287 THE TAU PARALLEL PERFORMANCE SYSTEM THE TAU PARALLEL PERFORMANCE SYSTEM Sameer S. Shende Allen D. Malony DEPARTMENT OF COMPUTER AND INFORMATION SCIENCE, UNIVERSITY OF OREGON, EUGENE, OR ([email protected]) Abstract The ability of performance technology to keep pace with the growing complexity of parallel and distributed systems depends on robust performance frameworks that can at once provide system-specific performance capabilities and support high-level performance problem solving. Flexibility and portability in empirical methods and processes are influenced primarily by the strategies available for instru- mentation and measurement, and how effectively they are integrated and composed. This paper presents the TAU (Tuning and Analysis Utilities) parallel performance sys- tem and describe how it addresses diverse requirements for performance observation and analysis. Key words: Performance evaluation, instrumentation, meas- urement, analysis, TAU 1 Introduction The evolution of computer systems and of the applications that run on them – towards more sophisticated modes of operation, higher levels of abstraction, and larger scale of execution – challenge the state of technology for empiri- cal performance evaluation. The increasing complexity of parallel and distributed systems, coupled with emerging portable parallel programming methods, demands that empirical performance tools provide robust performance observation capabilities at all levels of a system, while mapping low-level behavior to high-level performance abstractions in a uniform manner. Given the diversity of performance problems, evalua- tion methods, and types of events and metrics, the instru- mentation and measurement mechanisms needed to support performance observation must be flexible, to give maximum opportunity for configuring performance experiments, and portable, to allow consistent cross-platform perform- ance problem solving. In general, flexibility in empirical performance evaluation implies freedom in experiment design, and choices in selection and control of experiment mechanisms. Using tools that otherwise limit the type and structure of performance methods will restrict evaluation scope. Portability, on the other hand, looks for common abstractions in performance methods and how these can be supported by reusable and consistent techniques across different computing environments (software and hardware). Lack of portable performance evaluation environments forces users to adopt different techniques on different sys- tems, even for common performance analysis. The TAU (Tuning and Analysis Utilities) parallel per- formance system is the product of fourteen years of devel- opment to create a robust, flexible, portable, and integrated framework and toolset for performance instrumentation, measurement, analysis, and visualization of large-scale parallel computer systems and applications. The success of the TAU project represents the combined efforts of researchers at the University of Oregon and colleagues at the Research Centre Juelich and Los Alamos National Laboratory. The purpose of this paper is to provide a complete overview of the TAU system. The discussion will be organized first according to the TAU system archi- tecture and second from the point of view of how to use TAU in practice. 2 A General Computation Model for Parallel Performance Technology To address the dual goals of performance technology for complex systems – robust performance capabilities and widely available performance problem solving method- ologies – we need to contend with problems of system diversity while providing flexibility in tool composition, configuration, and integration. One approach to address The International Journal of High Performance Computing Applications, Volume 20, No. 2, Summer 2006, pp. 287–311 DOI: 10.1177/1094342006064482 © 2006 SAGE Publications Figures 1–13 appear in color online: http://hpc.sagepub.com

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

287THE TAU PARALLEL PERFORMANCE SYSTEM
THE TAU PARALLEL PERFORMANCE SYSTEM
Sameer S. Shende Allen D. Malony
DEPARTMENT OF COMPUTER AND INFORMATION SCIENCE, UNIVERSITY OF OREGON, EUGENE, OR([email protected])
Abstract
The ability of performance technology to keep pace withthe growing complexity of parallel and distributed systemsdepends on robust performance frameworks that can atonce provide system-specific performance capabilities andsupport high-level performance problem solving. Flexibilityand portability in empirical methods and processes areinfluenced primarily by the strategies available for instru-mentation and measurement, and how effectively they areintegrated and composed. This paper presents the TAU(Tuning and Analysis Utilities) parallel performance sys-tem and describe how it addresses diverse requirementsfor performance observation and analysis.
Key words: Performance evaluation, instrumentation, meas-urement, analysis, TAU
1 Introduction
The evolution of computer systems and of the applicationsthat run on them – towards more sophisticated modes ofoperation, higher levels of abstraction, and larger scale ofexecution – challenge the state of technology for empiri-cal performance evaluation. The increasing complexity ofparallel and distributed systems, coupled with emergingportable parallel programming methods, demands thatempirical performance tools provide robust performanceobservation capabilities at all levels of a system, whilemapping low-level behavior to high-level performanceabstractions in a uniform manner.
Given the diversity of performance problems, evalua-tion methods, and types of events and metrics, the instru-mentation and measurement mechanisms needed to supportperformance observation must be flexible, to give maximumopportunity for configuring performance experiments,and portable, to allow consistent cross-platform perform-ance problem solving. In general, flexibility in empiricalperformance evaluation implies freedom in experimentdesign, and choices in selection and control of experimentmechanisms. Using tools that otherwise limit the type andstructure of performance methods will restrict evaluationscope. Portability, on the other hand, looks for commonabstractions in performance methods and how these canbe supported by reusable and consistent techniques acrossdifferent computing environments (software and hardware).Lack of portable performance evaluation environmentsforces users to adopt different techniques on different sys-tems, even for common performance analysis.
The TAU (Tuning and Analysis Utilities) parallel per-formance system is the product of fourteen years of devel-opment to create a robust, flexible, portable, and integratedframework and toolset for performance instrumentation,measurement, analysis, and visualization of large-scaleparallel computer systems and applications. The successof the TAU project represents the combined efforts ofresearchers at the University of Oregon and colleagues atthe Research Centre Juelich and Los Alamos NationalLaboratory. The purpose of this paper is to provide acomplete overview of the TAU system. The discussionwill be organized first according to the TAU system archi-tecture and second from the point of view of how to useTAU in practice.
2 A General Computation Model for Parallel Performance Technology
To address the dual goals of performance technology forcomplex systems – robust performance capabilities andwidely available performance problem solving method-ologies – we need to contend with problems of systemdiversity while providing flexibility in tool composition,configuration, and integration. One approach to address
The International Journal of High Performance Computing Applications,Volume 20, No. 2, Summer 2006, pp. 287–311DOI: 10.1177/1094342006064482© 2006 SAGE PublicationsFigures 1–13 appear in color online: http://hpc.sagepub.com

288 COMPUTING APPLICATIONS
these issues is to focus attention on a sub-class of compu-tation models and performance problems as a way torestrict the performance technology requirements. Theobvious consequence of this approach is limited tool cov-erage. Instead, our idea is to define an abstract computationmodel that captures general architecture and softwareexecution features and can be mapped straightforwardlyto existing complex system types. For this model, we cantarget performance capabilities and create a tool frame-work that can adapt and be optimized for particular com-plex system cases.
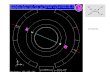
Our choice of general computation model must reflectreal computing environments, both in terms of the paral-lel systems architecture and the parallel software envi-ronment. The computational model we target was initiallyproposed by the HPC++ consortium (HPC++ WorkingGroup 1995) and is illustrated in Figure 1. Two com-bined views of the model are shown: a physical (hard-ware) view and an abstract software view. In the model, anode is defined as a physically distinct machine with oneor more processors sharing a physical memory system(i.e. a shared memory multiprocessor (SMP)). A nodemay link to other nodes via a protocol-based interconnect,ranging from proprietary networks, as found in tradi-tional MPPs, to local- or global-area networks. Nodes andtheir interconnection infrastructure provide a hardwareexecution environment for parallel software computa-tion. A context is a distinct virtual address space within anode providing shared memory support for parallel soft-ware execution. Multiple contexts may exist on a singlenode. Multiple threads of execution, both user and sys-tem level, may exist within a context; threads within a
context share the same virtual address space. Threads indifferent contexts on the same node can interact via inter-process communication (IPC) facilities, while threads incontexts on different nodes communicate using messagepassing libraries (e.g. MPI) or network IPC. Shared-mem-ory implementations of message passing can also be usedfor fast intra-node context communication. The bold arrowsin the figure reflect scheduling of contexts and threads onthe physical node resources.
The computation model above is general enough toapply to many high-performance architectures as well asto different parallel programming paradigms. Particularinstances of the model and how it is programmed definesrequirements for performance tool technology. That is,by considering different instances of the general computingmodel and the abstract operation of each, we can identifyimportant capabilities that a performance tool should sup-port for each model instance. When we consider a per-formance system to accommodate the range of instances,we can look to see what features are common and can beabstracted in the performance tool design. In this way,the capability abstraction allows the performance systemto retain uniform interfaces across the range of parallelplatforms, while specializing tool support for the particu-lar model instance.
3 TAU Performance System Architecture
The TAU performance system (Shende et al. 1998; Malonyand Shende 2000; University of Oregon b) is designed asa tool framework, whereby tool components and modulesare integrated and coordinate their operation using well-
Fig. 1 Execution model supported by TAU.

289THE TAU PARALLEL PERFORMANCE SYSTEM
defined interfaces and data formats. The TAU frameworkarchitecture is organized into three layers – instrumenta-tion, measurement, and analysis – where within each layermultiple modules are available and can be configured ina flexible manner under user control.
The instrumentation and measurement layers of theTAU framework are shown in Figure 2. TAU supportsa flexible instrumentation model that allows the userto insert performance instrumentation calling the TAUmeasurement API at different, multiple levels of pro-gram code representation, transformation, compilation,and execution. The key concept of the instrumentation
layer is that it is here where performance events aredefined. The instrumentation mechanisms in TAU sup-port several types of performance events, includingevents defined by code location (e.g. routines or blocks),library interface events, system events, and arbitraryuser-defined events. TAU is also aware of events associ-ated with message passing and multi-threading parallelexecution. The instrumentation layer is used to defineevents for performance experiments. Thus, one output ofinstrumentation are information about the events for aperformance experiment. This information will be usedby other tools.
Fig. 2 Architecture of TAU Performance System – Instrumentation and Measurement.

290 COMPUTING APPLICATIONS
The instrumentation layer interfaces with the measure-ment layer through the TAU measurement API. TAU’smeasurement system is organized into four parts. The eventcreation and management part determines how events areprocessed. Events are dynamically created in the TAUsystem as the result of their instrumentation and occur-rence during execution. Two types of events are sup-ported: entry/exit events and atomic events. In addition,TAU provides the mapping of performance measurementsfor “low-level” events to high-level execution entities.Overall, this part provides the mechanisms to manageevents as a performance experiment proceeds. It includesthe grouping of events and their runtime measurementcontrol. The performance measurement part supports twomeasurement forms: profiling and tracing. For each form,TAU provides the complete infrastructure to manage themeasured data during execution at any scale (number ofevents or parallelism). The performance data sources partdefines what performance data is measurable and can beused in profiling or tracing. TAU supports different timingsources, choice of hardware counters through the PAPI(Browne et al. 2000) or PCL (Berrendorf, Ziegler, andMohr) interfaces, and access to system performance data.The OS and runtime system part provide the couplingbetween TAU’s measurement system and the underlyingparallel system platform. TAU specializes and optimizesits execution according to the platform features available.
The TAU measurement systems can be customized andconfigured for each performance experiment by compos-ing specific modules for each part and setting runtimecontrols. For instance, based on the composition of mod-ules, an experiment could easily be configured to measurethe profile that shows the inclusive and exclusive countsof secondary data cache misses associated with basicblocks such as routines, or a group of statements. By pro-viding a flexible measurement infrastructure, a user canexperiment with different attributes of the system anditeratively refine the performance characterization of aparallel application.
The TAU analysis and visualization layer is shown inFigure 3. As in the instrumentation and measurementlayer, TAU flexibility allows use of several modules. Theseare separated between those for parallel profile analysisand parallel trace analysis. For each, support is given to themanagement of the performance data (profiles or traces),including the conversion to/from different formats. TAUcomes with both text-based and graphical tools to visual-ize the performance profiles. ParaProf (Bell, Malony, andShende 2003) is TAU’s parallel profile analysis and visu-alization tool. Also distributed with TAU is the PerfDMF(Huck et al. 2005) tool providing multi-experiment paral-lel profile management. Given the wealth of third-partytrace analysis and visualization tools, TAU does not imple-ment its own. However, trace translation tools are imple-
mented to enable use of Vampir (Intel Corporation; Nagelet al. 1996), Jumpshot (Wu et al. 2000), and Paraver (Euro-pean Center for Parallelism of Barcelona (CEPBA)). It isalso possible to generate EPILOG (Mohr and Wolf 2003)trace files for use with the Expert (Wolf et al. 2004) anal-ysis tool. All TAU profile and trace data formats are open.
The framework approach to TAU’s architecture designguarantees the most flexibility in configuring TAU capa-bilities to the requirements of the parallel performanceexperimentation and problem solving the user demands.In addition, it allows TAU to extend these capabilities toinclude the rich technology being developed by other per-formance tool research groups. In the sections that follow,we look at each framework layer in more depth and dis-cuss in detail what can be done with the TAU perform-ance system.
4 Instrumentation
In order to observe performance, additional instructionsor probes are typically inserted into a program. This proc-ess is called instrumentation. From this perspective, theexecution of a program is regarded as a sequence ofsignificant performance events. As events execute, theyactivate the probes which perform measurements. Thus,instrumentation exposes key characteristics of an execu-tion. Instrumentation can be introduced in a program atseveral levels of the program transformation process. Inthis section we describe the instrumentation options sup-ported by TAU.
4.1 Source-Based Instrumentation
TAU provides an API that allows programmers to manu-ally annotate the source code of the program. Source-level instrumentation can be placed at any point in theprogram and it allows a direct association between lan-guage- and program-level semantics and performancemeasurements. Using cross-language bindings, TAU pro-vides its API in C++, C, Fortran, Java, and Python lan-guages. Thus, language specific features (e.g. runtime typeinformation for tracking templates in C++) can be lever-aged. TAU also provides a higher-level specification inSIDL (Kohn et al. 2001; Shende et al. 2003) for cross-lan-guage portability and deployment in component-basedprogramming environments (Bernholdt et al. 2005).
TAU’s API can be broadly classified into the followingfive interfaces:
• Interval event interface• Atomic event interface• Query interface• Control interface• Sampling interface

291THE TAU PARALLEL PERFORMANCE SYSTEM
4.1.1 Interval event interface TAU supports the abil-ity to make performance measurements with respect toevent intervals. An event interval is defined by its startevents and its stop events. A user may bracket parts ofhis/her code to specify a region of interest using a pair ofstart and stop event calls. There are several ways to iden-tify interval events and performance tools have used dif-ferent techniques. It is probably more recognizable totalk about interval events as timers. To identify a timer,some tools advocate the use of numeric identifiers and anassociated table mapping the identifiers to timer names.While it is easy to specify and pass the timer identifieramong start and stop routines, it has its drawbacks. Main-taining a table statically might work for languages such
as Fortran 90 and C, but it extends poorly to C++, wherea template may be instantiated with different parameters.This aspect of compile time polymorphism makes it dif-ficult to disambiguate between different instantiations ofthe same code. Also, it can introduce instrumentationerrors in maintaining the table that maps the identifiers tonames. This is true for large projects that involve severalapplication modules and developers.
Our interface uses a dynamic naming scheme whereinterval event (timer) names are associated with the per-formance data (timer) object at runtime. An interval eventcan have a unique name and a signature that can be obtainedat runtime. In the case of C++, this is done using runtimetype information of objects. Several logically related inter-
Fig. 3 Architecture of TAU Performance System – Analysis and Visualization.

292 COMPUTING APPLICATIONS
val events can be grouped together using an optional pro-file group. A profile group is specified using a name theinterval event created.
In the case of C++, the TAU interface leverages thelanguage preprocessing system and object-oriented fea-tures. A single interval event macro inserted in a routineis sufficient to track its entry and exit. This is achieved bydefining a pair of objects. The first FunctionInfo object isa static object whose constructor is invoked exactly oncewith parameters such as its name, signature, and group.The second Profiler object’s constructor and destructor areinvoked when it comes in and goes out of scope respec-tively. In this manner, the constructor and destructormechanism is used to start and stop the interval eventassociated with the given basic block.
4.1.2 Atomic event interface TAU also allows forevents that take place atomically at a specific location inthe source code to be identified and tracked. The genericatomic event interface provides a single trigger methodwith a data parameter. This permits the user to associateapplication data with such an event. TAU internally usesthis interface for some of its performance measurements,such as tracking memory utilization and sizes of mes-sages involved in inter-process synchronization opera-tions using the MPI library. TAU implements the atomicevent interface by keeping track of the event name, andthe data associated with it. In the profiling mode of meas-urement, it currently tracks the maxima, minima, mean,standard deviation and the number of samples.
4.1.3 Profile query interface The profile query inter-face allows the program to interact with the measurementsubstrate to query the performance metrics recordedby TAU. These metrics are represented as a list of profilestatistics associated with each interval and atomic event.For each interval event, a set of exclusive and inclusivevalues is available in the profile for each performancemeasurement source. It provides the number of start/stoppairs executed (or the number of calls), and also the numberof timers that each timer called in turn. Instead of exam-ining this data at runtime, an application may ask TAUto store this information in files at the end of the execu-tion. The query interface also provides a access for anonline performance monitoring tool external to the appli-cation.
4.1.4 Event control interface The purpose of the eventcontrol interface is to allow the user to enable and disablea group of events at a coarse level. The user can disableall the groups and selectively enable a set of groups forrefining the focus of instrumentation. Similarly, the usercan start with all groups in an enabled state and selec-tively disable a set of groups. Again, the instrumentation
here is at the source level and the programmer is insert-ing event control calls into their program.
4.1.5 Sampling interface TAU’s sampling interfacecan be used to set up interrupts during program execution.Control of interrupt period and selection of system prop-erties to track are provided. Once enabled, an interrupthandler is invoked when a certain duration of time elapses.It tracks one or more entities by calling the atomic eventinterface. The user can set, enable or disable the samplingof events using the control interface.
While manual instrumentation affords the most flexi-bility, it can be tedious if the instrumentation involvesmanually annotating each routine in a large project. Forautomating the process of instrumentation TAU providesseveral powerful options described below.
4.2 Preprocessor-Based Instrumentation
The source code of a program can be altered by a preproc-essor before it is compiled. This approach typicallyinvolves parsing the source code to infer where instru-mentation probes are to be inserted. As a example of auto-matic instrumentation through the preprocessing builtinto a compiler, TAU’s memory allocation/deallocationtracking package can be used to re-direct the references tothe C malloc/free calls. The preprocessor invokes TAU’scorresponding memory wrapper calls with the added infor-mation about the line number and the file. The atomic eventinterface can then track the size of memory allocated anddeallocated to help locate potential memory leaks.
Preprocessor-based instrumentation is also commonlyused to insert performance measurement calls at intervalentry and exit points in the source code. To support auto-matic performance instrumentation at the source level, theTAU project has developed the Program Database Toolkit(PDT) (Lindlan et al. 2000). The purpose of PDT, shownin Figure 4 is to parse the application source code andlocate the semantic constructs to be instrumented. PDT iscomprised of commercial-grade front-ends that emit anintermediate language (IL) file, IL analyzers that walk theabstract syntax tree and generate a subset of semanticentities in program database (PDB) ASCII text files, and alibrary interface (DUCTAPE) to the PDB files that allowsus to write static analysis tools. PDT uses the Edison DesignGroup’s (EDG) C99 and C++ parsers, Mutek Solutions’Fortran 77 and Fortran 90 parser based on EDG, and wehave recently added Cleanscape Inc. Flint Fortran 95 parserto PDT. The DUCTAPE library provides TAU a uniforminterface to entities from several languages such as C,C++, and Fortran 77/90/95. We have developed a source-to-source instrumentation tool tau_instr that uses PDT. Itre-writes the original source code with performance anno-tations to record the interval event transitions (e.g. routine

293THE TAU PARALLEL PERFORMANCE SYSTEM
entry and exit). The instrumented source code is thencompiled and linked with the TAU measurement libraryto produce an executable code. When the application isexecuted subsequently, performance data is generated.
TAU also supports OpenMP instrumentation using a pre-processor tool called Opari (Mohr). Opari inserts POMP(Mohr et al. 2002) annotations and rewrites OpenMP direc-tives in the source code. TAU’s POMP library tracks thetime spent in OpenMP routines based on each region inthe source code. To track the time spent in user-level rou-tines, Opari instrumentation can be combined with PDTbased instrumentation as well.
4.3 Compiler-Based Instrumentation
A compiler can add instrumentation calls in the objectcode that it generates. There are several advantages toinstrumentation at the compiler level. The compiler has fullaccess to source-level mapping information. It has the abil-ity to choose the granularity of instrumentation and caninclude fine-grained instrumentation. The compiler canperform instrumentation with knowledge of source trans-formations, optimizations and code generation phases.Flexibility of instrumentation allows for examining theperformance of a program to an arbitrary level of detail.Fine-grained instrumentation at the source level, how-ever, interacts with compiler optimizations: instrumentationmay inhibit compiler optimizations, and optimizations maycorrupt measurement code. We have developed an Instru-mentation-Aware Compiler that extends a traditional com-piler to preserve the semantics of fine-grained performanceinstrumentation despite aggressive program restructuring.The compiler strips the instrumentation calls from the
source code and optimizes the compiled source code. Itthen re-instruments the optimized code using mappingsmaintained in the compiler that associate the optimizedinstructions to the original source code (Shende 2001).The instrumentor uses a fast-breakpoint scheme (Kessler1990) that replaces an instruction with a branch instruc-tion. The code branches to a new location, the global state(registers) is saved, an instrumentation call is invoked, theglobal state is restored, and the original replaced instruc-tion is executed. The code then executes a branch to theinstruction following the original instruction to continueexecution.
4.4 Wrapper Library-Based Instrumentation
A common technique to instrument library routines is tosubstitute the standard library routine with an instrumentedversion which in turn calls the orginal routine. The prob-lem is that you would like to do this without having todevelop a different library just to alter the calling inter-face. MPI provides an interface (Forum 1994) that allowsa tool developer to intercept MPI calls in a portable man-ner without requiring a vendor to supply proprietary sourcecode of the library and without requiring the applicationsource code to be modified by the user. This is achieved byproviding hooks into the native library with a name-shiftedinterface and employing weak bindings. Hence, everyMPI call can be accessed with its name shifted interfaceas well. The advantage of this approach is that library-level instrumentation can be implemented by defining awrapper interposition library layer that inserts instrumen-tation calls before and after calls to the native routines.
We developed a TAU MPI wrapper library that inter-cepts calls to the native library by defining routines withthe same name, such as MPI_Send. These routines thencall the native library routines with the name shifted rou-tines, such as PMPI_Send. Wrapped around the call, beforeand after, is TAU performance instrumentation. An addedadvantage of providing such a wrapper interface is that theprofiling wrapper library has access to not only the rou-tine transitions, but also to the arguments passed to thenative library. This allows TAU to track the size of mes-sages, identify message tags, or invoke other native libraryroutines. This scheme helps a performance tool track inter-process communication events.
TAU and several other tools (e.g. Upshot (Gropp andLusk), VampirTrace (Intel Corporation), and EPILOG(Mohr and Wolf 2003)) use the MPI profiling interface.However, TAU can also utilize its rich set of measurementmodules that allow profiles to be captured with varioustypes of performance data, including system and hard-ware data. In addition, TAU’s performance grouping capa-bilities allows MPI events to be presented with respect tohigh-level categories such as send and receive types.
Fig. 4 Program Database Toolkit (PDT).

294 COMPUTING APPLICATIONS
4.5 Binary Instrumentation
TAU uses DyninstAPI (Buck and Hollingsworth 2000)for instrumenting the executable code of a program.DyninstAPI is a dynamic instrumentation package thatallows a tool to insert code snippets into a running pro-gram using a portable C++ class library. For DyninstAPIto be useful with a measurement strategy, calls to a meas-urement library (or the measurement code itself) must becorrectly constructed in the code snippets. Our approachfor TAU uses the DyninstAPI to construct calls to theTAU measurement library and then insert these calls intothe executable code. TAU can instrument a program atruntime, or it can re-write the executable image with callsto the TAU measurement library at routine entry and exitpoints. TAU’s mutator program (tau_run) loads a TAUdynamic shared object (the compiled TAU measurementlibrary) in the address space of the mutatee (the applica-tion program). It parses the executable image for symboltable information and generates the list of modules androutines within the modules that are appropriate forinstrumentation; TAU routines and Dyninst modules areexcluded from consideration. Using the list of routinesand their names, unique identifiers are assigned to eachroutine. The list of routines is then passed as an argumentto a TAU initialization routine that is executed once bythe mutatee (as a one time code). This initialization rou-tine creates a function mapping table to aid in efficientperformance measurement. Code snippets are then insertedat entry and exit transition points in each routine.
Dynaprof (Mucci) is another tool that uses DyninstAPIfor instrumentation. It provides a TAU probe that allowsTAU measurements to interoperate with Dynaprof instru-mentation. An interval event timer is defined to track thetime spent in un-instrumented code. This timer is startedand stopped around each routine callsite. This enables usto precisely track the exclusive time spent in all otherinstrumented routines. Dynaprof can also use a PAPIprobe and generate performance data that can be read byParaProf. This illustrates the clear separation between theinstrumentation, measurement, and analysis layers in TAU.A user may choose to use TAU instrumentation, meas-urement, and analysis using tau_run and ParaProf or shemay choose Dynaprof for instrumentation, TAU for meas-urement, and ParaProf or Vampir for analysis, or she maychoose Dynaprof for instrumentation, a PAPI probe formeasurement, and ParaProf for analysis.
4.6 Interpreter-Based Instrumentation
Interpreted language environments present an interestingtarget for TAU integration. Often such environments sup-port easy integration with native language modules. In thiscase, it is reasonable to attempt to recreate the source-
based instrumentation in the interpreted language, call-ing through the native language support to the backendTAU measurement system. However, it is also true thatinterpreted language environments have built-in supportfor identifying events and monitoring runtime systemactions.
TAU has been integrated with Python by leveraging thePython interpreter’s debugging and profiling capabilitiesto instrument all entry and exit calls. By including the taupackage and passing the top level routine as a parameterto the tau package’s run method, all Python routinesinvoked subsequently are instrumented automatically atruntime. A TAU interval event is created when a call isdispatched for the first time. At routine entry and exitpoints, TAU’s Python API is invoked to start and stop theinterval events. TAU’s measurement library is loaded bythe interpreter at runtime. Since shared objects are used inPython, instrumentation from multiple levels see thesame runtime performance data.
Python is particularly interesting since it can be use todynamically link and control multi-language executablemodules. This raises the issue of how to instrument a pro-gram constructed from modules derived from differentlanguages and composed at runtime. We have demon-strated the use of TAU with the Python-based VTF (Cali-fornia Institute of Technology) code from ASCI ASAPcenter at Caltech. This program involved three modes ofinstrumentation:
• Python source level• MPI wrapper interposition library level• PDT-based automatic instrumentation of Fortran 90,
C++, and C modules
The ability to target multiple instrumentation option con-currently makes it possible for TAU to be used effectivelyin complex programming systems.
4.7 Component-Based Instrumentation
Component technology extends the benefits of scriptingsystems and object-oriented design to support reuse andinteroperability of component software, transparent oflanguage and location (Szyperski 1997). A component isa software object that implements certain functionalityand has a well-defined interface that conforms to a com-ponent architecture defining rules for how componentslink and work together (Bernholdt et al. 2005). It consistsof a collection of ports, where each port represents a set offunctions that are publicly available. Ports implementedby a component are known as provides ports, and otherports that a component is uses are known as uses ports.
The Common Component Architecture (CCA) (CCAForum) is a component-based methodology for develop-

295THE TAU PARALLEL PERFORMANCE SYSTEM
ing scientific simulation codes. The architecture consistsof a framework which enables components (embodimentsof numerical algorithms and physical models) to worktogether. Components are peers and derive no implemen-tation from others. Components publish their interfacesand use interfaces published by others. Components pub-lishing the same interface and with the same functional-ity (but perhaps implemented via a different algorithm ordata structure) may be transparently substituted for eachother in a code or a component assembly. Components arecompiled into shared libraries and are loaded in, instanti-ated and composed into a useful code at runtime.
How should a component-based program be instru-mented for performance measurement? The challengehere is in supporting an instrumentation methodology thatis consistent with component-based software engineering.The approach taken with TAU for CCA was to develop aTAU performance component that other components coulduse for performance measurement. The TAU instrumenta-
tion API is thus recreated as the performance compo-nent’s interface, supporting event creation, event control,and performance query. There are two ways to instru-ment a component based application using TAU. The firstrequires calls to the performance component’s measure-ment port to be added to the source code. This is usefulfor fine-grained measurements inside the component. Thesecond approach interposes a proxy component in front ofa component, thus intercepting the calls to its providesport. In this case, for each edge that represents a port inthe component connection graph, we can interpose theproxy along that edge. A proxy component implements aport interface and has a provides and a uses port. The pro-vides port is connected to the caller’s uses port and itsuses port is connected to the callee’s provides port. Theproxy performs measurements using TAU’s Mastermindor Measurement port (Shende et al. 2003; Ray et al. 2004)as shown in the wiring diagram of CFRFS CCA combus-tion component ensemble in Figure 5.
Fig. 5 Snapshot of the component application, as assembled for execution. We see three proxies (for AMRMesh,EFMFlux and States), as well as the TauMeasurement and Mastermind components to measure and record perform-ance-related data.

296 COMPUTING APPLICATIONS
To aid in the construction of proxies, it is important tonote that we only need to construct one proxy componentfor each port. Different components that implement a givenport use the same proxy component. To automate the proc-ess of creating a proxy component, TAU’s proxy genera-tor uses PDT to parse the source code of a component thatimplements a given port. It infers the arguments andreturn types of a port and its interfaces and constructs thesource code of a proxy component, which when compiledand instantiated in the framework allows us to measurethe performance of a component without any changes toits source or object code. This provides a powerful capa-bility to build performance-engineered scientific compo-nents that can provide computational quality of service(Norris et al. 2004) and allows us to build intelligent, per-formance-aware components.
4.8 Virtual Machine-Based Instrumentation
Support of performance instrumentation and measurementin language systems based on virtual machine (VM) execu-tion poses several challenges. Consider Java and the JVM.Currently, Java 2 (JDK1.2+) incorporates the Java VirtualMachine Profiler Interface (JVMPI) (SUN MicrosystemsInc.; Viswanathan and Liang 2000) which we have usedfor our work. This interface is re-organized in JDK 1.5+as Java Virtual Machine Tool Interface (JVMTI). JVMPIprovides profiling hooks into the virtual machine andallows a profiler agent to instrument the Java applicationwithout any changes to the source code, bytecode, or theexecutable code of the JVM. This is ideal since JVMPIprovides a wide range of events that it can notify to theagent, including method entry and exit, memory alloca-tion, garbage collection, and thread start and stop; see theJava 2 reference for more information. When the profileragent is loaded in memory, it registers the events of inter-est and the address of a callback routine to the virtualmachine using JVMPI. When an event takes place, thevirtual machine thread generating the event calls the pro-filer agent callback routine with a data structure that con-tains event specific information. The profiling agent canthen use JVMPI to get more detailed information regard-ing the state of the system and where the event occurred.The downside of this approach is that JVMPI is a heavy-weight mechanism.
When the TAU agent is loaded in the JVM as a sharedobject, a TAU initialization routine is invoked. It storesthe identity of the virtual machine and requests the JVMto notify it when a thread starts or terminates, a class isloaded in memory, a method entry or exit takes place, orthe JVM shuts down. When a class is loaded, TAU exam-ines the list of methods in the class and creates an associ-ation of the name of the method and its signature, asembedded in the TAU object, with the method identifier
obtained, using the TAU Mapping API (see the TAUUser’s Guide (University of Oregon b)). When a methodentry takes place, TAU performs measurements and cor-relates these to the TAU object corresponding to themethod identifier that it receives from JVMPI. When athread is created, it creates a top-level routine that corre-sponds to the name of the thread, so the lifetime of eachuser and system level thread can be tracked.
To deal with Java’s multi-threaded environment, TAUuses a common thread layer for operations such as gettingthe thread identifier, locking and unlocking the perform-ance database, getting the number of concurrent threads,and so on. (This is an example of the benefit of basing TAUon a general computation model.) The thread layer is thenused by the multiple instrumentation layers. When a threadis created, TAU registers it with its thread module andassigns an integer identifier to it. It stores this in a thread-local data structure using the JVMPI thread API describedabove. It invokes routines from this API to implementmutual exclusion to maintain consistency of performancedata. It is important for the profiling agent to use the samethread interface as the virtual machine that executes themulti-threaded Java applications. This allows TAU tolock and unlock performance data in the same way asapplication level Java threads do with shared global appli-cation data. TAU maintains a per-thread performance datastructure that is updated when a method entry or exit takesplace. Since this is maintained on a per thread basis, itdoes not require mutual exclusion with other threads andis a low-overhead scalable data structure. When a threadexits, TAU stores the performance data associated withthe thread to stable storage. When it receives a JVM shut-down event, it flushes the performance data for all run-ning threads to the disk.
Shende and Malony (2003) demonstrated how MPIevents can be integrated with Java language events fromthe JVM. Here, the JVM was running the Just-in-time(JIT) compiler where the Java bytecode is converted intonative code on the fly as the application executes. TAUcan also be used to profile Java code using Sun’s HotSpotcompiler embedded within the JVM while it transformstime-consuming segments of code to native code at runt-ime. This is in contrast to the operation of the JIT com-piler where all bytecode is converted to native code atruntime.
4.9 Multi-Level Instrumentation
As the source code undergoes a series of transformationsin the compilation, linking, and execution phases, it posesseveral constraints and opportunites for instrumentation.Instead of restricting the choice of instrumentation to onephase in the program transformation, TAU allows multi-ple instrumentation interfaces to be deployed concurrently

297THE TAU PARALLEL PERFORMANCE SYSTEM
for better coverage. It taps into performance data frommultiple levels and presents it in a consistent and a uni-form manner by integrating events from different lan-guages and instrumentation levels in the same addressspace. TAU maintains performance data in a common struc-ture for all events and allows external tools access to theperformance data using a common interface.
4.10 Selective Instrumentation
In support of the different instrumentation schemes TAUprovides, a facility for selecting which of the possibleevents to instrument has been developed (Malony et al.2003). The idea is to record a list of performance eventsto be included or excluded by the instrumentation in afile. The file is then used during the instrumentation proc-ess to restrict the event set. The basic structure of the fileis a list of names separated into include and exclude lists.File names can be given to restrict instrumentation focus.
The selective instrumentation mechanism is beingused in TAU for all automatic instrumentation methods,including PDT source instrumentation, DyninstAPI exe-cutable instrumentation, and component instrumentation.It has proven invaluable as a means to both weed outunwanted performance events, such as high frequency,small routines that generate excessive measurement over-head, and provide easy event configuration for custom-ized performance experiments.
4.11 TAU_COMPILER
To simplify the integration of the source instrumentorand the MPI wrapper library in the build process, TAUprovides a tool, tau_compiler.sh that can be invokedusing a prefix of $(TAU_COMPILER) before the nameof the compiler. For instance, in an application makefile,the variable:
F90=mpxlf90
is modified to
F90=$(TAU_COMPILER) mpxlf90.
This tool invokes the compiler internally after extract-ing the names of source or object files and compilationparameters. During compilation, it invokes the parserfrom PDT, then the tau_instrumentor for inserting meas-urement probes into the source code, and compiles theinstrumented version of the source to generate the desiredobject file. It can distinguish between object code crea-tion and linking phases of compilation and during linking,it inserts the MPI wrapper library and the TAU measure-ment library in the link command line. In this manner, a
user can easily integrate TAU’s portable performanceinstrumentation in the code generation process. Optionalparameters can be passed to all four compilation phases.
5 Measurement
All TAU instrumentation code makes calls to the TAUmeasurement system through an API that provides a port-able and consistent set of measurement services. Again,the instrumentation layer is responsible for defining theperformance events for an experiment, establishing rela-tionships between events (e.g. groups, mappings), andmanaging those events in the context of the parallel com-puting model being used. Using the TAU measurementAPI, event information is passed in the probe calls to beused during measurement operations to link events withperformance data. TAU supports parallel profiling andparallel tracing. It is in the measurement system configu-ration and usage where all choices for what performancedata to capture and in what manner are made. Thus, per-formance experiments are created by selecting the keyevents of interest to observe and by configuring measure-ment modules together into a particular composition ofmeasurement capabilities (Dongarra et al. 2003).
In the sections that follow, we will discuss in detailwhat the TAU measurement layer provides, first from thepoint of view of profiling, and then of tracing. We beginwith a discussion of the sources of performance data TAUsupports.
The TAU measurement system is the heart of TAU’scapabilities. It is highly robust, scalable, and has beenported to all HPC platforms.
5.1 Performance Data Sources
TAU provides access to various sources of performancedata. Time is perhaps the most important and ubiquitousdata type, but it comes in various forms on different systemplatforms. TAU provides the user with a flexible choice oftime sources based on what the range of sources a partic-ular system supplies. At the same time, it abstracts thetimer interface so as to insulate the rest of the measure-ment system from the nuances of different timer imple-mentations. In a similar manner, TAU integrates alternativeinterfaces for access to hardware counters (PAPI (Browneet al. 2000) and PCL (Berrendorf, Ziegler, and Mohr) aresupported) and other system-accessible performance datasources. Through TAU configuration, all of the linkagesto these packages are taken care of.
Within the measurement system, TAU allows for mul-tiple sources of performance data to be concurrently active.That is, it is possible for both profiling and tracing towork with multiple performance data. TAU also recognizesthat some performance data may come directly from the

298 COMPUTING APPLICATIONS
parallel program. This is supported in two ways. First,the TAU API allows the user to specify a routine to serveas a counter source during performance measurement.Second, the TAU measurement system supplies somestandard events and counters that can be used to trackprogram-related performance (e.g. tracking memory uti-lization and sizes of messages).
5.2 Profiling
Profiling characterizes the behavior of an application interms of aggregate performance metrics. Profiles are typ-ically represented as a list of various metrics (such aswall-clock time) and associated statistics for all perform-ance events in the program. There are different statisticskept for interval events (such as routines or statements inthe program) versus atomic events. For interval events,TAU profile measurements compute exclusive and inclu-sive metrics spent in each routine. Time is a commonlyused metric, but any monotonically increasing resourcefunction can be used. Typically one metric is measuredduring a profiling run. However, the user may configureTAU with the -MULTIPLECOUNTERS configurationoption and then specify up to 25 metrics (by setting envi-ronment variables COUNTER[1–25]) to track during asingle execution. For atomic events, different counters canbe used. As indicated above, statistics measured includemaxima, minima, mean, standard deviation, and the numberof samples. Internally, the TAU measurement system main-tains a profile data structure for each node/context/thread.When the program execution completes, a separate pro-file file is created for each. The profiling system is opti-mized to work with the target platform and profilingoperations are very efficient.
5.3 Flat Profiling
The TAU profiling system supports several profiling var-iants. The most basic and standard type of profiling iscalled flat profiling. If TAU is being used for flat profil-ing, performance measurements are kept for intervalevents only. For instance, flat profiles will report theexclusive performance (e.g. time) for a routine, say A, asthe amount of time spent executing in A exclusively. Anytime spent in routines called by A will be represented inA’s profile as inclusive time, but it will not be differenti-ated with respect to the individual routines A called. Flatprofiles also keep information on the number of times Awas called and the number of routines (i.e. events) calledby A. Again, TAU will keep a flat profile for every node/context/thread of the program’s execution.
TAU implements a sophisticated runtime infrastructurefor gaining both profiling measurement efficiency androbustness. In particular, we decided to maintain inter-
nally a runtime event callstack that shrinks and grows atevery interval event exit and entry. It is a simple matter toaccount for inclusive and exclusive performance usingthe event callstack. The real power of the callstack is dem-onstrated for the other profiling forms. It is important tounderstand that the callstack is a representation of thenesting of interval performance events. This makes itmore than just a routine callstack representation.
5.3.1 Callpath profiling To observe meaningful per-formance events requires placement of instrumentation inthe program code. However, not all information needed tointerpret an event of interest is available prior to execu-tion. A good example of this occurs in callgraph profil-ing. Here the objective is to determine the distribution ofperformance along the dynamic routine (event) callingpaths of an application. We speak of the depth of a call-path as the number of routines represented in the callpath.A callpath of depth 1 is a flat profile. A callpath of depthk represents a sequence of the last k – 1 routines called bya routine at the head of the callpath. The key concept tounderstand for callpath profiling is that a callpath repre-sents a performance event. Just as a callpath of depth 1will represent a particular routine and TAU will profileexclusive and inclusive performance for that routine, everyunique callpath of depth k in a program’s execution willrepresent a unique performance event to be profiled.
Unlike flat profiling, the problem with callpath profil-ing is that the identities of all k – 1 depth calling pathsending at a routine may not be, and generally are not,known until the application finishes its execution. How,then, do we identify the dynamic callpath events in orderto make profile measurements? One approach is not totry to identify the callpaths at runtime, and instead instru-ment just basic routine entry and exit events and recordthe events in a trace. Trace analysis can then easily calcu-late callpath profiles. There are two problems with thisapproach. One, it is not a profile-based measurement, andtwo, the trace generated may be excessively large.
Unfortunately, the measurement problem is significantlyharder if callpath profiles are calculated online. If thewhole source is available, it is possible to determine theentire static callgraph and enumerate all possible callpaths,encoding this information in the program instrumenta-tion. These callpaths are static, in the sense that they couldoccur; dynamic callpaths are the subset of static callpathsthat actually do occur during execution. Once a callpathis encoded and stored in the program, the dynamic call-path can then be determined directly by indexing a tableof possible next paths using the current routine id. Oncethe callpath is known, the performance information canbe easily recorded in pre-reserved static memory. Thistechnique was used in the CATCH tool (DeRose andWolf 2002). Unfortunately, this is not a robust solution

299THE TAU PARALLEL PERFORMANCE SYSTEM
for several reasons. First, source-based callpath analysisis non-trivial and may only be available for particularsource languages, if at all. Second, the application sourcecode must be available if a source-based technique isused. Third, static callpath analysis is possible at thebinary code level, but the routine calls must be explicitand not indirect. This complicates C++ callpath profiling,for instance. To deliver a robust, general solution, wedecided to pursue an approach where the callpath is cal-culated and queried at runtime.
As noted above, the TAU measurement system main-tains a callstack that is updated with each entry/exit per-formance event. Thus, to determine the k – 1 lengthcallpath when an event (e.g. routine) is entered, all that isnecessary is to traverse up the callstack to determine thelast events that define the callpath. If this is a newlyencountered callpath, it represents a new event, and anew measurement profile must be created at that timebecause it was not pre-allocated. The main problem ishow to do all of this efficiently.
Although performance events in TAU are handleddynamically, in the sense that they are not pre-determinedand pre-assigned event identities, “standard” performanceevents will have pre-allocated profile data structures, as aresult of the instrumentation inserted in the program code.Unfortunately, callpaths do not occur as a result of spe-cific event instrumentation, but instead as a result of thestate of the event callstack. Thus, new callpaths occurdynamically, requiring new profile data objects to be cre-ated at runtime. TAU builds a profile object for each call-path encountered in an associative map and creates a keyto use to retrieve it. The key is formed from the callpathdepth and callpath event names. It is constructed on thefly when an interval entry call takes place. Thus, no stringoperations are performed in looking up the key in the hashtable. To compare two keys, we first examine the callpathdepth by looking at the first element of the two arrays. Ifthey’re equal, then we traverse the other elements com-paring a pair of addresses at each stage. When TAU isconfigured with the -PROFILECALLPATH configura-tion option, callpath profiling is enabled. A user sets thedesired callpath depth as a runtime parameter by settingthe environment variable TAU_CALLPATH_DEPTH tothe appropriate value. If it is not set, a default value of 2 isassumed.
5.3.2 Calldepth profiling TAU’s callpath profilingwill generate a profile for each callpath of a depth desig-nated by TAU_CALLPATH_DEPTH, not just those thatinclude the topmost root event. For some performanceevaluation studies, it is desired to see how the perform-ance is distributed across program parts from a top-down,hierarchical perspective. Thus, a parallel profile thatshowed how performance data was distributed at differ-
ent levels of an unfolding event call tree could help tounderstand the performance better. TAU’s implementationof calldepth profiling does just that. It allows the user toconfigure TAU with the -DEPTHLIMIT option and spec-ify in the the environment variable TAU_DEPTH_LIMIThow far down the event call tree to observe performance.In this case, the profiles created show performance foreach callpath in the rooted call tree pruned to the chosendepth. The implementation of calldepth profiling is simi-lar to callpath profiling in that it requires dynamic eventgeneration and profile object creation, but it benefitsfrom certain efficiencies in pruning its search on the call-stack.
5.3.3 Phase profiling While callpath profiling andcalldepth profiling allow the distribution of performanceto be understood relative to event calling relationships, itis equally reasonable to want to see performance data rel-ative to execution state. The concept of a phase is com-mon in scientific applications, both in terms of howdevelopers think about the structural, logical, and numer-ical aspects of a computation, and how performance canbe interpreted. It therefore worthwhile to consider whethersupport for phases in performance measurement can aidin the interpretation of performance information. Phaseprofiling is an approach to profiling that measures per-formance relative to the phase of execution. TAU hasimplemented a phase profiling API that is used by thedeveloper to create phases and mark their entry and exit.When TAU is configured with the -PROFILEPHASEoption, TAU will effectively generate a separate profilefor each phase in the program’s execution.
Internally, phase profiling support in TAU builds onsimilar mechanisms used in callpath profiling. A phaseevent (enter and exit phase) activates special processingin TAU to record the transition between phases. A phasecan be static (where the name registration takes placeexactly once) or dynamic (where it is created each time).Phases can also be nested, in which case profiling fol-lows normal scoping rules and is associated with theclosest parent phase obtained by traversing up the call-stack. Phases should not overlap, as it also true for inter-val events (Shende et al. 1998). Each thread of executionin an application has a default phase and this correspondsto the top level event. This top level phase contains otherroutines and phases that it directly invokes, but excludesroutines called by child phases.
5.4 Tracing
While profiling is used to get aggregate summaries ofmetrics in a compact form, it cannot highlight the timevarying aspect of the execution. To study the post-mortemspatial and temporal aspect of performance data, event

300 COMPUTING APPLICATIONS
tracing, that is, the activity of capturing an event or anaction that takes place in the program, is more appropri-ate. Event tracing usually results in a log of the events thatcharacterize the execution. Each event in the log is anordered tuple typically containing a time stamp, a loca-tion (e.g. node, thread), an identifier that specifies thetype of event (e.g. routine transition, user-defined event,message communication, etc.) and event-specific infor-mation.
TAU implements a robust, portable, and scalable per-formance tracing facility. With tracing enabled, everynode/context/thread will generate a trace for instru-mented events. TAU will write traces in its modern traceformat as well as in VTF3 (Seidl 2003) format. Supportfor a counter value to be included in event records is fullyimplemented. In addition, certain standard events areknown by TAU’s tracing system, such as multi-threadingoperations and message communication. TAU writes per-formance traces for post-mortem analysis, but also sup-ports an interface for online trace access. This includesmechanisms for online and hierarchical trace merging(Brunst et al. 2003; Brunst, Nagel, and Malony 2003).
The following describes important aspects of TAUtracing system in more detail.
5.4.1 Dynamic event registration For runtime tracereading and analysis, it is important to understand whattakes place when TAU records performance events intraces. The first time an event takes place in a process, itregisters its properties with the TAU measurement library.Each event has an identifier associated with it. Theseidentifiers are generated dynamically at runtime as theapplication executes, allowing TAU to track only thoseevents that actually occur. This is in contrast to staticschemes that must predefine all possible events that couldpossibly occur. The main issue here is how the eventidentifiers are determined. In a static scheme, event IDsare drawn from a pre-determined global space of IDs,which restricts the scope of performance measurementscenarios. This is the case with most other performancetracing systems. In our more general and dynamic scheme,the event identifiers are generated on the fly, local to acontext. Depending on the order in which events firstoccur, the IDs may be different for the same event (i.e.events with the same name) across contexts. When eventstreams are later merged, these local event identifiers aremapped to a global identifier based on the event name.
Previously, TAU wrote the event description files todisk when the application terminated. While this schemewas sufficient for post-mortem merging and conversionof event traces, it could not be directly applied for onlineanalysis of event traces. This was due to the absence ofevent names that are needed for local to global eventidentifier conversion. To overcome this limitation, we
have re-designed our trace merging tool, tau_merge, so itexecutes concurrently with the executing applicationgenerating the trace files. From each process’s trace file,tau_merge reads event records and examines their glo-bally synchronized timestamps to determine which eventis to be recorded next in the ordered output trace file.When it encounters a local event identifier that it has notseen before, it reads the event definition file associatedwith the given process and updates its internal tables tomap that local event identifier to a global event identifierusing its event name as a key. The trace generation libraryensures that event tables are written to disk before writ-ing trace records that contain one or more new events. Anew event is defined as an event whose properties are notrecorded in the event description file written previouslyby the application. This scheme, of writing event defini-tions prior to trace records, is also used by the tau_mergetool while writing a merged stream of events and eventdefinitions. It ensures that the trace analysis tools downthe line that read the merged traces also read the globalevent definitions and refresh their internal tables whenthey encounter an event for which event definitions arenot known.
5.4.2 TAU trace input library To make the trace dataavailable for runtime analysis, we implemented the TAUtrace input library. It can parse binary merged or unmergedtraces (and their respective event definition files) and pro-vides this information to an analysis tool using a traceanalysis API. This API employs a callback mechanismwhere the tool registers callback handlers for differentevents. The library parses the trace and event descriptionfiles and notifies the tool of events that it is interested in,by invoking the appropriate handlers with event specificparameters. We currently support callbacks for findingthe following:
• Clock period used in the trace• Message send or receive events• Mapping event identifiers to their state or event prop-
erties• Defining a group identifier and associated group name• Entering and leaving a state
Each of these callback routines have event specificparameters. For instance, a send event handler has sourceand destination process identifiers, the message length,and its tag as its parameters. Besides reading a group ofrecords from the trace file, our API supports file manage-ment routines for opening or closing a trace file and fornavigating the trace file by moving the location of the cur-rent file pointer to an absolute or relative event position. Itsupports both positive and negative event offsets. Thisallows the analysis tool to read, for instance, the last

301THE TAU PARALLEL PERFORMANCE SYSTEM
10000 events from the tail of the event stream. The traceinput library is used by VNG (Brunst et al. 2003) to ana-lyze at runtime the merged binary event stream generatedby an application instrumented with TAU.
5.5 Measurement Overhead
The selection of what events to observe when measuringthe performance of a parallel application is an importantconsideration, as it is the basis for how performance datawill be interpreted. The performance events of interestdepend mainly on what aspect of the execution the userwants to see, so as to construct a meaningful performanceview from the measurements made. Typical events includecontrol flow events that identify points in the programthat are executed, or operational events that occur whensome operation or action has been performed. As we havediscussed, events may be atomic or paired to mark certainbegin and end points. Choice of performance events alsodepends on the scope and resolution of the performancemeasurement desired. However, the greater the degree ofperformance instrumentation in a program, the higher thelikelihood that the performance measurements will alterthe way the program behaves, an outcome termed perform-ance perturbation (Malony 1990). Most performance tools,including TAU, address the problem of performance per-turbation indirectly by reducing the overhead of perform-ance measurement.
We define performance intrusion as the amount of per-formance measurement overhead incurred during a per-formance experiment. Thus, intrusion will be a product ofthe numbers of events that occurred during execution andthe measurement overhead for processing each event. Wedefine performance accuracy as the degree to which ourperformance measures correctly represent “actual” per-formance. That is, accuracy is associated with error. If weare trying to measure the performance of small events, theerror will be higher because of the measurement uncer-tainty that exists due to the relative size of the overheadversus the event. If we attempt to measure a lot of events,the performance intrusion may be high because of theaccumulated measurement overhead, regardless of themeasurement accuracy for that event.
Performance experiments should be concerned with bothperformance intrusion and performance accuracy, espe-cially in regards to performance perturbation. TAU is ahighly-engineered performance system and delivers excel-lent measurement efficiencies and low measurement over-head. However, it is easy to construct naively an experimentthat will result in significant performance intrusion. Indeed,TAU’s default instrumentation behavior is to enable allevents it can instrument. We are developing a set of toolsin TAU to help the user manage the degree of perform-ance instrumentation as a way to better control performance
intrusion. The approach is to help the user identify perform-ance events that have either poor measurement accuracy(i.e. they are small) or a high frequency of occurrence.Once these events are identified, the event selectionmechanism described above can be used to reduce theinstrumentation degree in the next experiment, therebyreducing performance intrusion in the next program run.
5.6 Overhead Compensation
Unfortunately, by eliminating events from instrumenta-tion, we lose the ability to see those events at all. If theexecution of small routines accounts for a large portion ofthe execution time, that may be hard to discern withoutmeasurement. On the other hand, accurate measure-ment is confounded by high relative overheads. Opti-mized coarse-grained instrumentation helps the processof improving the accuracy of measurements using selec-tive instrumentation. However, any instrumentation per-turbs a program and modifies its behavior. The distortionin gathered performance data could be significant for aparallel program where the effects of perturbation arecompounded by parallel execution and accumulation ofoverhead from remote processes. Such distortions aretypically observed in wait times where processes syn-chronize their operation. Given an event stream stored inlog files, it is possible under certain assumptions to cor-rect the performance perturbation in a limited manner bycompensating for the measurement overhead and correct-ing event orderings based on known causality constraints,such as imposed by inter-process communication (Mal-ony 1990; Sarukkai and Malony 1993). Tracing the pro-gram execution is not always feasible due to the highvolume of performance data generated and the amount oftrace processing needed.
We have developed techniques in TAU profiling tocompensate for measurement overhead at runtime. Usingan estimate of measurement overhead determined atruntime, TAU will subtract this overhead during profilecalculation of inclusive performance. The way this isaccomplished is quite clever by tracking the number ofdescendant events and adjusting the total inclusive timeat event exit. This inclusive value is then used to computethe corrected exclusive time for the routine by subtract-ing the corrected inclusive time from the exclusivetime of each routines parent. A TAU measurement libraryconfigured with the -COMPENSATE configuration optionperforms online removal of overhead during the meas-urement stage.
5.7 Performance Mapping
The ability to associate low-level performance measure-ments with higher-level execution semantics is important

302 COMPUTING APPLICATIONS
in understanding parallel performance data with respectto application structure and dynamics. Unfortunately, mostperformance systems do not provide such support exceptin their analysis tools, and then only in a limited manner.The TAU measurement system implements a novel per-formance observation feature call performance mapping(Shende 2001). The idea is to provide a mechanismwhereby performance measurements, made by the occur-rence of instrumented performance events, can be associ-ated with semantic abstractions, possible at a differentlevel of performance observation. For instance, a meas-urement of the time spent in a MPI communication rou-tine might be associated with a particular phase of programexecution.
TAU has implemented performance mapping as anintegral part of its measurement system. In addition toproviding an API for application-level performance map-ping, TAU uses mapping internally to implement callpathprofiling, calldepth profiling, and phase profiling. In thecase of phase profiling, TAU’s measurement system treatsa phase profile as a callpath profile of depth 2. Here, acaller-callee relationship is used to represent phase inter-actions. At a phase or event entry point, we traverse thecallstack until a phase is encountered. Since the top levelevent is treated as the default application phase, each rou-tine invocation occurs within some phase. To store theperformance data for a given event invocation, we need todetermine if the current (event, phase) tuple has executedbefore. To do this, we construct a key array that includesthe identities of the current event and the parent phase.This key is used in a lookup operation on a global map ofall (phase, timer) relationships. If the key is not found, anew profiling object is created with the name that repre-sents the parent phase and the currently executing eventor phase. In this object, we store performance data rele-vant to the phase. If we find the key, we access the profil-ing object and update its performance metrics. As withcallpath profiling, a reference to this object is stored toavoid a second lookup at the event exit.
6 Analysis
TAU gives us the ability to track performance data inwidely diverse environments, and thus provides a wealthof information to the user. The usefulness of this infor-mation, however, is highly dependent on the ability ofanalysis toolsets to manage and present the information.As the size and complexity of the performance informa-tion increases, the challenge of performance analysis andvisualization becomes more difficult. It has been a con-tinuing effort to include as part of TAU a set of analysistools which can scale not only to the task of analyzingTAU data, but also to a more diverse arena outside of theTAU paradigm. This section discusses the developement
of these tools, and the resulting benefits to the user inperforming the often complex task of analyzing perform-ance data.
Our approach in this section will be to show the use ofthe TAU analysis tools on a single parallel application,S3D (Subramanya and Reddy 2000). S3D is a high-fidelityfinite difference solver for compressible reacting flowswhich includes detailed chemistry computations.
6.1 ParaProf
The TAU performance measurement system is capable ofproducing parallel profiles for thousands of processesconsisting of hundreds of events. Scalable analysis toolsare required to handled this amount of detailed perform-ance information. The ParaProf parallel profile analysistool represents more than six years of development. Shownin Figure 6, ParaProf abstracts four key components in itsdesign: the Data Source System (DSS), the Data Man-agement System (DMS), the Event System (ES), and theVisualization System (VS). Each component is independ-ent, and provides well-defined interfaces to other compo-nents in the system. The result is high extensibility andflexibility, enabling us to tackle the issues of re-use andscalability.
Current performance profilers provide a range of dif-fering data formats. As done in HPCView (Mellor-Crum-mey, Fowler, and Marlin 2002) external translators havetypically been used to merge profile data sets. Since muchcommonality exists in the profile entities being represented,this is a valid approach, but it requires the adoption of acommon format. ParaProf’s DSS addresses this issue in adifferent manner. DSS consists of two parts. One, DSScan be configured with profile input modules to read pro-files from different sources. The existing translators pro-vides a good starting point to implement these modules.An input module can also support interfaces for commu-nication with profiles stored in files, managed by per-formance databases, or streaming continuously across anetwork. Two, once the profile is input, DSS converts theprofile data to a more efficient internal representation.
The DMS provides an abstract representation of per-formance data to external components. Its supports manyadvanced capabilities required in a modern performanceanalysis system, such as derived metrics for relating per-formance data, cross experiment analysis for analyzingdata from disparate experiments, and data reduction forelimination of redundant data, thus allowing large datasources to be tolerated efficiently. The importance ofsophisticated data management and its support for expos-ing data relationships is an increasingly important area ofresearch in performance analysis. The DMS design pro-vides a great degree of flexibility for developing newtechniques that can be incorporated to extend its function.

303THE TAU PARALLEL PERFORMANCE SYSTEM
The VS components is responsible for graphical profiledisplays. It is based on the Java2D platform, enabling usto take advantage of a very portable development envi-ronment that continues to increase in performance andreliability. Analysis of performance data requires repre-sentations from a very fine granularity, perhaps of a sin-gle event on a single node, to displays of the performancecharacteristics of the entire application. ParaProf’s cur-rent set of displays range from purely textual based to fullygraphical. Significant effort has been put into making thedisplays highly interactive and fast to draw. In addition, itis relatively easy to extend the display types to better showdata relations.
Lastly, in the ES, we have provided a well-defined meansby which these components can communicate variousstate changes, and requests to other components in ParaP-rof. Many of the display types are hyper-link enabled,allowing selections to be reflected across currently openwindows. Support for runtime performance analysis andapplication steering, coupled with maintaining connectiv-ity with remote data repositories has required us to focusmore attention on the ES, and to treat it as a wholly sepa-rate component system.
To get a sense of the type of analysis displays ParaProfsupports, Figure 7 shows the S3D flat profile (stacked view)on sixteen processes. Different events are color coded.
Clicking on one event, INT_RTE, ParaProf will displaythat event’s performance in a separate window, as shownin Figure 8 for INT_RTE’s exclusive time. When call-path profile data is available, ParaProf can reconstruct theevent calling graph and display performance statistics in acallgraph display, as seen in Figure 9. Here the size of thenode is determined by its inclusive time and the color ismapped to exclusive time, red being the most.
6.2 Performance Database Framework
Empirical performance evaluation of parallel and distrib-uted systems or applications often generates significantamounts of performance data and analysis results frommultiple experiments and trials as performance is investi-gated and problems diagnosed. However, the managementof performance data from multiple experiments can belogistically difficult, impeding the effective analysis andunderstanding of performance outcomes. The PerformanceData Management Framework (PerfDMF) (Huck et al.2005) provides a common foundation for parsing, storing,querying, and analyzing performance data from multipleexperiments, application versions, profiling tools and/orplatforms. The PerfDMF design architecture is presentedbelow. We describe the main components and their inter-operation.
Fig. 6 ParaProf Architecture.

304 COMPUTING APPLICATIONS
Fig. 7 ParaProf view of S3D flat profile.
Fig. 8 ParaProf view of S3D INT_RTE exclusive time.

305THE TAU PARALLEL PERFORMANCE SYSTEM
PerfDMF consists of four main components: profileinput/output, profile database, database query and analy-sis API, and profile analysis toolkit. Figure 10 shows arepresentation of these four components, and their rela-tionships. PerfDMF is designed to parse parallel profiledata from multiple sources. This is done through the useof embedded translators, built with PerfDMF’s data utili-ties and targeting a common, extensible parallel profilerepresentation. Currently supported profile formats includegprof (Graham, Kessler, and McKusick 1982) TAU profiles(University of Oregon a), dynaprof (Mucci), mpiP (Vetterand Chambreau), HPMtoolkit (IBM) (DeRose 2001), andPerfsuite (psrun) (Ahn et al.). (Support for SvPablo (DeRoseand Reed 1998) is being added.) The profile data is parsedinto a common data format. The format specifies profile
data by node, context, thread, metric and event. Profiledata is organized such that for each combination of theseitems, an aggregate measurement is recorded. The simi-larities in the profile performance data gathered by differ-ent tools allowed a common organization to be used.Export of profile data is also supported in a common XMLrepresentation. In the future, we may also offer exportersto a subset of the formats above.
The profile database component is the center of Per-fDMF’s persistent data storage. It builds on robust SQLrelational database engines, some of which are freely dis-tributed. The currently supported Relational Database Man-agement Systems (DBMS) are PostgreSQL (PostgreSQL),MySQL (MySQL), Oracle (Oracle Corporation) and DB2(IBM). The database component must be able to handle
Fig. 9 ParaProf view of S3D callgraph.

306 COMPUTING APPLICATIONS
both large-scale performance profiles, consisting of manyevents and threads of execution, as well as many profilesfrom multiple performance experiments. Our tests withlarge profile data (101 events on 16K processors) showedthe framework adequately handled the mass of data.
To facilitate performance analysis development, thePerfDMF architecture includes a well-documented datamanagement API to abstract query and analysis operationsinto a more programmatic, non-SQL, form. This layer isintended to complement the SQL interface, which is directlyaccessible by analysis tools, with dynamic data manage-ment and higher-level query functions. It is anticipated thatmany analysis programs will utilize this API for imple-mentation. Access to the SQL interface is provided usingthe Java Database Connectivity (JDBC) API. Because allsupported databases are accessed through a common inter-face, the tool programmer does not need to worry aboutvendor-specific SQL syntax. We have developed severaltools that make use of the API, including ParaProf. Figure 11shows PerfDMF being used by ParaProf to load the S3Dprofile dataset.
The last component, the profile analysis toolkit, is anextensible suite of common base analysis routines thatcan be reused across performance analysis programs. Theintention also is to provide a common programming envi-ronment in which performance analysis developers can
contribute toolkit modules and packages. Analysis rou-tines are a useful abstraction for developing profile anal-ysis applications.
6.3 Tracing
We made an early decision in the TAU system to leverageexisting trace analysis and visualization tools. However,TAU implements it own trace measurement facility andproduces trace files in TAU’s own format. As a result,trace converters are supplied with the system to translateTAU traces to formats used by the tools. The primary toolwe support in TAU is Vampir (Intel Corporation; currentlymarketed as the Intel(R) Trace Analyzer 4.0). TAU providesa tau2vtf program to convert TAU traces to VTF3 for-mat. In addition, TAU offers tau2epilog, tau2slog2,and tauconvert programs to convert to EPILOG (Mohrand Wolf 2003), SLOG2 (Wu et al. 2000), and Paraver(European Center for Parallelism of Barcelona (CEPBA))formats, respectively. For convenience, the TAU tracingsystems also allows traces files to be output directly inVTF3 and EPILOG formats.
Figure 12 shows three Vampir displays of the S3D exe-cution. The timeline view identifies a performance com-munications bottleneck as the result of the imbalancedexecution of the INT_RTE routine. The communications
Fig. 10 TAU Performance Database Architecture.

307THE TAU PARALLEL PERFORMANCE SYSTEM
Fig. 11 ParaProf loading S3D parallel profile from PerfDMF database.
Fig. 12 Vampir displays of S3D performance trace: timeline (left), communication matrix (upper right), and call-graph (lower right).

308 COMPUTING APPLICATIONS
matrix view highlights the pattern and load distributionof process communication in the S3D benchmark. Theexpanded callgraph display points out the interesting var-iations in the performance of the DTM iterations. TAUalso can utilize the latest generation of the Vampir tool,VNG, and we have demonstrated the ability to analyzeand visualize traces with VNG online during execution.
By applying the EPILOG converter, TAU is able togain use of the Expert (Wolf et al. 2004) performanceanalysis tool. Expert is trace-based in its analysis and
looks for performance problems that arise in the exe-cution. The Expert tool provides a GUI showing prob-lem classes, code locations where a particular problemoccurs, and computing resources (e.g. threads) associ-ated with the problem and location. In this manner,Expert consolidates the performance information in atrace into a more statistics oriented display. Expert usesthe CUBE visualizer (Song et al. 2004) for presentingthe results. Figure 13 shows a view from Expert usingCUBE for S3D.
Fig. 13 Expert/CUBE display of TAU’s S3D performance data.

309THE TAU PARALLEL PERFORMANCE SYSTEM
TAU also provides a tool, vtf2profile, that willread a VTF3 trace and generated a parallel profile inTAU format. The tool can take parameters identifyingwhere to start and stop the profile generation in time,allowing parallel profiles to be generated for specificregions of the traces. The profile output can then be readby ParaProf.
7 Conclusion
Complex parallel systems and software pose challengingperformance evaluation problems that require robustmethodologies and tools. However, in rapidly evolvingparallel computing environments, performance technologycan ill-afford to stand still. Performance technology devel-opment always operates under a set of constraints as wellas under a set of expectations. While performance evalu-ation of a system is directly affected by what constraintsthe system imposes on performance instrumentation andmeasurement capabilities, the desire for performance prob-lem solving tools that are common and portable, now andinto the future, suggests that performance tools hardenedand customized for a particular system platform will beshort-lived, with limited utility. Similarly, performancetools designed for constrained parallel execution modelswill likely have little use in more general parallel and dis-tributed computing paradigms. Unless performance tech-nology evolves with system technology, a chasm willremain between the users expectations and the capabili-ties that performance tools provide.
The TAU performance system addresses performancetechnology problems at three levels: instrumentation, meas-urement, and analysis. The TAU framework supports theconfiguration and integration of these layers to target spe-cific performance problem solving needs. However, effec-tive exploration of performance will necessarily requireprudent selection from the range of alternative methodsTAU provides to assemble meaningful performance exper-iments that sheds light on the relevant performance prop-erties. To this end, the TAU performance system offerssupport to the performance analysis in various ways, includ-ing powerful selective and multi-level instrumentation,profile and trace measurement modalities, interactive per-formance analysis analysis, and performance data man-agement.
Portability, robustness, and extensibility are the hall-marks of the TAU parallel performance system. TAU isavailable on all HPC platforms and supports all majorparallel programming methodologies. It is in use in scien-tific research groups, HPC centers, and industrial labora-tories around the world. The entire TAU software isavailable in the public domain and is actively being main-tained and updated by the Performance Research Lab atthe University of Oregon.
Acknowledgments
Research at the University of Oregon is sponsored by con-tracts (DE-FG03-01ER25501 and DE-FG02-03ER25561)from the MICS program of the U.S. Dept. of Energy,Office of Science.
The TAU project has benefited from the contributionsof many project staff and graduate students. We wouldlike to recognize in particular those of Robert Bell, AlanMorris, Wyatt Spear, Chris Hoge, Nick Trebon, KevinHuck, Suravee Suthikulpanit, Kai Li, and Li Li of Uni-versity of Oregon, and Bernd Mohr of Research CentreJuelich, Germany for their work on the TAU system.
Author Biographies
Dr. Sameer S. Shende is a Postdoctoral Research Asso-ciate in the NeuroInformatics Center at the University ofOregon. He received the Bachelor of Technology (B. Tech)degree in Electrical Engineering from the Indian Instituteof Technology, Bombay, India in 1991. He received theM.S. and Ph.D. degrees from the University of Oregon in1996 and 2001 respectively. His research interests are inthe area of performance analysis of parallel programs,instrumentation, measurement and techniques for map-ping performance data. He helped develop the TAU per-formance system.
Dr. Allen D. Malony is a Professor in the Departmentof Computer and Information Science at the Unversity ofOregon. He received the B.S. and M.S. degrees in Com-puter Science from the University of California, LosAngeles in 1980 and 1982, respectively. He received thePh.D. degree from the University of Illinois at Urbana-Champaign in October 1990. He joined the faculty atOregon in 1991, spending his first year as a FulbrightResearch Scholar and visiting Professor at Utrecht Uni-versity in The Netherlands. He was awarded the NSFNational Young Investigator award in 1994. In 1999 hewas a Fulbright Research Scholar to Austria located at theUniversity of Vienna. He was awarded the prestigiousAlexander von Humboldt Research Award for SeniorU.S. Scientists by the Alexander von Humboldt Founda-tion in 2002. His research interests are in parallel comput-ing, performance analysis, supercomputing, and scientificsoftware environments. He is the Director of the Perform-ance Research Laboratory, the NeuroInformatics Center,and the Computational Science Institute at the Universityof Oregon.
Dr. Malony and Dr. Sameer S. Shende are the foundersof ParaTools, Inc., a company devoted to tools for high-performance parallel computing.

310 COMPUTING APPLICATIONS
References
Ahn, D., Kufrin, R., Raghuraman, A., and Seo, J. Perfsuite.http://perfsuite.ncsa.uiuc.edu/.
Bell, R., Malony, A. D., and Shende, S. 2003. A Portable,Extensible, and Scalable Tool for Parallel PerformanceProfile Analysis. Proceedings of the Europar 2003 Con-ference (LNCS 2790), pp. 17–26.
Bernholdt, D. E., Allan, B. A., Armstrong, R. et al. 2006. AComponent Architecture for High-Performance ScientificComputing. Intl. Journal of High-Performance Comput-ing Applications ACTS Collection Special Issue.
Berrendorf, R., Ziegler, H., and Mohr, B. PCL — The Perform-ance Counter Library. http://www.fz-juelich.de/zam/PCL/.
Browne, S., Dongarra, J., Garner, N., Ho, G., and Mucci, P. 2000.A Portable Programming Interface for Performance Eval-uation on Modern Processors. International Journal ofHigh Performance Computing Applications 14(3):189–204.
Brunst, H., Malony, A. D., Shende, S., and Bell, R. 2003.Online Remote Trace Analysis of Parallel Applications onHigh-Performance Clusters. Proceedings of the ISHPCConference (LNCS 2858), pp. 440–449. Springer.
Brunst, H., Nagel, W. E., and Malony, A. D. 2003. A Distrib-uted Performance Analysis Architecture for Clusters. Pro-ceedings of the IEEE International Conference on ClusterComputing (Cluster 2003), pp. 73–83. IEEE ComputerSociety.
Buck, B. and Hollingsworth, J. 2000. An API for Runtime CodePatching. Journal of High Performance Computing Appli-cations 14(4):317–329.
California Institute of Technology. VTF — Virtual Test ShockFacility. http://www.cacr.caltech.edu/ASAP.
CCA Forum. The Common Component Architecture Forum.http://www.cca-forum.org.
DeRose, L. 2001. The Hardware Performance Monitor Toolkit.Proceedings of the European Conference on ParallelComputing (EuroPar 2001, LNCS 2150), pp. 122–131.Springer.
DeRose, L. and Reed, D. 1998. SvPablo: A Multi-LanguageArchitecture-Independent Performance Analysis System.Proceedings of the International Conference on ParallelProcessing, ICPP ’99, pp. 311–318.
DeRose, L. and Wolf, F. 2002. CATCH – A Call-Graph BasedAutomatic Tool for Capture of Hardware PerformanceMetrics for MPI and OpenMP Applications. Proceedingsof the Europar 2002 Conference.
Dongarra, J., Malony, A. D., Moore, S., Mucci, P., and Shende,S. 2003. Performance Instrumentation and Measurementfor Terascale Systems. Proceedings of the ICCS 2003Conference (LNCS 2660), pp. 53–62.
European Center for Parallelism of Barcelona (CEPBA). Par-aver — Parallel Program Visualization and Analysis Tool –reference manual. http://www.cepba.upc.es/paraver.
Forum, M. P. I. 1994. MPI: A Message Passing Interface Stand-ard. International Journal of Supercomputer Applications(Special Issue on MPI) 8(3/4).
Graham, S., Kessler, P., and McKusick, M. 1982. gprof: A CallGraph Execution Profiler. SIGPLAN ’82 Symposium onCompiler Construction pp. 120–126.
Gropp, W. and Lusk, E. User’s Guide for MPE: Extensions forMPI Programs. http://www-unix.mcs.anl.gov/mpi/mpich/docs/mpeguide/paper.htm.
HPC++ Working Group. 1995. HPC++ White Papers. Techni-cal Report TR 95633, Center for Research on ParallelComputation.
Huck, K., Malony, A., Bell, R., and Morris, A. 2005. Designand Implementation of a Parallel Performance Data Man-agement Framework. Proc. International Conference onParallel Processing, ICPP-05.
IBM. IBM DB2 Information Management Software. http://www.ibm.com/software/data.
Intel Corporation. Intel (R) Trace Analyzer 4.0. http://www.intel.com/software/products/cluster/tanalyzer/.
Kessler, P. 1990. Fast Breakpoints: Design and Implementation.SIGPLAN Notices 25(6):78–84.
Kohn, S., Kumfert, G., Painter, J., and Ribbens, C. 2001.Divorcing Language Dependencies from a Scientific Soft-ware Library. Proceedings of the 10th SIAM Conferenceon Parallel Processing.
Lindlan, K., Cuny, J., Malony, A. D., Shende, S., Mohr, B.,Rivenburgh, R., and Rasmussen, C. 2000. A Tool Frame-work for Static and Dynamic Analysis of Object-OrientedSoftware with Templates. Proceedings of the SC’2000Conference.
Malony, A. D. 1990. Performance Observability. PhD thesis,University of Illinois, Urbana-Champaign.
Malony, A. and Shende, S. 2000. Performance Technology forComplex Parallel and Distributed Systems. In: Distributedand Parallel Systems: From Concepts to Applications (eds.G. Kotsis and P. Kacsuk), pp. 37–46, Norwell, MA: Klu-wer.
Malony, A., Shende, S., Bell, R., Li, K., Li, L., and Trebon, N.2003. Advances in the TAU Performance System. In: Per-formance Analysis and Grid Computing (eds. V. Getov,M. Gerndt, A. Hoisie, A. Malony, B. Miller), pp. 129–144. Norwell, MA: Kluwer.
Mellor-Crummey, J., Fowler, R., and Marlin, G. 2002.HPCView: A Tool for Top-down Analysis of Node Per-formance. The Journal of Supercomputing 23:81–104.
Mohr, B. KOJAK — Kit for Objective Judgment and Knowl-edge-based Detection of Bottlenecks. http://www.fz-juelich.de/zam/kojak.
Mohr, B., Malony, A., Shende, S., and Wolf, F. 2002. Designand Prototype of a Performance Tool Interface for OpenMP.The Journal of Supercomputing 23:105–128.
Mohr, B. and Wolf, F. 2003. KOJAK – A Tool Set for AutomaticPerformance Analysis of Parallel Applications. Proceed-ings of the European Conference on Parallel Computing(EuroPar 2003, LNCS 2790), pp. 1301–1304. Springer.
Mucci, P. Dynaprof. http://www.cs.utk.edu/~mucci/dynaprof.MySQL. MySQL: The World’s Most Popular Open Source
Database. www.mysql.org.Nagel, W., Arnold, A., Weber, M., Hoppe, H.-C., and Solchen-
bach, K. 1996. VAMPIR: Visualization and Analysis ofMPI Resources. Supercomputer 12(1):69–80.
Norris, B., Ray, J., McInnes, L., Bernholdt, D., Elwasif, W.,Malony, A., and Shende, S. 2004. Computational qualityof service for scientific components. Proceedings of the

311THE TAU PARALLEL PERFORMANCE SYSTEM
International Symposium on Component-based SoftwareEngineering (CBSE7). Springer.
Oracle Corporation. Oracle. http://www.oracle.com.PostgreSQL. PostgreSQL: The World’s Most Advanced Open
Source Database. http://www.postgresql.org.Ray, J., Trebon, N., Shende, S., Armstrong, R., and Malony, A.
2004. Performance Measurement and Modeling of Com-ponent Applications in a High Performance ComputingEnvironment: A Case Study. Proc. International Paralleland Distributed Processing Symposium (IPDPS’04).
Sarukkai, S. and Malony, A. D. 1993. Perturbation Analysis ofHigh Level Instrumentation for SPMD Programs. SIGP-LAN Notices 28(7).
Seidl, S. 2003. VTF3 – A Fast Vampir Trace File Low-LevelManagement Library. Technical Report ZHR-R-0304,Dresden University of Technology, Center for High-Per-formance Computing.
Shende, S. 2001. The Role of Instrumentation and Mapping inPerformance Measurement. PhD thesis, University ofOregon.
Shende, S. and Malony, A. D. 2003. Integration and Applica-tion of TAU in Parallel Java Environments. Concurrencyand Computation: Practice and Experience 15(3–5):501–519.
Shende, S., Malony, A. D., Cuny, J., Lindlan, K., Beckman, P.,and Karmesin, S. 1998. Portable Profiling and Tracing forParallel Scientific Applications using C++. Proceedingsof the SIGMETRICS Symposium on Parallel and Distrib-uted Tools, SPDT’98, pp. 134–145.
Shende, S., Malony, A. D., Rasmussen, C., and Sottile, M.2003. A Performance Interface for Component-BasedApplications. Proceedings of International Workshop
on Performance Modeling, Evaluation and Optimization,International Parallel and Distributed Processing Sympo-sium.
Song, F., Wolf, F., Bhatia, N., Dongarra, J., and Moore, S.2004. An Algebra for Cross-Experiment PerformanceAnalysis. Proc. of International Conference on ParallelProcessing, ICPP-04.
Subramanya, R. and Reddy, R. 2000. Sandia DNS code for 3Dcompressible flows – Final Report. Technical Report PSC-Sandia-FR-3.0, Pittsburgh Supercomputing Center, PA.
SUN Microsystems Inc. Java Virtual Machine Profiler Interface(JVMPI). http://java.sun.com/j2se/1.5.0/docs/guide/jvmpi/.
Szyperski, C. 1997. Component Software: Beyond Object-Ori-ented Programming. Addison-Wesley.
University of Oregon, a. TAU Portable Profiling. http://www.cs.uoregon.edu/research/paracomp/tau.
University of Oregon, b. Tuning and Analysis Utilities User’sGuide. http://www.cs.uoregon.edu/research/paracomp/tau.
Vetter, J. and Chambreau, C. mpiP: Lightweight, Scalable MPIProfiling. http://www.llnl.gov/CASC/mpip/.
Viswanathan, D. and Liang, S. 2000. Java Virtual Machine Pro-filer Interface. IBM Systems Journal 39(1):82–95.
Wolf, F., Mohr, B., Dongarra, J., and Moore, S. 2004. Efficient Pat-tern Search in Large Traces through Successive Refinement.Proceedings of the European Conference on Parallel Com-puting (EuroPar 2004, LNCS 3149), pp. 47–54. Springer.
Wu, C. E., Bolmarcich, A., Snir, M., Wootton, D., Parpia, F.,Chan, A., Lusk, E., and Gropp, W. 2000. From trace gen-eration to visualization: A performance framework fordistributed parallel systems. Proc. of SC2000: High Per-formance Networking and Computing.
Related Documents