Grab some coffee and enjoy the preshow banter before the top of the hour!

The Maturity Model: Taking the Growing Pains Out of Hadoop
Jul 28, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Grab some coffee and enjoy the pre-show banter
before the top of the
hour!

The Briefing Room
The Maturity Model: Taking the Growing Pains Out of Hadoop

Twitter Tag: #briefr The Briefing Room
Reveal the essential characteristics of enterprise software, good and bad
Provide a forum for detailed analysis of today’s innovative technologies
Give vendors a chance to explain their product to savvy analysts
Allow audience members to pose serious questions... and get answers!
Mission

Twitter Tag: #briefr The Briefing Room
Topics
June: INNOVATORS
July: SQL INNOVATION
August: REAL-TIME DATA
Twitter Tag: #briefr The Briefing Room
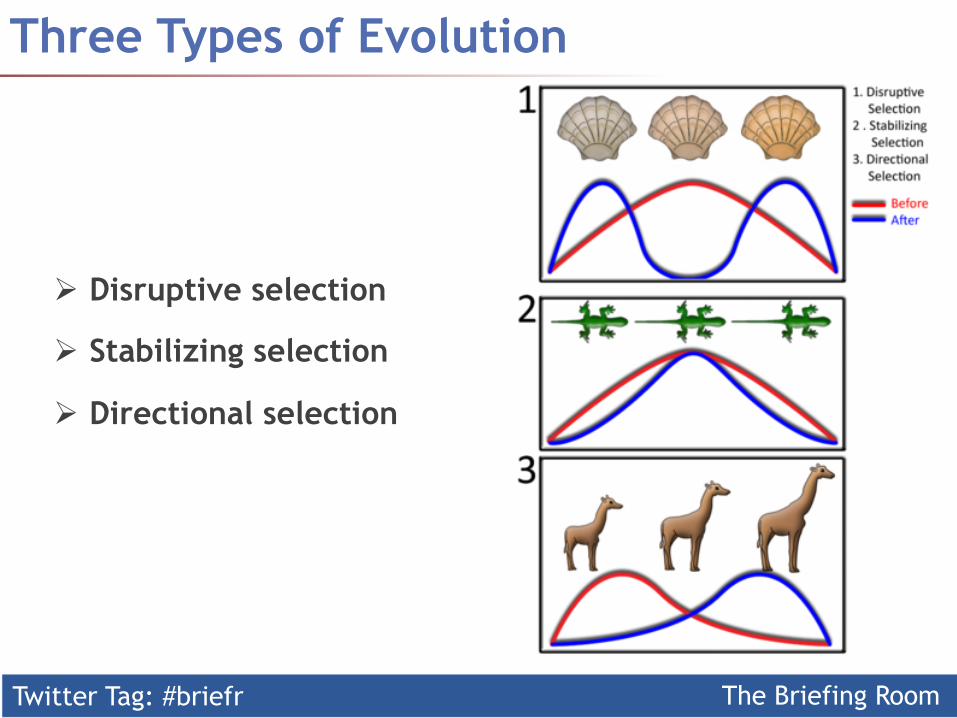
Three Types of Evolution
Ø Disruptive selection
Ø Stabilizing selection
Ø Directional selection

Twitter Tag: #briefr The Briefing Room
Types of Evolution?
WHAT GOES AROUND, COMES AROUND!

Twitter Tag: #briefr The Briefing Room
Analyst: Rick van der Lans
Rick F. van der Lans is an independent analyst, consultant, author and lecturer specializing in data warehousing, business intelligence, analytics, big data and database technology. He is Managing Director of R20/Consultancy. He has advised many large companies worldwide on defining their business intelligence architectures. His popular IT books have been translated into many languages and have sold over 100,000 copies. Rick writes for TechTarget.com and B-eye-Network. For the last 25 years, he has been presenting professionally around the globe and at international events.

Twitter Tag: #briefr The Briefing Room
Think Big, A Teradata Company
Last year Teradata acquired Think Big Analytics, Inc., a consulting and solutions company focused on big data solutions
Think Big has expertise in implementing a variety of open source technologies, such as Hadoop, Hbase, Cassandra, MongoDB and Storm, as well as experience with Hortonworks, Cloudera and MapR
Its consultants can assist with the planning, management and deployment of big data implementations

Twitter Tag: #briefr The Briefing Room
Guest: Ron Bodkin
Ron Bodkin is Founder & President of Think Big, A Teradata Company. Ron founded Think Big to help companies realize measurable value from Big Data. The company’s expertise spans all facets of data science and data engineering and helps our customers to drive maximum value from their Big Data initiative. Previously, Ron was vice president Engineering at Quantcast where he led the data science and engineer teams that pioneered the use of Hadoop and NoSQL for batch and real-time decision making. Prior to that, Ron was Founder of New Aspects, which provided enterprise consulting for Aspect-oriented programming. Ron was also Co-Founder and CTO of B2B applications provider C-Bridge, which he led to team of 900 people and a successful IPO. Ron graduated with honors from McGill University with a B.S. in Math and Computer Science. Ron also earned his Master’s Degree in Computer Science from MIT, leaving the PhD program after presenting the idea for C-bridge and placing in the finals of the 50k Entrepreneurship Contest.

MAKING BIG DATA COME ALIVE
The Maturity Model: Taking the Growing Pains out of Hadoop
Ron Bodkin Founder and President, Think Big

12
• What is Big Data?
• Hadoop Maturity Spectrum (from MapReduce to Integrated Hadoop Architecture)
• Taking the Growing Pains out of Hadoop
Agenda

13
• Data sets so large and complex that they become awkward to work with using standard tools and techniques
• Google, Quantcast, Yahoo, LinkedIn… customer innovation in open source
• Discover value in dark data and relationships among data sets – Customer behavior
– Product behavior
• Evolution: insight -> operational -> business innovation
Source: Hortonworks
What is Big Data?
© 2015 Think Big, a Teradata Company 6/16/15

14
Hadoop (Circa 2008)
• HDFS - Distributed File System
• MapReduce distributed parallel batch processing
• Community Open Source since 2005 many contributors
• Industry commitment: over $1 Billion invested in startups, all major software companies embrace
• 3 replicas for HA
• 50 PB+ scale
• Great for analytics, batch processing
© 2015 Think Big, a Teradata Company 6/16/15

15
SQL on Hadoop (Circa 2009 to Today)
• Expanded access to data in Hadoop
• Great for exploration of “raw” data, e.g., by data scientists – Can integrate UDFs – Tools integration expanding
access beyond SQL power users
• Fast moving space
• Also used for ETL/ELT processing
© 2015 Think Big, a Teradata Company 6/16/15
16
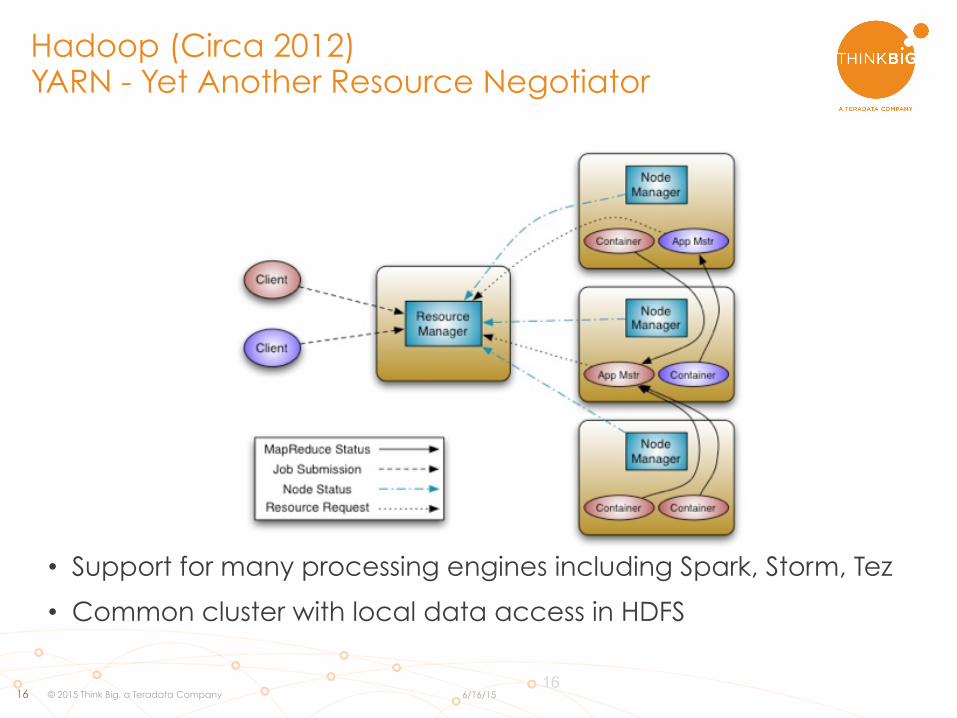
• Support for many processing engines including Spark, Storm, Tez
• Common cluster with local data access in HDFS
Hadoop (Circa 2012) YARN - Yet Another Resource Negotiator
16 © 2015 Think Big, a Teradata Company 6/16/15
17 © 2015 Think Big, a Teradata Company 6/16/15
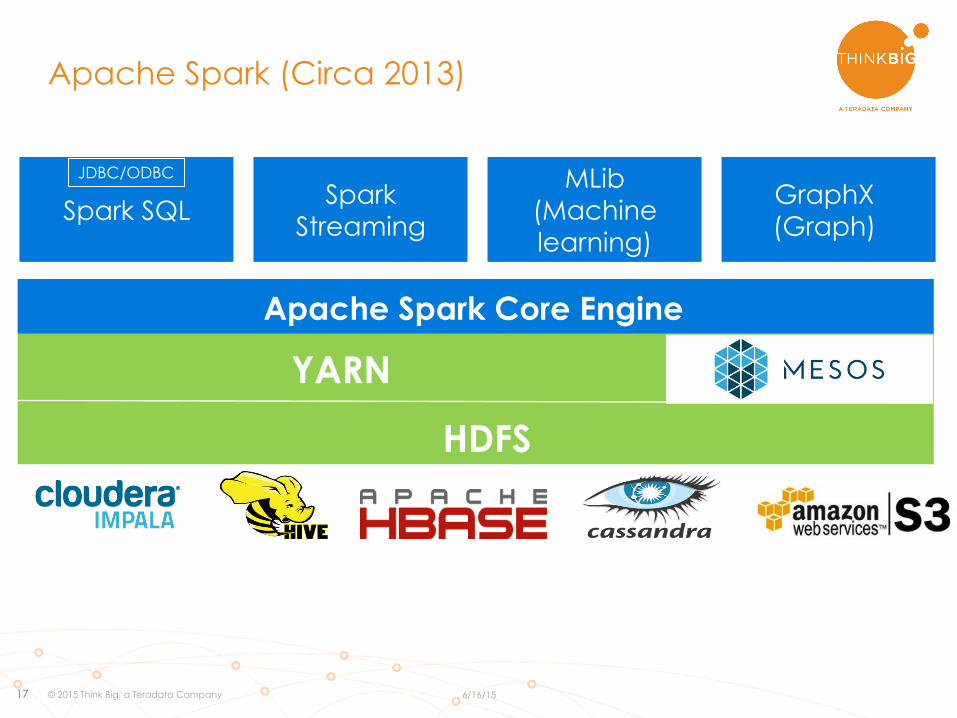
Apache Spark (Circa 2013)
Spark SQL Spark
Streaming
MLib (Machine learning)
GraphX (Graph)
Apache Spark Core Engine
YARN
JDBC/ODBC
HDFS
18
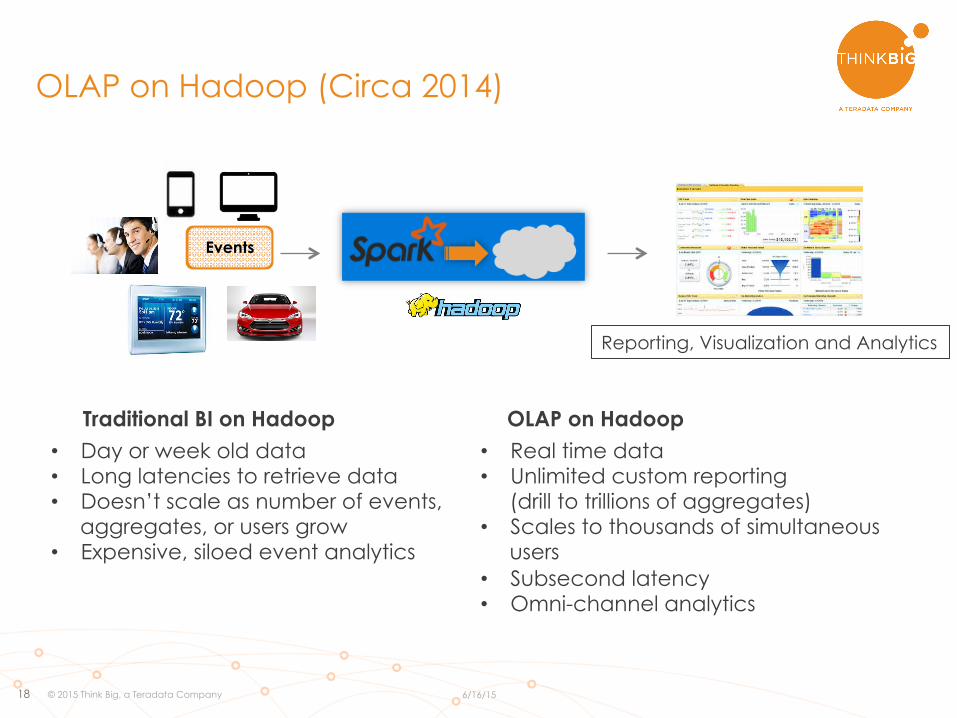
OLAP on Hadoop (Circa 2014)
Events
Reporting, Visualization and Analytics
Traditional BI on Hadoop • Day or week old data • Long latencies to retrieve data • Doesn’t scale as number of events,
aggregates, or users grow • Expensive, siloed event analytics
• Real time data • Unlimited custom reporting
(drill to trillions of aggregates) • Scales to thousands of simultaneous
users • Subsecond latency • Omni-channel analytics
OLAP on Hadoop
© 2015 Think Big, a Teradata Company 6/16/15
19
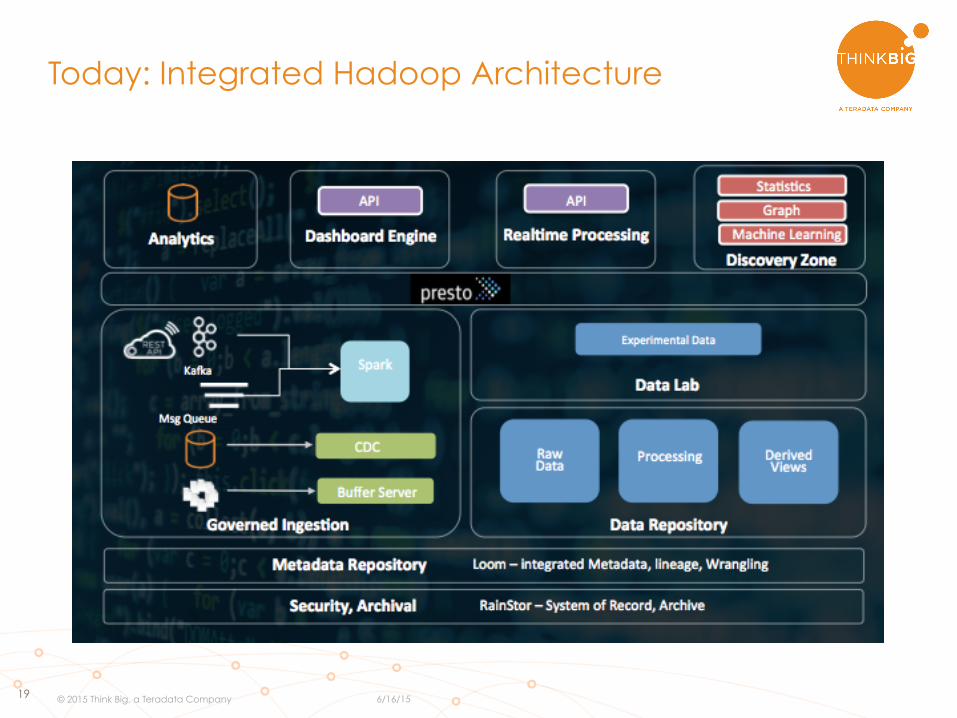
Today: Integrated Hadoop Architecture
© 2015 Think Big, a Teradata Company 6/16/15

MAKING BIG DATA COME ALIVE
How to Take the Growing Pains out of Hadoop

21
• Picking the wrong starting point – ho hum, boil the ocean
• Immature Governance
• Siloed Organization
• Change Management
• Skills Gap
• Business as usual
• Not fitting in with ecosystem
Big Data Pitfalls
© 2015 Think Big, a Teradata Company 6/16/15
22
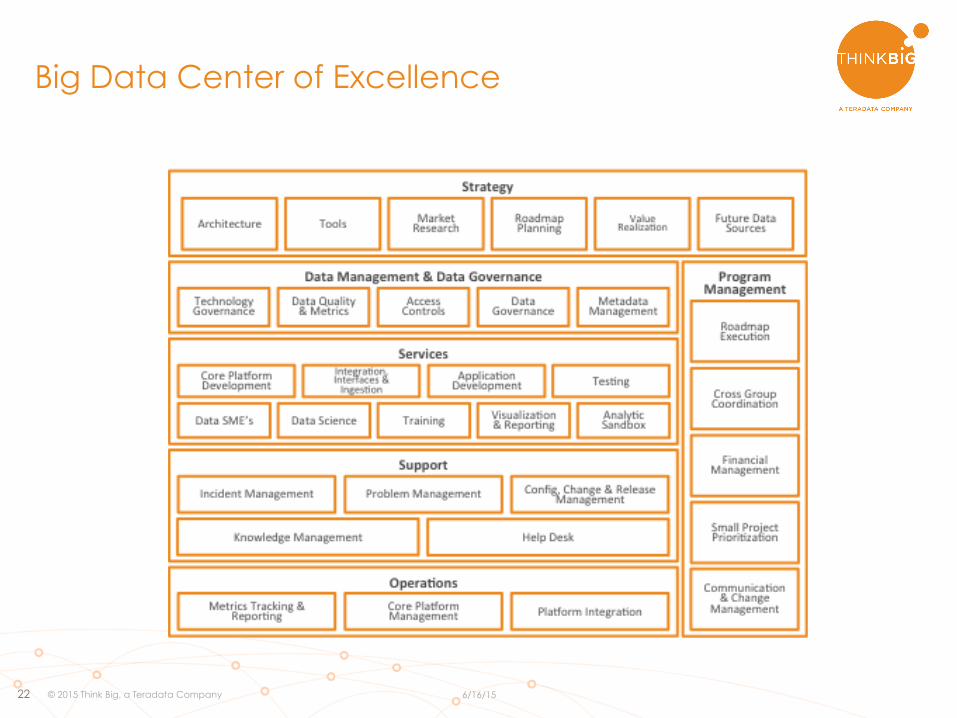
Big Data Center of Excellence
© 2015 Think Big, a Teradata Company 6/16/15
23
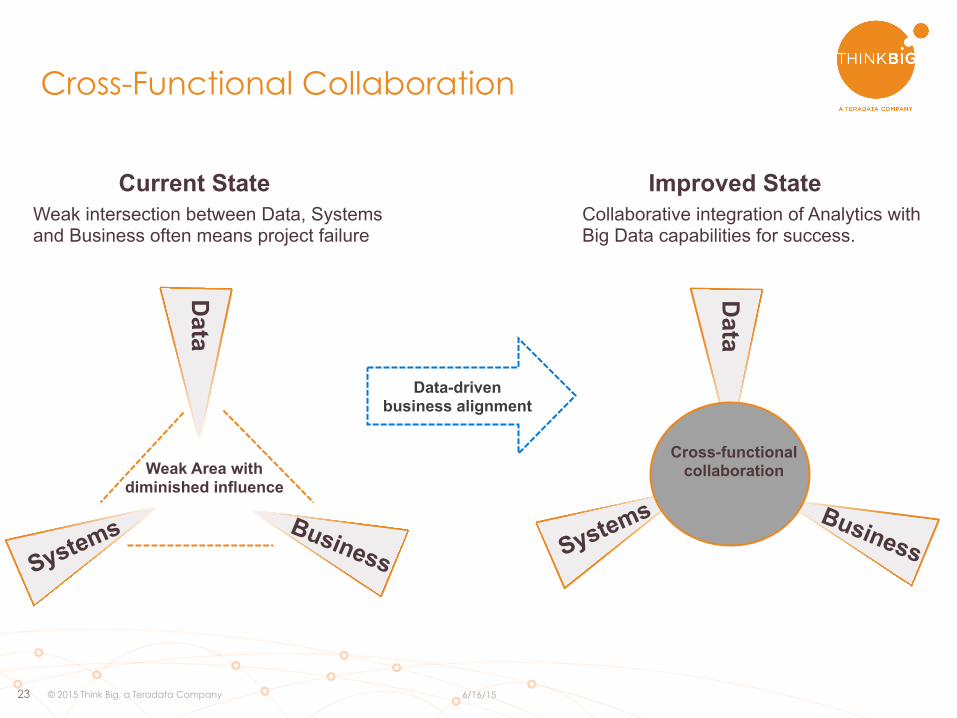
Cross-Functional Collaboration
Data
Weak intersection between Data, Systems and Business often means project failure
Current State Improved State Collaborative integration of Analytics with Big Data capabilities for success.
Data
Weak Area with diminished influence
Cross-functional collaboration
Data-driven business alignment
© 2015 Think Big, a Teradata Company 6/16/15
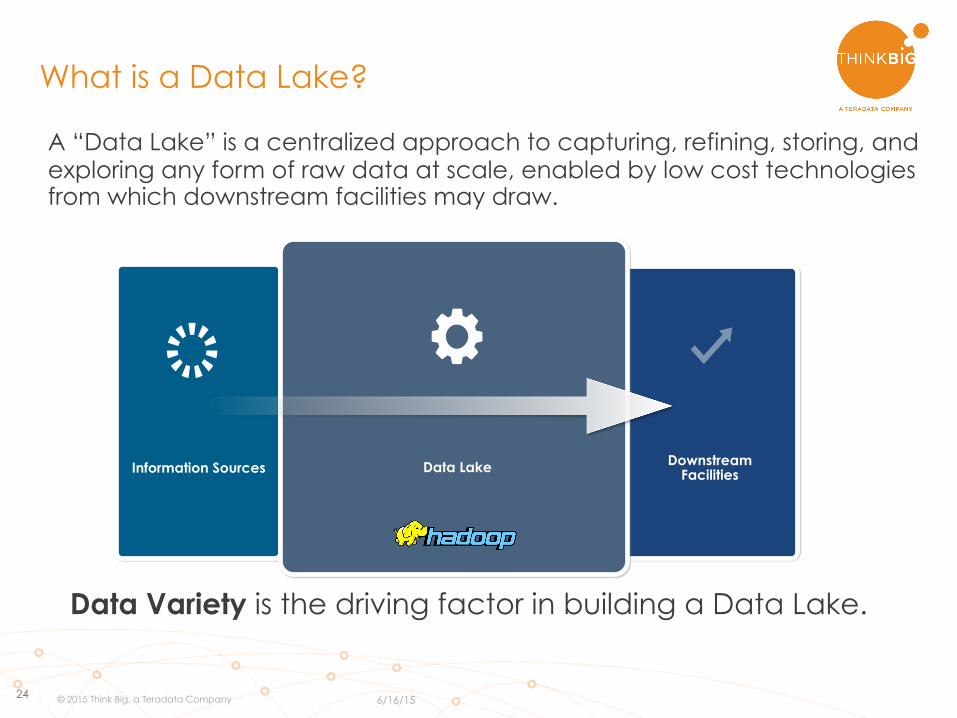
24
A “Data Lake” is a centralized approach to capturing, refining, storing, and exploring any form of raw data at scale, enabled by low cost technologies from which downstream facilities may draw.
What is a Data Lake?
Information Sources Data Lake Downstream Facilities
Data Variety is the driving factor in building a Data Lake.
© 2015 Think Big, a Teradata Company 6/16/15
25
Why a Data Lake?
• Benefit from open source big data innovation and cost savings
• Control over enterprise data with governance
• Offload history of operational and analytical data platforms
• Remix ETL, freeing capacity downstream
• Gain ultimate flexibility in data use and access
• Foundation for solving business problems – Big data solutions enable new uses of data via working with
new data sets and analytics
© 2015 Think Big, a Teradata Company 6/16/15

26
• Corporate Repository – Data sourcing repository, possibly system of record
• Active Archive – Offloaded history of operational and analytical data platforms that needs to be used infrequently
• Discovery – Data Profiling, schema on read, wrangling, discover signals
• ETL Offload – Move all or parts of current ETL processes into Hadoop
• NEW ETL Development – Develop new ETL processes on the Data Lake
• Analytics – Data Science, Custom/product built Analytics solutions (i.e. churn, machine learning)
• Business Intelligence/Reporting – Event analysis, dimensional rollup and pivot reports
Data Lake Use Cases
© 2015 Think Big, a Teradata Company 6/16/15
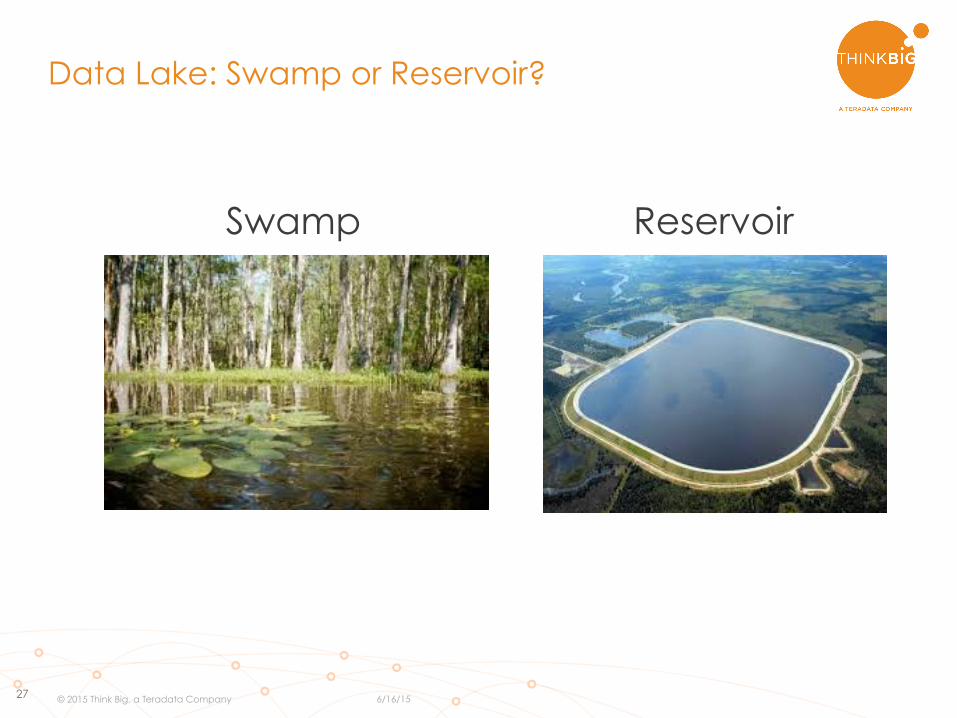
27
Swamp Reservoir
Data Lake: Swamp or Reservoir?
© 2015 Think Big, a Teradata Company 6/16/15
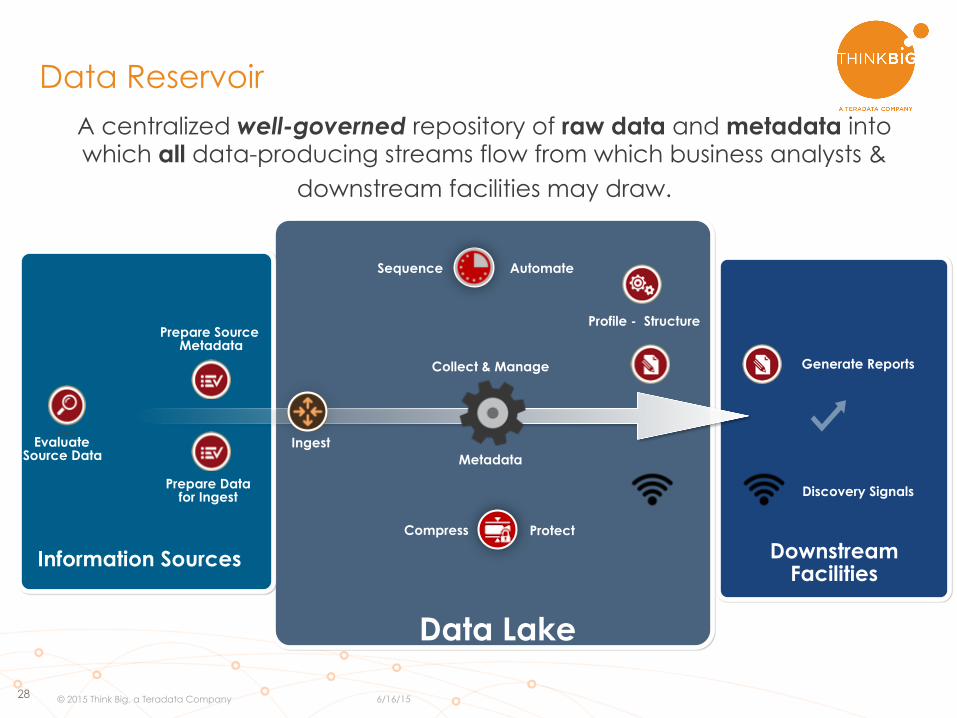
28
Data Lake
Information Sources
Evaluate Source Data
Ingest
Collect & Manage
Metadata
Profile - Structure
Sequence
Downstream
Facilities
Generate Reports
Discovery Signals
Compress
Automate
Protect
Prepare Data for Ingest
Prepare Source Metadata
A centralized well-governed repository of raw data and metadata into which all data-producing streams flow from which business analysts &
downstream facilities may draw.
Data Reservoir
© 2015 Think Big, a Teradata Company 6/16/15

29
Metadata is required to facilitate location of and entitlements to data
Schema Metadata is a foundation, but…
Operational Metadata & Business-Security is critical to governance • Where did it come from? … What is the data serialization?
• Who owns the data? Who can see the data? Who belongs to which group?
• What is the environment (landing zone, OS, Line of Business)?
• What processes touched my data?
• Did you lose any data (Checksums, etc.)?
• When did the data get ingested, transformed?
• Did it get exported, or archived…when, where how will it be used (organizational)?
Governance & Security
© 2015 Think Big, a Teradata Company 6/16/15
30
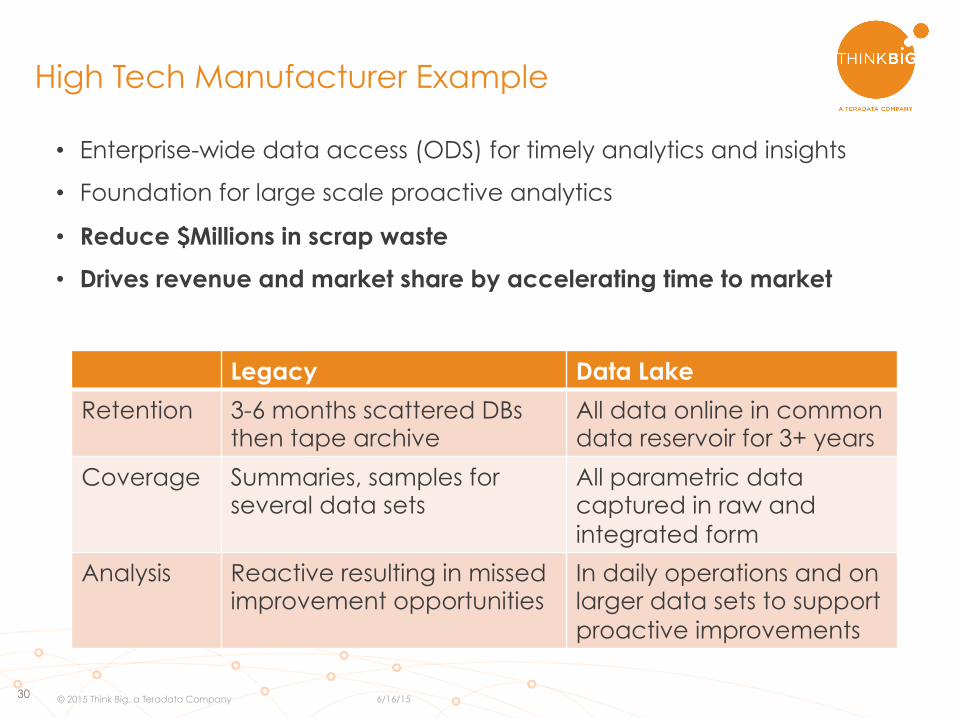
High Tech Manufacturer Example
• Enterprise-wide data access (ODS) for timely analytics and insights
• Foundation for large scale proactive analytics
• Reduce $Millions in scrap waste
• Drives revenue and market share by accelerating time to market
Legacy Data Lake
Retention 3-6 months scattered DBs then tape archive
All data online in common data reservoir for 3+ years
Coverage Summaries, samples for several data sets
All parametric data captured in raw and integrated form
Analysis Reactive resulting in missed improvement opportunities
In daily operations and on larger data sets to support proactive improvements
© 2015 Think Big, a Teradata Company 6/16/15

31
• Insight into new data (one time analysis)
• Decision support models (offline insights in production)
• Operational models (real-time analytics)
• Hadoop opportunities: new data, new algorithms, different resolution, frequency
• Hadoop blends with MPP, analytics, tools not the sole tool
Data Science Analytics
© 2015 Think Big, a Teradata Company 6/16/15
32
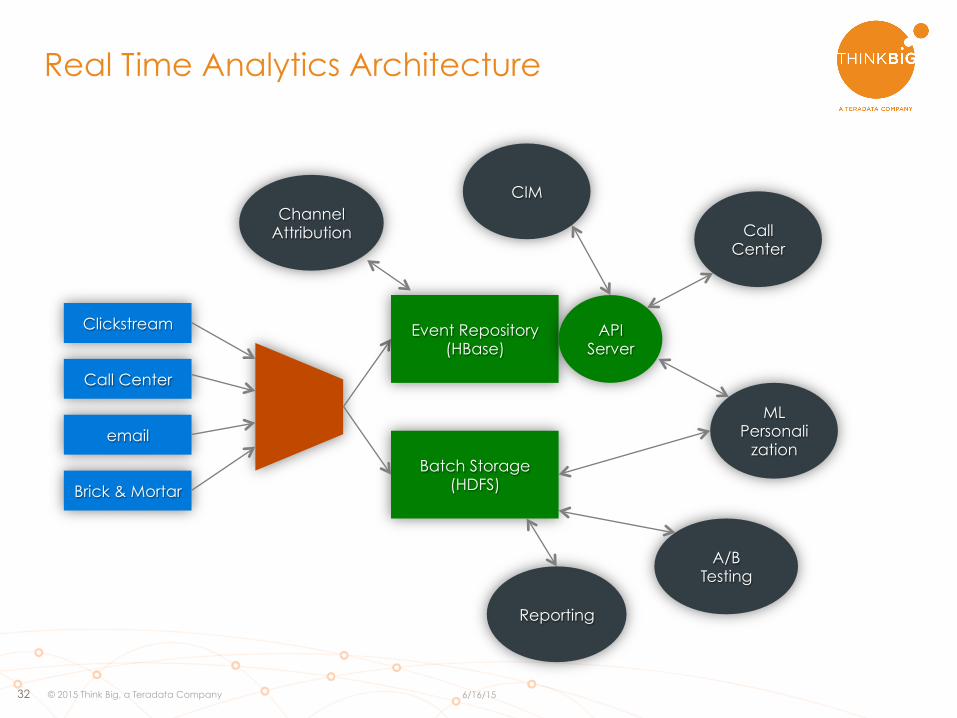
Real Time Analytics Architecture
Clickstream
Call Center
Brick & Mortar
Batch Storage (HDFS)
Event Repository (HBase)
API Server
CIM
ML Personali
zation
A/B Testing
Reporting
Call Center
Channel Attribution
© 2015 Think Big, a Teradata Company 6/16/15

33
• We’ve come a long way since MapReduce 1.0 enabled by YARN
• Don’t forget about the last mile for business (SQL on Hadoop, OLAP for Hadoop, training, etc.)
• Data lakes without governance, security, metadata management equates to failed projects/loss of $$
• Analytics on big data is where the real business value lies – from understanding to models to operationalization
Exploiting the Power of Hadoop
© 2015 Think Big, a Teradata Company 6/16/15

34
• 100% Big Data Focus
• Founded in 2010 with100+ engagements across 70 clients
• Unlock value of big data with data science and data engineering services
• Proven vendor-neutral open source integration expertise
• Agile team-based development methodology
• Think Big Academy for skills and organizational development
• Global delivery model
Who is Think Big?

Twitter Tag: #briefr The Briefing Room
Perceptions & Questions
Analyst: Rick van der Lans

Copyright © 1991 -‐ 2015 R20/Consultancy B.V., The Hague, The Netherlands. All rights reserved. No part
of this material may be reproduced, stored in a retrieval system, or transmiHed in any form or by
any means, electronic, mechanical, photographic, or otherwise, without the explicit wriHen permission of
the copyright owners.
The Next Stage of Hadoop and Big Data: Simplifica9on
by Rick F. van der Lans R20/Consultancy BV TwiHer @rick_vanderlans www.r20.nl
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 37
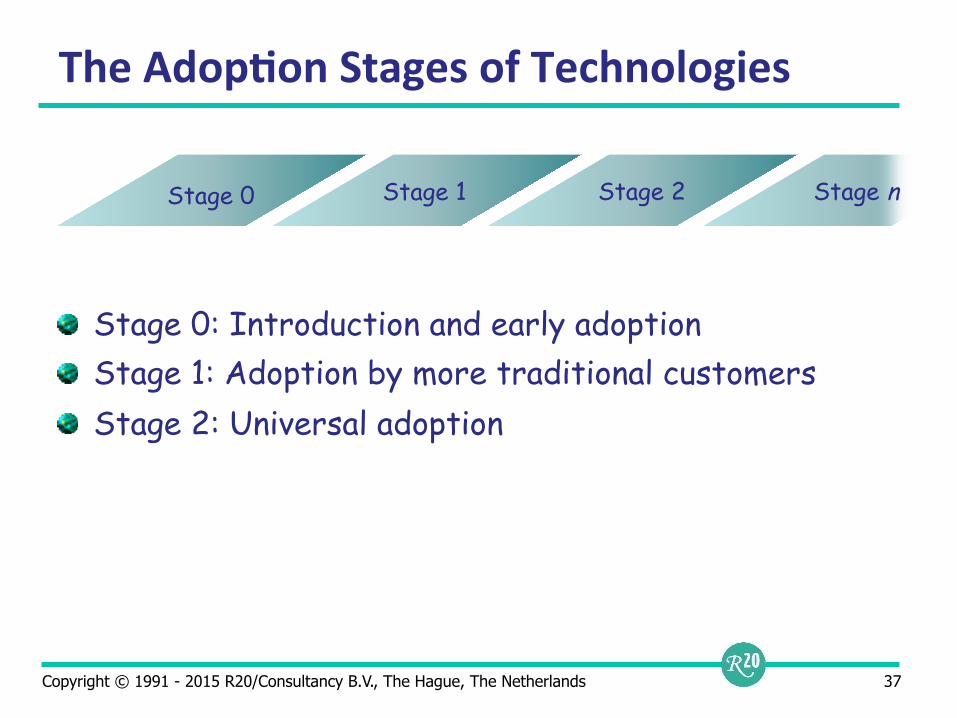
The Adop9on Stages of Technologies
Stage 0: Introduction and early adoption Stage 1: Adoption by more traditional customers Stage 2: Universal adoption
Stage 0 Stage 1 Stage 2 Stage n
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 38
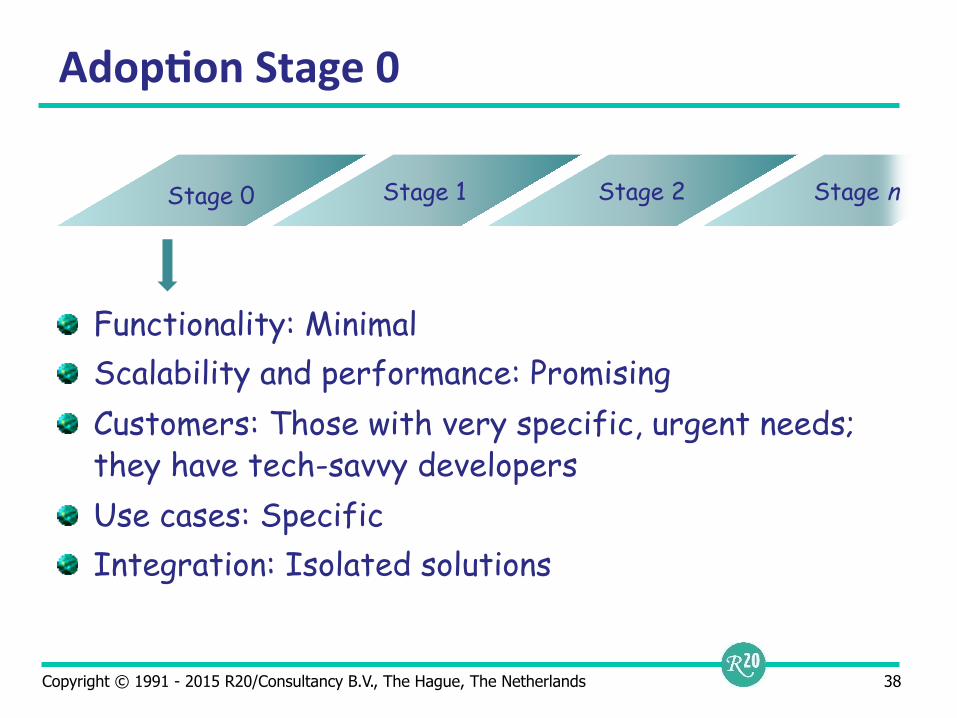
Adop9on Stage 0
Functionality: Minimal Scalability and performance: Promising Customers: Those with very specific, urgent needs; they have tech-savvy developers Use cases: Specific Integration: Isolated solutions
Stage 0 Stage 1 Stage 2 Stage n
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 39
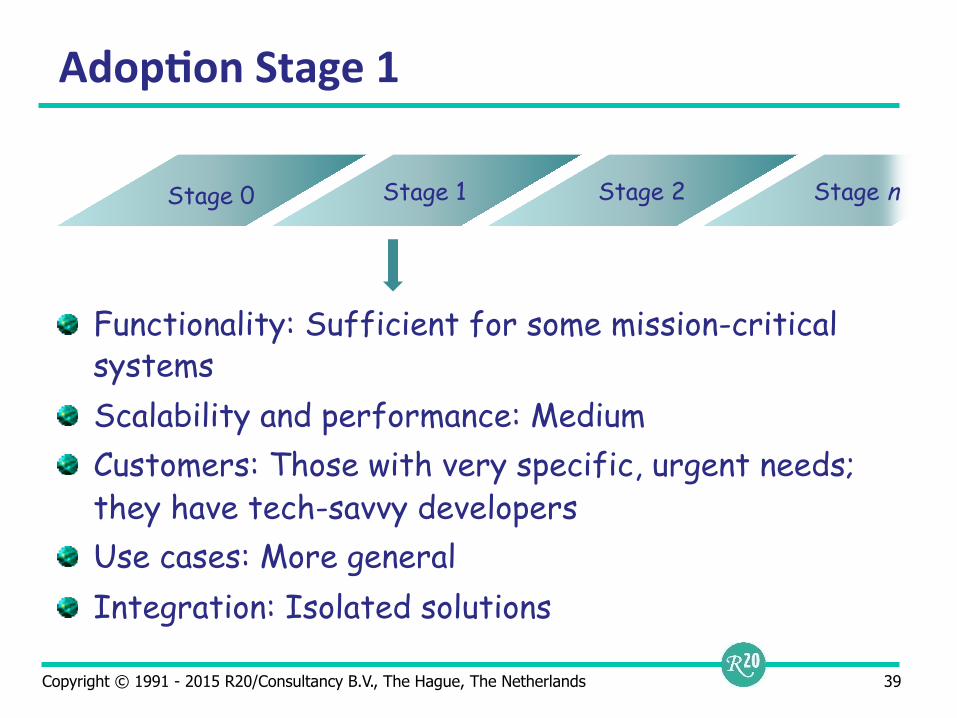
Adop9on Stage 1
Functionality: Sufficient for some mission-critical systems Scalability and performance: Medium Customers: Those with very specific, urgent needs; they have tech-savvy developers Use cases: More general Integration: Isolated solutions
Stage 0 Stage 1 Stage 2 Stage n
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 40
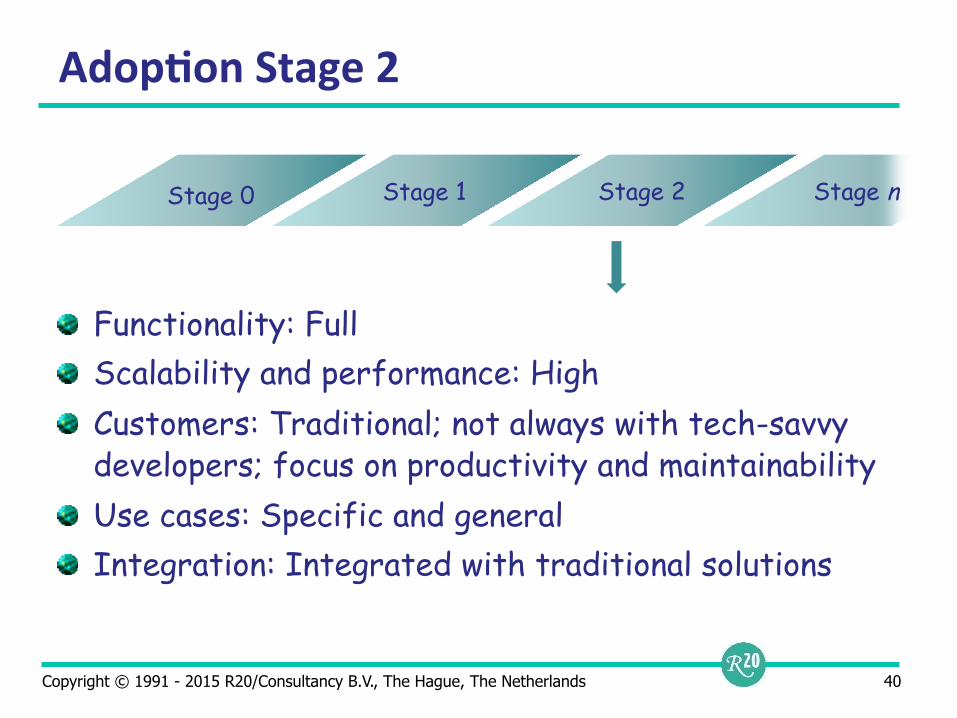
Adop9on Stage 2
Functionality: Full Scalability and performance: High Customers: Traditional; not always with tech-savvy developers; focus on productivity and maintainability Use cases: Specific and general Integration: Integrated with traditional solutions
Stage 0 Stage 1 Stage 2 Stage n
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 41
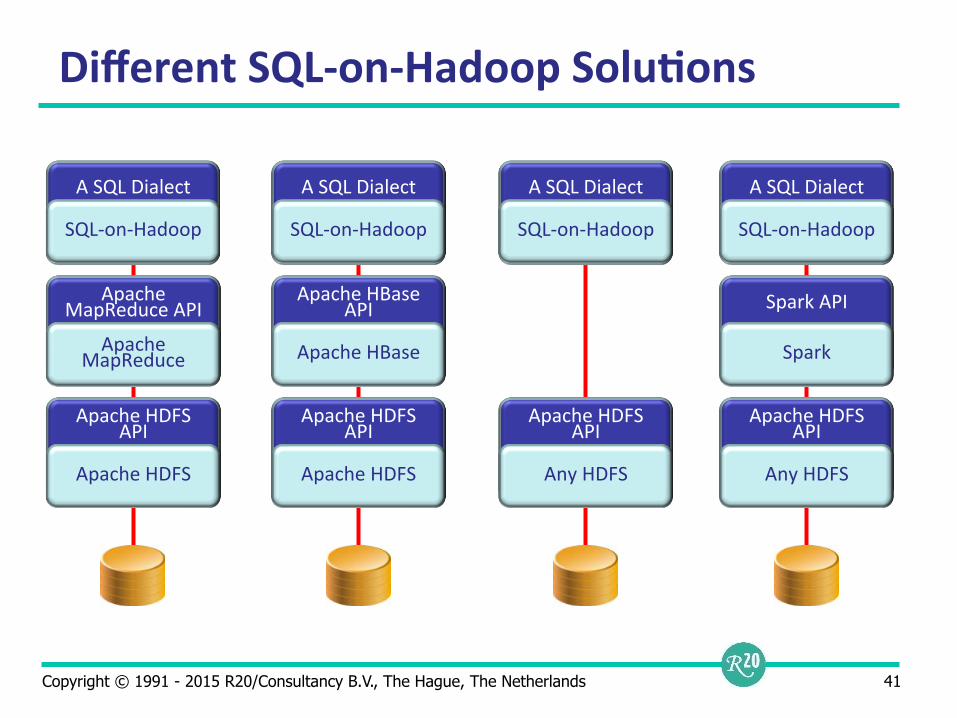
Different SQL-‐on-‐Hadoop Solu9ons
Apache MapReduce API
Apache
MapReduce
Apache HDFS API Apache HDFS
Apache HDFS API Apache HDFS
Apache HBase API Apache HBase
A SQL Dialect SQL-‐on-‐Hadoop
A SQL Dialect SQL-‐on-‐Hadoop
Apache HDFS API Any HDFS
A SQL Dialect SQL-‐on-‐Hadoop
Apache HDFS API Any HDFS
A SQL Dialect SQL-‐on-‐Hadoop
Spark API Spark

Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 42
Self-‐Service Data Prepara9on
Non-technical interface for studying data files Easy way of defining rules Data is fixed by defining filters, not by changing data in source systems Relationship with Data Blending
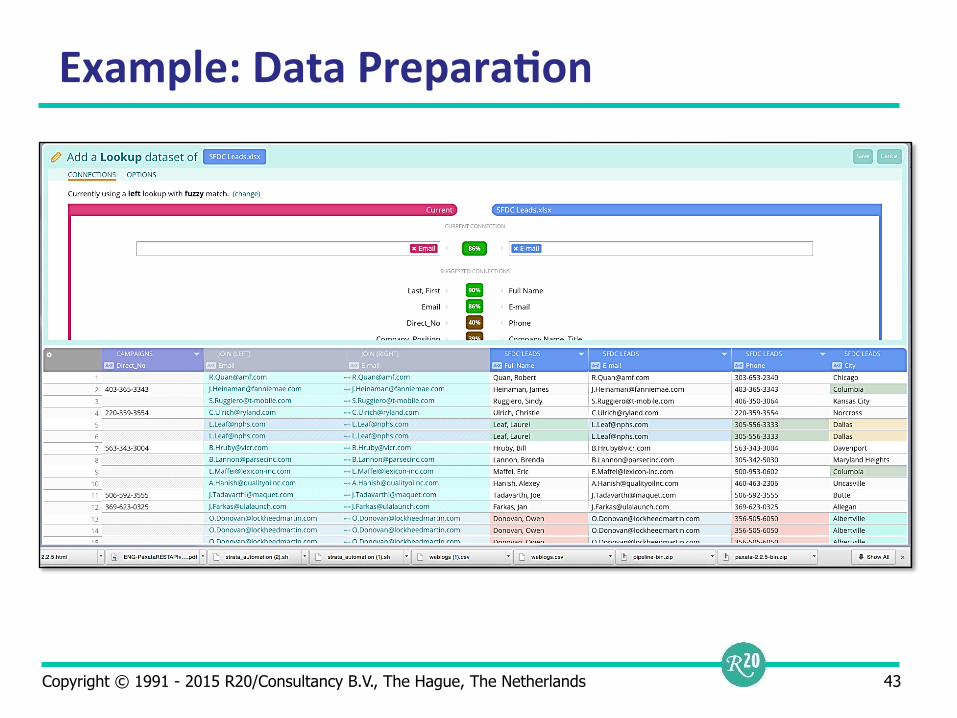
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 43
Example: Data Prepara9on
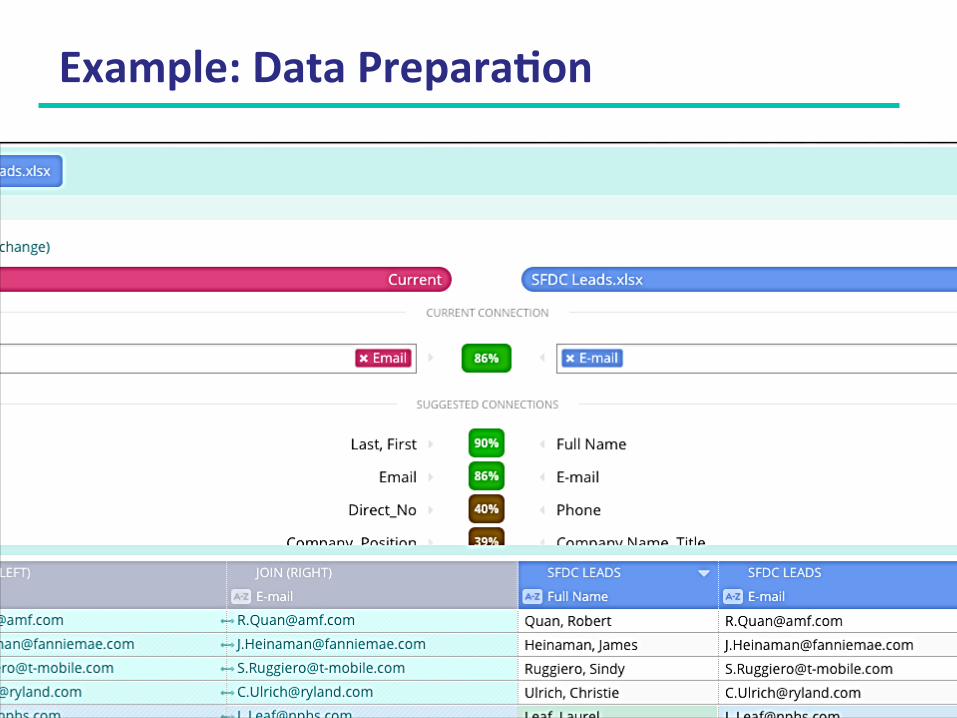
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 44
Example: Data Prepara9on
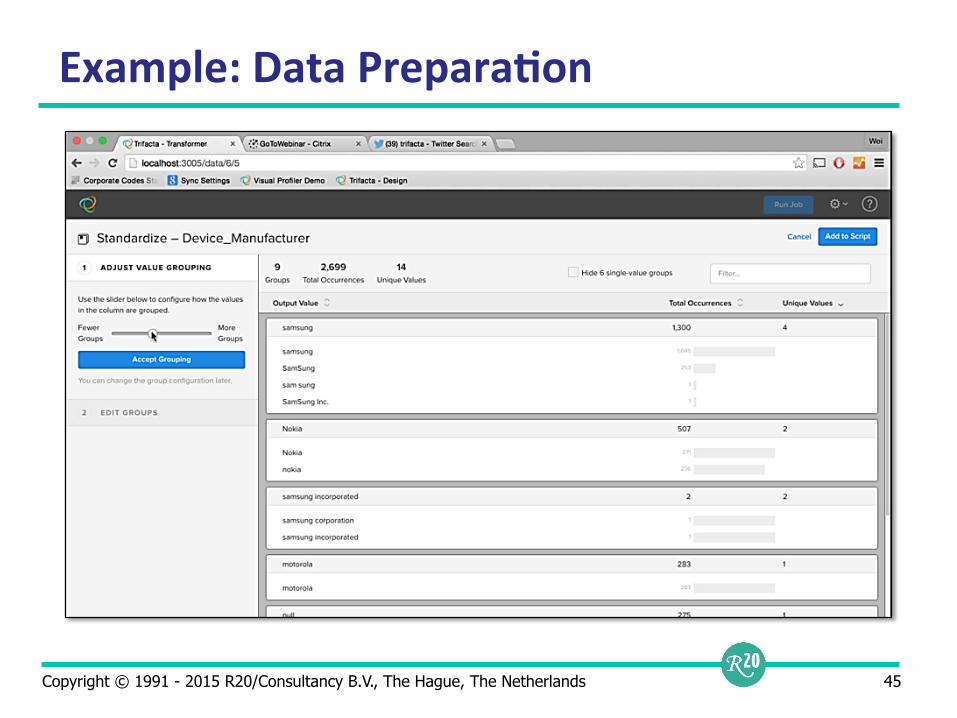
Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 45
Example: Data Prepara9on

Copyright © 1991 - 2015 R20/Consultancy B.V., The Hague, The Netherlands 46
Stage 2 = Simplifica9on

Questions on acceptance
You talked about the skills gap. Sometimes Hadoop is used to develop operational systems, and sometimes to develop BI systems. Now, many specialists working in BICCs are good ETL programming, reporting, data modeling, but not so good at low-level programming. For example, many of them have never programmed Java. What would you recommend them to do to be able to use Hadoop?
Should organizations use Hadoop for developing new systems, or for migrating existing systems? How easy do you think it is to integrate a new Hadoop-based system with the current infrastructure?
Normally, when a technology becomes more and more popular, it becomes clearer and clearer to everyone what the costs and the risks are. For example, how much man-hours should be spend on managing a Hadoop environment? So, what’s the productivity of a MapReduce programmer versus a SQL programmer?
Questions on architectural
Now that so much data is produced in a distributed fashion, is the concept of physically centralizing data for integration really realistic? Isn’t big data too big to move?
Over the years, large multi-national organizations have always struggled to develop one large centralized enterprise-wide data warehouse. In most cases, the problems were organizational. Who owns that data, and so on? Why would the data lake or data reservoir succeed today?

Questions on technical aspects
It was clear that for you YARN is a key module in the Hadoop platform. How mature is YARN today? How good is it, for example, in avoiding one massive query that monopolizes the entire platform and slows down all other applications?
My feeling is still that HDFS is not good at joins of files. The SQL-on-Hadoop engines are not strong in joins either. Do you think this will change? For example, can you take a star model from a SQL-based data mart, consisting of 7 dimensions and 1 fact, migrate it to Hadoop and expect a great performance?
Any idea what the tipping point is, when to forget about a proprietary SQL and move to Hadoop with SQL-on-Hadoop?
You mentioned OLAP on Hadoop using Spark and you indicated that such a solution scales to thousands of simultaneous users. Is that really true? Has that been proven? Or does that work when the reporting tools extract data and load it in memory of the client machine?
Almost every vendor of some big data tool publishes benchmark results showing how fast their product is. But many of these benchmarks are single user, single query benchmarks, which I think is not that useful. Why are they not showing multi-users benchmark results? Do you think they’re hiding something?

On one of your slides you said that Hadoop is 50 PB+ scale. But realistically, how many companies on this planet want to store that much data? And if it is 50PB+ scale, doesn’t that mean for the majority of the companies it’s overkill of functionality? In general, how big should big be to justify the Hadoop platform?
To end this list of questions and the finalize the briefing, you indicated that analytics on big data is where the real business value lies. I fully agree with that, but can you elaborate on this a little more?
Questions on technical aspects, cont’d.

Twitter Tag: #briefr The Briefing Room

Twitter Tag: #briefr The Briefing Room
Upcoming Topics
www.insideanalysis.com
June: INNOVATORS
July: SQL INNOVATION
August: REAL-TIME DATA

Twitter Tag: #briefr The Briefing Room
THANK YOU for your
ATTENTION!
Some images provided courtesy of Wikimedia Commons and "Selection Types Chart" by Azcolvin429 - Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons -
https://commons.wikimedia.org/wiki/File:Selection_Types_Chart.png#/media/File:Selection_Types_Chart.png and http://sagamer.co.za/img/evolution-phone.jpg
Related Documents











