Toward Extreme-Scale Manycore Architectures Josep Torrellas Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu USC October 2016

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Toward Extreme-Scale Manycore Architectures
Josep Torrellas Department of Computer Science
University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu
USC
October 2016
2
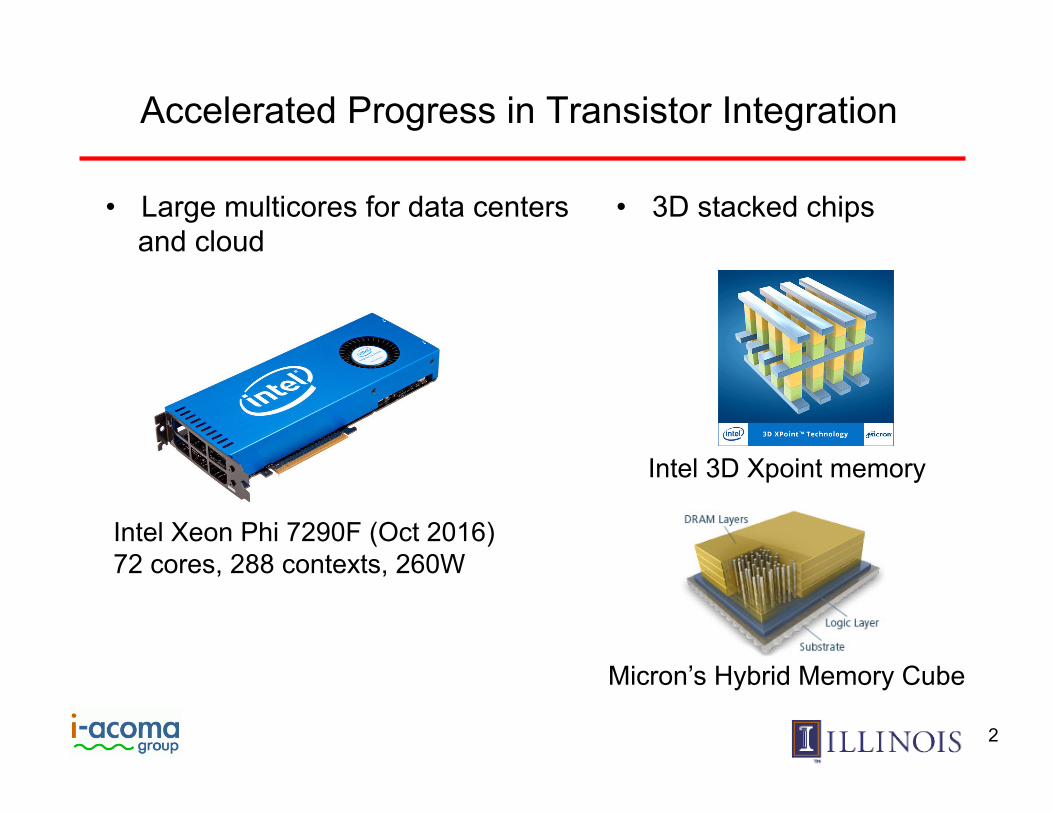
Accelerated Progress in Transistor Integration
• Large multicores for data centers and cloud
Intel Xeon Phi 7290F (Oct 2016) 72 cores, 288 contexts, 260W
Intel 3D Xpoint memory
• 3D stacked chips
Micron’s Hybrid Memory Cube

3
Research is Pushing Ever Farther Ahead
Heat Sink
Integrated Heat Spreader (IHS)
Thermal Interface Material (TIM)
Motherboard
Processor SiliconProcessor Frontside Metal (Cu)
DRAM Frontside Metal (Al)
DRAM Silicon
Die to Die (D2D) Layer
Through Silicon Vias (TSVs)
C4 pads
• Research on stacking multiple processor and memory dies
Runnemede prototype [HPCA-13]
• More integration à 1,000 cores/chip
Josep Torrellas Toward Extreme Scale… 4
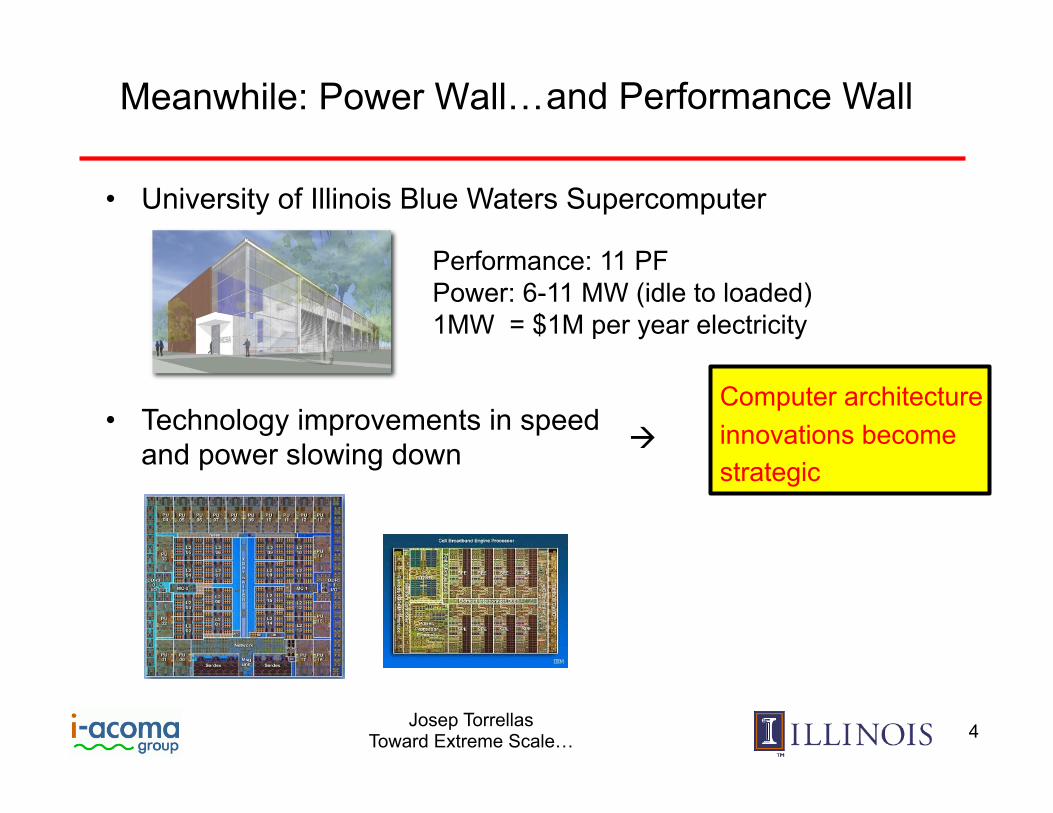
Meanwhile: Power Wall… and Performance Wall
Performance: 11 PF Power: 6-11 MW (idle to loaded) 1MW = $1M per year electricity
• University of Illinois Blue Waters Supercomputer
and Performance Wall
• Technology improvements in speed and power slowing down
Computer architecture innovations become strategic
à

Josep Torrellas Toward Extreme Scale…
All at the same time
5
• Very high energy efficiency
• Faster communication and synchronization
• Ease of programming
What We Need

Josep Torrellas Toward Extreme Scale… 6
Today’s Discussion
• Focus: Reducing the cost of basic primitives for parallelism • Flavor of other challenges: energy, programmability

Josep Torrellas Toward Extreme Scale… 7
Quest
Making synchronization inexpensive

Josep Torrellas Toward Extreme Scale… 8
Making Synchronization Inexpensive
• Scalable concurrent priority queues
QueueHead
node
node
node
node
• Breaking serialization in lock-free synchronization
x
Compare&Swap(CAS) CAS CAS CAS CAS
[ISCA-13][ASPLOS-15][ASPLOS-16]
wr x rd z
wr y rd x
wr z rd y
fence fence fence
• Make memory fences free

Josep Torrellas Toward Extreme Scale… 9
Making Synchronization Inexpensive
• Make memory fences free (WeeFence)
• Breaking serialization in lock-free synchronization
• Scalable concurrent priority queues
wr x rd z
wr y rd x
wr z rd y
fence fence fence
[ISCA-13]

Josep Torrellas Toward Extreme Scale…
Fence: a Primitive for Parallelism
• Instruction inserted by programmers or compilers • Prevents the compiler and HW from reordering memory accesses
10
Until these are finished • reads retired • writes retired + drained from write buffer
Cannot be observed by another processor
Write y
Fence
Read x
Read z
Tim
e

Josep Torrellas Toward Extreme Scale…
take() Tail = … fence …= Head
steal () Head = … fence …= Tail
11
Use of Fences (I)
Enforce the correct order between accesses
• Programmers insert fences in codes with fine-grain sharing: – Work-stealing algorithm in Cilk
Worker dequeues from tail and checks head
Thief takes from head and checks tail

Josep Torrellas Toward Extreme Scale…
• Compilers insert fences in C++: – Programmer uses intentional data race for performance à declares
variable as atomic – Compiler inserts fence after the access, does not reorder – Hardware does not reorder across fence
12
Use of Fences (II)

Josep Torrellas Toward Extreme Scale… 13
If We Remove Fences: Incorrect Execution
With fences: t1=1, t0=1 or both=1
A0: x =1
A1: t0 = yB0: y = 1
B1: t1 = x
x = y = 0PA PB
fence
fenceUnintuitive bug: Sequential Consistency(SC) Violation
t0 = t1 = 0A1B0B1A0
Without fences:
wr x
rd y
PA PBwr y
rd x
SC: execution appears as if accesses from multiple threads were interleaved in a uniprocessor
A0A1B0B1
B0B1A0A1
A0B0A1B1
write propagatedto memory

Josep Torrellas Toward Extreme Scale… 14
Fence Overhead
• Naïve implementation: stall all memory operations following the fence – The processor quickly stalls
Josep Torrellas Toward Extreme Scale… 15
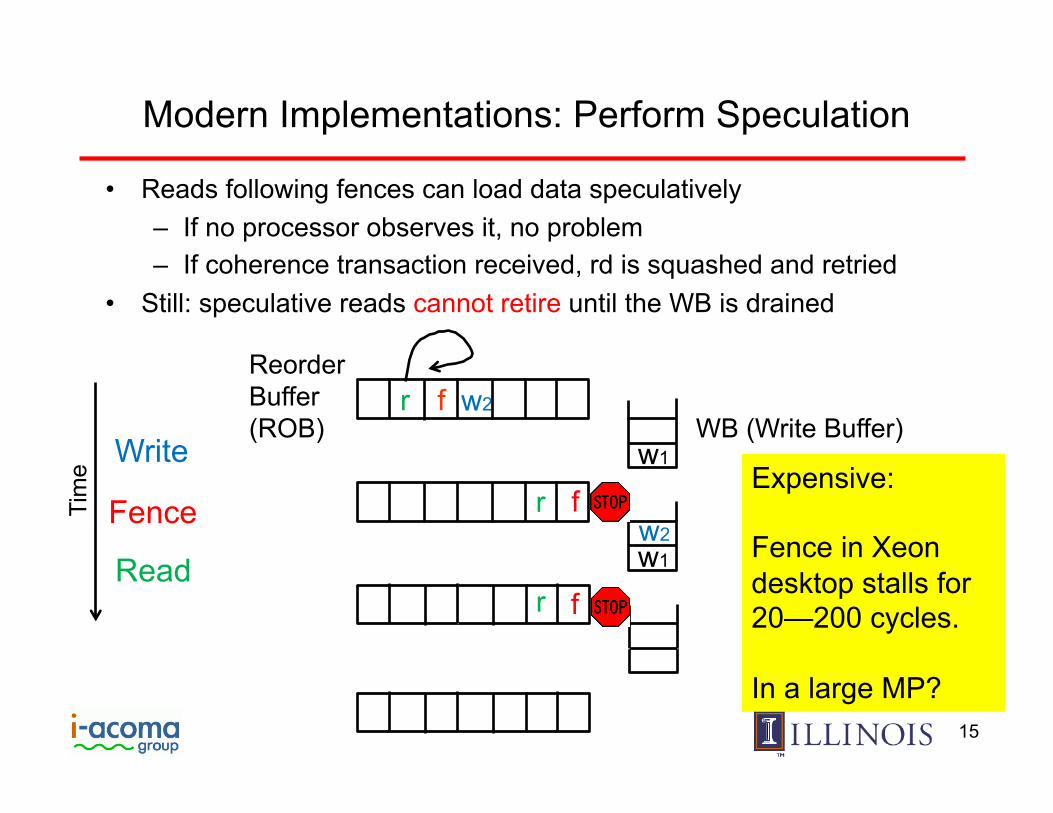
Modern Implementations: Perform Speculation
w2 f r
w1
w2 f r
w1
Reorder Buffer (ROB) WB (Write Buffer)
Write
Fence
Read
Tim
e Expensive: Fence in Xeon desktop stalls for 20—200 cycles. In a large MP?
• Reads following fences can load data speculatively – If no processor observes it, no problem – If coherence transaction received, rd is squashed and retried
• Still: speculative reads cannot retire until the WB is drained
f r

Josep Torrellas Toward Extreme Scale… 16
What if Fences Were Free?
• Programmers could write faster fine-grained concurrent algorithms
• C++/Java programmers would not have to worry about data races – Declare all shared variables as atomic – Compiler puts many fences, hardware still runs fast – Guaranteed Sequential Consistency (SC)

Josep Torrellas Toward Extreme Scale… 17
Proposal: WeeFence (or WFence)
• Post-fence read retires before the pre-fence writes have drained – “Skip” the fence
Substantial gains when write misses pile-up before the fence
w2 f r
w1
Spec execution
• Goal: Eliminate any stall in the pipeline [ISCA-13]
Write
Fence
Read
Tim
e
w1
w2 f r
WB
Reorder Buffer (ROB)
w2 f
w1

Josep Torrellas Toward Extreme Scale… 18
But… Not Stalling Can Cause Incorrect Execution
A0: x =1
A1: t0 = yB0: y = 1
B1: t1 = x
x = y = 0PA PB
WeeFence
Solution: Allow the reorder, check for this case, and stall the read (B1)
WeeFence
What we want: not stall but avoid these SC violations
Write
Fence
Read
Tim
e
write propagatedto memory

Josep Torrellas Toward Extreme Scale… 19
But… Not Stalling Can Cause Incorrect Execution
A0: x =1
A1: t0 = yB0: y = 1
B1: t1 = x
x = y = 0PA PB
WeeFence
Solution: Allow the reorder, check for this case, and stall the read (B1)
WeeFence
What we want: not stall but avoid these SC violations
Conventional fences always conservatively stall ßà Not WeeFence
Write
Fence
Read
Tim
e
write propagatedto memory

Josep Torrellas Toward Extreme Scale…
WeeFence: The Idea
• At a fence: record the thread’s incomplete writes in a HW structure
• Allow post-fence reads to execute before pre-fence writes complete • Check post-fence reads (rd x) against HW structure to find conflicts
with other threads’ incomplete writes. – Conflict? Stall read – Else: Retire
20
rd y
PA PB
WeeFencewr y
WeeFencerd x
wr xPrevent “rd x” retiring early if: - There is a concurrent fence - Accesses vars in opposite order

Josep Torrellas Toward Extreme Scale… 21
(3)
execute
wr x
rd y
PA PB
Wfence1
wr y
rd x
Wfence2
How WFence Works
PS: Pending Set
BS: Bypass Set rd y
PA PB
Wfence1wr y
Wfence2rd x
wr x
(1)PS
x
Table
(2)

Josep Torrellas Toward Extreme Scale… 22
wr x
rd y
PA PB
Wfence1
(1)(3) PS
execute
wr y
x
(5)
local check stall
(6)
How WFence Works
PS
y
(4)Wfence2
rd x
PS: Pending Set
BS: Bypass Set
wr x
rd y
PA PB
Wfence1wr y
Wfence2rd x
x
Table
(2)

Josep Torrellas Toward Extreme Scale… 23
(3)
execute
wr x
rd y
PA PB
Wfence1
wr y
wr x
y BS
(4)
How WFence Works (II)
(1)PS
x
Table
PS: Pending Set
BS: Bypass Set
wr x
rd y
PA PB
Wfence1wr y
wr xNo fence present in x86
(2)

Josep Torrellas Toward Extreme Scale… 24
wr x
rd y
PA PB
Wfence1
(1)(3) PS execute
x
wr y
wr x
y BS
(4)
How WFence Works (II)
Table
PS: Pending Set
BS: Bypass Set
wr x
rd y
PA PB
Wfence1wr y
wr xNo fence present in x86
(5) coherence
stall (2)

Josep Torrellas Toward Extreme Scale… 25
wr x
rd y
PA
Wfence1
wr x
rd y
PA
Wfence1
(1)PS
x
Summary: How WFence Works
z
Table
(6)stall
(4)y BS
(5)execute & retire
z
(2)check
(3)
PS: Pending Set BS: Bypass Set

Josep Torrellas Toward Extreme Scale…
• Cycles are rare: Wfence typically executes without stalling the processor • Works with cycles with any number of processors
• No compiler support needed: Unmodified off-the shelf executable
26
WFence
wr x Wfence
rd z
wr y Wfence
rd x
PA PB
wr z Wfence
rd y
PC

Josep Torrellas Toward Extreme Scale…
Improving WeeFence
27
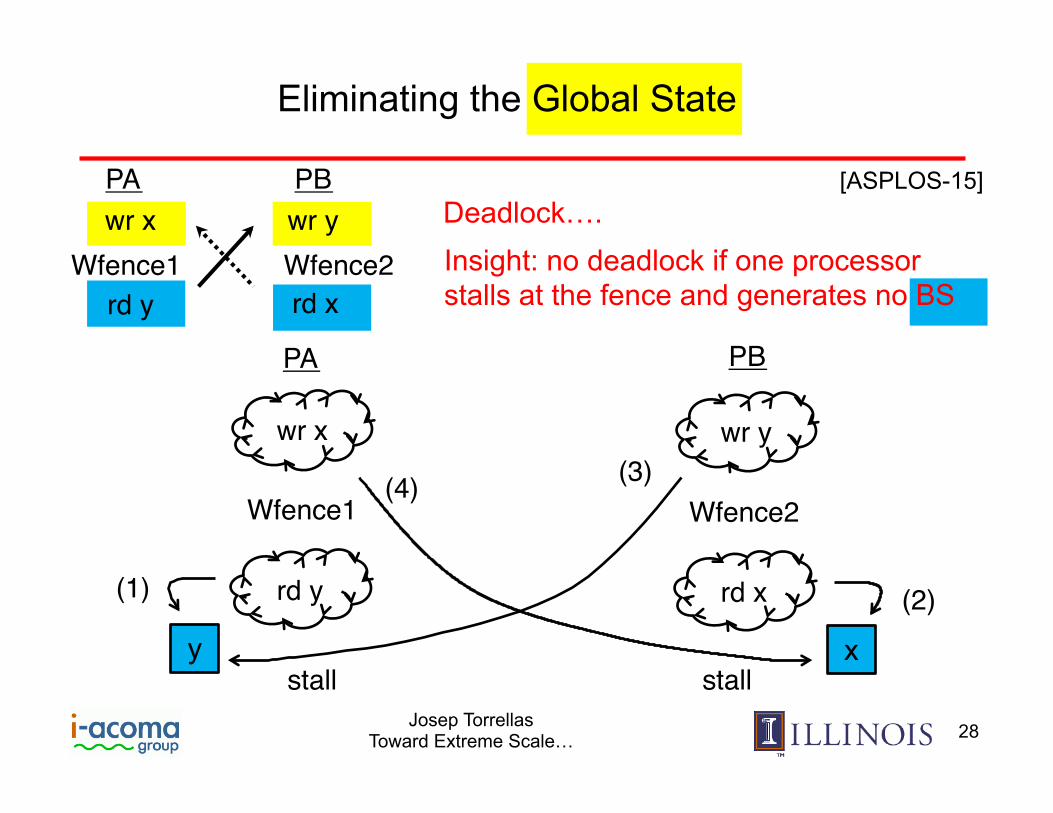
• The Global State is expensive to maintain with many threads
• Can we eliminate the Global State (Pending Set)
Josep Torrellas Toward Extreme Scale… 28
wr x
rd y
PA PB
Wfence1
wr y
rd x
Eliminating the Global State
wr x
rd y
PA PB
Wfence1wr y
rd xWfence2
Wfence2
y
(1)
x
(2)
Deadlock…. Insight: no deadlock if one processor stalls at the fence and generates no BS
[ASPLOS-15]
(3)
stall
(4)
stall

Josep Torrellas Toward Extreme Scale…
29
Asymmetric Fences: Strong Fence + Weak Fences
[ASPLOS-15]
wr x rd z
wr y rd x
PA PB
wr z rd y
PC
x z
Conventional fence
WeeFence Without PS
– N-1 weak fences that allow reordering = WeeFences without PS
• Given a conflict cycle with N processors: – 1 strong fence (no BS ) = conventional fence

Josep Torrellas Toward Extreme Scale…
30
Where to Put Strong Fence?
• Work stealing algorithm in Cilk: – Weak fences à workers – Strong fences à thiefs
tmp->field = 10; fence1; obj = tmp;
if (obj) { fence2; a = obj->field;
PA PB
Put strong fence in fence1, why?
It only executes once, at initialization
• Software transaction memory: – Weak fences à reads – Strong fences à writes
Josep Torrellas Toward Extreme Scale… 31
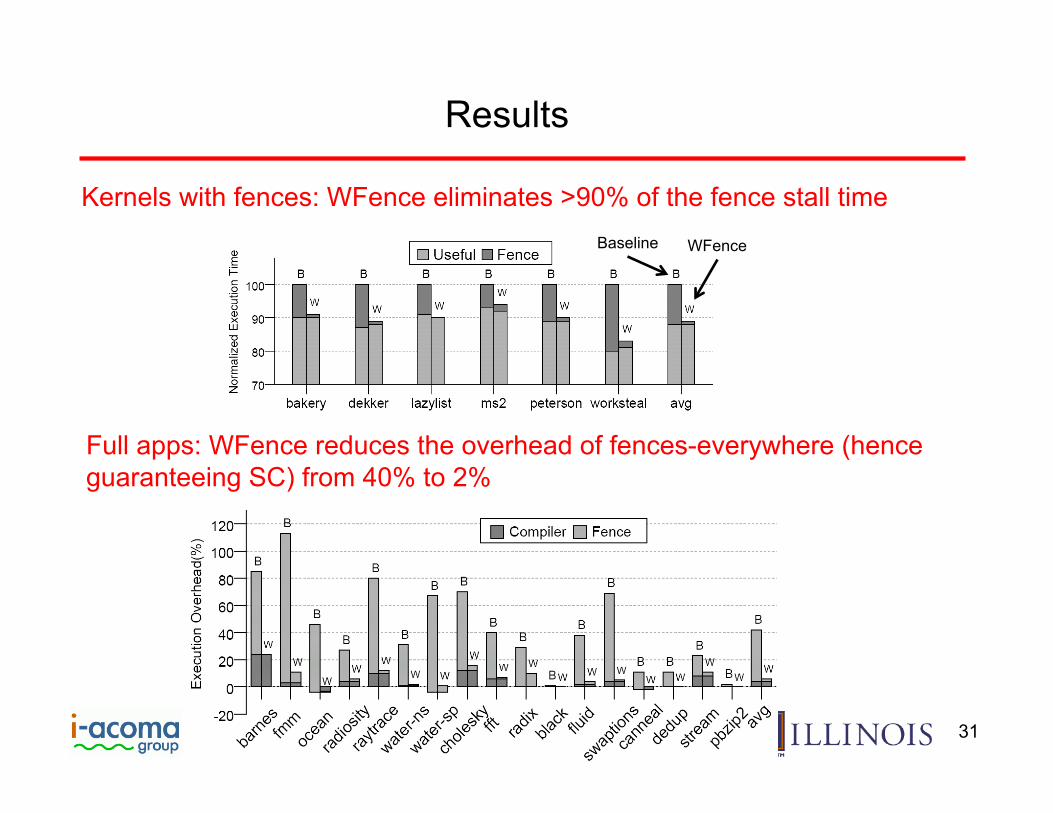
Results
Full apps: WFence reduces the overhead of fences-everywhere (hence guaranteeing SC) from 40% to 2%
Kernels with fences: WFence eliminates >90% of the fence stall time Baseline WFence

Josep Torrellas Toward Extreme Scale… 32
Making Synchronization Inexpensive
• Make memory fences free
• Breaking serialization in lock-free synchronization (CASPAR)
• Scalable concurrent priority queues
[ASPLOS-16]
x
Compare&Swap(CAS) CAS CAS CAS CAS

Josep Torrellas Toward Extreme Scale… 33
Bottleneck: Many Processors Synch on Same Var
• Operating systems, databases, language runtimes, mem allocators • Lock-free synchronization: Manipulates data using atomic instructions
instead of locks
if (mem[addr] == old) { mem[addr]=new }
Compare&Swap(addr,old,new)
[ASPLOS-16]

Josep Torrellas Toward Extreme Scale… 34
Simple Example Lock-Free Synchronization
x
CAS CAS CAS CAS CAS
if (mem[addr] == old) { mem[addr]=new }
Compare&Swap(addr,old,new)
Everyone adds 1:
while (true) { old = x new = old +1 if (CAS(mem, old, new)) return }
Josep Torrellas Toward Extreme Scale… 35
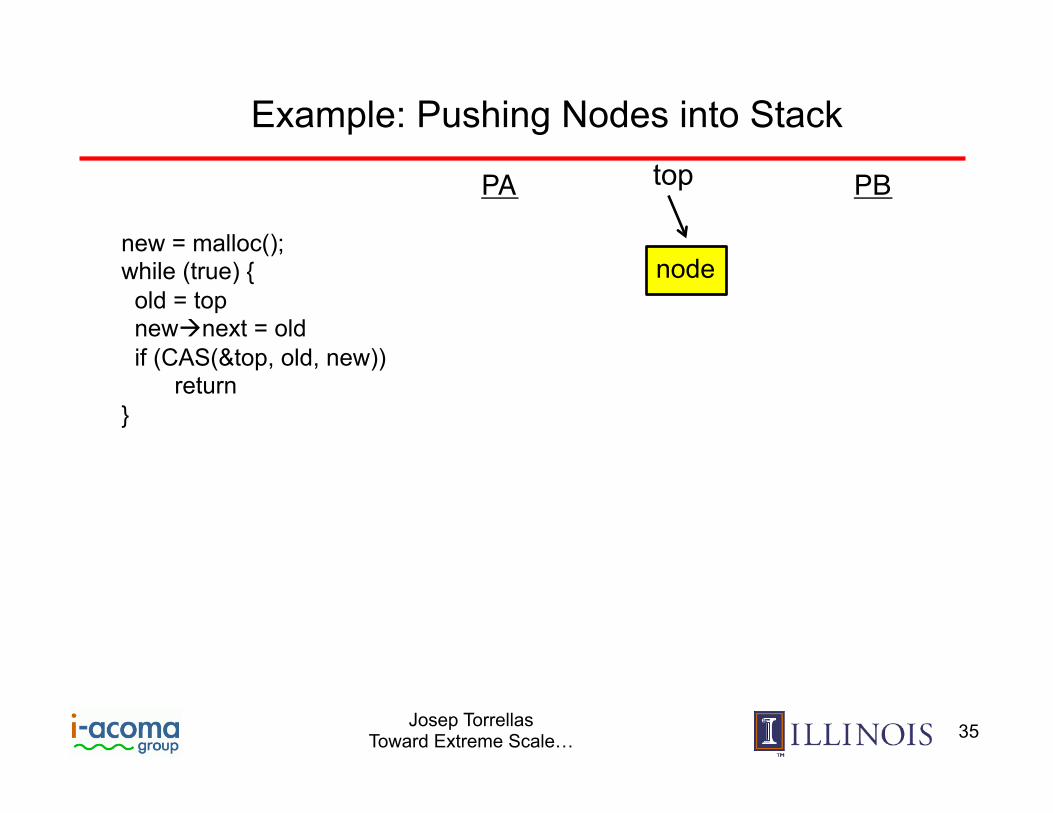
Example: Pushing Nodes into Stack
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
top
node
PA PB

Josep Torrellas Toward Extreme Scale… 36
Example: Pushing Nodes into Stack
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
top
node
PA PBnew
new

Josep Torrellas Toward Extreme Scale… 37
Example: Pushing Nodes into Stack
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
top
node
PA PB
oldA=top
oldB=top
new
new

Josep Torrellas Toward Extreme Scale… 38
Example: Pushing Nodes into Stack
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
top
node
PA PB
oldA=top
oldB=top
node
top
new
new
new
new

Josep Torrellas Toward Extreme Scale… 39
Example: Pushing Nodes into Stack
CAS
failed
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
top
node
PA PB
oldA=top
oldB=top
node
top
node
top
new
new
new
new
new
new

Josep Torrellas Toward Extreme Scale… 40
Problem: Serialization
Tim
e
newA
PA PB PC
newB
newC
ld old CAS
ld old CAS
Waste
Waste
ld old ld old
. . ld old CAS
. .
. .
. .
. .
. .
Our Goal: All processors perform a successful CAS at the same time, in parallel
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
CAS … ld old … CAS …
ld old CAS
. . ld old CAS
. .

Josep Torrellas Toward Extreme Scale…
CASPAR: Main Idea
Two steps: • Queue the “ld old” requests in HW in the directory
– Provides efficient serialization: only one proc attempts the CAS at a time (others remain idle)
– Similar to past work
• Break serialization: Two new ideas: – Eager forwarding – Parallel validation
41

Josep Torrellas Toward Extreme Scale… 42
Directory
Queue “ld old” Requests in HW in Directory
PA PC PB
ldPA ldPB ldPC
PD
ldPD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
Similar to past work….
line CAS

Josep Torrellas Toward Extreme Scale… 43
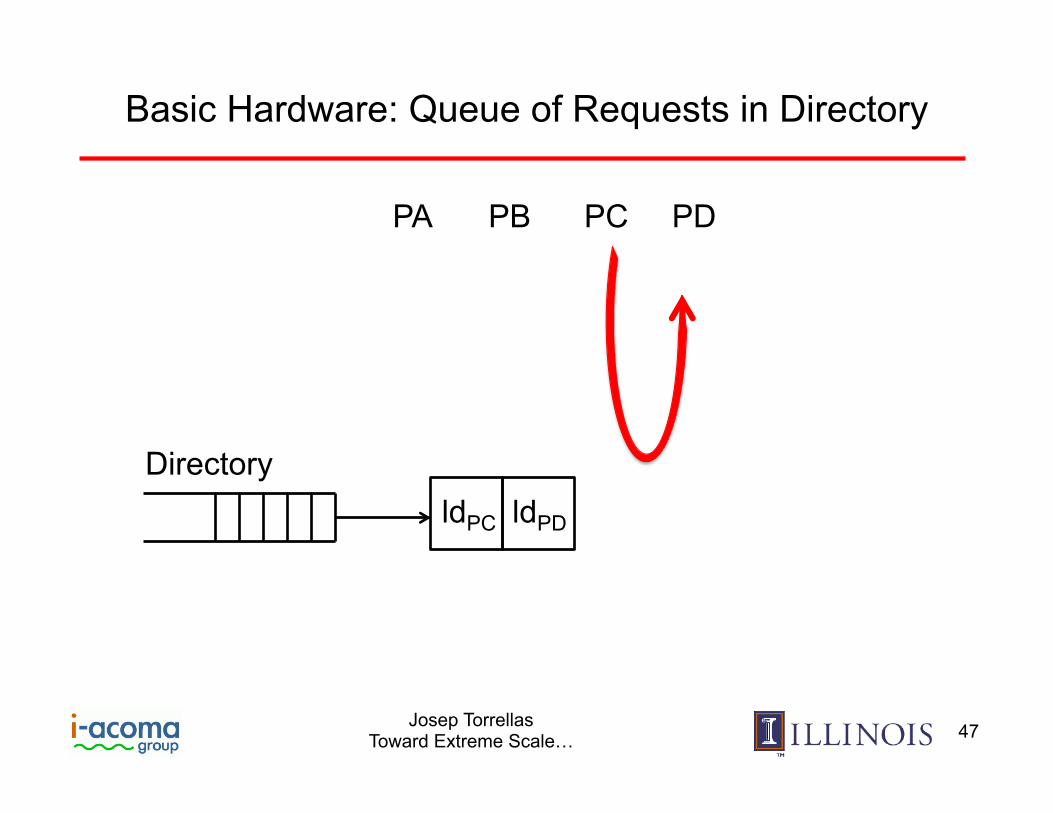
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
ldPA ldPB ldPC
Cache line
PD
ldPD

Josep Torrellas Toward Extreme Scale… 44
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
ldPB ldPC
PD
ldPD
CAS
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }

Josep Torrellas Toward Extreme Scale… 45
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
ldPB ldPC
PD
ldPD

Josep Torrellas Toward Extreme Scale… 46
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
ldPC ldPD
PD CAS
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
Josep Torrellas Toward Extreme Scale… 47
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
ldPC
PD
ldPD

Josep Torrellas Toward Extreme Scale… 48
Directory
Basic Hardware: Queue of Requests in Directory
PA PC PB
Completely serial execution
ldPD
PD CAS
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }

Josep Torrellas Toward Extreme Scale… 49
Breaking Serialization (1): Eager Forwarding
Observation: In a proc,
“new” does not depend on “old”
“new” is ready well before CAS
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
ld old CAS
ld old CAS
Waste
Waste
ld old ld old
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }

Josep Torrellas Toward Extreme Scale… 50
Breaking Serialization (1): Eager Forwarding
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
ld old CAS
ld old CAS
Waste
Waste
ld old ld old
Predecessors: Eagerly forward “new” Successors: * Use “new” to satisfy “ld old” * Perform a successful CAS, * Continue speculatively like TM, no stall
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }

Josep Torrellas Toward Extreme Scale…
Predecessors: Eagerly forward “new” Successors: * Use “new” to satisfy “ld old” * Perform a successful CAS, * Continue speculatively like TM, no stall
51
Breaking Serialization (1): Eager Forwarding
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
ld old ld old CAS
CAS Speculative
execution
Speculative execution
* All CAS succeeded in parallel * All wasted time is eliminated * Execution continues; does not stop * Need a validation step to compare forwarded and real value
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
i1
i2
i3
i4
i1
i2
i3
i4
i5
i5

Josep Torrellas Toward Extreme Scale… 52
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA
ldPA ldPB ldPC
newB newC
line PD
ldPD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }

Josep Torrellas Toward Extreme Scale… 53
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA
ldPA ldPB ldPC
newB newC
line PD
ldPD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return }
All procs decode CAS, find that “new” has been produced, and forward it to the directory in parallel

Josep Torrellas Toward Extreme Scale… 54
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA newB newC
newA
ldPA ldPB ldPC
newB newC
PD
ldPD
newD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } newD

Josep Torrellas Toward Extreme Scale… 55
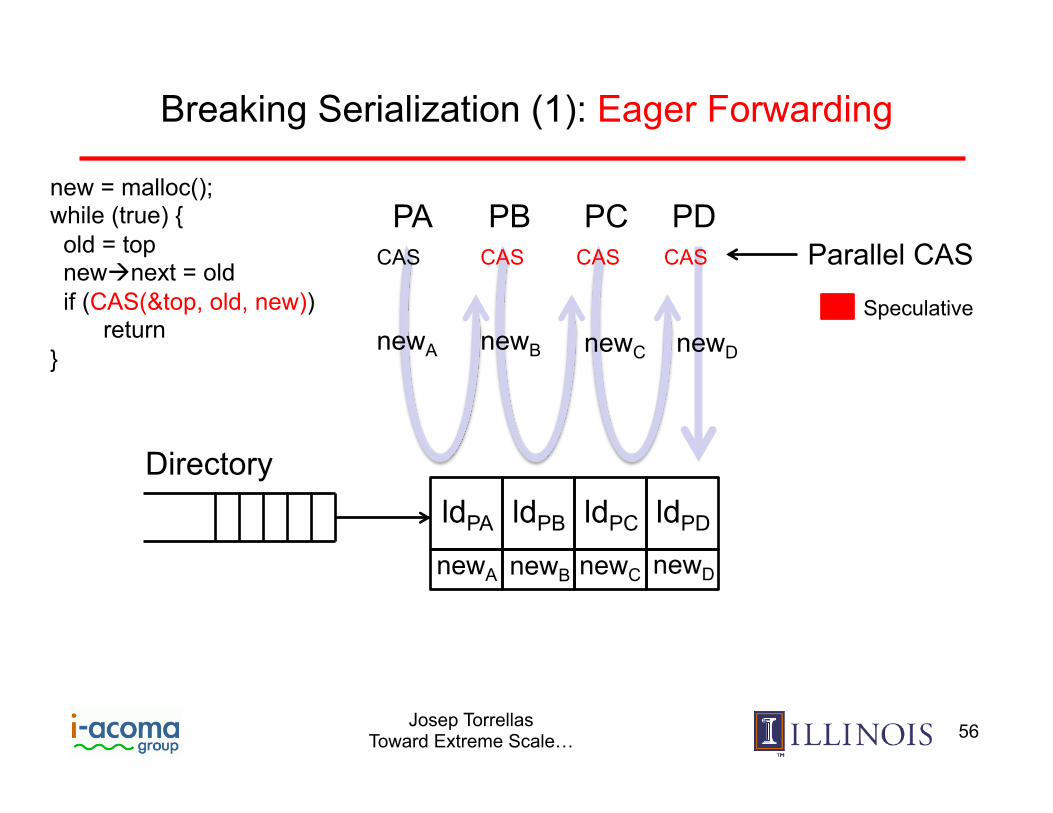
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA newB newC
newA
ldPA ldPB ldPC
newB newC
PD
ldPD
newD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } newD
Proci uses newi-1 as the response to its “ld old” and proceeds speculatively in parallel
Josep Torrellas Toward Extreme Scale… 56
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA newB newC
newA
ldPA ldPB ldPC
newB newC
PD
ldPD
newD
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } newD
CAS CAS CAS Parallel CAS CAS
Speculative
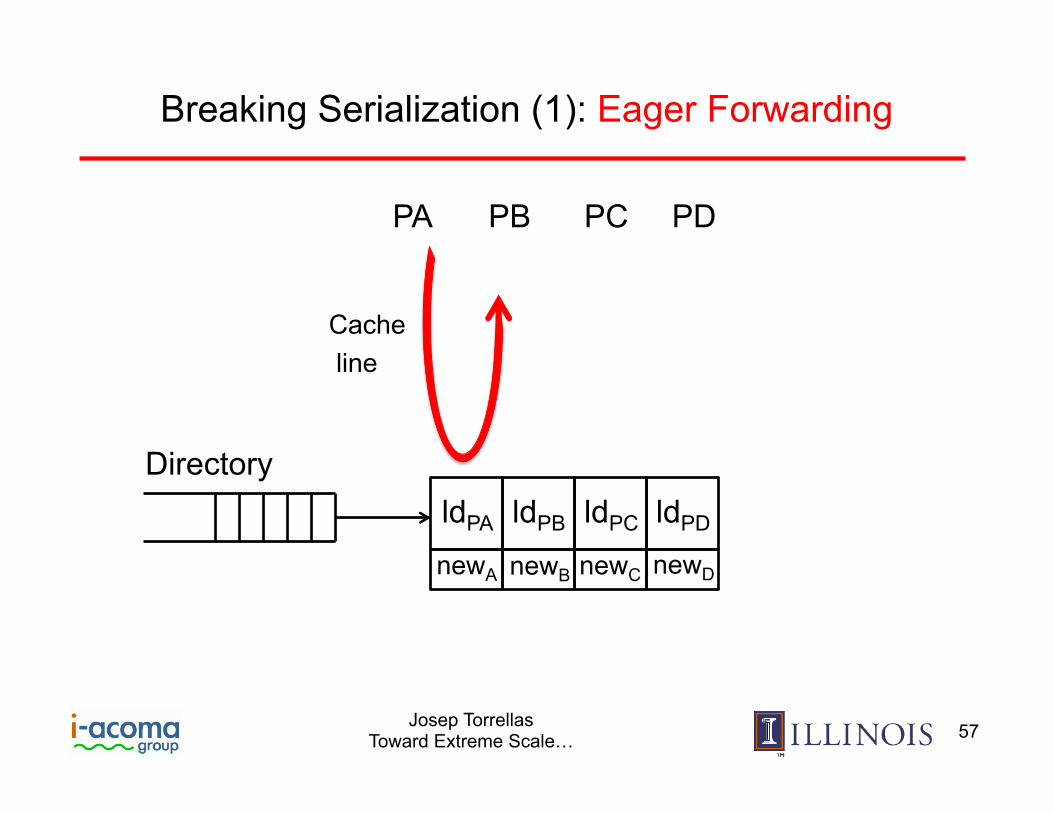
Josep Torrellas Toward Extreme Scale… 57
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newA
ldPA ldPB ldPC
newB newC
Cache line
PD
ldPD
newD

Josep Torrellas Toward Extreme Scale… 58
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newB
ldPB ldPC
newC
Cache line
PD
ldPD
newD
Validate Validate: * Compare the final value of the line to newA forwarded earlier on * Commit speculative execution

Josep Torrellas Toward Extreme Scale… 59
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newB
ldPB
Validate
PD
ldPC
newC
ldPD
newD

Josep Torrellas Toward Extreme Scale… 60
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newC
ldPC
Validate
PD
ldPD
newD

Josep Torrellas Toward Extreme Scale… 61
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newC
ldPC
Validate
PD
ldPD
newD

Josep Torrellas Toward Extreme Scale… 62
Directory
Breaking Serialization (1): Eager Forwarding
PA PC PB
newD
ldPD
Still serial validation
Parallel CAS execution
PD Validate

Josep Torrellas Toward Extreme Scale… 63
Limitation of Eager Forwarding
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } ld old ld old
CAS
CAS Speculative
execution
Speculative execution
i1
i2
i3
i4
i1
i2
i3
i4
i5
i5
Long speculation increases the chances of squashing the threads

Josep Torrellas Toward Extreme Scale… 64
Breaking Serialization (2): Parallel Validation
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } ld old ld old
CAS
CAS Speculative
execution
Speculative execution
i1
i2
i3
i4
i1
i2
i3
i4
i5
i5
Idea: Validate in the directory without ever sending line to cores How: Use newi stored in directory

Josep Torrellas Toward Extreme Scale…
Idea: Validate in the directory without ever sending line to core How: Use newi stored in directory
65
Breaking Serialization (2): Parallel Validation
ld old CAS
Tim
e
newA
PA PB PC
newB
newC
Parallel validation
DIRECTORY
Speculative execution reduced to a minimum Execution does not stop
new = malloc(); while (true) { old = top newànext = old if (CAS(&top, old, new)) return } ld old ld old
CAS
CAS Speculative
execution
Speculative execution
i1
i2
i3
i1
i2
i3

Josep Torrellas Toward Extreme Scale… 66
Directory
Breaking Serialization (2): Parallel Validation
PA PC PB
newA
ldPA ldPB ldPC
newB newC
PD
ldPD
newD
CAS CAS CAS CAS
Speculative
Parallel CAS

Josep Torrellas Toward Extreme Scale… 67
Directory
Breaking Serialization (2): Parallel Validation
PA PC PB
Cache line
PD
newA
ldPA ldPB ldPC
newB newC
ldPD
newD

Josep Torrellas Toward Extreme Scale… 68
Directory
Breaking Serialization (2): Parallel Validation
PA PC PB
newB
ldPB ldPC ldPD
newC newD
PD
Validate & Commit
newB newC
newD
Validate Validate Validate
Parallel CAS execution
Parallel validation

Josep Torrellas Toward Extreme Scale… 69
Summary
• Full parallel synchronization – Parallel successful CAS execution – Parallel validation
• Large speedups for 64-core runs: – Throughput of kernels increases by 80% avg – Execution time of application sections reduces by 60% avg

Josep Torrellas Toward Extreme Scale… 70
Making Synchronization Inexpensive
• WeeFence: Make memory fences free
• CASPAR: Breaking the serialization in lock-free synchronization
• Scalable concurrent priority queues
QueueHead
node
node
node
node

Josep Torrellas Toward Extreme Scale… 71
Today’s Discussion
• Focus: Reducing the cost of basic primitives for parallelism • Flavor of other challenges: energy, programmability
Energy-efficiency Performance
Programmability

Josep Torrellas Toward Extreme Scale… 72
QuickRec: A Prototype of Record and Replay (RnR)
• Finds non-deterministic software bugs and security intrusions
• Built FPGA platform with a Pentium multicore
[ISCA-13]
• HW + OS record all non-deterministic events, so that a parallel program can be replayed deterministically
Josep Torrellas Toward Extreme Scale…
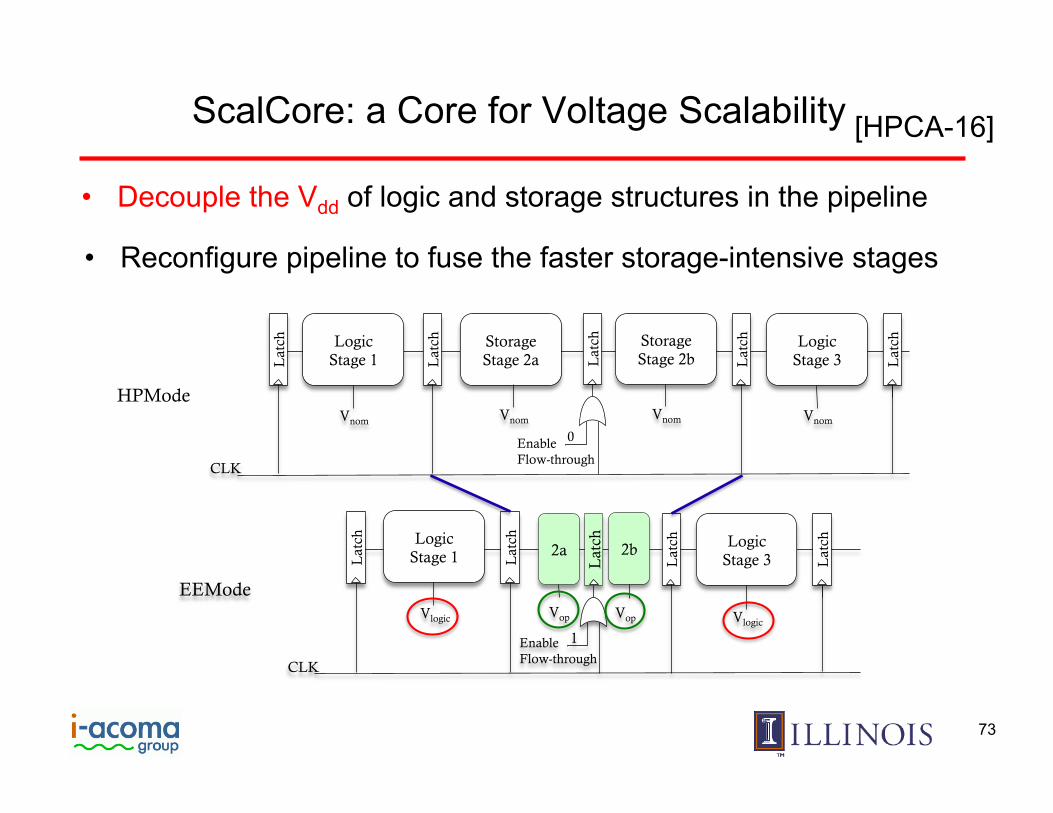
ScalCore: a Core for Voltage Scalability
73
[HPCA-16]
• Decouple the Vdd of logic and storage structures in the pipeline
Enable Flow-through
0
HPMode
Lat
ch
Storage Stage 2a L
atch
Storage Stage 2b L
atch
CLK
Logic Stage 3 L
atch
Logic Stage 1 L
atch
Vnom Vnom Vnom Vnom
Lat
ch
2a
Lat
ch
Lat
ch CLK
Logic Stage 3 L
atch
Logic Stage 1 L
atch
2b
Vlogic Vlogic Vop Vop Enable Flow-through
1
EEMode
• Reconfigure pipeline to fuse the faster storage-intensive stages

Josep Torrellas Toward Extreme Scale…
Control-Theoretic Energy/Performance Controllers
• Design control-theoretic controllers that track multiple outputs while actuating on multiple inputs
BIPS Ref
System Controller BIPS
Power
Outputs (y) Inputs (u)
Power Ref
Cache size Freq
ROB size
[ISCA-16]
• Attains most efficient use of resources to deliver highest performance

Josep Torrellas Toward Extreme Scale… 75
Conclusion
• Lots of room to innovate in computer architecture at this time • Many exciting interdisciplinary venues of research:
– Performance, energy-efficiency & programmability
Non-volatile memory Volatile memory Compute layer Volatile memory
Non-volatile memory
Monolithic architecture
3D-stacked layers

Toward Extreme-Scale Manycore Architectures
Josep Torrellas Department of Computer Science
University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu
USC
October 2016
Related Documents











