Topologie wirtualne Topologia wirtualna: zadany schemat połączeń pomiędzy procesorami; inaczej mówiąc schemat ich wzajemnego sąsiedztwa. W MPI można określić dwa typy topologii: • topologie zdefiniowane przez grafy połączeń między procesorami (przypadek ogólny) • topologie kartezjańskie (siatki) Wyróżnienie topologii siatek jest uzasadnione bardzo częstym ich stosowaniem (rozwiązywanie równań różniczkowych cząstkowych, mnożenie macierzy, itp.) Tworząc wirtualną topologię definiujemy nowy

Topologie wirtualne Topologia wirtualna: zadany schemat połączeń pomiędzy
Dec 30, 2015
Topologie wirtualne Topologia wirtualna: zadany schemat połączeń pomiędzy procesorami; inaczej mówiąc schemat ich wzajemnego sąsiedztwa. W MPI można określić dwa typy topologii: topologie zdefiniowane przez grafy połączeń między procesorami (przypadek ogólny) - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Topologie wirtualne
Topologia wirtualna: zadany schemat połączeń pomiędzyprocesorami; inaczej mówiąc schemat ich wzajemnego sąsiedztwa.
W MPI można określić dwa typy topologii:• topologie zdefiniowane przez grafy połączeń między
procesorami (przypadek ogólny)
• topologie kartezjańskie (siatki)
Wyróżnienie topologii siatek jest uzasadnione bardzo częstym ich stosowaniem (rozwiązywanie równań różniczkowych cząstkowych, mnożenie macierzy, itp.)
Tworząc wirtualną topologię definiujemy nowy komunikator.

Przykład: Schemat komunikacji w układzie 12 procesoróww topologii cylindra (kartezjańskiej z periodycznością w wymiarze poziomym).

Motywacja stosowania topologii wirtualnych: • pozwalają na dopasowanie nazewnictwa
procesorów do schematu komunikacji
• upraszczają strukturę programu i czynią go bardziej czytelnym
• informacja o topologii może pozwolić MPI na dodatkową optymalizację komunikacji przez odpowiednie mapowanie wirtualnej i sprzętowej topologii połączeń
• topologia kartezjanska pozwala na zdefiniowanie n-wymiarowej siatki z periodycznymi lub nie warunkami brzegowymi
Tworzenie topologii wirtualnej (kartezjańskiej)
MPI_CART_CREATE (comm_old, ndims, dims, periods, reorder, comm_cart)
comm_old - wejściowy komunikator ndims - liczba wymiarów siatki dims - tablica z rozmiarami siatki w każdym z wymiarów periods - tablica logiczna określająca warunki brzegowe dla każdego z
wymiarów (periodyczne dla true) reorder - jesli true numercja procesorów może być zmieniona w
tworzonym komunikatorze względem wejściowego komunikatora comm_cart - komunikator o topologii kartezjanskiej powstały w wyniku
wykonania procedury
int MPI_Cart_create (MPI_Comm comm_old, int ndims, int *dims, int *periods, int reorder, MPI_Comm *comm_cart)
MPI_CART_CREATE (COMM_OLD, NDIMS, DIMS, PERIODS, REORDER, COMM_CART,IERROR)
INTEGER COMM_OLD, COMM_CART, NDIMS, DIMS(*), PERIODS(*)LOGICAL REORDER, PERIODS(*)
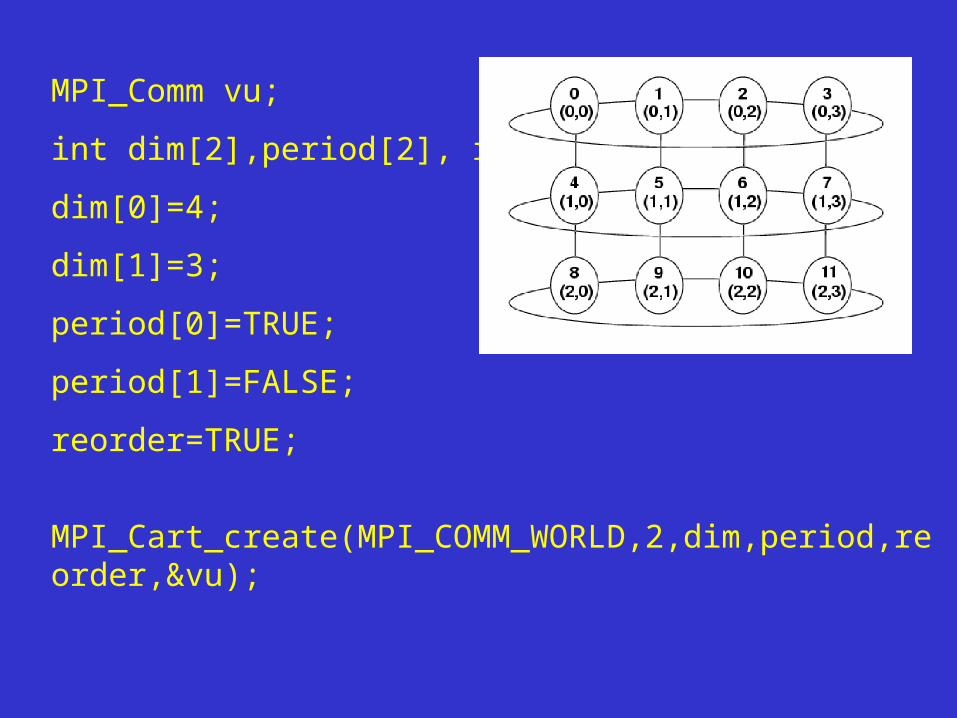
MPI_Comm vu;
int dim[2],period[2], reorder;
dim[0]=4;
dim[1]=3;
period[0]=TRUE;
period[1]=FALSE;
reorder=TRUE;
MPI_Cart_create(MPI_COMM_WORLD,2,dim,period,reorder,&vu);

Ogólnie (tworzenie topologii zdefiniowanej przez dowolny graf):
MPI_GRAPH_CREATE(comm_old, nnodes, index, edges, reorder, comm_graph)
nnodes - liczba wierzchołków grafuindex - tablica (liczb całkowitych) określająca liczbę dotychczas określonych połączeń pomiędzy wierzchołkamiedges - tablica (liczb całkowitych) określająca połączenia w grafie
#sąsiedzi
0 1,21 02 0,33 2
nnodes=4
index=2,3,5,6
edges=1,2,0,0,3,2

Ogólnie (tworzenie topologii zdefiniowanej przez dowolny graf) c.d.
w C index[0] zawiera liczbę połączeń procesu 0 index[i-1] zawiera ilość połączeń procesu iedges[j] dla 0 ≤ j ≤ index[0]-1 zawiera listę połączeń procesu 0edges[j] dla index[i-1] ≤ j ≤ index[i]-1 lista połączeń procesu i>0
w Fortranie index(1) zawiera liczbę połączeń procesu 0 index(i+1)- index(i) zawiera ilość połączeń procesu iedges(j) dla 1 ≤ j ≤ index(1) zawiera listę połączeń procesu 0edges(j) dla index(i)+1 ≤ j ≤ index(i+1) lista połączeń procesu i>0

Funkcje określające parametry topologii kartezjańskiej
Określanie wymiarowości:
MPI_CARTDIM_GET(comm, ndims) comm - komunikator z określoną strukturą kartezjańską ndims - wymiarowość struktury kartezjańskiej
int MPI_Cartdim_get(MPI_Comm comm, int *ndims)
MPI_CARTDIM_GET(COMM, NDIMS, IERROR)INTEGER COMM, NDIMS, IERROR
Określanie współrzędnych kartezjańskich danego procesora
MPI_CART_GET(comm, maxdims, dims, periods, coords)
comm – komunikator z określoną strukturą kartezjańską maxdims – wymiar przestrzeni kartezjańskiejdims – tablica liczb procesorów wzdłuż poszczególnych współrzędnych
periods – okresowość (tablica logiczna)
coords – współrzędne kartezjańskie procesora wołającego procedurę int MPI_Cart_get(MPI_Comm comm, int maxdims, int *dims, int *periods, int *coords)
MPI_CART_GET(COMM, MAXDIMS, DIMS, PERIODS, COORDS, IERROR)INTEGER COMM, MAXDIMS, DIMS(*), COORDS(*), IERROR LOGICAL PERIODS(*)

Określanie współrzędnych kartezjańskich procesora o danym rzędzie
MPI_CART_COORDS(comm, rank, maxdims, coords)
comm - komunikatorrank - rząd procesora maxdims - długość wektora coord coords - tablica całkowita zawierająca współrzędne kartezjańskie danego procesora
int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims, int *coords)
MPI_CART_COORDS(COMM, RANK, MAXDIMS, COORDS, IERROR)
INTEGER COMM, RANK, MAXDIMS, COORDS(*), IERROR

Określanie rzędu procesora odpowiadającego danym współrzędnym kartezjańskim
MPI_CART_RANK(comm, coords, rank)
comm - komunikator communicator coords - tablica współrzędnych danego procesorarank - rząd procesora (zwracany przez procedurę)
int MPI_Cart_rank(MPI_Comm comm, int *coords, int *rank)
MPI_CART_RANK(COMM, COORDS, RANK, IERROR)
INTEGER COMM, COORDS(*), RANK, IERROR

Znajdowanie sąsiadów danego procesora wzdłuż danej współrzędnej
MPI_CART_SHIFT(comm, direction, disp, rank_source, rank_dest)
comm - komunikatordirection - wymiar współrzędnej disp - przesunięcie (> 0: w górę,< 0: w dół) rank_source - rząd sąsiada poprzedniego w kierunku disp (procesu źródłowego) rank_dest - rząd sąsiada następnego w kierunku disp (procesu celowego) int MPI_Cart_shift(MPI_Comm comm, int direction, int disp, int *rank_source, int *rank_dest) MPI_CART_SHIFT(COMM, DIRECTION, DISP, RANK_SOURCE, RANK_DEST, IERROR)INTEGER COMM, DIRECTION, DISP, RANK_SOURCE, RANK_DEST, IERROR

Utworzenie nowego komunikatora z wybranych współrzędnych
MPI_CART_SUB(comm, remain, new_comm)
comm – komunikator o zdefiniowanej topologii kartezjańskiejremain – tablica logiczna z wartościa true dla tych wymiarów ktore
zostaną skopiowane new_comm - nowy komunikator zawierający wybrane wymiary wejściowej
topologii
int MPI_Cart_sub (MPI_Comm comm, int *remain, MPI_Comm *new_comm ) MPI_CART_SHIFT (COMM,REMAIN,NEW_COMM, IERROR) INTEGER COMM, COMM,REMAIN(*),NEW_COMM, IERROR

Przesuniecie każdej kolumny tablicy rozposzonej w topologii torusa 3x4
INTEGER comm_2d, rank, coords(2), ierr, source, dest INTEGER status(MPI_STATUS_SIZE), dims(2) LOGICAL reorder, periods(2)REAL a, b CALL MPI_COMM_SIZE(MPI_COMM_WORLD, isize, ierr) IF (isize.LT.12) CALL MPI_ABORT(MPI_COMM_WORLD, ERR, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
a = rank b = -1dims(1) = 3 dims(2) = 4 periods(1) = .TRUE. periods(2) = .TRUE.reorder = .TRUE.
CALL MPI_CART_CREATE(MPI_COMM_WORLD, 2, dims, periods, reorder, comm_2d, ierr) CALL MPI_CART_COORDS(comm_2d, rank, 2, coords, ierr) CALL MPI_CART_SHIFT(comm_2d, 0, coords(2), source, dest, ierr)CALL MPI_SENDRECV(a, 1, MPI_REAL, dest, 13, b, 1, MPI_REAL, source, 13, comm_2d, status, ierr)

Przykład zastosowania topologii wirtualnych: równoległy algorytm metody Jacobiego rozwiązywania zagadanienia brzegowego dla eliptycznych równań różniczkowych cząstkowych

Sformułowanie problemu
2
2
2
22
2
y)g(x,y)u(x,
),(
y
u
x
uu
yxfu
wewnątrz obszaru,
na granicy obszaru.

2
2
22
2
22
2
,4,,,,
,2,,
,2,,
h
yxuhyxuhyxuyhxuyhxuu
h
yxuhyxuhyxu
y
u
h
yxuyhxuyhxu
x
u
Dyskretyzacja zagadnienia

Dyskretyzacja zagadnienia na siatce prostokątnej
ij2ij1j,ij,1i1j,ij,1i f
h
u4uuuu
nx
nyx=i/nx
y=j/ny
fij – wartość funkcji stojącej po prawej stronie równania w węźle (i,j)
uij – wartość rozwiązania w węźle (i,j)
Założenia zadania:
fij=0 dla każdego i,j
u0i=1, ui0=1
uny+1,0=0, u0,nx+1=0

Rozwiązanie numeryczne metodą iteracji Jacobiego
toluu until
fhuuuu4
1u
repeat
)k()1k(
ij2)k(
1j,i)k(
j,1i)k(1j,i
)k(1j,i
)1k(ij

Kod szeregowy iteracji Jacobiego: część podstawowa
C Pętla główna DO WHILE(.NOT.converged) C Obliczanie nowego przybliżenia U DO j=1, n DO i=1, n UNEW(i,j)=0.25*(U(i-1,j)+U(i+1,j)+U(i,j-1)+U(i,j+1)- & H*H*F(I,J)) ENDDO ENDDO C Kopiujemy nowe przybliżenie do macierzy U DO j=1, n DO i=1, n U(i,j) = UNEW(i,j) ENDDO ENDDO ... C Test zbieżności (kod wycięty z braku miejsca) ENDDO

Przykładowy podział punktów siatki pomiędzy procesory dla 9 warstw i 3 procesorów
nx
ny

Do obliczenia elementów tablicy u leżących na granicy podziału, procesor o 1 będzie potrzebował elementów u z pierwszego rzędu przypisanego procesorowi 2 oraz ostatniego rzędu przypisanego procesorowi 0.Podobnie, procesory 0 i 2 będą potrzebowały od procesora 1 elementów z odpowiednio pierwszego i ostatniego rzędu jemu przypisanych.
Projektowanie komunikacji
nx
ny
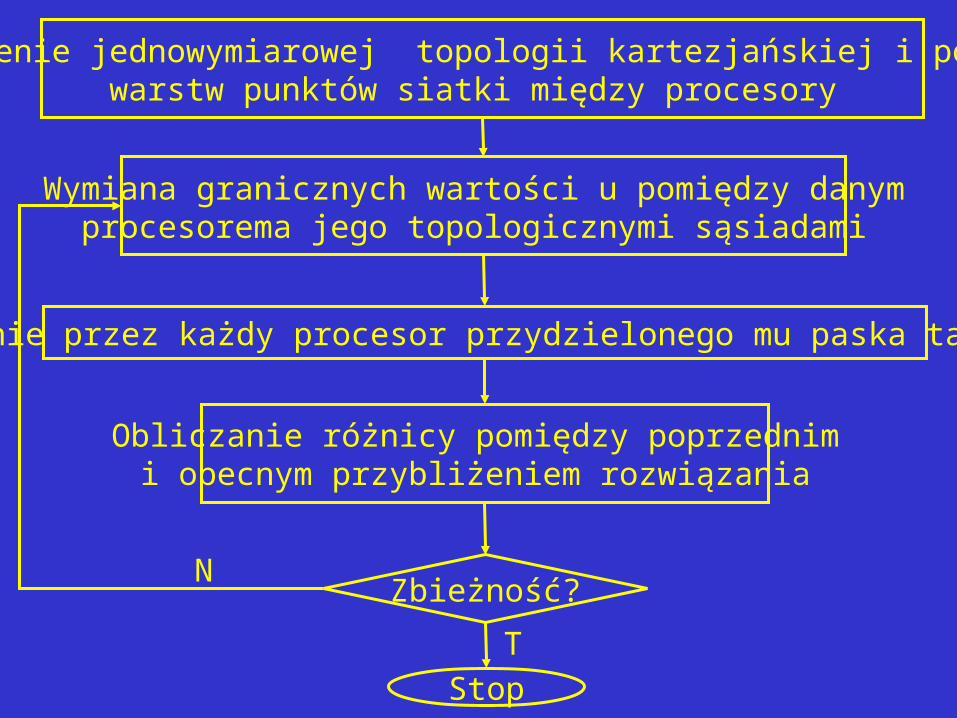
Tworzenie jednowymiarowej topologii kartezjańskiej i podziałwarstw punktów siatki między procesory
Wymiana granicznych wartości u pomiędzy danym procesorema jego topologicznymi sąsiadami
Obliczanie przez każdy procesor przydzielonego mu paska tablicy u
Obliczanie różnicy pomiędzy poprzednim i obecnym przybliżeniem rozwiązania
Zbieżność?N
Stop
T
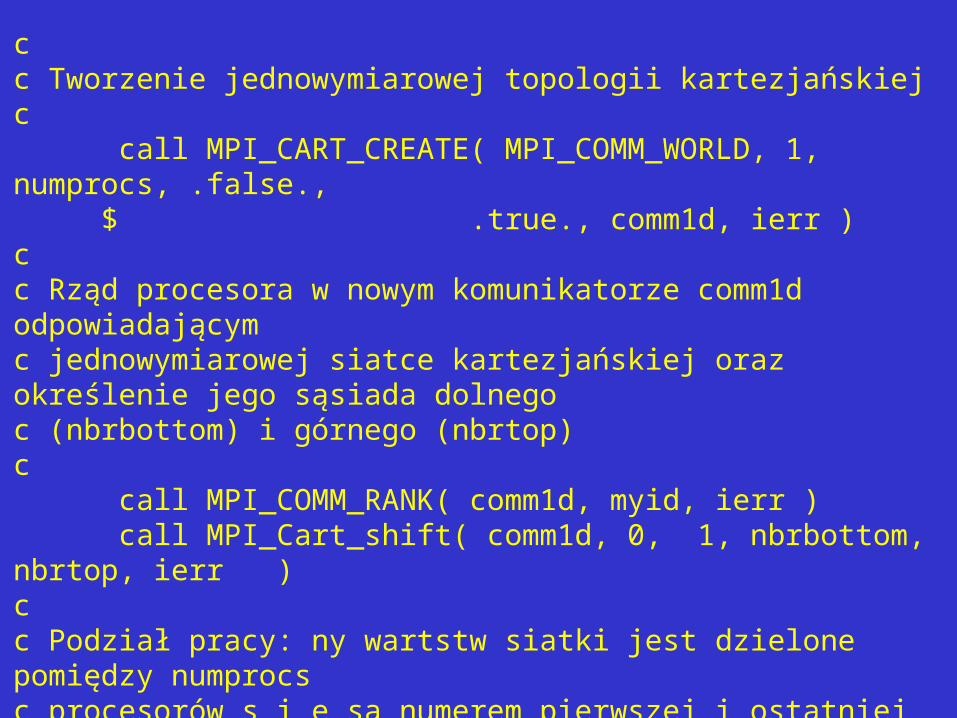
cc Tworzenie jednowymiarowej topologii kartezjańskiejc call MPI_CART_CREATE( MPI_COMM_WORLD, 1, numprocs, .false., $ .true., comm1d, ierr )cc Rząd procesora w nowym komunikatorze comm1d odpowiadającymc jednowymiarowej siatce kartezjańskiej oraz określenie jego sąsiada dolnegoc (nbrbottom) i górnego (nbrtop)c call MPI_COMM_RANK( comm1d, myid, ierr ) call MPI_Cart_shift( comm1d, 0, 1, nbrbottom, nbrtop, ierr )cc Podział pracy: ny wartstw siatki jest dzielone pomiędzy numprocs c procesorów s i e są numerem pierwszej i ostatniej warstwy obsługiwanej c przez dany procesor.c call MPE_DECOMP1D( ny, numprocs, myid, s, e )
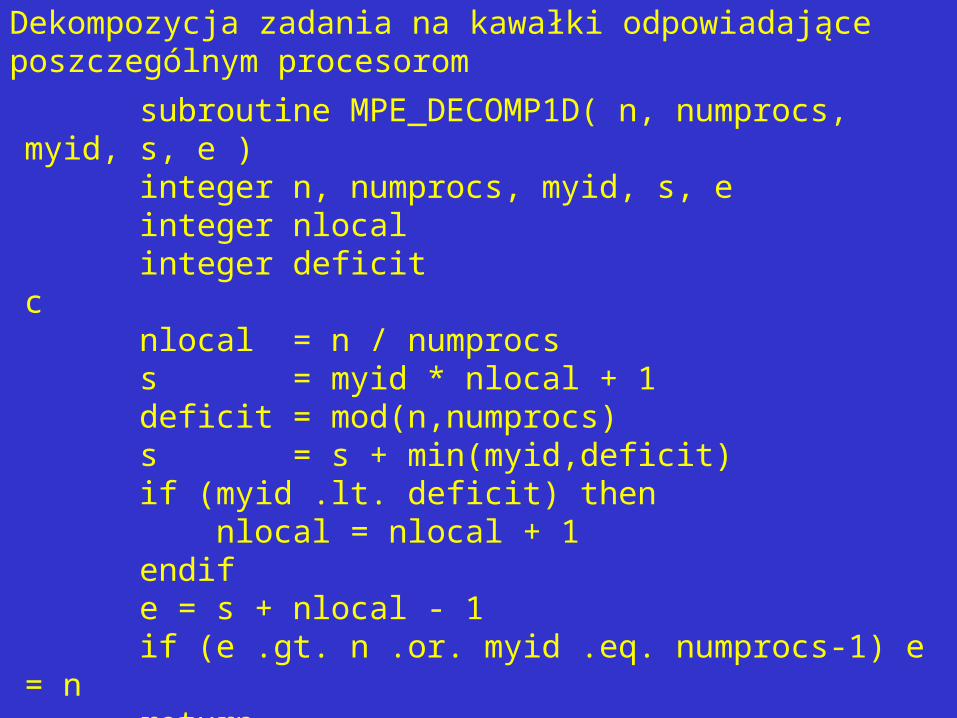
subroutine MPE_DECOMP1D( n, numprocs, myid, s, e ) integer n, numprocs, myid, s, e integer nlocal integer deficitc nlocal = n / numprocs s = myid * nlocal + 1 deficit = mod(n,numprocs) s = s + min(myid,deficit) if (myid .lt. deficit) then nlocal = nlocal + 1 endif e = s + nlocal - 1 if (e .gt. n .or. myid .eq. numprocs-1) e = n return end
Dekompozycja zadania na kawałki odpowiadające poszczególnym procesorom
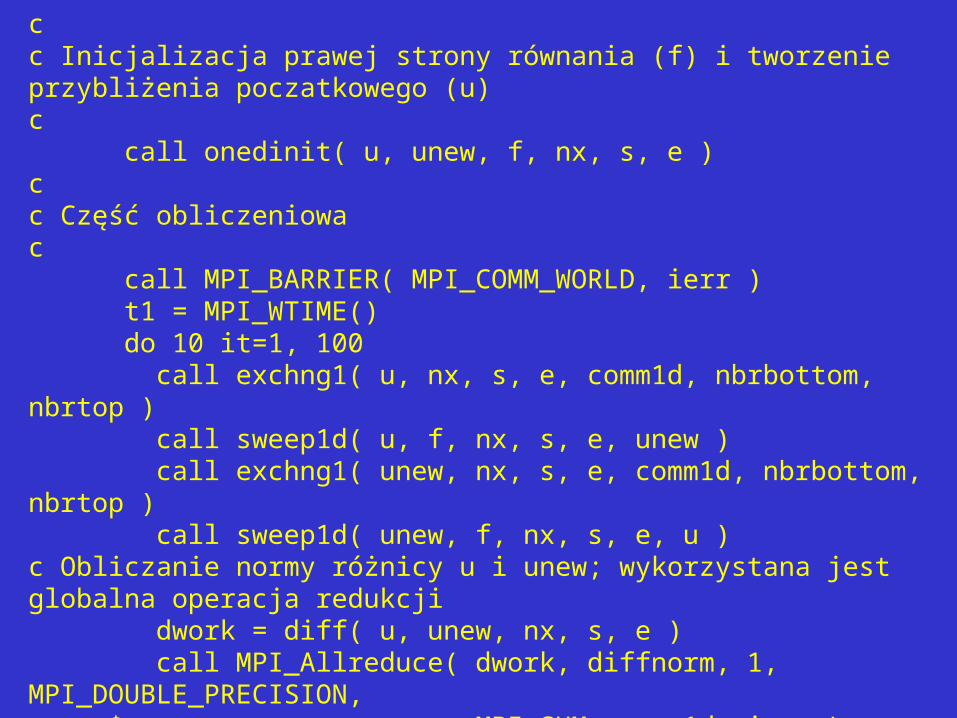
cc Inicjalizacja prawej strony równania (f) i tworzenie przybliżenia poczatkowego (u)c call onedinit( u, unew, f, nx, s, e )cc Część obliczeniowac call MPI_BARRIER( MPI_COMM_WORLD, ierr ) t1 = MPI_WTIME() do 10 it=1, 100 call exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) call sweep1d( u, f, nx, s, e, unew ) call exchng1( unew, nx, s, e, comm1d, nbrbottom, nbrtop ) call sweep1d( unew, f, nx, s, e, u )c Obliczanie normy różnicy u i unew; wykorzystana jest globalna operacja redukcji dwork = diff( u, unew, nx, s, e ) call MPI_Allreduce( dwork, diffnorm, 1, MPI_DOUBLE_PRECISION, $ MPI_SUM, comm1d, ierr ) if (diffnorm .lt. 1.0e-5) goto 2010 continue if (myid .eq. 0) print *, 'Failed to converge'20 continue

Kod iteracji Jacobiego dla warstwy punktów siatki przypisanej danemu procesorowic c Perform a Jacobi sweep for a 1-d decomposition. c Sweep from u into unew c subroutine sweep1d( u, f, nx, s, e, unew ) integer nx, s, e double precision u(0:nx+1,s-1:e+1), f(0:nx+1,s-1:e+1), unew(0:nx+1,s-1:e+1) c integer i, j double precision h c h = 1.0d0 / dble(nx+1) do 10 j=s, e do 10 i=1, nx unew(i,j) = 0.25 * (u(i-1,j)+u(i,j+1)+u(i,j-1) + u(i+1,j) - h * h * f(i,j) ) 10 continue return
end
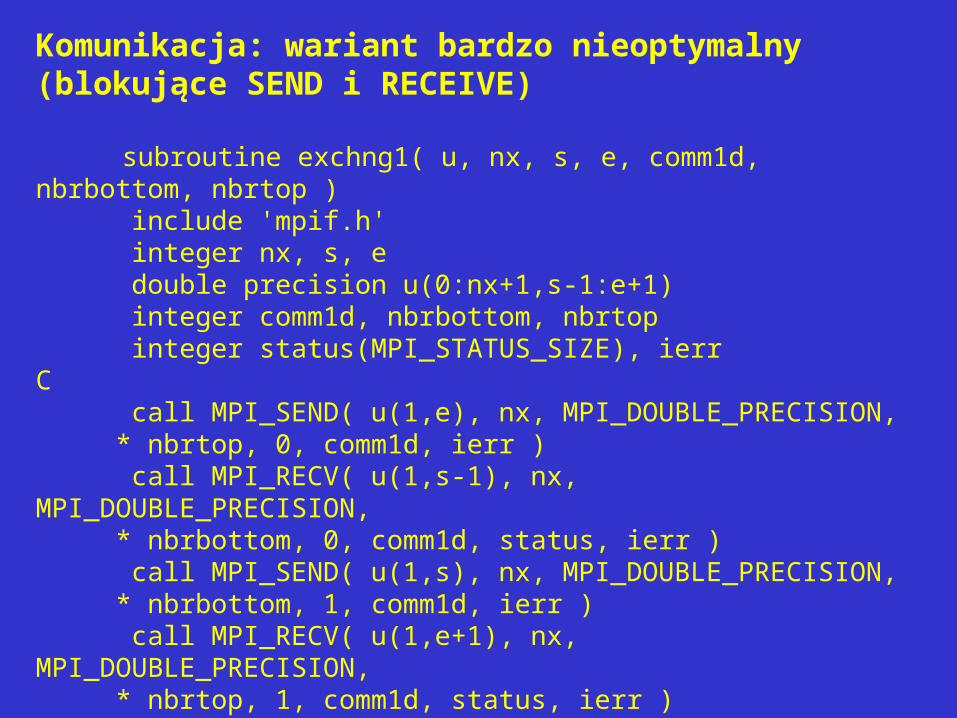
Komunikacja: wariant bardzo nieoptymalny (blokujące SEND i RECEIVE) subroutine exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) include 'mpif.h' integer nx, s, e double precision u(0:nx+1,s-1:e+1) integer comm1d, nbrbottom, nbrtop integer status(MPI_STATUS_SIZE), ierr C call MPI_SEND( u(1,e), nx, MPI_DOUBLE_PRECISION, * nbrtop, 0, comm1d, ierr ) call MPI_RECV( u(1,s-1), nx, MPI_DOUBLE_PRECISION, * nbrbottom, 0, comm1d, status, ierr ) call MPI_SEND( u(1,s), nx, MPI_DOUBLE_PRECISION, * nbrbottom, 1, comm1d, ierr ) call MPI_RECV( u(1,e+1), nx, MPI_DOUBLE_PRECISION, * nbrtop, 1, comm1d, status, ierr ) return end

Takie postępowanie daje poprawny kod ale procesor P0 może wymienić dane z P1 dopiero wtedy, gdy wszystkie następne wymienią dane.
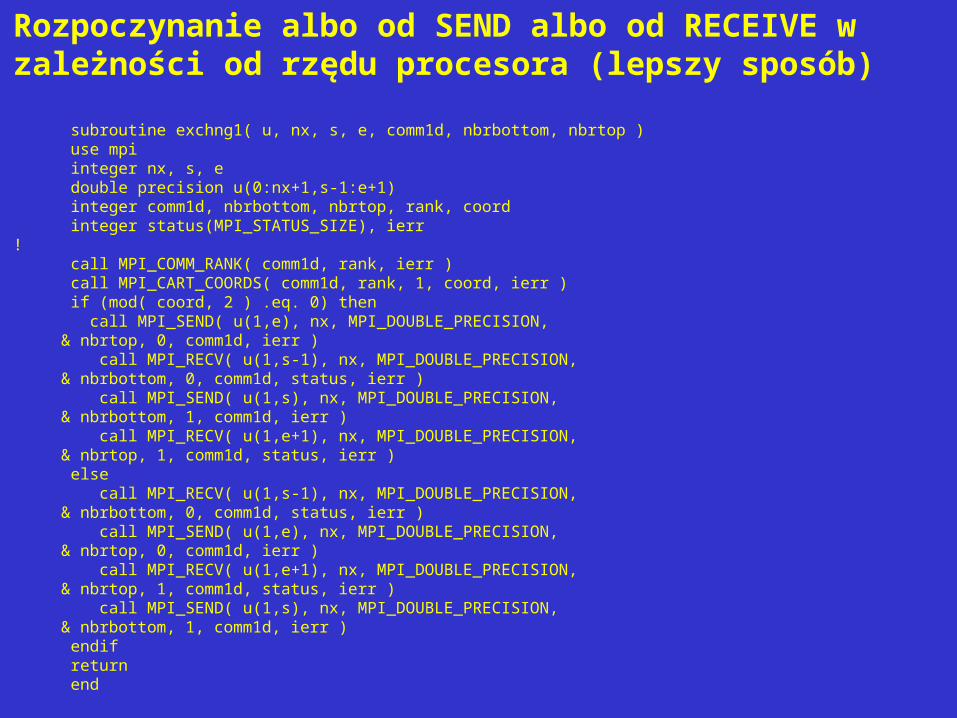
Rozpoczynanie albo od SEND albo od RECEIVE w zależności od rzędu procesora (lepszy sposób)
subroutine exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) use mpi integer nx, s, e double precision u(0:nx+1,s-1:e+1) integer comm1d, nbrbottom, nbrtop, rank, coord integer status(MPI_STATUS_SIZE), ierr ! call MPI_COMM_RANK( comm1d, rank, ierr ) call MPI_CART_COORDS( comm1d, rank, 1, coord, ierr ) if (mod( coord, 2 ) .eq. 0) then call MPI_SEND( u(1,e), nx, MPI_DOUBLE_PRECISION, & nbrtop, 0, comm1d, ierr ) call MPI_RECV( u(1,s-1), nx, MPI_DOUBLE_PRECISION, & nbrbottom, 0, comm1d, status, ierr ) call MPI_SEND( u(1,s), nx, MPI_DOUBLE_PRECISION, & nbrbottom, 1, comm1d, ierr ) call MPI_RECV( u(1,e+1), nx, MPI_DOUBLE_PRECISION, & nbrtop, 1, comm1d, status, ierr ) else call MPI_RECV( u(1,s-1), nx, MPI_DOUBLE_PRECISION, & nbrbottom, 0, comm1d, status, ierr ) call MPI_SEND( u(1,e), nx, MPI_DOUBLE_PRECISION, & nbrtop, 0, comm1d, ierr ) call MPI_RECV( u(1,e+1), nx, MPI_DOUBLE_PRECISION, & nbrtop, 1, comm1d, status, ierr ) call MPI_SEND( u(1,s), nx, MPI_DOUBLE_PRECISION, & nbrbottom, 1, comm1d, ierr ) endif return end

Wykorzystanie procedury MPI_Sendrecv: proste i prawie optymalne
subroutine exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) include 'mpif.h' integer nx, s, e double precision u(0:nx+1,s-1:e+1) integer comm1d, nbrbottom, nbrtop integer status(MPI_STATUS_SIZE), ierr c call MPI_SENDRECV(u(1,e), nx, MPI_DOUBLE_PRECISION, nbrtop, 0, & u(1,s-1), nx, MPI_DOUBLE_PRECISION, nbrbottom, 0, comm1d, status, ierr ) call MPI_SENDRECV(u(1,s), nx, MPI_DOUBLE_PRECISION, nbrbottom, 1, & u(1,e+1), nx, MPI_DOUBLE_PRECISION, nbrtop, 1, comm1d, status, ierr ) return end

Używanie buforowanego SEND
subroutine exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) use mpi integer nx, s, e double precision u(0:nx+1,s-1:e+1) integer comm1d, nbrbottom, nbrtop integer status(MPI_STATUS_SIZE), ierr call MPI_BSEND( u(1,e), nx, MPI_DOUBLE_PRECISION, nbrtop, 0, comm1d, ierr ) call MPI_RECV( u(1,s-1), nx, MPI_DOUBLE_PRECISION, nbrbottom, & 0, comm1d, status, ierr ) call MPI_BSEND( u(1,s), nx, MPI_DOUBLE_PRECISION, nbrbottom, & 1, comm1d, ierr ) call MPI_RECV( u(1,e+1), nx, MPI_DOUBLE_PRECISION, nbrtop, & 1, comm1d, status, ierr ) return end

Połączenie nieblokowanego SEND z WAITALL
subroutine exchng1( u, nx, s, e, comm1d, nbrbottom, nbrtop ) include 'mpif.h' integer nx, s, e double precision u(0:nx+1,s-1:e+1) integer comm1d, nbrbottom, nbrtop integer status_array(MPI_STATUS_SIZE,4), ierr, req(4) C call MPI_IRECV (u(1,s-1), nx, MPI_DOUBLE_PRECISION, nbrbottom, 0, * comm1d, req(1), ierr ) call MPI_IRECV (u(1,e+1), nx, MPI_DOUBLE_PRECISION, nbrtop, 1, * comm1d, req(2), ierr ) call MPI_ISEND (u(1,e), nx, MPI_DOUBLE_PRECISION, nbrtop, 0, * comm1d, req(3), ierr ) call MPI_ISEND (u(1,s), nx, MPI_DOUBLE_PRECISION, nbrbottom, 1, * comm1d, req(4), ierr ) C call MPI_WAITALL ( 4, req, status_array, ierr ) return end

Liczba proceso-rów
Blokujące send
Uporządkowane send
sendrecv Buforowane send
Nieblokujące send
1 5.38 5.54 5.54 5.38 5.40
2 2.77 2.88 2.91 2.75 2.77
4 1.58 1.56 1.57 1.50 1.51
8 1.15 0.947 0.931 0.854 0.849
16 1.18 0.574 0.534 0.521 0.545
32 1.94 0.443 0.451 0.452 0.397
64 3.73 0.447 0.391 0.362 0.391
Porównanie czasów wykonania równoległego kodu iteracji Jacobiego dla zagadnienia Poissona dla różnych wariantów komunikacji

Link do kompletnego zestawu składowych programów równoległych rozwiązywania zagadnienia Poissona przy założeniu topologii jedno- i dwuwymiarowej
Related Documents











