividirseen 4 etapas o fases, en función de las décadas en orden cronológico, con sus corres-pondientes logros y complicaciones [1].
Fase 1: Finales de los 40 - Principios de los 60
En esta época los estudios se centraban en la traducción automática, a finales de losaños 40 surgieron algunas ideas sobre ello, pero la investigación propia en el campo
3

2.1. Procesamiento de Lenguaje Natural (PLN)
del PLN tuvo lugar a principios de los años 50, con la traducción del ruso al inglés(de forma rudimentaria) en una demostración de IBM-Georgetown en el año 1954. Eljournal MT (precursor de Computacional Linguistics) empezó a publicar también en1954. El punto más importante en esta fase fue el Teddington International Confe-rence on Machine Translation of Languages and Applied Language Analysis en 1961,donde se expusieron trabajos de muchos países sobre aspectos del PLN centradosen: morfología, sintaxis, semántica e interpretación y generación de lenguaje. Comoocurrió en general en la IA, esta primera fase fue de entusiasmo y optimismo, dondese pensaba que se obtendrían resultados importantes. En este periodo, que empezócon la traducción automática, se puso mucho énfasis en el estudio de la sintaxis,aunque también en la semántica.
Uno de los métodos desarrollados en esta fase fue el de las reglas de producción,desarrolladas por Chomsky. Una regla de producción se compone de un conjuntode antecedentes y consecuencias (es decir, como las reglas IF, If <condiciones>Then<acciones>). El funcionamiento de un sistema de reglas de producción es desarrolladode forma cíclica mediante la ejecución de tres pasos (reconocer, resolver el conflicto yactuar) que se repite hasta que no hay más reglas aplicables en el campo de dominioen el que se utilice el sistema.
El paso de reconocer identifica las reglas cuyas condiciones en los antecedentes co-rresponden con la situación actual. El paso de resolver el conflicto examina el con-junto de reglas identificadas y selecciona un lista de ellas para su ejecución. El pasoactuar ejecuta las acciones definidas en dichas reglas y actualiza el estado vigentedel sistema.
Los aspectos positivos de este modelo son que cada regla es independiente de lasdemás, lo que permite añadir y eliminar reglas fácilmente. Su estructura de controlsencilla y las reglas son fácilmente comprensibles para los humanos (ya que las re-glas suelen desarrollarse a partir del conocimiento u observación de expertos). Sinembargo, hay problemas de escalabilidad cuando este tipo de sistemas intentan im-plementar demasiadas reglas de producción dentro del mismo, esto requeriría unacantidad significativa de mantenimiento y haría el sistema más difícil de controlar ymenos comprensible [2].
Figura 2.1: Ejemplo de las reglas de producción.
4

Desarrollo
Fase 2: Décadas de los 60-70
En esta segunda fase se hizo más hincapié en el conocimiento del mundo y de supapel en la construcción y manipulación de representaciones con significado.
Se podría decir que en este período se desarrollaron aplicaciones sobre sistemas depregunta-respuesta, con el fin de que se permitiese entablar conversaciones entrelas personas y las máquinas. Los primeros sistemas desarrollados recibían comoentradas preguntas en lenguaje natural y devolvían la respuesta a partir de las basesde datos que tuviese el sistema [3]. Uno de los primeros sistemas en desarrollarsefue BASEBALL (diseñado por Green, Wolf, Chomsky y Laughery), este sistema teníainformación sobre la liga de béisbol de Estados Unidos, el tipo de entradas que recibíaestaba restringido al dominio del béisbol y con una serie de limitadas preguntas,devolviendo respuestas simples como fechas o lugares.
Más adelante, surgieron otros sistemas de pregunta-respuesta, entre los que des-tacaron Eliza, LUNAR y SHRDLU, sistemas más sofisticados que se basaban en elmismo principio que BASEBALL, elaborando una base de datos de conocimiento es-crita manualmente sobre un dominio determinado.
Eliza era un sistema que podía mantener un diálogo sobre una serie de temas res-tringidos con el interlocutor, debido a la limitación de conocimiento que tenía. Fuedesarrollado por Joseph Weizenbaum en el MIT, en el año 1966, y podría considerarsecomo el primer chatbot que se desarrolló en la historia [4]. Los diálogos se producíande manera textual, gracias a guiones elaborados a mano, indicando las respuestasque se debían proporcionar en función de la entrada, de acuerdo a la concordanciade una serie de patrones (sistema basado en reglas) elaborados a mano.
SHRDLU fue desarrollado por Terry Winograd en 1970, era un sistema que, medianteun interfaz de lenguaje natural, permitía responder a preguntas sobre un mundovirtual en el cual se simulaba la acción de un robot moviendo piezas [5].
LUNAR fue desarrollada por Woods en 1972, este sistema era capaz de responder apreguntas sobre la geología de las piedras lunares que trajeron las misiones Apollodesde la Luna [5].
En los últimos años de esta fase se desarrollaron sistemas para identificar las creen-cias, objetivos y planes de los usuarios, trabajando en la función comunicativa entrepersona y máquina mediante diálogos. Sin embargo, a pesar de los grandes esfuer-zos realizados durante estas décadas, los investigadores se encontraron con que eldesarrollo de las técnicas de PLN era una tarea mucho más difícil de lo que parecía.
En esta fase los modelos más importantes que se desarrollaron fueron la concordan-cia de patrones semánticos y la lógica de primer orden.
La concordancia de patrones semánticos centra sus estudios, como su nombre in-dica, en la semántica. Ceccato, en 1967, desarrolló su investigación en este tipo demodelos aplicando categorías y frames semánticos, utilizando el conocimiento delmundo para poder interpretar y representar las componentes lingüísticas [2].
Los frames son un tipo de representación en el que se definen conceptos, relacionescon otros conceptos y los atributos de cada elemento.
5

2.1. Procesamiento de Lenguaje Natural (PLN)
Figura 2.2: Ejemplo de los frames.
La lógica de primer orden fue deserrollada por Barwise en 1977. Es un tipo de sistemadeductivo, que consta de axiomas y reglas de inferencias, usado para representar elmundo mediante predicados con gran variedad de relaciones. Este tipo de modelopermite operar a nivel sintáctico, semántico y pragmático. Por un lado, es capaz derepresentar correctamente el orden de los elementos en una oración, comprenderel significado de los palabras en la oración y aprovechar el contexto para eliminarambigüedad en los posibles significados que pueden tener las oraciones.
Sin embargo, la lógica tiene el problema de la monotonía: conforme el sistema semejore, se le irán añadiendo más sentencias a la base de conocimiento, esto puedehacer que se corra el riesgo de perder flexibilidad para cambiar de opinión o parasolventar excepciones a las reglas [2].
Figura 2.3: Ejemplo de la lógica de primer orden.
6

Desarrollo
Fase 3: Décadas de los 80-90
A principios de los años 80 se descubrió que los procesos de dominio abierto eranmucho más difíciles de crear que los de un dominio reducido. En esta fase, se cen-traron más esfuerzos en modelos lógico-gramaticales debido al desarrollo de la teoríagramatical y del uso de la lógica, viéndose reflejado por ejemplo en el crecimiento dellogic programming. Esta nueva área fue muy activa, siendo capaz de tratar con lasintenciones y creencias de los usuarios, permitiendo operar con expresiones tempo-rales o de estado de ánimo. Por ello, empezaron a diseñarse algunos proyectos sobresistemas de QA con mayor capacidad de comprensión de textos como el Unix Consul-tant (UC), un sistema capaz de responder a preguntas relativas al sistema operativoUNIX, creando para ello una base de conocimiento hecha a mano y que era capaz deamoldar la respuesta en función del tipo de usuario (principiante o experto) [5].
En este período se generó otro crecimiento exponencial debido a la obtención derecursos prácticos y herramientas disponibles (parsers o gramática, entre otras), rea-lizándose con mayor éxito estudios e investigaciones relevantes sobre sistemas dedialogo, generación de explicaciones y planificación.
Además, con las grandes cantidades de documentos generados por la web, se realiza-ron muchas aplicaciones de extracción y resumen de textos. Otra técnica que empezóa crecer fue el del reconocimiento del habla, para su uso en aplicaciones comerciales,incluso la invstigación en PLN tuvo gran apoyo de los distintos gobiernos como los deUSA y Europa.
En esta fase se siguieron desarrollando modelos lingüísticos, como las redes semán-ticas. Aunque también surgieron métodos estadísticos, como las redes bayesianas,no sólo centrándose en análisis de datos, sino en todo el proceso de PLN, reflejándoseen el éxito del Hidden Markov Modelling.
Las redes semánticas fueron desarrolladas por Sowa en 1987, sin embargo ya surgie-ron ideas parecidas a ésta a principios de los años sesenta realizadas por Simmons yQuillian, y desarrolladas a finales de los ochenta por Marvin Minsky. Una red semán-tica es un tipo de representación del conocimiento formado por un conjunto de nodosy arcos interconectados. Este tipo de representaciones pueden presentar definicioneso proposiciones [2].
Figura 2.4: Ejemplo de red semántica.
7

2.1. Procesamiento de Lenguaje Natural (PLN)
Las redes bayesianas fueron desarrolladas por Pearl en 1985, son una representaciónen forma de grafo acíclico dirigido (DAG), para expresar distribuciones de probabili-dad conjuntas sobre muchas hipótesis interrelacionadas.
En esta representación las variables son representadas mediante nodos y existen ar-cos que conectan dos variables entre las que existe una determinada relación. Ungrafo bayesiano es capaz de representar grados de confianza subjetivos. Este tipo derepresentación hace uso de la regla de Bayes, en la que tienen vital importancia el co-nocimiento previo y las probabilidad de los acontecimientos o variables. Para calcularla distribución conjunta de la red, es necesario conocer las tablas de prababilidadesconjuntas, en las que se determinan las probabilidades de una variable dados losnodos padres (los superiores al nodo actual).
Sin embargo, es díficil determinar la probabilidad de una variable, por lo que tambiénes difícil mejorar y mantener las tablas estadísticas para procesar toda la informaciónde un problema. Además, las redes bayesianas tienen una expresividad limitada [2].
Figura 2.5: Ejemplo de red bayesiana.
Fase 4: Actualidad
El NLP está creciendo mucho en la actualidad con importantes esfuerzos en la co-municación mediante el habla y en la información textual. Esto se debe al mejor en-tendimiento de las problemáticas y estructura de las técnicas de PLN, al crecimientocomputacional y del nivel de datos disponibles hoy en día. Gracias a las nuevas téc-nicas y estudios, se generan programas o sistemas muy eficientes en las distintasaplicaciones del PLN, pero centrándose en dominios más cerrados, no intentandoabarcar procesos muy generales que serían más inasumibles. Sin embargo, a pesarde los grandes avances que se realizan, todavía hay aspectos que están lejos de ha-berse solucionado, por ejemplo, en el resumen de textos (sistemas poco flexibles), lacomprensión de metáforas o poesía o el propio razonamiento de las máquinas sobrelo que está escrito o se dice. Por ello, a pesar de que hay muchos sistemas y que seha avanzado considerablemente en este campo, aún hay mucho trabajo que realizar.
Gracias al estudio realizado hasta la actualidad y los avances conseguidos se han
8

Desarrollo
desarrollado muchas herramientas para PLN en varias plataformas y en diferenteslenguajes de programación, y para diferentes aplicaciones. Muchas de estas herra-mientas son de código abierto, y aunque la mayoría están desarrolladas en inglés,también las hay disponibles en otros idiomas (aunque con una menor precisión). Engeneral, realizan los pasos de tokenizar los diferentes elementos del texto; encontrarlexicones, con el fin de establecer patrones o relaciones entre las palabras; separarlas oraciones; y definir las categorías gramaticales de las palabras en cada oración[6]. Algunas de ellas son:
GATE: la primera herramienta en desarrollarse (1995), es de código abierto yescrita en Java.
NLTK: desarrollada en 2001 para Python, es una de las más usadas actualmen-te, debido a su operatividad y a la cantidad de funciones y sencillez, además esde código abierto.
Monty Lingua: desarrollada en 2004 en los laboratorios del MIT para Python yJava, cubre gran parte de la demanda en NLP en inglés.
Ellogon: desarrollada en 2004 para C y C++, tiene una estructura muy potente,permitiendo su uso en múltiples lenguas.
IceNLP: desarrollada en 2007 para Java, es una herramienta de código abiertopara textos de Islandia
Apertium: desarrollada en 2009 para C++, principalmente es usada para el cas-tellano, aunque puede usarse para el danés, francés e italiano.
2.1.2. Estudio del PLN
Como se ha podido ver, durante mucho tiempo se creyó que las técnicas de PLNeran una tarea que podría desarrollarse de una manera sencilla (debido a la cienciaficción), sin embargo, es una tarea que no se ha desarrollado plenamente, aunque seestán realizando progresos en este campo (apps móviles, búsqueda web, traduccióno data mining) y hay un creciente interés comercial, debido a la interacción humano-máquina.
Es por ello que en este campo difícil, se ha realizado un estudio a lo largo del tiempo,con sus dificultades, que nos ha llevado hasta ahora mediante la investigación ydesarrollo de modelos que se deben tener en cuenta para el entendimiento de lossistemas actuales de PLN.
En este apartado, por tanto, vamos a profundizar en los aspectos que ha estudiado elPLN a lo largo de estas décadas, el lenguaje, su modelización y su estructura, comoaparece analizado en [7], en donde se explica lo que es un lenguaje natural, cómosurge el procesamiento del lenguaje natural, la arquitectura que suelen tener estossistemas y el análisis de este tipo de arquitectura.
El estudio del lenguaje natural tiene dos objetivos: facilitar la comunicación entrehumanos y máquinas, y diseñar sistemas que realicen tareas complejas (traducción,comprensión o extracción de información, como ejemplos). El lenguaje, desde el pun-to de vista lingüístico, es una función que expresa pensamientos y comunicacionesentre las personas (realizado mediante escritura y/o voz). Desde un punto de vistaformal, se define como un conjunto de frases mediante la combinación de elementos
9

2.1. Procesamiento de Lenguaje Natural (PLN)
de un alfabeto, respetando un conjunto de reglas sintácticas y semánticas. Además,el lenguaje debe ser funcional, es decir, debe permitir expresar ideas.
El lenguaje natural es aquel que ha evolucionado con el tiempo para fines de comu-nicación humana, por ejemplo, el castellano o el alemán. El lenguaje formal es aquelque se ha desarrollado para expresar situaciones que se dan en una determinadaárea de conocimiento cómo, por ejemplo, leyes mecánicas, físicas o matemáticas.
Dentro de estos lenguajes tienen especial relevancia los lenguajes de programación,en los que hay un conjunto de elementos organizados a través de constructores quepermiten crear programas utilizados y comprendidos por los computadores. Estoslenguajes de programación son útiles, ya que sirven de enlace entre los lenguajes na-turales y la manipulación por una máquina, para que, a través del lenguaje natural,una persona pueda comunicarse con un ordenador, lo que se conoce como PLN.
La arquitectura de un sistema de PLN podría ser descrita mediante una serie deniveles, adoptando enfoques según el tipo de conocimiento a tratar:
Nivel Fonológico: Cómo las palabras se relacionan con los sonidos que represen-tan.
Nivel Morfológico: Cómo las palabras se construyen mediante los morfemas.
Nivel Sintáctico: Cómo las palabras se unen formando oraciones, con el papelque cada una de ellas juega en la oración.
Nivel Semántico: El significado de las palabras y su unión para dar significadoa la oración, y el significado independiente del contexto (oración aislada).
Nivel Pragmático: Cómo las oraciones se unen en distintas situaciones y cómolos significados de las oraciones previas alteran el de la actual.
Figura 2.6: Tipos de conocimientos basándose en los niveles [7].
Un sistema típico que haga uso del PLN seguiría los siguientes pasos para procesarel lenguaje e interactuar con las personas:
10

Desarrollo
Figura 2.7: Arquitectura de un sistema de PLN [7].
El usuario se comunica con el ordenador (oral o textual).
El ordenador analiza morfológicamente y sintácticamente las oraciones. En estaetapa hay dos analizadores: el scanner, el encargado de identificar los compo-nentes léxicos (morfemas); y el parser, encargado de verificar si se cumplen lasreglas gramaticales entre los elementos del parser (si la estructura de las ora-ciones es correcta).
Analizar las oraciones semánticamente: saber el significado de cada oración.
Realizar el análisis pragmático: realizar un estudio conjunto de todas las oracio-nes analizadas previamente (el contexto de cada oración).
Ejecutar la expresión final para obtener un resultado y proporcionárselo alusuario.
Veamos un ejemplo en el que un usuario pide información a un sistema que utilizacomo base de conocimiento el siguiente párrafo (centrándonos en la segunda oración):
Pablo es el hermano mayor de la familia López. Él estudia medicina en Albacete.
Figura 2.8: Análisis morfológico y sintáctico.
11

2.1. Procesamiento de Lenguaje Natural (PLN)
Figura 2.9: Análisis semántico y pragmático.
La sintaxis se define como la disposición de palabras en una oración (la secuencia desímbolos válida). Proporciona la información importante que se necesita para enten-der un programa, y por tanto cómo debe escribirse correctamente.
Una gramática es un modelo lingüístico-matemático que describe el orden sintácticoque deben cumplir las oraciones, en este caso vamos a ver cómo se realizaría forman-do árboles de derivación. Ésta se define como una tupla de cuatro componentes:
El axioma: Es el elemento inicial, a partir del cual se genera el árbol de deriva-ción al aplicar diferentes reglas de producción.
Reglas de producción: Conjunto de reglas formado por símbolos terminales y/ono terminales para formar el árbol.
Símbolos no terminales: Conjunto de símbolos que pueden o no derivar en sím-bolos terminales.
Símbolos terminales: Elementos del lenguaje con el que finaliza una rama delárbol, con el fin de generar oraciones.
Podemos ver un ejemplo de una gramática en Figura 2.10, donde la oración a analizares El pequeño niño corre rápidamente.
12

Desarrollo
Figura 2.10: Gramática y ejemplo de aplicación [7].
El análisis sintáctico (parsing) comprueba si una oración pertenece al lenguaje defini-do por la gramática; para ello, se realizan las derivaciones de las reglas gramaticalesgenerando árboles de derivación. Con el fin de obtener buenos resultados, es nece-sario un lexicón que ofrezca información sobre las categorías gramaticales de cadapalabra.
Sin embargo, existen una serie de dificultades o problemas:
La posible asignación de múltiples interpretaciones para una oración (uno delos grandes problemas)
El gran número de unidades léxicas.
Las formas de adquisición de lexicones computacionales (se puede realizar deforma manual, mediante diccionarios en formato magnético o mediante córporatextuales informatizados) son costosas.
Identificar el contexto adecuado de las oraciones.
Las distintas dificultades que tenga de por sí cada uno de los niveles.
A pesar de ello, se han conseguido durante todos estos años muchos avances enlas técnicas de PLN, gracias por una parte al estudio previo que se realizó en estecampo en el siglo XX y a los grandes avances tecnológicos. Sobre todo, se esperaque los avances que se han hecho respecto a la gran cantidad de datos(computación,
13

2.1. Procesamiento de Lenguaje Natural (PLN)
aprendizaje automático y Deep learning) mejoren las prestaciones actuales en el pro-cesamiento del lenguaje, superando los problemas de la semántica, contexto o cono-cimiento, entre otros.
2.1.3. Campos del PLN
El PLN, como se ha visto, ha tenido y sigue teniendo una variedad de ámbitos en losque ha sido utilizado. Generalmente el PLN se ha dividido siempre en NLU (NaturalLanguage Understanding) y NLG (Natural Language Generation).
a. Comprensión del lenguaje natural (NLU)
Se encarga de recibir el mensaje y entender su significado (comprender lo que sedice). En este punto son necesarios datos en un idioma y dominio específico, reglasgramaticales, sintácticas, semánticas y pragmáticas (contexto e intención).
El NLU permite una interacción más expresiva y natural que la realizada medianteelementos como menús o comandos, éstos permiten una interacción dirigida, perolimitada. Es por ello que los sistemas que comprenden el lenguaje permiten un accesoa la información de forma más rápida y natural para el humano, aunque para ello lacomunicación debe ser efectiva; es decir, el sistema debe ser capaz de interpretar loque el usuario quiere expresar, tratando con elementos como anáforas y elipsis [8].
Los sistemas de NLU se suelen dividir en tres componentes: el parsing sintáctico, elparsing semántico y la interpretación del contexto [9].
El parsing sintáctico (nivel sintáctico y gramatical) consiste en analizar la funciónsintáctica de cada palabra, cómo las palabras están relacionadas con las otras, có-mo se agrupan en oraciones y cómo se modifican entre sí. Esto ayuda a resolver losproblemas de palabras que tengan más de una función sintáctica, por ejemplo, ce-leste puede ser un nombre (haría de sustantivo) o puede actuar como adjetivo. Lacomponente que lo realiza es el parser, encargado de analizar cómo las palabras seestructuran en las oraciones.
Veamos un ejemplo con la siguiente oración: El niño come pizza.
Figura 2.11: Parsing sintáctico.
14

Desarrollo
Una forma de representarlo es mediante Gramáticas libres de contexto (CFG), comoaparece representado en la Figura 2.11, donde las oraciones se estructuran de formajerárquica, creando árboles de derivación del parsing [9]. Hay 2 técnicas principalespara describir las gramáticas e implementar el parsing, y para ello se ilustrarán conla oración del ejemplo anterior:
Reglas reescribiendo la CFG: se tienen reglas con símbolos no terminales y losterminales, estas reglas se van generando de forma probabilística generandoárboles de derivación válidos.
Figura 2.12: Reglas reescribiendo la CFG.
Las reglas se van aplicando aleatoriamente simulando la generación de un árboldesde la raíz a los símbolos terminales. La raíz en este caso es la regla O quegenera los nodos SN y SV. Cada uno de estos nodos (si se tratan de no termina-les) tiene sus propias reglas de derivación que se van ejecutando aleatoriamente(ya que cada nodo puede tener diversas opciones). Finalmente, cuando todos losnodos sean terminales, se tendrá una oración aleatoria siguiendo las reglas dela gramática, en este caso generando la oración El niño come pizza.
Redes de transición: Tienen un funcionamiento similar a una máquina de esta-dos finita: se tienen nodos, que representan los estados de la oración, y arcosque modifican el estado actual, lo que conlleva a la generación de la oraciónfinal.
Figura 2.13: Redes de transición.
15

2.1. Procesamiento de Lenguaje Natural (PLN)
En este tipo de métodología la oración, que va cambiando de estado, quedarepresentada en los nodos con la letra O seguidos de un número. Para quela oración vaya cambiando de estado, cada nodo tiene 1 o más arcos, en estecaso la oración debe empezar siempre con un determinante y un nombre, yuna vez que llega a O2 la oración tiene varias formas de cambiar de estado.En este ejemplo, la oración evolucionaría añadiendo un verbo y, finalmente, uncomplemento directo. Cada una de las categorías gramaticales tendrá una listade términos que puede emplear para cada arco, obteniendo la oración El niñocome pizza.
Métodos estadísticos: Seleccionan la secuencia sintáctica que sea más probable,usando por ejemplo la regla de Bayes o los Hidden Markov Models (HMM).
El parsing semántico (nivel semántico) extrae el significado de las oraciones, inde-pendientemente del contexto, este tipo de parsing consigue solventar algunas de lasambigüedades que no realiza el parsing sintáctico, como los posibles significados quepuede tener una palabra, por ejemplo, el ratón animal o dispositivo electrónico. Aquíentran en juego las taxonomías, indicando el significado de cada palabra, algunosejemplos de estos significados serían el tiempo, lugar, posición, acción, sugerencia opetición [9].
En este parsing se procesa el resultado del análisis sintáctico anterior en algún tipode estructura simbólica para representar el significado de una manera adecuada. Lasformas de representación pueden ser muy variadas, usando representación lógica(como la lógica de primer orden), árboles de derivación o métodos estadísticos comolos HMM o las redes bayesianas.
La interpretación del contexto (nivel pragmático) refina la interpretación semántica yelimina la ambigüedad derivada de las anáforas (elementos que sustituyen palabrasen oraciones previas, actuales o posteriores), pronombres y elipsis. Este tipo de ele-mentos se suelen solventar con el Discourse Entity (DE), manteniendo una lista de loselementos que se han mencionado en el diálogo y que pueden omitirse o reemplazarsedespués [9].
Por tanto, este modulo se encarga de examinar el contexto que tienen los elementosanalizados respecto a las oraciones anteriores y a las fuentes de conocimiento que setengan en el sistema. Esta información del contexto es la que consigue mantener laestructura del diálogo y mantener el flujo de este de forma adecuada.
Sin embargo, las distintas técnicas de NLU tienen algunos problemas que minimizanla eficiencia, éstos son la variación lingüística y la ambigüedad, y hacen que estatarea sea difícil, afectando a los distintos niveles lingüísticos (morfológico, sintáctico,semántico o pragmático). La variación lingüística hace referencia a la posibilidad deusar diferentes palabras o expresiones para comunicar la misma idea, mientras quela ambigüedad es cuando una palabra o frase permite más de una interpretación[10].
Problemas de la variación lingüística:
Nivel morfológico: Tengo un regalo para mis padres. La palabra regalo puedehacer de sustantivo o de verbo.
Nivel sintáctico: El adoptó los perros en la tienda. Puede hacer referencia a que Éladoptó los perros que estaban en la tienda o Él adoptó los perros cuando estaba
16

Desarrollo
en la tienda.
Nivel semántico: Juan cogió el ratón. Puede hacer referencia al animal o al dis-positivo electrónico.
Nivel pragmático: Vete a freír espárragos. Puede ser literalmente que se pida freírespárragos o que lo deje tranquilo.
Variaciones léxicas (sinónimos): como por ejemplo casa, piso o apartamento.
Problemas derivados de la ambigüedad:
Anáforas: Juan hizo un regaló a Manuel, él se lo agradeció. Puede haber confu-sión en quién es "él 2a quien se lo agradeció.
Veamos un ejemplo de cómo podría ser la estructura de la comprensión del lenguajecon la siguiente oración: Celeste ha arreglado mi ratón.
Primero se debe realizar una representación de las palabras dichas por el usuario quesirva de entrada al parser sintáctico. Este tipo de representación en el proceso delparsing establece una serie de reglas sintácticas de cómo se combinan las distintascategorías sintácticas o lexicones extraídos.
Figura 2.14: Ejemplo del proceso del NLU (Parsing sintáctico).
El algoritmo de parsing extrae lexicones de las palabras que ha extraído de la pre-gunta del usuario (cada palabra puede tener más de una categoría gramatical) y lasreglas establecidas proponen cómo los lexicones extraídos se relacionan entre sí (portanto, elimina las categorías gramaticales que no estén en las reglas), creando asíarcos de relación entre cada palabra [8].
17

2.1. Procesamiento de Lenguaje Natural (PLN)
Figura 2.15: Ejemplo del proceso del NLU (Parsing semántico).
Obtenida la representación de la información sintáctica, hay que establecer la in-formación semántica para completar este tipo de representación. Una vez estableci-da, se tiene que evaluar esta representación con nuestra base de conocimiento paracomprender el mensaje, mediante relaciones entre las palabras extraídas y los com-ponentes y relaciones de nuestra base [8].
Habría un último paso donde debe intervenir el gestor de diálogo, que mantiene elhilo de la conversación, para resolver los problemas derivados de las anáforas y elipsis(nivel pragmático), pero en este caso sólo teníamos una oración. En este ejemplo, sepodría dar más información sobre quien es Celeste o quien es el pronombre Yo.
b. Generación del lenguaje natural (NLG)
Se encarga de crear una respuesta de forma autónoma a un humano. Obtenida lainformación que se quiere expresar, decide cómo organizarla y generarla.
El NLG se encarga de producir texto entendible, a partir de representaciones de infor-mación, de forma autónoma (decidiendo cómo organizarla y generarla). Si se quieregenerar habla, habría que combinarlo con sistemas de TTS (Text To Speech). El NLGsuele dividirse en 3 fases: Document planning, Microplanning y Surface realisation [9].
Para la explicación de los pasos que se realizan en un sistema de NLG vamos ausar como ejemplo los datos correspondientes a un partido de fútbol detallados en lapágina web FlashScore1. Imaginemos que un usuario le realiza al sistema la siguientepregunta: ¿Qué jugadores del Manchester City fueron amonestados?.
1https://www.flashscore.es/?rd=mismarcadores.com
18

Desarrollo
Figura 2.16: Base de conocimiento sobre el partido.
Fases del proceso de NLG:
El document planning: Se encarga de transformar los objetivos comunicativos dealto nivel en una secuencia de representaciones estructuradas de actos comu-nicativos que cumplan los objetivos iniciales.
A rasgos generales, se encarga de generar una primera visión de la estructuracon la que el sistema pretende organizar la respuesta que se va a generar. Esdecir, qué elementos considera el sistema que deben proporcionarse al usuarioy en qué orden.
Además, se encarga de seleccionar toda la información que considera puede serrelevante a la hora de generar la respuesta. Esta selección es como un preproce-sado de las fuentes de información que tiene, sin embargo, puede que seleccioneelementos que no sirvan en los futuros pasos.
19

2.1. Procesamiento de Lenguaje Natural (PLN)
Figura 2.17: Fase de Document planning.
El microplanning o sentence planning: Utiliza la estructura generada en el docu-ment planning para elaborar oraciones más concretas que formen la respues-ta; para ello, se eligen los recursos lingüísticos a fin de alcanzar los objetivosde la comunicación (lexicalización), generando expresiones en lenguaje natural,por ejemplo, seleccionando los verbos para expresar una determinada acciónde mejor manera. A continuación, se construye la estructura sintáctica de larespuesta mediante agregación, es decir, la combinación de distintas oracionesen una sóla (si fuera posible) para hacer que la respuesta sea más compacta ynatural, incluyendo también elementos como anáforas o pronombres.
Figura 2.18: Fase de Microplanning.
El Surface realisation: Utiliza la semiestructura de la respuesta generada en elmicroplanning para transformarla en una respuesta entendible con palabras au-xiliares como determinantes, dándole orden y sentido a la respuesta, es de-cir, infundiéndole información gramatical para generar respuestas entendiblesa partir de la planificación generada en los pasos anteriores.
Uno de los métodos que se usan es el análisis sintáctico inverso, es decir, usarlos modelos semánticas utilizadas en el NLU, pero usados de forma generativa,como por ejemplo las plantillas o las gramáticas libres de contexto.
Describiremos los modelos mencionados, aplicándolos por igual al ejemplo que
20

Desarrollo
estamos desarrollando, para comprobar cómo realiza cada uno la fase de surfacerealisation.
Las plantillas serían como las reglas de producción, se tiene una serie de reglas,de tal forma que, si se cumplen los antecedentes, se genera una oración prede-terminada. Este tipo de modelos están más limitados, ya que siguen unas reglasfijas, lo que produce poca variación, además, éstas deben realizarse de maneramanual, lo que es costoso, haciéndolo inviable en dominios abiertos.. Lo buenode estos modelos, es que en dominios restringidos son muy eficaces o cometenpocos errores.
Figura 2.19: Fase de Surface realisation mediante plantillas.
El uso de las gramáticas libres de contexto (CFGs), utilizaría unas reglas consímbolos terminales y no terminales, de acuerdo al dominio de aplicación, quedescribirían la gramática que es posible generar. Este modelo iría derivando lasreglas, hasta llegar a los elementos terminales para generar oraciones. Estosmétodos son menos restrictivos que las plantillas, sin embargo, pueden generaroraciones que no deseemos, para ello sería necesario introducir algunas restric-ciones manuales.
21

2.1. Procesamiento de Lenguaje Natural (PLN)
Figura 2.20: Fase de Surface realisation mediante gramáticas.
2.1.4. Áreas de aplicación de las técnicas de PLN
El procesamiento del lenguaje ha sido utilizado en muchas áreas diferentes, segúnel próposito, algunas de ellas son la recuperación de información, extracción de in-formación, reconocimiento y síntesis del habla, traducción automática o resumen detextos.
Recuperación de información (IR)
El campo de la recuperación de información se encarga de extraer un conjunto dedocumentos específicos a partir de una base de documentos más generales. Esteconjunto de documentos extraídos guardan una relación en función de la peticiónrealizada por un usuario al sistema.
El proceso general para la recuperación de información es el siguiente, según apareceindicado en [10] (donde se trata como las técnicas de PLN influyen en la recuperaciónde información):
Indexar el conjunto de documentos mediante una descripción donde se detallenlos aspectos más relevantes del documento, que puedan servir para clasificarlo.
Analizar la pregunta del usuario y, si es necesario, transformarla para repre-sentar la información requerida por el usuario de la misma manera en la que sehan representado los documentos indexados.
Comparar la descripción de la pregunta con la de cada elemento de cada docu-mento.
Mostrar los resultados en orden de relevancia, mediante un ránking (en funciónde la similitud del documento con la pregunta del usuario).
22

Desarrollo
Figura 2.21: Esquema típico de un sistema IR [10].
Este tipo de sistemas pueden ser usados en dominios cerrados (documentos de unaempresa, documentos legales, administrativos o médicos) o en dominios abiertos(donde existan multitud de temáticas y de fuentes de información).
Un ejemplo de esto, y motivo del nuevo impulso de los dominios abiertos, es el de larecuperación de información en la Web (en la que hay una gran multitud y variedadde información) [11]. Cuando usamos los motores de búsqueda web, como Google2
o Baidu3, lo que pretendemos es que al realizar una petición, estos motores de bús-queda analicen la cantidad enorme de documentos que hay disponibles en Internet,buscando lo que pedimos, entendiendo lo que tienen los documentos analizados, pa-ra que después puedan procesarlos, organizarlos y proporcionárselos a los usuarios[12].
Extracción de información
El área de la extracción de información se encarga de encontrar y extraer informaciónrelevante, que puede ser útil para otros sistemas o que sea pedida por un usuario.
Las fuentes de información sobre la que extraer datos pueden una gran cantidad dedocumentos o uno sólo, y esta información puede aparecer de forma estructuradao no. Además, estas fuentes no tienen porque ser textuales, pueden ser elementosmultimedia como imágenes o vídeos.
La información que se pretende extraer son nombres de entidades (el nombre de unapersona, lugar u organización), relaciones entre entidades (por ejemplo, el precio de
2https://www.google.com/3http://www.baidu.com/
23

2.1. Procesamiento de Lenguaje Natural (PLN)
un objeto, el jefe de una empresa o los síntomas de una enfermedad) o elementoscomo listas o tablas [13].
En la actualidad, con el interés de almacenar todos los datos y la información en ba-ses de datos estructurados, el problema de la extracción de información ha adquiridomayor relevancia y está siendo usada en multitud de aplicaciones.
Reconocimiento y síntesis del habla
Es el dominio que se encarga de procesar el audio y convertirlo en texto, despuésla respuesta generada puede volver a transformarse en audio (generar y reproducirel habla). Se divide en 2 módulos dependiendo de si hablamos de reconocimientodel habla, en el cual se utiliza ASR (Automatic Speech Recognition), o si hablamos degenerar audio se utiliza TTS (Text To Speech).
El diálogo fue una disciplina muy activa en los años 80, sin embargo, en la actuali-dad se ha expandido su uso para implementar sistemas de habla (Siri4 o Cortana5),para acceder a información o realizar tareas (apps, robots, tutores, negociadores osistemas médicos, entre otros). Requieren del reconocimiento y síntesis del habla,para identificar lo que dice el usuario, mediante comandos de voz, y proporcionarlela información deseada por audio [14].
Un aspecto a tener en cuenta es que son sistemas que funcionan muy bien en domi-nios limitados, pero con gran cantidad de problemas en dominios abiertos. Además,se deben mejorar diversos aspectos como la comprensión de las pausas y entonación,la coordinación en el turno de palabra o la precisión en los resultados obtenidos hastaahora en las técnicas de ASR y TTS.
Traducción automática
Su función es traducir textos de un idioma a otro, aunque puede ser usado en laautocorrección y autocompletado de textos [14]. La traducción es un elemento crucialhoy en día, de ahí la importancia de los sistemas que permitan analizar y generaroraciones en lenguaje natural, y comprender el significado y contexto de lo que sedice (ambigüedad) en varios idiomas.
Fue una de las primeras aplicaciones en desarrollarse (década de los 50), sin embar-go, no se obtuvo mucho éxito hasta el 1990, cuando IBM adquirió una gran cantidadde oraciones traducidas entre el inglés y el francés. A partir de este momento, y másadelante con los textos online, se permitió elaborar modelos más potentes [14].
Gracias a la tecnología actual, se obtienen traducciones instantáneas entre paresde lenguas, aunque todavía se producen traducciones erróneas debido a múltiplesfactores.
Resumen de textos
Se encarga de crear, automáticamente, una versión reducida de uno o varios textosque sea capaz de proporcionar la información útil. Puede ser usado, por ejemplo, en:resumenes de textos de ámbitos como el derecho, la medicina o administrativos.
4https://www.apple.com/es/siri/5https : //es.wikipedia.org/wiki/MicrosoftCortana
24

Desarrollo
En el mundo actual, existen grandes cantidades de texto en lenguaje humano (tan-to texto estructurado como no estructurado), por ello, es necesario un sistema queayude en las tareas de comprensión y resumen de textos [14].
El objetivo inicial es extraer hechos básicos (extracción de relaciones o datos) quedependen de las necesidades del usuario, pueden estar centradas en un tema quequiera el usuario o en resúmenes generales. También dependen del tipo de resúme-nes, pueden ser extractivos (eligiendo un subconjunto de oraciones del conjunto dedocumentos, las oraciones centrales) o abstractivos (donde se parafrasea el contenidode los documentos), siendo más complejos los segundos [15].
Combinación de dominios
A pesar de existir unos dominios predominantes bien definidos, no significa que seanlas únicas aplicaciones desarrollas. La mayoría de los dominios no se implementanen solitario, sino que se combinan con otros, con el fin de desarrollar aplicaciones osistemas más potentes y que cubran más necesidades. Ejemplos de ellos son:
Sistemas de pregunta-respuesta que utilicen comandos por voz, que hacen usode la extracción de información y del reconocimiento y síntesis del habla.
Sistemas de búsqueda de documentos en múltiples idiomas, que combinan larecuperación de información y la traducción automática.
Sistemas de interpretación de idiomas que combinan la síntesis de habla y latraducción automática, con el fin de generar sistemas que permitan comunicar-se en diferentes idiomas.
Por tanto, las aplicaciones que se pueden generar con las técnicas PLN son muyvariadas y es por ello que está sufriendo un crecimiento importante debido sobretodo a los avances que se han desarrollado y al interés e impulso, cada vez máscreciente, que diferentes sectores, como el comercial o social, ponen sobre este tipode tecnología.
2.2. Sistemas de pregunta-respuesta (QA)
Una de las aplicaciones más interesantes en las que se utiliza el procesamiento dellenguaje es el de los sistemas de pregunta-respuesta. Este tipo de tecnología es unsistema de la ingeniería lingüística basado en la búsqueda y extracción de informa-ción, en el cual se devuelve la información pedida por un usuario en lenguaje natural[5], recibiendo el mensaje rápidamente y de manera concisa, con el suficiente contex-to para validar la respuesta [16].
Además hay una serie de elementos, de los que se pretende dotar a los sistemasQA, para una mejor experiencia con el usuario, como es: proporcionar respuestasen tiempo razonable, de manera precisa y completa (deben centrarse en responderde manera correcta, evaluar las posibles respuestas que se puedan proporcionar alusuario, fusionar los elementos extraídos de las fuentes de información con cohe-rencia) y, además, deben ser elaborados a medida para la necesidad específica delusuario [5].
Por todo esto, hay una serie de líneas de investigación que sería necesario estudiar
25

2.2. Sistemas de pregunta-respuesta (QA)
para la elaboración de un sistema completo: Procesamiento y comprensión de los ti-pos de preguntas que pueden realizarse al sistema, incorporar el contexto adecuadoal dominio concreto, abastecerse de diversas fuentes de información y generar res-puestas adecuadas y completas [5]. Adicionalmente, se desea incorporar modelos quepermitan realizar sistemas de QA en tiempo real, también pueden ser multilingües eincluso interactivos (social), para mantener un diálogo más fluido con el usuario [3].
Agentes conversacionales
Una de las aplicaciones más interesantes que se han desarrollado dentro de los sis-temas de pregunta-respuesta, es la de los agentes conversacionales.
Desde décadas se han estado mejorando las interfaces de interacción hombre-máquina.Este desarrollo creciente (tanto a nivel investigador como industrial) puede verse enlos agentes conversacionales o chatbots, agentes virtuales (usando tanto texto co-mo habla), que sirven como interfaces de lenguaje natural para proporcionar datos yservicios [17].
Este tipo de sistema se está convirtiendo en una tecnología muy importante, debidoa que los chatbots pueden ser creados sin ningún tipo de conocimientos en progra-mación [18]. Además, este crecimiento exponencial se ve motivado por el aumento deplataformas de mensajería y los avances tecnológicos, tanto en capacidad de alam-cenamiento y computo, como en las técnicas y modelos implementados. Incluso hayquien dice que estos sistemas podrían eliminar la necesidad de utilizar páginas weby aplicaciones [19].
Las grandes compañías ven como los chatbots constituyen y constituirán un ele-mento clave en la mensajería (millones de personas utilizan diariamente mensajeríamóvil y redes sociales). Algunas de ellas son Microsoft6 (Skype7 y Cortana), Facebook(Messenger8), Google (Google Assistant9), Apple (Siri) o Amazon (Alexa10), creandoasistentes digitales mediante habla. Además, hay miles de ellos basados en texto,con funcionalidades específicas, según el dominio donde se utilicen [19]. También sepone empeño en la generación de entornos de desarrollo de agentes conversacionales,con el propósito de promover su uso y desarrollo por parte de estudiantes o investi-gadores, de forma rápida y sencilla, fomentando aún más este crecimiento. Algunosde los entornos de desarrollo de agentes conversacionales más populares son LUIS11
(Microsoft), Watson Conversation12 (IBM), Amazon Lex13 (Amazon) o RASA14 (start-updesarrollada en Berlín por Alex Weidauer y Alan Nichol).
Por ello, se puede ver que el desarrollo de los agentes conversacionales supone unelemento clave de cara a la interacción hombre-máquina que se avecina, ya que pue-den ser usados para múltiples tareas como: reservar vuelos, comprar productos, serusados en las llamadas telefónicas de servicio al cliente, entre otras muchas.
6https://www.microsoft.com/es-es7https://www.skype.com/es/8https://es-es.facebook.com/messenger9https : //assistant.google.com/intl/eses/
10https://developer.amazon.com/es-ES/alexa11https://www.luis.ai/12https://www.ibm.org/activities/watson-conversation13https://aws.amazon.com/es/lex/14https://rasa.com/
26

Desarrollo
Sin embargo, hay distintos aspectos en los que los agentes conversacionales debenmejorar (o características que sería deseable que tuviesen), como son la elaboraciónde agentes que se centren en interactuar mediante conversaciones (reduciendo el usode elementos mecánicos o visuales), que interpreten y comprendan la tarea que se lesdemande. Se debe mejorar también su integración con los elementos, tanto humanoscomo máquinas, con los que interaccionar y aprender. Finalmente, estos elementosdeben asegurar los aspectos éticos y privados de los usuarios para conseguir un grangrado de aceptabilidad [17].
Resumiendo, podríamos decir que, en esta época moderna de tecnología, los chat-bots se erigen como el gran elemento de la era de los servicios conversacionales.Estos asistentes virtuales de mensajería instantánea permiten proporcionar serviciosa los usuarios de manera eficiente, proporcionando una experiencia mejor que otrastecnologías, a un precio más reducido y de una manera más sencilla [20].
2.2.1. Estructura de los sistemas QA
La arquitectura de los sistemas de pregunta-respuesta, aunque no sigue un esquemauniversal, suele seguir un esquema básico en el que se tiene un módulo de interpre-tación de la solicitud (NLU), una búsqueda de lo que se ha solicitado (extracción de lainformación) y la generación del mensaje (NLG) [18]. A parte, estos sistemas puedenincluir información del contexto, teniendo en cuenta los datos del usuario, aspec-tos espacio-temporales y/o preguntas realizadas anteriormente [5]. Todo esto estaríamanejado por el gestor de diálogo, encargado de mantener el hilo de la conversación.
En Figura 2.22 se puede observar el esquema de este tipo de sistemas y los módulosde los que está compuesto.
Figura 2.22: Esquema de un sistema QA [21].
Módulo de análisis de la pregunta (NLG)
Se encarga de determinar la clase de la pregunta (por ejemplo, qué, quién o cómo),concretar la clase de la respuesta (objeto, persona o definición), determinar el foco dela pregunta y extraer los términos relevantes para la posterior extracción [5].
La entrada que recibe el sistema es una pregunta en lenguaje natural, éste debeser capaz de comprender las restricciones del lenguaje (vocabulario y sintaxis) y elcontexto al que esté sometido (el discurso del diálogo y el conocimiento que se tienesobre el perfil del usuario).
27
2.2. Sistemas de pregunta-respuesta (QA)
La salida en este módulo será una representación de la pregunta, que se utilizará enlas siguientes partes del sistema. Normalmente, este tipo de representaciones debenidentificar el significado semántico, las palabras clave y las relaciones sintácticas ysemánticas que debería presentar la respuesta candidata [16].
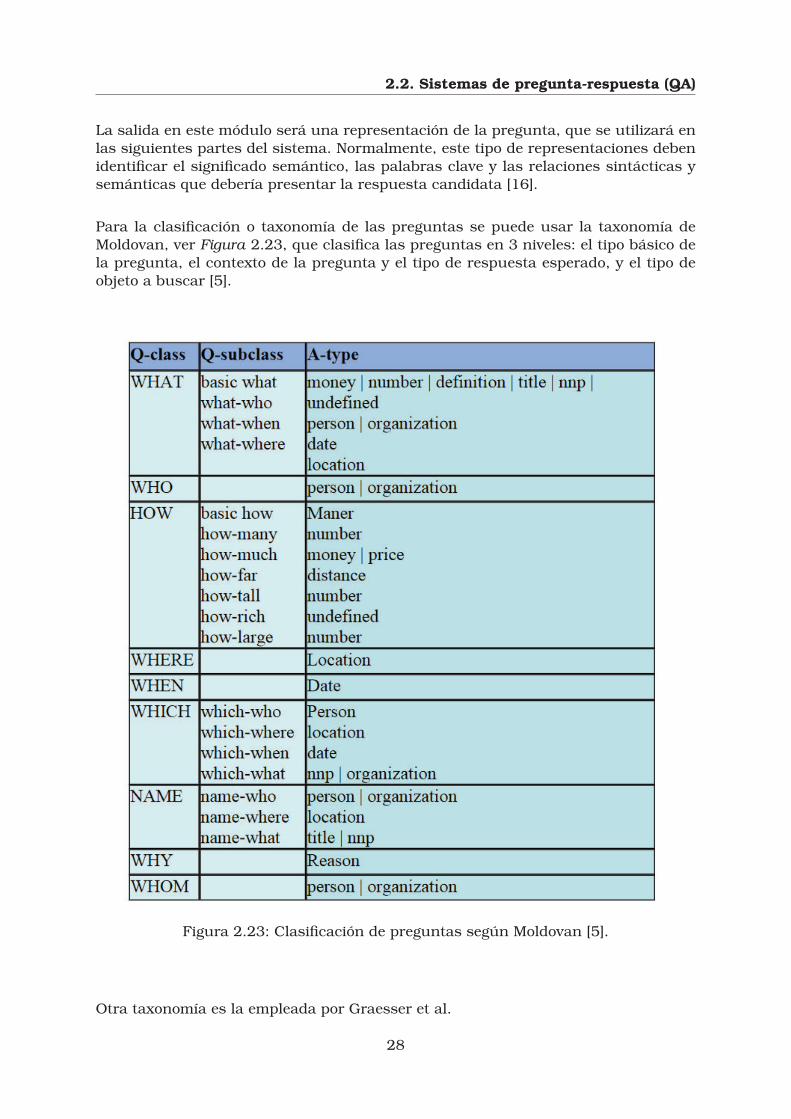
Para la clasificación o taxonomía de las preguntas se puede usar la taxonomía deMoldovan, ver Figura 2.23, que clasifica las preguntas en 3 niveles: el tipo básico dela pregunta, el contexto de la pregunta y el tipo de respuesta esperado, y el tipo deobjeto a buscar [5].
Figura 2.23: Clasificación de preguntas según Moldovan [5].
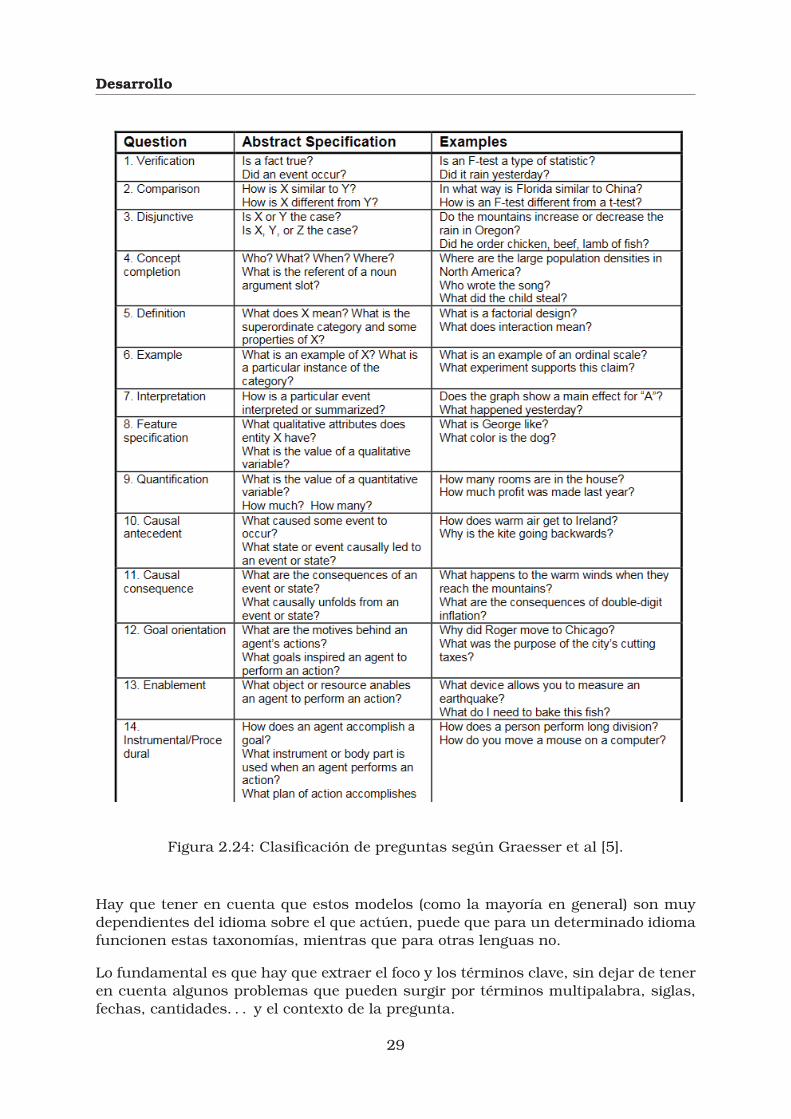
Otra taxonomía es la empleada por Graesser et al.
28
Desarrollo
Figura 2.24: Clasificación de preguntas según Graesser et al [5].
Hay que tener en cuenta que estos modelos (como la mayoría en general) son muydependientes del idioma sobre el que actúen, puede que para un determinado idiomafuncionen estas taxonomías, mientras que para otras lenguas no.
Lo fundamental es que hay que extraer el foco y los términos clave, sin dejar de teneren cuenta algunos problemas que pueden surgir por términos multipalabra, siglas,fechas, cantidades. . . y el contexto de la pregunta.
29
2.2. Sistemas de pregunta-respuesta (QA)
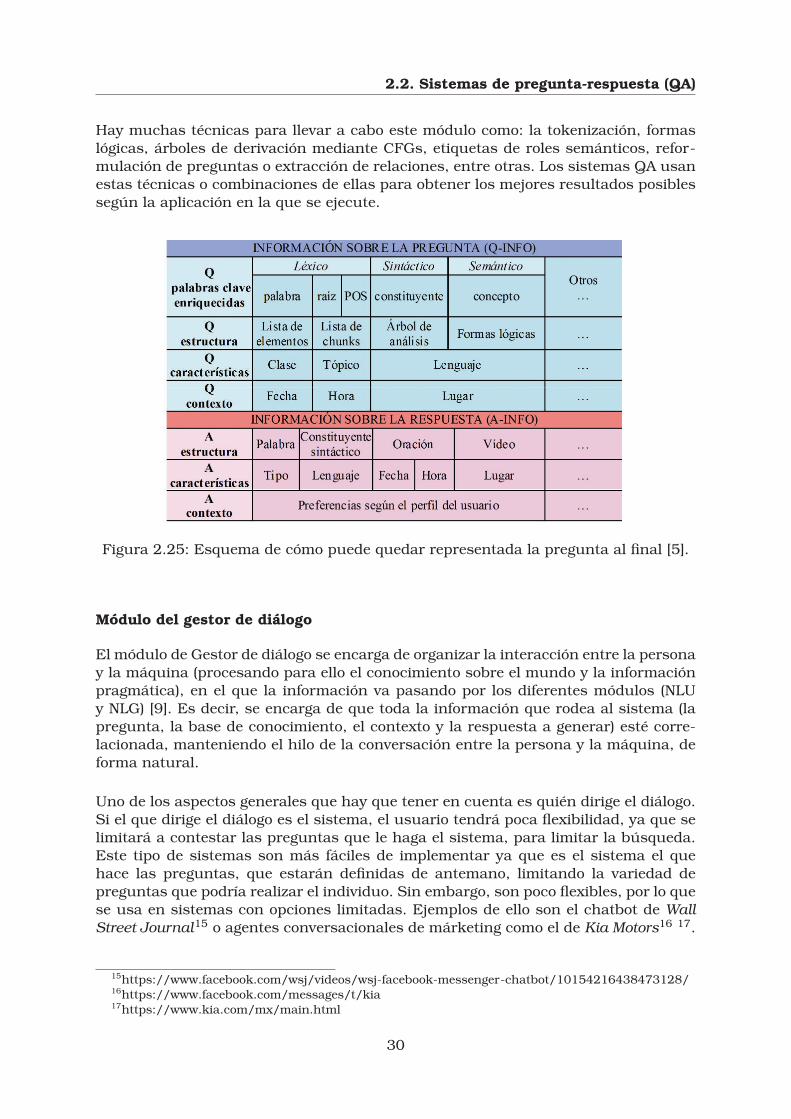
Hay muchas técnicas para llevar a cabo este módulo como: la tokenización, formaslógicas, árboles de derivación mediante CFGs, etiquetas de roles semánticos, refor-mulación de preguntas o extracción de relaciones, entre otras. Los sistemas QA usanestas técnicas o combinaciones de ellas para obtener los mejores resultados posiblessegún la aplicación en la que se ejecute.
Figura 2.25: Esquema de cómo puede quedar representada la pregunta al final [5].
Módulo del gestor de diálogo
El módulo de Gestor de diálogo se encarga de organizar la interacción entre la personay la máquina (procesando para ello el conocimiento sobre el mundo y la informaciónpragmática), en el que la información va pasando por los diferentes módulos (NLUy NLG) [9]. Es decir, se encarga de que toda la información que rodea al sistema (lapregunta, la base de conocimiento, el contexto y la respuesta a generar) esté corre-lacionada, manteniendo el hilo de la conversación entre la persona y la máquina, deforma natural.
Uno de los aspectos generales que hay que tener en cuenta es quién dirige el diálogo.Si el que dirige el diálogo es el sistema, el usuario tendrá poca flexibilidad, ya que selimitará a contestar las preguntas que le haga el sistema, para limitar la búsqueda.Este tipo de sistemas son más fáciles de implementar ya que es el sistema el quehace las preguntas, que estarán definidas de antemano, limitando la variedad depreguntas que podría realizar el individuo. Sin embargo, son poco flexibles, por lo quese usa en sistemas con opciones limitadas. Ejemplos de ello son el chatbot de WallStreet Journal15 o agentes conversacionales de márketing como el de Kia Motors16 17.
15https://www.facebook.com/wsj/videos/wsj-facebook-messenger-chatbot/10154216438473128/16https://www.facebook.com/messages/t/kia17https://www.kia.com/mx/main.html
30

Desarrollo
Figura 2.26: Esquema de un diálogo en el que el sistema dirige las interacciones.
Si el que dirige el diálogo es el usuario, es éste el que se encargará de preguntardirectamente al sistema lo que desee, limitando el espacio de búsqueda según susdeseos. Este tipo de sistema es más difícil de implementar ya que el sistema debeser capaz de comprender e identificar todas las preguntas que le haga el usuario y eltipo de entrada puede tener mucha variedad, por lo que no se habrán definido todaslas varientes posibles. Ejemplo de ellos son los asistentes personales como GoogleAssistant.
Figura 2.27: Esquema de un diálogo en el que el usuario dirige las interacciones.
Además, puede ocurrir que quien dirija el diálogo no esté del todo definido, sino quese realice de forma mixta, en algunas ocasiones lo dirigirá el usuario y en otras el
31

2.2. Sistemas de pregunta-respuesta (QA)
sistema.
Figura 2.28: Esquema de diálogo en el que se dirige de forma mixta las interacciones.
Para representar este sistema es conveniente también estudiar cómo se modela undiálogo entre personas, para servir de referencia a los diálogos humano-máquina,es decir cómo las conversaciones que mantenemos día tras día las personas puedenestructurarse, para poder ser analizadas e implementadas posteriormente en diálo-gos entre las personas y los agentes conversacionales. Esta matización del estudiodel discurso entre humanos para su posterior uso en los diálogos entre personas ymáquinas es descrito en [9], donde se analizan los distintos modelos de diálogos yalgunas de las implementaciones realizadas en el gestor de diálogo.
Algunas aproximaciones a modelos de diálogos entre humanos serían los dialoguegrammars y los modelos basados en planes:
Los dialogue grammars: consideran que hay una secuencia de elementos en eltranscurso del diálogo y que algunos de estos elementos o estructuras siguen aotros. Por ejemplo, una pregunta suele venir seguida de una respuesta.
Los modelos basados en planes: se basan en que las personas realizan accio-nes para conseguir objetivos, en este caso las acciones comunicativas producencambios en los estados mentales de las personas que escuchan, generando ob-jetivos. Por ejemplo, una persona está escuchando a otra, por el momento suestado mental está escuchando (a la espera), cuando la segunda persona leformaliza una pregunta, el estado mental de la persona pasa, de estar a escu-chando, a pensar en qué debe decir para proporcionar una respuesta. En esteejemplo, cuando la primera persona está escuchando (primer estado mental), segenera una acción comunicativa (alguien le pregunta algo), por tanto, la perso-na piensa en lo que debe decir (planificación, ha cambiado el estado mental), yfinalmente responde (objetivo).
El gestor de diálogo puede utilizar alguno de los modelos de diálogo entre humanos,como los mencionados anteriormente, con el objetivo de organizar cómo deben se-
32

Desarrollo
guirse los turnos de palabra entre las personas y el sistema implementado. Algunosde los modelos usados para esta tarea son:
El theorem proving: el sistema trata de demostrar que un problema está resuelto(teorema), realizando varios pasos para ello, utilizando axiomas y deducciones.Con el uso de estos pasos, el diálogo va avanzando para que el sistema puedaproporcionarle la información al usuario. Los axiomas son sentencias que sesabe que son verdaderas, mientras que las deducciones no se obtienen con esaseguridad, sino mediante inferencia lógica (presunciones). Es un método muyusado en programación lógica, sin embargo, al utilizar reglas prefijadas, es muydependiente del dominio y la tarea.
Figura 2.29: Esquema de un diálogo mediante Theorem Proving.
La máquina de estados finita: el diálogo se representa como una red de tran-sición de estados, donde se especifican los pasos que se pueden realizar de-pendiendo del estado del diálogo en que se encuentre el sistema. Las accionespueden ser, por ejemplo: pedir información, proporcionarla, pedir confirmacióno terminar la conversación, y al realizar dicha acción el sistema se desplaza aun nuevo estado. Una vez en este estado, el sistema tomará otras acciones quele conducirán a nuevos estados, y así sucesivamente.
Es una forma muy sencilla, intuitiva y bien estructurada de modelar un diálogo.Sin embargo, una de las desventajas es que deben conocerse todas las opcionesposibles, por lo que son usados en dominios concretos.
33

2.2. Sistemas de pregunta-respuesta (QA)
Figura 2.30: Esquema de un diálogo mediante máquina de estados finita.
Modelos de aprendizaje automático y estadísticos: los métodos más utilizadosson los de aprendizaje por refuerzo, en concreto el Markov Decision Process(MDP) y el Partially Observable MDP. Uno de problemas de estos modelos esla pequeña cantidad de datos (para el entrenamiento y testeo) que hay paraaprender y probar estrategias de diálogo. Por ello, la simulación del diálogo sue-le ser necesaria para ampliar el conjunto de datos existente, ya que se requieremuestras de datos elevadas para obtener mayor precisión.
El modelo form filling: son ideales cuando la aplicación consiste en la transfe-rencia de información en un sentido. En éstos, la información se representacomo un conjunto de parejas atributo-valor, donde se pide un valor de un atri-buto requerido [22]. La información de los elementos es representada como unframe, con una serie de atributos y sus valores. Cuando el usuario pide infor-mación, el sistema le indica el número de elementos y si no se han especificadotodos los atributos (hay atributos vacíos) va preguntándole al usuario sobre unode los atributos vacíos, para que sea más específico, y así reducir el rango debúsqueda.
Figura 2.31: Esquema de un diálogo mediante el modelo de form filling.
34

Desarrollo
Módulos de extracción de la información y de generación de la respuesta
La extracción de la respuesta debe localizar y producir la respuesta exacta en lasfuentes de información que tenga el sistema (datos estructurados o no, texto o ele-mentos audiovisuales). Para llevar a cabo esto, se establecen comparaciones entre larepresentación de la pregunta y la representación de las respuestas candidatas, enlas que se pueden incluir las restricciones comentadas anteriormente a nivel sintác-tico y semántico, con el fin de reducir el foco de búsqueda [16].
La respuesta generada puede elaborarse mediante una lista con un número prede-terminado de las mejores candidatas, sin embargo, esto no es muy natural y reducela interacción con el usuario. Lo mejor es generar respuestas según las reglas sintác-ticas y semánticas, utilizando algún modelo [16].
Algunos métodos utilizados son: los n-gramas, modelos de traducción automática,técnicas de aprendizaje automático, patrones léxico-semánticos o estructuras sintác-ticas [5].
a. Estructura de sistema QA usando el habla
En los sistemas de interacción hombre-máquina se desea ser lo más natural posible.El hecho de añadir el conocimiento del habla potencia esta naturalidad, sin embargo,esto añade más complejidad. En este tipo de diálogos, como entre personas, rigeun proceso por turnos de manera secuencial en los que intervienen la persona y elsistema del gestor de diálogo (DM).
La arquitectura es como la descrita generalmente, pero añadiendo la parte de recono-cimiento del habla. Por tanto, tenemos el reconocimiento automático del habla (ASR),NLU, el gestor de diálogo, extracción de información, NLG y la generación de hablaa partir de texto (TTS). En éstos la entrada es procesada por el ASR y el NLU y seencargan de interpretar lo que la persona quiere. Esta información se le pasa al DMpara que extraiga la información deseada, que será transmitida finalmente por losmódulos de NLG y TTS [23].
Figura 2.32: Esquema de un agente conversacional usando el habla [24]
35

2.2. Sistemas de pregunta-respuesta (QA)
2.2.2. Clasificación
Depende de varios factores, por lo que se pueden realizar varias clasificaciones, vere-mos algunas de ellas a continuación.
Según el tipo de dominio
Se puede dividir en 2 grandes grupos, dominio cerrado o abierto, dependiendo deldominio o dominios a los que se restrinja [3].
Dominio cerrado o restringido: aplicaciones centradas en 1 o pocos dominios.Ofrecen respuestas sobre un ámbito concreto (del que no pueden salir), paraobtener mejores prestaciones (elaborando previamente un conjunto de reglasy relaciones restringidas al campo de aplicación) sobre documentos precisos,predefinidos y homogéneos. Estos sistemas requieren un gran conocimientodel lenguaje para comprenderlo y proporcionar soluciones precisas. Además, sepueden combinar sistemas de dominio cerrado para crear sistemas de dominioabierto.
Dominio abierto: aplicaciones centradas en muchos dominios. Como se ha co-mentado son aplicaciones de una elevada complejidad, ya que proporcionan res-puestas a cualquier pregunta, no tienen restricciones. Se encargan de obtenerrelaciones del texto sin necesitar de un proceso previo manual como la elabo-ración de un vocabulario o reglas de relaciones (al igual que hacen las técnicastradicionales de los dominios cerrados) [25]. Esto supone un obstáculo para lossistemas abiertos, que deben permitir obtener información relevante de muchosdominios sin determinar y sin relaciones prefijadas que permiten obtener dichainformación. Normalmente, la calidad de estos sistemas no es elevado. Algunosejemplos son Google, Yodaqa18 o Answers.com19.
Según el tipo de preguntas
El tipo de preguntas también será decisivo para determinar el tipo de respuestas es-peradas [3]. Es importante el parafraseo de preguntas para abarcar más posibilidadesy después analizar el tipo de respuesta que se espera, para focalizarse mejor en loque se pide de forma más precisa [16].
Preguntas factoides: qué, cuándo, quién, cómo, dónde. Buscan una única res-puesta (normalmente entidades con nombre [NE]).
Preguntas tipo lista: la respuesta es una enumeración, normalmente de entida-des o hechos.
Preguntas tipo definiciones: buscan una parte de texto o un resumen de múlti-ples documentos. Normalmente son las “Qué es”, definiendo un evento o enti-dad.
Preguntas tipo hipotéticas: requieren información sobre un evento asumido, nor-malmente son las “Qué pasaría si”, este tipo de respuestas son subjetivas.
18http://ailao.eu/yodaqa/19https://www.answers.com/
36

Desarrollo
Preguntas causales: cómo o por qué. Requieren clarificaciones de las entidades,buscan dar explicaciones, razonamientos o elaboraciones de eventos específicosu objetivos.
Preguntas confirmativas: esperan respuestas de sí o no.
Según la fuente de información
Esta clasificación se basa en el tipo de fuente de información que posee el sistema[5].
Sistemas basados en texto: el tipo de fuente de información sobre la que extraenlos datos es textual. Estas fuentes además, pueden estar dispuestos de formaestructurada o no. Los datos estructurados tienen un esquema bien definido,como puede ser el caso de bases de datos o tablas. Los datos no estructuradosson aquellos en el que el formato de texto es libre, no hay ninguna estructurade datos. También están los datos semiestructurados, en los que se tiene textolibre pero con una cierta estructura, como puede ser una receta o un prospectomédico.
Sistemas multimedia: la fuente de información sobre la que extraen los datosno es textual, los datos provienen de archivos multimedia como imágenes, vídeoo audio.
Según la forma de las respuestas generadas
Se pueden esperar respuestas largas o cortas, generando la respuesta o extrayéndolade la fuente de información directamente, varían según el usuario que la solicite [16].
Respuestas extraídas: pueden ser oraciones (factoides), párrafos (causales o hi-potéticas) o información multimedia (audio o video).
Respuestas generadas: Pueden ser respuestas confirmativas (sí o no), respues-tas que ofrecen opiniones o respuestas en forma de diálogo.
Según el tipo de usuario que utilice el sistema
Basados según el tipo de usuario, pueden ser usuarios casuales o expertos[16], [26]:
Usuarios casuales o generalistas: utilizan el sistema pocas veces y no se nece-sita gran información sobre el dominio, ni respuestas altamente precisas, porejemplo (Siri o Cortana). Para los usuarios casuales se debería informar de laslimitaciones del sistema, para que entiendan cómo interpretar las respuestas.
Usuarios expertos o especialistas: utilizan el sistema en muchas ocasiones, sonpersonas expertas en su dominio de aplicación, por lo que esperan respuestasaltamente cualificadas. Para los usuarios expertos sería deseable que se desa-rrolle y actualice el sistema de acuerdo al usuario.
Según el tipo de métodos utilizados
Como se ha comentado anteriormente, se pueden utilizar métodos lingüísticos o es-tadísticos [3].
37

2.2. Sistemas de pregunta-respuesta (QA)
Métodos lingüísticos: explotan la información lingüística de los sistemas, gene-rarando técnicas para organizar la información, como: las formas lógicas, reglas,templates (relaciones triples), frames, redes semánticas u ontologías.
Estos métodos, sin embargo, tienen que centrarse en un dominio particular y,si se cambia de dominio, hay que reescribir las reglas y gramática. Además,construir la base de conocimiento supone un gran trabajo y es lento.
Métodos estadísticos: cogieron gran importancia gracias a la disponibilidad degran cantidad y variedad de datos de internet, manejables por este tipo de mé-todos. Necesitan muchos datos para ser más exactos, aunque pueden ser re-utilizados en otros dominios y lenguas. Uno de los problemas es que tratan lostérminos como independientes y fallan en palabras o frases que están relacio-nadas. Ejemplos como clasificadores SVM, bayesianos o modelos de máximaentropía.
Según la duración y quién dirige el diálogo
Pueden clasificarse por quién dirige el diálogo (el usuario o el sistema) o la duraciónde éste, según menciona [27].
Según la duración de la relación:
Relación corta: normalmente usados para un único uso, sin usar o almacenardatos del usuario. Ejemplos de ello son los que proporcionan contenidos comoel de la COPE20 o los de marketing.
Relación larga: son de una complejidad mayor, utilizando datos del usuario parauna interacción más personalizada. Ejemplos de ellos son los chatbot sociales(Replika21) o chatbots terapeutas ( Woebot22).
Si combinamos la clasificación según la duración y según quien dirige el diálogo, sepuede obtener una clasificación bidimensional con 4 tipos de chatbots, ver Figura2.33.
Figura 2.33: Tipos de chatbots según [27].
20https://www.facebook.com/COPE/21https://replika.ai/22https://woebothealth.com/
38

Desarrollo
2.2.3. Aplicaciones de los sistemas de pregunta-respuesta
Educación
Muchos agentes conversacionales, sobre todo los desarrollados por grandes compa-ñías, están diseñados para actuar dentro de la compañía o para el sector servicios;muchos otros actúan en internet como guías o compradores. Sin embargo, un campomuy interesante (y que está siendo muy investigado) es el de la enseñanza [28], con elque se puede conseguir una educación más personalizada y precisa, capaz de ense-ñar las bases del lenguaje (hablar, escribir, leer y escuchar) y mejorar la calidad de lasenseñanzas. Además, se pueden usar estas técnicas en las escuelas para solventarlos problemas actuales en educación [29].
Dentro de la enseñanza, hay muchos subcampos, como el de enseñar materias con-cretas, hacer de tutores personalizados o aprender idiomas extranjeros [26]. Lo buenode la aplicación de chatbots en la educación es que se puede realizar en cualquierlugar y momento, y al ritmo del usuario.
En los últimos años ha habido un incremento en el sector de software de aprendizajedel lenguaje online, con chatbots como Cleverbot23 y Mondly24.
Como se ha comentado, dentro de la educación se pueden tratar varios temas, unejemplo de ello sería la enseñanza de las ciencias de la computación. Uno de losproblemas de las universidades es que se gradúan pocos estudiantes dedicados alsector de la ingeniería y, en concreto, en el ámbito informático. Una de las principalescausas de esto es el hecho de que en la educación elemental no se enseñen tantosconceptos sobre este tipo de ciencias y, por ello, los alumnos no se ven motivadosa iniciar sus estudios universitarios en este ámbito [30]. Un ejemplo de ello seríaChatbot25, desarrollado por un equipo de expertos liderados por la Luciana Benotti,de la Universidad Nacional de Córdoba, en colaboración con la empresa LVK. Esun software educacional de código abierto para ayudar a los alumnos a comprenderconceptos informáticos, proponiendo una estrategia pedagógica para incrementar elinterés estudiantil en este campo (ayudando a crear sus propios chatbots).
Otra tema educacional es la tutorización personalizada, uno de los problemas de laeducación es que hay mucha ambigüedad en los tipos de centros y en las necesidadespropias de cada alumno. Para solventar esto, es posible aplicar la IA usando chat-bots para ofrecer servicios personalizados a cada estudiante [31]. Los servicios quepueden ofrecer estos sistemas son administrativos o académicos, un ejemplo seríaAdmitHub26.
Este tipo de sistemas debe tener en cuenta el nivel pedagógico del contenido textual,ya que el nivel de las respuestas que se dé debe ser acorde al nivel que tenga elestudiante o la persona que utilice el sistema. Es por ello que los sistemas de dominioabierto no podrían lidiar con esta adversidad.
Uno de los sistemas que tiene en cuenta el nivel pedagógico de los alumnos a la horade interactuar con ellos es EDUQA [32], en donde se propone una red conceptualdinámica (DCN) que permite comprender este nivel pedagógico y saber interpretar la
23https://www.cleverbot.com/24https://es.mondly.com/25http://www.daleaceptar.gob.ar/cms/coartada/descarga-chatbot/26https://www.admithub.com/
39

2.2. Sistemas de pregunta-respuesta (QA)
mejor solución, para proporcionársela al estudiante, de acuerdo con distintos aspec-tos como el nivel del estudiante, el curso, la asignatura o el capítulo correspondienteen el que se encuentre.
Uno de los ámbitos más usados es el del aprendizaje de idiomas. Ha sido utilizado enJapón, para el aprendizaje del japonés, demostrando una gran utilidad para innovary reformar los métodos de enseñanza [29].
Un ejemplo de los agentes conversacionales para el aprendizaje de idiomas es Gengo-bot27, un chatbot multilingüe usado para enseñar los conocimientos básicos del japo-nés, con descripciones en inglés e indonesio. Dispone de botones y menús que le sir-ven de interfaz, lo que supone una interacción limitada que necesita desarrollarse[26].
Como toda la IA, en general, los chatbots más utilizados son, mayoritariamente, parael aprendizaje en inglés (Cleverbot y CSIEC chatbot28). Aunque, el hecho de usarchatbots hace que los estudiantes se sientan más atraídos y con más alegría a lahora de aprender un idioma, suele darse el caso de que, generalmente, son útilespara estudiantes con niveles avanzados o con la ayuda de un profesor [26].
Multimedia y Robótica
Los sistemas de preguntas-respuesta también pueden ejecutarse sobre elementosvisuales (VQA), en los cuales, dada una imagen o vídeo, se hacen preguntas sobreésta en lenguaje natural y se proporcionan respuestas sobre ésta. La combinacióngenerada en los VQA entre la visión por computador, el procesamiento del lenguajey la representación y razonamiento del conocimiento está siendo estudiada de formamás elevada en los últimos años en aplicaciones multimedia [33].
En aplicaciones multimedia pueden existir datos en forma textual y en formato au-diovisual como imágenes, vídeos o audio [34]. La habilidad de asociar imágenes ovídeos con oraciones en lenguaje natural que describan entidades, eventos o la es-cena en estos medios es una tarea muy ambiciosa de la comprensión de imágenes[35]. Este tipo de aplicaciones se puede dividir en 2 tipos de tareas: la descripción ola recuperación visual.
La descripción visual: consiste en asociar las palabras con los datos audiovi-suales, haciendo descripciones o resúmenes de las propiedades de una imageno vídeo mediante palabras, incluso se puede describir información no visual (elcontexto en la que se hizo la imagen) [35] . Algunas aplicaciones podrían ser re-conocimiento de animales o caras, o encontrar e identificar objetos en el mundoreal o en la web.
La recuperación visual: trata de anotar en regiones de la imagen, palabras querepresenten dicha zona, es decir, etiquetar las imágenes. Esta tarea es clave a lahora de implementar aplicaciones de VQA, por ello, deben existir modelos quese encarguen de realizar un buen etiquetado de los objetos, escenas y accionespara su posterior uso en aplicaciones en las que se requiera la elaboración deuna descripción de imágenes [36].
Esta es una de las aplicaciones más codiciadas y de las que hay más interés eninvestigar y en generar sistemas sofisticados, por ello es una de las aplicaciones en
27https://gengobot.com/28http://www.csiec.com/
40

Desarrollo
las que los agentes conversacionales son muy utilizados, habiendo muchos artículossobre este tema.
Normalmente, en VQA el tipo de preguntas es abierto, es decir, no sabemos ni loque se va a preguntar ni la forma en la que se va a preguntar. Un campo de estudioen este aspecto es el de predecir los atributos de la imagen (representación internadel contenido de la imagen), como elementos, regiones o acciones, extrayendo las ca-racterísticas más relevantes a partir de bases de conocimiento externas (por ejemplo,DBpedia29) de la cual se generará después la respuesta, cubriendo un gran repertoriode preguntas [37]. Un ejemplo de ello puede verse en el modelo mQA, desarrollado porGao, H., Mao, J., et al., en el que se permite responder preguntas sobre una imagen,en inglés y chino, de forma libre, sin ningún tipo de restricción [38].
En [39] diseñan un framework que genera descripciones a partir de imágenes o ví-deos. Para ello sigue 3 pasos: las imágenes o frames de los vídeos se descomponenen patrones visuales mediante un motor de parsing de imágenes (similar al parsingde oraciones). Para realizar esto utilizan un grafo (AoG) para interconectar cada unode los elementos extraídos de la imagen, ver Figura 2.34. Con el uso de AoG seconsigue realizar una representación del conocimiento visual de los elementos queconstituyen la imagen, como, por ejemplo: objetos, partes de la escena y relacionesentre elementos o relaciones semánticas (espaciales, temporales o funcionales). Estarepresentación tiene forma de árbol, en la que la imagen se va ramificando en lassubescenas que contenga y cada uno de ellos seguirá subdividiéndose en los elemen-tos que contenga cada subescena.
Figura 2.34: Representación de un AoG [39].
Los resultados obtenidos en el AoG son transformados a una representación semán-tica en la forma de la Web Ontology Language (OWL). Este tipo de representación estámuy bien esquematizada y es representativa, sin embargo, es de difícil comprensión,
29https://www.dbpedia.org/
41

2.2. Sistemas de pregunta-respuesta (QA)
por ello, el último paso consiste en generar texto entendible para las personas, verFigura 2.35.
Figura 2.35: Generación de respuesta a partir del AoG [39].
Una visión muy interesante de la descripción visual es la de su estudio para ana-lizar como las personas nos fijamos en una imagen y relacionamos elementos a lahora de describir una escena, este estudio aperece reflejado en el sistema Baby Talk[40]. La forma en la que las personas describen, no sólo las escenas, sino tambiénlos objetos particulares de ésta, su localización y otro tipo de información, puedeser muy útil para descubrir modelos estadísticos de cómo las personas realizan estetipo de descripciones. Este estudio es posible, hoy en día, gracias a la gran canti-dad de imágenes disponibles en repositorios locales o en la web, lo que podrá servirposteriormente para ayudar en el campo del NLG.
De igual manera que en las aplicaciones multimedia, la combinación de NLP conla visión por computador ha sido utilizada en robótica [34]. El NLU es uno de losaspectos más importantes de la inteligencia de los sistemas robóticos, clave para lacomunicación entre los humanos y éstos, lo que supone una tarea extremadamentecompleja [41].
En este tipo de aplicaciones hay que percibir y manipular objetos, elemento funda-mental, ya que los operarios darán órdenes a los robots y éstos deben asociar lo quese le ordena con movimientos propios y el reconocimiento visual del entorno que lerodea; habrá una interacción humano-robot en la que se realizarán diversas tareasdonde se podrá dialogar o aprender rutinas [34].
Lo que se suele hacer en estos sistemas, para su simplificación, es seleccionar unode los niveles del lenguaje sobre el que operar, mientras que en los otros se minimizasu atención o se elimina [41].
Automatización de la vivienda
Los agentes conversacionales también pueden ser utilizados en un área creciente delos últimos años, los sistemas de domótica o automatización de la vivienda, hoteleso edificios, teniendo presente el uso adecuado y sostenible de recursos (haciendoun control del gasto energético). El hecho de que los agentes virtuales proporcionenuna interacción natural e intuitiva podría conllevar un buen uso en este tipo deámbito, proporcionando los datos y recomendaciones personalizadas en tiempo real[42]. Además, tienen la ventaja de tratar con el usuario, mediante texto o voz, de
42

Desarrollo
forma más natural y sencilla, evitándole navegar por menús, barras de herramientaso elementos visuales más complejos, ya que sobrecargan al usuario con demasiadainformación.
En el sistema propuesto por [43] se permite controlar los dispositivos eléctricos de lavivienda mediante IoT, incrementando la eficiencia de una manera más sencilla. Laentrada al sistema puede ser por texto escrito o hablado, que será procesado por elsistema (en este caso una Raspberry Pi) para ejecutar las acciones.
El consumo de energía es otro factor clave en la automatización de las casas deforma sostenible. Existen muchas implementaciones que proporcionen un feedbackenergético (como aplicaciones móviles o webs, SMS o emails).
En el sistema EFA (Energy Feedback Agent), implementado en [42] , se permite alos usuarios preguntar (de forma textual) por el consumo en el momento actual o elde tiempo atrás, proporcionar consejos sobre el consumo realizado y cómo reducirlo,e incluso alertarlos de consumos excesivos, en un determinado momento, de algúnelectrodoméstico. Pero, para conseguir una mejor satisfacción, EFA incluye un ele-mento más social que contiene características más humanas a la hora de interactuarcon el usuario, usando elementos como emojis o utilizando lenguaje más coloquial.
Sector económico y financiero
Los chatbots pueden ser usados en el sector servicios, en concreto en el comercioelectrónico, utilizando la información proporcionada en las descripciones de los pro-ductos y por la generada por el feedback de los usuarios. El servicio al cliente juegaun papel muy importante a la hora de generar ingresos por parte de las empresas.Los servicios por teléfono o mensajería tienen 2 problemas principales: por un lado,las preguntas suelen repetirse y, por otro lado, el servicio no se mantiene a todas ho-ras [44]. Por ello, los chatbots son la herramienta ideal para este tipo de aplicacionesen las que se orienta al comprador. En [44] se presenta SuperAgent, un chatbot paracomercio electrónico, como podría ser el caso de Ebay o Amazon.
Figura 2.36: Esquema general de SuperAgent [44].
Para ello, SuperAgent tiene en cuenta la información del producto en cuestión, unconjunto de FAQ y reviews de compradores, que le sirven como base de conocimientopara contestar a las preguntas que haga cada usuario.
43

2.2. Sistemas de pregunta-respuesta (QA)
Los chatbots también pueden ser usados en la industria financiera, que maneja unavariedad de productos y servicios compleja. Fujitsu ha creado FRAP, un chatbot deservicios para servir de apoyo en las ventas de productos financieros y de ayuda alcliente. FRAP combina los métodos basados en reglas, los FAQ y el text mining conaprendizaje automático para aplicaciones comerciales, en este caso en Sony Bank[45].
Medicina
El ámbito médico es de vital importancia en la vida humana. En el caso de algunaconsulta médica se podrían usar estos sistemas para encontrar respuestas de manerarápida usando archivos médicos cualificados. Además, existen repositorios enormescon gran cantidad de datos médicos fiables.
Dentro del ámbito clínico, el repositorio más grande es MEDLINE, con la informaciónmás relevante en este campo; sin embargo, los sistemas de búsqueda de MEDLINE,como PubMed, son inadecuados e incapaces de proporcionar respuestas relevantesen un tiempo óptimo. Además, los sistemas de extracción de información aplicadossobre MEDLINE, no consiguen obtener resúmenes sobre la información precisa. Elsistema que proponen en [46] consigue solventar los problemas comentados ante-riormente, mediante modelos híbridos entre métodos estadísticos y métodos basadosen conocimiento.
Figura 2.37: Esquema conceptual del sistema propuesto por [46].
Ocio
Hay muchas actividades de ocio y entretenimiento que pueden requerir del NLP, porejemplo preguntar sobre eventos deportivos, apuestas, videojuegos o agentes sociales.
Una de las aplicaciones de ocio que se ha mencionado es la de los chatbots sociales,sistemas de diálogo inteligentes que son capaces de mantener conversaciones empá-ticas con los humanos. La mayoría de ellos, al principio, eran exitosos pero basadosen reglas manuales que funcionaban bien en dominios restringidos, por lo que sebuscan aquellos que puedan ser utilizados en dominios abiertos [47].
XiaoIce (Microsoft) es uno de los chatbots sociales más populares en el mundo, im-plementado en 2014 con componentes emocionales para desarrollar comunicación,afecto y sociabilidad. XiaoIce pretende establecer relaciones largas con los humanosen dominios abiertos de forma empática y social. Este tipo de chatbot requiere de graninteligencia (conocimiento, memoria, NLU y razonamiento) para cumplir las necesi-dades y tareas de los usuarios; una gran capacidad emocional (empatía y habilidadessociales) para sentir lo que otra persona experimenta y comprender sus necesidades
44

Desarrollo
emocionales y sentimientos. Además, debe disponer de una personalidad consistenteque lo haga un agente distinguido con sus propios comportamientos.
Como se ha descrito anteriormente, este tipo de sistemas también puede implemen-tarse en videojuegos, un tipo de aplicación muy interesante, ya que muchas de lasinteracciones se producen a través de texto [48].
En [48] implementan un sistema en videojuegos basado en texto. Con este sistema sepretende aprender la decisión de los movimientos a escoger en un juego de estrategia,en el que se elaboran descripciones textuales del estado actual del personaje. En estetipo de videojuego, los jugadores leen la descripción y responden en lenguaje naturalla tarea a realizar.
A la hora de crear un jugador automático se tienen que tener en cuenta varios as-pectos para la elección de movimientos. En este caso, para desarrollar el proceso deNLU se utiliza el aprendizaje profundo mediante refuerzo para aprender las represen-taciones de los estados (extraídos de las descripciones textuales) y los movimientos arealizar conforme a estos.
Sector turístico y de atención al cliente
El incremento en el uso de las plataformas de mensajería como WhatsApp, Face-book Messenger, Snapchat y Skype implica un interés para las compañías, por elloque los chatbots (elementos también en auge) se están ofreciendo cada vez con másfrecuencia en el sector del servicio al consumidor [49] .
Este tipo de sector necesita una comunicación regular con los consumidores, con elfin de notificarles ofertas o de recibir feedback de la calidad de los servicios. En estesector, la calidad del servicio es crítica para la satisfacción y lealtad del consumidor,por lo que es una tarea muy demandada que requiere una interacción altamentepersonalizada. Normalmente, es un trabajo que se realiza mediante páginas webs,redes sociales, e-mails o por teléfono, elementos que no consiguen satisfacer a losclientes, por el trabajo tedioso y poco efectivo que supone [50].
Esto hace que se gaste gran cantidad de dinero en mantener este tipo de servicios,razón por la que el uso de chatbots puede suponer una gran mejora respecto a lasituación actual, permitiendo sistemas más accesibles y eficientes, manteniendo uncoste aceptable. Éstos asisten a los usuarios en las búsquedas, establecen mayoreslazos sociales con los consumidores, mantienen la confianza de los usuarios y, portanto, refuerzan la confianza en la compañía.
Hay compañías aéreas que emplean chatbots en sus servicios como Mildred30 (Lufthan-sa), Stopover Bot31 (Icelandair) y Finn32 (Finnair), y de otro tipo de servicios como elalquiler de coches, reservas de hotel, pedir comida a domicilio (TacoBot, por parte deTaco Bell, Dominos Pizza, Wingstop33 o Burger King), proporcionar información tu-rística, del estado de los vuelos o reviews de otros consumidores; sin embargo, haymuchas otras empresas que no se atreven a dar el salto [49].
30mildred.lh.com31https://www.icelandair.com/blog/messenger-bot/32https://es-es.facebook.com/Finnair/33https://twitter.com/wingstop?lang=es
45

2.2. Sistemas de pregunta-respuesta (QA)
Hay aspectos positivos o deseables que permiten acceder a la información de formarápida, están presentes las 24 horas del día para preguntas generales y simples, pro-porcionan respuestas de calidad. Otro aspecto que se menciona, que los usuariosno se sienten juzgados ante preguntas que algunos podrían considerar como estú-pidas; además, se dispone del tiempo que se quiera para preguntar al sistema sinsentir presión. Sería deseable que tuviesen cierto parecido humano, más cercano yque tuviesen una apariencia profesional [50].
Otro elemento importante que se desea en el servicio al consumidor es la confianzaque deposite el chatbot en los consumidores, algo que todavía no está muy logrado.Para mejorar la confianza y ofrecer servicios más fiables, podría usarse como fuen-te de información las FAQ, es decir, las preguntas más frecuentes que realizan losusuarios.
Por tanto, podrían generarse modelos centrados en responder al cliente de manerasatisfactoria, utilizando las FAQ. Ya se realizan estudios e implementaciones sobreeste tipo de sistemas, un ejemplo de ello sería FAQ FINDER En [51]. Con FAQ FINDERse observa que, si se tiene una gran cantidad de preguntas y respuestas sobre eltema a tratar, los sistemas de pregunta respuesta se pueden limitar a encontrar laspreguntas que se parezcan, esto haría que los sistemas fuesen más sencillos, con uncoste menor y con respuestas más satisfacientes.
Sin embargo, también hay aspectos negativos: no siempre comprenden lo que el con-sumidor pregunta, no suelen implementarse para contestar preguntas muy comple-jas y muchas personas están preocupadas por los asuntos de seguridad y privacidadde datos.
Servicio al trabajador
Como se describió anteriormente, los sistemas de pregunta-respuesta pueden serutilizados en el servicio de atención al cliente, sin embargo, también pueden ser usa-dos en el personal interno de una empresa, ayudando a los empleados y agilizandoprocesos de las empresas. Este tipo de sistemas han tenido menos repercusión queaquellos implementados en los servicios de atención al cliente o asistencia perso-nal, sin embargo, son agentes muy útiles y necesarios. En recursos humanos el usode estos sistemas es muy interesante, porque permite una interacción eficaz y rápi-da con los empleados existentes en la compañía y con los potenciales trabajadores,siendo útiles en los procesos de reclutamiento, consultas [24], formación y en lasevaluaciones34.
Los procesos de reclutamiento pueden ser costosos (hay que rellenar los formulariosde recursos humanos e introducir los mismos datos muchas veces), procesos quepueden ser realizados , por ejemplo, por agentes conversacionales y conseguir ungran ahorro de tiempo y de trabajo. Además, también pueden utilizarse en el procesode selección de talento, tanto para obtener información de los posibles empleados demanera rápida y eficaz, como para revisar la información que se obtuvo al entrevistara cada individuo.
En el proceso de formación de los nuevos trabajadores, en vez de usar procedimientosestándares y más antiguos, se pueden usar sistemas de pregunta-respuesta para im-
34https://www.sodexo.es/blog/chatbot-herramienta-recursos-humanos/
46

Desarrollo
partir formación, así como para reaccionar y responder a las preguntas del empleadoque se está formando.
Además, se trata de una herramienta ideal para mejorar la experiencia y satisfaccióntanto de los nuevos empleados como de los empleados existentes. Para el nuevo per-sonal, se puede utilizar en la iniciación, respondiendo a las preguntas frecuentes demanera más dinámica, facilitando la incorporación y adaptación. Por otro lado, tam-bién pueden mejorar la experiencia de los empleados ya existentes, respondiendo yresolviendo los problemas simples pero urgentes. Para estos casos, no siempre es fácilencontrar la información en la forma que le gustaría al empleado, y si la encuentra,es posible que el contenido sea denso y complicado. Por ello, los agentes conver-saciones pueden proporcionar respuestas de forma inmediata para la gran mayoríade intenciones expresadas por los empleados, por ejemplo, ahorrándoles tiempo enla búsqueda de información básica relacionada como los días de trabajo, las fechasde vacaciones, consultas de la nómina, programar reuniones teniendo en cuenta lasagendas de múltiples empleados, reservar salas de reuniones o realizar el registro dehoras 35.
Otro uso interesante de estos sistemas es el de recibir el nivel de satisfacción delos trabajadores en su puesto en la empresa, usando encuestas o cuestionarios. In-cluso, la empresa puede obtener información del rendimiento colectivo e individualde los trabajadores, pudiendo informar a cada empleado mediante chatbots de surendimiento y de si es necesario que mejore sus prestaciones.
Los agentes conversacionales pueden ser usados, por ejemplo, en las redes socialespara empresas, plataformas web usadas dentro de una compañía, para organizarservicios sobre el trabajo diario de una empresa como pueden ser los chats entreempleados, los servicios de autentificación, el calendario o la gestión de documentos,tareas o proyectos. Este tipo de servicios son de gran ayuda, sin embargo, no seencuentran muy bien implementados e integrados, es por ello que el uso de agentesinteligentes podría mejorar su eficiencia.
Existen tareas importantes dentro de una empresa, pero que conllevan mucho tiem-po para ser realizadas, sin ser tareas muy complejas, por ejemplo, el establecimientodel horario y lugar a la hora de realizar reuniones, y la búsqueda de empleados concompetencias específicas dentro de la empresa para obtener conocimientos concretosrespecto un tema de forma precisa y ágil. Estas 2 tareas son implementadas utilizan-do el chatbot Rasa Core36 en [52].
En el caso de las reuniones, el chatbot implementado se comunica con el usuario através de Humhub Mail37, para determinar la fecha, la hora, el lugar y la duraciónde la reunión. Una vez se han fijado estos parámetros, el chatbot accede a los ca-lendarios de las personas que deben estar en la reunión y se negocia, en funciónde quienes acepten o no los términos, la franja horaria y lugar final para realizar lareunión.
En el caso de la búsqueda de empleados con competencias que deseemos, el sistemabusca en la lista de empleados, aquellos que tengan dichas competencias, y permiteque el usuario se ponga en contacto con el candidato encontrado. Para la búsqueda
35https://www.inbenta.com/es/blog/5-ways-to-use-chatbots-for-internal-employees/36https : //github.com/RasaHQ/rasacore37https://www.humhub.com/en
47

2.2. Sistemas de pregunta-respuesta (QA)
de competencias podría ser útil incorporar información semántica para encontrarsinónimos de los términos que emplea el usuario, utilizando por ejemplo WordNet.
Uno de los lugares donde el uso de los sistemas pregunta-respuesta podría ser muyutilizado es en los call centers, en donde gran cantidad de trabajadores contestan laspreguntas de los clientes.Sin embargo, la mayor parte de las preguntas realizadasson iguales o muy parecidas, por lo que podrían aprovecharse las bases de datos deeste tipo de empresas, incorporando en el servicio interno de las empresas agentesconversacionales con el fin de encontrar respuestas a preguntas que ya han sidorealizadas, reduciendo el trabajo de los empleados, y mejorando la satisfacción de losclientes.
Un ejemplo de estos sistemas en call centers puede verse en Isa, agente inteligentedesarrollado para la empresa Intuit38, este agente es un chatbot desarrollado paraoperar a través del canal de comunicación interno de la empresa (mediante Slack 39)para comunicarse con los trabajadores sobre las dudas de los clientes, mejorando lasprestaciones de la empresa [53].
El esquema de este agente está formado por: el preprocesamiento de los datos, la re-presentación interna, la clasificación de la intención, el modelo de la mejor respuestay el feedback proporcionado por los empleados.
Figura 2.38: Esquema conceptual del sistema Isa [53].
El preprocesamiento de los datos consiste en transformar las preguntas realizadas,que son enviadas por Slack, mediante los procesos de stemming, tokenización y le-matización.
En el paso de la representación interna se realizan los métodos de Word embeddingy sentence embedding, en donde se modelan las palabras y oraciones como vectores,para que pueden ser comparadas entre sí con, por ejemplo, la similitud del coseno.A parte de estos modelos, se realiza una extracción de características, con el fin deencontrar keywords que puedan identificar el tipo de pregunta que se está reali-zando, como son los nombres específicos de entidades, correos electrónicos, valoresmonetarios o términos específicos de Intuit.
En la clasificación de la intención se espera encontrar la intención de cada una de laspreguntas (por ejemplo, de tipo fallo en el registro, dudas de recibos u ofertas), para
38http://www.intuit.com39http://www.slack.com
48

Desarrollo
ello utilizan un modelo neuronal con una capa de entrada (utilizando las palabrasdel Word embedding), 2 capas ocultas (para generar las representaciones internas decada token y para generar salidas de longitud uniforme) y una capa de salida.
En el paso del modelo de la mejor respuesta se encargan de evaluar la similitudentre 2 preguntas utilizando el Word Mover Distance, para comparar la preguntarealizada con las preguntas históricas de la base de datos. Primero escogen unaprelista mediante las preguntas más cercanas a la actual en el formato del sentenceembedding, y después se compara la pregunta con esta prelista utilizando el WordMover Distance.
WMD = mınT>0
n∑
i,j=1
Ti,j ∗ c(i, j)
Donde Ti,j es el número de veces que la palabra i de la primera pregunta, se asigna ala palabra j de la segunda, y donde c(i,j) es la distancia entre estas palabras c(i, j) =||xi − xj ||2.El paso de feedback es utilizado para mejorar el sistema continuamente, en las queel trabajador valorará la respuesta proporcionada por el sistema, sin interrumpir elflujo del diálogo, mediante botones o emoticonos.
Resumiendo, este tipo de sistemas son de vital importancia ya que ayudan a redu-cir y optimizar los procesos repetitivos y tediosos que se llevan a cabo día a día enuna empresa, como puede ser resolver FAQs, organizar reuniones o la contrataciónde nuevo personal. Este tipo de sistemas podrían ser muy utilizados en empresas uorganizaciones donde se reduzcan este tipo de procesos, como podría ser en empre-sas industriales, bancos o entidades financieras, hospitales o call centers. Un estudiorealizado por [54] analiza la experiencia de los trabajadores de un banco y un hospitalen 3 tareas de apoyo informático como, por ejemplo, establecer una contraseña, res-ponder a las FAQs o adjuntar un archivo por correo electrónico. Para el prototipo dechatbot utilizaron la plataforma RASA, con la interfaz en una página web, los resul-tados obtenidos muestran que este tipo de sistemas son del agrado de los empleados,ya que les permite resolver las dudas o realizar las tareas de forma rápida y sencilla.
Hay que tener en cuenta una serie aspectos importantes que debe considerar estetipo de sistemas, por un lado, deben ser utilizados sólo dentro de la propia empresa,por lo que deben tener un elevado nivel de seguridad. Además, este tipo de sistemasfuncionará mejor cuanto mayor cantidad de datos posea la empresa y le suministre alagente, sin embargo, al tratarse de agentes operativos dentro de una empresa debenposeer un gran nivel de privacidad y confidencialidad a la hora de tratar con los datos,tanto de la empresa como de lso clientes.
2.3. Conclusiones
Una vez realizado un repaso general a las tecnologías del procesamiento de lenguajenatural, a algunas de las técnicas utilizadas y a los dominios en los que se aplica; va-mos a matizar algunos aspectos importantes sobre algunas limitaciones encontradasen este ámbito:
49

2.3. Conclusiones
La mayoría de los sistemas de pregunta-respuesta (y de sistemas con uso detécnicas de PLN) están implementados en inglés. Este aspecto es muy deter-minante, ya que si bienes cierto que los avances realizados en este campo vanprogresando notablemente, también hay que destacar que este progreso se ob-serva únicamente en sistemas cuya lengua base es el inglés; mientras que ensistemas con otros idiomas este avance no es tan notable y no hay realizadostantos estudios ni mejoras. Hay que tener en cuenta que los modelos imple-mentados en una lengua, pueden no obtener la misma efectividad y acierto sise utiliza otro idioma, es decir, los modelos están determinados por el lenguajeutilizado y uno de los aspectos más óptimos del inglés es que es un lenguajemuy estructurado, lo que le otorga la capacidad de realizar deducciones másprecisas en el análisis lingüístico que otros idiomas.
El castellano es una lengua más desplazada que el inglés, en este sentido. Estoes debido a que no hay tantos estudios ni sistemas realizados en castellano.Además, es un lenguaje más complicado que el inglés (tiene muchas variacioneslingüísticas, muchas más formas verbales, utiliza adjetivos con género, entreotros), por lo tanto, analizar el castellano es una tarea mucho más laboriosay delicada, derivando en implementaciones que no alcanzan la calidad de lossistemas en inglés.
Se han observado varias aplicaciones en las que pueden aplicarse los sistemasde pregunta-respuesta, sin embargo, los sistemas de atención al empleado (ele-mento muy importante dentro de una empresa) no han sido desarrollados tantocomo otros, a pesar de su relevancia. Y si cerramos la búsqueda de estos siste-mas en España (o en castellano), observamos que hay muy pocos sistemas. Estetipo de aplicaciones depende mucho de la lengua que, como hemos comentado,no está tan estudiada como el inglés y si, además, no se realizan estudios dentrode este dominio de los sistemas de pregunta-respuesta, llegamos a la conclusiónde que no hay casi sistemas implementados en castellano.
Con el objetivpo de crear sistemas de este tipo en castellano, deberían realizarsemás estudios. Recientemente, es cierto que se están elaborando más estudios yartículos en análisis lingüístico, sin embargo, están muy lejos de verse imple-mentadas aplicaciones en el mercado de este tipo (incluso en inglés).
El otro elemento fundamental dentro de un idioma para llevar a cabo aplica-ciones robustas y eficaces, es la construcción de recursos lingüísticos, tanto dedominio específico, como general. Por ejemplo, desarrollando ontologías (costo-sas de mantener), tesauros (más económicos, pero de menor cobertura) o fun-ciones que analicen la lengua en sus diferentes niveles (morfológico, sintáctico osemántico). Pero, una vez más, nos encontramos que en lengua española prác-ticamente no existen estos recursos. Únicamente encontramos FreeLing40, unconjunto de librerías desarrolladas en C++ por la UPC (Barcelona), de códigolibre.
40http://nlp.lsi.upc.edu/freeling/node/1
50

Capítulo 3
Planteamiento del Problema
Una vez vistos algunos de los puntos débiles que sufren los sistemas de pregunta-respuesta, se va a elaborar un sistema dentro del campo de servicio de atención alcliente desarrollado en castellano. Como se concluyó en el apartado anterior, las apli-caciones diseñadas para mejorar las prestaciones de los trabajadores son escasas y,en España, el número es aún más reducido del que cabría esperar, debido a que lalengua castellana no está tan estudiada y desarrollada dentro del ámbito del pro-cesamiento de lenguaje natural, como lo está el inglés. Por estas razones, hay unanecesidad importante de elaboración de este tipo de sistemas para poder ser usadaspor los trabajadores de una empresa cuyo lengua sea el castellano.
Una empresa del sector transportes, en concreto ferroviaria, quiere aumentar el gra-do de satisfacción de sus trabajadores, poniendo a su disposición de una app queresuelva las dudas de éstos de una forma más rápida y eficaz.
Uno de los aspectos que la empresa ferroviaria quiere mejorar es el de ofrecerles a susmaquinistas una herramienta tecnológica que les indique la resolución de un proble-ma en aquellos casos en los que el tren sufra una avería. Actualmente, cuando lostrenes sufren algún tipo de avería, los maquinistas deben de buscar la informaciónconcreta que la resuelva, en los manuales de averías (libros de más de 400 páginas),lo que hace tedioso y lento el proceso de resolución. Por ello, el sistema ofrecería laposibilidad de encontrar la resolución de las averías que los maquinistas planteen enlenguaje natural, mostrándoles el contenido exacto del procedimiento para resolverel problema.
Los trabajadores del sector transportes trabajan a turno, por eso otro aspecto que lesparece interesante es el de mejorar la capacidad de acceder a la información que lesafecta como trabajadores, también de forma más rápida. Un trabajador en el sectorde transportes dispone de información relacionada con los turnos de trabajo, el con-tenido de cada turno, la fecha de sus vacaciones, las horas realizadas durante el meso la nómina, entre muchas otras cuestiones. Este tipo de información se encuentra,en el mejor de los casos, en un número determinado de tablas en las que la infor-mación aparece muy escueta, y en conjunto con todos los trabajadores de la mismacategoría profesional, por lo que el proceso de búsqueda es lento y tedioso. El accesoa estos datos también podría mejorarse con este tipo de sistemas, proporcionándo alos clientes la información solicitada de forma más rápida y detallada.
51

3.1. Hipótesis de trabajo
3.1. Hipótesis de trabajo
En este punto se va a describir el ámbito y capacidad de actuación del sistema, esdecir, las tareas que puede realizar y las que no:
La temática del sistema estará, únicamente, centrada en las averías de un tren,por lo que no se incluirán los aspectos relativos a las normas de circulación,turnos, vacaciones o nóminas, ni ningún otro tema. La fuente de informaciónque utilizará el sistema será el del manual de averías de un tren.
Aunque al sistema se le dotará de cierta flexibilidad a la hora de interactuar conel usuario, saludándolo al arrancar al sistema o proporcionándole informaciónde forma variada, no será un sistema que permite conversaciones fluidas, estarálimitado a contestar las preguntas.
Las preguntas que se realicen serán independientes unas de otras, el sistemano mantendrá el hilo de la conversación.
La forma de entrada y salida del sistema será mediante texto escrito, es decir,el usuario escribirá la pregunta en lenguaje natural de manera textual, y larespuesta también será textual. Por lo que no se incluyen módulos de detección(ASR) y generación del habla (TTS).
No va a haber corrección ortográfica, si alguien escribe mal la pregunta, depen-diendo del error, el sistema la detectará como incorrecta o realizará una bús-queda donde puede que obtenga resultados relacionados o no con la preguntaque quería realizar el usuario.
52

Capítulo 4
Modelo Propuesto
En este capítulo se tratará sobre el modelo que se ha propuesto para llevar a cabo elproceso de resolución del problema planteado en el apartado anterior.
Este modelo estará formado por tres módulos: el análisis de la pregunta, el gestorde diálogo y el generador de la respuesta. El usuario se comunicará con el sistemarealizando preguntas en lenguaje natural, cada pregunta será analizada con el fin dedeterminar qué es lo que pide el usuario. Cuando el sistema identifique el foco dela pregunta, buscará en su base de conocimiento la información requerida, que serámanejada por el gestor de diálogo, para usos posteriores. Una vez extraída la infor-mación solicitada, el generador de respuesta se encargará de formular una respuestade forma precisa y de acuerdo a las necesidades del usuario.
Figura 4.1: Esquema general del modelo propuesto.
Módulo de análisis de la pregunta.-
Este módulo se corresponde con la primera fase de la interacción, en la cual el usua-rio envía al sistema la pregunta en forma de lenguaje natural.
Primero hay que realizar un proceso de preprocesamiento de la pregunta, con el finde realizar una búsqueda más precisa y con la información más relevante posible.Para ello se pondrán en minúsculas todas las palabras de entrada y se eliminarán
53

los stopwords (palabras vacías de significado). En este punto hay que tener en cuen-ta que existen stopwords que pertenecen a palabras conjuntas, para poder tener encuenta esto habría que hacer una análisis morfológico, con el fin de determinar si elstopword detectado pertenece o no a palabras conjuntas. Si no se realiza de esta for-ma, el sistema perdería precisión. Sin embargo, este modelo se va a limitar a detectarpalabras de un sólo término, por lo que no se va a hacer uso de un analizador mor-fológico. Aún así, se va a proceder a eliminar los stopwords, ya que es posible que seobtengan mejores resultados quitando la multitud de palabras vacías de significado.
Otro aspecto importante sería el obtener los lemas de cada uno de los términos signi-ficantes, pero éste es un trabajo muy costoso y que no siempre suele obtener buenosresultados (sobre todo en castellano), por ello es mejor no realizar este proceso, sinorealizar stemming, es decir, obtener las raíces de las palabras para dotar al sistema demayor versatilidad, eliminando, gracias a este proceso, la variabilidad generada porel género y el número, incluso la variabilidad generada por las palabras derivadas(por ejemplo, norma y normativa). Hay que tener en cuenta que este paso de prepro-cesamiento también deberá ser realizado con las fuentes de conocimiento, para quetoda la información esté normalizada.
En segundo lugar, hay que determinar la clase de pregunta. En este paso se deter-minaría el tipo de respuesta que se espera recibir (por ejemplo, si se desea una expli-cación, devolver una entidad concreta, un lugar o información temporal). Para llevara cabo este parte, será necesario incorporar, tanto la información de las factoid (qué,quién, cuándo, dónde o cómo), como de la información semántica sobre los términosde la pregunta. La manera de aprovecharnos de estos dos tipos de informaciones serárealizada mediante lógica de primer orden y reglas lógicas, que determinen la clasede respuesta que espera el usuario.
Por último, una vez determinada el tipo de respuesta, se suministrará al siguientemódulo esta información y los keywords detectados para, así, centrar aún más labúsqueda de la información requerida.
Figura 4.2: Esquema del módulo de NLU en el modelo propuesto.
54

Modelo Propuesto
Módulo de gestor de diálogo.-
Obtenido el foco de la pregunta, el gestor de díalogo debe dirigir la búsqueda de lainformación entre las distintas fuentes que tiene en su base de conocimiento, en estecaso, los manuales de averías. Esta búsqueda dependerá de la clase de respuestaesperada y de la información relevante de las preguntas del usuario.
En el caso de las averías, las respuestas esperadas serán explicaciones u obtener ellugar del manual donde está la información solicitada. Para llevar a cabo esta tarea,se usará la métrica de similitud del coseno con la información del foco de la pregunta.En esta métrica, la pregunta bien formulada será representada mediante un vector,que será comparado con los vectores que representen cada uno de los párrafos (conun paso previo de preprocesamiento). Este proceso sería similar al de recuperaciónde información, pero, en vez de clasificar documentos, se obtendría una lista de lossubapartados de los manuales de averías, en orden descendente (en función de susimilitud con la pregunta planteada).
Un elemento importante, que incorporará el gestor de diálogo en este modelo, será elde hacer una memoria de las opiniones de los trabajadores con la respuesta obteni-da, es decir, con cada pregunta contestada, el sistema pedirá al usuario la valoraciónde la respuesta proporcionada y, si no le gusta, le mostrará las 5 mejores soluciones,pidiéndole sus correspondientes valoraciones. Esta información será almacenada yel gestor de diálogo, en posteriores preguntas, utilizará esta información para ajus-tar parámetros y, así, obtener mejores respuestas en cada iteración. En este pasopuede decirse que se generará una memoria de aprendizaje, en la cual se permitauna retroalimentación por parte de los trabajadores, incorporando en el sistema lainformación de los expertos en la materia, en este caso, los maquinistas.
El gestor de diálogo, finalmente, suministrará la información extraída al siguientemódulo y almacenará las nuevas valoraciones obtenidas.
Figura 4.3: Esquema del módulo de Gestor de Diálogo.
Módulo de generación de la respuesta.-
En la generación de la respuesta se debe utilizar la información encontrada paraproporcionársela al usuario de la mejor manera posible.
55

En este caso, la información obtenida aparecerá en forma de lista, con las candidatasa ser la mejor respuesta posible, de entro todas estas se seleccionará una, aquella conla mejor puntuación obtenida al usar la métrica de similitud de coseno, mostrando,no sólo el párrafo donde se encuentre la información, sino incorporándole el contextode ese párrafo (el subapartado entero en el que se encuentre el párrafo). Si, al usuariono le gusta la respuesta proporcionada se le mostrará el listado de las 5 mejoresrespuestas, sobre las que el dará su opinión al respecto. Esta información luegoserá suministrada al gestor de diálogo para su almacenamiento en la memoria deaprendizaje.
Hay que tener en cuenta que, gracias a la memoria de aprendizaje, habrá un mo-mento que, al generar la respuesta, no sólo se tendrá en cuenta la puntuación de lamétrica del coseno de los párrafos, sino también toda la información almacenada enla memoria de aprendizaje, que llevará consigo un reajuste de los parámetros a lahora de selccionar las mejores respuestas.
Como aspecto final, la forma de mostrar la respuesta será diferente en función deltipo de respuesta esperada. En el caso de desear obtener el lugar donde aparecela información, se le generará una respuesta que proporcionará al usuario la pági-na, capítulo y/o subapartado correspondiente, con la posibilidad de ofrecerle que sele muestre también el contenido. En el caso de explicaciones, al tratarse de infor-mación muy precisa y que va a ser manejada por expertos en la materia, es mejorproporcionarle al usuario la propia información extraída (el conjunto de párrafos delsubapartado obtenido).
Figura 4.4: Esquema del módulo de NLG en el modelo propuesto.
56

Capítulo 5
Experimentación
Una vez descrito el modelo propuesto, ha de llevarse a cabo una experimentación enla cual se pruebe la validez de este modelo y los resultados que ofrece. Esta experi-mentación va a ser desarrollada en Python 3, usando para ello el entorno de JupyterNotebook.
A continuación se van a indicar las librerías, las funciones y procesos utilizados quese han realizado durante la ejecución del bucle principal.
5.1. Librerías utilizadas
Para poder llevar a cabo la implementación del modelo han sido necesarias unascuantas librerías que permitiesen operar con las distintas bases de conocimiento yrealizar los procesos descritos en el modelo.
PymuPDF
Esta librería, gracias a la importación de fitz, permite operar con ficheros pdf, esto esde vital importancia, ya que la base de conocimiento principal es el manual de averías,cuyo formato es pdf (”averiasTren.pdf”). Con esta librería será posible almacenar cadauno de los párrafos del pdf en los capítulos o subcapítulos en los que está dividido.
NLTK y gensim
Estas dos librerías son las que permiten aplicar técnicas de procesamiento de len-guaje natural para tratar con el texto escrito en forma natural (tanto las preguntasdel usuario, como el texto adquirido del manual de averías).
NLTK nos permite incorporar el paquete tokenize para separar los términos que con-forman el texto, el paquete stopwords para eliminar el conjunto de palabras vacíaspresentes en el texto (tienen una lista disponible en castellano) y el paquete Snow-ballStemmer con el que se permite hacer stemming y quitar la variabilidad morfológi-ca.
Gensim incorpora los paquetes corpora y models para implementar distintos modeloscomo tf-idf, y el paquete similarities para obtener las correspondencias entre dostextos.
57

5.2. Almacenamiento de la información del pdf
xlwt, xlrd y xlutils
Estas tres librerías permiten trabajar con ficheros Excel. Esto también será de vitalimportancia, ya que la memoria de aprendizaje, en la cual se almacenen las opinionesde los usuarios, será un fichero de este tipo. Estas librerías son capaces de sobres-cribir un fichero existente (permitirá ir almacenando las nuevas opiniones) y leer losdatos que estén escritos (permitirá extraer las opiniones para usarlas en el móduo degeneración de la respuesta).
Otros
La librería collections nos permitirá aplicar la métrica de similitud de coseno, con elque obtener la lista de mejores respuestas.
La librería datetime permite operar con las fechas y la librería random permite ge-nerar números aleatorios. Estas dos librerías serán usadas para ofrecer variabilidaden las respuestas y oraciones que el sistema muestre al cliente, dotándole de mayorflexibilidad y cercanía con el usuario.
5.2. Almacenamiento de la información del pdf
La primera acción que ejecutará el programa será la de operar con el fichero pdf delmanual de averías y almacenar toda la información textual disponible en él.
Almacenar la información de los capítulos
La forma inicial de almacenar el texto será en los capítulos en los que se divide eltexto (en este caso doce). La manera de realizarlo será la de ir extrayendo cada unode los párrafos del pdf y almacenarlos en una lista, dentro de su correspondientecapítulo.
La forma de identificar cuándo hay un capítulo nuevo será realizada gracias a ladisposición de los capítulos en el texto. Todos los capítulos empiezan por un núme-ro y un punto, seguidos del nombre del capítulo, todo en mayúsculas, por lo que,atendiendo a este patrón, se puede detectar cuándo empieza un nuevo capítulo o no,almacenando los párrafos en el lugar que le pertenece.
Al terminar este almacenamiento de información, se obtendrá una lista, con doceapartados (los 12 capítulos), llamada ”apartadosAverias2”, en la que cada apartadocontendrá todo el texto correspondiente a su capítulo. Además, se generará tambiénotra lista ”bloquesAverias”, que contendrá también 12 apartados, pero cada uno deellos contendrá cada uno de los párrafos que estén dentro de su correspondiente ca-pítulo, de forma separada. Hay que tener en cuenta que los capítulos 2 y 12 contieneninformación confidencial y, por tanto, no se ha almacenado su información.
58

Experimentación
Figura 5.1: Texto almacenado en la lista ”apartadosAverias2”.
Almacenar la información de los subapartados
Una vez almacenada la información en capítulos, se procederá a obtener la informa-ción almacenada en subapartados. En este caso no será necesario volver a trabajarcon el pdf, ya que la lista ”bloquesAverias” contiene todo el texto distribuido en pá-rrafos. Aquí, para detectar los subapartados de cada capítulo se procederá de unamanera similar al método anterior. Todos los subapartados tienen un formato de unnúmero seguido de un punto, seguidos de otro número y punto, y el texto siempreempieza con una letra en mayúscula. Así que el método consistirá en detectar estepatrón en cada uno de los 12 capítulos, de tal forma que se agruparán los párrafosque pertenezcan a un mismo subapartado.
Como resultado final, en esta fase obtendremos una lista (”subApartadosAverias”), queestará formado por 12 apartados y cada uno de ellos contendrá tantos subapartadoscomo subcapítulos tenga cada apartado.
Figura 5.2: Texto almacenado en la lista ”subApartadosAverias”.
5.3. Pedir al usuario la pregunta
Una vez almacenada toda la información dentro del sistema, se procederá a la eje-cución del bucle principal, en el que el usuario irá preguntando y el sistema le iráproporcionando las mejores respuestas que considere.
Para iniciar el diálogo, el sistema saludará por primera vez al usuario, mediante lafunción saludarHora(). Esta función hace uso de la librería datetime para obtenerla hora actual y realizará el saludo inicial en función del momento del día (mañana,tarde o noche). Además, hace uso de la librería random, mediante la cual dotará acada tipo de saludo de mayor variabilidad, seleccionando al azar entre un conjuntopredeterminado de saludos para cada momento del día.
59

5.3. Pedir al usuario la pregunta
Figura 5.3: Variabilidad de los saludos iniciales en función del momento del día.
Una vez realizado el saludo inicial, se procede al bucle de interacciones entre el usua-rio y el sistema, pidiendo a la persona que formule su pregunta. Para ello, se haráuso de la función preguntasUsuario(), que pedirá al usuario la pregunta o, en elcaso de que quiera salir del sistema, le pedirá que escriba ”Deseo salir”.
En primer lugar, preguntasUsuario() pondrá en minúsculas toda la pregunta for-mulada y separará el texto en cada una de las palabras que la conforman. Si elusuario pide salir del sistema, la función devolverá la variable que permita salir delbucle y terminar la interacción, comunicándole al usuario que se va a terminar lainteracción. En el caso de que no se desee salir, se procederá a determinar el tipo derespuesta esperada.
Figura 5.4: Tipos de pregunta que pueden ser detectados y la forma de expresarlos.
Existen dos tipos de pregunta: las explicaciones y las que quieren determinar el lugardentro del manual donde aparece el texto. Para llevar a cabo este proceso se utilizaránreglas lógicas para determinar el tipo de pregunta y lógica de primer orden con el finde detectar las condiciones de las reglas lógicas. Se ha elaborado un corpus almace-nando la información semántica de las palabras que guardan relación con preguntasque quieran saber el lugar, utilizando sustantivos y verbos relacionados con estasrespuestas, y la información proporcionada por las factoid (dónde, en qué [lugar],cuál es el lugar). Una vez detectada esta información, será utilizada para determinarlas condiciones de las reglas lógicas, de tal forma que, dentro de las respuestas de”lugar”, se ha diferenciado entre ”donde” (mostrará la página y subapartado), ”pagina”(mostrará la página), ”seccion” (mostrará el nombre del capítulo) y ”subapartado” (mos-trará el nombre del subapartado).
60

Experimentación
En el caso de que una pregunta de tipo lugar no esté bien escrita, se devolverá que lapregunta está mal escrita y se pedirá al usuario que vuelva a escribirla correctamen-te. Si no se cumplen las condiciones de las reglas lógicas que determinan que unapregunta es del tipo ”lugar”, entonces la pregunta será determinada como que es deltipo ”explicacion”.
Si estos 2 tipos de preguntas están escritas correctamente, la función devolverá lapregunta en minúsculas y el tipo de respuesta que se espera, además de las variablesdeterminando que el usuario todavía no quiere salir del programa y que la preguntaestá escrita correctamente.
Figura 5.5: Ejemplo de aplicación de reglas y lógica para obtener el tipo de pregunta.
5.4. Preprocesamiento de la pregunta
Una vez que la pregunta ha sido escrita correctamente y se ha determinado el tipo derespuesta esperada, se procederá a realizar un preprocesamiento de la pregunta delusuario. Para ello, se someterá la pregunta (en minúsculas) a la función leerDocu-mentos(). Esta función se encargará de quitar los signos de puntuación y de prepararel contenido para suministrárselo a la función preprocesarSecciones().
La función preprocesarSecciones() se encargará de utilizar la librería NLTK paraeliminar el conjunto de stopwords del castellano, los signos de puntuación y tildes,y obtener las palabras de la pregunta que tienen más de una letra (tokens). Una vezobtenidos los tokens, se eliminarán los acentos y las palabras de la pregunta quefueron utilizadas en la fase anterior, para determinar el tipo de respuesta.
Finalmente, la fase de preprocesamiento de la pregunta devolverá una lista de laspalabras restantes de la pregunta, aplicándoles stemming en castellano, es decir,obteniendo las raíces de cada una de las palabras significativas. Si el conjunto depalabras restantes no es significativo, entonces no habrá palabras sobre las que rea-lizar la búsqueda, esto es, la pregunta no fue escrita apropiadamente para obtenerun resultado y se pedirá al usuario que vuelva a escribir una pregunta.
61

5.5. Aplicar la similitud del coseno a los capítulos
Figura 5.6: Preprocesamiento de la pregunta y obtención de las raíces significativas.
5.5. Aplicar la similitud del coseno a los capítulos
Una vez que la pregunta ha sido preprocesada y se han obtenido términos sobrelos que realizar la búsqueda, se procede a obtener las similitudes entre la preguntapreprocesada y cada uno de los 12 capítulos.
Antes de realizar la similitud, habrá que realizar el mismo preprocesamiento del apar-tado anterior, pero esta vez con cada uno de los capítulos, para así tener la preguntay los capítulos normalizados.
Teniendo ambas cadenas de texto preprocesadas, se procede a realizar la métricade similitud de coseno entre la pregunta con cada uno de los capítulos, utilizandopara ello la función similitudCoseno(). Esta función formará 2 vectores (para cadacadena de texto) donde queden representados todos los términos existentes en ambascadenas. Y en cada uno de los vectores se almacenará el número de veces que unapalabra aparece en cada uno de los textos. Finalmente, se aplica la distancia delcoseno entre los 2 vectores, que corresponderá a la puntuación que obtendrá cadacapítulo, según su similitud con la pregunta.
Estas puntuaciones serán almacenadas en una lista llamada ”ranking”, con las pun-tuaciones de cada apartado. En el caso de que ningún apartado guarde relación conla pregunta, se le informará al usuario de que, para esa pregunta, el sistema noencuentra soluciones.
Figura 5.7: Puntuaciones de los 12 apartados, según la similitud del coseno.
62

Experimentación
5.6. Obtener las mejores opiniones almacenadas en la me-moria de aprendizaje
En el momento en el que se obtenga el ránking de los mejores capítulos, el gestorde diálogo se encargará de buscar, en la memoria de aprendizaje, las opiniones delos usuarios que se almacenaron en iteraciones anteriores. Para ello, se emplearála función leerValoracionesUsuarios()que utilizará la pregunta preprocesada pa-ra realizar la búsqueda y empleará la librería xlrd para operar con el fichero excel”V aloracionesUsuario.xls”, que corresponde a la memoria de aprendizaje.
El primer paso será extraer la información del fichero excel en una lista con todaslas preguntas de la memoria de aprendizaje, para que el sistema pueda manejar lainformación de manera apropiada. Una vez que se han extraído las preguntas conlas correspondientes opiniones, se procederá a comparar la actual pregunta que harealizado el usuario con el conjunto de preguntas de la memoria de aprendizaje,utilizando para ello la métrica de similitud del coseno. Después de este proceso, seseleccionarán sólo aquellas preguntas cuya puntuación de relación con la preguntaactual supere un umbral definido (en 0.5).
El segundo paso será asignar la importancia que tenga cada subapartado, teniendoen cuenta la valoración de los usuarios. Cada una de las preguntas que han supera-do el umbral tienen un máximo de 5 subapartados con las opiniones de los usuarios(esta selección ocurre cuando un usuario, en iteraciones anteriores, no estuvo con-forme con la solución del sistema y es en esos casos cuando el sistema muestra las5 mejores soluciones obtenidas, con el fin de que el usuario dé su opinión respec-to a su precisión), por lo que habrá que determinar cómo de relevantes son estossubcapítulos, mediante nuevas puntuaciones. La manera de darle las puntuacionesserá multiplicando la puntuación que tuvo la pregunta determinada (cada una de lasque superó el umbral) por la opinión que tiene ese subapartado (un valor escaladoentre 0 y 1). Para finalizar este paso, como habrá muchos subapartados repetidos, serealizará una media entre las puntuaciones definidas que obtenga cada subcapítulo.
Finalmente, la función devolverá al sistema una lista con los 10 subapartados (comomáximo) que obtengan las mejores puntuaciones, según el criterio determinado.
Figura 5.8: Mejores opiniones extraídas de la memoria de aprendizaje.
5.7. Mostrar al usuario la mejor respuesta obtenida
Extraída la información de la memoria de aprendizaje, se procede a obtener la mejorsolución a la pregunta formulada, empleando para ello dicha memoria y el ránkingque obtuvo el sistema de similitud de los 12 capítulos con la pregunta. Para dichaparte, se utilizará la función mejorResultadoRanking3().
El primer paso será seleccionar un número máximo determinado (en este caso 5)de los mejores capítulos, según el ranking obtenido. Una vez obtenidos los 5 me-
63

5.7. Mostrar al usuario la mejor respuesta obtenida
jores apartados, se realizará la métrica de similitud del coseno de cada uno de lossubapartados, de estos 5 capítulos, con la pregunta formulada por el usuario, paraasí obtener un segundo ránking con las puntuaciones de estos subapartados. Parafinalizar este paso, se seleccionará únicamente el mejor subapartado de cada uno delos 5 capítulos.
El último paso será obtener el mejor subapartado de todos (el que será mostrado alusuario como respuesta final), pero en este paso se ha de incorporar la informaciónobtenida de las opiniones en la memoria de aprendizaje. Para ello, el mejor subapar-tado obtenido en la memoria de aprendizaje también será incorporado a la lista delos 5 mejores subapartados.
Finalmente, dicha función devolverá el ránking de las puntuaciones de todos lossubapartados de los 5 mejores capítulos (como máximo), ”rankingSubSecciones”, ymostrará al usuario la mejor respuesta (la que obtenga la mejor puntuación de entrelas 6 candidatas, como máximo). Para mostrar dicha respuesta se utilizará la funcióntipoRespuesta().
Figura 5.9: Mejor resultado y ránking de los subapartados detectados por el sistema.
5.7.1. Mostrar al usuario las 5 mejores respuestas
Una vez que se le muestra al usuario la mejor respuesta, se le preguntará si seencuentra conforme con la respuesta proporcionada. En caso afirmativo, se le agra-decerá y se reiniciará el bucle de interacción pidiéndole una nueva pregunta. Sinembargo, en caso negativo, se le mostrará al usuario el listado de las 5 mejores so-luciones, utilizando para ello la información del ránking de los subapartados y de lamemoria de aprendizaje, mediante la función lista5Mejores().
Esta función se encargará de almacenar una lista preliminar de las 10 mejores solu-ciones, esto se hace así porque podría darse el caso que las 5 mejores soluciones queproporciona la métrica del coseno, también fuesen las mejores soluciones adquiridasde la memoria de aprendizaje, al haber como máximo 5 posibles duplicaciones, sehace una lista de 10.
El primer paso será el de completar esta lista preliminar con los 10 mejores subapar-tados obtenidos del ránking de subapartados proporcionados mediante la métrica desimilitud del coseno.
El segundo paso será el de incoporar la información de la memoria de aprendiza-je, reestructurando la lista preliminar. De esta lista, se seleccionarán las 5 mejores
64

Experimentación
respuestas, sin incluir repeticiones de subapartados.
Finalmente, se le mostrará al usuario la lista de las cinco mejores respuestas y se lepedirá que de su opinión sobre estas, a través de la función valoracionUsuarios().
Mostrar las respuestas y pedir valoraciones
En el apartado anterior se indica que para mostrar las respuestas al usuario y pe-dir valoraciones se utilizan 2 funciones auxiliares, se va a proceder a explicar sufuncionamiento.
Mostrar las respuestas al usuario
Para este proceso se hace uso de la función tipoRespuesta (), en el que se utiliza eltexto almacenado en subapartados y el tipo de respuesta que se desea esperar.
Como se había indicado, existen 2 tipos de respuestas, las que desean saber el lugardonde se encuentra la información y las que desean obtener la explicación en sí. Paradotar al sistema de mayor flexibilidad, se hace uso de la librería random, con el fin dedotar de mayor variabilidad al sistema, a la hora de proporcionar cada una de las po-sibles respuestas. Para cada posible respuesta se ha creado un número determinadode oraciones que serán seleccionadas al azar, obteniendo así la variabilidad deseada.
Figura 5.10: Variabilidad de las 2 posibles respuestas (lugar o explicación).
En el caso de que la respuesta sea de tipo ”lugar”, se seleccionará al azar uno de lospatrones correspondientes de posibles respuestas, al que se le añadirá la informa-ción correspondiente según la subclase deseada. Si es de tipo ”donde” proporcionarála página y el subapartado correspondiente, si es ”pagina” mostrará la página, si es”seccion” mostrará el nombre del capítulo y si no, mostrará el nombre del subaparta-do. Además, aunque el tipo de respuesta esperado sea de ”lugar”, una vez mostradala respuesta, se le preguntará al usuario si desea o no que le muestren la explicación.
En el caso de que la respuesta sea de tipo ”explicacion” (o que el usuario desee que,a parte del lugar, le muestren el contenido), se procederá a mostrar el contenido delapartado o subapartado correspondiente.
65

5.8. Almacenar la información en la memoria de aprendizaje y reiniciar el bucle
Pedir opiniones a los usuarios
En el caso de que la mejor respuesta proporcionada al usuario no sea de su agrado,se deberá proporcionar el listado de las 5 mejores, pidiéndole que dé su opinión acada una de ellas, para ello se utilizará la función valoracionUsuarios().
Para cada una de las mejores respuestas se le mostrará al usuario la información,dependiendo del tipo de respuesta esperada (utilizando para ello la función de mos-trar las respuestas, tipoRespuesta ()). Por cada una de las respuestas, se le pediráal usuario que dé su opinión, con una puntuación entre 0 y 10.
Todas estas puntuaciones serán las que la función devuelva en forma de lista, alma-cenando cada puntuación con su correspondiente subapartado.
5.8. Almacenar la información en la memoria de aprendiza-je y reiniciar el bucle
En la última fase del bucle de interacción, una vez que se la mostrado la informaciónal usuario, se procederá a almacenar las opiniones suministradas por el usuario enla memoria de aprendizaje. Para ello se utilizará la función almacenarPuntUsuarios(), utilizando la pregunta preprocesada del usuario y las valoraciones obtenidas.
Hay que tener en cuenta que, en el caso de que al usuario no le gustase la mejorrespuesta, el sistema le proporcionaba las 5 mejores, pidiéndole al usuario la opiniónpara las 5 soluciones y almacenando la información en una lista con las puntuacionesy el correspondiente subapartado.
En el caso de que al usuario si le agradase la mejor respuesta, no se le pide valoración,el sistema automáticamente considera que dicho subapartado tiene una opinión devaloración 10 para la pregunta actual.
Esta función utilizará las librerías de xlrd, xlutils y xlbt para operar con la memoriade aprendizaje, que es el fichero excel ”V aloracionesUsuario.xls”.
La forma de operar de esta función será leyendo el fichero excel, para saber el númerode preguntas que ya hay almacenadas, para, posteriormente, sobreescribir el ficherocon las nuevas valoraciones sin solapar con las ya existentes. La forma de almacenarla información será escribiendo en una fila la palabra ”Pregunta”, seguida de todoslos términos preprocesados de la pregunta del usuario, y se pondrá un número má-ximo de 5 filas con la palabra ”V aloraciones”, seguido de la opinión del usuario y delsubapartado al que pertenece.
66

Experimentación
Figura 5.11: Formato del fichero Excel de la memoria de aprendizaje.
Una vez almacenada la información, se habrá finalizado la interacción correspondien-te a dicha pregunta y se procederá a pedir al usuario una nueva pregunta, iniciandode nuevo el bucle.
5.9. Resultados
Visto el procedimiento general que sigue el sistema y las funciones para que se llevea cabo, se va a proceder a explicar los resultados obtenidos, detallando los puntosfuertes y débiles del sistema, y describiendo paso a paso, la interacción entre elsistema con un usuario.
Preguntas incorrectas que el sistema es capaz de detectar
Figura 5.12: Palabras vacías de significado que el sistema no contempla.
67

5.9. Resultados
En el caso de que el usuario escriba preguntas sin sentido, en las que sólo se escribanpalabras vacías, el sistema detectará estos fallos y se lo indicará al usuario con laoración Para esa pregunta no podemos encontrar ninguna solución.
Figura 5.13: Preguntas de tipo lugar escritas incorrectamente.
Si el usuario realiza preguntas del tipo ”lugar”, pero escribe incorrectamente los tér-minos que ayudan al sistema a detectar este tipo de pregunta, pedirá al usuario quevuelva a formular la pregunta mediante la oración Por favor, escriba correctamente laconsulta.
Figura 5.14: Preguntas de una temática distinta.
Este sistema ha sido realizado, únicamente, para contestar preguntas sobre averíasde trenes, por lo que, si se realizan preguntas sobre otro tipo de temáticas, el sistemalo detectará y se lo indicará al usuario de la siguiente manera: Para esa pregunta nodisponemos actualmente de una solución.
68

Experimentación
Figura 5.15: Preguntas invariantes a las mayúsculas y tildes.
Como se indicó anteriormente en su funcionamiento, este sistema es invariante antelas mayúsculas y las tildes, por lo que el usuario puede escribir con o sin mayúsculasy acentos. Además, esta invariabilidad está presente en todas las posibles preguntasque realice el usuario, ya sea preguntando con palabras vacías, incorrectas, de otratemática o realizando preguntas correctas, es decir, al sistema no le afectan paranada.
Fallos del sistema
Figura 5.16: Preguntas que el sistema no detecta correctamente.
A pesar de que se ha comentado que el sistema es capaz de detectar ciertos fallos,no es capaz de detectar otros, y en algunos de los que es capaz de detectar también
69

5.9. Resultados
falla.
En el primer caso, se realiza una pregunta de tipo ”lugar”, en qué pagna se encuentrael apartado de las normas. Como se observa, el usuario desea obtener la página dondese encuentran las normas, sin embargo ha escrito mal la palabra página. Este hechodebería de ser detectado para volver a pedirle al usuario que formule la pregunta,sin embargo, al encontrarse también la palabra apartado, el sistema piensa que elusuario pide el apartado donde están las normas, hecho que es incorrecto.
En el segundo caso, el usuario realiza la siguiente pregunta: cómo puedo acelerarel tren?, pero se ha de recordar que este sistema está implementado para consultassobre averías, no para consultas sobre funciomiento del tren (o cualquier otro temá-tica), por lo que el sistema debería indicar que para esa pregunta no puede encontrarsolución. Sin embargo, el sistema encuentra similitudes con apartados del texto ymuestra la respuesta que más similitud tiene con esta pregunta, una respuesta quees incorrecta (ya que el modo de proceder es incorrecto). Este hecho también nos llevaa concluir que, si se realizan preguntas sobre la temática de averías pero con ciertaspalabras mal escritas, se puede dar el caso que no sepa discernir que está mal escritay, aún así, encuentre respuestas que mostrar al usuario (pudiendo dar casualmentecon la respuesta correcta, pero también con respuestas incorrectas).
En el tercer caso, el usuario escribe una palabra vacía, hecho que debería ser detec-tado, ya que los stopwords son eliminados, sin embargo, al escribir solamente hacia,el sistema muestra una respuesta (totalmente incorrecta). Esto es debido a que laforma de eliminar los stopwords es mediante la librería NLTK, a través su módulo deeliminar palabras vacías en castellano. Sin embargo, como se comentó anteriormen-te, el castellano es una lengua difícil y NLTK está mas especializado en inglés, porlo que la lista de stopwords que utiliza la librería NLTK no está completa, como sepuede observar en este ejemplo.
Ciclo de funcionamiento del sistema
En este subapartado se va a describir el funcionamiento del sistema a la hora deinteractuar con el usuario y, además, se va a demostrar cómo, ante preguntas simi-lares, el sistema adapta la respuesta que muestra.
Figura 5.17: Inicio del sistema y pregunta inicial (1º Iteración).
El primer paso de la interacción es el arranque del sistema, en el que se procedesaludando al usuario, en función del momento del día, para después iniciar el buclede interacción de preguntas por parte del usuario y de las respuestas que proporcionael programa.
70

Experimentación
En este caso, la pregunta a realizar será avería del control de tracción, un tipo deavería que está definido en el subapartado 7.3, sin embargo, la mejor solución queproporciona el sistema corresponde al capítulo 7 entero.
Figura 5.18: Disconformidad de la mejor respuesta y valoración (1º Iteración).
Una vez mostrada la respuesta, se pregunta al usuario si está conforme con la mis-ma, a lo que el usuario contesta que no está conforme, ya que él desea obtener lainformación concreta. Ante la disconformidad del usuario con la mejor respuestaproporcionada por el sistema, se procede a mostrar la lista de las 5 mejores respues-tas.
Cuando el sistema muestra esta lista, pide valoraciones al usuario, entre 0 y 10, paradespués almacenarlas en la memoria de aprendizaje (sirviéndole de retroalimenta-ción). A la mejor respuesta, el usuario le da un valor de 3.5, ya que, a pesar de que lamejor respuesta contiene la respuesta deseada por el usuario, no da la informaciónconcreta únicamente, por lo que no se le puede dar una valoración óptima.
Figura 5.19: Lista de las 5 mejores soluciones (1º Iteración).
Una vez valorada la mejor respuesta, el sistema sigue mostrando los otros 4 mejo-res resultados, pidiendo opiniones de éstos al usuario. En esta primera iteración, larespuesta esperada ante la pregunta está situada en el cuarto lugar de los mejoresresultados. Como ésta es la respuesta esperada, el usuario debería ponerle una va-loración elevada, sin embargo, para mostrar el funcionamiento del sistema, vamos a
71

5.9. Resultados
calificarla, por esta vez, con el valor de 5.5.
Figura 5.20: Almacenamiento de la pregunta y de las opiniones (1º Iteración).
En el momento en el que el usuario termine de puntuar las respuestas, el gestor dediálogo se encargará de almacenar dicha información en la memoria de aprendizaje.Se puede observar que se almacena primero la pregunta preprocesada, es decir, lasraíces de las palabras relevantes (control, traccion, averi). Seguidamente, se almace-nan las valoraciones de las 5 mejores respuestas, primero indicando la puntuación,después el capítulo al que pertenece la respuesta, y finalmente el subapartado con-creto de esta.
Figura 5.21: Información relevante al procesar la pregunta para obtener la respuesta.
Cuando se procesa una pregunta, se realizan una serie de fases para determinar larespuesta que el sistema considera mejor. El primer paso es almacenar en la variablelista ”ranking” la puntuación obtenida tras realizar la métrica de similitud del cosenoentre la pregunta y cada uno de los capítulos, es decir, el grado de corresponden-cia entre una y otra, según la métrica del coseno. Como se puede observar, la lista”ranking” tiene una serie de 13 números (del 0 al 12), del 1 al 12 corresponden a laspuntuaciones de cada uno de los 12 capítulos. De estos 12 capítulos, se seleccionaun máximo de 5 de ellos (los de mejor puntuación, siempre y cuando sean mayoresque 0), obteniéndose en este caso los capítulos 11, 8, 7, 6 y 1 como los mejores cinco.
Una vez obtenidos los 5 mejores capítulos, el sistema vuelve a utilizar la métrica desimilitud de coseno pero, esta vez, para obtener las puntuaciones de los subapar-tados de los mejores capítulos. Esta información se almacena en la variable lista”rankingSubSecciones”, que contiene 5 listas, correspondientes a los 5 capítulos, cadauna de ellas con las puntuaciones de sus subapartados. Se puede observar que lamejor puntuación es de aproximadamente 0.577, que es la correspondiente al capí-tulo 7 entero.
72

Experimentación
Figura 5.22: Inicio del sistema y pregunta inicial (2º Iteración).
Ahora, se va a proceder a realizar la segunda iteración, en este caso, el sistema yatiene almacenada en la memoria de aprendizaje información respecto a las averíasdel control de tracción (en la primera iteración no tenía este tipo de información),por lo que, a la hora de obtener los mejores resultados, tendrá en cuenta tanto lainformación que le proporciona la métrica de similitud del coseno, como la informa-ción de los usuarios, personas expertas en este dominio, contenida en la memoria deaprendizaje.
En esta segunda iteración se va a variar ligeramente la pregunta, en este caso lapregunta será Tengo el control de tracción averiado, que, como se puede observar,no es la misma pregunta que la anterior, pero guarda bastante relación. El sistemaextrae las raíces de las palabras, es por ello, que el hecho de modificar las palabrasno le afectará, siempre y cuando se conserven las raíces.
Sin embargo, como se muestra, a pesar de obtener información de los usuarios sobreeste tipo de averías, el sistema vuelve a proporcionarle al usuario el capítulo 7 ente-ro. Esto es debido a que la puntuación que se le dió anteriormente al subapartadocorrecto fue de 5.5, una valoración baja, pero vamos a ver qué pasa después.
Figura 5.23: Disconformidad de la mejor respuesta y valoración (2º Iteración).
El sistema vuelve a preguntar al usuario si está conforme con la respuesta, a lo queel usuario responde que no y le da una valoración de 2, esta vez el usuario es másestricto con la respuesta proporcionada y pone menor valoración a esta respuestaque muestra todo el capítulo entero.
73

5.9. Resultados
Figura 5.24: Lista de las 5 mejores soluciones (2º Iteración).
El sistema, una vez mostrada la disconformidad del usuario, muestra la lista de las5 mejores respuestas y, aprendiendo de la información de la memoria de aprendi-zaje, reajusta sus parámetros y muestra, esta vez, el subapartado 7.3 (la respuestaesperada) en la segunda mejor posición. De este resultado se deduce que gracias a lainformación obtenida en la primera iteración, el sistema muestra como segundo me-jor resultado la respuesta esperada, cuando en la primera iteración (sin informaciónsobre dicha pregunta en la memoria de aprendizaje) esta respuesta estaba situada enla cuarta posición. Esta vez, como sería lo normal, el usuario le da una puntuaciónalta a la respuesta, valorándola con un 10.
Figura 5.25: Almacenamiento de la pregunta y de las opiniones (2º Iteración).
Una vez se ha valorado la lista de mejores respuestas, el gestor de diálogo almacenadicha información en el fichero Excel correspondiente. En éste, se apila dicha infor-mación de la iteración actual con el de las iteraciones anteriores realizadas por otrosusuarios.
74

Experimentación
Figura 5.26: Última iteración.
Finalmente, un nuevo usuario arranca el sistema y realiza una pregunta relacionadacon la avería del control de tracción. En este caso, la pregunta es en qué subapartadoESTÁ la avería en el control de tracción (como se observa el sistema es invariante antemayúsculas y tildes). En este caso la pregunta es de tipo ”lugar” y espera que elsistema le devuelva el subapartado correspondiente. El hecho de elegir otro tipo depregunta no modifica los resultados del sistema, éste se encargará de utilizar, tantola información de la métrica del coseno, como la de la memoria de aprendizaje, paradevolver la mejor respuesta posible.
En esta iteración, el sistema indica al usuario que la información está disponibleen el subapartado 7.3, por lo que, finalmente, el sistema ha aprendido a modificarlos parámetros correspondientes para obtener la respuesta correcta ante preguntasrelativas a averías del control de tracción.
Al ser una pregunta de tipo ”lugar”, una vez mostrado el subapartado, se le preguntaal usuario si desea que se le muestre el texto con la información solicitada, a lo queel usuario responde que sí, comprobando que la respuesta es la correcta. Al mostrarel sistema como mejor respuesta la que es válida, el usuario indica su conformidadcon ésta y finaliza la interacción saliendo del sistema.
Aspectos a tener en cuenta
Hay una serie de aspectos a tener en cuenta a la hora de la implementación de estesistema y de conocer los logros y dificultades que existen.
Como se ha comentado, el sistema es invariante a las mayúsculas y acentos, lo que
75

5.9. Resultados
hace más flexible al usuario la escritura. Además, los elementos fundamentales alpreprocesar las cadenas de texto son la eliminación de stopwords y la utilizaciónde stemming para obtener simplemente las raíces de las palabras. Estos elementoshacen que los usuarios puedan escribir con mayor libertad a la hora de formularpreguntas con palabras vacías de significado y con palabras importantes con varia-bilidad morfológica. Sin embargo, hay que tener en cuenta que la librería utilizadapara ello es, fundamentalmente, NLTK, una librería especializada en el inglés y qué,por tanto, no realiza estas tareas tan eficientemente como cabría esperar.
Para este tipo de sistemas, en los que se debe trabajar durante varios minutos, eincluso horas, es importante que el usuario se sienta cómodo. Una forma de conse-guir este objetivo es dando variabilidad a la hora de responder al usuario, es decir,intentar interactuar de una forma más natural. Para lograrlo, se implementaron unaserie de oraciones predeterminadas a la hora de dar la bienvenida en el arranque delsistema y en cada iteración que se muestra un resultado, eligiendo al azar (mediantela librería random) entre estas oraciones predeterminadas.
A la hora de dar la bienvenida, se tiene en cuenta el momento del día en el que seactiva el programa y para cada momento del día hay una serie de oraciones (porejemplo, algunas de ellas por la mañana son Bienvenido, ¿qué tal el día?, Hola, ¿quétal la mañana?, Hola, buenos días o Buenos días).
Otra forma de dotar de flexibilidad al sistema es a la hora de mostrar las respues-tas al usuario, con otra serie de oraciones predeterminadas en función del tipo derespuesta, en el caso del tipo ”lugar” (por ejemplo, La información solicitada está en,La información se encuentra en o La información la puede obtener en); o en el ca-so de explicaciones (por ejemplo, La información solicitada es la siguiente:, Aquí estála información pedida:, Dicha información es la siguiente: o Aquí está la informaciónsolicitada:).
A la hora de implementar un sistema de este tipo, se ha de trabajar con las personasque lo van a utilizar, es decir, realizando una labor conjunta entre los diseñadores delprograma, los usuarios (en este caso maquinistas o mecánicos) y lingüistas. Además,se ha de trabajar con los materiales proporcionados para dicha tarea (en este caso losmanuales proporcionados por la empresa ferroviaria). Por lo tanto hay que considerarque se debe realizar una labor conjunta con un grupo muy heterogéneo de expertos,que puede llegar a ser complicado de lidiar conforme se va realizando el trabajo, peroque es lo necesario para conseguir la implementación de un sistema lo más eficaz,flexible y potente posible.
Además, otro elemento a tener en cuenta que el material proporcionado (los manua-les), que han sido diseñados por terceras personas con términos fuera de nuestroconocimiento, por lo que puede ser complicado tratar en las primeras instancias coneste material. En este caso, se presentaron algunas dificultades con los capítulos6 y 7, correspondientes a los reset y averías, ya que el manual a veces emplea es-tos dos términos como sinónimos, e incluso la forma en la que están escritos lossubapartados de reset son ambiguos. Por ejemplo, el reset de puertas hace referen-cia al procedimiento para volver a activar las puertas (cuando en realidad es averíasde puertas). Sin embargo, el reset de pantógrafo está correctamente expresado, yaque se realiza como herramienta para resetear o arreglar otro tipo de mecanismosaveriados. Por tanto, a veces resulta difícil trabajar con textos que no están escritoscorrectamente y sobre los que no se tiene un control excelente en el dominio a tratar
76

Experimentación
(están redactados en términos muy específicos).
Por ello, cuando se realizó el modelo de este sistema, se trabajó con un grupo demaquinistas, preguntándoles qué tipo de sistema sería ideal para implementar me-diante un programa, a lo que la mayoría indicó que un sistema que resolviese dudasde forma rápida y ágil sería ideal.
Además, como se ha podido ver en el ejemplo del ciclo de funcionamiento del sistema,a la información de la memoria de aprendizaje se le ha otorgado un peso mayor quea la información que proporciona el sistema mediante la métrica de similitud delcoseno. Esto es debido a que las preguntas y las valoraciones almacenadas en lamemoria de aprendizaje, en las diversas interacciones entre el sistema y el usuario,han sido realizadas mediante voluntarios maquinistas que han dado sus opinionesy valoraciones, tanto en la interfaz del sistema como en las puntuaciones que se lesdaba a cada una de las respuestas almacenadas en la memoria de aprendizaje, y estainformación es mucho más valiosa a la hora de facilitar los mejores resultados.
77


Capítulo 6
Conclusiones
En conclusión, como se ha podido ver, el campo de las técnicas de procesamientode lenguaje natural es muy amplio y muy útil para realizar tareas que nos permitaninteractuar mejor con los sistemas informáticos y, así, mejorar procesos actuales yfuturos que podrían realizarse automáticamente de forma más eficiente. Sin embargo,también tienen una elevada complejidad que impide que se consiga implementar unsistema completo (y mucho más universal).
En este trabajo se ha realizado el estudio e implementación de un campo concretodel PLN, en particular, los sistemas de pregunta-respuesta. Se ha podido observarel modelo planteado y su implementación, aplicando algunos de los conocimientosdescritos en el estado del arte. Se ha focalizado sobre un tema único (las averías delos trenes), en el que se han analizado también las ventajas y limitaciones de estesistema.
La idea es observar cómo el trabajo desarrollado en este foco concreto puede mejo-rarse, no sólo para esta temática, sino que puede ser escalable para ser utilizado enmuchos otros sectores.
Posibles mejoras
Una de las mejoras haría referencia al planteamiento del problema, ya que las solu-ciones demandadas por los trabajadores eran implementar un sistema que ayudasea resolver, de forma ágil y rápida, cuestiones sobre averías, circulación e informaciónlaboral (turnos, vacaciones o nóminas, entre otras). En este trabajo, sólo se ha de-sarrollado un sistema para resolver cuestiones correspondientes a averías, pudiendomejorarse el sistema para que permitiese resolver otras cuestiones (aumentando elnúmero de temas que puede manejar).
Otra mejora sería respecto a la interfaz del sistema, que podría mejorarse si se de-sarrollase una interfaz más amigable, implementando una app móvil que permitieseun acceso más rápido, con un entorno más manejable y flexible. Además, se podríanincorporar los módulos de Automatic Speech Recognition (ASR) y Text-to-Speech (TTS),para permitir formular preguntas mediante comandos por voz y obtener respuestasmediante generación de audio, de esta forma, no sólo se permitiría texto (como en elsistema actual), ofreciéndole al usuario mayor libertad.
79

Respecto a la implementación realizada, también hay una serie de aspectos que po-drían incluirse para obtener un sistema más robusto:
Se podría incorporar un analizador morfológico, con el fin de detectar palabras devarios términos, ya que en este trabajo se detectan términos independientes, conesto se puede perder información relativa a palabras conjuntas.
Otra forma de obtener información más rica sería implementar alguna función, yaque el texto es controlado, de pares de palabras que aparecen juntas, por ejemplo,para detectar términos que suelen aparecer en la misma oración y que guardan bas-tante relación entre sí.
Otro elemento que se podría incorporar, y que sería muy interesante, es un correctorortográfico, para que el usuario no tenga que perder el tiempo formulando otra vezla pregunta. Se podría hacer mediante el algoritmo de Levenstein, aunque lo másprobable es que habría que usar FreeLing, dada la complejidad de la labor.
A la hora de abordar mejoras en un sistema futuro (con mayor tiempo disponible)sería conveniente realizar un tesauro, sobre el dominio que se esté tratando (en estecaso sobre trenes) y sería muy útil para encontrar sinónimos y para tener una bús-queda más completa, ya que podría focalizar mejor el lugar sobre el que extraer lainformación y permitiría discernir con una precisión muy elevada la diferencia entredistintas temáticas.
El gestor de diálogo debería mejorarse, ya que también debe encargarse de almacenarcómo va transcurriendo la conversación, es decir, cual es el último asunto que se hatratado, para así mantener el hilo de la conversación y ser más robusto frente aelipsis. Para ello, se podría elaborar una lista en donde se almacene jerárquicamenteel foco de la última pregunta.
80

Bibliografía
[1] Jones K.S. (1994) Natural Language Processing: A Historical Review. In: ZampolliA., Calzolari N., Palmer M. (eds) Current Issues in Computational Linguistics: InHonour of Don Walker. Linguistica Computazionale, vol 9. Springer, Dordrecht.
[2] Cambria, E. and White, B. (2014). Jumping NLP Curves: A Review of NaturalLanguage Processing Research [Review Article]. IEEE Computational IntelligenceMagazine, 9, 48-57.
[3] Ojokoh, B.A. and Adebisi, E. (2019). A Review of Question Answering Systems.Journal of Web Engineering, 17, 717-758.
[4] Shum, H.-Y., He, X.-D. and Li, D. (2018). From Eliza to XiaoIce: challenges andopportunities with social chatbots. Frontiers of Information Technology and Elec-tronic Engineering 19, 10–26.
[5] Martínez-Barco, P., Vicedo, J. L., Saquete Boró, E. and Tomás, D. (2007). Siste-mas de pregunta-respuesta.
[6] Krithika, L., and Akondi, K.V. (2014). Survey on Various Natural Language Pro-cessing Toolkits. World Applied Sciences Journal 32 (3): 399-402, 2014.
[7] Cortez Vásquez, A., Vega huerta, H., Pariona Quispe, J., y Huayna, A. M. (2009).Procesamiento de lenguaje natural. Revista De Investigación De Sistemas E In-formática, 6(2), 45 - 54.
[8] Johnson, F. (1996). A Natural Language Understanding system for referenceresolution in information dialogues.
[9] Pietquin, O. (2010). Natural Language and Dialogue Processing.
[10] Vállez, M., and Pedraza, R. (2007). Natural Language Processing in Textual In-formation Retrieval and Related Topics. Hipertext.net: Revista Académica sobreDocumentación Digital y Comunicación Interactiva, 5 Anglés.
[11] Banko, M., Cafarella, M., J., Soderland, S., Broadhead, M., and Etzioni, O.(2007). Open information extraction from the web. In Proceedings of the 20th in-ternational joint conference on Artifical intelligence (IJCAI’07). Morgan KaufmannPublishers Inc., San Francisco, CA, USA, 2670–2676.
[12] Yue, X., Di, G., Yu, Y., Wang, W. and Shi, H. (2012). Analysis of the Combina-tion of Natural Language Processing and Search Engine Technology. ProcediaEngineering, Volume 29, Pages 1636-1639.
81

BIBLIOGRAFÍA
[13] Sarawagi, S. (2008), Information Extraction, Foundations and Trends in Databa-ses: Vol. 1: No. 3, pp 261-377.
[14] Hirschberg, J., and Manning, C. D. (2015). Advances in natural language pro-cessing. Science (New York, N.Y.), 349(6245), 261–266.
[15] Erkan, G., and Radev, D.R. (2004). LexRank: Graph-based Lexical Centrality asSalience in Text Summarization. Journal of Artificial Intelligence Research, 22,457-479.
[16] Hirschman, L. and Gaizauskas, R. (2001). Natural language question answe-ring: the view from here. Natural Language Engineering 7, 4 (December 2001),275–300.
[17] Følstad, A., and Brandtzæg, P. (2017). Chatbots and the new world of HCI. Inter-actions, 24, 38 - 42.
[18] Braun, D., Hernandez-Mendez, A., Matthes, F. and Langen, M. (2017). Eva-luating Natural Language Understanding Services for Conversational Ques-tion Answering Systems. Proceedings of the SIGDIAL 2017 Conference, pages174–185,Saarbrücken, Germany, 15-17 August 2017.
[19] DALE, R. (2016). The return of the chatbots. Natural Language Engineering,22(5), 811-817.
[20] Rahman, A.M., Mamun, A. and Islam, A. (2017). Programming challenges ofchatbot: Current and future prospective. 2017 IEEE Region 10 HumanitarianTechnology Conference (R10-HTC), 75-78.
[21] Kucherbaev, P., Bozzon, A., and Houben, G-J. (2018). Human Aided Bots. IEEEInternet Computing, 22(6), 36-43.
[22] Goddeau, D., Meng, H., Polifroni, J., Seneff, S. and Busayapongchai, S. (1996).A form-based dialogue manager for spoken language applications. Proceedingof Fourth International Conference on Spoken Language Processing. ICSLP ’96, 2,701-704 vol.2.
[23] Pietquin, O. and Dutoit, T. (2006). A probabilistic framework for dialog simu-lation and optimal strategy learning. IEEE Transactions on Audio, Speech, andLanguage Processing, 14, 589-599.
[24] Wolff, R.M., Masuch, K., Hobert, S. and Schumann, M. (2019). What Do YouNeed Today? - An Empirical Systematization of Application Areas for Chatbots atDigital Workplaces. In 25th Americas Conference on Information Systems, AMCIS2019, Cancún, Mexico, August 15-17, 2019. Association for Information Systems,2019.
[25] Mausam, Schmitz, M., Bart, R., Soderland, S., and Etzioni, O. (2012). Openlanguage learning for information extraction. In Proceedings of the 2012 JointConference on Empirical Methods in Natural Language Processing and Compu-tational Natural Language Learning (EMNLP-CoNLL ’12). Association for Compu-tational Linguistics, USA, 523–534.
[26] Haristiani, N. (2019). Artificial Intelligence (AI) Chatbot as Language LearningMedium: An inquiry. Journal of Physics: Conference Series 1387, 012020.
82

BIBLIOGRAFÍA
[27] Følstad, A., Skjuve, M. and Brandtzaeg, P.B. (2019). Different Chatbots for Dif-ferent Purposes: Towards a Typology of Chatbots to Understand Interaction De-sign. In: Bodrunova S. et al. (eds) Internet Science. INSCI 2018. Lecture Notes inComputer Science, vol 11551. Springer, Cham.
[28] Fryer, L.K., Coniam, D., Carpenter, R. and Lapus, neanu, D. (2020). Bots for Lan-guage Learning Now: Current and Future Directions. Language Learning andTechnology, 24, 8-22.
[29] Jing, Y. (2020). Research on the Application of Artificial Intelligence Natural Lan-guage Processing Technology in Japanese Teaching. Journal of Physics: Confe-rence Series 1682.
[30] Benotti, L., Martínez, M. C. and Schapachnik, F. (2014). Engaging high schoolstudents using chatbots. In Proceedings of the 2014 conference on Innovation andtechnology in computer science education (ITiCSE ’14). Association for ComputingMachinery, New York, NY, USA, 63–68.
[31] Srimathi, H. and Krishnamoorthy, A. (2019). Personalization of Student Sup-port Services using Chatbot. International Journal of Scientific and TechnologyResearch Volume 8 - Issue 9, September 2019 Edition.
[32] Agarwal, A., Sachdeva, N., Yadav, R., Udandarao, V., Mittal, V., Gupta, A. andMathur, A. (2019). EDUQA: Educational Domain Question Answering SystemUsing Conceptual Network Mapping. ICASSP 2019 - 2019 IEEE International Con-ference on Acoustics, Speech and Signal Processing (ICASSP), 8137-8141.
[33] Agrawal, A., Lu, J., Antol, S., Mitchell, M., Zitnick, C. L., Parikh, D., and Batra,D. (2017). VQA: Visual Question Answering. International Journal of ComputerVision 123, 1 (May 2017), 4–31.
[34] Wiriyathammabhum, P., Summers-Stay, D., Fermüller, C. and Aloimonos, Y.(2016). Computer Vision and Natural Language Processing: Recent Approachesin Multimedia and Robotics. ACM Comput. Surv. 49, 4, Article 71 (February 2017),44 pages.
[35] Hodosh, M., Young, P., and Hockenmaier, J. (2013). Framing image descriptionas a ranking task: data, models and evaluation metrics. Journal of Artificial Inte-lligence Research. 47, 1 (May 2013), 853–899.
[36] Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S. and Zhang,L. (2018). Bottom-Up and Top-Down Attention for Image Captioning and VisualQuestion Answering. 2018 IEEE/CVF Conference on Computer Vision and PatternRecognition.
[37] Wu, Q., Wang, P., Shen, C., Dick, A., and Hengel, A.V. (2016). Ask Me Anything:Free-Form Visual Question Answering Based on Knowledge from External Sour-ces. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),4622-4630.
[38] Gao, H., Mao, J., Zhou, J., Huang, Z., Wang, L. and Xu, W. (2015). Are youtalking to a machine? Dataset and methods for multilingual image questionanswering. In Proceedings of the 28th International Conference on Neural Infor-mation Processing Systems - Volume 2 (NIPS’15). MIT Press, Cambridge, MA, USA,2296–2304.
83

BIBLIOGRAFÍA
[39] Yao, B.Z., Yang, X., Lin, L., Lee, M. and Zhu, S. (2010). I2T: Image Parsing toText Description. Proceedings of the IEEE, 98, 1485-1508.
[40] Kulkarni, G., Premraj, V., Dhar, S., Li, S., Choi, Y., Berg, A., and Berg, T.L.(2013). BabyTalk: Understanding and Generating Simple Image Descriptions.IEEE Transactions on Pattern Analysis and Machine Intelligence 35, 2891–2903.
[41] Giachos, I., Papakitsos, E. and Chorozoglou, G. (2017). Exploring natural lan-guage understanding in robotic interfaces. International Journal of Advances inIntelligent Informatics, 3, 10-19.
[42] Gnewuch, U., Morana, S., Heckmann, C.S., and Maedche, A. (2018). DesigningConversational Agents for Energy Feedback. In Proceedings of the 13th Interna-tional Conference on Design Science Research in Information Systems and Tech-nology (DESRIST 2018), Chennai, India, June 3–6.
[43] Kadali, B., Prasad, N., Kudav, P. and Deshpande, M. (2020). Home AutomationUsing Chatbot and Voice Assistant. ITM Web of Conferences 32, 01002.
[44] Cui, L., Huang, S., Wei, F., Tan, C., Duan, C. and Zhou, M. (2017). SuperAgent:A Customer Service Chatbot for E-commerce Websites. Proceedings of the 55thAnnual Meeting of the Association for Computational Linguistics-System Demons-trations, pages 97–102Vancouver, Canada, July 30 - August 4, 2017.
[45] Okuda, T. and Shoda, S. (2018) .AI-based Chatbot Service for Financial In-dustry.Fujitsu Scientific and Technical Journal, Vol. 54, No. 2, pp. 4–8 (April 2018).
[46] Demner-Fushman, D. and Lin, J. (2007). Answering Clinical Questions withKnowledge-Based and Statistical Techniques. Computational Linguistics, 33, 63-103.
[47] Zhou, L., Gao, J., Li, D. and Shum, H. (2020). The Design and Implementationof XiaoIce, an Empathetic Social Chatbot. Computational Linguistics 46, 1 (March2020), 53–93.
[48] Narasimhan, K., Kulkarni, T.D. and Barzilay, R. (2015). Language Understan-ding for Text-based Games using Deep Reinforcement Learning. Proceedings ofthe 2015 Conference on Empirical Methods in Natural Language Processing, pages1–11,Lisbon, Portugal, 17-21 September 2015.
[49] Ukpabi, D., Aslam, B., and Karjaluoto, H. (2019). Chatbot Adoption in TourismServices: A Conceptual Exploration. In Ivanov, Stanislav; Webster, Craig (Eds.)Robots, Artificial Intelligence, and Service Automation in Travel, Tourism and Hos-pitality. Emerald Publishing Limited, 105-121.
[50] Følstad, A., Nordheim, C.B. and Bjørkli, C. (2018). What Makes Users Trust aChatbot for Customer Service? An Exploratory Interview Study. In: Bodrunova S.(eds) Internet Science. INSCI 2018. Lecture Notes in Computer Science, vol 11193.Springer.
[51] Burke, R. D., Hammond, K. J., Kulyukin, V., Lytinen, S. L., Tomuro, N. andSchoenberg, S. (1997). Question Answering from Frequently Asked Question Fi-les: Experiences with the FAQ FINDER System. AI Magazine, 18(2), 57.
[52] Frommert C., Häfner A., Friedrich J. and Zinke C. (2018) Using Chatbots toAssist Communication in Collaborative Networks. In: Camarinha-Matos L., Af-
84

BIBLIOGRAFÍA
sarmanesh H., Rezgui Y. (eds) Collaborative Networks of Cognitive Systems. PRO-VE 2018. IFIP Advances in Information and Communication Technology, vol 534.Springer, Cham.
[53] Xue, Z., Ko, T., Yuchen, N., Wu, M.D. and Hsieh, C. (2018). Isa: Intuit SmartAgent, A Neural-Based Agent-Assist Chatbot. 2018 IEEE International Conferenceon Data Mining Workshops (ICDMW), 1423-1428.
[54] Fiore, D., Baldauf, M. and Thiel, C. (2019). "Forgot your password again?": accep-tance and user experience of a chatbot for in-company IT support. Proceedingsof the 18th International Conference on Mobile and Ubiquitous Multimedia (MUM’19). Association for Computing Machinery, New York, NY, USA, Article 37, 1–11.
85
Related Documents