The Impact of Feature Extraction The Impact of Feature Extraction on the Performance of a on the Performance of a Classifier: Classifier: kNN, Naïve Bayes and C4.5 kNN, Naïve Bayes and C4.5 Mykola Pechenizkiy Department of Computer Science and Information Systems University of Jyväskylä Finland AI’05 Victoria, British-Columbia, Canada May 9- 11, 2005

The Impact of Feature Extraction on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 Mykola Pechenizkiy Department of Computer Science and Information.
Dec 18, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

The Impact of Feature Extraction on the The Impact of Feature Extraction on the Performance of a Classifier:Performance of a Classifier:
kNN, Naïve Bayes and C4.5kNN, Naïve Bayes and C4.5
Mykola Pechenizkiy Department of Computer Science
and Information Systems
University of Jyväskylä Finland
AI’05 Victoria, British-Columbia, Canada May 9-11, 2005

2
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
ContentsContents• DM and KDD background
– KDD as a process– DM strategy
• Classification– Curse of dimensionality and Indirectly relevant features– Dimensionality reduction
• Feature Selection (FS)• Feature Extraction (FE)
• Feature Extraction for Classification– Conventional PCA – Random Rrojection– Class-conditional FE: parametric and non-parametric
• Experimental Results– 4 FE methods, 3 Classifiers, 20 UCI datasets
• Conclusions and Further Research

3
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
What is What is Data MiningData MiningData mining or Knowledge discovery is the process of finding previously unknown and potentially interesting patterns and relations in large databases (Fayyad, KDD’96)
Data mining is the emerging science and industry of applying modern statistical and computational technologies to the problem of finding useful patterns hidden within large databases (John 1997)
Intersection of many fields: statistics, AI, machine learning, databases, neural networks, pattern recognition, econometrics, etc.

4
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Knowledge discovery as a processKnowledge discovery as a process
Fayyad, U., Piatetsky-Shapiro, G., Smyth, P., Uthurusamy, R., Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1997.
I

5
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
CLASSIFICATIONCLASSIFICATION
New instance to be classified
Class Membership ofthe new instance
J classes, n training observations, p features
Given n training instances
(xi, yi) where xi are values of
attributes and y is class
Goal: given new x0,
predict class y0
Training Set
The task of classificationThe task of classification
Examples:
- prognostics of recurrence of breast
cancer;
- diagnosis of thyroid diseases;
- heart attack prediction, etc.

6
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Goals of Feature ExtractionGoals of Feature Extraction
Improvement of representation space
7
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
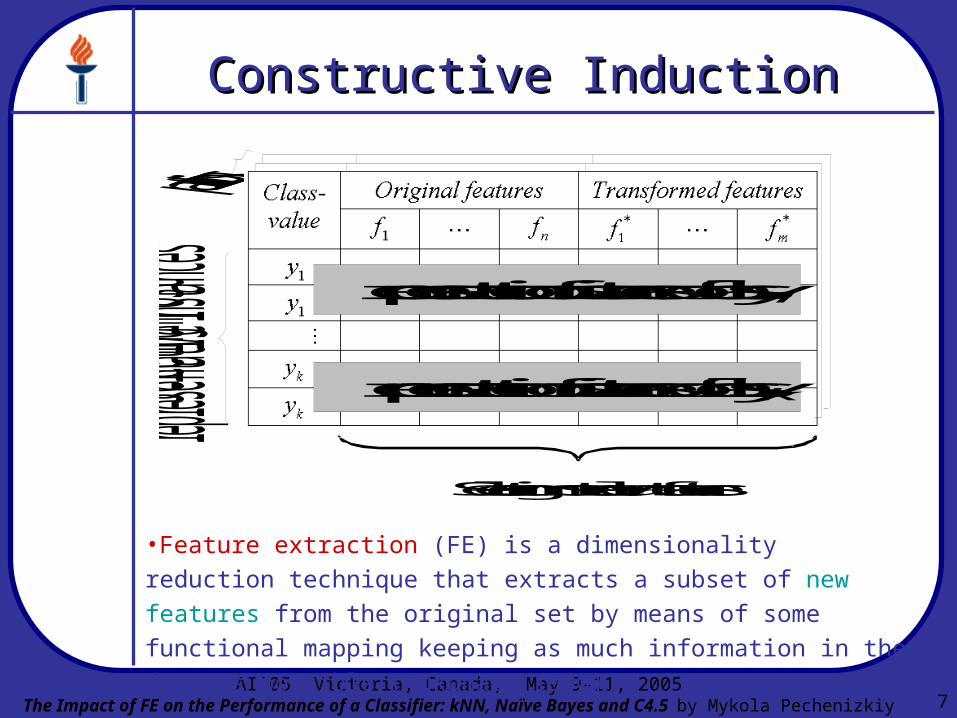
Constructive InductionConstructive Induction
representation of instances of class y1
representation of instances of class yk
Selecting most relevant features
Selecting most
representative instances
•Feature extraction (FE) is a dimensionality reduction technique that
extracts a subset of new features from the original set by means of
some functional mapping keeping as much information in the data as
possible (Fukunaga 1990).

8
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Feature selection or Feature selection or transformationtransformation
• Features can be (and often are) correlated
– FS techniques that just assign weights to individual features are insensitive to interacted or correlated features.
• Data is often not homogenous
– For some problems a feature subset may be useful in one part of the instance space, and at the same time it may be useless or even misleading in another part of it.
– Therefore, it may be difficult or even impossible to remove irrelevant and/or redundant features from a data set and leave only useful ones by means of feature selection.
• That is why the transformation of the given representation before weighting the features is often preferable.

9
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
FE for ClassificationFE for Classification

10
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Principal Component Analysis Principal Component Analysis
• PCA extracts a lower dimensional space by analyzing the covariance structure of multivariate statistical observations.
• The main idea – determine the features that explain as much of the total variation in the data as possible with as few of these features as possible.
PCA has the following properties:PCA has the following properties:(1) it maximizes the variance of the extracted features;
(2) the extracted features are uncorrelated;
(3) it finds the best linear approximation;
(4) it maximizes the information contained in the extracted
features.

11
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
The Computation of the PCA The Computation of the PCA

12
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
The Computation of the PCA The Computation of the PCA
1) Calculate the covariance matrix S from the input data.
2) Compute the eigenvalues and eigenvectors of S and sort them in a descending order with respect to the eigenvalues.
3) Form the actual transition matrix by taking the predefined number of components (eigenvectors).
4) Finally, multiply the original feature space with the obtained transition matrix, which yields a lower- dimensional representation.
• The necessary cumulative percentage of variance explained by the principal axes is used commonly as a threshold, which defines the number of components to be chosen.

13
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
FT example “Heart Disease”FT example “Heart Disease”
0.1·Age-0.6·Sex-0.73·RestBP-0.33·MaxHeartRate
-0.01·Age+0.78·Sex-0.42·RestBP-0.47·MaxHeartRate
-0.7·Age+0.1·Sex-0.43·RestBP+0.57·MaxHeartRate
100% Variance covered 87%
60% <= 3NN Accuracy => 67%

14
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
The Random Projection Approach The Random Projection Approach
• Dimensionality of data can be so high that commonly used FE techniques like PCA are almost inapplicable because of extremely high computational time/cost.
• In RP a lower-dimensional projection is produced by means of transformation like in PCA but the transformation matrix is generated randomly (although often with certain constrains).
• Johnson and Lindenstrauss Theorem: any set of n points in a d-dimensional Euclidean space can be embedded into a k-dimensional Euclidean space – where k is logarithmic in n and independent of d – so that all pairwise distances are maintained within an arbitrarily small factor
• Achlioptas showed a very easy way of defining (and computing) the transformation matrix for RP:
6/1yprobabilitwith1
3/2yprobabilitwith0
6/1yprobabilitwith1
3ijw
2/1yprobabilitwith1
2/1yprobabilitwith1ijw

15
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
PCA for ClassificationPCA for Classification
x2 PC(1) PC(2)
a) x1
x2 PC(1) PC(2)
b) x1
PCA for classification: a) effective work of PCA, b) the case where an irrelevant principal component was chosen from the classification point of
view.
PCA gives high weights to features with higher variabilities
disregarding whether they are useful for classification or not.

16
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Simultaneous Diagonalization Algorithm
• Transformation of X to Y: , where and are the
eigenvalues and eigenvectors matrices of SB.
• Computation of SB in the obtained Y space.
• Selection of m eigenvectors of SB, which correspond to the m largest
eigenvalues.
• Computation of new feature space , where is the set of selected eigenvectors.
The usual decision is to use some class separability criterion, based on a family of functions of scatter matrices: the within-class, the between-class, and the total covariance matrices.
wSw
wSww
WT
BT
J )(
XΦΛY T1/2
YΨZ Tm
Class-conditional Eigenvector-based Class-conditional Eigenvector-based FE FE

17
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Parametric Eigenvalue-based FEParametric Eigenvalue-based FE
in
j
Tiij
iij
c
iiW n
1
)()()()(
1
))(( mxmxS
Tiic
iiB n ))(( )()(
1
mmmmS
The within-class covariance matrix shows the scatter of samples around their respective class expected vectors:
The between-class covariance matrix shows the scatter of the expected vectors around the mixture mean:
where c is the number of classes, ni is the number of instances in a class i, is the j-th instance of i-th class, m(i) is the mean vector of the instances of i-th class, and m is the mean vector of all the input data.
)(ijx

18
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Nonparametric Eigenvalue-based FENonparametric Eigenvalue-based FE
c
ijj
Tjik
ik
jik
ik
n
kik
c
iiB
i
wn1
)(*
)()(*
)(
11
))(( mxmxS
c
j
jnNN
ik
jnNN
ikj
ik
d
dw
1
)()(
)()(
),(
)},({min
xx
xx
Tries to increase the number of degrees of freedom in the between-class covariance matrix, measuring the between-class covariances on a local basis. K-nearest neighbor (kNN) technique is used for this purpose.
The coefficient wik is a weighting coefficient, which shows importance of each summand.
• assign more weight to those elements of the matrix, which involve instances lying near the class boundaries and are more important for classification.

19
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
SSbb: Parametric vs Nonparametric: Parametric vs Nonparametric
Differences in the between-class covariance matrix calculation for nonparametric (left) and parametric (right)
approaches for the two-class case.

20
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Experimental SettingsExperimental Settings• 20 data sets with different characteristics taken from the UCI
machine learning repository
• 3 classifiers: 3-nearest neighbor classification (3NN), Naïve-Bayes (NB) learning algorithm, and C4.5 decision tree learning (C4.5)
– The classifiers were used from WEKA library with their defaults settings.
• 4 FE techniques and case with no FE– Random Projection (RP = A), PCA (B), parametric FE (PAR = C),
nonparametric FE (NPAR = D), no FE (Plain = E)– For PCA and NPAR we used a 0.85 variance threshold, and for RP
we took the number of projected features equal to 75% of original space. We took all the features extracted by parametric FE as it was always equal to no._of_classes – 1.
• 30 test runs of Monte-Carlo cross validation were made for each data set to evaluate the classification accuracy.
• In each run, the training set/the test set = 70%/30% by stratified random sampling to keep class distributions approximately same.

21
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy

22
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Summary of Results (1)Summary of Results (1)• For some data sets FE has no effect or deteriorates the classification
accuracy compared to plain case E. – for 3NN: 9 data sets from 20:
• Breast, Diabetes, Glass, Heart, Iris, Led, Monk-3, Thyroid, and Tic.
– for NB: 6 data sets from 20: • Diabetes, Heart, Iris, Lymph, Monk-3, and Zoo.
– for C4.5: 11 data sets from 20: • Car, Glass, Heart, Ionosphere, Led, Led17, Monk-1, Monk-3, Vehicle, Voting,
and Zoo.
• It can be seen also that often different FE techniques are the best for different classifiers and for different data sets.
• Class-conditional FE approaches, especially the nonparametric approach are most often the best comparing to PCA or RP.
• On the other hand it is necessary to point out that the parametric FE was very often the worst, and for 3NN and C4.5 parametric FE was the worst technique more often than RP. Such results highlight the very unstable behavior of parametric FE.
• Different FE techniques are often suited in different ways not only for different data sets but also for different classifiers.

23
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Ranking of the FE techniquesRanking of the FE techniques according to the results on 20 UCI data sets

24
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Summary of Results (2)Summary of Results (2)
• Basically, each bar on the histograms shows how many times an FE technique was the 1st, the 2nd, the 3rd, the 4th, or the 5th among the 20 possible. The number of times certain techniques got 1st-5th place is not necessary integer since there were draws between 2, 3, or 4 techniques. In such cases each technique gets the ½, 1/3 or 1/4 score correspondingly.
• It can be seen from the figure that there are many common patterns in the behavior of techniques for 3 different classifiers, yet there are some differences too. So, according the ranking results RP behavior is very similar with every classifier, PCA works better for C4.5, parametric FE is suited better for NB. Nonparametric FE is also suited better for NB, it is also good with 3NN. However, it is less successful for C4.5.

25
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Accuracy Changes due to the Use of Accuracy Changes due to the Use of FEFE

26
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Summary of Results (3)Summary of Results (3)
• The nonparametric approach is always the best on average for each classifier, the second best is PCA, then parametric FE, and, finally, RP shows the worst results.
• Classification in the original space (Plain) was almost as good as in the space of extracted features produced by the nonparametric approach when kNN classifiers is used.
• However, when NB is used, Plain accuracy is significantly lower comparing to the situation when the nonparametric FE is applied. Still, this accuracy is as good as in situation when PCA is applied and significantly higher in situations when RP or the parametric FE is applied.
• For C4.5 the situation is also different. So, Plain classification is the best option on average.
• With respect to RP our results differ from the conclusions made in (Fradkin and Madigan, 2003), where PR was found to be suited better for nearest neighbor methods and less satisfactory for decision trees (according to the results on 5 data sets).

27
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Conclusions and Further Conclusions and Further ResearchResearch
• Selection of FE method is not independent from the selection of classifier
• FE techniques are powerful tools that can significantly increase the classification accuracy producing better representation spaces or resolving the problem of “the curse of dimensionality”.
• However, when applied blindly, FE may have no effect for the further classification or even deteriorate the classification accuracy..
• Our experimental results show that for many data sets FE does increase the classification accuracy.
• There is no best FE technique among the considered ones, and it is hard to say which one is the best for a certain classifier and/or for a certain problem, however according to the experimental results some preliminary trends can be recognized.
– Class-conditional approaches (and especially nonparametric approach) were often the best ones. This indicated the fact how important is to take into account class information and do not rely only on the distribution of variance in the data.
– At the same time it is important to notice that the parametric FE was very often the worst, and for 3NN and C4.5 the parametric FE was the worst more often than RP. Such results highlight the very unstable behavior of parametric FE.

28
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Further Research (cont.)Further Research (cont.)• One possibility to improve the parametric FE, we think, is to combine it with
PCA or a feature selection approach in a way that a few PCs or the most useful for classification features are added to those extracted by the parametric approach.
• Although it is logical to assume that RP should have more success in applications where the distances between the original data points are meaningful and/or for such learning algorithms that use distances between the data points, our results show that this is not necessary the rule.
• Time taken to build classification models with and without FE and number of features extracted by a certain FE technique are interesting issues to analyze.
• A volume of accumulated empirical (and theoretical) findings, some trends, and some dependencies with respect to data set characteristics and use of FE techniques have been discovered and can be discovered.
– Thus, potentially the adaptive selection of the most suitable data mining techniques for a data set at consideration (that is a really challenging problem) might be possible. We see our further research efforts in this direction.
• Experiments on synthetically generated datasets: – generating, testing and validating hypothesis on DM strategy selection with respect
to a dataset at hand under controlled settings when some data characteristics are varied while the others are held unchangeable.

29
AI’05 Victoria, Canada, May 9-11, 2005The Impact of FE on the Performance of a Classifier: kNN, Naïve Bayes and C4.5 by Mykola
Pechenizkiy
Contact InfoContact Info
Mykola Pechenizkiy
Department of Computer Science and Information Systems,
University of Jyväskylä, FINLANDE-mail: [email protected]
Tel. +358 14 2602472Mobile: +358 44 3851845
Fax: +358 14 2603011www.cs.jyu.fi/~mpechen
THANK YOU!
Related Documents











