Recent research directions in automated timetabling Edmund Kieran Burke, Sanja Petrovic Automated Scheduling, Optimisation and Planning (ASAP) Research Group, School of Computer Science and Information Technology, University of Nottingham, Jubilee Campus, Nottingham NG8 1BB, UK Abstract The aim of this paper is to give a brief introduction to some recent approaches to timetabling problems that have been developed or are under development in the Automated Scheduling, Optimisation and Planning Research Group (ASAP) at the University of Nottingham. We have concentrated upon university timetabling but we believe that some of the methodologies that are described can be used for different timetabling problems such as employee timetabling, timetabling of sports fixtures, etc. The paper suggests a number of approaches and comprises three parts. Firstly, recent heuristic and evolutionary timetabling algorithms are discussed. In particular, two evolutionary algorithm develop- ments are described: a method for decomposing large real-world timetabling problems and a method for heuristic initialisation of the population. Secondly, an approach that considers timetabling problems as multicriteria decision problems is presented. Thirdly, we discuss a case-based reasoning approach that employs previous experience to solve new timetabling problems. Finally, we outline some new research ideas and directions in the field of timetabling. The overall aim of these research directions is to explore approaches that can operate at a higher level of generality than is currently possible. Ó 2002 Elsevier Science B.V. All rights reserved. Keywords: Combinatorial optimisation; Timetabling/Scheduling; Meta-heuristic approaches; Multiple criteria analysis; Case-based reasoning; Hyper-heuristics 1. Introduction Educational timetabling is a major administra- tive activity for a wide variety of institutions. A timetabling problem can be defined to be the problem of assigning a number of events into a limited number of time periods. Wren (1996) de- fines timetabling as follows: ‘‘Timetabling is the allocation, subject to con- straints, of given resources to objects being placed in space time, in such a way as to sat- isfy as nearly as possible a set of desirable ob- jectives.’’ In this paper, we will concentrate on university timetabling problems. Such problems can be di- vided into two main categories: course timetabling and exam timetabling. These problems are subject to many constraints that are usually divided into two categories: ‘‘hard’’ and ‘‘soft’’ (e.g., Burke et al., 1997). Hard constraints are rigidly enforced. Examples of such constraints are: • No resource (students or staff) can be demanded to be in more than one place at any one time. European Journal of Operational Research 140 (2002) 266–280 www.elsevier.com/locate/dsw E-mail addresses: [email protected] (E.K. Burke), sxp@cs. nott.ac.uk (S. Petrovic). 0377-2217/02/$ - see front matter Ó 2002 Elsevier Science B.V. All rights reserved. PII:S0377-2217(02)00069-3

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Recent research directions in automated timetabling
Edmund Kieran Burke, Sanja Petrovic
Automated Scheduling, Optimisation and Planning (ASAP) Research Group, School of Computer Science and Information
Technology, University of Nottingham, Jubilee Campus, Nottingham NG8 1BB, UK
Abstract
The aim of this paper is to give a brief introduction to some recent approaches to timetabling problems that have
been developed or are under development in the Automated Scheduling, Optimisation and Planning Research Group
(ASAP) at the University of Nottingham. We have concentrated upon university timetabling but we believe that some
of the methodologies that are described can be used for different timetabling problems such as employee timetabling,
timetabling of sports fixtures, etc. The paper suggests a number of approaches and comprises three parts. Firstly, recent
heuristic and evolutionary timetabling algorithms are discussed. In particular, two evolutionary algorithm develop-
ments are described: a method for decomposing large real-world timetabling problems and a method for heuristic
initialisation of the population. Secondly, an approach that considers timetabling problems as multicriteria decision
problems is presented. Thirdly, we discuss a case-based reasoning approach that employs previous experience to solve
new timetabling problems. Finally, we outline some new research ideas and directions in the field of timetabling. The
overall aim of these research directions is to explore approaches that can operate at a higher level of generality than is
currently possible. � 2002 Elsevier Science B.V. All rights reserved.
Keywords: Combinatorial optimisation; Timetabling/Scheduling; Meta-heuristic approaches; Multiple criteria analysis; Case-based
reasoning; Hyper-heuristics
1. Introduction
Educational timetabling is a major administra-tive activity for a wide variety of institutions. Atimetabling problem can be defined to be theproblem of assigning a number of events into alimited number of time periods. Wren (1996) de-fines timetabling as follows:
‘‘Timetabling is the allocation, subject to con-straints, of given resources to objects beingplaced in space time, in such a way as to sat-
isfy as nearly as possible a set of desirable ob-jectives.’’
In this paper, we will concentrate on universitytimetabling problems. Such problems can be di-vided into two main categories: course timetablingand exam timetabling. These problems are subjectto many constraints that are usually divided intotwo categories: ‘‘hard’’ and ‘‘soft’’ (e.g., Burkeet al., 1997).Hard constraints are rigidly enforced. Examples
of such constraints are:• No resource (students or staff) can be demandedto be in more than one place at any one time.
European Journal of Operational Research 140 (2002) 266–280
www.elsevier.com/locate/dsw
E-mail addresses: [email protected] (E.K. Burke), sxp@cs.
nott.ac.uk (S. Petrovic).
0377-2217/02/$ - see front matter � 2002 Elsevier Science B.V. All rights reserved.
PII: S0377 -2217 (02 )00069 -3

• For each time period there should be sufficientresources (e.g., rooms, invigilators, etc.) avail-able for all the events that have been scheduledfor that time period.Soft constraints are those that are desirable but
not absolutely essential. In real-world situations itis, of course, usually impossible to satisfy all softconstraints. Examples of soft constraints (in bothexam and course timetabling) are:• Time assignment. A course/exam may need to bescheduled in a particular time period.
• Time constraints between events. One course/ex-am may need to be scheduled before/after theother.
• Spreading events out in time. Students should nothave exams in consecutive periods or two examson the same day.
• Coherence. Professors may prefer to have alltheir lectures in a number of days and to havea number of lecture-free days. These constraintsconflict with the constraints on spreading eventsout in time.
• Resource assignment. Professors may prefer toteach in a particular room or it may be the casethat a particular exam must be scheduled in acertain room.There are, of course, significant differences be-
tween the two broad categories of universitytimetabling problem: course and exam time-tabling. For example, a number of exams may bescheduled in one room or an exam may be splitacross several rooms, while in course timetablingone course (usually) has to be scheduled into ex-actly one room. Exam timetabling often aims todecrease the number of students who have examsin adjacent periods while in course timetabling it isusually desirable for students to have two or morecourses in a row.A more detailed range of exam timetabling
constraints that are in use in British universitiescan be seen in Burke et al. (1996a). This paper is ananalysis of the examination requirements of over50 British universities. The soft constraints andtheir importance differs very much from universityto university and some of these differences arediscussed in the same paper. More details of ex-amination timetabling constraints and approachesarising in practice can be seen in Carter and La-
porte (1996), while the same authors discuss coursetimetabling in Carter and Laporte (1998).The large number of events (courses/exams) to
be scheduled and a wide variety of constraintsimposed on timetabling makes the set of all pos-sible solutions (i.e., the search space of the prob-lem) very large indeed. The construction of atimetable can be an extremely difficult task and itsmanual solution can require much effort. Time-tabling problems have attracted the attention ofthe scientific community from a number of disci-plines (including OR and Artificial Intelligence)for about 40 years and over the last decade or sothere has been an increased interest in the field.A wide variety of approaches to timetabling
problems have been described in the literature andtested on real data. They can be roughly dividedinto four types (Carter, 1986; Carter and Laporte,1996, 1998): (1) sequential methods, (2) clustermethods, (3) constraint-based methods, and (4)meta-heuristic methods.(1) Sequential methods. These methods order
events using domain heuristics and then assign theevents sequentially into valid time periods so thatno events in the period are in conflict with eachother (Carter, 1986). In sequential methods,timetabling problems are usually represented asgraphs where events (courses/exams) are repre-sented as vertices, while conflicts between theevents are represented by edges (de Werra, 1985).For example, if some students have to attend twoevents there is an edge between the nodes whichrepresents this conflict. The construction of aconflict-free timetable can therefore be modelled asa graph colouring problem. Each time period inthe timetable corresponds to a colour in the graphcolouring problem and the vertices of a graph arecoloured in such a way so that no two adjacentvertices are coloured by the same colour.A variety of graph colouring heuristics for
constructing conflict-free timetables is available inthe literature (Brelaz, 1979; Carter and Laporte,1996). These heuristics order the events based onan estimation of how difficult it is to schedulethem. The heuristics that are often used are:• Largest degree first. Events that have a largenumber of conflicts with other events (i.e., alarge degree) are scheduled early. The rationale
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 267

is that the events with a large number of con-flicts are more difficult to schedule and so shouldbe tackled first.
• Largest weighted degree. This is a modificationof the Largest degree first which weights eachconflict by the number of students involved inthe conflict.
• Saturation degree. In each step of the timetableconstruction an event which has the smallestnumber of valid periods available for schedulingin the timetable constructed so far is selected.
• Colour degree. This heuristic priorities thoseevents that have the largest number of conflictswith the events that have already been sched-uled.Once the events are ordered for scheduling, a
number of approaches can be employed to select avalid period for each event. For example, theearliest valid period can be selected, or the ‘‘best’’valid period in the context of a defined objectivefunction, etc.(2) Cluster methods. In these methods the set of
events is split into groups which satisfy hard con-straints and then the groups are assigned to timeperiods to fulfill the soft constraints. An earlypaper to describe this approach was written byWhite and Chan (1979). Different optimisationtechniques have been employed to solve theproblem of assigning the groups of events intotime periods (Fisher and Shier, 1983; Balakrishnanet al., 1992). The main drawback of these ap-proaches is that the clusters of events are formedand fixed at the beginning of the algorithm andthat may result in a poor quality timetable.(3) Constraint-based approaches. In these meth-
ods a timetabling problem is modelled as a set ofvariables (i.e., events) to which values (i.e.,resources such as rooms and time periods) have tobe assigned to satisfy a number of constraints(Brailsford et al., 1999; White, 2000). Usually anumber of rules is defined for assigning resourcesto events. When no rule is applicable to the currentpartial solution a backtracking is performed until asolution is found that satisfies all constraints.(4) Meta-heuristic methods. Over the last two
decades a variety of meta-heuristic approachessuch as simulated annealing, tabu search, geneticalgorithms and hybrid approaches have been in-
vestigated for timetabling. Some very good re-sults have been reported in Burke and Ross(1996), Burke and Carter (1998), Burke and Er-ben (2001) and the timetabling section of Fogarty(1995). Meta-heuristic methods begin with one ormore initial solutions and employ search strate-gies that try to avoid local optima. All of thesesearch algorithms can produce high quality so-lutions but often have a considerable computa-tional cost.We have just presented a very brief outline of
timetabling research over the years. Interestedreaders can see a number of surveys of existingtimetabling methods and applications (de Werra,1985; Carter, 1986; Carter and Laporte, 1996,1998; Bardadym, 1996; Burke et al., 1997; Sch-aerf, 1999). The aim of this paper is not to pro-vide another survey of timetabling research.Instead we aim to present an overview of some ofthe latest approaches and research directions thathave been, or are being undertaken, in the Au-tomated Scheduling, Optimisation and PlanningResearch Group (ASAP) at the University ofNottingham. A number of approaches are de-scribed which explore an interdisciplinary strategyalong promising avenues that have not yet beenfully studied in the timetabling field. Heuristic andmeta-heuristic methods developed for examtimetabling are described in Section 2. Section 3presents an approach to exam timetabling thatconsiders exam timetabling problems as multicri-teria problems. The application of case-basedreasoning to course timetabling problems is pre-sented in Section 4. Section 5 looks at some newresearch directions in timetabling research with anoverall aim of building timetabling systems thathandle a higher level of generality than is cur-rently available.
2. Heuristic and meta-heuristic methods for time-
tabling
This Section gives a brief tour of our researchinto timetabling over the last five years which re-sulted in innovations in heuristic and meta-heu-ristic methods for timetabling. This research wasfocused on exam timetabling problems.
268 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280

2.1. Hybrid heuristic methods
In order to direct a search of the solution spaceto more desirable areas, a simple efficient searchmethod based on heuristics was presented in 1998(Burke et al., 1998a). The events are ordered usinggraph colouring heuristics. The ordered events arescheduled in valid periods with respect to theevaluation function. The evaluation functioncostðtÞ takes into consideration a number of softconstraints in a timetable t:
costðtÞ ¼ 5000 � unscheduledðtÞþ 3 � sameDayðtÞ þ overNightðtÞ;
where unscheduledðtÞ holds the number of examsnot scheduled in a valid period, sameDayðtÞ andoverNightðtÞ present the number of conflicts wherestudents have exams in adjacent periods on thesame day and in overnight adjacent periods, re-spectively.Two types of selection, which include random
elements, have been proposed to replace the se-quential scheduling of the ordered events:(1) Tournament selection which generates a subset
of events randomly and then selects the eventfrom the subset that is ranked the first with re-spect to the employed heuristics.
(2) Bias selection where an event is randomly se-lected from the list of the first n events.Experiments have shown the advantages of
such a hybrid method over the ‘‘pure’’ heuristicsequential methods (Burke et al., 1998a). It can beobserved that the most notable improvements ofthe pure heuristic sequencing strategies have beenobtained using the Largest degree first heuristicwithin the described heuristic search with therandom elements.
2.2. Genetic and memetic algorithms for timetabling
The possibilities and advantages of the appli-cation of meta-heuristic methods to timetablingproblems have been studied extensively within thetimetabling research community. Within theASAP research group, special interest has beengiven to genetic and memetic approaches to examtimetabling problems.
The memetic algorithm attempts to improve theperformance of a genetic algorithm by incorpo-rating local neighbourhood search (Moscato andNorman, 1992). The main idea of the memeticalgorithm is to explore the neighbourhood of thesolutions obtained by a genetic algorithm and tonavigate the search toward the local optima (foreach solution) before passing back to the geneticalgorithm and continuing the process. Paechteret al. (1995, 1996) have used this approach forcourse timetabling.However, it is the case that, although meta-
heuristics have (relatively) recently provided suc-cessful approaches, domain specific heuristics havebeen utilised in timetabling problems for manyyears. It is a well established fact that methodsincorporating domain specific heuristics can giveacceptable solutions very quickly, but they oftenlack the optimisation capabilities of the more in-tensive search methods provided by meta-heuris-tics. This observation generated the motivation touse a range of graph colouring heuristics withinthe memetic algorithm to improve and acceleratethe search process. The main characteristics of thisapproach for exam timetabling are outlined below(Burke et al., 1995, 1996b, 1998b; Burke andNewall, 1999).
2.2.1. Representation of the solutionA population of a number of chromosomes
which encode solutions to the problem is gener-ated. Each member of the population consists of anumber of time periods that are allocated for theexamination. Each time period contains a list ofthe exams that are scheduled in that period androoms assigned to these exams.
2.2.2. Evaluation functionA linear weighted cost function has been de-
fined to assess the quality of the timetables. Itpenalises incomplete timetables and occurrenceswhere students have to attend two exams in con-secutive periods which are on the same day or onadjacent days.
2.2.3. Evolutionary operatorsA number of different operators have been de-
veloped and used within the memetic algorithms
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 269

which manipulate the chromosomes of the popu-lation to form chromosomes of the offspring. Theyare briefly described as follows.(1) The light mutation operator makes minor
changes to the timetable by rescheduling ran-domly chosen exams in other valid periods.The purpose of this mutation operator is to di-rect the search away from local optima.
(2) The heavy mutation operator reschedules theexams from ‘‘bad’’ time periods in timetables.In order to determine the ‘‘bad’’ time peri-ods, a probability of disruption is calculatedfor each time period. This probability takesinto consideration the penalties of the examsthat are scheduled in the period. All examsfrom disrupted periods are then rescheduledin random order in the valid periods thatcause the lowest increment of the cost func-tion. The application of heuristics to the hea-vy mutation operator results in substantiallybetter final timetables and also increases thespeed at which acceptable solutions can befound.
(3) The heuristic heavy mutation operator resched-ules exams from disrupted periods in heuristicorder. The Largest degree first graph colouringheuristic is used to order exams for reschedul-ing.
(4) The specialist recombination operator producesa new solution by combining two differenttimetables (parents). The exams that are sched-uled in the same time periods in both parentsare scheduled in the same period in the child.The exams that are scheduled differently inthe parents form the list of unscheduled events.Different heuristics have been investigated thatorder the list of unscheduled exams which arethen rescheduled in the valid periods with re-spect to the evaluation function. However,the recombination operator (enhanced withheuristics) has not significantly improved theperformance of the algorithm.
2.2.4. Hill-climbingAfter each mutation or recombination opera-
tor, a hill-climbing operator is applied to direct thesearch towards the local optima. The hill-climbingoperator takes exams sequentially from periods
that are randomly ordered, and reschedules themin valid periods that cause the least penalties. Ex-periments have shown that the designed operatorsshow better results when they are combined withhill-climbing.
2.2.5. Selection phaseThe selection process orders the members of the
population by the values of their evaluationfunctions and decides (according to a certainprobability) whether to leave the solution for thenext generation or not.
2.2.6. DecompositionReal-world university timetabling problems
usually have a very high number of events thathave to be scheduled. Algorithms for timetablingmight be more efficient if they consider subsets ofevents, rather then the whole set of events. Carterproposed an algorithm for timetabling decompo-sition (Carter, 1983). The algorithm schedulessubsets of events sequentially, adding the eventsfrom the current subset into an already createdschedule. Each subset of events is small enough tobe solved by conventional approaches such aslinear integer programming.Following the lines of decomposition proposed
by Carter, a memetic algorithm has been modifiedto decompose large exam timetabling problemsinto smaller ones (Burke and Newall, 1999). Thedrawback of such a decomposition could be that itmay be very difficult (or indeed impossible) toschedule events belonging to later subsets havingfixed the schedule for earlier subsets. To alleviatethis potential problem subsets are chosen using aheuristic ordering of events and the algorithmhandles two subsets at a time, but fixes only theevents from the first subset. It has been shown thatthis ‘‘look ahead’’ process combined with a goodchoice of heuristic and a proper size for the sub-sets can significantly reduce the computationalcost and can also improve the quality of the so-lutions.The experiments have been performed on
available real data from a number of universitiesaround the world (obtainable from ftp://ftp.cs.nott.ac.uk.ttp/Data and ftp://ie.utoronto.ca/mwc/testprob). Some of the characteristics of the
270 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280
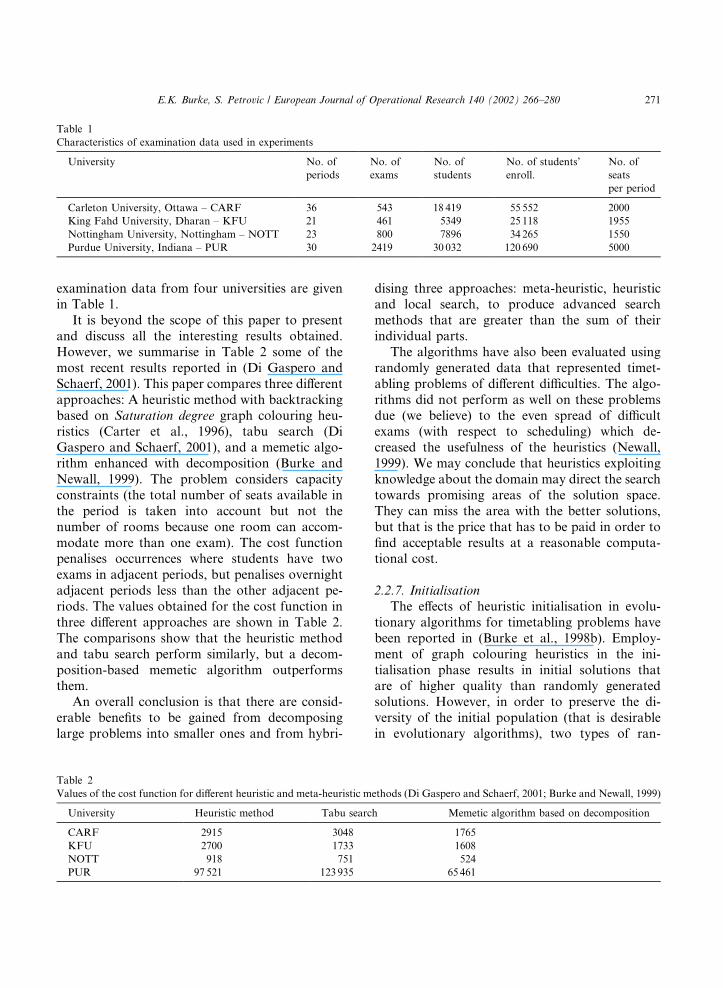
examination data from four universities are givenin Table 1.It is beyond the scope of this paper to present
and discuss all the interesting results obtained.However, we summarise in Table 2 some of themost recent results reported in (Di Gaspero andSchaerf, 2001). This paper compares three differentapproaches: A heuristic method with backtrackingbased on Saturation degree graph colouring heu-ristics (Carter et al., 1996), tabu search (DiGaspero and Schaerf, 2001), and a memetic algo-rithm enhanced with decomposition (Burke andNewall, 1999). The problem considers capacityconstraints (the total number of seats available inthe period is taken into account but not thenumber of rooms because one room can accom-modate more than one exam). The cost functionpenalises occurrences where students have twoexams in adjacent periods, but penalises overnightadjacent periods less than the other adjacent pe-riods. The values obtained for the cost function inthree different approaches are shown in Table 2.The comparisons show that the heuristic methodand tabu search perform similarly, but a decom-position-based memetic algorithm outperformsthem.An overall conclusion is that there are consid-
erable benefits to be gained from decomposinglarge problems into smaller ones and from hybri-
dising three approaches: meta-heuristic, heuristicand local search, to produce advanced searchmethods that are greater than the sum of theirindividual parts.The algorithms have also been evaluated using
randomly generated data that represented timet-abling problems of different difficulties. The algo-rithms did not perform as well on these problemsdue (we believe) to the even spread of difficultexams (with respect to scheduling) which de-creased the usefulness of the heuristics (Newall,1999). We may conclude that heuristics exploitingknowledge about the domain may direct the searchtowards promising areas of the solution space.They can miss the area with the better solutions,but that is the price that has to be paid in order tofind acceptable results at a reasonable computa-tional cost.
2.2.7. InitialisationThe effects of heuristic initialisation in evolu-
tionary algorithms for timetabling problems havebeen reported in (Burke et al., 1998b). Employ-ment of graph colouring heuristics in the ini-tialisation phase results in initial solutions thatare of higher quality than randomly generatedsolutions. However, in order to preserve the di-versity of the initial population (that is desirablein evolutionary algorithms), two types of ran-
Table 1
Characteristics of examination data used in experiments
University No. of
periods
No. of
exams
No. of
students
No. of students’
enroll.
No. of
seats
per period
Carleton University, Ottawa – CARF 36 543 18 419 55 552 2000
King Fahd University, Dharan – KFU 21 461 5349 25 118 1955
Nottingham University, Nottingham – NOTT 23 800 7896 34 265 1550
Purdue University, Indiana – PUR 30 2419 30 032 120 690 5000
Table 2
Values of the cost function for different heuristic and meta-heuristic methods (Di Gaspero and Schaerf, 2001; Burke and Newall, 1999)
University Heuristic method Tabu search Memetic algorithm based on decomposition
CARF 2915 3048 1765
KFU 2700 1733 1608
NOTT 918 751 524
PUR 97 521 123 935 65 461
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 271

dom selection of an event from the list of or-dered events have been employed: tournamentand bias selection.In order to study the effects of heuristic ini-
tialisation in the evolutionary algorithms threedifferent measures of diversity have been defined:(a) Events are in the same time period. This mea-
sure counts the number of occurrences wherean event is scheduled in the same time periodin both timetables. The drawback of this mea-sure is that it considers absolute positions ofthe events in timetables. For example, if onetimetable has events which are scheduled oneperiod later than in another timetable then thisdiversity measure would say that they are verydifferent, although they could be considered tobe similar to each other.
(b) Pairs of events are in the same period. Thismeasure takes into consideration the temporalrelationships between events. It counts pairs ofevents that are scheduled in the same period inboth timetables.
(c) Coverage of the search space. This measurecounts how many times each pair (event, timeperiod) appears in the members of the wholepopulation.
Method (b) was favoured because it allowed us torepresent diversity as a single value average anddid not have the drawback of method (a).Experiments have shown that the employment
of heuristic initialisation strategies can providesignificant benefits in terms of the quality and di-versity of the members of the population. A vari-ety of experiments have been performed whichinvolved timetabling problems of different diffi-culties (i.e., low and high conflicting timetablingproblems), different graph colouring heuristics anddifferent sizes of subsets in the tournament andbias selection. Dynamic heuristics, which changethe order of events for scheduling in each step ofthe timetable construction (e.g., Saturation degreeand Colour degree heuristics), provide better initialtimetables. The timetables obtained were shorterand have higher degrees of diversity in comparisonwith static heuristic sequencing strategies. The useof heuristic initialisation can significantly improvethe performance of evolutionary timetabling al-gorithms.
3. A multicriteria approach to timetabling
Many timetabling algorithms are relativelysimple and address only a subset of the con-straints. In this way a reasonable computationalcost is achieved at the expense of ‘‘comprehen-siveness’’. In order to overcome this drawback wehave considered timetabling problems as multi-criteria decision problems (Burke et al., 2001a). Ifwe assume that solutions which satisfy hard con-straints exist then the quality of the solutions canbe assessed on the basis of how well they satisfythe soft constraints. One hard constraint has beenintroduced which is common to all universities,that events which require the same resources mustnot be scheduled in the same time period. Conse-quently, a number of criteria have been definedwith respect to the other constraints. Each crite-rion expresses the measure of violations of thecorresponding constraint. A constraint which isnormally considered to be hard (namely that thetotal resources at any time must not exceedthe resources available) has been taken as one ofthe criteria.Initial research has been focused on exam
timetabling problems. Different groups of criteria(with 9 criteria in total) have been introducedwhose values describe the quality of the timetablesfrom different aspects:(a) Room capacities. Criterion C1 expresses the
number of students who cannot be seated inthe assigned rooms in the timetable.
(b) Proximity of exams. Criteria C2, C3, C4 and C5give the number of conflicts where studentshave two exams in adjacent periods, on oneday, in adjacent days, and in overnight adja-cent periods, respectively.
(c) Time and order of exams. Criterion C6 repre-sents the number of students’ enrollments af-fected when an exam is not scheduled in thetime period of appropriate duration. CriterionC7 represents the number of students’ enroll-ments when an exam is not scheduled in the de-sired time period. Criteria C8 and C9 representthe number of students’ enrollments whenexams do not satisfy temporal relationshipsbefore/after and immediately before/after,respectively.
272 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280

The criteria are of a different nature. They areincommensurable due to their different units ofmeasure with different scales. In addition, criteriaare partially or totally conflicting. For example,two exams which should be scheduled immediatelybefore/after each other may have common stu-dents, thus causing two criteria C2 and C9 to beconflicting. Criteria weights, which represent rela-tive importance of criteria, are subjectively definedby the timetable officer. They reflect different reg-ulations and requirements of universities and theirattitudes toward certain timetabling constraints.Each timetable is represented as a point in the
criteria space whose dimension is equal to thenumber of criteria. A point in the criteria space,which optimises all criteria simultaneously, iscalled an ideal point. It is generally the case thatthe solution that corresponds to the ideal pointdoes not exist. The difficulties caused by differentunits of measure and different scales of criteria areovercome by the introduction of a preferencespace in which criteria values are comparable(Petrovic and Petrovic, 1995). A linear mapping ofthe criteria space into the preference space is de-fined. The ideal point I in the criteria space ismapped onto the point W in the preference spacewhose co-ordinates are equal to the weights ofcriteria.A new algorithm has been developed for heu-
ristic search of the preference space. It is based onthe principal idea of compromise programming – amulticriteria decision making method that at-tempts to determine so-called compromise solu-tions with respect to all criteria simultaneouslythat are closest to the ideal point (Zeleny, 1973,1974). A family of Lp metrics which has been usedto measure the distance between the solutions andthe ideal point is defined by the following formula:
LpðS;W Þ ¼XKk¼1
½sk
(� wk�p
)1=p
; ð1Þ
where K is a number of criteria, p is a parameter tocontrol the metrics and LpðS;W Þ is the distancebetween a solution S with co-ordinates sk in thepreference space and the ideal pointW with the co-ordinates wk. Three values of p are of particularinterest: p ¼ 1, p ¼ 2, and p ¼ 1.
The algorithm starts the search of the prefer-ence space from a set of high quality timetables interms of each criterion separately. The procedurethen iteratively searches the neighbourhood ofeach of these timetables to improve other criteriavalues while approaching the ideal point. Twooperators have been used to explore the neigh-bourhood of the timetables. They are based on theconcepts of hill-climbing and the heavy mutationoperators employed in the memetic algorithm de-scribed in Section 2. These operators have beenmodified to take into consideration the distancesof the timetables from the ideal point.The multicriteria approach has been tested on
the examination data of the University of Not-tingham whose description is shown in Table 3.Experiments have been carried out with two
parameters: wk and p. We present the results ofdifferent experiments in Table 4 when all thecriteria are of the same importance and when thecriterion C2 (which expresses the number ofconflicts where students have two exams in ad-jacent periods) is more important than the othercriteria. The table presents the distances of theobtained timetables from the ideal point inthe preference space, and the criteria values of thetimetables which are also expressed percentagesof the worst possible values of criteria. Thehigher importance of the criterion C2 led to so-lutions with a lower number of violations of thecorresponding constraint. Smaller values of pimply that a bad value of one criterion can beoffset by a good value of another. Higher valuesof p do not favour compensation of criteria
Table 3
Characteristics of the constraints of the NOTT examination
data (23 periods)
Characteristics of constraints on
the NOTT examination data
Value
Number of time periods per day 3
Duration of time periods (hours) 3,2,2
Number of exams which require
particular time periods
9
Number of times that exams should be
scheduled before/after another
2
Number of times that exams should be
scheduled immediately before/after another
1
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 273
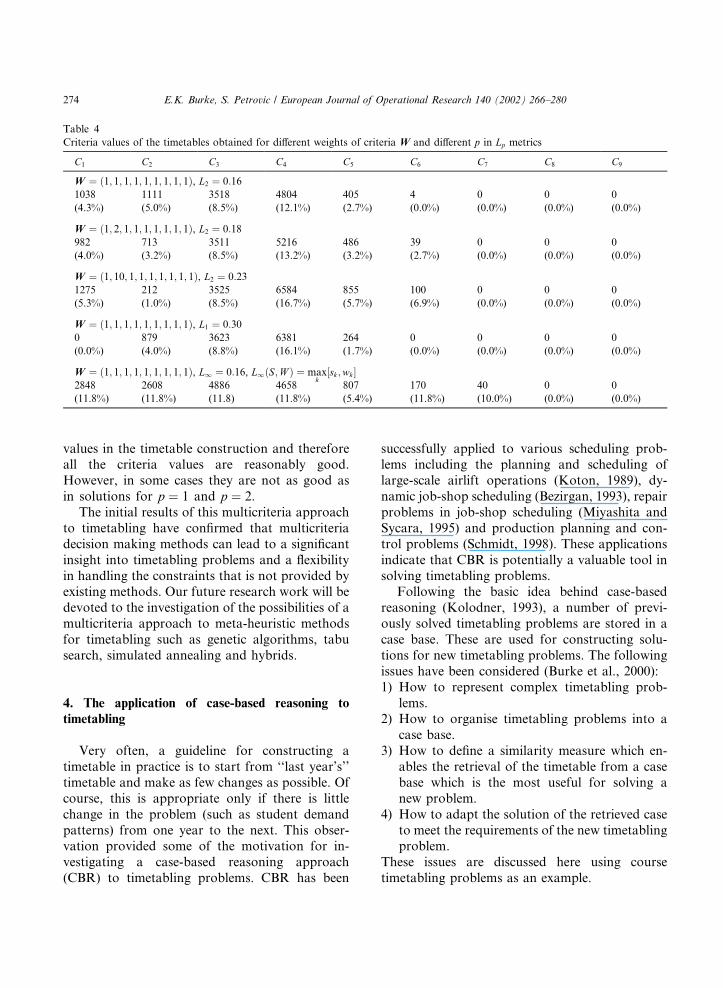
values in the timetable construction and thereforeall the criteria values are reasonably good.However, in some cases they are not as good asin solutions for p ¼ 1 and p ¼ 2.The initial results of this multicriteria approach
to timetabling have confirmed that multicriteriadecision making methods can lead to a significantinsight into timetabling problems and a flexibilityin handling the constraints that is not provided byexisting methods. Our future research work will bedevoted to the investigation of the possibilities of amulticriteria approach to meta-heuristic methodsfor timetabling such as genetic algorithms, tabusearch, simulated annealing and hybrids.
4. The application of case-based reasoning totimetabling
Very often, a guideline for constructing atimetable in practice is to start from ‘‘last year’s’’timetable and make as few changes as possible. Ofcourse, this is appropriate only if there is littlechange in the problem (such as student demandpatterns) from one year to the next. This obser-vation provided some of the motivation for in-vestigating a case-based reasoning approach(CBR) to timetabling problems. CBR has been
successfully applied to various scheduling prob-lems including the planning and scheduling oflarge-scale airlift operations (Koton, 1989), dy-namic job-shop scheduling (Bezirgan, 1993), repairproblems in job-shop scheduling (Miyashita andSycara, 1995) and production planning and con-trol problems (Schmidt, 1998). These applicationsindicate that CBR is potentially a valuable tool insolving timetabling problems.Following the basic idea behind case-based
reasoning (Kolodner, 1993), a number of previ-ously solved timetabling problems are stored in acase base. These are used for constructing solu-tions for new timetabling problems. The followingissues have been considered (Burke et al., 2000):1) How to represent complex timetabling prob-lems.
2) How to organise timetabling problems into acase base.
3) How to define a similarity measure which en-ables the retrieval of the timetable from a casebase which is the most useful for solving anew problem.
4) How to adapt the solution of the retrieved caseto meet the requirements of the new timetablingproblem.
These issues are discussed here using coursetimetabling problems as an example.
Table 4
Criteria values of the timetables obtained for different weights of criteria W and different p in Lp metrics
C1 C2 C3 C4 C5 C6 C7 C8 C9
W ¼ ð1; 1; 1; 1; 1; 1; 1; 1; 1Þ, L2 ¼ 0:161038 1111 3518 4804 405 4 0 0 0
(4.3%) (5.0%) (8.5%) (12.1%) (2.7%) (0.0%) (0.0%) (0.0%) (0.0%)
W ¼ ð1; 2; 1; 1; 1; 1; 1; 1; 1Þ, L2 ¼ 0:18982 713 3511 5216 486 39 0 0 0
(4.0%) (3.2%) (8.5%) (13.2%) (3.2%) (2.7%) (0.0%) (0.0%) (0.0%)
W ¼ ð1; 10; 1; 1; 1; 1; 1; 1; 1Þ, L2 ¼ 0:231275 212 3525 6584 855 100 0 0 0
(5.3%) (1.0%) (8.5%) (16.7%) (5.7%) (6.9%) (0.0%) (0.0%) (0.0%)
W ¼ ð1; 1; 1; 1; 1; 1; 1; 1; 1Þ, L1 ¼ 0:300 879 3623 6381 264 0 0 0 0
(0.0%) (4.0%) (8.8%) (16.1%) (1.7%) (0.0%) (0.0%) (0.0%) (0.0%)
W ¼ ð1; 1; 1; 1; 1; 1; 1; 1; 1Þ, L1 ¼ 0:16, L1ðS;W Þ ¼ maxk
½sk ;wk �2848 2608 4886 4658 807 170 40 0 0
(11.8%) (11.8%) (11.8) (11.8%) (5.4%) (11.8%) (10.0%) (0.0%) (0.0%)
274 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280

4.1. Representation of the cases
A list of (feature, value) pairs is often used incase-based reasoning to represent cases (Leake,1996). However, such data structures are inade-quate for representing complex timetabling prob-lems with various relations between courses.Attribute graphs have been used to represent
timetables structurally. Vertices of the graph rep-resent courses while edges represent relations be-tween the courses. Attributes have been assignedto both nodes and edges to represent constraintson courses and on pairs of courses, respectively.For example, attributes assigned to vertices maydenote that the course should be held once perweek, or n times per week, that the course shouldbe scheduled in a particular time period, etc. At-tributes of the edges may denote that two coursesare in conflict with each other (i.e., they havecommon students), that one course should be heldbefore/after the other, that two courses should beconsecutive to each other, etc.
4.2. Organisation of the case base
The attribute graphs are represented by adja-cency matrices whose diagonal elements containthe attributes of the vertices, while the other ele-ments denote the attributes of the edges betweenthe corresponding vertices. In order to handledifferent orders of courses of a new problem andthe timetabling problems stored in the case base,an adjacency matrix has been introduced for eachpermutation of the courses. Timetabling problemsare stored hierarchically in a decision tree. Nodesand branches of the decision tree store the attri-butes of the attribute graphs which represent thetimetabling problems. In this way the decisiontree stores the information about the structures ofthe timetabling problems contained in the casebase.
4.3. Retrieval process and the similarity measure
The goal of the retrieval process is to find a casefrom the case base which is structurally the mostsimilar to the new timetabling problem. Thematching process between two timetabling prob-
lems represented by attribute graphs is based ongraph isomorphism. An algorithm for graph iso-morphism presented in (Messmer, 1995) has beenenriched with a similarity measure in order to re-trieve the attribute graph which is structurally themost similar to the new problem and thus can bereused to solve the new problem. Instead of usingan exact match between the attributes of the newtimetabling problem and the attributes stored inthe decision tree, a partial match has been intro-duced which is based on the penalties defined forthe pairs of attributes. It has been observed thatnot only the cases which are graph isomorphic tothe new problem can be successfully reused, butalso the cases that have (sub)structures which arepartially similar to the new problem (Burke et al.,2001b).In the retrieval process a new timetabling
problem is classified to a node in the decision tree.The cases stored with the selected node and thenodes below the selected ones are retrieved. Thesimilarity measure between the new timetablingproblem T2 and the timetabling problem from thecase base T1 is defined in the following way:
SðT1; T2Þ ¼ 1�Pn
i¼0 pi þPm
k¼0 ak þPk
l¼0 dlP þ Aþ D
; ð2Þ
where• n is the number of matched attributes betweenthe cases T1 and T2;
• pi is the cost assigned for substituting a vertex oredge of the retrieved case T1, with a vertex oredge of T2;
• m and k are the total numbers of the vertices oredges that have to be inserted into and deletedfrom the retrieved case T1, respectively, to ob-tain a match with T2;
• ak, dl are the penalties assigned for inserting anddeleting a vertex or edge k and l into and fromthe retrieved case T1, respectively, to obtain amatch with T2;
• P is the sum of the penalties for substitution ofeach possible pair of vertices or edges in the re-trieved case T1 to match T2;
• A and D are the sums of the costs of insertingand deleting all of the vertices or edges intoand from the retrieved case T1, respectively, tomatch T2.
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 275

4.4. Adaptation
According to the isomorphism found, thecourses in the solution of the retrieved cases arereplaced with matching courses from the newproblem. Very often the solution of the retrievedcase violates some of the constraints of the newtimetabling problem. Therefore, it has to beadapted to fulfill the constraints of the new prob-lem. However, as the retrieval process comparesthe structures of the timetabling cases and thesimilarity measure takes into consideration howdifficult it is to adapt the solution of the retrievedcase, the adaptation process usually requires asmall number of steps. The courses that violate theconstraints are ordered using a graph heuristicmethod described in Burke et al. (1994) and thenrescheduled.A large number of systematically designed ex-
periments have been performed on a differentnumber of cases (5, 10, 15, 20) with differingcomplexity (15-course simple, 15-course complex,and 20-course simple cases) in the case base (Burkeet al., 2001b). We denote as complex cases thosecases which have vertices whose degree is between1 and 4, while simple cases have vertices whosedegree is between 1 and 3. The complex cases areusually more difficult to solve. The generated caseshad a range of properties that real-world problemsmay have and were designed with the aim of in-vestigating how the possible cases in the case baseaffect the retrieval process. Table 5 shows averagepercentages of successful retrievals which havefound either a partial or a complete match betweenthe new timetabling problem and a case from thecase base. Experiments have shown that storingcomplex cases in the case base enables more suc-cessful retrievals than storing simple cases becausemore new timetabling problems can find matching
cases. Also, it is not the number of cases in the casebase that is important for the successful retrievalbut the number of (sub)structures. For example,the average percentages of successful retrievals arethe same independently whether the case basecontains 15 or 20 cases of the same complexity.Storing larger (20-courses) simple cases in the casebase shows better performance than storingsmaller (15-courses) simple cases. However, itseems that storing a certain number of complexcases (here 15-course complex cases) produces abetter performance than storing larger cases orsimpler cases.The performance of the developed CBR system
has been compared with a graph heuristic methodwhich has been used to construct a timetable fromscratch (Burke et al., 2001c). The cost functiontakes the number of violations of the soft con-straints and the number of courses that cannot bescheduled without violation of the hard con-straints into account. It has been shown that in themajority of experiments, the CBR approach hasproduced better solutions with respect to the costfunction than those constructed by the graphheuristic method. However, the graph heuristicmethod outperformed the CBR approach when aninsufficient number of complex cases or largenumber of large cases which are difficult to adapthave been stored in the case base. This is, however,in line with the previous experiments on the size ofthe case base and the complexity of its cases.The drawback of the described CBR approach
is that it requires all of the permutations of thecourses of the timetabling problems to be stored.Therefore it is appropriate to store only small sizetimetabling problems. However, if the timetablingproblem has a larger size than the cases in the casebase, the retrieved process is not successful. Inorder to overcome this, an ongoing research is
Table 5
Average percentages of new timetabling problems that find a match in the case base
Number of cases in the case base 15-course simple case base 15-course complex case base 20-course simple case base
5 76.67% 78.3% 95%
10 90% 90% 95%
15 90% 98.33% 95%
20 90% 98.33% 95%
276 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280

devoted to a multiple retrieval process which re-trieves in each cycle a case from the case base thatmatches a part of the new problem (Burke et al.,2001c). The vertices of the retrieved case thatmatch the vertices of the new timetabling problemare replaced with a new vertex. Such a constructedgraph has been used as an input case in the nextcycle of the retrieval process.
5. Directions for future research work
Upon examination of the variety of existingapproaches to timetabling, the following questionnaturally arises: ‘‘Where do we stand now withregard to the automatic solution of timetablingproblems and in what directions should we aimfuture research efforts?’’ Whatever timetablingproblem is considered (university exam/coursetimetabling, employee timetabling, school timet-abling etc.) that problem usually varies signifi-cantly from institution to institution in terms ofspecific requirements and constraints. Many cur-rent successful university timetabling systems areoften applied only in the institutions where theywere designed. Indeed, Carter and Laporte (1996)say (of examination timetabling), ‘‘There havebeen hundreds of research papers on the subjectand probably thousands of computer programs(mostly by amateurs at each of these schools) to‘solve’ their own particular variation on thetheme’’. There is also a very wide variety of ap-proaches (heuristics, meta-heuristics, hybrids,constraint-based methods etc.) that have been in-vestigated and reported in the literature. Many ofthese methods have been very successful and havehelped to increase our understanding of how tosolve these difficult real-world problems. However,they are usually approaches that are specificallydesigned for the particular version of the timet-abling problem that is being addressed. There hasbeen little timetabling research work that has beencarried out on how to develop systems that canintelligently choose the right method in the rightsituation. There is currently a school of thoughtwithin the timetabling community that believesthat, rather than developing a specific algorithmfor particular problems, the next significant step
should be taken to investigate methodologies forautomatically and intelligently choosing an ap-propriate algorithm for the problem in hand. Forexample, Ross et al. (1998) say (in terms of geneticalgorithms for timetabling), ‘‘. . . . . . However, allthis naturally suggests a possibly worthwhile di-rection for timetabling research involving GeneticAlgorithms (GAs). We suggest that a GA might bebetter employed in searching for a good algorithmrather than searching for a specific solution to aspecific problem’’.It is, of course, very expensive to build special
purpose timetabling systems for one institution ornarrow class of problems. One of the overall mo-tivations for this line of work is that more generalsystems built by employing such methods wouldbe much less expensive and would still address theissues that are of concern to practitioners. Suchpeople do not usually care about provable opti-mality or about algorithms that can shave a fewpercent off the current best approaches on bench-mark problems. They usually care about ‘‘goodenough – soon enough’’ solutions (Ross, 2001) anda major challenge is to develop approaches thatcan generate such solutions within a generalisedframework that can handle a wide range of prob-lems. It would be difficult for a ‘‘general’’ algo-rithm to beat a special purpose algorithm on itsown problem but it would be a major achievementif the ‘‘general’’ algorithm could compete with thespecial purpose algorithms for a wide range ofproblems.The question of how to develop approaches
that can generate algorithms for a range oftimetabling problems raises a very important issuefor the timetabling (and indeed the wider sched-uling community) to address. One of our mainmotivations for future timetabling research is toinvestigate ways of building systems that can op-erate at a higher level of generality than currenttimetabling methods can support. We will verybriefly outline two major directions in our futureresearch work:1. A case-based reasoning approach to heuristic
selection. Earlier on in this paper we described acase-based reasoning approach to directly solvecourse scheduling problems. This was, essentially,motivated by the observation that timetabling
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 277

officers tend to re-use timetables where possible.Timetabling researchers also tend to re-use meth-ods that they have found to be effective on prob-lems that they consider to have certain similarities.This provided us with the motivation for one ofour major research initiatives: To explore case-based reasoning approaches for picking out asuitable heuristic for a particular timetablingproblem. The basic idea is to generate a case basewhich stores a variety of cases. Each case wouldinclude a timetabling problem (together with analgorithm for solving it). When presented with anew problem, the approach would consult the casebase and (based on previous experience) it wouldpick out suitable heuristics for the new problem.Our aim is to investigate the circumstances underwhich specific approaches are appropriate forparticular instances of the problem. We believethat the meta-heuristic, heuristic and hybridmethods used for solving previous timetablingproblems can be re-used in solving new timetablingproblems which are ‘‘similar’’ (in a certain sense).Of course, the question of when two timetables are‘‘similar’’ in terms of when particular methodswork well on both of them is a major research is-sue in itself. Indeed, we see it as one of the mainchallenges that needs to be addressed in estab-lishing a case-based approach to heuristic selec-tion. However, it is certainly not the only researchchallenge. The establishment of a case-based rea-soning methodology will also involve: Defining aset of training cases, organisation of the case base,evaluation, learning from failure (as well as suc-cess) and controlling the growth of the case base.2. Hyper-heuristic methods. A hyper-heuristic
denotes a heuristic that selects heuristics for a widevariety of problems, including timetabling. Notethat this differs from the widely used term meta-heuristic in that the term meta-heuristic usuallyrefers to a heuristic which manages one otherheuristic for a particular problem. A hyper-heu-ristic can be thought of as a heuristic to chooseheuristics. Of course, meta-heuristics can be usedas hyper-heuristics as Ross et al. (1998) suggestwhen they discuss a genetic algorithm to findsuitable timetabling heuristics. It may also be thecase that a hyper-heuristic chooses from a range ofheuristics, meta-heuristics and hybrids. The main
idea is to try and design an algorithm that willchoose the right algorithm to carry out a certaintask in a certain situation. There are a number ofresearch issues that need to be tackled. In partic-ular, we need to investigate and analyse whatmethods may or may not be successful as hyper-heuristics and we need to investigate the use of‘‘knowledge poor’’ algorithms on a range ofproblems. This work, of course, complements ourresearch on a case-based approach to heuristicselection and is being carried out in collaborationwith Peter Ross and his research team.
Acknowledgements
We would like to thank Prof. J. Krarup and theProgramme Committee of EURO 2000 for invit-ing us to present this work in a semi-plenary talk.We would also like to thank Prof. Krarup, Dr. J.P.Newall and the anonymous referees for theirhelpful comments in the preparation of this paper.Some of the research described in this paper wasfunded (or is being funded) by the UK Engineeringand Physical Sciences Research Council (EPSRC).
References
Balakrishnan, N., Lucena, A., Wong, R.T., 1992. Scheduling
examinations to reduce second-order conflicts. Computers
and Operations Research 19, 353–361.
Bardadym, V.A., 1996. Computer-aided school and university
timetabling: The new wave. In: Burke and Ross (1996) pp.
22–45.
Bezirgan, A., 1993. An application of case-based expert system
technology to dynamic job-shop scheduling. In: Bramer,
M.A., Milne, R.W. (Eds.), Research and Development in
Expert Systems IX, Proceedings of Expert Systems 92, The
Twelfth Annual Technical Conference of the British Com-
puter Society, Specialist Group on Expert Systems, 15–17
December 1992, London, UK, pp. 225–235.
Brailsford, S.C., Potts, C.N., Smith, B.M., 1999. Constraint
satisfaction problems: Algorithms and applications. Euro-
pean Journal of Operational Research 119, 557–581.
Brelaz, D., 1979. New methods to color the vertices of a graph.
Communications of the ACM 22 (4), 251–256.
Burke, E., Carter, M. (Eds.), 1998. The Practice and Theory of
Automated Timetabling II: Selected Papers from the 2nd
International Conference on the Practice and Theory of
Automated Timetabling, University of Toronto, August
278 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280

20–22, 1997. Springer Lecture Notes in Computer Science
Series, vol. 1408.
Burke, E., Ross, P. (Eds.), 1996. The Practice and Theory of
Automated Timetabling: Selected Papers from the 1st
International Conference on the Practice and Theory of
Automated Timetabling, Napier University, August/Sep-
tember 1995. Springer Lecture Notes in Computer Science
Series, vol. 1153.
Burke, E.K., Newall, J.P., 1999. A multi-stage evolutionary
algorithm for the timetable problem. IEEE Transactions on
Evolutionary Computation 3 (1), 63–74.
Burke, E., Erben, W. (Eds.), 2001. The Practice and Theory of
Automated Timetabling III: Selected Papers from the 3rd
International Conference on the Practice and Theory of
Automated Timetabling, University of Applied Sciences,
Konstanz, August 16–18, 2000. Springer Lecture Notes in
Computer Science Series vol. 2079.
Burke, E.K., Elliman, D.G., Weare, R.F., 1994. A university
timetabling system based on graph colouring and constraint
manipulation. Journal of Research on Computing in Edu-
cation 27, 1–18.
Burke, E.K., Elliman, D.G., Weare, R.F., 1995. A hybrid
genetic algorithm for highly constrained timetabling prob-
lems. In: Proceedings of the 6th International Conference on
Genetic Algorithms, Pittsburgh, USA, 15–19 July 1995.
Morgan Kaufmann, Los Altos, CA, pp. 605–610.
Burke, E.K., Elliman, D.G., Ford, P., Weare, R.F., 1996a.
Examination timetabling in British Universities – A survey.
In: Burke and Ross (1996) pp. 76–92.
Burke, E.K., Newall, J.P., Weare, R.F., 1996b. A memetic
algorithm for University exam timetabling. In: Burke and
Ross (1996) pp. 241–250.
Burke, E., Kingston, J., Jackson, K., Weare, R., 1997.
Automated university timetabling: The state of the art.
The Computer Journal 40 (9), 565–571.
Burke, E.K., Newall, J.P., Weare, R.F., 1998a. A simple
heuristically guided search for the timetable problem. In:
International ICSC Symposium on Engineering of Intelli-
gent Systems EIS’98. ICSC Academic Press, New York, pp.
574–579.
Burke, E.K., Newall, J.P., Weare, R.F., 1998b. Initialisation
strategies and diversity in evolutionary timetabling. Evolu-
tionary Computation 6 (1), 81–103 (special issue on Sched-
uling).
Burke, E., MacCarthy, B., Petrovic, S., Qu, R., 2000. Struc-
tured cases in CBR – Re-using and adapting cases for time-
tabling problems. Knowledge-Based Systems 13 (2-3),
159–165.
Burke, E., Bykov, Y., Petrovic, S., 2001a. A multicriteria
approach to timetabling problems. In: Burke and Erben
(2001), pp. 118–131.
Burke, E., MacCarthy, B., Petrovic, S., Qu, R., 2001b. Case-
based reasoning in course timetabling: An attribute graph
approach. In: Aha, D.W., Watson, I., Yang, Q. (Eds.),
Case-Based Reasoning Research and Development, Pro-
ceedings of the 4th International Conference on Case-Based
Reasoning, ICCBR-2001, Vancouver, Canada, 30 July–2
August 2001. Springer-Verlag Lecture Notes in Artificial
Intelligence vol. 2080, pp. 90–104.
Burke, E., MacCarthy, B., Petrovic, S., Qu, R., 2001c. Multi-
retrieval in a structured case based reasoning approach for
course timetabling problems. School of Computer Science
and IT Technical Report, University of Nottingham, 2001.
Carter, M.W., 1983. A decomposition algorithm for practical
timetabling problems. Technical Paper 83-06, Department
of Industrial Engineering, University of Toronto.
Carter, M.W., 1986. A survey of practical applications of
examination timetabling algorithms. Operations Research
34, 193–202.
Carter, M.W., Laporte, G., 1996. Recent developments in
practical examination timetabling. In: Burke and Ross
(1996) pp. 3–21.
Carter, M.W., Laporte, G., 1998. Recent developments in
practical course timetabling. In: Burke and Carter (1998)
pp. 3–19.
Carter, M.W., Laporte, G., Lee, S.Y., 1996. Examination
timetabling: Algorithmic strategies and applications. Jour-
nal of the Operational Research Society 74, 373–383.
de Werra, D., 1985. An introduction to timetabling. European
Journal of Operational Research 19, 151–162.
Di Gaspero, L., Schaerf, A., 2001. Tabu search techniques for
examination timetabling. In: Burke and Erben (2001), pp.
104–117.
Fisher, J.G., Shier, D.R., 1983. A heuristic procedure for large-
scale examination scheduling problems. Technical Report
417, Department of Mathematical Sciences, Clemson Uni-
versity.
Fogarty, T.C. (Ed.), 1995. Evolutionary Computing, Time-
tabling Section (3 papers). Springer LNCS, vol. 993.
Kolodner, J., 1993. Case-Based Reasoning. Morgan–Kauf-
mann, Los Altos, CA.
Koton, P., 1989. SMARTPlan: A case-based resource alloca-
tion and scheduling system. In: Hammond, K. (Ed.),
Proceedings: Workshop on Case-Based Reasoning (DAR-
PA), Pensacola Beach, Florida, San Mateo, CA. Morgan–
Kaufmann, Los Altos, CA, pp. 285–289.
Leake, D. (Ed.), 1996. Case-Based Reasoning, Experiences and
Future Directions. AAAI Press.
Messmer, B.T., 1995. Efficient graph matching algorithms for
preprocessed model graph. Ph.D. Thesis, University of
Bern, Switzerland.
Miyashita, K., Sycara, K., 1995. CABINS: A framework of
knowledge acquisition and iterative revision for schedule
improvement and reactive repair. Artificial Intelligence 76,
377–426.
Moscato, P., Norman, M., 1992. A ‘‘Memetic’’ approach for
the travelling salesman problem – Implementation of a
computational ecology for combinatorial optimisation on
message passing systems. In: Proceedings of the Interna-
tional Conference on Parallel Computing and Transputer
Applications. IOS Press, Amsterdam, pp. 177–186.
Newall, J.P., 1999. Hybrid methods for automated timetabling.
Ph.D. Thesis, Department of Computer Science, University
of Nottingham, UK.
E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280 279

Paechter, B., Cumming, A., Luchian, H., 1995. The use of local
search suggestion lists for improving the solution of
timetabling problems with evolutionary algorithms. In:
Burke and Ross (1996) pp. 86–102.
Paechter, B., Cumming, A., Norman, M.G., Luchian, H., 1996.
Extensions to a memetic timetabling system. In: Burke and
Ross (1996) pp. 251–266.
Petrovic, S., Petrovic, R., 1995. Eco-Ecodispatch: DSS for
multicriteria loading of thermal power generators. Journal
of Decision Systems 4 (4), 279–295.
Ross, P., 2001. Tutorial on evolutionary scheduling and
routing. In: 2001 Genetic and Evolutionary Computation
Conference, San Fransisco, 2001, Tutorial Program, pp.
193–210.
Ross, P., Hart, E. Corne, D., 1998. Some observations about
GA-based exam timetabling. In: Burke and Carter (1998)
pp. 115–129.
Schaerf, A., 1999. A survey of automated timetabling. Artificial
Intelligence Review 13 (2), 87–127.
Schmidt, G., 1998. Case-based reasoning for production
scheduling. International Journal of Production Economics
56–57, 537–546.
White, G.M., 2000. Constrained satisfaction, not so con-
strained satisfaction and the timetabling problem. In: A
Plenary Talk in the Proceedings of the 3rd International
Conference on the Practice and Theory of Automated
Timetabling, University of Applied Sciences, Konstanz,
August 16–18, 2000, pp. 32–47.
White, G.M., Chan, P.W., 1979. Towards the construction of
optimal examination timetables. INFOR 17, 219–229.
Wren, A., 1996. Scheduling, timetabling and rostering – A
special relationship? In: Burke and Ross (1996) pp. 46–75.
Zeleny, M., 1973. Compromise programming. In: Cochrane,
J.L., Zeleny, M. (Eds.), Multiple Criteria Decision Making.
University of South Carolina Press, Columbia, pp. 262–301.
Zeleny, M., 1974. A concept of compromise solutions and the
method of displaced ideal. Computers and Operations
Research 1 (4), 479–496.
280 E.K. Burke, S. Petrovic / European Journal of Operational Research 140 (2002) 266–280
Related Documents











