The optimisation of traffic count locations in road networks Anett Ehlert a, * , Michael G.H. Bell b , Sergio Grosso c a Civil Engineering and Geosciences, Transport Operations Research Group, University of Newcastle upon Tyne, Cassie Building, Newcastle upon Tyne NE1 7RU, United Kingdom b Centre for Transport Studies, Imperial College London, SW7 2BU, United Kingdom c PTV-Newcastle upon Tyne, NE2 3AD, United Kingdom Received 7 January 2005; received in revised form 15 June 2005; accepted 28 June 2005 Abstract Origin–destination (OD) matrix estimation largely depends on the quality and quantity of the input data, which in turn depends on the number and sites of count locations. In this paper, we focus on the net- work count location problem (NCLP), namely the identification of informative links in the road network. Two extensions to previous methods of great practical relevance are presented. Firstly, a solution taking existing detectors into account (referred to as the second-best solution) is sought. This involves a reformu- lation of the optimisation problem and also the use of the original detector counts to update the link choice proportions. Secondly, the information content of the prior OD flows is (optionally) taken into account. The extended approach has been implemented in a software tool. The application of the tool to a network of moderate size is reported and its performance assessed. Ó 2005 Elsevier Ltd. All rights reserved. Keywords: Traffic count location; Integer linear programming; Location theory 0191-2615/$ - see front matter Ó 2005 Elsevier Ltd. All rights reserved. doi:10.1016/j.trb.2005.06.001 * Corresponding author. Tel.: +44 191 222 8202; fax: +44 191 222 6502. E-mail address: [email protected] (A. Ehlert). www.elsevier.com/locate/trb Transportation Research Part B 40 (2006) 460–479

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

www.elsevier.com/locate/trb
Transportation Research Part B 40 (2006) 460–479
The optimisation of traffic count locations in road networks
Anett Ehlert a,*, Michael G.H. Bell b, Sergio Grosso c
a Civil Engineering and Geosciences, Transport Operations Research Group, University of Newcastle upon Tyne,
Cassie Building, Newcastle upon Tyne NE1 7RU, United Kingdomb Centre for Transport Studies, Imperial College London, SW7 2BU, United Kingdom
c PTV-Newcastle upon Tyne, NE2 3AD, United Kingdom
Received 7 January 2005; received in revised form 15 June 2005; accepted 28 June 2005
Abstract
Origin–destination (OD) matrix estimation largely depends on the quality and quantity of the inputdata, which in turn depends on the number and sites of count locations. In this paper, we focus on the net-work count location problem (NCLP), namely the identification of informative links in the road network.Two extensions to previous methods of great practical relevance are presented. Firstly, a solution takingexisting detectors into account (referred to as the second-best solution) is sought. This involves a reformu-lation of the optimisation problem and also the use of the original detector counts to update the link choiceproportions. Secondly, the information content of the prior OD flows is (optionally) taken into account.The extended approach has been implemented in a software tool. The application of the tool to a networkof moderate size is reported and its performance assessed.� 2005 Elsevier Ltd. All rights reserved.
Keywords: Traffic count location; Integer linear programming; Location theory
0191-2615/$ - see front matter � 2005 Elsevier Ltd. All rights reserved.doi:10.1016/j.trb.2005.06.001
* Corresponding author. Tel.: +44 191 222 8202; fax: +44 191 222 6502.E-mail address: [email protected] (A. Ehlert).
A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 461
1. Introduction
OD matrix estimation from traffic counts is regarded as a convenient and reliable way to obtainup-to-date information about travel patterns in a region (see Cascetta and Postorino, 2001, for anoverview of methods). In addition, this technique is relatively inexpensive compared with the con-duct of extensive surveys, including road side interviews, number plate recognition and householdsurveys. However, the accuracy of such estimates depends largely on the quality and quantity ofthe input data, of which the number and sites of count locations play an essential part. Relatedmathematical problems have been formulated. One such problem is the determination of the num-ber of count stations required for complete OD coverage. Another, the identification of informa-tive links for a given number of stations in the road network, is referred to as the network countlocation problem (NCLP). This is in contrast to the link count location problem (LCLP), whichrelates to the position of a detector on a single link.
The best option for reliable estimation is to have counts from every link, but due to resourcelimitations, a selection must be made that prioritises some links in the network, namely the infor-mative links. The data collected from these links contribute significantly towards a more accurateestimation of OD flows and other traffic characteristics in the study area.
One of the difficulties presented by the NCLP is the dependence of the optimal count locationson network flows, which are themselves the object of estimation. Consider the following example(from Chung, 2001):
Link
Flow [veh/h] OD pairs on link OD pairs covereda
1000 1,2,3 3 b 2000 2,3 2Although the flow on link b is twice that on link a, link a covers more OD pairs. Moreover,once link a has been observed, link b does not increase the OD coverage. However, whether ornot an OD pair uses link a may depend on route choice, which depends on network conditions(specifically the size and location of congestion), which in turn may depend on the OD flows.As OD flows are generally the subject of estimation, a circularity is introduced creating a simul-taneous estimation problem. It also means that the information of the count data varies with theobjective of the estimation exercise.
Recent approaches to solve the NCLP follow a number of selection rules. Yang and Zhou(1998) defined the most comprehensive set of rules:
Rule (1) OD covering rule: A certain minimum proportion of trips between each OD pair shouldbe observable.
Rule (2) Maximal flow fraction rule: For a particular OD pair, links with the highest fraction ofthat OD flow should be selected.
Rule (3) Maximal flow interception rule: The set of links which intercept the maximum number ofOD movements should be selected.
Rule (4) Link independence rule: Links with linearly independent flows should be selected.

462 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
In this paper, we report the development of a software tool designed to solve the NCLP. Com-pared to other recent formulations, the method includes extensions to the problem that accountfor user needs in practical applications. Namely, due to the large number of OD pairs in real sizedproblems it is often impracticable to observe all OD movements in a network. Furthermore, somedetectors are likely to be installed already which consequently affect the optimal positions foradditional count locations.
Since not all OD flows are observable, it is often desirable to introduce a ranking of OD pairsthat reflects the significance of the corresponding flows. As a result, more important ODmovements are more likely to be covered. The algorithm proposed here is based on a mixed inte-ger programming problem. The software implementation of the algorithm has been tested inconjunction with the path flow estimator (PFE) in an application to an area-wide network inthe district of Gateshead (UK). The PFE uses detector data to infer path flows and travel timeson the assumption that route choice conforms to the stochastic user equilibrium assignmentprinciple (Bell et al., 1996, 1997; Bell and Iida, 1997; Bell and Grosso, 1998, 1999). It, therefore,serves as data completion tool providing input data for the identification of optimal countlocations.
The paper is divided as follows: In the next section we introduce the notation and report recentformulations of the NCLP. In Section 3, model extensions are proposed, and their practical rel-evance is highlighted. Section 4, then, focuses on the application of the software tool developed toa moderate sized real network. Performance indicators illustrate advantages and drawbacks of theimplemented method. Finally, conclusions are presented in Section 5.
2. Network count location problem
2.1. Notation
Following Chung (2001), let
t OD flow vector, with elements tw equal to the traffic between OD pair w. This is oftena prior estimate of the OD flows, as the actual OD flows are the subject of esti-mation
l link coverage vector, with elements la = 1 if link a is observed, and 0 otherwiseP matrix of link choice proportions, with elements paw equal to the proportion of traffic be-
tween OD pair w choosing link aD incidence matrix of significant links used by each OD movement, with elements daw = 1 if
paw P aw and 0 otherwiseaw OD-specific thresholds to determine elements of the incidence matrixm OD movement coverage vector, with elements mw = 1 if
Padwla P 1, and 0 otherwise
c vector of detector purchase and installation costs, with elements ca equal to the cost ofinstalling a detector on link a
z vector of OD-specific weights, with elements zw for OD pair wB budget for installing detectors

A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 463
In addition, the following notation presents a number of OD-related measures, which can usu-
ally be obtained as a result of the assignment procedure utilizing a prior OD matrix and trafficcounts as input data. Xw
Xa
dawla ¼ number of OD pair observations
Xw
Min 1;X
a
dawla
( )¼ number of OD pairs covered
Xw
tw
Xa
dawla ¼ total OD flows observed
Xw
twMin 1;X
a
dawla
( )¼ total OD flows covered
Each of these measures contains the variable daw, which indicates whether link a is used signifi-cantly by traffic between OD pair w. Thus the contribution of a traffic count to the estimation of ODflows depends on route choice. In contrast to measures that can be obtained as a result of the assign-ment, measured link counts generally relate to the total flow on a particular link only. Empirical linkchoice proportions, for example, can only be obtained if roadside interviews have been conducted.
2.2. Model formulations
The ultimate objective of identifying informative links in the network is to utilise the informa-tion collected from these links for the estimation of an OD trip table and other traffic character-istics. As links contain varying amounts of information about OD flows, with some linkscontaining no information, different count locations yield estimates of OD flows with different lev-els of reliability. Yang et al. (1991) proposed a measure of the reliability of an estimated ODmatrix, referred to as the maximum possible relative error (MPRE). The concept of the MPREis based on the assumptions that route choice behaviour is correctly specified, i.e. the estimatedlink choice proportions from the assignment of a prior OD matrix agree with the behaviour oftravellers, and traffic counts are error-free. Therefore,
Xw
pawðt�w � twÞ ¼ 0 for all measured links a ð1Þ
where tw is the estimated OD flow and t�w is its true but unknown value. Denote the relative error by
kw ¼ ðt�w � twÞ=tw ð2Þ
yielding Xw
pawtwkw ¼ 0 ð3Þ
for all links a which are observed. As a measure of estimation error Yang et al. proposed
GðkÞ ¼
ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiXw
k2w
!,m
vuut ð4Þ

464 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
where m is the number of OD movements. The MPRE is found by maximising G(k) subject toEq. (3) for all links a which are observed. A prior estimate of the true OD flow is required. Yangand Zhou (1998) note that if there are any unobserved OD movements, the MPRE is infinite lead-ing to the OD covering rule (Rule 1), namely that the count locations should be such that the tripsbetween any OD pair are observed at least once.
Consequently, the following binary integer programming (BIP) problem has been formulatedto minimise the number of count locations subject to complete OD coverage (Yang et al., 1991).
BIP-1 MinimiseX
a
la ð5Þ
subject toX
a
dawla P 1 for all OD pairs w ð6Þ
la 2 f0; 1g ð7Þ
It can be shown that the resulting location vector satisfies both the OD covering rule and the linkindependence rule (Rules 1 and 4). To maximise the OD flows intercepted for a fixed number ofcounting points, a second BIP problem is formulated which also takes path flows into account.
BIP-2 MaximiseX
r
fryr ð8Þ
subject toX
a
la ¼ l� ð9ÞXa2r
la P yr for all routes r ð10Þ
Xa
dawla P 1 for all OD pairs w ð11Þ
la; yr 2 f0; 1g ð12Þ
where fr is the path flow, yr is a binary variable indicating whether path r is observed (yr = 1) ornot (yr = 0), and l* is the prescribed number of counting sites. To obtain a feasible solution l* mustbe equal to or greater than the minimum number required for complete OD coverage. Further-more, the given number of count locations determines whether or not this problem (BIP-2)satisfies the link independence rule (Rule 4). Link independence can be ensured for the mini-mum number of counting sites. Note also, that the solution to the second BIP problem is notunique.
To solve the two BIP problems (BIP-1 and BIP-2) different solution methods have been pro-posed. Generally, solution methods can be divided into ‘‘exact’’ algorithms or ‘‘heuristic’’ ap-proaches. Exact methods guarantee an optimal result to the problem by employing varioustechniques to search the solution space. However, because of the combinatorial nature of IP prob-lems exact solutions cannot be found for many real moderate to large-size problems. Heuristicmethods, on the other hand, overcome this difficulty and can produce near-optimal solutionsbut without defining the distance from an unknown optimal result. Yang and Zhou (1998), forexample, proposed greedy heuristics to solve the location problem (BIP-2), whereby the numberof count locations is increased until all flows in the network are observed at least once, or a

A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 465
prescribed number of counting sites has been located. The algorithms can be summarised by thefollowing procedure:
Step 1: Initialise the iteration counter.Step 2: Calculate the sum of uncovered flows for all counted links.Step 3: Locate counting point on the link with the maximal observed flow.Step 4: Remove observed flows from all links in the network.Step 5: Stop if all network flows are captured, or increase iteration counter by one and return to
Step 2.
This greedy algorithm gives rise to a location vector that satisfies location rules 1, 3, and 4.Exact methods include Branch and Bound (BB) and the cutting plane algorithm. The former
technique produces an optimal result by applying an implicit enumeration procedure whichefficiently eliminates infeasible and non-optimal solutions. The major difficulty of the BBalgorithm is that optimality of the solution cannot be guaranteed until all possible solutions havebeen eliminated from consideration, i.e. when the enumeration tree has been searched completely.Only if all decision variables have integer values in the solution to the LP relaxation of the originalIP problem, the optimal solution is found without enumerating all alternatives in the feasibleregion of the IP problem. Extensive enumeration for large size problems can be avoided byterminating the BB procedure at a near-optimal solution. As opposed to heuristic methods, anestimate of the optimum is obtained by the solution of the LP relaxation to the original problemwhich in the case of a maximisation problem provides an upper limit to the optimum of the IPproblem.
In contrast to Branch and Bound methods, cutting plane algorithms are less frequently used,mainly because of their slower computational performances. For this reason, cutting plane tech-niques will not be considered for the location problems defined in this paper.
2.3. Budget considerations
Chung (2001) added the cost of purchasing and installing detectors into the count locationproblem, generating two distinct problems; the first one minimises the budget subject to completeOD coverage, and the second problem maximises the coverage of OD pairs subject to budgetrestrictions. The minimisation problem takes the following form:
BIP-3 MinimiseX
a
cala ð13Þ
subject toX
a
dawla P 1 for all OD pairs w ð14Þ
la 2 f0; 1g ð15Þ
where ca represents the costs in monetary units for placing a detector on link a. Problem BIP-3 issimilar to BIP-1. In addition, it allows the estimation of the resources required for covering all ODpairs in a network. However, in reality it can be assumed that the budget is limited, meaning thatsome OD movements may remain uncovered. Consequently, Chung formulated the followingnon-linear BIP problem:

466 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
BIP-4 MaximiseX
w
Min 1;X
a
dawla
( )zw ð16Þ
subject toX
a
cala 6 B ð17Þ
la 2 f0; 1g ð18Þ
where Eq. (17) corresponds to the budget constraint. An OD-specific weight zw is introducedallowing the user to rank OD movements in order of importance (1 is the lowest rank). This isparticularly important where not all OD flows are coverable. To facilitate efficient solutions, thisproblem (BIP-4) was transformed into a linear BIP programXBIP-5 Maximisew
zwmw ð19Þ
subject toX
a
dawla P mw for all OD pairs w ð20ÞXa
cala 6 B ð21Þ
la;mw 2 f0; 1g ð22Þ
Constraints (20) ensure that a particular OD movement w is covered (mw = 1) if at least a pre-specified proportion of trips is observed on one of the relevant links.The above BIP problem only satisfies the link independence rule (Rule 4). The OD coverage(Rule 1) has become the object of the optimisation itself, whereas the flow fraction rule (Rule2) is partly captured by the definition of OD-specific thresholds aw. A higher threshold value willensure that links with larger proportions of trips are selected. However, as congestion levels in thenetwork increase trip-makers may use additional routes leading to a reduction of the relevant linkchoice proportions paw. Therefore, the determination of aw should assure that there are some linkssignificantly used by each OD pair which allow mw to become one. This is guaranteed if the fol-lowing inequality is satisfied
0 6 aw 6 max paw for all OD pairs w ð23Þ
Note that in the case of aw = 0 all links used by traffic of OD pair w are potential count locations.3. Extensions
Extensions to problem BIP-5 are mainly concerned with practical issues, because the applica-tion of location problems to real situations often involves substantial investment in equipmentand installation. As already pointed out by Chung (2001), budget restrictions need to play anessential part in the formulation of the problem. In addition, traffic data are used in various appli-cations of modelling, traffic management, safety initiatives, and transport studies. The require-ments as to where to place detectors in the network vary among different purposes. Generally,the data include traffic characteristics such as flows, which provide useful information for ODmatrix estimation. The proposed extensions to the count location problem offer opportunitiesto exploit detector data from existing count stations in a more systematic way by considering theircontribution to the estimation process.

A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 467
3.1. The second-best count locations
For real moderate to large problems, complete OD coverage is often impossible due to thenumber of origins and destinations in the network. In addition, it is reasonable to assume thatsome detectors may already be installed, for example in the vicinity of traffic signals. This leadsto the second-best NCLP, namely the optimisation of additional count locations. In other words,the problem to be solved relates to the next x detectors given that y detectors are already installed.One could look for the optimal locations of x + y detectors, but it may transpire that some or allof the existing y detectors are sub-optimally located. The sub-optimally located detectors maynone-the-less affect the optimal locations for the remaining x detectors. Hence it is not sufficientsimply to restrict the locations for new count stations to unobserved links, as this would ignore thecontribution of the existing detectors.
In the context of problem BIP-5, the existence of detectors in the network means that some OD-flows are covered already. Additional detectors should therefore be located on links which in-crease the OD coverage. Let UC be the set of uncovered OD flows and UO the set of unobservedlinks. This leads to the following second-best OD coverage NCLP:
BIP-6 MaximiseX
w2UC
zwmw ð24Þ
subject toX
a2UO
dawla P mw for all OD pairs w 2 UC ð25ÞX
a2UO
cala 6 B ð26Þ
la;mw 2 f0; 1g ð27Þ
3.2. Information content of OD movements
Generally, OD-specific weights strongly influence the best links on which to locate detectors. Itcan be seen that identical importance weights for all OD pairs (e.g. zw = 1) result in maximisingOD coverage. Moreover, the coverage of one OD movement appears to be as important as thecoverage of any other OD movement in the network. In some cases the analyst will be able toidentify OD pairs of particular interest and then weight these appropriately. For example, impor-tance weights may reflect uncertainty in prior OD flows, and subsequently influence the link selec-tion forcing the coverage of prioritised OD pairs. However, where the analyst has no preference, itis still the case that some OD relations yield more information than others. Information theoryhas a long history, going back to Nyquist (1924) and Hartley (1928), who formulated some ofthe basic concepts (see Usher, 1984). The concept of information was applied to the problemof OD matrix estimation by Van Zuylen and Willumsen (1980). The average information contentof an OD movement is proportional to
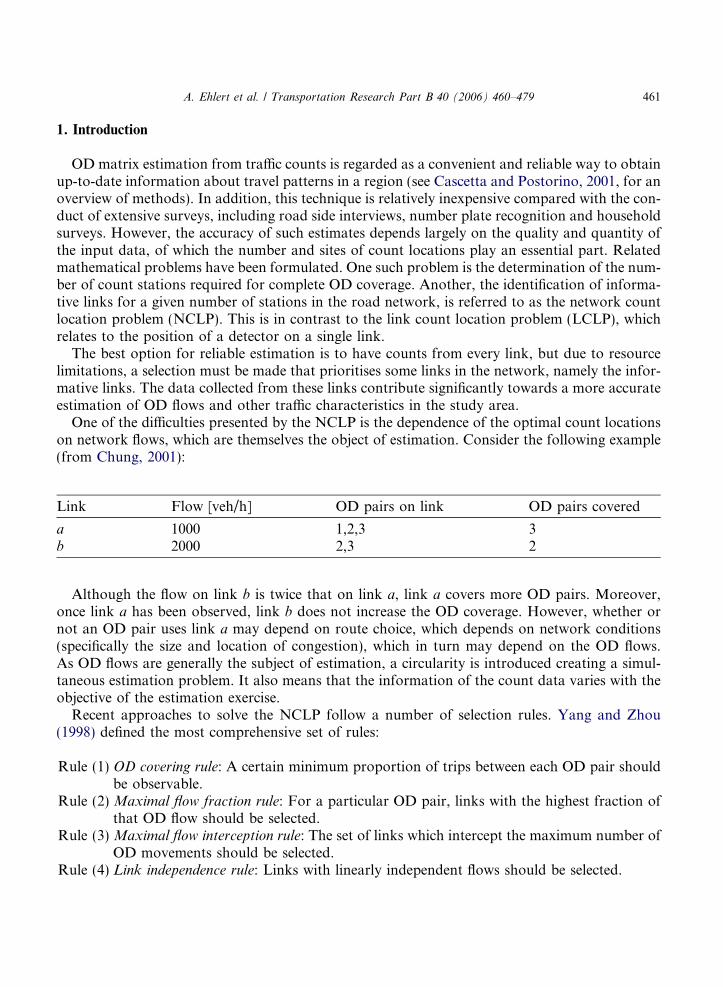
H w ¼ �pw ln pw ð28Þ
where pw is the probability of a trip selected at random from the set of all trips passing betweenOD pair w, as opposed to any other OD pair. This probability could be estimated from the priorOD matrix as follows: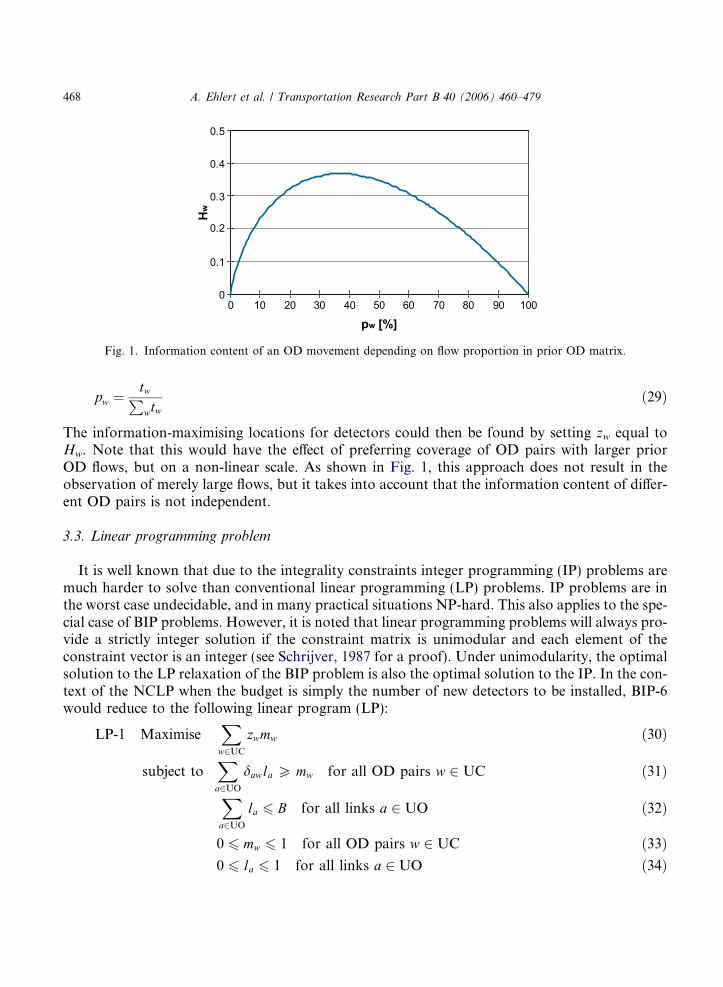
0
0.1
0.2
0.3
0.4
0.5
0 10 20 30 40 50 60 70 80 90 100
pw [%]
Hw
Fig. 1. Information content of an OD movement depending on flow proportion in prior OD matrix.
468 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
pw ¼twPwtw
ð29Þ
The information-maximising locations for detectors could then be found by setting zw equal toHw. Note that this would have the effect of preferring coverage of OD pairs with larger priorOD flows, but on a non-linear scale. As shown in Fig. 1, this approach does not result in theobservation of merely large flows, but it takes into account that the information content of differ-ent OD pairs is not independent.
3.3. Linear programming problem
It is well known that due to the integrality constraints integer programming (IP) problems aremuch harder to solve than conventional linear programming (LP) problems. IP problems are inthe worst case undecidable, and in many practical situations NP-hard. This also applies to the spe-cial case of BIP problems. However, it is noted that linear programming problems will always pro-vide a strictly integer solution if the constraint matrix is unimodular and each element of theconstraint vector is an integer (see Schrijver, 1987 for a proof). Under unimodularity, the optimalsolution to the LP relaxation of the BIP problem is also the optimal solution to the IP. In the con-text of the NCLP when the budget is simply the number of new detectors to be installed, BIP-6would reduce to the following linear program (LP):
LP-1 MaximiseX
w2UC
zwmw ð30Þ
subject toX
a2UO
dawla P mw for all OD pairs w 2 UC ð31ÞX
a2UO
la 6 B for all links a 2 UO ð32Þ
0 6 mw 6 1 for all OD pairs w 2 UC ð33Þ0 6 la 6 1 for all links a 2 UO ð34Þ

A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 469
This is because the simplex method generates extreme points, pushing mw and la to the extremesof their permissible ranges. The LP above is much easier to solve than BIP-6, particularly forlarge problems. Unfortunately, it seems that the property of unimodularity does not apply to thismodel, as the simplex method produces non-integer values in some cases.
3.4. Implementation
The problem (BIP-6) can be classified as a pure integer programming problem, because all deci-sion variables are required to be integer. However, due to the interdependencies between the loca-tion vector and OD coverage it is sufficient to apply the integrality constraint to decision variablela. More specifically, the knowledge of count locations automatically specifies OD coverage, whichfor the BB algorithm means that variable mw does not have to be considered for branching. Thefinally obtained mixed integer problem can be written as
MIP-1 MaximiseX
w2UC
zwmw ð35Þ
subject to mw �X
a2UO
dawla 6 0 for all OD pairs w 2 UC ð36Þ
Xa2UO
la 6 B for all links a 2 UO ð37Þ
0 6 mw 6 1 for all OD pairs w 2 UC ð38Þ
la 2 ð0; 1Þ for all links a 2 UO ð39Þ
Since in many real size problems the number of OD movements is considerable larger than thenumber of links in the network the removal of the integrality constraint on mw can reduce com-putation time significantly.
The software tool developed, called OptTool, is linked to the PFE. Underlying the PFE is astochastic user equilibrium traffic assignment method which, among other things, estimates pathflows and travel times from traffic counts and a prior OD matrix. In addition, as a result of theassignment the PFE also yields link choice proportions paw, which together with the OD-specificthresholds aw are required to generate the link-path incidence matrix D with elements daw. Giventhe pre-defined budget B the NCLP can be formulated for the optimisation of count stations inthe network. However, existing traffic count locations are required for the evaluation of the sec-ond-best locations, because they allow the set of unobserved links (UO), and subsequently the setof uncovered OD pairs (UC) to be defined. Furthermore, the prior OD matrix can be used to rankOD movements based on their information content (Eq. 28). The OptTool algorithm is summa-rised in Fig. 2.
Note that the formulation of a second-best NCLP and the use of weights based on informationtheory are optional user inputs, whereas link choice proportions and the budget are mandatorydata inputs. Without specifically selecting these user options, the default procedure finds countlocations that maximise OD coverage whereby all links and OD pairs in the network are consid-ered. To solve this problem (MIP-1), API routines of the GNU GLPK software (version 4.4) havebeen integrated. Besides the optimal count locations and the corresponding OD coverage,

Fig. 2. OptTool algorithm.
470 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
OptTool evaluates OD-related measures for both existing detectors and new detectors usingresults of the PFE assignment.
4. Example application
OptTool has been applied to the network of the district of Gateshead in the Northeast of Eng-land. The responsibility for the provision and maintenance of roads lies to 98% with GatesheadCouncil. The remaining part includes trunk roads which are managed by the UK HighwaysAgency. Consequently, data collection and installation of appropriate equipment is managedby different authorities. However, Gateshead Council also has access to traffic data collectedon the primary network.
The network model covers an area of approximately 55 square miles, and comprises 240 km ofmainly classified roads which are represented by 1414 directed links (Fig. 3).
The area under investigation has been divided into 23 zones which represent origins and desti-nations of traffic. Additionally, 22 external zones are defined to reproduce traffic originating and/or terminating outside the district. Overall, there exists a total of 1980 OD pairs.
4.1. Test scenarios
Two scenarios will be tested:
(a) information-maximising locations for 15 new detectors,(b) second-best solution for five additional detectors maximising OD coverage.

Fig. 3. Network model of application.
A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 471
Traffic is assigned by the PFE using the prior OD matrix and traffic data from existing countlocations. In contrast to assigning the prior OD only, the PFE updates the existing matrix and thecorresponding path flows. As a consequence, link choice proportions are improved reflecting amore likely route choice of travellers. The link choice proportions paw include the percentage oftraffic of one OD flow on a particular link. In addition to OD coverage, we also examine theOD flows intercepted by the optimal counting locations. In both scenarios aw is set to 25% forall OD pairs w. A sensitivity analysis with respect to this parameter is conducted in Section 4.4.
4.1.1. Scenario (a)In this scenario, the problem (MIP-1) can be characterised by the following figures:
la with a = 1,2, . . . , 1293*
mw with w = 1,2, . . . , 1980Number of constraints = 1981Number of decision variables = 3273Number of elements in constraint matrix = 6,483,813Number of non-zero elements in constraint matrix = 99,567 (1.54%)P
wzw ¼ 6.582 with w = 1,2, . . . , 1980Pwtw ¼ 432; 258 with w = 1,2, . . . , 1980
* Note that only links with traffic are considered.
As the result of the optimisation, optimal count locations for 15 new detectors are identified(Fig. 4).
These count sites result in the coverage of 1608 OD pairs with a weight of 5.552, that is 84.3% ofthe total weight. Note that paths of 67 further OD pairs cross links with count sites but the link

Fig. 4. Information-maximising count locations for 15 sensors.
472 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
choice proportions of these OD movements do not exceed threshold alpha. According to ourdefinition, the latter OD pairs are not considered as covered.
Using equal weights OD coverage is increased (1663) but at the costs of OD pairs with higherinformation contents. The count sites agree for seven out of the 15 links. In Table 1, the results arecompared depending on the user�s choice of the optimisation objective. The number of trips inter-cepted is considerably higher for the maximum information objective, while the ranking of theother two measures are in line with the optimisation objective. The higher number of interceptedtrips is due to parameter a and the weight option. Parameter a ensures that counting sites are lo-cated on paths with relatively more traffic, whereas the selected user option favours OD pairs withhigher flows.
Note that maximising information ensures coverage of OD pairs with relatively higher flows,but not necessarily on links with substantial link choice proportions. It means that regarding flowinterception the weight option is particularly effective if combined with relatively high a values.Fig. 5 shows the number of flow interceptions for scenario (a) when a takes two different values,namely 0% and 25%.
Table 1Comparison of optimisation results of scenario (a) by objective function
Max. OD coverage Max. information
Total unweighted OD coverage 1663 (84.0%) 1608 (81.2%)Total weighted OD coverage 5.190 (78.8%) 5.552 (84.3%)Trips intercepted 292,113 (67.2%) 327,722 (75.9%)
0
10
20
30
40
50
0 1 2 3 4Flow intercepted [No]
Trip
s [%
]
max. OD coverage
max. Information
alpha = 0%
0
10
20
30
40
50
0 1 2 3 4Flow intercepted [No]
Trip
s [%
]
max. OD coverage
max. Information
alpha = 25%
Fig. 5. Number of trip interceptions by optimisation objective for two a values.
A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 473
It can be seen that maximising information does not automatically results in observing moretrips when parameter a is set to zero (see right-hand diagram of Fig. 5), because the optimalcounting sites are located on links where less traffic of OD pairs with higher weights is observed.Given an a value of 25%, the more popular OD pairs can only be covered if counting sites inter-cept paths with more than 25% of OD flows. In this case, the total number of trips intercepted atleast once is considerably higher if the weighted coverage objective is selected.
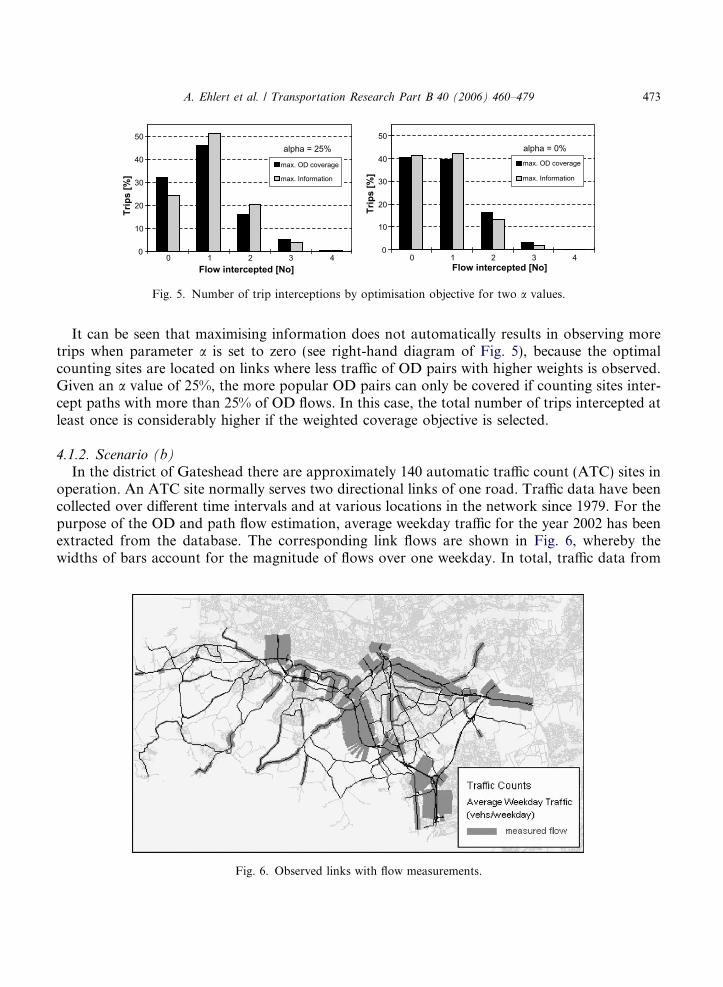
4.1.2. Scenario (b)In the district of Gateshead there are approximately 140 automatic traffic count (ATC) sites in
operation. An ATC site normally serves two directional links of one road. Traffic data have beencollected over different time intervals and at various locations in the network since 1979. For thepurpose of the OD and path flow estimation, average weekday traffic for the year 2002 has beenextracted from the database. The corresponding link flows are shown in Fig. 6, whereby thewidths of bars account for the magnitude of flows over one weekday. In total, traffic data from
Fig. 6. Observed links with flow measurements.

474 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
173 links are obtained. The first step of the optimisation in scenario (b) is to specify the MIP prob-lem, namely to identify potential links for additional detectors and to extract uncovered OD pairs.Output from the assignment shows that 1932 OD pairs are already covered. Therefore, the fiveadditional detectors must be placed such as to cover as many of the remaining OD pairs aspossible.
Because of the large number of existing traffic sensors, problem (MIP-1) for scenario (b) isreduced considerably:
la with a = 1,2, . . . , 1120mw with w = 1,2, . . . , 48Number of constraints = 49Number of decision variables = 1168Number of elements in constraint matrix = 57,232Number of non-zero elements in constraint matrix = 1702 (2.97%)P
wzw ¼ 48 with w = 1,2, . . . , 48Pwtw ¼ 2453 with w = 1,2, . . . , 48
The corresponding optimal count locations for five additional detectors are shown in Fig. 7. Asa result of placing the additional count stations, 28 out of the 48 OD movements considered arenow covered. However, it can be seen in the definition of MIP-1 for scenario (b) that these ODpairs include less than 1% of all trips in the network. More specifically, 1425 trips are additionallyintercepted by the five detectors.
Fig. 7. Optimal count locations for five additional traffic sensors.
A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 475
In the case of the second scenario, it can be concluded that existing count locations provide agood basis for the OD estimation, because more than 97% of OD movements are covered already.The installation of additional count sites result in the observation of minor OD flows in thenetwork.
4.2. OD coverage
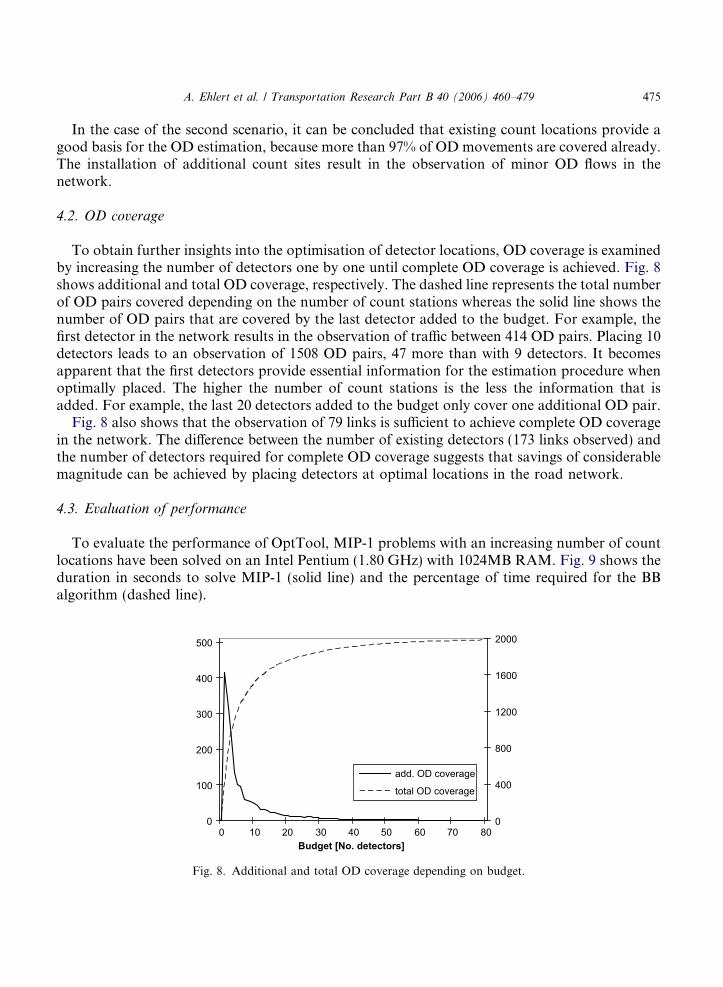
To obtain further insights into the optimisation of detector locations, OD coverage is examinedby increasing the number of detectors one by one until complete OD coverage is achieved. Fig. 8shows additional and total OD coverage, respectively. The dashed line represents the total numberof OD pairs covered depending on the number of count stations whereas the solid line shows thenumber of OD pairs that are covered by the last detector added to the budget. For example, thefirst detector in the network results in the observation of traffic between 414 OD pairs. Placing 10detectors leads to an observation of 1508 OD pairs, 47 more than with 9 detectors. It becomesapparent that the first detectors provide essential information for the estimation procedure whenoptimally placed. The higher the number of count stations is the less the information that isadded. For example, the last 20 detectors added to the budget only cover one additional OD pair.
Fig. 8 also shows that the observation of 79 links is sufficient to achieve complete OD coveragein the network. The difference between the number of existing detectors (173 links observed) andthe number of detectors required for complete OD coverage suggests that savings of considerablemagnitude can be achieved by placing detectors at optimal locations in the road network.
4.3. Evaluation of performance
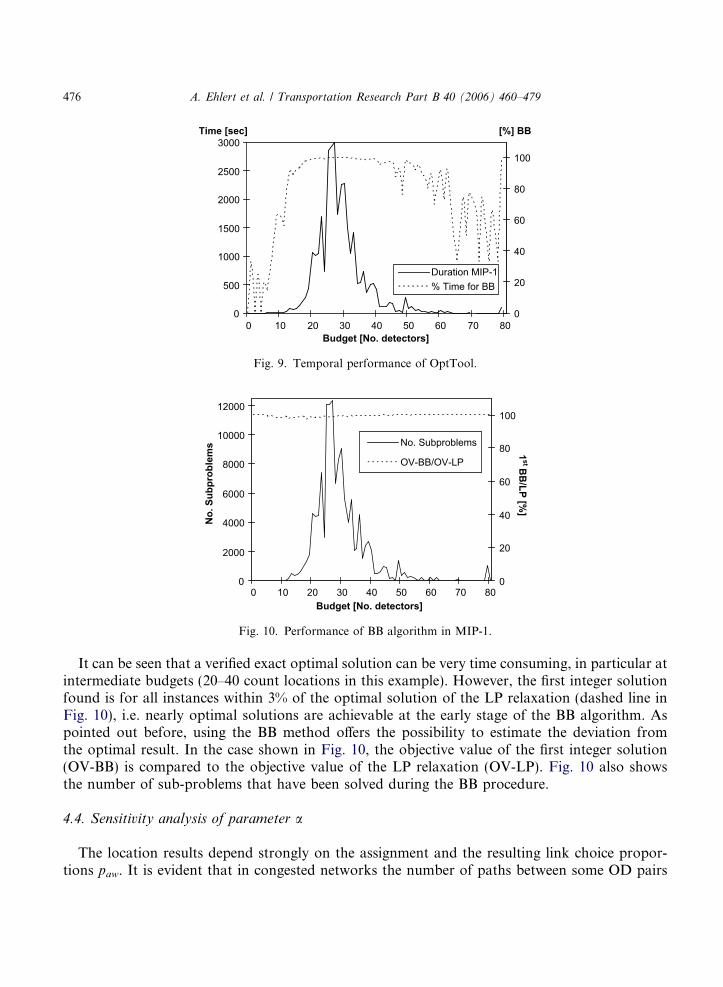
To evaluate the performance of OptTool, MIP-1 problems with an increasing number of countlocations have been solved on an Intel Pentium (1.80 GHz) with 1024MB RAM. Fig. 9 shows theduration in seconds to solve MIP-1 (solid line) and the percentage of time required for the BBalgorithm (dashed line).
0
100
200
300
400
500
0 10 20 30 40 50 60 70 80Budget [No. detectors]
0
400
800
1200
1600
2000
add. OD coverage
total OD coverage
Fig. 8. Additional and total OD coverage depending on budget.
0
500
1000
1500
2000
2500
3000
0 10 20 30 40 50 60 70 80Budget [No. detectors]
Time [sec]
0
20
40
60
80
100
[%] BB
Duration MIP-1% Time for BB
Fig. 9. Temporal performance of OptTool.
0
2000
4000
6000
8000
10000
12000
0 10 20 30 40 50 60 70 80Budget [No. detectors]
No.
Sub
prob
lem
s
0
20
40
60
80
100
1st B
B/LP [%
]
No. Subproblems
OV-BB/OV-LP
Fig. 10. Performance of BB algorithm in MIP-1.
476 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
It can be seen that a verified exact optimal solution can be very time consuming, in particular atintermediate budgets (20–40 count locations in this example). However, the first integer solutionfound is for all instances within 3% of the optimal solution of the LP relaxation (dashed line inFig. 10), i.e. nearly optimal solutions are achievable at the early stage of the BB algorithm. Aspointed out before, using the BB method offers the possibility to estimate the deviation fromthe optimal result. In the case shown in Fig. 10, the objective value of the first integer solution(OV-BB) is compared to the objective value of the LP relaxation (OV-LP). Fig. 10 also showsthe number of sub-problems that have been solved during the BB procedure.
4.4. Sensitivity analysis of parameter a
The location results depend strongly on the assignment and the resulting link choice propor-tions paw. It is evident that in congested networks the number of paths between some OD pairs
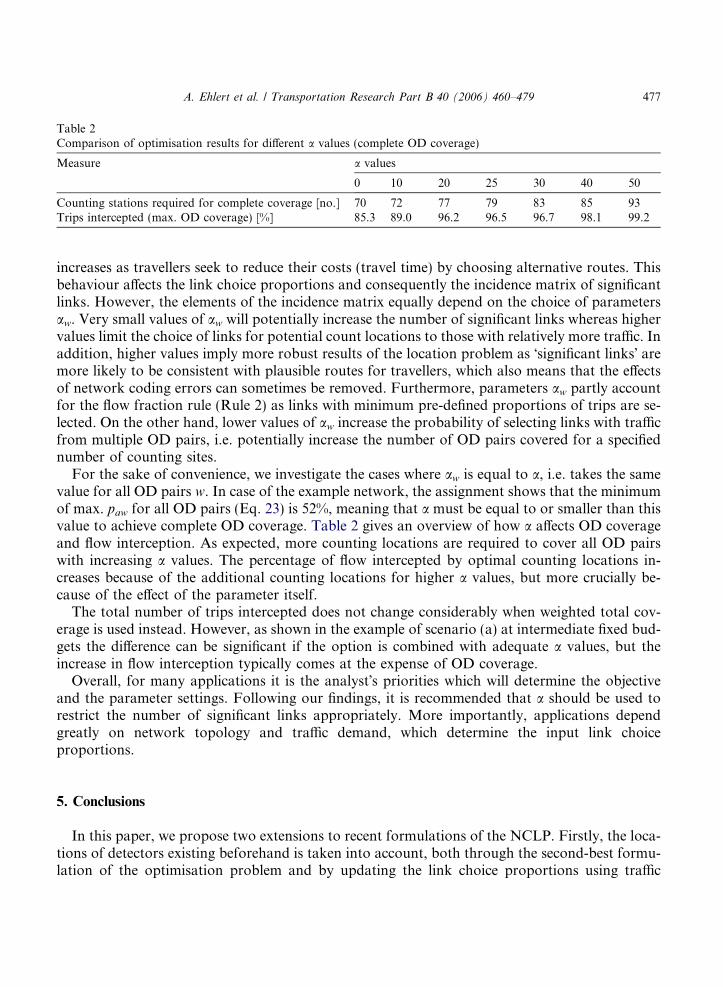
Table 2Comparison of optimisation results for different a values (complete OD coverage)
Measure a values
0 10 20 25 30 40 50
Counting stations required for complete coverage [no.] 70 72 77 79 83 85 93Trips intercepted (max. OD coverage) [%] 85.3 89.0 96.2 96.5 96.7 98.1 99.2
A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 477
increases as travellers seek to reduce their costs (travel time) by choosing alternative routes. Thisbehaviour affects the link choice proportions and consequently the incidence matrix of significantlinks. However, the elements of the incidence matrix equally depend on the choice of parametersaw. Very small values of aw will potentially increase the number of significant links whereas highervalues limit the choice of links for potential count locations to those with relatively more traffic. Inaddition, higher values imply more robust results of the location problem as �significant links� aremore likely to be consistent with plausible routes for travellers, which also means that the effectsof network coding errors can sometimes be removed. Furthermore, parameters aw partly accountfor the flow fraction rule (Rule 2) as links with minimum pre-defined proportions of trips are se-lected. On the other hand, lower values of aw increase the probability of selecting links with trafficfrom multiple OD pairs, i.e. potentially increase the number of OD pairs covered for a specifiednumber of counting sites.
For the sake of convenience, we investigate the cases where aw is equal to a, i.e. takes the samevalue for all OD pairs w. In case of the example network, the assignment shows that the minimumof max. paw for all OD pairs (Eq. 23) is 52%, meaning that a must be equal to or smaller than thisvalue to achieve complete OD coverage. Table 2 gives an overview of how a affects OD coverageand flow interception. As expected, more counting locations are required to cover all OD pairswith increasing a values. The percentage of flow intercepted by optimal counting locations in-creases because of the additional counting locations for higher a values, but more crucially be-cause of the effect of the parameter itself.
The total number of trips intercepted does not change considerably when weighted total cov-erage is used instead. However, as shown in the example of scenario (a) at intermediate fixed bud-gets the difference can be significant if the option is combined with adequate a values, but theincrease in flow interception typically comes at the expense of OD coverage.
Overall, for many applications it is the analyst�s priorities which will determine the objectiveand the parameter settings. Following our findings, it is recommended that a should be used torestrict the number of significant links appropriately. More importantly, applications dependgreatly on network topology and traffic demand, which determine the input link choiceproportions.
5. Conclusions
In this paper, we propose two extensions to recent formulations of the NCLP. Firstly, the loca-tions of detectors existing beforehand is taken into account, both through the second-best formu-lation of the optimisation problem and by updating the link choice proportions using traffic

478 A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479
counts from the original detectors. Secondly, the information content of the prior OD flows is(optionally) taken into account. Generally, the installation of traffic sensors and the data collec-tion are often long-term decisions that may be the responsibility of different highway authorities.Also, traffic data are used in a wide range of applications such as traffic management and signaloptimisation. Nevertheless, these data also provide useful input for matrix and flow estimation.These and other reasons may often favour a second-best solution to the NCLP, where the contri-bution from existing count locations is taken into account. Depending on the level of sensorisa-tion in a road network, the formulation of a second-best NCLP can reduce the number of decisionvariables, and consequently computation time, significantly.
The software tool developed is based on a MIP problem formulation in which budget restric-tions are taken into account. The extensions are implemented as user options. The application to anetwork of moderate size has shown the relevance of the user options to practical problems. Tothe knowledge of the authors, it is also the first time that this solution method has been applied toa real network of moderate size. The performance evaluation of the software indicates that com-putational efficiency can be improved further if near-optimal solutions are satisfactory. In con-trast to heuristic methods, the deviation from the optimum can be estimated. For manypractical problems near-optimal solutions may be acceptable, because traffic data from countlocations often need to satisfy data requirements for different estimation tasks, e.g. with temporaland spatial variations, or level of detail in the network. Also, link choice proportions vary with thelevel of congestion in the network, and the assumption of correctly specified route choice behav-iour may not always hold. However, in our formulation the definition of threshold alpha accountsto some extent for uncertainty in the link choice proportions.
We have also highlighted the importance of budget restrictions for practical problems resultingin the fact that the OD covering rule cannot always be satisfied. As a consequence, the method ofthe MPRE as a measure of the OD estimation error cannot be applied. On the other hand, thecontribution of count data from an additional count location to the estimation must be consid-ered. For example, it was shown that a limited number of count stations can cover a high propor-tion of OD movements and intercepts the majority of trips. If flow interception is of high prioritythe maximisation of information content should be combined with appropriate a values.
The application reported has proved that our implementation of the NCLP is satisfactoryfor many practical problems. Nevertheless, networks of large size may require a more efficientimplementation that always guarantees a solution within reasonable time. Furthermore, it isdesirable to quantify the contribution of optimal count locations towards more reliable ODestimation.
Acknowledgements
This research has been carried out as part of the SENSOR project (GRD2/30202/2000).SENSOR—Secondary Road Network Traffic Management Strategies. Handbook for DataCollection, Communication and Organisation—is a GROWTH Project supported by the Com-mission of the European Communities in the framework of the �Key Action II of GROWTHProgramme�. Finally, the seminal contribution of I.-H. Chung to this paper is gratefullyacknowledged.

A. Ehlert et al. / Transportation Research Part B 40 (2006) 460–479 479
References
Bell, M.G.H., Grosso, S., 1998. The path flow estimator as a network observer. Traffic Engineering and Control 39 (10),540–550.
Bell, M.G.H., Grosso, S., 1999. Estimating path flows from traffic counts. In: Wallentowitzm, H. (Ed.), Traffic andMobility. Springer Verlag, Berlin, Germany, pp. 85–105.
Bell, M.G.H., Iida, Y., 1997. Transportation Network Analysis. John Wiley & Sons, Chichester, UK.Bell, M.G.H., Lam, W.H.K., Iida, Y., 1996. A time-dependent multi-class path flow estimator. In: Proceedings of the
13th International Symposium on Transportation and Traffic Flow Theory, Lyon, France, 24–26 July 1996, pp. 173–193.
Bell, M.G.H., Shield, C.M., Busch, F., Kruse, G., 1997. A stochastic user equilibrium path flow estimator.Transportation Research Part C 5 (3–4), 197–210.
Cascetta, E., Postorino, M.N., 2001. Fixed point approaches to the estimation of O/D matrices using traffic counts oncongested networks. Transportation Science 35 (2), 134–147.
Chung, I.-H., 2001. An optimum sampling framework for estimating trip matrices from day-to-day traffic counts. Ph.D.Thesis, University of Leeds.
Hartley, R.V.L., 1928. Transmission of information. Bell System Technical Journal 7, 535–563.Nyquist, H., 1924. Certain factors affecting telegraph speed. Bell System Technical Journal 3, 324–346.Schrijver, A., 1987. Theory of Linear and Integer Programming. John Wiley & Sons, Chichester.Usher, M.J., 1984. Information Theory for Information Technologists. Macmillan Press, Basingstoke, UK.Van Zuylen, H.J., Willumsen, L.G., 1980. The most likely trip matrix estimated from traffic counts. Transportation
Research Part B 14 (3), 281–293.Yang, H., Zhou, J., 1998. Optimal traffic counting locations for origin–destination matrix estimation. Transportation
Research Part B 32 (2), 109–126.Yang, H., Iida, Y., Sasaki, T., 1991. An analysis of the reliability of an origin–destination trip matrix estimated from
traffic counts. Transportation Research Part B 25 (5), 351–363.
Related Documents











