CIS 890 – Information Retrieval Project Final Presentation Topics Modelling with LDA Collocations on NIPS Collection Presenter: Svitlana Volkova Instructor: Doina Caragea

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CIS 890 – Information Retrieval
Project Final Presentation
Topics Modelling with LDA
Collocations on NIPS
Collection
Presenter: Svitlana Volkova
Instructor: Doina Caragea

#
Agenda
I. Introduction
II. Project Stages
III. Topics Modeling
LDA Model
HMMLDA Model
LDA-COL Model
IV. NIPS Collection
V. Experimental Results
VI. Conclusions

#
I. Project Overview

#
Generative vs. Discriminative
Methods
Generative approaches produce a probability density model over all variables in a system and
manipulate it to compute classification and regression functions
Discriminative approaches provide a direct attempt to compute the input to output
mappings

#
From LSI -> to pLSA -> to LDA
• [Sal83] Gerard Salton and Michael J. McGill.
Introduction to Modern Information Retrieval.
McGraw-Hill, Inc., New York, NY, USA, 1983.
[Dee90] S. Deerwester, S. Dumais, T.
Landauer, G. Furnas, and R. Harshman.
Indexing by latent semantic analysis. Journal
of the American Society of Information
Science, 41(6):391-407, 1990.
• [Hof99] T. Hofmann. Probabilistic latent
semantic indexing. Proceedings of the
Twenty-Second Annual International SIGIR
Conference, 1999.
• [Ble03] Blei, D.M., Ng, A.Y., Jordan, M.I.
Latent Dirichlet allocation, Journal of Machine
Learning Research, 3, pp.993-1022, 2003.
TF-IDF
Salton and McGill (Sal„83)
Latent Semantic Indexing (LSI)
Deerwester et. al.(Dee„90)
Probabilistic Latent Semantic Indexing
Hofmann(Hof„99)
Latent Dirichlet Allocation (LDA)
Blei et. al.(Ble„03)
polysemy/synonymy -> probability -> exchangeability

#
Topic Models: LDA
#
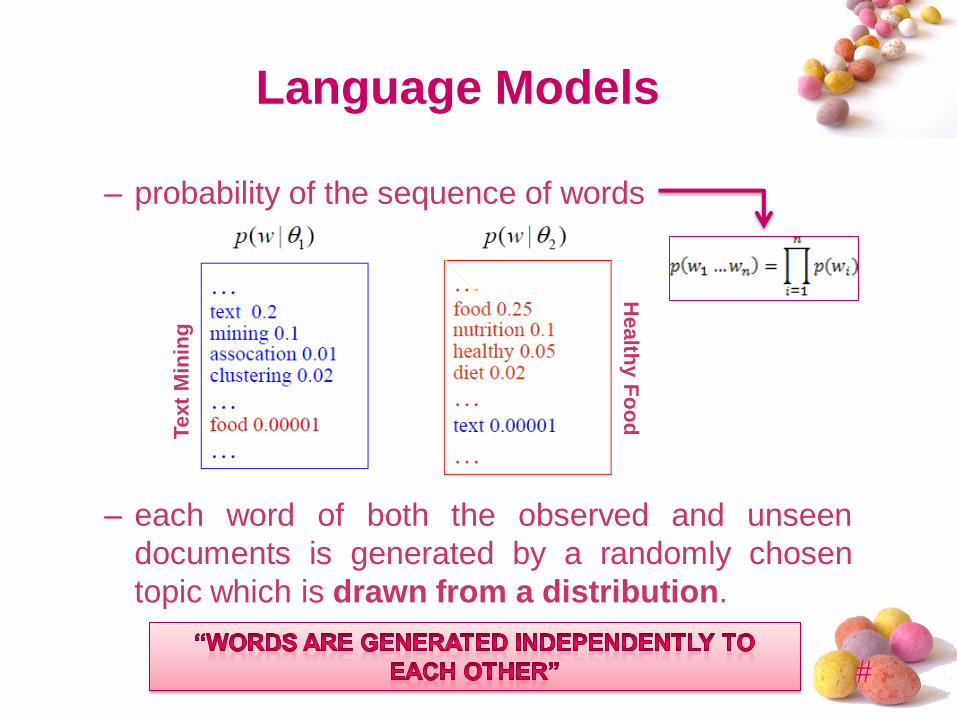
Language Models
– probability of the sequence of words
– each word of both the observed and unseen
documents is generated by a randomly chosen
topic which is drawn from a distribution.
Health
y F
oo
d
Text
Min
ing

#
Disadvantages of “Bag of word”
Assumption
• TEXT ≠ sequence of discrete word tokens
• The actual meaning can not be captured by words co-
occurrences only
• Word order is not important for syntax, but it is important
for lexical meaning
• Words order within “near by” context and phrases is
critical to capturing meaning of text

#
Problem Statement

#
Collocations = word phrases?
• Noun phrases:
– “strong tea”, “weapon of mass destruction”
• Phrasal verbs:
– “make up” = ?
• Other phrases:
– “rich and powerful”
• Collocation is a phrase with meaning beyond
the individual words (e.g. “white house”)
[Man’99] Manning, C., & Schutze, H. Foundations of statistical natural
language processing. Cambridge, MA: MIT Press, 1999.

#
Problem Statement
– How “Information Retrieval” Topic can be represented?
– What about “Artificial Intelligence”?
– Issues with using unigrams for topics modeling:
• Not enough representative for single topic
• Ambiguous (concepts sharing)
– system, modeling, information, data, structure…
Unigrams -> …, information, search, …, web
Unigrams -> agent, …, information, search, …

#
II. Project Stages

#
Project Stages
1. NIPS Data Collection and Preprocessing
http://books.nips.cc/
2. Learning topics models on NIPS collection
http://psiexp.ss.uci.edu/research/programs_data/
toolbox.htm
- Model 1: LDA
- Model 2: HMMLDA
- Model 3: LDA-COL
3. Results Comparison for LDA, LDA-COL,
HMMLDA and N-grams

#
NLP
Information Retrieval: 2
Natural Language Processing: 8
Active Learning (AL)
Cognitive Science: 1
Artificial Intelligence (AI)
Cognitive Science: 3
Object Recognition: 1
Information Retrieval: 2
Natural Language Processing: 6
Computer Vision
Object Recognition: 2
Visual Perception: 1
Information Retrieval (IR)
Information Retrieval: 35
Machine Learning (ML)
Object Recognition: 1
Natural Language Processing: 1
What are the limitations of using
wiki concepts?
Wiki Concept Graph
Follow links
N-grams distribution on the document is small
What level of concepts‟ abstraction

#
III. Topic Models: LDA
#
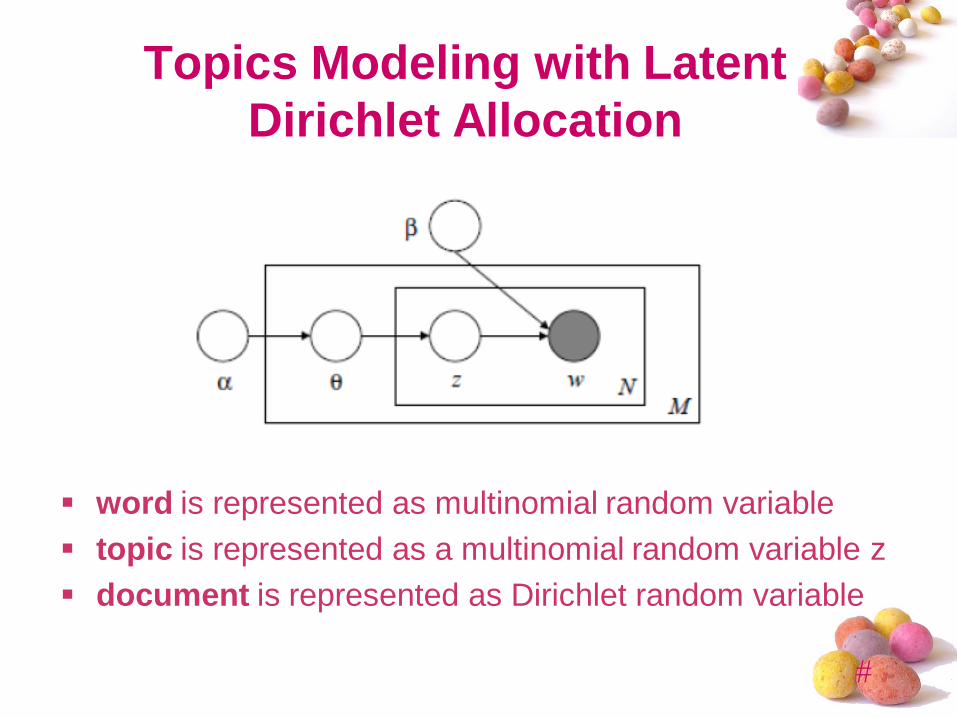
Topics Modeling with Latent
Dirichlet Allocation
word is represented as multinomial random variable
topic is represented as a multinomial random variable z
document is represented as Dirichlet random variable
#
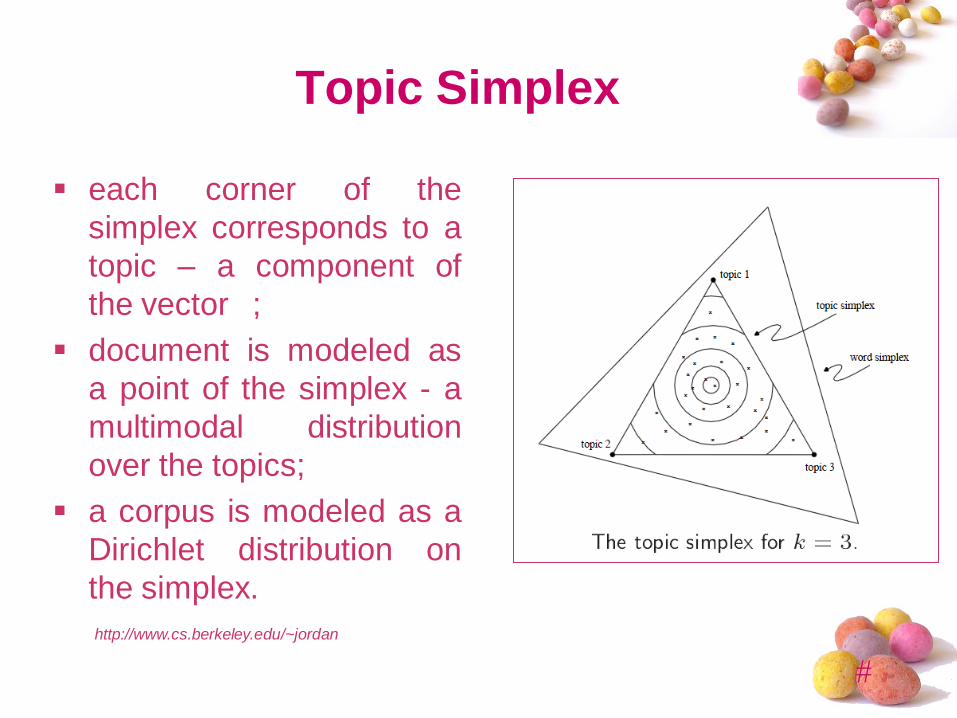
Topic Simplex
each corner of the
simplex corresponds to a
topic – a component of
the vector ;
document is modeled as
a point of the simplex - a
multimodal distribution
over the topics;
a corpus is modeled as a
Dirichlet distribution on
the simplex.
http://www.cs.berkeley.edu/~jordan

#
III. Topic Models: HMMLDA

#
Bigram Topic Models:
Wallach‟s Model
• Wallach‟s Bigram Topic Model (Wal„05) is based on
Hierarchical Dirichlet Language (Pet‟94)
[Wal’05] Wallach, H. Topic modeling: beyond bag-of-words. NIPS 2005
Workshop on Bayesian Methods for Natural Language Processing, 2005.
[Pet’94] MacKay, D. J. C., & Peto, L. A hierarchical Dirichlet language
model. Natural Language Engineering, 1, 1–19, 1994.
“neural network”

#
III. Topic Models: LDA-COL
#
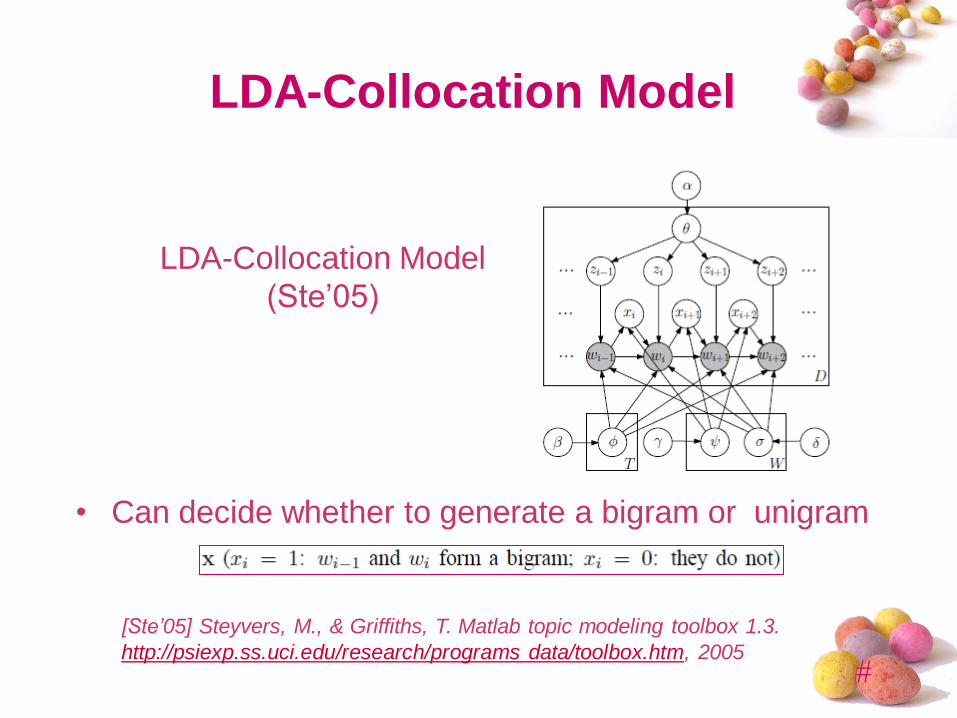
LDA-Collocation Model
• Can decide whether to generate a bigram or unigram
[Ste’05] Steyvers, M., & Griffiths, T. Matlab topic modeling toolbox 1.3.
http://psiexp.ss.uci.edu/research/programs data/toolbox.htm, 2005
LDA-Collocation Model
(Ste‟05)

#
Methods for Collocation Discovery
Counting frequency (Jus„95)Justeson, J. S., & Katz, S. M. (1995). Technical terminology: some linguistic properties and an algorithm for
identification in text. Natural Language Engineering, 1, 9–27
Variance based collocation (Sma„93)Smadja, F. (1993). Retrieving collocations from text: Xtract. Computational Linguistics, 19, 143–177.
Hypothesis testing -> assess whether or not two words
occur together more often than chance:
– t-test (Chu‟89)Church, K., & Hanks, P. Word association norms, mutual information and lexicography. In Proceedings of
the 27th Annual Meeting of the Association for Computational Linguistics (ACL) (pp. 76–83), 1989
– 2 test (Chu‟91)Church, K. W., Gale, W., Hanks, P., & Hindle, D. Using statistics in lexical analysis. In Lexical Acquisition:
Using On-line Resources to Build a Lexicon (pp. 115–164). Lawrence Erlbaum, 1991
– likelihood ratio test (Dun‟93)Dunning, T. E. Accurate methods for the statistics of surprise and coincidence. Computational Linguistics,
19, 61–74, 1993.
Mutual information (Hod‟96)Hodges, J., Yie, S., Reighart, R., & Boggess, L. An automated system that assists in the generation of
document indexes. Natural Language Engineering, 2, 137–160, 199
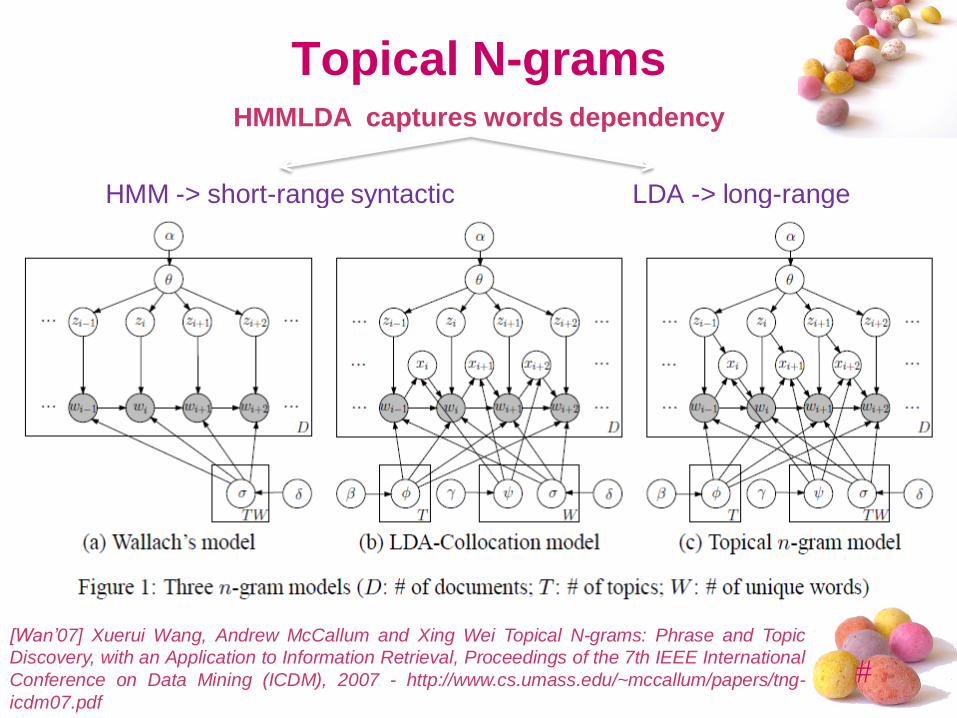
#
Topical N-gramsHMMLDA captures words dependency
HMM -> short-range syntactic LDA -> long-range
semantic
[Wan’07] Xuerui Wang, Andrew McCallum and Xing Wei Topical N-grams: Phrase and Topic
Discovery, with an Application to Information Retrieval, Proceedings of the 7th IEEE International
Conference on Data Mining (ICDM), 2007 - http://www.cs.umass.edu/~mccallum/papers/tng-
icdm07.pdf
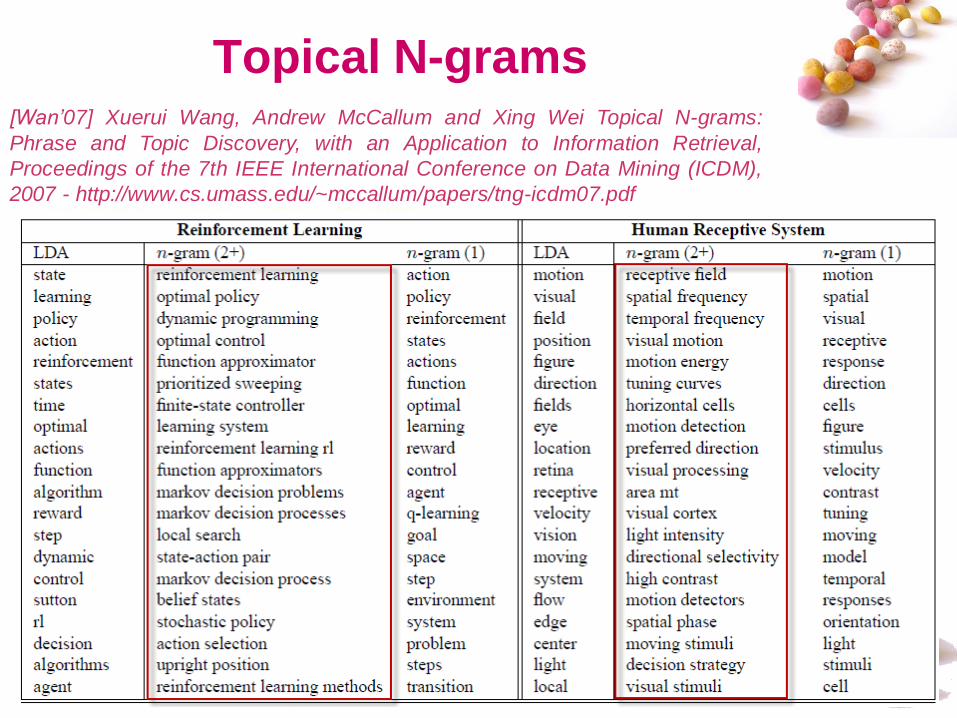
#
Topical N-grams[Wan’07] Xuerui Wang, Andrew McCallum and Xing Wei Topical N-grams:
Phrase and Topic Discovery, with an Application to Information Retrieval,
Proceedings of the 7th IEEE International Conference on Data Mining (ICDM),
2007 - http://www.cs.umass.edu/~mccallum/papers/tng-icdm07.pdf

#
IV. Data Collection: NIPS Abstracts

#
NIPS Collection
NIPS Collection Characteristics
Number of iterations N = 50
LDA hyper parameter ALPHA = 0.5
LDA hyper parameter BETA = 0.01
NIPS Collection Characteristics
Number of words W = 13649
Number of docs D = 1740
Number of topics T = 100
Randomly sampled document titles from NIPS Collection
#
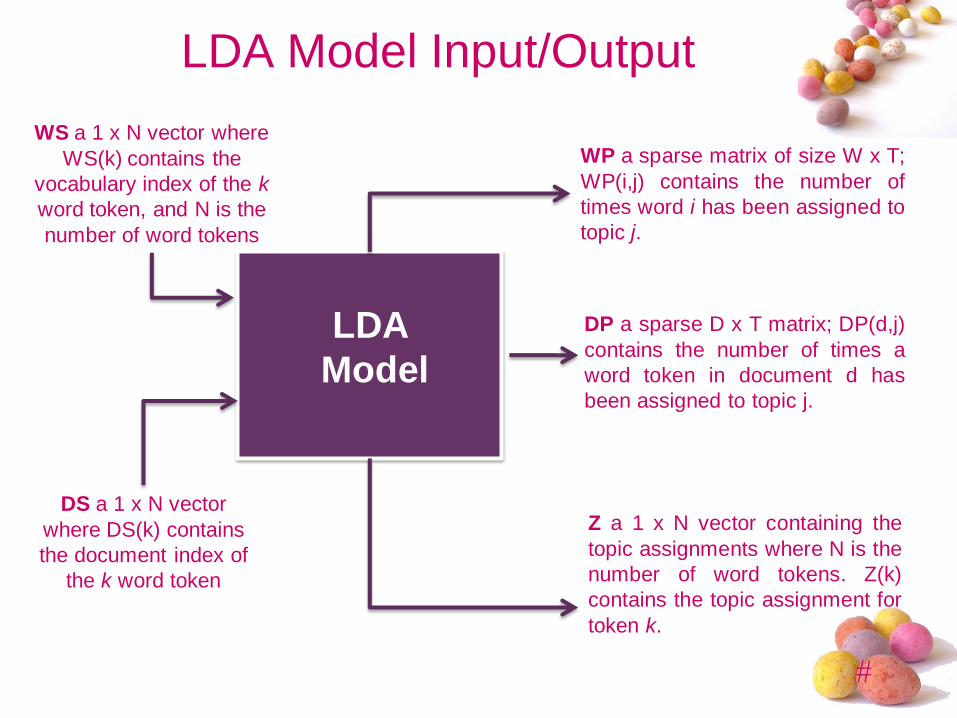
LDA Model Input/Output
WS a 1 x N vector where
WS(k) contains the
vocabulary index of the k
word token, and N is the
number of word tokens
DS a 1 x N vector
where DS(k) contains
the document index of
the k word token
LDA
Model
WP a sparse matrix of size W x T;
WP(i,j) contains the number of
times word i has been assigned to
topic j.
DP a sparse D x T matrix; DP(d,j)
contains the number of times a
word token in document d has
been assigned to topic j.
Z a 1 x N vector containing the
topic assignments where N is the
number of word tokens. Z(k)
contains the topic assignment for
token k.
#
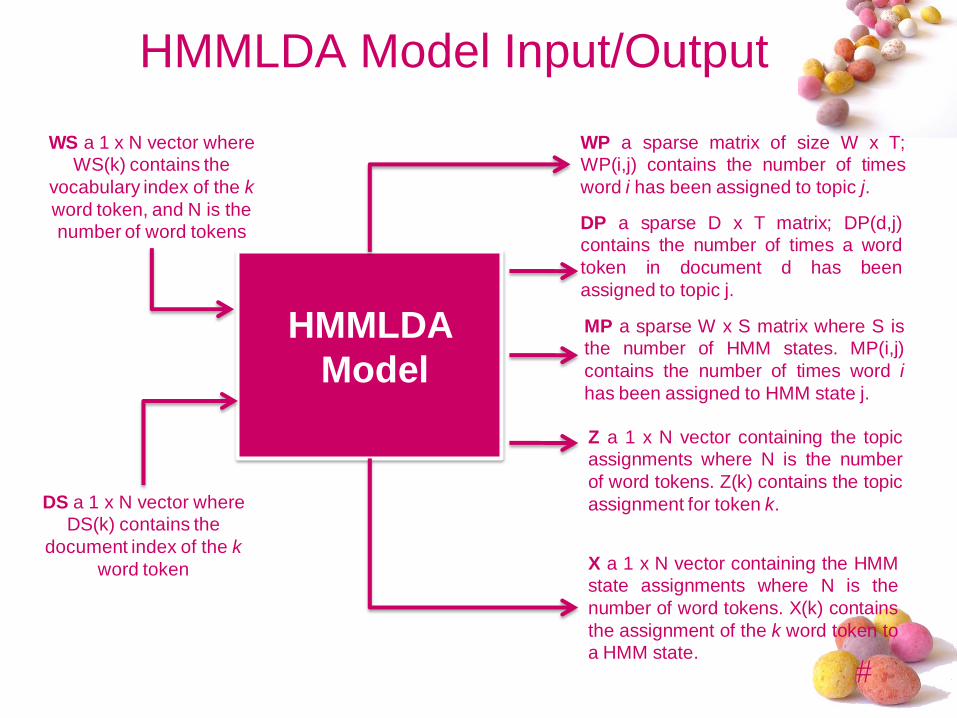
HMMLDA Model Input/Output
WS a 1 x N vector where
WS(k) contains the
vocabulary index of the k
word token, and N is the
number of word tokens
DS a 1 x N vector where
DS(k) contains the
document index of the k
word token
HMMLDA
Model
WP a sparse matrix of size W x T;
WP(i,j) contains the number of times
word i has been assigned to topic j.
DP a sparse D x T matrix; DP(d,j)
contains the number of times a word
token in document d has been
assigned to topic j.
MP a sparse W x S matrix where S is
the number of HMM states. MP(i,j)
contains the number of times word i
has been assigned to HMM state j.
Z a 1 x N vector containing the topic
assignments where N is the number
of word tokens. Z(k) contains the topic
assignment for token k.
X a 1 x N vector containing the HMM
state assignments where N is the
number of word tokens. X(k) contains
the assignment of the k word token to
a HMM state.
#
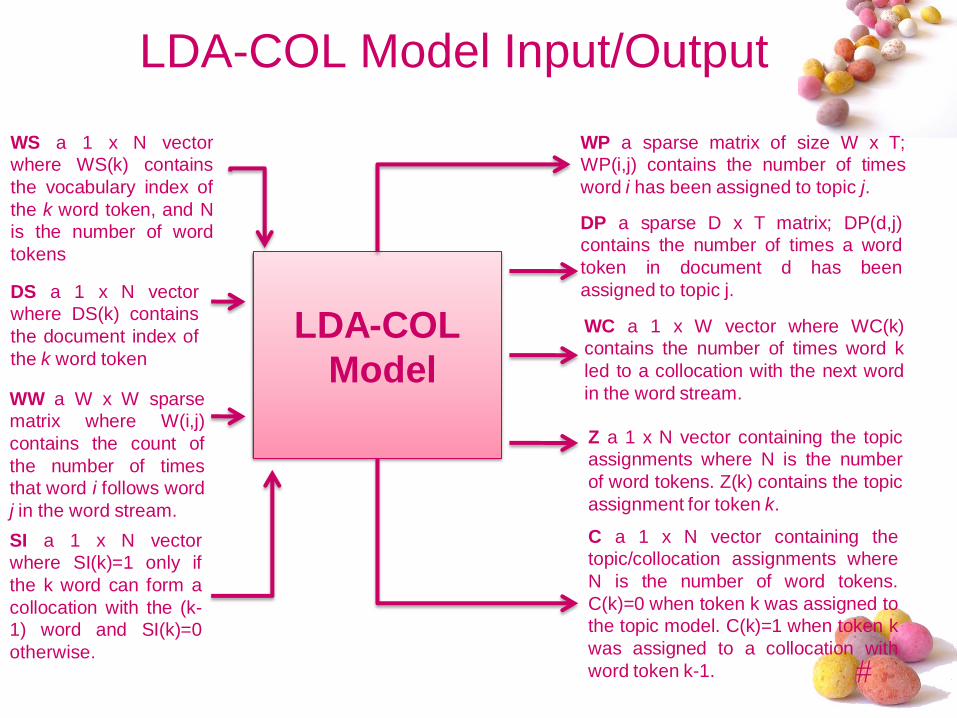
LDA-COL Model Input/Output
WS a 1 x N vector
where WS(k) contains
the vocabulary index of
the k word token, and N
is the number of word
tokens
DS a 1 x N vector
where DS(k) contains
the document index of
the k word token
LDA-COL
Model
WP a sparse matrix of size W x T;
WP(i,j) contains the number of times
word i has been assigned to topic j.
DP a sparse D x T matrix; DP(d,j)
contains the number of times a word
token in document d has been
assigned to topic j.
WC a 1 x W vector where WC(k)
contains the number of times word k
led to a collocation with the next word
in the word stream.
Z a 1 x N vector containing the topic
assignments where N is the number
of word tokens. Z(k) contains the topic
assignment for token k.
C a 1 x N vector containing the
topic/collocation assignments where
N is the number of word tokens.
C(k)=0 when token k was assigned to
the topic model. C(k)=1 when token k
was assigned to a collocation with
word token k-1.
WW a W x W sparse
matrix where W(i,j)
contains the count of
the number of times
that word i follows word
j in the word stream.
SI a 1 x N vector
where SI(k)=1 only if
the k word can form a
collocation with the (k-
1) word and SI(k)=0
otherwise.

#
V. Experimental Results

#
Experiment Setup
1. 100 Topics
2. Gibbs Sampling – 50 iterations
3. Optimized Parameters
LDA HMMLDA LDA-COL
ALPHA = 0.5
BETA = 0.01
ALPHA = 0.5
BETA = 0.01
GAMMA = 0.1
BETA = 0.01
ALPHA = 0.5
GAMMA0 = 0.1
GAMMA1 = 0.1
[Gri’04] Griffiths, T., & Steyvers, M. (2004). Finding Scientific Topics.
Proceedings of the National Academy of Sciences, 101 (suppl. 1), 5228-
5235.

#
LDA Model Results
#
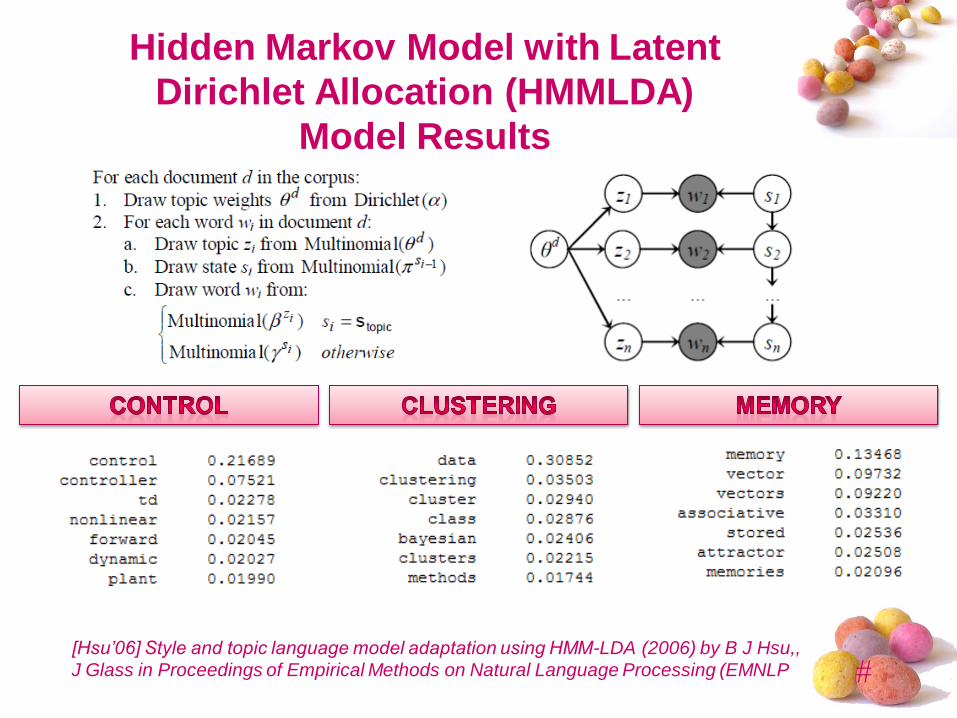
Hidden Markov Model with Latent
Dirichlet Allocation (HMMLDA)
Model Results
[Hsu’06] Style and topic language model adaptation using HMM-LDA (2006) by B J Hsu,,
J Glass in Proceedings of Empirical Methods on Natural Language Processing (EMNLP
#
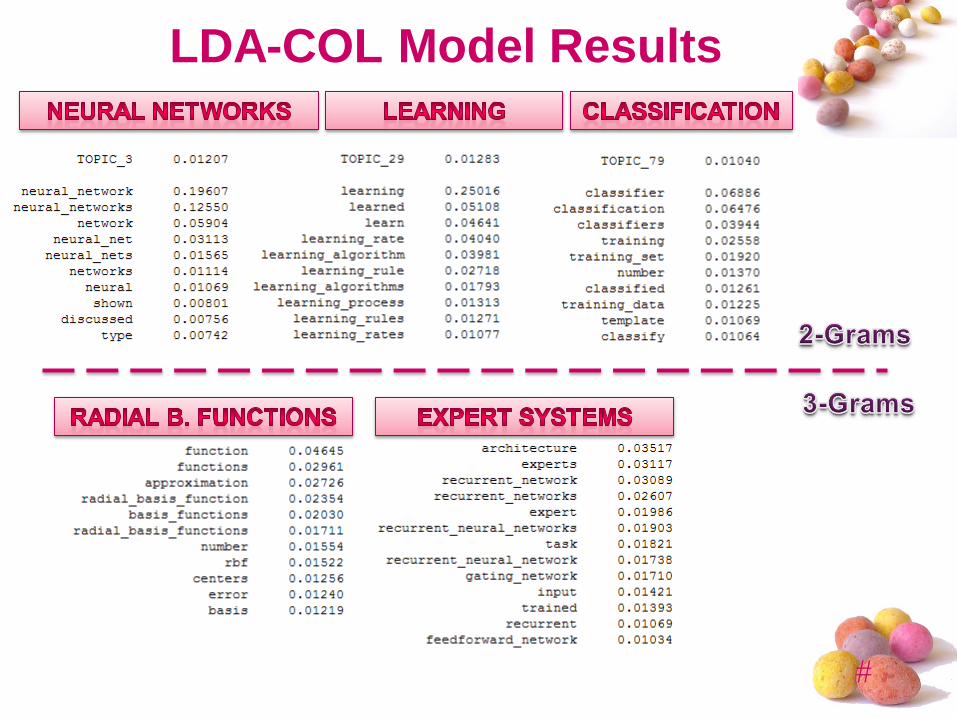
LDA-COL Model Results
#
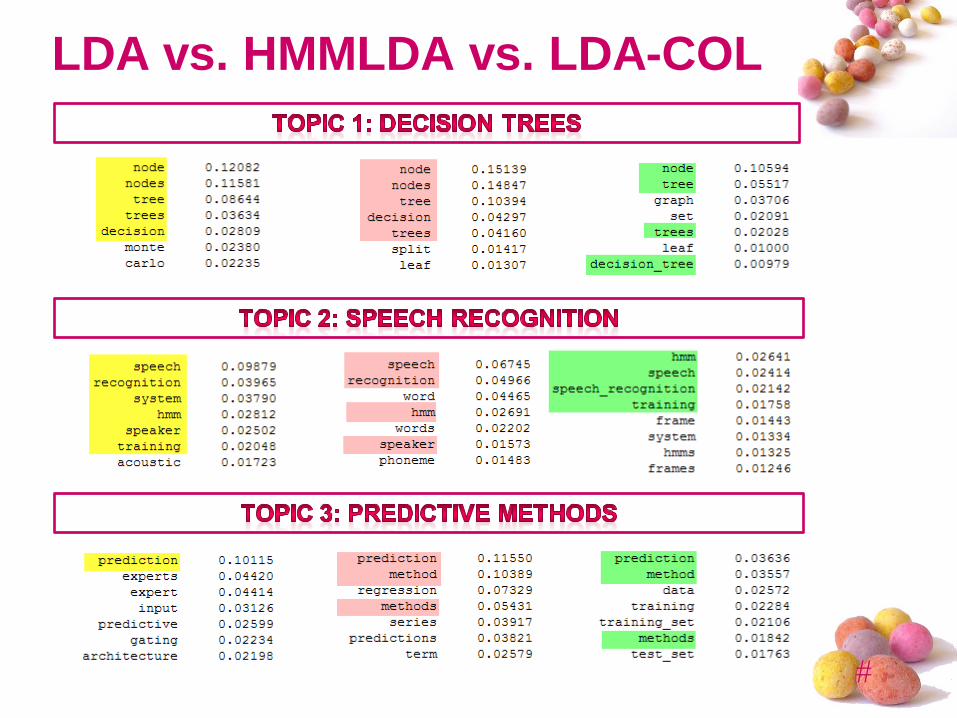
LDA vs. HMMLDA vs. LDA-COL

#
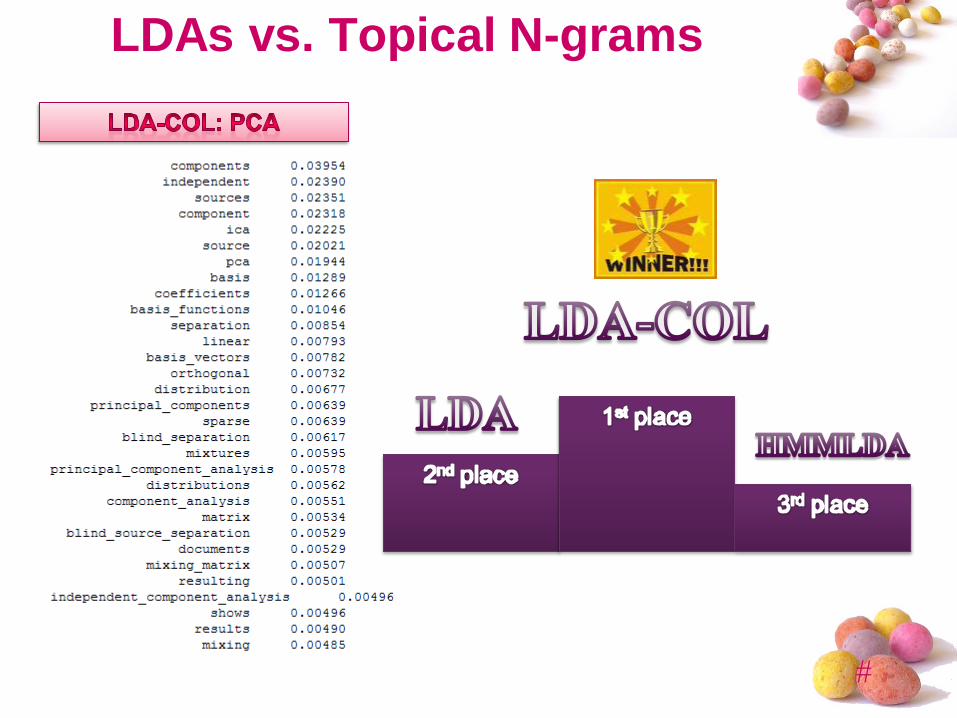
LDAs vs. Topical N-grams
[Wan’07] Xuerui Wang, Andrew McCallum and Xing Wei Topical N-grams: Phrase and Topic Discovery, with
an Application to Information Retrieval, Proceedings of the 7th IEEE International Conference on Data
Mining (ICDM), 2007 - http://www.cs.umass.edu/~mccallum/papers/tng-icdm07.pdf
#
LDAs vs. Topical N-grams

#
VI. Conclusions

#
Conclusions
I. HMMLDA showed the worst results, because
stop words removal was not done
II. LDA-COL had the best performance in
comparison to LDA and HMMLDA, but worse
than topical n-gram models
Future Work
Polylingual Topic Models
[Mim’2009] D. Mimno, H. M. Wallach, J. Naradowsky, D. A. Smith, and A. Mccallum,
"Polylingual topic models," in Proceedings of the 2009 Conference on Empirical Methods
in Natural Language Processing. Singapore: Association for Computational Linguistics,
August 2009, pp. 880-889, http://www.aclweb.org/anthology/D/D09/D09-1092.pdf

#
Acknowledgments
University of California, Irvine.
Department of Cognitive Sciences for
MatLab Topics Modeling Toolbox
Questions
Dr .Caragea
Related Documents











