
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Thread Scheduling for Cache Locality
James Philbin and Jan Edler
NEC Research Institute, 4 Independence Way, Princeton, NJ 08540
Otto J. Anshus
Department of Computer Science, Institute of Mathematical and Physical Sciences,
University of Tromso, N-9037 Tromso, Norway
Craig C. Douglas
IBM T.J. Watson Research Center, P.O. Box 218, Yorktown Heights, NY 10598-0218; and
Department of Computer Science, Yale University, P.O. Box 208285, New Haven, CT 06520-8285
Kai Li
Department of Computer Science, Princeton University, Princeton, NJ 08540
Abstract
This paper describes a method to improve the cache lo-cality of sequential programs by scheduling �ne-grainedthreads. The algorithm relies upon hints provided at thetime of thread creation to determine a thread executionorder likely to reduce cache misses. This technique maybe particularly valuable when compiler-directed tiling is notfeasible. Experiments with several application programs, ontwo systems with di�erent cache structures, show that ourthread scheduling method can improve program performanceby reducing second-level cache misses.
1 Introduction
The performance gap between processors and memory haswidened in the last few years. Since the beginning of the1980s, processor performance has been improving at the rateof about 50% per year, whereas the access time of DRAMshas improved at approximately 10% per year [19, 40]. Tocompensate for this gap, today's computer systems com-monly have two levels of cache memory. However, the costof a second-level cache miss is now, typically, more than 100instructions. For example, on an SGI Indigo2 (R4400) witha peak execution rate of 200 MIPS, a main memory accesstakes 1.17 microseconds [32]. As the memory access penaltyincreases, application performance becomes more sensitiveto cache misses. This is especially true for applications withdata sets larger than the cache size that do not exhibit a highdegree of memory reference locality.
One attractive way to ameliorate the processor/memoryperformance gap is to improve the data locality of applica-tions. Tiling (also called blocking), a well-known software
technique [1, 12, 18, 29], achieves this goal by restructuringa program to re-use certain blocks of data that �t in thecache. Tiling can reduce cache misses and can be applied toany level of the memory hierarchy, including virtual memory,caches, and registers. It can be done either automatically, bya compiler, or manually, by the programmer.
This paper describes an alternative technique to improvelocality using �ne-grained threads. The technique can besimpler than hand tiling and can generate better cachebehavior than untiled code. Threads have traditionally beenused to express concurrency and to exploit parallelism onmultiprocessors. We use threads in sequential programs tocreate separate units of computation, without data depen-dencies, which can then be reordered to improve data locality.Avoiding a secondary cache miss on current machines saves100 or so instruction times. This more than o�sets thecost of creating, scheduling, and running a lightweightthread [10, 17], assuming thread creation doesn't cause cachemisses. If the threads are scheduled in an order that resultsin many fewer cache misses, the resulting program will runfaster.
The scheduling algorithm uses address information, pro-vided by the programmer on thread creation, as hintsfor determining an execution ordering that increases datalocality. We have designed and implemented a user-levelthread package that relies upon our scheduling algorithmto reduce second-level cache misses. The thread packagesupports very �ne-grained, \run-to-completion" threads.
Tiling will normally yield better performance than ourtechnique when it can be applied. However, there are severalcases in which compiler directed tiling is infeasible. (1) Thecontrol or data ow complexity of a program may precludestatic analysis, e.g., data might be allocated dynamically oraccessed indirectly. (2) Physically addressed second levelcaches are more di�cult to analyze, because of virtualmemory e�ects [27], which may prevent the compiler fromdoing an e�ective job. (3) Many commercial compilers,particularly on PC's, do not perform tiling, or tile only simpleprograms. Without compiler help, the programmer who de-

sires good performance must manually tile the algorithm |a complex task. Our technique provides a potentially simpleralternative, while still achieving most of the performancebene�ts of tiling. It is conceivable that this technique couldbe used by a compiler, but that investigation is beyond thescope of this paper.
We have experimented with the thread package usingseveral application programs, including matrix multiplica-tion, a partial di�erential equation solver, a successive over-relaxation kernel, and an N{body program. We replacedcertain inner loops with �ne-grained threads, and then ranthe transformed programs on an SGI Power Indigo2 with anR8000 CPU and an SGI Indigo2 IMPACT with an R10000.Our results show that the thread scheduling method cansigni�cantly improve performance by reducing second-levelcache misses. In particular, it can improve the performanceof programs that have little or no compile time informationabout memory references.
2 Locality Scheduling
Our approach uses �ne-grained threads to decompose aprogram and schedules these threads so as to improve theprogram's data locality.
2.1 Fine-Grained Threads
It seemed to us that it would be easy for a programmerto transform a sequential program into a threaded program,with a thread system supporting very �ne-grained threads.By �ne-grained, we mean that the overhead of threadprimitives is small in both time and space requirements.With �ne-grained threads, for example, one can substitutea thread for the inner-most loop of a program that may becausing second-level cache misses.
Consider a matrix multiplication example, C = A � B,where A, B, and C are all n by n matrices. In orderto improve locality, A is transposed before and after thecomputation. One straightforward implementation usesnested loops:
for i = 1 to nfor j = 1 to nC[i; j] = 0;for k = 1 to nC[i; j] = C[i; j] + A[k; i] �B[k; j];
The inner-most loop computes the dot product of two n-element vectors. Note, we are using this example to illustratethe thread system. A good compiler can tile this expressioneasily.
With �ne-grained threads, we can simply replace the dot-product loop with a thread:
for i = 1 to nfor j = 1 to nFork(DotProduct; i; j);
RunThreads();
DotProduct(i; j) :C[i; j] = 0;for k = 1 to nC[i; j] = C[i; j] + A[k; i] �B[k; j];
Where Fork creates and schedules a thread that willcompute the speci�ed dot product, and RunThreads runseach thread in some order determined by the schedulingalgorithm.
This example shows how such transformations can beperformed by hand. However, �ne-grained threads presentchallenges in implementation. In order for our approach tobe e�ective, the total cost associated with threading must besigni�cantly less than the cost of the cache misses eliminated.This requires that the scheduling algorithm make intelligentdecisions that improve the program's locality.
2.2 The Scheduling Problem
In order to schedule threads for data locality, the schedulermust be informed about the memory references made bythe threads. To study the problem, let us assume thateach thread references k pieces of data during its executionand that the addresses of these k pieces are known tothe scheduler. Let us further assume that all threads areindependent.
Thread ti is denoted by ti(ai1; : : : ; aik) where aij is theaddress of the jth piece of data referenced by thread ti duringits execution. Thus, if n threads are executed in some ordert1; t2; : : : ; tn, they can be represented by the permutation:
t1(a11; : : : ; a1k);t2(a21; : : : ; a2k);
...tn(an1; : : : ; ank):
The goal in scheduling n threads for cache locality is to �nda permutation that minimizes the number of cache misses.We can view such a problem as a k-dimensional geometryproblem [11]. A thread ti(ai1; � � � ; aik) is a point in the k-dimensional space where the coordinates of the point are(ai1; � � � ; aik). The problem is then equivalent to �ndinga tour of the thread points in the space that satis�es therequirement of minimizing cache misses. Such requirementsdepend on the cache's design.
It may not be possible to obtain a precise de�nition fora realistic system. Second-level caches are often physicallyindexed, while the addresses associated with the threads arevirtual addresses. Past research has shown that the virtual-to-physical memory mapping maintained by the virtualmemory system can signi�cantly a�ect second-level cachebehavior [8]. Knowledge of the current virtual-to-physicalmemory mapping and of the page swapping algorithm forthe virtual memory would be needed to derive an optimalsolution.
Furthermore, the complexity of �nding a tour in a spacewith any global conditions based on the coordinates is likelyto be expensive. A good example is the traveling salesman

problem where the condition is to �nd the shortest globalpath. Instead of trying to de�ne the problem precisely andto �nd an optimal algorithm that solves it, we focus on ane�cient heuristic algorithm.
2.3 Our Algorithm
The main idea of our algorithm is to schedule threads in\bins" so that when the threads in a bin are run they will notcause many capacity cache misses. We use the k addressesassociated with a thread as hints to the scheduler. We �rstdescribe an algorithm that uses two addresses associated witheach thread and then explain how to extend the algorithmto use k addresses.
With k = 2 addresses, we constrain the general problem.The k addresses (ai1; : : : ; aik), which act as hints to thescheduler, become two (ai1; ai2). Intuitively, these might bethe two largest objects referenced by the thread or the twoobjects most frequently referenced by the thread.
Thus constrained, the scheduling problem then becomes�nding a tour of points in a two-dimensional plane as shownin Figure 1, where each thread is represented as a point in theplane with coordinates de�ned by the two address hints. Tominimize cache misses, the scheduling algorithm must �nda tour that has a \cluster" property, i.e., threads that havethe same or similar hints should be clustered together in thetour.
ji
2C
1.5C
C
0.5C
0 0.5C C 1.5C 2C
(h , h )
Figure 1: Scheduling threads in a 2-D plane.
The key idea of the algorithm is to use a two-dimensionalblock to determine the data locality of threads. Threadswith data in the same block will be placed in the same binso that they will be scheduled together. We divide the two-dimensional plane into equally sized blocks. The two addresshints (hi; hj) of a thread are used as coordinates to place itinto a bin. In other words, each block covers two pieces ofuser memory, one from each dimension. The insight is thatif the sum of the two dimensions of the block is less than thecache size C and if the threads falling into the same blockare scheduled together, then the execution of the threads willnot cause many cache misses. Thus, we make the size of eachdimension of a block be less than or equal to one half of thecache size.
Our scheduling algorithm uses bins to schedule threads.When a thread is created, its address hints are used to indexinto the scheduling plane to determine a bin for scheduling.Scheduling involves traversing the bins along some path,preferably the shortest one. For each non-empty bin, thescheduler runs all threads it contains in some order. If thescheduler focuses only on minimizing the cache misses ofthe largest cache (for example, the second-level cache in asystem with two levels of caches), then the scheduling orderof threads in the same bin can be arbitrary.
We implement this algorithm by hashing the hint ad-dresses to place threads into a �xed number of bins. Further-more, threads with address hints (hi; hj) and (hj; hi) can beplaced in the same bin, since they reference the same pieces ofdata. An implementation can take advantage of this propertyto reduce the number of bins by 50%.
The algorithm for k addresses is a simple extension tothe algorithm above. Instead of using a two-dimensionalblock in a two-dimensional plane to determine the localityof threads, the general algorithm uses a k-dimensional blockin a k-dimensional space. The sizes of the block dimensionsshould be set such that the sum of the k dimensions of theblock is less than or equal to the cache size. Threads withdata in the same block will be placed into the same bin.
2.4 An Example
To show how the thread scheduler works, let us consider asimple example of a 4�4 matrix multiplication (C = A�B)program using the threaded algorithm presented in section2.1. The inner-loop forks o� threads, each of which computesa dot product, in the following order:
t1(a1; b1); t2(a1; b2); t3(a1; b3); t4(a1; b4);t5(a2; b1); t6(a2; b2); t7(a2; b3); t8(a2; b4);t9(a3; b1); t10(a3; b2); t11(a3; b3); t12(a3; b4);t13(a4; b1); t14(a4; b2); t15(a4; b3); t16(a4; b4)
where ai and bj are the i-th vector of matrix A and j-thvector of matrix B respectively.
2C
1.5C
C
0.5C
0
3.1 3,2
0.5C C 1.5C 2C
2,1 2,2
1,1 1,2
2,3 2,4
1,3 1,4
4,3 4,4
3,3 3,4
4,1 4,2
Figure 2: An example of scheduling threads.

Suppose the cache holds only four vectors and the dimen-sion size of a block in the 2-D scheduling plane is one half thecache size. Then in one possible mapping (depending on thehashing function) threads fall into four blocks of the scheduleplane, as shown in Figure 2, where each i; j pair represents athread that computes the dot product for ai and bj.
Suppose each block maps to a bin, then our algorithmputs the threads in each block into the same bin:
bin1 = ft1(a1; b1); t2(a1; b2); t5(a2; b1); t6(a2; b2)gbin2 = ft3(a1; b3); t4(a1; b4); t7(a2; b3); t8(a2; b4)gbin3 = ft9(a3; b1); t10(a3; b2); t13(a3; b3); t14(a3; b4)gbin4 = ft11(a4; b1); t12(a4; b2); t15(a4; b3); t16(a4; b4)g
When the threads are run, the bins will be traversed in theabove order, with all threads in each bin being executedbefore moving to the next bin. The scheduler thus reordersthe dot-products in such a way that the execution of thethreads in each bin will not cause capacity cache misses. Thescheduling order exhibits similar locality to that provided bycourse grain tiling either by hand or by a compiler.
3 Thread Package
This section describes a thread package for data localityscheduling. The thread package consists of a thread schedulerthat conforms to the algorithm described in the previoussection, with primitive operations optimized to support �ne-grained, user-level threads.
In principle, a general purpose thread package [5, 7,9, 13, 15] could be adapted to schedule threads accordingto memory access hints. While signi�cant variation existsamong current thread packages, they all include supportfor synchronization, including context switching and threadstate saving. Many thread packages include additional fea-tures, such as preemptive scheduling, asynchronous signallingmechanisms, and private data areas; such features can bevaluable in some contexts, expanding the class of problemsfor which a package is applicable. However, our design forlocality scheduling keeps the thread package simple, makinglow-overhead the most important goal.
We have implemented a special-purpose thread systemfor locality scheduling that features a minimal user interfaceand very low overhead. Because our threads always \run-to-completion," and have no support for blocking and resumingexecution, the system is implemented without resorting toassembly language. In fact, the essential functionality of thelibrary is embodied in about 525 lines of C, including bothC and Fortran-callable interfaces. However, this does notimply that it is completely free of machine and con�gurationdependencies. In particular, as explained above, the cachesize is an important parameter of the scheduling algorithm.
Our thread package implements the scheduling algorithmfor the three-dimensional case, although it is quite easy to ex-tend it to higher dimensional cases. It uses three-dimensionalblocks to determine data locality to place threads into bins.
3.1 User Interface
The basic user interface currently consists of only three calls:
� th init(blocksize; hashsize)
Set block size and hash table size. This function canbe called more than once to change those sizes. Thecon�guration-dependent default value can be selectedby passing 0.
� th fork(f; arg1; arg2; hint1; hint2; hint3)
Create and schedule a thread to call f(arg1; arg2). Thehint1, hint2 and hint3 are memory addresses used asscheduling hints. For the two-dimensional case, hint3will be 0. Similarly, for one-dimensional case, bothhint2 and hint3 will be 0.
� th run(keep)
Run all threads that have been scheduled, by th fork,and then return. The thread speci�cations will bedestroyed if keep is 0, or saved to allow re-executionotherwise.
The user interface functions do not return any value.There are no handles or other identi�ers for threads, and nooperations that act on them individually. Error handling, asnecessary, is entirely internal, re ecting the current researchuse of the system in batch-oriented scienti�c programs.
3.2 Implementation
The thread package is implemented with four basic datastructures: thread group, bin, hash table, and ready list.Figure 3 shows the relationships of these data structures.
m
...
threads
. . ....
threads
...
threads
Bin Bin Bin
th_fork() places a thread into a bin
by hashing hint addresses
Ready list0 1
Figure 3: Relationships of threads, bins, and ready list.
The thread group data structure represents a numberof threads within a bin; by grouping threads together inthis way, amortization reduces the cost of thread structuremanagement. Since the thread package supports only non-preemptive scheduling, the data required to represent eachthread is very simple: a void function pointer and the twoarguments arg1 and arg2 supplied by the user to th fork.The thread group consists of an array of these structuresplus an integer to count the number of threads actually inthe group and a pointer to the next thread group in the bin.

Since the thread package has no preemptive scheduling,there is only one stack used by the program. As each threadterminates, the stack is given to the next thread by thescheduler.
The bin data structure contains three link �elds anda search key. The �rst �eld links bins that fall into thesame hash block. The hashing function guarantees thatthreads falling into the same block in the scheduling plane(as described in the previous section) will be placed in thesame bin. The second link �eld chains all threads groupsassociated with the same scheduling bin. The ready list usesthe third link �eld for scheduling.
The hash table organizes the bins. Hash collisionsare resolved by chaining, and the table is simply a three-dimensional array of pointers to bins. An application canchange the hash function by setting its own block size andhash table size.
The ready list contains threads that are ready to run. Theready list is a simple linked list containing all allocated bins.Each time a new bin is allocated, it is added to the end ofthis list. The scheduler does not allocate a bin in the hashtable until it schedules the �rst thread in it. When th runis called, the ready list is traversed, in order, to �nd andexecute all threads.
The mapping from hints to blocks and the hash functionare recon�gurable. The default dimension sizes of the blockare set such that their sum are the same as the second-levelcache size. The hashing function hashes all hints as indicesto a bin. The default hashing function simply performs ashift and a mask operation on each hint.
4 Experiments
Our experiments were designed to measure the overheadof the thread package and to measure the performance ofapplications threaded for cache locality. We experimentedwith the thread package on two computer systems: SGIPower Indigo2 and SGI Indigo2 IMPACT. We conductedexperiments on two di�erent machines to examine the ef-fect on the thread package of di�erent system performancecharacteristics. Both systems were equipped with the sameamount of memory (128MB), easily accommodating our testswithout any paging.
The SGI Power Indigo2 has a 75 MHz MIPS R8000 CPU,separate 16KB �rst-level instruction and data caches, and auni�ed 2 MB 4-way set associative second-level cache. Theline sizes are 32 and a 128 bytes for the �rst and second levelcaches, respectively. The R8000 has two oating point units,two integer units, and two memory load/store units [23]. Itis capable of executing up to four instructions each clockcycle. Its SPECint92 performance is 113 and SPECfp92 is269. (Estimated SPECint95 is 2.8 and SPECfp95 is 8.9.)
The SGI Indigo2 IMPACT is a newer system, with a195 MHz MIPS R10000 CPU, separate 32KB 2-way setassociative �rst-level instruction and data caches, and auni�ed 1 MB 2-way set associative second-level cache. Theline sizes are: 64 bytes, 32 bytes, and a 128 bytes, respectively(I, D, and L2 caches). The R10000 is a 4-way superscalar
CPU with two integer pipelines, two oating point pipelines,one load/store pipeline, and out of order execution [33]. ItsSPECint95 performance is 8.9 and SPECfp95 is 12.5.
We �rst measured the overhead of thread primitives andthen measured the performance of four applications. The�rst three applications are written in Fortran (column majorlayout), and the last is written in C (row major layout).Either layout works with our scheduler. In general, for eachapplication, we conducted the following sets of runs: the bestunthreaded/untiled version, the compiler tiled and/or handtiled or cache conscious version (when available), and thethreaded version. All times reported are in CPU seconds.
In order to understand our results better, we performedcache simulations, on the SGI Power Indigo2, using addressreference traces taken from the same executable binaryprograms that were used to produce the timing results. Theaddress traces were generated by Pixie [37], and processed bya modi�ed DineroIII cache simulator [20, 21]. Our modi�ca-tions to DineroIII allow it to process traces containing 231 ormore references, to classify misses as compulsory, capacity,or con ict in a single run, and to further reduce simulationtime by directly reading the binary Pixie trace output. Theresults presented exclude program initialization costs.
The rest of this section describes the benchmarks, reportsthe performance and cache simulation numbers, and analyzesthe results.
4.1 Micro Benchmarks
Table 1 reports the overhead to fork (create and schedule)and run (execute and terminate) a null thread on bothmachines. The total overhead associated with the threadis also shown. The last row of the table shows the cost of anL2 cache miss on each machine [24, 34, 35]
R8000 R10000Fork 1.38 0.95Run 0.22 0.14Total 1.60 1.09
L2 Miss 1.06 0.85
Table 1: Thread overhead in microseconds.
The thread overheads were calculated using a simple loopthat created 1,048,576 threads to call the null procedure andthen ran them. The threads were evenly distributed acrossthe scheduling plane.
4.2 Matrix Multiply
Matrix multiplication is a simple example to show thedi�erences among di�erent methods. A matrix multiplicationcan be computed in several ways. The most commonsequential method is:
for j = 1 to nfor k = 1 to nfor i = 1 to nC[i; j] = C[i; j] +A[i; k] � B[k; j];

This method interchanges the 3 loops to reduce cache misses(column-major storage order assumed). Since B[k; j] is notchanged in the inner-most loop, it can be lifted out and put ina register in the middle loop. Thus, the minimum number ofmemory references for each iteration of the inner-most loop istwo loads and one store. We call this version interchanged.
Another cache-conscious algorithm transposes matrix Abefore and after the multiplication so that the dot-productloop will access data elements from two sequentially storedvectors. The loops are:
for i = 1 to nfor j = 1 to nfor k = 1 to nC[i; j] = C[i; j] + A[k; i] �B[k; j];
In this program, the address of C[i; j] is not changed in theinner-most loop. This enables a compiler or a programmer touse a register in the inner-most loop and only store the valueback to memory when the loop �nishes. Thus, the minimumnumber of memory instructions in each iteration of the inner-most loop is two loads. Obviously, this approach musttranspose matrix A twice. However, since the complexityof a transpose is an order of magnitude less than the matrixmultiply, the overhead of transposes is small. We call thisversion transposed.
The threaded version is produced by substituting theinner-most loop with a thread:
for i = 1 to nfor j = 1 to nth fork(DotProduct; i; j;A[1; i];B[1; j]);
th run(0);
DotProduct(i;j) :for k = 1 to nC[i; j] = C[i; j] + A[k; i] �B[k; j];
We call this version threaded.
We have looked at several compiler tiled matrix mul-tiplication programs. We tiled both interchanged andtransposed with the KAP compiler of Kuck & Associates,Inc. for the R8000, and with the SGI Version 7.0 compilerfor the R10000.
Table 2 shows the performance of these matrix multiplica-tions (n = 1024). All programs were compiled with the SGIFortran compiler using its -O3, -mips4, and -n32 switches.For the tiled programs on the R8000, we �rst invoke the KAPcompiler to perform tiling and then use the SGI compiler tocompile the programs. On the R10000 we use SGI's version7.0 Fortran compiler which tiles the program without usingKAP.
The performance numbers for the transposed andthreaded versions include the overhead of two matrix trans-pose operations. The threaded version uses a 2-D schedulingplane to determine the locality of threads and sets the blocksize to be one half of the second-level cache size on bothsystems. On the R8000 (with 2MB cache), the threaded
R8000 R10000Interchanged 102.98 36.63Transposed 95.06 32.96Tiled interchanged 16.61 12.24Tiled transposed 19.73 18.71Threaded 20.32 16.85
Table 2: Matrix multiply performance in seconds.
version creates 1,048,576 threads distributed in 81 bins foran average of 12,945 threads per bin. The distribution of thethreads in the bins was quite uniform.
Although the threaded version improves the performanceof the untiled version by a factor of 5 on the R8000 and morethan a factor of 2 on the R10000, the compiler tiled versionenhances performance by factors of 6 and 3 respectively. Thecompiled version has better performance because it can tilethe registers, �rst-level cache and second-level cache, whereasthe threaded method only reduces misses in the second-levelcache.
R8000 Untiled Tiled ThreadedI fetches 5,388,645 2,184,458 3,929,858D references 3,222,274 728,256 2,193,690L1 misses 408,756 215,652 414,741
rate 4.8 7.4 6.8L2 misses 68,225 738 1,872
rate 4.6 0.3 0.4L2 compulsory 199 200 299L2 capacity 68,025 528 1,311L2 con ict 0 10 262
Table 3: Matrix multiply memory references and cachemisses in thousands.
Table 3 shows the cache simulation results for the R8000system. It includes the results for the untiled interchanged,compiler tiled interchanged, and threaded versions. Thetable shows that capacity misses dominate the L2 cachemisses and that both the tiled version and threaded versionscan reduce most of the misses.
The tiled version reduces the number of instruction anddata references by 3,204M and 2,494M respectively. Such asigni�cant reduction is due to di�erences in code generation.The forms of the inner loops are somewhat di�erent: theuntiled interchanged version has to store partial sums, whichthe threaded version (being based on a transposed algorithm)does not, this directly reduces the number of stores andalso allows the compiler to generate a tighter loop withfewer instructions per result. The transformations performedby KAP include tiling for the registers, which allows aneven greater reduction in memory references through re-useand produces even tighter inner loops. Although the SGIcompiler (with the same optimization switch) unrolls theinner loops for all three versions, the unrolled results arequite di�erent for the reasons above: 10 instructions with 2multiply-adds, 4 loads, 2 stores, 1 integer add, and 1 branchfor the untiled version; 18 instructions with 9 multiply-adds,6 loads, 2 integer adds, and 1 branch for the tiled version;

and 14 instructions with 4 multiply-adds, 8 loads, 1 integeradd, and 1 branch for the threaded version. If we ignore therest of the programs and consider only these inner loops, wecan account for nearly all instructions used to produce thenecessary 230 multiplications (that is 5,368,709, 2,147,484,and 3,758,096 thousand instructions, respectively).
Tiling for the registers and L1 cache not only reducesthe instruction count and total memory references, but italso signi�cantly reduces the number of L1 cache misses, byabout 193M, and L2 cache misses, by 67.5M.
The untiled version of the program is very memoryintensive; we are not able to �gure out exactly where the timegoes by simply making crude assumptions. On average, thereis one data memory reference for every three instructions andthere is about one L1 cache miss for every ten instructions.The R8000 CPU has two integer units, two oating-pointunits, and two load/store units, and the processor canexecute up to four instructions per cycle. It is di�cult tomake accurate assumptions about the pressure on the L1cache without detailed CPU pipeline simulations. If wesimply assume no L1 cache stalls and assume that overhead ofan L1 and L2 cache miss is 7 cycles [23] and 1.06 microsecondsrespectively, then the estimated time saved would be about83 seconds. The di�erence between such a crude estimate andthe actual time saved (87 seconds) is only about 4 seconds.But reducing 3,204M instructions and 2,494 data referenceswould take much more than 4 seconds. It would requirea detailed R8000 CPU and Power Indigo2 memory systemsimulation to fully understand the performance implications.
The threaded version reduces the number of instructionand data references by 1,459M and 1,029M respectively. Thisis also due to code generation of inner loops. Since thethreaded version is based on a transposed algorithm, it doesnot require storing partial sums, so the inner loop requiresfewer instructions and fewer data stores. Unlike the tiledversion, the threaded version increases the number of L1cache misses by about 6M while reduces the L2 cache missesby about 66.4M. Most of the L2 misses avoided were capacitymisses. Like the tiled version, this is a memory intensiveprogram. With the crude assumptions, the threaded versionwould save about 69 seconds in L1 and L2 cache misses.Again, this program is also a memory intensive one; itwould require detailed CPU pipeline and memory systemsimulations to fully understand where the time goes.
4.3 Linear Algebra Solvers
In this section we experiment with two iterative solvers.The �rst is meant to be nested inside a multigrid partialdi�erential equation (PDE) solver. The second is a standardtest case from the compiler community.
We experimented with three versions of the programs:regular implementation, cache-conscious version, and thethreaded version.
Linear elliptic PDE's with boundary conditions can besolved after standard discretization methods (e.g., �niteelements or di�erences) have been applied. A sequence of
sets of sparse linear equations are solved:
A(i)u(i) = b(i); i � 1:
When multigrid is used, i > 1; otherwise i = 1. The primarycomponent in multigrid is the iterative method used toapproximately solve each problem. While interpolation usessome time, it is a small percentage of the overall runningtime.
For an iterative method on a single grid, the typicalalgorithm has the form:
for i1 = 1 to itersaction1
...actionk
In practical multigrid solvers, iters � 5.
Consider the following example of an iterative method tosolve Laplace's equation on a rectangle with a uniform mesh:
for i1 = 1 to itersrb =mod(nx; 2)for krb = 1 to 2for i3 = 1 to nyfor i2 = rb + 1 to nx by 2u[i2; i3] = 1
4 (b[i2; i3]� u[i2 � 1; i3]� u[i2 + 1; i3]�u[i2; i3 � 1]� u[i2; i3 + 1]);
rb = 1� rb;
for i3 = 1 to nyfor i2 = 1 to nxr[i2; i3] = b[i2; i3] � 4u[i2i3]� u[i2 � 1; i3]
�u[i2 + 1; i3]� u[i2; i3 � 1] � u[i2; i3 + 1];
This is just the red-black ordered Gauss-Seidel relaxationmethod with the residuals calculated afterwards. After thelast iteration, the residuals would normally be projectedonto a smaller grid's right hand side or the approximatesolution would be interpolated into and added to a largergrid's approximate solution.
Neither the KAP compiler nor the SGI compiler can doany tiling transformations to improve the performance of thisprogram. To take better advantage of the caches, one needsto convert the algorithm above into an algorithm that is cacheconscious [14]. This method relaxes the i3 = 1 line on thered points �rst. Then, for lines 1 < i3 � ny, the red pointscan be relaxed on line j, followed by the black points on linei3 � 1. Finally, the black points can be relaxed on line j.The residual is calculated along with the black points wherepossible.
The threaded approach is similar. The block, whichcomputes red points on one line and black ones on the trailingline, can be used as the thread. Hence there are ny+1 threadsto do the work each iteration.
Both the cache conscious and threaded approaches resultin the data passing through the cache iters times instead of2�iters + 1 times.

R8000 R10000Regular 9.48 7.80Cache-conscious 5.21 5.21Threaded 7.24 4.98
Table 4: PDE performance in seconds.
Table 4 contains a summary of the CPU time to compute5 iterations of u followed by the residual, for a problem size of2049. The choice of 5 is motivated by what people routinelyuse in multigrid solvers.
The cache-conscious method is up to 45% faster than theregular method.
The threaded method creates one thread for each elementof the result matrix, i.e., 2049 threads. The performanceof the threaded method on the R8000 falls about half waybetween the regular and cache conscious methods. However,on the R10000 the threaded method is slightly faster then thecache conscious method, which shows no speedup over theR8000 version. It is not clear to us why the cache consciousalgorithm did not speed up on the R10000. There are notiled results in the table because neither the KAP nor theSGI compiler can tile this algorithm.
The threaded version is programmed with a speci�cordering (red-black) which determines when an element of uis updated. This is somewhat more complicated than whenany ordering is allowed. For the \any ordering" case, thethreaded implementation is both simple and easily veri�edto be correct. However, both of these cases are trivial incomparison to the cache conscious version of the red-blackordering code.
R8000 Regular Cache ThreadedConscious
I fetches 303,686 277,622 283,467D references 126,044 122,598 126,385L1 misses 80,767 85,040 94,516
rate 18.8 21.2 23.1L2 misses 6,038 2,888 3,415
rate 5.7 2.6 2.9L2 compulsory 788 788 789L2 capacity 5,251 2,100 2,627L2 con ict 0 0 0
Table 5: PDE: cache misses in thousands.
Table 5 reports the data for the PDE cache simulationon the R8000. The problem size simulated is 2,049, just asin the execution experiment. Most of the L2 cache misses ofthe regular program are due to capacity misses. The cache-conscious version can avoid about 60% of the capacity misseswhile the threaded versions avoids about 50%.
The cache-conscious version has 26M instruction refer-ences and 3.4M data references less than the regular versionbecause it uses a di�erent algorithm. On the other hand,the cache-conscious version has 4.3M more L1 cache missesthan the original, but it reduces L2 cache misses by about3.2M. If we perform a crude analysis by assuming that eachinstruction takes a single cycle and that the L1 and L2
cache miss overheads are 7 cycles [23] and 1.06 microseconds,respectively, then the total time saved would be about 3.5seconds, not so far from the actual time saved (4.3 seconds).
The threaded program has 20.2M instruction referencesless than the original program, but it has 345K more datareferences. The threaded program increases L1 cache missesby about 13.7M while reducing the L2 cache misses by about2.6M. With the same crude analysis, the total estimated timesaved is about 1.9 seconds, which is close to the actual timesaved (2.2 seconds).
Although the crude analysis does not take many thingsinto account, it o�ers some implications why the cache-conscious version outperforms the threaded version and whythey both outperform the original program.
The second example presented in this section is a standardtest case from the compiler community [29]. It is similar tothe �rst example, but has some subtle di�erences. First, ituses less data. Second, the ordering of the updates is quitedi�erent. Third, it performs many more iterations (30). Itis designed to solve a problem, not just accelerate anothersolver.
The successive over-relaxation (SOR) is an iterativemethod for solving large linear systems that are symmetric,positive de�nite. It is an extension of the Gauss-Seidelmethod. The SOR Nest, with t iterations is as follows:
for i1 = 1 to tfor i2 = 1 to n� 1for i3 = 1 to n� 1A[i2; i3] = 0:2 � (A[i2; i3] +A[i2 + 1; i3]
+A[i2 � 1; i3] +A[i2; i3 + 1]+A[i2; i3 � 1]);
By simply swapping the i2 and i3 loops, the performancewill increase since the matrix now is accessed column-majorinstead of row-major, reducing the number of cache misses.
The KAP and SGI compilers simply unroll the inner-mostloop instead of performing tiling transformations.
A threaded version of the basic SOR Nest is produced bytaking the inner-most loop and substituting it with a thread:
for i1 = 1 to tfor i3 = 1 to n� 1
th fork(Compute; i3; 0; A(0; i3 � 1); A(n; i3 + 1); 0);th run(0);
Compute(i3; dummy) :for k = 1 to n � 1A[k; i3] = 0:2 � (A[k; i3] + A[k + 1; i3]
+A[k � 1; i3] + A[k; i3 + 1] +A[k; i3 � 1]);
Although there are data dependencies among threads, thealgorithm works �ne because the goal is to reach convergence.Since there is only one data structure used in each thread,only one dimensional scheduling is required. The number ofthreads created is t�(n�1) Depending on the available cachesize, the hints can be �ne tuned to keep as much of the arrayas possible in the cache.
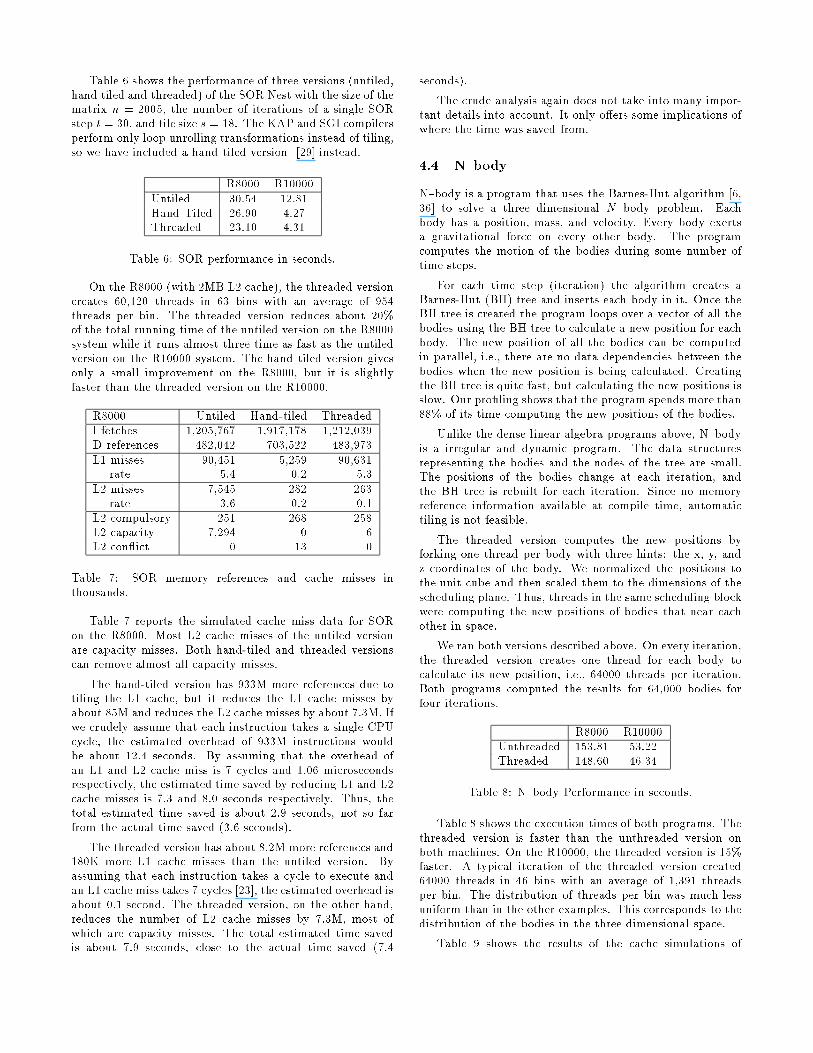
Table 6 shows the performance of three versions (untiled,hand tiled and threaded) of the SOR Nest with the size of thematrix n = 2005, the number of iterations of a single SORstep t = 30, and tile size s = 18. The KAP and SGI compilersperform only loop unrolling transformations instead of tiling,so we have included a hand tiled version [29] instead.
R8000 R10000Untiled 30.54 12.81Hand Tiled 26.90 4.27Threaded 23.10 4.31
Table 6: SOR performance in seconds.
On the R8000 (with 2MB L2 cache), the threaded versioncreates 60,120 threads in 63 bins with an average of 954threads per bin. The threaded version reduces about 20%of the total running time of the untiled version on the R8000system while it runs almost three time as fast as the untiledversion on the R10000 system. The hand tiled version givesonly a small improvement on the R8000, but it is slightlyfaster than the threaded version on the R10000.
R8000 Untiled Hand-tiled ThreadedI fetches 1,205,767 1,917,178 1,212,039D references 482,042 703,522 483,973L1 misses 90,451 5,259 90,631
rate 5.4 0.2 5.3L2 misses 7,545 282 263
rate 3.6 0.2 0.1L2 compulsory 251 268 258L2 capacity 7,294 0 6L2 con ict 0 13 0
Table 7: SOR memory references and cache misses inthousands.
Table 7 reports the simulated cache miss data for SORon the R8000. Most L2 cache misses of the untiled versionare capacity misses. Both hand-tiled and threaded versionscan remove almost all capacity misses.
The hand-tiled version has 933M more references due totiling the L1 cache, but it reduces the L1 cache misses byabout 85M and reduces the L2 cache misses by about 7.3M. Ifwe crudely assume that each instruction takes a single CPUcycle, the estimated overhead of 933M instructions wouldbe about 12.4 seconds. By assuming that the overhead ofan L1 and L2 cache miss is 7 cycles and 1.06 microsecondsrespectively, the estimated time saved by reducing L1 and L2cache misses is 7.3 and 8.0 seconds respectively. Thus, thetotal estimated time saved is about 2.9 seconds, not so farfrom the actual time saved (3.6 seconds).
The threaded version has about 8.2M more references and180K more L1 cache misses than the untiled version. Byassuming that each instruction takes a cycle to execute andan L1 cache miss takes 7 cycles [23], the estimated overhead isabout 0.1 second. The threaded version, on the other hand,reduces the number of L2 cache misses by 7.3M, most ofwhich are capacity misses. The total estimated time savedis about 7.9 seconds, close to the actual time saved (7.4
seconds).
The crude analysis again does not take into many impor-tant details into account. It only o�ers some implications ofwhere the time was saved from.
4.4 N{body
N{body is a program that uses the Barnes-Hut algorithm [6,36] to solve a three dimensional N body problem. Eachbody has a position, mass, and velocity. Every body exertsa gravitational force on every other body. The programcomputes the motion of the bodies during some number oftime steps.
For each time step (iteration) the algorithm creates aBarnes-Hut (BH) tree and inserts each body in it. Once theBH tree is created the program loops over a vector of all thebodies using the BH tree to calculate a new position for eachbody. The new position of all the bodies can be computedin parallel, i.e., there are no data dependencies between thebodies when the new position is being calculated. Creatingthe BH tree is quite fast, but calculating the new positions isslow. Our pro�ling shows that the program spends more than88% of its time computing the new positions of the bodies.
Unlike the dense linear algebra programs above, N{bodyis a irregular and dynamic program. The data structuresrepresenting the bodies and the nodes of the tree are small.The positions of the bodies change at each iteration, andthe BH tree is rebuilt for each iteration. Since no memoryreference information available at compile time, automatictiling is not feasible.
The threaded version computes the new positions byforking one thread per body with three hints: the x, y, andz coordinates of the body. We normalized the positions tothe unit cube and then scaled them to the dimensions of thescheduling plane. Thus, threads in the same scheduling blockwere computing the new positions of bodies that near eachother in space.
We ran both versions described above. On every iteration,the threaded version creates one thread for each body tocalculate its new position, i.e., 64000 threads per iteration.Both programs computed the results for 64,000 bodies forfour iterations.
R8000 R10000Unthreaded 153.81 53.22Threaded 148.60 46.34
Table 8: N{body Performance in seconds.
Table 8 shows the execution times of both programs. Thethreaded version is faster than the unthreaded version onboth machines. On the R10000, the threaded version is 15%faster. A typical iteration of the threaded version created64000 threads in 46 bins with an average of 1,391 threadsper bin. The distribution of threads per bin was much lessuniform than in the other examples. This corresponds to thedistribution of the bodies in the three dimensional space.
Table 9 shows the results of the cache simulations of

R8000 Unthreaded ThreadedI fetches 1,820,656 1,838,089D references 865,713 872,130L1 misses 54,313 55,035
rate 2.0 2.0L2 misses 1,674 778
rate 0.5 0.2L2 compulsory 175 190L2 capacity 1,131 495L2 con ict 369 93
Table 9: N{body memory references and cache misses inthousands.
one iteration of the N{body codes for the R8000 system.Although the threaded version performs about 23.8M moreinstruction fetches and data references, there were only 722Kmore L1 misses. A crude estimate of the threading overheadis about 0.3 seconds for each N{body iteration.
Even though the unthreaded version of N{body has anL2 miss rate of only 0.5%, threading reduces it to 0.2%,decreasing the L2 capacity misses by a factor of 2.3. If wecalculate the time saved in L2 misses using an L2 miss penaltyof 1.06 microseconds, the estimated time saved is 0.95 secondsper iteration. Since the estimated overhead of threading isabout 0.3 seconds, the estimated net time saving is about0.65 seconds. The crude estimate di�ers from the actual timesaved by about 0.75 seconds.
4.5 Sensitivity to Bin Dimension
The bin dimension is an important parameter in the schedul-ing algorithm. It determines the bin into which a thread isplaced. The threaded version of the above experiments wereall conducted with a �xed block size of which each dimensionis 1=k of the second-level cache size for the k-dimensionalcase.
In order to understand how the block size a�ects therunning time of our benchmarks, we ran them with varyingsizes from 128K to 8M. We used some sizes larger than thesecond level cache size to con�rm our intuitions. Figure 4shows the results of these experiments on the Power Indigo2with R8000 CPU. The X axis corresponds to the blockdimension sizes and the Y axis corresponds to the runningtimes.
These graphs show that when the sum of the blockdimensions are less than or equal to the size of the second-level cache, the performance of the programs is relativelyinsensitive to the block size. For a program that is sensitive toL2 cache misses such as the matrix multiply program, thereis a signi�cant performance degradation when the block sizeis greater than the L2 cache size.
5 Related Work
There is a large body of related work including: ar-ranging data structures to maximize locality of reference,
64k 128k 256k 512k 1M 2M 4M 8M
Block dimension size
0
20
40
60
80
Exe
cuti
on T
ime
(sec
onds
)
matrix multiply N-bodySORPDE (2049)
Figure 4: Execution times versus block sizes.
tiling, multi-threaded architectures, and implementations oflightweight thread packages.
Early research e�orts have proposed ways of rearrangingdata structures and altering algorithms to reduce pagefaulting in virtual memory [16, 1]. Tiling has become a well-known software technique for using the memory hierarchye�ectively [18, 29]. Tiling can be applied to any levels ofmemory hierarchy, including virtual memory, caches, andregisters. In particular, tiling can be very e�ective forscienti�c programs, but automatic tiling transformations arequite limited and manual transformation is di�cult.
Scheduling on multiprocessors based on cache a�nityis a technique that maintains processor/thread locality onmultiprocessors [38]. A�nity scheduling avoids cache �llsand invalidations on cache coherent multiprocessors whenthreads are allowed to migrate among processors.
Multi-threaded architectures have been proposed and im-plemented that support multi-threaded parallel programs [2,3, 26, 28, 39]. They typically have architectural support forscheduling threads in one or a few CPU cycles in order tohide various latencies in pipelines, memory references, andnetwork transactions. The success of this approach relies oncreating threads e�ciently at either compile time or run time.
Early ideas on Monitors provided the foundation forconcurrent programming with threads in programming lan-guages [22, 30]. The existence of multiprocessors havemotivated several e�orts to design and implement kerneland user-level thread packages [4, 7, 9, 13, 15] and verylightweight thread packages [25, 31]. However, none of thesee�orts have addressed the issue of scheduling threads forcache locality.
6 Limitations
The method described in this paper has several limitations.First of all, it attempts to reduce misses only for the largest

cache (the cache connecting to the DRAM system). Theoverhead of the thread primitive operations is too high toschedule threads to reduce �rst level cache misses. Onthe other hand, when static memory reference informationavailable, the tiling method used in compilers can takeadvantage of registers, �rst-level, and second-level caches.
Our experiments are limited to 3 address hints, thoughthe scheduling algorithm can use k (where k > 3) addressesas hints to schedule threads. Applications in our experimentsalso do not need more than three addresses.
The thread package supports only independent, \run-to-completion" threads. Such an application programminginterface can be conveniently used to program asynchronousiterative algorithms. However, it would not be convenientto program algorithms that have complex dependencies.Methods to specify dependencies and ways to implementthem e�ciently remain to be demonstrated.
Our experiments are also limited. We only experimentedwith four applications. We compared our results with onlythe tiled versions by the KAP compiler or the new SGIcompiler. It would be more useful to compare our resultswith the results from a compiler with more advanced tilingtechniques.
Our cache simulations for the R8000 system could onlyprovide us with memory reference and cache miss informa-tion. The simulation does not take many important detailsinto account. For example, it works with virtual addresseswhereas the L2 cache uses physical addresses. It does notmodel the cache hierarchy in detail so that there is noinformation on CPU stalls due to the presures on caches.Crude analysis could only o�er implications where saved timecomes from. To �gure out exactly where time goes, it wouldrequire detailed simulations of the R8000 CPU pipelines andits memory hierarchy.
Finally, we did not perform cache simulations for theR10000 and thus we are unable to analyze the performanceresults on that machine in detail.
7 Conclusions
This paper describes a method that uses �ne-grained threadsto improve the locality and execution time of programs. Ourresults with an experimental thread package show that thismethod can e�ectively reduce second-level cache misses andthat the overhead of the thread package is small. In thebest case (matrix multiply), the method can improve theperformance of the untiled version by a factor of 2 on a systemwith R10000 and by a factor of 5 on a system with the R8000CPU. In other cases, threads can also be used to improveperformance by reducing L2 cache misses. We expect thatlatency tolerance techniques such as thread scheduling willbecome more important as the performance gap betweenmemory and CPU increases.
Using a thread package as runtime support to reducesecond-level cache misses can be useful for applications thathave no information about memory reference patterns atcompile time. This is demonstrated by both the PDEand N{body applications. On the other hand, when static
information is available, a good compiler can do better thanour thread package. This is because compiler tiling canreduce total memory references and L1 cache misses, as wellas L2 cache misses.
The study in this paper represents an initial explorationof runtime thread scheduling to tolerate memory latency.Several questions are still open. For example, it is notclear whether the scheduling algorithm can be e�cientlyimplemented with a general-purpose thread package thatsupports synchronization and preemptive scheduling. Itappears that the idea proposed in this paper can be extendedin a straightforward manner to improve performance on sym-metric multiprocessors, but this remains to be demonstrated.
8 Acknowledgements
We would like to thank Thomas Anderson, Susan Eggers,Kathryn McKinley, and other programming committee mem-bers and reviewers for helpful comments and suggestions onthe initial draft of the paper. Monica Lam, David Padua,and John Ruttenberg answered numerous questions abouttiling and helped us �nd a good compiler for our experiments.Torsten Suel provided the N-Body simulation as well as usefulcomments on its data locality. Dave Parry, Bill Hu�man,and Steve Schroder provided us with the cache informationon the SGI machines. Michael Smith, Mike Uhler, andMarty Itzkowitz helped us to understand Pixie address traceformats.
Kai Li is supported in part by DARPA grant N00014-95-1-1144, and by NSF grants MIP-9420653 and CCR-9423123.
References
[1] W. Abu-Sufah, D.J. Kuck, and D.H. Lawrie. AutomaticProgram Transformations for Virtual Memory Computers.In Proceedings of the 1979 National Computer Conference,pages 969{974, June 1979.
[2] A. Agarwal, B. Lim, D. Kranz, and J. Kubiatowicz. APRIL:A Processor Architecture for Multiprocessing. In Proceedingsof the 17th Annual Symposium on Computer Architecture,pages 104{114, May 1990.
[3] R. Alverson, D. Callahan, D. Cummings, B. Koblenz,A. Porter�eld, and B. Smith. The Tera Computer System. InProceedings of International Conference on Supercomputing,pages 1{6, 1990.
[4] T.E. Anderson, B.N. Bershad, E.D. Lazowska, and H.M.Levy. Scheduler Activations: E�ective Kernel Support forthe User-Level Management of Parallelism. In Proceedings ofthe 13th Symposium on Operating Systems Principles, pages95{109, October 1991.
[5] Thomas E. Anderson, Edward D. Lazowska, , and Henry M.Levy. The Performance Implications of Thread ManagementAlternatives for Shared Memory Multiprocessors. IEEETransactions on Computers, 38(12):1631{1644, December1989.
[6] J. E. Barnes and P. Hut. A hierarchical O(NlogN) forcecalculation algorithm. Nature, 324:446{449, 1986.
[7] Brian Bershad, Edward Lazowska, Henry Levy, and DavidWagner. An Open Environment for Building Parallel Pro-gramming Systems. In Proc. ACM/SIGPLAN Conference

on Parallel Programming: Experience with Applications,Languages, and Systems (PPEALS), pages 1{9, June 1988.
[8] Brian N. Bershad, J. Bradley Chen, Dennis Lee, andTheodore H. Romer. Avoiding Con ict Misses Dynamicallyin Large Direct-Mapped Caches. In Proceedings of The6th International Conference on Architectural Support forProgramming Languages and Operating Systems, 1994.
[9] Andrew D. Birrell, John V. Guttag, Jim J. Horning, and RoyLevin. Synchronization Primitives for a Multiprocessor: AFormal Speci�cation. In Proceedings of the 11th Symposiumon Operating Systems Principles, pages 94{102, November1987.
[10] Robert D. Blumofe, Christopher F. Joerg, Bradley C. Kusz-maul, Charles E. Leiserson, Keith H. Randall, and YuliZhou. Cilk: An E�cient Multithreaded Runtime System.In Proceedings of the Fifth ACM SIGPLAN Symposium onPrinciples and Practice of Parallel Programming (PPoPP'95), July 1995.
[11] Bernard Chazelle. Private communication, 1996.
[12] S. Coleman and K. S. McKinley. Tile Size Selection UsingCache Organization and Data Layout. In Proceedings of theSIGPLAN '95 Conference on Programming Language Designand Implementation, LaJolla, CA, June 1995.
[13] Thomas Doeppner Jr. Threads: A System for the Supportof Concurrent Programming. Technical Report CS-87-11,Computer Science Department, Brown University, June 1987.
[14] C. C. Douglas. Caching in with multigrid algorithms:problems in two dimensions. Technical ReportTR/PA/95/15,CERFACS, Toulouse, France, 1995.
[15] Richard P. Draves and Eric C. Cooper. C Threads. Tech-nical Report CMU-CS-88-154, School of Computer Science,Carnegie-Mellon University, June 1988.
[16] J.L. Elsho�. Some Programming Techniques for ProcessingMulti-Dimentional Matrices in a Paging Environment. InProceedings of the NCC, 1974.
[17] Vincent W. Freeh, David K. Lowenthal, and Gregory R.Andrews. E�cient Support for Fine-Grain Parallelism onShared-Memory Machines. Technical Report TR 96-1, De-partment of Computer Science, The University of Arizona,January 1996.
[18] D. Gannon, W. Jalby, and K. Gallivan. Strategies for Cacheand Local Memory Management by Global Program Trans-formation. Journal of Parallel and Distributed Computing,5:587{616, October 1988.
[19] John L. Hennessy and Norman P. Jouppi. Computer Tech-nology and Architecture: An Evolving Interaction. IEEEComputer, 24(9):18{29, September 1991.
[20] Mark D. Hill. DineroIII 3.4 Documentation (UnpublishedUnix-style Man Page), June 1991.
[21] Mark D. Hill and Alan Jay Smith. Evaluating Associa-tivity in CPU Caches. IEEE Transactions on Computers,38(12):1612{1629, December 1989.
[22] C.A.R. Hoare. Monitors: An Operating System StructuringConcept. Communications of the ACM, 17(10):549{557,October 1974.
[23] Peter Y. Hsu. Design of the R8000Microprocessor. Submittedto IEEE MICRO, 1993.
[24] Bill Hu�man. Private communication, 1996.
[25] Suresh Jagannathan and James Philbin. A CustomizableSubstrate for Concurrent Languages. In Proceedings ofACM SIGPLAN '92 Conference on Programming LanguagesDesign and Implementation, 1992.
[26] Stephen W. Keckler and William J. Dally. Processor Cou-pling: Integrating Compile Time and Runtime Scheduling forParallelism. In Proceedings of the 19th Annual Symposiumon Computer Architecture, 1992.
[27] R. Kessler and M.D. Hill. Page Placement Algorithms forLarge Real-Indexed Caches. ACM Transactions on ComputerSystems, 10(4):338{359, November 1992.
[28] J. Kowalik, editor. Parallel MIMD computation : the HEPsupercomputer and its applications. MIT Press, 1985.
[29] M.S. Lam, E.E. Rothberg, and M.E. Wolf. The CachePerformance and Optimizations of Blocked Algorithms. InProceedings of The 4th International Conference on Archi-tectural Support for Programming Languages and OperatingSystems, pages 63{74, April 1991.
[30] B. M. Lampson and D. D. Redell. Experience with Processesand Monitors in Mesa. Communications of the ACM,23(2):105{117, February 1980.
[31] HenryMassalin and Calton Pu. Threads and Input/Output inthe Synthesis Kernel. In Proceedings of the 12th Symposiumon Operating Systems Principles, pages 191{201, December1989.
[32] Larry McVoy and Carl Staelin. lmbench: Portable tools forperformance analysis. In USENIX, January 1996.
[33] MIPS R10000 Microprocessor User's Manual. MIPS Tech-nologies, Inc, version 1.1 edition, 1996.
[34] Dave Parry. Private communication, 1996.
[35] Steve Schroder. Private communication, 1996.
[36] J. P. Singh, J. L. Hennessy, and A. Gupta. Scaling ParallelPrograms for Multiprocessors: Methodology and Examples.Computer, 26(7):42{50, July 1993.
[37] Michael D. Smith. Tracing with Pixie. Technical ReportCSL-TR-91-497, Computer Science Department, StanfordUniversity, November 1991.
[38] M. S. Squillante and E. D. Lazowska. Using processor-cachea�nity in shared-memory multiprocessor scheduling. IEEETransactions on Parallel and Distributed Systems, 4(2):131{143, February 1993.
[39] Dean Tullsen, Susan Eggers, and Henry Levy. Simultane-ous Multithreading: Maximizing On-Chip Parallelism. InProceedings of the 22nd Annual Symposium on ComputerArchitecture, June 1995.
[40] William A. Wulf and Sally A. McKee. Hitting the MemoryWall: Implications of the Obvious. ACM SIGARCH Com-puter Architecture News, 23(1):20{24, March 1995.
Related Documents











