Text Mining using the hierarchical syntactical structure of documents Roxana Danger 1 , José Ruíz-Shulcloper 3 , Rafael Berlanga 2 1 Universidad de Oriente, Santiago de Cuba (Cuba) 2 Universitat Jaume I, Castellón (Spain) 3 Institute of Cybernetics, Mathematics and Physics, La Habana (Cuba) Abstract. One of the most important tasks for determining association rules consists of calculating all the maximal frequent itemsets. Specifically, some methods to obtain these itemsets have been developed in the context of both databases and text collections. In this work, the hierarchical syntactical structure’s concept is introduced, which supplies an unexplored dimension in the task of describing and analysing text collections. Based on this conceptual framework, we propose an efficient algorithm for calculating all the maximal frequent itemsets, which includes either the Feldman’s or the Ahonen’s concept of frequency depending on the practical application. Keywords: Mining structured texts, Maximal co-occurrence, Association rules. 1. Introduction Discovering association rules is a relevant problem in the field of Data Mining, which was initially introduced by Agrawal in [1]. The main solutions to this problem are mainly focused in the computing of the frequent itemsets, which are used to construct the association rules (e.g. [7]). During the last years, several works have demonstrated that some data mining algorithms developed for relational databases can be also applied to texts [2][3][5]. The problem of mining texts was firstly introduced in [3], which consists in producing a set of association rules starting from the set of frequent terms of each document of the collection. In this work, the mining process is guided by a set of predefined predicates that state relevant semantic relationships between terms. In [2], a method to find out ordered maximal frequent itemsets in a document collection. Here, the concept of frequent term differs from that of [3] in that a frequent term must be frequent throughout the collection, independently of its frequency in each document. The fast adoption of the standard XML (eXtended Markup Language) in the current open information systems has produced the emergence of a new kind of information warehouses where traditional structured data lives together with unstructured textual information. In this scenario, it seems urgent to define new mining techniques that allow analysts to extract the useful knowledge that these warehouses contain.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Text Mining using the hierarchical syntactical structure of documents
Roxana Danger1, José Ruíz-Shulcloper3, Rafael Berlanga2
1 Universidad de Oriente, Santiago de Cuba (Cuba) 2 Universitat Jaume I, Castellón (Spain)
3Institute of Cybernetics, Mathematics and Physics, La Habana (Cuba)
Abstract. One of the most important tasks for determining association rules consists of calculating all the maximal frequent itemsets. Specifically, some methods to obtain these itemsets have been developed in the context of both databases and text collections. In this work, the hierarchical syntactical structure’s concept is introduced, which supplies an unexplored dimension in the task of describing and analysing text collections. Based on this conceptual framework, we propose an efficient algorithm for calculating all the maximal frequent itemsets, which includes either the Feldman’s or the Ahonen’s concept of frequency depending on the practical application.
Keywords: Mining structured texts, Maximal co-occurrence, Association rules.
1. Introduction
Discovering association rules is a relevant problem in the field of Data Mining, which was initially introduced by Agrawal in [1]. The main solutions to this problem are mainly focused in the computing of the frequent itemsets, which are used to construct the association rules (e.g. [7]).
During the last years, several works have demonstrated that some data mining algorithms developed for relational databases can be also applied to texts [2][3][5]. The problem of mining texts was firstly introduced in [3], which consists in producing a set of association rules starting from the set of frequent terms of each document of the collection. In this work, the mining process is guided by a set of predefined predicates that state relevant semantic relationships between terms. In [2], a method to find out ordered maximal frequent itemsets in a document collection. Here, the concept of frequent term differs from that of [3] in that a frequent term must be frequent throughout the collection, independently of its frequency in each document.
The fast adoption of the standard XML (eXtended Markup Language) in the current open information systems has produced the emergence of a new kind of information warehouses where traditional structured data lives together with unstructured textual information. In this scenario, it seems urgent to define new mining techniques that allow analysts to extract the useful knowledge that these warehouses contain.

Concerning to XML documents, few works in the literature has taken into account the document hierarchical structure for text mining purposes, and they are mainly concerned with mining the structure but not the contents [6]. In our opinion, regarding the hierarchical structure of the documents can improve the interpretation of the extracted itemsets (and therefore the association rules), and it can allow analysts to focus on a particular level of the hierarchy to obtain a different set of itemsets.
In this paper, we propose a new method to generate the maximal itemsets at any level of the hierarchical structure of the document collection (i.e. its XML-Schema or DTD). In this context, the concept of frequent term depends on the hierarchy level we are focusing on. Thus, if we focus on the top level of the hierarchy (the whole collection), the concept of frequent term corresponds to that of [2], whereas if we focus on the bottom level, the concept of frequent term corresponds to that of [3]. With our method, we can deal with any level of the structural hierarchy, providing in this way alternative itemsets, which can provide further knowledge of the application at hand.
The remainder of the paper is organised as follows. Section 2 introduces some preliminary concepts for the mining of hierarchical organised documents. Section 3 presents the proposed mining algorithm, which finds the itemsets depending on the selected hierarchical level. Section 4 presents the experimental results, and finally Section 5 gives some conclusions.
2. Preliminary Concepts
In the following paragraphs we introduce the necessary concepts to define the proposed mining algorithm. In this paper, we represent a document as a tree whose nodes are the XML elements and its leaves contain the texts we want to mine. We will denote each sub-tree of a document with Ttag, where tag is the root element of the sub-tree. Moreover, we will denote with Terms(Ttag) the set of textual terms appearing in the leaves of the tree Ttag. Finally, we will denote with MTtag to all the document sub-trees of the collection that have the element tag as its root.
Definition 1. Let Ttag be a document tree such that its leaves contains q terms, i.e. |Terms(Ttag)| = q. A term t∈Terms(Ttag) is a frequent term of Ttag if and only if it appears at least δk(q) times in Terms(Ttag), where δk is a function that states the frequency threshold according to the number of terms q.
This definition corresponds to the usual concept of frequent term (i.e. keyword) as defined in [3], but applied to any level of the hierarchy. Thus, the term is said to be frequent for a given tree (e.g. a chapter, a section, etc.), if it sufficiently appears in it.
Definition 2. A term is said to be a frequent term in MTtag if and only if it appears at least in )MT(δ tagMTtag
trees of MTtag.
This definition corresponds to the usual concept of frequent term but applied to any
level of the document hierarchy.

Definition 3. A term is said to be a strongly frequent term in MTtag if and only if it is a frequent term in at least in )MT( tagMTtag
δ trees of MTtag.
Definition 4. The set of terms {P1, ...,Pm}, with Pi∈
(i∈{1,..,m}) is a frequent itemset in MT
)( tagMTTTTerms
tagtag ∈∪
)(qtagδtag if its members co-occur at least times in Ttag.
Definition 5. A set of terms {t1, ..., tm}, with ti∈ Terms(Ttag) (i∈{1,.., m}) is a frequent itemset in MTtag if its members co-occur at least )MT(δ tagMTtag
trees of MTtag.
Morover, an itemset is said to be strongly frequent if it is a frequent itemset in at least )MT(δ tagMTtag
trees of MTtag.
Definition 6. A (strongly) frequent itemset in MTtag is said to be maximal if there not exists another (strongly) frequent itemset in MTtag that is superset of it.
The problem of mining maximal (strongly) frequent itemsets in MTtag consists of finding all the maximal (strongly) frequent itemsets in MTtag. The solution to this problem requires as a previous step, the extraction of the (strongly) frequent terms in MTtag, and to record the subsets (in which they are frequent) where they appear. This is because all the supersets of an infrequent itemset are also infrequent, and all the subsets of a frequent itemset are also frequent. The overall mining process is illustrated in the Figure 1.
Computing of (strongly)
frequents terms
Selection of the sub-trees of the
XML documents for the mining
Fig. 1. Extracting the maximal frequent it
3. Finding Maximal Frequent Itemsets
The proposed mining algorithm basically extracts all the for 3) for a given structure element, and then it extends titemsets. The lexicografical order between terms is used frequent sets. The algorithm takes as input the frequenwhich are represented by the list Fw. Moreover, the algwhose keys are the detected frequent terms and term paitree indexes of the MTtag where each key occurs.
Computing of maximal (strongly) frequent
itemsets
emsets..
requent terms (definitions 2 hem to obtain the maximal to incrementally extend the t terms at the MTtag level, orithm uses a hash table T rs, and their values are the

The number of combinations between frequent terms to be explored during the extension of itemsets can be reduced if all the itemsets of cardinality 2 are pre-computed.
The maximal frequent itemsets are obtained by taking each frequent term from Fw and then testing whether it is included in a frequent pair (Figure 2, lines 3-4). If it does not occur, the unitary set formed by the frequent term is considered a maximal frequent co-occurrence. Otherwise, the frequent term can be extended to produce several maximal itemsets that contain it. For this purpose, the algorithm takes all the already computed itemsets containing the term along with the terms with which it forms a frequent pair and they have not been included in the already computed itemsets. Then, it tries to extend the term as long as possible in order to obtain all the maximal frequent itemsets that contain it. (Figure 2, lines 6-8).
Algorithm GetMaximalItemsets(Fw, T, ,MaximalCo_Occs) tagMTδ
Objetive: Computing the maximal frequent itemsets Input: Fw: Ordered set of frequent terms to be considered during the mining process. T: A hash table with the occurrences of frequent terms and term pairs. δ : frequency threshold for the MT
tagMT tag level.
Output: MaximalCo_Ocs: Set of maximal frequent itemsets.
Method:
1. MaximalCo_Ocs =Ø 2. forall p in Fw 3. if p does not appear in a frequent pair then 4. MaximalCo_Occs = MaximalCo_Occs ∪ {p} 5. else 6. TermsToUseForExt={p | ∃pair=(p, p’) ∈ T.keys()} 7. Co_OccsToExtend = {CoOc | CoOc = (CoOcMax ∩ TermsToUseForExt) ∨ CoOc={p’} such that
Co_OcMax∈MaximalCo_Ocs, ∀CoOc’∈Co_OccsToExtend, CoOc⊄CoOc’, ’∈TermsToUseForExt } 8. Extend({p},T[p], Pf, T, Co_OccsToExtend,
tagMTδ , MaximalCo_Occs)
Fig. 2. Algorithm to compute the maximal itemsets for a given structure element.
Figure 3 shows the algorithm that extends a given itemset, FreqSet, by using the already computed frequent itemsets, which are recorded in Co_OccsToExtend. In the case that Co_OccsToExtend has just one element, the extension of FreqSet with this element is then added to MaximalCo_Occs if it is not yet in that set (Figure 3, lines 2-5). Otherwise, all the maximal frequent itemsets that contains FreqSet must be found (Figure 3, lines 7-36).
For this purpose, the algorithm takes each of the itemsets (Co_Oc) of Co_OccsToExtend (Figure 3, line 9) and it extends the frequent set FreqSet with it, generating a new frequent set FreqSet’. Then, the remaining itemsets (Co_Oc’) in Co_OccsToExtend are examined to know which of them can extend the new frequent itemset:
1. If FreqSet’ can be extended with Co_Oc’, then the following cases must be considered (Figure 3, lines 19-23):

a. If the occurrences of FreqSet' are equal to those of FreqSet, the extension of FreqSet with Co_Oc’ does not generate new itemsets different from those generated by FreqSet’. Therefore, this set should not be considered in the successive iterations (Figure 3, lines 19-21).
b. If their occurrences are different, Co_Oc’ must be recorded in order to find out all the possible combinations of maximal frequent itemsets generated from FreqSet’. This set is denoted with Co_OccsToExtend’ (Figure 3, lines 22-23).
To obtain the itemset occurrences, the method T.Hits(Itemset) is used to returns the indexes of the trees of MTtag that contain Itemset.
2. If FreqSet’ cannot be extended with Co_Oc’, then the following cases must be regarded (Figure 3, lines 24-30):
a. Co_Oc’ is a unitary set. Then, it is impossible to extend FreqSet' with Co_Oc’. Moreover, the term in Co_Oc’ should not be considered in the successive iterations for the extension of FreqSet’ (Figure 3, lines 24-25). Notice that those terms are discarded when the algorithm takes each itemset Co_Oc’ (Figure 3, line 17)
b. Co_Oc’ is not a unitary set. Then FreqSet is extended with all the pairs (p, p’) such that p is a member of Co_Oc\Co_Oc’, and p’ is a member of the Co_Oc’\Co_Oc (Figure 3, lines 27-30). The itemsets that can be used to extend FreqSet ∪ {p, p’} are obtained by using the function OthsFreqTerms, which returns the terms with which FreqSet ∪ {p, p’} co-occurs.
Finally, the algorithm takes the other terms that can also extend FreqSet’ but that were not included in any of the itemsets of Co_OccsToExtend’ (Figure 3, line 32). Thus, FreqSet’ is extended in turn by using a recursive call (Figure 3, line 33).
4. Results
To evaluate the obtained results we have taken two collections of news articles from the international section published in the Spanish newspaper “El País”. The first collection comprises the news articles published during June 1999, which mainly report about the Kosovo War. The other collection comprises news articles published during November 1999, which have a greater variety of topics. Before mining these collections, news articles are processed to reject stopwords (e.g. articles, prepositions and adverbs) and to extract the word lemmas (terms). We use as the hierarchical syntactical structure the following levels: the whole document collection, article, paragraph, sentences and terms. The characteristics of the document collection are summarised as follows:
June 1999 November 1999 Number of news articles: 530 Number of news articles: 456 Number of paragraph: 4549 Number of paragraph: 3542 Number of sentences: 10879 Number of sentences: 8853 Number of terms: 36342 Number of terms: 39568

We use as function for the frequency threshold the percentage of the sub-trees included in each tag (i.e. article, paragraph and sentence). In the experiments we only use the concept of maximal frequent itemset.
Regarding to the news of June, the optimal threshold for paragraphs and sentences is 0.44%., whereas for the article level is 5%. Table 1 presents the first 15 itemsets of each level ordered by the mutual information function [4], which calculates the information gain produced by each itemset.
Regarding to the news of November, the optimal thresholds for sentences and paragraphs is around 0.56%, and for articles is around 5%. Table 2 shows the first 15 itemsets obtained for each syntactical level.
From these experiments, we can notice that in the collection of June, many of the relevant itemsets are concerning with the Yugoslavian conflict. Nevertheless, the obtained itemsets for each syntactical level express different semantic relationships. Thus, the itemsets at the sentence and paragraph levels use to capture frequent linguistic relationhips between terms (e.g. {force, international},{million, dollar}). However, at the article level, the itemsets use to describe the keywords that frequently co-occur in the collection. It can be noticed also that some topics that are not relevant at the article level (e.g. Pinochet's trial) become relevant at the paragraph level, since they are very frequent in the few news that involve these topics.
It is worth mentioning that the mutual information function has the desired effects over the relevance of itemsets. Indeed, the frequent linguistic patterns used by the journalists obtain a low relevance with this function, whereas the itemsets with greater semantics obtain greater relevance values.
At the paragraph level, the itemsets with the greatest relevance are those that belong to little mentioned topics, which obtain significant differences with respect to the rest of the itemsets. On the other hand, the itemsets of the most mentioned topics have a relevance value between 7.0 and 5.0. At the article level, the function takes values in the same range as expected.
The collection of November has a similar behaviour, although the found frequent itemsets have lower relevance values. This is due to the greater number of mentioned topics.
As in the previous collection, we can also notice that the most relevant itemsets are always obtained at the paragraph level, and it is important to notice that those coincide with the most interesting itemsets

Algorithm Extend(FreqSet, TCoinc, T, Co_OccsToExtend,tagMTδ , MaximalCo_Occs)
Objetive: Add to MaximalCo_Ocs all the maximal frequent co-ocurrence sets that have its first term (following the lexicographical order) the first term of the frequent set FreqSet.
Input: FreqSet: Frequent set to be extended. TCoinc: Set of items of MTtag in which the terms of FreqSet co-occur. T: The hash table containing the indexes of the elements of the MTtag. Co_OccsToExtend: Frequent co-ocurrences to use for extending FreqSet (lexicographically ordered).
tagMTδ : frequency threshold for the MTtag level.
Output: MaximalCo_Occs: Set of maximal frequent co-ocurrences. Method: 1. if |Co_OcsToExtend| ≤1 then 2. if |Co_OcsToExtend| = 1 then 3. CoOcMax = FreqSet ∪ Co_OcsToExtend[0] 4. if CoOcMax ⊄ CoOcMax’, ∀CoOcMax’ in MaximalCo_Ocs then 5. MaximalCo_Ocs.Add(CoOcMax) 6. else 7. NotConsider = Ø 8. i = 0 9. while i ≤ |Co_OcsToExtend| 10. Co_Oc=Co_OcsToExtend [i] 11. FreqSet’=FreqSet ∪ Co_Oc 12. TCoinc’=TCoinc ∩ T.Hits(FreqSet ∪ Co_Oc) 13. Co_OcsToExtend’=∅ 14. StopTerms=∅ 15. j = i + 1 16. while j ≤ |Co_OcsToExtend | 17. Co_Oc’=Co_OcsToExtend[j] 18. TCoincs’’=TCoinc’ ∩ T.Hits(Co_Oc’) 19. if TCoincs’’=TCoinc’ then 20. FreqSet’=FreqSet’ ∪ {Co_Oc’} 21. NotConsider=NotConsider ∪ { j } 22. else If Tcoincs’’≥
tagMTδ
23. Co_OcsToExtend’=Co_OcsToExtend’ ∪ {Co_Oc’} 24. else If Co_Oc’ =1 then 25. StopTerms = StopTerms ∪ Co_Oc’ 26. else 27. forall p,p’∈ Fw, (p, p’)∈ T.keys( ), and p∈ Co_Oc\Co_Oc’, p’ ∈ Co_Oc’\Co_Oc 28. if T.Hits(FreqSet ∪ {p,p’}) ≥
tagMTδ then
29. CoOcsToExtend’’= OthsFreqTerms (FreqSet ∪ {p,p’}) 30. Extend(FreqSet ∪ {p,p’}, T.Hits(FreqSet ∪ {p,p’}),
T, Co_OcsToExtend’’, tagMTδ , MaximalCo_Ocs)
31. j = j + 1 32. Add to CoOcsToExtend’’ unitary set for each term in OthsFreqTerms ( )
U',
endCoOcsToExtCoOcFreqSetpCoOcp
p∈
∈∨∈
33. Extend (FreqSet’, TCoincs’, T, Co_OccsToExtend’, tagMTδ , MaximalCo_Occs)
34. i=i + 1 35. while i in NotConsider do 36. i= i + 1
Fig. 3. Algorithm for the extension of the itemsets.
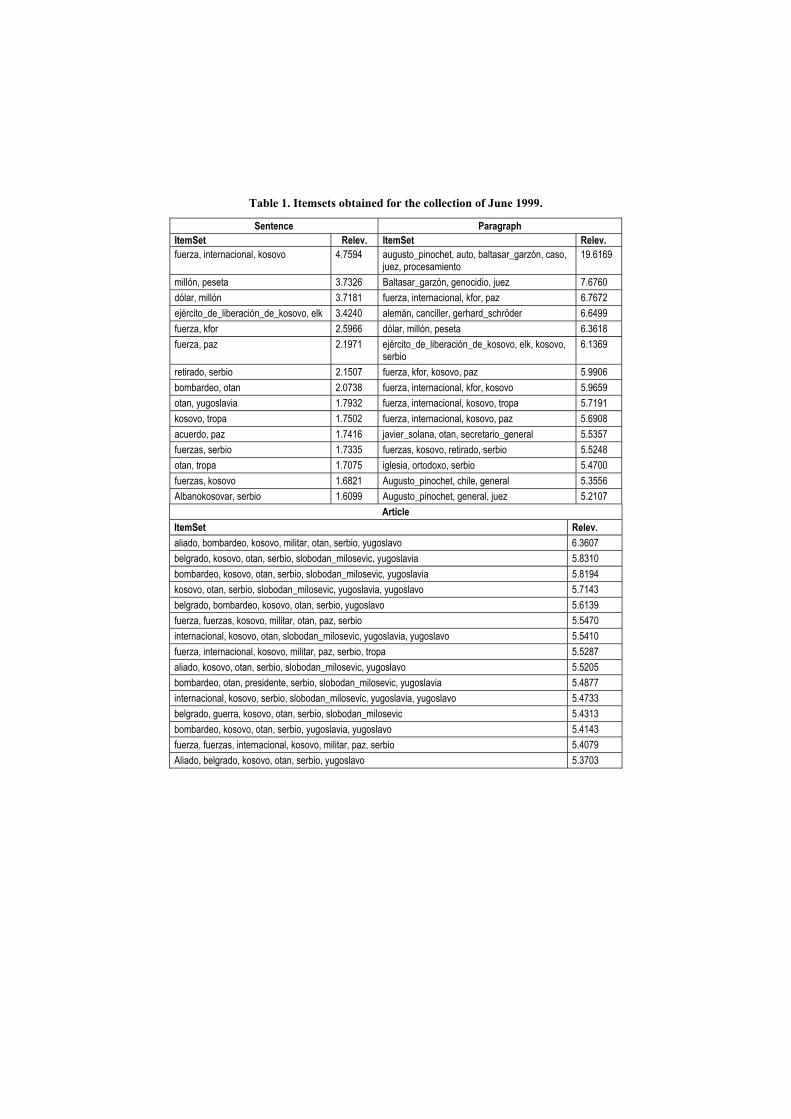
Table 1. Itemsets obtained for the collection of June 1999.
Sentence Paragraph ItemSet Relev. ItemSet Relev. fuerza, internacional, kosovo 4.7594 augusto_pinochet, auto, baltasar_garzón, caso,
juez, procesamiento 19.6169
millón, peseta 3.7326 Baltasar_garzón, genocidio, juez 7.6760 dólar, millón 3.7181 fuerza, internacional, kfor, paz 6.7672 ejército_de_liberación_de_kosovo, elk 3.4240 alemán, canciller, gerhard_schröder 6.6499 fuerza, kfor 2.5966 dólar, millón, peseta 6.3618 fuerza, paz 2.1971 ejército_de_liberación_de_kosovo, elk, kosovo,
serbio 6.1369
retirado, serbio 2.1507 fuerza, kfor, kosovo, paz 5.9906 bombardeo, otan 2.0738 fuerza, internacional, kfor, kosovo 5.9659 otan, yugoslavia 1.7932 fuerza, internacional, kosovo, tropa 5.7191 kosovo, tropa 1.7502 fuerza, internacional, kosovo, paz 5.6908 acuerdo, paz 1.7416 javier_solana, otan, secretario_general 5.5357 fuerzas, serbio 1.7335 fuerzas, kosovo, retirado, serbio 5.5248 otan, tropa 1.7075 iglesia, ortodoxo, serbio 5.4700 fuerzas, kosovo 1.6821 Augusto_pinochet, chile, general 5.3556 Albanokosovar, serbio 1.6099 Augusto_pinochet, general, juez 5.2107
Article ItemSet Relev. aliado, bombardeo, kosovo, militar, otan, serbio, yugoslavo 6.3607 belgrado, kosovo, otan, serbio, slobodan_milosevic, yugoslavia 5.8310 bombardeo, kosovo, otan, serbio, slobodan_milosevic, yugoslavia 5.8194 kosovo, otan, serbio, slobodan_milosevic, yugoslavia, yugoslavo 5.7143 belgrado, bombardeo, kosovo, otan, serbio, yugoslavo 5.6139 fuerza, fuerzas, kosovo, militar, otan, paz, serbio 5.5470 internacional, kosovo, otan, slobodan_milosevic, yugoslavia, yugoslavo 5.5410 fuerza, internacional, kosovo, militar, paz, serbio, tropa 5.5287 aliado, kosovo, otan, serbio, slobodan_milosevic, yugoslavo 5.5205 bombardeo, otan, presidente, serbio, slobodan_milosevic, yugoslavia 5.4877 internacional, kosovo, serbio, slobodan_milosevic, yugoslavia, yugoslavo 5.4733 belgrado, guerra, kosovo, otan, serbio, slobodan_milosevic 5.4313 bombardeo, kosovo, otan, serbio, yugoslavia, yugoslavo 5.4143 fuerza, fuerzas, internacional, kosovo, militar, paz, serbio 5.4079 Aliado, belgrado, kosovo, otan, serbio, yugoslavo 5.3703
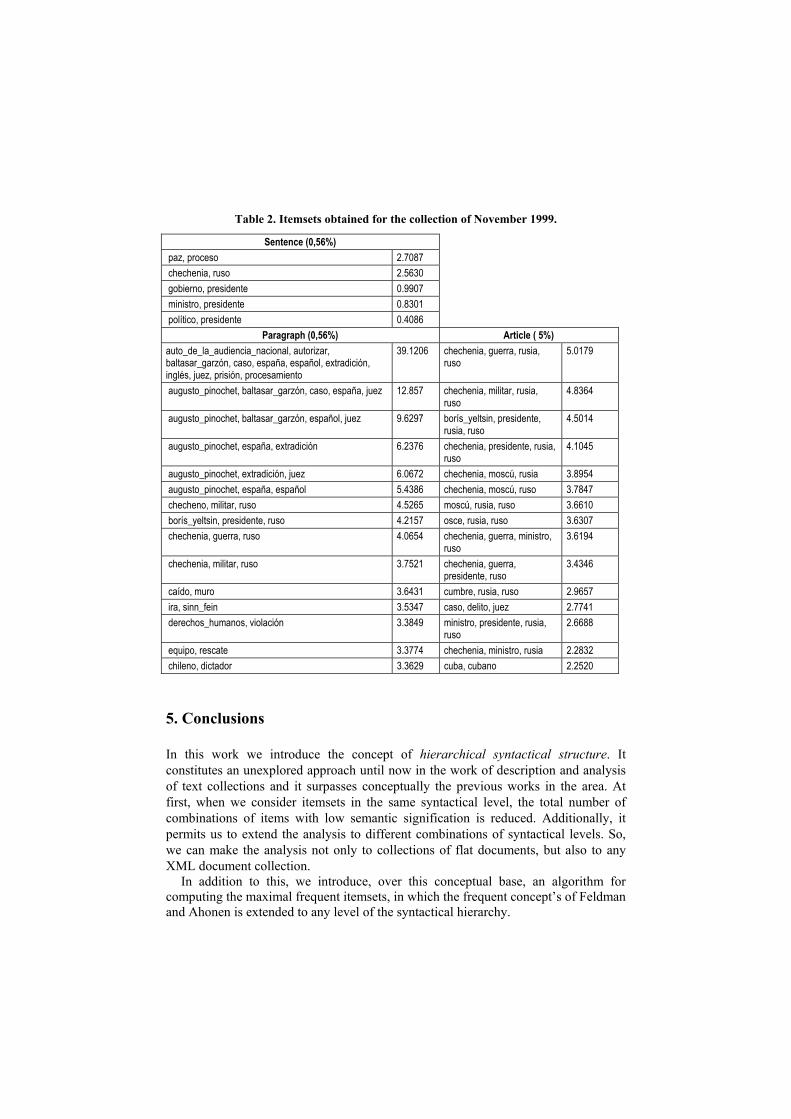
Table 2. Itemsets obtained for the collection of November 1999.
Sentence (0,56%) paz, proceso 2.7087 chechenia, ruso 2.5630 gobierno, presidente 0.9907 ministro, presidente 0.8301 político, presidente 0.4086
Paragraph (0,56%) Article ( 5%) auto_de_la_audiencia_nacional, autorizar, baltasar_garzón, caso, españa, español, extradición, inglés, juez, prisión, procesamiento
39.1206 chechenia, guerra, rusia, ruso
5.0179
augusto_pinochet, baltasar_garzón, caso, españa, juez 12.857 chechenia, militar, rusia, ruso
4.8364
augusto_pinochet, baltasar_garzón, español, juez 9.6297 borís_yeltsin, presidente, rusia, ruso
4.5014
augusto_pinochet, españa, extradición 6.2376 chechenia, presidente, rusia, ruso
4.1045
augusto_pinochet, extradición, juez 6.0672 chechenia, moscú, rusia 3.8954 augusto_pinochet, españa, español 5.4386 chechenia, moscú, ruso 3.7847 checheno, militar, ruso 4.5265 moscú, rusia, ruso 3.6610 borís_yeltsin, presidente, ruso 4.2157 osce, rusia, ruso 3.6307 chechenia, guerra, ruso 4.0654 chechenia, guerra, ministro,
ruso 3.6194
chechenia, militar, ruso 3.7521 chechenia, guerra, presidente, ruso
3.4346
caído, muro 3.6431 cumbre, rusia, ruso 2.9657 ira, sinn_fein 3.5347 caso, delito, juez 2.7741 derechos_humanos, violación 3.3849 ministro, presidente, rusia,
ruso 2.6688
equipo, rescate 3.3774 chechenia, ministro, rusia 2.2832 chileno, dictador 3.3629 cuba, cubano 2.2520
5. Conclusions
In this work we introduce the concept of hierarchical syntactical structure. It constitutes an unexplored approach until now in the work of description and analysis of text collections and it surpasses conceptually the previous works in the area. At first, when we consider itemsets in the same syntactical level, the total number of combinations of items with low semantic signification is reduced. Additionally, it permits us to extend the analysis to different combinations of syntactical levels. So, we can make the analysis not only to collections of flat documents, but also to any XML document collection.
In addition to this, we introduce, over this conceptual base, an algorithm for computing the maximal frequent itemsets, in which the frequent concept’s of Feldman and Ahonen is extended to any level of the syntactical hierarchy.

We have demonstrated that there are significant differences in the frequent itemsets found at the different syntactical levels. Moreover, we have shown that the mutual information function successfully express the relevance of these itemsets.
In the future, we are interested in comparing the obtained results with those generated by using the concept of maximal strongly frequent itemset.
Acknowledgements. This work has been partially funded by the research project CICYT (TIC2002-04586-C04-03).
References
1. Agrawal, R.; Imielinski, T.; Swami, A.: Mining Association Rules between Sets of Items in Large DataBases. In Proceeding of ACM SIGMOD Conference on Management of Data. Washington, DC. 1993. 207-216.
2. Ahonen-Myka, H.; Heinonen, O.; Klemettinen, M; Ikeri V, A.: Finding Co-occurring Text Phrases by Combining Sequence and Frecuent Set Discovery. In Ronen Feldman, editor, Proceedings of Sixteenth International Joint Conference on Artificial Intelligence (IJCAI-99) Workshop on Text Mining: Foundations, Techniques and Applications, pp. 1–9, Stockholm, Sweden, 1999.
3. Feldman, R.; Dagan, I. : Knowledge Discovery in textual databases (KDT). In the Proceedings of the first International Conference on Data Mining and Knowledge Discovery, KDD’95, pp. 112-117, Montreal, August 1995.
4. Fano, R.: Transmission of Information, MIT Press, 1961. 5. Feldman, R.; Hirsh, H.: Mining Associations in Text in the presence of background
knowledge. In Procedings of the Second International Conference on Knowledge Discovery and Data Mining. 1996.
6. Termier, A., Rousset M. C., Sebag M.: TreeFinder: a First Step towards XML Data Mining. IEEE International Conference on Data Mining (ICDM 2002), pp. 450-457, 2002.
7. Toivonen, H.: Discovery of frequent patterns in large data collections. PhD Thesis, Report A-1996-5, University of Helsinki, Department of Computer Science, November 1996.
Related Documents











