Think Like Spark Some Spark Concepts & A Use Case

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Think Like Spark Some Spark Concepts & A Use Case

Who am I?
• Software engineer, data scientist, and Spark enthusiast at Alpine Data (SF Based Analytics Company)
• Co – Author High Performance Spark http://shop.oreilly.com/product/0636920046967.do
Linked in: https://www.linkedin.com/in/rachelbwarren
• Slide share: http://www.slideshare.net/RachelWarren4
• Github : rachelwarren. Code for this talk https://github.com/high-performance-spark/high-performance-spark-examples
• Twitter: @warre_n_peace

Overview
• A little Spark architecture: How are Spark jobs evaluated?
Why does that matter for performance?
• Execution context: driver, executors, partitions, cores
• Spark Application hierarchy: jobs/stages/tasks
• Actions vs. Transformations (lazy evaluation)
• Wide vs. Narrow Transformations (shuffles & data locality)
• Apply what we have learned with four versions of the
same algorithm to find rank statistics

What is Spark?
Distributed computing framework. Must run in tandem with a data storage system
- Standalone (For Local Testing)
- Cloud (S3, EC2)
- Distributed storage, with cluster manager,
- (Hadoop Yarn, Apache Messos)
Built around and abstraction called RDDs “Resilient, Distributed, Datasets”
- Lazily evaluated, immutable, distributed collection of partition objects

What happens when I launch
a Spark Application?
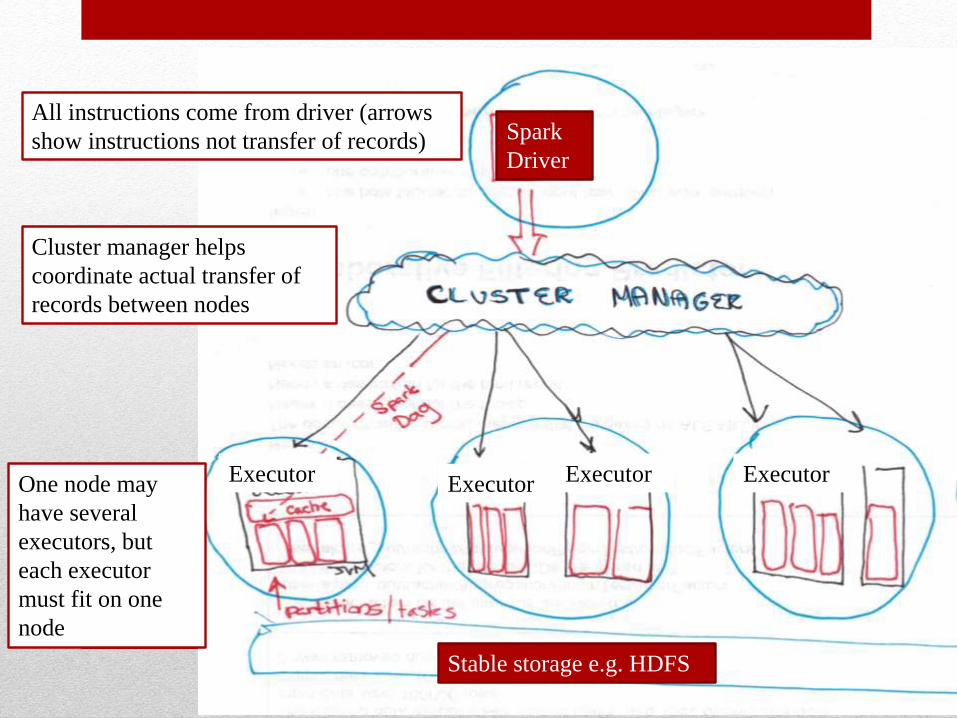
Spark
Driver
ExecutorExecutor Executor Executor
Stable storage e.g. HDFS
All instructions come from driver (arrows
show instructions not transfer of records)
Cluster manager helps
coordinate actual transfer of
records between nodes
One node may
have several
executors, but
each executor
must fit on one
node
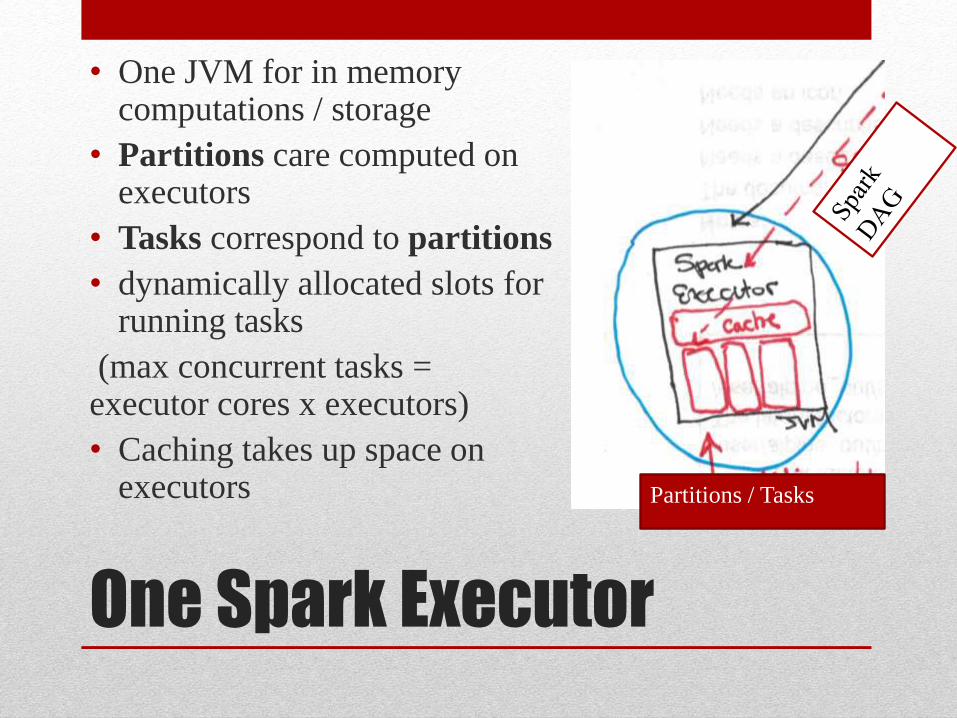
One Spark Executor
• One JVM for in memory computations / storage
• Partitions care computed on executors
• Tasks correspond to partitions
• dynamically allocated slots for running tasks
(max concurrent tasks = executor cores x executors)
• Caching takes up space on executors Partitions / Tasks

Implications
Two Most common cases of failures
1. Failure during shuffle stage
Moving data between Partitions requires communication with the driver
Moving data between nodes required reading and writing shuffle files
2. Out of memory errors on executors and driver
The driver and each executor have a static amount of memory*
*dynamic allocation allows changing the number of executors

How are Jobs Evaluated?
API Call Execution Element
Computation to evaluation one partition (combine
narrow transforms)
Wide transformations (sort, groupByKey)
Actions (e.g. collect, saveAsTextFile)
Spark Context Object Spark
Application
Job
Stage
Task Task
StageExecuted in
Sequence
Executed in
Parallel

Types Of Spark Operations
Actions
• RDD Not RDD
• Force execution: Each job ends in exactly one action
• Three Kinds
• Move data to driver: collect, take, count
• Move data to external system Write / Save
• Force evaluation: foreach
Transformations
• RDD RDD
• Lazily evaluated
• Can be combined and
executed in one pass of
the data
• Computed on Spark
executors

Implications of Lazy Evaluation
Frustrating:
• Debugging =
• Lineage graph is built backwards from action to reading in data or persist/ cache/ checkpoint if you aren’t careful you will repeat computations *
* some times we get help from shuffle files
Awesome:
• Spark can combine some types of transformations and execute them in a single task
• We only compute partitions that we need

Types of Transformations
Narrow
• Never require a shuffle
• map, mapPartitions, filter
• coalesce*
• Input partitions >= output partitions
• & output partitions known at design time
• A sequence of narrow transformations are combined and executed in one stage as several tasks
Wide
• May require a shuffle
• sort, groupByKey, reduceByKey, join
• Requires data movement
• Partitioning depends on data it self (not known at design time)
• Cause stage boundary: Stage 2 cannot be computed until all the partitions in Stage 1 are computed.

Partition Dependencies for
input and output partitions
Narrow Wide

Implications of Shuffles
• Narrow transformations are faster/ more parallelizable
• Narrow transformation must be written so that they can
be computed on any subset of records
• Narrow transformations can rely on some partitioning
information (partition remains constant in each stage)*
• Wide transformations may distribute data unevenly across
machines (depends on value of the key)
• Shuffle files can prevent re-computation
*we can loose partitioning information with map or
mapPartitions(preservesPartitioner = false)

The “Goldilocks Use Case”

Rank Statistics on Wide Data
Design an application that would takes an arbitrary list of
longs `n1`...`nk` and return the `nth` best element in each
column of a DataFrame of doubles.
For example, if the input list is (8, 1000, and 20 million),
our function would need to return the 8th, 1000th and 20
millionth largest element in each column.

Input Data
If we were looking for 2 and 4th elements, result would be:

V0: Iterative solution
Loop through each column:
• map to value in the one column
• Sort the column
• Zip with index and filter for the correct rank statistic (i.e.
nth element)
• Add the result for each column to a map

def findRankStatistics(
dataFrame: DataFrame, ranks: List[Long]): Map[Int, Iterable[Double]] = {
val numberOfColumns = dataFrame.schema.length
var i = 0
var result = Map[Int, Iterable[Double]]()
dataFrame.persist()
while(i < numberOfColumns){
val col = dataFrame.rdd.map(row => row.getDouble(i))
val sortedCol : RDD[(Double, Long)] =
col.sortBy(v => v).zipWithIndex()
val ranksOnly = sortedCol.filter{
//rank statistics are indexed from one
case (colValue, index) => ranks.contains(index + 1)
}.keys
val list = ranksOnly.collect()
result += (i -> list)
i+=1
}
result
}
Persist prevents
multiple data reads
SortBy is Spark’s sort

V0 = Too Many Sorts
• Turtle Picture
• One distributed sort
per column
(800 cols = 800 sorts)
• Each of these sorts
is executed in
sequence
• Cannot save
partitioning data
between sorts
300 Million rows
takes days!

V1: Parallelize by Column
• The work to sort each column can be done without
information about the other columns
• Can map the data to (column index, value) pairs
• GroupByKey on column index
• Sort each group
• Filter for desired rank statistics

Get (Col Index, Value Pairs)
private def getValueColumnPairs(dataFrame : DataFrame): RDD[(Double,
Int)] = {
dataFrame.rdd.flatMap{
row: Row => row.toSeq.zipWithIndex.map{
case (v, index) =>
(v.toString.toDouble, index)}
}
}
Flatmap is a narrow transformation
Column Index Value
1 15.0
1 2.0
.. …

GroupByKey Solution
• def findRankStatistics(dataFrame: DataFrame ,ranks: List[Long]): Map[Int, Iterable[Double]] = {require(ranks.forall(_ > 0))//Map to column index, value pairsval pairRDD: RDD[(Int, Double)] = mapToKeyValuePairs(dataFrame)
val groupColumns: RDD[(Int, Iterable[Double])] = pairRDD.groupByKey()groupColumns.mapValues(
iter => {//convert to an array and sortval sortedIter = iter.toArray.sorted
sortedIter.toIterable.zipWithIndex.flatMap({case (colValue, index) =>if (ranks.contains(index + 1))
Iterator(colValue)else
Iterator.empty})
}).collectAsMap()}

V1. Faster on Small Data fails on Big Data
300 K rows = quick
300 M rows = fails

Problems with V1
• GroupByKey puts records from all the columns with the
same hash value on the same partition THEN loads them
into memory
• All columns with the same hash value have to fit in
memory on each executor
• Can’t start the sorting until after the groupByKey phase
has finished

partitionAndSortWithinPartitions
• Takes a custom partitioner, partitions data according to
that partitioner and then on each partition sorts data by
the implicit ordering of the keys
• Pushes some of the sorting work for each partition into
the shuffle stage
• Partitioning can be different from ordering (e.g. partition
on part of a key)
• SortByKey uses this function with a range partitioner

V2 : Secondary Sort Style
1. Define a custom partitioner which partitions on column
index
2. Map to pairs to ((columnIndex, cellValue), 1) so that the
key is the column index AND cellvalue.
3. Use ‘partitionAndSortWithinPartitions’: with the
custom partitioner to sort all records on each partition
by column index and then value
4. Use mapPartitions to filter for the correct rank statistics

Iterator-Iterator-Transformation
With Map Partitions
• Iterators are not collections. They are a routine for
accessing each element
• Allows Spark to selectively spill to disk
• Don’t need to put all elements into memory
In our case: Prevents loading each column into memory
after the sorting stage

• class ColumnIndexPartition(override val numPartitions: Int)
extends Partitioner {
require(numPartitions >= 0, s"Number of partitions " +
s"($numPartitions) cannot be negative.")
override def getPartition(key: Any): Int = {
val k = key.asInstanceOf[(Int, Double)]
Math.abs(k._1) % numPartitions //hashcode of column index
}
}
Define a custom partition which partitions according to
Hash Value of the column index (first half of key)

def findRankStatistics(pairRDD: RDD[(Int, Double)],
targetRanks: List[Long], partitions: Int) = {
val partitioner = new ColumnIndexPartition(partitions)
val sorted = pairRDD.map((_1))
.repartitionAndSortWithinPartitions(
partitioner)
V2: Secondary Sort
Repartition + sort using
Hash Partitioner

val filterForTargetIndex = sorted.mapPartitions(iter => {
var currentColumnIndex = -1
var runningTotal = 0
iter.flatMap({
case (((colIndex, value), _)) =>
if (colIndex != currentColumnIndex) { //new column
//reset to the new column index
currentColumnIndex = colIndex runningTotal = 1
} else {
runningTotal += 1
}
if (targetRanks.contains(runningTotal)) {
Iterator((colIndex, value))
} else {
Iterator.empty
}
})
}, preservesPartitioning = true)
groupSorted(filterForTargetIndex.collect())
}
V2: Secondary Sort
Iterator-to-iterator
transformation
flatMap can be like both
map and filter

V2: Still Fails
We don’t have put each column into memory on on
executor,
but columns with the same hash value still have to be able
to fit on one partition

Back to the drawing board
• Narrow transformations are quick and easy to parallelize
• Partition locality can be retained across narrow transformations
• Wide transformations are best with many unique keys.
• Using iterator-to-iterator transforms in mapPartitions prevents
whole partitions from being loaded into memory
• We can rely on shuffle files to prevent re-computation of a
wide transformations be several subsequent actions
We can solve the problem with one sortByKey and three map
partitions

V3: Mo Parallel, Mo Better
1. Map to (cell value, column index) pairs
2. Do one very large sortByKey
3. Use mapPartitions to count the values per column on each partition
4. (Locally) using the results of 3 compute location of each rank statistic on each partition
5. Revisit each partition and find the correct rank statistics using the information from step 4.
e.g. If the first partition has 10 elements from one column . The13th element will be the third element on the second partition in that column.

def findRankStatistics(dataFrame: DataFrame, targetRanks: List[Long]):
Map[Int, Iterable[Double]] = {
val valueColumnPairs: RDD[(Double, Int)] = getValueColumnPairs(dataFrame)
val sortedValueColumnPairs = valueColumnPairs.sortByKey()
sortedValueColumnPairs.persist(StorageLevel.MEMORY_AND_DISK)
val numOfColumns = dataFrame.schema.length
val partitionColumnsFreq =
getColumnsFreqPerPartition(sortedValueColumnPairs, numOfColumns)
val ranksLocations =
getRanksLocationsWithinEachPart(targetRanks, partitionColumnsFreq, numOfColumns)
val targetRanksValues = findTargetRanksIteratively(sortedValueColumnPairs, ranksLocations)
targetRanksValues.groupByKey().collectAsMap()
}
Complete code here: https://github.com/high-performance-spark/high-performance-spark-
examples/blob/master/src/main/scala/com/high-performance-spark-examples/GoldiLocks/GoldiLocksFirstTry.scala
1. Map to (val, col) pairs
2. Sort
3. Count per partition
4.
5. Filter for element
computed in 4

Complete code here:
https://github.com/high-performance-spark/high-
performance-spark-
examples/blob/master/src/main/scala/com/high-
performance-spark-
examples/GoldiLocks/GoldiLocksFirstTry.scala

V3: Still Blows up!
• First partitions show lots of failures and straggler tasks
• Jobs lags or fails in the sort stage and fails in final
mapPartitions stage
More digging reveled data was not evenly distributed

Data skew¼ of columns are zero

V4: Distinct values per Partition
• Instead of mapping from (value, column index pairs),
map to ((value, column index), count) pairs on each
partition
e. g. if on a given partition, there are ten rows with 0.0 in
the 2nd column, we could save just one tuple:
(0.0, 2), 10)
• Use same sort and mapPartitions routines, but adjusted
for counts of records not unique records.

Different Key
column0 column2
2.0 3.0
0.0 3.0
0.0 1.0
0.0 0.0
(value, column Index), count)
((2.0, 0), 1)
(2.0,0), 3)
(3.0, 1), 2) ….

V4: Get (value, o
• Code for V4
def getAggregatedValueColumnPairs(dataFrame : DataFrame) : RDD[((Double, Int),
Long)] = {
val aggregatedValueColumnRDD = dataFrame.rdd.mapPartitions(rows => {
val valueColumnMap = new mutable.HashMap[(Double, Int), Long]()
rows.foreach(row => {
row.toSeq.zipWithIndex.foreach{
case (value, columnIndex) =>
val key = (value.toString.toDouble, columnIndex)
val count = valueColumnMap.getOrElseUpdate(key, 0)
valueColumnMap.update(key, count + 1)
}
})
valueColumnMap.toIterator
})
aggregatedValueColumnRDD
}
Map to ((value, column Index) ,count)
Using a hashmap to keep track of uniques

Code for V4
• Lots more code to complete the whole algorithm
https:
//github.com/high-performance-spark/high-performance-
spark-examples/blob/master/src/main/scala/com/high-
performance-spark-
examples/GoldiLocks/GoldiLocksWithHashMap.scala

V4: Success!
• 4 times faster than previous
solution on small data
• More robust, more
parallelizable! Scaling to
billions of rows!
Happy Goldilocks!

Why is V4: Better
Advantages
• Sorting 75% of original records
• Most keys are distinct
• No stragglers, easy to parallelize
• Can parallelize in many different ways

Lessons
• Sometimes performance looks ugly
• Best unit of parallelization? Not always the most intuitive
• Shuffle Less
• Push work into narrow transformations
• leverage data locality to prevent shuffles
• Shuffle Better
• Shuffle fewer records
• Use narrow transformations to filter or reduce before shuffling
• Shuffle across keys that are well distributed
• Best if records associated with one key fit in memory
• Know you data
Before We Part …
• Alpine Data is hiring!
http://alpinedata.com/careers/
• Buy my book!
http://shop.oreilly.com/product/0636920046967.do
Also contact me if you are interested in being a reviewer
Related Documents

![In-Memory Computation with Spark … · Concepts Architecture Computation Managing Jobs Examples Higher-Level AbstractionsSummary Overview to Spark [10, 12] In-memory processing (and](https://static.cupdf.com/doc/110x72/5f517397a1ab4b349326ac6c/in-memory-computation-with-spark-concepts-architecture-computation-managing-jobs.jpg)









