THE EVOLUTION OF HADOOP AT STRIPE colin marc @colinmarc

The Evolution of Hadoop at Stripe
Jan 26, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

THE EVOLUTION OF HADOOP AT STRIPEcolin marc @colinmarc

ABOUT STRIPE
• payments for the web
• based in SF
• last time I checked, ~75 people (stripe.com/about)
• main product is an API

WITH US, DATA WAS AN AFTERTHOUGHT

A LOT OF OUR DATA IS IN MONGO
• MongoDB is a fantastic application database
• uses BSON - like JSON, but has a binary representation
• MongoDB is schemaless, but has indexed queries and other features that are nice for applications

APPLICATION DBS SUCK FOR ANALYSIS
• well, sometimes. relational databases are OK
• MongoDB is awful (for this)
• no joins
• scans are painful
• no declarative query language

SOLUTION: PUT THE DATA SOMEWHERE ELSE

V1: TSV + IMPALA
• threw together a Hadoop cluster on the developer boxes
• “nightly” script dumped models to TSV files in HDFS
• janky script output the schema from our models
• query from Impala

ASIDE: IMPALA IS PRETTY COOL• developed by Cloudera
• absurdly fast queries over HDFS
• SQL is great
• most of our questions are ad-hoc
secrets =(
woah

A NICE EXPERIMENT, BUT...
• schema translation is hard
• SLOW SLOW SLOW
• TSV is not a great format
• script never runs
• not production data

V2: MONGO -> HBASE
• Impala can query HBase, I think?
• @nelhage wrote MoSQL - let’s do the same thing, but put the data in HBase!
• translating from one k/v store to another is easier


FIRST, SNAPSHOT
• using Mongo-Hadoop, map over your MongoDB database
• HFileOutputFormat, completeBulkLoad

THEN, STREAM
• tail the MongoDB oplog, like a replica set member
• replicate inserts/updates/deletes by _id

HAVING DATA IN HDFS IS A GREAT

THEN, QUERY IT WITH IMPALA...UM
• wait, impala can’t actually query HBase effectively
• 30-40x slower over the same data
• limiting factor is HBase scan speed, I think

LOST IN TRANSLATION
• our schema problem is still there!
• BSON is typed, but HBase is just strings
• nested hashes still don’t work
• lists???
• what is the canonical schema?


V3: PARQUET + THRIFT• instead of storing k/v pairs, just
store the raw BSON blobs
• write your MR jobs against HBase if you want up-to-date data
• also periodically dump out Parquet files
• use thrift definitions to manage schema

USING THRIFT AS SCHEMA• thrift is a nice way to define what
fields we expect to be in the BSON
• in most cases, we can do the translation automatically
• decode on the backend, instead of during replication
• no information loss

GENERATE THRIFT DEFINITIONS?
• thrift still isn’t the canonical schema for our application - that exists in our ODM
• wrote a quick ruby script to generate thrift definitions from our application models

PARQUET <3 THRIFT
• columnar, read-optimized
• with a little bit of glue, serialize any basic thrift struct easily

IMPALA <3 PARQUET
• more glue can automatically import parquet files into Impala
• Impala and parquet are designed to work well with each other
• nested structs don’t work yet =(

SCALDING <3 PARQUET• we use scalding for a lot of
MapReduce stuff
• added ParquetSource to scalding to make this easy (source and sink)

THIS WORKS FOR ANY DATA
• use thrift to define an intermediate or derived data type, and you get, for free:
• serialization using parquet
• easy MR jobs with scalding
• ad-hoc querying with Impala
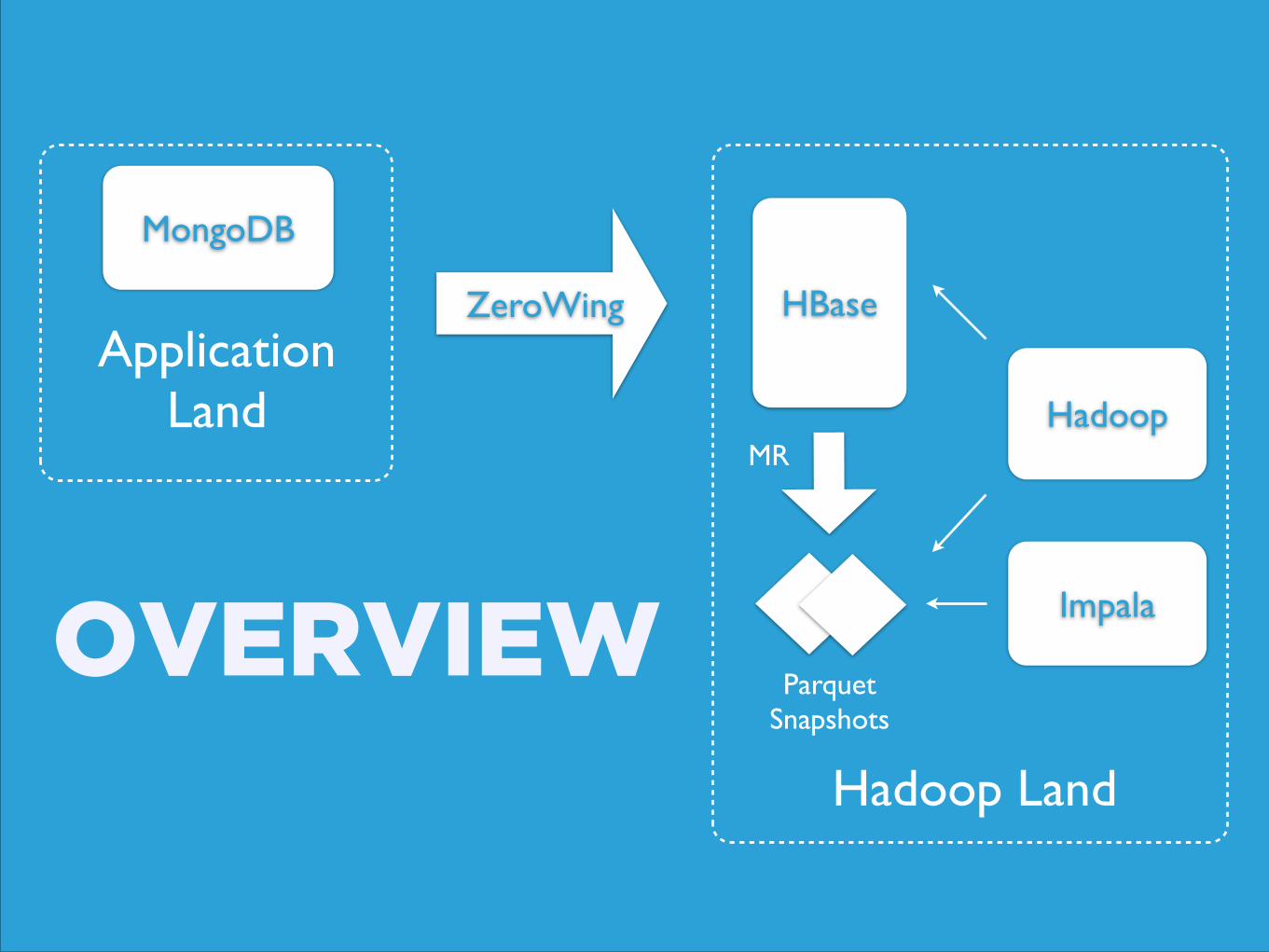
OVERVIEW
MongoDB
ZeroWingApplication
Land
Hadoop Land
HBase
Parquet Snapshots
MR
Impala
Hadoop

QUESTIONS?
• meeeee: @colinmarc
• Stripe: stripe.com
• we’re hiring! stripe.com/jobs
• ZeroWing: github.com/stripe/zerowing
• Impala: github.com/cloudera/impala
• Parquet: parquet.github.com
Related Documents











