Towards Safe Learning-Based Control Performance & Constraint Satisfaction under Uncertainties Melanie Zeilinger Institute for Dynamic Systems and Control [email protected] Collaboration with: E. Klenske, P. Hennig, B. Schölkopf (MPI) K. Akametalu, J. Fisac C. Tomlin (UC Berkeley)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Towards Safe Learning-Based ControlPerformance & Constraint Satisfaction under Uncertainties
Melanie ZeilingerInstitute for Dynamic Systems and Control
Collaboration with:E. Klenske, P. Hennig, B. Schölkopf (MPI)K. Akametalu, J. Fisac C. Tomlin (UC Berkeley)

Variable speed control of compressorsABB drives control the compressors of the world‘s longest gas export pipeline
theweek.comabb.com control.ee.ethz.ch
PerformanceSafety

Performance and SafetyGo Together
no knowledge of safety boundaries
with knowledge of safety boundaries
Video courtesy of Kene Akametalu

Variable speed control of compressorsABB drives control the compressors of the world‘s longest gas export pipeline
theweek.comabb.com control.ee.ethz.ch
Model! System dynamics
! Constraints
! Computation
PerformanceSafety

The Quest for a Good ModelModel Uncertainty
x = f (x, u, t, d) g(x, u, t, d) � 0
Complexity External effects Variation
tcadsolutions.com
autoguide.com

Optimization-based Control High Performance for Constrained Systems
6
mea
sure
men
ts
Dynamical System
control input
minN�
k=0
l(x(k), u(k)) + g(x(N))
Z�[� x(k + 1) = f (x(k), u(k), d(k))
(x(k), u(k)) � X
Standard control
Model predictive control

Optimization-based Control High Performance for Constrained Systems
7
mea
sure
men
ts
Dynamical System
control input
minN�
k=0
l(x(k), u(k)) + g(x(N))
Z�[� x(k + 1) = f (x(k), u(k), d(k))
(x(k), u(k)) � X
Rely on system model! High performance! Recursive constraint satisfaction! Stability by design! Automatic synthesis

Automatic Synthesis Of High Performance, Safe Controllers
8
Learning&
Controller
Performance &
Safety
Software/Implementation
mea
sure
men
ts
Dynamical System
control input
Environment Human
Online data
Specifications+
Online data
Learning-basedcontroller

Previous WorkReal-time Constraints in Optimization-based Control
9
ControllerPerformance
& Safety
Software/Implementation
! Real-time model predictive control [Zeilinger et al., 2008 – 2014]
! High-speed, certified optimization [Domahidi, Z. et al., 2012; Pu, Z. et al., 2014, 2016]
mea
sure
men
ts
Dynamical System
control input
minN�
k=0
l(x(k), u(k)) + g(x(N))
Z�[� x(k + 1) = f (x(k), u(k), d(k))
(x(k), u(k)) � X
Software/Specifications+
Online data

Outline
10
mea
sure
men
ts
Dynamical System
control input
Environment Human
Online data
This talk:! Learning for performance: Tailoring optimal controllers online ! Safety guarantees: Constraint satisfaction for any performance controller12
Learning-basedcontroller

Outline
11
mea
sure
men
ts
Dynamical System
control input
Environment Human
Online data
This talk:! Learning for performance: Tailoring optimal controllers online ! Safety guarantees: Constraint satisfaction for any performance controller12
minN�
k=0
l(x(k), u(k)) + g(x(N))
Z�[� x(k + 1) = f (x(k), u(k), d(k))
(x(k), u(k)) � X
How to predict complex behavior, quantify & reduce
uncertainties?

Quantifying Uncertain Predictions From Online Data
12
estimated RegressionDynamical
Model
Infer function d (t ) online:
measured states
applied inputs
{x(t k)}Kk=0
{u(t k)}Kk=0
�d(t k)
� Kk=0
inferred function d(t )
e.g. x(k + 1 )
= f (x(k ), u(k )) + d(x, u, k )
x(k + 1) = f (x(k), u(k), d(k))
d
x 1 x2
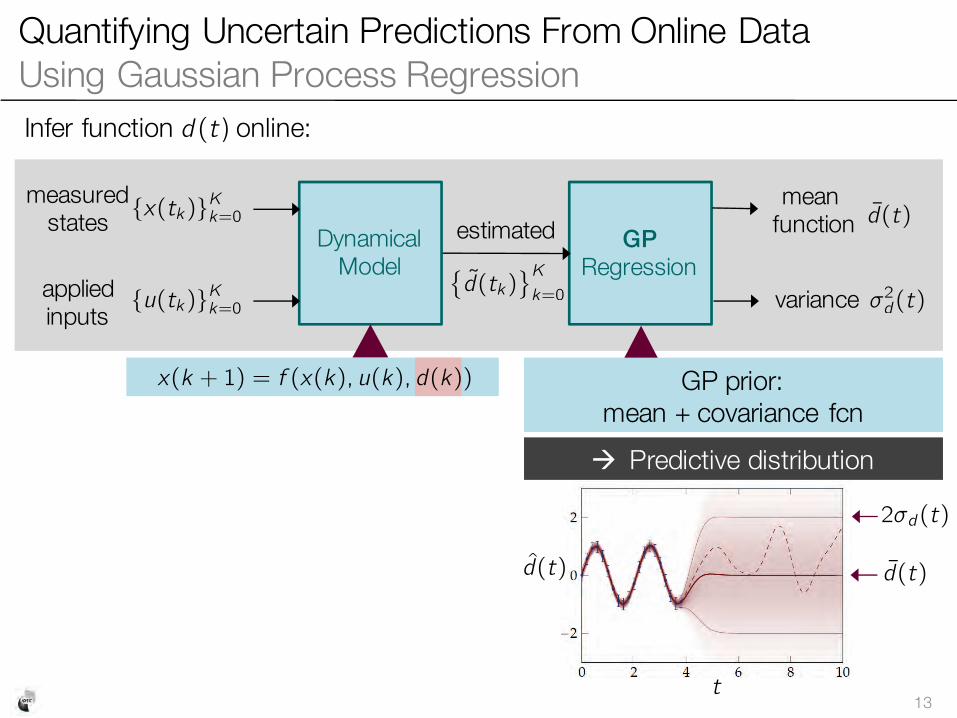
Quantifying Uncertain Predictions From Online Data Using Gaussian Process Regression
13
meanfunction
variance
measured states
applied inputs
estimated GPRegression
Dynamical Model
{x(t k)}Kk=0
{u(t k)}Kk=0
d(t )
� 2d (t )
" Predictive distribution
Infer function d (t ) online:
GP prior: mean + covariance fcn
d(t )
2 �d (t )
d(t )
t
�d(t k)
� Kk=0
x(k + 1) = f (x(k), u(k), d(k))

Quantifying Uncertain Predictions From Online Data Using Gaussian Process Regression
14
meanfunction
variance
measured states
applied inputs
estimated GPRegression
Dynamical Model
{x(t k)}Kk=0
{u(t k)}Kk=0
d(t )
� 2d (t )
Infer function d (t ) online:
GP prior: mean + covariance fcn
�d(t k)
� Kk=0
Examples:! Mechanical errors! Prediction of loads, efficiencies etc. in energy systems! Unknown nonlinear dynamics (e.g. ground effects)
Gears Cause Periodic Errorsexample: astrophotography
1
" Predictive distribution
x(k + 1) = f (x(k), u(k), d(k))

Example:Telescope Guiding
Photograph by Robert Vanderbei, La Palma, 2012
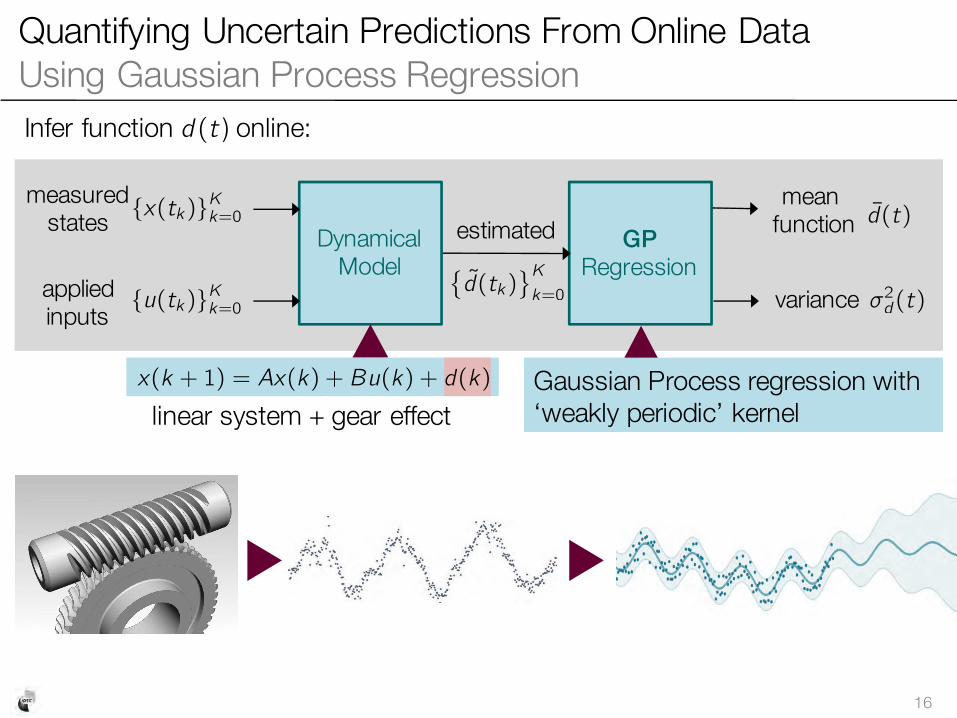
Quantifying Uncertain Predictions From Online Data Using Gaussian Process Regression
16
meanfunction
variance
measured states
applied inputs
estimated GPRegression
Dynamical Model
{x(t k)}Kk=0
{u(t k)}Kk=0
d(t )
� 2d (t )
Infer function d (t ) online:
Gaussian Process regression with ‘weakly periodic’ kernel
�d(t k)
� Kk=0
linear system + gear effectx(k + 1 ) = A x(k ) + B u(k ) + d(k )

Comparison to State of the ArtOpen Source Software PHD Guiding by Edgar Klenske
17currently own branch on github.com/OpenPHDGuiding/phd2
0 500 1,000 1,500 2,000 2,500 3,000 3,500�2�1
012
errorRA
[px]
Tracking Algorithm of PHD2 Guiding 2.5.0
0 500 1,000 1,500 2,000 2,500 3,000 3,500�2�1
012
errorRA
[px]
Tracking with GP Prediction
RMS(e) = 0.4174
RMS(e) = 0.3080
26% reduction
erro
r RA
[px]
erro
r RA
[px]
26% reduction
time [s]
Tracking Algorithm of PHD2 Guiding 2.5.0
Tracking with GP Prediction
RMS(error) = 0.4174
RMS(error) = 0.3080

Tracking in “Darkness”Robustness through Improved Predictions
18
0 200 400 600 800 1,000 1,200 1,400 1,600 1,800 2,0000
10
20
30
40
50
time [s]
accumulated
gear
errorRA
[px]
Tracking with ”cloud”
accu
mula
ted
gear
erro
r RA
[px]
time [s]

Outline
19
mea
sure
men
ts
Dynamical System
control input
Environment Human
Online data
This talk:! Learning for performance: Tailoring optimal controllers online ! Safety guarantees: Constraint satisfaction for any performance controller12
minN�
k=0
l(x(k), u(k)) + g(x(N))
Z�[� x(k + 1) = f (x(k), u(k), d(k))
(x(k), u(k)) � X

The Issue of The TransientAn Example
20
What if we have to learn while
satisfying constraints?
Stanford Autonomous Helicopter – Tic-toc learning from scratch [Abbeel, Coates, Quigley, Ng, NIPS 2007]
Transients make system traverse through unsafe behavior
Goal: Safe online learning in control

Safety GuaranteesInvariance & Stability
21
Constraint satisfactionSatisfy constraints now & in future" Utilize feasible, invariant set
StabilityControl system to output target" Show Lyapunov function
states x � X , inputs u � UModel: x(t) = f (x(t), u(t))
V (x) positive definite, bounded˙V (x) � ��(|x |) �x � X
O = {x � Rn | �u(·) � Uts.t. �� � [ 0,�),
�(� ; x, t, u(·)) � X}

Safety GuaranteesInvariance & Stability for Uncertain Systems
22
Robust Invariance Satisfy constraints now & in future" Utilize feasible, robust invariant set
Input-to-State Stability (ISS)Control system to output target" Show ISS Lyapunov function
, disturbances d � DModel: x(t ) = f (x(t ), u(t ), d(t ))
states x � X , inputs u � U
O = {x � R n | �u(· ) � U tZ�[� �� � [ 0 ,�), �d(· ) � D t�(� ; x, t , u(· ), d(· )) � X }
V (x) positive definite, bounded˙V (x, d) � ��(|x |) + �(|d |)
�x � X , d � D
Alternative: Constraint relaxation" Soft constraints with stability guarantees
[Zeilinger et al., TAC 2014]

Safety GuaranteesInvariance & Stability for Uncertain Systems
23
Robust Invariance Satisfy constraints now & in future" Utilize feasible, robust invariant set
Input-to-State Stability (ISS)Control system to output target" Show ISS Lyapunov function
, disturbances d � DModel: x(t ) = f (x(t ), u(t ), d(t ))
states x � X , inputs u � U
O = {x � R n | �u(· ) � U tZ�[� �� � [ 0 ,�), �d(· ) � D t�(� ; x, t , u(· ), d(· )) � X }
V (x) positive definite, bounded˙V (x, d) � ��(|x |) + �(|d |)
�x � X , d � D
Invariant set is based on system model" Common practice: Use conservative bound on model uncertainties" Small safe set restricts performance

" Distribution for model uncertainties" Estimate of disturbance set
Quantifying Model Uncertainties Using Gaussian Process Regression
24
meanfunction
variance
Infer disturbance function d (x ) online:
measured states
applied inputs
estimated GPRegression
Dynamical Model
{x(t k)}Kk=0
{u(t k)}Kk=0
x = f (x, u, d(x))
�d(xk)
� Kk=0
{x(t k)}Kk=0d(x)
� 2d (x)
ˆD (x) = [ d(x)� m � d (x), d(x) + m � d (x)]
Prior distribution
m chosen according to desired probability p(e.g. m=3 for p=99.7%)

Safety Based on Robust InvarianceMain Idea
25
Goal: Guarantee safety for any online controller
Floor
Ceilin
gSafe
Unsafe
Largest controlled invariant set within constraints
Example: Quadrotor tracking up and down reference (e.g.pick-up task)
x = f (x, u) + d(x)
states:vertical position
velocity
control:thrust
model uncertainty
Idea: Utilize robust invariant safe set
Unsafe
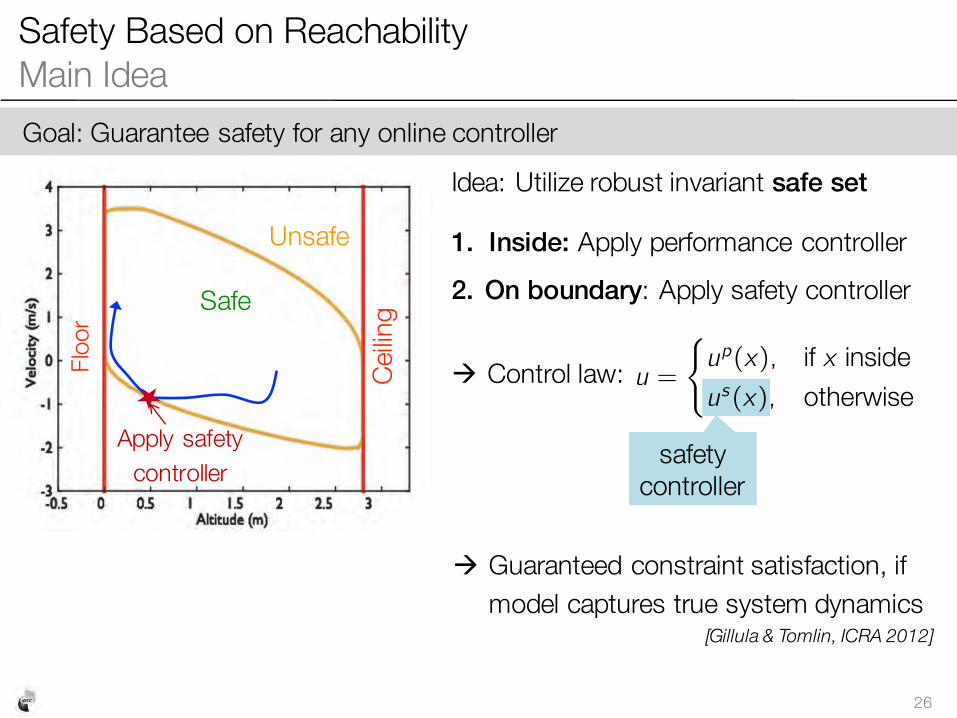
Safety Based on Reachability Main Idea
26
Goal: Guarantee safety for any online controller
Idea: Utilize robust invariant safe set
1. Inside: Apply performance controller2. On boundary: Apply safety controller
" Control law:
" Guaranteed constraint satisfaction, if model captures true system dynamics
[Gillula & Tomlin, ICRA 2012]
safety controller
u =
�u p (x), PM x PUZPKLu s (x), V[OLY^PZL
Floor
Ceilin
gSafe
Unsafe
Apply safety controller

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4x = f (x, u) + d1 (x)
d1 (x) � D 1 (x)
Safety Based on Reachability and Online Model Validation
27
Goal: Leverage online data to improve performance and safety properties
1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Apply performance controller
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Idea: Utilize robust invariant safe set

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4x = f (x, u) + d1 (x)
d1 (x) � D 1 (x)
Safety Based on Reachability and Online Model Validation
28
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4x = f (x, u) + d2(x)
d2(x) � D 2(x)1. Learn model from online data and
compute safe set2. On boundary: Apply safety controller
3. Inside: Apply performance controller
Idea: Utilize robust invariant safe set

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Safety Based on Reachability and Online Model Validation
29
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Check confidence in model! If confident: Apply performance-
maximizing controller! If unconfident: Contract safe set
and apply safety controller
Idea: Utilize robust invariant safe setx = f (x, u) + d2(x)
d2(x) � D 2(x)
Loss of model confidence

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Safety Based on Reachability and Online Model Validation
30
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Idea: Utilize robust invariant safe setx = f (x, u) + d2(x)
d2(x) � D 2(x)
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Contracted safe set
Loss of model confidence
1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Check confidence in model! If confident: Apply performance-
maximizing controller! If unconfident: Contract safe set
and apply safety controller
x = f (x, u) + d2(x)
d2(x) � D 2(x)

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Safety Based on Reachability and Online Model Validation
31
Safety by combining learning and control theoretic techniques
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Idea: Utilize robust invariant safe setx = f (x, u) + d2(x)
d2(x) � D 2(x)
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4 1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Check confidence in model! If confident: Apply performance-
maximizing controller! If unconfident: Contract safe set
and apply safety controller

0
0.5
1
1.5
2
2.5
3
Alti
tud
e (
m)
No Online Validation
0 10 20 30 40 50 600
0.5
1
1.5
2
2.5
3
Alti
tud
e (
m)
Online Disturbance Validation
Time (s)
Safety: increased thrust command
Safety: decreased thrust command
Physical Collision
Reaction to Incorrect ModelWith Model Validation, No Re-computation of Safe Set
32
ground collisions
Detect unmodeleddisturbance" Contract safe set" Wait for
recomputation of safe set
No online validation
Online disturbance validation

Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Safe Online Learning With Model Learning and Validation
33
! First updated model is invalid
! Method detects inconsistency, slightly contracts safe set
! Improved tracking after next model update
Initial Inaccurate Improved
System never leaves converged safe set

Safety Based on Reachability and Online Model Validation
34
Safety by combining learning and control theoretic techniques
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4 1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Check confidence in model! If confident: Apply performance-
maximizing controller! If unconfident: Contract safe set
and apply safety controller
Idea: Utilize robust invariant safe set

The Safe SetHamilton-Jacobi-Isaacs Formulation
35Constraint Set
u � U , d � DModel:
K
x = f (x, u, d)
Goal: Compute safe set = maximum robust control invariant subset
Stay in : Control u vs. disturbance d
K

The Safe SetHamilton-Jacobi-Isaacs Formulation
36
l(x )l(x ) : positive in setand negative otherwise
Safe Set
Constraint Set
u � U , d � D
J(x )
� J (x, t )
� t= �min
�
0 ,ma xu �U
mind �D
� J (x, t )
�x
T
f (x, u, d)
�
J (x, 0) = l(x)
[Mitchell, Bayen, Tomlin, TAC 2005]
Model:
{x : J (x) � 0 }
K
x = f (x, u, d)
Modified HJI equation:
Stay in : Control u vs. disturbance d
K
Safe Set:= Largest robust control invariant set = Set of states for which disturbance cannot win!

The Safe SetHamilton-Jacobi-Isaacs Formulation
37
l(x )
Safe Set:= Largest robust control invariant set = Set of states for which disturbance cannot win!
l(x ) : positive in setand negative otherwise
Safe Set
Constraint Set
u � U , d � D
J(x )
� J (x, t )
� t= �min
�
0 ,ma xu �U
mind �D
� J (x, t )
�x
T
f (x, u, d)
�
J (x, 0) = l(x)
[Mitchell, Bayen, Tomlin, TAC 2005]
Model:
{x : J (x) � 0 }
K
x = f (x, u, d)
Safetycontroller: u s (x) = HYNma x
u �Umind �D
� J (x) T
�xf (x, u, d)
Modified HJI equation:
Stay in : Control u vs. disturbance d
K

Safety Based on Reachability and Online Model Validation
38
Safety by combining learning and control theoretic techniques
Goal: Leverage online data to improve performance and safety properties
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]
Altitude (m)-0.5 0 0.5 1 1.5 2 2.5 3
Velo
city
(m/s
)
-3
-2
-1
0
1
2
3
4
1
2
3
4
Idea: Utilize robust invariant safe set
1. Learn model from online data and compute safe set
2. On boundary: Apply safety controller
3. Inside: Check confidence in model! If confident: Apply performance-
maximizing controller! If unconfident: Contract safe set
and apply safety controller

Benefit of HJI FormulationInfinite Number of Invariant Sets
39
� J (x, t )
� t= �min
�
0 ,ma xu �U
mind �D
� J (x, t )
�x
T
f (x, u, d)
�
Lemma:
Safe Set: {x : J (x) � 0 }
K
(U` UVUULNH[P]L Z\WLYSL]LS ZL[ VM J (x)�P�L� {x | J (x) � �,� � 0 }�PZ YVI\Z[ JVU[YVS PU]HYPHU[ �Y�[� d � D
x, u, d)
�
J (x)

Safety Strategy with Online Model Validation
40
Given:
! Initialize: Active safe set = biggest candidate set" Critical level JL = 0
! At each time step:Check confidence in If not confident:
Contract safe set to include current state
! Control law
ˆD (x)
ˆD (x), J (x)
Ku =
�u p (x), PM J (x) > J L
u s (x), V[OLY^PZL
J L = ma x {J (x), J L }
Standard:J (x) > 0
J (x)
J LJ L

Safety Strategy with Online Model Validation
41
Given:
! Initialize: Active safe set = biggest candidate set" Critical level JL = 0
! At each time step:Check confidence inIf not confident:
Contract safe set to include current state
! Control law
ˆD (x), J (x)
K
ˆD (x)
u =
�u p (x), PM J (x) > J L
u s (x), V[OLY^PZL
J L = ma x {J (x), J L }
J (x)
J L
J L

Safety Strategy with Online Model Validation
42
ˆD (x), J (x)
K
Given:
! Initialize: Active safe set = biggest candidate set" Critical level JL = 0
! At each time step:Check confidence inIf not confident:
Contract safe set to include current state
! Control law
ˆD (x)
re-compute
u =
�u p (x), PM J (x) > J L
u s (x), V[OLY^PZL
J L = ma x {J (x), J L }
= biggest candidate set
J (x)

Safety Strategy with Online Model ValidationGlobal Guarantees
43
Theorem:
Intuitively: Safety guaranteed, if there exists some superlevel set, such that disturbance is captured on its boundary
K
0M MVY ZVTL Z[H[L z [OL TVKLS JVUÄKLUJL PZ SV^ HUK �J S � [ 0 , J (z )] Z\JO [OH[d(x) � ˆD (x) �x � {x | J (x) = J S }� [OLU [OL JVU[YVS SH^ PZ N\HYHU[LLK [V RLLW [OLZ[H[L ^P[OPU [OL JVUZ[YHPU[Z H[ HSS [PTLZ�
[Akametalu, Fernandez-Fisac, Zeilinger, Tomlin CDC 2014]

Safety A First Experiment with Humans
44
Model inconsistency
Safer to stay above this altitude

SummaryPerformance & Safety for Learning-based Control
45
! Online model learning provides automatic enhancement of prediction & controller performance
" Important to characterize residual uncertainty
! Invariant sets provide safe exploration space, but require system model
! Model validation critical when learning online" Iteratively identify safe set
[Klenske et al., TCST 2015]
Acknowledgements:Edgar Klenske, Philipp Hennig, Bernhard SchölkopfKene Akametalu, Jaime Fisac, Shahab Kaynama, Claire Tomlin,
Optimal Controller
Dynamical System
External effects(human, environment)
Model Learning
d
[Akametalu, Fisac et al., CDC 2014]
Related Documents











